


Veri Bilimi
Öneri Sistemi (Recommendation System) Nedir?
Her gün kullandığımız alışveriş sitelerinin tam da ihtiyacımız olan ürünleri nasıl bulabildiğini ve bize nasıl önerdiğini hiç merak ettiğiniz oldu mu? Peki sürekli önümüze çıkan reklamların ihtiyaçlarımızla olan benzerliği daha önce dikkatinizi çekti mi? Bize önerilerde bulunan film siteleri, müzik uygulamaları nelerden hoşlanacağımızı nereden biliyor? Bunların hepsi bir sihir mi yoksa veri analizinin gücü mü? Hadi bu sihirli dünyayı beraber inceleyelim.
İçindekiler
1. Öneri Sistemi Nedir?
2. İçerik Tabanlı Öneri Sistemi Nedir?
3. Kosinüs Benzerliği Nedir?
4. Python ile Kosinüs Benzerliği Nasıl Hesaplanır?
5. Jaccard Benzerliği Nedir?
6. Python ile Jaccard Benzerliği Nasıl Hesaplanır?
7. Sonuç
1. Öneri Sistemi Nedir?
2. İçerik Tabanlı Öneri Sistemi Nedir?
3. Kosinüs Benzerliği Nedir?
4. Python ile Kosinüs Benzerliği Nasıl Hesaplanır?
5. Jaccard Benzerliği Nedir?
6. Python ile Jaccard Benzerliği Nasıl Hesaplanır?
7. Sonuç
Öneri Sistemi Nedir?
Öneri sistemi, kullanıcıların tercihlerini ve ürünlerin özelliklerini kullanarak en doğru ürünü en uygun kullanıcının önüne çıkarmayı amaçlayan çalışmalar bütünüdür. Bu yazıda ise öneri sisteminin alt alanı olan içerik tabanlı öneri sistemlerini inceleyeceğiz.
İçerik Tabanlı Öneri Sistemi Nedir?
İçerik tabanlı öneri sistemi, önerilecek olan ürünlerin özelliklerini inceleyerek önerilerini ürünlerin özelliklerine göre belirleyen ve kullanıcılara benzer özelliklere sahip ürünleri tavsiye eden öneri sistemi alanıdır. İçerik tabanlı öneri sisteminde kullanıcının daha önce ilgilendiği ürünlerin özellikleri ve bu özelliklerin ne kadar önemli olduğu belirlenir. Bu özellikler ve önem katsayıları göz önüne alınarak diğer ürünlerle kıyaslama yapılır. Bu kıyaslama sonucunda her ürün için bir benzerlik puanı elde edilir. En yüksek puana sahip ürünler kullanıcıya tavsiye edilir. Hayatımızın bir parçası olan ve sihir gibi görünen bu sistemler temelde bu kadar basit bir prensibi benimserler.
Dinlediğimiz müziklerden izlediğimiz filmlere, tıkladığımız reklamlardan incelediğimiz ürünlere kadar temasta olduğmuz her içerik için bu işlem uygulanır. Örneğin daha önce dinlediğimiz müzik 90 lar pop müziğiyse sistemimiz muhtemelen 90 lı yıllara ait başka bir pop müzik önerecektir. Tabii ki sadece iki özelliğe göre öneride bulunmak yanıltıcı olacaktır. Öneri sistemi oluşturulurken içeriklerin ve ürünlerin birden çok özelliği dikkate alınır. Bu özelliklerden bazıları sonucu daha çok etkilerden bazıları daha az etkiler. Örneğin müziği seslendiren şarkıcının ismi ile müziğin kategorisi yapılan önerileri farklı düzeyde etkileyecektir.
Peki hangi özelliğin daha önemli olduğuna nasıl karar vereceğiz? Bu aşamada farklı yöntemler deneyebiliriz. Bunlardan en basit olanı özelliklerin ne kadar önemli olacağını, başka bir ifadeyle özelliklerin katsayılarını manuel olarak belirlemektir. Örneğin şarkıcı isminin, şarkının tarzından daha önemli olduğunu düşünüyorsak şarkıcı ismi özelliğinin katsayısını daha yüksek olarak belirleyebiliriz. Bu sayede bu özelliğin sonuç üzerindeki etkisini arttırmış oluruz . Tabii ki bu her zaman işe yarayan bir yöntem değildir. Dikkatli davranılmazsa da öneri sisteminin yanlış çalışmasına da sebep olacaktır. Bir diğer yöntem kullanıcının ilgilendiği içeriklere göre katsayıların belirlenmesidir. Örneğin bir kullanıcı daha önce benzer tarzda şarkılar dinlemişse ve şarkının tarzını, şarkıyı seslendiren kişiden daha fazla önemsiyorsa o kullanıcı için şarkının tarzının katsayısı daha büyük olmalıdır. Öneri sistemi, kullanıcılara öneride bulunurken her kullanıcının neye önem verdiğini tespit etmeli ve önerisini kullanıcının tercihlerine göre şekillendirmelidir. Bu yöntem daha zor ve maliyetli olsa da daha tatmin edici sonuçlar vermektedir.
İçerik tabanlı öneri sisteminde bir diğer önemli nokta ise içeriklerin benzerliğinin nasıl hesaplanacağıdır. İki veri arasındaki benzerlik hesaplanırken kullanılan yöntemlerden en popüler iki tanesi Kosinüs Benzerliği ve Jaccard Benzerliği yöntemleridir. Hadi bu yöntemlerin özelliklerini beraber inceleyelim.
Kosinüs Benzerliği Nedir?
Kosinüs benzerliği yöntemi, iki vektör arasındaki benzerliği hesaplamada kullanılan meşhur bir yöntemdir. Aşağıdaki çok masum duran fonksiyonu kullanarak kosinüs benzerliği kolayca hesaplanabilir.
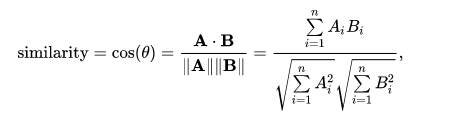
Formülü beraber inceleyelim. Benzerliğini hesaplamaya çalıştığımız iki vektörün nokta çarpımını (dot product) yaparak işleme başlıyoruz. Sonrasında ise vektörlerin uzunluklarını çarpıyoruz. Son olarak ilk değeri ikinci değere bölüyor ve kosinüs benzerlik değerini hesaplamış oluyoruz.
Python ile Kosinüs Benzerliği Nasıl Hesaplanır?
Python ile Kosinüs benzerliğini hesaplamak oldukça kolaydır. Yukarıdaki formüller sana yabancı gelmiş olabilir ama korkmana gerek yok. Tek tek hesaplama yapmak yerine bir kaç satırlık kod ile bu işlemi kolayca halledebiliriz. Aşağıdaki python kodu Kosinüs benzerliğini severek hesaplayacaktır.
def cosine_similarity(vector1, vector2):
import numpy as np
dot_product = np.dot(vector1, vector2)
norm_a = np.linalg.norm(vector1)
norm_b = np.linalg.norm(vector2)
cosine_similarity_value = dot_product / (norm_a * norm_b)
return cosine_similarity_value
Hadi bir deneme yapalım ve aşağıdaki grafikte bulunan ve birbirine yakın konumlanmış (3,1) ve (4,3) vektörlerinin kosinüs benzerliklerini inceleyelim.
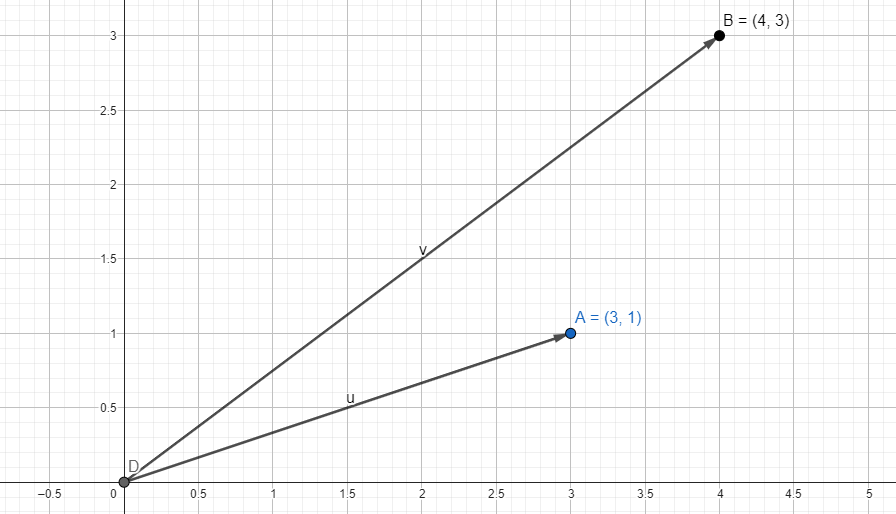
Üsteki cosine_similarity isimli fonksiyonu kullanarak bu iki vektörün benzerliğini bulabiliriz.
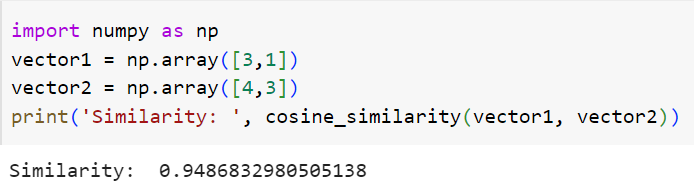
Bu iki vektörün birbirine benzediğini düşünüyorduk, fonksiyonumuzla da bunu onayladık. İki vektör arasında %94.87 lik benzerlik olduğunu tespit ettik. Fonksiyonumuz düzgün çalışıyor. Öneri sistemlerini inceleyecektik, vektörleri inceliyoruz diye düşünmeye başladıysanız matematiksel kısım bitti sayılır. Peki biz bu işlemleri, vektörleri öneri sistemlerinde nasıl kullanacağız? İçerik tabanlı öneri sistemleri burada başlıyor. Film öneri sistemi oluşturmak istediğimizi düşünelim ve kategorilerdeki benzerliğe göre önerilerde bulunacağız. Hadi kosinüs benzerliğini kullanarak bu işlemleri kategoriler üzerinde deneyelim.
film 1 in kategorileri = Aile, Komedi, Aksiyon
film 2 nin kategorileri = Aksiyon, Korku, Gerilim
Kategorileri incelediğimizde bu iki film birbirine çok benzer görünmüyor. Bakalım fonksiyonumuz da bizimle aynı fikirde mi?
Öncelikle iki filmdeki tüm kategorileri bir araya getirerek işleme başlıyoruz.
İki filmdeki tüm kategoriler = Aile, Komedi, Aksiyon, Korku, Gerilim
Sonraki aşamada ise her bir film için vektör oluşturuyoruz.
Filmlere ait tüm kategorileri bir araya getirmiştik. Bu kategroilere sırasıyla bakacağız. Filme ait kategoriler için 1, filme ait olmayanlar için 0 değerini vektöre yazacağız. Bu işlem sonucunda filme ait vektörü oluşturmuş olacağız.
Film 1 vektörü = [1, 1, 1, 0, 0]
Film 2 vektörü = [0, 0, 1, 1, 1]
Vektörleri oluşturduktan sonraki aşama ise bu vektörler arasındaki benzerliği hesaplamak. Yukarıdaki fonksiyonu kullanarak benzerliği hesaplayabiliriz.
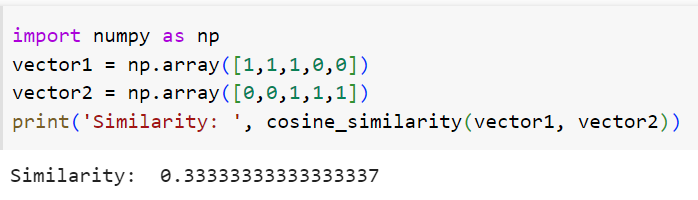
Bu iki film için kosinüs benzerlik değerini 33.3% olarak hesapladık. İyi bir benzerlik oranı olmadığı için ilk filmi izleyen birisine ikinci filmi önermemeliyiz. Başka bir örnek daha yapalım.
film1 kategoriler = Aile, Komedi, Aksiyon
film2 kategorileri = Komedi, Animasyon, Fantastik, Aile, Aksiyon
Film 1 in kategorileri önceki örnekteki film 1 ile aynı. Yeni bir film ile ilk filmin benzerlik oranını hesaplayacağız. Hesaplamaya kategorileri birleştirerek başlıyoruz.
İki filmdeki tüm kategoriler = Aile, Komedi, Aksiyon, Animasyon, Fantastik
Bundan sonraki aşamada filmlere ait vektörleri oluşturuyoruz.
Film 1 vektörü = [1, 1, 1, 0, 0]
Film 2 vektörü = [1, 1, 1, 1, 1]
Filmlerin vektörlerini oluşturduk. Fonksiyonumuzu kullanarak filmler arasındaki benzerliği hesaplayalım.
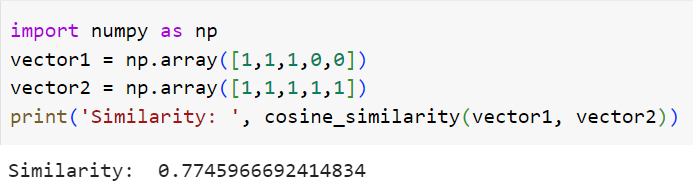
Bu iki film arasında çok güzel bir benzerlik olduğunu tespit ettik. İki filmin kosinüs benzerliğini 77.5% olarak hesapladık. Artık gönül rahatlığı ile yeni filmi kullanıcıya ya da arkadaşımıza tavsiye edebiliriz. Sadece kategori üzerinden benzerlik hesaplayarak bile çok güzel sonuçlar elde ettik. Daha güzel sonuçlar için öneri sistemi oluşturulurken birden çok özellik dikkate alınmalıdır.
Jaccard Benzerliği Nedir?
Benzerlik hesaplamak için kullanılan bir diğer yöntem ise Jaccard Benzerliği yöntemidir. Bu benzerlik yöntemi daha sade bir yapıya sahiptir. İki listedeki ortak eleman sayısının tüm eleman sayısına oranı Jaccard Benzerliği olarak bilinir.
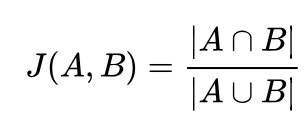
Daha önce incelediğimiz film kategorisi benzerliği örneğini tekrar kullanalım ve jaccard benzerliği formulünü detaylıca inceleyelim.
film1 kategoriler = Aile, Komedi, Aksiyon
film2 kategorileri = Aksiyon, Korku, Gerilim
Bu iki filmin kosinus benzerliğini 33% olarak önceki örnekte hesaplamıştık. Şimdi filmlerin Jaccard benzerliklerini inceleyelim.
İki filmdeki tüm kategoriler = Aile, Komedi, Aksiyon, Korku, Gerilim
Ortak kategoriler = Aksiyon
Ortak kategori sayısı = 1
Tüm kategorilerin sayısı = 5
Jaccard benzerliği = Ortak kategorilerin sayısı/ Tüm kategorilerin sayısı = 1/5 = 20%
Her iki hesaplama yöntemi de bu iki film için benzerlik oranını çok düşük hesapladı. Biz de bu iki filmin benzemediğini düşünüyorduk. Hesaplama yöntemleri gayet başarılı çalışıyor. Bir diğer örneği daha inceleyelim.
film1 kategoriler = Aile, Komedi, Aksiyon
film2 kategorileri = Komedi, Animasyon, Fantastik, Aile, Aksiyon
Bu iki film birbiririne benzer kategorilere sahip. Bu filmler için kosinus benzerliğini 77.5% olarak hesaplamıştık. Hadi Jaccard benzerliğini de hesaplayalım.
Tüm kategoriler = Aile, Komedi, Aksiyon, Animasyon, Fantastik
Ortak kategoriler = Aile, Komedi, Aksiyon
Tüm kategori sayısı = 5
Ortak kategori sayısı = 3
Jaccard Benzeriği = Ortak kategorilerin sayısı/ Tüm kategorilerin sayısı = 3/5 = 60%
Bu iki filmin Jaccard benzerliğini kategorilere bakarak hesapladığımızda yüzde 60 lık bir benzerlik tespit etmekteyiz. Bu yeterli ve güzel bir oran olduğu için birinci filmi izleyen bir arkadaşımıza ikinci filmi gönül rahatlığı ile önerebiliriz.
Peki jaccard benzerliğini hep manuel mi hesaplayacağız. Tabii ki hayır! Haydi python ile jaccard benzerliği nasıl hesaplanır beraber inceleyelim!
Python ile Jaccard Benzerliği Nasıl Hesaplanır?
Kosinüs benzerliğinde olduğu gibi jaccard benzerliğini hesaplamak için de python kullanabiliriz. Aşağıdaki basit python kodu ile jaccard benzerliğini kolayca hesaplayabiliriz.
def jaccard_similarity(list1, list2):
kesişim = len(list1.intersection(list2))
birleşim = len(list1.union(list2))
jaccard_benzerliği = kesişim / birleşim if birleşim != 0 else 0
return jaccard_benzerliği
Her gün kullandığımız pek çok website ve uygulama içerik tabanlı öneri sistemi yöntemini kullanmaktadır. Bizi ve tercih ettiğimiz içerikleri analiz etmekte ve bize önerilerde bulunmaktadır. İçerik tabanlı öneri sistemleri temel olarak yukarıdaki prensiplere göre temellenmektedir. Siz de kendi öneri sisteminizi oluşturabilir, hem eğlenceli hem de yararlı tavsiyeler veren bir sistem geliştirebilirsiniz.
Yazar Hakkında

Mustafa Bayhan
Merhaba ben Mustafa Bayhan. Veri analizi, veri görselleştirme, raporlama ve finansal analiz gibi veriyle yakından ilgili alanlarda çalışmalar yapan bir Endüstri mühendisiyim. Verilerin analiz edilmesi ve yönetilmesi konusunda çalışmalar yapmaktayım. Veriler üzerindeki hakimiyetim farklı sektörler üzerinde projeler geliştirebilmeme olanak sağlıyor. Kendimi sürekli geliştirmeyi ve öğrendiklerimi paylaşmayı seviyorum. Yeni fikirlerle tanışmak ve bu fikirleri hayata geçirmek beni her zaman mutlu ediyor. Benimle ilgili detaylı bilgi için hakkımda sayfamı ziyaret edebilirsiniz.
Beğenebileceğiniz gönderiler


2 Yorumlar
Yorum Yapmak İster misiniz?
Yeni Gönderiler

Excel Hataları: Sık Rastlanan Excel Hataları ve Çözümleri

Power Bi | Power Bi Nedir | Power Bi Eğitimleri

Excelde Yüzde Hesaplama İşlemi Nasıl Yapılır?
Chatgpt Nedir, Chatgpt Nasıl Kullanılır?

Excel Kısayolları | En Önemli Excel Kısayolları

SQL Select komutu nedir nasıl kullanılır?




avenue17 18 Kasım 2023 04:01
There is a site, with an information large quantity on a theme interesting you.
Can Benli 20 Haziran 2023 09:05
Harika anlatım.