Derin Öğrenme
Tensorflow Nedir? Tensorflow ile Yapay Sinir Ağları Modeli Nasıl Kurulur?
Yapay Sinir Ağları Nedir, Tensorflow Nedir?
Yapay sinir ağları, nöronlar ile aynı çalışma prensibine sahip derin öğrenme algoritmasıdır. Yapay sinir ağları; verileri alan, dönüştüren ve eğer koşullar sağlanıyorsa sonraki aşamaya ileten hücrelerden meydana gelir. Bu hücreler yapay sinir ağlarının içinde katmanlar halinde bulunur. Her katmanın belirli görevi varken bu katmanların ortak amacı gelen veriyi değerlendirmek ve elde edilen kazanımlarla öğrenme aşamasına katkıda bulunmaktır.
Derin Öğrenme Nedir?
Yapay Sinir Ağlarının bir derin öğrenme algoritması olduğunu öğrendik. Peki derin öğrenme nedir? Derin öğrenme, katmanlı yapıya sahip olan ileri seviye makine öğrenmesi tekniğidir. Bilgisayar teknolojilerindeki gelişmeler ile birlikte daha ileri seviye işlemler yapabilen derin öğrenme algoritmalarında önemli gelişmeler olmuştur. Derin öğrenme algoritmalarının en güzel örneği tabii ki yapay sinir ağlarıdır.
Tensorflow Nedir?
Tensorflow, makine öğrenmesi ve derin öğrenme için pek çok kütüphaneyi içeren açık kaynaklı büyük bir kütüphanedir. Google tarafından oluşturulan ve geliştirilen tensorflow pek çok derin öğrenme projesinde sıklıkla tercih edilmektedir. Tensorflow, sahip olduğu pek çok kütüphane sayesinde yapay sinir ağları ile yapılan projelerde de büyük kolaylık sağlamaktadı. Hadi başlayalım o zaman!
Tensorflow ile Yapay Sinir Ağları Modeli Nasıl Kurulur?
Tensorflow kütüphanesini kullarak bir Yapay sinir ağı modeli kurmaya çalışacağız. Bu çalışmayı veri analizi için çok önemli bir veri seti olan iris veri setiyle yapacağız. Veri setinde hedef sütunumuz "Iris-setosa", "Iris-versicolor" ve "Iris-virginica" olmak üzere üçe ayrılmaktadır. Elimizdeki verilerin ait olduğu türü doğru şekilde tahmin edecek algoritmayı kuracağız. Çalışmanın genel yapısını ve algoritmayı burada anlatacağım. Detaylı incelemek isteyenler için kodun tamamını da ayrıca paylaşacağım. Hadi başlayalım.
Tensorflow nasıl kurulur (Tensorflow install)?
Pip paket yükleyici ile tensorflow kurmak için aşağıdaki komutun terminalde çalıştırılması yeteridir.
pip install tensorflow
Conda paket yükleyici ile Anaconda'da tensorflow kurmak için aşağıdaki komutun terminalde çalıştırılması yeteridir.
pip install conda
Yapay sinir ağları örnek uygulama
Veri setini tanıyalım. Iris veri seti nedir?
Iris veri seti 5 sütundan oluşan (Id sütunu hariç) bir çiçeğe ait veri setidir. Species sütunu tahmin etmeye çalıştığımız hedef sütundur ve çiçeğin türlerinin isimlerinden oluşur.Diğer 4 sütun ile bu sütundaki türleri bulmaya çalışıyor. Peki diğer 4 sütun nedir? Bu 4 sütun sepal-length (alt yaprak uzunluğu cm), sepal-with (alt yaprak genişliği cm), pedal-length (üst yaprak genişliği cm), pedal-width (üst yaprak uzunluğu cm) verilerini barındırır. Çiçeğin yaprak ölçüleriyle ilgili bilgilerdir.
Veri setinin istatistiklerini anlamaya ve verileri görselleştirmeye çalışalım.
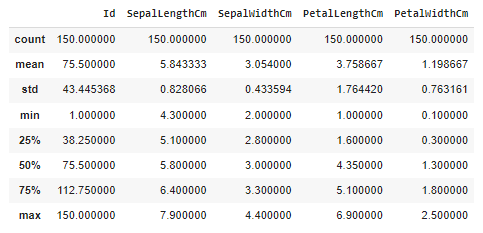
Bir sürü sayı var ne anlamamız lazım bunlardan? Bu veriler veri setini tanımlayan temel istatistiklerdir. Veri sayısını ve sütunların ortalamaları, standard sapmaları, min-max değerleri gibi verileri içerir. Bu verilerden çok fazla anlam çıkarılabilir fakat benim bunları buraya koyma amacım bir noktaya dikkat çekmek. 1. sütundaki veriler 5.843-7.900 aralığında dağılırken 4. sütun 1.199-2.50 aralığında dağılıyor. Ne var bunda diyebiliriz. Fakat bazı uzaklık metrikleri ve bazı algoritmalar bu farklılıktan fazlasıyla etkilenmektedir. Bu farklı aralıklardaki dağılımlar algoritma yapısını bozabildiği için veri seti standartlaştırılmalı ve sütunlar arası kullanım kolaylığı sağlanmalıdır. Bunu nasıl yapacağız peki? Algoritmayı kurarken bunu daha detyalı anlatacağım Haydi devam edelim.
Veri setinde eksik veri olup olmadığını kontrol ederiz. Resimdeki ilk satırdaki kod sütunlarda kaç tane eksik veri olduğunu gösterir (iris_dataset veri setini atadığımız değişken ismidir).
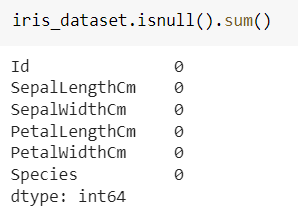
Çok güzel eksik verimiz yok veri setini tanımaya devam edebiliriz. Hedef sütununda he türden kaç tane olduğuna bakalım.
|
|
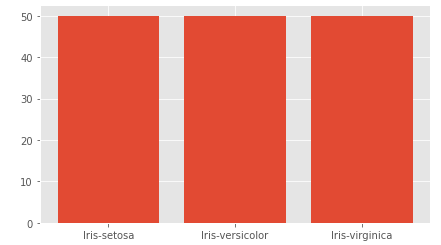
value_counts() metodu sayılara ulaşmamızı sağladı. Verilerin eşit dağıldığı görülmekte.
|
|
scatterplot verilerin birbirine göre konumunun görselleştirildiği bir dağılım grafiğidir. hue aracılığı ile garfiğe bir boyut daha katmış başka bir ifadeyle bu dağılımı Species sütunundaki türlere göre renklendirmiş olduk. Çıktıya bakıp yorumlayalım.

Grafikten anlaşıldığı üzere PetalLenght ve PetalWidth özellikleri çiçeğin türünü önemli derecede etkiliyor. PetalLenght ve PetalWidth ölçülinin küçük değerlere sahip olduğu sol alt köşede çiçeğin türünün Iris-setosa olma ihtimali artarken bu ölçü değerlerinin büyük olduğu sağ üst köşede çiçeğin türünün Iris-virginica olma ihtimali artmaktadır. Tabiki sadece bu dağılım yeterli değildir.

Sepalidth ile SepalLength sütunlarının scatter grafiği yukarıdaki gibidir. Daha önceki grafik kadar net gruplaşmalar olmasa da Iris-setosa türlerinin sol üst köşede gruplaştığı net bir şekilde belli olmaktadır.
Son olarak kutu grafiğini (boxplot) inceleyelim
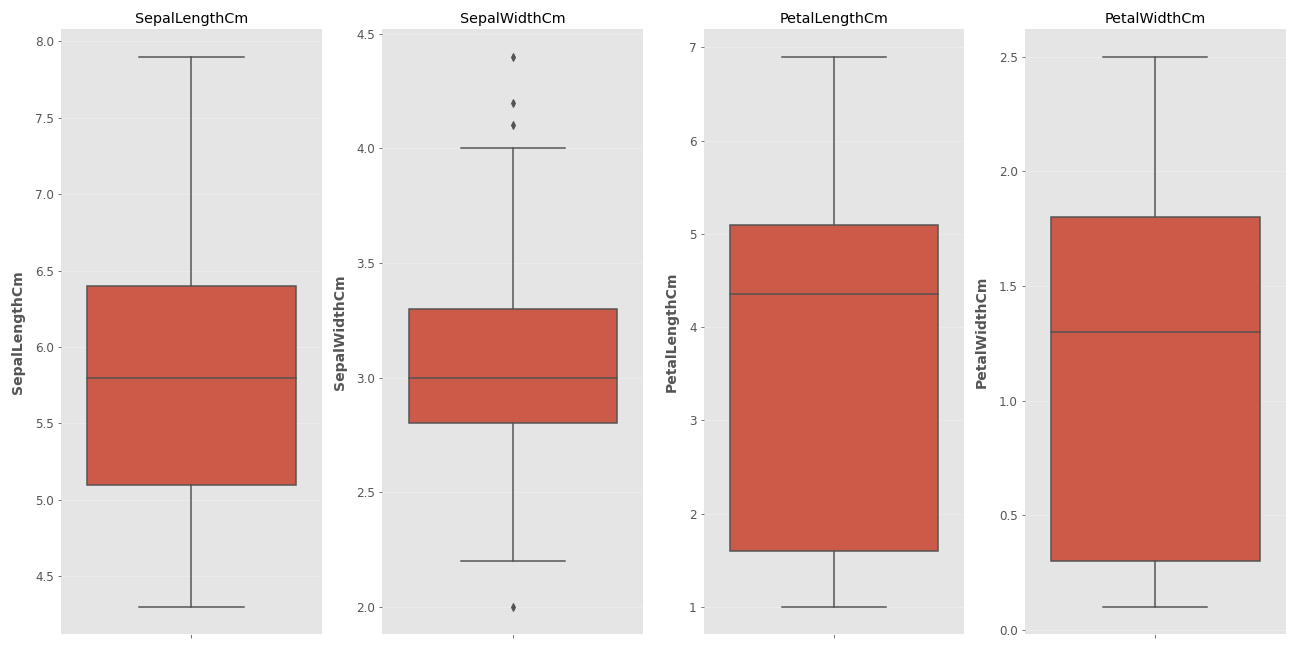
Kutu Grafiği Nedir, Ne İşe Yarar?
Kutu grafiği verinin dağılımını anlamamızı sağlayan ve istisnai verileri ayırt etmemize yardımcı olan bir veri görselleştime aracıdır. Peki bu grafikleri nasıl yorumlayacağız? Kutunun içindeki yatay çizgi verinin medyanını temsil eder. Kırmızı kutunun üst kenarı verilerin 3. çeyreğini (75%) alt kenarı ise 1. çeyreğini (25%) ifade eder. Bir dakika uzayıp giden çizgiler nedir o zaman? Bu kutunun dışında kalan verilerin nereye kadar normal karşılaşanacağını belirten kısımdır. Alt ve üst sınır çizgilerini geçen veriler artık istisnai veri olarak ifade edilmeye başlanır. İkinci grafikte istisnai veriler noktayla işaretlenirken diğer sütunlarda istisani veri yoktur. Peki alt ve üst sınır çizgileri nasıl belirlenir? Yukarıda veri setinin özelliklerini describe metodu ile görmüştük şimdi o verileri kullanma zamanı. Üst çeyrek değerine (75%) 1.5 IQR eklenir bunu aşan veriler istisnai veri kabul edilir. Aşırı istisnai veriler ise 3.çeyrek değeri + 3 IQR değerini aşan verilerdir. Benzer bir işlelm alt sınırı bulurken yapılır. 1. çeyrek değerinden 1.5 IQR çıkarılır ve bu noktanın altındaki veriler istisnai veri olarak adlandırılır. 1. çeyrek değeri - 3 IQR değerinin altındaki veriler ise aşırı istisnai veri olarak isimlendirilir. Çok karıştı her şey değil mi? Adım adım gidelim.
Öncelikle IQR nedir bunu söylememiz gerekir. IQR çeyrekler arası mesafedir.
IQR = Q3 ( 75% ) - Q1 (25%)
SepalWidth sütununun istisnai veri içerdiği grafikteki noktalardan anlaşılıyor. Peki bu istisnai verileri ne yapacağız? Burda kararı veri analizini yapan kişi verir. Veriler direkt atılabileceği gibi bu istisnai verilerin değerleri alt ve üst çeyrek değerlerine eşitlenerek etkileri azaltılabilir. Ben bu örnekte veriler aşırı istisnai değil ise bir değişiklik yapmayacağım.
Aşırı istisnai sınırını bulalım. SepalWidthCm için Q3 = 3.3 ve Q1=2.8 dir. bu veriler ilk tabloda yazmaktadır.
IQR = 3.3 - 2.8 = 0.5 tir
alt sınır = 2.3 - 3 * 0.5 = 0.8
üst sınır= 3.3 + 3 * 0.5 = 4.8
Yine aynı tablodan bu sütundaki verilerin 2 (min) - 4.4 (max) arasında dağıldığını öğrenebiliriz. Bu değerler aşırı istisnai sınırını aşmıyorlar. Ben bu örnek için istisnai verileri aşırı istisnai olmadıkları için temizlemeyeceğim ama tercihen temizlenmesi ya da düzeltilmesi de yanlış olmayacaktır.
Verileri standartlaştırıp modeli kurma zamanı geldi. Bazı standartlaştırma yöntemleri aşağıda verilmiştir. Bu formüllerin detayına girmeyeceğiz. Modeli kuararken nasıl yapacağımızı inceleyeceğiz. Bu yöntemleri bu çalışmada detaylıca incelemesek de her birinin mantığını anlamak çok önemlidir. Standartlaştırma yöntemleri için bu sayfanın incelenmesi faydalı olacaktır.

Bizim çalışmamızda standar scaler yöntemini kullanacağız.
|
|
Ne yaptık şimdi biz? Scikit-learn kütüphanesinden standard scaler formulünü uygulayacak sınıfı (class) import ettik. Bu sınıfla scaler isimli bir model oluşturduk. Hedef sütununu çıkarark X değişkenimizi tanımladık ve scaler modeline bu değerleri verdik. Bunun sonucunda X değerlerimiz standardize edilmiş bir şekilde fit_transform fonksiyonundan çıkmış oldu. Hedef sütunu kategorik verilerden oluştuğu için standartlaştırma işlemi yapmadık ama hedef sütunu için de bir değişime ihtiyacımız vardır.
Bu değişimi yapmalıyız çünkü hedef sütunumuz makinenin anlayacağı formatta değil. Hatırlayacağınız gibi hedef sütunda 3 farklı kategorik veri vardı. Bunların isimlerini 0, 1, 2 olarak değiştirebiliriz fakat makine bunu artık anlayabiliyor olsa da bu çok verimli bir yöntem olmayacaktır. Bunun sebebi makinenin bu değerleri nasıl verdiğimizi anlayamayacak olması ve muhtemelen 2 etiketine sahip veriyi diğerlerinden daha önemli kabul edecek olmasıdır. Peki o zaman ne yapacağız? One Hot Encoding yöntemini uygulayacsğız.

One Hot Encoding Nedir?
Kategorik sayıları matrix cinsinden sayılara dönüştürme yöntemidir. Bir örnekle bunu açıklayalım.
| Elma | Armut | Portakal | |
| Elma | 1 | 0 | 0 |
| Armut | 0 | 1 | 0 |
| Portakal | 0 | 0 | 1 |
| Portakal | 0 | 0 | 1 |
| Armut | 0 | 1 | 0 |
| Elma | 1 | 0 | 0 |
| Elma | 1 | 0 | 0 |
İlk satırdaki kategorik verileri kendilerine ait yerlere 1 yazarak, 1 ve 0 lardan oluşan bir matrikse çeviriyoruz. Bu sayede makine için daha anlamlı ve yorumlanması kolay bir veri ortaya çıkıyor Bu işleme One Hot Encoding denir. Iris veri seti için de bu dönüşümü yapalım.
|
|
Bu sefer Scikit-learn kütüphanesinden OneHotEncoder sınıfını import ettik. Bu sınıftan "ohe" adında bir nesne oluşturduk. "fit_transform" fonksiyonuyla veriyi matriks haline döndürdük. Aslında sadece fonksiyonları yazdık python bizim için bu dönüşümü yaptı. Şu an elimizde 1 ve 0 lardan oluşan 3 sütunlu bir y değeri var.
Şimdi sıra veriyi bölmede. Veriyi eğitim, test ve doğrulama verisi olarak ayıracağız. Eğitim verisiyle öğrenme gerçekleşirken, doğrulama verisiyle öğrenme aşamasını denetleyeceğiz ve test verisiyle sonuçları değerlendireceğiz.
|
|
Scikit-learn kütüphanesinden train_test_split fonksiyonunu aldık. Bu fonksiyon veriyi bölmemize yardımcı olacak. Parametre olarak bölünecek verileri (X, y) verdik. İkinci satırdaki kodla verilerin yüzde 40 ını test verisi olarak aldık fakat bunu tekrar bölüyoruz son satırda ve yarısını doğrulama (valid) verisi haline getiriyoruz. Sonuç olarak eğitim verisinin oranı yüzde 60, test ve doğrulama verilerimizin oranı yüzde 20 oluyor. random_state değeri ile bölünme şekli düzenlenmiş oluyor. Siz de bu parametreye 33 değerini verirseniz sizin verilerinizle benim verilerim aynı şekilde bölünmüş olacak. Bu çalışmalar arasında kontrol kolaylığı sağlıyor.
Verilerimizi de böldük şimdi modeli oluşturma zamanı.
|
|
Keras sequential sayesinde birbirine bağlı katmanların oluşturulması ve veri akışının bu katmanlar üzerinde ilerlemesi sağlanıyor. layers.dense yardımıyla katmanlar tanımlanıyor. Yukarıdaki layers Dense ile başlayan her satır bir katmanı temsil etmektedir. Katmanın içinde kaç sinir hücresi olacağını ve activasyon fonksiyonlarını yazıyoruz. Burada önemli iki nokta var giriş ve çıkış katmanı nöron sayısı kaç olmalı? Tercihen ilk katmanın nöron sayısının input verisinin sütun sayısına eşit olması beklenir. Bu algoritamanın başarısını etkileyecek bir detaydır. Asıl önemli kısım çıktı katmanıdır. Burada 3 nöron yer alıyor çünkü hatırlarsanız veri setimizdeki hedef sütunu 1 ve 0 lardan oluşan 3 sütuna ayırmıştık. Bu sebeple çıktı katmanındaki nöron sayısını 3 olarak belirledik.
Sırada modeli derleme aşaması var.
|
|
"compile" yardımıyla modeli derliyoruz. Optimizasyon algoritmasını loss fonksiyonunu belirliyoruz. Metrik olarak accuracy değerini verdik. Bu opsiyonel bir seçenektir metrics kısmı olmasa da kod çalışacaktır. Burada yeni bir kavramla tanışacağız: Early stopping.
Early Stopping Nedir?
Algoritma için belirli bir epoch sayısı verilir. Algoritmanın kaç tur çalışacağını beşlirtir. Bu değer gereğinden fazla verilmiş olabilir. Makine bir yerden sonra veriyi öğrenmek yerine ezberlemeye başlayacaktır. Makinenin yorumlama gücünü kaybetmemesi için aşırı öğrenme olmaya başlamadan önce durdurulması gerekir. Bu olay early stopping olarak bilinir. Doğrulama verisi burada devreye giriyor. Eğitim verisinde hata ne kadar azalırsa azalsın doğrulama verisinde hata azalmıyorsa artık makina yorumlama gücünü arttıramıyordur ve bu seviyede eğitim sonlandırlır.
|
|
Buradaki monitor parametresinde algoritmanın hangi hatayı takip edeceğini belirtiriz. "patience" ise sabır seviyesidir. "val_loss" değeri kaç iterasyon boyunca iyileştirilemezse öğrenmenin son bulacağını ifade eder. BUrada 20 değerini verdik. Eğere 20 iterasyon boyunca minimum değerden daha düşük bir val_loss değeri oluşmazsa öğrenme sona erer. Bu değer çok büyük ya da çok küçük seçilirse algoritmanın başarısı azalacaktır.
|
|
"fit" yardımıyla makine veriyi öğrenmeye başlar. Bu örnekte veri az olduğu için kullanmasak da batch_size isimli önemli bir parametre vardır. Veri sayısı çok olduğunda tüm verileri aynı anda eğitmek zor olmaktadır. İşte bu aşamada kaç tane verinin aynı anda eğitileceğini batch_size parametresine verdiğimiz değerle belirtiriz. Örneğin buraya 32 değerini verirsek veriler 32 şerli gruplar halinde eğitilir. Bu zamandan tasarruf sağlasa da doğruluk oranında dalgalanmalara sebep olur. Iterasyon sayısı arttıkça bu dalgalanmalar azalır.
Hadi kodu çalıştırıp çıktıya bakalım

Buna benzer bir çıktı aldıysanız her şey yolunda demektir. Görüldüğü gibi epoch olarak 1000 değerini versek bile öğrenme 182. adımda son buldu. Çıktıda eğitim ve doğrulama verileri için loss ve doğruluk dğerleri yer alıyor.
Ve grafiiiiiik ....
|
|
".history.history" ifadesi sayesinde modeldeki loss ve accuracy değerlerine ulaşabiliriz. Hadi grafiğe bakalım.

Mavi çizgi doğrulama verisine ait. Görüldüğü gibi iterasyon arttıkça hem eğitim hem de doğrulama verisi için hata miktarı düşmektedir.
Peki ya early stopping algoritmayı durdurmasaydı ne olacaktı diye soranları duyar gibiyim.

Eğitim hatası gittikçe düşerken işler aslında göründüğü kadar yolunda değil. Sadece eğitim hatasını takip etseydik ve early stopping kullanmasaydık yorumlama yeteneği olmayan çok kötü bir model çıkacaktı ortaya. Teşekkürler early stopping. Sana minnetarız :)
Hadi modeli bir de tahmin verilerimizle çalıştırıp sonucu görelim.
|
|

Bu da ne? Hani 1 ve 0 larla uğraşacaktık nasıl bu hale döndüler? Cevabı çok basit. Buradaki her veri aslında bir olasaılık. Çıktı katmanına aktivasyon fonksiyonu olarak softmax fonksiyonunu verdik. Softmax, sigmoid gibi fonksiyonlar bize olasılık değeri verirler. Peki nasıl seçeceğiz? Satırdaki en büyük olasılığa denk gelen sütuna 1 yazacağız. Bu sayede ihtimali en yüksek olan türü çıktı olarak kabul etmiş olacağız.
|
|
Test verilerinin y değerlerini ve tahmin değerlerimizi biliyoruz haydi karşılaştıralım.

Sadece sondan 3. veriyi yanlış tahmin ettik. 0.9667 temel düzeyde bir analiz için tatmin edici bir sonuç. Makinemiz gayet güzel çalışıyor. Bir kutlamayı haketti :)
Kaynak kod: mustafabayhan/artificial-neural-networks-model-with-tensorflow
Yapay Sinir Ağları teorik kısım : Yapay Sinir Ağları Nedir, Nasıl Çalışırlar?

Yazar Hakkında

Mustafa Bayhan
Merhaba ben Mustafa Bayhan. Veri analizi, veri görselleştirme, raporlama ve finansal analiz gibi veriyle yakından ilgili alanlarda çalışmalar yapan bir Endüstri mühendisiyim. Verilerin analiz edilmesi ve yönetilmesi konusunda çalışmalar yapmaktayım. Veriler üzerindeki hakimiyetim farklı sektörler üzerinde projeler geliştirebilmeme olanak sağlıyor. Kendimi sürekli geliştirmeyi ve öğrendiklerimi paylaşmayı seviyorum. Yeni fikirlerle tanışmak ve bu fikirleri hayata geçirmek beni her zaman mutlu ediyor. Benimle ilgili detaylı bilgi için hakkımda sayfamı ziyaret edebilirsiniz.
Beğenebileceğiniz gönderiler

0 Yorumlar
Yorum Yapmak İster misiniz?
Yeni Gönderiler

Kumru AI İncelemesi: Güçlü Yönleri, Zayıf Yönleri ve Kullanım Deneyimi

Büyük Dil Modelleri (LLM): RAG, Context Engineering ve Agent Yapıları

Veri Analizinde Model Seçimi: AIC ve BIC Nedir?

Veri Analizinde Kullanılan Histogram Türleri ve Anlamları

Korelasyon ile Nedensellik Çıkarımı Yapılabilir mi?
Histogram Nedir, Histogram Grafiği Nasıl Yapılır?