Makine Öğrenmesi
Yapay Sinir Ağları ile Kanser Hücresi Analizi
Yapay Sinir Ağları ile Veri Analizi Örnek Çalışması
Yapay sinir ağları modeli kullanarak bir kanser hücresinin iyi huylu bir hücre mi yoksa kötü huylu bir hücre mi olduğunu tahmin etmeye çalışacağız. Hedef sütunumuz iyi huylu ( B ) ve kötü huylu ( M ) olmak üzere 2 farklı etiket içermektedir. Toplamda 32 adet sütuna sahip çok özellikli bir veri seti olduğu için modelin başarısını etkileyecek istisnai verilere ve sütunlar arası korelasyon oranlarıyla ayrıca ilgileneceğiz. Öncelikle verimizi görselleştirerek temel özelliklerini keşfedelim.
veri seti adresi = kaggle.com/datasets/uciml/breast-cancer-wisconsin-data
|
|
"value_count" ile sütundaki etiket sayılarına ulaştık ve pie ( pasta ) garfiğini çizdirdik. "cancer_dataset" veri setimizi tutan değişkenin ismi.

Verilerin yaklaşık yüzde 37 si kötü huylu kansere aitmiş. Geri kalan çoğunluk veri iyi huylu kansere aitmiş. Hedef değişkenimizi makinenin anlayacağı şekilde sayılara dönüştürelim.
|
|
"y" değişkeni için hedef sütundaki M leri 1 e B leri 0 a dönüştürdüktür. "map" metodu bu dönüşümü yapmamıza imkan verdi. Hedef sütunun dönüştürülmüş halini y değişkenine atadağımız için veri setinden çıkarsak sorun olmaz. Ayrıca 'Id' sütunu ve 'Unnamed: 32" isimli veri içermeyen anlamsız sütunu veriden çıkarabiliriz.Bu uzaklaştırma işlemini ikinci satırda drop metodu ile yaptık.
Veriyi keşfetmeye devam edebiliriz. Diğer sütunlardaki verilerin hangi aralıklara nasıl yayıldıklarını incelemek için her sütunu görselleştirelim.

Bu sütunları herbiri birbriryle belli düzeyde ilişkilidir. Eğere bu ilişki oranı fazlaysa sütunlar neredeyse aynı bilgiyi içermeye başlarlar. Birbirleriyle bağlantılarının oranını korelasyon ile ölçeriz. Korelasyon verilerin birbirleriyle ilişki düzeyi ve beraber hareket etme oranı olarak düşünülebilir. Her ne kadar veriler farklı da olsa korelasyon oranları 1 e çok yakınsa bu verilerden birisini bilmemiz öğrenme aşaması için yeterli olacaktır ve kurulan modelin öğrenme aşaması daha verimli olacaktır. Sütunların korelasyon değerlerini görelim
.

Bir dakika bağlantı oranı dedik bu tablo nedir? Bu tablo her sütunun diğer sütunlarla olan korelasyon değerinin yer aldığı tablodur. Renkler açıldıkça korelasyon değeri 1 e yaklaşır ve değer 1 e ne kadar yakınsa bu iki sütun aynı hareketleri sergilemeye başlar. Renkler koyulaştıkça değer -1 e yaklaşır ve değer -1 e ne kadar yakınsa bu sütunlar o düzeyde zıt hareket ederler. Tek tek incelemeye gerek yoktur. Belli bir oran üstünde korelasyona sahip sütunları veriden uzaklaştırmak mantıklı olacaktır. 0.9 üzerinde benzerlik varsa bu satırlardan birisini uzaklaştıracağız. Burda dikkat etmemiz gereke bir kısım var yukarıdaki tablo (köşegene göre) simetrik bir tablo ve tüm tabloyu kullanmak yerine köşegenin bir tarafını kullanmalyız. Bu bize işlem kolaylığı sağlayacak.
|
|
Yukarıdaki kod ile veriyi temizliyoruz. Kodu ince ayrıntısına kadar anlatarak analizin anlaşılmasını zorlaştırmak istemiyorum fakat temel düzeyde kodun ne yaptığını bilmekte fayda var. İkinci satırdaki kod ile korelasyon verisetini oluşturduk. Burada çok küçük bir değişiklik yaptık abs metodu kullandık. Bu sayede eksi korelasyonları da artıya çevirdik. Bunun sebebi sütunların aşırı düzeyde beraber hareket etmesi kadar zıt hareket etmesi de modelin yapısını bozacaktır. İki veri tamamen zıt hareket ediyorsa birisi bilmemiz yine yetecektir. 3. ve 4. satırlar bu matriksteki köşegen altında kalan üçgendeki verileri almaya yarıyor. Sadece dataframe in yapısını değiştiriyoruz temel düzeyde bunun yapıldığının bilinmesi yeterli olacaktır. 4. satırdaki kod ile başka satırlarla 0.95 ve üzeri korelasyona sahip satırları bulduk ve 5. satırda bunları veri setinden uzaklaştırdık. Dikkat edilmesi gereken önemli bir nokta iki sütunu da uzaklaştırmadık. Birisini uzaklaştırmamız bizim için yeterli olacaktır. Sadece birisinin uzaklaşmasını ise korelasyon datasının yarısını kullanarak yaptık. Diğer yarıyı da kullansaydık işlemler uzayacak ve karışacaktı.
Silinen sütunlar = radius_mean, perimeter_mean, area_mean, radius_se, radius_worst, perimeter_worst
Yeni veri setindeki sütun sayısı (hedef sütun hariç) : 24
Sütunlar arasındaki verileri daha iyi karşılaştırabilmek için verileri standartlaştıralım.
|
|
X verisini StandardScaler() içindeki fit_transform fonksiyounyla standartlaştırdık. Standartlaştırma verilerin ifade ettikleri bilgileri kaybetmeden birbirlerine göre ve belli formüller dikkate alınarak dönüştürülmesidir. Bu sayede sütunlar arası yorumlama kolaylığı oluşurken uzaklık temelli algoritmaların veriyi doğru yorumlaması sağlanmış olunur. Her şey çok iyi gidiyor sırada veriyi bölme işlemi var. Veriyi eğitim, doğrulama ve test verisi olarak üçe böleceğiz. Eğitim verisiyle öğrenme gerçekleşirken doğrulama verisiyle bu eğitim sürecini kontrol edeceğiz. Test verisiyle ise eğitim bitince sonuçları değerlendireceğiz. Hadi başlayalım.
|
|
2. satırda veriyi eğitim ve ve test olarak ikiye ayırdık. Verilerin yüzde 25 i eğitim verisi oldu fakat bu veriyi 3. satırda ikiye ayırdık ve bir kısmını doğrulama verisi yapmış olduk. Son durumda verilerin 75 % i eğitim, 12.5% u tes ve 12.5% u doğğrulama verisi oldu. " random_state " parameteri ile verinin nasıl bölüneceğini kontrol ediyoruz. Bu parametreye 34 verirseniz eğer sizin verilerinizle benim verilerim aynı şekilde bölünürler. Bu çalışmalar arasında kolaylık sağlayan bir parametredir. Bu parametre belirtilmezse çıktı verimizde az da olsa farklılıklar oluşur ve kıyaslama aşamasında zorluk meydana gelir. Çok güzel gidiyoruz, haydi modeli kuralım.
|
|
Keras sequential sayesinde birbirine bağlı katmanların oluşturabiliyor ve bu katmanlar üzerinden veri akışının ilerlemesi sağlayabiliyoruz. "layers.dense" ile başlayan satırlarda katmanları ve bu katmanların özelliklerini tanımladık. Her katmandaki hücre sayısını ve aktivasyon fonksiyonunu belirttik. Giriş katmanı 24 nörondan oluşuyor çünkü 24 sütunluk bir girdi datamız vardı. Bu sayıya eşit olması zorunlu değil ama eğer girdi katmanında sütun sayısı ile eşit sayıda nöron bulunursa genellikle daha iyi sonuç elde edilir. Çıktı katmanına 1 nöron koyduk. Bunun sebebi bizim hedef verimizin tek sütundan oluşması. Ayrıca çıktı katmanında sigmoid fonksiyonu kullandık. Bu fonksiyon bir sınıflandırma fonksiyonu gibi düşünülebilir. 0 ile 1 arası bir değer yansıtır. Fonksiyona verilen verilerin değeri belirli bir seviyeyi geçerse fonksiyon çıktısı 1 e yakın geçemezse 0 a yakın olur. Bu sebeple ikili sınıflandırmada sık kullanılan bir fonksiyondur. Fonksiyonun grafiği aşağıdaki gibidir.

Ağ yapısını kurduğumuza göre devam edebiliriz.
|
|
Modelimizi derleme aşamasına geldik. Optimizasyon algoritması olarak Adam optimizasyon algoritmasını kullanalım. Hata metriği olarak ikili sınıflandırma modellerinde tercih edilen binary_crossentropy metriğini kullanalım. Accruracy metriği ile de modelin durumuna bakıyoruz fakat bu metrik opsiyoneldir ve accuracy olmadan da model çalışacaktır. Öğrenme oranı olarak ise 0.0005 oranını kullanalım. Biraz küçük bir değer olsa da verimiz az olduğu için çok sorun olmayacaktır. Burada geçen parametreler size yabancı geliyorsa önce Yapay Sinir Ağları Nedir, Nasıl Çalışırlar? isimli yazımı okumanız avantajınıza olacaktır.
|
|
Early stopping ile modelin belirlenenden önce durmasısağlanır. Peki buna neden ihityaç duyarız? Model bir yerden sonra öğrenmeyi bırakıp ezberlemeye ve yorum gücünü kaybetmeye başlar. Bunu yapmaya balayacağı zaman öğrenmenin durması gerekir. Bu işleme early stopping denir. Doğrulama verisindeki hata miktarı azalmamaya başladığında eğitim verisindeki hatanın azalmasını önemini kaybeder. Bu aşamada öğrenim durdurulur. "patience" parametresi ise kaç iterasyon boyunca minimum hatadan daha az hata elde edilemezse öğrenimin durdurulacağını belirttiğimiz parametredir. Sonraki aşamada fit metodu ile modelimizi eğitiyoruz. Eğitim ve doğrulama verimizi modele verdik. Epoch (döngü) sayısı olarak 1000 değerini yazdık. Erken durdurma fonksiyonunu da modelimize ekledik.

Eğer buna benzer bir çıktı aldıysan tebrikler model başarıyla kurulmuş. Dikkat ederseniz 1000 iterasyon belirtilmesine rağmen öğrenme 56. adımda durdu. Early stopping sayesinde bu aşamada öğrenimi durdurabildik. Acaba durdurmasak gerçekten sonuçlar daha mı kötü olacaktı? Bunu da inceleyeceğiz. Öncelikle çıktımıza bakalım. Yukarıdaki çıktı eğitim ve doğrulama verileri için loss ve doğruluk değerlerini gösteriyor. Loss değerlerini görselleştirelim.
|
|
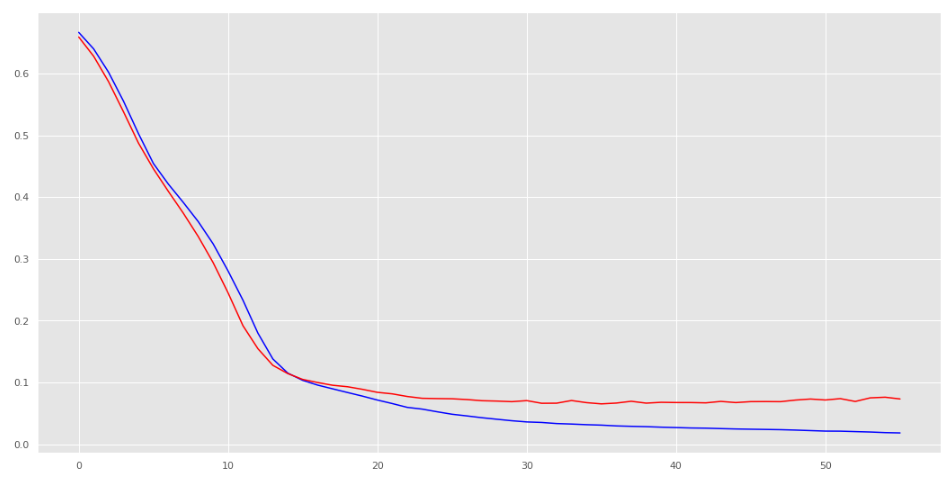
modele .history.history sorgusu yaparak yukarıdaki çıktıda yer alan verilere ulaşabiliriz ve bunların grafiğini çizebiliriz. Mavi çizgi eğitim verisine ait hata miktarını gösteren çizgidir. Kırmızı ise doğrulama verisine ait çizgidir. Bizim için kırmızı çizgi daha önemlidir. Eğer doğrulama verisi iyileşmeyi bırakırsa eğitim burada son bulur. Aşağıdaki resimde doğrulama verisine ait çizgi yatay hareket etmeye başlamış ve iyileşmeyi bırakmıştır.
Eğer modeli erken durdumasaydık ve 1000 iterasyonu tamamlasaydı ne olacaktı bir de o duruma ait grafiğe bakalım.
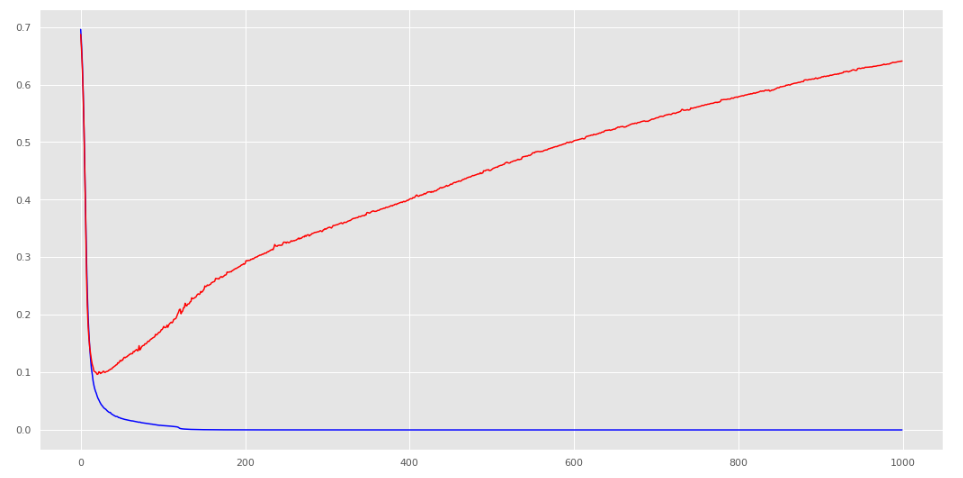
İşte böyle bir durumla karşılaşacaktık. Mavi çizgi 0 a yakın diye modelimizin iyi olduğunu düşünecektik. Maalesef makinemiz yorumlama yeteneğini gittikçe kaybedecek ve hata miktarı doğrulama veririsinde olduğu gibi hızlıca artacaktı. Teşekkürler early stopping. İyi ki varsın.

Şimdi tahmin zamanı.
|
|
Çıkış katmanında sigmoid fonksiyonu olduğunu ve bu fonksiyonun dış ortama 0 ile 1 arasında bir değer döndürdüğünü yukarıda öğrendik. İlk satır ile elimizdeki test verilerini verdik ve her veriye denk gelen 0-1 aralığında bir çıktı aldık. İkinci satırda bu çıktıyı 0 ve 1 li yapıya döndürüyoruz. her veriyi kontrol ediyoruz. Bu değer 0.5 ve üzeriyse 1 etiketine değil ise 0 etiketine dönüştürüyoruz. Çok güzel şimdi sonuçlarımızı görme zamanı.
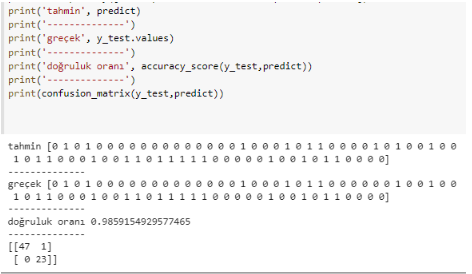
Çok güzel! 71 veriden 70 tanesini doğru tahmin ettik ve 0.985 gibi yüksek bir doğruluk oranı elde ettik. Burada dikkat edilmesi gereken çok önemli bir nokta var. Bazı çalışmaların hata toleransı fazla olsa da kanser gibi insan hayatını yakından ilgilendiren bir durum için analiz yapılıyorsa her hata tekrar incelenmelidir. Bizim modelimizde asıl sevindirici olay yaptığımız 1 hatanın iyi huylu bir kansere kötü huylu dememizdir. "Nasıl yani hata hatadır ne farkı var?" diye düşünüyor olabilirsiniz. Tabii ki farkı var. Ne kadar hata yapmak istemesek de eğer hata yapacaksak bile bu hatanın sonucunun ağır olmamasını tercih ederiz. Eğer kötü huylu bir kanser hücresini iyi huylu olarak tahmin etseydik insan yaşamını daha fazla tehlikeye atmış olacaktık. Bu hatanın sonucu bizim yaptığımız hatanın sonucundan daha ağır olacaktı. Tabii ki iyi huylu hücreyi kötü huylu olarak tahmin edersek de insan yaşamı etkilenmiş olacak fakat bu hatayı düzeltmek diğer hataya göre daha kolay olacaktır. Peki biz hatamızın hangi hata olduğunu nereden anladık? Karışıklık matriksi (Confusion Matrix) bize bu bilgiyi verdi. Yukarıdaki çıktıda en altta bir matriks bulunmaktadır. Bu matriksin sol alt köşedeki değeri sıfır olduğu için bu sonuca ulaştık. Confusion Matrix i detaylıca incelemek ve mantığını anlamak modelleri yorumlamak için önemlidir. Confusion Matrixi incelemek isteyenler için bu yazı yararlı olacaktır.
Kaynak Kod: kaggle.com/code/mustafabayhan
Yapay Sinir Ağları teorik anlatım: Yapay Sinir Ağları Nedir, Nasıl Çalışırlar?
Yapay sinir ağları örnek çalışma: Tensorflow ile yapay sinir ağları modeli nasıl kurulur?
Makinemizin bu başarıdan dolayı bir kutlamayı hakettiğini düşünüyorum.

Yazar Hakkında

Mustafa Bayhan
Merhaba ben Mustafa Bayhan. Veri analizi, veri görselleştirme, raporlama ve finansal analiz gibi veriyle yakından ilgili alanlarda çalışmalar yapan bir Endüstri mühendisiyim. Verilerin analiz edilmesi ve yönetilmesi konusunda çalışmalar yapmaktayım. Veriler üzerindeki hakimiyetim farklı sektörler üzerinde projeler geliştirebilmeme olanak sağlıyor. Kendimi sürekli geliştirmeyi ve öğrendiklerimi paylaşmayı seviyorum. Yeni fikirlerle tanışmak ve bu fikirleri hayata geçirmek beni her zaman mutlu ediyor. Benimle ilgili detaylı bilgi için hakkımda sayfamı ziyaret edebilirsiniz.
Beğenebileceğiniz gönderiler

0 Yorumlar
Yorum Yapmak İster misiniz?
Yeni Gönderiler

Kumru AI İncelemesi: Güçlü Yönleri, Zayıf Yönleri ve Kullanım Deneyimi

Büyük Dil Modelleri (LLM): RAG, Context Engineering ve Agent Yapıları

Veri Analizinde Model Seçimi: AIC ve BIC Nedir?

Veri Analizinde Kullanılan Histogram Türleri ve Anlamları

Korelasyon ile Nedensellik Çıkarımı Yapılabilir mi?
Histogram Nedir, Histogram Grafiği Nasıl Yapılır?