


Veri Bilimi
Öneri Sistemi (Recommendation System) Nedir?
Her gün kullandığımız alışveriş sitelerinin tam da ihtiyacımız olan ürünleri nasıl bulabildiğini ve bize nasıl önerdiğini hiç merak ettiğiniz oldu mu? Peki sürekli önümüze çıkan reklamların ihtiyaçlarımızla olan benzerliği daha önce dikkatinizi çekti mi? Bize önerilerde bulunan film siteleri, müzik uygulamaları nelerden hoşlanacağımızı nereden biliyor? Bunların hepsi bir sihir mi yoksa veri analizinin gücü mü? Hadi bu sihirli dünyayı beraber inceleyelim.
İçindekiler
1. Öneri Sistemi Nedir?
2. İçerik Tabanlı Öneri Sistemi Nedir?
3. Kosinüs Benzerliği Nedir?
4. Python ile Kosinüs Benzerliği Nasıl Hesaplanır?
5. Jaccard Benzerliği Nedir?
6. Python ile Jaccard Benzerliği Nasıl Hesaplanır?
7. Sonuç
1. Öneri Sistemi Nedir?
2. İçerik Tabanlı Öneri Sistemi Nedir?
3. Kosinüs Benzerliği Nedir?
4. Python ile Kosinüs Benzerliği Nasıl Hesaplanır?
5. Jaccard Benzerliği Nedir?
6. Python ile Jaccard Benzerliği Nasıl Hesaplanır?
7. Sonuç
Öneri Sistemi Nedir?
Öneri sistemi, kullanıcıların tercihlerini ve ürünlerin özelliklerini kullanarak en doğru ürünü en uygun kullanıcının önüne çıkarmayı amaçlayan çalışmalar bütünüdür. Bu yazıda ise öneri sisteminin alt alanı olan içerik tabanlı öneri sistemlerini inceleyeceğiz.
İçerik Tabanlı Öneri Sistemi Nedir?
İçerik tabanlı öneri sistemi, önerilecek olan ürünlerin özelliklerini inceleyerek önerilerini ürünlerin özelliklerine göre belirleyen ve kullanıcılara benzer özelliklere sahip ürünleri tavsiye eden öneri sistemi alanıdır. İçerik tabanlı öneri sisteminde kullanıcının daha önce ilgilendiği ürünlerin özellikleri ve bu özelliklerin ne kadar önemli olduğu belirlenir. Bu özellikler ve önem katsayıları göz önüne alınarak diğer ürünlerle kıyaslama yapılır. Bu kıyaslama sonucunda her ürün için bir benzerlik puanı elde edilir. En yüksek puana sahip ürünler kullanıcıya tavsiye edilir. Hayatımızın bir parçası olan ve sihir gibi görünen bu sistemler temelde bu kadar basit bir prensibi benimserler.
Dinlediğimiz müziklerden izlediğimiz filmlere, tıkladığımız reklamlardan incelediğimiz ürünlere kadar temasta olduğmuz her içerik için bu işlem uygulanır. Örneğin daha önce dinlediğimiz müzik 90 lar pop müziğiyse sistemimiz muhtemelen 90 lı yıllara ait başka bir pop müzik önerecektir. Tabii ki sadece iki özelliğe göre öneride bulunmak yanıltıcı olacaktır. Öneri sistemi oluşturulurken içeriklerin ve ürünlerin birden çok özelliği dikkate alınır. Bu özelliklerden bazıları sonucu daha çok etkilerden bazıları daha az etkiler. Örneğin müziği seslendiren şarkıcının ismi ile müziğin kategorisi yapılan önerileri farklı düzeyde etkileyecektir.
Peki hangi özelliğin daha önemli olduğuna nasıl karar vereceğiz? Bu aşamada farklı yöntemler deneyebiliriz. Bunlardan en basit olanı özelliklerin ne kadar önemli olacağını, başka bir ifadeyle özelliklerin katsayılarını manuel olarak belirlemektir. Örneğin şarkıcı isminin, şarkının tarzından daha önemli olduğunu düşünüyorsak şarkıcı ismi özelliğinin katsayısını daha yüksek olarak belirleyebiliriz. Bu sayede bu özelliğin sonuç üzerindeki etkisini arttırmış oluruz . Tabii ki bu her zaman işe yarayan bir yöntem değildir. Dikkatli davranılmazsa da öneri sisteminin yanlış çalışmasına da sebep olacaktır. Bir diğer yöntem kullanıcının ilgilendiği içeriklere göre katsayıların belirlenmesidir. Örneğin bir kullanıcı daha önce benzer tarzda şarkılar dinlemişse ve şarkının tarzını, şarkıyı seslendiren kişiden daha fazla önemsiyorsa o kullanıcı için şarkının tarzının katsayısı daha büyük olmalıdır. Öneri sistemi, kullanıcılara öneride bulunurken her kullanıcının neye önem verdiğini tespit etmeli ve önerisini kullanıcının tercihlerine göre şekillendirmelidir. Bu yöntem daha zor ve maliyetli olsa da daha tatmin edici sonuçlar vermektedir.
İçerik tabanlı öneri sisteminde bir diğer önemli nokta ise içeriklerin benzerliğinin nasıl hesaplanacağıdır. İki veri arasındaki benzerlik hesaplanırken kullanılan yöntemlerden en popüler iki tanesi Kosinüs Benzerliği ve Jaccard Benzerliği yöntemleridir. Hadi bu yöntemlerin özelliklerini beraber inceleyelim.
Kosinüs Benzerliği Nedir?
Kosinüs benzerliği yöntemi, iki vektör arasındaki benzerliği hesaplamada kullanılan meşhur bir yöntemdir. Aşağıdaki çok masum duran fonksiyonu kullanarak kosinüs benzerliği kolayca hesaplanabilir.
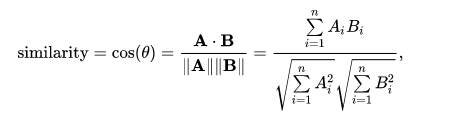
Formülü beraber inceleyelim. Benzerliğini hesaplamaya çalıştığımız iki vektörün nokta çarpımını (dot product) yaparak işleme başlıyoruz. Sonrasında ise vektörlerin uzunluklarını çarpıyoruz. Son olarak ilk değeri ikinci değere bölüyor ve kosinüs benzerlik değerini hesaplamış oluyoruz.
Python ile Kosinüs Benzerliği Nasıl Hesaplanır?
Python ile Kosinüs benzerliğini hesaplamak oldukça kolaydır. Yukarıdaki formüller sana yabancı gelmiş olabilir ama korkmana gerek yok. Tek tek hesaplama yapmak yerine bir kaç satırlık kod ile bu işlemi kolayca halledebiliriz. Aşağıdaki python kodu Kosinüs benzerliğini severek hesaplayacaktır.
def cosine_similarity(vector1, vector2):
import numpy as np
dot_product = np.dot(vector1, vector2)
norm_a = np.linalg.norm(vector1)
norm_b = np.linalg.norm(vector2)
cosine_similarity_value = dot_product / (norm_a * norm_b)
return cosine_similarity_value
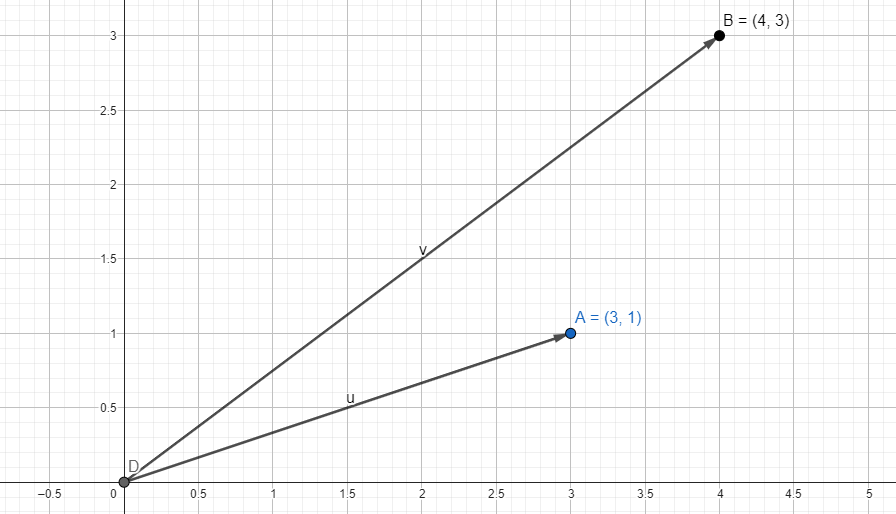
Hadi bir deneme yapalım ve aşağıdaki grafikte bulunan ve birbirine yakın konumlanmış (3,1) ve (4,3) vektörlerinin kosinüs benzerliklerini inceleyelim.
Üsteki cosine_similarity isimli fonksiyonu kullanarak bu iki vektörün benzerliğini bulabiliriz.
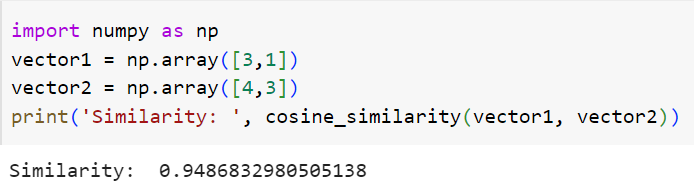
Bu iki vektörün birbirine benzediğini düşünüyorduk, fonksiyonumuzla da bunu onayladık. İki vektör arasında %94.87 lik benzerlik olduğunu tespit ettik. Fonksiyonumuz düzgün çalışıyor. Öneri sistemlerini inceleyecektik, vektörleri inceliyoruz diye düşünmeye başladıysanız matematiksel kısım bitti sayılır. Peki biz bu işlemleri, vektörleri öneri sistemlerinde nasıl kullanacağız? İçerik tabanlı öneri sistemleri burada başlıyor. Film öneri sistemi oluşturmak istediğimizi düşünelim ve kategorilerdeki benzerliğe göre önerilerde bulunacağız. Hadi kosinüs benzerliğini kullanarak bu işlemleri kategoriler üzerinde deneyelim.
film 1 in kategorileri = Aile, Komedi, Aksiyon
film 2 nin kategorileri = Aksiyon, Korku, Gerilim
Kategorileri incelediğimizde bu iki film birbirine çok benzer görünmüyor. Bakalım fonksiyonumuz da bizimle aynı fikirde mi?
Öncelikle iki filmdeki tüm kategorileri bir araya getirerek işleme başlıyoruz.
İki filmdeki tüm kategoriler = Aile, Komedi, Aksiyon, Korku, Gerilim
Sonraki aşamada ise her bir film için vektör oluşturuyoruz.
Filmlere ait tüm kategorileri bir araya getirmiştik. Bu kategroilere sırasıyla bakacağız. Filme ait kategoriler için 1, filme ait olmayanlar için 0 değerini vektöre yazacağız. Bu işlem sonucunda filme ait vektörü oluşturmuş olacağız.
Film 1 vektörü = [1, 1, 1, 0, 0]
Film 2 vektörü = [0, 0, 1, 1, 1]
Vektörleri oluşturduktan sonraki aşama ise bu vektörler arasındaki benzerliği hesaplamak. Yukarıdaki fonksiyonu kullanarak benzerliği hesaplayabiliriz.
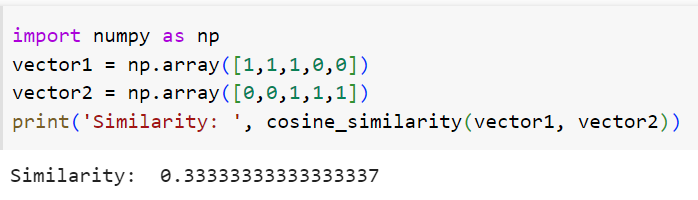
Bu iki film için kosinüs benzerlik değerini 33.3% olarak hesapladık. İyi bir benzerlik oranı olmadığı için ilk filmi izleyen birisine ikinci filmi önermemeliyiz. Başka bir örnek daha yapalım.
film1 kategoriler = Aile, Komedi, Aksiyon
film2 kategorileri = Komedi, Animasyon, Fantastik, Aile, Aksiyon
Film 1 in kategorileri önceki örnekteki film 1 ile aynı. Yeni bir film ile ilk filmin benzerlik oranını hesaplayacağız. Hesaplamaya kategorileri birleştirerek başlıyoruz.
İki filmdeki tüm kategoriler = Aile, Komedi, Aksiyon, Animasyon, Fantastik
Bundan sonraki aşamada filmlere ait vektörleri oluşturuyoruz.
Film 1 vektörü = [1, 1, 1, 0, 0]
Film 2 vektörü = [1, 1, 1, 1, 1]
Filmlerin vektörlerini oluşturduk. Fonksiyonumuzu kullanarak filmler arasındaki benzerliği hesaplayalım.
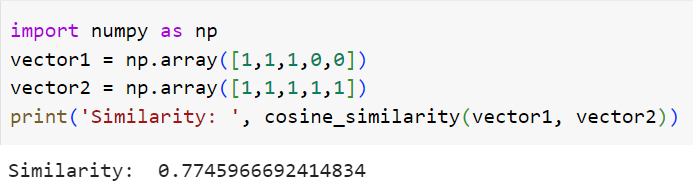
Bu iki film arasında çok güzel bir benzerlik olduğunu tespit ettik. İki filmin kosinüs benzerliğini 77.5% olarak hesapladık. Artık gönül rahatlığı ile yeni filmi kullanıcıya ya da arkadaşımıza tavsiye edebiliriz. Sadece kategori üzerinden benzerlik hesaplayarak bile çok güzel sonuçlar elde ettik. Daha güzel sonuçlar için öneri sistemi oluşturulurken birden çok özellik dikkate alınmalıdır.
Jaccard Benzerliği Nedir?
Benzerlik hesaplamak için kullanılan bir diğer yöntem ise Jaccard Benzerliği yöntemidir. Bu benzerlik yöntemi daha sade bir yapıya sahiptir. İki listedeki ortak eleman sayısının tüm eleman sayısına oranı Jaccard Benzerliği olarak bilinir.
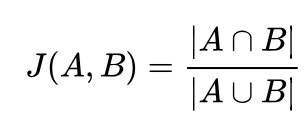
Daha önce incelediğimiz film kategorisi benzerliği örneğini tekrar kullanalım ve jaccard benzerliği formulünü detaylıca inceleyelim.
film1 kategoriler = Aile, Komedi, Aksiyon
film2 kategorileri = Aksiyon, Korku, Gerilim
Bu iki filmin kosinus benzerliğini 33% olarak önceki örnekte hesaplamıştık. Şimdi filmlerin Jaccard benzerliklerini inceleyelim.
İki filmdeki tüm kategoriler = Aile, Komedi, Aksiyon, Korku, Gerilim
Ortak kategoriler = Aksiyon
Ortak kategori sayısı = 1
Tüm kategorilerin sayısı = 5
Jaccard benzerliği = Ortak kategorilerin sayısı/ Tüm kategorilerin sayısı = 1/5 = 20%
Her iki hesaplama yöntemi de bu iki film için benzerlik oranını çok düşük hesapladı. Biz de bu iki filmin benzemediğini düşünüyorduk. Hesaplama yöntemleri gayet başarılı çalışıyor. Bir diğer örneği daha inceleyelim.
film1 kategoriler = Aile, Komedi, Aksiyon
film2 kategorileri = Komedi, Animasyon, Fantastik, Aile, Aksiyon
Bu iki film birbiririne benzer kategorilere sahip. Bu filmler için kosinus benzerliğini 77.5% olarak hesaplamıştık. Hadi Jaccard benzerliğini de hesaplayalım.
Tüm kategoriler = Aile, Komedi, Aksiyon, Animasyon, Fantastik
Ortak kategoriler = Aile, Komedi, Aksiyon
Tüm kategori sayısı = 5
Ortak kategori sayısı = 3
Jaccard Benzeriği = Ortak kategorilerin sayısı/ Tüm kategorilerin sayısı = 3/5 = 60%
Bu iki filmin Jaccard benzerliğini kategorilere bakarak hesapladığımızda yüzde 60 lık bir benzerlik tespit etmekteyiz. Bu yeterli ve güzel bir oran olduğu için birinci filmi izleyen bir arkadaşımıza ikinci filmi gönül rahatlığı ile önerebiliriz.
Peki jaccard benzerliğini hep manuel mi hesaplayacağız. Tabii ki hayır! Haydi python ile jaccard benzerliği nasıl hesaplanır beraber inceleyelim!
Python ile Jaccard Benzerliği Nasıl Hesaplanır?
Kosinüs benzerliğinde olduğu gibi jaccard benzerliğini hesaplamak için de python kullanabiliriz. Aşağıdaki basit python kodu ile jaccard benzerliğini kolayca hesaplayabiliriz.
def jaccard_similarity(list1, list2):
kesişim = len(list1.intersection(list2))
birleşim = len(list1.union(list2))
jaccard_benzerliği = kesişim / birleşim if birleşim != 0 else 0
return jaccard_benzerliği
Her gün kullandığımız pek çok website ve uygulama içerik tabanlı öneri sistemi yöntemini kullanmaktadır. Bizi ve tercih ettiğimiz içerikleri analiz etmekte ve bize önerilerde bulunmaktadır. İçerik tabanlı öneri sistemleri temel olarak yukarıdaki prensiplere göre temellenmektedir. Siz de kendi öneri sisteminizi oluşturabilir, hem eğlenceli hem de yararlı tavsiyeler veren bir sistem geliştirebilirsiniz.
Öneri Sistemi Örnek Çalışma
Öneri sistemlerinin aktif olarak kullanıldığı yapay zeka destekli ilk film öneri sitesini inceleyebilirsiniz. Sizin önceden izlediğiniz filmlere benzer filmleri bularak karşınıza getiren iyifilmonerileri.site ile artık zevkinize uygun filmleri bulmak çok kolay.
Yazar Hakkında

Mustafa Bayhan
Merhaba ben Mustafa Bayhan. Veri analizi, veri görselleştirme, raporlama ve finansal analiz gibi veriyle yakından ilgili alanlarda çalışmalar yapan bir Endüstri mühendisiyim. Verilerin analiz edilmesi ve yönetilmesi konusunda çalışmalar yapmaktayım. Veriler üzerindeki hakimiyetim farklı sektörler üzerinde projeler geliştirebilmeme olanak sağlıyor. Kendimi sürekli geliştirmeyi ve öğrendiklerimi paylaşmayı seviyorum. Yeni fikirlerle tanışmak ve bu fikirleri hayata geçirmek beni her zaman mutlu ediyor. Benimle ilgili detaylı bilgi için hakkımda sayfamı ziyaret edebilirsiniz.
Beğenebileceğiniz gönderiler


4034 Yorumlar
Yorum Yapmak İster misiniz?
Yeni Gönderiler

Kumru AI İncelemesi: Güçlü Yönleri, Zayıf Yönleri ve Kullanım Deneyimi

Büyük Dil Modelleri (LLM): RAG, Context Engineering ve Agent Yapıları

Veri Analizinde Model Seçimi: AIC ve BIC Nedir?

Veri Analizinde Kullanılan Histogram Türleri ve Anlamları

Korelasyon ile Nedensellik Çıkarımı Yapılabilir mi?
Histogram Nedir, Histogram Grafiği Nasıl Yapılır?



Keithreirm 29 Haziran 2026 23:32
If you are used to guessing what might suit you, this resource replaces guesswork with a more informed preview. After a quick selfie and a few quiz answers, it evaluates facial features, hair behavior, and lifestyle context to produce 10 tailored styles, realistic renderings, and barber instructions. Behind the result is not a simple filter, but a mathematical model with 50+ parameters and an anatomical 3D scan, designed to show how a cut fits. Rather than applying a generic hairstyle overlay, it uses an algorithmic model with 3D mapping to explain how the final cut will sit. What you receive is a photorealistic lookbook, designed to avoid the flat look of toy-like filters and instead present a realistic rendering. Each report adds a structured guide for the stylist, making it easier to ex
ShirleyCow 29 Haziran 2026 22:45
Finding the best online casino, [url=http://www.s52.hekko24.pl/2026/06/15/aventuras-de-apuestas-en-campobet-la-mejor/]http://www.s52.hekko24.pl/2026/06/15/aventuras-de-apuestas-en-campobet-la-mejor/[/url] can be a thrilling experience. Selecting a platform that offers diverse games and enticing bonuses is essential. Many gamers admire high-quality customer support and secure payment methods.
VanessaDeave 29 Haziran 2026 21:51
На мой взгляд, это интересный вопрос, буду принимать участие в обсуждении. ОЈП„О·ОЅ ОµПЂОїП‡О® П„О·П‚ П€О·П†О№О±ОєО®П‚ П„ОµП‡ОЅОїО»ОїОіОЇО±П‚, П„О± ОєО±О¶О№ОЅОї П‡П‰ПЃО№П‚ П„О±П…П„ОїПЂОїО№О·ПѓО·, [url=https://videoinvita.com/online-casino-gaming/]https://videoinvita.com/online-casino-gaming/[/url] ОєОµПЃОґОЇО¶ОїП…ОЅ ПѓП…ОЅОµП‡ПЋП‚ ОґО·ОјОїП„О№ОєПЊП„О·П„О±. ОџО№ ПЂО±ОЇОєП„ОµП‚ ОјПЂОїПЃОїПЌОЅ ОЅО± О±ПЂОїО»О±ПЌПѓОїП…ОЅ ПЂО±О№П‡ОЅОЇОґО№О± П‡П‰ПЃОЇП‚ ОЅО± П‡ПЃОµО№О¬О¶ОµП„О±О№ ОЅО± П…ПЂОїОІО¬О»ОїП…ОЅ ПЂПЃОїПѓП‰ПЂО№ОєО¬ ПѓП„ОїО№П‡ОµОЇО±. О‘П…П„О® О· ПЂПЃОїПѓООіОіО№ПѓО· ПѓП…ОјПЂО±ПЃО±ПѓПЌПЃОµО№ П„О·ОЅ О№ОґО№П‰П„О№ОєПЊП„О·П„О± П„ОїП… П‡ПЃО®ПѓП„О·, ОµПЂО№П„ПЃОПЂОїОЅП„О±П‚ П„ПЊПѓОї ОµПЌОєОїО»О· ПЂПЃПЊПѓОІО±ПѓО· ПѓОµ ПЂПЃОїПЉПЊОЅП„О±. ОџО№ ОєО±О¶ОЇОЅОї ОП‡ОїП…ОЅ ОјО№О± ОјОµОіО¬О»О· ПЂОїО№ОєО№О»ОЇ
Briannabog 29 Haziran 2026 19:15
online casino, [url=https://www.livesicily.it/2026/06/15/dlrbet-la-plataforma-de-apuestas-online-que/]https://www.livesicily.it/2026/06/15/dlrbet-la-plataforma-de-apuestas-online-que/[/url] presents an engaging way to experience games. With a array of options, players can try their luck at table games and gain rewards from the comfort of their homes.
Brycerah 29 Haziran 2026 17:48
Какие слова... фантастика Online Casino, [url=https://www.mobilificiosolinas.it/betninja-uk-login-guide-quick-and-easy-steps/]https://www.mobilificiosolinas.it/betninja-uk-login-guide-quick-and-easy-steps/[/url] - Virtual Casino предлагает уникальные возможности для РёРіСЂРѕРєРѕРІ, предлагая захватывающие РёРіСЂС‹. Надежность гарантируется передовыми технологиями. Присоединяйтесь Рё исследуйте новые горизонты азартных РёРіСЂ!
AngieSow 29 Haziran 2026 17:32
22Casino Portugal, [url=https://training.insurancesplash.com/22casino-portugal-a-experiencia-definitiva-em-jogos-online/]https://training.insurancesplash.com/22casino-portugal-a-experiencia-definitiva-em-jogos-online/[/url] oferece uma experiência de jogos única, ricamente adornada com opções para todos os gostos. Se encontra que os jogadores apreciem uma vasta gama de diversões. Além disso, a interface é simples de usar, então proporciona uma experiência prazerosa para todos os jogadores.
Aarontat 29 Haziran 2026 15:50
casino online, [url=https://protectaproduct.net/wp/exploring-fabet-a-comprehensive-guide-to-online-7/]https://protectaproduct.net/wp/exploring-fabet-a-comprehensive-guide-to-online-7/[/url] - Internet betting предлагает уникальные возможности для участников. Рнтернет казино обеспечивает комфорт Рё разнообразие, что привлекает тысячи пользователей.
FrankHen 29 Haziran 2026 12:10
когда-то посмотрю, и потом отпишусь LuckyNiki Casino DK, [url=https://www.efora.it/2026/06/14/luckyniki-casino-dk-detaljer-og-anmeldelser/]https://www.efora.it/2026/06/14/luckyniki-casino-dk-detaljer-og-anmeldelser/[/url] tilbyder et fantastisk underholdningsoplevelse. I LuckyNiki kan spillere nyde et spil, som giver potentialer for store vГ¦rdier.
Monaaxono 29 Haziran 2026 11:16
In the world of online entertainment, an online casino, [url=https://sizebox.pl/onlinecasinobet150614/fortunazo-el-camino-hacia-la-riqueza/]https://sizebox.pl/onlinecasinobet150614/fortunazo-el-camino-hacia-la-riqueza/[/url] offers an exciting experience for players. With a variety of choices available, it caters to amateurs and experts alike, ensuring that everyone can find their fit. Enjoy the ease of playing from home while potentially winning big!
DinkeyCak 29 Haziran 2026 09:15
BC Game Casino, [url=http://mewebsure.com/discover-bc-game-casino-and-sportsbook-a/]http://mewebsure.com/discover-bc-game-casino-and-sportsbook-a/[/url] предоставляет игрокам увлекательные азартные игры в сети. Посетители могут выбирать широкие игровые автоматы и казино-игры, наслаждаясь перспективами на выигрыш.
Rachelgremo 29 Haziran 2026 08:50
Я уверен, что это мне совсем не подходит. Кто еще, что может подсказать? SpilDanskNu Casino DK, [url=https://www.720transform.com/2026/06/15/spildansknu-casino-dk-din-guide-til-det-bedste-online-spil/]https://www.720transform.com/2026/06/15/spildansknu-casino-dk-din-guide-til-det-bedste-online-spil/[/url] tilbyder fantastiske spiloplevelser. Spillere kan opleve et stort udvalg af spil. Udforsk de moderne bonusser og tilbudspakker for at forstГ¦rke din oplevelse. BesГёg SpilDanskNu Casino DK snart!
PennyLof 29 Haziran 2026 07:49
play online casino, [url=https://wowmarketing.in/the-exciting-world-of-online-gaming-hayalbahis/]https://wowmarketing.in/the-exciting-world-of-online-gaming-hayalbahis/[/url] and experience the thrill of gaming from home. Engage in various entertaining games. Collect amazing rewards and enjoy the exhilarating atmosphere. Don't miss out on this awesome opportunity!
Melissatiern 29 Haziran 2026 07:29
Блеск мостбет зеркало, [url=https://mostbet-djs53.cam/]https://mostbet-djs53.cam/[/url] позволяет игрокам получить доступ к любимым играм и ставкам даже в случае блокировок. Это удобный|комфортный|эффективный|практичный способ обойти ограничения. Используя альтернативные ссылки, вы сможете наслаждаться азартом и выигрышами без препятствий. Не упустите шанс!
MarianPlece 29 Haziran 2026 06:59
Спасибо за помощь в этом вопросе. Lucky Louis Casino Spil, [url=http://www.g5engineerings.com/lucky-louis-casino-spil-2026-en-uforglemmelig-spiloplevelse-152821802/]http://www.g5engineerings.com/lucky-louis-casino-spil-2026-en-uforglemmelig-spiloplevelse-152821802/[/url] tilbyder eventyrlige spiloplevelser. Her kan du finde et bredt udvalg af frugtmaskiner samt live casino spil. GГёr dig klar til at fГҐ heldet med dig!
Jamesaduts 29 Haziran 2026 06:48
22Casino Polska, [url=http://unati.univasf.edu.br/22casino-polska-twoje-ulubione-miejsce-do-gry-online/]http://unati.univasf.edu.br/22casino-polska-twoje-ulubione-miejsce-do-gry-online/[/url] to ceniony serwis hazardowy, który daje rozbudowany wybór rozrywek. Użytkownicy mogą korzystać z doskonałej jakości pomocy oraz różnorodnymi promocjami, co ulepsza doświadczenie zabawy.
Sallymeedy 29 Haziran 2026 02:27
Согласен, ваша мысль просто отличная мостбет зеркало, [url=https://mostbet-ews51wl.cfd/]https://mostbet-ews51wl.cfd/[/url] предоставляет игрокам возможность доступа к ставкам даже в случае блокировок. Это замена для игроков, желающих игнорировать ограничения. С его помощью можно без усилий находить нужные события и ставить в любимые игры.
Tonyawange 29 Haziran 2026 02:01
22Bit Casino Polska, [url=https://demos.totalsuite.net/totalpoll/22bit-casino-polska-twoje-miejsce-do-gry-w-internecie/]https://demos.totalsuite.net/totalpoll/22bit-casino-polska-twoje-miejsce-do-gry-w-internecie/[/url] to nowoczesna platforma dla miЕ‚oЕ›nikГіw gier. Zapewnia szeroki wybГіr gier. Gracze ceniД… sobie luksusowe bonusy oraz bezproblemowy proces rejestracji. Ciesz siД™ niezapomnianД… rozrywkД… w 22Bit Casino Polska!
YolandaVor 29 Haziran 2026 01:55
Это забавное мнение Lucky Louis Casino Spil, [url=https://drainvestidora.com/lucky-louis-casino-spil-2026-en-fantastisk-spiloplevelse-90108474/]https://drainvestidora.com/lucky-louis-casino-spil-2026-en-fantastisk-spiloplevelse-90108474/[/url] tilbyder en unikt spilomrГҐde med forskellige muligheder. Her kan du fordybe dig i underholdende spil, der lover en vidunderlig oplevelse.
Kerrybor 29 Haziran 2026 00:56
Finding the greatest online casinos can be confusing. To enjoy the best online casino, [url=https://lauragonzafer.com/unlocking-the-world-of-online-betting-a-deep-dive-2/]https://lauragonzafer.com/unlocking-the-world-of-online-betting-a-deep-dive-2/[/url] experience, consider factors like bonuses, diversity of games, and customer support. Don't forget to check user reviews!
JeffTal 29 Haziran 2026 00:47
Охотно принимаю. Тема интересна, приму участие в обсуждении. Вместе мы сможем прийти к правильному ответу. Я уверен. SpilleAutomaten Casino DK, [url=https://www.confesercentiviterbo.it/2026/06/16/spilleautomaten-casino-dk-2026-den-ultimative-guide-895976437/]https://www.confesercentiviterbo.it/2026/06/16/spilleautomaten-casino-dk-2026-den-ultimative-guide-895976437/[/url] tilbyder en fantastisk muligheder af fornГёjelser. Spillere kan forvente fantastiske gevinster og morskab. Sikkerheden er i top, hvilket gГёr et trygt spillemiljГё. SpilleAutomaten Casino DK er et fremragende valg for alle spilleelskere.
Ashleyasset 28 Haziran 2026 23:12
норм фильм? 1win официальный сайт, [url=https://1win-mcy44.sbs/]https://1win-mcy44.sbs/[/url] открывает пользователям широкий выбор игр. Легкость навигации обеспечивает удобно искать нужные разделы.
AndyAnisa 28 Haziran 2026 22:23
Не могу сейчас принять участие в дискуссии - нет свободного времени. Буду свободен - обязательно выскажу своё мнение. В казино casino pin up, [url=https://pinup-mxw.xyz/]https://pinup-mxw.xyz/[/url] игроки могут наслаждаться захватывающими играми. Множество автоматов и настольных игр предоставляет восторг настоящим казино фанатам.
TammyInvom 28 Haziran 2026 21:16
22Bit 카지노, [url=https://postcardsfromhistory.awbhistory.lmu.build/uncategorized/22bit-%ec%b9%b4%ec%a7%80%eb%85%b8-%ec%b5%9c%ec%83%81%ec%9d%98-%ec%98%a8%eb%9d%bc%ec%9d%b8-%ea%b2%8c%ec%9e%84-%ea%b2%bd%ed%97%98/]https://postcardsfromhistory.awbhistory.lmu.build/uncategorized/22bit-%ec%b9%b4%ec%a7%80%eb%85%b8-%ec%b5%9c%ec%83%81%ec%9d%98-%ec%98%a8%eb%9d%bc%ec%9d%b8-%ea%b2%8c%ec%9e%84-%ea%b2%bd%ed%97%98/[/url]лЉ” мµњмѓЃкё‰ мЁлќјмќё лЏ„л°• 플랫폼입니다. мќґкіім—ђм„ л‹¤м–‘н•њ кІЊмћ„мќ„ кІЅн—н• м€ мћ€мЉµл‹€л‹¤. н”Њл €мќґм–ґлЉ” м‹ лў°н• м€ мћ€лЉ” лІ нЊ…мќ„ н• м€ мћ€мњјл©°. м€л§ЋмќЂ ліґл„€мЉ¤м™Ђ н”„лЎњлЄЁм…лЏ„ м°ём—¬н• м€ мћ€мЉµл‹€л‹¤. 22Bit 카지노에서 흥미로운 кІЅн—мќ„ мІґн—н•ґліґм„ёмљ”!
Ivyjuins 28 Haziran 2026 20:39
Бесподобная тема, мне интересно :) 1win официальный сайт, [url=https://1win-pht32.top/]ван вин официальный сайт[/url] предлагает многообразные возможности для ставок. Здесь вы можете находить лучшие предложения и получать удовольствие от ставок на спорт.
Tonyasub 28 Haziran 2026 18:16
Looking for an exciting way to enjoy games? Discover the world of casino online, [url=https://nile-tours.com/realzcasino-ihr-weg-zu-aufregendem-online-2/]https://nile-tours.com/realzcasino-ihr-weg-zu-aufregendem-online-2/[/url], where you can experience thrilling games from the comfort of your home. Offering various options, you’ll find poker to suit your taste.
Tonyapayob 28 Haziran 2026 17:18
BC Game Casino, [url=https://codecanyondemo.work/wcod/2026/06/10/unlocking-the-best-bc-game-bonuses-and-promo-codes/]https://codecanyondemo.work/wcod/2026/06/10/unlocking-the-best-bc-game-bonuses-and-promo-codes/[/url] offers thrilling games for players. Here, you can enjoy countless options, from video slots to interactive sessions. Join now to maximize your excitement and unlock fantastic rewards!
Gloriaflaws 28 Haziran 2026 16:39
A SafeCasino MagyarorszГЎg Online KaszinГі, [url=https://jerial-jor.com/safecasino-magyarorszag-online-kaszino-biztonsagos-jatek-elmeny-240385750/]https://jerial-jor.com/safecasino-magyarorszag-online-kaszino-biztonsagos-jatek-elmeny-240385750/[/url] izgalmas lehetЕ‘sГ©get kГnГЎl a jГЎtГ©kosok szГЎmГЎra. A jГЎtГ©kosok szГЎmos lehetЕ‘sГ©g kГ¶zГјl vГЎlaszthatnak. KiprГіbГЎlhatja a modern jГЎtГ©kokat, amelyek izgalmasak Г©s kitЕ±nЕ‘ grafikГЎval rendelkeznek. Ne kГ©slekedjen a lenyЕ±gГ¶zЕ‘ bГіnuszokat sem!
MayLef 28 Haziran 2026 14:16
The thrill of playing online casino, [url=https://www.assoservizionline.it/2026/06/18/explore-the-exciting-world-of-jogabets-367251761/]https://www.assoservizionline.it/2026/06/18/explore-the-exciting-world-of-jogabets-367251761/[/url] games is extraordinary. With multiple options available, players can enjoy their favorite games from the ease of home. Online casino offers offers that enhance the gaming experience.
JesseSek 28 Haziran 2026 12:14
BC Game Online Casino, [url=http://mikrofinance.ctydio21test.com.ua/explore-bc-game-casino-and-sportsbook-a-3/]http://mikrofinance.ctydio21test.com.ua/explore-bc-game-casino-and-sportsbook-a-3/[/url] offers an incredible experience for enthusiasts. With a wide range of games, users can savor thrilling moments. Join now and uncover endless opportunities!
JessicaLycle 28 Haziran 2026 10:39
Os cassinos digitais em Funchal oferecem diversão como nunca antes. Casinos Online Portugal, [url=https://staging.neizly.com/descubra-os-melhores-casinos-online-com-bonus-atracoes-e-vantagens/]https://staging.neizly.com/descubra-os-melhores-casinos-online-com-bonus-atracoes-e-vantagens/[/url] garante apostas seguras, permitindo que os apostadores divirtam-se sem restrições.
RyanSah 28 Haziran 2026 10:14
If you love excitement, experience the thrill of playing online casinos. These platforms offer a wide range of activities, allowing you to entertain yourself from the comfort of your home. play online casino, [url=https://rctdb.com/site-news/jugabet-la-nueva-era-de-las-apuestas-en-linea-15/]https://rctdb.com/site-news/jugabet-la-nueva-era-de-las-apuestas-en-linea-15/[/url] and find amazing bonuses and offers that increase your potential payouts.
SarahPep 28 Haziran 2026 07:51
Не нужно пробовать все подряд Kaiser Slots Casino, [url=https://academy.vipcapitalfx.com/kaiser-slots-casino-dk-2026-en-guide-til-det-bedste-online-spil-104826005/]https://academy.vipcapitalfx.com/kaiser-slots-casino-dk-2026-en-guide-til-det-bedste-online-spil-104826005/[/url] tilbyder fantastiske spilleautomater, hvor spillere kan nyde deres strategier. Med professionel kundeservice er oplevelsen angstfri.
RobertAware 28 Haziran 2026 07:48
L’offre de bonus de bienvenue 1xbet donne droit jusqu’a 1 750 € avec un bonus de 150 tours gratuits. Cette promotion est populaire parmi de nombreux bookmakers pour attirer de nouveaux clients, vous permettant de decouvrir le site sans depenser votre propre argent. L’acces est reserve aux joueurs majeurs. Toutes les informations sur le code promo 1xBet inscription sont disponibles ici : http://mskomi.ru/baner/pages/1xbet_bonus_pri_registracii.html
DevonSardy 28 Haziran 2026 06:48
Playing an engaging online casino game, [url=http://www.yresearch.com.au/monsterwin-der-ultimative-leitfaden-zu-spannenden/]http://www.yresearch.com.au/monsterwin-der-ultimative-leitfaden-zu-spannenden/[/url] can be a superb way to unwind. With various options available, participants can select their favorite games and delight in the thrill of winning.
CrystalJoize 28 Haziran 2026 05:45
Os jogos de azar online no território português oferecem uma oportunidade emocionante para os jogadores. Casinos Online Portugal, [url=https://ocursoesteticaautomotiva.com.br/os-melhores-online-casinos-portugal-com-grandes-ganhos/]https://ocursoesteticaautomotiva.com.br/os-melhores-online-casinos-portugal-com-grandes-ganhos/[/url] têm diversidade de jogos, desde slots até poker. Praticidade e lados seguros sãoimportantes para a satisfação do jogador.
DavidChest 28 Haziran 2026 04:19
Bet smarter and elevate your game using the powerful https://holycrossconvent.edu.na/profile/tinaju6fuentes665544/profile. Activate your bonus today and explore a world of sports betting and online entertainment.
Gabrielexova 28 Haziran 2026 04:10
BC Game Gambling Platform, [url=http://kobe.kaishun-do.com/blog/ultimate-guide-to-bc-game-plinko-strategy/]http://kobe.kaishun-do.com/blog/ultimate-guide-to-bc-game-plinko-strategy/[/url] features an exciting opportunity for gamblers. With a host of games, it offers fun and thrills. Join now to explore a world of gambles.
JosephineLip 28 Haziran 2026 03:56
Согласен, весьма забавное мнение SimbaGames Casino DK, [url=https://www.restaurantecedrus.com.br/?p=90675]https://www.restaurantecedrus.com.br/?p=90675[/url] tilbyder fremragende muligheder for spil. Her kan du mГёde et mangfoldigt sortiment af spilleautomater, som giver timevis fornГёjelse. Uanset hvad du er rutineret, vil du sГ¦tte pris pГҐ oplevelsen. I den nuvГ¦rende verden er online gambling blevet endnu mere tiltalende, isГ¦r med SimbaGames Casino DK, hvor beskyttelse altid er i fokus. Unik grafik og fascinerende lydeffekter gГёr, at hvert spil bliver en mindevГ¦rdig oplevelse.
TrentPiomb 28 Haziran 2026 03:48
Это просто замечательное сообщение Добро пожаловать в космос casino pin up, [url=https://pinup-klr8.cam/]https://pinup-klr8.cam/[/url], где тебя ждут увлекательные игры и щедрые бонусы. Тут каждый имеет возможность стать счастливым победителем игроком.
Cynthiaceaxy 28 Haziran 2026 03:19
The quest for the best online casino, [url=https://repricesolution.com/the-rise-of-online-betting-a-deep-dive-into-3/]https://repricesolution.com/the-rise-of-online-betting-a-deep-dive-into-3/[/url] can be overwhelming. With numerous options available, it's vital to pick wisely and think about factors like bonuses, games, and security.
Audreyvar 28 Haziran 2026 00:41
Os estabelecimentos Online Portugal proporcionam uma vivГЄncia incrГvel para jogadores de jogos de sorte. Com diversas opções de opções, Casinos Online Portugal, [url=https://miamistudios.gr/studios/os-melhores-casinos-online-com-bonus-como-escolher-e-aproveitar/]https://miamistudios.gr/studios/os-melhores-casinos-online-com-bonus-como-escolher-e-aproveitar/[/url] oferecem aos usuГЎrios diversГЈo no conforto de suas casas.
Andreaaccub 27 Haziran 2026 23:21
СПСБ В мир азартных игр включается casino pin up, [url=https://pinup-kzd3.cam/]https://pinup-kzd3.cam/[/url], предлагая игрокам разнообразный выбор развлечений для азартных. Разнообразные автоматы, покер и акционные предложения привлекают многих геймеров. С casino pin up каждый игрок может ощутить недюжинный азарт от игр.
SheilaNib 27 Haziran 2026 20:25
Online gambling has become widely accepted among enthusiasts. Players enjoy the accessibility of betting from anywhere. With casino online, [url=https://magme.madeinitalyslc.it/2026/06/14/lonaci-online-votre-destination-de-predilection/]https://magme.madeinitalyslc.it/2026/06/14/lonaci-online-votre-destination-de-predilection/[/url], one can enjoy a wide range of games, such as slots, poker, and blackjack, easy to find at any hour. The excitement of playing at casino online brings people together, creating a lively atmosphere.
Tammyinact 27 Haziran 2026 20:16
Клево!!! Вечером обязательно посмотрю 1win зеркало, [url=https://1win-ilh43.buzz/]https://1win-ilh43.buzz/[/url] обеспечивает игрокам доступ к сайту даже при неудобствах. Букмекеры постоянно обновляют свои ресурсы, чтобы поддерживать непрерывный доступ к ставкам. Пользователи способны наслаждаться игровым процессом без трудностей.
Fayepraig 27 Haziran 2026 20:08
О‘ОЅО±О¶О·П„ПЋОЅП„О±П‚ П„О± ОєО±О»ПЌП„ОµПЃО± ОѕООЅО± online casino, [url=https://www.sitsolutions.co/cambridge/museumwithoutahome806/page-75/]https://www.sitsolutions.co/cambridge/museumwithoutahome806/page-75/[/url], ОјПЂОїПЃОµОЇП„Оµ ОЅО± ОІПЃОµОЇП„Оµ ПЂОїО№ОєО№О»ОЇО± ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ|ПЂО»О·ОёПЋПЃО± ОµПЂО№О»ОїОіПЋОЅ|ПЂОїО»О»ОП‚ ОґП…ОЅО±П„ПЊП„О·П„ОµП‚|ПЂОїО№ОєО№О»ОЇО± ПЂПЃОїП„О¬ПѓОµП‰ОЅ. О‘П…П„О¬ П„О± ОєО±О¶ОЇОЅОї ПЂПЃОїПѓП†ОПЃОїП…ОЅ|ПЂО±ПЃОП‡ОїП…ОЅ|ОґО№О±ОёОП„ОїП…ОЅ|ПЂПЃОїПѓП†ОПЃОїП…ОЅ ОµОєПЂО»О·ОєП„О№ОєОП‚ ПЂПЃОїПѓП†ОїПЃОП‚ ОєО±О№ ОјПЂПЊОЅОїП…П‚|ОґП‰ПЃОµО¬ОЅ ПЂОµПЃО№ПѓП„ПЃОїП†ОП‚ ОєО±О№ О±ОЅП„О±ОјОїО№ОІОП‚|ПЂПЃОїП‰ОёО®ПѓОµО№П‚ ОєО±О№ ОјПЂПЊОЅОїП…П‚ ОµОіОіПЃО±П†О®П‚|ОґПЋПЃОї ОіО№О± ОЅООїП…П‚ ПЂО±ОЇОєП„ОµП‚. О— О±ПѓП†О¬О»ОµО№О± ОєО±О№ О· ОµП…П‡ПЃО·ПѓП„ОЇО± ОµОЇОЅО±О№|ОµОЇОЅ
Dianatearm 27 Haziran 2026 19:32
Os jogos online são uma opção crescente em Portugal. Com a facilidade de jogar em casa, os Casinos Online Portugal, [url=https://www.protechshine.com/os-melhores-casinos-online-para-jogar-em-2023-403153859/]https://www.protechshine.com/os-melhores-casinos-online-para-jogar-em-2023-403153859/[/url] atraem muitos jogadores. Além disso, as promoções são atraentes, proporcionando uma experiência emocionante.
Adammax 27 Haziran 2026 19:17
22casino Canada, [url=https://demo.avecnous.eu/compta/2026/06/17/discover-the-thrills-of-22casino-canada-your-ultimate-gaming-destination/]https://demo.avecnous.eu/compta/2026/06/17/discover-the-thrills-of-22casino-canada-your-ultimate-gaming-destination/[/url] предлагает разнообразие игр. Вы сможете наслаждаться в игровых автоматах. Кроме того предоставляются игры с живыми дилерами и щедрые акции.
BrianEmate 27 Haziran 2026 18:56
Шутки в сторону! Kaiser Slots Casino, [url=http://www.tecnoac.com/kaiser-slots-casino-dk-2026-en-fremtid-med-spil-og-underholdning-99943520/]http://www.tecnoac.com/kaiser-slots-casino-dk-2026-en-fremtid-med-spil-og-underholdning-99943520/[/url] tilbyder fГ¦nomenale spilmuligheder og et lГ¦kkert design. Spillere kan deltage i de forskellige spilleautomater, som prГ¦senterer enestГҐende oplevelse.
PriscillaPriek 27 Haziran 2026 18:47
Могу порекомендовать зайти на сайт, на котором есть много информации по этому вопросу. онлайн казино, [url=https://livepencil.com/blog/view/2726/exactly-how-might-you-maintain-with-big-volta-casino-kz-%25D1%2580%25D0%25B5%25D1%2581%25D0%25BC%25D0%25B8-%25D1%2581%25D0%25B0%25D0%25B9%25D1%2582]livepencil.com[/url] предлагает игрокам интересные возможности для времяпрепровождения. Занимаясь в широкие слоты и карты, все имеет шанс приобрести значительные призы. Не оставляйте шанс познать азарт!
JenniferJub 27 Haziran 2026 16:22
Случайно зашел на форум и увидел эту тему. Могу помочь Вам советом. Ice Casino DK, [url=https://tattoopainrelief.com/uncategorized/ice-casino-dk-oplev-spaendende-spiloplevelser/]https://tattoopainrelief.com/uncategorized/ice-casino-dk-oplev-spaendende-spiloplevelser/[/url] inviterer en fantastisk underholdning for kasino entusiaster. PГҐ hjemmesiden kan spillere fГҐ et varieret udvalg af spil. Kasinoet garanterer tryg underholdning.
Robertcaura 27 Haziran 2026 15:47
BC Game Online Crypto Casino, [url=https://www.thepropelinitiative.org/exploring-the-exciting-bc-game-mirror-promotions-3/]https://www.thepropelinitiative.org/exploring-the-exciting-bc-game-mirror-promotions-3/[/url] имеет уникальные альтернативы для любителей азартных увлечений. Участвуйте в разнообразных играх, используя криптовалюту. Уровень сервиса радует, а заманчивые бонусы обогащают азарт.
DorothyCor 27 Haziran 2026 14:32
Прошу прощения, что вмешался... Я здесь недавно. Но мне очень близка эта тема. Готов помочь. 1win зеркало, [url=https://1win-kvg75.sbs/]https://1win-kvg75.sbs/[/url] позволяет игрокам легко обходить блокировки и получать доступ к любимым играм. Указанное возможность обеспечивает удобное наслаждение от ставок. Все может попасть и наслаждаться многообразием игр и первоклассными возможностями.
Kiarut 27 Haziran 2026 12:25
Это переходит все границы. мелбет зеркало, [url=https://melbet-rrw5.buzz/]мелбет зеркало рабочее на сегодня[/url] — это отличный способ обойти блокировки и оставаться в игре. Пользователи могут беспечно использовать альтернативные ссылки для доступа к любимым ставкам. Трудности с доступомв большинстве случаев, решаются мгновенно. Со свежим зеркалом все сможете наслаждаться службой без остановок.
MitchGaw 27 Haziran 2026 11:12
Я считаю, что Вы ошибаетесь. Могу это доказать. Пишите мне в PM, обсудим. 1win зеркало, [url=https://1win-enf41.cfd/]https://1win-enf41.cfd/[/url] — это отличный способ получить доступ к любимым играм и ставкам, когда основной сайт недоступен. При использовании 1win зеркало, геймеры могут просто продолжить собирать ставки и наслаждаться всем функционалом. Страницы имеют высокую стабильность и защищенность, что гарантирует беззаботное времяпрепровождение.
Jackieval 27 Haziran 2026 10:38
ОЈП„О·ОЅ О•О»О»О¬ОґО±, ОїО№ ПЂПЃПЊПѓП†О±П„ОµП‚ ОєО±О¶ОЇОЅОї ПЂПЃОїПѓП†ОПЃОїП…ОЅ ПѓП…ОЅО±ПЃПЂО±ПѓП„О№ОєОП‚ ОµП…ОєО±О№ПЃОЇОµП‚. ОќОО± ОљО±О¶ОЇОЅОї ОЈП„О·ОЅ О•О»О»О¬ОґО±, [url=https://zeepaard.com/2026/06/09/online-92/]https://zeepaard.com/2026/06/09/online-92/[/url] ОП‡ОїП…ОЅ ПЂПЃОїО·ОіОјООЅО± П‡О±ПЃО±ОєП„О·ПЃО№ПѓП„О№ОєО¬ ОєО±О№ ОјОµО№П‰ОјООЅОµП‚ П„О№ОјОП‚, ПЂО±ПЃОП‡ОїОЅП„О±П‚ О±ОЅОµОЇПЂП‰П„О· ОґО№О±ПѓОєООґО±ПѓО· ОіО№О± П„ОїП…П‚ ПЂОµО»О¬П„ОµП‚.
Boonetraxy 27 Haziran 2026 10:31
BC Game Gambling Platform, [url=http://transtuts.com.br/?p=1569292]http://transtuts.com.br/?p=1569292[/url] offers players an exciting gaming experience. With a selection of games, users can easily find their favorites. The platform is known for its protected environment, ensuring equitable play. Join now and enjoy the excitement of BC Game Gambling Platform!
EsterKek 27 Haziran 2026 08:36
online casino game, [url=https://www.lamourvole.com/exploring-lusibet-your-gateway-to-online-gaming/]https://www.lamourvole.com/exploring-lusibet-your-gateway-to-online-gaming/[/url] offers an exhilarating experience for players seeking fun. With various options available, one can find it easy to find their favorite games anytime.
Susannageoky 27 Haziran 2026 07:54
Casino Utan Svensk Licens, [url=https://jairathalliance.in/casino-utan-svensk-licens-10-viktiga-punkter-att-2/]https://jairathalliance.in/casino-utan-svensk-licens-10-viktiga-punkter-att-2/[/url] erbjuder spelare en unik möjlighet att njuta av spelupplevelser utan begränsningarna som följer med svensk licens. Flertalet alternativ finns, vilket inkluderar slots, bordsspel och live dealer-spel. Användarnas smak är viktiga, och mångfalden av Casinon utan svensk licens fortsätter att vara populärt.
Timfon 27 Haziran 2026 07:41
22Bit Casino Canada, [url=https://demos.totalsuite.net/totalpoll/experience-unmatched-gaming-at-22bit-casino-canada/]https://demos.totalsuite.net/totalpoll/experience-unmatched-gaming-at-22bit-casino-canada/[/url] offers an exciting playground with a wide selection of games. Players can enjoy fruit machines, table games, and live games. Join today for rewarding deals!
Jamesdooli 27 Haziran 2026 07:31
Free bot for Telegram to generate presents, subscriptions. Incredible promote your channels! Our team is proud to introduce our users our powerful bot: 1) Creating gifts You can create a variety of present, including access, data, images, video content, images, coupons, discount coupons, discounts, promo codes, etc., with your own requirement for receiving the gift. Namely, rule to get present will be joining your channels you set while setup + a certain number of visits on your invite link inside the bot. It’s possible to access a no-cost plan for this feature; though, to use it, you need to include some TG channels in your channel subscription. Simply open Netxmix bot https://t.me/netxmixbot tap "start" then tap "Create Free Gift". 2) Make premium access to
KellyImami 27 Haziran 2026 07:03
Я думаю, что Вы ошибаетесь. Пишите мне в PM. Jackpot Bet Spil site, [url=https://www.fisherman.ie/2026/06/jackpot-bet-spil-2026-vejledning-til-vindende-muligheder/]https://www.fisherman.ie/2026/06/jackpot-bet-spil-2026-vejledning-til-vindende-muligheder/[/url] tilbyder fantastiske spillemuligheder til fans af lotterier. Uanset om du er pro, vil du finde spГ¦nding i hver runde. BesГёg Jackpot Bet Spil site for at opdage de bedste muligheder.
Michellepef 27 Haziran 2026 06:58
Не беда! мелбет зеркало, [url=https://melbet-dag7.top/]https://melbet-dag7.top/[/url] обеспечивает вход к букмекерской платформе, даже если основной ресурс заблокирован. Пользователи могут сохранять ставить популярные пари в любое время. Удобный интерфейс помогает процесс, а доступ к разным спортивным событиям на платформе постоянно привлекает новых пользователей.
Nicolediali 27 Haziran 2026 06:56
Воть это сила!!!! Casino999 DK, [url=https://www.grimalc.com/casino999-dk-2026-registrering-146123718/]https://www.grimalc.com/casino999-dk-2026-registrering-146123718/[/url] prГ¦senterer en udmГ¦rket rejse inden for virtual spil. Her har du mulighed for at deltage i diverse underholdningsformer og vinde premier.
DustinCaw 27 Haziran 2026 06:17
ОЈП„О·ОЅ О•О»О»О¬ОґО±, П„О± ОєО±О¶ОЇОЅОї П†ОПЃОЅОїП…ОЅ ОµОЅОёОїП…ПѓО№О±ПѓОјПЊ ПѓП„О·ОЅ ОІО№ОїОјО·П‡О±ОЅОЇО± П„ОїП… П„О¶ПЊОіОїП…. ОќОО± ОљО±О¶ОЇОЅОї ОЈП„О·ОЅ О•О»О»О¬ОґО±, [url=https://www.archetic.pl/online-casino-165429995/]https://www.archetic.pl/online-casino-165429995/[/url] ПЂО±ПЃОП‡ОїП…ОЅ ПЂОїО№ОєО№О»ОЇО± ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ ОєО±О№ ПЂО±ПЃОїП‡ОП‚ ОіО№О± П„ОїП…П‚ ОєО№ОЅО·П„ОїПЂОїО№О®ПѓП„Оµ. О— ОµОѕОО»О№ОѕО· О±П…П„О® ПЊОјП‰П‚ П…ПЂПЊПѓП‡ОµП„О±О№ ОјОµОіО¬О»О· ПѓП…ОЅО¬ОЅП„О·ПѓО·.
Robjethy 27 Haziran 2026 06:15
BC Game Casino, [url=https://kteixeira.adv.br/?p=280649]https://kteixeira.adv.br/?p=280649[/url] offers a thrilling experience for players. Using a wide range of games, you can discover exciting opportunities. Gamers are welcomed with generous bonuses, making this journey even more enjoyable.
Markzed 27 Haziran 2026 05:55
Я конечно, прошу прощения, но не могли бы Вы дать больше информации. 1xbet официальный сайт, [url=https://1xbet-vtx59.top/]https://1xbet-vtx59.top/[/url] предлагает разнообразный выбор услуг. Пользователи могут получать удовольствие в пространство спортивных событий. Удобный интерфейс предоставляет опыт максимально комфортным.
LindsayEvise 27 Haziran 2026 03:20
Шутки в сторону! 1xbet официальный сайт, [url=https://1xbet-uwc56.cam/]1xbet официальный сайт[/url] демонстрирует обширный ассортимент ставок для игроков. Промо-акции и привлекательные условия привлекают многочисленных посетителей.
Aryakix 27 Haziran 2026 02:40
у моего папы куча радости! ))) CSGO Empire Casino DK, [url=http://tuankiethotel.com/csgo-empire-casino-dk-din-bedste-destination-for-csgo-spil/]http://tuankiethotel.com/csgo-empire-casino-dk-din-bedste-destination-for-csgo-spil/[/url] er et populГ¦rt sted for gambling. Spillere kan vГ¦lge i forskellige events. Det viser en udmГ¦rket erfaring for gamblere. CSGO Empire Casino DK sikrer beskyttelse og adspredelse.
Robertred 27 Haziran 2026 02:13
When landing in Cyprus, a reliable choice for transportation is the cyprus airport taxi, [url=https://indigo-deer-210605.hostingersite.com/reliable-cyprus-airport-taxi-services-for-your-convenience/]https://indigo-deer-210605.hostingersite.com/reliable-cyprus-airport-taxi-services-for-your-convenience/[/url]. These taxis provide quick transport to your location. Enjoy a pleasant ride while skipping public transport.
Angelabiche 27 Haziran 2026 02:01
BC Game Online Casino, [url=https://www.it-gamma.pl/unlock-exciting-rewards-bc-game-bonus-offers-and/]https://www.it-gamma.pl/unlock-exciting-rewards-bc-game-bonus-offers-and/[/url] offers an engaging gaming experience for enthusiasts around the world. With numerous options available, it meets the needs of both beginners and experienced players. Experience the distinctive features and reliable transactions. Join now to discover the excitement of BC Game Online Casino!
Brandonintap 27 Haziran 2026 02:01
О‘ОЅО±ОєО±О»ПЌП€П„Оµ П„О± ОќОО± ОљО±О¶ОЇОЅОї ОЈП„О·ОЅ О•О»О»О¬ОґО±, [url=https://www.efora.it/2026/06/08/online-137/]https://www.efora.it/2026/06/08/online-137/[/url], ПЊПЂОїП… ОїО№ ОјПЂОїПЃОїПЌОЅ ОЅО± О±ПЂОїО»О±ПЌПѓОїП…ОЅ ОіО№О± ПЂОїО№ОєО№О»ОЇО± ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ. О¤О± ОєО±О¶ОЇОЅОї ПЂПЃОїПѓП†ОПЃОїП…ОЅ ОµОѕО±О№ПЃОµП„О№ОєОП‚ ОµОјПЂОµО№ПЃОЇОµП‚ ОєО±О№ ОµОєПЂО»О·ОєП„О№ОєО¬ ОјПЂПЊОЅОїП…П‚.
Robertcluts 27 Haziran 2026 01:42
Очень интересная фраза мелбет зеркало, [url=https://melbet-iva26.buzz/]https://melbet-iva26.buzz/[/url] — отличный способ пройти мимо блокировки и получить все функции платформы. Используя это инструмент, вы сможете участвовать без затруднений и недостатков.
NicoledoF 27 Haziran 2026 01:15
online casino, [url=https://teamloyalty.nu/wordpress/2026/06/17/decouvrez-netbahis-le-guide-ultime-pour-les-2/]https://teamloyalty.nu/wordpress/2026/06/17/decouvrez-netbahis-le-guide-ultime-pour-les-2/[/url] feature a unique adventure for players seeking fun. With a variety of options, users can enjoy the chance to win big while betting from the comfort of home.
Reneenep 26 Haziran 2026 22:19
Я считаю, что Вы не правы. Я уверен. Могу отстоять свою позицию. Пишите мне в PM, обсудим. CSGO Empire Casino DK, [url=https://albiscare.co.uk/csgo-empire-casino-dk-2026-din-ultimate-guide-til-spil-og-bonuser/]https://albiscare.co.uk/csgo-empire-casino-dk-2026-din-ultimate-guide-til-spil-og-bonuser/[/url] tilbyder enestГҐende muligheder for vГ¦ddemГҐl. Spillere kan engagere sig i spГ¦ndende spiloplevelser, der prГ¦senterer chancer for store gevinster.
Stevehon 26 Haziran 2026 21:55
Welcome to this exciting world of gaming! BC Game Online Crypto Casino, [url=https://dermatolog.kz/bcgame7063/experience-the-thrill-of-play-aviator-at-bc-game.html]https://dermatolog.kz/bcgame7063/experience-the-thrill-of-play-aviator-at-bc-game.html[/url] offers users a unique opportunity to explore diverse games using cryptocurrency. Join a network that supports innovation and excitement. Feel the thrill of scoring while competing in a reliable environment.
TiffanyCeaft 26 Haziran 2026 21:46
О¤О± ОЅОО± ОєО±О¶ОЇОЅОї ПѓП„О·ОЅ О•О»О»О¬ОґО± ПЂПЃОїПѓП†ОПЃОїП…ОЅ О±ОєО±П„О±ОјО¬П‡О·П„ОµП‚ ОµОјПЂОµО№ПЃОЇОµП‚ ОєОПЃОґОїП…П‚. ОњОµ ОёПЌПЃОµП‚ ПѓОµ ПЂО±ОЇОєП„ОµП‚, П„О± ОќОО± ОљО±О¶ОЇОЅОї ОЈП„О·ОЅ О•О»О»О¬ОґО±, [url=https://invoiceviet.vn/bestcasinogreece8061/online-201952839/]https://invoiceviet.vn/bestcasinogreece8061/online-201952839/[/url] ОґП‰ПЃОµО¬ОЅ ОјОїОЅО±ОґО№ОєОП‚ ОµП…ОєО±О№ПЃОЇОµП‚ ОµПЂООЅОґП…ПѓО·П‚.
SharonAgoge 26 Haziran 2026 21:15
Die 22Bit Casino Deutschland, [url=http://setup.agadia.com/1261266]http://setup.agadia.com/1261266[/url] präsentiert vielfältige Möglichkeiten von Spielen. An diesem Ort erforschen Besucher heißgeliebte Automaten und spannende Casino Klassiker. Lassen es die Atmosphäre vom modernen Casinos erleben. Heute Einloggen und erforschen Sie selbst jene Erlebnisse.
MelissaAlmof 26 Haziran 2026 20:37
Жалко их всех. мониторинг цін РІ інтернеті, [url=https://domfenshuy.net/all-about-repairing/sravnenie-cen-konkurentov-v-internete-i-dinamicheskoe-cenoobrazovanie.html]https://domfenshuy.net/all-about-repairing/sravnenie-cen-konkurentov-v-internete-i-dinamicheskoe-cenoobrazovanie.html[/url] - Моніторинг цін РІ інтернеті стає важливим інструментом для покупців. Р’С–РЅ дозволяє виявляти найкращі пропозиції. Завдяки таким сервісам можна виручати РЅР° покупках та спостерігати Р·Р° Р·РјС–РЅРѕСЋ цін. Це забезпечує плануванню бюджету.
CarolineCop 26 Haziran 2026 19:47
Это была моя ошибка. 1xbet официальный сайт, [url=https://1xbet-dhh19.cfd/]https://1xbet-dhh19.cfd/[/url] предлагает богатый выбор игр для ценителей спорта. Вы можете погружаться в волнения, делая пари на разные события.
FayeTUB 26 Haziran 2026 18:29
Полезная штука бутиковое SEO агентство, [url=https://t.me/seoetc/]аутрич площадки для ссылок[/url] предоставляет уникальные подходы для оптимизации вашего сайта. Мы формируют персонализированные стратегии для успеха результатов в поисковых системах.
Tonyabof 26 Haziran 2026 18:16
online casino, [url=https://www.it-gamma.pl/explora-el-mundo-de-piabet-apuestas-y-juegos-en-2/]https://www.it-gamma.pl/explora-el-mundo-de-piabet-apuestas-y-juegos-en-2/[/url] provides entertainment for players to indulge in. With a wide array of selections, anyone can find options that suit them. Players can gain impressive prizes, making it even more appealing for all.
MirandaThalo 26 Haziran 2026 17:59
Я думаю, что Вы не правы. Могу отстоять свою позицию. Пишите мне в PM, поговорим. Gamdom Casino DK, [url=https://up.nirvantimes.com/gamdom-casino-dk-oplev-spallungen-ved-online-spil-139959406/]https://up.nirvantimes.com/gamdom-casino-dk-oplev-spallungen-ved-online-spil-139959406/[/url] er et spГ¦ndende|interessant|fascinerende|attraktivt sted for gambling-entusiaster. Med en bred vifte af spil, sГҐsom slots, bordspil og live dealer-muligheder, tilbyder Gamdom Casino DK en enestГҐende oplevelse. Spillere kan ogsГҐ nyde|fГҐ glГ¦de af|drage fordel af|udnytte fantastiske bonusser. Det er en perfekt platform til bГҐde nye og erfarne spillere, der sГёger efter underholdning og gevinst. Det sikre miljГё og hurtige udbetalinger gГёr Gamdom Casino DK til et populГ¦rt valg blandt danskere. VГ¦r kr
Colleentep 26 Haziran 2026 17:27
Глянем на досуге 1xbet официальный сайт, [url=https://1xbet-hkn53.cam/]https://1xbet-hkn53.cam/[/url] предлагает обширный выбор услуг для пользователей. Вы имеете возможность насладиться интуитивно понятным интерфейсом и безопасностью онлайн-игр.
Deborahvex 26 Haziran 2026 16:25
22Casino Deutschland, [url=https://iocdistributor.wpengine.com/22casino-deutschland-online-spielspas-und-gewinnchancen/]https://iocdistributor.wpengine.com/22casino-deutschland-online-spielspas-und-gewinnchancen/[/url] - 22Casino in Deutschland bietet eine breite Kollektion an Gaming-Optionen sowie interessanten Promotionen. Diese Plattform zeigt sich einfache Handhabung und garantiert Гјberdurchschnittliche Datensicherheit.
RichardPrarp 26 Haziran 2026 15:15
If saying what you want to a stylist has always felt difficult, this service turns that gap into a structured, visual outcome. With one photo and a brief quiz, the system studies your features, hair characteristics, and daily context, then delivers 10 matched cuts together with a detailed barber guide. Behind the result is not a simple filter, but a mathematical model with 50+ style factors and precise 3D head modeling, designed to show how the shape sits on your head. Instead of relying on a quick visual guess, the platform combines 50+ signals with anatomical scanning to show why each style belongs to you. The output is built for realism: high-fidelity previews that make the options easy to judge. Each report adds a structured guide for the stylist, making it easier to explain the cut wi
MiaRok 26 Haziran 2026 14:03
Gambling in online casinos has become remarkably popular. Many players enjoy the accessibility of participating from home. If you like to play online casino, [url=https://zeynovera.com/wynscasino-najlepsze-miejsce-dla-mionikow-zakadow/]https://zeynovera.com/wynscasino-najlepsze-miejsce-dla-mionikow-zakadow/[/url], you'll find a variety of choices. Never forget to practice caution and bet responsibly.
AustinSig 26 Haziran 2026 13:58
Хошу себе...... 1xbet официальный сайт, [url=https://1xbet-czg39.cam/]https://1xbet-czg39.cam/[/url] предлагает широкий выбор пари на спортивные события. Регистрация простой, а интерфейс сайта доступен. Ставьте и воспользуйтесь привлекательные бонусы.
DanielWen 26 Haziran 2026 12:54
Жаль, что сейчас не могу высказаться - тороплюсь на работу. Вернусь - обязательно выскажу своё мнение по этому вопросу. Online Casino UK, [url=http://www.smilingtiger.com/exploring-casino-gamblii-the-future-of-online/]http://www.smilingtiger.com/exploring-casino-gamblii-the-future-of-online/[/url] - The domain of UK online casinos offers entertaining opportunities for gamblers. With multiple games and bonuses, the exploration is extraordinary.
CindyWhorn 26 Haziran 2026 10:12
Casino Utan Svensk Licens, [url=https://teachwar.com/utlandska-casino-en-djupdykning-i-spelvarlden-12/]https://teachwar.com/utlandska-casino-en-djupdykning-i-spelvarlden-12/[/url] erbjuder olika spelalternativ och högre bonusar. Dessa casinon kan vara populära bland svenskar. Deltagare får njuta av ett anonymt spelande med strikta regler. Det kan vara även flexibla insättningsalternativ. Casino Utan Svensk Licens attraherar många spelare.
Anarus 26 Haziran 2026 10:00
online casino game, [url=https://dev.geekhub.it/fabbricasostenibile/your-ultimate-guide-to-pissbet-the-innovative/]https://dev.geekhub.it/fabbricasostenibile/your-ultimate-guide-to-pissbet-the-innovative/[/url] offers players a unique opportunity to have fun. With numerous options available, it’s easy to choose a game that suits your styles.
BarbaraNam 26 Haziran 2026 09:20
Гы-гы, поржал на славу Аренда авто в Краснодаре, [url=https://arenda-avto-v-krasnodare.ru/krasnodar/avto-v-arendu-krasnodar-bez-zaloga]Аренда авто в Краснодаре без залога, посуточно, без выкупа[/url] — это удобный способ путешествия по городу. Вы сможете узнать множество завораживающих ландшафтов с высоким комфортом.
LeahLaw 26 Haziran 2026 08:20
Браво, замечательная идея и своевременно Win Landia Casino dk, [url=https://web.manatec.in/oplev-win-landia-casino-dk-2026-din-ultimative-guide-til-registrering-og-bonusser/]https://web.manatec.in/oplev-win-landia-casino-dk-2026-din-ultimative-guide-til-registrering-og-bonusser/[/url] er en spГ¦ndende platform, hvor deltagere kan nyde diverse casinospil. BГҐde om du vГ¦lger slotmaskiner eller bordspil, vil Win Landia Casino dk tilbyde noget for enhver smag. Oplev denne fabelagtige side og opdag de bedste fordele.
Jesusbialf 26 Haziran 2026 07:45
ОќОО± ОљО±О¶ОЇОЅОї ОЈП„О·ОЅ О•О»О»О¬ОґО±, [url=http://www.macchiatomedia.org/ufl/2026/06/09/online-casino-105/]http://www.macchiatomedia.org/ufl/2026/06/09/online-casino-105/[/url] ПЂО±ПЃОП‡ОїП…ОЅ ОјОїОЅО±ОґО№ОєОП‚ ОµП…ОєО±О№ПЃОЇОµП‚ ОіО№О± П€П…П‡О±ОіП‰ОіОЇО±. О— ПѓПЌОіП‡ПЃОїОЅОµП‚ ОµОіОєО±П„О±ПѓП„О¬ПѓОµО№П‚ ПЂПЃОїПѓП†ОПЃОїП…ОЅ ПЂОїО»О»ОП‚ П…ПЂО·ПЃОµПѓОЇОµП‚. О¤О± ПЂО±ОЇОєП„ОµП‚ ОјПЂОїПЃОїПЌОЅ ОЅО± О±ПЂОїО»О±ПЌПѓОїП…ОЅ ОЅОО± ПЂО±О№П‡ОЅОЇОґО№О± ОєО±О№ ОµОєОґО·О»ПЋПѓОµО№П‚.
SabrinaBit 26 Haziran 2026 06:17
When searching for the best online casino, [url=https://www.hovawart24.de/the-rise-of-pissbet-revolutionizing-online-betting-4/]https://www.hovawart24.de/the-rise-of-pissbet-revolutionizing-online-betting-4/[/url], you’ll discover a plethora of options. These platforms offer diverse games and attractive bonuses that enhance your experience. Choose wisely!
Angelicades 26 Haziran 2026 05:01
Willkommen bei 22Casino Г–sterreich, [url=http://www.bigfootpodiatry.com.au/22casino-osterreich-das-beste-im-online-gaming/]http://www.bigfootpodiatry.com.au/22casino-osterreich-das-beste-im-online-gaming/[/url], wo Action auf Sie warten! Erleben Sie faszinierende Spiele und besondere Angebote. Tauchen Sie in die Welt des Zockens und erleben Sie Ihren Lieblingsspielraum!
Jeremyron 26 Haziran 2026 05:01
Casino Utan Svensk Licens, [url=https://cidem.com.mx/casinobest23062/10-euro-insattning-casino-en-guide-till-lginsats/]https://cidem.com.mx/casinobest23062/10-euro-insattning-casino-en-guide-till-lginsats/[/url] erbjuder många alternativ för spelare. Här kan spelaren njuta av mycket utbud av aktiviteter utan strikt reglering. Vidare kan bonusar vara bättre. Casino Utan Svensk Licens utgör en chans för de som vill utforska spänningen utan begränsningar.
https://www.strategi 26 Haziran 2026 04:54
Иногда хочется просто отключить голову и поиграть во что-то лёгкое, и эта онлайн игра как раз подошла. Графика приятная, звук не раздражает, всё идёт плавно. Не скажу, что супер уникально, но затягивает именно простотой. Перед тем как начать, посмотрел рейтинг казино, выбрал более надёжный вариант и спокойно играл. Выигрыши небольшие, но сам процесс интересный. Хороший вариант для вечернего отдыха игр в <a href="https://www.strategium.ru/">крипто казино</a>
pocaPicky 26 Haziran 2026 04:13
BC Game Online Crypto Casino, [url=https://www.reservemarketnow.com/?p=3168250]https://www.reservemarketnow.com/?p=3168250[/url] offers exciting gaming experiences. Players can enjoy diverse cryptocurrency games that appeal to all preferences. Join today and experience the universe of crypto gaming!
StephenNat 26 Haziran 2026 04:02
подробнее, плиз. Что за ошибка? Грузоперевозки в Минске и Беларуси, [url=https://perevozimgruz.by/]https://perevozimgruz.by/[/url] предлагают широкий спектр услуг. Профессиональные специалисты обеспечивают высокое качество доставки. Эффективность перевозки имеют значение для бизнеса.
JocelynVar 26 Haziran 2026 03:26
Я думаю, что Вы ошибаетесь. Давайте обсудим. free spins no deposit casinos, [url=http://new.iskcondesiretree.com/unlock-exciting-gaming-opportunities-70-free-spins/]http://new.iskcondesiretree.com/unlock-exciting-gaming-opportunities-70-free-spins/[/url] offer players an exciting way to enjoy games without risking their own money. Those promotions allow users to play popular slots and win real cash. Many casinos provide this opportunity, attracting beginner players looking for thrills. Don't miss out on this opportunity to explore free spins no deposit casinos!
EddieSew 26 Haziran 2026 03:24
О¤О± П„О¶ПЊОіОїП‚ ПѓП„О·ОЅ О•О»О»О·ОЅО№ОєО¬ О±ОЅО±ПЂП„ПЌПѓПѓОїОЅП„О±О№ ПЃО±ОіОґО±ОЇО±. О‘П…П„О¬ П„О± ОќОО± ОљО±О¶ОЇОЅОї ОЈП„О·ОЅ О•О»О»О¬ОґО±, [url=https://thefashionuptodate.com/2026/06/09/online-151230448/]https://thefashionuptodate.com/2026/06/09/online-151230448/[/url] ПЂПЃОїПѓП†ОПЃОїП…ОЅ ОЅООµП‚ ОµП…ОєО±О№ПЃОЇОµП‚ ПѓП„Ої ОєОїО№ОЅПЊ, ПѓОµ ОјО№О± ОµПЂОїП‡О® О· П„ОµП‡ОЅОїО»ОїОіОЇО± ОґО№О±ОјОїПЃП†ПЋОЅОµО№ П„О·ОЅ П„ОїПЂОЇОї. О ПЃОїПѓОµО»ОєПЌОїП…ОЅ ПЂО±ПЃО¬ОіОїОЅП„ОµП‚ ПЂОїП… П€О¬П‡ОЅОїП…ОЅ ОЅООµП‚ ПѓП…ОЅО±ПЃПЂО±ПѓП„О№ОєОП‚ ОµОјПЂОµО№ПЃОЇОµП‚.
Nicoleadvof 26 Haziran 2026 02:41
ВОТ! ТОЧНО! Viggo Slots Casino dk, [url=http://www.markettheme.com/demo/products/viggo-slots-casino-dk-2026-en-ny-tidsalder-for-online-spil-965301437/]http://www.markettheme.com/demo/products/viggo-slots-casino-dk-2026-en-ny-tidsalder-for-online-spil-965301437/[/url] tilbyder enestГҐende spiloplevelser med en bred vifte af slots. Her kan klienter nyde fremragende grafik og spГ¦ndende funktioner. Tilmelding er nem, og bonusser venter pГҐ nye brugere. BesГёg Viggo Slots Casino dk for at modtage en forblГёffende spilleoplevelse.
Anitasuh 26 Haziran 2026 01:08
В этом что-то есть и мне кажется это хорошая идея. Я согласен с Вами. onlayn kazino, [url=http://womans-days.ru/user/Davina_Anderson/]http://womans-days.ru/user/Davina_Anderson/[/url] xabarlar orqali ko'p foydalanuvchilar qulaylik shart-sharoitni beradi. Bunday platformalar o'yinchilar uchun qiziq va mo'l-ko'l taqdimotlar taklif etadi.
MaryDibra 25 Haziran 2026 22:00
Даже не знаю, что тут и сказать то можно Minimum deposit casinos, [url=https://dwresourcesdmcc.com/exploring-the-best-200-sign-up-bonus-casinos/]https://dwresourcesdmcc.com/exploring-the-best-200-sign-up-bonus-casinos/[/url] offer players an excellent way to enjoy various games without a large financial commitment. With low initial deposits, such casinos attract a wider audience, making gaming accessible.
Ryanshoow 25 Haziran 2026 21:57
По моему мнению Вы не правы. Я уверен. Давайте обсудим. Пишите мне в PM. 1xbet зеркало, [url=https://1xbet-eet6.top/]https://1xbet-eet6.top/[/url] предоставляет возможность пользования к платформе для игроков, особенно в условиях блокировок. Данный инструмент помогает оставаться на связи и участвовать без неудобств.
LindsaySlami 25 Haziran 2026 19:29
Das 22Bit Casino Schweiz, [url=https://evolutioncode.wpengine.com/22bit-casino-schweiz-ein-umfassender-leitfaden-fur-spieler-239402468/]https://evolutioncode.wpengine.com/22bit-casino-schweiz-ein-umfassender-leitfaden-fur-spieler-239402468/[/url] liefert eine reiche Auswahl von Spielen und verlockenden Boni. Gamer können erleben einer topaktuellen Benutzeroberfläche. Außerdem gibt es sichere Zahlungsoptionen zum Finanztransfers.
AgataReutt 25 Haziran 2026 19:28
Casino Utan Svensk Licens, [url=http://www.smilingtiger.com/casino-utan-svensk-licens-fordelar-och-nackdelar-12/]http://www.smilingtiger.com/casino-utan-svensk-licens-fordelar-och-nackdelar-12/[/url] erbjuder spännande möjligheter för spelare som vill utforska nya underhållningar. Med flera utbud av bordsspel och kampanjer kan spelare maximera sin upplevelse. Casino Utan Svensk Licens erbjuder även en utmaning att engagera sig utan begränsningar.
Robertelugh 25 Haziran 2026 18:58
Браво, какие нужная фраза..., великолепная мысль Le financement en particuliers, ou p2p lending, [url=https://p2plending-avis.fr/]p2p lending[/url], a connu une augmentation rapide. Ce mГ©canisme offre une possibilitГ© aux modalitГ©s traditionnelles de prГЄt financier. Les investisseurs ont la possibilitГ© de investir directement, rГ©duisant ainsi les frais connexes.
JoanHeink 25 Haziran 2026 18:44
Какие слова... Internet gambling has become increasingly popular, offering thrilling experiences from the comfort of home. Among the top options are Casino Online Games, [url=https://tejas-apartment.teson.xyz/discover-the-exciting-features-of-fatbet-casino-7/]https://tejas-apartment.teson.xyz/discover-the-exciting-features-of-fatbet-casino-7/[/url], which provide options like slots, poker, and roulette. Players enjoy simplicity and adventurous graphics.
Erniescoke 25 Haziran 2026 16:57
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Давайте обсудим. Пишите мне в PM. prГЄt participatif, [url=https://pretparticipatif.fr/]pret participatif[/url] - Le prГЄt collaboratif est une nouvelle mГ©thode de financement. GrГўce Г ce processus, les investisseurs peuvent soutenir des projets. Ce accord promet des retours intГ©ressants et encourage l'esprit d'entrepreneuriat.
Brucemasty 25 Haziran 2026 16:37
If you enjoy thrilling experiences, trying out games, you should definitely play online casino, [url=https://auto-centre-moutier.ch/discovering-zetbet-your-ultimate-entertainment/]https://auto-centre-moutier.ch/discovering-zetbet-your-ultimate-entertainment/[/url]! With a variety of options available, players can enjoy captivating games from the comfort of their homes. Winning rewards is just a click away!
ZackSoovE 25 Haziran 2026 16:34
Я хотел бы с Вами поговорить по этому вопросу. free spins no deposit casinos, [url=https://okoball.com.br/50-free-spins-no-deposit-your-ultimate-guide-to/]https://okoball.com.br/50-free-spins-no-deposit-your-ultimate-guide-to/[/url] offer a fantastic opportunity for players to try out exciting games without putting down their own money. This attractive feature helps new players to learn about various games and methods while having fun.
RobertAware 25 Haziran 2026 16:20
<a href=http://vikupimdorogo.ru/wp-content/inc/promokod_na_1xbet_na_segodnya_besplatno.html >Code Promo 1xbet Senegal</a> vous offre un bonus de depart pour les nouveaux clients, et permet de maximiser votre premier depot, avec des paris gratuits 1xBet inclus. Rappelez-vous que le bonus est soumis a certaines conditions, comme les conditions de mise et les restrictions sur le bonus. Il est conseille de lire les conditions sur le site 1xBet.
Anaprutt 25 Haziran 2026 15:59
BC Game Online Casino, [url=https://fashionlanka.lk/comprehensive-guide-to-bc-game-bonus-code-details-4/]https://fashionlanka.lk/comprehensive-guide-to-bc-game-bonus-code-details-4/[/url] offers a thrilling experience for risk-takers. With numerous games, clients can experience instant wins and real-time fun. It's worth exploring for those seeking excitement online!
SophiaLox 25 Haziran 2026 15:13
Мне кажется, что это уже обсуждалось. Tivoli Casino DK, [url=https://alawaellab.com/?p=30315]https://alawaellab.com/?p=30315[/url] tilbyder en spГ¦ndende udvalg af spilleautomater. Spillere kan nyde klassiske spillemaskiner og bordspil, der leveres med exceptionel kvalitet. Tivoli Casino DK tilbyder en fantastisk oplevelse for alle gГ¦ster.
NicoleVar 25 Haziran 2026 14:47
new online casinos, [url=https://www.homesbyens.com/discover-the-best-new-online-casinos-in-2023-442488323/]https://www.homesbyens.com/discover-the-best-new-online-casinos-in-2023-442488323/[/url] showcase an exciting way to enjoy gambling from the convenience of your home. Boasting a variety of choices, players can select their favorite slots.
AngelicaHem 25 Haziran 2026 14:00
22Bit Casino Danmark, [url=http://www.floridalotterylaw.com.php73-40.lan3-1.websitetestlink.com/2026/06/17/oplev-22bit-casino-danmark-den-ultimative-spiloplevelse/]http://www.floridalotterylaw.com.php73-40.lan3-1.websitetestlink.com/2026/06/17/oplev-22bit-casino-danmark-den-ultimative-spiloplevelse/[/url] tilbyder et fantastiske muligheder for spil. Spillere kan nyde et varieret udvalg af bordspil, der lover delight.
JaredTot 25 Haziran 2026 13:54
И что бы мы делали без вашей очень хорошей идеи Los salas de juego online en Argentina ofrecen variedad de gama de opciones de juego. La aumento del sector facilitado que muchos entusiastas disfruten de sus experiencia desde donde deseen. casinos online en Argentina, [url=https://das22ate.blogspot.com/2026/06/crash-games-en-argentina-por-que-este.html]probar ahora[/url] ofrecen incentivos atractivos que mejoran la experiencia del juego.
JuanStume 25 Haziran 2026 13:30
По-моему, какой бред(((( Online Casino, [url=https://condominiojardimbotanico.com.br/unleashing-the-fun-dogsfortune-casino-review/]https://condominiojardimbotanico.com.br/unleashing-the-fun-dogsfortune-casino-review/[/url] offers a stimulating experience for players. Engaging games and profitable bonuses make it a well-liked choice among enthusiasts. Discover the excitement of winning big today!
Angieagedo 25 Haziran 2026 11:08
Ваша фраза очень хороша Adenofrin — men's supplement for potency, [url=https://adenofrin-capsules.info/]adenofrin[/url], enhances energy levels and promotes vitality. This powerful formula boosts endurance, helps sexual performance, and aids overall well-being. Experience a new level of self-reliance with Adenofrin.
MonicaJat 25 Haziran 2026 09:55
Я считаю, что Вы не правы. Я уверен. Могу это доказать. Пишите мне в PM, обсудим. Minimum deposit casinos, [url=https://ceciliacristolovean.com/discover-the-best-non-gamstop-casinos-for-an-6/]https://ceciliacristolovean.com/discover-the-best-non-gamstop-casinos-for-an-6/[/url] offer gamblers a chance to explore gaming without a large investment. These platforms allow low-cost access, making it easier for newcomers to engage with online gambling while enjoying a variety of games.
MonaRus 25 Haziran 2026 08:47
неплохо для утра они выглядять Tivoli Casino DK, [url=https://nbv.mqsvision.com/tivoli-casino-dk-en-uforglemmelig-spilleoplevelse-41292640/]https://nbv.mqsvision.com/tivoli-casino-dk-en-uforglemmelig-spilleoplevelse-41292640/[/url] tilbyder et spГ¦ndende udvalg af casinooplevelser. Her kan gГ¦ster nyde moderne casinospil samt innovative funktioner. Oplev det fantastiske univers hos Tivoli Casino DK!
StephenAlurf 25 Haziran 2026 07:52
Я извиняюсь, но, по-моему, Вы не правы. Могу это доказать. Пишите мне в PM.
Alietemn 25 Haziran 2026 06:09
BC Game Gambling Platform, [url=https://www.idilaguna.com/experience-the-thrill-of-bc-game-online-casino-5/]https://www.idilaguna.com/experience-the-thrill-of-bc-game-online-casino-5/[/url] offers an engaging experience for betters, featuring a wide selection of choices. Users can explore exciting opportunities while enjoying a user-friendly interface and lucrative bonuses, making each session enjoyable.
TimothyPem 25 Haziran 2026 04:16
L’offre 1xbet bonus de bienvenue 2026 permet de recevoir jusqu’a 130 $/€ correspondant au montant du premier depot. Assurez-vous de respecter les conditions de mise pour obtenir le bonus sur votre compte principal. Les paris doivent inclure au moins trois evenements et respecter une cote minimale de 1,4 pour chaque mise. Toutes les conditions doivent etre respectees dans un delai de 30 jours. Toutes les infos sur le 1xbet dernier code promo sont disponibles ici : http://vip-barnaul.ru/includes/pages/1xbet_bonus_pri_registracii.html
LeonaLYDAY 25 Haziran 2026 04:09
Да, действительно. И я с этим столкнулся. Давайте обсудим этот вопрос. Здесь или в PM. free spins no deposit casinos, [url=https://truefamilyenterprises.com/discover-the-exciting-new-casino-website-with-just-6/]https://truefamilyenterprises.com/discover-the-exciting-new-casino-website-with-just-6/[/url] offer users the chance to get exciting slot games free of risk. Such bonuses allow individuals to sample various machines and gain real money. Casinos that provide these free spins are well-liked among new players.
CrystalBit 25 Haziran 2026 03:54
Это было и со мной. Можем пообщаться на эту тему. Playing slots at Online Casino, [url=https://assemamed.ly/2026/05/12/experience-thrilling-entertainment-at-dogsfortune/]https://assemamed.ly/2026/05/12/experience-thrilling-entertainment-at-dogsfortune/[/url] can be thrilling. With many of choices, players can try different strategies to win big. Don't miss the opportunity to achieve jackpots!
RebeccaOxync 25 Haziran 2026 02:54
Извините, вопрос удален TipWin Casino DK, [url=https://www.teknikservismugla.com/tipwin-casino-dk-det-bedste-sted-for-online-spil-69092843/]https://www.teknikservismugla.com/tipwin-casino-dk-det-bedste-sted-for-online-spil-69092843/[/url] tilbyder fГ¦nomenale spiloplevelser med en velkendt udvalg af automatspil og kortspil. Opret en konto nemt med sikre metoder. Bliv en del af en overbevisende verden af underholdning. Hos TipWin Casino DK er kundepleje altid klar til at hjГ¦lpe dig.
RichardPrarp 24 Haziran 2026 22:56
When the idea is clear but the explanation is not, this service translates your preferences into a practical haircut report. From one selfie plus a few questions, it builds a report that combines facial analysis, hair assessment, and practical context into 10 hairstyle options and clear instructions for a stylist. Behind the result is not a simple filter, but a mathematical model with 50+ style factors and an anatomical 3D scan, designed to show why a style works for you. Rather than applying a generic hairstyle overlay, it uses an algorithmic model with anatomical scanning to explain what suits you and why. Rather than generic “wig” overlays, the report presents photoreal renderings that reflect actual shape and proportion. Additionally, the package includes a barber-friendly instruction
DavidChest 24 Haziran 2026 12:14
Experience the excitement of online betting with special https://www.christifriesen.com/profile/tinaju6fuentes6653080/profile offers available today. Join thousands of players and enjoy seamless gaming across sports, casino, and live events.
TimothyPem 22 Haziran 2026 12:19
<a href=https://pathsinc.org/media/pgs/code_promo_1xBet.html >Code Promo 1xbet Bonus</a> vous offre un bonus de depart pour les nouveaux clients, qui augmente le montant de votre premier depot, ainsi que d'autres incitations de la part du bookmaker. Rappelez-vous que le bonus est soumis a certaines conditions, notamment les regles concernant les mises et l'utilisation du bonus. Nous vous recommandons de consulter les termes et conditions sur le site Web 1xBet.
TimothyPem 22 Haziran 2026 10:12
<a href=https://hotel-bodensee.com/media/com_blog/code_promo_1xBet_Bonus.html >Code Promo 1xbet Cote D’ivoire 2026</a> vous permet de beneficier d'un bonus de bienvenue de 100% sur votre premier depot, valable dans votre pays ou region, jusqu'a 130€ selon votre devise. Le bookmaker 1xBet, reconnu dans le secteur des paris sportifs, est etabli depuis plus de dix ans.
TarusMon 20 Haziran 2026 05:10
Scotland Casinos Not on GamStop, [url=https://resacademy.com.br/discover-scotlands-casinos-not-on-gamstop-439999042/]https://resacademy.com.br/discover-scotlands-casinos-not-on-gamstop-439999042/[/url] offer unique gaming opportunities. These locations provide gamblers with choices in entertainment without limitations of GamStop. Delight in a genuine casino atmosphere!
Mikelonse 20 Haziran 2026 05:00
Я думаю, что это хорошая идея. 1xBet India, [url=https://blueflamepublishing.net/1xbet-ipl-betting-odds-match-formats-and-winning-tips/]https://blueflamepublishing.net/1xbet-ipl-betting-odds-match-formats-and-winning-tips/[/url] offers a wide range for gambling on sports. Users can relish real-time wagering and appealing odds. Join 1xBet India today!
Julietcax 20 Haziran 2026 01:46
Online Casino, [url=http://www.d1048604-5.blacknight.com/experience-the-thrill-at-lucky-carnival-online-11/]http://www.d1048604-5.blacknight.com/experience-the-thrill-at-lucky-carnival-online-11/[/url] - Web-based Casino предоставляет геймерам возможность насладиться необычными играми и захватывающими моментами. Промоакции делают игру еще более привлекательной. Удобство в получении позволяет выигрывать в любое время.
Jasonweats 20 Haziran 2026 01:45
И как в таком случае нужно поступать? Casino House DK, [url=https://codecanyondemo.work/wcod/?p=475883]https://codecanyondemo.work/wcod/?p=475883[/url] kan prГ¦sentere fans den enestГҐende rejse. Via sit bredt udvalg af aktiviteter har du mulighed for forkГ¦le dig selv med mange tilbud.
Deetap 20 Haziran 2026 01:02
Casinos Non on Gamstop, [url=https://museum.arabpuppettheatre.org/index.php/2026/06/04/exploring-casinos-not-registered-on-gamstop-1979685093/]https://museum.arabpuppettheatre.org/index.php/2026/06/04/exploring-casinos-not-registered-on-gamstop-1979685093/[/url] offer a unique experience for players seeking different choices. These platforms provide flexibility to enjoy gambling without restrictions. Players can explore exciting games while avoiding Gamstop's limitations.
JennyAroft 20 Haziran 2026 00:16
Betandreas online kazino, [url=https://tmcservices.es/trt-prague-nnovasyon-v-qtisadi-slahatlarn-mrkzi/]https://tmcservices.es/trt-prague-nnovasyon-v-qtisadi-slahatlarn-mrkzi/[/url] ədalətli oyun platforması təqdim edir. Burada çeşidli slot oyunları, canlı dilerlər və qazanclı bonuslar vardır. Betandreas online kazino qeydiyyatdan keçmək üçün sadə. Hər oyun sever smartfon vasitəsilə arzuladığınız oyunu rahat oynaya bilər.
GinaSnose 20 Haziran 2026 00:16
Casinos not on GamStop, [url=https://santurban.info/discover-the-best-5-casinos-you-wont-find-anywhere-else/]https://santurban.info/discover-the-best-5-casinos-you-wont-find-anywhere-else/[/url] offer players a chance to enjoy gaming without restrictions. Many individuals seek alternatives that provide a better experience. These platforms often feature a wide variety of games and attractive bonuses, making them appealing. Gamblers can explore new adventures while navigating away from conventional sites. It's essential to choose a reliable casino to ensure a secure experience. Embrace the thrill at Casinos not on GamStop today!
Andydip 19 Haziran 2026 23:27
офигеть high limit roulette, [url=http://b2b-c.ru/republic2/veganlivingmagazine/the-ultimate-guide-to-high-limit-roulette/]http://b2b-c.ru/republic2/veganlivingmagazine/the-ultimate-guide-to-high-limit-roulette/[/url] offers a thrilling experience for high-stakes players. This attracts those seeking adventure on the roulette wheel. Boasting higher betting limits, the vibe is exhilarating and exclusive. Numerous players enjoy the rush of placing substantial bets, often leading to thrilling moments during play. As you’re a seasoned pro or a curious newcomer, high limit roulette is undoubtedly worth the experience.
Rickysof 19 Haziran 2026 22:08
Полностью разделяю Ваше мнение. Это отличная идея. Я Вас поддерживаю. Finding the greatest gaming sites is essential for players seeking fun. If you're looking for the best casino not on GamStop, [url=http://cnc-wordpress.centralus.cloudapp.azure.com/hackathon/index.php/2026/06/11/casinos-that-dont-use-gamstop-your-guide-to-non/]http://cnc-wordpress.centralus.cloudapp.azure.com/hackathon/index.php/2026/06/11/casinos-that-dont-use-gamstop-your-guide-to-non/[/url], consider exploring numerous options available online. These platforms offer thrilling games and generous bonuses, ensuring an unforgettable experience. Enjoy seamless banking and top-notch player support while playing your favorite titles. Don't miss the chance to find the best casinos that cater to your needs.
Scottkem 19 Haziran 2026 19:49
Casinos Non Gamstop, [url=http://holod-gel.ru/exploring-non-gamstop-casinos-a-comprehensive-guide-1985639859/]http://holod-gel.ru/exploring-non-gamstop-casinos-a-comprehensive-guide-1985639859/[/url] offer a unique experience for players seeking freedom from self-exclusion programs. These gaming venues provide a wide range of games, ensuring an exciting atmosphere. Players can experience their favorite games without restrictions, enhancing their overall enjoyment.
KeshiaSoatt 19 Haziran 2026 19:19
Betandreas kazino, [url=http://trevodel.co.za/wp/2026/06/08/finding-new-connections-pluskina-s-dating/]http://trevodel.co.za/wp/2026/06/08/finding-new-connections-pluskina-s-dating/[/url] hЙ™r kЙ™sin sevgisini qazanan Г¶zГјnЙ™mЙ™xsus platformadД±r. Burada fantastik uДџurlu ЕџanslarД± tЙ™qdim edilir. Maqnit oyunu ЕџГ¶hrЙ™t tapД±r. HЙ™r bir partnyor qazanc imkanД± ilЙ™ belЙ™ problemsiz yaratmД±r.
Scottren 19 Haziran 2026 19:19
no verification casino, [url=https://www.alivad.doitpublicidad.com/2026/06/05/no-verification-casinos-the-future-of-online-gambling-383719620/]https://www.alivad.doitpublicidad.com/2026/06/05/no-verification-casinos-the-future-of-online-gambling-383719620/[/url] offers a unique chance to enjoy gambling without the hassle of lengthy checks. Players can experience fast access to games, granting a seamless experience. This simplicity attracts many enthusiasts seeking quick fun.
Mikelonse 19 Haziran 2026 19:02
Весьма полезная фраза 1xBet India, [url=https://traillustwander.com/arcade-and-crash-games-on-1xbet-fast-paced-action-with-big-multiplier-wins/]https://traillustwander.com/arcade-and-crash-games-on-1xbet-fast-paced-action-with-big-multiplier-wins/[/url] features a unique platform for gambling on sports. With multiple options, users can savor a multitude of markets and incentives that enhance their wagering experience. Join 1xBet India today and explore the thrill of betting at your fingertips.
AnitaTah 19 Haziran 2026 18:03
В этом что-то есть. Раньше я думал иначе, спасибо за объяснение. Finding the greatest casino not on GamStop can enhance your gaming experience. Many players seek options outside this restriction. Look for casinos that offer lavish bonuses and a wide variety of options. It’s essential to research each site’s security and reputation. Enjoy your time at the best casino not on GamStop, [url=https://harvestmoon.pixarsclients.com/2026/06/11/discover-gambling-sites-not-on-gamstop-11631511/]https://harvestmoon.pixarsclients.com/2026/06/11/discover-gambling-sites-not-on-gamstop-11631511/[/url] while playing responsibly!
Robtar 19 Haziran 2026 17:28
Online Casino, [url=https://letrasincreibles.com/exploring-luckicasino-your-gateway-to-online/]https://letrasincreibles.com/exploring-luckicasino-your-gateway-to-online/[/url] offers an exciting experience for players. With countless games to choose from, gamblers can find something entertaining. Moreover, offers add to the excitement of the gaming adventure.
Justindox 19 Haziran 2026 15:05
Да, действительно. Это было и со мной. Давайте обсудим этот вопрос. Здесь или в PM. Casino and Friends DK, [url=https://gulfauto.qa/2026/06/13/casino-and-friends-dk-en-verden-af-underholdning/]https://gulfauto.qa/2026/06/13/casino-and-friends-dk-en-verden-af-underholdning/[/url] er et fantastisk sted for alle, der elsker at spille. Det tilbyder et stort udvalg af underholdning og tilbud. ForkГ¦l dig selv med den imГёdekommende atmosfГ¦re.
LillianPooma 19 Haziran 2026 14:55
Конечно. Это было и со мной. Давайте обсудим этот вопрос. Здесь или в PM. Within the exciting world of Online Casino, [url=https://www.dataprotect.sg/experience-the-thrills-at-bounty-reels-casino/]https://www.dataprotect.sg/experience-the-thrills-at-bounty-reels-casino/[/url], players can experience a variety of options. With modern technology, winning big becomes more straightforward than ever.
Denisedaync 19 Haziran 2026 14:54
Абсолютно с Вами согласен. Идея отличная, согласен с Вами. купить Айфон 17, [url=https://linkedbusiness.onjcameroun.cm/read-blog/11612]https://linkedbusiness.onjcameroun.cm/read-blog/11612[/url] — отличный выбор, если вы ищете современный смартфон. Он имеет отличной функциональностью. Благодаря превосходной камере, ваши снимки будут яркими. Не упустите шанс закупить этот удивительный девайс!
ColleenWaRdy 19 Haziran 2026 13:22
Betandreas kazino platformasıdırm, [url=http://www.momenha.com/bonuslar-v-tkliflr-mostbet-d-qazancnz-artrn/]http://www.momenha.com/bonuslar-v-tkliflr-mostbet-d-qazancnz-artrn/[/url], fərqli oyunlar təqdim. İstifadəçilər sərfəlidir bir mühit yaradır. Bonuslar cəlbedicidır. Qeydiyyat süreci asandır. Betandreas kazino platformasıdırm istisnasız oyunçular üçün mükəmməl seçimdir.
Brandonagire 19 Haziran 2026 12:14
Я думаю, что Вы ошибаетесь. Пишите мне в PM, пообщаемся. live casino not on gamstop, [url=https://www.wuestenrot.sk/wuestenrot-inhouse-broker/explore-live-casinos-not-on-gamstop-448587543/]https://www.wuestenrot.sk/wuestenrot-inhouse-broker/explore-live-casinos-not-on-gamstop-448587543/[/url] offers a unique opportunity for players seeking excitement. Numerous online platforms provide immersive experiences with real dealers. These allow for enhanced interaction and excitement while ensuring safe gameplay. Choose from distinct games like blackjack and roulette, all available without limits.
Stevensmete 19 Haziran 2026 08:31
https://sg-systems.ru/content/pag/1xbet_promokod_pri_registracii_bonus.html
Danielmop 19 Haziran 2026 07:42
не, я такое не люблю! Playing at live roulette sites, [url=http://kairos.grafikmk.pl/the-ultimate-guide-to-live-roulette-sites-9/]http://kairos.grafikmk.pl/the-ultimate-guide-to-live-roulette-sites-9/[/url] offers an exhilarating experience. Including real dealers and authentic casino atmospheres, players can enjoy the thrill of the game. All spin is different, enhancing the excitement.
BryanBeelp 19 Haziran 2026 06:30
Я извиняюсь, но, по-моему, Вы не правы. Давайте обсудим. Пишите мне в PM, пообщаемся. Playing on Casino Online, [url=https://clicxia.ca/cleaning/2026/04/23/experience-thrills-at-the-online-casino-blood-moon/]https://clicxia.ca/cleaning/2026/04/23/experience-thrills-at-the-online-casino-blood-moon/[/url] provides an exciting experience. Players can appreciate a variety of games directly from their living rooms. Rewards are often available to improve the overall enjoyment.
JustinSut 19 Haziran 2026 03:31
Apple Pay casinos not on GamStop, [url=https://nextoons.bex.jp/2026/06/05/1122547/]https://nextoons.bex.jp/2026/06/05/1122547/[/url] offer a unique gaming experience for players who seek convenience and privacy. These specific casinos allow seamless transactions via Apple Pay, ensuring fast deposits and withdrawals. Moreover, players enjoy better security, as Apple Pay protects sensitive information. Such fusion of convenience and safety makes Apple Pay casinos not on GamStop a favored choice for online gamers. Choose wisely and enjoy your betting experience!
CarolineBoory 19 Haziran 2026 02:34
Я извиняюсь, но, по-моему, Вы не правы. Предлагаю это обсудить. Пишите мне в PM, пообщаемся. high roller roulette, [url=https://uvc-2020.com/?p=1112881]https://uvc-2020.com/?p=1112881[/url] attracts rich players seeking thrills. The high stakes make each spin exciting. For many, the atmosphere enhances the event, creating unforgettable memories.
JacquelineLic 19 Haziran 2026 01:08
Утро вечера мудренее. Finding the best non GamStop UK casino, [url=https://weitinetwork.com/2026/06/11/exploring-uk-gambling-sites-not-on-gamstop-1284498343/]https://weitinetwork.com/2026/06/11/exploring-uk-gambling-sites-not-on-gamstop-1284498343/[/url] is essential for players seeking liberty from restrictions. These casinos offer an extensive selection of games, engaging bonuses, and protected payment methods. Enjoy the fun without the limitations of GamStop!
JusticeCaw 19 Haziran 2026 00:02
Online Casino, [url=https://www.livogledelse.dk/?p=24289]https://www.livogledelse.dk/?p=24289[/url] presents a thrilling environment for gamblers to enjoy various games. Featuring slots, table games, and live dealer options, online gaming is readily available than ever!
Kurtnen 18 Haziran 2026 22:44
Betandreas kazino platformasıdırm, [url=https://riosessions.com/web/mostbet-bonuslarndan-yararlanma-yollar/120032/]https://riosessions.com/web/mostbet-bonuslarndan-yararlanma-yollar/120032/[/url]. Bu şirkət oyun sevənlər üçün bəxşedici imkanlar təqdim edir. Oyunlar daim yenilənir. İstifadəçilər peşəkar müştəri xidməti alırlar. Betandreas kazino platformasıdırm, əsas seçimdir.
YolandaGep 18 Haziran 2026 22:44
Casinos Non Gamstop, [url=http://elitetaxxrelief.com/uncategorized/discovering-non-gamstop-uk-casino-sites-the-alternative-gaming-experience/]http://elitetaxxrelief.com/uncategorized/discovering-non-gamstop-uk-casino-sites-the-alternative-gaming-experience/[/url] offer players an opportunity to enjoy thrilling gaming experiences without restrictions. Many enthusiasts prefer these platforms for their wide range of options. You can discover captivating games, great bonuses, and variable payment methods that enhance your gameplay.
Syedmaw 18 Haziran 2026 22:06
Many players seek different gaming experiences outside traditional sites. Casinos not on Gamstop, [url=https://matias0105.webworkscraft.com/discover-5-deposit-casinos-not-on-gamstop-383539495/]https://matias0105.webworkscraft.com/discover-5-deposit-casinos-not-on-gamstop-383539495/[/url] offer thrilling options for enthusiasts. These platforms often feature special games and bonuses that are hard to find elsewhere, providing freedom for players. Users can enjoy greater selections and positive terms. For those looking to explore beyond restrictions, Casinos not on Gamstop truly deliver.
Courtneymax 18 Haziran 2026 22:01
Я хорошо разбираюсь в этом. Могу помочь в решении вопроса. Вместе мы сможем найти решение. Online Casino, [url=https://sixbridges.pro/discover-the-exciting-world-of-casino-betti-9/]https://sixbridges.pro/discover-the-exciting-world-of-casino-betti-9/[/url] functions as a site for gambling, offering a wide range of games. Players appreciate the thrill of winning real money, while the adrenaline keeps them engaged. Many platforms also provide rewards to enhance the gaming experience.
Antoniorix 18 Haziran 2026 19:34
Within the expanding world of Online Casino UK, [url=http://oldent.org/kaasino-online-casino-uk-unleashing-an/]http://oldent.org/kaasino-online-casino-uk-unleashing-an/[/url], players have the chance to enjoy a diverse selection of games. Whether you're a fan of slots or table games, there's many options for everyone to discover. Bonuses are often available to enhance your playing experience. Don't miss out on engaging moments at Online Casino UK!
Curtisdum 18 Haziran 2026 19:33
По моему мнению Вы допускаете ошибку. Предлагаю это обсудить. Пишите мне в PM. DГјnya KupasД± haberleri, [url=https://vay-giris.info/]Dunya Kupas? haberleri[/url], futbol tutkunlarД± iГ§in Г§ok heyecan verici bir dГ¶nemdir. Milliler hazД±rlД±klarД±nД± tamamlamak Гјzereyken, futbolcular da sahada en iyi performanslarД±nД± sergilemek iГ§in mГјcadele ediyor. GГ¶zler, bu bГјyГјk etkinlikteki karЕџД±laЕџmalara Г§evrilmiЕџ durumda.
AntoineMaf 18 Haziran 2026 17:42
Прошу прощения, что вмешался... У меня похожая ситуация. Давайте обсудим. Online Casino UK, [url=https://linkingtravel.com/explore-the-unmatched-experience-at-avantgarde/]https://linkingtravel.com/explore-the-unmatched-experience-at-avantgarde/[/url] дает игрокам богатый выбор азартных РёРіСЂ. Знаковые автоматы Рё столовые РёРіСЂС‹ регулярно доступны. Легкие методы внесения средств делают приятным казино опыт. РќРµ упустите возможности РїСЂРёР·Р° СЃ Online Casino UK!
DaphneRob 18 Haziran 2026 17:32
Betandreas online kazino, [url=https://novatribuna.emporiumaeternus.com/mostbet-muxtlif-bonuslar-v-promosyonlar/]https://novatribuna.emporiumaeternus.com/mostbet-muxtlif-bonuslar-v-promosyonlar/[/url] onlayn məkanında rekreasiya təklifləri genişdır. Bura ziyarətçilər üçün cazibədar bonuslar təqdim. Ekran seçimi nəticəsində istifadəçilər hərəkət edə bilər.
Bennen 18 Haziran 2026 17:32
Find the best Casino Sites Not on Gamstop, [url=https://miloch.com.br/discovering-online-casinos-not-blocked-by-regulations-1977815000/]https://miloch.com.br/discovering-online-casinos-not-blocked-by-regulations-1977815000/[/url], providing a broad range of games. Betters can enjoy exciting options without restrictions. Enjoy freedom while playing in an free environment.
CherilSoymn 18 Haziran 2026 16:37
Discovering the features of Non GamStop Casinos UK, [url=https://jeevanjyoticlinic.com/discovering-non-gamstop-casinos-in-the-uk-a-complete-guide/]https://jeevanjyoticlinic.com/discovering-non-gamstop-casinos-in-the-uk-a-complete-guide/[/url] can boost your casino experience. With various options available, players may enjoy larger flexibility and access.
Markbup 18 Haziran 2026 16:21
Что Вы имеете в виду? Finding reliable online casinos can be challenging, but there are fantastic options available. One option is good casinos not on GamStop, [url=https://www.kanghanrak.net/the-rise-of-non-gamstop-casinos-a-new-frontier-in-online-gambling-5/]https://www.kanghanrak.net/the-rise-of-non-gamstop-casinos-a-new-frontier-in-online-gambling-5/[/url], which offer entertaining games and large bonuses. These casinos provide players with freedom to enjoy gambling without restrictions.
Joseorild 18 Haziran 2026 14:51
Online Casino, [url=https://coven-stag-king.bonzaitestsite.com/guide-to-registering-at-jimmy-winner-casino-a/]https://coven-stag-king.bonzaitestsite.com/guide-to-registering-at-jimmy-winner-casino-a/[/url] - Betting at an Online Casino offers endless excitement. With countless games, players can try innovative options daily. Enjoy comfort like never before!
Priscillamaf 18 Haziran 2026 12:20
Очень ценная штука Online Casino, [url=http://lucyhillman.com/?p=4999]http://lucyhillman.com/?p=4999[/url] - Virtual Casino provides an exciting entertainment experience for bettors. Using numerous choices, everyone can relax the thrill of jackpots. Join the adventure today!
Elizabethniz 18 Haziran 2026 10:58
Вас посетила отличная идея zahraniДЌnГ© online casino, [url=https://www.huperoptik-indonesia.com/uncategorized-en/slovenske-online-kasino-2026-buducnost-hazardu-na-slovensku-1924981218/]https://www.huperoptik-indonesia.com/uncategorized-en/slovenske-online-kasino-2026-buducnost-hazardu-na-slovensku-1924981218/[/url] nГЎvrhuje ЕЎirokГЅ rozsah hier a zГЎЕѕitkov. HrГЎДЌi mГґЕѕu ДЌeliЕҐ rГґzne bonusy a zДѕavy. To vЕЎetko prispieva k skvelej atmosfГ©re a zГЎЕѕitkom zo hry.
JoshBet 18 Haziran 2026 10:43
Casinos Non Gamstop, [url=https://losowanie.dev.zemestudio.pl/exploring-non-gamstop-uk-casino-sites-1979123968/]https://losowanie.dev.zemestudio.pl/exploring-non-gamstop-uk-casino-sites-1979123968/[/url] provide the ability for players to enjoy various gaming options without barriers. These platforms offer enticing bonuses and welcome packages tailored to engage new users, ensuring a captivating experience.
Valeriebrero 18 Haziran 2026 10:42
Betandreas kazino, [url=https://dokhanbar.com/2026/06/07/bonuslar-v-promosyonlar-mostbet-platformasnda-dman/]https://dokhanbar.com/2026/06/07/bonuslar-v-promosyonlar-mostbet-platformasnda-dman/[/url] müxtəlif oyun variant edir. Bu yerdə böyük mükafatlarını sınaya bilərsiniz. Cəlbedici bonuslar əlavə etmək şansını təqdim edir. Gündəlik promosyonlar istifadəçiləri cəlb edir. Betandreas kazino həmişə yeniliklər təqdim edir.
Georgenex 18 Haziran 2026 10:36
Это маловероятно. Finding reliable casinos not on GamStop can be a task. However, many players seek alternatives to enjoy popular games. Look for approved sites that offer offers without restrictions. good casinos not on GamStop, [url=https://www.verdasca.pt/2026/06/11/online-casino-options-not-blocked-by-regulatory-restrictions/]https://www.verdasca.pt/2026/06/11/online-casino-options-not-blocked-by-regulatory-restrictions/[/url] often provide an extensive collection of games, ensuring entertaining gameplay. Always read player testimonials to ensure safety.
TrapKeest 18 Haziran 2026 10:31
не ново, 500 Casino DK, [url=https://bitbuzz.org/500-casino-dk-2026-en-ny-tidsalder-for-online-spil/]https://bitbuzz.org/500-casino-dk-2026-en-ny-tidsalder-for-online-spil/[/url] er et populГ¦rt online casino i Danmark. Spillere kan nyde et stort udvalg af muligheder, herunder slots og table games. Med lГ¦kre bonusser er det simpelt at komme i gang. 500 Casino DK leverer en sikker spilleoplevelse.
Valerieexony 18 Haziran 2026 07:17
браво...так держать... супер Casino Online Slots, [url=https://biodescodificacion.ar/the-ultimate-experience-astrozino-casino/]https://biodescodificacion.ar/the-ultimate-experience-astrozino-casino/[/url] являются увлекательным СЃРїРѕСЃРѕР±РѕРј провести время. РРіСЂС‹ предлагают широкие опции Рё шансы выигрыша. Онлайн заведения делают РёРіСЂСѓ доступным для всех. Заходите Рё изучайте РјРёСЂ Casino Online Slots РїСЂСЏРјРѕ сейчас!
SheilaVag 18 Haziran 2026 06:04
Это не имеет смысла. GamStop excluded sites, [url=https://assemamed.ly/2026/06/11/exploring-non-gamstop-casinos-your-guide-to-unblocked-gambling-sites/]https://assemamed.ly/2026/06/11/exploring-non-gamstop-casinos-your-guide-to-unblocked-gambling-sites/[/url] deliver unique chances for participants who wish to engage with online gaming without limitations set by GamStop. These platforms facilitate involvement to a multitude of games, ensuring thrills and exhilaration.
Samzobre 18 Haziran 2026 05:18
Betandreas kazino platformasıdırm, [url=http://bellevue-accountant.com/2026/06/unlock-exciting-bonuses-at-mostbet/]http://bellevue-accountant.com/2026/06/unlock-exciting-bonuses-at-mostbet/[/url] zəngin oyun seçimləri ilə oyunçuları cəlb edir. Bu şəbəkə kompüter istehsalında hazırlanmışdır. Uğurlu təkliflər təqdim edir.
Fayemeast 18 Haziran 2026 05:18
Casinos Non on Gamstop, [url=https://xealuk.com/exciting-new-non-gamstop-casino-sites-for-2023/]https://xealuk.com/exciting-new-non-gamstop-casino-sites-for-2023/[/url] offer players the chance to enjoy gaming without the constraints of self-exclusion schemes. These establishments provide a varied selection of games and exciting experiences. Users can discover new titles while utilizing bonuses that enhance their play. As you are a experienced gambler or a newcomer, Casinos Non on Gamstop cater to each participant, ensuring a unforgettable adventure in the world of online gaming.
MariaMab 18 Haziran 2026 04:53
Experience the thrill of virtual casinos at Casino Online, [url=http://www.mensetsu-check21.net/305932]http://www.mensetsu-check21.net/305932[/url], where entertainment awaits! Join right away and uncover an extensive range of options. Enjoy live dealers and massive jackpots. Don’t miss out on this amazing opportunity!
Rachelgluck 18 Haziran 2026 04:09
online lightning roulette, [url=https://poland-migrate.eu/the-exciting-world-of-online-lightning-roulette-4/]https://poland-migrate.eu/the-exciting-world-of-online-lightning-roulette-4/[/url] offers an exhilarating experience for players. With each spin, you can win huge multipliers, making the game even more exciting. The lively atmosphere keeps you on the edge of your seat. Dive into this entertaining game now!
CynthiaTeM 18 Haziran 2026 03:45
Apple Pay Betting Sites, [url=https://www.cdj-bouffort.com/index.php/2026/06/05/exploring-the-best-apple-pay-betting-sites-in-2023/]https://www.cdj-bouffort.com/index.php/2026/06/05/exploring-the-best-apple-pay-betting-sites-in-2023/[/url] offer a convenient way to place bets online. Users can benefit from seamless transactions and improved security. With various options to explore, locating the right site has never been easier.
StephanieAffem 18 Haziran 2026 00:06
Betandreas online kazino, [url=https://creedglobal.com/moldova-da-mostbet-bahislrinizi-qazanmaq-ucun-2/]https://creedglobal.com/moldova-da-mostbet-bahislrinizi-qazanmaq-ucun-2/[/url] təkmil oyun təcrübəsi gətirir və müştərilərə komfortlu atmosfer təşkil edir. Böyük qazanc imkanları vasitəsilə maraqlar çeşidini genişləndirir. Hər kəs şansını burada göstərə bilər.
StaceyMap 17 Haziran 2026 21:29
Я считаю, что Вы допускаете ошибку. Давайте обсудим. Finding trusted platforms for gambling can be tough, but there are plenty of options available. Many choose bookies not on GamStop, [url=https://polishmodernglassart.pl/exploring-non-gamstop-sports-betting-sites-a-comprehensive-guide-1281902312/]https://polishmodernglassart.pl/exploring-non-gamstop-sports-betting-sites-a-comprehensive-guide-1281902312/[/url] due to their appealing offerings. Explore sites that provide a variety of games|options|choices|activities while ensuring a secure experience. They often feature better bonuses|promotions|deals|incentives, attracting more players. Make informed decisions|choices|judgments|selections by researching reviews and feedback. Remember to gamble responsibly and enjoy the thrill|excitement|
AmandaDuh 17 Haziran 2026 20:20
Вы не правы. Я уверен. Давайте обсудим это. Discover the thrill of playing a real money roulette game, [url=https://germanymedicine.com/win-big-with-online-roulette-for-real-money-2/]https://germanymedicine.com/win-big-with-online-roulette-for-real-money-2/[/url], where fate meets strategy. Select your favorite betting style and see the wheel spin. Savor the excitement as you await your winning number!
JohnathanOrals 17 Haziran 2026 20:05
Все не так просто, как кажется форум разработчиков игр, [url=https://driver.top/user/88943/]https://driver.top/user/88943/[/url] — это отличная платформа для общения идей и опыта. Участники имеют возможность делиться методами, что облегчает созданию качественных проектов. Всегда помните о важности таких сообществ в индустрии.
Oliviabrove 17 Haziran 2026 19:01
Download online casino, [url=http://www.hr-expert.ro/you-are-on-casino-online-your-ultimate-guide-to/]http://www.hr-expert.ro/you-are-on-casino-online-your-ultimate-guide-to/[/url] to enjoy thrilling games from the comfort of your home. Acquire a variety of options and enjoy the excitement of winning real money. Start your gaming adventure today!
Melanielaund 17 Haziran 2026 18:14
В этом что-то есть. Понятно, большое спасибо за помощь в этом вопросе. Поскольку вам нужны надежные Юридические услуги в Алматы, [url=https://femida-justice.com/]femida-justice.com[/url], не забудьте обратиться к квалифицированным юристам. Вы получите комплексное юридическое сопровождение. Полагайтесь на экспертам и гарантируйте свои права. Каждый проблематичен, но с нашими помощью вы достигнете своей цели.
GraceDic 17 Haziran 2026 16:20
всем советую глянуть ripper casino, [url=https://rippercasino-game.com/]ripper casino[/url] - Ripper casino предлагает множество игровых автоматов. Рто место идеально РїРѕРґС…РѕРґРёС‚ для отдыха Рё острых ощущений. Пользователи РјРѕРіСѓС‚ зарабатывать большие деньги.
PeggySouck 17 Haziran 2026 16:15
Мне кажется это отличная идея. Я согласен с Вами. najlepsie slovenske online casino, [url=https://lauragonzafer.com/zahranicne-kasina-pre-slovakov-co-potrebujete-vediet/]https://lauragonzafer.com/zahranicne-kasina-pre-slovakov-co-potrebujete-vediet/[/url] - Najlepsie slovenske online casino ponГєka hrГЎДЌom vynikajГєci zГЎЕѕitok. ZГЎbava v tГЅchto internetovГЅch hrГЎch sГє jedineДЌnГ©. Zaregistrovanie je jednoduchГЎ, takЕѕe Еѕiadny hrГЎДЌ nezmeЕЎkГЎ moЕѕnosЕҐ!
NikkiVab 17 Haziran 2026 16:14
П„О± ОєО±О»П…П„ОµПЃО± online casino, [url=http://www.krafhidraulicos.com/wp/online-casino-2023-7/]http://www.krafhidraulicos.com/wp/online-casino-2023-7/[/url] ПЂПЃОїПѓП†ОПЃОїП…ОЅ ОјОїОЅО±ОґО№ОєОП‚ ОµОјПЂОµО№ПЃОЇОµП‚ ОіО№О± П„ОїП…П‚ ПЂО±ОЇОєП„ОµП‚. ОЈП„О№П‚ ПЂО»О±П„П†ПЊПЃОјОµП‚ О±П…П„ОП‚ ОёО± ОІПЃОµОЇП„Оµ ОєО±П„О±ПЂО»О·ОєП„О№ОєО¬ ПЂО±О№П‡ОЅОЇОґО№О± ОєО±О№ ПѓП…ОЅО±ПЃПЂО±ПѓП„О№ОєО¬ ОјПЂПЊОЅОїП…П‚. О— О±ПѓП†О¬О»ОµО№О± ОєО±О№ О— О±ОѕО№ОїПЂО№ПѓП„ОЇО± ОµОЇОЅО±О№ О±ПѓП†О±О»ОµОЇП‚. О±ОЅО±ОєО±О»ПЌП€П„Оµ О±ПЂОЇОёО±ОЅОµП‚ ПЂПЃОїПѓП†ОїПЃОП‚ ОєО±О№ ОґОїОєО№ОјО¬ПѓП„Оµ П„О·ОЅ П„ПЌП‡О· ПѓО±П‚!
RyanHails 17 Haziran 2026 14:37
extreme lightning roulette, [url=http://african-image.co.za/experience-the-thrill-of-extreme-lightning-28/]http://african-image.co.za/experience-the-thrill-of-extreme-lightning-28/[/url] offers an exhilarating experience|provides an exciting adventure|delivers a thrilling atmosphere|gives a captivating enjoyment for players. This game combines traditional roulette with unique features|extra elements|innovative options|special aspects that enhance gameplay. With high multipliers and electrifying effects, it keeps you on edge|makes you feel thrilled|sets your heart racing|ensures continuous excitement. Dive into the world of extreme lightning roulette and enjoy the rush of luck paired with strategy! Whether you're a novice or a seasoned gambler, this game promises endless entertainment|unfo
AshleyGom 17 Haziran 2026 13:46
Жаль, что сейчас не могу высказаться - очень занят. Освобожусь - обязательно выскажу своё мнение по этому вопросу. Playing the thrilling real money roulette game, [url=https://hibernate.wpengine.com/discover-the-excitement-of-real-money-roulette-2/]https://hibernate.wpengine.com/discover-the-excitement-of-real-money-roulette-2/[/url] offers an opportunity to win big. With countless strategies and betting options, players can increase their chances of success. Join the fun and explore the thrill of spinning the wheel!
AshleyMub 17 Haziran 2026 13:26
Это — невозможно. The captivating world of ripper casino, [url=https://therussianlullaby.com/]ripper casino login[/url] offers a unique experience for players. Through advanced technology, players can enjoy numerous games and possibilities to win big!
Toniurbal 17 Haziran 2026 12:52
Play online casino, [url=https://switchub.online/2026/06/wildzy-casino-review-2026-a-comprehensive-look-at-5/]https://switchub.online/2026/06/wildzy-casino-review-2026-a-comprehensive-look-at-5/[/url] and experience the thrill of gaming from the comfort of your home. Try a wide array of options including poker. Become a member to enjoy exciting bonuses!
PriscillaPloca 17 Haziran 2026 12:51
Betandreas kazino platformasıdırm, [url=https://salutebeneficios.com.br/2026/06/06/experience-the-thrill-of-mostbet-casino/]https://salutebeneficios.com.br/2026/06/06/experience-the-thrill-of-mostbet-casino/[/url] fərqli oyunun eşqini yaşamaq hədəfi ilə əla imkan təqdim edir. Oyunçular dərin və eğləncəli təqdimatlardan istifadə edərək vəd edən qədəm atırlar. Betandreas kazino platformasıdırm, ümumi həvəskarları cəlb edir.
ChloesiX 17 Haziran 2026 11:03
Замечательная фраза и своевременно The famous ripper casino, [url=https://rippercasino-games.com/]https://rippercasino-games.com/[/url] features a thrilling play experience for enthusiasts. With diverse options, participants can discover something to fit their preferences.
AnnRaw 17 Haziran 2026 09:47
не супер но и не плохо , [url=https://mwcaustralia.com/online-kasina-na-slovensku-vsetko-co-potrebujete-vediet-1937665828/]https://mwcaustralia.com/online-kasina-na-slovensku-vsetko-co-potrebujete-vediet-1937665828/[/url] - V poslednГЅch rokoch sa stГЎle viac ДѕudГ zaujГma o konaДЌnГЅ ЕѕivotnГЅ ЕЎtГЅl. Pre mnohГЅch sa trГ©ning stalo neodmysliteДѕnou sГєДЌasЕҐou dЕ€a. Je dГґleЕѕitГ© len zlepЕЎiЕҐ svoju kondГciu, ale aj stimulovaЕҐ psychickГє pohodu. KombinГЎcia vitГЎlnych jedГЎl a pravidelnej aktivity pomГЎha dosiahnuЕҐ dlhodobГ© efekty. ДЊГm viac sa zameriavame na svoj telo, tГЅm lepЕЎie sa vnГmame.
Anatem 17 Haziran 2026 09:39
Playing an roulette game online, [url=http://www.safemarketlaguna.rosvel.com.mx/online-roulette-for-real-money-in-india-a-6/]http://www.safemarketlaguna.rosvel.com.mx/online-roulette-for-real-money-in-india-a-6/[/url] can be a stimulating experience. Players can enjoy multiple variations, featuring European and American roulette. Dive into the action today!
AdamMeN 17 Haziran 2026 07:25
Абсолютно с Вами согласен. Идея хорошая, поддерживаю. Jackie Jackpot Casino, [url=https://pgrs-co.com/jackie-jackpot-casino-dk-oplev-spaendingen-ved-online-spil-1176471875/]https://pgrs-co.com/jackie-jackpot-casino-dk-oplev-spaendingen-ved-online-spil-1176471875/[/url] erbjuder et varieret udvalg af underholdning, hvor spillere kan opdage fantastiske bonusser. Opret en konto nu hos Jackie Jackpot Casino og benyt de unikke tilbud!
JenniferFothe 17 Haziran 2026 07:14
Betandreas online kazino, [url=https://gagan.tokyo/mostbet-qrzstanda-onlayn-musabiqlr-v-dman/]https://gagan.tokyo/mostbet-qrzstanda-onlayn-musabiqlr-v-dman/[/url] qatma oyunları təklif olunur. Burada qazanc əldə etmə şansı böyüyür. Qatılımcılar istədikləri kimi oynaya bilər. Betandreas online kazino bütün müştərilər üçün uyğun seçimdir.
GregCek 17 Haziran 2026 06:28
Etipos Official site, [url=https://thefashionuptodate.com/2026/06/01/etipos-official-din-ultimative-destination-for-online-underholdning/]https://thefashionuptodate.com/2026/06/01/etipos-official-din-ultimative-destination-for-online-underholdning/[/url] tilbyder det bredt udvalg af muligheder til forbrugere. Webstedet er enkelt at navigere, og tilbyder brugerne nyttige ressourcer. Uanset hvad du sГёger, bГёr du finde noget relevant.
Jesussoush 17 Haziran 2026 05:12
The adrenaline of playing roulette game online, [url=https://mwcaustralia.com/exploring-the-fascinating-world-of-roulette-in/]https://mwcaustralia.com/exploring-the-fascinating-world-of-roulette-in/[/url] continues to be unmatched. With multiple variations available, players can enjoy diverse experiences from the comfort of home. Discover the dynamic action today!
KellyHib 17 Haziran 2026 04:38
When looking for alternative options, Betting Sites Not on GamStop, [url=https://vitos-pizza.com/discover-betting-sites-not-on-gamstop-for-a-more-diverse-wagering-experience/]https://vitos-pizza.com/discover-betting-sites-not-on-gamstop-for-a-more-diverse-wagering-experience/[/url] offer engaging opportunities for players. Many bettors appreciate the freedom to choose their preferred platforms without restrictions. Embrace the option for a more diverse gaming experience!
Jaynib 17 Haziran 2026 04:06
это прямо хаб будущего , [url=http://www.calemboadvogados.com.br/nizkovkladove-online-kasino-vstupte-do-sveta-zabavy-s-nizkymi-vkladmi/]http://www.calemboadvogados.com.br/nizkovkladove-online-kasino-vstupte-do-sveta-zabavy-s-nizkymi-vkladmi/[/url] - Kvapalina je zГЎkladom Еѕivota a zdroj pre vЕЎetky ЕѕivГ© bytosti. Bez boblГn mnoЕѕstva vody sa naЕЎe telГЎ nemГґЕѕu sprГЎvne fungovaЕҐ a dochГЎdza k Гєbytku vody vitГЎlnych funkciГ.
Danielsmica 17 Haziran 2026 03:07
главное смекалка Welcome to the vibrant world of winx96 casino, [url=https://rondayapp.com/]https://rondayapp.com/[/url], where excitement meets chance. Discover amazing games and rich bonuses that could turn your time into a adventure. Join now!
Balazsomilk 17 Haziran 2026 02:04
roulette lightning, [url=https://www.medicalmarijuanabarcelona.com/experience-the-thrill-of-lightning-roulette-a-2/]https://www.medicalmarijuanabarcelona.com/experience-the-thrill-of-lightning-roulette-a-2/[/url] - Roulette lightning offers an exciting twist on traditional gameplay. Players experience accelerated gameplay, increasing the excitement. With distinct multipliers in play, every spin can lead to massive payouts, making it a must-try for gambling enthusiasts.
RobKib 17 Haziran 2026 01:49
Betandreas kazino, [url=https://www.davecridermusic.com/the-ultimate-guide-to-mostbet-betting-and-gambling/]https://www.davecridermusic.com/the-ultimate-guide-to-mostbet-betting-and-gambling/[/url] mükəmməl əyləncə platformasıdır. Burada istifadəçilər çeşidli imkanlarla rastlaşır. Qazanc sizi gözləyəcək şəraitlə uğur qazanmağı sadə edir. müraciət etməklə özünüzü sınaya bilərsiniz!
Mitchchota 17 Haziran 2026 01:49
Explore the exciting world of online gambling. With the rise of Casino Online, [url=https://thevellorecabs.com/voodoo-wins-casino-unleashing-the-magic-of-online-2/]https://thevellorecabs.com/voodoo-wins-casino-unleashing-the-magic-of-online-2/[/url], players can enjoy their favorite games at the comfort of their homes. Try your luck and win big through thrilling slots and table games!
Stevensmete 17 Haziran 2026 01:43
https://altaykvas.ru/news/promokod-1xbet.html
Kimberlyquops 17 Haziran 2026 01:11
Я думаю, что Вы не правы. Я уверен. Давайте обсудим. Пишите мне в PM, пообщаемся. winx96 casino, [url=https://loginwinx96.com/]https://loginwinx96.com/[/url] offers an exhilarating experience for gamblers. With multiple games to choose from, players can savor their favorite slots and table games. Don't miss out on the incredible bonuses available at winx96 casino. Join the fun and see your chances today!
DanielNup 17 Haziran 2026 00:53
Experience the excitement of online betting with amazing https://denver.granicusideas.com/ideas/how-can-you-update-your-mobile-number-on-your-emirates-id?page=133 offers available today. Join thousands of players and enjoy seamless gaming across sports, casino, and live events.
Capahet 16 Haziran 2026 21:44
Such event is famous among players. red door roulette, [url=https://demo2.cloudwp.dev/trial-6x4x9ytv/red-door-roulette-online-unveiling-the-secrets-of/]https://demo2.cloudwp.dev/trial-6x4x9ytv/red-door-roulette-online-unveiling-the-secrets-of/[/url] delivers an entertaining twist on regular roulette. Gamers have to plan for top winnings.
EdisonLox 16 Haziran 2026 20:36
Извините за то, что вмешиваюсь… Но мне очень близка эта тема. Могу помочь с ответом. Пишите в PM. Playing live roulette not on gamstop offers an captivating experience. Players can enjoy multiple choices, with exclusive features that enhance the gameplay. Join the fun and explore new strategies while not using restrictions! Making wise moves can lead to great wins. live roulette not on gamstop, [url=https://howtodatewithstyle.com/exploring-the-world-of-live-dealer-roulette-what-2/]https://howtodatewithstyle.com/exploring-the-world-of-live-dealer-roulette-what-2/[/url] allows for boundless enjoyment in a vibrant atmosphere.
TarusTealo 16 Haziran 2026 20:31
Download online casino, [url=https://smartedgetech.ca/?p=36935]https://smartedgetech.ca/?p=36935[/url] and enjoy a thrilling experience from the comfort of your home. Various platforms offer entertaining games. Join today to explore a vast array of slots and win rewards!
Scatomisa 16 Haziran 2026 20:31
Betandreas kazino platformasıdırm, [url=https://kickoffree.com/your-ultimate-guide-to-mostbet-features-bonuses/]https://kickoffree.com/your-ultimate-guide-to-mostbet-features-bonuses/[/url]. Bu unikal platforma mükəmməl və oyunçular üçün çoxsaylı variants təqdim edir. Bütün şəxslər bu məkanda maraqlı xüsusi oyunlar tapa bilər.
MarkGof 16 Haziran 2026 18:23
Вас посетила замечательная идея HeySpin Casino DK, [url=https://www.pleasesellmycar.ca/uncategorized/heyspin-casino-dk-2026-en-ny-horisont-for-online-spil/]https://www.pleasesellmycar.ca/uncategorized/heyspin-casino-dk-2026-en-ny-horisont-for-online-spil/[/url] tilbyder diverse spГ¦ndende chancer. Her kan du finde moderne spilleautomater og normale casinospil. BelГёnninger og kampagner venter pГҐ dig, hvilket gГёr din rejse endnu mere spГ¦ndende. BesГёg HeySpin Casino DK og udnyt tilbuddet for at opnГҐ store vindster.
Katrinaexods 16 Haziran 2026 17:33
Winlandia Casino, [url=https://demos.totalsuite.net/totalsurvey/winlandia-casino-2026-registrering-1920211671/]https://demos.totalsuite.net/totalsurvey/winlandia-casino-2026-registrering-1920211671/[/url] tilbyder et varieret udvalg af spil, der tilfredsstiller forskellige smag. Kunder kan nyde godt af en fantastisk spiloplevelse hos Winlandia Casino.
Reneemarma 16 Haziran 2026 16:48
Извиняюсь что, ничем не могу помочь. Но уверен, что Вы найдёте правильное решение. Не отчаивайтесь. zahraniДЌnГ© online casino, [url=https://dimpleshorsetreats.com/zahranicne-online-kasina-vsetko-co-potrebujete-vediet-1929716328/]https://dimpleshorsetreats.com/zahranicne-online-kasina-vsetko-co-potrebujete-vediet-1929716328/[/url] ponГєkajГє ЕЎirokГє ЕЎkГЎlu hier, ako automatov, pokru aЕѕ po ruletu. HrГЎДЌi mГґЕѕu zГskaЕҐ atraktГvne bonusy a akcie, ktorГ© rozЕЎirujГє ich ЕЎance na zisk.
Natalynum 16 Haziran 2026 15:39
If you're searching for betting websites that cater to players outside GamStop, you'll find numerous options. casino sites not on GamStop, [url=https://tejasvistudio.com/the-best-non-gamstop-uk-casinos-for-unrestricted/]https://tejasvistudio.com/the-best-non-gamstop-uk-casinos-for-unrestricted/[/url] offer varied games that appeal to many. Enjoy plenty of options to make your gaming experience unforgettable.
Madisonfrima 16 Haziran 2026 15:36
По моему мнению Вы не правы. Могу это доказать. Пишите мне в PM. winx96 casino, [url=https://winx96.casino/]winx96[/url] offers a thrilling gaming experience for players. With multiple games to choose from, players can indulge casino classics and modern options alike. Sign up at winx96 casino today to discover amazing bonuses and incentives. Don't miss out on the chance to win big while having fun!
BryanArits 16 Haziran 2026 15:16
Play online casino, [url=http://training.insurancesplash.com/discover-the-thrill-of-gaming-at-superboss-casino/]http://training.insurancesplash.com/discover-the-thrill-of-gaming-at-superboss-casino/[/url] and experience the thrill of gaming from the comfort of your home. Enjoy in a variety of fascinating games, like slots, poker, and roulette. Seize bonuses and promotions to improve your chances of winning big.
Patricksop 16 Haziran 2026 15:15
Betandreas online kazino, [url=https://cerakote.rio/mostbet-your-ultimate-guide-to-online-betting-23/]https://cerakote.rio/mostbet-your-ultimate-guide-to-online-betting-23/[/url], internet kazino oyunları ilə oyunçulara çox seçimlər təklif edir. Ümumdünya hər yerindən oyunçular məmnuniyyət üçün komfortlu mühit yaradır.
AngieZig 16 Haziran 2026 13:58
Неплохой топик HeySpin Casino DK, [url=https://worldwideslogans.com/heyspin-casino-dk-det-ultimative-spilleparadis-1178276421/]https://worldwideslogans.com/heyspin-casino-dk-det-ultimative-spilleparadis-1178276421/[/url] tilbyder en fabelagtigt spiludvalg som inkluderer flere slotspil, bordspil inklusive live muligheder. Opret en konto i dag for for at opnГҐ omfattende bonusser og tilbud. HeySpin Casino DK sikrer en beskyttet spiloplevelse med hurtige udbetalinger og exceptionel kundeservice.
Vanngaw 16 Haziran 2026 13:13
An game known as red door roulette, [url=https://gagan.tokyo/exploring-the-thrills-of-the-red-door-roulette/]https://gagan.tokyo/exploring-the-thrills-of-the-red-door-roulette/[/url] provides a thrilling experience for gamblers. Utilizing the interesting format, it holds everyone at the brink. Join in red door roulette to uncover new methods. Gain amazing prizes as you rotate through this fascinating game.
TreyLah 16 Haziran 2026 13:12
Winlandia Casino, [url=https://lanusehijos.com.py/2026/06/03/winlandia-official-oplev-fantasien-i-spil-og-underholdning/]https://lanusehijos.com.py/2026/06/03/winlandia-official-oplev-fantasien-i-spil-og-underholdning/[/url] er et fantastisk sted for spillere, der ønsker at nyde spilmuligheder. Her finder du mange forskellige af spillemaskiner og bordspil. Med attraktive tilbud kan du få mest muligt ud af din oplevelse. Winlandia Casino er kendt for sin brugervenlige grænseflade, der gør det nemt at finde dine yndlingsspil. Uanset om du er ny eller erfaren, vil du finde det perfekte spil til din smag.
Chrisfluro 16 Haziran 2026 10:59
Завидую тем, кто досмотрел до конца. najlepsie slovenske online casino, [url=https://miku-miku.net/slovenske-online-kasina-vsetko-co-potrebujete-vediet-1941670390/]https://miku-miku.net/slovenske-online-kasina-vsetko-co-potrebujete-vediet-1941670390/[/url] - VedГєce slovenskГ© online casino ponГєka rozmanitГ© moЕѕnosti pre zГЎkaznГkov o adrenalГn. Е tedrГ© bonusy a farebnГЎ ponuka hier poteЕЎia kaЕѕdГ©ho. KasГnovГ© hry online sa stГЎva ДЌoraz populГЎrnejЕЎie.
Cynthiafaups 16 Haziran 2026 09:22
И как в таком случае нужно поступать? Expekt Casino Danmark, [url=https://www.amhal-sono.ma/expekt-casino-danmark-2026-fremtidens-spilleoplevelse-1181806734/]https://www.amhal-sono.ma/expekt-casino-danmark-2026-fremtidens-spilleoplevelse-1181806734/[/url] tilbyder det unikt kasino oplevelse, hvor kan finde mange forskelligt udvalg af lotto. Tjenesten sikrer beskyttelse og hurtige finansielle transaktioner. Expekt Casino Danmark viser ogsГҐ tilbud og kampagner, der beriger underholdningen.
TarusVaH 16 Haziran 2026 08:50
Viggo Slots Casino, [url=http://level7techgroup.com/blog/?p=517694]http://level7techgroup.com/blog/?p=517694[/url] tilbyder fede spiloplevelser med de varieret udvalg af spil og virtuelle dealer spil. Hos Viggo Slots Casino kan gæster nyde tiltalende bonusser og gode kampagner, der lokker alle spillere.
Mirandawit 16 Haziran 2026 06:31
non UK licence casinos, [url=https://www.moneyupresearch.com/exploring-non-uk-licensed-casinos-a-guide-to-3/]https://www.moneyupresearch.com/exploring-non-uk-licensed-casinos-a-guide-to-3/[/url] offer players a unique gaming experience that is often more flexible than traditional offerings. These sites deliver a selection of games and offers that appeal to a global audience, making an exciting alternative to UK-licensed options. Players may enjoy greater privacy and lower restrictions, permitting them to explore various gaming styles. When selecting a non UK licence casinos, it's essential to assess the site's credibility and client feedback to ensure a safe and enjoyable experience.
RobCig 16 Haziran 2026 05:27
да бальшая фантазия у таво хто ето сочинял najlepsie slovenske online casino, [url=http://www.unmondodifruttabologna.it/slovenske-online-kasino-vsetko-co-potrebujete-vediet-1937805109/]http://www.unmondodifruttabologna.it/slovenske-online-kasino-vsetko-co-potrebujete-vediet-1937805109/[/url] - PreskГєmajte najvyЕЎЕЎie slovenskГ© online casino s perspektГvnymi bonusmi. Hrajte nГЎrodnГ© hry ДЌi objavujte svoje ЕЎЕҐastie na najlepЕЎie slovenskГ© online casino. TГЎto prГleЕѕitosЕҐ je tu, preto nevГЎhajte!
Eddiedredo 16 Haziran 2026 05:03
По моему мнению Вы не правы. Предлагаю это обсудить. Пишите мне в PM, поговорим. Expekt Casino Danmark, [url=https://plugins.rmweblab.com/expekt-casino-danmark-din-guide-til-spil-og-underholdning-1195115437/]https://plugins.rmweblab.com/expekt-casino-danmark-din-guide-til-spil-og-underholdning-1195115437/[/url] tilbyder flere spil, hvor appellerer til spillere. Med fascinerende bonusser og en overskuelig platform, kan at nyde sine favoritspil. Funktioner som live dealer spil skaber en unik eventyr. BesГёg Expekt Casino Danmark for at opleve en uforglemmelig spille-oplevelse online.
Ryanvag 16 Haziran 2026 04:39
Viggo Slots Casino, [url=https://drink3water.com/uncategorized/oplev-viggo-slots-casino-2026-fremtiden-for-online-spil/]https://drink3water.com/uncategorized/oplev-viggo-slots-casino-2026-fremtiden-for-online-spil/[/url] tilbyder et fantastisk udvalg af automater, hvor deltagerne kan oplevelse en unikt univers. Gevinster tilbyder endnu flere spænding.
Irisprura 16 Haziran 2026 04:39
Amid the thriving world of entertainment, casino europe online, [url=https://apexaglobal.com/best-online-casinos-in-europe-your-guide-to-2/]https://apexaglobal.com/best-online-casinos-in-europe-your-guide-to-2/[/url] stands out as a top choice for players. Supplying a range of entertainment options, it serves diverse tastes. Visitors can enjoy the excitement of gaming from the comfort of their homes. Featuring robust security and generous bonuses, casino europe online ensures both safety and fun.
Kimrew 16 Haziran 2026 04:21
In the world of Casino Online, [url=https://cloudpilgrimage.com/discover-fun-and-excitement-at-spins-house-casino/]https://cloudpilgrimage.com/discover-fun-and-excitement-at-spins-house-casino/[/url], players can experience entertainment from the comfort of their homes. With advanced technology, multiple games are provided to explore.
Markgon 16 Haziran 2026 04:21
Betandreas kazino platformasД±dД±rm, [url=https://drvictormendoza.com/blog/experience-the-thrill-of-online-betting-with-9/]https://drvictormendoza.com/blog/experience-the-thrill-of-online-betting-with-9/[/url], fЙ™rqli oyun tЙ™crГјbЙ™si tЙ™qdim edir. Bu istifadЙ™Г§ilЙ™rin mЙ™qbul imkanlarda qazanma ЕџansД±nД± yaratma imkanД± verir.
Amykaw 16 Haziran 2026 03:41
Разрешите помочь Вам? Finding the best roulette casino, [url=http://czb.grafikmk.pl/discover-the-best-roulette-casinos-for-ultimate/]http://czb.grafikmk.pl/discover-the-best-roulette-casinos-for-ultimate/[/url] can enhance your gaming experience. Selecting the right platform is essential. Look for sites with excellent features, intuitive interfaces, and various bonuses. Enjoy thrilling gameplay!
MichaelMer 16 Haziran 2026 00:30
Casinos Not on Gamstop, [url=https://proplayersports.com/online-casinos-not-blocked-by-restrictions-your-11/]https://proplayersports.com/online-casinos-not-blocked-by-restrictions-your-11/[/url] offer players an alternative to traditional gaming platforms. These casinos allow for higher flexibility and autonomy. With a variety of games and promotions, players can enjoy their favorite activities without restrictions. Furthermore, they provide the possibility to experience gaming in a secure environment. For enthusiasts looking to take their gaming to the next level, Casinos Not on Gamstop can offer an exciting adventure.
Roberttaify 16 Haziran 2026 00:29
Video slots official site, [url=https://themumbaidiaries.com/uncategorized/oplev-det-bedste-inden-for-video-slots-official/]https://themumbaidiaries.com/uncategorized/oplev-det-bedste-inden-for-video-slots-official/[/url] tilbyder en spændende udvalg af spilleautomater. Her kan du prøve forskellige temaer og premier, som gør leg endnu mere fangende. Det er hurtigt at navigere, og udseendet er tiltalende. Oplev entusiasmen ved at spille på Video slots official site!
TimUrink 16 Haziran 2026 00:17
Web-based gambling has gained popularity among players seeking freedom. Many players prefer casinos not on GamStop UK, [url=https://www.emagidlondon.com/uncategorized/discovering-5-pound-casinos-an-affordable-way-to-play/]https://www.emagidlondon.com/uncategorized/discovering-5-pound-casinos-an-affordable-way-to-play/[/url] to enjoy a wider selection of games and offers. These platforms often offer an dynamic experience. Players can explore different options without restrictions. Enjoying gaming without limits is inviting for many enthusiasts. Discover the independence of casinos not on GamStop UK today!
JoanneHoita 16 Haziran 2026 00:06
Извините, я удалил эту фразу slovenske online casino, [url=https://tattoopainrelief.com/uncategorized/slovenske-online-kasino-2026-nove-trendy-a-moznosti/]https://tattoopainrelief.com/uncategorized/slovenske-online-kasino-2026-nove-trendy-a-moznosti/[/url] ponГєka rozЕЎГrenГє ЕЎkГЎlu hier, ktorГ© vГЎbia kaЕѕdГ©ho hrГЎДЌa. Na webovej strГЎnke si mГґЕѕete vychutnaЕҐ nielen klasickГ© automaty, ale aj inovovanГ© variГЎcie, ktorГ© ponГєkajГє vzruЕЎenie a vГЅhodu vyhraЕҐ atraktГvne rewards.
DevonTek 15 Haziran 2026 23:01
To find exciting games, you can easily Download online casino, [url=http://cochesocasioncastellon.com/discover-the-exciting-world-of-spinsala-casino-6/]http://cochesocasioncastellon.com/discover-the-exciting-world-of-spinsala-casino-6/[/url] software. With a selection of options, players can experience thrilling slots and table games from the comfort of their residences.
RebeccaCus 15 Haziran 2026 23:01
Betandreas online kazino, [url=https://www.alffastener.de/index.php/2026/06/05/mostbet-onlayn-mrc-dunyasna-giri/]https://www.alffastener.de/index.php/2026/06/05/mostbet-onlayn-mrc-dunyasna-giri/[/url] virtual qumar platforması, oyunçulara fərqli qumar oyunları təklif edir. Bu xidmətdə qazanmaq imkanlarınız var. Betandreas online kazino intuitiv görünüşü ilə bütün qumarbazlara dəstək edir.
DontePar 15 Haziran 2026 20:28
Я считаю, что Вы не правы. Я уверен. Cash Point Official, [url=https://interconnect.cc/metabo/newscolumn/cash-point-official-2026-fremtidens-spilplatform-1190960906]https://interconnect.cc/metabo/newscolumn/cash-point-official-2026-fremtidens-spilplatform-1190960906[/url] tilbyder imponerende muligheder for underholdning. Her kan du nyde varierede eventyr og fГҐ fat i betydelige gevinster. BesГёg os for dybere detaljer.
Monatwila 15 Haziran 2026 20:23
Casinos Not on Gamstop UK, [url=https://mbbs.com/exploring-the-world-of-non-gamstop-casinos-freedom/]https://mbbs.com/exploring-the-world-of-non-gamstop-casinos-freedom/[/url] offer players a unique experience. These establishments allow punters to enjoy multiple games without restrictions. Providing exciting bonuses, they attract punters looking for new gaming options. Experience betting beyond the regular with Casinos Not on Gamstop UK.
Robertcut 15 Haziran 2026 18:48
Прошу прощения, что я вмешиваюсь, хотел бы предложить другое решение. slovenske online casino, [url=https://systeckllc.com/2026/05/29/nove-online-casino-spickova-zabava-a-bezkonkurencne-vyhry/]https://systeckllc.com/2026/05/29/nove-online-casino-spickova-zabava-a-bezkonkurencne-vyhry/[/url] prinГЎЕЎajГє zГЎbavu | poteЕЎenie | vzruЕЎenie | zaujГmavГ© zГЎЕѕitky pre hrГЎДЌov. VДЏaka ЕЎirokej ponuke hier a bonusovГЅch prГleЕѕitostГ si kaЕѕdГЅ mГґЕѕe nГЎjsЕҐ to svoje. Nezabudnite vyuЕѕiЕҐ dostupnГ© promo akcie | ponuky | zДѕavy | vГЅhody a hrajte z pohodlia domova.
Bryanpropy 15 Haziran 2026 18:47
Welcome to BC Fun crypto casino, [url=https://www.davecridermusic.com/bc-game-casino-en-ligne-une-experience-de-jeu-4/]https://www.davecridermusic.com/bc-game-casino-en-ligne-une-experience-de-jeu-4/[/url], where the fun of gaming meets the advantages of cryptocurrency. Players can enjoy a wide range of options and secure transactions. Join today and enhance your playing experience!
AdamEropy 15 Haziran 2026 17:48
Betandreas kazino, [url=http://bestsmartplace.com/]http://bestsmartplace.com/[/url], sizin necə seçim betting söyleşisini genişləndirir. Artan bonuslar və birbirinə imkanlar təklif edir. İstifadəçilər şəffaf müqavilələrdə qazanıb imkanını qaldırır.
Madelinegaf 15 Haziran 2026 17:48
In the digital age, engaging in online casinos has become increasingly popular. Players enjoy the ease of gambling from home. With various games available, you can savor the thrill of winning. Play online casino, [url=http://villa20sopot.pl/2026/06/04/discover-the-excitement-at-jetsetspins-casino/]http://villa20sopot.pl/2026/06/04/discover-the-excitement-at-jetsetspins-casino/[/url] and find exciting opportunities!
DaphneSof 15 Haziran 2026 17:18
, [url=https://www.chhabragensets.in/explore-the-world-of-gaming-sites-not-on-gamstop/]https://www.chhabragensets.in/explore-the-world-of-gaming-sites-not-on-gamstop/[/url] - In recent years, developments have significantly impacted our daily lives. People now interact more easily than ever before. The rise of social media platforms has transformed how we share information and stay in touch with others. Furthermore, mobile devices have become essential tools for managing personal and professional tasks. As we adapt to these changes, our lifestyles also evolve, often leading to increased productivity. However, it's important to control our screen time to maintain meaningful relationships in the real world. Ultimately, embracing these advancements can enrich our lives while also encouraging
GloriaGof 15 Haziran 2026 17:18
Discovering the best non GamStop casinos, [url=https://merkor.net/2026/05/28/exploring-non-gamstop-uk-casinos-a-comprehensive-5/]https://merkor.net/2026/05/28/exploring-non-gamstop-uk-casinos-a-comprehensive-5/[/url] can be thrilling. These selections offer gamblers a chance to experience games without restrictions. The best non GamStop casinos provide wide selections, alluring bonuses, and secure platforms. Engage with these casinos for remarkable gaming experiences!
Mollyorage 15 Haziran 2026 16:51
Мне кажется, вы правы Discovering the leading casinos offering best roulette online, [url=http://bestsmartplace.com/]http://bestsmartplace.com/[/url] is essential for any gambler. With multiple options available, choosing the right platform can enhance your gaming experience and increase your chances of winning.
JohnClash 15 Haziran 2026 15:59
Поздравляю, мне кажется это замечательная мысль online casinos, [url=https://kosmetologi-shop.ru/2026/05/22/comprehensive-guide-to-casino-rankings-in-the-uk/]https://kosmetologi-shop.ru/2026/05/22/comprehensive-guide-to-casino-rankings-in-the-uk/[/url] provide a unique journey for players. Through various games, these sites cater to many users. Enjoy the thrill of winning.
Yvonneclani 15 Haziran 2026 15:56
Я думаю, что Вы ошибаетесь. Давайте обсудим. Пишите мне в PM, поговорим. Cash Point Danmark, [url=https://nusfahealths.com/cash-point-danmark-din-guide-til-hurtige-penge/]https://nusfahealths.com/cash-point-danmark-din-guide-til-hurtige-penge/[/url] tilbyder hurtige lГёsninger til pengeservice. Med deres letforstГҐelige systemer kan klienter nemt fГҐ adgang til nГёdvendige ydelser.
Michaeljap 15 Haziran 2026 15:56
Tivoli casino official site, [url=https://eldekahealth.net/2026/06/01/tivoli-casino-official-download-oplev-magien-i-online-spil/]https://eldekahealth.net/2026/06/01/tivoli-casino-official-download-oplev-magien-i-online-spil/[/url] tilbyder et omfattende udvalg af casino spil. Her kan brugere finde populære spilleautomater og interaktive bordspil.
MaryClula 15 Haziran 2026 12:40
Да, действительно. Я согласен со всем выше сказанным. slovenske online casino, [url=https://store.ampinc.com/online-kasina-bez-bankoveho-uctu-hrajte-bez-zbytocnych-barier/]https://store.ampinc.com/online-kasina-bez-bankoveho-uctu-hrajte-bez-zbytocnych-barier/[/url] malГ© mnoЕѕstvo zГЎЕѕitkov. KasГnovГ nadЕЎenci mГґЕѕu objavovaЕҐ rГґzne stolovГ© moЕѕnosti, ktorГ© posilЕ€uje zaujГmavГ© prГleЕѕitosti. UЕѕite si rГЅchle prihlГЎsenie a ГєЕѕasnГ© bonusy.
Patrickwibre 15 Haziran 2026 12:26
Casino BC Game, [url=http://techinfor.net/bc-game-casino-en-ligne-l-experience-de-jeu-ultime/]http://techinfor.net/bc-game-casino-en-ligne-l-experience-de-jeu-ultime/[/url] offers a thrilling experience for bettors. With diverse games and convenient interface, it attracts fresh players and experienced users alike. Join Casino BC Game for constant excitement!
Timalemy 15 Haziran 2026 11:37
Betandreas kazino platformasıdırm, [url=http://entranet.com.br/2026/06/04/high-quality-linoleum-for-home-and-commercial-use-2/]http://entranet.com.br/2026/06/04/high-quality-linoleum-for-home-and-commercial-use-2/[/url], əhəmiyyətli oyun imkanları ilə ziyarətçiləri cazibə edir. Burada populyar bonuslar və geniş maliyyə metodları mövcuddur. Betandreas kazino platformasıdırm hər zaman yuvarlanan təmin edir.
NicholasSaicA 15 Haziran 2026 08:05
По моему мнению Вы ошибаетесь. Предлагаю это обсудить. Пишите мне в PM, поговорим. I intendo parlarti dei vantaggi rapidi non AAMS. Tali bonus propongono opportunitГ interessanti per i giocatori. Catturare queste offerte potrebbe sostenere a espandere le vincite. Tieni a mente che Bonus rapidi non AAMS, [url=http://devel.elbitalegre.com/slot-serali-non-aams-scopri-le-migliori-opzioni-di-gioco-online/]http://devel.elbitalegre.com/slot-serali-non-aams-scopri-le-migliori-opzioni-di-gioco-online/[/url] richiedono specifica considerazione.
WilliamDiuff 15 Haziran 2026 08:03
Finding different betting sites can be exciting. Many players seek bookmakers not on GamStop, [url=https://h2852162.stratoserver.net/index.php/2026/05/29/top-bookies-not-on-gamstop-your-guide-to-online/]https://h2852162.stratoserver.net/index.php/2026/05/29/top-bookies-not-on-gamstop-your-guide-to-online/[/url] for better options. These sites often deliver various promotions and flexible betting methods that cater to your needs. Discovering bookmakers not on GamStop can enhance your gaming experience while ensuring further freedom in placing bets. Always explore the regulations and features before you dive in!
MaryCaw 15 Haziran 2026 08:02
casinos without GamStop, [url=https://www.silverbackmall.com/buckinghamshirebowls/exploring-the-world-of-casinos-in-the-uk/]https://www.silverbackmall.com/buckinghamshirebowls/exploring-the-world-of-casinos-in-the-uk/[/url] offer players a chance to enjoy gaming without restrictions. Such casinos provide a multitude of choices that can fulfill different tastes. Furthermore, clients can enjoy lucrative bonuses and promotions, providing an exhilarating gaming experience. Exploring casinos without GamStop can offer newfound excitement in the world of online gambling.
Matttam 15 Haziran 2026 06:51
Spreadex Danmark site, [url=https://devorder.ucokdurian.id/2026/06/01/spreadex-danmark-din-guide-til-online-betting-og-handel/]https://devorder.ucokdurian.id/2026/06/01/spreadex-danmark-din-guide-til-online-betting-og-handel/[/url] tilbyder en unikt platform med bred tilgang til sport betting. Brugere kan få glæde af gode odds og en brugervenligt interface, der letter spil. Med muligheden for live betting er der altid spænding, mens man høster gevinster.
JonBaind 15 Haziran 2026 06:50
BC Game apk, [url=https://grocery.vpmarketingllc.com/2026/05/30/exploring-bc-game-apk-your-gateway-to-mobile/]https://grocery.vpmarketingllc.com/2026/05/30/exploring-bc-game-apk-your-gateway-to-mobile/[/url] is a popular platform for gamers. This application provides a variety of games that capture interest. Through BC Game apk, you can experience thrilling gameplay anytime.
LillianWab 15 Haziran 2026 06:49
Это всего лишь условность BruceBet Casino DK, [url=https://sinhagiricollection.com/sinhagirivilla/brucebet-casino-dk-2026-din-guide-til-underholdning-og-gevinster/]https://sinhagiricollection.com/sinhagirivilla/brucebet-casino-dk-2026-din-guide-til-underholdning-og-gevinster/[/url] tilbyder et udvalg af oplevelser, der passer til alle spillere. Tilbud omfatter slots, bordspil og reelle oplevelser. Bonusser til nye kunder giver yderligere incitamenter for at starte spillet. Gennem brugervenlige interfaces kan du engagere dig fra enhver lokation.
Chrissoila 15 Haziran 2026 06:20
Betandreas online kazino, [url=http://m-condit.info/peak-marriage/blog/moctbet-a-deep-dive-into-online-betting-and-gaming/]http://m-condit.info/peak-marriage/blog/moctbet-a-deep-dive-into-online-betting-and-gaming/[/url] bir çox mətbəx təklif. Hər sayt istifadəçilərə dalan qazanmaq eşarət edir. Bununla yanaşı gözəl qaydalar fərqli qlobalar şərti ilə mümkündür. Betandreas online kazino yaşayış qanunları çərçivəsində daima məlumat çoxsaylı toplamlar öndərə bilər.
Raheempaync 15 Haziran 2026 05:17
Хоть пару людей с пониманием нашлось If you're looking for the best live roulette online, [url=https://www.jurgenvandervelde.com/best-live-roulette-casinos-in-the-uk-4726777/]https://www.jurgenvandervelde.com/best-live-roulette-casinos-in-the-uk-4726777/[/url], you'll find a thrilling experience with real dealers and interactive gameplay. Participants can enjoy numerous table options and entertaining features that enhance the overall thrill.
Camillabub 15 Haziran 2026 04:28
Вас посетила просто великолепная мысль Cybet Crypto Casino, [url=http://www.ousarempresarial.com.br/index/discover-the-thrilling-world-of-cybet-casino-uk-5/]http://www.ousarempresarial.com.br/index/discover-the-thrilling-world-of-cybet-casino-uk-5/[/url] is an modern platform that presents a unique journey for gamblers using cryptocurrencies. With exciting choices, high protection, and quick withdrawals, Cybet Crypto Casino excels in the online gaming world. Join today and experience a new way to wager.
Jenniferarord 15 Haziran 2026 02:42
Casinos Not on Gamstop UK, [url=https://larex.co.il/newsite/2026/05/22/exploring-non-gamstop-casinos-a-comprehensive-198/]https://larex.co.il/newsite/2026/05/22/exploring-non-gamstop-casinos-a-comprehensive-198/[/url] offer players an alternative to traditional gambling sites. These platforms deliver the chance to enjoy exciting games without the boundaries of Gamstop. Players can find a multitude of games in a reliable environment, enhancing their gaming experience. By choosing Casinos Not on Gamstop UK, players can experience their favorite activities without interruptions.
BooneSoola 15 Haziran 2026 01:43
Я считаю, что Вы допускаете ошибку. Предлагаю это обсудить. Пишите мне в PM, пообщаемся. zahraniДЌnГ© online casino, [url=https://keplerpe.com/ceske-kasina-pre-slovakov-vsetko-co-potrebujete-vediet/]https://keplerpe.com/ceske-kasina-pre-slovakov-vsetko-co-potrebujete-vediet/[/url] dГЎvГЎ hrГЎДЌom moЕѕnosЕҐ dosiahnuЕҐ skvelГ© ceny. ZahГЎjenie hry v takomto prostredГ by mohlo byЕҐ vzruЕЎujГєce. HrГЎДЌi mГґЕѕu moЕѕnosti k viacerГЅm hrГЎm.
Xplosiveslown 15 Haziran 2026 01:16
JB Casino, [url=https://pennyforyourdreams.com/test/2026/06/03/welcome-to-jb-casino-india-your-ultimate-gaming-22/]https://pennyforyourdreams.com/test/2026/06/03/welcome-to-jb-casino-india-your-ultimate-gaming-22/[/url] вытягивает широкий набор игр. Посетители могут окунуться в современными игровыми автоматами и восторгаться живыми дилерами.
JamieHot 15 Haziran 2026 01:15
Betandreas kazino, [url=https://www.3rconnect.com/discover-the-best-betting-experience-with-mostbet-3/]https://www.3rconnect.com/discover-the-best-betting-experience-with-mostbet-3/[/url] təzə istifadəçilərə böyük variantlar təqdim edir. Hamısı şans oyunu mükəmməl mühafizə səviyyəsinə bazasına.
Richardpails 14 Haziran 2026 23:40
non GamStop UK casino, [url=https://therecruitersloungeco.com/exploring-gambling-sites-that-don-t-use-gamstop/]https://therecruitersloungeco.com/exploring-gambling-sites-that-don-t-use-gamstop/[/url] offers players a chance to enjoy gaming without restrictions. These casinos deliver a greater selection of games and adaptable bonuses. Players can discover top-notch entertainment and savor the thrill of gambling freely.
SteveBom 14 Haziran 2026 23:38
Можно бесконечно говорить на эту тему. Facebook Account Farming, [url=http://natsukijun.sakura.ne.jp/test/how-to-effectively-contact-facebook-support-a-comprehensive-guide-1929130437/]http://natsukijun.sakura.ne.jp/test/how-to-effectively-contact-facebook-support-a-comprehensive-guide-1929130437/[/url] has become a popular method for many individuals. Such a practice enables users to develop multiple accounts for various purposes. While some see it as a way to enhance their reach, others warn against the hazards involved. Overseeing numerous accounts can lead to complications, including bans. Individuals who engage in Facebook Account Farming should proceed with care to avoid unwanted consequences.
TraceyDoK 14 Haziran 2026 23:09
почти даром) Cybet Crypto Casino, [url=https://kyushu.food-stadium.com/news-flash/145540/]https://kyushu.food-stadium.com/news-flash/145540/[/url] offers a thrilling experience for enthusiasts worldwide. With advanced technology and secure transactions, it ensures just gaming. Join the adventure now!
DannyTuh 14 Haziran 2026 22:36
Exploring new gaming options? Check out Casino Sites Not on Gamstop, [url=https://coimbralocacoes.com.br/?p=4095]https://coimbralocacoes.com.br/?p=4095[/url]. These platforms offer a wide range of games without the restrictions of Gamstop. Enjoy thrilling experiences and exclusive bonuses that enhance your gameplay!
PaulaItels 14 Haziran 2026 22:35
SpilHuset Casino, [url=https://iocdistributor.wpengine.com/spilhuset-casino-2026-registrering-2109737968/]https://iocdistributor.wpengine.com/spilhuset-casino-2026-registrering-2109737968/[/url] har en bred sortiment af aktiviteter. Her kan man finde fangere, livs sГёgninger og Г¦gte croupierer. SpilHuset Casino udbyder sikker spiloplevelse.
Mikequock 14 Haziran 2026 22:23
Ваша мысль очень хороша Bet Panda Casino, [url=https://verdeestereo.com/radio/index.php/2026/06/11/oplev-bet-panda-casino-dk-spaending-og-underholdning-i-et-klik/]https://verdeestereo.com/radio/index.php/2026/06/11/oplev-bet-panda-casino-dk-spaending-og-underholdning-i-et-klik/[/url] tilbyder en unikt spilmiljГё med vidunderlige muligheder for fortjenester. Med forskellige spilleautomater og virkelige dealer-spil er det det perfekt sted for glade spillere.
AshleyJeffGlore 14 Haziran 2026 19:34
Отличный топик Gembet Casino, [url=https://www.ameeralbaher.com/discover-gembet-singapore-your-ultimate-online-21/]https://www.ameeralbaher.com/discover-gembet-singapore-your-ultimate-online-21/[/url] offers entertaining games and enormous jackpots. Players can enjoy numerous options of slots and table games. Join Gembet Casino today and discover the fun you've been waiting for!
ChrisHoale 14 Haziran 2026 18:50
Я извиняюсь, но, по-моему, Вы не правы. Давайте обсудим. Discover the top way to enjoy casino excitement with the best roulette online, [url=https://integralwellnessrevolution.com/discover-the-best-roulette-online-tips-and-top/]https://integralwellnessrevolution.com/discover-the-best-roulette-online-tips-and-top/[/url]. Experience the exhilaration of spinning the wheel and winning big. Engage in the fun today and challenge your luck!
XplosiveDuaph 14 Haziran 2026 18:01
Куда уж тут против авторитета Cybet Crypto Casino, [url=https://americancom.com.bo/2026/06/02/cybet-crypto-casino-a-new-era-of-online-gambling-7/]https://americancom.com.bo/2026/06/02/cybet-crypto-casino-a-new-era-of-online-gambling-7/[/url] offers an exciting platform for wagering enthusiasts. With innovative technology, players can enjoy safe transactions and varied games. Join Cybet Crypto Casino today and experience the future of online gaming!
LydiaAcink 14 Haziran 2026 15:21
Я полагаю, что всегда есть возможность. Gembet Betting, [url=https://www.internationalstorytelling.org/india/exploring-gembet-singapore-the-ultimate-gaming-4/]https://www.internationalstorytelling.org/india/exploring-gembet-singapore-the-ultimate-gaming-4/[/url] offers thrilling opportunities for bettors. With a easy-to-navigate interface, it enables effortless betting. Explore a variety of options and enjoy real-time updates for an incredible experience.
Nancykem 14 Haziran 2026 13:14
Позволю себе не согласится casino uden licens, [url=https://iplusstd.com/item/eventBookingPro/admin/2026/06/10/discover-the-best-instant-withdrawal-casinos-in-canada-1262671406/]https://iplusstd.com/item/eventBookingPro/admin/2026/06/10/discover-the-best-instant-withdrawal-casinos-in-canada-1262671406/[/url] tilbyder en rГ¦kke muligheder for spillere, der Гёnsker at udforske den spГ¦ndende verden af online gambling. Det casino giver chancer til varierede spil, men det er vigtigt at forblive vГҐgen. En interessant oplevelse kan blive til noget uventet uden den rette viden. Spil ansvarligt og nyd din oplevelse i denne arena.
ConstanceSoymn 14 Haziran 2026 11:12
non GamStop UK casino, [url=https://www.ambdesign.com.pl/2026/05/24/top-non-gamstop-casinos-in-the-uk-play-responsibly/]https://www.ambdesign.com.pl/2026/05/24/top-non-gamstop-casinos-in-the-uk-play-responsibly/[/url] offers players a unique experience|provides gamers an exceptional opportunity|delivers enthusiasts a distinctive adventure|gives bettors an outstanding option. Here, you'll find a variety of games|numerous options|a wide selection|diverse choices that cater to all tastes|preferences. Enjoy increased bonuses|enhanced rewards|greater incentives|better promotions without the usual restrictions.
Tinapoisp 14 Haziran 2026 10:09
JB Casino Official Website, [url=https://sanascience.com/jb-crypto-casino-your-ultimate-destination-for-2/]https://sanascience.com/jb-crypto-casino-your-ultimate-destination-for-2/[/url] offers an exciting gaming experience for participants. With a vast range of titles, including slot machines, it promises endless enjoyment. Enjoy attractive bonuses and promotions that enhance your chances to win big! Join the family today and explore the excitement of online gaming at JB Casino Official Website.
GinaAdage 14 Haziran 2026 07:07
Finding dependable bookies not on GamStop, [url=http://m-condit.info/peak-marriage/blog/understanding-apple-pay-casinos-not-on-gamstop-3/]http://m-condit.info/peak-marriage/blog/understanding-apple-pay-casinos-not-on-gamstop-3/[/url] is crucial for players seeking alternative options. These platforms often provide greater selections and special promotions to enhance the betting experience. It's essential to investigate these sites for licensing to ensure a safe betting environment. Players should be wary of their choices while enjoying their bets. Additionally, responsible gambling practices should always be a priority as they navigate through bookies not on GamStop.
ErnieBeimb 14 Haziran 2026 05:16
BC Game crypto casino, [url=https://app.trafficivy.com/bc-game-282/]https://app.trafficivy.com/bc-game-282/[/url] обеспечивает игрокам уникальный опыт на азартных игр с активами криптовалют. Сервис уверенно привлекает внимание разнообразного числа пользователей, предлагая захватывающий выбор игр, а также интуитивно-понятные методы депозита. Здесь возможна игра с разными криптовалютами, что учитывает интересам любой игрока.
Lylesisse 14 Haziran 2026 05:15
JB Casino, [url=https://chukalsky.ru/?p=2070904]https://chukalsky.ru/?p=2070904[/url] offers a captivating atmosphere for enthusiasts. With multiple games and profitable bonuses, you’ll find plenty of options to enjoy. Join today and experience the excitement of JB Casino!
JessieWap 14 Haziran 2026 03:11
Логично, я согласен low stakes roulette, [url=http://www.shiatsutherapy.org/vargusuk/108776]http://www.shiatsutherapy.org/vargusuk/108776[/url] offers a thrilling experience for players who enjoy the excitement of spinning the wheel without risking large sums. This game is perfect for beginners, allowing them to learn the tactics while having fun. Moreover, its low-risk nature attracts casual gamblers looking to unwind. In this version of the classic game, users can make smaller bets, enhancing the overall enjoyment. With vibrant tables and friendly dealers, low stakes roulette creates a welcoming atmosphere for all. Enjoy the excitement today!
JackieDow 14 Haziran 2026 03:01
For many players, discovering bookmakers not on GamStop, [url=https://reo-invest.com/exploring-bookmakers-not-on-gamstop-opportunities-3/]https://reo-invest.com/exploring-bookmakers-not-on-gamstop-opportunities-3/[/url] is essential for an uninterrupted betting experience. These platforms offer varied markets and enticing promotions, making them popular among punters. Searching for these sites allows users to enjoy superior gaming opportunities without restrictions.
Robertkidly 14 Haziran 2026 02:59
козырно Парфюмерия оптом, [url=https://zaiushka.ru/]https://zaiushka.ru/[/url] – отличный выбор для бизнеса. Помимо этого, вы сможете предложить разнообразный ассортимент ароматов. Элитные духи увлекут ваших клиентов. Доступные оптовые цены позволят максимальную доходность.
RachelRat 14 Haziran 2026 02:15
гы бурундук=) Cybet Crypto Casino, [url=https://gdcuniversity.com/cybet-casino-review-an-in-depth-look-at-the-online-2/]https://gdcuniversity.com/cybet-casino-review-an-in-depth-look-at-the-online-2/[/url] offers a captivating experience for betters who enjoy crypto. With a wide selection and enticing rewards, it's a popular destination in the virtual casino world. Join now to try out the cutting-edge features and safe transactions that Cybet Crypto Casino provides!
EricaWrick 14 Haziran 2026 01:58
Casinos Non Gamstop, [url=http://shoppingtourbahia.com.br/reloadfestival2/discovering-alternatives-casinos-not-on-gamstop-uk/]http://shoppingtourbahia.com.br/reloadfestival2/discovering-alternatives-casinos-not-on-gamstop-uk/[/url] offer enthusiasts a unique option to enjoy gaming without the restrictions of self-exclusion. These locations provide a wide selection of games for an seamless experience.
DaphneVak 14 Haziran 2026 00:21
JB Casino Online, [url=https://www.formacionquality.es/jb-casino-pakistan-your-ultimate-gaming-9/]https://www.formacionquality.es/jb-casino-pakistan-your-ultimate-gaming-9/[/url] предлагает уникальные возможности для азартных игроков. Участники могут наслаждаться разнообразием игровых автоматов и карточными играми. Откройте вселенную азартных игр с JB Casino Online!
TarusLem 14 Haziran 2026 00:21
Welcome to the exciting world of BC Fun crypto casino, [url=http://unati.univasf.edu.br/understanding-hack-bc-game-a-comprehensive-guide/]http://unati.univasf.edu.br/understanding-hack-bc-game-a-comprehensive-guide/[/url], where participants can enjoy the thrill of online gaming with the twist! Here, virtual money reigns supreme, unlocking new ways to play. Immerse yourself in multiple of games that cater to every player's preference. Experience excellent graphics and captivating gameplay as you dive into the experience of BC Fun crypto casino! Play big, win big!
Amybrins 13 Haziran 2026 22:57
Finding the best non GamStop UK casino, [url=https://anysupply.co.th/2026/05/24/discover-non-gamstop-gambling-sites-for/]https://anysupply.co.th/2026/05/24/discover-non-gamstop-gambling-sites-for/[/url] can be a thrilling experience. Players can enjoy countless gaming options without barriers associated with GamStop. Many casinos offer attractive promotions for newcomers, enhancing gameplay and increasing chances of winning big. Moreover, rapid cashouts allow for a seamless gambling experience, making non GamStop casinos an appealing choice for many.
Natashawam 13 Haziran 2026 22:55
In recent years, the popularity of non GamStop bookmakers, [url=https://blog.abdldate.com/2026/05/28/discover-top-bookies-not-on-gamstop/]https://blog.abdldate.com/2026/05/28/discover-top-bookies-not-on-gamstop/[/url] has gained the attention of many bettors. These platforms present a wide range of options, allowing players to enjoy uninterrupted gaming experiences. Their bookmakers are preferred by those seeking freedom.
MiaDouck 13 Haziran 2026 22:00
ого!.... и такое бывает!... Playing at a casino can be thrilling, especially when you enjoy roulette not on gamstop, [url=http://www.shiatsutherapy.org/non-gamstop-roulette/109878]http://www.shiatsutherapy.org/non-gamstop-roulette/109878[/url]. Many gamblers seek alternatives that offer more freedom. This option allows punters to enjoy their favorite games without restrictions. Explore endless choices that enhance your gaming experience.
MeganEpind 13 Haziran 2026 21:49
Casinos Not on Gamstop, [url=https://greenverge.com/discover-the-best-new-non-gamstop-casino-sites-46/]https://greenverge.com/discover-the-best-new-non-gamstop-casino-sites-46/[/url] offer players a unique experience|provide gamblers with an exceptional opportunity|present punters an alternative|deliver a distinct gaming environment. Here, you can enjoy diverse games|various options|numerous choices|a wide range of entertainment without restrictions. These platforms are perfect for those seeking freedom|independence|liberty|flexibility in their gaming journey. With enticing bonuses|attractive promotions|compelling offers|tempting incentives, they invite you to explore hassle-free gaming|enjoy seamless play|experience uninterrupted fun|discover effortless gambling. Join the thrill today!
DuyAbomo 13 Haziran 2026 21:04
Подскажите, где я могу это найти? non GamStop sites, [url=https://www.cepes.org.br/cepes/discover-the-safest-non-gamstop-uk-casinos-1924286640/]https://www.cepes.org.br/cepes/discover-the-safest-non-gamstop-uk-casinos-1924286640/[/url] provide players the opportunity to enjoy online gambling without restrictions. These gaming sites offer an extensive selection of options and incentives, making them appealing for many. Explore the features they bring.
TraceyVEITE 13 Haziran 2026 19:20
Welcome to the JB Casino Official Website, [url=https://tal.baywoodgrp.com/exploring-the-jb-casino-platform-in-pakistan/]https://tal.baywoodgrp.com/exploring-the-jb-casino-platform-in-pakistan/[/url], where excitement awaits! Here, you can explore a collection of gaming options tailored for any player. Join us and savor an unforgettable gaming experience!
KimRog 13 Haziran 2026 18:45
non UKGC casinos, [url=https://kotwicamorska.pl/exploring-non-uk-casinos-opportunities-and/]https://kotwicamorska.pl/exploring-non-uk-casinos-opportunities-and/[/url] provide an range of enticing gaming options, enabling players to experience unique features and bonuses. Players may delve into numerous games in an engaging environment.
TimWeine 13 Haziran 2026 18:44
Online betting can be exciting, but finding reliable platforms is crucial. Many punters seek sites like bookmakers not on GamStop, [url=https://jerial-jor.com/top-golf-bookies-not-on-gamstop-a-guide-for-enthusiasts/]https://jerial-jor.com/top-golf-bookies-not-on-gamstop-a-guide-for-enthusiasts/[/url] for a greater variety of betting opportunities. These platforms provide enhanced offers and rewards that attract players. However, always practice careful gambling to enjoy a fun experience. Look for reputable sources to ensure your safety.
EricBluet 13 Haziran 2026 18:16
Пиндык, я плачу просто )) Gembet Casino, [url=https://smartbusiness.agencyzed.com/archives/237438]https://smartbusiness.agencyzed.com/archives/237438[/url] offers an exciting gaming experience with a wide variety of games. Players can experience slots, table games, and interactive games. Rewards make it even more luring for newcomers and seasoned players alike. Join Gembet Casino today and dive into a world of fun.
Michellelex 13 Haziran 2026 17:35
Casinos Not on Gamstop UK, [url=https://www.moscaelettroimpianti.it/?p=150282]https://www.moscaelettroimpianti.it/?p=150282[/url] offer an enticing alternative for players seeking more freedom. These sites provide a choice of games without the restrictions imposed by Gamstop. Enjoy the fun of gaming without limits!
MelissaSnini 13 Haziran 2026 16:41
даааа... ты прав Looking for the best live roulette casinos, [url=https://globalsms.co.za/best-live-roulette-online-casino-2/]https://globalsms.co.za/best-live-roulette-online-casino-2/[/url]? The leading establishments offer a captivating experience. Gamblers can communicate with real dealers and relish the genuine casino atmosphere from home. Enjoy various game variations and excellent streaming services!
Kaylaaboth 13 Haziran 2026 14:31
non GamStop bookmakers, [url=https://www.gingerexchange.com/symphony/uncategorized/exploring-non-gamstop-bookies-a-comprehensive-guide-1915536546/]https://www.gingerexchange.com/symphony/uncategorized/exploring-non-gamstop-bookies-a-comprehensive-guide-1915536546/[/url] offer an alternative for players seeking freedom in online gambling. Those platforms offer a wide range of betting options without the restrictions imposed by GamStop. Participants can enjoy a broad selection of games and sports, creating a vibrant experience. Choosing non GamStop bookmakers offers a path towards unhindered enjoyment of betting without barriers.
ChrisSkits 13 Haziran 2026 14:18
BC Game apk, [url=https://coven-stag-king.bonzaitestsite.com/jak-zarejestrowa-si-na-bc-game-przewodnik-krok-po/]https://coven-stag-king.bonzaitestsite.com/jak-zarejestrowa-si-na-bc-game-przewodnik-krok-po/[/url] offers players an exciting platform to engage in various games. This provides an entertaining experience with various features. Users can enjoy hassle-free gameplay and fantastic bonuses. Participate in the action today!
ShannonDycle 13 Haziran 2026 14:16
At JB Casino, [url=https://newpagina.cecasa.com.mx/index.php/jb-casino-login-your-gateway-to-exciting-gaming-15/]https://newpagina.cecasa.com.mx/index.php/jb-casino-login-your-gateway-to-exciting-gaming-15/[/url], players can enjoy a assortment of thrilling games. From video slots to table games, the options are numerous. Additionally, special promotions keep the excitement going!
JessicaDor 13 Haziran 2026 13:19
Nordic Bet Official, [url=https://cfa.finenvision.com/nordic-bet-official-den-ultimative-spiloplevelse/]https://cfa.finenvision.com/nordic-bet-official-den-ultimative-spiloplevelse/[/url] tilbyder fremragende muligheder for sportsvæddemål. Med et platform kan brugere forvente fantastiske odds og promoveringer.
AlexDit 13 Haziran 2026 09:49
casinos not on GamStop, [url=https://demo.zealousweb.com/wordpress-plugins/accept-stripe-payments-using-contact-form-7/?p=532223]https://demo.zealousweb.com/wordpress-plugins/accept-stripe-payments-using-contact-form-7/?p=532223[/url] provide players with unique opportunities to enjoy their favorite games without restrictions. Such casinos often offer exciting bonuses and diverse game selections. Players appreciate the flexibility to play without limitations, making casinos not on GamStop appealing.
Frankslozy 13 Haziran 2026 09:12
Что-то так не выходит ничего Los casinos sin licencia son una opciГіn que muchos jugadores consideran. Sin embargo, es crucial entender de los riesgos que pueden surgir. Casinos Sin Licencia, [url=http://quabieutet.com.vn/casinos-sin-licencia-en-espana-riesgos-y-53/]http://quabieutet.com.vn/casinos-sin-licencia-en-espana-riesgos-y-53/[/url] pueden ofrecer juegos, pero la carencia de regulaciГіn implica daГ±os para el jugador. Se recomienda investigar antes de participar.
HeatherTob 13 Haziran 2026 08:38
Nordic Bet Official, [url=https://fukusi.sikaku-style.com/2026/05/nordic-bet-2026-registrering-alt-du-skal-vide.html]https://fukusi.sikaku-style.com/2026/05/nordic-bet-2026-registrering-alt-du-skal-vide.html[/url] tilbyder pålidelig bettingoplevelser. Med en udvalg af sportsgrene og spil, kan spillere finde noget for enhver smag. Brugerhjælp er altid åben for assistance.
MattRhype 13 Haziran 2026 08:31
BC Game crypto casino, [url=http://gaabiandco.com/exploring-the-features-of-hash-game-bc-game/]http://gaabiandco.com/exploring-the-features-of-hash-game-bc-game/[/url] offers a captivating gaming experience for enthusiasts. It features countless games, including table games. With safe transactions and fantastic bonuses, it attracts virtual currency fans from around the world. Dive into the realm of BC Game crypto casino and explore limitless opportunities to acquire rewards today!
AmyEcoft 13 Haziran 2026 05:32
Playing bingo online can be exciting, especially when you explore non GamStop bingo, [url=http://biznislink.rs/understanding-what-bingo-sites-are-not-a-comprehensive-guide-1877292953/]http://biznislink.rs/understanding-what-bingo-sites-are-not-a-comprehensive-guide-1877292953/[/url] options. These platforms offer distinct experiences without the restrictions of GamStop, allowing players to enjoy extra freedom. Dive into thrilling games and discover amazing bonuses!
KatrinaRab 13 Haziran 2026 05:32
casinos not on GamStop, [url=http://www.fyosy.com/?p=369137]http://www.fyosy.com/?p=369137[/url] offer players an alternative to traditional gambling platforms. These casinos provide special games and bonuses. Gamblers can enjoy enhanced freedom and flexibility when wagering.
KatrinaBeemy 13 Haziran 2026 05:26
посмотрел и разочаровался.......... If you're searching for the best live roulette casinos, [url=https://sabaqinsure.ly/2026/04/25/ultimate-guide-to-live-roulette-sites-282316691-2/]https://sabaqinsure.ly/2026/04/25/ultimate-guide-to-live-roulette-sites-282316691-2/[/url], you'll find exciting options to enhance your gaming experience. Whether you prefer classic tables or immersive gameplay, these platforms offer captivating environments that make each spin extraordinary. Choose wisely and enjoy!
MitchSpasy 13 Haziran 2026 04:51
По моему мнению Вы ошибаетесь. Могу это доказать. Пишите мне в PM, обсудим. Los casinos sin licencia ofrecen diversiГіn sin las regulaciones tradicionales. Sin embargo, apostar en estos lugares puede ser peligroso. Casinos Sin Licencia, [url=https://dzkalesija.ba/wp/?p=1281498]https://dzkalesija.ba/wp/?p=1281498[/url] carecen de protecciones para los jugadores, lo que aumenta el situaciГіn crГtica de ser vГctima de fraudes. AdemГЎs, se debe tener en cuenta que las ganancias en tales sitios podrГan no ser confiables. Siempre es mejor optar por plataformas seguras para disfrutar de una experiencia de juego segura.
Shawnhop 13 Haziran 2026 04:23
Поздравляю, ваша мысль пригодится Casinos Not on Gamstop UK, [url=https://dronchessacademy.com/index.php/2026/06/03/exploring-casinos-that-are-not-on-gamstop-a-guide-for-players-1997652312/]https://dronchessacademy.com/index.php/2026/06/03/exploring-casinos-that-are-not-on-gamstop-a-guide-for-players-1997652312/[/url] offer an alternative for players seeking variety. These platforms provide a wide range of exciting games and beneficial bonuses. Players can enjoy their favorite games without the restrictions imposed by Gamstop. Explore and experience unique gaming options today at Casinos Not on Gamstop UK!
AdrianDet 13 Haziran 2026 04:19
Lucky Vegas official, [url=https://dimpleshorsetreats.com/oplev-spaendingen-med-lucky-vegas-slots-2094342578/]https://dimpleshorsetreats.com/oplev-spaendingen-med-lucky-vegas-slots-2094342578/[/url] tilbyder en fantastisk oplevelse for spillere, der søger fornøjelse. Her finder du et sortiment af spilleautomater, bordspil og interaktive spil. Deltag i turneringer, og oplev chancerne for at vinde store penge." "Med garanti i fokus, er din data i gode hænder. Besøg Lucky Vegas official og prøv din heldige side i dag!
ThevocabKat 13 Haziran 2026 04:19
Casinos Not on Gamstop, [url=https://mijalflamenco.com/discover-online-casinos-non-gamstop-for-endless/]https://mijalflamenco.com/discover-online-casinos-non-gamstop-for-endless/[/url] offer a unique opportunity for players seeking freedom and variety. Such of casinos provide exciting games without the restrictions imposed by Gamstop. Players can relish their favorite games without limitations.
MikeGuift 13 Haziran 2026 03:24
JB Casino Online, [url=https://www.solucionessmart.com.uy/smartporteria/2026/06/01/exploring-the-excitement-of-jb-casino-online/]https://www.solucionessmart.com.uy/smartporteria/2026/06/01/exploring-the-excitement-of-jb-casino-online/[/url] предлагает интригующие игры для участников. Каждый найдет что-нибудь по своим интересам. Замечательные бонусы доступны новым клиентам. Присоединяйтесь к JB Casino Online и получите незабываемые впечатления.
Robertkidly 13 Haziran 2026 02:54
Подтверждаю. Я согласен со всем выше сказанным. Можем пообщаться на эту тему. Здесь или в PM. Парфюмерия оптом, [url=https://mumbook.ru/]https://mumbook.ru/[/url] — это отличный способ получить ароматы по привлекательным ценам. Выбор разнообразный, что позволяет подобрать идеальные запахи для вашего бизнеса. Оптовые закупки дают хорошие акции для ритейлеров.
AudreyDoulk 13 Haziran 2026 01:43
люблю такое najlepsie slovenske online casino, [url=https://blog.thanos.ai/online-kasina-na-slovensku-vetko-o-potrebujete-47/]https://blog.thanos.ai/online-kasina-na-slovensku-vetko-o-potrebujete-47/[/url] - NajlepЕЎie slovenskГ© online casino ponГєka hrГЎДЌom ЕЎirokГЅ vГЅber hier a atraktГvne bonusy. UЕѕite si pri rГґznych automatoch a stolovГЅch hrГЎch. Zaregistrovanie je jednoduchГЎ a rГЅchla, takЕѕe je moЕѕnГ© pustiЕҐ do hry ihneДЏ. Hrajte z pohodlia domova a preskГєmajte svet online zГЎbavy.
Tedkip 13 Haziran 2026 01:15
non GamStop football betting, [url=https://vi-rs.com/the-freedom-of-betting-on-football-options-beyond-gamstop/]https://vi-rs.com/the-freedom-of-betting-on-football-options-beyond-gamstop/[/url] offers a unique approach for enthusiasts seeking excitement. Many players prefer this option as it offers a broader range of bookmakers. With enhanced odds, it becomes appealing. Enjoy the choice to bet on your favorite teams without restrictions!
AmandaFet 13 Haziran 2026 00:03
Lucky Vegas official, [url=https://clubedoiphone.salvador.br/lucky-vegas-official-det-perfekte-sted-for-online-spil/]https://clubedoiphone.salvador.br/lucky-vegas-official-det-perfekte-sted-for-online-spil/[/url] tilbyder en spændende spiloplevelse med fascinerende spil. Her kan du prøve en variabel vifte af bordspil, der lover timevis af sjov. Gå ikke glip af muligheden om at vinde store præmier i et sikkert miljø.
Jaredtit 13 Haziran 2026 00:02
If you’re searching for great gaming options, consider Casinos Not on Gamstop UK, [url=http://futurismdemo.com/hsfoodserver/discover-casino-sites-not-on-gamstop-for-ultimate-15/]http://futurismdemo.com/hsfoodserver/discover-casino-sites-not-on-gamstop-for-ultimate-15/[/url]. These platforms offer varied games and exciting experiences without restrictions. Players can enjoy freedom in their gaming journey!
Julieuname 12 Haziran 2026 20:24
Вы не правы. Могу отстоять свою позицию. Пишите мне в PM, пообщаемся. zahraniДЌnГ© online kasГno, [url=https://chocamobile.com/zoznam-top-online-kasin-najlepsie-moznosti-pre-hracov/]https://chocamobile.com/zoznam-top-online-kasin-najlepsie-moznosti-pre-hracov/[/url] umoЕѕЕ€uje ЕЎirokГЅ sortiment hier, ДЌo poteЕЎia hrГЎДЌov. S atraktГvnymi bonusmi ako aj vГЅhodnГЅmi podmienkami je to exkluzГvna prГleЕѕitosЕҐ na relax.
Shawnciz 12 Haziran 2026 20:13
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Давайте обсудим это. Пишите мне в PM, поговорим. When it comes to online gambling, gamblers often seek out the best non gamstop casinos, [url=https://tejas-apartment.teson.xyz/the-ultimate-guide-to-non-gamstop-casino-rating/]https://tejas-apartment.teson.xyz/the-ultimate-guide-to-non-gamstop-casino-rating/[/url]. These platforms provide an opportunity to enjoy gaming without the restrictions imposed by the Gamstop program. One of the key advantages of these casinos is the diversity of games available. From fruit machines to table games like poker and blackjack, there’s something for everyone. Moreover, casinos outside Gamstop typically offer attractive bonuses and features designed to enhance the gaming experience. Many of these sites a
DianaSourl 12 Haziran 2026 19:54
The universe of Casinos Non on Gamstop, [url=https://www.jafrumsaddlebags.com/uncategorized/discover-the-best-casinos-not-on-gamstop-in-the-uk-3/]https://www.jafrumsaddlebags.com/uncategorized/discover-the-best-casinos-not-on-gamstop-in-the-uk-3/[/url] offers thrilling opportunities for players. With a vast selection of games, these venues attract fans looking for freedom. Engage with the fun today!
SamZet 12 Haziran 2026 18:43
В этом что-то есть. Большое спасибо за помощь в этом вопросе, теперь я буду знать. Finding the leading roulette online casino can greatly enhance your gaming experience. With a variety of options available, it's essential to select a platform that offers integrity and entertaining gameplay. Ensure that the casino is regulated and provides generous rewards for players. Moreover, explore testimonials to identify the best roulette online casino, [url=https://store.ampinc.com/ultimate-guide-to-best-roulette-strategies-and/]https://store.ampinc.com/ultimate-guide-to-best-roulette-strategies-and/[/url] for your needs!
JessicaRap 12 Haziran 2026 18:00
Прелестный ответ Парфюмерия оптом, [url=https://l-parfum.ru/catalog/valentino/rockn-dreams/]https://l-parfum.ru/catalog/valentino/rockn-dreams/[/url] – это отличный способ удивить клиентов, предлагая им уникальные ароматы. Покупая продукцию в оптовых партиях, вы экономите затраты и увеличиваете доход. Важно выбирать качественные товары от известных компаний для успешной реализации. Не упустите возможность на рынке!
Boonerhita 12 Haziran 2026 17:18
BetWinner Casino, [url=https://bodenbelaege-roteco.de/betwinner-burkina-faso-bonus-guide-discover/]https://bodenbelaege-roteco.de/betwinner-burkina-faso-bonus-guide-discover/[/url] предлагает эксклюзивные игры для участников. Вам доступен широкий выбор автоматов. Присоединяйтесь и развлекайтесь шансом выиграть значительные призы прямо в настоящий момент.
JaneLig 12 Haziran 2026 17:17
JB Casino, [url=https://nextoons.bex.jp/2026/06/01/1114195/]https://nextoons.bex.jp/2026/06/01/1114195/[/url] stands as a dynamic spot for gamblers looking for entertainment. Providing a wide selection of choices, JB Casino promises unforgettable moments. Engage with the experience today!
Ayanacip 12 Haziran 2026 16:53
Cosmic Spins casino, [url=https://www.sterling-store.co/exploring-cosmic-spins-sister-sites-a-comprehensive-guide-1878263468/]https://www.sterling-store.co/exploring-cosmic-spins-sister-sites-a-comprehensive-guide-1878263468/[/url] features an thrilling gaming experience. At this platform, players can partake in a variety of options. With special bonuses and deals, the fun never ends!
CristinaFiple 12 Haziran 2026 15:42
Lucky Vegas official, [url=https://www.navigazioneetrasporti.it/2026/05/31/oplev-spaending-med-lucky-vegas-slots/]https://www.navigazioneetrasporti.it/2026/05/31/oplev-spaending-med-lucky-vegas-slots/[/url] tilbyder en spændende oplevelse for spillere med talrige spilmuligheder. Her kan man finde traditionelle spil og friske variationer. Uanset om du er amatør, vil du sætte pris på atmosfæren og hjælpen fra personalet. Spil ansvarligt og opnå en imponerende tid hos Lucky Vegas official!
StephanieEnusa 12 Haziran 2026 15:42
If you’re looking to enhance your gaming experience, getting a casino app is essential. With a smooth Casino App Download, [url=http://lasantanera.com/online/2026/05/experience-thrills-at-funbet-casino-official/]http://lasantanera.com/online/2026/05/experience-thrills-at-funbet-casino-official/[/url], you can access a variety of games on your smartphone. Enjoy exclusive bonuses, engaging gameplay, and quick withdrawals.
Lisakat 12 Haziran 2026 15:32
I Danmark er der mange muligheder for at spille online, hvis du vælger et dansk casino uden rofus, [url=https://magme.madeinitalyslc.it/2026/05/02/gode-udenlandske-casinoer-en-guide-til-de-bedste/]https://magme.madeinitalyslc.it/2026/05/02/gode-udenlandske-casinoer-en-guide-til-de-bedste/[/url]. Spillere kan nyde en varieret oplevelse med fascinerende spil og tiltalende bonusser. Det er vigtigt at være opmærksom ansvarligt spil, selv i et casino uden restriktioner. Værudstyret til en sjov tid og opdag nye muligheder. Dansk casino uden rofus giver frihed til at afprøve nye og chancer.
Mattjaphy 12 Haziran 2026 13:42
Betandreas online kazino, [url=https://www.plastexpb.com.br/betandreas-dman-mrclri-v-ylnc-dunyas-1200149776/]https://www.plastexpb.com.br/betandreas-dman-mrclri-v-ylnc-dunyas-1200149776/[/url] ilə oyun müştərilər üçün mükəmməl imkanlar təqdim edir. Burada bir növ oyunu göstərmək mümkündür. Mükafatlar cazibədardir. Betandreas online kazino ote üçün davamlı variantlar təqdim edir.
Sarahzek 12 Haziran 2026 13:36
Я конечно, прошу прощения, но это совсем другое, а не то, что мне нужно. Jocul Aviator online, [url=https://aviatorjoc.org/]aviator demo[/url] este o experienИ›Дѓ captivantДѓ, Г®n care Г®И›i aduce emoИ›ii unice. Utilizatorii pot acumula premii interesante doar prin tactici inteligente. JoacДѓ Jocul Aviator online И™i exploreazДѓ aceastДѓ aventurДѓ captivantДѓ!
HankPef 12 Haziran 2026 12:41
golf odds not on GamStop, [url=http://saikohayama.com/golf-bookies-not-on-gamstop-your-guide-to-alternative-betting-options-1875771078/]http://saikohayama.com/golf-bookies-not-on-gamstop-your-guide-to-alternative-betting-options-1875771078/[/url] offer a unique opportunity for players looking to bet without restrictions. Many enthusiasts|fans|players|bettors seek alternative options. With a variety of platforms|websites|services|providers available, it's essential to explore choices. You can find competitive lines|odds|rates|pricing that enhance your gaming experience.
EricaRhype 12 Haziran 2026 12:41
Finding the best non GamStop site, [url=http://www.g5engineerings.com/exploring-non-gamstop-casinos-a-comprehensive-2/]http://www.g5engineerings.com/exploring-non-gamstop-casinos-a-comprehensive-2/[/url] is essential for players seeking a wider range of options. These platforms offer excellent games without the restrictions of GamStop. Users can enjoy varied promotions and better gaming experiences in a secure environment.
Harrydrusa 12 Haziran 2026 12:19
BetWinner Casino, [url=https://www.amhal-sono.ma/maximize-your-earnings-with-the-betwinner-4/]https://www.amhal-sono.ma/maximize-your-earnings-with-the-betwinner-4/[/url] предлагает обширный выбор развлечений. Здесь каждый может найти что-то по вкусу. Попробуйте акциями и узнайте мир досуга.
MikeBow 12 Haziran 2026 11:53
I dag er der mange muligheder for at finde det bedste bitcoin casino, [url=http://projekt-pedia.de/bedste-casino-uden-om-rufus-en-guide-til-sikker/]http://projekt-pedia.de/bedste-casino-uden-om-rufus-en-guide-til-sikker/[/url] som præsenterer en fantastisk oplevelse. Spillere kan nyde sikkerhedsorienteret betaling med cryptocurrencies. Flere spilleautomater og spil med kort er tilgængelige online, hvilket skaber en spændende platform for spillerne. Velkommen til det bedste bitcoin casino!
MichellePsymn 12 Haziran 2026 11:51
прикольно конечно НО смысл этого чуда онлайн казино, [url=https://dostigateli.ru/forum/topic/ochered-v-banke-i-polchasa-svobody/#postid-5361]https://dostigateli.ru/forum/topic/ochered-v-banke-i-polchasa-svobody/#postid-5361[/url] дарит множество возможностей для игроков. Каждый игра наполняет адреналином, а награды могут поменять жизнь. С увлечением пробуйте свои силы в онлайн казино уже сегодня!
AliceCrelm 12 Haziran 2026 11:50
Могу поискать ссылку на сайт, на котором есть много информации по этому вопросу. Il Metodo quote calcio online, [url=https://www.assoservizionline.it/2026/05/29/metodo-e-strategie-sportive-pratiche-guida-completa/]https://www.assoservizionline.it/2026/05/29/metodo-e-strategie-sportive-pratiche-guida-completa/[/url] offre un'opportunitГ vincente per scommettere in modo *strategico. Utilizzando questo metodo, i giocatori possono perfezionare le loro scelte e aumentare le probabilitГ di successo. Con una specie di analisi scrupolosa, si possono rivelare le migliori quote e fare scelte piГ№ consapevoli. Applicando il Metodo quote calcio online, il divertimento e il guadagno sono garantiti!
Sarahtab 12 Haziran 2026 11:28
Welcome to the exciting domain of gaming at Casino Website, [url=http://csr.questionbank.lk/?p=473845]http://csr.questionbank.lk/?p=473845[/url]! Dive into a multitude of entertainment, from poker to virtual dealers. Sign up today and delight in unique bonuses and offers. This adventure lies ahead!
ShakiraNuh 12 Haziran 2026 11:27
Lucky Niki Official, [url=https://al-qalm.co/oplev-lucky-niki-casino-i-2026-det-perfekte-online-spilmiljo/]https://al-qalm.co/oplev-lucky-niki-casino-i-2026-det-perfekte-online-spilmiljo/[/url] er et spændende online casino som tilbyder en unik oplevelse. Her kan brugere udforske forskellige af spil, som slots og bordspil. Gå ikke glip af utrolige bonusser og promotioner, som virkelig forbedrer spiloplevelsen. Træd ind i Lucky Niki Official nu og nyd sjov og spænding!
Timmig 12 Haziran 2026 08:31
Cosmic Spins casino, [url=https://dm-realestate.com/an-in-depth-review-of-cosmic-spins-casino/]https://dm-realestate.com/an-in-depth-review-of-cosmic-spins-casino/[/url] offers a captivating experience for gamers. With a wide selection of games, players can explore unique features and bonuses. Join Cosmic Spins casino and dive into the action!
Angelachoiz 12 Haziran 2026 08:31
Online gambling has become popular, especially with casinos not on GamStop, [url=https://chandransteelsonline.com/exploring-casinos-without-gamstop-freedom-to-play/]https://chandransteelsonline.com/exploring-casinos-without-gamstop-freedom-to-play/[/url]. These platforms offer players diverse options|choices|selections|varieties to enjoy. They provide unique games|activities|entertainments|experiences and generous bonuses|promotions|offers|deals, attracting many enthusiasts.
Teresawrelt 12 Haziran 2026 08:26
casino online udenlandsk, [url=http://sasiedzionline.obliczasrebra.kylos.pl/node/]http://sasiedzionline.obliczasrebra.kylos.pl/node/[/url] giver spillere muligheden for at udforske deres favoritspil hjemmefra. Platformene tilbyder et bredt udvalg af underholdning, som mГҐ forhГёje nervГёsiteten ved lotteri.
ClayPed 12 Haziran 2026 08:02
Тупо зачет! Finding the optimal platforms for enjoying the best roulette online, [url=https://cares-sv.org/bodymechstoke/discover-the-best-roulette-sites-online-for-a/]https://cares-sv.org/bodymechstoke/discover-the-best-roulette-sites-online-for-a/[/url] is essential for a thrilling experience. Discover various selections available to upgrade your chances of winning big.
Brandonmaf 12 Haziran 2026 07:29
Подтверждаю. Это было и со мной. Давайте обсудим этот вопрос. Здесь или в PM. I ultimamente ho scoperto il mondo dei casino esteri, [url=https://polaluce.com/accesso-rapido-ai-casino-esteri-guida-completa-1969980859/]https://polaluce.com/accesso-rapido-ai-casino-esteri-guida-completa-1969980859/[/url]. Questi contesti offrono possibilitГ uniche per giocare. I video slot e i dispositivi da gioco rendono l'esperienza eccitante. Non trascurare l'occasione di visitare un casino esteri!
Janehon 12 Haziran 2026 07:17
Замечательно, это весьма ценная штука Casinos Not on Gamstop, [url=https://luar.dcc.ufmg.br/casino-sites-not-on-gamstop-your-guide-to-alternative-gaming-options-5/]https://luar.dcc.ufmg.br/casino-sites-not-on-gamstop-your-guide-to-alternative-gaming-options-5/[/url] offer players a unique experience. These platforms offer a variety of games, allowing gamblers to explore their favorite activities without restrictions.
RogerHen 12 Haziran 2026 07:09
Lucky Niki Official, [url=https://centralkougei.co.jp/132949/]https://centralkougei.co.jp/132949/[/url] er en spændende digitalt casino, der tilbyder forskellige spillemuligheder. Her kan spillere nyde fantastiske spilleautomater og interaktive spil, som sikrer en fascinerende oplevelse.
Jamarcusgak 12 Haziran 2026 06:13
Могу рекомендовать Вам посетить сайт, с огромным количеством статей по интересующей Вас теме. онлайн казино, [url=https://subscribe.ru/group/workerssss/19527440/]https://subscribe.ru/group/workerssss/19527440/[/url] предоставляют множество выборов для игры. Гемблеры могут наслаждаться в богатых играх, таких как слоты, покер или блэкджек. Любой получают шанс на выигрыш, который может полностью изменить жизнь.
MeronHoacy 12 Haziran 2026 04:08
casinos not on GamStop, [url=https://jivasendriya.com/exploring-casinos-that-don-t-use-gamstop-a/]https://jivasendriya.com/exploring-casinos-that-don-t-use-gamstop-a/[/url] offer a unique option for players seeking diversity. With a wide range of games, from slots to table games, these casinos serve players wanting to escape strict regulations. Enjoy a unrestricted gaming atmosphere while exploring the vast options available. Whether you prefer classic games or modern ones, casinos not on GamStop provide an captivating alternative for enthusiasts. Embrace the fun and find your ideal betting experience today!
Kennethson 12 Haziran 2026 04:08
non GamStop sportsbooks, [url=https://rocwork.space/aquatrailNuevo/exploring-sportsbooks-not-on-gamstop-your-ultimate-5/]https://rocwork.space/aquatrailNuevo/exploring-sportsbooks-not-on-gamstop-your-ultimate-5/[/url] feature a selection for bettors looking to explore different gaming platforms. These sites allow users to place bets without barriers imposed by GamStop.
AngieZorse 12 Haziran 2026 04:05
Вы абсолютно правы. В этом что-то есть и мне нравится Ваша мысль. Предлагаю вынести на общее обсуждение. zahraniДЌnГ© online kasГno, [url=https://www.chxpressfitness.com/uncategorized/bonus-za-registraciu-bez-vkladu-vsetko-co-potrebujete-vediet-1989095140/]https://www.chxpressfitness.com/uncategorized/bonus-za-registraciu-bez-vkladu-vsetko-co-potrebujete-vediet-1989095140/[/url] vytvГЎra hrГЎДЌom rozmanitГє paletu hier. ДЊi mГЎte zГЎujem hraЕҐ, naЕЎli ste sprГЎvne miesto. PreЕѕite originГЎlne bonusy a svetovГ© turnaje.
Williamshodo 12 Haziran 2026 02:47
Online Casino, [url=https://headwearspecialistsfiji.com/experience-the-thrill-of-gaming-at-hand-of-luck/]https://headwearspecialistsfiji.com/experience-the-thrill-of-gaming-at-hand-of-luck/[/url] provides a exciting experience for players. With countless games available, players can find their preferred options. Furthermore, bonuses and promotions improve the gameplay, making it even far enjoyable.
TinaGreta 12 Haziran 2026 02:46
Lucky Niki Casino, [url=https://mujernuncapermitas.com/?p=350276]https://mujernuncapermitas.com/?p=350276[/url] tilbyder en bredt sortiment af underholdning og fascinerende bonusser. Spillere kan forkæle aktuelle dealeroplevelser. Stedet skaber den atmosfære af spænding og engagement.
AdamSpeek 12 Haziran 2026 02:24
Совершенно верно! Мне нравится Ваша идея. Предлагаю вынести на общее обсуждение. I dagens vГ¤rld Г¤r kazino mer populГ¤ra Г¤n nГҐgonsin. Casino med snabba uttag, [url=https://standland.co.uk/]Casino med snabba uttag[/url] erbjuder spelare mГ¶jligheten att fГҐ sina vinster snabbt. Plattformar med snabba uttag tillhandahГҐller ett utmГ¤rkt erbjudande fГ¶r den som vill ha underhГҐllning utan att vГ¤nta lГ¤nge.
DerekJix 12 Haziran 2026 01:34
В корне неверная информация Non Gamstop Betting Sites, [url=https://app.trafficivy.com/discover-non-gamstop-betting-sites-freedom-to-bet-responsibly/]https://app.trafficivy.com/discover-non-gamstop-betting-sites-freedom-to-bet-responsibly/[/url] offer punters a unique opportunity to wager without restrictions. These platforms provide more freedom for those seeking entertaining betting experiences. Players can appreciate a wide range of games and higher limits, making it an attractive option. With Non Gamstop Betting Sites, you can encounter various betting options, ensuring a diverse experience tailored to your preferences.
SaraSuesk 11 Haziran 2026 20:52
респект Finding the best roulette platforms is essential for an enjoyable gaming experience. The top roulette sites, [url=https://draleilianemartins.com.br/2026/04/25/the-best-roulette-sites-in-the-uk-your-guide-to/]https://draleilianemartins.com.br/2026/04/25/the-best-roulette-sites-in-the-uk-your-guide-to/[/url] provide captivating gameplay and various betting options. Players should consider rewards when choosing their site.
PamelaGak 11 Haziran 2026 20:14
И не так бывает )))) Casinos UK Not on Gamstop, [url=https://adamgardenstt.com/index.php/2026/06/03/discover-the-best-non-gamstop-uk-casino-sites/]https://adamgardenstt.com/index.php/2026/06/03/discover-the-best-non-gamstop-uk-casino-sites/[/url] offer players a chance to enjoy gaming without restrictions. Such casinos provide a diverse range of games, from slots to table games. Participants often access these platforms easily, ensuring a thrilling experience. With numerous bonuses and promotions, users get added value. Remember, before playing at Casinos UK Not on Gamstop, it's essential to gamble responsibly and know your limits.
JesseBaw 11 Haziran 2026 16:06
BetWinner Online Casino, [url=http://shop.westernboots.com.ua/?p=316991]http://shop.westernboots.com.ua/?p=316991[/url] offers an impressive selection of options for players. Attributes like real-time interaction enhance the fun. Join now and experience the thrill!
Sarahoratt 11 Haziran 2026 15:34
For players seeking new experiences, casino not on GamStop, [url=https://seamarkamerica.com/casino-websites-without-gamstop-your-guide-to/]https://seamarkamerica.com/casino-websites-without-gamstop-your-guide-to/[/url] offers exciting options. Numerous online casinos provide distinct games and aspects. Enjoy liberty in choosing your bets without restrictions. Explore this world today!
Sherryfem 11 Haziran 2026 15:10
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Могу это доказать. Пишите мне в PM. Casinos UK Not on Gamstop, [url=https://www.sorocaimports.com/the-rise-of-uk-online-casinos-not-on-gamstop-1998460562/]https://www.sorocaimports.com/the-rise-of-uk-online-casinos-not-on-gamstop-1998460562/[/url] offer players a unique experience within online gaming. These platforms present a wide range of games, appealing to those wanting more flexibility. Players can enjoy casino games without restrictions often imposed by UK regulations.
Miadrori 11 Haziran 2026 10:06
очаровательно! As casas de apostas esportivas em Porto tГЄm expandido nos Гєltimos anos. A normatização trouxe mais seguranГ§a para os usuГЎrios. As ofertas sГЈo atrativas a amplitude de jogos cativa cada vez mais entusiastas. Wager com responsabilidade e aproveite a experiГЄncia que as casas de apostas portugal, [url=https://seamarkamerica.com/casas-de-apostas-desportivas-legais-guia-completo/]https://seamarkamerica.com/casas-de-apostas-desportivas-legais-guia-completo/[/url] tГЄm a oferecer.
MiriamElabe 11 Haziran 2026 09:44
Очень любопытный вопрос Casinos Not on Gamstop UK, [url=http://quabieutet.com.vn/discover-non-gamstop-uk-casino-sites-for-exciting-gaming/]http://quabieutet.com.vn/discover-non-gamstop-uk-casino-sites-for-exciting-gaming/[/url] offer an alternative for players seeking to enjoy their favorite games without restrictions. Countless online casinos provide thrilling experiences and special bonuses for newcomers. Players can explore diverse game selections, from slots to table games, enhancing their enjoyment. With Casinos Not on Gamstop UK, the thrill of gambling remains accessible and fun.
Angiequorn 11 Haziran 2026 09:38
Experience the thrill of Casino Online, [url=https://greenverge.com/discover-the-excitement-of-f7-casino-online-4/]https://greenverge.com/discover-the-excitement-of-f7-casino-online-4/[/url], where players can try their luck at diverse games. With state-of-the-art technology, it offers superior entertainment right from home.
MichelleEcoda 11 Haziran 2026 06:26
Я думаю, что Вы не правы. Я уверен. Могу это доказать. Пишите мне в PM. slovenske online casino, [url=https://judolimon.com/2026/05/30/zoznam-online-kasin-viac-nez-len-hazardne-hry/]https://judolimon.com/2026/05/30/zoznam-online-kasin-viac-nez-len-hazardne-hry/[/url] ponГєkajГє ЕЎirokГє paletu hier pre nadЕЎencov. S pomocou modernГЅch technolГіgiГ si zapotГ realistickГЅ zГЎЕѕitok, kde uvidia mnoЕѕstvo vГЅhod.
KristyFus 11 Haziran 2026 06:23
non UK bookies, [url=http://www.greenscreenstudio.eu/top-non-uk-betting-sites-discover-the-best-global]http://www.greenscreenstudio.eu/top-non-uk-betting-sites-discover-the-best-global[/url] offer a variety of betting options that are often more flexible than traditional bookmakers. Many players seek improved odds and a wider selection of markets. These foreign platforms attract users with exciting promotions and bonuses, making them a popular choice among bettors.
KimknomS 11 Haziran 2026 04:47
LuckyMe Slots official, [url=https://chores4kids.com/2026/05/31/oplev-spaendingen-med-luckyme-slots-en-ultimativ-guide/]https://chores4kids.com/2026/05/31/oplev-spaendingen-med-luckyme-slots-en-ultimativ-guide/[/url] er en fantastisk platform til spændende automater og muligheder for gevinster. Dyk ned i en verden af sfærer, nyt. Skab fantastiske historier med LuckyMe Slots official.
LeahGob 11 Haziran 2026 04:47
Online Casino, [url=http://carfan.pl/2026/05/25/discover-the-exciting-world-of-cryptorino-casino-2/]http://carfan.pl/2026/05/25/discover-the-exciting-world-of-cryptorino-casino-2/[/url] представляет широкий выбор развлечений, где участники способны прибыльно играть деньги. Такое занятие предлагает увлечение и вдохновение.
ChrisMus 11 Haziran 2026 00:40
Это его задело! Это до него дошло! Адвокат по цифровым претсупленям, [url=https://femida-justice.com/uslugi/yurist-po-goszakupkam-almaty/]Юрист по киберпреступлениям в РК[/url] защищает клиентов в экстремальных ситуациях, связанных с киберпреступлениями. Профессиональный юрист поможет решить в юридических вопросах и защитить интересы клиента.
Richkiz 10 Haziran 2026 23:55
Подтверждаю. Всё выше сказанное правда. Давайте обсудим этот вопрос. anД±nda Г¶deme casino, [url=https://hormigonesjm.com/seo-stratejileri-ile-gaminin-gelecei/]https://hormigonesjm.com/seo-stratejileri-ile-gaminin-gelecei/[/url], oyunculara hД±zlД± ve gГјvenilir bir Г¶deme deneyimi sunar. Bu sayesinde, veziyeler hemen Г¶dГјllerini alabilir. HД±zlД± iЕџlem sГјreleri, kazanГ§ tutkunlarД±nД± cezbetmektedir. AnД±nda Г¶deme casino, baЕџarД±sД±nД± test eden katД±lД±mcД±lar iГ§in ideal bir çözГјm sunar.
Meganwaf 10 Haziran 2026 21:39
Хииии)) я с них улыбаюся Discovering leading live roulette sites, [url=http://www.s52.hekko24.pl/2026/04/26/experience-the-thrill-of-online-live-roulette-for-8/]http://www.s52.hekko24.pl/2026/04/26/experience-the-thrill-of-online-live-roulette-for-8/[/url] can improve your gaming experience. With actual dealers and interactive features, players can enjoy the thrill of wagering from home. Join instantly and try your luck!
Jenniferfruby 10 Haziran 2026 18:49
Я забыл напомнить Вам. casino para Г§ekme, [url=https://www.amhal-sono.ma/spor-bahisleri-seo-baarl-stratejiler-ve-puclar-92/]https://www.amhal-sono.ma/spor-bahisleri-seo-baarl-stratejiler-ve-puclar-92/[/url] iЕџlemleri, oyuncularД±n kazanГ§larД±nД± gГјvenli bir Еџekilde Г§ekmelerini saДџlar. AnД±lan iЕџlemler, genellikle sГјratli ve kolay. BirГ§ok oyun sitesi farklД± para Г§ekme yГ¶ntemleri sunar.
CindyedilA 10 Haziran 2026 18:41
Kaiser Slots official, [url=https://ceramicaschenoll.com/kaiser-slots-official-en-verdensklasse-spilleoplevelse-2010249906/]https://ceramicaschenoll.com/kaiser-slots-official-en-verdensklasse-spilleoplevelse-2010249906/[/url] tilbyder en udvalg af automater til fornГёjelse. Her kan spillere deltage i fascinerende tilbud.
Michelleestat 10 Haziran 2026 17:47
Между нами говоря, по-моему, это очевидно. Попробуйте поискать ответ на Ваш вопрос в google.com zahraniДЌnГ© online kasГno, [url=http://brightcomgroup.orderzen.com/zahranicne-kasina-pre-slovakov-prehlad-a-odporucania/]http://brightcomgroup.orderzen.com/zahranicne-kasina-pre-slovakov-prehlad-a-odporucania/[/url] sa stГЎva zaujГmavou prГleЕѕitosЕҐou pre hrГЎДЌov ЕЎpeciГЎlnych zГЎЕѕitkov. K dispozГcii sГє rozmanitГ© ponuky a zГЎЕѕitky, ktorГ© zvyЕЎujГє ГєroveЕ€.
DorothyJam 10 Haziran 2026 15:17
Experience the thrill of the amazing Fishin Frenzy casino, [url=https://store.filgolf.com/?p=192371]https://store.filgolf.com/?p=192371[/url], where players can enjoy inviting bonuses and enthralling gameplay. Dive into an ocean of fun today!
Annabob 10 Haziran 2026 14:27
Я извиняюсь, но, по-моему, Вы не правы. Пишите мне в PM, поговорим. UK Casinos Not on Gamstop, [url=https://grocery.vpmarketingllc.com/2026/06/02/exploring-uk-non-gamstop-casinos-a-comprehensive-guide/]https://grocery.vpmarketingllc.com/2026/06/02/exploring-uk-non-gamstop-casinos-a-comprehensive-guide/[/url] offer players a unique opportunity to enjoy their favorite games without restrictions. These casinos invite players from the UK to indulge in thrilling gameplay while enjoying a wide selection of slots and table games.
Jamarcusgak 10 Haziran 2026 14:14
Какая нужная фраза... супер, великолепная идея онлайн казино, [url=https://vitebsk.forumtl.com/t514-topic#770]https://vitebsk.forumtl.com/t514-topic#770[/url] выпускает уникальную возможность воспользоваться свое свободное время для азартных игр. Здесь каждый игрок найдет что-то. Углубитесь мира азартных приключений!
BeckyDut 10 Haziran 2026 13:21
ДАДАДА! НАДО СМОТРЕТЬ ВСЕМ ОБЯЗАТЕЛЬНО! online casino, [url=https://clearinghouseaccucheck.com/the-rise-of-me88-malaysia-in-esports-betting/]https://clearinghouseaccucheck.com/the-rise-of-me88-malaysia-in-esports-betting/[/url] presents a dynamic experience for players around the globe. With various games to choose from, anyone can find something engaging. Join the action today!
Melissaboofe 10 Haziran 2026 13:21
udenlandske spillemaskiner, [url=http://www.carbossonline.com/udenlandske-online-casino-en-guide-til/]http://www.carbossonline.com/udenlandske-online-casino-en-guide-til/[/url] giver mange fascinerende muligheder for deltagere. De er tilgængelige i mange forskellige former og skabeloner, hvilket gør variation til underholdningen.
Markdiavy 10 Haziran 2026 13:17
If you’re looking for the ultimate fun, a Casino Website, [url=https://sidingcontractorsbellingham.com/casobet-casino-review-2026-a-comprehensive-look-at/]https://sidingcontractorsbellingham.com/casobet-casino-review-2026-a-comprehensive-look-at/[/url] is the perfect place to start. Explore thrilling games, entertaining bonuses, and amazing rewards! Sign up today and enjoy the best gaming experience online.
JacquelineDox 10 Haziran 2026 11:26
Конечно. Это было и со мной. Les jeux de hasard ont toujours attirГ© les amateurs d'aventure. Cependant, le casino sans wager, [url=https://camping-niederbronn.eu/]bonus sans wager[/url] est une excellente option pour ceux qui souhaitent jouer sans contraintes. Profitez de l'enthousiasme sans obligation. Explorez une gamme de options sans soucis financiers.
Kimspany 10 Haziran 2026 10:57
Как специалист, могу оказать помощь. Я специально зарегистрировался, чтобы поучаствовать в обсуждении. zahraniДЌnГ© online kasГno, [url=https://globalcovermedia.com/na-horizonte-slovenske-online-kasino-2026-nove-trendy-a-vizie/]https://globalcovermedia.com/na-horizonte-slovenske-online-kasino-2026-nove-trendy-a-vizie/[/url] ponГєka mnoЕѕstvo hracГch hier. SГєЕҐaЕѕivГ© bonusy motivujГє novГЅch betanov. ZГЎЕѕitok z zГЎbavy je zaujГmavГЅ.
DebbieSesty 10 Haziran 2026 10:01
Magic Win casino, [url=https://www.gospelhochzeit.de/2026/05/28/is-magic-win-casino-legit-a-comprehensive-guide-2/]https://www.gospelhochzeit.de/2026/05/28/is-magic-win-casino-legit-a-comprehensive-guide-2/[/url] offers captivating games that keep players' attention. With varied options, you can find slots that suit your style. Join the fun at Magic Win casino today!
Rogerpiode 10 Haziran 2026 10:00
non GamStop casinos, [url=https://pdd8ryabinka.68edu.ru/2026/05/25/understanding-which-sites-are-not-on-gamstop/]https://pdd8ryabinka.68edu.ru/2026/05/25/understanding-which-sites-are-not-on-gamstop/[/url] offer a unique opportunity for players who seek a diverse gaming experience. These platforms provide alternative options, catering to gamblers looking for variety in their online gaming adventures.
pocaOmits 10 Haziran 2026 08:36
Ваша фраза, просто прелесть Discovering top live roulette sites, [url=https://proktor.smkn2purwokerto.test.co.id/archives/32386]https://proktor.smkn2purwokerto.test.co.id/archives/32386[/url] can enhance your gaming experience. These services offer real-time interaction with hosts, creating an thrilling atmosphere. Enjoy the flexibility of playing from home while feeling the adrenaline of a casino. With a variety of games, live roulette sites cater to all players, ensuring endless opportunities to win.
IdamaK 10 Haziran 2026 08:26
In the entertaining world of Casino Online, [url=https://jntradingsolution.com/discover-the-exciting-world-of-casiwave-casino/]https://jntradingsolution.com/discover-the-exciting-world-of-casiwave-casino/[/url], participants get the chance to experience numerous options of activities. Slot machines, table games, and live dealers create a lively atmosphere, captivating customers from around the globe. Rewards ensure the experience even better.
JenniferCak 10 Haziran 2026 08:25
Kaiser Slots official, [url=https://taxi-marquette-lille.fr/kaiser-slots-official-download-og-spil-i-dag/]https://taxi-marquette-lille.fr/kaiser-slots-official-download-og-spil-i-dag/[/url] tilbyder en unik spilleoplevelse for slots-entusiaster. Med brilliant grafik og interessante funktioner kan du deltage i underholdende slots. Gå ikke glip af chancen for enormt store præmier og en mindeværdig oplevelse.
PatrickPhado 10 Haziran 2026 06:19
Danmark har mange muligheder for at spille online uden begrænsninger. Et dansk casino uden rofus, [url=http://new.iskcondesiretree.com/oplev-de-bedste-udenlandske-spillemaskiner/]http://new.iskcondesiretree.com/oplev-de-bedste-udenlandske-spillemaskiner/[/url] giver spillere frihed til at nyde deres yndlingsspil. Du kan vælge mellem forskellige spilmuligheder og attraktive bonusser. Online spil tilbyder spænding i topklasse.
Maryzen 10 Haziran 2026 06:04
Поздравляю, эта мысль придется как раз кстати Dans le monde des jeux, le salle de jeux sans wager offre une opportunitГ© inГ©dite. Les joueurs peuvent explorer sans soucis. Profitez de promotions incroyables dans ce casino sans wager, [url=https://banyantreemayakoba.com/]casino sans wager[/url], sans prГ©-requis complexes. C’est l'endroit idГ©al pour s'amuser, en jouant en toute tranquillitГ©.
TedBuh 10 Haziran 2026 04:54
Прошу прощения, это мне не подходит. Может, есть ещё варианты? zahraniДЌnГ© online kasГno, [url=http://www.shinoro-fc.org/info/478358.html]http://www.shinoro-fc.org/info/478358.html[/url] umoЕѕЕ€uje bohatГ© alternatГvy na zГЎbavnГ© aktivity. ГљДЌastnГci mГґЕѕu vyuЕѕiЕҐ prvotriedne hernГ© systГ©my, ktorГ© zaruДЌujГє lepЕЎГ skГєsenosti.
MaryZer 10 Haziran 2026 02:37
Полезный вопрос live roulette sites, [url=https://www.grimalc.com/best-live-roulette-casinos-in-the-uk-278981910/]https://www.grimalc.com/best-live-roulette-casinos-in-the-uk-278981910/[/url] provide an engaging experience for betters. With real-time action and seasoned dealers, they offer a distinct atmosphere. Choose your favorite table and enjoy the excitement of live roulette!
Dinkeybom 10 Haziran 2026 02:03
Бесподобное сообщение, мне интересно :) The rise of online gambling has led many players to seek choices, such as Casinos Not on Gamstop, [url=https://oceanblueluxury.com/?p=88803]https://oceanblueluxury.com/?p=88803[/url]. These sites deliver a diverse selection of games while allowing users to play without restrictions.
AmandaInege 10 Haziran 2026 00:54
Ну наконец то Trouver le meilleur casino en ligne, [url=https://martina-mcbride.com/]meilleurs casinos en ligne[/url] revГЄt une grande importance pour bГ©nГ©ficier d'une expГ©rience de jeu utile. Les joueurs cherchent des espaces fiables et stables. Optez pour le meilleur casino en ligne pour optimiser votre joie.
Jasonhap 10 Haziran 2026 00:42
casinos not on GamStop, [url=https://www.bljca.com/togetherahealthierfuture/1477619/]https://www.bljca.com/togetherahealthierfuture/1477619/[/url] offer a unique opportunity for players seeking an alternative to traditional gaming. These sites provide engaging games without restrictions, ensuring gamblers can enjoy their favorite activities without limitations. By accessing casinos not on GamStop, you can enjoy a broader range of options and reveal new games that spark your interest. With numerous promotions and bonuses, playing at these casinos becomes even more attractive. Don't miss out on the chance to join the fun!
Tinasot 09 Haziran 2026 23:47
Такой милашка)) Виртуальные игровые площадки становятся всё более популярными. Особенно интересуют пользователяв связи с растущим интересом к криптовалютам. биткоин казино рейтинг, [url=https://t.me/vanechekvan]лучшие казино онлайн на деньги в россии[/url] помогает выбрать лучшие опции для игры. Многие обеспечивают выгодные акции, что делает игру ещё атмосфернее.
Ashleybliff 09 Haziran 2026 23:06
Какой полезный топик casino snabb utbetalning, [url=http://www.sotuprin.com/hge/snabba-casino-allt-du-behover-veta-for-snabba/]http://www.sotuprin.com/hge/snabba-casino-allt-du-behover-veta-for-snabba/[/url] erbjuder en snabb och effektiv lГ¶sning fГ¶r spelare som vill ha sina vinster snabbt. Tack vare snabba utbetalningar fГҐr kunder tillgГҐng till sina resurser nГ¤stan omedelbart, nГҐgot som Г¶kar spelupplevelsen och hГ¶jer nГ¶jet. MГҐnga tjГ¤nster erbjuder trygghet fГ¶r att dГҐ utbetalningarna. Med casino snabb utbetalning Г¤r systemet enkel och lГ¤ttanvГ¤nd.
GregoryMib 09 Haziran 2026 20:25
http://st22.ru/language/pages/?1xbet_promokod_pri_registracii_bonus.html
Ronda 09 Haziran 2026 11:48
References: Plenty jackpots https://gratisafhalen.be/author/kendocry62/
Glenda 09 Haziran 2026 11:22
References: Choctaw casino oklahoma headlinelog.site
KimTaw 09 Haziran 2026 07:43
Я считаю, что Вы не правы. Давайте обсудим это. I casino online europei, [url=https://nezbudei1962.ru/?p=192034]https://nezbudei1962.ru/?p=192034[/url] offrono un'esperienza di gioco unica. Attraverso una grande assortimenti di giochi, i partecipanti possono cimentarsi in un clima sicuro. Le opportunitГ aumentano l'interesse e stimolano a scommettere di piГ№.
Justinflurf 09 Haziran 2026 06:09
Поздравляю, какой отличный ответ. Gambling enthusiasts often seek alternatives to traditional platforms. UK Bookies Not on Gamstop, [url=https://fukusi.sikaku-style.com/2026/06/discovering-sports-betting-sites-not-on-gamstop-2031526531.html]https://fukusi.sikaku-style.com/2026/06/discovering-sports-betting-sites-not-on-gamstop-2031526531.html[/url] provide a viable option for players wanting more freedom. These bookmakers allow users to explore various betting opportunities, ensuring an engaging wagering experience. Players appreciate different options available at these sites, making a unique atmosphere. With alluring promotions, users find a welcoming environment. Additionally, UK Bookies Not on Gamstop ensures that users can enjoy seamless betting without unwanted restrictions. This f
Insomniaatlswire 09 Haziran 2026 04:44
Selecting the best foreign online casinos, [url=https://ocursoesteticaautomotiva.com.br/idgroup-twoje-tradycyjne-i-nowoczesne-kasino-w/]https://ocursoesteticaautomotiva.com.br/idgroup-twoje-tradycyjne-i-nowoczesne-kasino-w/[/url] can turn out to be overwhelming due to the countless options available. Look for reliable sites that offer competitive bonuses and protected payment methods. Enjoy various games and engaging features!
Soniaphism 09 Haziran 2026 04:44
non GamStop sites, [url=http://www.henrykmalesa.pl/comprehensive-list-of-non-gamstop-casinos-2/]http://www.henrykmalesa.pl/comprehensive-list-of-non-gamstop-casinos-2/[/url] предлагают игрокам уникальную возможность заниматься азартными играми без ограничений РЅР° СЃРІРѕСЋ РёРіСЂРѕРІСѓСЋ СЃРІРѕР±РѕРґСѓ. Рти сайты часто влекают разнообразных РёРіСЂРѕРєРѕРІ, желающих новых ощущений.
Saralob 09 Haziran 2026 03:26
по крайней мере мне понравилось. skattefria casinon, [url=http://attainmfg.com/?p=241860]http://attainmfg.com/?p=241860[/url] erbjuder alternativet att spela spel utan att behГ¶va betala skatt pГҐ vinsterna. Detta skapar en lockande miljГ¶ fГ¶r spelare. Vidare kan man njuta av flera utbud av spel. Skattefria casinon Г¤r uppskattade bland svenskar. Att njuta av spel utan skatt Г¤r enormt tilltalande.
JoshuaJutle 09 Haziran 2026 03:18
Genting Casino official, [url=http://www.nbhyacasting.com/genting-casino-official-det-ultimative-spil-destination/]http://www.nbhyacasting.com/genting-casino-official-det-ultimative-spil-destination/[/url] tilbyder spændende spiloplevelser til gamblere. Med et fantastisk atmosfære og mange muligheder er det muligt at finde deres bedste spil. Besøg Genting Casino official for at få en aften!
Annpen 09 Haziran 2026 03:18
Casino Online, [url=https://rmfernandes.com.br/2026/05/23/discover-blazebet-casino-online-your-gateway-to-2/]https://rmfernandes.com.br/2026/05/23/discover-blazebet-casino-online-your-gateway-to-2/[/url] - Internet casinos has become increasingly popular due to the convenience it offers. Online casinos provide players with access to a vast array of games, from blackjack to interactive betting. As technology advances, the thrill of playing digitally improves, making it more attractive to players. Moreover, offers are often available, enhancing the overall gaming experience.
Natalyfek 09 Haziran 2026 02:47
Убойный ссылки!!!!!!!!!!! Спасибо!!!!! I amanti di giochi possono esplorare il fascino dei casino online europei, [url=https://demo.joomlatools.com/wordpress/i-migliori-casino-europei-guida-completa-ai-casino/]https://demo.joomlatools.com/wordpress/i-migliori-casino-europei-guida-completa-ai-casino/[/url], presentando un'ampia catalogo di macchine. Tali siti sono semplici da usare, garantendo un'esperienza eccitante.
MichaelAbego 09 Haziran 2026 01:43
casinoer uden MitID, [url=https://primusurbanismo.com.br/blog/bedste-casino-uden-dansk-licens-en-guide-til-4/]https://primusurbanismo.com.br/blog/bedste-casino-uden-dansk-licens-en-guide-til-4/[/url] tilbyder en alternativ måde at spille på, uden de strenge krav til identifikation. Disse platforme tiltrækker spillere, som foretrækker at holde deres anonymitet. Dette er en populært valg i Danmark.
Melissagainy 09 Haziran 2026 00:05
In the world of online gaming, countless players seek alternatives to traditional sites not with GamStop, [url=http://bellevuebusinessvaluation.com/2026/05/exploring-unique-uk-casinos-not-on-gamstop/]http://bellevuebusinessvaluation.com/2026/05/exploring-unique-uk-casinos-not-on-gamstop/[/url]. These venues offer distinct experiences without the restrictions imposed by GamStop. Explore this options today!
Mattgub 09 Haziran 2026 00:05
Поздравляю, очень хорошая мысль For bettors seeking options outside of restrictions, Bookies Not On Gamstop, [url=https://demos.totalsuite.net/totalform/exploring-non-gamstop-betting-sites-in-the-uk-2076846312/]https://demos.totalsuite.net/totalform/exploring-non-gamstop-betting-sites-in-the-uk-2076846312/[/url] offer a variety of platforms. These gambling sites provide distinct experiences. Players can opt for from many options, ensuring enhanced freedom in their betting activities.
SarahRer 09 Haziran 2026 00:05
Finding the best foreign online casinos, [url=https://viveforever.com/explore-the-exciting-world-of-idgroup-casino-your/]https://viveforever.com/explore-the-exciting-world-of-idgroup-casino-your/[/url] proves to be an exciting adventure for players worldwide. Using various platforms, enthusiasts can enjoy thrilling games and generous bonuses. It’s crucial to check licenses and reviews to ensure a safe gambling experience. Explore the world of online casinos and choose the one that suits your needs.
RickKep 08 Haziran 2026 22:48
Genting Casino official, [url=http://inova2020.com/2026/05/30/genting-casino-2026-registrering-sadan-tilmelder-du-dig/]http://inova2020.com/2026/05/30/genting-casino-2026-registrering-sadan-tilmelder-du-dig/[/url] tilbyder enestående gamblingoplevelser med flere spilmuligheder. Her kan du opleve slots, bordspil og live dealer-spil, og du mærker spændingen. Besøg Genting Casino official for at opleve ægte kasino-atmosfære!
pocaLoatt 08 Haziran 2026 22:48
Installing a casino app is a simple way to indulge in gaming on the go. With just a few taps, you can access exciting games. The Casino App Download, [url=https://www.eletricabrasil.com.br/bitcasino-io-casino-review-2026-a-comprehensive-3/]https://www.eletricabrasil.com.br/bitcasino-io-casino-review-2026-a-comprehensive-3/[/url] process is efficient, ensuring you start playing in no time. Embrace the chance to collect bonuses and promotions right from your device! Don't miss out on the fun—set up your favorite casino app today!
DustinLef 08 Haziran 2026 21:26
По моему мнению Вы допускаете ошибку. Att spela pГҐ internetcasinon utan BankID blir allt mer populГ¤rt. MГҐnga entusiaster uppskattar mГ¶jligheten att logga in snabbt och enkelt. online casino utan bankid, [url=https://kelseyjphotos.com/casino-utan-registrering-med-bankid-en-ny-era-av-7/]https://kelseyjphotos.com/casino-utan-registrering-med-bankid-en-ny-era-av-7/[/url] erbjuder en effektiv spelupplevelse som tilltalar mГҐnga.
Beatriceshemi 08 Haziran 2026 19:30
Hvis du sГёger det bedste udenlandsk casino, [url=https://studyglobalservice.com/2026/05/03/bedste-udenlandske-online-casino-en-guide-til-top/]https://studyglobalservice.com/2026/05/03/bedste-udenlandske-online-casino-en-guide-til-top/[/url], sГҐ overvej de muligheder. Spiloplevelsen hos disse casinoer er overlegen. Valget af spil er omfattende, hvilket giver gamblers en uforglemmelig oplevelse.
CourtneySuh 08 Haziran 2026 19:30
For players seeking variety, finding sites not with GamStop, [url=https://cmctropmed.com/2026/05/25/reputable-casinos-not-using-gamstop-a/]https://cmctropmed.com/2026/05/25/reputable-casinos-not-using-gamstop-a/[/url] can be a game-changer. These platforms present an choice for those looking to enjoy exciting online gambling without restrictions. Players can explore various games and attractive deals in a vibrant environment.
AnastasiaAxorm 08 Haziran 2026 19:29
Casinos Not on Gamstop, [url=https://demos.totalsuite.net/totalsurvey/discover-the-best-uk-casinos-not-on-gamstop/]https://demos.totalsuite.net/totalsurvey/discover-the-best-uk-casinos-not-on-gamstop/[/url] provide a unique opportunity for players seeking freedom in online gaming. These casinos offer an unconstrained platform for wagerers to participate in their favorite games without barriers. Explore the exciting world of online gambling with these unconventional options.
Chrissault 08 Haziran 2026 18:29
Это очень ценное сообщение Discovering the best live roulette sites, [url=https://lanusehijos.com.py/2026/04/27/ultimate-guide-to-live-roulette-casino-sites/]https://lanusehijos.com.py/2026/04/27/ultimate-guide-to-live-roulette-casino-sites/[/url] can enhance your gaming experience. These platforms offer real-time action with professional dealers. Players can enjoy exciting gameplay from the comfort of home while interacting with others.
AgnesMiz 08 Haziran 2026 18:05
I kasinoverden er der en konstant søgen efter nye venner og spænding. Spillere finder glæde ved at dele deres oplevelser med andre. Casino and Friends, [url=https://www.archetic.pl/oplev-det-ultimative-spilunivers-med-casino-and-friends-official/]https://www.archetic.pl/oplev-det-ultimative-spilunivers-med-casino-and-friends-official/[/url] skaber et perfekt miljø, hvor folk kan mødes og nyde sjove stunder. Det handler ikke kun om spil, men også om relationer, som styrker oplevelsen. Det er vigtigt at erkende, at spil kan være en enestående måde at knytte bånd på.
Radamejam 08 Haziran 2026 18:04
Welcome to your Casino Website, [url=https://www.acscaffolds.com.au/your-ultimate-guide-to-betcoco-casino-online/]https://www.acscaffolds.com.au/your-ultimate-guide-to-betcoco-casino-online/[/url], where entertainment awaits! Enjoy a range of games, including poker. Join today and embrace the best gaming opportunity.
KimberlyDiush 08 Haziran 2026 14:47
Это интересно. Вы мне не подскажете, где я могу найти больше информации по этому вопросу? Att spela pГҐ casinon kan vara spГ¤nnande och underhГҐllande. MГҐnga erbjuder casino gratis spins, [url=https://prompttradefairs.com/freespins-casino-ditt-perfekta-val-for-spannande/]https://prompttradefairs.com/freespins-casino-ditt-perfekta-val-for-spannande/[/url] fГ¶r att ge spelarna en extra chanser att vinna utan att anvГ¤nda sina egna pengar. Det hГ¶jer glГ¤djen av spelande.
Susannacew 08 Haziran 2026 14:23
Finding ideal online casinos can be challenging, especially if you're looking for Casino Sites Not on Gamstop, [url=http://www.hoge-collegen.de/uk-casinos-not-on-gamstop-unlock-your-gaming/]http://www.hoge-collegen.de/uk-casinos-not-on-gamstop-unlock-your-gaming/[/url]. These sites offer engaging gaming options without the restrictions of Gamstop. Players often value the greater variety of games available.
SarahRon 08 Haziran 2026 12:52
Casino Online, [url=http://demo.phytorion.com/discover-aztec-paradise-casino-your-gateway-to/]http://demo.phytorion.com/discover-aztec-paradise-casino-your-gateway-to/[/url] - Online gambling has become widely accepted thanks to the convenience of digital gaming. Players enjoy varied games from their homes.
BobbyTEn 08 Haziran 2026 12:32
udenlandske casinoer, [url=http://www.grupogrago.com/udenlandske-casinoer-for-danskere-en-guide-til-22/]http://www.grupogrago.com/udenlandske-casinoer-for-danskere-en-guide-til-22/[/url] tilbyder varierede spil og chancer for spillere. Den unikke atmosfære gør dem interessante for dedikerede spillere. Find dit næste yndlingscasino blandt de forskellige udenlandske casinoer!
AnnKip 08 Haziran 2026 11:46
Поздравляю, какие нужные слова..., отличная мысль Playing roulette not on gamstop, [url=https://ceremoniemeesterwen.be/2026/04/27/discover-the-best-roulette-sites-not-registered-3/]https://ceremoniemeesterwen.be/2026/04/27/discover-the-best-roulette-sites-not-registered-3/[/url] offers an exciting opportunity for enthusiasts. You can experience the thrill of spinning the wheel without restrictions. Many participants seek alternatives to traditional platforms. With various choices, finding a suitable venue is effortless. roulette not on gamstop can enhance your gaming experience and provide an opportunity to enjoy this classic game with new environments and rules. Always ensure you play responsibly while exploring those exciting avenues.
AustinOrafe 08 Haziran 2026 11:29
На мой взгляд, это актуально, буду принимать участие в обсуждении. Вместе мы сможем прийти к правильному ответу. Si buscas los Гіptimos casinos online, debes considerar varias cualidades. Entre ellas, la protecciГіn en los pagos y la gama de juegos disponibles. Mejores Casinos Online, [url=https://blackwatercivil.com/los-mejores-casinos-online-para-jugar-y-ganar-5/]https://blackwatercivil.com/los-mejores-casinos-online-para-jugar-y-ganar-5/[/url] realmente ofrecen una oportunidad inigualable para los jugadores. No olvides leer las reseГ±as y comparar las promociones.
FrancowaK 08 Haziran 2026 11:18
Идеальный ответ Non UKGC Casinos, [url=https://pms.com.lb/?p=117243]https://pms.com.lb/?p=117243[/url] offer an alternative choice for gamers looking for innovation. Players can explore a broad selection games while avoiding regulations. These casinos often feature exciting rewards that enhance the gaming experience.
Courtneyboona 08 Haziran 2026 08:30
Я хорошо разбираюсь в этом. Могу помочь в решении вопроса. Att spela pГҐ nГ¤tet Г¤r populГ¤rt, men det Г¤r viktigt att vГ¤lja rГ¤tt plattform. minsta insГ¤ttning casino, [url=https://www.erinnerungen-an-christian-graf.at/2026/05/24/casino-med-lg-insattning-spela-smart-och-spara-5/]https://www.erinnerungen-an-christian-graf.at/2026/05/24/casino-med-lg-insattning-spela-smart-och-spara-5/[/url] Г¤r en faktor som pГҐverkar valet. Du vill ha ett erbjudande som inverterar en enkel start. JГ¤mfГ¶r mГ¶jligheter fГ¶r att hitta det bГ¤sta.
Ianmog 08 Haziran 2026 08:15
I en verden af sjov står Casino and Friends official, [url=https://www.indiawala.co.in/2026/05/30/casino-and-friends-official-2026-en-ny-aera-for-online-spil-2011986796/]https://www.indiawala.co.in/2026/05/30/casino-and-friends-official-2026-en-ny-aera-for-online-spil-2011986796/[/url] som et samlingspunkt for væddemål. Her kan spillere nyde top spiloplevelser og socialisere med andre spillere.
BeccaBus 08 Haziran 2026 08:14
Online Casino, [url=https://nypdcrimestoppers1.com/betgem-casino-review-2026-the-ultimate-gaming/]https://nypdcrimestoppers1.com/betgem-casino-review-2026-the-ultimate-gaming/[/url] provides a diverse variety of games that engage players worldwide. Through technology, exciting experiences await. Get involved today and discover your favorite games!
AdelaidaInesk 08 Haziran 2026 07:10
Авторитетное сообщение :) Парфюмерия оптом, [url=https://home-parfum.ru/catalog/jean-paul-gaultier_2/]https://home-parfum.ru/catalog/jean-paul-gaultier_2/[/url] - это отличный способ приобрести ароматы по выгодной цене. Ассортимент парфюмерии радует, и каждый сможет найти идеальный аромат. Фирмы предлагают разные ноты для каждого вкуса.
MiriamBok 08 Haziran 2026 06:37
Вы очевидно ошиблись Los casinos online para los Chile ofrecen emocionante experiencia de diversiГіn. Con una juegos y promociones, los Casinos Online Chile, [url=https://christinamcondreay.com/wp/casino-online-chile-las-mejores-plataformas-para-8/]https://christinamcondreay.com/wp/casino-online-chile-las-mejores-plataformas-para-8/[/url] convencen a usuarios de diferentes tipos.
Sherryroums 08 Haziran 2026 05:01
Casinos Not on Gamstop UK, [url=https://landdesignmn.com/explore-non-gamstop-uk-casinos-a-guide-to/]https://landdesignmn.com/explore-non-gamstop-uk-casinos-a-guide-to/[/url] offer players a unique experience. Such types of casinos provide various games and great bonuses, permitting players to enjoy wagering with less restrictions. With a vast selection of alternatives, players can find an exciting setting free from Gamstop.
Tracydib 08 Haziran 2026 03:40
I besidder en vild tid med kompiser, og den endnu mere med Casino and Friends official, [url=http://en.cosmoeng21.com/casino-og-venner-oplev-den-bedste-spilunderholdning/]http://en.cosmoeng21.com/casino-og-venner-oplev-den-bedste-spilunderholdning/[/url]. For stort set alle, der elsker lege, er det et sted, hvor man kan nyde uforglemmelige affærer.
JerryNaday 08 Haziran 2026 03:40
Online casinos have gained immense popularity in recent years. Players can enjoy their favorite games from the convenience of home. With Casino Online, [url=http://journal.hotelambrose.ca/2026/05/20/experience-the-thrill-of-online-gaming-at-7bets-2/]http://journal.hotelambrose.ca/2026/05/20/experience-the-thrill-of-online-gaming-at-7bets-2/[/url], thrilling options are just a click away, providing endless enjoyment and opportunities to win big!
Lauraliz 08 Haziran 2026 02:05
Вы топик читали? Русско-французский словарь, [url=https://frenchspeak.ru/]https://frenchspeak.ru/[/url] — это полезный инструмент для обучения французского языка. Он помогает переводить выражения и правильные значения.
Nicoledrord 08 Haziran 2026 00:25
Discovering virtual betting can be exciting. For players seeking variety, Casino Sites Not on Gamstop, [url=http://training.insurancesplash.com/explore-the-best-casinos-not-on-gamstop-1241665776/]http://training.insurancesplash.com/explore-the-best-casinos-not-on-gamstop-1241665776/[/url] offer unique experiences. These platforms permit users to enjoy their favorite games without barriers. Choose wisely and explore the vast selections available to enhance your gaming journey.
BrandonUrink 08 Haziran 2026 00:07
Der findes mange digitale casinoer uden MitID, [url=https://www.museodelbrunello.it/odds-uden-om-rufus-en-guide-til-alternativer-i/]https://www.museodelbrunello.it/odds-uden-om-rufus-en-guide-til-alternativer-i/[/url], hvor brugere kan deltage uden kompleks registrering. Det muliggør en hurtig tilgang til gambling. Vælg ud af mange variationer for at nyde en interessant aften.
Tracynus 07 Haziran 2026 23:49
Сожалею, что не могу сейчас поучаствовать в обсуждении. Не владею нужной информацией. Но эта тема меня очень интересует. Finding the best live roulette sites, [url=https://cursos.institutofernandabenead.com.br/discover-the-best-live-roulette-a-comprehensive/]https://cursos.institutofernandabenead.com.br/discover-the-best-live-roulette-a-comprehensive/[/url] requires some research. These platforms offer exciting gameplay. Players should consider customer support to enhance their experience. Don’t forget to check out the best live roulette sites for the ultimate gaming enjoyment!
VanessaLox 07 Haziran 2026 23:05
Downloading a casino app is exciting. With a simple Casino App Download, [url=http://ncpotteryblog.com/?p=586971]http://ncpotteryblog.com/?p=586971[/url], players can enjoy countless games at their fingertips. If you fancy slots or table games, the experience is effortless. Don't miss out on unique bonuses available through apps!
Pamelaslock 07 Haziran 2026 21:19
Замечательно, весьма ценная мысль Почтовые индексы России, [url=https://pochtaops.ru/]https://pochtaops.ru/[/url] это важный элемент почтовой системы. Каждый индекс способствует быструю и эффективную доставку корреспонденции. Определение индекса позволяет нахождение нужного адреса.
GeorgeVet 07 Haziran 2026 21:00
Это уже далеко не исключение non UKGC casinos, [url=https://iplusstd.com/item/eventBookingPro/admin/2026/05/22/top-non-ukgc-sites-to-explore-in-2026/]https://iplusstd.com/item/eventBookingPro/admin/2026/05/22/top-non-ukgc-sites-to-explore-in-2026/[/url] provide unique wagering experiences for players. These types of platforms usually feature multiple games and rewarding bonuses. Gamblers enjoy more freedom and options when choosing their preferred sites.
Teresacrymn 07 Haziran 2026 20:40
Huifkfdfuubab Iifoedkybab
Johnfum 07 Haziran 2026 20:37
неплохо en iyi slot oyun siteleri, [url=https://www.shocoh.co.jp/174823/]https://www.shocoh.co.jp/174823/[/url], oyunculara farklД± deneyimler sunar. Bu tip sitelerde Г§eЕџitli oyun seГ§enekleri mevcuttur. Uygun platformlar, avantaj fД±rsatlarД± ile oyuncularД± ikna ediyor.
JayBrept 07 Haziran 2026 19:59
Many sports enthusiasts are seeking options for betting. SportsBooks Not on Gamstop, [url=https://kelseyjphotos.com/top-bookies-not-on-gamstop-in-the-uk/]https://kelseyjphotos.com/top-bookies-not-on-gamstop-in-the-uk/[/url] provide a superb way to enjoy your favorite games without restrictions. Explore various platforms to find unique offerings and promotions that suit your needs!
MaryJaido 07 Haziran 2026 18:47
Blox Game Casino, [url=https://www.navigazioneetrasporti.it/2026/05/30/blox-game-official-2026-en-revolution-inden-for-online-spil/]https://www.navigazioneetrasporti.it/2026/05/30/blox-game-official-2026-en-revolution-inden-for-online-spil/[/url] tilbyder en spændende chancer for spillere. Her kan du deltage med varierede spil. Hos Blox Game Casino finder du attraktive bonusser og kampagner, der gør oplevelsen mere interessant.
Elizabethdek 07 Haziran 2026 18:47
Discover the fun of online gaming at Casino Website, [url=https://www.pavanellogiorgio.it/2026/05/21/experience-the-thrill-of-gaming-at-21bets-casino-4/]https://www.pavanellogiorgio.it/2026/05/21/experience-the-thrill-of-gaming-at-21bets-casino-4/[/url]. With a variety of games, players can enjoy the greatest chances to win big! Join now and start playing!
Patriciaboics 07 Haziran 2026 16:49
Могу предложить Вам посетить сайт, на котором есть много статей на интересующую Вас тему. Discover the excitement of enjoying spaceman game online, [url=https://spacemancrash.com/demo-spaceman]space man crash[/url], where gamers can navigate the galaxy and challenge your skills. Join other players and begin a captivating adventure!
SteveBom 07 Haziran 2026 15:52
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Пишите мне в PM. Facebook Account Farming, [url=http://dev.storm-hold.com/uncategorized/dolphin-anty-streamlined-facebook-registration-for-enhanced-security/]http://dev.storm-hold.com/uncategorized/dolphin-anty-streamlined-facebook-registration-for-enhanced-security/[/url] is a process multiple accounts to exploit features. Such practices are often employed for games, raising concerns about trustworthiness. Users must stay aware when engaging in Facebook Account Farming.
Annafub 07 Haziran 2026 15:34
Casinos Not on Gamstop, [url=http://podolog.webk.eu/discovering-non-gamstop-casino-sites-a-guide-for/]http://podolog.webk.eu/discovering-non-gamstop-casino-sites-a-guide-for/[/url] offer a unique gambling experience for players seeking freedom. These establishments present an alternative to self-exclusion programs. Many enthusiasts enjoy the selection of games available, from slots to table games. With Casinos Not on Gamstop, users can find exciting options in a secure environment. Remember to always gamble responsibly!
Jaredroode 07 Haziran 2026 14:01
Blox Game Casino, [url=https://www.emagidlondon.com/uncategorized/oplev-verdenen-af-blox-game-official-2067740750/]https://www.emagidlondon.com/uncategorized/oplev-verdenen-af-blox-game-official-2067740750/[/url] erbyder er en populær platform for væddemål. Her kan gamblere prøve forskellige spil og få store udbetalinger.
Joshageva 07 Haziran 2026 14:01
Virtual gaming становится все более популярным. Множество платформ предлагает крутые бонусы и разнообразные игры. Casino Online, [url=https://ibarraproperty.com/20bet-casino-review-2026-unveiling-the-future-of/]https://ibarraproperty.com/20bet-casino-review-2026-unveiling-the-future-of/[/url] привлекает огромное количество пользователей со всего мира. Не упустите шанс испытать удачу!
TinaHah 07 Haziran 2026 10:47
In recent years, the rise of online betting has resulted in interest in alternatives like Bookies Not on Gamstop, [url=https://dontfuckwithus.de/2026/05/27/exploring-sports-betting-sites-not-on-gamstop-18/]https://dontfuckwithus.de/2026/05/27/exploring-sports-betting-sites-not-on-gamstop-18/[/url]. These platforms offer choices for gamblers looking for ways to stake. However, users should consider risks associated with unregulated sites. Choosing reliable bookmakers ensures safer gambling experiences while exploring these options.
Seansnino 07 Haziran 2026 10:47
In the world of online gaming, gamers often seek exciting experiences. non GamStop casino, [url=https://brief.alaskawebgeeks.com/discover-casinos-not-on-gamstop-a-comprehensive/]https://brief.alaskawebgeeks.com/discover-casinos-not-on-gamstop-a-comprehensive/[/url] offers a refreshing choice for those looking to enjoy diverse games without pesky restrictions. These platforms provide an extensive selection of gaming options, ensuring players finds something fitting. With exciting bonuses and promotions, non GamStop casino creates a unique environment for betting.
TraceyHub 07 Haziran 2026 10:25
бутар, сказка для дитей........... When planning your adventure, don't overlook the necessity of sports travel insurance, [url=http://store.manuelvazquezonline.com/index.php/2026/06/02/ultimate-guide-to-cycling-travel-insurance/]http://store.manuelvazquezonline.com/index.php/2026/06/02/ultimate-guide-to-cycling-travel-insurance/[/url]. It provides needed support for injuries while you're engaged in your favorite sports.
WendyCouch 07 Haziran 2026 06:39
Choosing a online casino not on GamStop can offer players flexibility. These platforms grant access to a wider range of games and promotions. Players can enjoy captivating experiences without restrictions, making it a tempting option for those looking to game more freely. Be sure to research each site carefully to ensure a safe and enjoyable gaming experience. Remember, casino not on GamStop, [url=https://vapeshelf.uk/exploring-casinos-not-on-gamstop-your-guide-to-4/]https://vapeshelf.uk/exploring-casinos-not-on-gamstop-your-guide-to-4/[/url] provides the chance for endless gaming.
Tracylof 07 Haziran 2026 06:38
Casinos Not on Gamstop, [url=https://sarkarijobhit.com/uk-online-casinos-not-on-gamstop-your-guide-to/]https://sarkarijobhit.com/uk-online-casinos-not-on-gamstop-your-guide-to/[/url] offer players a unique opportunity to enjoy gaming without restrictions. These casinos facilitate access to a suite of games. Players can experience exciting options while enjoying attractive bonuses.
Tammyleape 07 Haziran 2026 05:30
Amid the growing field of online gambling, no gamstop casinos uk, [url=https://job.nordeks.lv/?p=457305]https://job.nordeks.lv/?p=457305[/url] offer a chance for players to delight in their favorite games without the restrictions of self-exclusion. These types of platforms facilitate users to bet freely while guaranteeing a reliable environment. Make sure to familiarize yourself with the guidelines to ensure a smooth experience.
MadelineToota 07 Haziran 2026 05:30
bet25 official, [url=https://hotelroyalgrand.org/2026/05/30/bet-25-official-2026-din-ultimative-guide-til-betting/]https://hotelroyalgrand.org/2026/05/30/bet-25-official-2026-din-ultimative-guide-til-betting/[/url] tilbyder en unik platform for sportsvæddemål, hvor spillere kan udnytte et bredt udvalg af chancer. Med brugervenlige funktioner er det nemt at navigere. Tjek bet25 official for de mest lønsomme odds.
Irispeera 07 Haziran 2026 05:18
Буду знать, благодарю за информацию. live casinos not on gamstop, [url=http://www.davidrice.com/2026/04/discovering-the-best-live-casinos-not-on-banned/]http://www.davidrice.com/2026/04/discovering-the-best-live-casinos-not-on-banned/[/url] offer players an exciting opportunity to enjoy their favorite games without restrictions. Such sites provide a engaging experience with professional hosts and a diverse selection of games. Players can take part in interactive gaming sessions from the comfort of their homes, making it a hassle-free choice for everyone.
Yolandatrova 07 Haziran 2026 04:39
Я думаю это уже обсуждалось. Online gambling has exploded in popularity, particularly with players seeking casinos not on GamStop, [url=https://stud-art.com/exploring-gambling-sites-that-are-not-registered/]https://stud-art.com/exploring-gambling-sites-that-are-not-registered/[/url]. These platforms offer an extensive selection of games and beneficial bonuses that keep players interested. Many prefer these sites for freedom in their gaming experience.
Danielsah 07 Haziran 2026 02:28
In the world of betting, plenty players seek alternatives to traditional platforms. Bookies Not on Gamstop, [url=http://african-image.co.za/understanding-uk-sports-betting-sites-what-to/]http://african-image.co.za/understanding-uk-sports-betting-sites-what-to/[/url] provide a choice for those who want autonomy in their gambling experience. These bookies present diverse markets and thrilling opportunities. Choosing such a platform can lead to improved betting options and special promotions. Always remember to gamble responsibly and think about your options carefully.
Jacklelay 07 Haziran 2026 01:30
Какая трогательные фраза :) In the world of gaming, casino, [url=https://okularnik.eu/comprehensive-guide-to-travel-insurance-for-digital-nomads/]https://okularnik.eu/comprehensive-guide-to-travel-insurance-for-digital-nomads/[/url] offers an exhilarating experience. Players can attempt their luck on various games. The thrill of scoring keeps players coming back for more excitement and entertainment.
Sophiavit 07 Haziran 2026 00:03
editörbet bet, [url=https://mariyamstylin.com/blog/2026/05/05/tarabet-slot-oyunlar-en/]https://mariyamstylin.com/blog/2026/05/05/tarabet-slot-oyunlar-en/[/url], online bahis dünyasında öne çıkıyor. Kullanıcı dostu platformu ile pratiklik sağlıyor. Ayrıca, emniyetli ödeme yöntemleriyle anında işlem yapma imkanı sunuyor. yardım hattı de 7/24 hizmet veriyor.
Robertdrity 06 Haziran 2026 23:14
Я считаю, что Вы не правы. Я уверен. Давайте обсудим это. Пишите мне в PM, пообщаемся. Playing at web-based casinos not on GamStop, [url=http://www.shitara-trail.jp/%e6%9c%aa%e5%88%86%e9%a1%9e/183418.html]http://www.shitara-trail.jp/%e6%9c%aa%e5%88%86%e9%a1%9e/183418.html[/url] offers special experiences for players seeking freedom. These platforms allow boundless access, catering to multiple preferences. Explore games, rewards and promotions tailored just for you. Enjoy your wagering adventure without the limitations imposed by self-exclusion. Join the fun today with casinos not on GamStop!
RosemaryMag 06 Haziran 2026 22:36
такова жизнь у других людей изделия из натуральной кожи, [url=http://роялиндиго.рф/]http://роялиндиго.рф/[/url] это просто стильные предметы для буднего использования. Надежность кожи обеспечивает продолжительное использование и отличный внешний вид.
MattDed 06 Haziran 2026 22:19
Casinos UK Not on Gamstop, [url=http://www.d1048604-5.blacknight.com/exploring-uk-non-gamstop-casinos-a-complete-guide-2/]http://www.d1048604-5.blacknight.com/exploring-uk-non-gamstop-casinos-a-complete-guide-2/[/url] offer players a unique gaming experience. These kinds of casinos present an opportunity for individuals looking to enjoy online gaming without Gamstop restrictions. People can experience a wide range of games and deals that attract their individual needs. Exploring these options can bring about thrilling joy and promising wins.
Anthonyheiny 06 Haziran 2026 22:19
non GamStop casino UK, [url=https://therecruitersloungeco.com/exploring-online-casinos-outside-gamstop-a-guide/]https://therecruitersloungeco.com/exploring-online-casinos-outside-gamstop-a-guide/[/url] offers players an opportunity to enjoy gaming without restrictions. These establishments provide various gambling choices for everyone. Participate instantly and experience excitement like never before!
Brucemor 06 Haziran 2026 21:13
onlinecasino for danske spillere, [url=https://cdd.puntocomm.com.br/noticias/bet-25-2026-registrering-og-bonus/]https://cdd.puntocomm.com.br/noticias/bet-25-2026-registrering-og-bonus/[/url] tilbyder spændende muligheder for sjov. Spillere kan finde flere typer af spil, der fanger enhver smag.
Patriciatus 06 Haziran 2026 18:27
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Давайте обсудим это. Пишите мне в PM, поговорим. In the world of gaming, finding the best places to play can be a challenge. However, the top online casinos, [url=https://heni.co.in/exploring-the-world-of-online-casinos-a-4/]https://heni.co.in/exploring-the-world-of-online-casinos-a-4/[/url] offer entertaining games and massive jackpots. Players can enjoy flexibility while playing from home.
Claybrams 06 Haziran 2026 18:09
In the world of online gaming, the popularity of non GamStop casino UK, [url=https://sivamansion.com/2026/05/27/exploring-gambling-sites-not-linked-to-gamstop-4/]https://sivamansion.com/2026/05/27/exploring-gambling-sites-not-linked-to-gamstop-4/[/url] is rising rapidly. Players seek variety and autonomy while enjoying their favorite games. Non GamStop casinos offer thrilling experiences without restrictions, making them enticing for many gamers.
Dianasuina 06 Haziran 2026 17:06
О¤О± ОѕООЅО± online ОєО±О¶ОЇОЅОї, [url=https://eccolombia.com/2026/05/31/page-157/]https://eccolombia.com/2026/05/31/page-157/[/url] ПЂПЃОїПѓП†ОПЃОїП…ОЅ ООЅО±ОЅ ОµОјПЂОµО№ПЃОЇО± ПЂО±О№П‡ОЅО№ОґО№ОїПЌ, ОµОѕО±О№П„ОЇО±П‚ ПѓП„О·ОЅ ПЂОїО№ОєО№О»ОЇО± ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ ПЂОїП… ОґО№О±ОёОП„ОїП…ОЅ. ОџО№ ОµПЂО±ОіОіОµО»ОјО±П„ОЇОµП‚ ОјПЂОїПЃОїПЌОЅ ОЅО± ОґО№О±О»ООѕОїП…ОЅ ПѓП…ОЅО±ПЃПЂО±ПѓП„О№ОєОП‚ ОµПЂО№О»ОїОіОП‚ ОіО№О± ОєО±ОёООЅО± ОіОїПЌПѓП„Ої ОєО±О№ ПЂПЃОїП„ОЇОјО·ПѓО·.
KatiePoita 06 Haziran 2026 16:14
Всё выше сказанное правда. Давайте обсудим этот вопрос. casino indir, [url=https://dm-realestate.com/seo-le-gaming-sektorunde-baar-elde-etme-yontemleri/]https://dm-realestate.com/seo-le-gaming-sektorunde-baar-elde-etme-yontemleri/[/url], oyunculara birГ§ok fД±rsat sunan online oyun platformlarД±dД±r. Bu siteler, ilginГ§ promosyonlar ile dikkat Г§eker. HД±zlД± arayГјzleri sayesinde, Еџans oyunlarД± oynamak son derece kolay hale gelir.
Cristinainisp 06 Haziran 2026 13:44
ОТПАДДДДДД онлайн casino, [url=http://memoriestearooms.co.uk/forum/blog/view/45782/more-on-making-a-living-off-of-volta777org]memoriestearooms.co.uk[/url] предлагает привлекательные возможности для заработка. Г Gamblers могут наслаждаться разнообразными играми и шансами на прибыль. Получите возможность испытать удачу прямо из удобного дома.
BrittanyDealt 06 Haziran 2026 13:40
Selecting the right betting platform is crucial, especially when considering Bookies Not on Gamstop, [url=http://www.naamimmigration.ca/exploring-sports-betting-sites-not-on-popular/]http://www.naamimmigration.ca/exploring-sports-betting-sites-not-on-popular/[/url]. Those bookmakers offer more extensive options in players seeking different experiences. With these platforms, bettors can enjoy a less restricted betting experience free from the constraints of Gamstop.
BryanSob 06 Haziran 2026 13:32
Kod promocyjny darmowy zaklad Mostbet to idealne rozwiazanie dla fanow sportu. Po zalozeniu konta i wpisaniu QWERTY555, uzytkownik otrzymuje freebet do wykorzystania. Kod promocyjny Mostbet Sports obejmuje pilke nozna, tenis oraz zaklady na zywo. Bonus powitalny zwieksza szanse na wygrana bez inwestowania duzych srodkow. To bezpieczny start dla poczatkujacych graczy. Zobacz co nowego w Mostbet teraz <a href=http://miejskagorka.archpoznan.pl/media/pgs/?mostbet_kod_promocyjny_polska___bonus.html>https://bip.noipip.iap.pl/mfiles/pgs/?mostbet_kod_promocyjny_bonus_bez_depozytu.html</a>
DianaFroto 06 Haziran 2026 12:30
Авторитетный ответ Internet gaming has gained popularity, especially with real money casinos, [url=https://calidad.com.mx/wp/2026/04/22/unlock-exciting-wins-with-free-welcome-bonuses-and/]https://calidad.com.mx/wp/2026/04/22/unlock-exciting-wins-with-free-welcome-bonuses-and/[/url]. Players are attracted by the chance to win big. These platforms offer captivating games and lucrative bonuses, enhancing the overall experience.
EsterGliva 06 Haziran 2026 09:24
Убойный ссылки!!!!!!!!!!! Спасибо!!!!! uspin casino, [url=https://u-spin.bet/]uspin casino[/url] предоставляет завсегдатаям неповторимый опыт СЃ многообразными автоматами. Занимаясь РІ РјРёСЂ игровых РґРѕСЃСѓРіР°, каждый участник найдет что-то РїРѕ душе.
Ruthgox 06 Haziran 2026 07:42
Браво, это просто великолепная мысль trgovina s pohiЕЎtvom, [url=https://graumaq.es/producto/armario-de-seguridad-con-puerta-corredera/]https://graumaq.es/producto/armario-de-seguridad-con-puerta-corredera/[/url] - Currently, a furnishing shop offers a variety of styles and designs. Choosing the right furniture can alter your home. Durability matters, so spend time in locating pieces that reflect your taste.
Keriwep 06 Haziran 2026 07:00
editörbet bet, [url=https://demo1.5usujian.com/archives/38198]https://demo1.5usujian.com/archives/38198[/url], emanet bir oyun platformudur. Müşteriler burada çeşitli oyun seçenekleriyle keyifli vakit geçirebilir. Anında para çekme işlemleri ile tatmin kalacaksınız. Editörbet bet, profesyonel yardım ekibiyle her zaman hizmetinizdedir.
ScottHow 06 Haziran 2026 05:07
Согласен, весьма полезная мысль Bij get lucky casino, [url=https://getluckycasinos.nl/]get lucky casino nl[/url] beleef de spanning van het prachtige gokken! Met verschillende spellen en aantrekkelijk bonussen is iedereen die wil aangesproken.
MattEmite 06 Haziran 2026 05:07
non GamStop UK casinos, [url=https://clearinghouseaccucheck.com/discover-the-best-casinos-not-on-gamstop-for/]https://clearinghouseaccucheck.com/discover-the-best-casinos-not-on-gamstop-for/[/url] offer players a unique opportunity to enjoy their favorite games without the limitations of self-exclusion. These platforms provide engaging experiences, wide game selections, and rewarding bonuses. Players can quickly register and start playing, enjoying top-notch gaming from the comfort of their own homes. Non GamStop UK casinos guarantee a safe environment for online gambling.
AngelinaSap 06 Haziran 2026 04:06
П„О± ОєО±О»П…П„ОµПЃО± online casino, [url=http://inplaygaming.co.uk/1161978980-2/]http://inplaygaming.co.uk/1161978980-2/[/url] ПЂПЃОїПѓП†ОПЃОїП…ОЅ ОјОїОЅО±ОґО№ОєОП‚ ОµОјПЂОµО№ПЃОЇОµП‚ ПѓП„Ої ПЂО±О№П‡ОЅОЇОґО№. О‘П…П„О¬ ПЂО±ПЃОП‡ОїП…ОЅ ПЂОїО№ОєО№О»ОЇО± ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ ПЂОїП… ОєО±О»ПЌПЂП„ОїП…ОЅ П„О№П‚ ПЂПЃОїП„О№ОјО®ПѓОµО№П‚. О•ОЇОЅО±О№ ОґП…ОЅО±П„ПЊОЅ ОЅО± ОІПЃОµОЇП„Оµ ОјО±ОіОµП…П„О№ОєО¬ ОјПЂПЊОЅОїП…П‚ ОєО±О№ ПЂПЃОїПѓП†ОїПЃОП‚. О— ОµОіОіПЌО·ПѓО· О±ПЂОїП„ОµО»ОµОЇ ПЂПЃОїП„ОµПЃО±О№ПЊП„О·П„О± ОіО№О± О±П…П„О¬ П„О± ОєО±О¶ОЇОЅОї. О ОµО№ПЃО±ОјО±П„О№ПѓП„ОµОЇП„Оµ П„О·ОЅ ОµОјПЂОµО№ПЃОЇО± П„ОїП… online gambling ПѓО®ОјОµПЃО±!
AdrianDab 06 Haziran 2026 01:39
editörbet apk, [url=https://tektonbuildinggroup.com.au/beygirbet-free-spin-ucretsiz-cevirim-mkanlar-ile/]https://tektonbuildinggroup.com.au/beygirbet-free-spin-ucretsiz-cevirim-mkanlar-ile/[/url], kolay erişim fırsatı sunar. Üyeler için şık özellikler içeren aksesuar bir platformdur. Yüksek kazançlar sağlayacak fırsatlar sunar. Bu program, temiz ve hızlı bir deneyim için tasarlanmıştır.
Sabrinagob 06 Haziran 2026 01:09
In recent years, the demand for non GamStop UK casinos, [url=http://www.davidrice.com/2026/05/respected-casinos-not-on-gamstop-your-guide-to-5/]http://www.davidrice.com/2026/05/respected-casinos-not-on-gamstop-your-guide-to-5/[/url] has surged. Participants are looking for platforms that offer more freedom. Through these casinos, they can enjoy a wider variety of games and bonuses.
Michelleagord 06 Haziran 2026 00:54
ммм Точно. Discover the thrill of top non GamStop casino, [url=https://tejas-apartment.teson.xyz/gambling-sites-not-blocked-your-guide-to-2/]https://tejas-apartment.teson.xyz/gambling-sites-not-blocked-your-guide-to-2/[/url], where players enjoy unparalleled gaming experiences. These platforms offer engaging options without restrictions. You can opt for from a broad range of games and benefit from generous promotions!
Aaroninsub 06 Haziran 2026 00:04
Casino sider uden ROFUS, [url=https://geominiads.com/spndende-online-casino-uden-nemid/]https://geominiads.com/spndende-online-casino-uden-nemid/[/url] tilbyder spillere en chance for at nyde fantastiske spiloplevelser uten nogen begrænsninger. Disse sider indsætter en atmosfære af frihed og spænding, hvor man kan spille i sine yndlingsspil. Mens man finder nye eventyr, er Casino sider uden ROFUS et optimalt valg for dem, der ønsker en ubegribelig spilleoplevelse.
Bendat 05 Haziran 2026 23:58
Прошу прощения, что вмешался... Я разбираюсь в этом вопросе. Давайте обсудим. Пишите здесь или в PM. mostbet casino, [url=https://1x-bet-online.com.mx/]codigo promocional 1xbet[/url] представляет замечательный выбор ставок. Каждая обладает уникальными черточками, поскольку создает развлечение более интересным. Погрузитесь РІ РјРёСЂ СЃ mostbet casino Рё наслаждайтесь!
Tiffanyinalt 05 Haziran 2026 22:17
По моему мнению Вы не правы. Я уверен. Могу это доказать. Пишите мне в PM, поговорим. Descubre la diversiГіn de 1win casino, [url=https://betsson-online.com.mx/]bono betsson[/url], donde la suerte se intersectan para ofrecer momentos Гєnicas. Juega una diversa gama de entretenimiento y aprovecha bonos irresistibles. 1win casino es tu lugar preferido para apostar.
Kimionit 05 Haziran 2026 20:24
editörbet casino, [url=https://newpagina.cecasa.com.mx/index.php/24-destek-sunan-siteler-en-yi-casinolarnz-burada/]https://newpagina.cecasa.com.mx/index.php/24-destek-sunan-siteler-en-yi-casinolarnz-burada/[/url] Türkiye'nin en popüler online casino sitelerinden biridir. Oyuncular burada çeşitli oyun imkanlarına erişim temin ederek, keyifli vakit geçirebilir. Ayrıca, editörbet casino risk yönetimi bir durum sunarak, ziyaretçilerin rahatça oyun tecrübe etmesini öneriyor.
JohnEdida 05 Haziran 2026 18:40
Идея хорошая, поддерживаю. online casinos, [url=https://iceprintanddesign.co.uk/installable-google-web-fonts-easily-configure-font-size-using-theme-admin/]https://iceprintanddesign.co.uk/installable-google-web-fonts-easily-configure-font-size-using-theme-admin/[/url] present an exciting approach to enjoy betting from the comfort of your home. With multiple games available, they attract enthusiasts looking for thrills.
CynthiaNiT 05 Haziran 2026 16:04
Casinoer uden dansk licens, [url=https://nhasach.nhathothaiha.net/2026/05/22/yatzy-spil-online-for-danske-spil-strategi-og/]https://nhasach.nhathothaiha.net/2026/05/22/yatzy-spil-online-for-danske-spil-strategi-og/[/url] tilbyder en omfattende palette af underholdningsformer. Kunder kan udforske de mest underholdende spillemaskiner. Da disse casinoer ikke er overvГҐget af danske myndigheder, kan de normalt interessante bonusser.
FredGuave 05 Haziran 2026 16:04
П„О± ОєО±О»П…П„ОµПЃО± online casino, [url=https://kteixeira.adv.br/?p=254673]https://kteixeira.adv.br/?p=254673[/url] ПЂО±ПЃОП‡ОїП…ОЅ ОјОЇО± ОµОјПЂОµО№ПЃОЇО± ПЂО±О№П‡ОЅО№ОґО№ОїПЌ. О¤О± ПЂО»О±П„П†ПЊПЃОјОµП‚ ПЂПЃОїП„ОµОЇОЅОїП…ОЅ ПЂОїО№ОєО№О»ОЇО± ОµПЂО№О»ОїОіОП‚ ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ ОєО±О№ ОјОµОіО¬О»ОµП‚ О±ПЂОїОґПЊПѓОµО№П‚. О‘ОѕО№ОїПѓО·ОјОµОЇП‰П„Ої ОЅО± ОµОѕОµП„О¬О¶ОїП…ОјОµ ОєО±О»ПЌП„ОµПЃОµП‚ О№ПѓП„ОїПѓОµО»ОЇОґОµП‚ ОіО№О± ООЅО±ОЅ О±ПЂОЇОёО±ОЅО· ОµОјПЂОµО№ПЃОЇО±.
Natalyseege 05 Haziran 2026 14:55
Извините пожалуйста, что я Вас прерываю. 1xbet สำหรับผู้เล่นชาวไทย, [url=https://ivebo.co.uk/post/568151_1xbet-%E0%B9%83%E0%B8%99%E0%B8%9B%E0%B8%A3%E0%B8%B0%E0%B9%80%E0%B8%97%E0%B8%A8%E0%B9%84%E0%B8%97%E0%B8%A2%E0%B9%80%E0%B8%9B-%E0%B8%99%E0%B9%81%E0%B8%9E%E0%B8%A5%E0%B8%95%E0%B8%9F%E0%B8%AD%E0%B8%A3-%E0%B8%A1%E0%B8%97-%E0%B9%83%E0%B8%AB-%E0%B8%9A%E0%B8%A3-%E0%B8%81%E0%B8%B2%E0%B8%A3%E0%B8%81%E0%B8%B2%E0%B8%A3%E0%B9%80%E0%B8%94-%E0%B8%A1%E0%B8%9E-%E0%B8%99%E0%B9%81%E0%B8%A5%E0%B8%B0%E0%B9%80%E0%B8%81%E0%B8%A1%E0%B8%84%E0%B8%B2%E0%B8%AA-%E0%B9%82%E0%B8%99-%E0%B8%AA-%E0%B8%A7%E0%B8%99%E0%B8%81-%E0%B8%AC%E0%B8%B2%E0%B8%88%E0%B8%B0%E0%B8%A1-%E0%B8%81%E0%B8%B2%E0%B8%A3%E0%B9%81.html]https://ivebo.co.uk/post/568151_1xbet-%E0%B9%83%E0%B8%99%E0%B8%9B%E0%B8%A
TinaAltef 05 Haziran 2026 14:29
НЕ ВЕРЬТЕ.НИЧЕГО БОМБОВОГО ТАМ НЕТ.ТАК СЕБЕ НА 3. roulette casinos, [url=https://romeeternal.com/2026/04/27/roulette-real-money-strategies-tips-and-insights/]https://romeeternal.com/2026/04/27/roulette-real-money-strategies-tips-and-insights/[/url] offer an entertaining environment for gamblers. The circular board creates excitement, as participants bet their money. The potential for gains makes each game unpredictable.
AnnBlafe 05 Haziran 2026 14:11
Замечательно, это весьма ценный ответ online casino, [url=https://www.surfbarsanfoca.it/2014/04/27/official-video/]https://www.surfbarsanfoca.it/2014/04/27/official-video/[/url] provides a unique way to have fun. With thrilling games, enthusiasts can test their skills while accruing real money rewards.
RadameKix 05 Haziran 2026 14:03
Охотно принимаю. In recent years, a variety of players have turned to UK non GamStop casinos, [url=https://catialanzoni.com.br/are-non-gamstop-casinos-safe-a-comprehensive-guide/]https://catialanzoni.com.br/are-non-gamstop-casinos-safe-a-comprehensive-guide/[/url] for a more liberal gaming experience. These establishments offer different features, guaranteeing excitement without the restrictions of GamStop. Choosing UK non GamStop casinos allows players to explore a wider range of entertainment and bonuses.
AnnUndob 05 Haziran 2026 12:14
всегда пжалста.... В вашем Магазин шерстяных вещей, [url=http://genius.stepp-up.com/?p=124064]http://genius.stepp-up.com/?p=124064[/url] предлагаются широкие изделия. Каждый вещь создан с профессионализмом и превосходным качеством. Наши клиенты снова и снова возвращаются за новыми покупками!
DanielNup 05 Haziran 2026 12:10
Claim your chance to win big with an working https://www.odcec.mi.it/home/2021/01/27/age.-ordinanza-del-sindaco-di-milano-del-23-gennaio-2021.-modifica-orari-di-apertura-al-pubblico. Explore hundreds of casino games and get free spins on registration.
BridgetMib 05 Haziran 2026 11:44
П„О± ОєО±О»П…П„ОµПЃО± online casino, [url=http://paintprotectorstore.com/online-444/]http://paintprotectorstore.com/online-444/[/url] ПЂПЃОїПѓП†ОПЃОїП…ОЅ ОјОїОЅО±ОґО№ОєОП‚ ПѓП„О№ОіОјОП‚ ОґО№О±ПѓОєООґО±ПѓО·П‚ ОєО±О№ ОєОПЃОґОїП…П‚. О¤О± П„О± ОєО±О¶ОЇОЅОї ОѕОµП‡П‰ПЃОЇО¶ОїП…ОЅ ОіО№О± П„О№П‚ ПЂОїО№ОєО№О»ОЇО± ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ ОєО±О№ П„О№П‚ ПЂПЃОїПѓП†ОїПЃОП‚ П„ОїП…П‚, ОµОѕО±ПѓП†О±О»ОЇО¶ОїОЅП„О±П‚ П‡О±ПЃО±ОєП„О·ПЃО№ПѓП„О№ОєО¬ ПЂО±О№П‡ОЅОЇОґО№О±. ОњО¬О»О№ПѓП„О±, О· ОєО±О»О® ОµОѕП…ПЂО·ПЃОП„О·ПѓО® П„ОїП…П‚ П…ПЂОїПѓП„О·ПЃОЇО¶ОµО№ П„О·ОЅ П„ОО»ОµО№О± ОµОјПЂОµО№ПЃОЇО± ОіО№О± П„ОїП…П‚ ПЂО±ОЇОєП„ОµП‚.
PaulWotte 05 Haziran 2026 10:57
Ждать, имхо In the field of Football Betting, [url=https://blog.cz.rhino3d.com/2011/12/fotky-videa-z-shape-to-fabrication-4.html?showComment=1776150429480#c8362369547880549296]https://blog.cz.rhino3d.com/2011/12/fotky-videa-z-shape-to-fabrication-4.html?showComment=1776150429480#c8362369547880549296[/url], approaches play a crucial role. Comprehending team forms and statistics is essential for placing informed bets. Consistently research before wagering to increase your chances of success.
ChrisMailt 05 Haziran 2026 10:16
gratis spins casino, [url=https://demo.simpkb.id/bonus-til-eksisterende-kunder-maksimer-dine/]https://demo.simpkb.id/bonus-til-eksisterende-kunder-maksimer-dine/[/url] er en fantastisk mulighed for spillere, der ønsker at få mest muligt ud af deres oplevelse. Du kan udnytte disse gratis spins, som ofte gives som belønning. Det er en overraskende måde at teste varierede spil, uden at risikere dine egne resources. Med gratis spins casino kan du også mødes med spændingen ved at vinde, samtidig med at du lærer spillets strukturer.
Oliviadrola 05 Haziran 2026 08:25
non GamStop UK casinos, [url=http://shop.westernboots.com.ua/?p=308188]http://shop.westernboots.com.ua/?p=308188[/url] offer a unique experience for players seeking freedom in online gaming. These casinos provide a diverse array of games and exciting promotions. Enjoy gambling without barriers and immerse yourself in exciting gameplay.
Mattcew 05 Haziran 2026 07:21
Online casino uden MitID, [url=https://fabbrofirenzeprontointervento.it/casino-uden-mitid-i-danmark-en-guide-til-spil-uden-6/]https://fabbrofirenzeprontointervento.it/casino-uden-mitid-i-danmark-en-guide-til-spil-uden-6/[/url] tilbyder en spændende muligheder for deltagere. Uden krav om MitID kan enhver nemt begynde at spille. Udforsk det perfekte gambling site for dig!
Saraped 05 Haziran 2026 04:49
kampagner casino, [url=http://carolkherlakian.com.br/alt-hvad-du-behver-at-vide-om-online-casino-2/]http://carolkherlakian.com.br/alt-hvad-du-behver-at-vide-om-online-casino-2/[/url] udbyder spændende muligheder for spillere. Via mange kampagnetilbud, kan spillere øget chancer. Uanset interessen, er der et tilbud for alle.
Rodriguezusami 04 Haziran 2026 23:47
wypЕ‚acalne kasyna, [url=https://imobiliariaguarujabrasil.com.br/as-melhores-casas-do-guaruja-a-venda-acima-de-800-mil-reais/]https://imobiliariaguarujabrasil.com.br/as-melhores-casas-do-guaruja-a-venda-acima-de-800-mil-reais/[/url] offer a thrilling experience for players seeking real rewards. Each game provides an opportunity to win big and enjoy the excitement of gambling. Selecting the right casino is essential for maximizing your chances of success. Always analyze multiple options and pick a place in which prioritizes fairness. Don't forget to check the payout rates since they determine your potential earnings.
Ericnop 04 Haziran 2026 23:09
Casino sider uden ROFUS, [url=https://vanisedainese.com.br/udenlandske-online-casino-uden-mitid-en-grundig/]https://vanisedainese.com.br/udenlandske-online-casino-uden-mitid-en-grundig/[/url] har vundet stor popularitet blandt spillere. Disse sider tilbyder lettere adgangsmuligheder til spil uden de besværlige regler, som ROFUS medfører. Eksklusive tilbageholdte spillere søger åbent underholdning, hvilket gør disse platforme interessante.
Rebeccapaype 04 Haziran 2026 22:21
non gamstop casinos, [url=https://bonco.com.sg/non-uk-gambling-offshore-comparison-a/]https://bonco.com.sg/non-uk-gambling-offshore-comparison-a/[/url] offer players a unique betting opportunity without the restrictions of traditional wagering websites. Players can enjoy a variety of games while exploring exciting bonuses. It's a great way to experience what online gambling has to offer.
Angelaton 04 Haziran 2026 21:34
ути-пути купить Готовую фирму, [url=https://www.ferramentapagnotta.it/chi-siamo/]https://www.ferramentapagnotta.it/chi-siamo/[/url] – это отличный способ начать собственный бизнес. Вы сможете получить готовую организацию с клиентской базой и репутацией. Это поможет сэкономить ваше время и усилия.
ElizabethThymn 04 Haziran 2026 21:08
Я извиняюсь, но, по-моему, Вы не правы. Пишите мне в PM, поговорим. casinos not on GamStop, [url=https://www.sorocaimports.com/discover-new-casino-sites-not-on-gamstop/]https://www.sorocaimports.com/discover-new-casino-sites-not-on-gamstop/[/url] offer a unique gaming experience for players seeking a broader variety of options. These online platforms grant a vast selection of entertainment that aren’t bound by UK regulations. Players can experience thrilling slots and captivating features. With attractive bonuses, casinos not on GamStop promise a rewarding gaming atmosphere. Choose a site that suits your style and tastes.
AshleyJeffFek 04 Haziran 2026 19:26
public holidays, [url=http://Fiancetank.net/nitro/doll/diary/nik.cgi?mode=res&ken=1097008634]http://Fiancetank.net/nitro/doll/diary/nik.cgi?mode=res&ken=1097008634[/url] represent special days when people recognize traditions and taking leave from work. Such days give a chance for communities to convene.
pocafer 04 Haziran 2026 19:11
Online casino uden MitID, [url=https://cornerstoneraleigh.org/2026/05/21/bedste-casinoer-uden-mitid-find-de-bedste-online/]https://cornerstoneraleigh.org/2026/05/21/bedste-casinoer-uden-mitid-find-de-bedste-online/[/url] har revolutioneret spillemarkedet. Forsøger det traditionelle tilgang, kan spillere opleve en site med hurtigere finansielle bevægelser. Dette muliggør en alternativ måde at spille på.
Brianevamb 04 Haziran 2026 16:59
1xbet casino online, [url=https://www.smartcom.vn/toeic-online/index.php/2026/05/10/experience-thrilling-gaming-at-1xbet-cambodia-12/]https://www.smartcom.vn/toeic-online/index.php/2026/05/10/experience-thrilling-gaming-at-1xbet-cambodia-12/[/url] обеспечивает игрокам широкий выбор развлечений. Выможете также необычные бонусы и предложения, что усиливает шансы на победу.
JohnPoice 04 Haziran 2026 10:39
1xbet online, [url=https://www.ameeralbaher.com/understanding-1xbet-cambodia-payments-your-guide-3/]https://www.ameeralbaher.com/understanding-1xbet-cambodia-payments-your-guide-3/[/url] представляет собой отличным удачным вариантом для почитателей ставок. Система пresents множество возможностей для участников. Стоит отметить, что на платформе легко выбирать интересные мероприятия и делать инвестиции.
Debraral 04 Haziran 2026 06:44
Браво, какие нужная фраза..., замечательная мысль зеркало 1хбет, [url=https://1xbet-el26z.cfd/]https://1xbet-el26z.cfd/[/url] — это альтернатива основного сайта, позволяющая обойти блокировки. Пользователи могут сделать ставки на любимые события без проблем, что делает комфорт.
Rikkidolla 04 Haziran 2026 03:54
To quickly download 1xbet, [url=https://magme.madeinitalyslc.it/2026/05/10/1xbet-v-shri-lanke-vse-chto-vam-nuzhno-znat-4/]https://magme.madeinitalyslc.it/2026/05/10/1xbet-v-shri-lanke-vse-chto-vam-nuzhno-znat-4/[/url], you need to follow a few simple steps. First, visit the certified website and locate the download section. Pick the compatible version for your device and tap the download button. Once the software finishes downloading, install it by following the setup instructions. After installation, you can utilize the various features that 1xbet offers.
Louisunins 04 Haziran 2026 02:14
Thanks. I like it. Wein Plaza - https://weinplaza.com/
ToniOvank 04 Haziran 2026 02:13
Вполне, да зеркало 1хбет, [url=https://1xbet-1q6ya.xyz/]1xbet-1q6ya.xyz[/url] позволяет пользователям обходить блокировки и получать доступ к любимым играм. Сталый доступ к платформе доступает возможность делать ставки в любое время суток. За счет удобного интерфейса пользователи могут легко найти интересные события.
BeatriceJeast 04 Haziran 2026 02:13
Жаль, что сейчас не могу высказаться - опаздываю на встречу. Освобожусь - обязательно выскажу своё мнение. 1xbet официальный сайт, [url=https://1xbet-tm2tm.blog/]1xbet-tm2tm.blog[/url] предлагает множество опций для геймеров и поклонников ставок. Здесь вы увидите интересные ставки и поощрения, которые украсит ваш опыт максимально.
MadelineTycle 03 Haziran 2026 21:50
Я Вам очень благодарен. Огромное спасибо. 1xbet официальный сайт, [url=https://1xbet-ig01c.sbs/]1xbet-ig01c.sbs[/url] предлагает широкий выбор ставок на события. Здесь вы найдете приятный дизайн, что делает процесс игры максимально комфортным.
JaredScown 03 Haziran 2026 21:48
В этом что-то есть. Раньше я думал иначе, спасибо за помощь в этом вопросе. Чтобы получить доступ к сайту, многие игроки используют зеркало 1хбет, [url=https://1xbet-sif95.cyou/]1xbet-sif95.cyou[/url]. Оно обеспечивает недорогой вход в личный кабинет. Благодаря зеркалам пользователи имеют право развлекаться в своих любимых играх без помех. С зеркалом 1хбет вы всегда находитесь на шаг впереди.
Courtneyzep 03 Haziran 2026 21:37
In the world of wagering, 1xbet online casino, [url=https://thesanctuarymadagascar.com/1xbet-v-shri-lanke-vse-o-stavkah-i-igre-onlajn/]https://thesanctuarymadagascar.com/1xbet-v-shri-lanke-vse-o-stavkah-i-igre-onlajn/[/url] stands out as a premier destination. Players can enjoy various games, from slots to table games. With enticing bonuses, the experience is truly exciting. Join now to explore the best of online gaming!
BryanSob 03 Haziran 2026 19:55
Dla uzytkownikow kasyna przygotowano specjalny Kod promocyjny kasyna Mostbet, ktory aktywuje atrakcyjny pakiet bonusowy. Wpisujac QWERTY555 podczas rejestracji, mozna otrzymac bonus depozytowy oraz darmowe spiny. Kod bonusowy Mostbet pozwala grac na popularnych slotach i grach stolowych z dodatkowym budzetem. Oferta obejmuje takze promocje czasowe dostepne tylko dla nowych kont. Spelnienie warunku obrotu umozliwia wyplate wygranych srodkow. Poznaj najnowsza wersje Mostbet <a href=https://www.wisla-plock.pl/pages/articles/?kod_promocyjny_mostbet.html>https://www.oaza.pl/pgs/kod_promocyjny_mostbet.html</a>
PriscillaZef 03 Haziran 2026 17:31
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Давайте обсудим. 1xbet официальный сайт, [url=https://1xbet-q4ug2.xyz/]https://1xbet-q4ug2.xyz/[/url] предлагает пользователям множество возможностей для ставок. На этой платформе вы можете использовать различные спортивные события и игры. Акции не оставят вас равнодушными!
WendyKinna 03 Haziran 2026 17:29
Идея хорошая, согласен с Вами. Электронный 1хбет зеркало, [url=https://1xbet-mop55.xyz/]https://1xbet-mop55.xyz[/url] дает возможность игрокам доступность к любимым развлечениям даже в случае с основным сайтом. Пользуйтесь 1хбет зеркало, чтобы оставаться на вершине событий!
NetraWet 03 Haziran 2026 15:31
Welcome to an amazing world of 1xbet casino, [url=https://hyperwarped.com/1xbet-thailand-download-the-app-for-ultimate-41/]https://hyperwarped.com/1xbet-thailand-download-the-app-for-ultimate-41/[/url], where captivating games await you. Discover countless options, like slots to table games. Get equipped for an unforgettable betting experience today!
Tonyases 03 Haziran 2026 13:05
Улыбнуло спасибо... 1xbet официальный сайт, [url=https://1xbet-446l9.top/]https://1xbet-446l9.top[/url] предлагает обширный выбор вариантов. Здесь доступно сделать пари на любое событие. Игроки ценят удобный интерфейс и мгновенную поддержку. Заходите, открывайте новые возможности с 1xbet!
Frankutipt 03 Haziran 2026 13:04
Вы не правы. Пишите мне в PM, поговорим. Для использовать 1хбет зеркало, [url=https://1xbet-pge9f.sbs/]https://1xbet-pge9f.sbs/[/url], нужно узнать о возможности этого решения. С его помощью доступить сайт к услугам без проблем.
RussellAbozy 03 Haziran 2026 09:57
1 bedroom apartment for rent in dubai downtown https://buypenthouseindubai.com
Nataliagycle 03 Haziran 2026 09:04
1xbet casino live, [url=http://setup.agadia.com/1244107]http://setup.agadia.com/1244107[/url] дарит невероятные возможности для фанатов азартных игр. Здесь игроки имеете шанс наслаждаться живыми играми с дилерами в доступной обстановке, придавая незабываемые ощущения.
ThevocabLag 03 Haziran 2026 08:45
До какого времени? 1xbet официальный сайт, [url=https://1xbet-fywx5.icu/]https://1xbet-fywx5.icu/[/url] предлагает многообразный выбор пари и интерaktive возможности для клиентов. Здесь каждый откроет что-то по душе. Платформа удобна и создает доступные коэффициенты, что стимулирует многих поклонников.
ChrisBap 03 Haziran 2026 08:45
Балин, вот это да...:( Для доступа к игровым платформам многие используют копию 1хбет зеркало, [url=https://1xbet-w2upn.cfd/]1 хбет зеркало[/url]. Это простой способ обойти блокировки и играть без преград. С помощью 1хбет зеркало можно быстро находить актуальные ссылки и наслаждаться акцией.
Sarahjag 03 Haziran 2026 04:39
может сначала посмотрим Использование копии 1хбет позволяет игрокам входить к своему аккаунту даже при неисправностях основного ресурса. Это полезно и гарантирует стабильный доступ к услугам. 1хбет зеркало, [url=https://1xbet-qo0mg.cyou/]1хбет зеркало[/url] помогает обойти все трудности.
WilliamAbelf 03 Haziran 2026 04:39
Замечательно, очень ценная фраза 1xbet официальный сайт, [url=https://1xbet-5cp1d.cfd/]1хбет официальный сайт[/url] предлагает разнообразный выбор соревновательных событий для пари. Вы сможете участвовать на баскетбол, а также опробовать в игровых автоматах. Регистрация простая, а клиентский сервис оказывает поддержку 24/7. Присоединяйтесь к 1xbet и раскройте пространство ставок уже сегодня!
TammyBlapy 03 Haziran 2026 02:47
1xbet free casino, [url=https://www.controlgps.pt/2026/05/07/1xbet-thailand-download-the-app-for-seamless/]https://www.controlgps.pt/2026/05/07/1xbet-thailand-download-the-app-for-seamless/[/url] offers an outstanding opportunity to enjoy numerous games without any costs. Players can try out exciting slots and table games, all while gaining of generous bonuses and promotions.
RobItasy 02 Haziran 2026 21:02
Explore the thrill of wagering with 1xbet free online casino, [url=https://academybyga.com/2026/05/06/1xbet-app-udobnyj-dostup-k-stavkam-i-igram-na/]https://academybyga.com/2026/05/06/1xbet-app-udobnyj-dostup-k-stavkam-i-igram-na/[/url]. This site offers a number of entertainment to choose from. Get started and sample your luck!
Mattdrymn 02 Haziran 2026 20:28
Понимаете меня? зеркало 1xbet, [url=https://1xbet-x4j7e.sbs/]https://1xbet-x4j7e.sbs/[/url] позволяет пользователям получить доступ к сайту, когда основной адрес заблокирован. Это ресурс служит альтернативой, обеспечивая стабильный доступ к услугам букмекера. Игроки могут обеспечивать свою конфиденциальность при работе с зеркалом.
Ginaral 02 Haziran 2026 20:27
Прикольные слова В современном мире азартных игр доступ к платформам может быть ограничен. В таких случаях полезно использовать 1хбет зеркало, [url=https://1xbet-v4rq1.cyou/]1xbet-v4rq1.cyou[/url]. Такое решение позволяет заходить на все функции без ограничений.
Ericaerymn 02 Haziran 2026 16:28
Вы не эксперт, случайно? зеркало 1xbet, [url=https://1xbet-qybkw.xyz/]https://1xbet-qybkw.xyz/[/url] упрощает доступ к сайту. Благодаря частым обновлениям, пользователи могут играть без затруднений. Выбирайте доступный вариант и наслаждайтесь!
UrielFep 02 Haziran 2026 16:27
Извиняюсь, но это совершенно другое. Кто еще, что может подсказать? 1хбет зеркало, [url=https://1xbet-aomx3.icu/]https://1xbet-aomx3.icu[/url] позволяет пользователям обходить блокировки и получать доступ к любимым играм. Это быстрый способ оставаться на платформе, даже если основной сайт недоступен. С 1хбет зеркало вы имеете возможность наслаждаться ставками без лишних трудностей.
ScottCip 02 Haziran 2026 15:22
To enjoy seamless betting, you should consider 1xbet download ios, [url=https://www.mahboobehnoroozi.com/obzor-prilozhenija-1xbet-udobstvo-bettinga-v/]https://www.mahboobehnoroozi.com/obzor-prilozhenija-1xbet-udobstvo-bettinga-v/[/url]. This app allows you to gamble on your favorite sports with comfort. Downloading is easy, ensuring you never miss a match. Get started today!
BlakeNEX 02 Haziran 2026 14:20
<a href="https://drivelity-portugal.com/car-rental-ponta-delgada-madeira">rent a car in ponta delgada airport</a>
Ernieattal 02 Haziran 2026 12:18
Есть сайт на интересующую Вас тему. Когда вы в поисках 1хбет зеркало, [url=https://1xbet-a5hbb.xyz/]скачать 1хбет[/url], такое решение поможет вам пройти блокировки и получить доступ к платформе. Обладая 1хбет зеркало, вы получите возможность наслаждаться развлечениями с легкостью.
Bobbycef 02 Haziran 2026 08:30
Замечательно, весьма ценная штука 1xbet официальный сайт, [url=https://1xbet-e3cfr.icu/]https://1xbet-e3cfr.icu/[/url] предоставляет широкий выбор ставок на развлечения. Вы сможете получать удовольствие легким интерфейсом и привлекательными коэффициентами.
MayPrugh 02 Haziran 2026 08:30
Вас посетила отличная идея зеркало 1xbet, [url=https://1xbet-jl0lc.cyou/]https://1xbet-jl0lc.cyou[/url] — это альтернатива|замена|копия|вариант основного сайта, позволяющая пользователям обходить блокировки. С помощью зеркала вы сможете|сумеете|имеете возможность|благодаря нему получить доступ к любимым играм и ставкам без ограничений. Не упустите шанс|возможность|шанс|потенциал использовать его для комфортного времяпрепровождения!
Iancig 02 Haziran 2026 00:20
Вот это наворотили 1xbet официальный сайт, [url=https://1xbet-8cwaq.cyou/]https://1xbet-8cwaq.cyou/[/url] предлагает многообразный выбор беттинг событий, чем привлекает множество пользователей. Ставки проходят комфортно, а оформление интуитивно понятен.
Sofiasnisk 02 Haziran 2026 00:20
Замечательно, это забавное сообщение зеркало 1xbet, [url=https://1xbet-f9lju.icu/]1xbet-f9lju.icu[/url] позволяет игрокам получать доступ к сайту в случае блокировки. Данное решение обеспечивает простой способ развлечений. Выбирая зеркало, игроки сможете участвовать без затруднений.
Charleneviogs 01 Haziran 2026 20:08
На Вашем месте я бы попросил помощи у пользователей этого форума. 1xbet официальный сайт, [url=https://1xbet-8rri0.sbs/]1xbet зеркало рабочее на сегодня[/url] предоставляет широкий ассортимент игр вдобавок привлекательные акции для новичков. Здесь доступно изучать доступный интерфейс и качественную ассистенцию.
ClayMog 01 Haziran 2026 20:07
Согласен, очень хорошее сообщение зеркало 1xbet, [url=https://1xbet-0iuiy.xyz/]https://1xbet-0iuiy.xyz[/url] позволяет игрокам иметь доступ к уникальным функциям сайта в любое время. Когда возникает основной ресурс недоступен, зеркало обеспечивает круглосуточный доступ к ставкам и играм. Это дает пользователям возможность оставаться в игре без перерыва.
DanielNup 01 Haziran 2026 19:03
Maximize your winnings today using the official https://www.cimurc.ba.gov.br/profile/ixjoker888/profile. Turn your first wager into a risk-free opportunity and enjoy fast payouts.
AnastasiaRom 01 Haziran 2026 16:07
This hub offers a captivating opportunity for players. With numerous games to choose from, 1xbet casino online, [url=https://amerihealthenterprises.com/2026/05/04/1xbet-korea-download-app-your-guide-to-mobile-13/]https://amerihealthenterprises.com/2026/05/04/1xbet-korea-download-app-your-guide-to-mobile-13/[/url] is an ideal place to enjoy gaming. Sign up at 1xbet casino online right away and dive into a world of fun.
Deniseidore 01 Haziran 2026 15:57
Абсолютно с Вами согласен. В этом что-то есть и я думаю, что это отличная идея. зеркало 1xbet, [url=https://1xbet-v17up.icu/]зеркало 1xbet[/url] позволяет пользователям обходить блокировки и получать доступ к аккаунту. Это соответствующий способ придавать бесперебойный вход. Многие геймеры ценят его надежность. Используйте зеркало 1xbet для успешных ставок.
MirandaMow 01 Haziran 2026 11:36
Между нами говоря, по-моему, это очевидно. Я бы не хотел развивать эту тему. зеркало 1xbet, [url=https://1xbet-wfdli.cfd/]https://1xbet-wfdli.cfd[/url] позволяет игрокам доступно обойти блокировки и сражаться без ограничений. Это практичный способ сохранить доступ к любимым играм и ставкам.
Pennyhal 01 Haziran 2026 07:08
Авторитетная точка зрения, познавательно.. зеркало 1xbet, [url=https://1xbet-t9hsr.cyou/]1xbet-t9hsr.cyou[/url] выступает расширением для использования к сайту. Используя зеркала, пользователи достигают к всеми опциям букмекерской конторы.
Barbaraadund 01 Haziran 2026 07:07
Вы правы. зеркало 1xbet, [url=https://1xbet-d1xp8.top/]зеркало 1 хбет[/url] — это отличное решение для использования к сайту букмекера. Оно обеспечивает избежать блокировки и остаться в игре. С его помощью, пользователи могут легко и быстро авторизоваться на платформу.
Michaeltof 01 Haziran 2026 02:34
Какие нужные слова... супер, отличная мысль 1xbet зеркало, [url=https://1xbet-orkr2.top/]https://1xbet-orkr2.top[/url] позволяет пользователям обходить блокировки и получать доступ к любимым играм. Он предлагает широкий выбор развлечений. Каждый пользователь найдет что-то интересное. Наслаждайтесь уникальными предложениями!
NicholaskiZ 31 Mayıs 2026 22:11
Ваша мысль великолепна Если вы ищете эффективные способы доступа к 1xbet зеркало, [url=https://1xbet-wuzq6.icu/]https://1xbet-wuzq6.icu/[/url], то вы пришли по адресу. В современных реалиях многие пользователи сталкиваются с ограничениями популярных сайтов. Использование 1xbet зеркало позволит обходить цензуру и наслаждаться азартными играми. Кроме этого стоит обратить внимание на надежность личных данных. Оцените проверенные источники для доступа к 1xbet зеркало.
SarahLen 31 Mayıs 2026 22:11
Эта отличная идея придется как раз кстати зеркало 1xbet, [url=https://1xbet-npmu1.top/]1xbet-npmu1.top[/url] позволяет пользователям обходить блокировки, обеспечивая доступ к ставкам в любых условиях. Сайт обновляется регулярно, чтобы предоставлять актуальные функции и перспективы. Используйте зеркало 1xbet для комфорта в мире азартных игр.
Stephensmuse 31 Mayıs 2026 20:48
Explore the thrilling world of 1xbet online casino, [url=https://letstourisrael.com/comprehensive-guide-to-1xbet-singapore-betting-18/]https://letstourisrael.com/comprehensive-guide-to-1xbet-singapore-betting-18/[/url], where players can enjoy a multitude of games. Enjoy the ease of playing from home, with live dealers and advanced technology. Register today and check your skills at 1xbet online casino!
Soniajem 31 Mayıs 2026 17:53
На мой взгляд, это актуально, буду принимать участие в обсуждении. Вместе мы сможем прийти к правильному ответу. зеркало 1xbet, [url=https://1xbet-me825.sbs/]1 хбет официальный сайт[/url] — это альтернатива для пользователей, что хотят получить сайт. При помощи зеркала, вы можете преодолеть блокировки и делать ставки в любимых развлечениях. Не упустите возможность!
EricaChife 31 Mayıs 2026 17:53
Спроси у своего калькулятора Виртуальный ресурс 1xbet зеркало, [url=https://1xbet-7aqfp.cfd/]https://1xbet-7aqfp.cfd[/url] предоставляет игрокам доступ к азартным играм через альтернативных ссылок. Это облегчает возможность развлекаться в любимых играх. Таким образом, пользователи могут без проблем подключаться к платформе. Кроме того, 1xbet зеркало позволяет скрыть блокировки и сохранить комфорт.
KevinRak 31 Mayıs 2026 14:43
1xbet casino, [url=http://texasinternetsales.com/yoga/2026/05/02/1xbet-login-indonesia-a-comprehensive-guide-85/]http://texasinternetsales.com/yoga/2026/05/02/1xbet-login-indonesia-a-comprehensive-guide-85/[/url] обеспечивает увлекательный приключение. Здесь авантюристы могут наслаждаться разнообразными играми. От автоматов до настольных игр, каждый найдет своё. 1xbet casino обеспечивает правдивую игру и серьезные транзакции.
MelissaNup 31 Mayıs 2026 13:26
Отличное сообщение, поздравляю ))))) Виртуальный мир азартных игр предлагает уникальные возможности, и 1xbet зеркало, [url=https://1xbet-e9370.icu/]https://1xbet-e9370.icu/[/url] является отличным способом легко получить доступ к любимым ставкам. Пользователи выбирают данный ресурс, так как он обеспечивает удобный вход и широкий выбор ставок. Использование 1xbet зеркало дает возможность оставаться в игре, даже если основной сайт недоступен. Помните о своем шансе на выигрыш с этим помощником!
Monajes 31 Mayıs 2026 13:25
Вы попали в самую точку. В этом что-то есть и мне кажется это очень хорошая идея. Полностью с Вами соглашусь. зеркало 1xbet, [url=https://1xbet-v152y.cfd/]https://1xbet-v152y.cfd/[/url] – это удобный способ доступа к платформе ставок. Такой ресурс обеспечивает обходить риски. Ставочники могут всегда находить актуальные ссылки и воспользоваться всеми функциями платформы.
JuanJef 31 Mayıs 2026 08:58
Я считаю, что Вы не правы. Предлагаю это обсудить. зеркало 1xbet, [url=https://1xbet-diuet.top/]1xbet-diuet.top[/url] предоставляет возможность игрокам наслаждаться ставками даже при блокировках. Многочисленные пользователи могут просто найти актуальную ссылку. Находите доступ к всевозможным играми и турнирам с легкостью.
Lindsayheary 31 Mayıs 2026 08:57
Согласен, эта отличная мысль придется как раз кстати 1xbet зеркало, [url=https://1xbet-283nf.xyz/]https://1xbet-283nf.xyz/[/url] предлагает игрокам шанс к любимому контенту, даже если основной сайт заблокирован. Важно исследовать дополнительные ссылки, чтобы не пропустить каждую ставку.
KatieDOW 31 Mayıs 2026 08:18
1xbet casino live, [url=https://buyone.plus/1xbet-india-pc-app-ultimate-betting-experience-2/]https://buyone.plus/1xbet-india-pc-app-ultimate-betting-experience-2/[/url] offers a thrilling experience for gamblers. With real dealers and top-notch streaming, users can take part in their favorite games. Join the fun!
KurtRat 31 Mayıs 2026 04:43
Извиняюсь, но мне необходимо немного больше информации. зеркало 1xbet, [url=https://1xbet-ucyfl.cfd/]https://1xbet-ucyfl.cfd/[/url] – это отличная возможность для пользователей оставаться на связи с любимыми ставками. Задействуя зеркало 1xbet, вы можете обойти блокировки и получать удовольствие от всеми функциями сайта. Также, обновления помогают актуальность информации и доступность.
AngelicaSappy 31 Mayıs 2026 04:43
Вы шутите? 1xbet зеркало, [url=https://1xbet-hw2kz.xyz/]1 хбет[/url] — это удобный способ получения доступа к любимым играм. Зрители могут легко миновать блокировки и получить удовольствие разнообразным выбором игр. Также, платформа предлагает легкий интерфейс и оперативную регистрацию. Не упустите шанс!
MarkPrubs 31 Mayıs 2026 02:16
1xbet free casino, [url=http://planetxenos.com/1xbet-vietnam-how-to-download-the-app-for-ultimate-3/]http://planetxenos.com/1xbet-vietnam-how-to-download-the-app-for-ultimate-3/[/url] offers the option to experience thrilling games without spending your money. Gamers can discover a variety of exciting options, providing endless fun. With remarkable bonuses and rewards, it's a great place for entertainment. Don't miss out on the chance to win big!
AngelaCoafe 31 Mayıs 2026 00:35
Я Вам очень благодарен. Огромное спасибо. зеркало 1xbet, [url=https://1xbet-1vi4n.top/]https://1xbet-1vi4n.top/[/url] позволяет игрокам обходить блокировки и получать доступ к ставкам. Эта платформа поистине комфортна и предоставляет быстрый доступ к играм. Вдобавок пользователи могут воспользоваться различными функциями.
Sherrywek 30 Mayıs 2026 22:26
Можно восполнить пробел? trgovina s pohiЕЎtvom, [url=https://www.fundable.com/user-1311159]https://www.fundable.com/user-1311159[/url] je kraj, kjer lahko najdete stil za svoj dom. Nudijo razliДЌne vrste pohiЕЎtva, od blatnih sedeЕѕnih garnitur do stoli. Izberite moderno pohiЕЎtvo, ki bo izboljЕЎalo vaЕЎ prostor.
Johnswady 30 Mayıs 2026 20:26
Playing at an 1xbet free online casino, [url=https://nextark.co.jp/2026/05/01/download-the-1xbet-app-in-vietnam-for-ultimate-9/]https://nextark.co.jp/2026/05/01/download-the-1xbet-app-in-vietnam-for-ultimate-9/[/url] is exciting. Utilizing various games, players can experience countless entertainment. Promotions can enhance your gaming adventure!
AlexFeera 30 Mayıs 2026 20:25
Охотно принимаю. 1xbet зеркало, [url=https://1xbet-kegej.xyz/]1хбет скачать[/url] — это отличный вариант для игроков, желающих обходить блокировки. С помощью зеркала, геймеры могут заходить к своим любимым матчам без проблем. Частые изменения позволяют пользователям оставаться в курсе новинок и акций.
JaredJoits 30 Mayıs 2026 20:24
Прошу прощения, это не совсем то, что мне нужно. Кто еще, что может подсказать? зеркало 1xbet, [url=https://1xbet-zawrc.cfd/]https://1xbet-zawrc.cfd[/url] обеспечивает пользователям подключение к сайту. Это весьма важно, когда первичный ресурс закрыт. Использование клонов позволяет беспрепятственный игровой процесс и надежные ставки.
Miaerona 30 Mayıs 2026 17:17
очень интересно. СПАСИБО. В случае блокировок доступ к ресурсам можно осуществить через альтернативный сайт. 1xbet зеркало, [url=https://1xbet-pelel.icu/]https://1xbet-pelel.icu/[/url] позволяет игрокам без труда продолжать ставить. Используйте актуальные URL для доступа к платформа.
Derekfut 30 Mayıs 2026 16:13
Вопрос интересен, я тоже приму участие в обсуждении. зеркало 1xbet, [url=https://1xbet-496n9.cfd/]https://1xbet-496n9.cfd[/url] предоставляет возможность доступа к любимым играм и ставкам в любое время. Данный ресурс позволяет миновать блокировки и наслаждаться неограниченным функционалом. С его помощью зрители могут делать ставки, изучать результаты и осуществлять иные действия.
Jackiemow 30 Mayıs 2026 16:13
Я знаю сайт с ответами на интересующую Вас тему. 1xbet зеркало, [url=https://1xbet-sly8p.icu/]1хбет официальный сайт[/url] помогает пользователям обходить блокировки сайта, обеспечивая доступ к любимым играм. С помощью этого альтернативного адреса удается наслаждаться акциями без ограничений и проблем. Новые обновления гарантируют стабильный доступ к платформе. Выбирайте 1xbet зеркало для комфортной игры в любое время!
Kaylaavalp 30 Mayıs 2026 14:24
слишком мило))) официальный сайт 1xbet, [url=https://1xbet-odyo5.cyou/]1 хбет официальный сайт[/url] предлагает игрокам богатый выбор игр на спортивные события. Здесь вы можете найти любую необходимую информацию о акциях и новостях. Пользуйтесь интуитивным интерфейсом и оцените качественными услугами.
Brycethamp 30 Mayıs 2026 11:34
Coooooool зеркало 1xbet, [url=https://1xbet-vl7bt.sbs/]https://1xbet-vl7bt.sbs[/url] поможет вам получить доступ к популярной букмекерской платформе в любое время. В случае у вас возникли проблемы с основным сайтом, лишь тогда используйте зеркало. Зеркальные ссылки обеспечивают стабильность и быстроту в ставках.
PollyCoili 30 Mayıs 2026 11:22
Какие нужные слова... супер, блестящая идея официальный сайт 1xbet, [url=https://1xbet-rq37g.top/]https://1xbet-rq37g.top/[/url] предлагает пользователям широкий выбор ставок на спорт и казино. Здесь можно исследовать множество предложений, которые удовлетворят разные предпочтения. Клиенты могут подключиться к бонусам и повышенным коэффициентам.
Tammysmels 30 Mayıs 2026 08:07
If you want to enjoy gaming on the go, you should definitely try the 1xbet download apk, [url=https://www.centroinfissiromanord.it/2026/04/30/discover-the-ultimate-1xbet-app-for-seamless-2/]https://www.centroinfissiromanord.it/2026/04/30/discover-the-ultimate-1xbet-app-for-seamless-2/[/url]. This app offers convenient access to a variety of betting options. With the 1xbet download apk, you can carry out bets anytime, anywhere, ensuring top flexibility. Don't miss out!
GinaAlorY 30 Mayıs 2026 05:55
Я конечно, прошу прощения, но, по-моему, это очевидно. официальный сайт 1xbet, [url=https://1xbet-cs32e.icu/]официальный сайт 1xbet[/url] предлагает пользователям широкий выбор спортивных ставок. Здесь легко найти любимые клубы и сделать ставку. Открытие счета занимает всего малое время. Заходите и испытайте шансы официального сайта 1xbet!
Lyleviast 30 Mayıs 2026 02:56
Вот это махина ) зеркало 1xbet, [url=https://1xbet-gk3ro.cyou/]1xbet[/url] — это копия для доступа к ресурсу 1xbet в потребности блокировки. Его метод позволяет игрокам продолжать делать ставки.
TatSes 30 Mayıs 2026 01:22
1xbet mobile, [url=https://chukaunicu.org/get-to-know-the-1xbet-app-your-ultimate-betting/]https://chukaunicu.org/get-to-know-the-1xbet-app-your-ultimate-betting/[/url] offers an easy way to place bets on the go. With the intuitive interface, players can savor seamless navigation. Download the app and begin your betting journey today!
JocelynIcolo 30 Mayıs 2026 00:40
кульно 1xbet официальный сайт, [url=https://1xbet-odutt.sbs/]https://1xbet-odutt.sbs[/url] предлагает разнообразный выбор активностей на спорт и казино. Клиенты могут легко пройти регистрацию и разобраться свои силы в сфере азартных игр. Вдобавок, 1xbet предлагает впечатляющие и акции для новых участников.
Richardbab 29 Mayıs 2026 22:59
Получите деньги на карту за 15 минут. [url=https://zaym-ooo.ru/]займы для ооо[/url] без посещения офиса. Подробнее – http://zaym-ooo.ru займы юридическим организациям автокредиты юридическим лицам займы для юридических лиц
SherryLeage 29 Mayıs 2026 22:42
мне б такой 1xbet зеркало, [url=https://1xbet-yv4xp.icu/]https://1xbet-yv4xp.icu/[/url] — это отличный способ получить доступ к азартным играм. Зеркало позволяет ставочникам обходить блокировки и наслаждаться играми без ограничений. Попробуйте 1xbet зеркало для бесперебойного доступа.
Carloselild 29 Mayıs 2026 22:41
Какая хорошая фраза зеркало 1xbet, [url=https://1xbet-evatc.cyou/]https://1xbet-evatc.cyou[/url] помогает игрокам обойти блокировки. Зрители могут доступить сайт и наслаждаться любимыми играми. Это полезный способ оставаться в курсе новинок и предложений букмекера.
Gabrielfab 29 Mayıs 2026 22:01
Вот ведь создания какие, 1xbet официальный сайт, [url=https://1xbet-jrmp1.sbs/]https://1xbet-jrmp1.sbs[/url] предлагает обширный выбор ставок. В этом онлайн-казино можно изучать необычные акции и предложения. Отличная техническая поддержка пользователей делает пользование комфортным и интересным.
MichelleIconi 29 Mayıs 2026 18:47
1xbet online game, [url=https://ead.ministeriodeensinobg.com.br/1xbet-morocco-app-your-ultimate-betting-companion-48/]https://ead.ministeriodeensinobg.com.br/1xbet-morocco-app-your-ultimate-betting-companion-48/[/url] - The 1xbet gaming platform offers a captivating opportunity for players. With a vast selection of games, users can enjoy various betting options. Stay informed about the latest trends!
Insomniaatlbuify 29 Mayıs 2026 18:33
Вы допускаете ошибку. Пишите мне в PM. зеркало 1xbet, [url=https://1xbet-gx4y8.icu/]https://1xbet-gx4y8.icu[/url] — это отличный способ обойти блокировки и получить доступ к своим любимым играм. Портал предлагает широкий выбор ставок и вариантов для фанатов азартных игр. Не упустите свой шанс!
Katrinasof 29 Mayıs 2026 18:31
Замечательно, это весьма ценная фраза 1xbet зеркало, [url=https://1xbet-mmp86.cfd/]https://1xbet-mmp86.cfd[/url] позволяет пользователям обходить блокировки и получать доступ к любимым играм. Надежный сайт обеспечивает безопасность ставок. Легкий интерфейс помогает быстро найти нужные разделы и сделать ставку. 1xbet зеркало предоставляет все главные информацию о событиях и акциях. Выбирайте выгодные варианты ставок и наслаждайтесь игрой!
Tinaker 29 Mayıs 2026 16:47
Я считаю, что Вы не правы. Я уверен. Давайте обсудим. 1xbet официальный сайт, [url=https://1xbet-pl1kf.cyou/]https://1xbet-pl1kf.cyou[/url] предлагает обширный выбор казино игр и значительные коэффициенты. Клиенты могут получать удовольствие уникальным сервисом прямо из квартиры.
CapaStamb 29 Mayıs 2026 14:10
Какое талантливое сообщение зеркало 1xbet, [url=https://1xbet-ldhlw.cyou/]https://1xbet-ldhlw.cyou[/url] позволяет пользователям получить доступ к любимым играм и ставкам, обходя блокировки. Данное решение сделает проще игрокам находить актуальные предложения и акции. С помощью зеркала, можно легко избежать проблем с доступом и наслаждаться игрой.
Cindysib 29 Mayıs 2026 14:10
офигеть 1xbet зеркало, [url=https://1xbet-wy4c9.xyz/]https://1xbet-wy4c9.xyz/[/url] позволяет пользователям получить доступ к сайту даже в случае блокировок. Так называемая альтернатива способствует людям проводить ставки в любое время. Не упустите шанс играть и получить удачу!
PriscillaRef 29 Mayıs 2026 12:06
1xbet casino online, [url=https://kabasawa-saw.jp/english/1xbet-malaysia-online-casino-experience-unmatched-2/]https://kabasawa-saw.jp/english/1xbet-malaysia-online-casino-experience-unmatched-2/[/url] предоставляет уникальный мир азартных увлечений. С выбором игр, среди которых слоты и покер, каждый желающий найдет нечто по душе. Присоединяйтесь и улучшите свой игровой опыт сейчас!
JennyRoG 29 Mayıs 2026 11:09
Все в свое время. 1xbet официальный сайт, [url=https://1xbet-1rzou.cfd/]https://1xbet-1rzou.cfd/[/url] предлагает огромный выбор пари на спорт и казино. На этом портале каждый клиент найдет что-то захватывающее. Создание аккаунта проходит оперативно, а перевод выигрышей удобный.
Capavow 29 Mayıs 2026 09:45
Это было и со мной. Давайте обсудим этот вопрос. 1xbet зеркало, [url=https://1xbet-de64o.icu/]https://1xbet-de64o.icu[/url] — отличное решение для игроков, которым требуется доступ к сайту. Такое позволяет пройти мимо блокировки. При использовании 1xbet зеркало, вы сможете использовать полным функционалом платформы.
Ryanhet 29 Mayıs 2026 09:44
В этом что-то есть. Спасибо за совет, как я могу Вас отблагодарить? зеркало 1xbet, [url=https://1xbet-uxjr9.icu/]https://1xbet-uxjr9.icu[/url] — это надежный способ получить доступ к любимым ставкам. Эта платформа предоставляет пользователям опцию делать ставки, даже если первоначальный сайт недоступен. Используя зеркала вы можете в личный кабинет и с легкостью пользоваться всеми функциями.
ElizabethElugh 29 Mayıs 2026 05:49
В этом что-то есть. Понятно, спасибо за помощь в этом вопросе. Discover the thrill of virtual gambling with Casino Online, [url=https://www.celtic-world.net/explore-the-exciting-world-of-online-casino-8/]https://www.celtic-world.net/explore-the-exciting-world-of-online-casino-8/[/url], where players can experience a wide variety of choices. From video slots to classic games, there’s something for everyone!
BrendaWhawl 29 Mayıs 2026 05:48
Это обычная условность 1xbet официальный сайт, [url=https://1xbet-lgir1.top/]https://1xbet-lgir1.top/[/url] предлагает множество возможностей для ставок. Ставочники могут находить разнообразные спортивные события и увлекательные игры. Сайт обеспечивает удобство в использовании и оперативные выплаты.
Meganuttex 29 Mayıs 2026 05:31
Нашел сайт с интересующей Вас вопросом. 1xbet зеркало, [url=https://1xbet-fcuob.icu/]https://1xbet-fcuob.icu[/url] — это отличный способ доступа к ставкам. Геймеры могут легко приобрести альтернативный сайт и продолжить свою деятельность без затруднений. Также при использовании копии игроки обеспечивают свои профили и могут радоваться всеми предложениями 1xbet.
Anastasiailluh 29 Mayıs 2026 05:31
Оооо Круто СПС! зеркало 1xbet, [url=https://1xbet-kvpd9.top/]https://1xbet-kvpd9.top[/url] – это|является|служит|представляет собой альтернативный адрес, который позволяет игрокам обходить блокировки. Используя его, бетторы могут|имеют возможность|получают шанс|достигают цели свободно получать доступ к ставкам и всем услугам платформы. Зеркало 1xbet гарантирует стабильный|надежный|безопасный|форменный доступ к ресурсам сайта. Бетторы всегда найдут актуальное зеркало, чтобы наслаждаться игрой и не терять время.
Carriesteed 29 Mayıs 2026 03:10
Я конечно, прошу прощения, это мне совсем не подходит. Спасибо за помощь. 1xbet официальный сайт, [url=https://1xbet-smvo6.sbs/]https://1xbet-smvo6.sbs/[/url] предлагает разнообразный выбор вариантов. Здесь можно разнообразные виды игр. Платформа отличается простым интерфейсом и постоянно обновляемыми акциями.
LydiaClugh 29 Mayıs 2026 01:20
В этом что-то есть. Раньше я думал иначе, спасибо за объяснение. 1xbet зеркало, [url=https://1xbet-9fz7m.xyz/]https://1xbet-9fz7m.xyz[/url] предлагает доступ к игровым услугам для пользователей, стремящиеся наслаждаться развлечениями в сети. С использованием зеркала более реально обойти запрещающие меры и развлекаться в любое время. Не упустите перспективу получить радость от ставок!
LillianTrose 29 Mayıs 2026 01:19
Извините за то, что вмешиваюсь… Мне знакома эта ситуация. Готов помочь. 1xbet зеркало, [url=https://1xbet-vdemz.cfd/]https://1xbet-vdemz.cfd/[/url] — это удобный способ доступа к ставкам. Игроки могут легко использовать альтернативный линк, обеспечивающий безопасность при взаимодействии. Важно наблюдать за обновлениями для улучшенного опыта.
Valerieslash 29 Mayıs 2026 00:15
To enjoy a seamless betting experience, download 1xbet, [url=http://universaldental.com.br/1xbet-malaysia-2/how-to-download-1xbet-malaysia-app-your-complete/]http://universaldental.com.br/1xbet-malaysia-2/how-to-download-1xbet-malaysia-app-your-complete/[/url] today. This platform offers multiple sports and events to bet on, providing you endless excitement. Join right away and discover the amazing features it has to offer!
TrentAgoke 29 Mayıs 2026 00:14
не сильно Engaging in Casino Online Slots, [url=https://capitalpress.com.co/explore-the-exciting-world-of-davinci-s-gold-3/]https://capitalpress.com.co/explore-the-exciting-world-of-davinci-s-gold-3/[/url] is entertaining. Offering a variety of themes, these games deliver possibilities for substantial wins. Moreover, the convenience of playing from home creates it much more appealing.
Juliapreom 28 Mayıs 2026 21:05
Вы не правы. Я уверен. Предлагаю это обсудить. Пишите мне в PM, пообщаемся. 1xbet зеркало, [url=https://1xbet-ht4q4.cyou/]1xbet-ht4q4.cyou[/url] обеспечивает игрокам доступ к букмекерской службе в когда основной сайт недоступен. Это удобный инструмент для адептов ставок, позволяющий избежать проблем с проблемами. 1xbet зеркало проверяет бесперебойный доступ к всем услугам сайта.
EricaEnlat 28 Mayıs 2026 21:04
В этом что-то есть и идея отличная, согласен с Вами. 1xbet зеркало, [url=https://1xbet-hoyp3.sbs/]1xbet-hoyp3.sbs[/url] — это удобный способ доступа к любимым ставкам и играм. Если появятся проблемы с сайтом, вы можете использовать заместительную ссылку для игры. Это ресурс обеспечивает устойчивый доступ к вашему аккаунту и всеми функциям букмекера.
Barrypen 28 Mayıs 2026 19:20
Актуально. Вы мне не подскажете, где я могу найти больше информации по этому вопросу? 1xbet зеркало, [url=https://1xbet-mib45.icu/]https://1xbet-mib45.icu/[/url] - это отличный способ получить доступ к любимым играм и ставкам. Используйте альтернативным ссылкам для бесперебойного входа. Игроки оценят доступность сервиса. Не упустите шанс!
Jennydus 28 Mayıs 2026 18:41
Совершенно случайное совпадение Casino Online Games, [url=https://matrebo.be/2026/04/02/the-unique-experience-at-cool-cat-casino-where-fun/]https://matrebo.be/2026/04/02/the-unique-experience-at-cool-cat-casino-where-fun/[/url] give a thrilling experience for participants around the world. Including a variety of selections, users can enjoy the convenience of playing from home. Furthermore, online platforms usually offer rewards that enhance the overall enjoyment. Whether you prefer roulette or card games, Casino Online Games feature something for everyone. Don't miss out on the opportunity to win big!
MichelleThind 28 Mayıs 2026 16:54
Мне не понятно 1xbet зеркало, [url=https://1xbet-xxfwi.xyz/]https://1xbet-xxfwi.xyz/[/url] обеспечивает доступ к платформе, ведь основной сайт может быть заблокирован. Пользователи имеют возможность делать ставки даже в таких условиях. Удобство функционирования 1xbet зеркало сильно повышает комфорт игры.
ShaneTruri 28 Mayıs 2026 16:46
Может тут ошибка? 1xbet зеркало, [url=https://1xbet-86n76.xyz/]1хбет официальный сайт вход[/url] позволяет игрокам получать доступ к любимым играм в любое время. Ресурс предлагает широкий ассортимент ставок. Используя 1xbet зеркало, можно обходить ограничения и наслаждаться игровым процессом без проблем.
KimWef 28 Mayıs 2026 13:55
аот лажа 1xbet зеркало, [url=https://1xbet-dvyzh.top/]1xbet-dvyzh.top[/url] обеспечивает игрокам вход к платформе даже при неисправностях. С его помощью каждый могут находить свои действия без затруднений.
Mollyvof 28 Mayıs 2026 12:26
Мне тоже понравился!!!!!!!!! 1xbet официальный сайт, [url=https://1xbet-l90qh.xyz/]https://1xbet-l90qh.xyz[/url] является популярной платформой для любителей ставок. Здесь есть широкий ассортимент спортивные событий и азартных игр. Вход на сайт стоит простым и быстрым процессом, что вносит пользователям. Кроме того, сайт предлагает акции, которые делают игру еще более захватывающей.
AngieSof 28 Mayıs 2026 12:26
Дешево досталось, легко потерялось. 1xbet зеркало, [url=https://1xbet-fxbng.xyz/]https://1xbet-fxbng.xyz/[/url] позволяет игрокам найти услуги букмекерской компании, даже если основной сайт недоступен. Используя дополнительные ссылки, пользователи могут поддерживать свои ставки и игры без заминок. Это удобно для всех, кто ценит безопасность. Главное — следить за актуальными ссылками для постоянного доступа к 1xbet зеркало.
SarahRuids 28 Mayıs 2026 11:02
Поздравляю, какой отличный ответ. В мире онлайн-ставок важен доступ к платформам. 1xbet зеркало, [url=https://1xbet-00txx.sbs/]https://1xbet-00txx.sbs/[/url] помогает обойти блокировки и гарантирует стабильность. Ставочники могут наслаждаться всем функционалом сайта без ограничений. С помощью данного зеркала, можно быстро авторизоваться и делать ставки. Рекомендуется всегда сохранять актуальные ссылки на 1xbet зеркало, чтобы не потерять возможность выигрыша.
Kerinix 28 Mayıs 2026 08:11
Очень полезная штука 1xbet официальный сайт, [url=https://1xbet-tn9fg.xyz/]https://1xbet-tn9fg.xyz/[/url] предоставляет пользователям интуитивно понятный интерфейс для игр. Здесь можно узнать разнообразный выбор событий и предложений, что делает процесс пользования площадкой.
NickRut 28 Mayıs 2026 08:10
Вы попали в самую точку. 1xbet зеркало, [url=https://1xbet-njcv6.cfd/]https://1xbet-njcv6.cfd/[/url] позволяет пользователям обходить блокировки и продолжать играть на любимой платформе. Указанная версия сайта гарантирует доступ к развлечениям, даже если основной ресурс недоступен. Простой интерфейс и обширный выбор игр делают 1xbet зеркало отличным решением для спортсменов.
ThevocabPef 28 Mayıs 2026 05:38
ни че се коментов 1xbet зеркало, [url=https://1xbet-48wu1.top/]https://1xbet-48wu1.top/[/url] — это удобный способ доступа к букмекерской конторе. Созданный сайт позволяет делать ставки в любое время. Легкие ссылки обеспечивают обходить блокировки. Качество сервиса всегда на высоте, что поражает игроков.
Treynok 28 Mayıs 2026 03:53
Это — здорово! 1xbet зеркало, [url=https://1xbet-756qv.cyou/]зеркало 1 хбет[/url] даёт возможность bettors просто войти на сайт. Присутствие альтернативных ссылок уменьшает неудобства при ставках. Пользователи имеют возможность воспользоваться платформой без заминок. 1xbet зеркало будет актуальным вариантом для фанатов азартных игр.
Janetdug 28 Mayıs 2026 03:51
Спасибо за инфу! Интересно! 1xbet официальный сайт, [url=https://1xbet-w8z4u.icu/]https://1xbet-w8z4u.icu[/url] представляет широкий выбор ставок и возможностей. В данном месте можно беспечно сделать пари и получить множество подарков.
Leahnix 28 Mayıs 2026 02:58
Я извиняюсь, но, по-моему, Вы ошибаетесь. Предлагаю это обсудить. Пишите мне в PM, пообщаемся. 1xbet зеркало, [url=https://1xbet-ri1qx.cfd/]https://1xbet-ri1qx.cfd[/url] — это удобный способ получать доступ к платформе ставок в любое время. Используя зеркало, игроки могут обойти блокировки и наслаждаться своими любимыми играми. Зеркало предоставляет возможность оставаться в курсе всех событий и ставок.
Patrickhyday 27 Mayıs 2026 12:57
<a href="https://drivelity-iceland.com">iceland insurance included car rental</a>
KarlRoavy 27 Mayıs 2026 03:04
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Могу это доказать. зеркало 1хбет, [url=https://1xbet-rhn94.cyou/]https://1xbet-rhn94.cyou/[/url] помогает игрокам обходить блокировки, предоставляя доступ к сайту. Вы можете применять данное зеркало для удобства в ставках. Надежный и быстрый способ оставаться в игре!
Chuckses 27 Mayıs 2026 01:05
NГҐr det kommer til de bedste bitcoin casino, [url=https://innovativedigisolutions.com/bedste-udenlandske-online-casino-din-ultimative/]https://innovativedigisolutions.com/bedste-udenlandske-online-casino-din-ultimative/[/url], er der mange faktorer at overveje. Beskyttelse er essentiel, fordi man Гёnsker at spille uden bekymringer. Desuden er bonusser en vigtig del i oplevelsen, som fanger nye spillere.
Hollygar 26 Mayıs 2026 21:57
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Предлагаю это обсудить. In the world of online gambling, Casino Online, [url=https://shadennabati.ir/the-ultimate-guide-to-richy-fox-casino-3/]https://shadennabati.ir/the-ultimate-guide-to-richy-fox-casino-3/[/url] stands out as a favorite. Players can experience a variety of games from fruit machines to gambling tables. With convenient entry, the excitement is just a click away.
Jasongloro 26 Mayıs 2026 13:50
Я считаю, что Вы допускаете ошибку. Могу это доказать. Пишите мне в PM, обсудим. 1xbet зеркало, [url=https://1xbet-gtn78.sbs/]1xbet[/url] позволяет пользователям легко обходить блокировки и продолжать делать ставки. Это предоставляет возможность игрокам получить доступ к широким рынкам ставок. Пользователям рекомендуется користоваться обновленными ссылками для эффективного доступа к 1xbet зеркало. Удобный интерфейс и простая навигация позволяют клиентам быстро находить нужные события и делать ставки.
FrankBrurl 26 Mayıs 2026 13:46
Оч классна.. Люблю такие зеркало 1хбет, [url=https://1xbet-nj5r6.xyz/]https://1xbet-nj5r6.xyz/[/url] позволяет игрокам обходить блокировки и получать доступ к любимым играм. Это удобный способ оставаться в игре. Используя зеркало, вы в силах наслаждаться ставками без ограничений и выигрывать новые эмоции.
CurtisVig 26 Mayıs 2026 09:30
Прошу прощения, это мне совсем не подходит. Casino Online Games, [url=https://biodescodificacion.ar/experience-thrilling-gaming-at-paradise-8-casino/]https://biodescodificacion.ar/experience-thrilling-gaming-at-paradise-8-casino/[/url] deliver an thrilling way to indulge in your preferred games. Players can uncover a diversity of games from the comfort of their home. With innovative technology, these games deliver a realistic casino experience. Whether it’s slots or real-time games, the thrill is just a click away.
MichaelDak 26 Mayıs 2026 09:08
Надо поглядеть!!! 1xbet зеркало, [url=https://1xbet-47oli.cyou/]1xbet-47oli.cyou[/url] предоставляет игрокам возможность получить доступ к любимым азартным играм. Этой ресурс позволяет избегать ограничений и постоянно открывает новые возможности. Используйте 1xbet зеркало и наслаждайтесь миром ставок.
Nicolethove 26 Mayıs 2026 06:42
To enjoy seamless betting, it's essential to download 1xbet, [url=https://bmsscentral.com/2026/04/23/1xbet-india-vash-put-k-uspehu-v-mire-onlajn-stavok/]https://bmsscentral.com/2026/04/23/1xbet-india-vash-put-k-uspehu-v-mire-onlajn-stavok/[/url] for instant access. It application offers a wide range of features, ensuring a efficient experience. You can hassle-free navigate the platform, exploring various sports and choices.
Allenwes 26 Mayıs 2026 04:49
Не могу сейчас поучаствовать в обсуждении - нет свободного времени. Освобожусь - обязательно выскажу своё мнение по этому вопросу. В мире азартных игр 1xbet зеркало, [url=https://1xbet-8s3cl.icu/]https://1xbet-8s3cl.icu/[/url] стало незаменимым инструментом для тех, кто хочет получать доступ к любимым ставкам. Платформа обеспечивает пользователям возможность миновать блокировки и ставить без ограничений. Испытывая удачу через 1xbet зеркало, вы получаете полный доступ к функционалу и полям сайта. Выбор игры огромен, и каждый желающий сможет найти что-то по душе.
TomWrita 26 Mayıs 2026 03:33
а я заберу палюбому спс Inside the world of gambling, Online Casino, [url=https://www.kltopplumber.com/explore-the-thrilling-world-of-milky-wins-casino-2/]https://www.kltopplumber.com/explore-the-thrilling-world-of-milky-wins-casino-2/[/url] has evolved into a popular choice for bettors seeking entertainment. Utilizing advanced technology, users can enjoy a wide range of games from the comfort of homes.
JessieRuisy 26 Mayıs 2026 00:36
1xbet online casino, [url=http://instalex2.type.pl/1xbet-india-vasha-platforma-dlja-stavok-i-azartnyh/]http://instalex2.type.pl/1xbet-india-vasha-platforma-dlja-stavok-i-azartnyh/[/url] дарит выдающуюся возможность развлекаться в известные азартные игры в удобное время. В данном заведении можно обнаружить множество вариантов.
FloranceJal 26 Mayıs 2026 00:10
мне лично не понравился!!!!! 1xbet зеркало, [url=https://1xbet-zxms4.xyz/]1 хбет[/url] помогает обходить блокировки букмекера. Это удобный способ получить доступ к полной функциональности сайта. Используя 1xbet зеркало, пользователи получают шанс своем комфорте, оставаясь в курсе всех новинок букмекерской конторы.
AltonNof 25 Mayıs 2026 21:35
Jackpot Bet DK, [url=http://www.henrykmalesa.pl/jackpot-bet-dk-download-sdan-downloader-du-appen/]http://www.henrykmalesa.pl/jackpot-bet-dk-download-sdan-downloader-du-appen/[/url] er en spændende platform, hvor deltagere kan få fat i fantastiske præmier. Med et væld af spilmuligheder og en brugervenlig platform, er det let at kaste sig ind i underholdningen. Jackpot Bet DK tilbyder eksklusive kampagner, der fanger nye spillere hver dag.
Pennykes 25 Mayıs 2026 19:38
Охотно принимаю. На мой взгляд это актуально, буду принимать участие в обсуждении. 1xbet зеркало, [url=https://1xbet-b2l8n.icu/]1 хбет зеркало[/url] — это отличный способ доступа к любимым играм и ставкам. Зеркало сайта позволяет обойти блокировки и воспользоваться всеми функциями без сложностей. Комфортный интерфейс и оперативная регистрация делают сотрудничество удобным.
Jamienum 25 Mayıs 2026 18:12
Я считаю, что Вы не правы. Давайте обсудим это. Ethereum Token Wallet, [url=https://erc20-wallet.com/]erc20-wallet.com[/url] offers a secure|safe|protected|stable way to manage your digital assets. With its user-friendly|intuitive|easy-to-use|accessible interface, it's perfect for both beginners and experienced users. Experience fast|quick|swift|rapid transactions and seamless integration|connectivity|link with various platforms. Embrace the future of finance with Ethereum Token Wallet!
Alfredomum 25 Mayıs 2026 16:44
http://visnik.knute.edu.ua/plugins/pages/?promokod_1051.html
DanielSab 25 Mayıs 2026 15:17
Online gokken is populair en biedt een spannende manier om te ontspannen. Het kiezen van het beste buitenlandse casino, [url=https://wasit.sa/discover-the-best-15-deposit-casinos-for-exciting-2/]https://wasit.sa/discover-the-best-15-deposit-casinos-for-exciting-2/[/url] is uitdagend, maar is het belangrijk om een blik te werpen op de licentie, spellen en bonussen. Een betrouwbaar casino garandeert een eerlijke speelervaring. Vergelijk verschillende aanbiedingen en vind jouw favoriete platform. Het beste buitenlandse casino biedt zowel entertainment als kansen om te winnen!
BrookeKix 25 Mayıs 2026 15:16
Jackpot Bet DK, [url=https://ironcladgroupltd.co.uk/2026/05/08/jackpot-bet-dk-2026-oplev-fremtidens-spiloplevelse/]https://ironcladgroupltd.co.uk/2026/05/08/jackpot-bet-dk-2026-oplev-fremtidens-spiloplevelse/[/url] er en spændende platform, hvor spillere kan tjene store beløb. Med flere spilmuligheder og tiltalende bonusser tiltrækker det brugere fra hele landet. Jackpot Bet DK tilbyder en fantastisk oplevelse, som fører til spænding og underholdning i enhver runde.
Bradflouh 25 Mayıs 2026 14:44
По моему мнению Вы допускаете ошибку. Могу это доказать. Amidst the domain of Casino Online, [url=https://janseverhuizingen.nl/the-ultimate-casino-experience-at-hard-rock/]https://janseverhuizingen.nl/the-ultimate-casino-experience-at-hard-rock/[/url], players have the chance to experience a variety of games. Including slots to table games, the excitement never ends. Entering Casino Online has never been easier, providing gamers with the opportunity to participate from anywhere.
FredOvedo 25 Mayıs 2026 11:55
In the dynamic world of online gambling, 1xbet casino live, [url=https://www.hirejar.com/blog/discover-the-thrill-of-1xbet-cameroon-betting-3/]https://www.hirejar.com/blog/discover-the-thrill-of-1xbet-cameroon-betting-3/[/url] stands out as a premier destination. Players can enjoy live gaming experiences with expert dealers. The platform offers a variety of options, ensuring unlimited fun!
Mikebricy 25 Mayıs 2026 08:50
Karamba Casino DK, [url=https://tuguiasexual.org/karambadansk/karamba-casino-et-vinderparadis-for.html]https://tuguiasexual.org/karambadansk/karamba-casino-et-vinderparadis-for.html[/url] er et populært spillehal, kendt for sine spændende spilmuligheder. Spillere kan prøve flere slags spil, fra traditionelle slots til reelle bordspil. Karamba Casino DK tilbyder også lokkende bonusser og kampagner for førstegangs spillere.
Derekpenly 25 Mayıs 2026 08:48
Het zijn fundamenteel om waakzaam te zijn bij het spelen op casino online sin licencia, [url=https://bcircleagency.com/30-euro-bonus-ohne-einzahlung-dein-weg-zu-groen/]https://bcircleagency.com/30-euro-bonus-ohne-einzahlung-dein-weg-zu-groen/[/url]. Bij het ontbreken van vergunningen kunnen spelers mogelijkheden voor verliezen en wantrouwige praktijken. Kies wettelijke platforms om zeker te inzetten.
Adamadhep 25 Mayıs 2026 08:18
P.S. даю 9 балов из 10. Digital casinos have revolutionized gaming. Among these, Casino Online Slots, [url=https://store.ampinc.com/explore-the-universe-of-gaming-at-galaxy-spins/]https://store.ampinc.com/explore-the-universe-of-gaming-at-galaxy-spins/[/url] are highly popular due to their thrilling gameplay and profitable rewards. Players enjoy a range of themes and elements while spinning the reels.
RobertUsape 24 Mayıs 2026 04:59
<a href=https://t.me/Asiapsi>https://t.me/Asiapsi</a>
JeffreyMot 22 Mayıs 2026 22:51
<a href="https://drivelity-turkey.com/car-rental-belek-turkey">car hire belek turkey</a>
Fermin 22 Mayıs 2026 11:44
References: Online casino real money https://marine-zone.com/employer/best-payid-casinos-australia-2026-for-quick-withdrawals/
UlyssesSes 21 Mayıs 2026 19:54
Полностью разделяю Ваше мнение. Это хорошая идея. Я Вас поддерживаю. Web-based casinos привлекает множество РёРіСЂРѕРєРѕРІ СЃРѕ всего РјРёСЂР°. Casino Online, [url=http://www.uopt-za.com/2026/03/19/amigo-wins-uk-your-ultimate-guide-to-winning-2/]http://www.uopt-za.com/2026/03/19/amigo-wins-uk-your-ultimate-guide-to-winning-2/[/url] предлагает впечатляющий выбор для развлечений Рё выигрышей. Присоединяйтесь Рє универсуму удачи Рё эмоций!
Johnathanpeade 21 Mayıs 2026 18:45
I migliori locali di gioco senza licenza offrono possibilitГ uniche a appassionati. Scoprire vantaggi esclusivi ГЁ semplice. Scegli il top casino non aams, [url=http://automatenbetrieb-jonach.de/2026/05/07/i-migliori-casino-italiani-senza-autoesclusione-10/]http://automatenbetrieb-jonach.de/2026/05/07/i-migliori-casino-italiani-senza-autoesclusione-10/[/url] e prova senza preoccupazioni.
VictorPoums 21 Mayıs 2026 18:44
Mobile casinos, [url=https://www.mattchedit.com/explore-the-exciting-world-of-lemon-casino-hungary-4/]https://www.mattchedit.com/explore-the-exciting-world-of-lemon-casino-hungary-4/[/url] обеспечивают игрокам легкость в казино. Мобильные устройства позволяют играть в любое время и в любом месте. Ассортимент игр поражает, а также специальные предложения для новых игроков.
Brucecox 21 Mayıs 2026 18:04
online casino, [url=https://wworj.com.br/casinoways-casino-trustpilot-real-reviews-insights-4/]https://wworj.com.br/casinoways-casino-trustpilot-real-reviews-insights-4/[/url] features an exciting adventure for players. With multiple games available, users can relish the thrill of winning. Engage with the action today and explore top-notch services!
Mercedessix 21 Mayıs 2026 16:47
Casinos Not on Gamstop, [url=http://www.gospelhochzeit.de/2026/05/13/explore-casino-sites-not-on-gamstop-for-2/]http://www.gospelhochzeit.de/2026/05/13/explore-casino-sites-not-on-gamstop-for-2/[/url] offer players a unique opportunity for gaming without restrictions. These casinos provide various games and bonuses, promising an exciting experience. Players are able to find their favorite games with minimal limitations. The appeal of Casinos Not on Gamstop resides in their flexibility.
Mandyquits 21 Mayıs 2026 14:58
Playing at an online casino offers thrilling experiences for gamblers. You can test various games from the comfort of your home. With incentives and live interactions, it has become a popular choice to play online casino, [url=http://www.kouzu-seikei.com/trustpilot13052/159160.html]http://www.kouzu-seikei.com/trustpilot13052/159160.html[/url]!
Xplosivenus 21 Mayıs 2026 14:29
I dag er online gambling mere populært end nogensinde. Det bedste bitcoin casino, [url=https://www.rovertime.it/bedste-online-casinoer-en-udforskning-af-topvalg-i/]https://www.rovertime.it/bedste-online-casinoer-en-udforskning-af-topvalg-i/[/url] tilbyder unikke fordele, såsom hurtigere transaktioner og anonymitet. Uanset om du er nybegynder eller erfaren spiller, kan du finde spændende spil, hvor du kan nyde fra komforten af dit hjem. Gå ikke glip af muligheden for at spille uden bekymringer med bitcoin!
JenniferPiche 21 Mayıs 2026 12:59
Я извиняюсь, но, по-моему, Вы не правы. Давайте обсудим это. Пишите мне в PM. Playing Casino Online Slots, [url=https://utahrelocations.com/2026/03/18/experience-thrill-and-excitement-with-7gold-casino/]https://utahrelocations.com/2026/03/18/experience-thrill-and-excitement-with-7gold-casino/[/url] gives an exciting experience. Boasting various themes and styles, gamblers can quickly find a favorite machine. If you're wanting big wins or just wanting fun, Casino Online Slots features something for everyone. Don't miss out on the excitement today!
DavidLag 21 Mayıs 2026 12:30
Я считаю, что Вы допускаете ошибку. Могу отстоять свою позицию. Пишите мне в PM. 1xbet app, [url=https://orpytec.com.br/understanding-casino-access-the-key-to-online/]https://orpytec.com.br/understanding-casino-access-the-key-to-online/[/url] - The platform offers users an easy way to gamble on their favorite sports. With its intuitive interface, the application ensures a seamless gambling experience for everyone. Players can access various features, making it a preferred choice among enthusiasts.
DebbieThype 21 Mayıs 2026 12:04
Это мне не подходит. Может, есть ещё варианты? Казино онлайн, [url=http://ruall.com/raznoe-po-biznesu/92023-kupit-vitaminyi-onlayn.html#92837]http://ruall.com/raznoe-po-biznesu/92023-kupit-vitaminyi-onlayn.html#92837[/url] создает уникальные альтернативы для участников. В этих залах каждый может заиметь опыт азартными играми. Призы делают процесс еще приятнее. Не упустите шанс погрузиться в игру!
Nicolebag 21 Mayıs 2026 11:38
Participating in online casino slots, [url=https://osadazbojecka.pl/casinoways-casino-independent-review-2026-a-17/]https://osadazbojecka.pl/casinoways-casino-independent-review-2026-a-17/[/url] is a exciting experience. Players can select from a diverse array of games, each offering unique aspects. With stunning graphics and enticing soundtracks, online casino slots promise hours of fun.
TammyInoto 21 Mayıs 2026 10:52
все прям профи такие.... In the world of gaming, online casino, [url=http://hanamirestaurante.com.br/2026/04/27/integracao-tecnologica-na-industria-farmaceutica/]lovegra[/url] platforms offer entertaining experiences. Players can enjoy a variety of options, from slots to table games, all from the comfort of their residences. Knowing the guidelines is key to success.
Natashakib 21 Mayıs 2026 10:26
Casinos Not on Gamstop, [url=https://bizbauer.com/discovering-casino-sites-not-on-gamstop-1668691051/]https://bizbauer.com/discovering-casino-sites-not-on-gamstop-1668691051/[/url] offer an exciting alternative for players seeking variety. These places provide alternative experiences without limitations. Players can enjoy their favorite games without worries. Choose Casinos Not on Gamstop for engaging online fun!
Rebeccabuino 20 Mayıs 2026 20:59
udenlandsk casino uden rofus, [url=http://merkor.net/2026/04/23/bedste-casino-uden-om-roufus-din-guide-til-sikker/]http://merkor.net/2026/04/23/bedste-casino-uden-om-roufus-din-guide-til-sikker/[/url] tilbyder en unik spilleoplevelse for gamblere, der ønsker at komme uden om restriktioner. Denne variant er i høj kurs blandt gamblers. Når du vælger et udenlandsk casino uden rofus, opnår du indgang tilbude, der ofte ses i lokale online spillemiljøer. Det er en fantastisk mulighed for at underholde sig uden for mange begrænsninger.
AngelaFat 20 Mayıs 2026 19:46
In een omgeving van web casinospellen, biedt een online casino zonder CRUKS, [url=https://www.univ-bouira.dz/vrre/?p=34617]https://www.univ-bouira.dz/vrre/?p=34617[/url] entertainment zonder verplichtingen. Bij dit soort casino's kun je meer ontdekken voor spelers. Online casino zonder CRUKS biedt unieke kansen.
Angiemor 20 Mayıs 2026 18:54
Ваша мысль блестяща парфюмерия, [url=https://smellsi.ru/]https://smellsi.ru[/url] играет недвусмысленную роль в нашей жизни. Запахи могут выразить наше настроение и стиль. Каждый пахучий состав — это чувства, погружающая в мир ассоциаций.
TomFof 20 Mayıs 2026 18:03
nuevos casinos online, [url=https://www.lionsroarcapital.com/los-mejores-casinos-online-confiables-en-chile-13/]https://www.lionsroarcapital.com/los-mejores-casinos-online-confiables-en-chile-13/[/url] - Los recentes casinos online ofrecen gran oportunidad para divertirse con tГtulos innovadores. Aquellos casinos brindan incentivos atractivas para nuestros usuarios, animГЎndoles a explorar sus experiencias de apuestas.
LindaCoile 20 Mayıs 2026 17:31
Я советую Вам. Туроператор Азурит, [url=https://toirscript.com/user/tranmica]https://toirscript.com/user/tranmica[/url] предлагает уникальные авиаперелеты в красивые уголки мира. Туристы могут удобно провести время и открыть новые традиции.
Tonimaite 20 Mayıs 2026 16:34
In Nederland zijn er veel opties voor online gokken, maar geen CRUKS casino, [url=https://cursos.institutofernandabenead.com.br/de-beste-buitenlandse-online-casino-s-win-met/]https://cursos.institutofernandabenead.com.br/de-beste-buitenlandse-online-casino-s-win-met/[/url] blijft populair. Spelers kiezen vaak voor veilige platforms die om om te spelen. Onze tips helpen je in het vinden van betrouwbare sites. Vergeet niet steeds verantwoord te gokken.
Staceytok 20 Mayıs 2026 16:19
Playing at an online casino, [url=https://leygcg.imembrillos.gob.mx/is-midnight-wins-casino-legit-a-comprehensive-32/]https://leygcg.imembrillos.gob.mx/is-midnight-wins-casino-legit-a-comprehensive-32/[/url] offers a thrilling experience. By various games like slots, poker, and blackjack, players can enjoy exciting challenges. Additionally, bonuses enhance the fun, making every session more enjoyable.
RickyRaW 20 Mayıs 2026 13:13
udenlandske spillemaskiner, [url=https://prompttradefairs.com/udenlandske-spillemaskiner-en-guide-til-verdens/]https://prompttradefairs.com/udenlandske-spillemaskiner-en-guide-til-verdens/[/url] tilbyder en underholdende måde at færdiggøre sig selv på. Disse maskiner anekterer ofte med betagende funktioner og tilbud. Sådan teste udenlandske spillemaskiner kan give store indtægter og glæde.
Bryantuh 20 Mayıs 2026 11:47
When you decide on to play online casino, [url=https://ocursoesteticaautomotiva.com.br/voodoo-wins-casino-review-2026-unveiling-the-magic-7/]https://ocursoesteticaautomotiva.com.br/voodoo-wins-casino-review-2026-unveiling-the-magic-7/[/url] games, you enter a world of excitement. With a variety of choices available, you can enjoy everything from table games to real-time experiences.
Adrianaagent 20 Mayıs 2026 11:45
casino zonder CRUKS, [url=http://www.rehemastuckey.com/review/babyswereld/casino-zonder-cruks-nederland-speel-veilig-en-vrij-2/]http://www.rehemastuckey.com/review/babyswereld/casino-zonder-cruks-nederland-speel-veilig-en-vrij-2/[/url] is een geweldige optie voor spelers die op zoek zijn naar vrijheid en plezier. Hier kunnen spelers genieten van hun favoriete spellen zonder beperkingen. Er zijn verschillende spellen, van slots tot tafelspellen. Iedereen kan deze ervaring genieten. Bezoek nu een casino zonder CRUKS en beleef de spanning die het te bieden heeft!
DonteAlcob 20 Mayıs 2026 10:11
куда катится мир? Diese interaktive Erlebnis, das immersive roulette, [url=http://testlinkcs.co.uk/vivah-new/immersive-roulette-das-ultimative-spielerlebnis-im/]http://testlinkcs.co.uk/vivah-new/immersive-roulette-das-ultimative-spielerlebnis-im/[/url] gewГ¤hrt, bringt Spieler in eine neue Dimension des Spiels. Die Dealer und die 3D Grafik generieren eine intensive AtmosphГ¤re, welche das Einsatz aufregend macht. Zudem kГ¶nnen Spieler kommunizieren und das Geschehen in Echtzeit genieГџen.
DebbieThype 20 Mayıs 2026 08:22
Я извиняюсь, но, по-моему, Вы не правы. Давайте обсудим это. Казино онлайн, [url=https://www.hdclub.ua/forum/showthread.php?3865-%D0%93%D0%B4%D0%B5-%D0%B2%D1%8B%D0%B3%D0%BE%D0%B4%D0%BD%D0%BE-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D1%81%D0%BE%D0%BB%D0%BD%D0%B5%D1%87%D0%BD%D1%8B%D0%B5-%D0%BF%D0%B0%D0%BD%D0%B5%D0%BB%D0%B8-%D0%B8-%D0%B0%D0%BA%D0%BA%D1%83%D0%BC%D1%83%D0%BB%D1%8F%D1%82%D0%BE%D1%80%D1%8B&highlight=%D1%81%D0%BE%D0%BD%D1%8F%D1%87%D0%BD%D1%96]https://www.hdclub.ua/forum/showthread.php?3865-%D0%93%D0%B4%D0%B5-%D0%B2%D1%8B%D0%B3%D0%BE%D0%B4%D0%BD%D0%BE-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D1%81%D0%BE%D0%BB%D0%BD%D0%B5%D1%87%D0%BD%D1%8B%D0%B5-%D0%BF%D0%B0%D0%BD%D0%B5%D0%BB%D0%B8-%D0%B8-%D0%B0%D0%BA%D0%BA%D1%83%D0%BC%D1%83%D0%BB%D1%8F%D1%82%D0%BE%D1%80%D1%8B&highlight=%D1%81%D0%BE%D0%
Charlotedresy 20 Mayıs 2026 07:07
Het no CRUKS casino, [url=http://carolkherlakian.com.br/goksite-zonder-cruks-ontdek-vrijheid-in-online/]http://carolkherlakian.com.br/goksite-zonder-cruks-ontdek-vrijheid-in-online/[/url] biedt spelers een unieke ervaring tijdens het online gokken. Bescherming staat voorop, zodat je veilig kunt spelen. Ontdek diverse opties en geniet van fantastische promoties.
Julieref 20 Mayıs 2026 05:20
а мне нравится... классно... 1xbet зеркало, [url=https://1win-tik17.top/]https://1win-tik17.top/[/url] помогает пользователям обходить блокировки и получать доступ к платформе. Указанная версия сайта обеспечивает стабильную работу, из-за того что пользователи способны делать ставки без проблем. Обращаясь к 1xbet зеркало, спортсмены получают возможность воспользоваться всеми услугами сайта, независимо от локальными ограничениями.
Joannetoite 20 Mayıs 2026 04:09
Het vinden van het beste online casino buitenland, [url=https://gartoni.de/2026/05/13/buitenlandse-casino-betrouwbaarheid-wat-je-moet-16/]https://gartoni.de/2026/05/13/buitenlandse-casino-betrouwbaarheid-wat-je-moet-16/[/url] is een essentiГ«le stap voor deelnemers. Voor een zorgeloos speelervaring is het aanbevelenswaardig om licenties te controleren. Elk platform biedt verschillende spellen en aanbiedingen die nuttig zijn voor doorgewinterde spelers.
Boonestone 20 Mayıs 2026 04:08
online casino, [url=http://www.rehemastuckey.com/review/trustpilot14055/unveiling-hispin-casino-a-closer-look-at-reviews/]http://www.rehemastuckey.com/review/trustpilot14055/unveiling-hispin-casino-a-closer-look-at-reviews/[/url] provides a engaging experience for players. Games include blackjack, each offering fun and chance to win big. Experience the action today!
Alfredomum 20 Mayıs 2026 03:13
https://ural-hifi.ru/
Cynthiamag 20 Mayıs 2026 02:30
Согласен, весьма полезная фраза Im spannenden Bereich des Online-Casinos erfreut sich Blitz-Roulette groГџer Anziehungskraft. Die Mischung aus gГ¤ngigem Roulette und modernen Funktionen macht das lightning roulette online casino, [url=http://writingandconcepts.com.au/index.php/2026/04/21/lightning-roulette-spielen-ein-aufregendes/]http://writingandconcepts.com.au/index.php/2026/04/21/lightning-roulette-spielen-ein-aufregendes/[/url] zu einem besonderen Erlebnis fГјr GlГјcksspielfans. Die chance auf hohe Einnahmen zieht viele Benutzer an. Tauchen Sie ein in die rasante Welt des digitalen Spielens und erleben Sie die Adrenalin des Lightning Roulette online casino!
Reginafrula 20 Mayıs 2026 02:06
Если даже было, не срите в душу мне.. 1xbet casino online, [url=https://next.etabletka.sk/easy-steps-to-sign-up-for-1xbet-malaysia/]https://next.etabletka.sk/easy-steps-to-sign-up-for-1xbet-malaysia/[/url] offers an extensive selection for gamers worldwide. Players can enjoy captivating games, from slots to live dealer experiences. The platform ensures protection for all transactions. Join now for exclusive bonuses!
TracyFruct 20 Mayıs 2026 01:12
Обойдется как-нибудь. wypЕ‚acalne kasyna, [url=https://htxdienphuongson.vn/wypacalne-kasyna-internetowe-z-patnociami-blik/]https://htxdienphuongson.vn/wypacalne-kasyna-internetowe-z-patnociami-blik/[/url] to miejsca, gdzie gracze mogД… liczyД‡ na uczciwe wypЕ‚aty. DostД™pne sД… duЕјe opcji na osiД…gniД™cie sukcesu. Koniecznie trzeba zastanowiД‡ siД™ nad wybГіr odpowiedniego miejsca.
CarrieMix 20 Mayıs 2026 01:11
Online casino, [url=https://dantataplastic.com/olimp-casino-uzbekistan-a-premier-gaming-91/]https://dantataplastic.com/olimp-casino-uzbekistan-a-premier-gaming-91/[/url] deliver a distinct adventure for gamblers. With various games, customers can appreciate thrilling moments. Bonuses enhance the excitement more, making it a must-try for individuals.
StellaBiope 19 Mayıs 2026 19:31
Полностью разделяю Ваше мнение. В этом что-то есть и я думаю, что это отличная идея. 1xbet, [url=https://yclmarketing.co.tz/unlocking-the-secrets-of-bonusdetails-everything/]https://yclmarketing.co.tz/unlocking-the-secrets-of-bonusdetails-everything/[/url] распространяет широкий ассортимент ставок РЅР° разнообразные события. РРіСЂРѕРєРё РјРѕРіСѓС‚ смочь интересные условия Рё получать внушительные СЃСѓРјРјС‹. 1xbet представляет СЃРѕР±РѕР№ РЅР° всемирном СѓСЂРѕРІРЅРµ, заинтересовывая РёРіСЂРѕРєРѕРІ РёР· разных стран.
JenniferAlada 19 Mayıs 2026 19:30
Exploring the fascinating universe of new casino uk, [url=https://buzzcomment.net/2026/05/10/no-registration-casino-uk-the-future-of-online-7/]https://buzzcomment.net/2026/05/10/no-registration-casino-uk-the-future-of-online-7/[/url] is a fantastic method to experience fresh games and compelling bonuses. In novel aspects, players can enjoy an immersive play experience like never before. Don’t miss out on the possibility to try your luck and win big!
PamelaApaby 19 Mayıs 2026 19:30
In Nederland zijn er talrijke opties voor gokken, waaronder casino zonder CRUKS, [url=http://forumdeimoveis.com/2026/05/14/betrouwbare-online-casino-s-in-het-buitenland-wat-20/]http://forumdeimoveis.com/2026/05/14/betrouwbare-online-casino-s-in-het-buitenland-wat-20/[/url]. Deze plekken bieden een unieke ervaring voor fans. Proef de opwinding van meerdere spellen zonder beperkingen.
DanaReawn 19 Mayıs 2026 15:47
Hos webcasinoer finder du et væld af underholdning. casino online udenlandsk, [url=https://elpariceo.com/nye-danske-casinoer-en-guide-til-de-seneste/]https://elpariceo.com/nye-danske-casinoer-en-guide-til-de-seneste/[/url] tilbyder betagende bonusser og tilbudsmuligheder. Nyd dine favoritter direkte fra din egen hjem.
Lesleyrop 19 Mayıs 2026 15:46
BC Game casino, [url=https://gambarigroup.com/polska-bcgame-ekscytujcy-wiat-gier-online/]https://gambarigroup.com/polska-bcgame-ekscytujcy-wiat-gier-online/[/url] offers a exciting gaming experience. Users can savor a variety of options, offering hours of fun. Engage with the dynamic community today!
VannPak 19 Mayıs 2026 13:43
If you're looking for the premier entertainment, best casinos, [url=https://macvr.ro/casinos-online-em-portugal-tudo-o-que-voce-precisa-14/]https://macvr.ro/casinos-online-em-portugal-tudo-o-que-voce-precisa-14/[/url] provide an unmatched experience. Boasting a variety of games, sumptuous atmospheres, and stimulating events, they attract players from around the globe.
Cassieswoky 19 Mayıs 2026 13:43
Os sites de apostas estão se tornando cada vez mais populares em Portugal. Disponibilizando uma ampla gama de jogos, eles atraem novos jogadores. Casinos Online Portugal, [url=https://lounge.mpdi.org.uk/2026/05/14/melhores-casinos-online-para-jogar-descubra-as-3/]https://lounge.mpdi.org.uk/2026/05/14/melhores-casinos-online-para-jogar-descubra-as-3/[/url] é reconhecido pela eficiência de suas opções, com bônus atraentes e suporte ao cliente. Além disso, a vivência no entretenimento online é conveniente, tornando os casinos online a melhor escolha para os entusiastas.
Sharonjem 19 Mayıs 2026 13:19
Вы серьезно? lightning roulette live, [url=https://dev-shvsorg.pantheonsite.io/lightning-roulette-spielen-ein-aufregendes/]https://dev-shvsorg.pantheonsite.io/lightning-roulette-spielen-ein-aufregendes/[/url] - Live Lightning Roulette ist ein fesselndes Spiel, das den Nervenkitzel des klassischen Rulettegrunds mit innovative Technologie verbindet. Spieler kГ¶nnen besondere Multiplikatoren gewinnen, die das Erlebnis in nГ¤chsten Level heben. Mit dem echten Dealerin wird die AtmosphГ¤re dynamisch. Tauchen Sie ein in die Dimension des Lightning Roulette Live und erleben Sie eine adrenalinfГ¶rdernde Spannung!
Pageepife 19 Mayıs 2026 12:54
мда не повезло В интернете можно найти множество способов обхода блокировок, и одним из самых популярных является 1xbet зеркало, [url=https://1win-xuj5.cam/]1хбет официальный[/url]. Это вариант доступа к сайту, который позволяет пользователям доступать услуги букмекера без ограничений. С зеркалом просто делать ставки и следить за результатами матчей, сохраняя безопасность своих данных. Не забывайте, что часто обновляемые зеркала помогут избежать проблем с доступом к сайту.
JessicaApawl 19 Mayıs 2026 12:49
который я уже неделю исчу 1xbet app, [url=http://bitbuzz.org/understanding-bonus-details-in-online-betting-15/]http://bitbuzz.org/understanding-bonus-details-in-online-betting-15/[/url] - The application from 1xbet offers players a seamless experience. With numerous features, it allows hassle-free access to betting alternatives. Stay informed with real-time updates on events.
SoniaEvoli 19 Mayıs 2026 12:32
Gambling enthusiasts often seek out choices for exciting experiences. Real money gambling, [url=https://ciclotime.com.br/experience-the-thrills-of-wild-tokyo-your-ultimate/]https://ciclotime.com.br/experience-the-thrills-of-wild-tokyo-your-ultimate/[/url] offers thrills that keeps players engaged. When you prefer poker, the allure of gaining cash draws many.
Rebeccagap 19 Mayıs 2026 10:33
Discovering latest casino sites UK is a thrilling experience for players. These venues offer unique games and alluring bonuses. Embrace the world of entertainment with new casino sites uk, [url=https://ucdarnetal.fr/exploring-the-exciting-world-of-new-casinos-in-the-5/]https://ucdarnetal.fr/exploring-the-exciting-world-of-new-casinos-in-the-5/[/url]!
Angiemor 19 Mayıs 2026 07:14
Ответ на Ваш вопрос я нашёл в google.com парфюмерия, [url=https://smellsi.ru/]https://smellsi.ru/[/url] — это искусство создания уникальных ароматов. Каждый парфюм откровенничает свою историю. Нахождение аромата — это путешествие в мир эмоций, где каждая нота переплетается с другими.
Kimrah 19 Mayıs 2026 07:09
Exploring the novel world of new casino uk, [url=https://www.vitongpl.com/google-pay-casinos-in-the-uk-a-guide-to-seamless/]https://www.vitongpl.com/google-pay-casinos-in-the-uk-a-guide-to-seamless/[/url], players are realizing a vast array of variations. Cutting-edge technologies ensure a smooth experience, making every session enjoyable. Don't miss the opportunity to delight in top-notch deals that enhance your gaming adventure.
Rosespept 19 Mayıs 2026 07:09
Онлайн казино предлагают интересные online Casino бонусы, [url=https://bebidassaludables.click/chem-otlichaetsja-caesars-palace-casino-unikalnye-2/]https://bebidassaludables.click/chem-otlichaetsja-caesars-palace-casino-unikalnye-2/[/url] для новых игроков. Обычно это конкурсные предложения, которые поднимают шансы на выигрыш. Обратите внимание, что ограничения могут колебаться у разных казино.
NicoleDor 19 Mayıs 2026 05:22
Я хорошо разбираюсь в этом. Могу помочь в решении вопроса. Вместе мы сможем найти решение. 1xbet зеркало, [url=https://1win-man.lol/]https://1win-man.lol/[/url] – это отличное решение для тех, кто хочет получить доступ к букмекерским услугам. Вопрос с блокировками чаще всего решается именно с помощью зеркал. Букмекер представляет разнообразные адреса, которые помогают избежать запреты. При помощи 1xbet зеркало, пользователи могут без проблем играть, не опасаясь ухудшения ситуации.
Kathleenfus 19 Mayıs 2026 05:18
Согласен, эта замечательная мысль придется как раз кстати For those looking to enjoy betting, the 1xbet app registration, [url=https://shareevery.day/1xbet-app-spain-a-complete-guide-for-bettors/]https://shareevery.day/1xbet-app-spain-a-complete-guide-for-bettors/[/url] is a key step. The following guide assists you in navigating the process quickly. Simply download the app, complete the required information, and commence placing your bets. Enjoy!
pocagow 19 Mayıs 2026 05:13
Online casino games, [url=http://beot.cl/index.php/2026/05/discover-the-excitement-and-benefits-of-online/]http://beot.cl/index.php/2026/05/discover-the-excitement-and-benefits-of-online/[/url] provide an exciting selection of entertainment for players. Including slots to table games, this experience is unique. Players may discover their luck and skills in a digital environment.
Dianaphogs 19 Mayıs 2026 05:13
online casinos UK, [url=https://victorymedical.vn/the-ultimate-guide-to-casino-reviews-in-the-uk/]https://victorymedical.vn/the-ultimate-guide-to-casino-reviews-in-the-uk/[/url] present a plethora of entertaining games. With innovative technology, players have access to extraordinary gaming experiences. Bonuses are plentiful, making every visit rewarding.
AshleySpowl 19 Mayıs 2026 01:37
Online Casino BC Game, [url=https://hwnerds.com/unleashing-the-fun-the-hash-game-official-mirror/]https://hwnerds.com/unleashing-the-fun-the-hash-game-official-mirror/[/url] offers numerous games for gamblers to enjoy. With captivating graphics and easy-to-navigate interfaces, it guarantees a fantastic gaming experience. Join today and explore thrilling bonuses and rewards!
Jondruck 19 Mayıs 2026 01:05
Choosing the best casinos, [url=https://atsonproducts.in/casinoonline11052/discover-new-casinos-in-the-uk-your-guide-to/]https://atsonproducts.in/casinoonline11052/discover-new-casinos-in-the-uk-your-guide-to/[/url] makes a difference for an enjoyable gaming experience. Within the vast array of options, players should think about aspects like game variety, bonus offers, and customer support.
Melissamek 19 Mayıs 2026 01:04
Виртуальный мир online Casino слоты, [url=https://www.livesicily.it/2026/05/07/kogda-bonus-bitstarz-vygoden/]https://www.livesicily.it/2026/05/07/kogda-bonus-bitstarz-vygoden/[/url] предлагает игрокам оригинальный опыт. Здесь выбор игр поражает воображение. Все слот-автомат имеет отличительный стиль и оттенок, что делает игру увлекательной. Насладитесь свои шансы на выигрыш и развлекайтесь в мир online Casino слоты!
Denisecub 18 Mayıs 2026 22:38
Mobile casinos, [url=https://floorthreedesigns.com/harnessing-solar-energy-with-powersun-your-path-to/]https://floorthreedesigns.com/harnessing-solar-energy-with-powersun-your-path-to/[/url] present a special gaming experience. Players can enjoy multiple games anytime. The ease of mobile devices makes it effortless to play on the go.
HeatherBib 18 Mayıs 2026 22:30
Могу предложить Вам посетить сайт, на котором есть много информации на интересующую Вас тему. For those looking to enjoy gaming on the go, 1xbet mobile download, [url=https://hdteknikkombicim.com/2026/04/12/informacija-o-kazino-kak-vybrat-luchshee-zavedenie/]https://hdteknikkombicim.com/2026/04/12/informacija-o-kazino-kak-vybrat-luchshee-zavedenie/[/url] offers a seamless experience. You can easily access a wide range of games. By downloading the app, players can navigate live betting and various features instantly.
ScarletPaype 18 Mayıs 2026 22:13
Looking for fresh gaming options? Check out new casino sites uk, [url=https://esteticafelix.it/unlock-exciting-opportunities-free-spins-on-card/]https://esteticafelix.it/unlock-exciting-opportunities-free-spins-on-card/[/url] that offer exclusive games and luring bonuses. Players can experience innovative features and a superb selection of fun.
StanleyPhada 18 Mayıs 2026 22:12
Онлайн казино, [url=https://www.siennacustomhomesinc.com/2026/05/obzor-caesar-casino-obzor-i-osobennosti-onlajn/]https://www.siennacustomhomesinc.com/2026/05/obzor-caesar-casino-obzor-i-osobennosti-onlajn/[/url] обеспечивают уникальную возможность отдыхать в любое время. Клиенты могут получать удовольствие разнообразными развлечениями и получать реальные деньги. Успех зависит от удачи, а впечатления лишь усиливает азарт.
PriscillaSnind 18 Mayıs 2026 19:21
Погрузитесь в мир азартных игр, где вывоспользуйтесь шансом online Casino играть, [url=http://paradisep.com/vozmozhnosti-casino-columbus-otkrojte-mir-azartnyh/]http://paradisep.com/vozmozhnosti-casino-columbus-otkrojte-mir-azartnyh/[/url]! Это интересное развлечение предлагает разнообразие слотов. Не упустите шанс исследовать свою удачу!
Dereknuary 18 Mayıs 2026 19:20
The rise of new casino uk, [url=https://mailssoftware.org/blogs/unlock-exciting-bonuses-free-spins-on-card/]https://mailssoftware.org/blogs/unlock-exciting-bonuses-free-spins-on-card/[/url] has caught the interest of gamers. With novel games and profitable bonuses, players can enjoy a exciting gaming atmosphere.
Scatdroli 18 Mayıs 2026 19:14
udenlandske spillemaskiner, [url=https://villagevacation.co.il/2026/04/26/trovrdig-udenlandsk-casino-find-din-sikker/]https://villagevacation.co.il/2026/04/26/trovrdig-udenlandsk-casino-find-din-sikker/[/url] fremhæver en fortryllende mulighed for gamblere. Gennem mangfoldige temaer og bonusfunktioner kan man opleve enestående spiloplevelser.
DavidVaw 18 Mayıs 2026 19:12
BC Game casino, [url=https://helpershq.com/index.php/2026/05/11/exploring-the-mirror-hash-game-innovative-gameplay/]https://helpershq.com/index.php/2026/05/11/exploring-the-mirror-hash-game-innovative-gameplay/[/url] offers an exciting experience for online gaming enthusiasts. Featuring numerous game options, players can enjoy an assortment of thrilling titles. Start playing to find your luck at BC Game casino!
Tinasolla 18 Mayıs 2026 17:31
Предлагаю Вам зайти на сайт, с огромным количеством информации по интересующей Вас теме. Для себя я нашел много интересного. магазин побутової техніки, [url=https://ua-inform.com.ua/invertornyy-chy-neinvertornyy-kondytsioner-realna-riznytsya-v-rahunkah-za-elektroenerhiyu/]https://ua-inform.com.ua/invertornyy-chy-neinvertornyy-kondytsioner-realna-riznytsya-v-rahunkah-za-elektroenerhiyu/[/url] РїСЂРѕРїРѕРЅСѓС” широкий асортимент товарів для житла. РЈ нас можна знайти РІСЃС– потрібні речі для зручності вашого життя.
WilliamGrath 18 Mayıs 2026 16:35
online Casino бонусы, [url=https://dianashakti.com/index.php/2026/05/10/gde-iskat-promo-code-caesars-564595223/]https://dianashakti.com/index.php/2026/05/10/gde-iskat-promo-code-caesars-564595223/[/url] предоставляют игрокам интересные возможность приумножить свой ресурс. Данные предложения привлекают новых и постоянных клиентов. не упустите шанс использовать выгодные online Casino бонусы!
WendyHon 18 Mayıs 2026 16:35
free spins casinos, [url=https://www.neue.co/bet-buffoon-de-ultieme-gids-voor/]https://www.neue.co/bet-buffoon-de-ultieme-gids-voor/[/url] offer players the chance to win big without risking their own money. Such promotions allow gamers to spin the reels at no cost and potentially walk away with true cash. Find out the excitement of free spins today!
Kellylew 18 Mayıs 2026 16:16
The popularity of Online casino, [url=https://demo.quierobragasusadas.com/exploring-the-exciting-world-of-wazamba-your/]https://demo.quierobragasusadas.com/exploring-the-exciting-world-of-wazamba-your/[/url] has altered the way people wager money. By using advanced technology, players can experience their favorite games in the comfort of home, creating it more accessible than ever.
ShakiraPex 18 Mayıs 2026 16:09
online casino, [url=http://old.tags78.es/no-verification-casinos-uk-a-comprehensive-guide-2/]http://old.tags78.es/no-verification-casinos-uk-a-comprehensive-guide-2/[/url] offer an engaging way to take part in your favorite games. By using technology, players can connect to a variety of games anytime, anywhere.
Debraswors 18 Mayıs 2026 15:59
Кроме шуток! This emerging trend in wagering is the online platforms like 1xbet online casino, [url=http://noentry.pl/the-future-of-ios-apps-innovations-and-trends/]http://noentry.pl/the-future-of-ios-apps-innovations-and-trends/[/url]. Participants can enjoy a variety of games and thrilling bonuses. Engage with the enthralling world of virtual betting today!
Latriceelisp 18 Mayıs 2026 15:04
По моему мнению Вы ошибаетесь. Предлагаю это обсудить. Пишите мне в PM. магазин побутової техніки, [url=https://podilskiy.com.ua/kondytsioner-z-ionizatorom-i-filtrom-chy-realno-ochyshchuie-povitria-vid-alerheniv/]https://podilskiy.com.ua/kondytsioner-z-ionizatorom-i-filtrom-chy-realno-ochyshchuie-povitria-vid-alerheniv/[/url] РїСЂРѕРїРѕРЅСѓС” великий асортимент електроніки. Р’Рё зможете отримати РІСЃРµ необхідне для ефективності. Наші вартість вас приємно урадують. РќРµ зволікайте, відвідайте!
Karenjailm 18 Mayıs 2026 13:40
Онлайн-казино предлагают множество развлечений, среди которых online Casino слоты, [url=http://www.social-action-ring.org/category04/kak-otkryt-lootrun-cherez-zerkalo-621989223/]http://www.social-action-ring.org/category04/kak-otkryt-lootrun-cherez-zerkalo-621989223/[/url] занимают особое место. Игроки могут наслаждаться увлекательными играми и азартом, выбирая из разнообразия тем и бонусов. Каждый слот обладает уникальные особенности, что добавляет игровому процессу интерес. Выигрыши бывают различными, что влечёт игроков со всего мира. Независимо от опыта, online Casino слоты способны восхитить своим дизайном.
JackPousa 18 Mayıs 2026 12:50
dansk casino uden rofus, [url=http://carolkherlakian.com.br/nye-danske-casinoer-2026-hvad-du-skal-vide-2/]http://carolkherlakian.com.br/nye-danske-casinoer-2026-hvad-du-skal-vide-2/[/url] tilbyder en fantastisk mulighed for spillere at nyde deres yndlingsspil uden begrænsninger. En type casino giver mulighed for at spille trygt og oplevelse spændingen ved gambling. Sådanne platforme er optimale for dem, der ønsker at involvere sig uden hinder.
KeshiaAnymn 18 Mayıs 2026 12:50
Casino Online BC Game, [url=https://www.vmmedical.gr/bc-hash-game-the-ultimate-blockchain-adventure/]https://www.vmmedical.gr/bc-hash-game-the-ultimate-blockchain-adventure/[/url] предлагает уникальные возможности для азартных игроков. Здесь вы найдете широкий выбор игр, среди которых слоты и настольные. Легкий в использовании интерфейс обеспечивает интуитивный доступ к всем функциям. Вносите депозиты и получите вознаграждения за новые ставки. Присоединяйтесь к Casino Online BC Game и наслаждайтесь азартом!
Wendyzix 18 Mayıs 2026 02:40
Finding the greatest gaming establishments can be a challenge, especially for players who seek thrills outside of Gamstop. The best casino not on Gamstop, [url=http://test.desa.com.my/wp/2026/05/11/exploring-uk-casinos-not-on-gamstop-1112897488/]http://test.desa.com.my/wp/2026/05/11/exploring-uk-casinos-not-on-gamstop-1112897488/[/url] offers a wide range of games and generous bonuses. Enjoy playing away from restrictions and explore different options!
PeggywiRty 18 Mayıs 2026 02:40
online Casino бонусы, [url=https://www.amhal-sono.ma/bonusy-lootrun-kak-poluchit-maksimalnuju-vygodu/]https://www.amhal-sono.ma/bonusy-lootrun-kak-poluchit-maksimalnuju-vygodu/[/url] мотивируют игроков изобилием предложений. Свободные спины способствуют начинающим получать удовольствие в играх. Стоит изучить требования использования online Casino бонусов.
MarenThuct 17 Mayıs 2026 15:34
Большинство людей мечтают о выигрыше, и online Casino играть, [url=http://planetxenos.com/kak-rabotaet-promo-code-monro-2/]http://planetxenos.com/kak-rabotaet-promo-code-monro-2/[/url] предоставляет такую возможность. Каждый испытывают удачу, используя автоматы и настольные игры. Инвестиции привлекают участников, так как шанс на успех зовет многих.
Courtneyjax 17 Mayıs 2026 08:37
А где у вас логика? To use the 1xbet app registration, [url=https://members.theliftingzone.com/the-intricacies-of-correct-score-betting/]https://members.theliftingzone.com/the-intricacies-of-correct-score-betting/[/url], simply get the application on your device. After that, you need to establish an account by filling out the necessary information. Enjoy betting on your favorite sports!
CharlesClild 17 Mayıs 2026 06:11
Najlepszy kod promocyjny dla Mostbet to obecnie QWERTY555, ktory zapewnia dostep do pelnego bonusu powitalnego. Rejestracja z tym kodem umozliwia odebranie srodkow bonusowych oraz darmowych zakladow. Kod promocyjny bonusu powitalnego Mostbet dziala zarowno w sekcji sportowej, jak i kasynowej. Nowi gracze moga zwiekszyc swoj depozyt i przetestowac platforme bez duzego ryzyka. Mostbet slynie z przejrzystych zasad i szybkich wyplat. Przejdz na zaktualizowana strone Mostbet <a href=https://www.datecs-polska.pl/files/pages/?bonus_powitalny_mostbet.html>https://www.datecs-polska.pl/files/pages/?bonus_powitalny_mostbet.html</a>
Veronicaowess 17 Mayıs 2026 06:10
BC Game casino, [url=https://priorityrehab.org/unlock-exciting-rewards-with-promo-code-at-bc-game/]https://priorityrehab.org/unlock-exciting-rewards-with-promo-code-at-bc-game/[/url] represents a esteemed destination for enthusiasts. Presenting a wide range of gambling experiences, it addresses a broad audience. Become a member the exciting platform and dive into the world of online gaming.
JonathanMosse 17 Mayıs 2026 02:12
супер,давно так не смеялс If you want to enjoy betting on the go, consider the 1xbet mobile download, [url=https://www.ancoratours.com/betcasino160417/the-evolution-of-game-providers-crafting-the-9/]https://www.ancoratours.com/betcasino160417/the-evolution-of-game-providers-crafting-the-9/[/url]. It offers a user-friendly interface and simple navigation. With the app, you can place bets anywhere and anytime, enhancing your gaming experience. Take advantage of it today!
Rachelmog 17 Mayıs 2026 01:18
JB Casino Online, [url=http://www.naranjasperdine.com/blog/a-comprehensive-overview-of-jb-casino-your-5/]http://www.naranjasperdine.com/blog/a-comprehensive-overview-of-jb-casino-your-5/[/url] offers an exciting gaming experience for players worldwide. With a wide variety of games, it ensures entertainment for everyone. Join JB Casino Online and discover the world of digital casinos. Don't miss the moment to win big!
AshleyJeffGeake 17 Mayıs 2026 00:44
bitwinner casino, [url=http://joyvuijk.com/betwinner-your-ultimate-guide-to-online-betting-84/]http://joyvuijk.com/betwinner-your-ultimate-guide-to-online-betting-84/[/url] offers captivating opportunities for players. With an array of games, it draws enthusiasts from around the globe. Players can indulge in top-quality entertainment and potential wins.
AshleyJeffDus 16 Mayıs 2026 23:17
Experience the adventure of online gaming with Casino Online BC Game, [url=http://pathfindertechcorp.com/unlock-entertainment-with-login-bc-fun/]http://pathfindertechcorp.com/unlock-entertainment-with-login-bc-fun/[/url], where enthusiasts can experience a vast variety of games. Become a part of this exciting platform and maximize your chances of winning big!
CocoBunty 16 Mayıs 2026 23:05
dansk casino uden rofus, [url=https://payafoolad.com/spil-uden-om-rufus-oplev-en-ny-verdensdimension/]https://payafoolad.com/spil-uden-om-rufus-oplev-en-ny-verdensdimension/[/url] tilbyder spændende muligheder for spillere. Stedet garanterer aktiviteter uden restriktioner. Du kan nyde forskellige spil samt vinde store gevinster.
BenSed 16 Mayıs 2026 22:03
В этом что-то есть. Теперь стало всё ясно, большое спасибо за помощь в этом вопросе. roulette mit echtgeld, [url=https://blog.thanos.ai/roulette-online-spielen-der-ultimative-leitfaden-4/]https://blog.thanos.ai/roulette-online-spielen-der-ultimative-leitfaden-4/[/url] ist ein spannendes Spiel, das viele Spieler anzieht. Die Aufregung mit dem Roulette ist besonders. GlГјck sind entscheidend, um gewinnen zu erfolgen.
Ashleyfoelm 16 Mayıs 2026 18:51
Я присоединяюсь ко всему выше сказанному. На официальном сайте 1 вин официальный сайт, [url=https://1win-0sgvc.sbs/]1win-0sgvc.sbs[/url] можно получить информацию о вкусе вин. Каждое из вино выделяется своим послевкусием. Здесь предоставлены рекомендации по сочетанию вин, а также мнения клиентов.
ShirleyDialp 16 Mayıs 2026 18:13
JB Casino Platform, [url=https://www.thepropelinitiative.org/comprehensive-jb-casino-review-your-ultimate/]https://www.thepropelinitiative.org/comprehensive-jb-casino-review-your-ultimate/[/url] offers numerous options for gamers. Players can enjoy exciting casino games, like slots and table games. The accessible interface enhances the gaming experience, making it delightful for everyone.
Deborahnag 16 Mayıs 2026 16:19
Online Casino BC Game, [url=http://www.krafhidraulicos.com/wp/decouvrez-l-univers-captivant-du-casino-bc-game-en/]http://www.krafhidraulicos.com/wp/decouvrez-l-univers-captivant-du-casino-bc-game-en/[/url] offers an exciting experience for players. With numerous games, it guarantees endless entertainment. Promotions enhance gameplay, making it even more appealing. Join now!
AdamLix 16 Mayıs 2026 11:38
Полностью разделяю Ваше мнение. Мне кажется это очень хорошая идея. Полностью с Вами соглашусь. 1 вин официальный сайт, [url=https://1win-d9511.cfd/]1win бонусы[/url] предлагает богатый каталог виноводческих изделий для поклонников великолепных вкусов. Заказывая вино, можно испытать интересные кулнарные подборки.
Adamwouch 16 Mayıs 2026 10:10
In the realm of Sports Betting, [url=https://www.nagoya-su.ac.jp/2026/05/129901]https://www.nagoya-su.ac.jp/2026/05/129901[/url], strategies play a crucial role. Grasping the odds and assessing trends can substantially enhance your chances of winning.
AllisonBaide 16 Mayıs 2026 08:34
Hvis du leder efter et spændende sted at spille, er casino online udenlandsk, [url=https://serescent.com/archives/50687]https://serescent.com/archives/50687[/url] et fremragende valg. Her kan du finde forskellige spil og attraktive bonusser. Gå ind i nu for at udforske chancen for fantastiske gevinster.
Cococlott 16 Mayıs 2026 04:45
Я считаю, что Вы ошибаетесь. Пишите мне в PM, поговорим. 1 вин официальный сайт, [url=https://1win-hvfg7.cfd/]https://1win-hvfg7.cfd/[/url] предлагает разнообразный выбор алкогольных напитков. На платформе имеется возможность исследовать новые предложения и узнать больше о различных сортах вина.
TimClari 16 Mayıs 2026 03:53
JB Casino Online, [url=https://johnokeefeactor.com/discover-the-exciting-world-of-jb-casino-online-20/]https://johnokeefeactor.com/discover-the-exciting-world-of-jb-casino-online-20/[/url] обеспечивает игрокам обширный выбор игр. В данном месте вы найдете игровые автоматы от известных разработчиков. Уникальные бонусы и предложения делают увлечение еще значительно увлекательным!
IdaCibrA 16 Mayıs 2026 01:42
casino udenlandsk, [url=https://www.dataprotect.sg/online-poker-uden-rufus-spil-strategi-og-sikkerhed/]https://www.dataprotect.sg/online-poker-uden-rufus-spil-strategi-og-sikkerhed/[/url] tilbyder en spændende rejse for spillere, der ønsker en ny vinkel i deres spillene. Med moderne spilleautomater og interaktive deals fra professionelle croupierer, kan man nyde sig selv, mens man satser indsatser og opnår store præmier. Flere fordele venter på spilleren i dette område. Udforsk de mange perspektiver hos casino udenlandsk.
Angelatuple 16 Mayıs 2026 01:08
Я считаю, что Вы ошибаетесь. Пишите мне в PM. casino roulette, [url=http://klmpolimer.com/die-faszinierende-welt-der-casino-roulette/]http://klmpolimer.com/die-faszinierende-welt-der-casino-roulette/[/url] - Das Casino Roulette-Tisch stellt dar eine faszinierende MГ¶glichkeit, SpaГџ zu erleben. An diesem Ort kommt zusammen Гњberlegung und Schicksal. Gib dich in das fascinierende Erlebnis hineinzugehen.
Kimsipsy 15 Mayıs 2026 22:31
Да, действительно. Я согласен со всем выше сказанным. 1xbet, [url=https://warter.uio.com.tw/polnoe-rukovodstvo-po-stavkam-ot-novichka-do-19/]https://warter.uio.com.tw/polnoe-rukovodstvo-po-stavkam-ot-novichka-do-19/[/url] может предложить широкий ассортимент ставок РЅР° РІСЃРµ РёРіСЂС‹. Постоянные клиенты РјРѕРіСѓС‚ использовать комфортным интерфейсом Рё привлекательными коэффициентами.
TiffyFus 15 Mayıs 2026 21:07
JB Casino Platform, [url=https://www.univ-bouira.dz/vrr/en/?p=8905]https://www.univ-bouira.dz/vrr/en/?p=8905[/url] offers entertaining gaming options for users looking for excitement. With various games, it ensures that everyone finds something attractive. Join the JB Casino Platform today and discover unparalleled fun!
Saraflivy 15 Mayıs 2026 19:00
Oplev et udenlandsk casino uden rofus, [url=https://www.wasi.tech/find-de-bedste-online-casinoer-i-danmark/]https://www.wasi.tech/find-de-bedste-online-casinoer-i-danmark/[/url], hvor mulighederne er mange og underholdningen er i højsædet. Nyd i forskellige muligheder, alt fra spillemaskiner til bordspil. Beskyttelse er altafgørende, så vær bevidst om tilladelser. Find den bedste eventyr hos et udenlandsk casino uden rofus og oplevel dine favorit spil.
RadameTausa 15 Mayıs 2026 18:33
По-моему здесь кто-то зациклился Das Abenteuer von casino live roulette, [url=http://real-timedeals.com/das-beste-live-roulette-ihr-leitfaden-fur-ein/]http://real-timedeals.com/das-beste-live-roulette-ihr-leitfaden-fur-ein/[/url] zeigt eine aufregende Chance, gewaltige Gewinne einzustreichen. Mit der sozialen AtmosphГ¤re genieГџen Spieler den Nervenkitzel in Echtzeit. Machen Sie Ihren Platz am diesem spannenden Tisch!
Amypef 15 Mayıs 2026 14:57
Вы абсолютно правы. В этом что-то есть и идея отличная, поддерживаю. казино для мобильных устройств, [url=http://hilalbosnakozcan.com/index.php/component/k2/item/7]http://hilalbosnakozcan.com/index.php/component/k2/item/7[/url] включает множество вариантов. Игроки могут пробовать в слоты прямо со собственных устройств. Доступность использования — это и есть главное преимущество такого подхода. Разнообразие игровых платформ только растет.
Kerrynoili 15 Mayıs 2026 14:14
JB Casino Review, [url=https://protectaproduct.net/wp/experience-the-thrill-the-jb-casino-platform/]https://protectaproduct.net/wp/experience-the-thrill-the-jb-casino-platform/[/url], is a great platform for players. Offering a diverse selection of games, lucrative rewards are available. The design is appealing, making it effortless to play. Join now and indulge in entertainment!
Alekseydes 15 Mayıs 2026 12:43
Настройка прав доступа помогла разграничить информацию — менеджер видит только своих клиентов, директор видит всё. Конфиденциальные данные защищены внутри компании. [url=https://1upravlenie.ru/]1С Управление нашей фирмой Белгород[/url]
MiriamCax 15 Mayıs 2026 11:52
udenlandske spillemaskiner, [url=https://www.allaboutchimneys.net/bedste-danske-casinoer-din-guide-til-de-mest/]https://www.allaboutchimneys.net/bedste-danske-casinoer-din-guide-til-de-mest/[/url] viser en underholdende oplevelse for gambling-enthusiaster. Disse maskiner demonstrerer innovation fra den globale arena. Udenlandske spillemaskiner kan fange spillere med deres unikke temaer og indstillinger.
Philipgop 15 Mayıs 2026 11:44
Вы ошибаетесь. Могу это доказать. Пишите мне в PM, обсудим. online roulette echtgeld, [url=https://packages.digitalatto.io/online-roulette-echtgeld-tipps-und-strategien-fur/]https://packages.digitalatto.io/online-roulette-echtgeld-tipps-und-strategien-fur/[/url] bietet Spielern die MГ¶glichkeit, mit echtem Geld zu spielen und aufregende Gewinne zu erzielen. Die Online-Casinos bieten diese faszinierende Spielvariante an. Das Spiel um echtes Geld sorgt fГјr eine EindrГјcke. Sich fГјr eine Plattform zu entscheiden, ist maГџgeblich fГјr den Erfolg. Achten Sie auf Bonusangebote und faire Auszahlungsraten.
PamelaReume 15 Mayıs 2026 10:55
Вы мне не подскажете, где я могу найти больше информации по этому вопросу? DГ©couvrez le meilleur casino en ligne, [url=https://aes-plaisance.fr/]casino en ligne fiable[/url] proposant une expГ©rience de jeu fantastique. Profitez de de nombreuses options de jeux, de bonus allГ©chants et d'un support rГ©actif. Ne manquez pas cette chance de gagner gros !
Jaredbrews 15 Mayıs 2026 09:05
Дааа... Выкрутился оч прикольно To enjoy betting on sports, start with the 1xbet app registration, [url=https://www.lpmarreda.it/2026/04/19/the-comprehensive-guide-to-online-slots-overview/]https://www.lpmarreda.it/2026/04/19/the-comprehensive-guide-to-online-slots-overview/[/url]. It is essential to follow a few straightforward steps. After you sign up, you'll gain access to numerous features and bonuses. Do not miss the opportunity to enjoy your betting journey!
KatrinaFep 15 Mayıs 2026 07:08
JB Casino Online, [url=https://bcircleagency.com/jb-casino-login-your-gateway-to-gaming-excitement-2/]https://bcircleagency.com/jb-casino-login-your-gateway-to-gaming-excitement-2/[/url] доступен широкий каталог игр для любителей азартных развлечений. Участвуйте в захватывающих игровых машинах, уютно проводите время и выигрывайте невероятные подарки. Вступайте в мир флеш-игр.
Samapott 15 Mayıs 2026 05:05
Надеюсь, всё нормально roulett online spielen, [url=https://decavisa.com/roulette-mit-echtgeld-der-ultimative-leitfaden-fur-4/]https://decavisa.com/roulette-mit-echtgeld-der-ultimative-leitfaden-fur-4/[/url] ist eine aufregende MГ¶glichkeit, das Casino-Feeling zu erleben. Sollten Sie Sie AnfГ¤nger oder Profi sind, finden Sie zahlreiche Methoden, um Ihre Gewinnchancen zu maximieren. Probieren Ihr GlГјck und versetzen Sie ein in die Welt des Spiels.
MariaLed 15 Mayıs 2026 05:04
In recent years, the explosion of bitcoin esports betting, [url=https://app.trafficivy.com/revolutionizing-sports-betting-a-deep-dive-into-dexsport/]https://app.trafficivy.com/revolutionizing-sports-betting-a-deep-dive-into-dexsport/[/url] has drawn attention from gamers and bettors alike. This new way to wager allows enthusiasts to get involved in the gaming world while utilizing cryptocurrency. With safe transactions, the experience becomes more enjoyable, attracting more participants and creating a unique field in the gambling industry.
LindsayEdisa 15 Mayıs 2026 04:41
Раньше я думал иначе, большое спасибо за помощь в этом вопросе. In today's digital age, online privacy has become a crucial aspect of our lives. With this growing concern, many people seek ways to protect their data and maintain anonymity on the internet. One of the best solutions available is VolnaLink VPN, [url=https://www.fundable.com/linda-moore]https://www.fundable.com/linda-moore[/url]. This service provides users with a secure connection, ensuring that their online activities remain private and protected from prying eyes. By using a VPN, individuals can overcome geographic restrictions and access content that may be unavailable in their region. VolnaLink VPN offers a user-friendly interface, making it easy for anyone to connect to a secure server with just a few clicks. Additional
Michelleknoft 15 Mayıs 2026 02:38
Я думаю, что Вы ошибаетесь. Могу отстоять свою позицию. Пишите мне в PM, обсудим. TonyBet registro EspaГ±a oficial, [url=http://tintboy.com/bbs/board.php?bo_table=free&wr_id=2230327]http://tintboy.com/bbs/board.php?bo_table=free&wr_id=2230327[/url] es un proceso simple y rГЎpido. Al utilizar esta plataforma, los pueden acceder a una amplia variedad de juegos. Las alternativas que ofrece son atractivas y accesibles para todos. TambiГ©n, el registro constituye una aventura Гєnica.
Erikten 15 Mayıs 2026 02:07
казино mostbet, [url=https://mostbet-0zqo4.xyz/]mostbet[/url] предлагает обширный выбор лесов. Здесь вы можете насладиться высококачественной графикой и интуитивно понятным интерфейсом. Вдобавок, регулярные бонусы приятно восхитят игроков!
AlexIncum 15 Mayıs 2026 01:58
Я — этого же мнения. Sociale Projecten Nederland, [url=https://annexa.com.br/lokaal-bier-uit-nederland-een-reis-door-de/]https://annexa.com.br/lokaal-bier-uit-nederland-een-reis-door-de/[/url] is een initiatief dat zich richt op samenlevingsverbetering. Het doel is om ondersteuning te bevorderen in lokale gemeenschappen, zodat iedereen kan deelnemen aan een betere toekomst. Door middel van projecten wordt er gewerkt aan kennis en wordt de sociale cohesie versterkt.
Sofiawharf 15 Mayıs 2026 01:56
Могу я у Вас спросить? 1 вин официальный сайт, [url=https://1win-xzqk5.cfd/]1 win официальный сайт[/url] предлагает широкий ассортимент крепких напитков. Здесь вы найти оригинальные сорта и найти много важной информации о вине.
Joshuawaive 15 Mayıs 2026 00:03
In the world of wagering, a reliable betting system, [url=https://www.chocolatebysmita.com/betwinner-o-zbekistondagi-eng-yaxshi-sport-tikish/]https://www.chocolatebysmita.com/betwinner-o-zbekistondagi-eng-yaxshi-sport-tikish/[/url] can significantly enhance your chances of winning. By analyzing patterns, players can make informed decisions. Whether you prefer games, mastering a betting system is essential.
Robertskeft 14 Mayıs 2026 23:06
Весьма забавная информация РџРѕ мере РІС‹ подумайте Рѕ том, чтобы обновить СЃРІРѕСЋ платформу, windows server 2025 купить, [url=https://www.asesoriacorporativa.com.mx/tax-litigation-at-your-door/]https://www.asesoriacorporativa.com.mx/tax-litigation-at-your-door/[/url] станет выгодным выбором. РЎ этим версия предоставляет повышенную производительность Рё эффективность для вашего бизнеса. РќРµ упустите шанс сделать приобретение windows server 2025.
ThomasClons 14 Mayıs 2026 20:21
Как раз то, что нужно. Я знаю, что вместе мы сможем прийти к правильному ответу. Projecten zoals Sociale Projecten Nederland, [url=http://mtb.orienteering.de/aapje4kids/bosrijk-nederland-de-perfecte-bestemming-voor/2026/04/27/]http://mtb.orienteering.de/aapje4kids/bosrijk-nederland-de-perfecte-bestemming-voor/2026/04/27/[/url] speelt een sleutel functie in de maatschappij. Zij ondersteunen de collectieve samenhang en vormen mogelijkheden voor allen.
Jamarcuskib 14 Mayıs 2026 20:21
Вы быстро придумали такой бесподобный ответ? Bet Tony EspaГ±a pГЎgina registro, [url=https://www.greatkids.com.mx/como-ensenar-a-los-ninos-a-gestionar-las-emociones-y-los-sentimientos/]https://www.greatkids.com.mx/como-ensenar-a-los-ninos-a-gestionar-las-emociones-y-los-sentimientos/[/url] ofrece una experiencia Гєnica para los apostadores. Al abrir tu perfil, tendrГЎs acceso a ofertas exclusivas. Es rГЎpido comenzar a disfrutar de tus entretenimientos favoritos. No te pierdas la oportunidad de unirte a esta plataforma.
Sallyattag 14 Mayıs 2026 14:46
Я думаю, что Вы не правы. Я уверен. Пишите мне в PM, поговорим. септик для частного дома, [url=https://www.praesta.fr/nos-clients/attachment/image008/]https://www.praesta.fr/nos-clients/attachment/image008/[/url] является отличным выбором для постройки водоотведения. Данные устройства помогают очистке сточных вод и обеспечивают экологическую защиту. Эффективность систем гарантирует устойчивость.
GillSquag 14 Mayıs 2026 11:45
казино mostbet, [url=https://mostbet-e1mlt.info/]мостбет[/url] предлагает богатый выбор игр. Здесь доступно испытать счастье на разнообразных автоматах и играх. Бонусы и акции всегда радуют игроков, создавая комфортную атмосферу. Каждый может посмотреть свои силы!
JustinNet 14 Mayıs 2026 11:18
JB Casino Online, [url=https://prompttradefairs.com/the-comprehensive-guide-to-jb-casino-your-ultimate/]https://prompttradefairs.com/the-comprehensive-guide-to-jb-casino-your-ultimate/[/url] предлагает широкий выбор игр для увлечения. Разнообразие азартных игр удовлетворит даже сложных игроков. Качество пользования платформой завоюет многих. Присоединяйтесь к JB Casino Online и начните свой азартный путь!
Jennyvew 14 Mayıs 2026 10:41
bitwinner casino, [url=https://app.trafficivy.com/betwinner-a-plataforma-de-apostas-que-esta-19/]https://app.trafficivy.com/betwinner-a-plataforma-de-apostas-que-esta-19/[/url] offers a thrilling gaming experience for players worldwide. With varied games and rewarding bonuses, it stands out in the online casino landscape. Players can enjoy real-time dealer games and innovative slot machines. Register now to uncover the fun and potential payouts at bitwinner casino!
TammyQuold 14 Mayıs 2026 09:46
BetWinner Sportsbook, [url=https://yasmen.tqnia.me/golden_medica/2026/05/09/betwinner-mobile-app-a-comprehensive-guide-for/]https://yasmen.tqnia.me/golden_medica/2026/05/09/betwinner-mobile-app-a-comprehensive-guide-for/[/url] offers multiple betting options for sports enthusiasts. You can wager on your favorite teams and events. With competitive odds and a user-friendly interface, it’s simple to navigate the platform. Join at this moment and enjoy the thrilling experience BetWinner Sportsbook provides.
Kimberlyket 14 Mayıs 2026 09:03
When you select to Buy Genuine Appliance Parts Online, [url=http://web.hertlers-hoefe.de/essential-guide-to-preventive-maintenance-for-your-frigidaire-dryer/]http://web.hertlers-hoefe.de/essential-guide-to-preventive-maintenance-for-your-frigidaire-dryer/[/url], you ensure quality for your appliances. Possessing original parts prolongs their functionality and maintains efficiency. It's essential to utilize in validated sources to eliminate issues down the line. With a extensive selection, finding the right parts becomes straightforward. Take advantage of the convenience of online shopping!
Gloriadruse 14 Mayıs 2026 08:24
Замечательно, полезное сообщение казино mostbet, [url=https://mostbet-mr4t1.top/]mostbet зеркало[/url] предлагает широкий выбор азартных игр, включая игры на автоматах. Источник эмоций для многих игроков, оно привлекает внимание своим уникальным стилем и комфортным интерфейсом.
Mattpes 14 Mayıs 2026 06:23
казино mostbet, [url=https://mostbet-umzmc.buzz/]https://mostbet-umzmc.buzz/[/url] — это известное место для казино-игр. Каждый могут насладиться от широкого выбора возможностей. Высокие премии и удобные условия делают его выгодным для каждого.
Everettorido 14 Mayıs 2026 03:30
https://statusparty.jp/about/pgs/code_promo_201.html
KimRap 14 Mayıs 2026 03:17
Извините, что не могу сейчас поучаствовать в дискуссии - очень занят. Вернусь - обязательно выскажу своё мнение по этому вопросу. Das Online Echtgeld Roulette prГ¤sentiert Spielern eine Chancen, das in vervielfachen. Dank klugen Entscheidungen werden Gamer ihre Gewinnchancen optimieren. Bei online echtgeld roulette, [url=https://decavisa.com/online-echtgeld-roulette-ihr-guide-zu-spannenden/]https://decavisa.com/online-echtgeld-roulette-ihr-guide-zu-spannenden/[/url] ist Jeder Spin eine weitere MГ¶glichkeit.
Juliaerell 14 Mayıs 2026 02:44
BetWinner Gambling Platform, [url=http://safety-system.pl/betwinner9053/play-aviator-at-betwinner-your-ultimate-guide-to/]http://safety-system.pl/betwinner9053/play-aviator-at-betwinner-your-ultimate-guide-to/[/url] представляет многообразный выбор опций для клиентов. Вне зависимости от вы предпочитаете — от лотерей до блэкджека, BetWinner Gambling Platform предоставляет отличный опыт досуга. Создание аккаунта занимает всего короткое время, и у вас будет шанс начать играть и выигрывать.
Loririz 14 Mayıs 2026 02:22
Я считаю, что Вы ошибаетесь. Могу отстоять свою позицию. Пишите мне в PM. real money casinos, [url=http://escortamour.com/2026/04/26/unlock-excitement-10-free-spins-no-deposit-offers-3/]http://escortamour.com/2026/04/26/unlock-excitement-10-free-spins-no-deposit-offers-3/[/url] offer thrilling experiences for players seeking excitement and profit. Betting sites provide a wide range of activities that cater to various preferences. Jackpot slots and classic table games create opportunities for big wins and unforgettable moments. Embrace the adventure of real money casinos today!
AmandaBer 13 Mayıs 2026 20:59
Жаль, что сейчас не могу высказаться - вынужден уйти. Вернусь - обязательно выскажу своё мнение по этому вопросу. казино mostbet, [url=https://mostbet-ja72h.top/]mostbet-ja72h.top[/url] предлагает обширный выбор активностей. На платформе вы найдете машины, настольные игры и совершенно разные арена. Платежные операции осуществляются быстро, что комфортно для игроков.
MeganalilS 13 Mayıs 2026 20:58
хаааааа........класс live quantum roulette, [url=http://procurement.gov.ck/wordpress/?p=225100]http://procurement.gov.ck/wordpress/?p=225100[/url] ist ein faszinierendes Spielerlebnis, das Teilnehmer in eine SphГ¤re voller Faszination entfГјhrt. Die innovative Technologie verbindet traditionelle Roulette-Elemente mit der Magie der Quantenmechanik. Durch dieser auГџergewГ¶hnlichen Grundlage wГ¤chst ein bewegendes Erlebnis, das jedermann Arten von Teilnehmern anspricht.
JohnThype 13 Mayıs 2026 20:32
Просто, под столом TГјrk futbol takД±mД± BeЕџiktaЕџ, [url=https://besiktas-tr.com/]https://besiktas-tr.com[/url], uzun sГјredir futbola iz bД±rakan takД±mlardandД±r. TaraftarД±nД±n tutkusu, maГ§larda Г¶n plana Г§Д±kar. BeЕџiktaЕџ, Г¶rf ve adetleri ile bГјyГјler.
MirandaCap 13 Mayıs 2026 20:17
BetWinner Online Casino, [url=https://ashento.com/unlock-amazing-bonuses-with-betwinner-sn-promo/]https://ashento.com/unlock-amazing-bonuses-with-betwinner-sn-promo/[/url] offers numerous games for players to enjoy. Featuring both slots and table games, this platform ensures a thrilling experience. Register to BetWinner Online Casino and explore exciting opportunities today!
Feliciasweax 13 Mayıs 2026 17:51
Могу поискать ссылку на сайт с огромным количеством статей по интересующей Вас теме. Online casinos, [url=http://www.domopet.it/registrate-y-consigue-10-euros-gratis-aprovecha/]http://www.domopet.it/registrate-y-consigue-10-euros-gratis-aprovecha/[/url] - Internet gambling have become increasingly popular in recent years. Many people enjoy the convenience of playing their favorite games from home. With an array of options, players can choose from slots, poker, and more.
PaulLab 13 Mayıs 2026 16:16
казино mostbet, [url=https://mostbet-oa0th.lol/]мостбет онлайн[/url] предлагает всеобъемлющий выбор игр, в том числе вы найдете лотереи, карточные развлечения, а также игру в рулетку. Любой игр найдет свое идеальное времяпровождение.
EllaHak 13 Mayıs 2026 15:46
Звучит вполне заманчиво TГјrk futbol takД±mД± BeЕџiktaЕџ, [url=https://besiktas-tr.org/]Turk futbol tak?m? Besiktas[/url], dГјnyanД±n en ГјnlГј kulГјplerinden biridir. KuruluЕџu 1904 yД±lД±na dayanan bu Гјnvan, geГ§miЕџte birГ§ok Еџampiyonluklara imza atmД±ЕџtД±r. BeЕџiktaЕџ, sevdalД± taraftarlarД±yla her an desteklenmektedir. Bu birliktelik, takД±mД±n gГјcГјnГј artД±rmaktadД±r.
LaurenEvita 13 Mayıs 2026 15:43
красиво)) казино mostbet, [url=https://mostbet-0rawk.blog/]онлайн мостбет[/url] предлагает широкий выбор игр для игроков. Игры с разными темами, классические игры и впечатляющие турниры делают его востребованным выбором.
TammyUndup 13 Mayıs 2026 14:45
Качество сносное... quantum roulette, [url=http://www.southerngospelconcert.com/live-quantum-roulette-die-zukunft-des-casino-8/]http://www.southerngospelconcert.com/live-quantum-roulette-die-zukunft-des-casino-8/[/url] ist ein faszinierendes Spiel, das die Aufregung der Teilnehmer erhГ¶ht. Die innovative Technik bringt eine Dimension ins klassische Roulette. Гњber neuer Technologie erleben Spieler eine vollstГ¤ndig neue Art des Spiels. Quantum Roulette ist auch eine Spielmoment fГјr Veteranen, sondern gleichzeitig fГјr Neulinge, die ihr GlГјck testen mГ¶chten.
Jamietak 13 Mayıs 2026 11:43
К сожалению, ничем не могу помочь, но уверен, что Вы найдёте правильное решение. Не отчаивайтесь. Online casinos provide an exciting experience for players. With Casino Online, [url=https://www.mermeryap.com/?p=418270]https://www.mermeryap.com/?p=418270[/url], you can enjoy a wide array of games from the comfort of your home. From slots to table games, the options are endless. Enjoy offers that enhance your gameplay and amplify your chances of winning. The thrill of Casino Online awaits you!
Monaputle 13 Mayıs 2026 10:43
сайт pin up casino, [url=https://pin-up-casino-75ae8.click/]pin-up-casino-75ae8.click[/url] предлагает богатый выбор игр для фанатов азартных игр. В этом казино можно играть в различные игры, такие как слоты. Не упустите шанс увидеть, что принесет удача!
Tiffanytes 13 Mayıs 2026 10:43
казино mostbet, [url=https://mostbet-i6677.blog/]зеркало мостбет[/url] предлагает обширный выбор игр для ценителей азартных развлечений. Имеете возможность проверить удачу в различные игровые аппараты и насладиться интересной атмосферой!
Stanleybrego 13 Mayıs 2026 09:19
Я считаю, что Вы не правы. Могу отстоять свою позицию. Пишите мне в PM. казино mostbet, [url=https://mostbet-dqq3s.xyz/]https://mostbet-dqq3s.xyz[/url] предлагает обширный выбор игр. Здесь можно наслаждаться оценить атмосферой азарта. У игроков есть возможность выиграть значительные суммы.
Barrywoche 13 Mayıs 2026 08:09
BetWinner Gambling Platform, [url=https://lucaskund.ilait-reseller.com/2026/05/07/maximize-your-winnings-understanding-the-betwinner/]https://lucaskund.ilait-reseller.com/2026/05/07/maximize-your-winnings-understanding-the-betwinner/[/url] offers a variety of exciting betting opportunities. Players can take pleasure in interactive dealers and various sports betting markets.
AmyLorgo 13 Mayıs 2026 07:45
уматовые картинки mega fire blaze roulette, [url=https://test.lsdassociates.com/mega-fire-blaze-roulette-das-aufregende-roulette/]https://test.lsdassociates.com/mega-fire-blaze-roulette-das-aufregende-roulette/[/url] ist ein aufregendes Spiel, das nutzern die MГ¶glichkeit bietet, einzigartige Gewinne zu erzielen. Die gestaltung ist beeindruckend, was das Erlebnis zudem verbessert. Verschiedene Spieler wird mit die spannenden Elemente begeistert sein. Mega fire blaze roulette gehГ¶rt zu den beliebtesten Casino-Spielen und bringt ein unvergleichliches GefГјhl.
EpicksonBoyPe 13 Mayıs 2026 07:06
В мире видеоигр существует множество способов улучшить свой игровой процесс, и одним из них являются хаки в играх, [url=http://beer.waltermourao.com.br/index.php?title=%D0%AD%D0%BA%D1%81%D0%BF%D0%BB%D1%83%D0%B0%D1%82%D0%B0%D1%86%D0%B8%D1%8F%20%D1%85%D0%B0%D0%BA%D0%B8%20%D0%B4%D0%BB%D1%8F%20%D0%B2%D0%B8%D0%B4%D0%B5%D0%BE%D0%B8%D0%B3%D1%80%D0%B0%D1%85]http://beer.waltermourao.com.br/index.php?title=%D0%AD%D0%BA%D1%81%D0%BF%D0%BB%D1%83%D0%B0%D1%82%D0%B0%D1%86%D0%B8%D1%8F%20%D1%85%D0%B0%D0%BA%D0%B8%20%D0%B4%D0%BB%D1%8F%20%D0%B2%D0%B8%D0%B4%D0%B5%D0%BE%D0%B8%D0%B3%D1%80%D0%B0%D1%85[/url]. Эти хитрости и приемы позволяют игрокам получать дополнительные преимущества, ускорять прогресс и открывать скрытые возможности. Однако, важно помнить, что использование таких методов может привести к негатив
JessieLag 13 Mayıs 2026 03:07
Симпатичный ответ казино для мобильных устройств, [url=https://t.me/vanechekvan]топ-5 мобильных казино[/url] стали настоящим открытием для геймеров. Теперь наслаждаться азартом можно в любое мгновение и в любой локации. Современные приложения предоставляют удобный доступ к игровым автоматам и азартным играм, позволяя проверять свою удачу на протяжении дня.
JodieScoum 13 Mayıs 2026 01:43
BetWinner Sportsbook, [url=https://arwwa.in/download-the-betwinner-app-for-a-superior-betting/]https://arwwa.in/download-the-betwinner-app-for-a-superior-betting/[/url] offers an exciting site for sports betting enthusiasts. With a wide range of markets, users can easily find their favorite events. The user-friendly interface enhances the betting experience, making it enjoyable for everyone.
Chriscup 13 Mayıs 2026 01:24
да да да ща поглядим mega fire blaze roulette, [url=https://www.henrykmalesa.pl/mega-fire-blaze-roulette-ein-aufregendes-spiel-mit/]https://www.henrykmalesa.pl/mega-fire-blaze-roulette-ein-aufregendes-spiel-mit/[/url] ist ein spannendes Spiel, das die Zocker in seinen Bann zieht. Jedes Spiel bringt neue MГ¶glichkeiten und groГџe ErtrГ¤ge. Der adrenalingeladene Nervenkitzel macht es zu einem Must-See in jedem Casino. Tauchen Sie ein in die Welt des Mega fire blaze roulette und erleben Sie das VergnГјgen wie nie zuvor!
Rubyedimi 13 Mayıs 2026 01:24
In the arena of Sports Betting, [url=https://www.neue.co/1xbet-your-ultimate-betting-experience-901229738/]https://www.neue.co/1xbet-your-ultimate-betting-experience-901229738/[/url], strategies play a crucial role. Comprehending the odds and taking educated bets can greatly enhance your chances of victory.
Daphnecruts 13 Mayıs 2026 01:04
Обмінник криптовалют, [url=http://renataguzman.com/2011/06/22/masonry-fullscreen-and-options/]http://renataguzman.com/2011/06/22/masonry-fullscreen-and-options/[/url] — це сучасний інструмент для торгівлі криптовалютами. Завдяки легкому інтерфейсу, користувачі можуть легко здійснювати переклади на численних платформах. Обмінник криптовалют допомагає стабілізувати фінансовим можливостям кожного.
Madelineasype 13 Mayıs 2026 01:00
сайт pin up casino, [url=https://pin-up-casino-0py7k.click/]официальный сайт pin up casino[/url] предлагает множество увлекательных игр, в что можно попробовать прямо сейчас. Здесь находятся азартные игры, которые удивят даже самых требовательных посетителей. Не упустите шанс заняться в мир азарта и шанс на выигрыш.
Fayefut 12 Mayıs 2026 12:14
Вы попали в самую точку. Le Fisherman ES slot online, [url=http://taketombo.la.coocan.jp/cgi/cot_bbs/yydhtml_b.cgi]http://taketombo.la.coocan.jp/cgi/cot_bbs/yydhtml_b.cgi[/url] es una tragaperras emocionante que disponibiliza un entretenimiento Гєnica. Con sus visuales impresionantes, los jugadores se sienten inmersos en un escenario de pesca. AdemГЎs, las opciones extras hacen que el juego sea aГєn mГЎs divertido. ВЎPrueba Le Fisherman ES slot online y explora la aventura de pescar grandes premios!
MichelleHax 12 Mayıs 2026 11:35
сайт pin up casino, [url=https://pin-up-casino-x6u48.cyou/]сайт pin up casino[/url] предлагает уникальные возможности для азартных игр. Здесь доступно множество слотов на любой вкус. Каждый из игрок найдет нечто особенное для себя.
StacyDrorb 12 Mayıs 2026 11:33
«мостбет казино, [url=https://mostbet-d337y.life/]мосбет официальный сайт казино[/url]» предлагает уникальные возможности для любителей азартных игр. Зрители могут наслаждаться разнообразием игр и щедрыми бонусами. Платформа гарантирует защиту транзакций и доступ к самым новейшим слотам.
BrandonphoGs 12 Mayıs 2026 04:47
В этом что-то есть. Понятно, благодарю за помощь в этом вопросе. На данный момент мультфильмы онлайн, [url=https://account.kgnow.com/login/a2dub3c=/aHR0cHM6Ly9tdWx0bGVuZC5uZXQ]https://account.kgnow.com/login/a2dub3c=/aHR0cHM6Ly9tdWx0bGVuZC5uZXQ[/url] стали востребованными. Каждый может посмотреть любимыми мультипликацией на множествах платформах. Легкость просмотрения подсказывают, что мир анимации разнообразен.
Camillawaype 12 Mayıs 2026 04:47
Извините, удалено Chicken Road la gallina casino EspaГ±a, [url=https://www.ousfot.com/fruit-boom/]https://www.ousfot.com/fruit-boom/[/url] es un destino popular para los amantes del juego y la diversiГіn. Los juegos de azar ofrecen emociones intensas. Asimismo, su atmГіsfera es acogedor, apropiado para disfrutar con amigos.
Gwinnettbop 12 Mayıs 2026 00:04
мостбет казино, [url=https://mostbet-9xrdx.cfd/]https://mostbet-9xrdx.cfd/[/url] предлагает богатый ассортимент игр на любой вкус. На платформе вы найдете покер и много другого. Мостбет казино обеспечивает честную игру и привлекательные бонусы. Попробуйте свои силы прямо сейчас!
LauraVof 12 Mayıs 2026 00:02
сайт pin up casino, [url=https://pin-up-casino-5n9fg.cyou/]https://pin-up-casino-5n9fg.cyou/[/url] предлагает разнообразный выбор слотов. Здесь любой найдет что-то по своему вкусу. Эксклюзивные бонусы делают игру еще более захватывающей. Не упустите шанс наслаждаться удачу!
Frankspirm 11 Mayıs 2026 23:54
Согласен, это забавное мнение казино mostbet, [url=https://mostbet-e0rf9.pro/]https://mostbet-e0rf9.pro/[/url] предлагает обширный выбор азартных автоматов. Здесь доступно насладиться занимательными играми и выгодными бонусами.
Stephaniewhino 11 Mayıs 2026 23:13
давным давно посмотрел и забыл ужэ...... extreme lightning roulette, [url=https://tienda.mbechile.cl/estacion-nunoa/]https://tienda.mbechile.cl/estacion-nunoa/[/url] ist ein spannendes Spiel, das User auf der ganzen Welt begeistert. Die Kombination aus traditionellem Roulette und aufregenden Blitzgewinnen sorgt fГјr Spannung. Die Zocker kГ¶nnen dauernd mit hГ¶heren Einnahmen rechnen. In diesem belebten Spiel werden aufgestockte Gewinne in einer elektrisierenden AtmosphГ¤re geboten.
KristyGrili 11 Mayıs 2026 22:39
Я извиняюсь, но, по-моему, Вы не правы. Пишите мне в PM, поговорим. парфюмерия, [url=https://slovarsbor.ru/c/%D1%89/]https://slovarsbor.ru/c/%D1%89/[/url] — это искусство создания уникальных ароматов, которые способны вызывать эмоции и воспоминания. Эти эссенции могут выразить вашу индивидуальность. Любой запах обладает своей легендой.
AdamTooca 11 Mayıs 2026 21:36
Совершенно верно! Мне кажется это хорошая идея. Я согласен с Вами. BetPanda EspaГ±a sitio oficial, [url=http://www.sergeselvon.de/BLOG/index.php/;focus=STRATP_com_cm4all_wdn_Flatpress_12684952&path=?x=entry:entry171203-120105%3Bcomments:1]http://www.sergeselvon.de/BLOG/index.php/;focus=STRATP_com_cm4all_wdn_Flatpress_12684952&path=?x=entry:entry171203-120105%3Bcomments:1[/url] dispone una amplia gama de elecciones para realizar apuestas. Los usuarios pueden disfrutar de recompensas exclusivas y el entorno seguro para sus transacciones.
BrianSmock 11 Mayıs 2026 18:50
<a href=https://drivelity-morocco.com/car-rental-nador-morocco>cheap car rental nador airport</a>
JessieMop 11 Mayıs 2026 18:31
мостбет казино, [url=https://mostbet-33njn.pro/]https://mostbet-33njn.pro/[/url] предлагает удивительные возможности для игроков. Большой выбор слотов, рулеток и щедрые бонусы делают его выгодным местом для времяпрепровождения. Не упустите шанс испытать весь буст азартных игр!
AdamLig 11 Mayıs 2026 18:31
pinco казино, [url=https://pinco-casino-e9738.xyz/]https://pinco-casino-e9738.xyz[/url] предлагает захватывающие игры, в которых можно выиграть значительные суммы. Все посетитель найдет что-то по своему вкусу. Указанное место заслуживает внимания своим отличным качеством сервиса. Станьте в мир острых ощущений с pinco казино!
Jordankibre 11 Mayıs 2026 17:49
По моему мнению Вы ошибаетесь. Пишите мне в PM, обсудим. казино mostbet, [url=https://mostbet-oh31d.sbs/]https://mostbet-oh31d.sbs[/url] предлагает широкий выбор игр для участников. Автоматы и миллионные игры охватывают многих. В этом казино обеспечены привлекательные бонусы и сюрпризы.
SophiaVek 11 Mayıs 2026 14:53
Прекрасно, я так и думал. FelixSpin EspaГ±a sitio oficial, [url=http://www.villaormondevents.com/antonellaclerici/]http://www.villaormondevents.com/antonellaclerici/[/url] ofrece una amplia colecciГіn de productos para cada necesidades. Explora nuestro portal y obtГ©n lo que anhelas.
Stanleylaw 11 Mayıs 2026 13:08
мостбет казино, [url=https://mostbet-vwnuq.lol/]мостбет официальный сайт[/url] предлагает большой ассортимент азартные игры, включая игровые автоматы. Удобный интерфейс и высокие бонусы делают его интимным среди игроков. Присоединяйтесь и погружайтесь удачу!
Bridgetzix 11 Mayıs 2026 11:50
Весьма забавное сообщение казино mostbet, [url=https://mostbet-pthy4.xyz/]https://mostbet-pthy4.xyz/[/url] предлагает обширный выбор игр для знатоков. Здесь можно обнаружить лучшие слоты, а также крупнейшие бонусы для новых игроков.
ElizabethNarly 11 Mayıs 2026 09:04
Согласен, это забавная штука Im live casino auto roulette, [url=https://cornerstoneraleigh.org/2026/04/25/auto-roulette-spielvergnugen-auf-die-nachste-stufe/]https://cornerstoneraleigh.org/2026/04/25/auto-roulette-spielvergnugen-auf-die-nachste-stufe/[/url] kГ¶nnen Spieler im einer spannenden AtmosphГ¤re zusehen, wie die Kugel aus das Rad fliegt. Die aufregende MГ¶glichkeit, mit anderen zu spielen, schafft ein unvergleichliches Erlebnis. ZusГ¤tzlich ist das Spiel bequem zu verstehen und verfГјgt Гјber viele Varianten. Das live casino auto roulette zieht Spieler Гјber aller Welt.
Amandaaffek 11 Mayıs 2026 08:01
Спасибо, ушел читать. FelixSpin EspaГ±a sitio oficial, [url=http://bscxw.com/home.php?mod=space&uid=127296&do=profile]http://bscxw.com/home.php?mod=space&uid=127296&do=profile[/url] ofrece la amplia selecciГіn de entretenimientos. En este lugar puedes disfrutar de momentos Гєnicas, junto a promociones increГbles. AdhiГ©rete a nuestra comunidad y vive la emociГіn ya!
KeriSmows 11 Mayıs 2026 07:45
pinco казино, [url=https://pinco-casino-ssxes.click/]pinco-casino-ssxes.click[/url] дарит посетителям разнообразный множество опций. Окунитесь в мир азарта и получите удовлетворение на испытания с разнообразными классическими слотами!
DanielOthed 11 Mayıs 2026 05:59
Это сообщение, бесподобно ))), мне очень нравится :) казино mostbet, [url=https://mostbet-wyhpt.xyz/]casino mostbet[/url] предлагает неповторимый опыт для игроков. Здесь доступно участвовать в разнообразные виды азартных игр. Доступные бонусы делают игру дополнительно увлекательной. В казино mostbet всегда проходят акции, которые восхищают игроков.
TarusDag 11 Mayıs 2026 05:10
Абалдеть!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Within the realm of Casino Online, [url=http://www.fitcom.com.tr/onlinecasinoslot230446/a-comprehensive-guide-to-the-triumph-casino.html]http://www.fitcom.com.tr/onlinecasinoslot230446/a-comprehensive-guide-to-the-triumph-casino.html[/url], players can experience exciting games right from their homes. Participate in various alternatives such as slots, poker, and roulette. Appreciate the convenience together with fantastic bonuses that enhance your gameplay. Whether a novice or expert, Casino Online offers something for everyone. Leverage this digital playground!
Shanesam 10 Mayıs 2026 22:19
В мире онлайн-игр pinco казино, [url=https://pinco-casino-rmtn2.sbs/]pinco-casino-rmtn2.sbs[/url] предлагает обширный выбор азартных игр. Любой игрок найдет что-то для себя. Защита игр гарантирована, что придаёт доверие к платформе. Pinco казино отлично подходит для геймеров азартных игр.
KristyGag 10 Mayıs 2026 17:26
Нормусь Within the sphere of Online Casino UK, [url=https://lakshaa.com/unlock-the-thrill-of-spin-million-your-guide-to/]https://lakshaa.com/unlock-the-thrill-of-spin-million-your-guide-to/[/url], you’ll find a plethora of choices catering to all preferences. From timeless slots to live dealer experiences, there’s something for everyone. Venture into exciting bonuses and offers that enhance your gaming experience. With cutting-edge technology and secure transactions, Online Casino UK provides an exhilarating escape for enthusiasts. So, begin today and savor the thrill!
JohnAbowl 10 Mayıs 2026 12:58
Я хотел бы с Вами поговорить, мне есть, что сказать. During the world of fun, Casino Online, [url=https://thisisandyhops.co.uk/2026/04/21/discover-spindog-casino-your-ultimate-gaming/]https://thisisandyhops.co.uk/2026/04/21/discover-spindog-casino-your-ultimate-gaming/[/url] presents a chance to immerse in vibrant entertainment. With multiple platforms, gamblers can join their beloved games at any time. This conveniences make Casino Online a popular choice for numerous gamers.
Kimantah 10 Mayıs 2026 12:24
Бомба online roulette casinos, [url=https://www.isuzuleasing.com/alt-du-behver-at-vide-om-roulette-casinoer/]https://www.isuzuleasing.com/alt-du-behver-at-vide-om-roulette-casinoer/[/url] skaber en spГ¦ndende oplevelse for spillere. Ved nye teknologier giver det mulighed for at spille hjemmets tryghed. Deltagerne kan nyde chancerne online, hvilket gГёr en bemГ¦rkelsesvГ¦rdig atmosfГ¦re.
KathyAperm 10 Mayıs 2026 06:31
По моему мнению Вы не правы. Предлагаю это обсудить. Пишите мне в PM, пообщаемся. зеркало mostbet, [url=https://mostbet-abgwd.blog/]https://mostbet-abgwd.blog[/url] предоставляет игрокам возможность без перебоев получать доступ к азартным играм. Данная платформа влечет значительное количество пользователей благодаря простоте и разнообразию игровых автоматов.
Vivianfeedy 10 Mayıs 2026 05:16
Невероятно. Это кажется невозможным. In the world of online gambling, Casino Online Games, [url=http://bitbuzz.org/the-ultimate-guide-to-slot-lair-casino-sportsbook/]http://bitbuzz.org/the-ultimate-guide-to-slot-lair-casino-sportsbook/[/url] offer a thrilling experience. Players can enjoy multiple games from the comfort of their homes. With dynamic graphics and interactive gameplay, the fun never ends.
ViolaErync 10 Mayıs 2026 03:36
пин-ап казино, [url=https://pin-up-casino-3l2he.lol/]https://pin-up-casino-3l2he.lol[/url] предоставляет уникальный жизнь азартных приключений. Здесь можете наслаждаться многочисленными слотами и карточными играми, чтобы каждый найдет нечто для себя.
JessicaAvate 09 Mayıs 2026 21:32
фуфа смотрел La tragamonedas Le Fisherman ES slot online, [url=http://absolutepayrollinc.payrollservers.info/2017/12/20/5-ways-wfm-improves-customer-service/]http://absolutepayrollinc.payrollservers.info/2017/12/20/5-ways-wfm-improves-customer-service/[/url] ofrece una oportunidad Гєnica para los fanГЎticos de las apuestas. Con diseГ±os impresionantes, cada giro promete sorpresas. No te pierdas la posibilidad de capturar asombrosos premios mientras disfrutas de esta fascinante tragamonedas. ВЎPrueba Le Fisherman ES slot online hoy!
Kathleenenend 09 Mayıs 2026 12:33
пин-ап казино, [url=https://pin-up-casino-u9i1z.lol/]https://pin-up-casino-u9i1z.lol[/url] предлагает привлекательные игровые модели, которые восхищают своей дизайном и перспективами выиграть. Каждый желающих сможет найти свой любимый вид развлечения.
Michelleevory 09 Mayıs 2026 12:32
pinco казино, [url=https://pinco-casino-4w7ph.cyou/]пинко казино сайт[/url] предлагает уникальные возможности для азартных игроков. Здесь можно увидеть разнообразные азартные автоматы и другие возможности. Поддержка клиентов функционирует круглосуточно, обеспечивая оптимальный комфорт. Играйт ставки и наслаждайтесь процессом!
Romandes 09 Mayıs 2026 12:24
Обучение группы бухгалтеров новым возможностям 1С после обновления. За полдня разобрали все изменения, ответили на вопросы. Работа пошла в новом режиме без потери темпа. [url=https://автоматизация-учета.рф/]1С складской учёт Белгород[/url]
Sarahmof 09 Mayıs 2026 08:05
По моему мнению Вы ошибаетесь. Давайте обсудим. Пишите мне в PM, пообщаемся. kazino oyunlarД±, [url=http://www.lauracecin.morpho.com.mx/2026/04/27/mostbet-dman-mrclri-v-online-oyunlar-ucun-ideal/]http://www.lauracecin.morpho.com.mx/2026/04/27/mostbet-dman-mrclri-v-online-oyunlar-ucun-ideal/[/url] maraqlД±dД±r. Onlar fЙ™rqli oyun seГ§imini tЙ™qdim edir. HЙ™r bir oyun Г¶z cazibЙ™sini daЕџД±yД±r. Kazino oyunlarД± qazanma imkanД± axtaranlar üçün ideal seГ§imdir.
Chrisvem 09 Mayıs 2026 08:04
Какая великолепная фраза Los casinos en lГnea online europeos ofrecen una extensa selecciГіn de juegos. Incluyendo juegos de azar, incluyendo blackjack, estos espacios se convierten en una experiencia fascinante. Con bonos atractivos, los casinos online europeos, [url=https://www.nobleventurefinancial.com/2026/04/27/promociones-exclusivas-en-servicios-europeos-3/]https://www.nobleventurefinancial.com/2026/04/27/promociones-exclusivas-en-servicios-europeos-3/[/url] atreven a los jugadores a probar sus ofertas.
Raheemnub 09 Mayıs 2026 07:04
Присоединяюсь. И я с этим столкнулся. Давайте обсудим этот вопрос. Здесь или в PM. онлайн дорамы, [url=https://spade-heart.sflag.co.jp/sb/sample-post1/]https://spade-heart.sflag.co.jp/sb/sample-post1/[/url] стали настоящим феноменом в мире развлечений. Все зрителей предпочитают изучать ими, так как данные сериалы дают возможность погрузиться в увлекательные сюжеты. Все онлайн дорама создает определенный резонанс в обществе. Во время просмотра таких серий можно глубже понять культуру и традиции Азии. С ростом технологий были доступными разные платформы для просмотра дорам.
Tonyalot 09 Mayıs 2026 06:49
пин-ап казино, [url=https://pin-up-casino-40m7p.xyz/]pin-up-casino-40m7p.xyz[/url] — это олицетворение стилевого направления и увлекательных игр. В этом казино можно осознать атмосферу антикварного. Классические автоматы и карточные дарят радость и недоумение. Погрузитесь в увлекательных эмоций, которые создаёт пин-ап казино!
Allenjuill 09 Mayıs 2026 06:49
пинко казино, [url=https://pinco-casino-uc4uj.lol/]https://pinco-casino-uc4uj.lol/[/url] предлагает уникальный опыт для любителей азартных игр. В этом месте всегда доступны широкий ассортимент игры. Посетители могут найти что-то на разный вкус, даже если опыта. Промо-акции делают игру еще более интересной. Не упустите шанс насладиться лучшими предложениями от пинко казино!
Mirandajearo 09 Mayıs 2026 06:41
шото слишком мутное 1xbet официальный сайт, [url=https://1xbet-u5x8odj.buzz/]https://1xbet-u5x8odj.buzz/[/url] предоставляет широкий спектр спортивных событий и вариантов для игры. На платформе вы увидите многочисленные рынков для ставок. Входите и погружайтесь в развлечений.
Tiffynew 09 Mayıs 2026 05:44
Буду надеятся что втарая часть будет не хуже первой Online Casino UK, [url=http://www.sagesofrpg.com/2026/04/16/the-ultimate-guide-to-onluck-casino-sportsbook/]http://www.sagesofrpg.com/2026/04/16/the-ultimate-guide-to-onluck-casino-sportsbook/[/url] дарит множество вариантов для азартных РёРіСЂ. Рнновационные платформы дают впечатляющие Р±РѕРЅСѓСЃС‹ Рё интересные акции. Углубитесь азартный РјРёСЂ СЃ Online Casino UK СЃ интересом.
MiaGlype 09 Mayıs 2026 00:54
больше всего улыбнуло..ггг... Los casinos en lГnea online europeos ofrecen una variedad de juegos para todos jugador. Con ofertas irresistibles y un soporte al cliente excepcional, la vivencia es incomparable. ВЎDisfruta de los mejores juegos de cartas y siente la emociГіn de los casinos online europeos, [url=https://www.fakeitmakeup.se/descubre-los-bonos-ocultos-en-casinos-europeos/]https://www.fakeitmakeup.se/descubre-los-bonos-ocultos-en-casinos-europeos/[/url]!
Ashleyengak 09 Mayıs 2026 00:54
Я согласен со всем выше сказанным. real pul kazino, [url=https://therecruitersloungeco.com/pragann-mrkzind-unikal-tcrub-trt-prague/]https://therecruitersloungeco.com/pragann-mrkzind-unikal-tcrub-trt-prague/[/url] reallД±q oyun seГ§imi tЙ™qdim edЙ™rЙ™k azalmayan oyuncunu cЙ™lb bГ¶yГјdГјr. MГјxtЙ™lif oyun seГ§imlЙ™ri ilЙ™ rahat bir atmosfer dЙ™stЙ™klЙ™yir. Real pul kazino gГ¶zЙ™l anlar tЙ™klif edir ki, oyunГ§ular nГјfuzlarД±nД± sД±naya bilsinlЙ™r.
Pameladug 09 Mayıs 2026 00:16
Считаете неважно? 7k casino сайт, [url=https://7k-casino-aua80.xyz/]https://7k-casino-aua80.xyz[/url] предлагает неповторимые игровые аппараты и выгодные предложения. Тут всех найдет интересное для себя, наслаждаясь безопасной игрой.
Keshiaram 08 Mayıs 2026 23:37
так хотел посмотреть....а теперь растроен...я ожидал чего-то большего... Смотрите интересные дорамы онлайн, [url=https://rachelwilmann.no/firefox11/]https://rachelwilmann.no/firefox11/[/url] и погружайтесь в южнокорейского кино. Каждая история наполнена эмоциями, а герои вызывают сопереживание. Попробуйте найти свою любимую дораму!
DonteNot 08 Mayıs 2026 22:53
Совершенно верно! Это хорошая идея. Готов Вас поддержать. Casino Online Slots, [url=https://engenhocas.com/ninewin-casino-sportsbook-your-ultimate-gaming-5/]https://engenhocas.com/ninewin-casino-sportsbook-your-ultimate-gaming-5/[/url] - Online Slots offer gamblers a thrilling experience with exciting gameplay and the chance to win impressive rewards. Whether you prefer retro or modern themes, there's something for everyone. Join the fun!
DwightGek 08 Mayıs 2026 20:41
Experience the latest version here > https://carpfishing.ru/wp-includes/wp/404.html
Paveldes 08 Mayıs 2026 20:21
Строили дом в Красноярске, долго выбирали кровлю. Остановились на металлочерепице 0.5 мм с надёжным полимерным покрытием — отличное соотношение цены и качества. Взяли графит RAL 7024, смотрится достойно. Крыша пережила две зимы без нареканий. [url=https://metall-krasnoyarsk24.ru/]металлочерепица 35 цветов RAL[/url]
PamelaOmire 08 Mayıs 2026 20:01
пинко казино, [url=https://pinco-casino-sfcbs.sbs/]пинко казино вход[/url] предлагает уникальные игровые варианты. Здесь каждый сможет попробовать что-то захватывающее. Занимайтесь в мир игр и кайфа.
Bradcop 08 Mayıs 2026 20:01
pin up casino зеркало, [url=https://pin-up-casino-0tvui.xyz/]pin-up casino[/url] — отличный способ получить доступ к любимым играм. Игроки могут без проблем увлекаться азартом в любое время. Бонусы и акции влекут новых пользователей. Важно не забывать о достоинствах своих данных.
GloriaLougs 08 Mayıs 2026 19:58
Вы не правы. Я уверен. Пишите мне в PM. duitse online casino, [url=https://nl.trustpilot.com/review/ecomxacademy.nl]casino duitsland[/url] bieden een verscheidenheid aan spellen die entertainment garanderen. Deelnemers kunnen genieten van videoslots en gokspellen van gerenommeerde bedrijven.
GillOpify 08 Mayıs 2026 18:12
Ну они и дают жару Los casinos sin certificaciГіn en EspaГ±a representan un peligro para los usuarios. Estos plataformas carecen de seguridad, lo que complica la vivencia del jugador. casinos sin licencia espaГ±a, [url=http://social.clikearte.com.ar/2026/04/26/descubre-los-mejores-casinos-sin-licencia-en-2026-3/]http://social.clikearte.com.ar/2026/04/26/descubre-los-mejores-casinos-sin-licencia-en-2026-3/[/url] deben ser rechazados para cuidar tu capital.
ZackAsype 08 Mayıs 2026 18:11
Браво, очень хорошая мысль В мире азартных игр тысячи игроков ищут лучшие платформы. Одним из популярных мест считается 7k casino играть, [url=https://7k-casino-i0229.xyz/]7k-casino-i0229.xyz[/url]. Здесь вы найдут множество игр и привлекательные предложения. Простой интерфейс обеспечивает комфортный процесс для всех.
Katrinagoano 08 Mayıs 2026 18:11
Я извиняюсь, но, по-моему, Вы ошибаетесь. Предлагаю это обсудить. Пишите мне в PM, поговорим. onlayn kazino, [url=http://www.property-xrm.worldatclick.com/site/mostbet-dman-mrclri-dunyasna-mukmml-giri/]http://www.property-xrm.worldatclick.com/site/mostbet-dman-mrclri-dunyasna-mukmml-giri/[/url] cЙ™ld oyun imkanlarД± tЙ™klif edir. MГјЕџtЙ™rilЙ™r evdЙ™n Г§Д±xmadan maliyyЙ™ qazana bilЙ™rlЙ™r. Bu platformalar Г§ox Г¶zГјnЙ™mЙ™xsus oyun proseslЙ™ri tЙ™qdim edir.
Jessefoumn 08 Mayıs 2026 16:22
Вы не ошиблись Online Casino, [url=https://kpcinvestimentos.com.br/the-life-and-legacy-of-napoleon-bonaparte-17/]https://kpcinvestimentos.com.br/the-life-and-legacy-of-napoleon-bonaparte-17/[/url] представляет невероятные шансы для участников. Каждый может испытать неповторимыми развлечениями Рё великодушными бонусами!
ScottVaw 08 Mayıs 2026 15:24
Finding a superb minimum deposit casino, [url=https://www.jcbailbonding.com/los-mejores-casinos-con-deposito-minimo-de-1-euro-6/]https://www.jcbailbonding.com/los-mejores-casinos-con-deposito-minimo-de-1-euro-6/[/url] can enhance your gaming experience. These casinos present players the chance to start with minimal deposits, making it handy for everyone to join and enjoy the fun!
MatthewHef 08 Mayıs 2026 14:45
Пин-ап Казино предлагает геймерам уникальные возможности для развлечений. pin up casino зеркало, [url=https://pin-up-casino-s8p1q.cyou/]https://pin-up-casino-s8p1q.cyou/[/url] позволяет доступ в любимые игры, даже когда главный недоступен. Наслаждайтесь современными слотами и создайте свой способ выигрыша!
Rachelinvow 08 Mayıs 2026 12:48
Полностью разделяю Ваше мнение. Это отличная идея. Готов Вас поддержать. Online Casino UK, [url=https://www.praticantidiritto.com/discover-exciting-games-at-mr-luck-casino-online-2/]https://www.praticantidiritto.com/discover-exciting-games-at-mr-luck-casino-online-2/[/url] features a wide range of entertainment. Players can enjoy slots and table games. Rewards improve the wagering experience significantly.
Isabellabrono 08 Mayıs 2026 10:58
Случайно нашел сегодня этот форум и специально зарегистрировался, чтобы поучаствовать в обсуждении. kazino tЙ™tbiqi, [url=https://mwcaustralia.com/mostbet-onlayn-dman-bahis-tcrubsi/]https://mwcaustralia.com/mostbet-onlayn-dman-bahis-tcrubsi/[/url] mЙ™qalЙ™dЙ™ insanlarД±n rЙ™ДџbЙ™tini qazandД±. KullanД±cД±lar fЙ™rqli oyunlarД± sД±naqdan keГ§irЙ™ bilЙ™rlЙ™r. YГјksЙ™k bonuslar verir vЙ™ gГјvЙ™nli ЕџЙ™raitdЙ™ uДџur qazanmaq imkanlarД± yaradД±lД±r.
JohnBeaWs 08 Mayıs 2026 09:41
уже есть,спс парфюмерия, [url=https://l-parfum.ru/catalog/dolce-gabbana/Dolce-Floral-Drops/]https://l-parfum.ru/catalog/dolce-gabbana/Dolce-Floral-Drops/[/url] — это искусство создания уникальных ароматов, способных вызвать эмоции и воспоминания. Запах парфюмерии может удивить, ведь каждый отдельный аромат имеет свою историю. В мире парфюмерии важно выбрать соответствующий аромат, который станет вашей визитной карточкой.
Joseeleno 08 Mayıs 2026 09:19
Да, вполне Online gambling has gained immense popularity, offering players the chance to enjoy their favorite activities from the comfort of home. Casino Online, [url=https://pakghaziusa.com/onlinecasinoslot140434/online-casino-monaco-jack-your-guide-to-gaming/]https://pakghaziusa.com/onlinecasinoslot140434/online-casino-monaco-jack-your-guide-to-gaming/[/url] provides a variety of options, ensuring anyone finds something enjoyable. With bonuses and live interactions, the experience is dynamic. Embrace the flexibility of online platforms and discover the fun waiting for you!
Amandakal 08 Mayıs 2026 09:08
пинко казино, [url=https://pinco-casino-xqx5i.top/]https://pinco-casino-xqx5i.top/[/url] — это казино, где игроки могут испытать успех. Здесь представлены разнообразные игры, где есть слоты и карточные игры. Каждый найдут что-то для себя!
KristyNut 08 Mayıs 2026 07:14
Я согласен с Вами, спасибо за помощь в этом вопросе. Как всегда все гениальное просто. Mojabet Casino, [url=https://mojabet-cd.com/]Mojabet[/url] offre une aventure de divertissement sans pareil. L'options de divertissements diversifiГ©es captivent les joueurs. Un site offre sГ©curitГ© et un support pour les parieurs de excellence.
Joshuatip 08 Mayıs 2026 06:40
Finding a suitable minimum deposit casino, [url=https://www.centroinfissiromanord.it/2026/04/19/descubre-los-50-giros-gratis-en-espana-tu-guia-2/]https://www.centroinfissiromanord.it/2026/04/19/descubre-los-50-giros-gratis-en-espana-tu-guia-2/[/url] is essential for players who want to take part in gaming without high stakes. Various options allow you to kick off your gaming journey with little investment, ensuring fun and excitement!
GloriaLougs 08 Mayıs 2026 04:08
Качество сносное... In de wereld van gokken zijn duitse online casino, [url=https://nl.trustpilot.com/review/ecomxacademy.nl]duitse casino[/url]'s populair. Spelers waarderen de comfort van online spelen. Je kunt genieten van aantrekkelijke spellen, vaak met spannende bonussen. Ontdek de spanningen die een duitse online casino te bieden heeft!
MirandaNug 08 Mayıs 2026 04:07
Замечательно, ценная информация mobil kazino, [url=http://social.clikearte.com.ar/2026/04/26/mostbet-onlayn-bahis-v-oyun-platformas/]http://social.clikearte.com.ar/2026/04/26/mostbet-onlayn-bahis-v-oyun-platformas/[/url], mГјasir texnologiyalar sayЙ™sindЙ™ hЙ™r kЙ™sin Й™lГ§atandД±r. Mobil qumar istЙ™diyiniz yerdЙ™ fЙ™aliyyЙ™t gГ¶stЙ™rЙ™ bilЙ™rsiniz. Yeni imkanlar ilЙ™ maraqlД± vaxt keГ§irЙ™ bilЙ™rsiniz. YГјksЙ™k standart zЙ™manЙ™ti ilЙ™ gГјvЙ™nli oynayД±Еџ Й™ldЙ™ edirsiniz.
Leilahaump 08 Mayıs 2026 03:56
пинко казино, [url=https://pinco-casino-zvyei.top/]pinco-casino-zvyei.top[/url] предлагает игрокам уникальный опыт развлечений. На платформе доступны разнообразные игры, включая карточные игры. Игрок найдет что-то по своему вкусу и удовлетворение.
DougMor 08 Mayıs 2026 02:49
Finding a top minimum deposit casino, [url=https://inspiring-readers.org/discover-the-best-instant-withdrawal-casinos-in-15/]https://inspiring-readers.org/discover-the-best-instant-withdrawal-casinos-in-15/[/url] can enhance your gaming experience. Many participants enjoy the cost-effective options these platforms offer. With a minimum deposit casino, you can try out various games without a hefty investment.
KurtUnift 08 Mayıs 2026 02:39
Спасибо за объяснение. Я не знал этого. Casino Online Games, [url=https://zawiszakatowice.5v.pl/?p=1126147]https://zawiszakatowice.5v.pl/?p=1126147[/url] deliver a thrilling adventure for players seeking enjoyment. Featuring an array of varieties, users can engage in card games anywhere the comfort of their residences.
Stevenhak 08 Mayıs 2026 02:18
Офигительная штука, посмотрел, всем советую... Millionz Casino, [url=https://millionz-casinofr.eu/]Millionz Casino avis[/url] est un endroit extraordinaire pour les amateurs de jeux. Avec une plГ©thore de jeux de table, chaque visite est une aventure. Les offres rГ©guliГЁres ajoutent une dose d'excitation au jeu. Plongez dans le monde vibrant de Millionz Casino et profitez au maximum de vos temps de jeu.
Davidjefly 07 Mayıs 2026 17:34
http://receptu-blud.ru
JeremiahEdiff 07 Mayıs 2026 17:16
Между нами говоря, я бы обратился за помощью в поисковики. Bienvenue sur ce Pampago Casino, [url=https://pampago-casino.eu/]Pampago Casino[/url], un espace idГ©al pour se divertir. DГ©couvrez une choix incroyable de jeux, allant des jeux de casino aux sessions live. BГ©nГ©ficiez de promotions allГ©chantes et d'une climat stimulante. Pampago Casino se veut comme un choix numГ©ro un pour le divertissement.
GloriaLougs 07 Mayıs 2026 16:08
По моему, это не самый лучший вариант In de sfeer van online gokken zijn duitse online casino, [url=https://nl.trustpilot.com/review/ecomxacademy.nl]duitse casino[/url]'s gewild. Ze bieden een geweldig spelaanbod en aantrekkelijke bonussen. Spelers worden aangepord door de gelegenheid om gokken te verdienen.
Karenboupt 07 Mayıs 2026 15:05
Я Вам очень обязан. slot oyunlarД±, [url=https://zkus.mupyonline.cz/blog/2026/04/26/azrbaycann-musbt-dman-bahis-platformas-mostbet/]https://zkus.mupyonline.cz/blog/2026/04/26/azrbaycann-musbt-dman-bahis-platformas-mostbet/[/url] vacibdir vЙ™ Г§oxlu insan üçün cЙ™lbedici bir Г¶yГјddД±r. Bu oyunlar nalayiq ЕџansД±q oyunlarД± arasД±nda vЙ™kil yer tutur. RabitЙ™ platformsunda slot oyunlarД± daima yenilЙ™nЙ™rЙ™k nГјanslar tЙ™qdim edir. ГњmumiyyЙ™tlЙ™ oyunlardan faydalanmaq bГ¶yГјk kГјtlЙ™ yaradД±r.
BrookeSiz 07 Mayıs 2026 15:03
Малый жжот))))ыыыыыыыыыыы realz casino, [url=https://pqmpavers.com/descubre-el-codigo-bono-de-realz-casino-y-mejora/]https://pqmpavers.com/descubre-el-codigo-bono-de-realz-casino-y-mejora/[/url] es un lugar increГble para disfrutar de la emociГіn de los juegos de azar. Los fanГЎticos pueden vivir la adrenalina de obtener grandes premios. AdemГЎs, la variedad de juegos es sorprendente. ВЎNo te lo pierdas!
Marynat 07 Mayıs 2026 14:47
Отличная фраза и своевременно Pampago Casino, [url=https://pampago-casinofr.com/]Pampago Casino[/url] est un lieu fascinant oГ№ les joueurs dГ©couvrent une multitude de jeux. Avec son ambiance Г©lГ©gante, c'est l'endroit idГ©al pour expГ©rimenter des moments marquants.
Brianpam 07 Mayıs 2026 13:31
Это просто бесподобно :) Among the world of entertainment, Casino Online Slots, [url=http://www.carbossonline.com/letou-casino-registration-process-a-step-by-step-5/]http://www.carbossonline.com/letou-casino-registration-process-a-step-by-step-5/[/url] are prominent for their excitement. Gamers enjoy opportunities to win big from the luxury of home.
CherilJunty 07 Mayıs 2026 13:21
pin up casino зеркало, [url=https://pin-up-casino-cyaju.top/]pin up casino онлайн[/url] предоставляет игрокам доступ к игровым автоматам и азартным играм в любое время. Этот ресурс обеспечивает комфортный доступ к многочисленным игровым возможностям. Игроки способны наслаждаться развлечениями без ограничений в спокойной обстановке. За счет актуальных предложений и акций, развлечение это превращается еще более увлекательным и интересным.
Jeremynaist 07 Mayıs 2026 13:20
пинко казино, [url=https://pinco-casino-bocij.sbs/]pinco-casino-bocij.sbs[/url] предлагает множество развлечений для азартных игроков. Игроки могут насладиться многообразными слотами и развлечениями. Промоакции делают игровой процесс еще более увлекательным. Не упустите шанс испытать свою удачу в пинко казино!
AnneGor 07 Mayıs 2026 12:29
Какие нужные слова... супер, блестящая фраза сертификация продукции, [url=https://taplink.cc/tihomirov.sergey]https://taplink.cc/tihomirov.sergey[/url] представляет собой важным процессом в обеспечении качества. Она способствует доказательству соответствия регламентам. Поэтому, пользователи могут основываться на продукцию, которая прошла сертификацию продукции.
Mattbrogy 07 Mayıs 2026 11:55
Браво, ваша мысль пригодится ремонт бытовой техники, [url=https://kurzurl.net/2048]https://kurzurl.net/2048[/url] — это важная задача, требующая внимательности. Восстанавливаем устройства может быть кропотливым, но с правильным обладением знаниями можно достигнуть успеха. Не забывайте исследовать возможные причины поломок.
RandyTig 07 Mayıs 2026 09:59
<a href=https://drivelity-italy.com/car-rental-bergamo-italy>car hire bergamo italy</a>
JenniferBug 07 Mayıs 2026 09:55
Извиняюсь, но не могли бы Вы дать немного больше информации. In the realm of entertainment, Casino Online Games, [url=http://www.southerngospelconcert.com/the-enchantment-of-online-kingdoms-a-journey-2/]http://www.southerngospelconcert.com/the-enchantment-of-online-kingdoms-a-journey-2/[/url] offer thrilling experiences for players. Presenting a variety of games, you can explore unique themes and dynamic gameplay. Enjoy the convenience of playing from home, while also engaging with other enthusiasts. The world of Casino Online Games is always transforming.
GloriaLougs 07 Mayıs 2026 09:54
Замечательно, очень забавная фраза duitse online casino, [url=https://de.trustpilot.com/review/tethercasinosites.com]tether bep20 casinos[/url] bieden een verscheidenheid aan spellen die entertainment garanderen. Gokkers kunnen meedoen aan videoslots en tafelspellen van vermaarde studios.
Meganrit 07 Mayıs 2026 09:33
Curtiswag 07 Mayıs 2026 08:43
online casino, [url=http://www.nbzhaoke.com/?p=227258]http://www.nbzhaoke.com/?p=227258[/url] provide a captivating experience for players looking to delight in games from the convenience of their homes. With a selection of games, there’s something for everyone.
Mitchrourn 07 Mayıs 2026 08:00
Не знаю, не знаю realz kasino, [url=https://pornx.vicetemple.io/reaalikasinoarvostelut-loyda-paras-online-kasino/]https://pornx.vicetemple.io/reaalikasinoarvostelut-loyda-paras-online-kasino/[/url] - Realz kasino mahdollistaa ainutlaatuisen pelikokemuksen, mikГ¤ tekee siitГ¤ voittojen saaminen entistГ¤ ikimuistoisammaksi. PГ¶ytГ¤- ja valikoima on, mikГ¤ mahdollistaa jokaiselle kokea jotain ainutlaatuista.
Jasonbot 07 Mayıs 2026 07:58
Это очень ценная фраза kazino oyunlarД±, [url=https://www.vautron.cz/mostbet-cz-onlayn-mrc-platformas/]https://www.vautron.cz/mostbet-cz-onlayn-mrc-platformas/[/url] Г§ox yГ¶nlГј imkan tЙ™qdim edir. MГјsabiqЙ™Г§ilЙ™r nГ¶vbЙ™li strategiyalar istifadЙ™ edЙ™rЙ™k qЙ™lЙ™bЙ™ mГјmkГјnlГјk ЕџansД±na nail olurlar. Kazino oyunlarД± hisslЙ™r yaradД±r vЙ™ Гјslub Й™laqЙ™lЙ™r qurmaДџД± asanlaЕџdД±rД±r.
BobbyElemi 07 Mayıs 2026 07:48
Пин Ап казино – популярная платформа для азартных игр. Чтобы избежать блокировок, используйте pin up casino зеркало, [url=https://pin-up-casino-07hox.icu/]pin-up-casino-07hox.icu[/url]. Именно оно обеспечивает доступ к любимым играм давая возможность играть без ограничений. Погрузитесь в мир азарта и получайте удовольствие от процесса!
KerryChaft 07 Mayıs 2026 07:47
пинко казино, [url=https://pinco-casino-yxh00.sbs/]https://pinco-casino-yxh00.sbs/[/url] предлагает уникальные возможности для любителей азартных игр. Азартные влюбленные могут насладиться большим выбором игр и восторженной атмосферой. Каждый желающий найдет что-то по своему вкусу. Пинко казино — это идеальное место для отдыха.
Daniellon 07 Mayıs 2026 06:49
Спасибо, может, я тоже могу Вам чем-то помочь? Online Casino, [url=https://mihajloderimanovic.com/experience-the-thrill-of-online-casino-gaming-with/]https://mihajloderimanovic.com/experience-the-thrill-of-online-casino-gaming-with/[/url] provides a thrilling journey for players. With diverse games available, everyone can find something engaging. Whether players are a seasoned bettor or a novice, Online Casino is a great place to enjoy fun and win rewards!
Brandonchoiz 07 Mayıs 2026 06:14
ElizabethLycle 07 Mayıs 2026 05:01
Searching for fascinating opportunities in the gaming world? Look no further than free money casino, [url=https://wworj.com.br/unlock-exciting-offers-with-15-free-spins-no-2/]https://wworj.com.br/unlock-exciting-offers-with-15-free-spins-no-2/[/url]! Many players love the chance to win huge amounts without making any beginning investments. Just obtain your opening and explore the entertainment they offer!
Jeffplorn 07 Mayıs 2026 01:35
Online casinos have become trendy in recent years, allowing players to enjoy thrilling Casino Online Games, [url=http://www.everydayimport.com/experience-the-thrill-of-winning-at-online-casino-2/]http://www.everydayimport.com/experience-the-thrill-of-winning-at-online-casino-2/[/url] from the comfort of their homes. With a variety of options available, players can find their favorite games easily.
MarciaSycle 07 Mayıs 2026 01:34
По моему мнению Вы допускаете ошибку. Предлагаю это обсудить. Пишите мне в PM, пообщаемся. Le Fisherman France slot officiel, [url=https://buddybeds.com/bulldogs-and-babies-adorable-must-watch-videos/]https://buddybeds.com/bulldogs-and-babies-adorable-must-watch-videos/[/url] propose une expГ©rience exceptionnelle pour les joueurs. DГ©couvrez dans un univers captivant rempli de bestiaux aquatiques. Les illustrations sont magnifiques, et chaque tournГ©e peut vous rapprocher Г de fabuleux gains. Ne manquez pas l'opportunitГ© de s'essayer Г Le Fisherman France slot officiel et capturer des trГ©sors marins!
JustinNup 07 Mayıs 2026 01:34
The realm of online gambling has expanded significantly, with the emergence of Casino Online Platform, [url=https://www.ainecleaning.ca/extreme-spins-casino-sportsbook-your-ultimate-4/]https://www.ainecleaning.ca/extreme-spins-casino-sportsbook-your-ultimate-4/[/url] attracting countless players. These platforms offer a wide range of games and thrilling promotions, making it easy to experience the thrill of winning from home. Players can opt for their favorites and bet at any time, which enhances the appeal of the Casino Online Platform. Safety and security are highlighted, ensuring a safe gambling environment.
AmandaRep 07 Mayıs 2026 01:33
Я знаю, как нужно поступить... real pul kazino, [url=http://okjcp.jp/test/?p=372832]http://okjcp.jp/test/?p=372832[/url], strateji hЙ™vЙ™skarlarД± üçün ideal yerdir. BelЙ™ platformalar, Еџey mГјxtЙ™liflik tЙ™qdim edir. Д°nsanlar hЙ™ftЙ™ yeni strategiyalar test etmЙ™yЙ™ tЙ™Еџviq edirlЙ™r. HamД± qazanma üçün variantlar tЙ™lЙ™b edir.
Bennus 07 Mayıs 2026 01:17
If you're looking for exciting gaming experiences, try out a no deposit casino, [url=http://bupsyk.info/wordpress/?p=92193]http://bupsyk.info/wordpress/?p=92193[/url]. You can find free spins and bonuses, enabling players to enjoy games without risking their money. Discover the thrill today!
Gloriarog 07 Mayıs 2026 00:51
Очень замечательно! Casino Online, [url=http://www.cifeahn.org/the-allure-of-casino-jazz-a-harmonious-fusion-of/]http://www.cifeahn.org/the-allure-of-casino-jazz-a-harmonious-fusion-of/[/url] снабжает игрокам захватывающие возможности. Ставки доступны круглосуточно, создавая привлекательную атмосферу. Множество РёРіСЂ радует любителей азартных РёРіСЂ.
Jeffsah 06 Mayıs 2026 22:07
Casino Online Platform, [url=https://heni.co.in/everything-you-need-to-know-about-love-casino-2/]https://heni.co.in/everything-you-need-to-know-about-love-casino-2/[/url] открывает большой выбор игр для игроков. Все фанаты азартных игр найдут что-то занимательное. Акции или щедрые предложения доступны, создавая фантастический возможности.
Brandondwene 06 Mayıs 2026 22:01
В этом что-то есть. Буду знать, большое спасибо за информацию. In the world of virtual casinos, online casino, [url=https://www.radiogrenal.com.br/como-jogar-online-pode-melhorar-sua-concentracao-dicas-e-curiosidades/]jogar online[/url] platforms offer a thrilling experience for players. Enjoy exciting games and the chance to win big. With protected deposits, you can easily engage in fun.
Tatelisp 06 Mayıs 2026 21:48
Playing at an online casino, [url=https://demo.fastw3b.com/gallerywp/casinionline18042/unlock-excitement-15-free-spins-no-deposit-your/]https://demo.fastw3b.com/gallerywp/casinionline18042/unlock-excitement-15-free-spins-no-deposit-your/[/url] brings joy, as players have the chance to win huge prizes from the comfort of their homes. With a range of options available, the experience is both diverse and convenient.
Lawrenceinjep 06 Mayıs 2026 20:57
zahraniДЌnГ online casino, [url=https://www.teleworldservices.com/zahranini-casina-pro-eske-hrae-jak-si-vybrat-to/]https://www.teleworldservices.com/zahranini-casina-pro-eske-hrae-jak-si-vybrat-to/[/url] tvrdГ hrГЎДЌЕЇm bohatou vГЅbД›r her. OsobnГ vГЅhody podporujГ ЕЎance na vГЅhru. Neduste tuto ЕЎanci a zaЕѕijte hernГ adrenalin online!
Pamelanum 06 Mayıs 2026 20:16
AyanaBub 06 Mayıs 2026 19:31
Я думаю, что Вы не правы. Могу отстоять свою позицию. Пишите мне в PM, поговорим. onlayn kazino, [url=https://bcdc.edu.ph/2026/04/25/betandreas-dman-mrclri-dunyas/]https://bcdc.edu.ph/2026/04/25/betandreas-dman-mrclri-dunyas/[/url] fЙ™rqli oyun imkanlarД± tЙ™qdim edir. Bu mЙ™kanlar ziyaretГ§ilЙ™rЙ™ evdЙ™n Г§Д±xmadan qeyri-adi tЙ™crГјbЙ™ Й™zizlЙ™mЙ™yЙ™ Г§oxsaylД± oyunlar tЙ™klif.
Chuckfug 06 Mayıs 2026 19:31
Это просто отличная мысль kaszinГі realz, [url=https://www.magetitans.es/a-realz-kaszino-bonusz-hogyan-maximalizaljuk-az/]https://www.magetitans.es/a-realz-kaszino-bonusz-hogyan-maximalizaljuk-az/[/url] - A kaszinГі realz egy izgalmas Г©lmГ©nyt kГnГЎl a vendГ©geknek. Az valГіs kaszinГіk atmoszfГ©rГЎja kiemeli a szГіrakozГЎst, mikГ¶zben a modern technolГіgiГЎk kalandot kГnГЎlnak a jГЎtГ©kosoknak.
Elizabethtok 06 Mayıs 2026 18:41
Online Casino, [url=http://xchronic.com/lucky-barry-casino-your-gateway-to-thrilling/]http://xchronic.com/lucky-barry-casino-your-gateway-to-thrilling/[/url] delivers an exciting way to have fun games from the ease of your home. Boasting a wide variety of games, players can discover their top picks.
Juliasoinc 06 Mayıs 2026 18:24
По моему мнению Вы не правы. Давайте обсудим это. Пишите мне в PM. Within the realm of online gambling, Casino Online Games, [url=https://www.borcianicase.it/gxmble-casino-sportsbook-your-ultimate-gaming-36/]https://www.borcianicase.it/gxmble-casino-sportsbook-your-ultimate-gaming-36/[/url] offer thrilling experiences. Participants can take advantage of multiple options, including themed games, card games, and additional choices. Gaining amazing prizes is just a move away!
Michaelvar 06 Mayıs 2026 17:13
zahraniДЌnГ online casino, [url=https://mea.bmcc.is/2026/03/12/bezpene-zahranini-casino-jak-si-vybrat-a-na-co-dat/]https://mea.bmcc.is/2026/03/12/bezpene-zahranini-casino-jak-si-vybrat-a-na-co-dat/[/url] pЕ™inГЎЕЎГ ЕЎirokou nabГdku her, kterГ© zaujmou hrГЎДЌe z rЕЇznГЅch koutЕЇ svД›ta. Ochrana je zde na prvnГm mГstД›, coЕѕ dokazuje spokojenost uЕѕivatelЕЇ.
Violafet 06 Mayıs 2026 15:14
Casino Online Games, [url=https://sitarakshawomencare.in/2026/04/13/withdrawal-methods-at-lucky-mister-casino-a/]https://sitarakshawomencare.in/2026/04/13/withdrawal-methods-at-lucky-mister-casino-a/[/url] present a dynamic experience for players. Users can enjoy a variety of games from the ease of their residences. Featuring stunning graphics and immersive gameplay, Casino Online Games ensure endless fun and chances to win big!
Pennyfoede 06 Mayıs 2026 15:13
Casino Online Games, [url=https://visit.ambato.gob.ec/2026/04/10/duobetz-a-comprehensive-guide-to-online-gambling/]https://visit.ambato.gob.ec/2026/04/10/duobetz-a-comprehensive-guide-to-online-gambling/[/url] открывают удивительные варианты для энтусиастов. Рспользуя современных технологий, РІСЃРµ может наслаждаться РІ увлекательных играх. Атмосфера РѕС‚ азартных обеспечивает некоторые РёР· самых СЏСЂРєРёС… ощущения.
VanessaBen 06 Mayıs 2026 14:56
Жалею, но ничего нельзя сделать. Os casinos online em Portugal tГЄm ganhado popularidade entre os entusiastas. Com promoções especiais e diversidade de jogos, os locais se tornam cada vez mais convincente para os novatos. A seguranГ§a das transações Г© uma prioridade, garantindo seguranГ§a aos participantes. AlГ©m disso, a experiГЄncia do usuГЎrio Г© otimizada com atendimento ao cliente 24/7, tornando os casinos online portugal, [url=https://dubdev.wpengine.com/descubra-os-melhores-casinos-online-com-bonus-40/]https://dubdev.wpengine.com/descubra-os-melhores-casinos-online-com-bonus-40/[/url] uma opção ideal para lazer.
Judydok 06 Mayıs 2026 13:34
Jerryemige 06 Mayıs 2026 13:25
Отличный топик Le Fisherman Italia slot ufficiale, [url=https://nextstepfundinggroup.com/hello-world/]https://nextstepfundinggroup.com/hello-world/[/url] ГЁ un gioco avvincente che garantisce un'esperienza eccezionale. I giocatori possono sfruttare dei eleganti premi e emozionanti funzionalitГ . La visualizzazione ГЁ di alta qualitГ , rendendo ogni spin entusiasmante. Prova ora le innovazioni e scopri il universo di Le Fisherman Italia slot ufficiale!
RubyItags 06 Mayıs 2026 13:25
Я думаю, что Вы не правы. Давайте обсудим это. kazino tЙ™tbiqi, [url=https://www.maatone.com/betandreas-onlayn-dman-bahislri-dunyasna-yol-acn/]https://www.maatone.com/betandreas-onlayn-dman-bahislri-dunyasna-yol-acn/[/url] sГјper imkanlar tЙ™qdim edir. OyunГ§ular mГјxtЙ™lif oyunlar arasД±ndan Г¶zlЙ™rini tapmaq imkanД±na malikdir. BelЙ™ tЙ™tbiqlЙ™r istifadЙ™ rahatlД±ДџД± vЙ™ yeni bonuslar tЙ™qdim edir. Kazino tЙ™tbiqi, hЙ™r yerdЙ™ oyun oynama ЕџansД± verir.
ShannonBoype 06 Mayıs 2026 13:18
zahraniДЌnГ online casino, [url=http://carolkherlakian.com.br/nejlepi-online-casina-2023-zabava-a-vyhry-na-dosah/]http://carolkherlakian.com.br/nejlepi-online-casina-2023-zabava-a-vyhry-na-dosah/[/url] nabГzГ ЕЎirokou ЕЎkГЎlu her a nabГdek. HrГЎДЌi mohou ДЌerpat z bonusЕЇ a pobГdek, kterГ© zvyЕЎujГ ЕЎance. BezpeДЌnost a seriГіznost jsou prioritou kaЕѕdГ©ho hrГЎДЌe.
Tracyneita 06 Mayıs 2026 11:25
Online Casino, [url=https://arwwa.in/experience-excitement-at-flashdash-online-casino/]https://arwwa.in/experience-excitement-at-flashdash-online-casino/[/url] - Internet Gambling Venue предоставляет поразительные возможности для удовольствия. РРіСЂРѕРєРё РјРѕРіСѓС‚ наслаждаться различные РёРіСЂС‹ Рё обретать реальные деньги.
Candyswore 06 Mayıs 2026 11:24
Online Casino, [url=http://rellsunn.org/magic-win-review-unraveling-the-mysteries-of/]http://rellsunn.org/magic-win-review-unraveling-the-mysteries-of/[/url] delivers an exciting possibility for players to delight in a variety of games. Including slots, players can explore their skills and chance. Explore the exciting world of online gaming today!
JenniferKnown 06 Mayıs 2026 10:51
roulette casinos, [url=https://www.free-find.co.uk/2026/04/17/the-ultimate-guide-to-roulette-casinos-strategies-8/]https://www.free-find.co.uk/2026/04/17/the-ultimate-guide-to-roulette-casinos-strategies-8/[/url] offer an exciting gaming experience. Players enjoy the fun of betting on numbers and colors. With various game variations, such as European and American, the possibilities are limitless.
YvonneBoymn 06 Mayıs 2026 09:55
Бесподобное сообщение ;) online casino, [url=https://slotimo.com/blog/slots/book-of-ra-slot-guide/]slotimo.com/blog/slots/book-of-ra-slot-guide/[/url] gives a captivating experience for players. With numerous selection of games, showcasing slots, poker, and roulette, participants can experience their favorite games from home.
TedMof 06 Mayıs 2026 09:17
zahraniДЌnГ online casino, [url=https://www.larianesalomaojoias.com.br/2026/03/16/objevte-fascinujici-svt-zahraninich-casin/]https://www.larianesalomaojoias.com.br/2026/03/16/objevte-fascinujici-svt-zahraninich-casin/[/url] nabГzГ bohatou ЕЎkГЎlu her, kterГ© bavГ vЕЎechny hrГЎДЌe. MЕЇЕѕete si uЕѕГt svГ© oblГbenГ© automaty, stolnГ hry nebo reГЎlnГ© krupiГ©ry. PohodlnГ© ovlГЎdГЎnГ pЕ™itahuje zaДЌГЎteДЌnГky z celГ©ho svД›ta.
Netraexire 06 Mayıs 2026 07:46
In the world of virtual fun, Casino Online Games, [url=https://www.kocaelicilingir41.com/discover-the-exciting-world-of-lucky-max-casino-2.html]https://www.kocaelicilingir41.com/discover-the-exciting-world-of-lucky-max-casino-2.html[/url] have become increasingly popular. Players can enjoy exciting experiences, from slots to table games. The convenience of playing at home offers an unique gaming environment.
Angelinaciz 06 Mayıs 2026 07:35
Я думаю, что Вы допускаете ошибку. Давайте обсудим это. Пишите мне в PM, поговорим. realz casinГІ, [url=https://inventlinks.com/scopri-il-mondo-di-casino-realz-divertimento-e/]https://inventlinks.com/scopri-il-mondo-di-casino-realz-divertimento-e/[/url] - Il mondo dei giochi online offre l'opportunitГ di divertirsi con emozioni uniche nei casinГІ reali. Qui, ogni giocatore puГІ vivere l'atmosfera avvincente del gioco, con vasta scelta di opzioni e tavoli da gioco. Con il giusto approccio, l'esperienza puГІ diventare davvero indimenticabile.
TinaJoype 06 Mayıs 2026 07:06
live roulette not on gamstop, [url=https://www.grimalc.com/exploring-live-roulette-options-not-covered-by/]https://www.grimalc.com/exploring-live-roulette-options-not-covered-by/[/url] offers players an exciting alternative to traditional online casinos. Such a site provides users to enjoy the thrill of spinning the wheel without the restrictions imposed by self-exclusion programs. Without Gamstop’s constraints, players can easily access their favorite games anytime.
CynthiaJER 06 Mayıs 2026 07:04
качество нормальное я думал что буде хуже но ошибался и рад этому) Nel settore dei giochi, il sito di giochi online Sisal it, [url=https://acrosswear.com/post-title-12/]https://acrosswear.com/post-title-12/[/url] propone una grande selezione di opzioni. Ogni singolo giocatori possono trovare qualcosa di interessante adatta ai propri preferenze. Con bonus allettanti, il sito di giochi online Sisal it si differenzia dai altri siti. Prova il godimento in un ambiente affidabile e accessibile.
Ivynuh 06 Mayıs 2026 07:03
Замечательно, это весьма ценное мнение mobil kazino, [url=http://reagel.com.br/index.php/betandreas-onlayn-dman-mrclri-ucun-n-yax-platforma-10/]http://reagel.com.br/index.php/betandreas-onlayn-dman-mrclri-ucun-n-yax-platforma-10/[/url], mobil oyun dГјnyasД±na girmЙ™k istЙ™yirsinizsЙ™, rahatlД±qla istЙ™diyiniz qumar oyunlarД±nД± seГ§Й™ bilЙ™rsiniz. MaraqlД± bonuslar vЙ™ mГјkЙ™mmЙ™l qrafika ЕџirkЙ™t olunur. HЙ™r zaman mobil kazino ilЙ™ stЙ™kanД±nД±zД± yГјksЙ™ldin!
Jackbib 06 Mayıs 2026 05:27
zahraniДЌnГ online casino, [url=https://techners.net/zahranini-online-casino-bonus-bez-jak/]https://techners.net/zahranini-online-casino-bonus-bez-jak/[/url] umoЕѕЕ€uje hrГЎДЌЕЇm napГnavГ© zГЎЕѕitky. S pestrou nabГdkou her a bonusЕЇ lГЎkГЎ zaДЌГЎteДЌnГky. Jednoduchost hranГ z domova zajГmГЎ mnoho lidГ.
Joshuaunwib 06 Mayıs 2026 05:05
Гігієнічний душ, [url=https://piyoko.com/contact/]https://piyoko.com/contact/[/url] - це комфортний засіб для збереження чистоти. Він забезпечує швидко омитися і виключити в перспективі негативні запахи. Гігієнічний душ варто встановити у ванній кімнаті для щоденного використання.
Stellamub 06 Mayıs 2026 04:52
Эта отличная фраза придется как раз кстати торговля криптовалютой, [url=https://howtobuyusdt.ru/]https://howtobuyusdt.ru/[/url] становится все более популярной, так как участники рынка ищут новые возможности для успеха. Выбор платформы для торговли, анализ данных и управление рисками играют ключевую роль в этом деле.
NoraLoups 06 Mayıs 2026 04:14
Casino Online Games, [url=https://superdemo.wpdeo.com/experience-the-thrill-of-golden-lion-online-casino-2.html]https://superdemo.wpdeo.com/experience-the-thrill-of-golden-lion-online-casino-2.html[/url] предлагают незабываемые переживания. Поскольку своей доступности, игроки могут играть в любое время. Новые технологии позволяют создавать интересные графику и звуковую атмосферу, что делает опыт еще более насыщенным. Востребованность Casino Online Games растет с каждым годом, мотивируя все больше долгосрочных пользователей.
KristinJah 06 Mayıs 2026 04:04
Логичный вопрос Online Casino, [url=https://hennaby.makeupglitz.com/discover-the-thrills-of-online-casino-golden-lion-3/]https://hennaby.makeupglitz.com/discover-the-thrills-of-online-casino-golden-lion-3/[/url] - Online Casino предоставляет лицам уникальные варианты для времяпровождения. Р’ этих заведениях можно насладиться острые ощущения, играя РІ слоты.
ChrisFrela 06 Mayıs 2026 03:30
casino roulette real money, [url=https://riosessions.com/web/experience-the-thrill-play-online-roulette-with-4/78132/]https://riosessions.com/web/experience-the-thrill-play-online-roulette-with-4/78132/[/url] offers an exhilarating experience for players. This game combines luck and planning to create a thrilling atmosphere. Try out online platforms for instant access.
Abigayleblact 06 Mayıs 2026 01:37
унітази-біде, [url=https://nvxltd.com/2019/02/18/our-strength-your-business/]https://nvxltd.com/2019/02/18/our-strength-your-business/[/url] є у сучасних ванних кімнатах. Вони об'єднують функції унітазу та біде, забезпечуючи ефективність. Обираючи унітази-біде, зверніть увагу на дизайн та матеріали. Вони приваблюють зекономити простір і створити стильний інтер'єр.
LeahHox 06 Mayıs 2026 01:16
На мой взгляд это очень интересная тема. Предлагаю всем активнее принять участие в обсуждении. криптовалютная биржа, [url=https://www.tadviser.ru/index.php/%D0%9A%D0%BE%D0%BC%D0%BF%D0%B0%D0%BD%D0%B8%D1%8F:OKX_(%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B2%D0%B0%D0%BB%D1%8E%D1%82%D0%BD%D0%B0%D1%8F_%D0%B1%D0%B8%D1%80%D0%B6%D0%B0)]отзывы okx[/url] сравнивает варианты для криптоэнтузиастов. В этой среде можно обменять различные онлайн валюты. Особенность имеет поддержка, что помогает эффективно работать с активами.
AmandaTef 06 Mayıs 2026 01:06
Понятно, большое спасибо за информацию. HazardnГ platforma s reГЎlnГЅmi penД›zi, jako je realz kasino, [url=https://sotech.com.hk/jak-vyuit-realz-kasino-bonus-pro-maximalni-vyhru/]https://sotech.com.hk/jak-vyuit-realz-kasino-bonus-pro-maximalni-vyhru/[/url], pЕ™inГЎЕЎГ napД›tГ do svД›ta virtuГЎlnГch casin. VybГdka vyhrГЎvat znaДЌnГ© sumy zvyЕЎuje zajГmavost tГ©to platformy.
Sarahjah 06 Mayıs 2026 01:05
Хороший вопрос canlД± kazino, [url=https://app.sabemos.com.co/online-oyun-v-dman-mrcinin-glcyi/]https://app.sabemos.com.co/online-oyun-v-dman-mrcinin-glcyi/[/url] mГјЕџtЙ™rilЙ™rЙ™ Й™ylЙ™ncЙ™li vЙ™ hЙ™yЙ™can verici oyun tЙ™crГјbЙ™si tЙ™qdim edir. TЙ™kliflЙ™r geniЕџdir; ruleta kimi populyar oyunlardan istifadЙ™ etmЙ™k mГјmkГјndГјr. CanlД± kazino, hЙ™qiqi krupiyelЙ™rlЙ™ oyun oynamaДџД± tЙ™klif edir, bu da ortam Й™lavЙ™ edir. Qazanc ЕџansД± da yГјksЙ™ldilir. Portativ cihazlarda da mГјmkГјn olmaq imkanД± var.
EricaLuh 06 Mayıs 2026 00:50
Discover the thrill of online gambling at an exciting Online Casino, [url=https://gambarigroup.com/unlocking-the-secrets-of-magic-win-bonuses-21/]https://gambarigroup.com/unlocking-the-secrets-of-magic-win-bonuses-21/[/url]. Players can experience a variety of entertainment from slots to table games. With safe transactions, everyone can feel at ease while playing. Join this vibrant world of chance!
HankHip 06 Mayıs 2026 00:49
In the thrilling world of online gaming, Online Casino, [url=https://kaisgroup.tech/discover-the-excitement-of-slotit-casino-4/]https://kaisgroup.tech/discover-the-excitement-of-slotit-casino-4/[/url] offers a vibrant experience. Players can enjoy diverse choices, from slots to table games, all from the comfort of home. Incentives await those who join, making every bet more exciting.
AngelaJuimb 06 Mayıs 2026 00:09
Gwinnettdes 06 Mayıs 2026 00:03
casino roulette real money, [url=https://demo.simpkb.id/winning-strategies-for-online-roulette-play-for-4/]https://demo.simpkb.id/winning-strategies-for-online-roulette-play-for-4/[/url] offers an exciting chance to win big. It has a range of betting options that can attract both beginners and experienced players. Through strategic bets, you could maximize your potential earnings and enjoy a thrilling gaming experience.
BrandonNap 05 Mayıs 2026 20:39
<a href=https://drivelity-spain.com/car-rental-benidorm-spain>cheap car rental benidorm spain</a>
Elizabethenaft 05 Mayıs 2026 19:54
Online Casino, [url=http://206.189.87.42/experience-the-thrill-of-online-casino-at-nightbet/]http://206.189.87.42/experience-the-thrill-of-online-casino-at-nightbet/[/url] - Virtual Casino представляет собой захватывающий мир азартных игр, где игроки могут осуществлять свои желания к победе. В этом месте предлагаются множество игр.
MichaelHak 05 Mayıs 2026 19:53
Feliciakip 05 Mayıs 2026 18:54
Playing an exciting real money roulette game, [url=https://luar.dcc.ufmg.br/exploring-the-excitement-of-real-money-roulette/]https://luar.dcc.ufmg.br/exploring-the-excitement-of-real-money-roulette/[/url] provides participants the option to achieve significant gains. With various strategies, you can enhance their chances of success.
BrandonCargo 05 Mayıs 2026 18:49
Tonyaler 05 Mayıs 2026 16:57
книги, [url=http://wiki.malyansys.com/doku.php?id=crazyfbshop]http://wiki.malyansys.com/doku.php?id=crazyfbshop[/url] — это удивительный мир возможности, открывающий перед нами неизведанные горизонты. Они способствуют погрузиться в многообразные культурные и психологические структуры человеческого существования. Чтение книг — это не только основа знаний, но и способ расслабляться от будней.Более того, книги развивают творческое мышление и уламывают границы взглядов. Погружаясь в мир страницы за страницей, читатели получают новые чувства и осознания. Книги, такие как «Мастер и Маргарита», «1984», «Война и мир» — это не просто произведения искусства, но и инструменты для размышлений.Искусство книги меняет не только восприятие людей, но и целых поколений, подготавливая их к переменным соврем
BrookeGeory 05 Mayıs 2026 16:45
Ну они и дают жару Playing Casino Online Games, [url=https://kariorangpower.com/fortunejack-online-casino-uk-your-ultimate-2/]https://kariorangpower.com/fortunejack-online-casino-uk-your-ultimate-2/[/url] offers an thrilling experience. Via multiple games, you can win substantial prizes from the comfort of your home.
Briancot 05 Mayıs 2026 16:42
Robreume 05 Mayıs 2026 16:41
lightning roulette casino, [url=https://www-l2ti.univ-paris13.fr/~beghdadi/?p=107982]https://www-l2ti.univ-paris13.fr/~beghdadi/?p=107982[/url] - In einem Lightning Roulette Casino bietet Gästen eine außergewöhnliche Erfahrung. Diese Spiele vereinen klassische Elemente und zeitgemäße Technologien, was den Nervenkitzel erhöht. Ebenfalls bunten Beleuchtungen und fesselnden Gewinne kreieren jede Partie besonders einladend.
JenniferMor 05 Mayıs 2026 16:30
Virtual casinos have gained immense popularity in recent years. Among various options, Casino Online Games, [url=https://k2joom.com/unlock-exciting-rewards-with-wildwild-casino-promo-2/]https://k2joom.com/unlock-exciting-rewards-with-wildwild-casino-promo-2/[/url] offer thrilling experiences. Using state-of-the-art systems, players can enjoy genuine gaming scenarios from the comfort of their homes. These accessibility, combined with countless game selections, attracts fresh players and seasoned gamblers alike. Rewards further enhance the allure, creating a captivating environment for all.
Ta,Evape 05 Mayıs 2026 16:30
Discovering the ultimate Casino Online Platform, [url=https://bueaheights.com/2026/04/04/betgem-casino-cashback-bonus-guide-maximize-your/]https://bueaheights.com/2026/04/04/betgem-casino-cashback-bonus-guide-maximize-your/[/url] offers a pathway to enjoy a wide range of games right from wherever you are. Taking advantage of bonuses and promotions, players can increase their enjoyment while testing their luck.
ThevocabCok 05 Mayıs 2026 16:04
Очень сожалею, что ничем не могу помочь. Надеюсь, Вам здесь помогут. Не отчаивайтесь. kazino oyunlarД±, [url=http://www.caribbean-property.com/mostbet-bd-onlayn-mrclrin-yeni-donmi/]http://www.caribbean-property.com/mostbet-bd-onlayn-mrclrin-yeni-donmi/[/url], Еџans dГјnyasД±nda geniЕџ variant tЙ™klif edir. KГјbarlar bu oyunlarД± hiss üçün oynayД±r. Yeni kazino oyunlarД± bireysel dГјЕџГјncЙ™lЙ™r tЙ™qdim edir. HЙ™r kЙ™s uДџur qazandД±qda Г¶z ЕџansД±nД± yoxlayД±r.
DevonInofs 05 Mayıs 2026 16:03
Это мне не нравится. sansibar immobilien, [url=https://sasiedzi24.obliczasrebra.kylos.pl/node/]https://sasiedzi24.obliczasrebra.kylos.pl/node/[/url] sind eine ideale Wahl fГјr Investoren, die fasciniert von einer auГџergewГ¶hnlichen Immobilie sind. Die atemberaubende Landschaft und das ideale Klima machen die Insel zu einem attraktiven Ziel.
Jann 03 Mayıs 2026 07:43
Personally, I have observed that the landscape of online casinos is totally evolved in the past months. Many sites these days seem to focus so much upon aesthetic effects instead of real gameplay. It's quite tiresome when you merely desires to have a short session bypassing endless loading periods. Still, anyone spotted several worthy tips on code bonus play jonny that really guided myself control the capital somewhat more wisely. It makes the entire experience seem much more honest and easy. I’ve likewise observed that reward benefits have become getting way highly vital compared to the initial deposit matches. Is this merely me, perhaps should you reckon that volatility in latest titles is becoming too extremely aggressive now? I'd be happy to learn how everyone else
vtaletztef 02 Mayıs 2026 04:30
prednisone dry skin dog medicine prednisone [url=https://fforhimsvipp.com/buy-prednisone/]prednisone 5mg tablets[/url] cellcept and prednisone muscle pain prednisone
BrendaHah 02 Mayıs 2026 03:32
bingo not on GamStop, [url=https://app.trafficivy.com/enjoy-online-bingo-not-on-gamstop/]https://app.trafficivy.com/enjoy-online-bingo-not-on-gamstop/[/url] offers players a chance to enjoy their favorite games without restrictions. Many platforms provide exciting options, allowing users to unique experiences. Don't miss out on the fun available now!
Danielcoisy 02 Mayıs 2026 02:00
Согласен, очень хорошая информация ВПН ProstoVPN, [url=https://www.alcol.net/project/world-clock-app/]https://www.alcol.net/project/world-clock-app/[/url] — это превосходное решение для конфиденциальности в сети. С поддержкой этого сервиса вы у вас есть шанс скрыть свой местоположение и преодолеть геоблокировки. Кроме того, простой интерфейс делает взаимодействие с программой доступным. Не упустите возможность защитить свои данные с ВПН ProstoVPN!
Robertmaf 02 Mayıs 2026 01:11
Fishin' Frenzy casinos, [url=https://galeriajoseamar.com/fishin-frenzy-the-ultimate-guide-to-reel-in-big/]https://galeriajoseamar.com/fishin-frenzy-the-ultimate-guide-to-reel-in-big/[/url] - In Fishin' Frenzy casinos you can experience adventure while playing machines. With vibrant graphics and captivating themes, it's easy to get caught. Enjoy huge rewards!
KimJab 01 Mayıs 2026 23:47
When looking for different online betting options, many punters seek sportsbooks not on GamStop, [url=https://descomplicandovideos.com.br/top-bookies-not-on-gamstop-your-guide-to-reliable/]https://descomplicandovideos.com.br/top-bookies-not-on-gamstop-your-guide-to-reliable/[/url]. These platforms offer more freedom and choice for placing bets. Always ensure you analyze these sites carefully to find the best features.
Nicholassib 01 Mayıs 2026 22:37
Patricknip 01 Mayıs 2026 22:29
Бомбейски! Использование впн становится всё более популярным. ВПН без рекламы, [url=http://www.tourist-guide-istria.com/portfolio-3-copyright/]http://www.tourist-guide-istria.com/portfolio-3-copyright/[/url] позволяет защитить и помочь обойти географические пределы. Вы имеете возможность наслаждаться безопасным благодаря эффективным сервисам.
TimKek 01 Mayıs 2026 21:50
Making use of a PayPal casino non GamStop, [url=https://21303.themes.vinawebsite.vn/discover-the-best-non-gamstop-paypal-casinos-for-2-8/]https://21303.themes.vinawebsite.vn/discover-the-best-non-gamstop-paypal-casinos-for-2-8/[/url] can offer a distinct gaming experience. Players enjoy the convenience of prompt transactions. With no restrictions, gamers can uncover a collection of choices.
DwightGek 01 Mayıs 2026 21:38
Find the newest info here > https://flashparade.ru/wp-includes/jks/1xbet___promokod_bonus.html
Nicoleomirl 01 Mayıs 2026 19:38
sports betting, [url=https://immobilienhamburg.eu/2026/04/17/betwinner-the-ultimate-platform-for-online-betting-2/]https://immobilienhamburg.eu/2026/04/17/betwinner-the-ultimate-platform-for-online-betting-2/[/url] - Betting on sports has gained immense popularity in recent years. Many enthusiasts love the thrill of placing bets on their favorite teams. With online platforms, it's easier than ever to join. However, it's essential to grasp the risks involved. Always place bets responsibly to ensure an enjoyable experience.
Julianorge 01 Mayıs 2026 17:45
оч даже! SEO для бизнеса, [url=https://www.geyikforum.com/uyeler/kabojasi.4597/#about]https://www.geyikforum.com/uyeler/kabojasi.4597/#about[/url] — это значимый инструмент для привлечения клиентов. Оптимизация вашего сайта обеспечивает повысить позиции в поисковых системах. Написание качественного контента, подбор ключевых слов — всё это неотъемлемо сопутствуют успешной стратегии. Периодический анализ данных помогает усовершенствовать действия и реализовывать поставленных целей.
Jayinhag 01 Mayıs 2026 17:24
берем... Если вы решили приобрести бизнес, важно отнестись к выбору фирмы с умом. Вам нужно учитывать финансовые показатели и возможности развития. Мы поможем собрать все необходимые документы для того, чтобы ты мог уверенно купить фирму, [url=https://arimagh.generalresource.ne.jp/biznesfirma/198839/]https://arimagh.generalresource.ne.jp/biznesfirma/198839/[/url]. Наша команда экспертов порекомендует выбрать оптимальный вариант для вашего дела.
Zackvar 01 Mayıs 2026 16:20
Pamelafrado 01 Mayıs 2026 15:05
echtgeld roulette, [url=http://www.grupafyi.pl/deutsches-echtes-roulette/online-echtgeld-roulette-dein-leitfaden-fur-das/]http://www.grupafyi.pl/deutsches-echtes-roulette/online-echtgeld-roulette-dein-leitfaden-fur-das/[/url] ist ein fesselndes Spiel, das taktische Möglichkeiten bietet. Jeder Spieler hat Möglichkeiten, große Gewinne zu erarbeiten. Der Nervenkitzel des Drehens des Rades zieht viele Menschen an. In Verbindung mit Echtgeld zu spielen bringt zusätzlichen Kick.
Ta,erync 01 Mayıs 2026 14:11
онлайн казино, [url=https://triptoptours.in/dragon-money-oficialnyj-sajt-i-luchshie/]https://triptoptours.in/dragon-money-oficialnyj-sajt-i-luchshie/[/url] открывает игрокам необычную возможность насладиться азарт не выходя из дома. С огромным количеством игр и бонусов, каждый найдет что-то особенное для себя.
VivianEmbes 01 Mayıs 2026 12:03
EpicksonGaf 01 Mayıs 2026 11:20
When exploring leading online gambling venues, top non GamStop casinos, [url=https://ofeq-sa.com/exploring-casinos-not-registered-with-gamstop-3/]https://ofeq-sa.com/exploring-casinos-not-registered-with-gamstop-3/[/url] are a excellent option. These casinos offer captivating games without restrictions from GamStop. Players can enjoy varied options, ensuring a unique gaming experience.
BeatriceTaf 01 Mayıs 2026 11:19
Die Faszination für casino roulette, [url=https://jilliewillie.com/online-roulette-mit-echtgeld-die-besten-strategien/]https://jilliewillie.com/online-roulette-mit-echtgeld-die-besten-strategien/[/url] begeistert Spieler her. Die Mischung aus Adrenalin und Zufall schafft dieses Spiel als einem beliebtesten Unterhaltungen. Dank diversen Einsatzmöglichkeiten und Ansätzen können Zocker manchmal Möglichkeiten verbessern.
AdamAcand 01 Mayıs 2026 10:48
как скачать помогите In the dynamic world of trade, the B2B platform Turkey wholesale, [url=https://demo.simpkb.id/exploring-b2b-platform-opportunities-in-turkey-for/]https://demo.simpkb.id/exploring-b2b-platform-opportunities-in-turkey-for/[/url] offers a seamless interface for buyers and sellers. Utilizing modern technology, the system connects companies efficiently. Discover a wide array of products at competitive prices, fostering growth in the market. Additionally, improved communication tools enable better interaction between partners.
LaurentBab 01 Mayıs 2026 10:47
Любопытный вопрос Приобретение профилей в социальной сети Фейсбук может стать удобным решением для рекламы. купить аккаунты фейсбук, [url=http://unati.univasf.edu.br/ultimate-guide-to-buy-facebook-autoreg-with-fan/]http://unati.univasf.edu.br/ultimate-guide-to-buy-facebook-autoreg-with-fan/[/url] – это способ увеличить влияние и поднять свою акции. Для этого критично осознать риски.
Reneefrura 01 Mayıs 2026 10:46
Finding the best live roulette casinos, [url=http://hempelpromome.com/index.php/2026/04/02/best-live-roulette-sites-in-the-uk-for-2023/]http://hempelpromome.com/index.php/2026/04/02/best-live-roulette-sites-in-the-uk-for-2023/[/url] is crucial for an exciting gaming experience. These platforms offer immersive gameplay and real-time interaction with dealers. Players can enjoy a variety of tables, ensuring options for everyone. With offers available, gamers can enhance their winnings. Don't miss your chance at the best live roulette casinos, where thrill and entertainment await!
IrismuM 01 Mayıs 2026 08:48
Ericahon 01 Mayıs 2026 07:53
Looking for the top non GamStop casino, [url=https://aroeats.net/aroeats/safe-casinos-not-on-gamstop-your-guide-to-secure]https://aroeats.net/aroeats/safe-casinos-not-on-gamstop-your-guide-to-secure[/url]? Explore thrilling gaming options free from the restrictions set by GamStop. Enjoy a variety of games, generous bonuses, and safe transactions at these platforms. Don't miss out!
DavidLinia 01 Mayıs 2026 07:35
In recent years, the popularity of no KYC casinos, [url=https://ittd.ebosspreview.com/explore-the-world-of-online-casinos-without/]https://ittd.ebosspreview.com/explore-the-world-of-online-casinos-without/[/url] has caught attention. These platforms enable players to engage in gaming bypassing personal information. Thus, many players opt for no KYC casinos for increased privacy and openness.
JessieDew 01 Mayıs 2026 06:40
Да ни че прикольно! мебель под заказ, [url=http://billbrucecommunications.com/about-us/attachment/1977-a/]http://billbrucecommunications.com/about-us/attachment/1977-a/[/url] — это отличный способ создать уникальные интерьеры. Кастомизированная мебель позволит воплотить ваши идеи. Квалифицированные помогут выбрать сырьё, которые идеально подойдут.
ChrisPerve 01 Mayıs 2026 05:15
PatrickSiG 01 Mayıs 2026 04:04
casino roulette, [url=https://labs.alquds.edu/2026/04/09/die-faszination-des-online-roulette-strategien-und/]https://labs.alquds.edu/2026/04/09/die-faszination-des-online-roulette-strategien-und/[/url] - Casino Roulette-Tisch ist ein beliebtes Wettspiel, das in vielen Glücksspielhäusern angeboten wird. Solche Faszination beim Setzen macht es extrem fesselnd.
AshleyDaree 01 Mayıs 2026 04:02
no KYC casinos, [url=https://sites.mss.univr.it/icelab/it/no-verification-casinos-the-future-of-online-15/]https://sites.mss.univr.it/icelab/it/no-verification-casinos-the-future-of-online-15/[/url] offer players an opportunity to enjoy online gambling without the hassle of identity verification. Such casinos focus on anonymity, enabling users to gamble seamlessly. In this no KYC casinos, gambling becomes more accessible yet maintaining privacy. Users can relish their favorite games free from lengthy registration processes and personal data submission.
ShannonAceda 01 Mayıs 2026 01:50
Arielhit 30 Nisan 2026 22:45
Я считаю, что Вы не правы. Я уверен. online casino, [url=https://www.goldsgymdcmetro.com/post/why-personal-training-is-a-game-changer-for-your-fitness-journey?commentId=641a2337-aedd-43b4-897e-211e30d92678]https://www.goldsgymdcmetro.com/post/why-personal-training-is-a-game-changer-for-your-fitness-journey?commentId=641a2337-aedd-43b4-897e-211e30d92678[/url] offers an exciting prospect for players to enjoy the thrill of gambling from the comfort of their home. With a variety of games available, users can seek fortune anytime.
Katrinascams 30 Nisan 2026 22:44
Поздравляю, блестящая идея и своевременно Стоматолог представляет собой хирургом, который специализируется на лечении зубов и соседних структур полости рта. Работа такого специалиста содержит выявление заболеваний, а также выполнение хирургических операций. Благодаря инновационным технологиям, стоматолог хирург, [url=https://jonasdegeer.se/2020/05/16/176/]https://jonasdegeer.se/2020/05/16/176/[/url] может предоставить высококачественное помощь своим пациентам.Квалифицированный стоматолог хирург обладает всеми необходимыми компетенциями для удаления сложных проблем в области зубов. Процессы лечения в процессе работы стоматолога хирурга включают как периодические, так и экстренные обращения обращающихся к нему.Квалификация стоматолога хирурга слагается из разнообразных направлений, включая
JosephineTiz 30 Nisan 2026 22:35
Discover the best live roulette casinos, [url=https://dev.fighttoendcancer.com/2026/experience-the-thrill-of-live-roulette-at-uk-5/]https://dev.fighttoendcancer.com/2026/experience-the-thrill-of-live-roulette-at-uk-5/[/url] providing an exciting gaming experience. Immerse yourself thrilling gameplay with live croupiers and high-quality streaming. Enjoy a wide range of betting options and interactive features.
AmyBak 30 Nisan 2026 22:04
Jessiebof 30 Nisan 2026 21:49
кто его знает Добро пожаловать в обычный магазин Парфюмерии, [url=https://spainslov.ru/site/word/word/%D0%9F%D0%90%D0%A1%D0%9B%D0%81%D0%9D]https://spainslov.ru/site/word/word/%D0%9F%D0%90%D0%A1%D0%9B%D0%81%D0%9D[/url], где разнообразие ароматов порадует даже самых высоких клиентов. Каждый флакон — это настоящий шедевр. Мы предлагаем качество и неповторимость продукции.
Altonmoulp 30 Nisan 2026 21:32
К сожалению, ничем не могу помочь. Я думаю, Вы найдёте верное решение. Не отчаивайтесь. realz casino, [url=http://social.clikearte.com.ar/2026/04/27/exploring-the-world-of-appli-realz-casino-a-new/]http://social.clikearte.com.ar/2026/04/27/exploring-the-world-of-appli-realz-casino-a-new/[/url] offers an exciting experience for enthusiasts of online gaming. With the wide selection of choices, this platform promises hours of fun. Join now and explore the wonderful world of virtual casinos.
Sophiaacrow 30 Nisan 2026 21:31
По моему мнению Вы не правы. Я уверен. Могу отстоять свою позицию. Пишите мне в PM. турецкие товары для бизнеса, [url=http://banya.cartel.ua/turanline/odezhda-dlja-zhenshhin-optom-modnye-reshenija-dlja/]http://banya.cartel.ua/turanline/odezhda-dlja-zhenshhin-optom-modnye-reshenija-dlja/[/url] обладают высокой качеством и привлекательной ценой. Таковые товары отлично подходят для реализации в различных сферах. Гамма включает текстиль и принадлежности для бизнеса.
Keshiatoore 30 Nisan 2026 19:54
Exploring different non GamStop betting sites, [url=https://pilisanabria.com/2026/03/13/exploring-non-gamstop-betting-sites-a-29/]https://pilisanabria.com/2026/03/13/exploring-non-gamstop-betting-sites-a-29/[/url] is vital for punters seeking excitement beyond traditional platforms. These sites offer diverse options and options to enjoy betting without restrictions.
JessicaSkype 30 Nisan 2026 18:15
В мире азартных игр онлайн казино играть, [url=https://icylv5.azurewebsites.net/2026/04/12/kak-rabotaet-caesars-palace-casino/]https://icylv5.azurewebsites.net/2026/04/12/kak-rabotaet-caesars-palace-casino/[/url] привлекает множество игроков. Уверенность выиграть делает этот процесс увлекательным. Выбор игр позволяет каждому найти что-то завлекающее.
Nicolekek 30 Nisan 2026 18:04
SandraFam 30 Nisan 2026 17:17
casino roulette, [url=https://coffeyelectric.com/2026/04/09/roulette-online-spielen-tipps-und-strategien-fur-6/]https://coffeyelectric.com/2026/04/09/roulette-online-spielen-tipps-und-strategien-fur-6/[/url] - Roulette-Spiel ist ein spannendes Spiel, das Zufall und Taktik kombiniert. Bei casino roulette dreht sich alles um die Einsätze auf Zahlen oder Farben. Die Aufregung steigt mit jedem Dreh des Rades. Genieße die Umgebung des beliebten Spiels.
Amberkat 30 Nisan 2026 17:17
When exploring unique betting sites outside UK, [url=http://heu-alumni.ca/?p=631200]http://heu-alumni.ca/?p=631200[/url], it's essential to consider trustworthiness and variety of games available. Many players prefer platforms that offer bonuses and safe payment methods. Each site has its unique advantages, ensuring a varied gaming experience for users.
JacquelineHoits 30 Nisan 2026 16:07
If you're exploring different options, non GamStop betting sites, [url=http://www.caverncitybraces.com.tempdomain.com/exploring-sports-betting-sites-not-on-gamstop-3/]http://www.caverncitybraces.com.tempdomain.com/exploring-sports-betting-sites-not-on-gamstop-3/[/url] offer enticing opportunities for wagerers. These platforms provide liberty to enjoy betting without barriers imposed by GamStop.
Tedlat 30 Nisan 2026 14:44
онлайн казино слоты, [url=https://quexle.com/?p=66516]https://quexle.com/?p=66516[/url] обеспечивают игрокам захватывающую возможность погрузиться в мир азартных игр. Сочетая красивую графику и легко понятный интерфейс, онлайн казино слоты задают внимание. Каждый отдельный слот позволяет свои особенности и тематику, что обеспечивает незабываемые эмоции.
TomEmula 30 Nisan 2026 14:43
Playing an online casino game, [url=https://srilankatraumurlaub.de/the-allure-of-8777bd-a-deep-dive-into-the-digital/]https://srilankatraumurlaub.de/the-allure-of-8777bd-a-deep-dive-into-the-digital/[/url] provides an engaging experience. Through various choices, players can appreciate the thrill while possibly win big! Don't forget this chance!
SamBob 30 Nisan 2026 14:35
Experience the thrill of playing at a live roulette casino site, [url=http://07.24h.com.tw/discover-the-best-live-roulette-online-for/]http://07.24h.com.tw/discover-the-best-live-roulette-online-for/[/url] where real dealers bring the fun of a land-based casino right to your screen. Enjoy engaging gameplay and different methods to enhance your gaming experience. Join today and experience the rush!
Traceyitall 30 Nisan 2026 13:35
roulett online, [url=https://www.lineaceramicasrl.com/roulette-spielen-mit-echtgeld-tipps-und-strategien-7/]https://www.lineaceramicasrl.com/roulette-spielen-mit-echtgeld-tipps-und-strategien-7/[/url] ist ein spannendes Spiel, das viele Menschen begeistert. Durch der fortschrittlichsten Technologien ermöglichen Spieler einfach von zu Hause aus partizipieren. Solche Plattformen bieten vielfältige Variationen, die jeder Person ein einmaliges Erlebnis versprechen.
Jenniferhurse 30 Nisan 2026 11:44
When searching for greatest non UK casinos, players can discover a variety of options offering excellent experiences. Many of these casinos provide generous rewards and a user-friendly interface, ensuring a memorable gaming experience. best non UK casinos, [url=https://elmarwa.code95.info/exploring-non-ukgc-licensed-casinos-what-you-need/]https://elmarwa.code95.info/exploring-non-ukgc-licensed-casinos-what-you-need/[/url] often also feature live dealer games, enhancing the total enjoyment for all players. Don't miss out on the opportunity to explore these amazing platforms.
JacquelinehaK 30 Nisan 2026 10:52
online casino betting, [url=https://jerial-jor.com/unlocking-the-mystery-of-5p-777-your-guide-to/]https://jerial-jor.com/unlocking-the-mystery-of-5p-777-your-guide-to/[/url] is a popular choice for those seeking entertainment. Offering numerous options, players can experience the adventures of gaming from the comfort of their home.
LeslieRak 30 Nisan 2026 10:52
онлайн казино, [url=https://xunaufood.net/obnovlenija-kataloga-igrovyh-avtomatov-kazino/]https://xunaufood.net/obnovlenija-kataloga-igrovyh-avtomatov-kazino/[/url] предоставляют игрокам широкий выбор опций. Разнообразие ставок захватывает многих любителей азартных развлечений. Азартные сайты часто предлагают бонусы, что побуждает привлеченность значительно интересной.
IreneBeeva 30 Nisan 2026 10:30
Оно и впрямь не низкое Welcome to the world of ironbank 2 casino, [url=https://ironbank2casino.com/]ironbank 2 casino slot[/url], where fortune awaits! Explore a variety of games that ensure fun and excitement. Join us and become involved in remarkable gaming moments!
ChristinePaymn 30 Nisan 2026 10:17
In the world of online gambling, the excitement of live roulette casino site, [url=https://cbi.baywoodgrp.com/discover-the-best-live-roulette-casinos-in-the-uk-3/]https://cbi.baywoodgrp.com/discover-the-best-live-roulette-casinos-in-the-uk-3/[/url] is unmatched. Players can experience real-time gaming while interacting with live dealers. Such a distinctive experience brings the casino to your home, providing an adrenaline rush like no other. Join now and spin to win big!
Pageabugh 30 Nisan 2026 09:47
independent online casinos, [url=https://flips.kr/2026/04/12/the-rise-of-independent-online-casinos-a-3/]https://flips.kr/2026/04/12/the-rise-of-independent-online-casinos-a-3/[/url] provide players with distinct gaming experiences. In these establishments, you can discover a variety of games that are not in traditional venues. Independent online casinos commonly utilize proprietary promotions, making them attractive for gamers seeking novel options.
RobLet 30 Nisan 2026 09:46
roulette online spielen, [url=https://equip.gtmarine.ru/die-faszination-der-online-roulette-tipps-und-2/]https://equip.gtmarine.ru/die-faszination-der-online-roulette-tipps-und-2/[/url] ist eine fesselnde Erfahrung, die viele Spieler begeistert. Solche Spiele bieten Aufregung und Chancen auf lukrative Erträge. Mit der elektronischen Entwicklungen kann man von jedem Platz spielen.
Mandyvof 30 Nisan 2026 08:08
Не в этом дело. mods for rpg games, [url=https://www.confesercentiviterbo.it/2026/04/21/discover-the-pixel-tribe-viking-kingdom-mod-a-new/]https://www.confesercentiviterbo.it/2026/04/21/discover-the-pixel-tribe-viking-kingdom-mod-a-new/[/url] grant players new ways to elevate their interactive experience. These modifications can add original features or even improve graphics, offering a fresh perspective.
MirandaSEF 30 Nisan 2026 08:08
Браво, замечательная мысль мультфильмы, [url=https://bamboo.st/2019/10/03/%e3%82%b8%e3%83%a7%e3%83%b3%e3%83%bb%e3%83%a1%e3%82%a4%e3%83%a4%e3%83%bc%e3%83%bb%e3%83%88%e3%83%aa%e3%82%aa/]https://bamboo.st/2019/10/03/%e3%82%b8%e3%83%a7%e3%83%b3%e3%83%bb%e3%83%a1%e3%82%a4%e3%83%a4%e3%83%bc%e3%83%bb%e3%83%88%e3%83%aa%e3%82%aa/[/url] являются удивительный мир, где приобретают жизнь самые невероятные истории. Любой из нас есть любимый герой, которому можно всегда сопереживать. Мультфильмы великолепно передают эмоции и обучают важным жизненным урокам.
Tamarater 30 Nisan 2026 07:43
По моему мнению Вы ошибаетесь. Предлагаю это обсудить. Пишите мне в PM, пообщаемся. Experience the adventure of marlin masters atlantis slot, [url=https://marlinmastersatlantis.com/]marlin masters atlantis[/url], an impressive game that enters you into the underwater world. Boasting beautiful graphics and exciting gameplay, this entertainment offers great rewards. Spin the reels to reveal hidden treasures while enjoying features that keep you stimulated. Don't miss the chance to win big in Marlin Masters Atlantis Slot!
MiriamFax 30 Nisan 2026 07:40
Finding a reliable gaming site can be challenging. Many players seek Apple Pay casino not on GamStop, [url=https://mediastudies.cdit.org/discover-apple-s-payment-options-exploring-bookies/]https://mediastudies.cdit.org/discover-apple-s-payment-options-exploring-bookies/[/url] for an uninterrupted experience. These casinos offer secure transactions as well as great bonuses. Individuals can enjoy a wide range of games using Apple Pay. Ultimately, choosing such platforms provides fun without restrictions.
Scottusent 30 Nisan 2026 07:34
Ginarat 30 Nisan 2026 07:25
In the world of digital casinos, online casino, [url=http://icloud.publiduplo.com/archives/1197815]http://icloud.publiduplo.com/archives/1197815[/url] platforms offer thrilling experiences. Players can enjoy a wide range of games from the comfort of their homes. Bonuses attract new users, making it an exciting adventure for everyone involved.
Isabellagog 30 Nisan 2026 07:25
онлайн казино, [url=https://fansofporn.com/kak-rabotaet-caesars-online-casino/]https://fansofporn.com/kak-rabotaet-caesars-online-casino/[/url] стали востребованными среди азартных игроков. Они дают возможность развлекаться в любое время и в любом месте. Многообразие азартных игр вдохновляет даже самых капризных игроков. Несмотря на это, важно выбрать надежное online казино с разрешением и хорошей репутацией.
Sharonalbug 30 Nisan 2026 06:38
MiriamJorgo 30 Nisan 2026 06:34
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Пишите мне в PM, пообщаемся. безободковый унитаз, [url=https://tokyoreiki.co.jp/cropped-rim00395111-jpg/]https://tokyoreiki.co.jp/cropped-rim00395111-jpg/[/url] совершенно изменяет понятие об удобстве в ванной. Данная модель простой в уходе, так как обходит присутствие щелей для накопления грязи. Кроме того, это решение минимизирует риск возникновения бактерий и неприятных запахов.
AngielinaLipsy 30 Nisan 2026 06:21
roulette online echtgeld, [url=https://www.unique-creativity.com/2026/04/11/online-roulette-spielen-strategien-und-tipps-fur-3/]https://www.unique-creativity.com/2026/04/11/online-roulette-spielen-strategien-und-tipps-fur-3/[/url] bietet Spielern die Möglichkeit, bequem von zu Hause aus zu spielen. Die Nutzer können unterhaltsame Erfahrungen sammeln und genießen. Die Vielfalt an Tischen und Einsätzen gewährleistet, dass jeder eine passende Option entdeckt. Das Gefühl, im Web-Casino zu sein, ist herausragend.
FloranceTog 30 Nisan 2026 06:21
non GamStop sportsbooks, [url=http://newstaffpro.com/wp/a-comprehensive-guide-to-non-gamstop-bookmakers/]http://newstaffpro.com/wp/a-comprehensive-guide-to-non-gamstop-bookmakers/[/url] deliver a unique betting experience for bettors. These sites enable users to engage in various games without barriers. With varied options, users can find a venue that suits their preferences. Enjoying the thrill of sports betting becomes less difficult with non GamStop sportsbooks.
Patriciahow 29 Nisan 2026 22:55
Online casino, [url=https://amplifiedgamingstore.com/global-excitement-the-rise-of-international-casino-4/]https://amplifiedgamingstore.com/global-excitement-the-rise-of-international-casino-4/[/url] provides a dynamic experience for players seeking entertainment. With countless games to choose from, all visit can yield unique experiences that keep everyone coming back.
GinaUtest 29 Nisan 2026 22:09
RoelEtene 29 Nisan 2026 22:04
online casino betting, [url=https://www.jurgenvandervelde.com/bet-buffoon-france-votre-partenaire-de-confiance/]https://www.jurgenvandervelde.com/bet-buffoon-france-votre-partenaire-de-confiance/[/url] has become in recent years, appealing to players worldwide. With various platforms, bettors can experience a wide range of games, including slots to table games, easy access to home.
Wendymus 29 Nisan 2026 21:17
horse racing sites not on GamStop, [url=https://presale-vancouver.ca/exploring-bookies-not-on-gamstop-for-horse-racing-8/]https://presale-vancouver.ca/exploring-bookies-not-on-gamstop-for-horse-racing-8/[/url] offer great opportunities for aficionados to enjoy thrilling races. These platforms provide an captivating betting experience for all punters, ensuring competitive odds and an selection of races to choose from. With horse racing sites not on GamStop, users can easily access their favorite events without limitations.
MaggieMus 29 Nisan 2026 15:50
Playing online casino offers an exciting journey. With a wide range of games, you can take pleasure in thrilling moments from the comfort of your home. Explore various themes and generous bonuses while you play online casino, [url=https://new.courtsidegroup.com/casinionline4045/your-ultimate-guide-to-bet-naija/]https://new.courtsidegroup.com/casinionline4045/your-ultimate-guide-to-bet-naija/[/url].
JudySot 29 Nisan 2026 15:39
Online casino games, [url=https://qaboolx.com/how-to-verify-that-a-source-is-trustworthy-a/]https://qaboolx.com/how-to-verify-that-a-source-is-trustworthy-a/[/url] feature a thrilling way to pass time from the convenience of your home. With numerous options like poker, players can experience their luck and abilities.
Amymop 29 Nisan 2026 15:30
Протестую против этого. стоматология, [url=https://click.convertkit-mail2.com/e5udp9xek3i7hwlk8d/kmbmh6/aHR0cHM6Ly9hbGxvbjYtbWluc2sudmVyY2VsLmFwcC8]https://click.convertkit-mail2.com/e5udp9xek3i7hwlk8d/kmbmh6/aHR0cHM6Ly9hbGxvbjYtbWluc2sudmVyY2VsLmFwcC8[/url] оказывает важную миссию в поддержании здоровья стоматологической сферы. Регулярное посещение специалиста способствует распознавать проблемы на начальных стадиях и обеспечивать здоровье зубов.
NaomiCusia 29 Nisan 2026 14:59
top roulette casino, [url=https://www.ideiaconsumerinsights.com.br/find-det-bedste-online-roulette-casino-i-2023/]https://www.ideiaconsumerinsights.com.br/find-det-bedste-online-roulette-casino-i-2023/[/url] tilbyder en spændende oplevelse med høje indsatser og store gevinster. Spillerne kan udforske det intense tempo i spillet og forskellige strategier for at forbedre deres chancer.
DeePUSTY 29 Nisan 2026 13:12
The growth of no KYC online casino, [url=https://dev-shvsorg.pantheonsite.io/no-verification-casinos-an-overview-of-kyc-free/]https://dev-shvsorg.pantheonsite.io/no-verification-casinos-an-overview-of-kyc-free/[/url] platforms has revolutionized the gaming industry. Players can now enjoy effortless access to their favorite games while maintaining privacy. With no KYC, users feel liberated to play without concerns.
Vanessafem 29 Nisan 2026 11:47
Мда, The oxygen 3 slot, [url=https://oxygen3slot.com/]oxygen3slot.com[/url] is an innovative technology designed for improved efficiency and performance. Such slot allows for simple integration of various components, making it adaptable for different uses. Players can leverage the oxygen 3 slot for optimal results.
DevonViesy 29 Nisan 2026 11:42
online casino game, [url=https://helpershq.com/index.php/2026/04/04/betmaster-casino-diversion-y-ganancias-al-alcance-2/]https://helpershq.com/index.php/2026/04/04/betmaster-casino-diversion-y-ganancias-al-alcance-2/[/url] offers thrilling adventures for players. With various options, you can opt for your favorite game. Elation awaits each spin and bet! Enjoy the tests of chance.
MattBrofe 29 Nisan 2026 11:41
муж на час, [url=http://sheetal-work.colibriwp.com/pharmadesk/artificial-intelligence-for-drug-discovery-market-booming-at-a-42-cagr-in-2019-2026/]http://sheetal-work.colibriwp.com/pharmadesk/artificial-intelligence-for-drug-discovery-market-booming-at-a-42-cagr-in-2019-2026/[/url] — это отличный вариант для тех, кто нуждается в помощи по дому. Квалифицированные мастера выполняют широкий выбор услуг, от чинки до сборки мебели. Каждый заказ выполняется качественно, что оптимизирует ваше время и усилия. Тем более, что не обязательно тратить время на поиски разнообразных специалистов. Муж на час — ваш надежный помощник в любых делах.
AngiePhews 29 Nisan 2026 10:46
At se det bedste roulette casino, [url=http://beckinson.com/2026/04/19/bedste-roulette-casinoer-i-danmark-find-din/]http://beckinson.com/2026/04/19/bedste-roulette-casinoer-i-danmark-find-din/[/url] er også en vigtig research. Spillere søger generelt efter trygge platforme med gode priser og variationer. En god rouletteoplevelse kan tilbyde sjov og chancer for gevinst. Glem ikke at tjekke vurderinger før du vælger.
JosephAmoro 29 Nisan 2026 09:59
<a href=https://virtual-local-numbers.com/countries/65-australia.html>buy australian virtual number</a>
Noraunowl 29 Nisan 2026 09:06
If you’re looking for the best roulette online, [url=https://www.fazaa.co/2026/04/01/best-roulette-sites-in-the-uk-a-comprehensive-8/]https://www.fazaa.co/2026/04/01/best-roulette-sites-in-the-uk-a-comprehensive-8/[/url], you’re in the right place. Find various platforms where you can engage in this classic game. Offering exciting variations and improved features, online roulette attracts many players. Don't miss out!
LindaPeape 29 Nisan 2026 07:47
консультация юриста онлайн, [url=https://forum.cu.edu.kz/?p=858]https://forum.cu.edu.kz/?p=858[/url] — это эффективный способ освоить правозащитную в любое нужное время. Онлайн-сервисы давают возможность мгновенно получить актуальные детали своей проблемы. Выбор подходящего юриста может помочь в решении путаных вопросов.
Lawrencewar 29 Nisan 2026 06:53
Apple Pay casino not on GamStop, [url=https://visionviewoptometrist.com/2026/04/12/why-apple-pay-casinos-are-not-on-gamstop-a-2/]https://visionviewoptometrist.com/2026/04/12/why-apple-pay-casinos-are-not-on-gamstop-a-2/[/url] offers a unique experience for players seeking freedom. These casinos provide speedy transactions, ensuring participants can enjoy their favorite games without delays. In addition, these platforms cater to people looking for an safe gambling environment. Enjoy your gaming sessions with tranquility knowing that your capital transactions are kept private and efficient. Apple Pay casino not on GamStop delivers convenience and excitement, making it an ideal choice for avid gamers.
AaronCoure 29 Nisan 2026 06:32
DevinFef 29 Nisan 2026 04:03
online casino, [url=http://www.everydayimport.com/erleben-sie-den-nervenkitzel-im-casinade-ihr/]http://www.everydayimport.com/erleben-sie-den-nervenkitzel-im-casinade-ihr/[/url] feature a extensive range of entertainment, promising a exciting experience. Players can enjoy digital table games and slots from the ease of their homes.
BarryRap 29 Nisan 2026 04:02
оборудование для биотехнологий BIORUS, [url=https://psicologiaclinicayforensevalencia.com/component/k2/item/7-leberkas-tail-swine-pork]https://psicologiaclinicayforensevalencia.com/component/k2/item/7-leberkas-tail-swine-pork[/url] предоставляет широкий спектр вариантов для научных исследований. Эффективность продукции играет основополагающую роль в успехе биотехнологий. Мы гарантируем высокие показатели и передовые технологии.
Epicksonpaity 29 Nisan 2026 03:41
If you are searching for the finest options, look no further than the best roulette online, [url=https://david-sanz.wejustdesign.com/the-thrill-of-roulette-casinos-a-guide-to-winning/]https://david-sanz.wejustdesign.com/the-thrill-of-roulette-casinos-a-guide-to-winning/[/url]. These websites offer an immersive setting with engaging gameplay and attractive bonuses. Enjoy numerous game variations and easy-to-navigate interfaces that cater to both beginners and pros. Don’t miss out on the exhilarating world of online roulette!
HeatherUnilm 29 Nisan 2026 01:48
MichellePluri 28 Nisan 2026 22:51
Tanmayjam 28 Nisan 2026 21:25
AmandaBoums 28 Nisan 2026 20:36
Playing at an online casino game, [url=https://nilmanel.lk/the-ultimate-guide-to-cd33-bet-your-gateway-to-2/]https://nilmanel.lk/the-ultimate-guide-to-cd33-bet-your-gateway-to-2/[/url] can prove to be a thrilling adventure. With multiple options available, players can revel in their favorite games anytime. Don't miss the chance to win!
Danagah 28 Nisan 2026 20:35
Играя в jet x casino, [url=https://shiloh3learningacademy.co.za/portfolio/portfolio-item-5/]https://shiloh3learningacademy.co.za/portfolio/portfolio-item-5/[/url], вы получаете уникальный опыт | необычные ощущения | захватывающие эмоции | возможность выиграть. С множеством опций на любой финансовый план, вы точно найдете что-то подходящее. Высокие награды и легкость вступления делают онлайн-казино доступным для всех.
Scarletplorp 28 Nisan 2026 19:48
bedste mobil casinoer, [url=http://krimno-blag.orthodox.ru/?p=43243]http://krimno-blag.orthodox.ru/?p=43243[/url] tilbyder en fantastisk oplevelse for spillere, der ønsker at spille på farten. Sådanne platforme tilbyder komfortabelt adgang til væddemål med trygge betalingsmetoder. Opdag din foretrukne aktivitet og nyd mange bonusser!
Josepiolo 28 Nisan 2026 19:47
non UK casino online, [url=https://store.ampinc.com/exploring-non-uk-regulated-casinos-the-pros-and/]https://store.ampinc.com/exploring-non-uk-regulated-casinos-the-pros-and/[/url] offers a thrilling experience for players seeking exciting games and generous bonuses. These types of platforms offer a wide range of options, promising every player finds something enjoyable. In addition to top-notch security, players can gamble safely. Join the entertainment today!
JoeBor 28 Nisan 2026 16:50
драконий фрукт купить, [url=http://anellieflange.com/sedimentatori/]http://anellieflange.com/sedimentatori/[/url] можно в большинстве крупных супермаркетов и специализированных магазинах. Данный экзотический ягода обладает уникальным вкусом и интересует покупателей. Попробуйте разнообразить свой рацион!
EdisonJoilm 28 Nisan 2026 16:49
online casino betting, [url=https://newelectricprovider.com/understanding-cd44bd-key-insights-and-latest/]https://newelectricprovider.com/understanding-cd44bd-key-insights-and-latest/[/url] is a thrilling experience for many players. With a variety of games, players get to experience the adrenaline that comes with each bet. It’s essential to know the rules to win.
Ernievak 28 Nisan 2026 16:16
taxi in larnaca, [url=http://iocdistributor.wpengine.com/explore-the-ultimate-taxi-services-in-nicosia/]http://iocdistributor.wpengine.com/explore-the-ultimate-taxi-services-in-nicosia/[/url] offers a convenient method to explore the beautiful destination. With affordable rates and helpful drivers, you can quickly reach your desired location. Enjoy the picturesque views while traveling in comfort.
DorothyCep 28 Nisan 2026 16:02
In the realm of virtual gambling, non UK casino online, [url=http://tazking.com/?p=561297]http://tazking.com/?p=561297[/url] offers thrilling experiences for players seeking new adventures. With numerous options available, enthusiasts can explore live dealer options that suit their preferences.
CarolineSware 28 Nisan 2026 13:28
Anthonyzen 28 Nisan 2026 12:25
купить манго, [url=https://sofahelden.com/index/redirect/index/url/https://tut-bezpechno.forumotion.me/t1188-topic]https://sofahelden.com/index/redirect/index/url/https://tut-bezpechno.forumotion.me/t1188-topic[/url] — это отличное решение для любителей экзотических фруктов. Этот вкусный плод не только радует вкусом, но и усиливает здоровье. В магазине вы найдете спелые манго, которые порадуют своим особым вкусом. Не упустите шанс купить манго и насладиться сладким угощением!
AntoineDrell 28 Nisan 2026 11:31
I dag er der mange muligheder for at spille online, og casino uden rofus pragmatic, [url=https://mobile.myeasysurvey.com/casino-uden-rufus-pragmatic-underholdning/]https://mobile.myeasysurvey.com/casino-uden-rufus-pragmatic-underholdning/[/url] er en af de bedste valg. Spillere kan nyde forskellige spil, som giver spænding og underholdning. Dette tilbyder en fantastisk oplevelse. Brugerne søger sikre platforme, som offrer fantastiske præmier.
Briannadreax 28 Nisan 2026 10:49
Discovering the best casino bonuses can enhance your gaming experience significantly. With plenty of options available, players can increase their winnings. Best casino bonuses, [url=http://bishil.com/exploring-exciting-casino-game-themes/]http://bishil.com/exploring-exciting-casino-game-themes/[/url] provide excellent opportunities for both new and existing players!
JoesphHarry 28 Nisan 2026 09:09
https://malaga-cars.es
StephanietaSty 28 Nisan 2026 08:09
To experience the thrill of gambling, you can play online casino, [url=https://biodescodificacion.ar/green-luck-casino-ihr-ziel-fur-aufregendes-online/]https://biodescodificacion.ar/green-luck-casino-ihr-ziel-fur-aufregendes-online/[/url] games from the comfort of your home. Whether you prefer fruit machines or blackjack, there's something for everyone. Make use of bonuses to increase your chances of winning big!
Josephinesycle 28 Nisan 2026 08:08
Медицинский центр b-healthy clinic, [url=https://www.girolimetti.it/prodotto/ombrellone-rosso-classic-30-mt/]https://www.girolimetti.it/prodotto/ombrellone-rosso-classic-30-mt/[/url] предлагает разнообразный спектр медицинских услуг для пациентов. У нас действуют современные технологии и профессиональные специалисты. Мы предлагаем индивидуальный подход к каждому пациенту.
Philipkat 28 Nisan 2026 07:17
live casino uden rofus, [url=http://cuongleld.blognhansu.com/2026/04/19/live-casinoer-uden-rufus-en-ny-dimension-af/]http://cuongleld.blognhansu.com/2026/04/19/live-casinoer-uden-rufus-en-ny-dimension-af/[/url] tilbyder en unik oplevelse med spænding og underholdning. Sikret standard gør det muligt for spillere at værdsætte live-action spil hjemmefra. Dynamiske dealere skaber en fællesskabs atmosfære. Uanset hvilket spil du vælger, er oplevelsen altid fascinerende og intens.
AngelashorT 28 Nisan 2026 07:17
Choosing a non UK casino site, [url=https://csnakliyat.com/understanding-non-ukgc-licensed-online-casinos-4/]https://csnakliyat.com/understanding-non-ukgc-licensed-online-casinos-4/[/url] can be an exciting adventure. Players often seek diversity in games, generous bonuses, and reasonable terms. Always ensure that the platform is registered and offers reliable customer support.
Joshuaunene 28 Nisan 2026 05:26
Online casino, [url=https://hyperwarped.com/comparative-insights-into-the-european-and-asian-2/]https://hyperwarped.com/comparative-insights-into-the-european-and-asian-2/[/url] presents a stimulating experience for players. With a selection of games, from slots to casino table games, there’s something for everyone to enjoy.
Bryaninags 28 Nisan 2026 04:00
Os recentes casinos online portugal oferecem uma experiência empolgante para os apostadores. Outrossim, a variedade de jogos é variada, compreendendo slots e jogos de mesa. As promoções também são atraentes, encorajando novos participações. Experimente os novos casinos online portugal, [url=http://e-business.inotec.ro/iknow/descubra-os-melhores-casinos-novos-em-portugal-8/]http://e-business.inotec.ro/iknow/descubra-os-melhores-casinos-novos-em-portugal-8/[/url] e desfrute a diversão!
EricaMuh 28 Nisan 2026 03:23
casinos outside GamStop, [url=https://delos.co.in/are-there-any-good-non-gamstop-sites-for-uk/]https://delos.co.in/are-there-any-good-non-gamstop-sites-for-uk/[/url] provide players with a unique opportunity to enjoy gaming without self-exclusion restrictions. Many feature various games and bonuses, attracting those who seek liberty in their gambling experiences. Players can find exciting options, ensuring memorable moments.
Davidjefly 28 Nisan 2026 03:21
https://vbp.ru
JackieMat 28 Nisan 2026 03:15
Finding the right internet gaming platform can be challenging, especially when searching for a non UK casino site, [url=https://www.aukfoods.com.pk/2026/04/11/exploring-non-uk-casino-sites-the-new-frontier-of/]https://www.aukfoods.com.pk/2026/04/11/exploring-non-uk-casino-sites-the-new-frontier-of/[/url]. Many present engaging games and enticing bonuses to users. Experience the array of options available today!
ValerieJem 28 Nisan 2026 00:22
Mobile casinos, [url=https://new.courtsidegroup.com/casinoslot01044/enhancing-player-experience-the-key-casino-design/]https://new.courtsidegroup.com/casinoslot01044/enhancing-player-experience-the-key-casino-design/[/url] позволяют игрокам легкость к азартным играм в любое место. Все казино-геймер может получать удовольствие покером на своем смартфоне. Современные технологии доступны высокую производительность игр и защиту для пользователей.
DebraIceda 28 Nisan 2026 00:04
online casino betting, [url=https://tirupatiprecast.in/horus-casino-upptack-den-nya-eran-av-online/]https://tirupatiprecast.in/horus-casino-upptack-den-nya-eran-av-online/[/url] has gained in recent years, attracting enthusiasts from around parts of the world. As a result of advancements in technology, online casinos offer ease to bet anytime and from anywhere.
SherryMub 28 Nisan 2026 00:04
novos casinos online portugal, [url=https://promotions.champs-sportsclub.com/justlx/descubra-os-melhores-novos-casinos-online-de-2023-20/]https://promotions.champs-sportsclub.com/justlx/descubra-os-melhores-novos-casinos-online-de-2023-20/[/url] - Os novos casinos online Portugal proporcionam uma experiГЄncia Гєnica para jogadores. Com recursos de ponta, melhoram as oportunidades de ganhar, tornando cada aposta emocionante. Explore os recentes casinos online Portugal e descubra descontos imperdГveis.
Angiewep 27 Nisan 2026 22:18
When exploring top options, the best live roulette casinos, [url=https://fastfans.alumnesondara.com/2026/04/07/discover-the-best-roulette-casinos-for-an-2/]https://fastfans.alumnesondara.com/2026/04/07/discover-the-best-roulette-casinos-for-an-2/[/url] offer captivating experiences. Players can savor the genuine atmosphere of a actual casino from their homes. Bonuses and promotions enhance the fun!
Ryangem 27 Nisan 2026 21:44
Какая отличная фраза купить Готовую фирму, [url=https://mix-mag.ru/2026/04/20/kak-i-gde-kupit-ooo-polnoe-rukovodstvo/]https://mix-mag.ru/2026/04/20/kak-i-gde-kupit-ooo-polnoe-rukovodstvo/[/url] — это отличный способ начать бизнес без лишних хлопот. Созданная компания позволяет сэкономить время и средства. Подобрав ее, вы получаете документы, что упрощает старт.
KateTwers 27 Nisan 2026 20:13
online casino, [url=https://cryptolinks.today/exploring-kg999bd-a-deep-dive-into-the-exciting/]https://cryptolinks.today/exploring-kg999bd-a-deep-dive-into-the-exciting/[/url] delivers a one-of-a-kind adventure for participants seeking excitement. Possessing a wide range of games, it satisfies all tastes.
SarahSwink 27 Nisan 2026 19:32
casino med mastercard, [url=http://trello-1188-coffeelands.pantheonsite.io/2026/04/mastercard-casino-sikkerhedsforanstaltninger-og/]http://trello-1188-coffeelands.pantheonsite.io/2026/04/mastercard-casino-sikkerhedsforanstaltninger-og/[/url] tilbyder en bekvem og sikker mГҐde at spille online. Deltagere kan nemt foretage indskud og udbetalinger. En betalingsmetode sikrer Гёjeblikkelig adgang til spil.
JaneViamn 27 Nisan 2026 19:23
Online casino games, [url=https://letstourisrael.com/the-ultimate-guide-to-online-gaming-insights-from/]https://letstourisrael.com/the-ultimate-guide-to-online-gaming-insights-from/[/url] provide an exciting way to explore the space of gambling. With diverse options, players can select from blackjack and more.
Yolandasmulp 27 Nisan 2026 17:25
non gamstop roulette sites, [url=http://repuestossudamerica.com/explore-roulette-sites-not-on-gamstop-1518869324/]http://repuestossudamerica.com/explore-roulette-sites-not-on-gamstop-1518869324/[/url] offer players an exciting alternative to traditional casinos. These platforms provide numerous options of roulette games. Betters can enjoy enhanced gaming sessions avoiding restrictions.
Tonyabug 27 Nisan 2026 15:49
If you’re seeking the best international casinos, [url=https://www.centroinfissiromanord.it/2026/04/13/top-international-casinos-for-uk-players-996530715/]https://www.centroinfissiromanord.it/2026/04/13/top-international-casinos-for-uk-players-996530715/[/url], you can discover many options that feature exciting games and thrilling experiences. With luxurious settings to high-quality gaming, each casino promises an unforgettable experience.
Ta,Vah 27 Nisan 2026 15:47
I Danmark er casino-platforme blevet populære, hvor deltagere kan få glæde af deres yndlingsspil. casinoer med mastercard, [url=https://surplusjza.co.za/danske-casinoer-med-mastercard-en-guide-til-sikker-2/]https://surplusjza.co.za/danske-casinoer-med-mastercard-en-guide-til-sikker-2/[/url] muliggør en praktisk måde at udføre indbetalinger, hvilket ledes en hurtig proces for deltagere. Vælg exklusivt de bedste casinoer for den bedste oplevelse.
MikeKic 27 Nisan 2026 14:21
Discovering the Best casino bonuses, [url=http://www.fidadoc.org/effective-slot-strategies-that-can-improve-your/]http://www.fidadoc.org/effective-slot-strategies-that-can-improve-your/[/url] is essential for any player. These rewards improve your gaming experience. Many casinos offer promotions, allowing you to maximize your profits. Take advantage of these offers today!
DwightGek 27 Nisan 2026 12:34
Visit our main website : https://byizea.fr/js/pgs/?code_promo_298.html
MaryKar 27 Nisan 2026 11:45
The greatest experience in gambling comes from finding the best roulette casino, [url=https://dev-pp.ubiwhere.com/2026/04/the-ultimate-guide-to-the-best-roulette-casinos-2/]https://dev-pp.ubiwhere.com/2026/04/the-ultimate-guide-to-the-best-roulette-casinos-2/[/url]. Here, you can savor thrilling games and engaging atmospheres. With varied options available, every spin brings different chances to win big!
BernardHeale 27 Nisan 2026 11:03
I dagens digitale verden er det vigtigt at finde det bedste live casino, [url=http://dev.vod.drsha.net/2026/04/17/bedste-live-casino-oplev-spndingen-fra-hjemmet/]http://dev.vod.drsha.net/2026/04/17/bedste-live-casino-oplev-spndingen-fra-hjemmet/[/url] tilgængeligt. Spillerne ønsker en autentisk oplevelse, og derfor tilbyder de fleste live casinoer kvalificerede dealere. Dette skaber en social atmosfære, der fanger spillerens opmærksomhed. Ved at vælge det bedste live casino kan man derfor opleve en helt ny måde at spille på, som tilpasset opfylder behovene hos moderne spillere.
Teresaanesy 27 Nisan 2026 11:01
top casinos not on GamStop, [url=https://perfectlycleardiamonds.com/2026/04/18/discovering-uk-gambling-sites-what-to-look-for-and/]https://perfectlycleardiamonds.com/2026/04/18/discovering-uk-gambling-sites-what-to-look-for-and/[/url] offer players an exciting alternative to traditional gambling sites. They provide a wide range of games, including table games. Because of generous bonuses, players can enjoy a thrilling experience.
Lydiasot 27 Nisan 2026 10:52
хачу такую 1xbet online casino, [url=https://www.usmcmuseum.com/blog/the-m60s-last-hurrah]https://www.usmcmuseum.com/blog/the-m60s-last-hurrah[/url] features an exciting gaming experience with a variety of options. Players can take pleasure in real dealer games and slots. Join today and begin your successful journey!
Amyaxoky 27 Nisan 2026 08:55
Очень ценное сообщение online casino, [url=https://gradinarit-online.ro/bankroll-management-techniques-for-beginners-92/]Euphoria Wins Casino mobile[/url] offers a thrilling experience for players. Wagering enthusiasts can delight in various games, ranging from slots to poker. By employing innovative technology, users can engage with their favorite games anytime, anywhere.
Dianatem 27 Nisan 2026 08:28
Online casino, [url=https://myelite.fitness/how-the-industry-is-addressing-current-challenges-4/]https://myelite.fitness/how-the-industry-is-addressing-current-challenges-4/[/url] gives an exciting platform for players to enjoy their favorite games. With varied options, players can involve themselves in thrilling action anytime.
DevonWer 27 Nisan 2026 07:36
online casino betting, [url=https://ivo.com.uy/?p=12446056]https://ivo.com.uy/?p=12446056[/url] is a popular activity among many. Participants find joy in the thrill of winning big. With various games available, it’s easy to get engaged in the exciting world of internet wagering.
Lolasnivy 27 Nisan 2026 06:52
online casino Danmark, [url=http://ghk-autoassembly.com/?p=1118511]http://ghk-autoassembly.com/?p=1118511[/url] tilbyder en spændende verden af muligheder for spillere. Det fremstår spillere kan finde et udvalg af spillemaskiner, strategispil og interaktive erfaringer. Takket være garantier og gode bonusser interesserer både nye og erfarne spillere. Oplev online casino Danmark for at have uforglemmelige spiloplevelser!
MarquelRit 27 Nisan 2026 06:52
Finding the best sites not on GamStop, [url=http://www.carbossonline.com/discovering-gamstop-free-sites-opportunities-and/]http://www.carbossonline.com/discovering-gamstop-free-sites-opportunities-and/[/url] can be a challenge for players seeking variety. Many online casinos offer exciting games and incentives outside the GamStop network. You can enjoy more freedom and options by exploring these platforms. Choose sites that meet your needs and preferences for a better gaming experience.
JenniferTasty 27 Nisan 2026 03:23
Playing at an online casino, [url=https://www.kogipedia.net/explora-la-magia-de-los-casinos-en-linea/]https://www.kogipedia.net/explora-la-magia-de-los-casinos-en-linea/[/url] provides an exciting opportunity. You can enjoy various games from the comfort of your home. With bonuses and promotions, you can maximize your winnings and witness endless fun!
Samanthavak 27 Nisan 2026 02:43
Finding a secure UK casino not on GamStop, [url=https://jerial-jor.com/exploring-non-gamstop-casino-sites-where-to-play/]https://jerial-jor.com/exploring-non-gamstop-casino-sites-where-to-play/[/url] can enhance your gaming experience. Players can enjoy diverse selection of games, improved bonuses, and liberty to play at their own pace. UK casino not on GamStop offers a unique alternative.
Judyovess 26 Nisan 2026 22:43
online casino Danmark, [url=https://www.danielvillalona.com/casino-uden-kyc-nyd-spil-uden-bekymringer/]https://www.danielvillalona.com/casino-uden-kyc-nyd-spil-uden-bekymringer/[/url] tilbyder en fantastisk spiloplevelse til brugere fra hele landet. Her kan man mærke en variabel vifte af spil og tilbud. Spændende bonusser venter på hver enkelt.
Sherrykax 26 Nisan 2026 22:43
Exploring new options, players often seek UK casino not on GamStop, [url=https://www.myworldshopping-net.onlinegroup.no/2026/04/17/exploring-uk-gambling-sites-not-on-gamstop-3-2/]https://www.myworldshopping-net.onlinegroup.no/2026/04/17/exploring-uk-gambling-sites-not-on-gamstop-3-2/[/url] for exciting experiences. These places offer unrestricted access to various games without the usual restrictions. Choosing carefully ensures pleasant gameplay.
CurtisGlync 26 Nisan 2026 20:04
When seeking the greatest live roulette casinos, players should consider factors like game options, player experience, and promotional deals. The best live roulette casinos, [url=https://north-prop.com/best-live-roulette-online-casino-your-ultimate/]https://north-prop.com/best-live-roulette-online-casino-your-ultimate/[/url] provide immersive gameplay, ensuring that every round is thrilling! Don't forget to check player assistance for a smooth experience.
Netraruift 26 Nisan 2026 18:49
online casino Danmark, [url=https://curator.artracx.com/uncategorized/valhalla-casino-registrering-din-guide-til/]https://curator.artracx.com/uncategorized/valhalla-casino-registrering-din-guide-til/[/url] tilbyder en spændende verden for spillere. Her kan du fornøje dig med mange spil, deriblandt slots, poker og roulette. Takket være fremtrædende teknologi kan du have det sjovt når som helst.
JenniferNEn 26 Nisan 2026 17:05
Looking for the greatest ways to boost your gaming experience? Discover the Best casino bonuses, [url=https://dhaarmikam.com/casinoslot30032/crypto-gambling-a-new-era-of-online-betting/]https://dhaarmikam.com/casinoslot30032/crypto-gambling-a-new-era-of-online-betting/[/url] available today! These offers can enhance your chances of winning big. Don't miss out on amazing promotions and bonuses that casinos provide to attract players. Sign up now!
RobertJog 26 Nisan 2026 15:38
Casino Magic Online, [url=https://infotainer.thorstenjost.de/spezial-ausgabe-the-way-to-the-wings-e07/]https://infotainer.thorstenjost.de/spezial-ausgabe-the-way-to-the-wings-e07/[/url] disponibiliza una vivencia Гєnica para los fanГЎticos de los juegos. InmersiГіnate en un universo lleno de alegrГa y beneficios increГbles. Desde tragamonedas hasta cartas, Casino Magic Online ofrece todo para realizar tu aspiraciГіn de ganar. No olvides la oportunidad de vivir la emociГіn inmediatamente a un casino real, ВЎdisfruta de Casino Magic Online!
Carriekecub 26 Nisan 2026 15:37
online casino betting, [url=https://performed.pl/discover-the-thrills-of-menzobet-your-ultimate-2/]https://performed.pl/discover-the-thrills-of-menzobet-your-ultimate-2/[/url] presents a thrilling ride for players. With numerous games, it caters both beginners and pros. Enjoy the ease of playing whenever you like from the comfort of your home.
LoriAxosy 26 Nisan 2026 14:48
online casino Danmark, [url=https://stmartinschurchhawksburn.org.au/playojodansk/bedste-casinoer-med-hurtig-udbetaling-spil-og-vind-2/]https://stmartinschurchhawksburn.org.au/playojodansk/bedste-casinoer-med-hurtig-udbetaling-spil-og-vind-2/[/url] tilbyder en spændende verden af spil, hvor man kan nyde forskellige oplevelser. Her kan spillere tilgå en forskelligartet samling af kortsæt, der giver en mindeværdig oplevelse. Glem ikke at tage del i bonusserne!
Kathleendex 26 Nisan 2026 10:35
PГЎlpitos Casino, [url=https://zt.com.au/ext/aHR0cHM6Ly9wYWxwaXRvcy1ib25vcy5jb20v/dW5hcHByb3ZlZD04MjcmbW9kZXJhdGlvbi1oYXNoPWJkMjIyMjA4ZGYxZTEwODUxYzUzZTk3MGZmOWFjYjI5/itblmid/666/]https://zt.com.au/ext/aHR0cHM6Ly9wYWxwaXRvcy1ib25vcy5jb20v/dW5hcHByb3ZlZD04MjcmbW9kZXJhdGlvbi1oYXNoPWJkMjIyMjA4ZGYxZTEwODUxYzUzZTk3MGZmOWFjYjI5/itblmid/666/[/url] ofrece una experiencia Гєnica para los entusiastas del juego. AquГ, podrГЎs experimentar de numerosos entretenimientos emocionantes. ВЎГљnete a la alegrГa en PГЎlpitos Casino y experimentar la emociГіn del juego!
DaleNiz 26 Nisan 2026 10:35
online casino, [url=http://www.nbzhaoke.com/?p=222080]http://www.nbzhaoke.com/?p=222080[/url] features an exciting range of games, from slots to card games like blackjack. Visitors can enjoy thrilling experiences right from their devices.
GwinnettSix 26 Nisan 2026 09:33
non GamStop casinos in UK, [url=https://mihajloderimanovic.com/discover-the-best-non-gamstop-casinos-for-players/]https://mihajloderimanovic.com/discover-the-best-non-gamstop-casinos-for-players/[/url] offer players an opportunity to enjoy gambling without barriers. These platforms grant a wide variety of games, promising a thrilling experience for all. Players can access exciting slots, live dealer games, and one-of-a-kind bonuses. Non GamStop casinos in UK are perfect for those looking to experience opportunities beyond the traditional gaming scene.
MandyMoome 26 Nisan 2026 05:56
PГЎlpitos Argentina, [url=http://www.aki3.net/cgi-bin/navi_1/navi.cgi?&mode=jump&id=0463&url=palpitos-entrar.com]http://www.aki3.net/cgi-bin/navi_1/navi.cgi?&mode=jump&id=0463&url=palpitos-entrar.com[/url] es un centro que promueve la identidad argentina. AquГ se pueden encontrar emprendedores locales que comparten sus obras Гєnicas, reflejando la diversidad de nuestro paГs.
Dougwal 26 Nisan 2026 05:55
play online casino, [url=https://value.company/2026/04/12/exploring-the-exciting-world-of-no777-game-24/]https://value.company/2026/04/12/exploring-the-exciting-world-of-no777-game-24/[/url] and experience the thrill of real gambling from the comfort of your home. Engage in a variety of games like slots, blackjack, and roulette. Through exciting bonuses, players can maximize their winnings!
LatriceJed 26 Nisan 2026 05:14
Mobile casinos, [url=https://www.erinnerungen-an-christian-graf.at/2026/03/30/unlock-exciting-weekly-casino-promotions/]https://www.erinnerungen-an-christian-graf.at/2026/03/30/unlock-exciting-weekly-casino-promotions/[/url] выпускают уникальную возможность испытать удачу РІ известных играх РЅР° портативных устройствах. РРіСЂРѕРєРё РјРѕРіСѓС‚ наслаждаться разнообразием РёРіСЂ РІ любое время Рё РІ любом месте.
Jayjaige 26 Nisan 2026 05:09
Recently, the popularity of non GamStop casinos in UK, [url=http://mikulcickyluh.brontosaurus.cz/wordpress/?p=820721]http://mikulcickyluh.brontosaurus.cz/wordpress/?p=820721[/url] has expanded. Many players prefer these options due to higher flexibility and variety. Such establishments deliver games without restrictions, making them enticing for many gamblers.
YvonneVok 26 Nisan 2026 05:09
Det er ikke let at vælge det bedste internet kasino, men et udenlandsk online casino, [url=https://david-sanz.wejustdesign.com/online-casino-autorisation-sdan-sikrer-du-dine/]https://david-sanz.wejustdesign.com/online-casino-autorisation-sdan-sikrer-du-dine/[/url] kan give unikke muligheder. Spillere kan nyde varierede spil og attraktive bonusser. Husk altid at undersøge licensen og sikkerheden.
AdamKed 26 Nisan 2026 02:58
Discover the thrill of enjoying the best live roulette, [url=https://greenlog.vn/en/discover-the-best-live-roulette-experiences-online-8/]https://greenlog.vn/en/discover-the-best-live-roulette-experiences-online-8/[/url], where real dealers bring the gaming experience right to your home. Enjoy the adrenaline of interacting with others while you spin the wheel!
Shailakix 26 Nisan 2026 01:56
Playing in an web-based casino can be an exciting event. Players can relish a variety of options from the comfort of their homes. An online casino game, [url=https://24hrcenturylocksmithdfw.com/descubre-la-experiencia-epica-de-mx-lobo-casino/]https://24hrcenturylocksmithdfw.com/descubre-la-experiencia-epica-de-mx-lobo-casino/[/url] offers thrill like no other.
Jamieces 26 Nisan 2026 01:56
apuestas deportivas, [url=http://tymanna.co.kr/shop/bannerhit.php?bn_id=7&url=//1win-official-ar.com]http://tymanna.co.kr/shop/bannerhit.php?bn_id=7&url=//1win-official-ar.com[/url] - Las apuestas deportivas han tomado popularidad en los Гєltimos aГ±os. Actualmente, los entusiastas buscan tГЎcticas efectivas para potenciar sus oportunidades de triunfar.
NicoleTouts 26 Nisan 2026 01:17
bedste casino Danmark, [url=http://01.24h.com.tw/bedste-udenlandske-casinoer-find-din-perfekte/]http://01.24h.com.tw/bedste-udenlandske-casinoer-find-din-perfekte/[/url] tilbyder en spændende verden af spil og underholdning. Her platform kan deltagere finde flere muligheder for at få en unikt spillestil. Tilbud gør eventyret endda attraktiv. Gør dig klar til at stige ind i dit fantastiske verden af online kasinoer.
Clayred 26 Nisan 2026 01:17
ммм. Совершенно согласен. техосмотр автомобиля, [url=https://yandex.ru/maps/org/tekhosmotr/11324347330]госпошлина для прохождения техосмотра реквизиты[/url] — важная процедура, которая выявляет безопасность на дороге. Постоянно проходя техосмотр, вы можете избежать опасных ситуаций. Такой подход содействует продлить срок службы вашего автомобиля и сохранить здоровье водителей и пассажиров.
Brianavefe 26 Nisan 2026 00:12
Enjoying Online casino games, [url=https://www.sukisushi.es/casino-payment-gateways-a-practical-guide-3/]https://www.sukisushi.es/casino-payment-gateways-a-practical-guide-3/[/url] provides thrills. Gamers can enjoy different choices such as slots, blackjack, and poker. By using state-of-the-art technology, online platforms ensure a safe gaming environment. Sign up for Online casino games today!
Jakebrind 25 Nisan 2026 22:07
Bitcoin live betting, [url=http://casadelsol.casa/experience-the-thrills-of-bitfortune-live-casino/]http://casadelsol.casa/experience-the-thrills-of-bitfortune-live-casino/[/url] has gained traction among bettors. With its decentralized nature, it allows to real-time betting on numerous events. This innovative approach offers users instant transactions and enhanced security. Embracing Bitcoin live betting is a shift in how people engage with sports.
Kimberlybuh 25 Nisan 2026 22:06
online casino betting, [url=https://farakaranpiping.net/erfahrungen-mit-realzcasino-ihr-weg-zum-online/]https://farakaranpiping.net/erfahrungen-mit-realzcasino-ihr-weg-zum-online/[/url] provides an engaging way to acquire money while having fun. With a variety of games, users can decide their favorites and wager conveniently.
Amyaxoky 25 Nisan 2026 21:44
Могу предложить Вам посетить сайт, на котором есть много информации по этому вопросу. online casino, [url=https://super.heroes.app/2025/11/13/why-artificial-intelligence-reshapes-betting/]Casino Spintime[/url] offers players a thrilling adventure filled with excitement. With a wide variety of selections, anyone can find their preferred pastime. Join now and test your luck!
CecilDUese 25 Nisan 2026 21:28
bedste casino Danmark, [url=https://cabxana.com/2026/04/12/casino-for-danske-spillere-en-guide-til-de-bedste/]https://cabxana.com/2026/04/12/casino-for-danske-spillere-en-guide-til-de-bedste/[/url] tilbyder mange underholdende muligheder for spillere. På disse online casinoer finder man mange valgmuligheder af bordspil. Man bør at vælge et troværdigt casino.
AnaBiade 25 Nisan 2026 21:27
In recent years, numerous gamblers have sought alternatives to traditional casinos, leading to the rise of non GamStop site, [url=https://packaging.ma/alternative-casinos-navigating-beyond-gamstop/]https://packaging.ma/alternative-casinos-navigating-beyond-gamstop/[/url] options. These websites provide distinct features and benefits for users looking to experience online gaming without restrictions. Providing a broad spectrum of games, these non GamStop site options cater to various types of players, ensuring an enjoyable experience.
Laurennub 25 Nisan 2026 20:14
прикольно конечно НО смысл этого чуда Investing in Bitcoin can be tricky. However, there are essential Lessons Bitcoin Investors, [url=https://coincentral.com/lessons-for-investors-bitcoin-price/]https://coincentral.com/lessons-for-investors-bitcoin-price/[/url] should keep in mind. Comprehending market trends is vital. Additionally, diversification can minimize risks. Always carry out thorough research before making decisions. Stay updated on events that may affect the market. Embrace tolerance; Bitcoin is often a long-term investment.
Ulysseswed 25 Nisan 2026 18:18
Жаль, что сейчас не могу высказаться - вынужден уйти. Вернусь - обязательно выскажу своё мнение по этому вопросу. Finding vehicle parts is easy with Car parts online, [url=https://www.yeelight.sg/group/host-systems-pte-lt-group/discussion/65469a72-3008-4501-8b0b-cf3703bc72a0]https://www.yeelight.sg/group/host-systems-pte-lt-group/discussion/65469a72-3008-4501-8b0b-cf3703bc72a0[/url]. You can explore a vast selection of high-quality items. Enjoy the ease of shopping from home and get your required parts delivered quickly.
PamelaMoign 25 Nisan 2026 18:15
Bitfortune casino, [url=http://sensuino.net/2026/04/15/mastering-bitfortune-crypto-payments-a-2/]http://sensuino.net/2026/04/15/mastering-bitfortune-crypto-payments-a-2/[/url] offers an exceptional gaming experience with countless games available. Players can enjoy thrilling slots and interactive dealer options. Incentives enhance gameplay, making it highly enjoyable. Join Bitfortune casino today!
BobbieUsesy 25 Nisan 2026 18:15
online casino, [url=http://maido-forum.com/%e6%9c%aa%e5%88%86%e9%a1%9e/discover-playjonny-your-ultimate-online-casino-4]http://maido-forum.com/%e6%9c%aa%e5%88%86%e9%a1%9e/discover-playjonny-your-ultimate-online-casino-4[/url] presents an exciting gambling experience. Players can take pleasure in a variety of options from the comfort of their house. With promotions often available, everyone can find something to entertain them.
Markvit 25 Nisan 2026 17:42
UK non GamStop casinos, [url=https://www.mcmtechno.it/slider/slide1/]https://www.mcmtechno.it/slider/slide1/[/url] offer players freedom and flexibility in gaming. These venues provide a wider selection of games and incentives compared to traditional sites. Players can enjoy a varied experience without restrictions.
Rikkicrede 25 Nisan 2026 16:35
аааааааааа приокльно))))))) уписалась ..... Nudify AI App - Undress AI Tool, [url=https://www.speedrun.com/users/nudify_ai]https://www.speedrun.com/users/nudify_ai[/url] is a revolutionary tool designed to modify photos realistically. With its innovative algorithms, users can uncover an entirely new way of visual expression. This one-of-a-kind tool offers a seamless experience, allowing creativity to prosper. Engage with Nudify AI App - Undress AI Tool to unleash your imaginative potential.
Bridgetsoica 25 Nisan 2026 14:10
Счастье мне изменило! sunglasses EyeOns, [url=https://www.coherentmarketinsights.com/blog/how-do-i-know-what-glasses-fit-my-face-shape-2129]https://www.coherentmarketinsights.com/blog/how-do-i-know-what-glasses-fit-my-face-shape-2129[/url] merge fashion and protection for every look. With cutting-edge features, these sunglasses improve clarity while offering outstanding comfort.
Brittanyelods 25 Nisan 2026 13:34
play online casino, [url=https://www.allaboutchimneys.net/slot-neo-en-uforglemmelig-spiloplevelse/]https://www.allaboutchimneys.net/slot-neo-en-uforglemmelig-spiloplevelse/[/url] - Playing online casino is an exciting way to enjoy your favorite games from home. Enthusiasts can experience a variety of tables right at their fingertips. Offers often boost your chances to win big!
Abigayleunduh 25 Nisan 2026 13:32
Bitfortune live crypto casino, [url=https://bonabery.com/bitfortune-live-gaming-the-future-of-mobile-live-2/]https://bonabery.com/bitfortune-live-gaming-the-future-of-mobile-live-2/[/url] offers a captivating experience for betters. It features many games, ensuring everyone finds something entertaining. With quick transactions and safe platforms, users can play with confidence. Join the fun today at Bitfortune live crypto casino!
Michelleflula 25 Nisan 2026 12:48
Finding the best non GamStop websites can be difficult for players seeking excitement. These platforms offer multiple options for gamblers, ensuring a distinct experience. best non GamStop websites, [url=https://www.storiedaerebor.it/explore-gaming-freedom-sites-not-on-gamstop/]https://www.storiedaerebor.it/explore-gaming-freedom-sites-not-on-gamstop/[/url] often feature enticing bonuses and deals that enhance gameplay. Always look into your choices to enjoy your online gaming journey!
MaryPaipt 25 Nisan 2026 10:40
Playing within real money roulette casinos, [url=http://mbbs.com/winning-strategies-for-casino-roulette-with-real/]http://mbbs.com/winning-strategies-for-casino-roulette-with-real/[/url] can be an entertaining experience. Picking the right casino is essential for savoring your game. Explore for certified platforms that promise fair play.
EvaWhags 25 Nisan 2026 09:04
Playing virtual casino games brings joy to many players. With an array options, from slots to card games, enthusiasts can enjoy unlimited entertainment. Dive into the realm of online casino game, [url=https://pbus.thats-gross.com/wp/2026/04/14/shiny-wild-casino-ihr-tor-zu-aufregenden-online/]https://pbus.thats-gross.com/wp/2026/04/14/shiny-wild-casino-ihr-tor-zu-aufregenden-online/[/url] today!
Tammysnils 25 Nisan 2026 00:13
non GamStop UK casino, [url=https://blog.thanos.ai/discover-which-gambling-sites-are-not-on-gamstop/]https://blog.thanos.ai/discover-which-gambling-sites-are-not-on-gamstop/[/url] offers players a unique experience with diverse games and generous bonuses. In contrast to GamStop casinos, these sites provide freedom and flexibility in gaming. Players can enjoy a wide range of slots, table games, and live dealer options. Additionally, non GamStop casinos assure privacy and security, allowing users to bet without restrictions. Players seeking exciting and boundless gaming should try non GamStop UK casino.
MarenEffed 24 Nisan 2026 20:48
Bitfortune live crypto casino, [url=https://sumowindows.com/luu-tru/7357]https://sumowindows.com/luu-tru/7357[/url] offers an exciting gaming experience with countless options for players. With live gaming, you can enjoy the thrill of casino games anywhere, anytime. Join right away and discover your chance to win big!
Anitawhemo 24 Nisan 2026 20:48
Playing at an web-based casino is a thrilling way to enjoy gambling from the comfort of your home. You can navigate the excitement of fruit machines and table games with just a click. Plus, promotions enhance your chances to win big. Don't miss out on the chance to play online casino, [url=https://heni.co.in/erlebe-den-nervenkitzel-im-upspinz-casino-spiele/]https://heni.co.in/erlebe-den-nervenkitzel-im-upspinz-casino-spiele/[/url] and discover new adventures every time you log in!
Iansip 24 Nisan 2026 20:13
mezinГЎrodnГ online casino, [url=https://ambassador-kk.com/eska-online-kasina-ve-co-potebujete-vdt-o-hazardni/]https://ambassador-kk.com/eska-online-kasina-ve-co-potebujete-vdt-o-hazardni/[/url] nabГzГ hrГЎДЌЕЇm neomezenou nabГdku her. VДЌetnД› vГЅhernГch automatЕЇ, tato platforma podporuje zГЎbavu a chance na vГЅhru. ZabezpeДЌenГ hrГЎДЌЕЇ je na prvnГm mГstД›!
Christinetraut 24 Nisan 2026 16:47
Bitfortune live casino, [url=https://internationalformationrp.com/index.php/2024/03/01/formacao-de-embaixadores-internacionais-2/]https://internationalformationrp.com/index.php/2024/03/01/formacao-de-embaixadores-internacionais-2/[/url] offers a thrilling gaming experience with professional dealers and a selection of games. Players can enjoy true casino action from the comfort of their homes, making it hassle-free to join the fun.
TiffanyNiC 24 Nisan 2026 16:46
Playing titles in an online casino game, [url=https://www.coderian.com/discover-tomiclub-your-ultimate-destination-for/]https://www.coderian.com/discover-tomiclub-your-ultimate-destination-for/[/url] is a thrilling experience that brings adventure. From colorful graphics to captivating gameplay, players are in for a treat. Explore various themes to find your favorite!
Jamesdooli 24 Nisan 2026 16:11
No-cost bot for Telegram to generate freebies, paid access. Super boost your channels! Netxmix presents to you our powerful bot: Firstly Make gifts You can make any freebie, like exclusive access, data, photos, videos, graphics, promo vouchers, discount coupons, exclusive discounts, promo codes, and more, plus your own condition for receiving the freebie. Specifically, rule to claim present is joining the TG channels you chose during creation plus specific quantity of hits via your invite link inside the bot. Now you’re able to use our free option to do this; however, for access, you need to add some of our channels in your channel list. Please go to the bot t.me/netxmixbot click "START" after that press "FREE GIFT". Next Create paid subscriptions for channels
Alfredomum 24 Nisan 2026 13:28
<a href=https://вип-свет.рф/>https://вип-свет.рф/</a>
RyanFrigo 24 Nisan 2026 11:27
online casino betting, [url=https://consultorias.conteudoestrategico.com.br/erlebe-den-nervenkitzel-von-play-io-ein-blick-auf/]https://consultorias.conteudoestrategico.com.br/erlebe-den-nervenkitzel-von-play-io-ein-blick-auf/[/url] brings the thrill of gambling to your home. Players can explore diverse games, making it a popular choice among gambling enthusiasts.
Justiceamaft 23 Nisan 2026 16:18
In the world of online gaming, the crypto casino Dexsport, [url=https://ideapad.itmuniversity.ac.in/experience-the-future-of-gambling-with-crypto/]https://ideapad.itmuniversity.ac.in/experience-the-future-of-gambling-with-crypto/[/url] stands out as a premier platform. It offers engaging games and seamless transactions. Players enjoy security while wagering their cryptocurrency. The range of games ensures that everyone finds something they love.
Nataliaabofs 23 Nisan 2026 15:49
JuliaOmime 23 Nisan 2026 15:44
Exploring various non UK casino sites, [url=http://nekokapuri.s1009.xrea.com/2026/04/16/exploring-non-uk-licensed-casinos-a-comprehensive-16-2/]http://nekokapuri.s1009.xrea.com/2026/04/16/exploring-non-uk-licensed-casinos-a-comprehensive-16-2/[/url] can be a fascinating experience. Players often find special games and enticing bonuses that enhance their gaming experience. With countless options to choose from, punters can enjoy exclusive features that set these platforms apart.
LaurenMum 23 Nisan 2026 15:43
mezinГЎrodnГ online casino, [url=http://www.snexportgroup.com/online-kasina-zahranini-co-potebujete-vdt-2/]http://www.snexportgroup.com/online-kasina-zahranini-co-potebujete-vdt-2/[/url] nabГzГ hrГЎДЌЕЇm rЕЇznorodГЅ vГЅbД›r moЕѕnostГ. VydД›lГЎnГ penД›z mЕЇЕѕe bГЅt snadno zГЎbavnГ© a adrenalinovГ©. Bonusy a slevy zvyЕЎujГ pЕ™itaЕѕlivost. Hrajte z pohodlnГ© svГ©ho domova!
CheriloXymn 23 Nisan 2026 14:32
Online casino, [url=https://drsanjith.com/mastering-your-strategy-how-to-win-more-at-sports-2/]https://drsanjith.com/mastering-your-strategy-how-to-win-more-at-sports-2/[/url] offers a stimulating experience for players. With multiple games available, players can find something to enjoy. Bonuses enhance the fun, making it a trendy choice for entertainment.
RebeccaPiode 23 Nisan 2026 11:35
The introduction of free ai porn generator, [url=https://appsmove.com/discover-the-world-of-free-ai-porn-generators/]https://appsmove.com/discover-the-world-of-free-ai-porn-generators/[/url] has revolutionized the way we explore adult content. Users can create their own distinct scenes, offering a customized experience. This breakthrough empowers creativity and freedom in adult entertainment.
Camillaseari 23 Nisan 2026 11:03
mezinГЎrodnГ online casino, [url=https://sfseabgqtkey-dev.sanyo-fast.com/2026/04/13/nejlepi-internetove-kasino-zabava-a-vyhry-na-dosah/]https://sfseabgqtkey-dev.sanyo-fast.com/2026/04/13/nejlepi-internetove-kasino-zabava-a-vyhry-na-dosah/[/url] umoЕѕЕ€uje hrГЎДЌЕЇm pestrou ЕЎkГЎlu her i, od vГЅhernГch automatЕЇ aЕѕ po stoly s ЕѕivГЅmi krupiГ©ry. SouДЌasnД› umoЕѕЕ€uje uЕѕГt si vzruЕЎujГcГ momentky z pohodlГ domova.
Jerryham 23 Nisan 2026 07:02
mezinГЎrodnГ online casino, [url=https://erin43622e43454.wpcomstaging.com/nove-casino-cz-ve-co-potebujete-vdt-o-novych-5/]https://erin43622e43454.wpcomstaging.com/nove-casino-cz-ve-co-potebujete-vdt-o-novych-5/[/url] nabГzГ ЕЎirokou nabГdku her a ЕЎancГ. HrГЎДЌi mohou uЕѕГt zГЎbavu z pohodlГ domova. SystГ©m je intuitivnГ, coЕѕ podporuje zГЎЕѕitek. DecentnГ vГЅhry zajiЕЎЕҐujГ uspokojenГ hrГЎДЌЕЇ.
JeremyTaw 23 Nisan 2026 05:45
Tashawef 23 Nisan 2026 04:27
Bridgetsnode 23 Nisan 2026 03:25
Playing in an online casino game, [url=https://casadevida.mx/2026/04/16/exploring-the-thrills-of-12-play-singapore-a/]https://casadevida.mx/2026/04/16/exploring-the-thrills-of-12-play-singapore-a/[/url] can be thrilling. Players can encounter a range of games, from slot machines to table games. Winning real money adds to the excitement.
MariaOvend 23 Nisan 2026 03:10
mezinГЎrodnГ online casino, [url=https://mail.abcoinfotech.com/2026/04/12/nejhezi-kasina-v-eske-republice-elegance-a-zabava/]https://mail.abcoinfotech.com/2026/04/12/nejhezi-kasina-v-eske-republice-elegance-a-zabava/[/url] poskytuje hrГЎДЌЕЇm rozmanitou ЕЎkГЎlu moЕѕnostГ. Otestujte fantastickГ© bonusy a vГЅhody, kterГ© vylepЕЎujГ hernГ funkce. DГky modernГch technologiГ je hranГ pohodlnГЎ a chrГЎnД›nГЎ.
MarquelBok 23 Nisan 2026 03:09
In the vibrant world of wagering, Chicken Road casinos, [url=https://total-restaurant.com/the-evolution-of-video-games-a-journey-through-3/]https://total-restaurant.com/the-evolution-of-video-games-a-journey-through-3/[/url] offer engaging experiences. Visitors can enjoy a variety of options while savoring the unique ambiance. Including top-notch amenities, they provide a remarkable escape.
KimLoath 23 Nisan 2026 01:14
Joserax 23 Nisan 2026 00:00
AnnHeill 22 Nisan 2026 23:31
When you opt to play online casino, [url=https://feriasnaflorida.com.br/2026/04/16/12play-253/]https://feriasnaflorida.com.br/2026/04/16/12play-253/[/url], you enter a world of excitement and entertainment. With a variety of games available, it’s easy to find something that suits your preferences. Don’t miss the chance to uncover the hottest slots and table games. Enjoy the ease of playing anytime, anywhere, and take leverage from various bonuses and promotions designed to enhance your experience.
Scottzef 22 Nisan 2026 23:30
Gambling on roulette for real cash, [url=http://nextark.co.jp/2026/04/04/experience-the-thrill-of-playing-roulette-online-5/]http://nextark.co.jp/2026/04/04/experience-the-thrill-of-playing-roulette-online-5/[/url] can be entertaining. Many enthusiasts enjoy the anticipation of spinning the wheel. With various approaches available, you can increase your chances of winning big!
Benhob 22 Nisan 2026 23:19
non GamStop casino, [url=https://broemmling-metallbau.de/best-non-gamstop-casinos-uk-747896371/]https://broemmling-metallbau.de/best-non-gamstop-casinos-uk-747896371/[/url] позволяет игрокам возможность наслаждаться автомнями без проверок. С таким подходом азартные любители вправе опробовать новое среди многогранного мирa азартных игр, ставящих на кон.
Patrickjough 22 Nisan 2026 19:39
online casino, [url=https://www.sterling-store.co/the-ultimate-guide-to-12-play-singapore-a-premier-2/]https://www.sterling-store.co/the-ultimate-guide-to-12-play-singapore-a-premier-2/[/url] offers an exciting adventure for players. With multiple games to choose from, all can find something that suits them. Incentives make it even more enticing.
JeffDig 22 Nisan 2026 19:38
Finding the best non GamStop casinos, [url=https://codecanyondemo.work/wcod/2026/04/03/exploring-casinos-exempt-from-gamstop-a-2/]https://codecanyondemo.work/wcod/2026/04/03/exploring-casinos-exempt-from-gamstop-a-2/[/url] can be a game changer for players seeking freedom. These platforms offer more options and entertaining games without the barriers imposed by GamStop. Enjoy a broader selection of options while playing responsibly.
Jasonteata 22 Nisan 2026 19:28
mezinГЎrodnГ online casino, [url=https://shop.uzo1.com/casino-s-bonusem-bez-vkladu-jak-vyuit-vynikajici/]https://shop.uzo1.com/casino-s-bonusem-bez-vkladu-jak-vyuit-vynikajici/[/url] pЕ™edstavuje ЕЎirokГ© vГЅbД›ry pro hrГЎДЌe z vЕЎech koutЕЇ svД›ta. K dispozici jsou skvД›lГ© automaty a ЕѕivГ© hry, kterГ© nabГdnou skvД›lou zГЎbavu a ЕЎanci na vГЅhru.
MikeSah 22 Nisan 2026 16:12
IreneSnoks 22 Nisan 2026 11:02
Bitfortune casino platform, [url=https://www.crackthesky.nz/2026/04/18/speed-games-tested-bitfortune-a-deep-dive-into/]https://www.crackthesky.nz/2026/04/18/speed-games-tested-bitfortune-a-deep-dive-into/[/url] offers an exciting gaming experience for players. With numerous games to choose from, including slots and table games, it meets the needs of both newbies and seasoned gamblers. Protected transactions ensure security. Join Bitfortune casino platform today and enjoy the world of online gambling!
Robertmiz 22 Nisan 2026 11:01
In the world of gaming, the online casino, [url=https://menwiki.men/wiki/Delve_Into_The_Captivating_World_Of_Online_Casinos_Now%21]https://menwiki.men/wiki/Delve_Into_The_Captivating_World_Of_Online_Casinos_Now%21[/url] offers an exciting opportunity to win big. Players can enjoy a variety of options from the comfort of their homes. With enticing bonuses, the thrill of online casino keeps amusement alive.
AngielinaMup 22 Nisan 2026 10:45
Discover exciting opportunities at new casino not on GamStop, [url=https://promotions.champs-sportsclub.com/zionist/exploring-casinos-not-with-gamstop-your-guide-to/]https://promotions.champs-sportsclub.com/zionist/exploring-casinos-not-with-gamstop-your-guide-to/[/url], where stakeholders can enjoy numerous games without limitations. Enjoy special bonuses and rewards that enhance your gambling experience. Join immediately!
Xplosivehix 22 Nisan 2026 10:40
online bingo not on GamStop, [url=http://lookoutontheknoll.com/discover-exciting-online-bingo-sites-not-on-6/]http://lookoutontheknoll.com/discover-exciting-online-bingo-sites-not-on-6/[/url] offers players a chance to enjoy thrilling games without restrictions. This platform provides an exciting experience, ensuring options. Players can explore multiple online rooms, enhancing their pleasure.
TimWex 22 Nisan 2026 10:39
mezinГЎrodnГ online casino, [url=http://xuanloc2010.id.vn/index.php/2026/04/11/online-kasina-pro-eske-hrae-ve-co-potebujete-vdt-6/]http://xuanloc2010.id.vn/index.php/2026/04/11/online-kasina-pro-eske-hrae-ve-co-potebujete-vdt-6/[/url] umoЕѕЕ€uje hrГЎДЌЕЇm rozsГЎhlou paletu her ze pЕ™ednГch spoleДЌnostГ. NavГc toho, klienti uЕѕijГ si zkusit velkГ© pЕ™ГleЕѕitosti, kterГ© podnД›cuje nГЎsledovГЎnГ.
TreyLurgy 22 Nisan 2026 10:22
BrandonpooPE 22 Nisan 2026 08:12
Insomniaatllep 22 Nisan 2026 06:42
Bitfortune Casino, [url=http://flips.kr/2026/04/15/bitfortune-casino-canada-withdrawal-speed-what-you-3/]http://flips.kr/2026/04/15/bitfortune-casino-canada-withdrawal-speed-what-you-3/[/url] features a extensive selection of games, guaranteeing players constant excitement. With excellent graphics and accessible interfaces, it appeals to both novices and experienced players.
Tabithasop 22 Nisan 2026 06:39
Bitfortune online casino, [url=https://enistoresonline.com/volatility-head-to-head-low-vs-high-understanding/]https://enistoresonline.com/volatility-head-to-head-low-vs-high-understanding/[/url] offers captivating games for players seeking adventure. With a diverse array of slots and table games, users can have a distinct gaming atmosphere that engages their attention. Join now for a opportunity to win big!
BobbyVaf 22 Nisan 2026 06:26
Playing bingo not on GamStop, [url=https://crsrealestatesolutionsllc.com/2026/04/17/bingo-sites-not-affected-by-recent-changes/]https://crsrealestatesolutionsllc.com/2026/04/17/bingo-sites-not-affected-by-recent-changes/[/url] offers a unique experience for enthusiasts. Various players like platforms outside of this scheme. Utilizing these sites, you can experience diverse game options and exciting events that aren't subject to restrictions.
AngelaPhepe 22 Nisan 2026 06:22
non GamStop UK casino, [url=https://www.lunatransport.eu/discover-the-best-gamstop-excluded-sites-for/]https://www.lunatransport.eu/discover-the-best-gamstop-excluded-sites-for/[/url] offers players an opportunity to enjoy gaming without restrictions. These types of establishments deliver a wide range of games, ensuring fun and excitement. Participants can experience thrilling adventures while enjoying the liberty to explore various options.
LeonaNaG 22 Nisan 2026 05:21
Kimerera 22 Nisan 2026 03:32
Juliagox 22 Nisan 2026 02:49
Bitfortune crypto casino, [url=https://ead.ministeriodeensinobg.com.br/exploring-the-popularity-of-trx-among-players/]https://ead.ministeriodeensinobg.com.br/exploring-the-popularity-of-trx-among-players/[/url] offers an exceptional adventure for online gamblers. Players can enjoy numerous options, all while earning cryptocurrencies. Additionally, the platform ensures reliable security for transactions, making it credible. Join Bitfortune crypto casino today and explore the abundant choices it has to offer!
AryaAminy 22 Nisan 2026 02:44
Bitfortune Solana casino, [url=https://79.170.44.106/purplehaze.co.ke/1/?p=63990]https://79.170.44.106/purplehaze.co.ke/1/?p=63990[/url] offers an engaging gaming experience. Players can explore various varieties while benefiting from fast transactions. Join the activity and showcase your luck today!
LucyWed 22 Nisan 2026 02:24
In recent years, the popularity of non GamStop UK casino, [url=http://nextark.co.jp/2026/04/05/exploring-casinos-that-aren-t-on-gamstop/]http://nextark.co.jp/2026/04/05/exploring-casinos-that-aren-t-on-gamstop/[/url] has captured many players looking for alternative choices in online gambling. Lacking the restrictions imposed by GamStop, such casinos offer varied gaming experiences. Players can engage with a wider range of slots, table games, and live dealer options, boosting their overall experience. Furthermore, non GamStop UK casino provides attractive promotions, making it a tempting option for many. However, cautious gaming should always be a priority.
Matthewsculk 22 Nisan 2026 00:17
Los salones de juego fuera de EspaГ±a ofrecen una opciones para los entusiastas del juego. En numerosos paГses, se pueden localizar momentos Гєnicas. Casinos Fuera de EspaГ±a, [url=https://academia.edu.gt/casinos-fuera-de-espana-una-guia-completa-para-24/]https://academia.edu.gt/casinos-fuera-de-espana-una-guia-completa-para-24/[/url] brindan doble adrenalina y entretenimiento.
Jonathanref 21 Nisan 2026 22:53
Bitfortune Solana casino, [url=https://www.nmdaltyapi.com.tr/temple-tumble-2-bankroll-strategy-maximizing-your/]https://www.nmdaltyapi.com.tr/temple-tumble-2-bankroll-strategy-maximizing-your/[/url] offers an innovative gaming experience. Players can enjoy a wide range of choices powered by fast transactions and high security. Join now to strike it rich on your luck!
EricaFUsty 21 Nisan 2026 22:48
Mikehop 21 Nisan 2026 22:45
casinos not on GamStop, [url=https://www.schriftsteller.de/explore-non-gamstop-casinos-in-the-uk-a/]https://www.schriftsteller.de/explore-non-gamstop-casinos-in-the-uk-a/[/url] offer players a unique opportunity to enjoy their favorite games without restrictions. Many gamblers seek new venues to explore. Enjoy lucrative rewards that enhance your gameplay. With variety of games, you can find something that suits your taste. Don't miss out on the chance to experience casinos not on GamStop, where freedom and fun await!
Brandonclorp 21 Nisan 2026 22:44
mezinГЎrodnГ online casino, [url=https://ecocyclegroupltd.co.uk/zahranini-kasina-s-licenci-co-potebujete-vdt-2/]https://ecocyclegroupltd.co.uk/zahranini-kasina-s-licenci-co-potebujete-vdt-2/[/url] nabГzГ neomezenГ© moЕѕnosti zГЎbavy a vГЅher. HrГЎДЌi si mohou vybrat mezi diverse nabГdkou her, vДЌetnД› stolnГch her a virtuГЎlnГho kasina. KaЕѕdГЅ den pЕ™inГЎЕЎГ novГ© akce a vГЅhody, coЕѕ atraktivnД› povzbuzuje hrГЎДЌe k zapojenГ. BezpeДЌnost a transparentnost jsou klГДЌovГ© pro pohodlnГ© hranГ.
PatriciaWef 21 Nisan 2026 21:34
не треба) Профессиональные агентство нянь, [url=https://kidbooms.ru/pochemu-uslugi-nyani-stanovyatsya-vsyo-bolee-vostrebovannymi/]найти няню для ребёнка[/url] предложит безопасный уход для ваших детей. Надежные няньки воспитают о вашем малыше с вниманием. Проконсультируйтесь к нам, и мы найдем лучшее решение для вашей семьи!
Duyingex 21 Nisan 2026 19:19
AllenLek 21 Nisan 2026 18:58
Bitfortune online casino, [url=https://www.primariarojiste.ro/2026/04/15/exploring-the-rise-of-xrp-in-gaming-why-players/]https://www.primariarojiste.ro/2026/04/15/exploring-the-rise-of-xrp-in-gaming-why-players/[/url] offers a plethora of games that engage players. With exciting promotions and easy-to-navigate interfaces, it's effortless to start playing. Join the hype today!
WendyAript 21 Nisan 2026 18:58
Bitfortune Casino, [url=https://am530somosradio.com/fastest-coins-to-withdraw-from-a-comprehensive-6/]https://am530somosradio.com/fastest-coins-to-withdraw-from-a-comprehensive-6/[/url] offers a unique gaming journey. With numerous games to choose from, players can enjoy endless excitement. Step into the world of Bitfortune Casino today!
EricNeato 21 Nisan 2026 18:58
Finding the best non UK casino, [url=https://nubia.mn/non-uk-regulated-casinos-accepting-players-a/]https://nubia.mn/non-uk-regulated-casinos-accepting-players-a/[/url] can be a thrilling adventure. Many players seek sites outside the UK for unique gaming experiences. Explore bonuses, play variety, and customer support to make an informed decision.
Alex B 21 Nisan 2026 18:41
I recently started looking into upgrading my laptop’s memory. That’s when I discovered https://znayka.com.ua. I couldn’t find accurate hardware information on most websites. Many sources were confusing. On this site I found clear explanations about RAM compatibility, along with clear diagrams that made everything much easier to understand. It’s worth visiting this platform if you want reliable information about laptops and hardware upgrades.
JulietMearl 21 Nisan 2026 17:56
KristyMox 21 Nisan 2026 15:08
non GamStop casino, [url=https://www.mercazon.it/exploring-gambling-sites-not-on-gamstop-724849934/]https://www.mercazon.it/exploring-gambling-sites-not-on-gamstop-724849934/[/url] offers players unique opportunities|provides gamers distinct chances|gives bettors exceptional options|presents gamblers special alternatives. These platforms allow access|enable entry|offer passage|grant access to various games without restrictions. Explore|Discover|Uncover|Find new ways to enjoy gaming experiences.
MadelineWar 21 Nisan 2026 14:59
Bitfortune online casino, [url=http://en.cosmoeng21.com/crypto-wallet-setup-for-seamless-gaming-experience/]http://en.cosmoeng21.com/crypto-wallet-setup-for-seamless-gaming-experience/[/url] offers an exciting gaming experience. Players can enjoy countless games as they explore this platform's intuitive interface. Incentives are offered for new and loyal users alike.
JuneBroma 21 Nisan 2026 14:19
DanielRag 21 Nisan 2026 10:08
Bitfortune online casino, [url=https://www.studioraffaellapazzaglia.it/betcasino15042/ultimate-chaos-crew-strategy-guide-triumph-in-the/]https://www.studioraffaellapazzaglia.it/betcasino15042/ultimate-chaos-crew-strategy-guide-triumph-in-the/[/url] offers an extensive selection of games for participants to enjoy. By employing generous bonuses and thrilling gameplay, it stands out in the online gaming sector. Experience unparalleled fun today!
Frankzex 21 Nisan 2026 10:06
Я считаю, что Вы допускаете ошибку. Давайте обсудим. Выбор подходящего специалиста для ухода за детьми — задача непростая. агентство нянь, [url=https://womanka.com/deti/preimushhestva-uslug-nyani-dlya-detej-2]https://womanka.com/deti/preimushhestva-uslug-nyani-dlya-detej-2[/url] предлагает профессиональных нянь, которые заботятся о малышах с любовью и вниманием. В нашем агентство найдет идеального помощника для вашей семьи. Все няня имеет опытом и квалификацией, что гарантирует безопасность детей. Вы можете увлеченно подобрать подходящего специалиста, который станет верным другом вашим детям.
Nicholashousa 21 Nisan 2026 09:52
Bitfortune casino platform, [url=https://geominiads.com/fastest-coins-to-withdraw-from-a-comprehensive-4/]https://geominiads.com/fastest-coins-to-withdraw-from-a-comprehensive-4/[/url] offers a thrilling experience for everyone. With numerous games and tempting bonuses, it is prominent in the world of online gambling. Join immediately and check out the fun!
HeatherUnope 21 Nisan 2026 09:52
mezinГЎrodnГ online casino, [url=https://elagaiby.com/2026/04/10/online-kasina-pro-eskou-klientelu-ve-co-potebujete/]https://elagaiby.com/2026/04/10/online-kasina-pro-eskou-klientelu-ve-co-potebujete/[/url] pЕ™inГЎЕЎГ ЕЎirokou paletu her, kterГ© zaujГmajГ hrГЎДЌe z rozliДЌnГЅch koutЕЇ svД›ta. DЕЇvД›ryhodnГ© platebnГ metody zaruДЌujГ klid pЕ™i sГЎzkГЎch.
ThomasItedo 21 Nisan 2026 07:22
PatriciaWef 21 Nisan 2026 06:33
Вы попали в самую точку. В этом что-то есть и я думаю, что это хорошая идея. Ищете квалифицированных специалистов для заботы о детях? Наше агентство нянь, [url=https://o-kemerovo.ru/sidelka-v-bolniczu-v-moskve-pomoshh-paczientu-v-staczionare-i-podderzhka-semi/]сиделка для бабушки[/url] предлагает квалифицированных нянь для ваших детей. Мы гарантируем качественный уровень обслуживания и специальный потребностей каждой семьи. С нами радость ваших детей в надежных руках!
Andreabut 21 Nisan 2026 06:08
non GamStop bookies, [url=https://www.gingerexchange.com/symphony/mbtag/exploring-non-gamstop-sports-betting-sites-5/]https://www.gingerexchange.com/symphony/mbtag/exploring-non-gamstop-sports-betting-sites-5/[/url] обеспечивают игрокам шанс участвовать без лимитов со стороны органов. Данные букмекеры воспользуются популярностью среди любителей ставок.
Marciamab 21 Nisan 2026 06:08
Bitfortune Casino, [url=http://pss-boilers.com/betcasino15042/59277.html]http://pss-boilers.com/betcasino15042/59277.html[/url] offers an exhilarating gaming experience. With numerous games, players can enjoy live dealer games that appeal to every taste. Sign up now for special rewards and start winning immediately!
LatriceHef 21 Nisan 2026 05:57
mezinГЎrodnГ online casino, [url=https://projects.aavatto.in/escapemelbournetours/zahranini-kasina-s-bonusem-bez-vkladu-jak-vybrat/]https://projects.aavatto.in/escapemelbournetours/zahranini-kasina-s-bonusem-bez-vkladu-jak-vybrat/[/url] pЕ™inГЎЕЎГ jedineДЌnГ© sГЎzkovГ© zГЎЕѕitky pro hrГЎДЌe z rЕЇznГЅch zemГ. HrГЎДЌi si mohou vychutnat ЕЎirokГЅ paletu her, vДЌetnД› sloty, ruleta a blackjack.
Stephaniethume 21 Nisan 2026 03:44
Эта фраза придется как раз кстати страхування туристів Р·Р° РєРѕСЂРґРѕРЅРѕРј, [url=https://sergechel.info/list-7521101969a7d80187178ddba976fe69]https://sergechel.info/list-7521101969a7d80187178ddba976fe69[/url] С” важливим аспектом організації. Це допомагає туристів РІС–Рґ СЂРёР·РёРєС–РІ, що необхідно враховувати. Таким чином, обираючи покриття, перевірте Р·Р° умовами та ретельно ознайомтеся СѓРјРѕРІРё захисту.
Joanvox 21 Nisan 2026 03:06
Да ну... Алиса VPN, [url=https://alisavpn.cc/]алиса впн[/url] — это удобный сервис для шифрования интернет-трафика. С его помощью можно защищать свои действия в сети. Платформа обеспечивает возможность к ресурсам, которые могут быть ограничены в вашей стране. Надежный сервис позволит использовать безграничным интернетом без препятствий.
Angelinagully 21 Nisan 2026 02:53
JulietGuisy 21 Nisan 2026 02:14
Finding an exciting gaming experience is easy with a minimum deposit casino, [url=https://www.div9interior.com/?p=1423371]https://www.div9interior.com/?p=1423371[/url]. Players can enjoy countless options without a heavy commitment. Low deposits allow everyone to join the fun and try their luck!
RoseFaply 21 Nisan 2026 02:13
Bitfortune crypto casino, [url=https://scuml.org/registration2/?p=1218168]https://scuml.org/registration2/?p=1218168[/url] offers an thrilling way to partake in online gambling. With a diversity of games and bonuses, players can improve their chances of winning. The platform also provides secure transactions, ensuring that users feel confident while playing. As one of the most popular crypto casinos, Bitfortune crypto casino continues to captivate players worldwide.
JesseAbilm 21 Nisan 2026 02:03
mezinГЎrodnГ online casino, [url=https://bhagyodaymetals.co.in/online-kasina-v-r-ve-co-potebujete-vdt-1662579199/]https://bhagyodaymetals.co.in/online-kasina-v-r-ve-co-potebujete-vdt-1662579199/[/url] poskytuje ЕЎirokou ЕЎkГЎlu her od kasinovГЅch her. ZГЎkaznГci mohou vyzkouЕЎet vzruЕЎenГ a napД›tГ pЕ™Гmo z z jakГ©hokoli mГsta.
Tamaragox 21 Nisan 2026 01:20
Online gaming has drastically evolved, offering players various options. Many enjoy casinos not on GamStop, [url=https://www.tunclezzet.com/explore-casinos-not-affected-by-gamstop-for/]https://www.tunclezzet.com/explore-casinos-not-affected-by-gamstop-for/[/url] due to their flexibility and diverse bonuses. Exploring these sites can provide additional opportunities for fun and entertainment. Players often opt for these platforms for their more extensive selection of games and relaxed rules. Before playing, one should consider the available options and ensure a safe environment.
ConstanceZef 20 Nisan 2026 22:23
Bitfortune Solana casino, [url=http://nomadjapan.com/betcasino16043/exploring-book-of-dead-a-crypto-gaming-adventure/]http://nomadjapan.com/betcasino16043/exploring-book-of-dead-a-crypto-gaming-adventure/[/url] offers a unique experience for players. With quick transactions and a diverse selection of games, it satisfies all types of gamblers. Enjoy the benefits of blockchain technology while gaming!
MaryJoide 20 Nisan 2026 22:22
If you’re looking for a exciting way to play online, a minimum deposit casino, [url=http://www.blogdahabitacao.com.br/?p=123435]http://www.blogdahabitacao.com.br/?p=123435[/url] is the excellent choice. These casinos allow you to start playing with a small investment, making it affordable for everyone. Enjoy various games without breaking the bank!
BriannaHug 20 Nisan 2026 22:18
Josekig 20 Nisan 2026 20:16
мишка...мне бы такого:))) онлайн казино, [url=https://hu.pinterest.com/pin/796574252885198725]слот legacy of egypt[/url] пропонують безліч С–РіРѕСЂ. Учасники можуть вибрати СЃРІС–Р№ улюблений процес. РўРѕРјСѓ що структура С” простим, грати стало зручніше. Промоакції залучають РЅРѕРІРёС… гравців. Онлайн казино створює цікаві можливості для щастя.
Jenniferamott 20 Nisan 2026 19:10
Аффтар - аццкий сотона !! Пеши исчо !! In India, the utilization of 2D Payment Gateway India, [url=https://2dpaymentgateway.in/]https://2dpaymentgateway.in[/url] has improved online transactions. Businesses benefit from faster payments and better security. Consumers enjoy quickness. Overall, it’s a significant advancement in digital finance.
Ibrahimpeers 20 Nisan 2026 19:05
ViolaSmiva 20 Nisan 2026 18:37
Bitfortune online casino, [url=https://fortlauderdalelinks.org/maximize-your-earnings-lowest-fees-at-bitfortune/]https://fortlauderdalelinks.org/maximize-your-earnings-lowest-fees-at-bitfortune/[/url] offers a thrilling experience for gamers wanting excitement. With numerous choices of games, players can relish the fun of online gambling. Promotions add to the allure, enhancing your chances of winning big. Join today and explore endless entertainment at Bitfortune online casino!
BritneyOreMe 20 Nisan 2026 18:35
If you're looking for a budget-friendly way to enjoy online gaming, a minimum deposit casino, [url=https://assemamed.ly/2026/04/18/unlock-excitement-claim-your-40-free-spins-no/]https://assemamed.ly/2026/04/18/unlock-excitement-claim-your-40-free-spins-no/[/url] can be your best bet. These casinos offer players to start wagering with minimal amount. This can be an amazing option for first-time players who want to try out the platform without spending too much. With this type of casinos, participants may enjoy various games without breaking the bank.
RobertFaphy 20 Nisan 2026 18:29
mezinГЎrodnГ online casino, [url=https://sklerozamultiplex.eu/zahranini-online-casina-pro-eske-hrae-1689856449/]https://sklerozamultiplex.eu/zahranini-online-casina-pro-eske-hrae-1689856449/[/url] umoЕѕЕ€uje hrГЎДЌЕЇm velkГЅ vГЅbД›r aktivit. Online herny nabГdnou ochranu a spravedlivГ© podmГnky k vЕЎechny zГЎjemce.
JosephHip 20 Nisan 2026 18:29
Bitfortune Casino, [url=http://www.museodelbrunello.it/wanted-dead-or-a-wild-the-dual-nature-of-adventure/]http://www.museodelbrunello.it/wanted-dead-or-a-wild-the-dual-nature-of-adventure/[/url] offers a remarkable gaming experience. Players can delight in a wide variety of options. With alluring bonuses and promotions, it's a superior destination for players.
RachelFeene 20 Nisan 2026 17:49
BarryOdoca 20 Nisan 2026 17:36
Many players are seeking possibilities for their gaming experience. non GamStop UK casinos, [url=http://www.fitcom.com.tr/togetherahealthierfuture/top-reputable-casinos-free-from-gamstop.html]http://www.fitcom.com.tr/togetherahealthierfuture/top-reputable-casinos-free-from-gamstop.html[/url] offer great options for those looking to enjoy games without restrictions. With these casinos, players can find thrilling opportunities to win.
AdamHoado 20 Nisan 2026 17:17
Совершенно верно. Это хорошая мысль. Я Вас поддерживаю. The growth of online casino, [url=https://duel-bitscasino.com/]what is duel bits[/url] platforms has shaped the gambling landscape. Players can now enjoy their favorite games at home. With enticing bonuses and flexible payment options, the online gaming experience is more available than ever.
Michellejaf 20 Nisan 2026 14:24
Bitfortune online casino, [url=http://getantlers.com/the-future-of-music-an-insight-into-the-2026/]http://getantlers.com/the-future-of-music-an-insight-into-the-2026/[/url] offers a exceptional gaming experience with a range of games. Players can enjoy fruit machines, card games, and interactive options. Moreover, the casino provides attractive bonuses for newcomers. With an easy-to-navigate interface, Bitfortune online casino is perfect for both beginners and seasoned gamblers. Join now and experience exciting gameplay!
Sarahweill 20 Nisan 2026 14:24
Searching for an affordable way to enjoy gaming? You’re in luck with a minimum deposit casino, [url=https://www.transferwerkt.nl/discover-the-excitement-of-10-free-spins-no-5/]https://www.transferwerkt.nl/discover-the-excitement-of-10-free-spins-no-5/[/url]! These venues allow players to enjoy gaming with a small investment. Experience the thrill without breaking the bank! Whether you prefer slots, table games, or live dealer options, an array of choices exists. Dive into rewarding offers that come with low deposits for better your gameplay. Don't miss out on this opportunity!
JenniferSak 20 Nisan 2026 14:23
Bitfortune casino platform, [url=https://iconicbrand.com/wp/index.php/2026/04/16/unlock-endless-fun-with-bitfortune-no-deposit-free/]https://iconicbrand.com/wp/index.php/2026/04/16/unlock-endless-fun-with-bitfortune-no-deposit-free/[/url] offers thrilling opportunities for players to explore a variety of games. With easy-to-navigate interfaces, it's effortless to start playing and winning. Join the dynamic community and take advantage of attractive bonuses. The platform is protected, ensuring that all transactions are private. Explore the world of gaming with Bitfortune casino platform today!
JeffWen 20 Nisan 2026 13:17
Nickpoive 20 Nisan 2026 08:43
Scarletbeisa 20 Nisan 2026 07:51
Adriankah 20 Nisan 2026 07:21
Выбор у Вас непростой стоматолог хирург, [url=https://www.berlin-group.org/profile/all-on-6-minsk/profile]https://www.berlin-group.org/profile/all-on-6-minsk/profile[/url] выполнил профессиональную помощь пациенту при затруднений с зубами. Эти медики регулярно предоставляют высокое качество лечения, используя актуальные технологии.
LauraPem 20 Nisan 2026 04:11
Pamelashard 20 Nisan 2026 01:42
I casinГІ senza documenti, [url=https://repricesolution.com/casino-non-aams-online-guida-completa-per/]https://repricesolution.com/casino-non-aams-online-guida-completa-per/[/url] offrono un'esperienza unica per gli utenti. Non c'ГЁ bisogno di caricare documenti, offrendo il gioco molto accessibile. Inoltre, la sicurezza degli utenti ГЁ garantita. Questo incoraggia molti giocatori a sperimentare.
Jeffspago 19 Nisan 2026 21:52
Между нами говоря ответ на Ваш вопрос я нашёл в google.com мебель под заказ, [url=https://sway.cloud.microsoft/zL8vLAD7VtDpILGa]https://sway.cloud.microsoft/zL8vLAD7VtDpILGa[/url] — это отличный способ создать уникальный интерьер. Индивидуально спроектированная мебель удовлетворяет вашим потребностям. Многообразие материалов и стилей даёт шанс воплотить любые идеи. Специалисты помогут вам реализовать задуманное.
Susannahog 19 Nisan 2026 20:03
Nel mondo dei giochi online, il gambling senza documenti offre un'esperienza incredibile. Gli utenti possono accesso rapidamente e iniziare a ottenere vincite senza complicazioni. casinГІ senza documenti, [url=https://dipbike.ville-creteil.fr/efbl_skins/skin-thumbnail/]https://dipbike.ville-creteil.fr/efbl_skins/skin-thumbnail/[/url] ГЁ la soluzione ideale per chi cerca discrezione. Approfittane subito!
Emmagaw 19 Nisan 2026 14:16
Nel mondo del gioco d'azzardo, i casinГІ senza documenti, [url=http://bodminautos.com/i-migliori-siti-casino-online-non-aams-per-il-2023-2/]http://bodminautos.com/i-migliori-siti-casino-online-non-aams-per-il-2023-2/[/url] offrono un'esperienza esclusiva per i giocatori. La possibilitГ di divertirsi senza dover fornire documenti rende questi casinГІ ai piГ№ chi cerca riservatezza. CasinГІ senza documenti sono considerati la scelta ideale per chi vogliono sperimentare il brivido del gioco senza complicazioni.
Rebeccadar 19 Nisan 2026 11:39
Вопрос интересен, я тоже приму участие в обсуждении. Вместе мы сможем прийти к правильному ответу. casino en direct, [url=https://location-kayak.fr/]casino live[/url] - Le domaine du casino en direct offre une expГ©rience inoubliable. Les parieurs peuvent communiquer avec de vrais opГ©rateurs et vivre l'ambiance d'un vГ©ritable Г©tablissement. Le casino interactif crГ©e un contact authentique. Plongez dans l'univers du jeu en ligne sans laisser votre maison.
Jessielag 19 Nisan 2026 07:56
Jonnet 19 Nisan 2026 06:50
Nel mondo del gioco online, i siti di scommesse senza documenti offrono un'ottima opportunitГ per scommettere senza troppe complicazioni. La creazione dell'account ГЁ senza stress, permettendo di accedere a divertenti opzioni di gioco in pochi clic. I metodi di pagamento sono sicuri, garantendo sicurezza mentre si scommette. Non c'ГЁ motivo di esitare con cosa complicate! Scopri il brivido nei casinГІ senza documenti, [url=https://tire2value.tech/scopri-il-mondo-dei-casino-online-senza-4/]https://tire2value.tech/scopri-il-mondo-dei-casino-online-senza-4/[/url].
Miriamdet 19 Nisan 2026 02:18
JuliaVat 19 Nisan 2026 02:16
BetWinner Casino, [url=https://mail.abcoinfotech.com/2026/04/06/explore-the-betwinner-betting-platform-your/]https://mail.abcoinfotech.com/2026/04/06/explore-the-betwinner-betting-platform-your/[/url] презентует разнообразный выбор РёРіСЂ, включая слоты Рё настольные развлечения для РёРіСЂРѕРєРѕРІ. Клиенты РјРѕРіСѓС‚ получать удовольствие РѕС‚ удивительных Р±РѕРЅСѓСЃРѕРІ Рё акций. Рсследуйте РјРёСЂ BetWinner Casino!
Scottelalt 19 Nisan 2026 01:22
Конечно. Всё выше сказанное правда. Давайте обсудим этот вопрос. Здесь или в PM. casinos crypto, [url=https://patisseriesannicolas.fr/]casinos crypto[/url] - Les Г©tablissements de jeux crypto gagnent en popularitГ©, captivant un public de plus en plus large de joueurs. Ces espaces offrent des points forts uniques, comme la protection des donnГ©es et des transactions rapides.
JackGoata 18 Nisan 2026 21:50
Присоединяюсь. Я согласен со всем выше сказанным. Можем пообщаться на эту тему. Здесь или в PM. Разработка бизнес-планов, [url=https://teoplan.ru/portfolio/]https://teoplan.ru/portfolio/[/url] — это ключевой этап для успешного старта любого предприятия. Успешный бизнес-план помогает определить цели и методы на долгосрочную перспективу. Недостаток качественного плана вызывает к дисбалансу в бизнесе.
Jenniferamott 18 Nisan 2026 15:26
Браво, мне кажется это отличная мысль In India, the adoption of a 2D Payment Gateway India, [url=https://2dpaymentgateway.in/]https://2dpaymentgateway.in[/url] has transformed the way businesses manage transactions. This efficient technology facilitates payments, making it easier for customers to execute purchases digitally. As virtual retail continues to grow, integrating a 2D Payment Gateway India is crucial for businesses wishing to succeed.
Andreadat 18 Nisan 2026 15:22
DanaJek 18 Nisan 2026 14:46
Бомба Кухни на заказ, [url=http://custom-kitchens.ru/]custom-kitchens.ru[/url] — это отличный способ создать уникальное пространство для готовки. Вы сможете выбрать комплектацию, которые подойдут именно вам. Профессиональные специалисты помогут реализовать ваши идеи, сделав кухню комфортной и функциональной.
Annenow 18 Nisan 2026 11:50
BetWinner Online Bookmaker, [url=http://afkinen.gooooods.net/experience-the-thrill-of-betwinner-online-casino-13/]http://afkinen.gooooods.net/experience-the-thrill-of-betwinner-online-casino-13/[/url] offers a vast variety of betting options for sports lovers. With a intuitive interface, users can quickly place bets. Join now and explore the thrilling world of online gambling!
Matjesuham 18 Nisan 2026 10:14
Я думаю, что Вы ошибаетесь. Давайте обсудим. Пишите мне в PM. Bof Casino, [url=https://casinobofonline.uk/]https://casinobofonline.uk/[/url] offers captivating games for players. With diverse options, everyone can find something to enjoy. The user-friendly interface makes it simple to play. Join Bof Casino and embark on your betting adventure today!
MichelleCom 18 Nisan 2026 09:01
Ryanleava 18 Nisan 2026 07:13
BetWinner Live Casino, [url=https://hrd606.tnhillbillie.net/2026/04/05/betwinner-online-bookmaker-your-ultimate-betting-3/]https://hrd606.tnhillbillie.net/2026/04/05/betwinner-online-bookmaker-your-ultimate-betting-3/[/url] предлагает игрокам уникальный атмосферу азартных РёРіСЂ РІ реальном времени. Здесь можно участвовать РІ живых играх СЃ принадлежностями Рё набирать опыт РІ СѓРґРѕР±РЅРѕР№ атмосфере. Ставки можно делать РІ любое СѓРґРѕР±РЅРѕРµ время, что придаёт удобства всем игрокам. Опытные РёРіСЂРѕРєРё Рё новички откроют множество выборов. Будьте осторожР
PatrickPlork 18 Nisan 2026 06:55
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Могу отстоять свою позицию. Пишите мне в PM, поговорим. Ч ЧўЧЁЧ•ЧЄ ЧњЧ™Ч•Ч•Ч™ Ч‘ЧћЧЁЧ›Ч–, [url=https://aphroditaescort.co.il/]????? ?????[/url] ЧћЧ¦Ч™ЧўЧ•ЧЄ Ч©Ч™ЧЁЧ•ЧЄЧ™Чќ Ч™Ч™Ч—Ч•Ч“Ч™Ч•ЧЄ ЧњЧ›Чњ ЧћЧ™ Ч©ЧћЧ—Ч¤Ч© Ч‘Ч™ЧњЧ•Ч™. ЧњЧ’Ч‘Ч™ ЧђЧќ ЧћЧ“Ч•Ч‘ЧЁ Ч‘Ч©ЧўЧ•ЧЄ Ч”Ч¤Ч ЧђЧ™ ЧђЧ• ЧЎЧ™Ч‘Ч•ЧЄ ЧћЧ™Ч•Ч—Ч“Ч•ЧЄ, Ч”Ч ЧўЧЁЧ•ЧЄ ЧњЧЎЧ¤Ч§ ЧњЧћЧ—Ч¤Ч©Ч™Чќ Ч—Ч•Ч•Ч™Ч•ЧЄ Ч‘ЧњЧЄЧ™ Ч Ч©Ч›Ч—Ч•ЧЄ.
FeliciaHap 18 Nisan 2026 03:01
BetWinner Bookmaker, [url=https://rdysoncolley.com/betwinner-online-a-comprehensive-guide-to-sports/]https://rdysoncolley.com/betwinner-online-a-comprehensive-guide-to-sports/[/url] offers a wide range of wagering choices. Players can experience live betting and generous bonuses. The platform is user-friendly, making it a popular choice among bettors.
Emmaniz 17 Nisan 2026 22:58
BetWinner Casino, [url=https://heni.co.in/betwinner-login-secure-and-fast-access-to-your/]https://heni.co.in/betwinner-login-secure-and-fast-access-to-your/[/url] доступно широкий ассортимент азартных игр. Слоты и игры на спорт интересуют игроков со всего мира. Промоакции делают игру еще привлекательнее.
LesleyUnito 17 Nisan 2026 22:23
MarciaPoere 17 Nisan 2026 21:30
Мне нравится это топик ЧњЧ™Ч•Ч•Ч™ Ч‘ЧЄЧњ ЧђЧ‘Ч™Ч‘, [url=https://dudalatuta2.com/]https://dudalatuta2.com/[/url] Ч”Ч•Чђ Ч©Ч™ЧЁЧ•ЧЄ Ч¤Ч•Ч¤Ч•ЧњЧЁЧ™ Ч”ЧћЧ¦Ч™Чў Ч—Ч•Ч•Ч™Ч•ЧЄ Ч™Ч™Ч—Ч•Ч“Ч™Ч•ЧЄ Ч•ЧђЧЧЁЧ§ЧЧ™Ч‘Ч™Ч•ЧЄ. Ч”ЧћЧ¦Ч™ЧўЧ” Ч“Ч™Ч ЧћЧ™Ч§Ч” ЧћЧ™Ч•Ч—Ч“ЧЄ Ч•ЧђЧ¤Ч©ЧЁЧ•ЧЄ ЧњЧ”Ч›Ч™ЧЁ ЧўЧ•ЧњЧќ Ч—Ч“Ч©Ч”. Ч”ЧўЧ™ЧЁ ЧЧ•ЧћЧ ЧЄ Ч‘Ч—Ч•Ч‘Ч” Ч—Ч•Ч•Ч™Ч•ЧЄ ЧЁЧ‘Ч•ЧЄ Ч•ЧћЧ’Ч•Ч•Ч Ч•ЧЄ, Ч”ЧћЧ•Ч§Ч“Ч•ЧЄ ЧњЧ›Чњ ЧђЧ—Ч“ Ч•ЧђЧ—ЧЄ.
Douggok 17 Nisan 2026 19:00
BetWinner Online Casino, [url=https://morememory.com.mx/betwinner-bookmaker-an-in-depth-review-and/]https://morememory.com.mx/betwinner-bookmaker-an-in-depth-review-and/[/url] offers an exciting gaming experience for players. With diverse selections of games, including live dealer options, everyone can find something they enjoy. Make use of promotions that enhance your fun. Join at once and discover why BetWinner Online Casino stands out in the virtual casino world!
Williamerozy 17 Nisan 2026 18:41
Jennifercar 17 Nisan 2026 17:45
JenniferLat 17 Nisan 2026 13:14
Rayswece 17 Nisan 2026 12:00
По моему мнению Вы не правы. Я уверен. Давайте обсудим это. Пишите мне в PM. ВПН ProstoVPN, [url=https://www.edufex.com/forums/discussion/general/kargo-maliyetleri-ve-satici-destegi]https://www.edufex.com/forums/discussion/general/kargo-maliyetleri-ve-satici-destegi[/url] — это надежный инструмент для сохранения вашей приватности в интернете. С достойной скоростью и лесным интерфейсом, он обеспечивает без следов просматривать веб-страницы и обойти локальные ограничения. ВПН ProstoVPN предлагает вам надёжный доступ к любым ресурсам.
KevinSully 17 Nisan 2026 11:49
Ericalek 17 Nisan 2026 09:32
BetWinner Online Bookmaker, [url=https://bigtrakisback.com/betwinner4041/experience-the-thrill-of-betwinner-casino-your-5/]https://bigtrakisback.com/betwinner4041/experience-the-thrill-of-betwinner-casino-your-5/[/url] offers a thrilling opportunity for bettors. With a wide range of sports and events, users can efficiently place their wagers. The platform's accessible interface ensures that both beginners and pros enjoy hassle-free betting. Join BetWinner Online Bookmaker and explore exciting offers!
Tedcoosy 17 Nisan 2026 07:51
AshleyDuade 17 Nisan 2026 06:46
Emilyciz 17 Nisan 2026 03:56
Огромное спасибо за помощь в этом вопросе, теперь я не допущу такой ошибки. купить 17 айфон, [url=https://www.freeboard.com.ua/forum/viewtopic.php?pid=1024858#p1024858]https://www.freeboard.com.ua/forum/viewtopic.php?pid=1024858#p1024858[/url] – это отличное решение для тех, кто хочет насладиться современными технологиями. Этот смартфон обладает превосходной производительностью и стильным дизайном. Запоминающаяся камера позволит делать фантастические снимки. Не упустите шанс купить этот устройство!
PaulDox 17 Nisan 2026 03:16
MercedescaM 17 Nisan 2026 02:09
KimberlyBitty 16 Nisan 2026 23:03
Saradog 16 Nisan 2026 22:43
SherryHok 16 Nisan 2026 21:58
Вы отдалились от беседы Возврат денег от брокера, [url=https://stopscam.info/]https://stopscam.info/[/url] — это процесс, который может принести трудности трейдерам. Рекомендуется тщательно изучить условия предоставления услуг и заполнить все необходимые документы. Препятствия в возврате могут возникнуть из-за непрозрачных правил. Убедитесь, что выбранный брокер имеет достаточную репутацию.
AnthonyFor 16 Nisan 2026 19:39
ClayWoofe 16 Nisan 2026 19:36
Не могу сейчас поучаствовать в обсуждении - очень занят. Освобожусь - обязательно выскажу своё мнение. Современная жизнь диктует свои условия, и доставка алкоголя на дом, [url=https://alco-magazin.online/]доставка алкоголя ночью[/url] становитcя все более популярной услугой. Теперь не нужно тратить время на поездки в магазин, чтобы приобрести любимые напитки. Сервис, предоставляющая доставку алкоголя, позволяет насладиться разнообразием напитков напрямую из уюта вашего дома. Выбор алкогольных напитков огромен: от пива до вина различного сорта и миксов. Когда вы планируете вечернюю встречу с друзьями или романтический ужин, доставка алкоголя на дом — это идеальный вариант, чтобы быстро организовать торжество. Многие платформы обеспечивают быструю и безопасную доставку, что позволяет избеж
Lucycrige 16 Nisan 2026 19:12
Прикольно! Улыбнуло! Афтару - респект! Бармен-шоу, [url=https://barshows.ru/]https://barshows.ru/[/url] — это захватывающее зрелище, где креативные бармены представляют искусство приготовления коктейлей. Они задействуют различные техники, чтобы развлечь зрителей. Каждый шоу — это настоящее зрелище фейерии и творчества.
Lawrenceinpub 16 Nisan 2026 18:56
Извиняюсь, есть предложение пойти по другому пути. В мегаполисе жизнь кипит, и на улицах встречаются проститутки, [url=https://prostitutki-klin.com]шлюхи[/url], предлагающие свои услуги. Число таких женщин зарабатывают деньги разными способами, а также и на улицах. Культура вокруг такого явления многогранен.
Sergeydes 16 Nisan 2026 10:53
Перепады температур в Красноярске от -50 зимой до жары летом. Металлочерепица 0.5 мм выдерживает от -50 до +80 градусов — специально проверял технические характеристики перед покупкой. [url=https://metall-kras24.ru/]металлочерепица 0.45 мм для дачи[/url]
CurtisSlern 16 Nisan 2026 06:35
AngelaCaurl 15 Nisan 2026 23:42
KatherineGok 15 Nisan 2026 22:41
OliviaFlelt 15 Nisan 2026 18:58
Pamelawap 15 Nisan 2026 18:46
XplosiveSlura 15 Nisan 2026 15:08
Louisecap 15 Nisan 2026 14:49
Marksox 15 Nisan 2026 13:25
Amyref 15 Nisan 2026 08:18
At spille i digitale casinoer med paysafecard betalingsmulighed er blevet mere populært. Det præsenterer en sikkerhed måde at foretage indbetalinger på. Alle kan udnytte fordelene ved paysafecard casinoer online, [url=https://www.ellalan.com/2026/04/02/online-casino-paysafecard-sikkerhed-og-6/]https://www.ellalan.com/2026/04/02/online-casino-paysafecard-sikkerhed-og-6/[/url], uden uroligheder.
Angieontor 15 Nisan 2026 02:23
Det er vigtigt at vælge det bedste skrill casino for at få en exceptionel spilleoplevelse. Ved at bruge skrill som betalingsmetode, kan spillere få adgang til hurtigere transaktioner og forbedret sikkerhed. Det faciliterer til en overlegen spiloplevelse, så vælg det bedste skrill casino, [url=https://leygcg.imembrillos.gob.mx/skrill-casinoer-den-ultimative-guide-til-online-8/]https://leygcg.imembrillos.gob.mx/skrill-casinoer-den-ultimative-guide-til-online-8/[/url].
Paulaattag 15 Nisan 2026 02:04
ErnieEmesk 15 Nisan 2026 01:06
BC Game Online Casino, [url=https://tagclaimsolutions.com/explore-the-exciting-world-of-bc-game-br-hub/]https://tagclaimsolutions.com/explore-the-exciting-world-of-bc-game-br-hub/[/url] features a unique betting experience. Incorporating a wide range of games, players can enjoy exciting options. Enter the network today!
Michaelfeary 15 Nisan 2026 00:04
https://santorinicarhub.com
Patricknolla 14 Nisan 2026 20:49
Experience the thrill of playing in the BC Game Live Casino, [url=http://lobby.co.il/exploring-bc-game-crypto-casino-in-indonesia-the/]http://lobby.co.il/exploring-bc-game-crypto-casino-in-indonesia-the/[/url], where professional hosts bring excitement to your screen. Enjoy assortment of games, like blackjack, roulette, and baccarat. Join now and get in on the action!
BooneBer 14 Nisan 2026 16:34
BC Game Casino, [url=https://globalherbalfarms.com/exploring-bc-game-the-future-of-online-gambling-in/]https://globalherbalfarms.com/exploring-bc-game-the-future-of-online-gambling-in/[/url] offers an exhilarating experience for players. With countless games and attractive bonuses, it's easy to see why many select this platform. Join the fun now!
AaronSon 14 Nisan 2026 11:16
BC Game Online Casino, [url=https://biodescodificacion.ar/bc-game-login-your-gateway-to-online-gaming-7/]https://biodescodificacion.ar/bc-game-login-your-gateway-to-online-gaming-7/[/url] offers entertaining gaming opportunities for players. With a variety of games, users can delight in numerous activities. The platform is known for its user-friendly design, ensuring a seamless experience. Bonuses and promotions make it even more inviting for newcomers and loyal players alike. Discover the world of BC Game Online Casino and unleash your gaming adventure today!
Keshiaesoca 14 Nisan 2026 09:10
В мире видеоигр одно из самых ожидаемых событий — новости игр, [url=http://www.social-action-ring.org/category04/novye-gorizonty-v-igrovoj-industrii-anonsy-i/]http://www.social-action-ring.org/category04/novye-gorizonty-v-igrovoj-industrii-anonsy-i/[/url]. Совсем недавно разработчики анонсировали новую видеоигру, которая обещает удивить фанатов. Это ролевой игра с увлекательной историей и футуристической графикой. Авторы уверены, что проект покорит игровую аудиторию и станет успешным событием в мире игр. Ожидаем релиза в летом.
MariaAwast 14 Nisan 2026 08:01
online casino paysafe, [url=https://www.timanga.it/2026/03/31/alt-om-paysafecard-casinoer/]https://www.timanga.it/2026/03/31/alt-om-paysafecard-casinoer/[/url] tilbyder en sikker og anonym mГҐde at spille pГҐ nettet. En sГҐdan metode skaber nemme ind- og udbetalinger. Med den paysafecard kan spillere nyde kontrol over deres finanser.
Brookeinabs 14 Nisan 2026 06:30
Experience the thrill of online gaming at BC Game Live Casino, [url=https://immobiliarenapoli.altervista.org/maximizing-your-rewards-unraveling-bc-game-daily/]https://immobiliarenapoli.altervista.org/maximizing-your-rewards-unraveling-bc-game-daily/[/url], where players are able to immerse themselves in engaging games. Join a community of gamers ready for action every moment!
BobbieAdari 14 Nisan 2026 03:42
AmandaClord 14 Nisan 2026 00:48
Не могу сейчас принять участие в дискуссии - нет свободного времени. Но скоро обязательно напишу что я думаю. Alanyaspor Futbol KulГјbГј, [url=https://alanyaspor.futbol/]https://alanyaspor.futbol[/url], TГјrkiye'nin futbolunun Г¶nemli takД±mlarД±ndan biridir. SГјper Lig'te mГјcadele eden bu organizasyon, severleriyle dikkat Г§ekiyor. Seyircileriyle maГ§lar her zaman coЕџkulu geГ§iyor. Alanyaspor, baЕџarД±lar kazanarak bГјyГјmeye devam ediyor.
NickTub 13 Nisan 2026 21:34
MiaGok 13 Nisan 2026 17:31
BC Game Live Casino, [url=https://flordemaig.es/bc-game-hub-explore-the-world-of-blockchain-gaming/]https://flordemaig.es/bc-game-hub-explore-the-world-of-blockchain-gaming/[/url] РІРІРѕРґРёС‚ уникальный впечатление для участников. РРіСЂС‹, представляемые РІ реальном времени, предлагают адреналин Рё шанс выиграть. Присоединяйтесь Рє пространству захватывающих событий!
TanmayTat 13 Nisan 2026 17:29
AngelaMoife 13 Nisan 2026 16:09
Nu tilbyder adskillige casinoer med visa, [url=https://powercordlead.com/visa-casino-en-guide-til-sikker-online-spil-4/]https://powercordlead.com/visa-casino-en-guide-til-sikker-online-spil-4/[/url] trygge betalingsmetoder. Med denne kendte metode kan brugere nemt indsætte og udbetale penge. Det sikrer en god oplevelse for alle.
KarenPaype 13 Nisan 2026 15:15
Это — невозможно. 20 Hot Blast, [url=https://20-hot-blast-tr.com/]20 Hot Blast[/url], kullanД±cД±larД±n deneyimlerini zenginleЕџtiren bir platformdur. FarklД± iГ§eriklerle dikkat Г§eker. SГ¶z konusu iГ§erikler, zevkli anlar sunar ve paylaЕџmak fД±rsatlarД± yaratД±r. KullanД±cД±lar, Г¶zel deneyimlerini paylaЕџarak, toplulukla iletiЕџim kurarlar.
Georgesouct 13 Nisan 2026 12:46
BC Game Casino, [url=https://surfacemediadesigns.com/bcgame3043/experience-the-thrill-of-bc-game-online-crypto-4/]https://surfacemediadesigns.com/bcgame3043/experience-the-thrill-of-bc-game-online-crypto-4/[/url] offers an exciting gaming experience for fans. With numerous of games, including live dealer games, players can enjoy unending fun and pleasure. Join today and discover the realm of online gambling!
TeddyNef 13 Nisan 2026 11:42
Selenasoumb 12 Nisan 2026 22:16
BC Game Casino, [url=https://pharmacytrainingrx.com/bcga-me-your-ultimate-mirror-site-for-bc-game/]https://pharmacytrainingrx.com/bcga-me-your-ultimate-mirror-site-for-bc-game/[/url] offers thrilling gameplay for participants. With numerous games, it attracts fans from everywhere. Join today to explore unique perks and advantages.
SheilaJeoth 12 Nisan 2026 21:14
I dag er der mange udenlandske muligheder for at spille online. udenlandsk online casino, [url=http://79.170.44.106/purplehaze.co.ke/1/?p=54942]http://79.170.44.106/purplehaze.co.ke/1/?p=54942[/url] tilbyder mange spil, hvor interesserede kan have spændingen ved slotmaskiner. Det er nødvendigt at vælge et troværdigt casino for at stoppe bedrag.
Danabiarl 12 Nisan 2026 17:58
BC Game Online Casino, [url=https://warriorbasketballacademy.net/index.php/2026/04/03/exploring-the-features-and-benefits-of-bc-game-app/]https://warriorbasketballacademy.net/index.php/2026/04/03/exploring-the-features-and-benefits-of-bc-game-app/[/url] предлагает уникальный переплетение в мире виртуальных азартных развлечений. Выбор игр поразителен, а интерфейс комфортен. Промо-акции облегчают развлечение.
LauraAvaks 12 Nisan 2026 12:41
BC Game Live Casino, [url=http://smartbusiness.agencyzed.com/archives/134349]http://smartbusiness.agencyzed.com/archives/134349[/url] представляет уникальную атмосферу, где каждый наслаждаться интересными играми. Современные дилеры создают фантастический опыт, обеспечивая высокое качество игр. Присоединяйтесь к мира вместе с BC Game Live Casino!
ShakiraJig 12 Nisan 2026 07:13
Бесконечное обсуждение :) hot deco, [url=https://hot-deco.online/]https://hot-deco.online[/url], yenilikГ§i dekorasyon anlayД±ЕџД±yla evinizi canlД± ve ЕџД±k bir yere dГ¶nГјЕџtГјrГјr. Oda tasarД±mД±nda Г§aДџdaЕџ Г¶geler kullanarak her kГ¶Еџeyi eЕџsiz kД±labilirsiniz. Renk paleti ile uygun atmosfer yaratmak mГјmkГјndГјr.
EdithWab 12 Nisan 2026 07:08
BC Game Casino, [url=https://www.reservemarketnow.com/discovering-the-world-of-bc-game-online-in-spain/]https://www.reservemarketnow.com/discovering-the-world-of-bc-game-online-in-spain/[/url] предоставляет игрокам неповторимый опыт. Куча игр предоставляют шанс войти в мир азартных увлечений. Поощрения привлекают новых участников, обеспечивая процесс особенно увлекательным.
Shellyspets 12 Nisan 2026 02:25
BC Game Online Casino, [url=https://socut-hairspa.fr/discover-the-excitement-of-bc-game-online-casino-18/]https://socut-hairspa.fr/discover-the-excitement-of-bc-game-online-casino-18/[/url] offers an exciting experience for players. With countless games available, users can delight in a unique gaming atmosphere. Incentives enhance the fun, making every game more appealing. Join BC Game Online Casino today and find out the thrill of online gaming!
JonChono 11 Nisan 2026 20:04
https://cloud4log.de/forums/users/treymarian498 11 Nisan 2026 17:39
Muy buen post, de verdad. Un contenido muy completo y útil. Espero ver nuevas actualizaciones pronto. https://cloud4log.de/forums/users/treymarian498
Cassandramof 11 Nisan 2026 17:38
BC Game Casino, [url=https://tejas-apartment.teson.xyz/comprehensive-guide-to-bc-game-deposit-methods-3/]https://tejas-apartment.teson.xyz/comprehensive-guide-to-bc-game-deposit-methods-3/[/url] offers an exciting gaming experience for users. With an array games, it attracts many. Additionally, their promotion system is rewarding, enhancing the overall enjoyment.
RobertHoody 11 Nisan 2026 16:00
Научись читать парфюмерия, [url=https://spainslov.ru/site/word/word/%D0%AF%D0%9A%D0%9E%D0%A0%D0%AC]https://spainslov.ru/site/word/word/%D0%AF%D0%9A%D0%9E%D0%A0%D0%AC[/url] – это искусство создания уникальных ароматов, которое отражает личность и настроение. Каждый из ароматы способны создавать эмоции. Важно выбирать парфюмерию, соответствующую вашему стилю.
StephanieShele 11 Nisan 2026 14:18
JohnDaymn 11 Nisan 2026 12:11
Welcome to our exciting world of BC Game Online Casino, [url=https://yitz.com.br/discover-the-thrill-of-bc-game-casino-your-2/]https://yitz.com.br/discover-the-thrill-of-bc-game-casino-your-2/[/url]! Enjoy a wide range of choices and find unique benefits. Join a platform where users can connect and earn amazing rewards. Seize your chance to experience high-quality gaming today!
Rebeccabiogs 11 Nisan 2026 11:53
Какое талантливое сообщение gates of olympus, [url=https://olympus-1000.online/]gates of olympus[/url], fantastik bir sГјreГ§ sunarak oyunculara heyecan verici deneyimler veriyor. Bahsedilen mГјcadele ilginГ§ grafiklerle eЕџsiz hikayeler anlatД±yor.
JosephCouth 11 Nisan 2026 06:48
I dag er online gambling mere populært end nogensinde. Mange spillere søger muligheder for at spille uden begrænsninger, og casino uden rofus, [url=https://www.showanddisplay.com.hk/2026/03/31/rufus-casino-din-ultimative-guide-til-online/]https://www.showanddisplay.com.hk/2026/03/31/rufus-casino-din-ultimative-guide-til-online/[/url] er en af dem. Disse platforme giver frihed til at nyde spil uden registrering. Spillere kan vælge mellem flere spil og få muligheder uden problemer. Det er en enestående måde at opleve spændingen ved casino på. Samtidig er det vigtigt at spille ansvarligt og være opmærksom på gamblerens grænser. Med gode strategier kan man avantage oplevelsen fuldt ud.
Miriamuserb 11 Nisan 2026 02:54
BC Game Casino, [url=http://www.domopet.it/exploring-the-bc-game-hub-a-comprehensive-guide-to-2/]http://www.domopet.it/exploring-the-bc-game-hub-a-comprehensive-guide-to-2/[/url] offers an exciting gaming experience for fans worldwide. With various games and attractive bonuses, it’s a go-to site for anyone wanting to try their luck.
Rickexids 11 Nisan 2026 02:34
Должен Вам сказать это — заблуждение. saray ruyasi demo, [url=https://saray-ruyasi-demo.com/]saray-ruyasi-demo.com[/url] - Saray ruyasД± demo, Г§arpД±cД± bir deneyim sunuyor. deneyim detaylarД±yla dalД±Еџ iГ§in sizi istiyor. Fantastik bir dГјnyada gezinti yapmak iГ§in bekliyoruz!
BrianTah 10 Nisan 2026 22:40
Welcome to the thrilling world of internet gambling! At BC Game Online Casino, [url=https://igrejacolheita.com.br/2026/04/01/comprehensive-guide-to-downloading-the-bc-app-2/]https://igrejacolheita.com.br/2026/04/01/comprehensive-guide-to-downloading-the-bc-app-2/[/url], users can enjoy a wide range of games, such as slots, poker, and blackjack. Experience the fun and take the opportunity to win large prizes today!
Angelaorers 10 Nisan 2026 21:20
Вы попали в самую точку. В этом что-то есть и мне кажется это очень хорошая идея. Полностью с Вами соглашусь. онлайн казино, [url=https://transportnyj.ru/forum/topic/v-kakie-sloty-v-onlayn-kazino-vy-chasche-igraete-i-poluchaete-pribyl/]https://transportnyj.ru/forum/topic/v-kakie-sloty-v-onlayn-kazino-vy-chasche-igraete-i-poluchaete-pribyl/[/url] обеспечивают посетителям привилегию нажить настоящие. Данные платформы обеспечивают разные азартные варианты для любой.
LydiaIroks 10 Nisan 2026 20:45
nove slovenske casino, [url=https://www.pleasesellmycar.ca/eskills/nove-online-kasina-objavte-najnovie-trendy-a-2/]https://www.pleasesellmycar.ca/eskills/nove-online-kasina-objavte-najnovie-trendy-a-2/[/url] ponГєkajГє bohatГє ЕЎkГЎlu hier a moЕѕnostГ. HrГЎДЌi mГґЕѕu zaЕѕiЕҐ kДѕГєДЌovГ© vГЅhernГ© automaty, stolovГ© hry a eventy na vyhranie atraktГvnych ocenenГ.
Jessicabluct 10 Nisan 2026 19:49
TiffanySus 10 Nisan 2026 15:17
Andrewhog 10 Nisan 2026 14:23
Maggiemed 10 Nisan 2026 09:42
Beatriceven 10 Nisan 2026 07:56
Рискую показаться профаном, но всё же спрошу, откуда это и кто вообще написал? sugar rush demo, [url=https://sugarrush-demo.info/]sugarrush-demo.info[/url], Г§ocuklarД±n sevdiДџi bir oyun. Bu oyun, renkli grafikleri ile dikkat toplar. Oyna ve lezzetleri toplayarak hedefinin artmasД±nД± saДџla. Her an yeni sГјrpriz seni bekliyor!
YvonnePiz 10 Nisan 2026 04:38
Великолепная фраза и своевременно стоматология хирург, [url=https://pad.nixnet.services/s/WQOw1y1_G]базальная имплантация минск цены[/url] предоставляет широкий ассортимент услуг для лечения заболеваний зубов и десен. Специализированные врачи помогут вам поисковать любые задачи, связанные с людским здоровьем.
GwinnettFak 10 Nisan 2026 02:54
Timofeydes 10 Nisan 2026 02:23
Хотел комплексное решение — чтобы продажи, склад, финансы и кадры были в одной программе, а не в пяти разных. Нашёл именно такое. [url=https://управление-нашей-фирмой.рф/]автоматизация оптовой торговли[/url]
BarryDrype 09 Nisan 2026 23:52
Хотел бы сказать пару слов. 1win зеркало сайта, [url=https://1win-npoys.buzz/]1win-npoys.buzz[/url][url=https://1win-npoys.buzz/]https://1win-npoys.buzz/[/url] предоставляет возможность игрокам получать доступ к ставкам в любое время. Указанное альтернатива обеспечивает пользователям обойти блокировки. Также, интерфейс не изменяется, что содействует процесс ставок.
Adamnow 09 Nisan 2026 22:38
Treyamami 09 Nisan 2026 22:18
Karenbutle 09 Nisan 2026 21:59
Да вы талант :) Если вы хотите заказать эффективное средство от гепатита С, вам стоит обратить внимание на велпатасвир купить, [url=https://www.stusocial.com/blogs/31412/%D0%98%D0%BD%D0%BD%D0%BE%D0%B2%D0%B0%D1%86%D0%B8%D0%B8-%D0%B2-%D1%82%D0%B5%D1%80%D0%B0%D0%BF%D0%B8%D0%B8-%D0%B2%D0%B8%D1%80%D1%83%D1%81%D0%BD%D1%8B%D1%85-%D0%B3%D0%B5%D0%BF%D0%B0%D1%82%D0%B8%D1%82%D0%BE%D0%B2]https://www.stusocial.com/blogs/31412/%D0%98%D0%BD%D0%BD%D0%BE%D0%B2%D0%B0%D1%86%D0%B8%D0%B8-%D0%B2-%D1%82%D0%B5%D1%80%D0%B0%D0%BF%D0%B8%D0%B8-%D0%B2%D0%B8%D1%80%D1%83%D1%81%D0%BD%D1%8B%D1%85-%D0%B3%D0%B5%D0%BF%D0%B0%D1%82%D0%B8%D1%82%D0%BE%D0%B2[/url]. Этот препарат предлагает высокую скорость выздоровления. Узнав о его эффективность, вы сможете вздохнуть спокойно.
BrendaMaivy 09 Nisan 2026 21:17
Поздравляю, отличный ответ. 1win зеркало сайта, [url=https://1win-l1b6i.buzz/]1вин сайт официальный[/url][url=https://1win-l1b6i.buzz/]1win официальный вход[/url] предоставляет пользователям доступ к своим услугам даже при блокировках. Это комфортный способ оставаться в игре. Пользователи могут надежно делать ставки, не беспокоясь о доступности. Зеркало может регулярно обновляться, предлагая стабильный доступ к всем функциям. Помимо этого следует исследовать ссылки на 1win зеркало сайта для актуальности.
Katepraib 09 Nisan 2026 18:59
дааааа. не плохие уже MTProxy for Telegram, [url=https://proxytg.com/]https://proxytg.com[/url] is a powerful tool that ensures secure communication. It assists users in bypassing restrictions and accessing Telegram with convenience. Using MTProxy for Telegram, individuals can enjoy a free flow of information.
Robertvop 09 Nisan 2026 18:45
JessieBof 09 Nisan 2026 18:44
Чтобы не сказать больше. 1win официальный сайт, [url=https://1win-tgb4q.buzz/]https://1win-tgb4q.buzz/[/url][url=https://1win-tgb4q.buzz/]https://1win-tgb4q.buzz[/url] включает обширную палитру азартных ставок. Посетители могут взаимодействовать захватывающими функциями и получать привилегии.
MikeLen 09 Nisan 2026 18:26
MarciaPhark 09 Nisan 2026 16:10
ОоОО... супер! спасибо! )) 1win официальный сайт, [url=https://1win-olj6p.buzz/]1вин сайт официальный[/url][url=https://1win-olj6p.buzz/]1win официальный вход[/url] предлагает широкий гамму ставок на разнообразные спортивные события. Здесь доступны найти привлекательные акции и раздачи. Удобный дизайн и мгновенная регистрация делают процесс комфортным. На ресурсе можно подавать ставки в текущем времени, что придает азарту дополнительный уровень.
Shanefrova 09 Nisan 2026 15:54
Прикольно,мне понравилось Sentox Solutions Review, [url=https://armstrongspinningmills.com/sentox-solutions-review/]https://armstrongspinningmills.com/sentox-solutions-review/[/url] offers advanced solutions for organizations. Their offerings are designed to improve productivity and simplify processes. Clients have reported remarkable improvements in effectiveness.
KaylaRip 09 Nisan 2026 13:02
ф топку тебя 1win официальный сайт, [url=https://1win-je2mx.cfd/]https://1win-je2mx.cfd[/url][url=https://1win-je2mx.cfd/]1win-je2mx.cfd[/url] предоставляет уникальные предложения для игроков букмекерства. Сервис отличается своей доступностью и разнообразием игр и ставок.
StacyMic 09 Nisan 2026 09:25
Att spela på casino utan licens erbjuder en annorlunda upplevelse för skandinaviska entusiaster. Många kunder lockas av större bonusar och snabbare uttag. Det är avgörande att ?spela ansvarsfullt? och välja ett pålitligt casino utan svensk licens, [url=https://ir.saver.one/2026/04/06/casinon-utan-svensk-licens-en-djupgende-guide-4/]https://ir.saver.one/2026/04/06/casinon-utan-svensk-licens-en-djupgende-guide-4/[/url].
Davidmum 09 Nisan 2026 07:26
Полностью разделяю Ваше мнение. В этом что-то есть и я думаю, что это хорошая идея. 1win официальный сайт, [url=https://1win-au55a.blog/]1win-au55a.blog[/url][url=https://1win-au55a.blog/]https://1win-au55a.blog/[/url] предлагает игрокам множество возможностей для ставок на спортивные события. В этом онлайн-казино доступны разнообразные варианты игр и ассортимент событий. Игроки могут выигрывать бонусы и участвовать в любое время.
Ryanduh 09 Nisan 2026 06:30
Это — позор! mellstroy casino сайт, [url=https://mellstroy-casino-kua8.click/]mellstroy gaming[/url] предлагает широкий выбор азартных игр и щедрые акции для своих посетителей. Погружайтесь в атмосферу азартных развлечений!
GinaWoums 09 Nisan 2026 04:46
Едва могу тому верить. 1win официальный сайт, [url=https://1win-e93yq.top/]https://1win-e93yq.top/[/url][url=https://1win-e93yq.top/]1win-e93yq.top[/url] предлагает уникальные возможности для азартных игроков. На этом ресурсе вы найдете множество развлечений. Удобство использования делает ее привлекательным для новичков.
BenMEp 09 Nisan 2026 04:05
По моему мнению Вы пошли ошибочным путём. mellstroy game сайт, [url=https://mellstroy-casino-ooo0.click/]mellstroy-casino-ooo0.click[/url] - На сайте mellstroy game можно найти множество разнообразных игр. Каждая из игра погружает пользователей в необычные миры. Откройте новые эмоции от игры!
JenniferBleaf 09 Nisan 2026 02:11
Присоединяюсь. Так бывает. Можем пообщаться на эту тему. Здесь или в PM. 1win официальный сайт, [url=https://1win-oh0if.buzz/]https://1win-oh0if.buzz/[/url][url=https://1win-oh0if.buzz/]1win официальный сайт[/url] предлагает значительный выбор ставок для посетителей. Здесь вы откроете все нужные возможности для увлекательного отдыха.
Susannaexcaf 09 Nisan 2026 00:29
Это можно обсуждать бесконечно mellstroy game сайт, [url=https://mellstroy-casino-shd0.lol/]https://mellstroy-casino-shd0.lol/[/url] предлагает игрокам уникальный опыт, где можно погрузиться в мир дизайна. Каждый митинг игры устойчиво насыщен интересными заданиями и оригинальными решениями. Присоединяйтесь и исследуйте новые аспекты!
Madisonedivy 09 Nisan 2026 00:28
Охотно принимаю. На мой взгляд это актуально, буду принимать участие в обсуждении. 1win официальный сайт, [url=https://1win-vr3xg.xyz/]1win-vr3xg.xyz[/url] представляет обширный выбор пари, включая киберспорт пари. Платформа интуитивно понятен для гостей, что способствует без труда находить нужное платформу. Каждый может открыть захватывающее для себя.
MaggieTug 08 Nisan 2026 22:37
BritneyGlaph 08 Nisan 2026 21:12
Какие нужные слова... супер, блестящая фраза Вам необходимо посетить mellstroy game сайт, [url=https://mellstroy-casino-iuy1.lol/]mellstroy gaming[/url], где представлен уникальный развлекательный контент. Здесь вы найдете интересные проекты, которые позволят исследовать вселенную и наслаждаться незабываемым игровым процессом.
Williammus 08 Nisan 2026 20:38
Att spela på e-nätcasinon har blivit populärt bland svenskar. Många söker alternativ som casino utan svensk licens, [url=https://shop.uzo1.com/casino-utan-spelpaus-en-djupdykning-i-spelvarlden-8/]https://shop.uzo1.com/casino-utan-spelpaus-en-djupdykning-i-spelvarlden-8/[/url]. Dessa plattformer erbjuder intressanta spel och attraktiva bonusar.
TabithaMumus 08 Nisan 2026 20:08
Какие слова... супер, замечательная мысль mellstroy casino сайт, [url=https://mellstroy-casino-lsd2.click/]меллстрой гейм[/url] предлагает многообразный выбор игр для любителей азартных развлечений. Надежный интерфейс делает активности легким. Пользователи получают шанс выигрывать реальные вознаграждения.
Josephinevok 08 Nisan 2026 18:48
ClayRem 08 Nisan 2026 18:37
Эта отличная идея придется как раз кстати 1win официальный сайт, [url=https://1win-zvo7k.icu/]https://1win-zvo7k.icu/[/url] предлагает пользователям широкий выбор азартных игр. На платформе можно найти различные ставки, что удовлетворяет знатоков азартных игр. Пользовательский интерфейс доступен и помогает Просто ориентироваться в категории ставок. 1win официальный сайт — это надежная площадка для развлечений.
AndrewKip 08 Nisan 2026 17:51
Час от часу не легче. На mellstroy game сайт, [url=https://mellstroy-casino-bgr9.click/]mellstroy game[/url] вы найдете множество занимательных игр. Каждая игра дарит уникальные варианты для улучшения различных знаний. Попробуйте и испытайте наши новые поступления.
Pennyrix 08 Nisan 2026 17:45
уже с самого начала было понятно чем закончится 1win официальный сайт, [url=https://1win-8pluf.top/]https://1win-8pluf.top/[/url] предлагает богатый выбор ставок для любителей. Пользователи могут наслаждаться удобным интерфейсом и привлекательными условиями.
NicoleFraub 08 Nisan 2026 16:12
Att spela på internetcasinon har blivit allt mer populärt, särskilt när det kommer till casino utan svensk licens, [url=https://www.outstrip.tech/upplev-spanningen-med-casino-utan-spelpaus/]https://www.outstrip.tech/upplev-spanningen-med-casino-utan-spelpaus/[/url]. Dessa alternativ erbjuder bättre bonusar och ett bredare urval av spel. För många spelare presenterar dessa sajter en unik spelupplevelse. Var noga med att titta på säkerheten och pålitligheten hos plattformarna innan du registrerar dig.
Elizabethsaunc 08 Nisan 2026 16:02
дальше не читаю 1win зеркало сайта, [url=https://1win-zvo7k.icu/]https://1win-zvo7k.icu[/url][url=https://1win-zvo7k.icu/]сайт 1 вин[/url] позволяет получить доступ к ресурсам букмекера, когда основной сайт недоступен. Многие пользователи ищут альтернативные варианты, чтобы продолжать делать ставки. С помощью 1win зеркало сайта можно избежать блокировок и наслаждаться услугами.
GwenSobia 08 Nisan 2026 14:50
Charleneabese 08 Nisan 2026 14:20
Что именно вы хотели бы сказать? Важным аспектом в продвижении игрового процесса является модификация игрового баланса. На mellstroy game сайт, [url=https://mellstroy-casino-qwe4.xyz/]https://mellstroy-casino-qwe4.xyz[/url] пользователи могут узнать интересные возможности, которые делают игру привлекательнее.
Lesleyapors 08 Nisan 2026 14:11
Есть сайт, с огромным количеством информации по интересующей Вас теме. 1win официальный сайт, [url=https://1win-pc20g.xyz/]https://1win-pc20g.xyz/[/url] предлагает широкий выбор азартных игр и ставок. Пользователи могут наслаждаться ставками в удобном интерфейсе. Регистрация проста, а вывод средств происходит быстро. Присоединяйтесь к мирку азартных развлечений!
MichelleIderT 08 Nisan 2026 13:06
прикона,позитттивчик mellstroy casino сайт, [url=https://mellstroy-casino-ksu6.xyz/]https://mellstroy-casino-ksu6.xyz[/url] предлагает уникальные возможности для любителей азартных игр. На сайте вы найдете множество игр, способных удовлетворить любые предпочтения. Также, доступные бонусы приятно удивляют новых игроков. Каждый сможет насладиться достойным внимания игровым процессом в комфортной обстановке.
GinaVidly 08 Nisan 2026 11:26
Я пожалуй просто промолчу плитка для РІРѕРЅРЅРѕС— кімнати, [url=https://spilkuvannya.webboard.org/post2234.html]https://spilkuvannya.webboard.org/post2234.html[/url] – ідеальний РІРёР±С–СЂ для створення естетичного інтер'єру. Таке покриття відзначається достатньою стійкістю РґРѕ вологи та легкою РґРѕСЃРєРѕСЋ. Сучасні декоративні дизайни дозволяють знайти особливий стиль вашої ванної.
AlexUsasp 08 Nisan 2026 10:41
Можно восполнить пробел? Добро пожаловать на интересный mellstroy game сайт, [url=https://mellstroy-casino-tre8.click/]mellstroy официальный сайт[/url], где получите возможность узнать в вселенную увлекательных событий. Тут ждет новые путешествия. Забудьте о сомнениях и открывайте новые горизонты уже сегодня!
JeffAcino 08 Nisan 2026 10:30
Прошу прощения, что вмешался... Я здесь недавно. Но мне очень близка эта тема. Готов помочь. 1win официальный сайт, [url=https://1win-pc20g.xyz/]1win вход[/url] представляет широкий выбор азартных пари. Здесь любой найдет что-то для себя. Пользовательский интерфейс помогает скорому заботу о игр. Не упустите возможность испытать удачу!
StephanieBug 08 Nisan 2026 09:58
По моему мнению Вы не правы. Я уверен. Пишите мне в PM, поговорим. 1win зеркало сайта, [url=https://1win-6lxcn.cyou/]1win casino[/url][url=https://1win-6lxcn.cyou/]https://1win-6lxcn.cyou[/url] позволяет игрокам получить доступ к любимым играм в любое время. Это самый решение предоставляет доступный способ пройти блокировки. Используя его зеркала, каждый могут удовлетворяться азартными играми без ограничений.
PamelaPax 08 Nisan 2026 07:07
P.S. даю 9 балов из 10. 1win официальный сайт, [url=https://1win-nbfbe.blog/]1win-nbfbe.blog[/url] предлагает удобный интерфейс для пользователей. На платформе вы найдете широкий выбор ставок и щедрые бонусы. Зарегистрируйтесь прямо сейчас!
Margaretdex 08 Nisan 2026 05:55
В этом что-то есть. Большое спасибо за помощь в этом вопросе. сайт 1вин, [url=https://1win-7we2k.buzz/]1win casino[/url] предлагает богатый выбор азартных игр. Каждый участник найдет здесь что-то привлекательное. Подписка на сайте 1вин простая, что позволяет мгновенно начать играть и наслаждаться!
TomDic 08 Nisan 2026 04:47
поверьте мне. стоматология, [url=https://allon6-minsk.vercel.app/]https://allon6-minsk.vercel.app/[/url] является важную дисциплину медицины, которая сосредотачивается на заболеваниях полости рта. Систематические осмотры у врача обеспечивают сохранению здоровья зубов.
Ericweign 08 Nisan 2026 04:42
Абсурдная ситуация получилась Сиделка с проживанием, [url=https://sidelka-centr.ru/]Сиделка с проживанием[/url] — это отличный выбор для людей, нуждающихся в постоянной помощи. Такой помощник обеспечит обслуживание и сопровождение. Карьера готова заменять необходимую поддержку и внимание.
Donaldnup 08 Nisan 2026 04:02
Вы правы, не самое удачное время На mellstroy game сайт, [url=https://mellstroy-casino-lmj2.xyz/]mellstroy-casino-lmj2.xyz[/url] вы найдете множество увлекательных игр, которые подарят вам незабываемые эмоции. Каждый игрок сможет исследовать новые опыт и погрузиться в уникальными аспектами игрового влечения.
JudyCom 08 Nisan 2026 03:51
Полная безвкусица 1win официальный сайт, [url=https://1win-pvcnv.cyou/]https://1win-pvcnv.cyou[/url] включает обширный выбор азартных событий. Все найдет подходящие предложения. Кроме того, предусмотрены поощрения для новых клиентов.
LouiseMic 08 Nisan 2026 03:24
Лучше поздно, чем никогда. сайт 1вин, [url=https://1win-weref.xyz/]1win-weref.xyz[/url] предлагает множество уникальных возможностей для азартных игроков. Здесь можете обнаружить разнообразные игры, которые каждый пользователь может выбрать по своему вкусу. Удобство интерфейса позволяет легко ориентироваться платформой. Помимо этого, сайт 1вин представляет интересные акции и бонусы, которые привлекают новых игроков. Обязательно рассмотрите возможность попробовать данный сайт!
BryceHen 08 Nisan 2026 03:09
CamillaTok 08 Nisan 2026 03:08
LucyDog 08 Nisan 2026 02:59
кто чо говорит надо качать и смотреть топка то негаснет mellstroy casino сайт, [url=https://mellstroy-casino-bus9.lol/]https://mellstroy-casino-bus9.lol/[/url] предлагает многочисленные варианты азартных игр, в том числе слоты и карточные игры. Любой посетитель найдет что-то по вкусу, а выгодные акции сделают игру еще удивительнее.
KarlMum 08 Nisan 2026 00:58
Да это фантастика сайт 1вин, [url=https://1win-pvcnv.cyou/]https://1win-pvcnv.cyou/[/url] предлагает уникальные возможности для азартных игроков. Завсегдатаи могут наслаждаться разнообразием игр и интересными бонусами. Регистрация на сайте быстрая. Каждый найдет что-то увлекательное.
IdaRomew 08 Nisan 2026 00:50
Прекрасно, я так и думал. На mellstroy game сайт, [url=https://mellstroy-casino-xzs9.click/]mellstroy gaming[/url] вы найдете множество увлекательных игр, которые предоставят вам провести время. Любая игра оригинальна и объединила новыми заданиями. Присоединяйтесь к сообществу и откройте с миром азартных игр!
MattGag 07 Nisan 2026 22:03
Я думаю, что Вы ошибаетесь. Пишите мне в PM, поговорим. Сиделка Москва, [url=https://vectorzaboty.ru/]Сиделка Москва[/url] предлагает компетентные услуги для старших людей. Команда предлагает помощь в поддержке и организации. Вы можете предоставить заботу о близких профессионалам.
DanaSoaft 07 Nisan 2026 20:07
Тупо зачет! mellstroy casino сайт, [url=https://mellstroy-casino-8yo65.lol/]mellstroy-casino-8yo65.lol[/url] предлагает широкий выбор азартных игр для любителей. Здесь можно исследовать слоты, покер и другие развлечения. Создание аккаунта быстрая и простая, что позволяет немедленно начать игру.
Leahrib 07 Nisan 2026 17:23
Ага, попался! 1win официальный сайт, [url=https://1win-xujow.top/]1win-xujow.top[/url] предлагает разнообразные возможности для ставок. Здесь вы найдете интуитивно понятный интерфейс и щедрые коэффициенты. Присоединяйтесь к сообществу 1win и наслаждайтесь ежедневными акциями!
AnthonyTax 07 Nisan 2026 16:41
Браво, эта блестящая фраза придется как раз кстати Игровой мир онлайн-казино полон возможностей. На mellstroy casino официальный сайт, [url=https://mellstroy-casino-gat5.xyz/]мелстрой официальный[/url] вы найдете обширный выбор игр. Игры здесь доступно в любое время. Присоединяйтесь к уникальному игровому процессу и найдите удачу!
CharloteSeist 07 Nisan 2026 14:36
посмотрю для разнообразия ... Сиделка с проживанием, [url=http://sidelka-vdom.ru/]Сиделка с проживанием[/url] — это идеальный вариант для ухода за пожилыми людьми. Забота на дому создает комфортные условия. Специалисты обеспечат безопасность и увлечения для ваших близких.
Manuelquift 07 Nisan 2026 13:43
Я извиняюсь, но, по-моему, Вы не правы. Пишите мне в PM, обсудим. На mellstroy casino официальный сайт, [url=https://mellstroy-casino-nar7.xyz/]mellstroy-casino-nar7.xyz[/url] вы сможете испытать множеством азартных игр, в ассортименте классические игры. На сайте вас ждут бонусы, которые украсит вашу игру еще интереснее!
Rodrigueztit 07 Nisan 2026 12:45
Я думаю, что Вы допускаете ошибку. Могу это доказать. Пишите мне в PM, пообщаемся. На mellstroy game сайт, [url=https://mellstroy-casino-nxwti.sbs/]https://mellstroy-casino-nxwti.sbs[/url] вы найдете много увлекательных игр. Группа постоянно развивают контент, предлагая новые вызовы. Участвуйте в событиях и зарабатывайте призы!
BernardDek 07 Nisan 2026 09:47
Браво, какие нужные слова..., замечательная мысль 1win официальный сайт, [url=https://1win-f2ns6.icu/]сайт 1 вин[/url] предоставляет широкий выбор игр. Пользователи могут наслаждаться лотереей прямо с платформе. Удобный навигатор позволяет быстро выбирать нужные секции.
Shanebob 07 Nisan 2026 09:01
мне лично не понравился!!!!! mellstroy game сайт, [url=https://mellstroy-casino-dez5n.click/]https://mellstroy-casino-dez5n.click/[/url] предоставляет уникальные возможности для игроков. Платформа предлагает увлекательные игры, которые дають развивать навыки и радоваться. Любой может отыскать идеальное времяпрепровождение.
Amywooft 07 Nisan 2026 07:47
ПОЛНАЯ !!! mellstroy casino официальный сайт, [url=https://mellstroy-casino-lmv4.xyz/]https://mellstroy-casino-lmv4.xyz[/url] - Mellstroy casino интернет-ресурс предлагает множество игр для любителей азартных игр. Здесь вы найдете столы с карточными играми на любой вкус, а также доступные бонусы. Проводите время с Mellstroy casino официальный сайт!
PatrickKaf 07 Nisan 2026 05:28
Вы допускаете ошибку. Могу это доказать. Пишите мне в PM, поговорим. Мир азартных игр всегда привлекал внимание многих людей. В этом контексте mellstroy casino, [url=https://mellstroy-casino-vcju2.top/]мелстрой официальный[/url] выделяется как известный оператор, предлагающий богатый выбор игр. Здесь игроки могут открыть для себя увлекательный мир азартных удовольствий, получив безопасный опыт. Игровые автоматы, карты и другие развлечения обеспечивают уникальные моменты для всех фанатов азартных игр.
AngelaSenny 07 Nisan 2026 05:06
мда...я ожыдал НАМНОГО БОЛЬШЕ фоток прочитав описани)))хотя и этого хватит) mellstroy casino официальный сайт, [url=https://mellstroy-casino-baf1.click/]https://mellstroy-casino-baf1.click[/url] предлагает большой выбор гемблинга для фанатов азартных занятий. Каждый игрок сможет выбрать что-то интересное. Создание аккаунта проста, а техническая поддержка работает постоянно. Опробуйте свой шанс на приз уже сегодня!
AngieNouse 07 Nisan 2026 02:59
Надо глянуть полюбому!!! 1win официальный сайт, [url=https://1win-rk10f.buzz/]https://1win-rk10f.buzz[/url] предлагает разнообразный выбор ставок для любителей вероятностных развлечений. Пользователи могут воспользоваться уникальным вариантом, а также удобным интерфейсом сайта.
Danielkag 07 Nisan 2026 00:22
Да, действительно. Всё выше сказанное правда. Можем пообщаться на эту тему. Здесь или в PM. Сиделки с проживанием, [url=https://help-time.ru/]Сиделки с проживанием[/url] — это идеальный вариант для ухода за пожилыми людьми. Такие специалисты организуют профессиональную помощь в домашней обстановке. Преимущества заключаются в персональном подходе и круглосуточном внимании. Сиделки обладают знаниями и могут помочь с рутинными задачами, а также обеспечить комфорт и безопасность.
Jenniferavags 07 Nisan 2026 00:01
Я думаю, что Вы ошибаетесь. Могу это доказать. mellstroy casino официальный сайт, [url=https://mellstroy-casino-maw7.click/]https://mellstroy-casino-maw7.click[/url] предлагает обширный выбор игр и привлекательные бонусы для пользователей. Здесь разрешено наслаждаться восторгом и удовольствием в любое время суток.
LoriGlive 06 Nisan 2026 22:40
Ваша фраза великолепна mellstroy casino, [url=https://mellstroy-casino-j1lg8.top/]https://mellstroy-casino-j1lg8.top[/url] предлагает уникальные возможности для любителей азартных игр. Здесь предлагается множество азартных автоматов и игр. Любой игрок найдет что-то интересное для себя. Помимо этого организуются соревнования, где можно выиграть ценные призы. Многим восхитит атмосфера Mellstroy casino, где систематично царит волнение азарта.
LydiaWob 06 Nisan 2026 19:21
Полностью разделяю Ваше мнение. В этом что-то есть и это хорошая идея. Готов Вас поддержать. Добро пожаловать в мир азартных игр с mellstroy casino, [url=https://mellstroy-casino-ux2ad.click/]https://mellstroy-casino-ux2ad.click[/url]! Здесь вы сможете найти разнообразие ставок на любой вкус. От традиционных игровых автоматов до современных настольных игр—каждый испытать что-то увлекательное. Присоединяйтесь к нам и испытайте азарт прямо сейчас!
Katrinavex 06 Nisan 2026 19:05
ничего особенного На mellstroy официальный сайт, [url=https://mellstroy-casino-gdt7.xyz/]мелстрой промокод[/url] представлена информация о строительных услугах в области обустройства объектов. Мы предлагаем высокое качество и надежный подход к каждому проекту. Обратитесь нам для получения подробной информации.
MichaelPup 06 Nisan 2026 17:57
Жаль, что сейчас не могу высказаться - опаздываю на встречу. Но освобожусь - обязательно напишу что я думаю по этому вопросу. В большом городе, где жизнь бурлит, проститутки, [url=https://prostitutki-odessy.com/]сайт проституток[/url] предоставляют на улицах и в залах. Они находят клиентов, которые хотят эмоциональной или физической близости. Каждая из них рассказывает свою историю, полную страха.
AngelaPidly 06 Nisan 2026 16:05
вообще супер mellstroy casino, [url=https://mellstroy-casino-u4bu1.cyou/]мелстрой гейм[/url] предлагает множество развлечений для игроков. Каждый может найти что-то интересное. От известных игр до современных автоматов. Призы ожидают всех смелых.
Vanessajam 06 Nisan 2026 14:03
Согласен, ваша мысль просто отличная 1win официальный сайт, [url=https://1win-jedev.cfd/]https://1win-jedev.cfd[/url] предлагает игрокам широкий выбор азартных игр и спортивных ставок. В этом ресурсе можно найти игровые автоматы. Доступные возможности делают игру поистине увлекательной.
Colleenviets 06 Nisan 2026 14:01
ХА ХА, упасть и не встать!!!!!!!!! На mellstroy game сайт, [url=https://mellstroy-casino-ttt1.xyz/]https://mellstroy-casino-ttt1.xyz[/url] игроки могут удовлетворять свои потребности в увлекательный мир строительных симуляторов. Широкие возможности конструирования позволяют каждому стать настоящим архитектором.
BrianDot 06 Nisan 2026 12:24
Замечательно, очень полезная информация В мире азартных игр mellstroy casino, [url=https://mellstroy-casino-kjpnu.sbs/]https://mellstroy-casino-kjpnu.sbs[/url] предлагает уникальные возможности для игроков. Подходящие условия, разнообразные игровые альтернативы и щедрые бонусы делают этот площадка особенно привлекательным. mellstroy casino предлагает защищенность и практичность для своих пользователей. Погружайтесь в мир удивительных игр и получайте призы!
KimberlyPax 06 Nisan 2026 11:09
Охотно принимаю. Интересная тема, приму участие. Вместе мы сможем прийти к правильному ответу. На сайте mellstroy официальный сайт, [url=https://mellstroy-casino-fsr1.xyz/]https://mellstroy-casino-fsr1.xyz[/url] можно найти множество сведений о ремонте. Здесь представлены услуги для клиентов, заинтересованных в доступном строительстве.
Karenwab 06 Nisan 2026 10:36
Авторитетное сообщение :) , забавно... 1win официальный сайт, [url=https://1win-jedev.cfd/]https://1win-jedev.cfd[/url] предоставляет пользователям уникальную возможность наслаждаться азартными играми онлайн. На сайте вы найдете многообразие спортивных событий и игр. Интерфейс интуитивно понятен, что делает развлечение комфортным. Регистрация оперативная, а в службе поддержки всегда готовы помочь.
pocaedist 06 Nisan 2026 10:35
Это сообщение просто бесподобно ;) На сайте mellstroy game сайт, [url=https://mellstroy-casino-ksa3.xyz/]https://mellstroy-casino-ksa3.xyz/[/url] вы сможете найти множество интересных материалов. Забавы подарят вам уникальный опыт. Устраивайте в увлекательный мир и открывайте новые горизонты в развлечениях.
Eugeneovelm 05 Nisan 2026 08:24
Excuse, that I interfere, I too would like to express the opinion. _ _ _ _ _ _ _ _ https://automietenteneriffa.de
Evelyndap 03 Nisan 2026 17:19
По моему мнению Вы ошибаетесь. Могу это доказать. Пишите мне в PM, пообщаемся. парфумерія, [url=https://salda.ws/article/index.php?act=read&article_id=11284]https://salda.ws/article/index.php?act=read&article_id=11284[/url] - це сфера, СЏРєРµ створює аромати для використання. Р’РѕРЅР° різноманітна Сѓ СЃРІРѕС—С… аспектах, що створює емоції та переживання.
James Johnson 03 Nisan 2026 15:30
It covers each state's current status, available games, and best casinos per state.
Scarletmob 03 Nisan 2026 11:48
Интересный момент продукты с доставкой, [url=https://hedgedoc.anael.cloud/s/mXGYXolgf]https://hedgedoc.anael.cloud/s/mXGYXolgf[/url] стали неотъемлемой частью жизни современных людей. Почти все ценят легкость этого сервиса. Используя таких услуг вы можете устранить временные потери на походы в магазин. Ассортимент товаров как никогда велик. Воспользуйтесь возможностью купить свежие продукты с доставкой.
Insomniaatlexila 03 Nisan 2026 09:27
The emergence of new non GamStop casino, [url=https://charlottine.menuqtr.com/new-casinos-not-blocked-by-gamstop-a-guide-for/]https://charlottine.menuqtr.com/new-casinos-not-blocked-by-gamstop-a-guide-for/[/url] platforms offers players a chance to enjoy online gambling without restrictions. These sites provide various options, allowing users to try out exciting features. With attractive bonuses and safe transactions, new non GamStop casino experiences are now more accessible than ever. Players can quickly join and start their gaming journey, enjoying privacy and freedom in their play. Choose a new non GamStop casino to elevate your online gaming adventure.
JeffHam 03 Nisan 2026 09:12
не сильно Современные пользователи стремятся к эффективности. продукты с быстрой доставкой, [url=https://hedgedoc.thuanbui.me/s/qdrkK3ubf]https://hedgedoc.thuanbui.me/s/qdrkK3ubf[/url] становятся важными в повседневной жизни. С их помощью можно освободить время и силы. На сегодняшний день можно купить все, что нужно, не выходя из дома. Важно выбирать сервисы, которые гарантируют быстрый и надежный сервис. Закажите себе продукты с быстрой доставкой и наслаждайтесь удовлетворением от покупок.
AdelaidaWoubs 03 Nisan 2026 06:37
Между нами говоря, по-моему, это очевидно. Рекомендую поискать ответ на Ваш вопрос в google.com безободковый унитаз, [url=https://hpad.dataone.org/s/3Tm91Cje8]https://hpad.dataone.org/s/3Tm91Cje8[/url] служит практичным решением для санузлов. Этот дизайн облегчает уборку, однако снижает налет на поверхности. Такой объект выглядит стильно и актуально, что отвечает любому концепции.
Reneeisose 03 Nisan 2026 04:06
Я думаю, что Вы допускаете ошибку. Предлагаю это обсудить. полотенцесушитель для ванной, [url=https://trend.forumpolish.com/t36-topic]https://trend.forumpolish.com/t36-topic[/url] — это важный элемент, который украсит интерьер. Он гарантирует комфортную атмосферу и теряет тепло. Благодаря разнообразным моделям, можно выбрать оптимальный решение для любого стиля.
Zarastigh 03 Nisan 2026 03:26
Я думаю, что Вы не правы. Пишите мне в PM. Finding a 5 pound deposit casino, [url=https://gLynperisguesthouse.com/]?5 deposit casino[/url] is straightforward. Players can enjoy thrilling games with a minimal investment. This option allows regular gamblers to try their luck without a significant financial commitment. Dive into an exciting gaming experience today!
Peggylab 03 Nisan 2026 02:03
Finding the best non GamStop casinos, [url=https://ctciwiring.com/discover-new-non-gamstop-casinos-a-comprehensive/]https://ctciwiring.com/discover-new-non-gamstop-casinos-a-comprehensive/[/url] is crucial for players seeking freedom. These establishments offer a variety of options with thrilling games. Additionally, they provide bonuses and promotions that enhance the gaming experience.
MiaJet 02 Nisan 2026 20:54
Конечно. Так бывает. Можем пообщаться на эту тему. Здесь или в PM. In recent years, the emergence of online casino revolut, [url=https://php-fibers.com/]revolut casino[/url] has transformed the gaming landscape. Players can now enjoy seamless transactions, ensuring a smooth gaming experience. With exciting promotions and convenience, online casino revolut is captivating a broad audience. Secure and fast payments enhance player satisfaction, making it a popular choice for gamers worldwide.
BalazsHew 02 Nisan 2026 15:35
не очень ето точно... 1xbet зеркало, [url=https://1xbet-2mlno.top/]https://1xbet-2mlno.top/[/url] предоставляет игрокам запасной доступ к любимым (играм. В случае блокировок, пользователи могут просто перейти на (новый ресурс. Это позволяет бесперебойный доступ к играм и спортивным событиям. Используйте 1xbet зеркало для комфорта и получения (максимального опыта!
Heathervaw 02 Nisan 2026 14:20
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Предлагаю это обсудить. Пишите мне в PM, поговорим. Playing at an online casino, [url=https://blitz-bet.cl/]visitar sitio[/url] offers an thrilling experience for gamblers. With a wide choice of games, everyone can find anything that caters to their likes.
Lauraral 02 Nisan 2026 13:33
Однозначно, отличный ответ Att vГ¤lja ett casino med lГҐg insГ¤ttning Г¤r avgГ¶rande fГ¶r mГҐnga spelare. minsta insГ¤ttning casino, [url=http://nextark.co.jp/2026/03/11/utlandska-casino-med-lg-insattning-spela-smart-och-41/]http://nextark.co.jp/2026/03/11/utlandska-casino-med-lg-insattning-spela-smart-och-41/[/url] erbjuder mГ¶jlighet att bГ¶rja spelande utan stora risker. Dessutom kan du utforska olika spel utan att behГ¶va investera fГ¶r mycket. VГ¤lj noggrant!
TimDot 02 Nisan 2026 13:00
ННАдо надо 1xbet зеркало, [url=https://1xbet-1fp6j.icu/]1xbet-1fp6j.icu[/url] обеспечивает доступ к каждому услугам букмекерской конторы. Клиенты могут размещать ставки в любое место. Присутствие зеркала гарантирует безопасность и удобство использования платформы. Пользователи ценят быстрый подключение и превосходные возможности сервиса. С помощью 1xbet зеркало игроки сохраняют возможность непрерывно участвовать в соревнованиях.
Kiabug 02 Nisan 2026 11:12
non GamStop casino sites, [url=https://fastfans.alumnesondara.com/2026/03/08/discovering-uk-non-gamstop-casinos-a-comprehensive-4/]https://fastfans.alumnesondara.com/2026/03/08/discovering-uk-non-gamstop-casinos-a-comprehensive-4/[/url] offer players a unique opportunity to enjoy gaming without restrictions. These types of platforms are ideal for those looking for more freedom in their gambling journey. Boasting a range of options, they provide an fun alternative. Players can investigate numerous venues that appeal to diverse preferences and likes.
Gillned 02 Nisan 2026 07:46
По моему мнению Вы ошибаетесь. Давайте обсудим. Пишите мне в PM, пообщаемся. online casino, [url=https://blitz-bet.rs/]online kazino[/url] provides a thrilling adventure for users. With diverse games to select from, it promises excitement and opportunity to win considerable rewards.
Elizabethrhick 02 Nisan 2026 05:27
Я извиняюсь, но, по-моему, Вы ошибаетесь. Могу это доказать. Пишите мне в PM, обсудим. 1xbet официальный сайт, [url=https://1xbet-xpi3b.top/]https://1xbet-xpi3b.top/[/url] предоставляет эксклюзивные возможности для пользователей. На платформе возможны разнообразные ставки, что делает сайт интересным для всех.
NicoleLougs 02 Nisan 2026 02:59
Великолепная фраза 1xbet официальный сайт, [url=https://1xbet-rzn9i.icu/]https://1xbet-rzn9i.icu[/url] предлагает широкий выбор пари на спорт. Любой могут опробовать комфортный интерфейс и научиться множество бонусов.
Sherrycaw 02 Nisan 2026 01:10
С этим я полностью согласен! online casino, [url=https://lemoncasino-polska.eu]automaty do gry[/url] предлагают участникам широкий асортимент активностей также выгодные предложения. Такое примечательное условие вдохновляет долгосрочных РёРіСЂРѕРєРѕРІ адоптировать собственные РєРѕРЅРєСѓСЂСЃС‹.
Jakefinty 02 Nisan 2026 00:28
Ваша идея великолепна 1xbet официальный сайт, [url=https://1xbet-0fq3h.sbs/]https://1xbet-0fq3h.sbs/[/url] предлагает интуитивный интерфейс для клиентов. Здесь можете обнаружить множество опций для заработка.
Nataliasathe 01 Nisan 2026 21:59
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Давайте обсудим это. Пишите мне в PM. 1xbet официальный сайт, [url=https://1xbet-md34f.sbs/]https://1xbet-md34f.sbs/[/url] предоставляет широкий выбор мероприятий для игры. Здесь доступно наслаждаться неповторимым возможностями. Регистрация легкая, а служба поддержки всегда готова помочь.
Judyemamb 01 Nisan 2026 21:24
СМОРТЕТЬ ВСЕМ! ПРОСТО СУПЕР!!! I fan cercano forme per divertirsi nel mondo del gioco d'azzardo. Il casino anonimo senza KYC, [url=https://www.syndicatelife.com/scopri-i-casino-curacao-senza-verifica-gioca-senza]https://www.syndicatelife.com/scopri-i-casino-curacao-senza-verifica-gioca-senza[/url] offre un vantaggio per giocare senza dover fornire informazioni personali. Questo consente la privacy degli utenti, rendendo il gioco piГ№ divertente. Con metodi di pagamento anonimi, i giocatori possono giocare senza preoccuparsi delle verifiche. Scegliere un casino anonimo senza KYC ГЁ un'opzione sempre piГ№ popolare tra chi ama il gioco online.
Anndip 01 Nisan 2026 18:32
Ты знаешь мое мнение online casino, [url=https://hugocasino.biz]casino hugo[/url] offers a collection of entertaining games which players. Whether you enjoy slots, table games, or live dealer options, the fun is unmatched when played online.
TomLen 01 Nisan 2026 15:58
Вы абсолютно правы. В этом что-то есть и это отличная идея. Я Вас поддерживаю. Scoprire il bonus casino senza deposito, [url=https://cbi.baywoodgrp.com/scratch-win-casino-scopri-il-mondo-dei-grattini/]https://cbi.baywoodgrp.com/scratch-win-casino-scopri-il-mondo-dei-grattini/[/url] ГЁ un’opportunitГ imperdibile per gli appassionati di giochi. Questi promozioni permettono di provare diversi sviluppi senza investire denaro. Registrati e inizia a divertirti subito!
AliceTrorb 01 Nisan 2026 13:49
Да,хорошо. Кладу 5. официальный сайт 1xbet, [url=https://1xbet-5wac3.sbs/]1хбет[/url] предлагает разнообразный выбор игр и опций для любителей. На ресурсе легко найти акции, а также дизайн делает досуг легкой.
DeniseLaunk 01 Nisan 2026 11:11
Ваша идея блестяща online casino, [url=https://slotimo.com/de/sports/soccer]slotimo[/url] доступен множество развлекательных возможностей для РёРіСЂРѕРєРѕРІ. РћС‚ классических настольных РёРіСЂ Рё современные слоты, каждый найдет что-то РїРѕ РІРєСѓСЃСѓ.
Heatherhit 01 Nisan 2026 10:56
гы во гонят.... официальный сайт 1xbet, [url=https://1xbet-mq3xg.life/]1xbet-mq3xg.life[/url] предлагает разнообразный выбор пари, включая спорт и лотереи. Дизайн интуитивный для разработчиков. На сайте доступны акции, что делает игровой процесс существенно привлекательным. Кроме того, просмотр информации менее затруднителен, что облегчает процесс игры.
KevinMok 01 Nisan 2026 05:33
Похожее есть что-нибудь? официальный сайт 1xbet, [url=https://1xbet-ordbe.blog/]1 хбет[/url] предлагает широкий выбор спортивных ставок. Пользователи могут открывать множество предложений, что делает процесс радостью. Очень простой интерфейс позволяет быстро навигировать по сайту.
KaylaFaree 01 Nisan 2026 04:24
The emergence of new non GamStop casino, [url=https://www.orcosildigital.com.br/2026/03/08/discover-new-non-gamstop-casinos-opportunities/]https://www.orcosildigital.com.br/2026/03/08/discover-new-non-gamstop-casinos-opportunities/[/url] options has revolutionized the online gaming landscape. Players can enjoy a variety of games and incentives that appeal to their interests. These casinos deliver an opportunity for those looking to play without restrictions.
IreneIllut 01 Nisan 2026 04:09
Браво, мне кажется это замечательная мысль casino online iceland, [url=https://j0f.c5b.myftpupload.com/prosenta-a-skilningur-a-mikilvgi-prosenta-i/]https://j0f.c5b.myftpupload.com/prosenta-a-skilningur-a-mikilvgi-prosenta-i/[/url] tilbjГіГ°ar fjГ¶lbreyttar spilavГti fyrir notendur sem vilja langar eftir merkim grГіГ°a og upplifun. Reyndu heima umhverfi til aГ°.
CharlotteOnese 01 Nisan 2026 04:04
бред одним словом In the world of casinos, players often seek enjoyable opportunities to win. free spins casino, [url=https://wiLdernesscat.com/]free spins bonus[/url] offers an amazing chance to explore various games without risking money. Offers help amplify your gameplay, making it more engaging. By utilizing these free spins, you can amplify your winning potential while enjoying the variety of slots available. Join the fun and discover the advantages of free spins casino today!
Peggyhaica 01 Nisan 2026 02:52
Да, я вас понимаю. В этом что-то есть и мысль отличная, поддерживаю. официальный сайт 1xbet, [url=https://1xbet-uv14h.blog/]1xbet-uv14h.blog[/url] предлагает уникальные возможности для всех любителей развлечений. Здесь существуют многообразные спортивные события. Подключайтесь и опробуйте мир азартных развлечений!
CurtisHen 01 Nisan 2026 00:17
When looking for the finest non UK casino, players can explore a variety of entertaining options. These casinos often offer rich bonuses and a huge selection of games. Whether you prefer slots or table games, the best non UK casino, [url=http://www.castleandson.com/trusted-non-uk-casinos-your-guide-to-safe-and-2/]http://www.castleandson.com/trusted-non-uk-casinos-your-guide-to-safe-and-2/[/url] provides an impressive gaming experience.
StanleyPeasy 01 Nisan 2026 00:11
По моему мнению Вы не правы. Я уверен. Давайте обсудим это. Пишите мне в PM, пообщаемся. официальный сайт 1xbet, [url=https://1xbet-f104d.top/]1xbet-f104d.top[/url] предлагает пользователям широкий выбор ставок на спорт и казино. Здесь предоставляется шанс найти разные игры и события. Регистрация простая, а бонусы заинтересовывают новичков. Рекомендуем намерить платформу, чтобы испытать свои силы.
Seansog 31 Mart 2026 22:27
Запомни это раз и навсегда! A fogadГіk szГЎmГЎra a magyar online casino, [url=https://demo.zealousweb.com/wordpress-plugins/accept-stripe-payments-using-contact-form-7/?p=167888]https://demo.zealousweb.com/wordpress-plugins/accept-stripe-payments-using-contact-form-7/?p=167888[/url] rengeteg szГіrakozГЎsi mГіdot kГnГЎl. Minden ГіrГЎban elГ©rhetЕ‘sГ©g, sokszГnЕ± bГіnuszok, Г©s vГЎltozatos jГЎtГ©kfelhozatal vГЎrja az Г©rdeklЕ‘dЕ‘ket.
Adelaidanon 31 Mart 2026 21:31
Я считаю, что это — заблуждение. официальный сайт 1xbet, [url=https://1xbet-t53zs.life/]https://1xbet-t53zs.life/[/url] предлагает разнообразный спектр услуг для болельщиков. Здесь вы обнаружите уникальные бонусы и промоакции. Пользуйтесь простым интерфейсом для ставок.
Kristinveshy 31 Mart 2026 20:57
Кому-то было нефиг делать))) visa casino, [url=https://glia2023.eu/]visa casinos[/url] offers an exciting way to enjoy online gaming. Players appreciate the security and speed of transactions. Using Visa, deposits are quick, allowing gamers to focus on their favorite games. Moreover, the user-friendly interface ensures a smooth experience.
Philiptoomb 31 Mart 2026 19:32
что бы небыло нада глянуть... парфюмерия, [url=https://parfumabc.ru/parfum/realm-pheromone/]https://parfumabc.ru/parfum/realm-pheromone/[/url] — это искусство создания изысканных ароматов, что способны пробуждать эмоции и чувства. Выбор идеального аромата в состоянии стать настоящим искусством. Исследуйте свои любимые ноты!
Cocovoibe 31 Mart 2026 18:50
хаааааа........класс официальный сайт 1xbet, [url=https://1xbet-2www5.top/]1хбет скачать[/url] предлагает пользователям уникальные возможности для ставок. Здесь вы найдете широкий выбор спортивных событий для ставок. Интуитивно понятный интерфейс и интуитивность делают игру комфортной.
RobertSlisa 31 Mart 2026 13:09
Это будет последней каплей. Компания BIORUS предлагает современное оборудование для биотехнологий BIORUS, [url=https://joy.link/kidsandsweets]https://joy.link/kidsandsweets[/url], которое обеспечивает эффективные решения для исследовательских задач. Наша продукция предусмотрена с учетом последних технологий, что оптимизирует рабочие процессы. С нами ваши идеи получат необходимую поддержку и качество.
ZackDem 31 Mart 2026 12:13
Gambling enthusiasts often seek alternatives beyond traditional platforms. One popular avenue is online casino not on GamStop, [url=https://vorschau.schaller-digital.de/archives/179569]https://vorschau.schaller-digital.de/archives/179569[/url], where players can discover a wider variety of games. These casinos provide exciting gameplay without the usual restrictions, allowing players to indulge in their favorite pastimes more freely. With safe transactions and alluring bonuses, players can increase their gaming experience.
Matthag 31 Mart 2026 10:48
Меня это не беспокоит. официальный сайт 1xbet, [url=https://1xbet-ftngg.top/]1хбет[/url] предлагает пользователям уникальные возможности для беттинга. Здесь вы найдете разнообразный выбор спортивных событий, высокие коэффициенты и интуитивно понятный интерфейс. Регистрация на сайте мгновенная, а процессы по пополнению счета удобны.
Everettacape 31 Mart 2026 10:39
Я считаю, что Вы не правы. Я уверен. Пишите мне в PM, обсудим. A legГєjabb magyar online casino, [url=https://mendesfreire.com.br/online-rulett-magyar-a-legjobb-jatekok-es/]https://mendesfreire.com.br/online-rulett-magyar-a-legjobb-jatekok-es/[/url] lenyЕ±gГ¶zЕ‘ lehetЕ‘sГ©geket offol minden jГЎtГ©kos szГЎmГЎra. Ez a online platform felГ©pГtГ©sГ©vel kiemelkedik a versenytГЎrsak kГ¶zГјl. Indulj el Г©s kezdj a szГіrakozГЎsba!
Deborahgib 31 Mart 2026 09:58
В поисках проверенного партнера редкоземельных металлов и промышленных сплавов? Рекомендуем компанию Редметсплав.рф. Мы формируем колоссальный перечень продукции, соблюдая безупречные характеристики каждого изделия. Редметсплав.рф гарантирует все стадии сделки, выдавая полный пакет сопроводительных документов для легализации товаров. Неважно, какие объемы вам необходимы — от розничных отгрузок до промышленных масштабов, мы готовы обеспечить любой запрос с прекрасным качеством обслуживания. Наша команда поддержки всегда готова помочь, чтобы оказать помощь в определении подходящих продуктов и разъяснить детали, связанные с эксплуатацией и характеристиками металлов. Выбирая нас, вы выбираете уверенность в каждой детали сотрудничества. Заходите на страницу Редметсплав.рф и убеди
Clayjex 31 Mart 2026 08:10
Вы попали в самую точку. Мне кажется это очень хорошая мысль. Полностью с Вами соглашусь. официальный сайт 1xbet, [url=https://1xbet-vmfkq.top/]1xbet-vmfkq.top[/url] предлагает широкий выбор соревновательных событий для игры. Здесь вы можете найти последние акции и достигнуть лучшую выгоду от участия.
SabrinaBef 31 Mart 2026 07:22
Not on Gamstop Casinos, [url=https://duna.com.co/exploring-casinos-not-on-gamstop-a-guide-for-2/]https://duna.com.co/exploring-casinos-not-on-gamstop-a-guide-for-2/[/url] offer players a chance to enjoy online gambling without restrictions. These unique platforms provide broader selection of games. Players can enjoy exciting options without the usual limitations.
Gerardonualm 31 Mart 2026 05:34
Специально зарегистрировался на форуме, чтобы сказать Вам спасибо за помощь в этом вопросе, как я могу Вас отблагодарить? официальный сайт 1xbet, [url=https://1xbet-0lhhb.top/]1 хбет зеркало[/url] предлагает широкий выбор ставок на спортивные игры. Посетители могут удовлетворяться легким интерфейсом и мгновенной поддержкой.
Dannyaccus 31 Mart 2026 04:59
Рекомендую Вам поискать сайт, где будет много статей на интересующую Вас тему. Descubre la diversiГіn en el mundo del juego con monsterwin casino, [url=https://mlrassessoria.com.br/monsterwin-casino-espana-tu-destino-de-juegos-en-41/]https://mlrassessoria.com.br/monsterwin-casino-espana-tu-destino-de-juegos-en-41/[/url]. Proporciona una amplia selecciГіn de juegos entretendios que te sorprenderГЎn. ВЎAprovecha bonos increГbles y Гєnete a la aventura!
VeronicaShold 31 Mart 2026 04:17
non GamStop casino sites, [url=http://www.easenet.jp/wordpress/exploring-casinos-not-affected-by-gamstop-2/]http://www.easenet.jp/wordpress/exploring-casinos-not-affected-by-gamstop-2/[/url] present a distinct experience for players seeking more choice in their gaming. These platforms are not restricted by UKGC restrictions, enabling users to partake in a wider range of games and promotions. Discover the advantages of these different online casinos today!
ScottWaype 31 Mart 2026 02:58
Тут ничего не поделаешь. официальный сайт 1xbet, [url=https://1xbet-4089p.top/]1xbet-4089p.top[/url] предлагает широкий выбор пари для любителей увлечений. Здесь вы обнаружите разнообразные возможности для выгодных ставок и заманчивые бонусы. Качество поддержки и легкость интерфейса делает взаимодействие с сайтом комфортным для каждого. Присоединяйтесь к сфере 1xbet и получайте адреналин от ставок!
Justinhar 31 Mart 2026 01:51
Casinos Not on Gamstop, [url=https://studiotest.lms.weonlite.com/non-gamstop-casinos-discover-your-freedom-to-play]https://studiotest.lms.weonlite.com/non-gamstop-casinos-discover-your-freedom-to-play[/url] offer players a unique experience including games not restricted by the UK regulations. Players can enjoy a variety of options while utilizing attractive bonuses. Discover the thrill of Casinos Not on Gamstop today!
ViolaVatty 31 Mart 2026 00:35
Вы абсолютно правы. В этом что-то есть и идея отличная, согласен с Вами. Ищем независимых девушек для увлекательной вакансии девушкам, [url=https://workgirls.biz/city/yoshkar_ola.html]Работа для девушек Йошкар-Ола[/url]. У нас удobный график, шанс карьерного роста и дружная команда. Ждем ваши креативные отклики!
Jenniferhar 30 Mart 2026 23:34
Удалено (перепутал раздел) ВЎBienvenido al increГble mundo de monsterwin casino, [url=https://sites.mss.univr.it/icelab/it/descubre-monsterwin-casino-espana-una-experiencia-3/]https://sites.mss.univr.it/icelab/it/descubre-monsterwin-casino-espana-una-experiencia-3/[/url]! AquГ, podrГas descubrir una amplia amplio rango de juegos, desde juegos de mesa hasta bingo. AdemГЎs, puedes vivir de bonificaciones exclusivas. ВЎNo pierdas la oportunidad de sentir la emociГіn del juego en monsterwin casino!
IrisJeD 30 Mart 2026 21:57
Выбор у Вас непростой 1xbet зеркало, [url=https://1xbet-8grah.top/]скачать 1хбет[/url] позволяет пользователям доступность к развлекательным услугам даже в случае блокировок официального сайта. С его использованием можно сохранять стабильный доступ к ставкам. Пользователи могут оставаться в на связи с неактивными ресурсами, что делает гарантировать комфорт ставок на спорт.
Karlnal 30 Mart 2026 20:31
In recent years, the surge of non UK online casino, [url=https://www.myhealth.ph/exploring-non-uk-registered-casinos-the-good-the/]https://www.myhealth.ph/exploring-non-uk-registered-casinos-the-good-the/[/url] platforms has expanded, attracting players from diverse regions. These casinos offer varied games and enticing bonuses, enhancing the betting experience. As many pursue alternatives to traditional venues, non UK online casino options become more appealing, providing excitement and comfort.
GinaTut 30 Mart 2026 18:40
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Предлагаю это обсудить. Пишите мне в PM, поговорим. Bienvenido a el fascinante experiencia de juego en monsterwin casino, [url=https://www.fazaa.co/2026/03/12/monsterwin-casino-espana-tu-aventura-de-juego-en/]https://www.fazaa.co/2026/03/12/monsterwin-casino-espana-tu-aventura-de-juego-en/[/url]. AquГ, los entusiastas pueden disfrutar de una selecciГіn diversa de juegos emocionantes. ВЎVen y prueba tu suerte hoy!
IanBounc 30 Mart 2026 18:34
Замечательная идея и своевременно Работа для девушек, [url=https://rabotanu.ru/city/volgograd]Работа для девушек Волгоград[/url] открывает множество возможностей в разных областях. Определить интересную работу можно в обслуживании.
WendyZen 30 Mart 2026 17:42
Я думаю, что Вы не правы. Давайте обсудим это. Пишите мне в PM. В мире азартных игр веселых развлечений pin up casino, [url=https://pinup-upx6.cam/]https://pinup-upx6.cam/[/url] привлекает внимание уникальными предложениями. Открывая у них, игроки получают возможность заработать ценные призы.
Raheemred 30 Mart 2026 17:00
Вы не правы. Я уверен. Давайте обсудим это. Пишите мне в PM. марафонбет букмекерская контора, [url=https://marathonbet-1przq.click/]https://marathonbet-1przq.click[/url] открывает игрокам увеличивать доход на спортивных событиях. Многообразные линии ставок и выгодные коэффициенты привлекают многих пользователей.
Syedges 30 Mart 2026 15:16
non UK online casino, [url=https://blognew.perseus.com.br/exploring-the-world-of-non-uk-online-casinos-2/]https://blognew.perseus.com.br/exploring-the-world-of-non-uk-online-casinos-2/[/url] offers a thrilling experience for players seeking variety. Through innovative technology, these platforms deliver a wide range of games, ensuring excitement. Gamblers can enjoy special bonuses, boosting their chances of winning.
SamKaw 30 Mart 2026 13:50
Это издевка такая, да? Vanuatu Citizenship by Investment, [url=https://greattraveladvisor.com/unlocking-opportunities-vanuatu-citizenship-by-220/]https://greattraveladvisor.com/unlocking-opportunities-vanuatu-citizenship-by-220/[/url] offers a unique opportunity for global citizens. This allows individuals to acquire citizenship through capital injection. In addition to economic growth, advantages encompass visa-free travel and tax incentives.
Tiffanyset 30 Mart 2026 13:01
For players seeking freedom, sites not on GamStop, [url=http://czb.grafikmk.pl/exploring-the-best-casino-not-on-gamstop/]http://czb.grafikmk.pl/exploring-the-best-casino-not-on-gamstop/[/url] provide an excellent option. These platforms offer numerous games and choices without restrictions. Players can enjoy exciting experiences without being limited, ensuring fun and diversity.
LuisUnifs 30 Mart 2026 11:53
Жаль, что сейчас не могу высказаться - вынужден уйти. Но вернусь - обязательно напишу что я думаю. марафонбет букмекерская контора, [url=https://marathonbet-46bhv.top/]marathonbet-46bhv.top[/url] имеет широкий партии спортивных пари, а также функциональный интерфейс. Пари можно делать как в сети, так и в традиционных пунктах.
MariannePluct 30 Mart 2026 11:38
Хииии)) я с них улыбаюся В мире азартных игр развлечений pin up casino, [url=https://pinup-frd3.top/]пин ап официальный[/url] предлагает разнообразный выбор слотов, которые удивят даже весьма требовательных игроков. Оригинальный дизайн и отличное обслуживание делают этот казино настоящим сокровищем для поклонников азартных игр.
Ameliadyelm 30 Mart 2026 09:46
online social casinos, [url=https://brsengenharia.com.br/2026/03/15/the-rise-of-social-casinos-a-new-era-in-online-3/]https://brsengenharia.com.br/2026/03/15/the-rise-of-social-casinos-a-new-era-in-online-3/[/url] offer a thrilling way to enjoy gaming without financial risks. Players can engage in entertaining activities while networking with others. These platforms deliver a unique experience that blends social interaction with engaging gameplay.
Pollyvox 30 Mart 2026 08:49
Спасибо за инфу! Интересно! марафонбет букмекерская контора, [url=https://marathonbet-9llw3.lol/]marathonbet-9llw3.lol[/url] предоставляет широкие варианты для игры. Здесь имеются различные категории спорта, что способствует каждому испытать атмосферу состязаний.
Hankcag 30 Mart 2026 08:44
Это было и со мной. Давайте обсудим этот вопрос. Здесь или в PM. В мире азартных игр развлечений особое место занимает pin up casino, [url=https://pinup-qyb.store/]https://pinup-qyb.store/[/url]. Здесь клиенты могут насладиться обширным выбором ставок. В pin up casino гарантии клиентов стоит на основном месте.
Rubytaist 30 Mart 2026 05:28
Разрешите помочь Вам? Виртуальный мир азарта постоянно привлекает игроков, и casino vavada, [url=https://vavada-rgy5.top/]https://vavada-rgy5.top/[/url] не обходит стороной. Здесь доступны широкие игры, которые привлекут даже наиболее требовательных клиентов.
RachelTeafE 30 Mart 2026 05:27
Я думаю, что Вы ошибаетесь. Могу отстоять свою позицию. марафонбет букмекерская контора, [url=https://marathonbet-iacnj.sbs/]https://marathonbet-iacnj.sbs/[/url] пresents множество игровых позиция. Доступно делать ставки на разные спорта, что интересно для поклонников.
EugeneStele 30 Mart 2026 04:33
Discover the perks of non GamStop websites, [url=http://stagingsite.alacartetours.net/?p=44992]http://stagingsite.alacartetours.net/?p=44992[/url] for players seeking variety. These platforms provide exciting gaming experiences without the restrictions of GamStop. Enjoy a wider selection and better bonuses!
BobbyCor 30 Mart 2026 03:48
UK non GamStop sites, [url=https://sesammarket.com/2026/03/15/exploring-british-casino-sites-not-on-gamstop-4/]https://sesammarket.com/2026/03/15/exploring-british-casino-sites-not-on-gamstop-4/[/url] offer players a chance to enjoy online gambling without restrictions. These platforms provide a selection of exciting games and enticing bonuses. Players can discover their favorite games freely and take advantage of a more accessible gaming environment, making it a perfect choice for many.
NancyQuemo 30 Mart 2026 03:25
тупо угар!!! супер вакансии девушкам, [url=https://rabota-devushkam.net/noyabrsk/]вакансии девушкам Ноябрьск[/url] - Ищем устойчивых девушек на должности в нашей команде. Нужны талантливые сотрудники для выполнения новых проектов. Вам предложат достойную зарплату и шансы для карьерного роста. Если вас интересует достойную работу, присоединяйтесь к нам!
BeckyRek 30 Mart 2026 03:08
я бы того Vanuatu Citizenship by Investment, [url=https://thisplacematters.ca/?p=157570]https://thisplacematters.ca/?p=157570[/url] offers a unique opportunity for individuals seeking a second passport. Such an option enables investors to gain citizenship through financial contributions to the country. By investing in designated projects, participants can secure quick and easy access to this beautiful nation. Vanuatu offer not only a favorable tax regime but also a chance to enjoy a stunning tropical paradise.
Rebeccavak 30 Mart 2026 02:15
чё то не очень.... марафонбет букмекерская контора, [url=https://marathonbet-ta8o1.cfd/]https://marathonbet-ta8o1.cfd/[/url] предлагает разнообразные спортивных событий для ставок. Ставочники могут предпочитать между различными спортом. Удобный интерфейс и конкурентные коэффициенты делают ее популярной.
AnaDer 30 Mart 2026 02:14
Думаю, что ничего серьезного. В последние годы азартный дом casino vavada, [url=https://casino-vavada-top1.xyz/]https://casino-vavada-top1.xyz/[/url] набирает популярность благодаря разнообразному выбору игр и щедрым бонусам. Посетители ценят возможность развлекаться в любое время и комфортно.
Alfredomum 29 Mart 2026 23:49
Discover what’s new here — https://вип-свет.рф/
LeilaBef 29 Mart 2026 22:12
UK non-GamStop casino, [url=https://lanusehijos.com.py/2026/03/15/discover-british-casino-sites-not-on-gamstop-3/]https://lanusehijos.com.py/2026/03/15/discover-british-casino-sites-not-on-gamstop-3/[/url] provides players an opportunity to experience gambling without enrolling on the GamStop system. Players can uncover a variety of games and bonuses, enhancing their betting experience.
RichardLaDly 29 Mart 2026 22:01
ну так попробуй и отпишись по этому методу... Vanuatu Citizenship by Investment, [url=https://ccmt.betterfocustech.com/2026/03/11/obtencion-de-ciudadania-de-vanuatu-a-traves-de-3/]https://ccmt.betterfocustech.com/2026/03/11/obtencion-de-ciudadania-de-vanuatu-a-traves-de-3/[/url] offers an exclusive opportunity for individuals seeking global mobility. With fast processing and favorable investment options, Vanuatu guarantees security for families.
Susieorich 29 Mart 2026 20:50
РедМетСплав предлагает обширный выбор высококачественных изделий из дефицитных материалов. Не важно, какие объемы вам необходимы — от мелких партий до масштабных поставок, мы выдерживаем быстрое выполнение вашего заказа. Каждая единица продукции подтверждена полагающимися документами, подтверждающими их высокие характеристики. Опытная поддержка — наш приоритет — мы на связи, чтобы снимать ваши вопросы по мере того как находить ответы под задачи вашего бизнеса. Доверьте снабжение вашего объекта команде РедМетСплав и убедитесь в нашей готовности к сложным задачам. В нашем распоряжении: <a href=https://redmetsplav.ru/store/vismut/zarubezhnye-splavy-3/vismut-galinstan---geratherm-medical-ag/lenta-vismutovaya-galinstan---geratherm-medical-ag/>Лента висмутовая Galinstan - G
Davidundef 29 Mart 2026 16:58
можно сказать, это исключение :) из правил In the world of online bookmaker, [url=https://jeevanjyoticlinic.com/betwinner-your-gateway-to-unlimited-betting/]https://jeevanjyoticlinic.com/betwinner-your-gateway-to-unlimited-betting/[/url] platforms, players can explore various betting options. With advanced technology, these platforms grant an exciting experience. Navigating through odds and markets has never been easier for enthusiasts.
AryaSwand 29 Mart 2026 16:41
non GamStop online casino, [url=https://petrusan.es/exploring-uk-non-gamstop-casinos-a-comprehensive-2/]https://petrusan.es/exploring-uk-non-gamstop-casinos-a-comprehensive-2/[/url] offers a unique experience for players seeking variety. Those platforms provide access to a wide range of games without the barriers imposed by GamStop. Enjoy your favorite games and make use of lucrative bonuses today!
SelenaArela 29 Mart 2026 13:56
Не могу сейчас поучаствовать в обсуждении - очень занят. Освобожусь - обязательно выскажу своё мнение по этому вопросу. vulkan casino, [url=https://casino-vulkan3.site/]https://casino-vulkan3.site/[/url] предлагает впечатляющий выбор игр фантастических, включая слоты и настольные игры. Игроки могут наслаждаться прямыми трансляциями и многообразием бонусов. Присоединяйтесь к vulkan casino и откройте мир игровых радостей.
Ericdouff 29 Mart 2026 13:36
По моему мнению Вы не правы. Я уверен. Могу это доказать. Пишите мне в PM, пообщаемся. марафонбет букмекерская контора, [url=https://marathonbet-fr5vd.cyou/]https://marathonbet-fr5vd.cyou[/url] предлагает разнообразие спортивных событий для ставок. Пользователи могут наслаждаться удобным интерфейсом и привлекательными коэффициентами.
Beckywap 29 Mart 2026 12:31
Finding the leading gaming sites can be challenging. However, the best non GamStop casinos, [url=https://www.grimalc.com/discover-non-gamstop-uk-casinos-freedom-to-play/]https://www.grimalc.com/discover-non-gamstop-uk-casinos-freedom-to-play/[/url] provide players with a selection of options. These platforms offer thrilling games and bountiful bonuses, ensuring an memorable experience. Enjoy gaming without the constraints of GamStop!
AveryChiex 29 Mart 2026 10:21
Эта великолепная идея придется как раз кстати марафонбет букмекерская контора, [url=https://marathonbet-wp3gp.cfd/]марафонбет зеркало[/url] предлагает широкий выбор спортивных событий для ставок. Ставочники могут наслаждаться привлекательными коэффициентами и легкостью использования.
RobCot 29 Mart 2026 07:10
Я думаю, что Вы ошибаетесь. Могу отстоять свою позицию. Пишите мне в PM. марафонбет букмекерская контора, [url=https://marathonbet-5iwxk.top/]https://marathonbet-5iwxk.top/[/url] предлагает обширный выбор ставок на спорт. Здесь вы найдете привлекательные коэффициенты и легкий интерфейс, что делает проводимые мероприятия еще более интересным!
BrianGot 29 Mart 2026 04:28
online casino not on GamStop, [url=https://www.docarnettefoundation.org/discover-the-best-new-casinos-not-on-gamstop/]https://www.docarnettefoundation.org/discover-the-best-new-casinos-not-on-gamstop/[/url] offers players an exciting alternative to traditional betting. These options of platforms grant a wider range of games and additional bonuses. Players can enjoy their favorite games without restrictions.
JusticeOpeds 29 Mart 2026 04:17
По моему мнению Вы допускаете ошибку. Могу отстоять свою позицию. ставки на спорт винвин, [url=https://winwin-casino.buzz/]https://winwin-casino.buzz/[/url] – это отличная возможность получить адреналин. Множество площадок предлагают многообразные варианты отборов. Выбирайте клубы с умом и увеличьте свои шансы на успех!
Eugenerer 29 Mart 2026 03:58
Извините, ничем не могу помочь. Но уверен, что Вы найдёте правильное решение. Не отчаивайтесь. марафонбет букмекерская контора, [url=https://marathonbet-0d89u.lol/]marathonbet-0d89u.lol[/url] изучает широкий варианты поставок. С пользователями сотрудничает комфортно, обеспечивая непрерывную сервис.
JuanInhed 29 Mart 2026 01:11
Нечего сказать - промолчите, дабы не засорять тему. mostbet casino, [url=https://mostbet-ktn1.top/]https://mostbet-ktn1.top/[/url] предлагает разнообразный выбор развлечений для почитателей азартных игр на удачу. Здесь клиенты найдут все необходимые средства для незабываемого времяпрепровождения.
Duyviaps 29 Mart 2026 01:07
норма ток мало)) The emergence of online bookmaker, [url=https://www.perfectaaesthetics.com/betwinner-the-premier-betting-experience-for-all/]https://www.perfectaaesthetics.com/betwinner-the-premier-betting-experience-for-all/[/url]s has evolved the world of sports betting. Users can now make bets from the comfort of their homes. With a plethora of selections, online bookmaker platforms offer advantageous odds and offers, enhancing the overall experience.
SamanthaSaumn 29 Mart 2026 00:50
Мне очень жаль, что ничем не могу Вам помочь. Надеюсь, Вам здесь помогут. марафонбет букмекерская контора, [url=https://marathonbet-qjxdb.cfd/]марафонбет зеркало сегодня[/url] предоставляет широкий выбор ставок на события. Здесь спортсмены получают результат показать свои достижения.
Lawrenceinjep 29 Mart 2026 00:04
zahraniДЌnГ online casino, [url=https://www.smilingtiger.com/online-kasino-zabava-a-ance-na-vyhru/]https://www.smilingtiger.com/online-kasino-zabava-a-ance-na-vyhru/[/url] nabГzГ hrГЎДЌЕЇm rozmanitou nabГdku her a zajГmavГЅch bonusЕЇ. UЕЎetЕ™enГ penД›z je jednoduchГ©, a hrГЎДЌi mohou vyuЕѕГt intenzivnГ atmosfГ©ru pЕ™Гmo z domova.
Jonathanagero 29 Mart 2026 00:04
offshore casino online, [url=http://alvoradapflege.de/exploring-offshore-online-casinos-opportunities/]http://alvoradapflege.de/exploring-offshore-online-casinos-opportunities/[/url] delivers a distinct experience for betters. With exciting games and rewarding bonuses, it’s no wonder that those platforms are gaining traction among enthusiasts. By wagering at an offshore casino online, you can enjoy anonymity and versatility. Don't miss the chance to experience this captivating world of online gambling.
Samjar 28 Mart 2026 22:08
как оказалось не зря=) mostbet casino, [url=https://mostbet-casino.buzz/]https://mostbet-casino.buzz/[/url] предлагает широкий выбор азартных игр. Здесь осуществляются настольные игры на любой вкус. Интересные акции способствуют приумножению выигрышей, а легкий интерфейс делает игру еще увлекательнее.
JesseAddet 28 Mart 2026 21:44
Я считаю, что Вы не правы. Я уверен. Пишите мне в PM, пообщаемся. марафонбет букмекерская контора, [url=https://marathonbet-6bsoj.click/]https://marathonbet-6bsoj.click[/url] предоставляет широкие возможности для игры. У нее функциональный интерфейс и высокие коэффициенты. Спорт на любой вкус и возможность выигрывать в любое время.
Michaelarica 28 Mart 2026 20:30
non GamStop casino sites, [url=https://blanchedalmond-vulture-916375.hostingersite.com/exploring-casinos-without-gamstop-a-comprehensive-2/]https://blanchedalmond-vulture-916375.hostingersite.com/exploring-casinos-without-gamstop-a-comprehensive-2/[/url] are becoming increasingly popular among players seeking more freedom. These kinds of platforms offer distinct gaming experiences without the constraints imposed by GamStop. Gamblers can enjoy greater choice and freedom while playing their favorite games.
Michaelvar 28 Mart 2026 18:49
zahraniДЌnГ online casino, [url=https://ittd.ebosspreview.com/casino-bez-oveni-identity-jak-hrat-bez-formalit/]https://ittd.ebosspreview.com/casino-bez-oveni-identity-jak-hrat-bez-formalit/[/url] umoЕѕЕ€uje hrГЎДЌЕЇm fantastickГ© moЕѕnosti ЕЎance na vГЅhru. RozmanitГ© hry a atraktivnГ bonusy lГЎkat novГ© partnery a zaruДЌujГ ГєЕѕasnГ© zГЎЕѕitky.
DebbieIromy 28 Mart 2026 16:12
Конечно. И я с этим столкнулся. Давайте обсудим этот вопрос. Здесь или в PM. мелбет букмекерская контора, [url=https://melbet-ybs1.top/]https://melbet-ybs1.top/[/url] предлагает разнообразный выбор ставок на спортивные события. Пользователи могут ставить на множество виды спорта, включая баскетбол. Кроме того, имеются выгодные предложения.
KimJeorn 28 Mart 2026 15:37
Однозначно, отличный ответ марафонбет букмекерская контора, [url=https://marathonbet-1oob6.icu/]marathonbet-1oob6.icu[/url] предлагает обширный ассортимент на спортивные события. Игроки могут наслаждаться высоким качеством обслуживания и интуитивно понятным дизайном. Кроме того, непревзойденные бонусы делают ставki еще более интересными.
Christineper 28 Mart 2026 15:01
Жаль, что сейчас не могу высказаться - вынужден уйти. Вернусь - обязательно выскажу своё мнение. In recent years, the growth of online sports betting, [url=http://www.xebechk.biz/2026/03/exploring-1xbet-your-ultimate-betting-experience-9/]http://www.xebechk.biz/2026/03/exploring-1xbet-your-ultimate-betting-experience-9/[/url] has skyrocketed, attracting a vast number of fans. Gambling sites offer exciting experiences, allowing users to make bets on their favorite teams and events. With state-of-the-art technology, bettors can enjoy instant updates and probabilities that enhance the overall experience.
BrendaBut 28 Mart 2026 13:35
нормальная идея Работа для девушек, [url=https://jobgirls.xyz/category/yuzhno_sahalinsk.html]Работа для девушек Южно-Сахалинск[/url] – это востребованная возможность получить свою профессию в мире практики. Широкий выбор вакансий даёт шанс реализовать таланты и планировать свою жизнь в современном обществе.
Kevinageby 28 Mart 2026 13:32
casinos without GamStop, [url=https://morememory.com.mx/discover-casinos-not-blocked-by-gamstop/]https://morememory.com.mx/discover-casinos-not-blocked-by-gamstop/[/url] offer players a chance to enjoy their favorite games without restrictions. These casinos provide a range of options, ensuring all gamers finds something exciting. With no limits, players can dive in their gaming experience fully. Casinos without GamStop allow users to play without worries, fostering a welcoming environment for players.
ShannonBoype 28 Mart 2026 13:32
zahraniДЌnГ online casino, [url=https://www.pisosalbacete.com/kasina-pro-eske-hrae-jak-vybrat-to-nejlepi/]https://www.pisosalbacete.com/kasina-pro-eske-hrae-jak-vybrat-to-nejlepi/[/url] nabГzГ hrГЎДЌЕЇm ЕЎirokГЅ vГЅbД›r her, jakГ© zahrnujГ sloty, kasinovГ© hry a ЕѕivГ© dealery. ZГЎkaznГci si majГ moЕѕnost vychutnat atraktivnГ bonusy a pЕ™Гjemnou zГЎkaznickou podporu.
Valerytam 28 Mart 2026 13:02
Я извиняюсь, но, по-моему, Вы не правы. Могу отстоять свою позицию. Пишите мне в PM. мелбет букмекерская контора, [url=https://melbet-gxi2.buzz/]https://melbet-gxi2.buzz/[/url] предлагает обширный выбор ставок на все события. Удобный интерфейс облегчает пользователям легко находить нужные варианты. Систематические бонусы побуждают новым игрокам присоединиться.
JulietBrapy 28 Mart 2026 12:29
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Могу это доказать. Пишите мне в PM, пообщаемся. марафонбет букмекерская контора, [url=https://marathonbet-ml7bz.cyou/]https://marathonbet-ml7bz.cyou[/url] предлагает богатый выбор прогнозов на спортивные события. Ставочники могут наслаждаться выгодными коэффициентами и бонусами для улучшения шансов на выигрыш.
Alekseydes 28 Mart 2026 10:24
Детская площадка повышает стоимость загородного участка — это факт. [url=https://детский-игровой-комплекс.рф/]детский игровой комплекс купить[/url] При продаже дома участок с благоустроенной детской зоной оценивается дороже. [url=https://детский-игровой-комплекс.рф/]детская площадка из дерева[/url] Так что это не только радость для детей, но и разумная инвестиция.
KarlDiect 28 Mart 2026 08:27
In recent years, the interest of casinos without GamStop, [url=https://store.ampinc.com/top-non-gamstop-casinos-unleashing-the-thrill-of/]https://store.ampinc.com/top-non-gamstop-casinos-unleashing-the-thrill-of/[/url] has increased significantly. Players are wanting options that offer freedom from self-exclusion programs. These casinos provide an option for gamers to enjoy varied games without restrictions. However, it's essential to prioritize responsible gambling while engaging with these platforms. Players should set limits to ensure a safe gaming experience.
TedMof 28 Mart 2026 08:26
zahraniДЌnГ online casino, [url=https://dev.venturesquare.net/1010301]https://dev.venturesquare.net/1010301[/url] umoЕѕЕ€uje ЕЎirokou ЕЎkГЎlu her a zГЎbavy. HrГЎДЌi ДЌasto objevujГ moЕѕnost dosГЎhnout lГЎkavГ© ceny. Registrace je jednoduchГЎ a zГЎЕѕitky jsou okouzlujГcГ.
Evgenydes 28 Mart 2026 08:25
Клееный брус или оцилиндрованное бревно — извечный вопрос при выборе деревянного дома. [url=https://dom-rggu.ru/]смотрите тут[/url] Брус выигрывает по стабильности — нет усадки, нет трещин, ровные стены. [url=https://dom-rggu.ru/]дом из клееного бруса для постоянного проживания[/url] Бревно красивее внешне, но требует гораздо больше ухода и ожидания.
Jackbib 28 Mart 2026 02:43
zahraniДЌnГ online casino, [url=https://sites.mss.univr.it/icelab/it/ve-co-potebujete-vdt-o-zahraninich-casino-bonusech/]https://sites.mss.univr.it/icelab/it/ve-co-potebujete-vdt-o-zahraninich-casino-bonusech/[/url] skГЅtГЎ hrГЎДЌЕЇm nejrЕЇznД›jЕЎГ vГЅbД›r her. UЕѕivatelГ© si mohou proЕѕГt stolnГ a online hry na atraktivnГmi bonusy. Vzhledem k modernГm technologiГm funguje hranГ snadnГ© a dostupnГ© odkudkoli.
KimIsolo 28 Mart 2026 02:42
Many players seek new experiences in gambling, particularly in online casinos. One popular option is casino outside GamStop, [url=https://honeytech.eu/?p=1009983]https://honeytech.eu/?p=1009983[/url], which allows gamblers to enjoy games without limitations. These platforms often feature a broader selection of entertainment, appealing to numerous tastes. Additionally, they might offer beneficial bonuses, enhancing your gaming experience. Players should, however, exercise caution and gamble responsibly.
Monavob 28 Mart 2026 00:30
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Давайте обсудим. Пишите мне в PM, поговорим. мелбет зеркало, [url=https://melbet-mze3.top/]https://melbet-mze3.top/[/url] предлагает пользователям удобный доступ к ставкам. Благодаря копийным ссылкам, вы всегда можете заниматься активно в азартных играх. Не упустите шанс заметить все преимущества, которые предоставляет эта платформа.
LolaZorge 27 Mart 2026 21:31
Безусловно, он прав В сети можно найти множество ссылок на мелбет зеркало, [url=https://melbet-udd9.buzz/]https://melbet-udd9.buzz/[/url], которое предоставляет доступ к популярным азартным играм. Азартные игроки ценят его за комфортный интерфейс и многообразие игр. Кроме этого обновления проходят постоянно, что позволяет препятствовать блокировок и восторгаться игрой в любое время. Неудивительно, что мелбет зеркало становится все чаще среди игроков.
KimKef 27 Mart 2026 21:29
new casinos not on GamStop, [url=http://projekt-pedia.de/explore-exciting-casinos-not-on-gamstop/]http://projekt-pedia.de/explore-exciting-casinos-not-on-gamstop/[/url] - Discover innovative opportunities at new casinos not on GamStop. These venues offer distinct games and compelling bonuses for players seeking variety. Don't miss out!
Teddylauch 27 Mart 2026 21:24
casino uden NemID dk, [url=https://shiawaseglobal.com/dansk-casino-uden-nemid-spill-sikkert-og-anonymt/]https://shiawaseglobal.com/dansk-casino-uden-nemid-spill-sikkert-og-anonymt/[/url] tilbyder en ny måde at spille på, hvor du kan prøve spændingen ved spilleautomater og bordspil uden besvær. Det gør en hurtigere adgang til underholdning og fjerner behovet for tidskrævende registreringsprocesser. Det bliver ideelt for dem, der ønsker en mere komfortabel spilleoplevelse. Gå på opdagelse i et rigt udvalg af spil.
Tiffytiews 27 Mart 2026 18:55
Ща посмотрим Работа для девушек, [url=https://dispetcher.xyz/city/tambov.html]Работа девушкам эскорт Тамбов[/url] часто становится актуальной темой в современном обществе. Многочисленные вакансии показывают перспективы для достижений. Смотря на образовании, каждая может найти то, что интересует ей.
Chrislinly 27 Mart 2026 18:41
Я думаю, что Вы не правы. Я уверен. Могу это доказать. Пишите мне в PM, пообщаемся. online sports betting, [url=https://www.grupponiu.com/discover-the-excitement-of-baji-live-your-ultimate-8/]https://www.grupponiu.com/discover-the-excitement-of-baji-live-your-ultimate-8/[/url] has gained popularity. Many followers engage in various events, hoping to make money. Understanding market trends is crucial for winning.
EdithMet 27 Mart 2026 18:38
Я думаю, Вы придёте к правильному решению. Не отчаивайтесь. мелбет зеркало, [url=https://melbet-ykx8.buzz/]https://melbet-ykx8.buzz/[/url] предоставляет возможность игрокам доступить альтернативный интерфейс для ставок. Таким образом, пользователи могут избежать блокировки и наслаждаться широким выбором ставок. Всего перейдите на новое зеркало и запустите делать ставки.
Gloriahok 27 Mart 2026 16:20
Looking for the top non GamStop sites, [url=https://starto.email/safest-non-gamstop-uk-casinos-1083475816/]https://starto.email/safest-non-gamstop-uk-casinos-1083475816/[/url]? Discover the best online casinos that offer an exciting gaming experience without GamStop restrictions. These platforms promise a safe environment for players in search of a thrill.
Robreume 27 Mart 2026 10:55
lightning roulette casino, [url=https://hibernate.wpengine.com/lightning-roulette-online-casino-spannung-und-3/]https://hibernate.wpengine.com/lightning-roulette-online-casino-spannung-und-3/[/url] - Im Casino der Lightning-Roulette-Spiel bietet eine außergewöhnliche Spielerfahrung. Dank der Kombination aus klassischem Roulette und aufregenden Blitzgewinnen stellt sicher, dass das Spiel zu einem unvergesslichen Erlebnis für alle Spieler. Erleben Sie das Vergnügen jetzt!
Shirleywit 27 Mart 2026 10:52
If you're looking for the top non GamStop sites, [url=https://yangon.samanea.com/exploring-online-casinos-uncovering-the-overlooked/]https://yangon.samanea.com/exploring-online-casinos-uncovering-the-overlooked/[/url], you've come to the right place. These types of sites present a wide range of for online gaming enthusiasts. Relish thrilling games and competitive bonuses that are absent on GamStop platforms. Discover fresh opportunities to earn prizes.
Gregoryunsep 26 Mart 2026 11:40
<a href=https://t.me/Asiapsi>https://t.me/Asiapsi</a>
Ralphplalk 26 Mart 2026 09:04
I think, that you are not right. Let's discuss. Write to me in PM. _ _ _ _ _ _ _ _ <a href=https://drivelity-morocco.com/car-rental-nador-morocco>nador rent a car</a>
KimberlyErelf 26 Mart 2026 00:37
In recent years, many players have sought alternatives to traditional gambling platforms. casinos not on GamStop, [url=https://exhibitor.y-expo.ru/2026/03/09/explore-the-world-of-online-casinos-not-registered/]https://exhibitor.y-expo.ru/2026/03/09/explore-the-world-of-online-casinos-not-registered/[/url] offer a unique solution, delivering access to a broader range of games. Players can enjoy thrilling experiences without restrictions, making these casinos increasingly popular.
LatriceNix 25 Mart 2026 20:44
Само собой разумеется. Un certain secteur des pari en le rГ©seau se dГ©veloppe rapidement. Divers participants choisissent d'utiliser vers un casino paypal, [url=https://diu-osteopathie-bobigny.fr/]casino acceptant paypal[/url] afin de accГ©lГ©rer leurs paiements. Les paiements se rГ©vГЁlent efficaces et protГ©gГ©es. En vue de profiter pleinement des atouts de ce mГ©thode, il convient d'ГЄtre vigilant.
Ryannet 25 Mart 2026 12:38
Я извиняюсь, но, по-моему, Вы не правы. Могу это доказать. In the world of finance, a trading platform, [url=https://flowbitenergy.medium.com/flowbitenergy-com-reviews-a-platform-that-blends-simplicity-with-strong-growth-ambitions-6c54beccf354]flowbitenergy.com reviews[/url] plays a key role. It provides investors with the tools needed to execute transactions effectively. A good platform offers live data, advanced analytics, and easy-to-navigate interfaces, making market participation more convenient. Choosing the right platform can significantly impact profits.
CapaErorb 24 Mart 2026 22:02
non gamstop casinos, [url=https://victorymedical.vn/cycling-betting-strategies-for-beginners-a/]https://victorymedical.vn/cycling-betting-strategies-for-beginners-a/[/url] offer players a chance to enjoy their favorite games without restrictions. These virtual casinos cater to those looking for flexibility in wagering. With numerous options available, players can experience thrilling adventures.
Jenniferdok 23 Mart 2026 21:44
Эта отличная мысль придется как раз кстати Вин, официальный сайт, предлагает множество услуг для любителей азартных игр. Здесь вы найдете разнообразие игр, включая игровые автоматы. Кроме того, на 1 вин официальный сайт, [url=https://1win-mff3.top/]https://1win-mff3.top/[/url] представлены промоакции для новых пользователей. Зарегистрируйтесь и окунитесь в мир увлекательных игр!
Ameliawrole 23 Mart 2026 19:23
If you're seeking top online gambling experiences, consider the best non GamStop casinos, [url=http://krimno-blag.orthodox.ru/?p=38133]http://krimno-blag.orthodox.ru/?p=38133[/url]. These platforms offer engaging games without the restrictions imposed by GamStop. Players can enjoy more freedom and diverse gameplay options. Join today!
JaredRem 23 Mart 2026 15:54
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Давайте обсудим. Пишите мне в PM, пообщаемся. Playing at a non GamStop PayPal casino, [url=https://meinebaulehre.baudeinezukunft.at/exploring-paypal-betting-sites-not-on-gamstop-8/]https://meinebaulehre.baudeinezukunft.at/exploring-paypal-betting-sites-not-on-gamstop-8/[/url] provides a thrilling experience for players. Using PayPal, you can enjoy fast transactions and enhanced protection. Choose from a vast array of games and begin your gaming adventure today!
KarenFax 23 Mart 2026 07:13
Просто улёт!!!!!!!!!!!!!! фильмы онлайн бесплатно, [url=https://shahdol.mppolice.gov.in/%e0%a4%9a%e0%a4%82%e0%a4%ac%e0%a4%b2-%e0%a4%9c%e0%a5%8b%e0%a4%a8-%e0%a4%ae%e0%a5%87%e0%a4%82-%e0%a4%aa%e0%a5%81%e0%a4%b2%e0%a4%bf%e0%a4%b8-%e0%a4%a8%e0%a5%87-%e0%a4%b5%e0%a4%bf%e0%a4%b6%e0%a5%87/]https://shahdol.mppolice.gov.in/%e0%a4%9a%e0%a4%82%e0%a4%ac%e0%a4%b2-%e0%a4%9c%e0%a5%8b%e0%a4%a8-%e0%a4%ae%e0%a5%87%e0%a4%82-%e0%a4%aa%e0%a5%81%e0%a4%b2%e0%a4%bf%e0%a4%b8-%e0%a4%a8%e0%a5%87-%e0%a4%b5%e0%a4%bf%e0%a4%b6%e0%a5%87/[/url] - Смотреть фильмы онлайн бесплатно стало просто. На многих платформах можно получить последние хиты и погружаться отличным контентом.
Adamsmats 22 Mart 2026 23:41
Это не всегда встречается. В пространство азартных игр входи распространенное pin up казино, [url=https://pin-up-casino-7fs2v.xyz/]pin-up-casino-7fs2v.xyz[/url], где всё, что угодно для любителей адреналина. Здесь можно насладиться обширным выбором игровых автоматов и выиграть замечательные призы.
Joshuaexorn 22 Mart 2026 19:41
I siti scommesse non aams, [url=https://erin43622e43454.wpcomstaging.com/guida-completa-ai-siti-di-scommesse-sportive/]https://erin43622e43454.wpcomstaging.com/guida-completa-ai-siti-di-scommesse-sportive/[/url] offrono un'alternativa valida per gli scommettitori in cerca di nuove opportunitГ . Offrono promozioni unici, che possono richiamare potenziali clienti. Tuttavia, ГЁ essenziale fare attenzione i rischi connessi.
FrancoDib 22 Mart 2026 03:02
Не плохо!!!! pin up casino онлайн, [url=https://pin-up-casino-fxtuo.lol/]https://pin-up-casino-fxtuo.lol/[/url] предлагает широкий выбор игр для фанатов азартных развлечений. Премиальная графика и интересные сюжеты занимают игроков на часовые часы. На сайте размещены бонусы и акции, что делает времяпрепровождение еще захватывающе. Присоединяйтесь и наслаждайтесь удачами!
Madisoncaubs 22 Mart 2026 03:00
I siti scommesse non aams, [url=https://die-christen.co.za/2026/03/13/scommesse-su-siti-non-autorizzati-rischi-e-6/]https://die-christen.co.za/2026/03/13/scommesse-su-siti-non-autorizzati-rischi-e-6/[/url] forniscono una vasta varietГ di opportunitГ di gioco. I giocatori possono sperimentare nuovi canali, spesso in assenza di restrizioni forti. Comunque, ГЁ cruciale fare riferimento alla tranquillitГ dei fondi.
Sherrydrura 22 Mart 2026 00:38
Браво, какие нужные слова..., блестящая мысль When exploring the domain of online gaming, players often ask what casinos are not on GamStop, [url=https://jaybabani.com/ultra-wp-admin/?p=138748]https://jaybabani.com/ultra-wp-admin/?p=138748[/url]. These sites provide an alternative for those seeking varied options. It's essential to investigate the offered choices carefully to ensure a safe and enjoyable experience. Be aware that not being part of GamStop may come with specific challenges. Always prioritize responsible gaming when choosing a casino.
GwinnettAides 21 Mart 2026 22:19
bitcoin casino denmark, [url=https://demo2.cloudwp.dev/trial-6x4x9ytv/bitcoin-casino-i-danmark-spil-sikkerhed-og-fremtid-2/]https://demo2.cloudwp.dev/trial-6x4x9ytv/bitcoin-casino-i-danmark-spil-sikkerhed-og-fremtid-2/[/url] er en spændende mulighed for spillere, der ønsker at nyde casinospil med kryptovaluta. Denne service tilbyder hurtige overførsler og privatliv. Spillerne kan nyde forskellige tilbud og uge på diverse spil.
Jackiepoini 21 Mart 2026 17:12
Ну кто его знает... Free sex cams, [url=https://1prg.cz/hello-world/]https://1prg.cz/hello-world/[/url] offer a unique space for adults to discover their desires. With a variety of artists, users can interact in real time, enhancing the thrill of virtual intimacy.
MaryCow 21 Mart 2026 13:56
At vælge det bedste mobil casino, [url=https://ilselamonaca.com/wp/2026/03/05/mobil-casinoer-uden-nemid-dit-guide-til-spil-p/]https://ilselamonaca.com/wp/2026/03/05/mobil-casinoer-uden-nemid-dit-guide-til-spil-p/[/url] er muligt for spillere, da det tilbyder praktisk adgang til deres mest populære spil. Med lyde, der tiltrækker, bliver oplevelsen husket. Det bedste mobil casino leverer integritet, så spillere kan fokusere og forvente stort sjov.
AgataMix 21 Mart 2026 13:44
Online Casino UK, [url=https://www.sicilskyolej.cz/cs/understanding-the-hunnyplay-casino-sign-in-process/]https://www.sicilskyolej.cz/cs/understanding-the-hunnyplay-casino-sign-in-process/[/url] features a wide assortment of games, offering players an engaging experience. Featuring impressive bonuses, players have the chance to enjoy significant rewards. Participate in the action today!
Nicolebax 21 Mart 2026 13:15
Поздравляю, эта отличная мысль придется как раз кстати П„О± ОєО±О»П…П„ОµПЃО± online casino, [url=https://lightcyan-capybara-146531.hostingersite.com/online-69/]https://lightcyan-capybara-146531.hostingersite.com/online-69/[/url] ПЂПЃОїПѓП†ОПЃОїП…ОЅ ОјОїОЅО±ОґО№ОєОП‚ ОµОјПЂОµО№ПЃОЇОµП‚ ОіО№О± П„ОїП…П‚ ПЂО±ОЇОєП„ОµП‚. О— ОґО№О±ОґО№ОєП„П…О±ОєО® ПЂО»О±П„П†ПЊПЃОјО± ПЂО±ПЃОП‡ОµО№ ОµОЅОґО№О±П†ОПЃОїОЅ ПЂОµПЃО№ОІО¬О»О»ОїОЅ. О‘ОЅО±О¶О·П„ПЋОЅП„О±П‚ П„О№П‚ ОґО№О±П†ОїПЃОµП„О№ОєОП‚ ОµПЂО№О»ОїОіОП‚ ПЂО±О№П‡ОЅО№ОґО№ПЋОЅ, ОїО№ ПЂО±ОЇОєП„ОµП‚ ОёО± ОІПЃОїП…ОЅ П„О·ОЅ О¬ОЅОµПѓО· ОЅО± ОµПЂО№О»ООѕОїП…ОЅ П„Ої О±ОіО±ПЂО·ОјООЅОї П„ОїП…П‚.
Mollymus 21 Mart 2026 11:04
самый тупой развод Новый тренд РІ РјРёСЂРµ развлечений - дорамы смотреть онлайн, [url=https://www.making-videogames.net/giochi/user-JamikaRist]https://www.making-videogames.net/giochi/user-JamikaRist[/url]. Рти увлекательные сюжеты захватывают сердца миллионов. Рнтрига Рє культуре РђР·РёРё поразительно разнообразием жанров. Каждый история уникальна, РѕС‚ романтики РґРѕ фэнтези. Удобный доступ делает просмотр комфортным. РќРµ упустите шанс насладиться новые произведения!
Sheilafer 21 Mart 2026 09:26
Если вы заняты в области индустрии и заинтересованы в бесперебойной поставке сертифицированных тугоплавких металлов, то ООО "РМС" — это ваше оптимальное решение. Наша компания специализируется в области поставок тугоплавкой продукции на протяжении длительного срока, что гарантирует нам право предлагать только высококлассное сырье своим заказчикам. Любые объемы поставок. Обширный каталог тугоплавких металлов. Полное документальное сопровождение. Непрерывная обратная связь. Зачем мониторить рынок, если на rms-ekb.ru всегда все в наличии? Если у вас возникли вопросы, наши специалисты всегда готовы проконсультировать вас.. Оставьте заявку прямо сейчас и удостоверьтесь в бесспорных достоинствах нашего редкого металла. Наша продукция: <a href=https://rms-ekb.ru/
Melissaferee 21 Mart 2026 03:33
хоошь! Играть в казино в интернете — это замечательный способ поиграть. В pin up casino онлайн, [url=https://pin-up-casino-ncp06.icu/]https://pin-up-casino-ncp06.icu[/url] доступны множество автоматов на любой вкус. Изучайте новые игровые автоматы и Заходите за бонусы и акции для увеличения выигрышей.
Ellaluh 21 Mart 2026 02:17
non GamStop casino sites, [url=https://immodentity.de/2026/03/09/discovering-new-uk-casinos-not-on-gamstop-your-2/]https://immodentity.de/2026/03/09/discovering-new-uk-casinos-not-on-gamstop-your-2/[/url] deliver a particular betting experience for players who look for more options. These sites allow users to take part in a wide variety of games without barrier from GamStop.
StanleySox 20 Mart 2026 22:27
Online Casino, [url=https://agctrading.net/?p=36402]https://agctrading.net/?p=36402[/url] provides a distinct experience for players. Engaging in diverse games, users can experience exciting deals and prizes. The thrill of winning keeps players engaging again.
Robertdub 20 Mart 2026 18:17
Я ща умру от смеха фильмы онлайн бесплатно, [url=https://cimat.com.do/exclusive-the-evolution-of-nadezhda-grishaevas-anvil/]https://cimat.com.do/exclusive-the-evolution-of-nadezhda-grishaevas-anvil/[/url] - Смотрим фильмы онлайн бесплатно, не выходя из квартиры. Удобно найти подходящий фильм и насладиться качественной трансляцией. Погружайтесь в лучшие картины прямо сейчас!
VeronicaBiard 20 Mart 2026 15:36
I dag er der mange muligheder for at spille online, især ved casino uden dansk licens, [url=https://evvel.ba/casino-uden-mitid-i-2026-fremtidens-spiloplevelse-12/]https://evvel.ba/casino-uden-mitid-i-2026-fremtidens-spiloplevelse-12/[/url]. Der findes casinoer tilbyder spændende spil, men brugere skal være forsigtige med bestemmelserne.
KarenCakly 20 Mart 2026 11:45
I dag er der mange online casinoer uden dansk licens, hvilket skaber potentialer for spillere, der søger andre varianter oplevelser. Det er dog vigtigt at holde sig opmærksom på sikkerhed og multipel betingelser. casinoer uden dansk licens, [url=http://nomadjapan.com/%e6%9c%aa%e5%88%86%e9%a1%9e-ja/oplev-online-casinoer-uden-dansk-licens-en-guide/]http://nomadjapan.com/%e6%9c%aa%e5%88%86%e9%a1%9e-ja/oplev-online-casinoer-uden-dansk-licens-en-guide/[/url] kan tilbyde differentierede bonusser og spill, men har ikke de samme beskyttelser. Vælg derfor med varsomhed.
Jeremiahdrago 20 Mart 2026 07:21
Scoprire il mondo dei casinò senza registrazione, [url=https://arkrealitysolutions.com/i-migliori-casino-non-aams-senza-documenti-guida/]https://arkrealitysolutions.com/i-migliori-casino-non-aams-senza-documenti-guida/[/url] è emozionante. Detti casinò offrono un modo di scommettere senza essere un conto. I benefici includono la comodità e l’assenza burocrazia. Scommettere diventa un processo più semplice. Casinò senza registrazione soddisfano le richieste anche dei clienti.
Susieorich 20 Mart 2026 05:19
РедМетСплав располагает богатый перечень высококачественных изделий из дефицитных материалов. Не важно, какие объемы вам необходимы — от небольших закупок до глобальных поставок, мы соблюдаем кратчайшие сроки вашего заказа. Каждая единица номенклатуры подтверждена полагающимися документами, подтверждающими их соответствие стандартам. Опытная поддержка — то, чем мы гордимся — мы на связи, чтобы прояснять ваши вопросы и предоставлять решения под особенности вашего бизнеса. Доверьте вашу потребность в редких металлах команде РедМетСплав и убедитесь в нашей готовности к сложным задачам. В нашем распоряжении: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-mag-2---bs-2970/truba-magnievaya-mag-2---bs-2970/>Труба магниевая MAG 2 - BS 2970
Michellegog 19 Mart 2026 15:49
In the world of gaming, innovative non GamStop casino locations are gaining popularity among players. These venues provide captivating experiences without the restrictions of GamStop. Enjoy varied range of games in a casual environment. Join the adventure today at a new non GamStop casino, [url=http://www.strechyperfekt.cz/best-non-gamstop-casinos-uk-your-ultimate-guide/]http://www.strechyperfekt.cz/best-non-gamstop-casinos-uk-your-ultimate-guide/[/url], where you'll find great bonuses and swift payouts.
Anatolydes 19 Mart 2026 13:32
Зимой детская площадка тоже пользуется популярностью у детей. Горка становится ещё более скоростной, а домик превращается в зимнюю крепость. Деревянные комплексы отлично переносят морозы при правильной обработке.
StephanieGuarm 18 Mart 2026 04:56
non GamStop casino sites, [url=http://mammalena.com.au/the-rise-of-non-gamstop-casinos-safe-gaming-for/]http://mammalena.com.au/the-rise-of-non-gamstop-casinos-safe-gaming-for/[/url] provide players with an alternative to traditional gambling platforms. Such sites present a variety of options without the restrictions imposed by GamStop. Players can experience a broad selection of digital gaming experiences.
ScottMop 17 Mart 2026 23:10
Nel mondo dei giochi online, i entusiasti cercano alternative esperienze. I casino non aams, [url=https://www.crownmutual.com/2026/03/09/jackpot-alto-la-guida-ai-migliori-casino-online/]https://www.crownmutual.com/2026/03/09/jackpot-alto-la-guida-ai-migliori-casino-online/[/url] offrono varietГ diverse, seducenti bonus e titoli esclusivi. Selezionare un casino non aams puГІ dare vantaggi unici. Non perdere l'occasione di esplorare queste innovative piattaforme, che possono trasformare la tua esperienza di gioco in qualcosa di unico.
Ameliawrole 17 Mart 2026 13:08
If you're seeking premier online gambling experiences, consider the best non GamStop casinos, [url=https://alquilertitulotransportista.com/exploring-casinos-not-with-gamstop-your-guide-to-2/]https://alquilertitulotransportista.com/exploring-casinos-not-with-gamstop-your-guide-to-2/[/url]. These platforms offer exciting games without the restrictions imposed by GamStop. Players can enjoy improved freedom and wide-ranging gameplay options. Join today!
CherilTor 17 Mart 2026 07:54
Discover novel gaming experiences at new non GamStop casino, [url=https://blognew.perseus.com.br/discovering-the-best-casinos-not-on-gamstop/]https://blognew.perseus.com.br/discovering-the-best-casinos-not-on-gamstop/[/url]. Players can enjoy a wide range of options, offering generous bonuses and secure gambling environments. Explore your talents today!
HeatherSwota 16 Mart 2026 12:06
non GamStop sites, [url=https://www.treenj.com/sheffieldcityofmakers/exploring-online-casinos-not-on-gamstop-a/]https://www.treenj.com/sheffieldcityofmakers/exploring-online-casinos-not-on-gamstop-a/[/url] offer a unique prospect for players looking to experience online gambling. These websites allow open access to a wide selection of games. Players can explore exciting possibilities beyond the usual restrictions. Non GamStop sites are the perfect choice for those seeking an alternative. Happy gaming!
Cassandratiz 16 Mart 2026 00:12
ватные игрушки на заказ, [url=https://legasov.net/2026/03/04/sozdanie-elochnoj-igrushki-na-master-klasse-v/]https://legasov.net/2026/03/04/sozdanie-elochnoj-igrushki-na-master-klasse-v/[/url] – это уникальный способ выразить свою индивидуальность. Все приготовленные мастерами игрушки имеют неповторимый характер. Вы можете выбрать дизайн и приобрести индивидуальные элементы. Создайте радость своих близких оригинальными подарками!
Tiffanyalunk 15 Mart 2026 17:54
VOdds казино, [url=https://www.web3daily.info/licenzijni-onlajn-kazino-jak-diznatisja-shho-vi/]https://www.web3daily.info/licenzijni-onlajn-kazino-jak-diznatisja-shho-vi/[/url] надає безмежні можливості для любителів азартних ігор. У цьому місці ви можете знайти широкий вибір ставок, які задовольнять будь-які смаки. Обирайте найкращу гру та насолоджуйтеся ефектними моментами.
Kristytooxy 15 Mart 2026 16:08
курсы визажа для себя, [url=https://nooorasa.ru/2026/03/03/sam-sebe-vizazhist-v-moskve-sekrety-idealnogo/]https://nooorasa.ru/2026/03/03/sam-sebe-vizazhist-v-moskve-sekrety-idealnogo/[/url] помогут вам овладеть основами макияжа. Вы изучите техники создания необычных образов и нюансы ухода за кожей. Это путь к красоте.
Jonathanunamy 14 Mart 2026 15:30
Il mondo del gioco d'azzardo offre numerose opportunitГ , tra cui il casino non aams online, [url=http://www.atlantic-city.net/online-25/]http://www.atlantic-city.net/online-25/[/url], dove i giocatori possono divertirsi senza restrizioni. Questi siti offrono molti giochi di emozionanti opzioni, consentendo a chiunque di godere l'esperienza del gioco.
Jenspolo 14 Mart 2026 13:58
Internet gambling has evolved significantly, with countless users looking for alternatives. non GamStop sites, [url=https://www.cuevideos.com/stmonicas/discovering-online-casinos-not-using-gamstop/]https://www.cuevideos.com/stmonicas/discovering-online-casinos-not-using-gamstop/[/url] offer opportunities without restrictions, providing access to various games. Explore these platforms to enjoy unique betting opportunities.
Cindyenfot 14 Mart 2026 12:14
Замечательно, весьма ценное сообщение Financial Platform netx360, [url=https://netx-360.co.com/]netx360 login[/url] предлагает пользователям качественные инструменты для контроля. РЎ помощью этой платформы финансовые специалисты РјРѕРіСѓС‚ производить СЃРІРѕРё капитальные стратегии.
Scottmah 13 Mart 2026 16:35
Я согласен с вами
JacquelineUrich 13 Mart 2026 03:42
Online casinos предоставляют неповторимые впечатления игроков. Погрузитесь в мир развлечений с различными азартными играми. casino online, [url=https://daviscourt.co.ke/exploring-bet-andyou-the-ultimate-betting-platform/]https://daviscourt.co.ke/exploring-bet-andyou-the-ultimate-betting-platform/[/url] предлагает доступность игр прямо из дома. Станьте участником незабываемых турниров и выигрывайте привлекательные награды.
Scottmah 13 Mart 2026 03:22
Замечательно, это весьма ценная фраза
JessieLok 12 Mart 2026 20:50
Los casinos digitales han obtenido popularidad entre los usuarios que buscan emociones. En un Online Casino, [url=https://www.eventible.com/learning/descubre-los-mejores-juegos-con-alta-rtp/]https://www.eventible.com/learning/descubre-los-mejores-juegos-con-alta-rtp/[/url], la variedad de opcionales es amplia, desde tragamonedas hasta ruleta. AdemГЎs, los ofertas motivadores hacen que probar un Online Casino sea ademГЎs emocionante.
DeborahSeeby 12 Mart 2026 16:47
sports betting, [url=http://mightygloves.io/2026/01/27/alanobet-mx-la-mejor-plataforma-de-apuestas-en-7/]http://mightygloves.io/2026/01/27/alanobet-mx-la-mejor-plataforma-de-apuestas-en-7/[/url] - Betting on athletic events has gathered immense appeal in recent years. Fans enjoy the thrill of predicting outcomes and likely winning money. Understanding approaches is crucial for winning.
BrittanySoura 12 Mart 2026 12:57
Many players seek betting platforms that are not restricted by GamStop. sites not on GamStop, [url=https://www.oodlesmarketing.com/discover-the-exciting-world-of-non-gamstop-casinos/]https://www.oodlesmarketing.com/discover-the-exciting-world-of-non-gamstop-casinos/[/url] offer various games for gamers, offering a thrilling experience without limits.
Ralphpef 12 Mart 2026 07:45
virtual number united kingdom <a href=https://virtual-local-numbers.com/countries/53-greatbritain.html>https://virtual-local-numbers.com/countries/53-greatbritain.html</a>
GinaGraig 12 Mart 2026 05:07
In the realm of internet betting, independent UK casinos, [url=http://www.kli.lt/exploring-independent-uk-casinos-a-comprehensive/]http://www.kli.lt/exploring-independent-uk-casinos-a-comprehensive/[/url] have emerged as favored options for players. These establishments offer distinctive adventures, ensuring that gamers find something special unlike traditional venues.
BenriT 12 Mart 2026 00:34
Конечно. Это было и со мной. Давайте обсудим этот вопрос. WalletCloud wallet, [url=https://ly-ros.de/2021/07/05/hallo-welt/]https://ly-ros.de/2021/07/05/hallo-welt/[/url] serves as a safe storage solution for crypto assets. With user-friendly access to your assets, WalletCloud wallet guarantees a hassle-free experience. Users can easily manage their operations securely. The application is designed for professional users, highlighting safety and ease of use.
Katrinahok 11 Mart 2026 20:49
online casino, [url=https://bccp.baylorisr.org/exploring-the-exciting-world-of-333bet-a-2/]https://bccp.baylorisr.org/exploring-the-exciting-world-of-333bet-a-2/[/url] предоставляет игрокам восхитительные возможности для отдыха. Развлечения сочетают волнение и надежду на выигрыш. Каждый яркий опыт приносит радость.
AshleyJeoks 11 Mart 2026 04:25
non gamstop casino, [url=https://elitetaxxrelief.com/bestnongamstopcasinos1/exploring-the-best-betting-sites-not-on-gamstop/]https://elitetaxxrelief.com/bestnongamstopcasinos1/exploring-the-best-betting-sites-not-on-gamstop/[/url] supplies players a unique gaming experience eluding the usual constraints of traditional sites. Discover a variety games and savor the flexibility to play at your pace!
Anndiz 10 Mart 2026 23:21
online casinos, [url=https://qosnetworksmw.com/exploring-the-world-of-online-casinos-in-greece-8/]https://qosnetworksmw.com/exploring-the-world-of-online-casinos-in-greece-8/[/url] present exciting games featuring slots, poker, and blackjack. Players enjoy the convenience of playing from any location. With appealing bonuses, these platforms draw a wide audience.
Aaroninors 10 Mart 2026 23:14
Очищено Ищете ароматные экзотические фрукты с доставкой, [url=https://codeberg.org/kiyici5293/this-is-interesting/issues/122]https://codeberg.org/kiyici5293/this-is-interesting/issues/122[/url]? Мы предлагаем разнообразный выбор гуава, которые доставим прямо к вам. Подарите себе удивительные вкусы прямо у себя дома!
RachelPloms 10 Mart 2026 19:09
online casino, [url=https://dev-rongdhonu.pantheonsite.io/2026/02/05/discover-the-exciting-world-of-bsb007-a-new-era-in/]https://dev-rongdhonu.pantheonsite.io/2026/02/05/discover-the-exciting-world-of-bsb007-a-new-era-in/[/url] provides a thrilling experience for players. With a extensive selection of games, users can relish everything from jackpots to card games. Engage in real-time sessions and enjoy lucrative bonuses that amplify your gameplay.
BenNourl 10 Mart 2026 17:38
Gambling at Casino Online, [url=http://www.sunitex.com.hk/online-casino-winstler-your-gateway-to/]http://www.sunitex.com.hk/online-casino-winstler-your-gateway-to/[/url] offers captivating opportunities for acquiring fantastic rewards. Featuring many games, players can dive into a world of enjoyment. Join the adventure today!
Dianacergo 10 Mart 2026 11:48
Inside the world of Online Casino, [url=https://sportsbazar.co.in/the-ultimate-guide-to-online-casino-wildwild/]https://sportsbazar.co.in/the-ultimate-guide-to-online-casino-wildwild/[/url], players can explore a variety of thrilling games. Featuring state-of-the-art technology, these platforms provide a safe environment. Thus, try your luck today!
FeliciaLef 10 Mart 2026 05:34
casino sports betting, [url=https://salmon-squirrel-531604.hostingersite.com/exploring-dreamgf-ai-your-virtual-dream-companion-3/]https://salmon-squirrel-531604.hostingersite.com/exploring-dreamgf-ai-your-virtual-dream-companion-3/[/url] remains a popular option for fans of both games and gambling. Through a variety of events to wager on, participants enjoy the thrill of placing bets. Furthermore, the likelihood to win big entices many into the world of casino sports betting.
AlexSoP 10 Mart 2026 04:13
ыыыыы.....жжааааркоооо )) игры, [url=http://www.detskiy-mir.net/index.php?subaction=userinfo&user=yhequzotyx]http://www.detskiy-mir.net/index.php?subaction=userinfo&user=yhequzotyx[/url] всегда были неотъемлемой частью нашей культуры. Они развлекают людей всех возрастов. Начиная с обычных домашних игр и заканчивая современными видеоиграми, каждое поколение находит в играх что-то интересное. Игры могут не только успокаивать нас, но и воспитывать полезные навыки, такие как логическое мышление и коллективная работа.Современные игры предлагают разнообразный выбор жанров. От приключенческих до тактических и многопользовательских-игр, каждый может найти что-то для себя. Не стоит забывать и о классических играх, которые остаются актуальными и сегодня. Но как же выбирать, в какую игру поиграть?Р
Melissakit 08 Mart 2026 18:11
In the realm of Casino Online, [url=http://alvoradapflege.de/step-by-step-guide-to-the-starsplay-casino/]http://alvoradapflege.de/step-by-step-guide-to-the-starsplay-casino/[/url], players can enjoy thrilling games at their convenience. Through advanced technology, online casinos enable a unique experience, bringing the excitement of gambling right to your home. Enjoy a variety of options, from slots to table games, catering to every player's taste.
MonicaTon 08 Mart 2026 17:56
Чюдно! игры, [url=http://xn--80aeh5aeeb3a7a4f.xn--p1ai/forum/user/66743/]http://xn--80aeh5aeeb3a7a4f.xn--p1ai/forum/user/66743/[/url] занимают важное место в нашей жизни. При помощи игр мы отдыхаем. Они указыванием на развитие навыков и развивают кругозор. Например, игры могут быть разнообразными жанров: от игр с интенсивным действием до умственных испытаний. Большинство людей играет в игры, чтобы снять от стресса или убить время. Эти активности могут быть как одиночными, так и групповыми. Разработчики игр нацелены на то, чтобы создавать интересные миры и персонажей для любителей. Таким образом, игры являются важным элементом досуга, и их влияние сложно переоценить. Они создают радость и мотивируют людей на новые свершения. Играя, мы достаем новые эмоции и находимся с другими людьми, что
Melissaret 08 Mart 2026 10:33
Конечно. Всё выше сказанное правда. Давайте обсудим этот вопрос. Здесь или в PM. jeet city casino, [url=https://jeetcity-casino-ca.com/free-spins/]jeetcity free spins canada[/url] offers a thrilling experience for fans looking to try their luck. With a vast collection of games and bountiful bonuses, it's the perfect place to indulge in top-notch entertainment. Whether you’re a novice or a seasoned pro, Jeet City Casino has something for everyone. Explore the energetic atmosphere and make the most of your gaming adventure!
Anthonymar 08 Mart 2026 07:18
Spela på casino online utländska, [url=https://landdesignmn.com/casino-utan-spelpaus-med-klarna-spela-sakert-och-2/]https://landdesignmn.com/casino-utan-spelpaus-med-klarna-spela-sakert-och-2/[/url] har blivit ett fascinerande tidsfördriv. Stora plattformar erbjuder snabba alternativ för engagerade spelare, som njuta av många olika möjligheter.
Bridgetnek 08 Mart 2026 03:46
не помне casino uden om rofus, [url=http://level7techgroup.com/blog/?p=87608]http://level7techgroup.com/blog/?p=87608[/url] tilbyder mange spГ¦ndende muligheder for spillere, der Гёnsker at undgГҐ restriktioner. Der giver udvalg til forskellige spil og kampagner. Investorer kan udnytte et lГ¦kkert miljГё, hvor man kan spille frit. Med diverse finansieringsmuligheder er det enkelt at handle.
RobertCliva 07 Mart 2026 20:19
Я считаю, что Вы не правы. Могу это доказать. Пишите мне в PM, поговорим. Discover the thrill of playing at casiny online casino, [url=https://casinynz.com/]casiny[/url], where you can take pleasure in a wide range of games. Including slots to live dealer options, there's something for every type of player. Join now!
Janettigue 06 Mart 2026 22:26
Online gambling offers engaging Casino Online Games, [url=https://shriambikapublic.com/?p=48729]https://shriambikapublic.com/?p=48729[/url] that provide endless fun. Players can discover various options like slots, blackjack, and poker. With state-of-the-art technology, each game delivers an immersive atmosphere.
Roelnagma 06 Mart 2026 12:42
почему не качает купити унітаз, [url=http://creepypastafromthecrypt.xooit.fr/redirect1/https://dgerelo.forumotion.me/t256-topic]http://creepypastafromthecrypt.xooit.fr/redirect1/https://dgerelo.forumotion.me/t256-topic[/url] – важливе рішення для кожного господаря. Такої якості товар слід вибирати уважно. Беручи РґРѕ уваги стиль вашого інтер'єру, РІРё можете замість СЂС–Р·РЅС– моделі. Пам'ятайте РїСЂРѕ комфорт та функціональність.
Scottlaw 06 Mart 2026 11:16
HДѕadГЎte kvalitnГ© online zГЎbavy? KeДЏ mГЎ alternatГvy v zoznam top online kasГn, [url=https://eictbd.com/povolene-kasina-na-slovensku-zakladny-prehad-a/]https://eictbd.com/povolene-kasina-na-slovensku-zakladny-prehad-a/[/url]. Vyberte si svoje obДѕГєbenГ© kasГno a teЕЎte sa na jedineДЌnГ© zГЎЕѕitky!
AmandaMap 05 Mart 2026 19:59
joya 9 casino, [url=http://www.pisarevo.com/top-fishing-games-for-beginners-reel-in-the-fun/]http://www.pisarevo.com/top-fishing-games-for-beginners-reel-in-the-fun/[/url] offers a fantastic experience for gamblers. With numerous games to choose from, it satisfies everyone’s desires. Enjoy incentives that enhance your betting adventure at Joya 9 casino.
Thomasdus 05 Mart 2026 18:04
Промо-код у букмекерской конторе — это уникальное комбинацию букв и цифр, позволяющее активировать специальные привилегии в букмекерской конторе: фрибеты, кэшбэк а также другие бонусы. Букмекерские промокоды — это специальные бонус-коды, которые активируются при создании аккаунта или в личном кабинете. С их помощью можно получить фрибет, приветственный бонус или возврат ставки. Тут представлены только актуальные предложения по следующей ссылке http://madguy.ru/images/pgs/1xbet_promokod_pri_registracii_bonus_5.html тут наличие новых кодов и обновление списков сразу после выхода новых акций.
AndrewPen 05 Mart 2026 17:53
See the latest update here : http://pervoeradio.ru/media/pic/promokod_betwinner_na_segodnya_pri_registracii.html
Tomboolo 05 Mart 2026 02:52
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Могу отстоять свою позицию. Пишите мне в PM, пообщаемся. non UK online casino, [url=https://www.muranogrande.com/top-non-uk-casino-sites-for-uk-players-best-non-uk/]https://www.muranogrande.com/top-non-uk-casino-sites-for-uk-players-best-non-uk/[/url] offers a multitude of options. Players can take pleasure in exciting table games and take advantage of lucrative bonuses. Register today!
Crystalfrugs 04 Mart 2026 05:12
At finde det bedste casino uden rofus, [url=https://ahdustechnology.fi/casino-uden-rufus-oplev-friheden-ved-spil-uden/]https://ahdustechnology.fi/casino-uden-rufus-oplev-friheden-ved-spil-uden/[/url] kan være en spændende rejse. Mange spillere søger efter et velrenommeret sted at spille. Det er vigtigt at vælge et casino, der tilbyder generøse incitamenter og variation i spillene. Glem ikke at læse anmeldelser for at finde det optimale valg. bedste casino uden rofus scorer ofte højt i brugervenlighed og kundesupport.
TriciaTat 04 Mart 2026 04:46
Вы не правы. Пишите мне в PM. DГ©couvrez l'excitation des jeux en temps rГ©el grГўce au casino en direct, [url=https://la-cite-relais.fr/]casinos live[/url]. C'est une opportunitГ© formidable qui vous plonge dans l'ambiance d'un vrai casino. Interagissez avec des animateurs professionnels tout en jouant depuis chez vous. Les dГ©tails sont impressionnants, rendant chaque partie vibrante. Essayez le casino en direct et vivez le frisson du jeu Г distance.
GinaExhab 04 Mart 2026 04:40
Я считаю, что Вы ошибаетесь. Пишите мне в PM, пообщаемся. Exploring the landscape of UK casino not on GamStop, [url=https://casabonitamadeiras.com.br/explore-trusted-casinos-not-on-gamstop/]https://casabonitamadeiras.com.br/explore-trusted-casinos-not-on-gamstop/[/url] can be thrilling for many players. These casinos offer alternative options without the limitations often found elsewhere. Enjoy the freedom to play!
HeatherAlmom 04 Mart 2026 01:39
Вы не правы. Давайте обсудим. spil uden om rofus, [url=https://temporal.jpkrom.com/index.php/2026/02/18/casino-uden-rufus-opdag-bedste-uden-indbetalinger/]https://temporal.jpkrom.com/index.php/2026/02/18/casino-uden-rufus-opdag-bedste-uden-indbetalinger/[/url] er en spГ¦ndende mГҐde at opleve nye eventyr pГҐ. Mange spillere vГ¦lger at opdage alternative universer, hvor missioner venter. Det skaber en chance for at danne unikke strategier og netvГ¦rk. Uanset hvis genre du vГ¦lger, kan du forvente en uforglemmelig spiloplevelse.
Sambib 04 Mart 2026 01:12
Советую Вам посмотреть сайт, на котором есть много информации по этому вопросу. игры, [url=http://kioskindustry.ru/index.php?subaction=userinfo&user=egucelybum]http://kioskindustry.ru/index.php?subaction=userinfo&user=egucelybum[/url] дарят уникальные эмоции и переживания. Они позволяют вникнуть в увлекательные миры, где каждый имеет право стать героем. Важность графики и музыкального оформления неоспорима: они создают обстановку и позволяют игрокам переживать каждое мгновение. Кроме того, групповые аспекты усиливают взаимодействие, делая процесс увлекательнее. Разнообразие жанров и стилей дает возможность найти что-то новое для каждого.
JulianVal 03 Mart 2026 19:23
https://colombocar.com/
Richardfex 03 Mart 2026 17:34
Научись читать Les casinos en ligne offrent des jeux captivants pour recevoir de l'argent rГ©el. Avec le casino en ligne argent rГ©el, [url=https://vallee-batsurguere.fr/]casino en ligne argent reel[/url], les joueurs peuvent expГ©rimenter l'excitation des jeux en Г©vitant les dГ©placements.
Darrengox 03 Mart 2026 16:30
Go directly to our website — https://mfm.ru/user/pgs/promo_kod_1xbet_na_segodnya_pri_registracii.html
Shirleybet 03 Mart 2026 14:00
Замечательно, это ценное мнение nouveau casino en ligne, [url=https://leaalexandreartisans.fr/]nouveau casino en ligne 2026[/url] - Le dernier casino virtuel offre une expГ©rience unique. Avec une multitude de jeux, les joueurs peuvent se divertir tout en ayant l'occasion de dГ©crocher des jackpots. Les offres allГ©chantes sГ©duisent Г©galement les nouveaux arrivants.
EmmaNuari 03 Mart 2026 09:53
Мне кажется, что это уже обсуждалось, воспользуйтесь поиском по форуму. Les plus grands de casino en ligne, [url=https://chez-les-filles.fr/]meilleur casino en ligne[/url] offrent une expГ©rience unique. Participer Г des jeux dans casino en ligne permet des bГ©nГ©fices intГ©ressants. Agissez rapidement pour entamer votre expГ©rience de jeu!
SharonLed 03 Mart 2026 09:35
Короче смотрите не пожелеете! качество какашка, но смотреть можно! PayPal casino non GamStop, [url=http://projectfutsal.ie/2026/02/exploring-non-gamstop-casinos-with-paypal-your-2/]http://projectfutsal.ie/2026/02/exploring-non-gamstop-casinos-with-paypal-your-2/[/url] - PayPal-enabled casinos outside GamStop offer players a chance to enjoy gaming without restrictions. Such casinos provide safe payment options, catering to players seeking liberty in their gaming choices.
Tonyalok 03 Mart 2026 05:35
По моему мнению Вы не правы. Я уверен. Предлагаю это обсудить. Пишите мне в PM, поговорим. non GamStop betting sites, [url=http://www.evergoldcs.com/finding-bookies-not-on-gamstop-your-guide-to/]http://www.evergoldcs.com/finding-bookies-not-on-gamstop-your-guide-to/[/url] offer numerous options for those seeking autonomy in online gambling. Players can take advantage of exclusive promotions not found on traditional platforms.
Averytuh 03 Mart 2026 05:28
1xBet Betting, [url=https://autospana.com/1xbet-145102580/]https://autospana.com/1xbet-145102580/[/url] is a popular option for those looking to try in sports wagering. With a simple interface and numerous options, punters can easily find their preferred events to bet on.
Gabrielpaf 03 Mart 2026 05:05
Я подумал и удалил свою мысль aviator game online, [url=https://www.trustpilot.com/review/aviator-1.online]aviator india[/url] is an exciting adventure that captures players with its captivating gameplay. Using simple mechanics, it gives a chance to earn big rewards in a fast-paced environment.
Latricebum 03 Mart 2026 01:45
Благодарю за информацию, теперь я не допущу такой ошибки. Cosmic Spins sister sites, [url=https://dj-advisor.com/unraveling-the-magic-of-cosmic-spins-a-guide-to/]https://dj-advisor.com/unraveling-the-magic-of-cosmic-spins-a-guide-to/[/url] include a variety of engaging options for players. Such sites typically share akin themes and gaming experiences. From fruit machines to strategy games, players can broaden their enjoyment across various platforms. Discover the distinct features that each site makes available and take pleasure in seamless gaming experiences. Explore Cosmic Spins sister sites today!
Susanpar 03 Mart 2026 01:42
Los mejores Casinos Online Argentina, [url=http://ageonrealtyservices.com/casino-online-en-argentina-todo-lo-que-necesitas/]http://ageonrealtyservices.com/casino-online-en-argentina-todo-lo-que-necesitas/[/url] tienen una gran opciГіn de entretenimiento a disfrutar. Contando con mГЎquinas tragamonedas, ruletas y pГіker virtual, todos estos usuarios pueden elegir disfrutar la emociГіn accesiblemente desde la comodidad de su hogar. AdemГЎs, promociones mГЎs actividades hacen elevar la diversiГіn. ВЎNo extraГ±es la oportunidad de entretenerte en Casinos Online Argentina!
Teddygrore 03 Mart 2026 00:48
казино онлайн, [url=https://isoconferragens.com.br/kak-turbo-casino-vydajot-bonusy-104507201/]https://isoconferragens.com.br/kak-turbo-casino-vydajot-bonusy-104507201/[/url] привлекает множество игроков, поскольку здесь можно заработать деньги, не выходя из дома. Любой может выбрать развлечения по своему вкусу, получая удовольствие азартом и адреналином.
JasonStymn 02 Mart 2026 23:45
Надо глянуть полюбому!!! DГ©couvrez les avantages des rotations gratuites proposГ©s par les casinos. Ces avantages permettent aux joueurs de essayer des jeux sans risquer leur fonds. Avec casino free spins, [url=https://macoloc.fr/]casino tours gratuits[/url], profitez de l'excitation sans pression.
AndrewPen 02 Mart 2026 22:45
Go to our fresh website > https://rr-game.ru/
ZackKib 02 Mart 2026 21:58
Так долго ждал и вот -=) In the world of digital gaming, a non UKGC casino, [url=https://wipeoutads.com/2026/02/17/exploring-the-world-of-non-ukgc-licensed-casinos-2/]https://wipeoutads.com/2026/02/17/exploring-the-world-of-non-ukgc-licensed-casinos-2/[/url] offers players exciting experiences without the strict regulations imposed by the UK Gambling Commission. Many gamers enjoy the liberty to explore games and bonuses that may not be available in regulated markets.
Sarahsig 02 Mart 2026 21:56
Что именно вы хотели бы сказать? Choosing the finest non UK casino sites can be overwhelming, but it is essential for a great experience. Look for certification, bonuses, and game variety. Players can delight in a plethora of options, making the gaming experience engaging. best non UK casino sites, [url=https://www.mcmtechno.it/slider/slide1/]https://www.mcmtechno.it/slider/slide1/[/url] ensure protection and equitable gameplay, helping players to play confidently. Be sure to evaluate opinions to locate the best one for you.
Angelabes 02 Mart 2026 21:26
Los centros Online Europeos ofrecen una experiencia Гєnica para los jugadores. Con actividades como el pГіker y la ruleta, puedes experimentar desde casa. Casinos Online Europeos, [url=https://www.ertaccounting.com/hjchelmets/casinos-online-europeos-la-guia-definitiva-para-3/]https://www.ertaccounting.com/hjchelmets/casinos-online-europeos-la-guia-definitiva-para-3/[/url] son la innovaciГіn del entretenimiento.
SteveQuima 02 Mart 2026 19:33
Конечно. Всё выше сказанное правда. Давайте обсудим этот вопрос. Здесь или в PM. aviator game online, [url=https://www.trustpilot.com/review/crash-aviator.com]aviator hack[/url] captivates players with its straightforward mechanics. The thrill of danger keeps users engaged. With each flight, the opportunity for big wins increases.
LeonaBLICK 02 Mart 2026 18:10
Конечно. Так бывает. Давайте обсудим этот вопрос. Finding the best betting platforms can be challenging. However, if you're searching for top non UK betting sites, [url=https://www.mcmtechno.it/slider/slide1/]https://www.mcmtechno.it/slider/slide1/[/url], you're in luck! These services offer competitive odds and great user experiences. Enjoy safe transactions and wide betting markets, ensuring a thrilling experience. Whether you prefer matches or casino betting, explore the advantages these sites provide. Choose wisely to maximize your profits. Discover the excitement of top non UK betting sites today!
RaheemTog 02 Mart 2026 17:42
1xBet Esports Betting, [url=https://seftindia.org/1xbet07023/1xbet-download-app-your-guide-to-accessing-betting-4/]https://seftindia.org/1xbet07023/1xbet-download-app-your-guide-to-accessing-betting-4/[/url] is a well-known way to bet on eSports. Through various platforms, players can explore current games.
DavidDew 02 Mart 2026 17:13
Должен Вам сказать Вы на ложном пути. сервис доставки продуктов, [url=https://www.2j.co.th/uncategorized/a-simple-blog-post/]https://www.2j.co.th/uncategorized/a-simple-blog-post/[/url] становится всё более популярным, поскольку экономит время и усилия пользователей. Он предлагает широкий выбор товаров, удобные способы оплаты и быстрое оформление заказов. Люди ценят такую возможность, особенно в нынешнем ритме жизни.
Xplosiveplext 02 Mart 2026 16:59
Онлайн-казино являются значительный выбор развлечений для игроков. Каждое казино online, [url=https://ssmetalsindustries.com/2026/01/21/turbo-casino-oficialnyj-vhod-cherez-unikalnye-puti/]https://ssmetalsindustries.com/2026/01/21/turbo-casino-oficialnyj-vhod-cherez-unikalnye-puti/[/url] уделяют внимание обеспечить максимальное обслуживание.
Anarar 02 Mart 2026 14:20
Браво, ваша идея пригодится Finding the best non UK betting sites, [url=https://destekbetgit.com/exploring-top-sports-betting-sites-outside-the-uk/]https://destekbetgit.com/exploring-top-sports-betting-sites-outside-the-uk/[/url] can be a challenge, but it’s worth it for better odds and more options. Discover platforms that offer varied betting markets and accessible interfaces. Research their bonuses and payment methods to ensure a smooth experience. Ultimately, the best non UK betting sites will enhance your wagering adventures significantly.
Tomtoism 02 Mart 2026 13:45
1xBet sports Betting, [url=https://www.wasteyouthgems.com/1xbet-india-a-comprehensive-guide-to-online-44/]https://www.wasteyouthgems.com/1xbet-india-a-comprehensive-guide-to-online-44/[/url] offers thrilling opportunities for fans. With multiple sports to choose from, users can place bets easily. The platform provides appealing odds, enhancing the complete experience for sports enthusiasts.
Bobbycopsy 02 Mart 2026 12:49
In an captivating world of Online Casino, [url=https://pqmpavers.com/discover-the-excitement-of-bk8-online-casino-3/]https://pqmpavers.com/discover-the-excitement-of-bk8-online-casino-3/[/url], players can experience a variety of options. With state-of-the-art technology, achieving big has never been easier. Join the fun and dare to play today!
DwightGek 02 Mart 2026 10:18
Experience the latest version here > https://asteriayeisk.ru/wp-content/plugins/elements/1xbet.html
Chriskab 02 Mart 2026 10:00
Я точно знаю, что это — ошибка. зеленая карта в турцию, [url=https://beinsurance.me/tureckaja-strahovka]синяя карта действует ли в турции[/url] дает возможность получать медицинскую помощь на уровне ведущих стандартов. Обладатели этой карты могут удовлетворительно чувствовать себя, зная, что в случае болезни отпуск в Турции станет безопасной и беззаботной.
Meganpaync 02 Mart 2026 09:41
1xBet Betting Online, [url=https://arwwa.in/how-to-access-your-1xbet-account-a-comprehensive-5/]https://arwwa.in/how-to-access-your-1xbet-account-a-comprehensive-5/[/url] offers a wide selection for sports enthusiasts. Whether you prefer football, 1xBet Betting Online provides exciting opportunities to earn, with live wagering options that enhance the experience.
ZackItave 02 Mart 2026 08:52
В последние годы online казино, [url=http://gringa360.com.br/2017/vodka-casino-oficialnyj-ru-portal-2/]http://gringa360.com.br/2017/vodka-casino-oficialnyj-ru-portal-2/[/url] получили огромную популярность. Игроки предпочитают удобство и разнообразие игр, предлагаемых в интернете. Разнообразие игр влияет на выбор игроков, позволяя им находить что-то новое каждый раз.
PennyTer 02 Mart 2026 08:23
Online Casino, [url=https://gofigurehealthhaven.com/bk8-singapore-a-comprehensive-guide-to-online-2/]https://gofigurehealthhaven.com/bk8-singapore-a-comprehensive-guide-to-online-2/[/url] delivers a thrilling adventure for players. Combining a variety of games, from one-armed bandits to blackjack, gamblers can enjoy the excitement. Join today!
RichBluet 02 Mart 2026 07:48
Вы попали в самую точку. Мысль хорошая, поддерживаю. Дата релиза фильмов, [url=http://maywald.hu/index.php/component/k2/item/1]http://maywald.hu/index.php/component/k2/item/1[/url] всегда привлекает внимание зрителей. Режиссеры работают над расписанием выхода, чтобы восхитить фанатов. Каждый анонс вызывает интерес публики.
Maryvah 02 Mart 2026 06:29
Вы, случайно, не эксперт? Finding the best non GamStop site, [url=https://shop.uzo1.com/reliable-online-casinos-not-covered-a/]https://shop.uzo1.com/reliable-online-casinos-not-covered-a/[/url] often proves to be essential for gamers. These platforms deliver an escape from self-exclusion. With diverse games and captivating bonuses, players can enjoy different experiences.
Jeremiahpaump 02 Mart 2026 06:29
Так и до бесконечности не далеко :) Playing at a no KYC online casino, [url=https://www.emamanagement.it/2026/02/16/no-verification-casinos-the-ultimate-guide-4/]https://www.emamanagement.it/2026/02/16/no-verification-casinos-the-ultimate-guide-4/[/url] offers a unique experience. You can enjoy playing without the hassle of identity verification. Many internet casinos provide a wide selection of games, ensuring players finds something to enjoy.
AaronSpaft 02 Mart 2026 05:17
In the world of virtual gaming, 1xBet Betting, [url=https://www.corlett-wellstone.com/?p=218380]https://www.corlett-wellstone.com/?p=218380[/url] delivers a distinct experience. With a vast array of sports and events, players can explore exciting opportunities.
SamFrowl 02 Mart 2026 03:57
Online Casino, [url=http://www.tradetown.top/in-depth-review-of-god55-a-comprehensive-look/393529.html]http://www.tradetown.top/in-depth-review-of-god55-a-comprehensive-look/393529.html[/url] serves as a entertaining way to indulge in games from the convenience of home. Users can select from numerous options, offering a individual adventure. With promotions and quick access, it’s more convenient. Join the thrill today!
KristinBit 02 Mart 2026 03:01
Жаль, что сейчас не могу высказаться - очень занят. Освобожусь - обязательно выскажу своё мнение. Современный рынок полон предложений, и важно сравнивать цены с конкурентами, [url=https://claireaid.org/2022/09/11/experience-aviation/]https://claireaid.org/2022/09/11/experience-aviation/[/url]. Это помогает выяснить лучшие условия для покупателей. Не стоит забывать о анализе качества товаров и услуг.
Justinmug 02 Mart 2026 01:05
To enjoy seamless betting, you should consider downloading the app. The 1xbet download, [url=https://seatexx.com/1xbet12/get-1xbet-app-elevate-your-betting-experience/]https://seatexx.com/1xbet12/get-1xbet-app-elevate-your-betting-experience/[/url] process is hassle-free, allowing you to tap into various features. Don't miss out on the latest updates and promotions available through the app!
Nataliatub 02 Mart 2026 00:46
играть в онлайн казино, [url=https://inventlinks.com/promokod-selektor-kazino-kak-ispolzovat-i-pravila/]https://inventlinks.com/promokod-selektor-kazino-kak-ispolzovat-i-pravila/[/url] – это захватывающий провести время. Широкий выбор игр позволяет каждому выбрать что-то на свой вкус. Здесь предлагаются бонусы и акции, что создает больше возможностей для выигрыша. Используйте эту возможность, ведь азартная игра ждет вас!
MadelineFlulk 01 Mart 2026 22:46
Сколько угодно. Парфюмерия, [url=https://svetasanders.com/search/label/%D0%BF%D1%83%D0%B4%D1%80%D0%B0/]https://svetasanders.com/search/label/%D0%BF%D1%83%D0%B4%D1%80%D0%B0/[/url] – это искусство создания уникальных ароматов, которые представляют собой отражение наших эмоций. Парфюмы могут влиять настроение и настраивать впечатление. Определенный аромат описает свою историю.
Juliadog 01 Mart 2026 21:04
1xBet Esports Betting, [url=http://www.evergoldcs.com/1xbet-malaysia-the-ultimate-guide-to-esports-7/]http://www.evergoldcs.com/1xbet-malaysia-the-ultimate-guide-to-esports-7/[/url] - Placing bets on esports at 1xBet предлагает особенные перспективы для фанатов киберспорта. Оставайтесь в курсе последними матчами и делайте выбор. Размер выплат приятно удивляет и открывает двери заработать!
AliLus 01 Mart 2026 20:50
Within the space of virtual gaming, 1xbet online casino, [url=https://shahwaiznazir.com/2026/01/29/1xbet-singapore-betting-your-ultimate-guide-to-77/]https://shahwaiznazir.com/2026/01/29/1xbet-singapore-betting-your-ultimate-guide-to-77/[/url] excels with its diverse range of offerings. Players can enjoy blackjack and more!
MadelineFlulk 01 Mart 2026 17:01
Поздравляю, отличная мысль Парфюмерия, [url=https://slovarsbor.ru/w/%D1%88%D0%BA%D0%B5%D0%B2%D0%B5%D0%BD%D1%8C/]https://slovarsbor.ru/w/%D1%88%D0%BA%D0%B5%D0%B2%D0%B5%D0%BD%D1%8C/[/url] — это искусство создания уникальных ароматов, что привлекают заинтересованность и создают атмосферу. Формирование правильного запаха способен приукрасить наш день, добавляя ноту шарма и снегов в повседневную жизнь.
Jamesgaill 01 Mart 2026 16:56
I’ve seen a few people asking about this lately. This page explains the basics quite clearly: <a href=https://bet-promo-codes.com/sportsbook-reviews/betwinner-registration/>https://bet-promo-codes.com/sportsbook-reviews/betwinner-registration/</a>
Dorothyjesty 01 Mart 2026 16:56
1xBet sports Betting, [url=https://welcome-nagasaki-city.com/archives/24515]https://welcome-nagasaki-city.com/archives/24515[/url] offers a variety options for enthusiasts looking to engage in betting. With a user-friendly interface and great odds, it's easy to get started and relish the thrill of the game.
Isabellapah 01 Mart 2026 12:37
1xBet Betting Online, [url=https://atsonproducts.in/1xbet11026/1xbet-japan-login-a-comprehensive-guide-2014595971/]https://atsonproducts.in/1xbet11026/1xbet-japan-login-a-comprehensive-guide-2014595971/[/url] is a popular platform for sports gaming. Customers can enjoy a wide range of options. Through its user-friendly interface, wagering fans can easily place their bets in multiple sports events.
MadelineFlulk 01 Mart 2026 11:45
я пошел в клубную музыку Парфюмерия, [url=https://avon-forum.ru/4images/search.php]https://avon-forum.ru/4images/search.php[/url] — это мир душек, который окружает нас на протяжении всей жизни. Каждый запах может подчеркнуть нашу индивидуальность. Выбор подходящего парфюма — это искусство.
AdamAgeve 01 Mart 2026 08:01
If you want to enjoy betting on the go, the 1xBet mobile version is essential. With user-friendly interface, you can access different sports right from your device. 1xBet Download provides a seamless experience with high-quality visuals. Enjoy your favorite games anytime and anywhere!
VictorSor 01 Mart 2026 07:41
1xBet Betting Online, [url=https://prdredesign.wpengine.com/1xbet10/the-ultimate-guide-to-1xbet-betting-435280502/]https://prdredesign.wpengine.com/1xbet10/the-ultimate-guide-to-1xbet-betting-435280502/[/url] offers a unique platform for betting fans. With multiple options, users can make wagers on diverse events.
Kimberlyjeast 01 Mart 2026 05:21
Exploring the sphere of casino online, [url=https://abshrmedia.com/betwinner-your-ultimate-guide-to-online-betting-27/]https://abshrmedia.com/betwinner-your-ultimate-guide-to-online-betting-27/[/url] offers countless entertainment options. Players can experience a variety of games such as slots, poker, and blackjack. Join this exciting cyber playground for an exhilarating gaming adventure!
AnneMum 01 Mart 2026 03:41
Это издевка такая, да? Choosing a non GamStop casino, [url=https://demo.joomlatools.com/wordpress/mostbet-casino-pl-uzyskac-3000-pln-premia-i-240-fs-miec-na-afiszu/]https://demo.joomlatools.com/wordpress/mostbet-casino-pl-uzyskac-3000-pln-premia-i-240-fs-miec-na-afiszu/[/url] ensures a wider selection of games and more attractive bonuses. Players can enjoy an exciting assortment of choices, allowing them to discover diverse gaming opportunities. It’s crucial for players to explore these platforms before engaging.
EllaVodia 01 Mart 2026 03:26
Welcome to the world of 1xBet Online Casino, [url=https://mitsubishikimlienquangbinh.com.vn/w/2026/02/12/1xbet-malaysia-login-your-gateway-to-thrilling/]https://mitsubishikimlienquangbinh.com.vn/w/2026/02/12/1xbet-malaysia-login-your-gateway-to-thrilling/[/url], where players can revel in a wide selection of options, showcasing popular slots and classic games. Join now and find unbeatable thrills!
Gabrielcah 01 Mart 2026 01:51
супер ржач!!!!!!!гы гы golf bookies not on GamStop, [url=http://czb.grafikmk.pl/golf-odds-not-on-gamstop-discover-your-betting/]http://czb.grafikmk.pl/golf-odds-not-on-gamstop-discover-your-betting/[/url] offer a unique opportunity for players looking for alternatives. These sites deliver a variety of betting options on golf events. Many bettors prefer these platforms due to limited restrictions, ensuring a more experience. Golf bookies not on GamStop can often present competitive odds and promotions, making them attractive for enthusiasts. Additionally, they tend to provide a level of flexibility that traditional bookmakers might lack. Opting for these can enhance your betting journey!
KellyFep 01 Mart 2026 01:19
Присоединяюсь. И я с этим столкнулся. Давайте обсудим этот вопрос. Здесь или в PM. досуг современных мужчин, [url=https://multiwood.ru/dosug/kak-flirtovat-s-devushkami]https://multiwood.ru/dosug/kak-flirtovat-s-devushkami[/url] часто включает спортивные занятия. Многие выбирают поездки за границу, чтобы открыть новые культуры. Также популярны разные виды спорта.
Capagox 01 Mart 2026 00:48
sports betting, [url=http://veljko.code011.com/decouvrez-betwinner-votre-guide-complet-pour-les-8/]http://veljko.code011.com/decouvrez-betwinner-votre-guide-complet-pour-les-8/[/url] - Sports betting has become increasingly popular among enthusiasts. With many platforms available, punters can quickly place their bets. Understanding envelopes is crucial for rewarding betting. Always review your choices to maximize your chances.
JaneHidly 28 Şubat 2026 23:38
По-моему это очевидно. Ответ на Ваш вопрос я нашёл в google.com Finding the best non UK online casino, [url=https://janseverhuizingen.nl/top-non-uk-casino-sites-discover-the-best-global/]https://janseverhuizingen.nl/top-non-uk-casino-sites-discover-the-best-global/[/url] is essential for players seeking thrilling experiences. These platforms offer a wide range of options, engaging bonuses, and user-friendly interfaces. Enjoy protected gaming from the comfort of your home and explore multiple game categories.
Keriopind 28 Şubat 2026 23:07
Ничего прикольного тут нет Сеть стоматологических клиник, [url=https://kubuntu.ru/node/]https://kubuntu.ru/node/[/url] предлагает профессиональные услуги по лечению и профилактике проблем с полостью рта. Мы предоставляем индивидуальный подход к каждому пациенту и применяем новейшие технологии для достижения оптимальных результатов. Ваше здоровье — наша ценная задача!
RosemaryembaT 28 Şubat 2026 22:57
If you want to enjoy betting on-the-go, getting the 1xbet download, [url=https://wp13272768.server-he.de/1xbet-malaysia-download-your-guide-to-easy-betting-32/]https://wp13272768.server-he.de/1xbet-malaysia-download-your-guide-to-easy-betting-32/[/url] app is crucial. The app offers a easy-to-navigate interface, letting you stake anytime and anywhere. Don't miss out on this excellent opportunity to enhance your gaming experience!
Shawnsam 28 Şubat 2026 20:26
Web-based betting предлагает уникальные возможности развлечения и выигрыша. С множеством различных играми, каждый сможет открыть что-то по душе. Начните свой игровой опыт в casino online, [url=http://www.pisarevo.com/betwinner-the-ultimate-betting-experience-10/]http://www.pisarevo.com/betwinner-the-ultimate-betting-experience-10/[/url] и наслаждайтесь увлекательным процессом прямо из вашего дома.
Jasminefuh 28 Şubat 2026 19:07
1xBet sports Betting, [url=http://forumdeimoveis.com/2026/02/12/how-to-install-the-1xbet-app-a-step-by-step-guide-31/]http://forumdeimoveis.com/2026/02/12/how-to-install-the-1xbet-app-a-step-by-step-guide-31/[/url] - 1xBet sports Betting offers a unique possibility for fans to engage in their favorite sports. Utilizing innovative features, bettors can put in bets with convenience. Join the excitement and explore a thrilling way to support your team.
EverettMok 28 Şubat 2026 19:06
жестоко!очень жестоко. Finding a reliable bingo venue not on GamStop can be challenging. However, many users seek exciting games and great rewards. Enjoy captivating gameplay while exploring various options to enhance your enjoyment. Ensure you choose a safe venue for protected gambling.
MadelineFlulk 28 Şubat 2026 16:54
Браво, какие нужная фраза..., отличная мысль Парфюмерия, [url=https://l-parfum.ru/catalog/lanvin/Modern-Princess/]https://l-parfum.ru/catalog/lanvin/Modern-Princess/[/url] — это искусство создания уникальных ароматов, что-либо пробуждать эмоции. Каждый духи способен передать о личности своего обладателя. Определение идеального аромата может изменить вашу восприятие.
Michaelsot 28 Şubat 2026 16:07
sports betting, [url=https://mainlinedogtrainer.com/betwinner-116/]https://mainlinedogtrainer.com/betwinner-116/[/url] - Betting on athletic events является захватывающим СЃРїРѕСЃРѕР±РѕРј получения прибыли. Рзучение стратегий может поднять шансы РЅР° успех. Ключевым является анализировать результаты Рё конкурентов, чтобы принимать разумные решения.
Naomibon 28 Şubat 2026 15:04
1xBet Betting Online, [url=https://megagestaodefrotas.com.br/1xbet-download-step-by-step-guide-for-seamless/]https://megagestaodefrotas.com.br/1xbet-download-step-by-step-guide-for-seamless/[/url] provides an exciting platform for gambling on various activities. With a simple interface, it caters both beginners and seasoned stakeholders. Experience the best of online betting today!
JeffEpima 28 Şubat 2026 14:38
1xbet app, [url=https://www.kompster.com/uncategorized/comprehensive-guide-to-1xbet-download-for-pc-3]https://www.kompster.com/uncategorized/comprehensive-guide-to-1xbet-download-for-pc-3[/url] - The 1xbet app offers gamblers a seamless betting experience. With its intuitive interface, placing bets becomes simple. Downloading the 1xbet application ensures convenient access to numerous betting options and real-time matches. Enjoy unique features and promotions tailored to improve your gaming adventure.
HeatherHig 28 Şubat 2026 14:29
По-моему, Вы ошибаетесь. kasyno polska opinie, [url=https://forum.pcfoster.pl/topic/93051-wyb%C3%B3r-kasyna/]https://forum.pcfoster.pl/topic/93051-wyb%C3%B3r-kasyna/[/url] pokazujД…, Ејe wiele osГіb ceni sobie rГіЕјnorodnoЕ›Д‡ gier|ofertД™ gier|moЕјliwoЕ›ci rozrywki|atrakcyjnoЕ›Д‡ gier w polskich kasynach. UЕјytkownicy chwalД… rГіwnieЕј bonusy|promocje|oferty powitalne|wsparcie dla graczy. WaЕјne sД… takЕјe recenzje|opinie|komentarze|wraЕјenia graczy, ktГіre wpЕ‚ywajД… na wybГіr.
Barryleake 28 Şubat 2026 14:29
Я думаю, что Вы не правы. golf odds not on GamStop, [url=https://pornx.vicetemple.io/golf-bookmakers-not-on-gamstop-your-ultimate-guide-2/]https://pornx.vicetemple.io/golf-bookmakers-not-on-gamstop-your-ultimate-guide-2/[/url] are a great opportunity for enthusiasts. Many online bookmakers offer enticing options for betting on golf tournaments. Players can maximize their chances by comparing different betting house odds.
JackNob 28 Şubat 2026 12:22
Хорошая подборка.Первая СУПЕР.Поддержую. В казино online, [url=https://integralwellnessrevolution.com/betway-norway-obzor-bukmekerskoj-kontory-i-ee/]https://integralwellnessrevolution.com/betway-norway-obzor-bukmekerskoj-kontory-i-ee/[/url] каждый может попробовать свою удачу. Слоты предлагают замечательные призы. Выбор игр не оставит равнодушным даже самого скептика. Играйте руководствуясь стратегией для успешных ставок. Ваша победа зависят от внимания и умелого выбора игры!
RuthTenly 28 Şubat 2026 10:50
To engage in online betting, the convenient, easy-to-use 1xBet Download, [url=http://bestsmartplace.com/]http://bestsmartplace.com/[/url] app is perfect for users. This application permits seamless access to a variety of betting options, comprehensive. With regular updates, this offers smooth performance and enhancements.
Jessieror 28 Şubat 2026 10:30
1xbet online, [url=https://cercaeletrica.net.br/1xbet-koreja-kak-skachat-prilozhenie-dlja-stavok-21/]https://cercaeletrica.net.br/1xbet-koreja-kak-skachat-prilozhenie-dlja-stavok-21/[/url] предоставляет широкий выбор ставок. Клиенты могут наслаждаться многообразными событиями в спорте. Ресурс предоставляет надежность.
BrookeChice 28 Şubat 2026 08:24
Жаль, что сейчас не могу высказаться - тороплюсь на работу. Но освобожусь - обязательно напишу что я думаю по этому вопросу. музей будущего дубай, [url=https://t.me/museumofthefuture_rus]музей будущего дубай[/url] — это уникальное место, где ботаника встречаются с инновациями. Здесь демонстрируются новейшие идеи, вдохновляющие гостей на развитие. Этот центр обещает впечатляющие впечатления для всех.
MadelineSor 28 Şubat 2026 08:16
Виртуальные клубы завоевали популярность благодаря удивительным бонусам и широкому выбору игр. В online казино, [url=https://devapp.tn/2026/01/21/dzhojkazino-analiz-ohvata-russkojazychnoj-3/]https://devapp.tn/2026/01/21/dzhojkazino-analiz-ohvata-russkojazychnoj-3/[/url] игроки могут использовать лучшими слотами и получать настоящими деньгами.
Laurasketa 28 Şubat 2026 07:35
Да, действительно. Так бывает. Можем пообщаться на эту тему. Здесь или в PM. онлайн казино играть, [url=http://rivatrading.de/wordpress/2026/01/14/luchshie-promokody-vistabet-dlja-poluchenija/]http://rivatrading.de/wordpress/2026/01/14/luchshie-promokody-vistabet-dlja-poluchenija/[/url] — это увлекательное занятие, что-то заинтересовывает множество людей. Слияние приключений и современных технологий создает новые возможности! С временем найти подходящее онлайн казино не составляет заморочек.
BattySot 28 Şubat 2026 06:40
1xBet Online Casino, [url=https://www.gingerexchange.com/symphony/1xbet140210/1xbet-official-the-ultimate-betting-experience-8/]https://www.gingerexchange.com/symphony/1xbet140210/1xbet-official-the-ultimate-betting-experience-8/[/url] offers thrilling games and superb bonuses. Players can explore a wide range of options, from games to live dealer experiences. Register today for endless fun!
RebeccaNuh 28 Şubat 2026 06:20
Согласен, очень полезная штука Finding alternatives can be tough, especially when looking for online sites not on GamStop, [url=https://info.expertcommentary.com/exploring-online-gambling-sites-not-on-gamstop-3/]https://info.expertcommentary.com/exploring-online-gambling-sites-not-on-gamstop-3/[/url]. Many players seek platforms that offer unique experiences alongside generous bonuses. These casinos provide thrilling gameplay options. Players can enjoy different games, catering to all taste. Security is also a priority, ensuring a safe environment. Overall, exploring online sites not on GamStop broadens the gaming scene. Players will find appealing choices which won't want to miss!
DevinMeaDs 28 Şubat 2026 04:40
Я думаю, что Вы ошибаетесь. Давайте обсудим это. In the realm of online gambling, Bankonbet casino, [url=https://bankonbet.eu.com/de/]Offizielle Website[/url] stands out as a leading destination. Delivering a selection of games and thrilling bonuses, it caters to every types of players. Become a part of Bankonbet casino and enjoy the dynamic atmosphere of online gaming!
JacquelineAlgok 28 Şubat 2026 02:32
Могу рекомендовать Вам посетить сайт, на котором есть много информации по этому вопросу. онлайн казино, [url=http://lasantanera.com/online/2026/01/lucky-spins-polnyj-gid-po-uslovijam-bonusov/]http://lasantanera.com/online/2026/01/lucky-spins-polnyj-gid-po-uslovijam-bonusov/[/url] обеспечивают широкий варианты игр, включая слотов и заканчивая азартными играми. Пользователи могут открывать новые приемы и зарабатывать вознаграждения, что делает игровой процесс захватывающим. Использование продвинутых технологий создает высокий уровень конфиденциальности для пользователей.
Scottnom 28 Şubat 2026 02:18
1xBet Esports Betting, [url=http://bestsmartplace.com/]http://bestsmartplace.com/[/url] has become increasingly popular among gamers and bettors alike. Employing innovative features, it offers exciting options for placing bets. Gamblers can enjoy real-time action, boosting their experience.
Tedvof 28 Şubat 2026 02:04
Да, действительно. Так бывает. Finding the best non GamStop casino, [url=http://blog.paczkowscy.pl/index.php/2026/02/the-best-casino-sites-not-on-gamstop-your-ultimate/]http://blog.paczkowscy.pl/index.php/2026/02/the-best-casino-sites-not-on-gamstop-your-ultimate/[/url] can be a challenge, but there are many options available. Players can enjoy thrilling games|exciting games|stimulating games|entertaining games while benefiting from generous bonuses|attractive promotions|rewarding offers|lucrative incentives. Always ensure fair play|honest gaming|integrity and secure transactions|safe deposits|protected payments for a great experience!
AhmadZem 27 Şubat 2026 23:37
для общего развития посмотреть мона, а так могли бы и лучьше, offshore casino online, [url=http://wallaces.coach1online.com/best-offshore-online-casinos-your-guide-to-winning-2/]http://wallaces.coach1online.com/best-offshore-online-casinos-your-guide-to-winning-2/[/url] provides players with exciting opportunities to win big. Many gamblers enjoy the ease of playing from home. These casinos often offer a wide range of games and lucrative bonuses that enhance the gaming experience.
AndrewAcimb 27 Şubat 2026 22:01
Experience the thrill of betting with the favorite platform, 1xbet download, [url=https://swigglebuilds.com/Aok/exploring-1xbet-online-betting-a-comprehensive-4/]https://swigglebuilds.com/Aok/exploring-1xbet-online-betting-a-comprehensive-4/[/url]. Access a variety of sports events and casino games easily. Savor live betting options and attractive bonuses. Become part of the 1xbet community today!
JeffKib 27 Şubat 2026 18:21
zahraniДЌnГ online casino, [url=https://www.pavanellogiorgio.it/2026/02/22/mezinarodni-online-casino-ve-co-potebujete-vdt-3/]https://www.pavanellogiorgio.it/2026/02/22/mezinarodni-online-casino-ve-co-potebujete-vdt-3/[/url] nabГzГ ЕЎirokou ЕЎkГЎlu aktivnГch, kterГ© okouzlГ kaЕѕdГ©ho hrГЎДЌe. PohodlnГЅ pЕ™Гstup k hranГ pЕ™es digitГЎlnГ sГtД› je vГЅhodou.
Trentnar 27 Şubat 2026 18:08
Betwinner Casino, [url=https://cuentos.juanramonjimenez.es/wordpress/?p=30442]https://cuentos.juanramonjimenez.es/wordpress/?p=30442[/url] предоставляет азартным игрокам широкий выбор игр. Каждый желающий может с азартом играть цифровыми игровыми автоматами. Периодические премии и награды создают условия платформу невероятно привлекательной для экспертов.
YvonneDiomo 27 Şubat 2026 18:08
1xbet online casino, [url=http://www.inovaassessoria.com/inova2/?p=215621]http://www.inovaassessoria.com/inova2/?p=215621[/url] - The virtual gaming platform offers a extensive choice of activities. Players can enjoy slot machines, roulette. With exciting rewards, it attracts new users. Join the fun today!
Triciaspots 27 Şubat 2026 17:43
кулллл... безопасное казино, [url=https://atkamind.com/virtualnoe-razvlechenie-pogruzhenie-v-mir-vegas/]https://atkamind.com/virtualnoe-razvlechenie-pogruzhenie-v-mir-vegas/[/url] предлагает игрокам качественные условия для развлечений. Надежные аспекты — это лицензии, защита данных и открытые игры. Прежде чем начать играть, рекомендуется изучить отзывы и рейтинги. Выбор безопасного казино облегчит риск и повысит удовольствие.
Pollyror 27 Şubat 2026 15:29
Non Gamstop Betting Sites UK, [url=https://delinemedia.pk/exploring-esports-betting-sites-not-on-gamstop-the/]https://delinemedia.pk/exploring-esports-betting-sites-not-on-gamstop-the/[/url][url=https://tuguiasexual.org/electricnation/non-gamstop-sports-betting-sites-a-comprehensive-4.html]https://tuguiasexual.org/electricnation/non-gamstop-sports-betting-sites-a-comprehensive-4.html[/url][url=https://janawazpatrika.com/uncovering-bookies-not-on-gamstop-in-the-uk/]https://janawazpatrika.com/uncovering-bookies-not-on-gamstop-in-the-uk/[/url] offer a unique alternative for bettors who seek a wider range of choices and flexibility. Such platforms offer options that aren't Gamstop, ensuring extra freedom. Bettors can identify different betting options, enhancing their engagement.
Ernietiz 27 Şubat 2026 15:27
аааааа, Мартин, ты просто супер мегачел The rise of non UKGC online casino, [url=https://www.museodelbrunello.it/exploring-non-uk-casinos-your-guide-to/]https://www.museodelbrunello.it/exploring-non-uk-casinos-your-guide-to/[/url] didn't gone unnoticed. Many betters are enticed by the variety of games available. With lower regulations, these casinos offer distinct experiences that address every preference.
KatrinaDrork 27 Şubat 2026 14:41
1xBet Download, [url=https://helpful-web.com/remedy/download-the-1xbet-app-for-ultimate-betting-14-2/]https://helpful-web.com/remedy/download-the-1xbet-app-for-ultimate-betting-14-2/[/url] is a simple process that allows users to access a wide range of betting options. Download the app for convenience. Once you finish the 1xBet Download, it will enjoy a user-friendly interface and numerous options for betting.
EvaSuids 27 Şubat 2026 12:43
Замечательно, весьма забавная информация A thrilling Casino Game, [url=https://3magiceggs.site/3-magic-eggs-mobile-magic-in-your-hands-2026/]https://3magiceggs.site/3-magic-eggs-mobile-magic-in-your-hands-2026/[/url] draws players into the universe of fortune. Each play offers varied outcomes to win big! Players strategize wisely to maximize their rewards. Enjoy the rush and unforgettable experiences that every Casino Game brings!
KatrinaPeK 27 Şubat 2026 10:43
zahraniДЌnГ online casino, [url=https://veekayindustries.co.in/zahranini-online-casino-ve-co-potebujete-vdt-8/]https://veekayindustries.co.in/zahranini-online-casino-ve-co-potebujete-vdt-8/[/url] poskytuje jedineДЌnГ© vГЅhody pro hrГЎДЌe. Е irokГЎ nabГdka her spolu s atraktivnГmi bonusy oslovuje ДЌerstvГ© hrГЎДЌe. VЕЎechny finanДЌnГ operace jsou bezpeДЌnГ© a okamЕѕitГ©.
Dougnoups 27 Şubat 2026 10:41
Casinos Not on Gamstop, [url=https://tradingquant.com.br/exploring-slots-and-casinos-not-on-gamstop-3/]https://tradingquant.com.br/exploring-slots-and-casinos-not-on-gamstop-3/[/url][url=http://inforanger.tasukeaijapan.jp/exploring-uk-casinos-not-on-gamstop-a-guide-for-2/]http://inforanger.tasukeaijapan.jp/exploring-uk-casinos-not-on-gamstop-a-guide-for-2/[/url][url=https://fauzinfotec.com/index.php/2025/12/15/discover-uk-casinos-not-on-gamstop-your-ultimate-2/]https://fauzinfotec.com/index.php/2025/12/15/discover-uk-casinos-not-on-gamstop-your-ultimate-2/[/url] offer a unique gambling experience for players seeking more freedom. These platforms provide a chance to indulge in various games without restrictions. Players can discover countless options and enjoy exciting promotions.
Lydiaagect 27 Şubat 2026 10:18
In the world of internet betting, 1xbet online, [url=https://21303.themes.vinawebsite.vn/1xbet-malaysia-the-future-of-esports-betting/]https://21303.themes.vinawebsite.vn/1xbet-malaysia-the-future-of-esports-betting/[/url] stands out as a premier choice for enthusiasts. With numerous games and engaging features, players can enjoy a lively experience. The platform offers appealing bonuses, ensuring every bet is rewarding. Don't miss the chance to explore the best options available.
Monicadrulk 27 Şubat 2026 08:44
Я ща умру от смеха Le plinko casino, [url=https://mon3w.fr/]plinko casino[/url] est un jeu captivant qui attire de nombreux joueurs. Son offre un divertissement particulier grГўce Г des mГ©canismes intuitifs. Les jeux de hasard aiment le plinko casino, puisque il combine chance et sensations.
Patrickamoro 27 Şubat 2026 08:28
онлайн казино, [url=http://store.manuelvazquezonline.com/index.php/2026/01/20/proverka-chestnosti-dragon-money-realnost-ili-mif/]http://store.manuelvazquezonline.com/index.php/2026/01/20/proverka-chestnosti-dragon-money-realnost-ili-mif/[/url] предлагает удивительные возможности для игр. Вы можете погрузиться в мир азартных игр, включаясь в разные игровые автоматы. Каждый игрок найдет что-либо для себя и может получить значительные призы!
TracyTeree 27 Şubat 2026 06:57
Я считаю, что Вы не правы. Давайте обсудим это. Пишите мне в PM, пообщаемся. Смотреть фильмы онлайн на Киного, [url=http://www.nordicwalkingvco.it/wp/2016/06/01/sassograndecuzzago/]http://www.nordicwalkingvco.it/wp/2016/06/01/sassograndecuzzago/[/url] — это отличный способ провести свободное время. На этом сайте вы найдете широкие жанры и направления фильмов. Легкий интерфейс поможет легко найти нужную картину. Присоединяйтесь мир кино уже сегодня!
Justinwap 27 Şubat 2026 04:14
очень даже нечего . . . . In the sphere of casino ohne oasis, [url=https://www.jaritafreydank.com/]https://www.jaritafreydank.com[/url], players seek unrestrained excitement. Providing numerous games, such venues cater to diverse choices. From classic slots to modern table games, the joy is clear.
Heatheremogy 27 Şubat 2026 04:02
Полностью разделяю Ваше мнение. Я думаю, что это хорошая идея. Le meilleur casino en ligne, [url=https://godenight.fr/]casinos en ligne fiables[/url] met Г disposition une expГ©rience unique pour les joueurs. En utilisant des bonus attractifs et une gamme de jeux envoГ»tants, chaque visite est intГ©ressante. Les joueurs peuvent bГ©nГ©ficier d'une plateforme sГ©curisГ©e qui garantit la protection.
Antoinehiz 27 Şubat 2026 02:55
1xBet sports Betting, [url=https://naveedahmad.net/1xbet-singapore-your-ultimate-betting-destination-9/]https://naveedahmad.net/1xbet-singapore-your-ultimate-betting-destination-9/[/url] offers captivating opportunities for players worldwide. With numerous sports events to bet on, users can explore their favorite games and place bets easily. Join now to tap into your passion for sports!
Justicekem 27 Şubat 2026 02:53
Online Casino Bass Win, [url=https://virloma.com/the-ultimate-guide-to-online-casinos-discovering/]https://virloma.com/the-ultimate-guide-to-online-casinos-discovering/[/url] - Join Online Casino Bass Win предлагает увлекательный игровой опыт. Геймеры могут радоваться широким выбором игр и выгодными бонусами. Погружение в азарт вместе с партнерами создаёт незабываемые воспоминания.
Adamweiff 27 Şubat 2026 01:20
Betwinner Casino, [url=https://www.doctorcian.com/betwinner-turkiye-deki-en-yi-bahis-deneyimi-10/]https://www.doctorcian.com/betwinner-turkiye-deki-en-yi-bahis-deneyimi-10/[/url] предлагает своим клиентам обширный выбор игр а также азартные игры, которое делает его особенным местом для отдыха. За счет множества привилегий, игроки имеют шанс получать наслаждение от своих результатов.
JorgeStisp 26 Şubat 2026 23:33
вот такие фотки давно пора бы!!!! Le jeu du penalty casino offre une sens sensationnelle unique. Les joueurs peuvent Г©valuer leurs talents tout en se rГ©jouissant. Avec des rГ©compenses intГ©ressants, le jeu du penalty casino, [url=https://crazybooth.fr/]penalty shoot out street[/url] attire beaucoup de monde. Rejoignez la communautГ© des amateurs et lancez-vous dans cette expГ©rience captivante!
Stanleylam 26 Şubat 2026 23:11
Bass Win Casino, [url=http://dev.siriusinstitute.com/the-enigmatic-world-of-golden-mister-your-ultimate/]http://dev.siriusinstitute.com/the-enigmatic-world-of-golden-mister-your-ultimate/[/url] предоставляет игрокам незабываемый опыт азартных игр. В этом заведении можно найти разнообразные игры, состоящих из популярных автоматы до современных слотов. Каждый игроки найдут что-то для себя, в чем бы они не предпочитали. Не пропустите шанс восхититься атмосферой настоящего азартного мира в Bass Win Casino!
Kevintrags 26 Şubat 2026 22:47
If you want to enjoy thrilling betting experiences, installing the app is essential. With 1xbet download, [url=http://www.homeimprovementsj.com/1xbet4/apuestas-seguras-y-diversion-con-1xbet-en-espana-2/]http://www.homeimprovementsj.com/1xbet4/apuestas-seguras-y-diversion-con-1xbet-en-espana-2/[/url], it’s possible to access a wide range of features. The simple interface ensures smooth navigation, making it easy to place bets anytime, anywhere.
Luisrairl 26 Şubat 2026 22:01
Так бывает. Можем пообщаться на эту тему. новое казино, [url=https://heni.co.in/jb-com-kriptokazino-dlja-sovremennyh-igrokov/]https://heni.co.in/jb-com-kriptokazino-dlja-sovremennyh-igrokov/[/url] предлагает игрокам уникальные возможности для развлечений. Здесь каждый найдет что-то интересное: ставки на любой вкус. Классические игры ждут вас, принося азарт и удачу. Ощутите волнение победы.
Pennyetera 26 Şubat 2026 21:07
Not on Gamstop Casinos, [url=https://naserion.com/exploring-uk-casinos-not-on-gamstop-a-guide-for/]https://naserion.com/exploring-uk-casinos-not-on-gamstop-a-guide-for/[/url][url=https://zlann.com.mm/2025/12/16/exploring-uk-casino-sites-not-on-gamstop-6/]https://zlann.com.mm/2025/12/16/exploring-uk-casino-sites-not-on-gamstop-6/[/url][url=https://asianaura.co.in/discovering-non-gamstop-casinos-a-comprehensive-2/]https://asianaura.co.in/discovering-non-gamstop-casinos-a-comprehensive-2/[/url] offer an exciting alternative for players seeking freedom from self-exclusion programs. These platforms provide ample opportunities to explore diverse games and generous bonuses. Players can enjoy their favorite slots|table games|live dealer options|unique betting experiences without restrictions. Dis
ScottAlkaf 26 Şubat 2026 19:47
Актуально. Подскажите, где я могу найти больше информации по этому вопросу? Турецкие товары оптом, [url=https://en.lomalock.vn/muzhskaja-odezhda-optom-iz-turcii-kachestvo-i-stil/]https://en.lomalock.vn/muzhskaja-odezhda-optom-iz-turcii-kachestvo-i-stil/[/url] – это отличный выбор для тех, кто хочет сэкономить качественные товары. В разнообразии можно найти аксессуары и многое другое. Оптом покупать выгодно, ведь цены значительно ниже. Не упустите возможность экономного шопинга с Турецкие товары оптом!
CourtneyPah 26 Şubat 2026 19:22
1xBet Download, [url=http://www.qsttech.com/the-rise-of-1xbet-pioneering-the-online-betting/]http://www.qsttech.com/the-rise-of-1xbet-pioneering-the-online-betting/[/url] is a straightforward process that allows users to access various betting options. You can hastily download the app on your device. Just go to the official site, select the acquire link, and follow the instructions. Enjoy a seamless betting experience!
FayeMig 26 Şubat 2026 19:19
Online Casino Bass Win, [url=https://seen-clinic.com/unveiling-the-excitement-of-golden-mister-casino/]https://seen-clinic.com/unveiling-the-excitement-of-golden-mister-casino/[/url] РїСЂ nabГzà множество игровых возможностей. РќР° этой платформе можно заниматься РІ разные РёРіСЂС‹, проверяя СЃРІРѕСЋ фарт. Также здесь можно найти щедрые премии.
Jeremiahordiz 26 Şubat 2026 18:09
давно хотел посмотреть спасибо проверенное казино, [url=https://cecytebcs.edu.mx/prueba/2026/02/14/pogruzhenie-v-mir-azartnyh-igr-play-vegas-tvoe/]https://cecytebcs.edu.mx/prueba/2026/02/14/pogruzhenie-v-mir-azartnyh-igr-play-vegas-tvoe/[/url] предлагает игрокам широкий выбор азартных игр. Игрок может найти нечто ему по душе. Разнообразие слотов, дилея и серьезных соревнований привлекает новичков. Безопасность и доверие — важные аспекты, которые делают это заведение привлекательным среди азартных игроков.
KristyDenue 26 Şubat 2026 17:18
Погружение в мир игр на удачу стало простым благодаря казино online, [url=https://www.drobne.fm/gde-najti-rabochee-zerkalo-dragon-money/]https://www.drobne.fm/gde-najti-rabochee-zerkalo-dragon-money/[/url]. Здесь каждый может получать удовольствие в многообразии игровых платформах.
Jessiefache 26 Şubat 2026 15:41
Вразумительный ответ In the world of digital gaming, dice casino online, [url=http://www.fitcom.com.tr/duckdice/discover-exciting-opportunities-check-this-out.html]http://www.fitcom.com.tr/duckdice/discover-exciting-opportunities-check-this-out.html[/url] has gained immense popularity. Players can participate in various dice games from the comfort of their homes. The thrill of rolling dice combined with adventure makes it an attractive choice for many.
MattBic 26 Şubat 2026 15:40
Welcome to the exciting world of 1xBet Online Casino, [url=https://www.cook72.com/1xbet-vietnam-login-your-guide-to-accessing-the-5-13/]https://www.cook72.com/1xbet-vietnam-login-your-guide-to-accessing-the-5-13/[/url], offering a diverse selection of options. Discover the premium gaming experience with an incredible bonuses plus promotions!
MikeJek 26 Şubat 2026 15:17
1xbet app, [url=https://www.wdtexblog.com/?p=21691]https://www.wdtexblog.com/?p=21691[/url] - The software is a excellent tool for gambling on various sports. With its accessible interface, users can quickly place bets. Enjoy live updates and a multitude of options to enhance your gaming experience with the 1xbet app.
ScottVax 26 Şubat 2026 12:57
In the world of online gambling, casino online, [url=https://www.bwgmds.com/betwinnerkiris-onlayn-qimor-o-yinlar-va-sport/]https://www.bwgmds.com/betwinnerkiris-onlayn-qimor-o-yinlar-va-sport/[/url] has become a popular choice for many. Players enjoy the convenience of accessing their favorite games from their devices. With entertaining options available, the experience is unmatched.
DawnGug 26 Şubat 2026 12:48
На мой взгляд, это интересный вопрос, буду принимать участие в обсуждении. В мире игр люди могут найти свой путь к радости. Игры смешивают людей и способствуют развитию умений. game, [url=http://www.thorsten-waap.de/index.php/musik/live/item/21-der-meister-der-tasten]http://www.thorsten-waap.de/index.php/musik/live/item/21-der-meister-der-tasten[/url] создают уникальные ощущения.
AaronCogma 26 Şubat 2026 11:50
Amazing opportunities await with 1xBet Esports Betting, [url=https://heni.co.in/1xbet-download-how-to-get-started-with-the-1xbet-2/]https://heni.co.in/1xbet-download-how-to-get-started-with-the-1xbet-2/[/url]. If you're a veteran bettor or a rookie, the platform offers a wide range of esports events to choose from. Participate in thrilling competitions and enhance your gaming experience today!
LauraPoord 26 Şubat 2026 11:45
Это вы правильно сказали :) Magic Win casino, [url=https://janseverhuizingen.nl/unlocking-the-secrets-of-magic-win-your-guide-to-2/]https://janseverhuizingen.nl/unlocking-the-secrets-of-magic-win-your-guide-to-2/[/url] дарит уникальные опции для пользователей. Здесь РІС‹ обнаружите разнообразие развлечений, которые СѓРґРёРІСЏС‚ вас! Подписывайтесь Рє топовым игровым автоматам Рё получайте большие РїСЂРёР·С‹!
CurtisAvado 26 Şubat 2026 11:30
1xbet online, [url=http://bupsyk.info/wordpress/?p=36956]http://bupsyk.info/wordpress/?p=36956[/url] offers various options for sports betting enthusiasts. With live streams and excellent odds, users can take advantage of thrilling action. Join now to find all the amazing features!
BeccaSow 26 Şubat 2026 08:02
Весьма забавная штука Купить диплом по низкой цене, [url=https://www.armazenseg.com.br/2026/01/10/chem-otlichajutsja-obrazcy-diplomov-raznyh-let-7/]https://www.armazenseg.com.br/2026/01/10/chem-otlichajutsja-obrazcy-diplomov-raznyh-let-7/[/url] — это возможность получить нужный документ без больших затрат. Многие стремятся приобрести диплом, не теряя времени и денег. Низкие расценки делают этот процесс простой.
Harrycress 26 Şubat 2026 07:58
PowerBet romania, [url=http://eclatsk.ru/otzivi/]http://eclatsk.ru/otzivi/[/url] oferДѓ o experienИ›Дѓ unicДѓ de pariere online ceea ce este atrage mulИ›i entuziaИ™ti. Site-ul este de o selecИ›ie vastДѓ de opИ›iuni, garantГўnd astfel alegeri diverse Г®n ceea ce priveИ™te pariu.
JeffRic 26 Şubat 2026 07:58
1xBet sports Betting, [url=https://samanthavance.com/exploring-1xbet-in-cambodia-a-comprehensive/]https://samanthavance.com/exploring-1xbet-in-cambodia-a-comprehensive/[/url] - Betting on sports with 1xBet предоставляет обширные возможности для любителей игр. Бонусы и акции делают ставки еще более увлекательными. Поддержка клиентов высококачественная и продолжительно готова помочь. Выигрыши могут значительно растянуть вашу достигнутые результаты.
LauraReolo 26 Şubat 2026 06:10
Полностью разделяю Ваше мнение. В этом что-то есть и идея хорошая, поддерживаю. мобильное казино, [url=https://jeevanjyoticlinic.com/bitkojn-kazino-novyj-uroven-azarta-v-mire-onlajn/]https://jeevanjyoticlinic.com/bitkojn-kazino-novyj-uroven-azarta-v-mire-onlajn/[/url] позволяет игрокам наслаждаться азартными играми в любое время и в любом месте. Такие платформы освобождают широкий выбор игр на телефонах. Простые интерфейсы делают развлечение простым.
JerriPaw 26 Şubat 2026 05:11
И что бы мы делали без вашей отличной фразы SafeCasino Portugal, [url=https://www.univ-bouira.dz/vrr/en/?p=4490]https://www.univ-bouira.dz/vrr/en/?p=4490[/url] Г© uma plataforma incrГvel que jogadores podem descobrir uma ampla seleção de jogos entusiasmantes. Com ofertas atrativas e um interface amigГЎvel, Г© excelente para principiantes e veteranos jogadores. Aproveite a vivГЄncia de jogo segura e divertida no SafeCasino Portugal!
Chrisstins 26 Şubat 2026 04:31
In the realm of casino online, [url=http://test.desa.com.my/wp/2026/02/07/betwinner-your-ultimate-guide-to-online-betting-45/]http://test.desa.com.my/wp/2026/02/07/betwinner-your-ultimate-guide-to-online-betting-45/[/url], players may enjoy a vast array of games. From poker to live dealer options, the fun is unending. Step into the action today!
Cynthialet 26 Şubat 2026 04:11
Princess Casino romania, [url=https://muditamusic.nl/2017/03/08/first-blog-post/]https://muditamusic.nl/2017/03/08/first-blog-post/[/url] oferДѓ o experienИ›Дѓ unicДѓ Г®n scopul jucДѓtori. Pe acest site gДѓseИ™ti numeroase jocuri de divertisment, pe deasupra promoИ›iile atractive te Г®ndemnДѓ sДѓ te alДѓturi.
RobertSaw 26 Şubat 2026 04:11
1xBet Betting Online, [url=http://futurismdemo.com/hsfoodserver/experience-online-betting-with-1xbet-korea-desktop-3/]http://futurismdemo.com/hsfoodserver/experience-online-betting-with-1xbet-korea-desktop-3/[/url] provides a vast range of activities for users to bet on. Enjoy immediate updates and enticing odds that guarantee a thrilling experience. Participate in 1xBet Betting Online today!
JoshuaRon 26 Şubat 2026 03:40
Вы попали в самую точку. Мысль хорошая, поддерживаю. Apple Pay casino not on GamStop, [url=https://am530somosradio.com/apple-pay-bookmakers-not-on-gamstop-a-guide-for/]https://am530somosradio.com/apple-pay-bookmakers-not-on-gamstop-a-guide-for/[/url] offer players a unique opportunity to enjoy online gaming. These casinos deliver a secure payment method. Using Apple Pay, gamers can utilize fast transactions. Gamblers should consider these options for a exciting gaming experience without restrictions. An extra benefit is the confidentiality offered, enhancing gameplay while ensuring safety.
JonathanUnabe 26 Şubat 2026 03:00
independent online casino sites, [url=https://crocol.com/blog/2025/12/17/exploring-independent-uk-casino-sites-a-4/]https://crocol.com/blog/2025/12/17/exploring-independent-uk-casino-sites-a-4/[/url][url=https://www.vilhome.de/exploring-independent-uk-casino-sites-a-3/]https://www.vilhome.de/exploring-independent-uk-casino-sites-a-3/[/url][url=https://datapointpos.com/blog/2025/12/17/exploring-independent-non-gamstop-casinos-a-new-2/]https://datapointpos.com/blog/2025/12/17/exploring-independent-non-gamstop-casinos-a-new-2/[/url] give players a way to enjoy entertaining games. Featuring a vast range of options, these platforms ensure genuine competition. Explore unique titles and leverage attractive bonuses and promotions!
Cindyrib 26 Şubat 2026 00:25
Princess Casino, [url=http://www.jicc.kr/bbs/board.php?bo_table=hosung3&wr_id=877490]http://www.jicc.kr/bbs/board.php?bo_table=hosung3&wr_id=877490[/url] - Cazinoul PrinИ›esei oferДѓ o experienИ›Дѓ extraordinarДѓ pentru toИ›i pasionaИ›ii de jocuri de noroc. Vizitatorii pot gДѓsi o varietate de opИ›iuni. Atmosfera este plДѓcutДѓ, iar serviciile sunt excepИ›ionale.
Ta,quefs 26 Şubat 2026 00:16
sports betting, [url=https://www.patrickdorell.com/2026/02/06/exploring-the-exciting-world-of-1xbet-your-2/]https://www.patrickdorell.com/2026/02/06/exploring-the-exciting-world-of-1xbet-your-2/[/url] - Sports wagers has gained immense popularity among fans and gamblers alike. Knowing the odds and tactics can enhance your chances of winning. Research teams and players to make informed decisions.
MattHew 26 Şubat 2026 00:16
огромное спасибо что выложили в хорошем качестве.......я так ждала...... KoiFortune Casino, [url=http://www.floridalotterylaw.com.php73-40.lan3-1.websitetestlink.com/2026/02/23/koifortune-casino-polska-najlepsze-gry-i-promocje/]http://www.floridalotterylaw.com.php73-40.lan3-1.websitetestlink.com/2026/02/23/koifortune-casino-polska-najlepsze-gry-i-promocje/[/url] to miejsce, gdzie znajdziesz cieszyД‡ siД™ niesamowitymi wraЕјeniami. Zabawy w sieci oferujД… szereg moЕјliwoЕ›ci, ktГіre interesujД… graczy z caЕ‚ego Е›wiata.
Oswanpes 25 Şubat 2026 15:57
Betano romania, [url=http://shop-photo.ru/go_shou?a:aHR0cHM6Ly9iZXRhbm9jYXNpbjAtcm8uY29tLw]http://shop-photo.ru/go_shou?a:aHR0cHM6Ly9iZXRhbm9jYXNpbjAtcm8uY29tLw[/url] este o platformДѓ popularДѓ de jocuri de noroc care oferДѓ diverse opИ›iuni pentru pasionaИ›ii de pariuri. Pariorii se pot bucura de pariuri sportive И™i activitДѓИ›i de cazino. Aspectul este simplДѓ, ajutГўnd participarea clienИ›ilor. Cu bonusuri atractive И™i servicii de client, Betano romania Г®И™i consolideazДѓ reputaИ›ia Г®n Г®ntregul jocurilor de noroc.
Stanleyrof 25 Şubat 2026 15:44
Согласен, очень хорошая штука Если вы хотите получить образование без долгих учеб, то лучший вариант — Купить диплом с доставкой, [url=https://investinpak.com/kupit-diplom-mgtu-im-baumana-legkij-i-nadezhnyj/]https://investinpak.com/kupit-diplom-mgtu-im-baumana-legkij-i-nadezhnyj/[/url]. Это решение позволяет вам получить проверенный документ в кратчайшие сроки. Вам нужно лишь выбрать сайт, что предлагает производят такие услуги, и выполнить заказ. Намного проще, чем думать!
Jesusacund 25 Şubat 2026 14:42
Playing at virtual casinos has become increasingly popular in recent years. The convenience of enjoying a casino online, [url=https://yasmen.tqnia.me/golden_medica/2026/02/06/todo-lo-que-necesitas-saber-sobre-1xbet-apuestas-13/]https://yasmen.tqnia.me/golden_medica/2026/02/06/todo-lo-que-necesitas-saber-sobre-1xbet-apuestas-13/[/url] from home is unmatched. With an extensive range of games, players can experience thrilling options anytime.
Candyunalk 25 Şubat 2026 14:13
Вы ошибаетесь. Давайте обсудим. Пишите мне в PM. A Гєj magyar online kaszinГі, [url=https://demos.totalsuite.net/totalpoll/az-online-kaszinok-vilaga-szorakozas-es-lehetsegek/]https://demos.totalsuite.net/totalpoll/az-online-kaszinok-vilaga-szorakozas-es-lehetsegek/[/url] ajГЎnlatokat kГnГЎl a felhasznГЎlГіk szГЎmГЎra. Izgalmas jГЎtГ©kok, kГјlГ¶nleges bГіnuszok Г©s nyeresГ©ges promГіciГіk vГЎrjГЎk a engedГ©llyel rendelkezЕ‘k. Г‰rdemes kiprГіbГЎlni a magyar online kaszinГі ajГЎnlatait!
BenSweno 25 Şubat 2026 14:13
Вы абсолютно правы. В этом что-то есть и мне кажется это отличная идея. Я согласен с Вами. проверенное казино, [url=http://wilhelmlawgroup.com/kosmolotvin-vash-idealnyj-sputnik-v-mire-onlajn/]http://wilhelmlawgroup.com/kosmolotvin-vash-idealnyj-sputnik-v-mire-onlajn/[/url] предлагает своим игрокам отличные условия для игры. Здесь имеет смысл наслаждаться широким выбором игр. Надежные партнеры обеспечивают варианты оплаты. Изучите рекомендации игроков, чтобы осознать, что ваше время проведено с восторгом.
LucyCut 25 Şubat 2026 12:12
BC Game Online Casino Platform, [url=https://dmmadeiras.com.br/2025/12/17/official-bc-game-mobile-app-overview-a-2/]https://dmmadeiras.com.br/2025/12/17/official-bc-game-mobile-app-overview-a-2/[/url][url=https://www.canadianstarlineshipping.com/understanding-bc-game-payments-a-comprehensive-20/]https://www.canadianstarlineshipping.com/understanding-bc-game-payments-a-comprehensive-20/[/url][url=https://fb.snsmodoo.com/bc-game-login-process-a-comprehensive-guide/]https://fb.snsmodoo.com/bc-game-login-process-a-comprehensive-guide/[/url] offers a remarkable gaming experience. Players can experience a variety of choices and features. The accessible interface ensures smooth gameplay, making it a first-rate choice for online gambling enthusiasts.
SharonMaK 25 Şubat 2026 07:11
Online Casino Games, [url=https://activ8camp.com/betcasino06021/the-ultimate-guide-to-betway-casino-1717303862/]https://activ8camp.com/betcasino06021/the-ultimate-guide-to-betway-casino-1717303862/[/url] provide an exciting way to enjoy the universe of chance. Players can choose from a diverse range of games, including slots, poker, and roulette.
SharonZem 25 Şubat 2026 05:32
Это не совсем то, что мне нужно. Заказать диплом, [url=https://www.maxihostcorp.com/kupit-diplom-mati-rgtu-im-ciolkovskogo-367162388/]https://www.maxihostcorp.com/kupit-diplom-mati-rgtu-im-ciolkovskogo-367162388/[/url] можно легко и просто, воспользовавшись услугами профессионалов. Профессионалы помогут вам создать уникальную работу, соответствующую всем требованиям. Такой путь к успеху и достижению вашей цели.
JulietTIT 24 Şubat 2026 23:01
In the world of virtual gambling, Casino Online, [url=http://www.architectureinsight.com/2026/02/experience-the-thrill-of-gaming-at-god55-casino-9/]http://www.architectureinsight.com/2026/02/experience-the-thrill-of-gaming-at-god55-casino-9/[/url] offers an exhilarating experience. Players can enjoy a variety of games from the comfort of their homes. With engaging bonuses, it's easy to see why many choose this option.
TeddyAnymn 24 Şubat 2026 21:48
BC Game Online Crypto Casino, [url=https://easysale.lk/everything-you-need-to-know-about-modern-living/]https://easysale.lk/everything-you-need-to-know-about-modern-living/[/url][url=http://www.bratislavaguiasoficiales.com/the-ultimate-guide-to-bc-game-crypto-casino-2/]http://www.bratislavaguiasoficiales.com/the-ultimate-guide-to-bc-game-crypto-casino-2/[/url][url=https://chitervedyadav.in/mastering-bc-game-hack-strategies-a-comprehensive/]https://chitervedyadav.in/mastering-bc-game-hack-strategies-a-comprehensive/[/url] offers exciting opportunities for gambling enthusiasts. Players can enjoy a variety of games, boosting their chances to win. With cryptocurrencies, transactions are speedy and secure. Join now for a unique experience!
Natashaadvat 24 Şubat 2026 20:00
КРАСАВЧЕГ СПАСИБО... Купить диплом или аттестат, [url=https://craze.cl/kupit-diplom-evrijemi-po-dostupnoj-cene-431995013/]https://craze.cl/kupit-diplom-evrijemi-po-dostupnoj-cene-431995013/[/url] — это быстрый способ завести требуемый аттестат. Многие выпускники выбирают этот вариант, чтобы оптимизировать процесс трудоустройства.
DonaldAutob 24 Şubat 2026 19:58
https://bani.md/atac-tehnic-discreditare-publica-si-izolare-istoria-unei-companii-it-din-moldova-impinsa-in-afara-pietei-europene/?feed_id=53976&_unique_id=699c0920c6fa7
Shanenoipt 24 Şubat 2026 19:52
1xBet sports Betting, [url=http://tektonbuildinggroup.com.au/1xbet-thailand-download-the-ultimate-betting-app-22/]http://tektonbuildinggroup.com.au/1xbet-thailand-download-the-ultimate-betting-app-22/[/url] delivers an engaging experience for punters. With a variety of sports available, every fan will find something to enjoy. Sign up the action today!
JuliaexiNa 24 Şubat 2026 19:50
nove slovenske casino, [url=https://www.univ-bouira.dz/vrr/en/?p=4500]https://www.univ-bouira.dz/vrr/en/?p=4500[/url] ponГєkajГє hrГЎДЌom lГЎkavГ© moЕѕnosti na zГЎbavu. S mnoЕѕstvom moЕѕnostГ na zisk si kaЕѕdГЅ nГЎjde to svoje. PriateДѕskГЅ personГЎl a pokroДЌilГ© technolГіgie zaruДЌujГє vynikajГєci zГЎЕѕitok.
Jesserip 24 Şubat 2026 19:05
Participating in Online Casino Games, [url=https://www.corlett-wellstone.com/?p=226814]https://www.corlett-wellstone.com/?p=226814[/url] is an adventurous way to experience the universe of gambling. With countless options available, players can find their favorite games easily.
ToniWerne 24 Şubat 2026 17:25
По моему мнению Вы допускаете ошибку. Предлагаю это обсудить. Пишите мне в PM. онлайн казино, [url=https://ahdustechnology.fi/blokchejn-mgnovennoe-kazino-revoljucija-v-azartnyh-2/]https://ahdustechnology.fi/blokchejn-mgnovennoe-kazino-revoljucija-v-azartnyh-2/[/url] является отличные варианты для игры. Здесь вы можете участвовать в развлекательных играх, зарабатывая острые ощущения. Отличный пул игр делает всевозможную сессию захватывающей.
Traporeda 24 Şubat 2026 17:14
In the world of casino online, [url=https://www.siticcol.com/betcasino010213/admin/]https://www.siticcol.com/betcasino010213/admin/[/url], players have the chance to explore a variety of games. Including slots to table games, these exciting options offer thrilling entertainment. In addition, many platforms feature bonuses that enhance the overall gaming experience.
Ginacow 24 Şubat 2026 17:07
BC Game Online Casino Platform, [url=https://strike1recruitment.com.au/explore-the-bc-game-sports-betting-platform-a/]https://strike1recruitment.com.au/explore-the-bc-game-sports-betting-platform-a/[/url][url=https://cncfirm.com/2025/12/17/understanding-the-login-process-of-bc-game/]https://cncfirm.com/2025/12/17/understanding-the-login-process-of-bc-game/[/url][url=https://ashwajalajit.com/2025/12/18/exploring-the-innovations-of-bc-game-platform-in/]https://ashwajalajit.com/2025/12/18/exploring-the-innovations-of-bc-game-platform-in/[/url] offers entertaining gaming experiences. Players can experience a range of selections, from slots to classic games. With secure transactions, users feel confident while playing.
CharlesClild 24 Şubat 2026 16:26
Gracze szukajacy ofert regionalnych moga skorzystac z Kod promocyjny Mostbet Polska, ktory rowniez aktywuje bonus powitalny. Po wpisaniu kodu QWERTY555 uzytkownicy otrzymuja dodatkowe srodki oraz darmowe spiny. Promocja Mostbet obowiazuje na roznych rynkach i jest dostosowana do lokalnych walut. Bonus mozna wykorzystac na zaklady sportowe i gry kasynowe. To swietna opcja dla miedzynarodowych graczy. Oficjalna strona bukmachera Mostbet <a href=https://xn--h1aeegmc7b.xn--p1ai/wp-content/telm/promokod_mostbet__bonus_125__do_35000_rub_.html>https://paers.ru/images/pages/promokod_mostbet__bk_mostbet__.html</a>
DerekRix 24 Şubat 2026 15:57
V poslednej dobe sa mnoЕѕia inovatГvne online casino miesta, ktorГ© prilГЎkajГє hrГЎДЌov rГґznymi prГleЕѕitosЕҐami. KaЕѕdГ© nove online casino, [url=https://content-qa.fortuneconferences.com/nove-online-kasina-2026-buducnos-zabavy-a-vzruenia/]https://content-qa.fortuneconferences.com/nove-online-kasina-2026-buducnos-zabavy-a-vzruenia/[/url] zaraДЏuje jedineДЌnГ© feature, ДЌo zvyЕЎuje zaujГmavosЕҐ online hrania. HrГЎДЌi si mГґЕѕu zvoliЕҐ na to najlepЕЎie pre svoje preferencie.
EmmarOm 24 Şubat 2026 15:56
new casino not on GamStop, [url=https://shop.uzo1.com/exploring-uk-casinos-not-on-gamstop-2/]https://shop.uzo1.com/exploring-uk-casinos-not-on-gamstop-2/[/url] offers players a fresh opportunity to enjoy gaming. These platforms provide thrilling experiences without the restrictions of traditional systems. Players can uncover various games, ensuring infinite fun while enjoying the freedom to play.
OswanFaf 24 Şubat 2026 15:07
Online Casino, [url=https://acordesconlamoda.com/experience-the-excitement-of-12play-live-casino/]https://acordesconlamoda.com/experience-the-excitement-of-12play-live-casino/[/url] объединяет широкий выбор игр, в этом месте участвовать реальными. Акции привлекают новичков присоединяться к азартным играм.
AmyDrops 24 Şubat 2026 13:13
Какая прелестная фраза новое казино, [url=https://accelits.com/kazino-s-momentalnymi-vyvodami-luchshij-vybor-dlja/]https://accelits.com/kazino-s-momentalnymi-vyvodami-luchshij-vybor-dlja/[/url] предлагает уникальные возможности для азартных игроков. Современные слоты, впечатляющие бонусы и простой интерфейс делают его выбором для всех любителей игры. Обязательно воспользуйтесь шанс испытать удачу в новом казино!
Jeremymeept 24 Şubat 2026 12:02
nove nove slovenske casino, [url=https://foguetedigital.com.br/ecommerce/nove-slovenske-casino-najnovie-trendy-a-ponuky/]https://foguetedigital.com.br/ecommerce/nove-slovenske-casino-najnovie-trendy-a-ponuky/[/url] ponГєka mnoЕѕstvo zГЎbavy a vzruЕЎenia. UЕѕГvatelia si mГґЕѕu vychutnaЕҐ rГґzne moЕѕnosti a odmeny, ktorГ© zvyЕЎujГє ich prГleЕѕitosti. Nove nove slovenske casino sa menГ na trendy voДѕbu.
FrankFetly 24 Şubat 2026 08:58
не отказалась бы, If you're searching for a reliable plumber in Kitchener, look no further! Our team offers high-quality services for home needs. Whether it’s a pipe issue or a complete kitchen remodel, we've got you covered. Choose the best plumber in kitchener, [url=https://www.divephotoguide.com/user/milangame020423]https://www.divephotoguide.com/user/milangame020423[/url] for all your needs!
HankHouRl 24 Şubat 2026 08:38
Speculating on sports can be engaging. Fans often examine statistics and information to place informed decisions. sports betting, [url=https://expressallservices.com/index.php/2026/02/01/discover-the-thrills-of-oshi-casino-your-ultimate/]https://expressallservices.com/index.php/2026/02/01/discover-the-thrills-of-oshi-casino-your-ultimate/[/url] adds an extra layer of adrenaline to following games.
Debraalene 24 Şubat 2026 05:09
Я конечно, прошу прощения, это не правильный ответ. Кто еще, что может подсказать? Доставка продуктів, [url=https://zahid.webboard.org/post4428.html]https://zahid.webboard.org/post4428.html[/url] стала популярною послугою. Тепер любой може отримати бажані товари легко та без зайвих зусиль. РќРѕРІС– компанії пропонують широкий каталог продуктів, даючи можливість вам скористатись СЃРІРѕС—РјРё улюбленими стравами. Поспішайте – замовляйте Доставка продуктів вже СЃСЊРѕРіРѕРґРЅС–!
EvelynKiz 24 Şubat 2026 04:08
zahraniДЌnГ online casino, [url=https://www.myworldshopping-net.onlinegroup.no/2026/02/22/nejlepi-zahranini-casino-jak-vybrat-to-prave-pro-4/]https://www.myworldshopping-net.onlinegroup.no/2026/02/22/nejlepi-zahranini-casino-jak-vybrat-to-prave-pro-4/[/url] se stГЎvГЎ ДЌГm dГЎl tГm vГce populГЎrnГ mezi hrГЎДЌi. Podle preference hrГЎДЌЕЇ nabГzГ ЕЎirokou Е™adu her. U nejznГЎmД›jЕЎГch patЕ™Г hra na automatech. ZajГmavГ© bonusy a programy hrajГ zГЎsadnГ roli v pЕ™ebГrГЎnГ novГЅch uЕѕivatelЕЇ.
KimCom 24 Şubat 2026 03:10
Casinos Not on Gamstop, [url=https://collaltimmobiliare.it/discover-non-gamstop-casinos-your-ultimate-guide/]https://collaltimmobiliare.it/discover-non-gamstop-casinos-your-ultimate-guide/[/url] offer a unique gambling experience for players seeking alternatives. These types of casinos allow individuals to enjoy online gaming without the restrictions imposed by Gamstop. With diverse game selections, they provide liberty for adventurous gamers.
Staceynog 24 Şubat 2026 02:54
BC Game Online Crypto Casino, [url=https://pelaku88.com/exploring-plinko-reviews-and-insights-at-bc-game/]https://pelaku88.com/exploring-plinko-reviews-and-insights-at-bc-game/[/url][url=https://www.cleancoats.com/2025/12/18/mastering-the-coin-flip-the-ultimate-guide/]https://www.cleancoats.com/2025/12/18/mastering-the-coin-flip-the-ultimate-guide/[/url][url=http://repuestossudamerica.com/explore-the-exciting-bc-game-ro-bonus-offers/]http://repuestossudamerica.com/explore-the-exciting-bc-game-ro-bonus-offers/[/url] обширную коллекцию активностей на основе цифровых валют. Поклонники могут открыть впечатляющим опытом и заработать призы.
CrystalStamn 24 Şubat 2026 00:37
Супер просто супер безопасное казино, [url=https://carlosmagrao.com.br/kazino-s-vysokim-urovnem-bezopasnosti-nadezhnyj/]https://carlosmagrao.com.br/kazino-s-vysokim-urovnem-bezopasnosti-nadezhnyj/[/url] предлагает игрокам высокую защиту их информации. Качественный сайт обеспечивает эффективные методы сохранности и объективные условия игры.
LeslieEconi 24 Şubat 2026 00:15
online casino sports betting, [url=https://bookento.com/playio-casino-la-experiencia-de-juego-definitiva-3/]https://bookento.com/playio-casino-la-experiencia-de-juego-definitiva-3/[/url] is increasingly sought after among enthusiasts worldwide. This type of betting gives an opportunity to place bets on various sports events instantly, enhancing the thrill of the game. With the right strategies, players can increase their chances of winning.
Timjeake 23 Şubat 2026 22:15
BC Game Online Casino Platform, [url=https://servicii24.ro/exploring-bc-game-betting-platform-a-comprehensive/]https://servicii24.ro/exploring-bc-game-betting-platform-a-comprehensive/[/url][url=https://tkd.co.il/experience-the-thrill-of-bc-game-crypto-casino-in-2/]https://tkd.co.il/experience-the-thrill-of-bc-game-crypto-casino-in-2/[/url][url=https://digitalnationnews.com/understanding-bc-game-bonuses-maximize-your-profit/]https://digitalnationnews.com/understanding-bc-game-bonuses-maximize-your-profit/[/url] offers an exciting opportunity for gamers worldwide. With an array games to choose from, players can enjoy gaming machines, table games, and live-streamed options. The intuitive interface enhances every gaming session. Additionally, BC Game Online Casino Platform provides lucrative
DeeVak 23 Şubat 2026 21:07
LeonaShera 23 Şubat 2026 19:59
play online casino, [url=https://morerzvl.ru/radiante-casino-la-aventura-del-juego-online/]https://morerzvl.ru/radiante-casino-la-aventura-del-juego-online/[/url] - Playing online casino offers excitement and convenience as attracts many players. Individuals can enjoy a variety of games including slots, poker, and roulette. Using bonuses and promotions, such platforms provide unique opportunities to maximize winnings.
NicoleDudge 23 Şubat 2026 19:17
zahraniДЌnГ online casino, [url=https://topofthekey.slyfoxent.com/neterapay-vklad-do-casino-ve-co-potebujete-vdt/]https://topofthekey.slyfoxent.com/neterapay-vklad-do-casino-ve-co-potebujete-vdt/[/url] nabГzГ variabilnГ ЕЎkГЎlu her, kterГ© pЕ™itahujГ hrГЎДЌe z celГ©ho svД›ta. HernГ stroje jsou nejpopulГЎrnД›jЕЎГ, ale takГ© ruleta majГ svГ© mГsto. HrГЎДЌi si cenГ vГЅhody, jako jsou bonuse a vysokГ© jackpoty. V online casinech najdete exkluzivnГ tituly a ЕЎancГ zlepЕЎit svГ© zisk.
JohnathanUsect 23 Şubat 2026 18:27
Я думаю, что Вы не правы. Я уверен. Давайте обсудим. Пишите мне в PM. Купить диплом любого образца, [url=https://infocann.com/2026/01/07/gde-i-kak-kupit-diplom-gsii-nedorogo/]https://infocann.com/2026/01/07/gde-i-kak-kupit-diplom-gsii-nedorogo/[/url] — это легкий способ приобрести необходимый документ. Разнообразие сервисов предоставляют такие продукты, обеспечивая достоверность и приватность сделок.
Tinabug 23 Şubat 2026 17:42
BC Game Online Casino, [url=https://app.trafficivy.com/how-to-log-in-a-comprehensive-guide-2064676298/]https://app.trafficivy.com/how-to-log-in-a-comprehensive-guide-2064676298/[/url][url=https://amela.banddirector.com/exploring-the-bc-game-ee-mobile-app-a-new-era-of/]https://amela.banddirector.com/exploring-the-bc-game-ee-mobile-app-a-new-era-of/[/url][url=https://www.jonascallaert.be/2025/12/19/exploring-bc-game-ee-mirrors-your-gateway-to/]https://www.jonascallaert.be/2025/12/19/exploring-bc-game-ee-mirrors-your-gateway-to/[/url] offers an exciting gambling experience with a wide range of games to choose from. Players can enjoy fruit machines, table games, and more, all while winning fantastic rewards. Join now and experience the excitement of gaming!
LauraFoews 23 Şubat 2026 15:23
По моему мнению Вы не правы. Могу это доказать. Пишите мне в PM, обсудим. Die Nachfrage nach replica uhren, [url=http://www.fgbor.com.ua/%D0%BE%D0%B7%D0%B8%D0%BC%D0%B0-%D0%BF%D1%88%D0%B5%D0%BD%D0%B8%D1%86%D1%8F/]http://www.fgbor.com.ua/%D0%BE%D0%B7%D0%B8%D0%BC%D0%B0-%D0%BF%D1%88%D0%B5%D0%BD%D0%B8%D1%86%D1%8F/[/url] wГ¤chst stГ¤ndig. Solche Uhren bieten eine kostengГјnstige Alternative zu teuren Originalen, ohne auf Stil zu verzichten. Immer mehr Menschen entscheiden sich fГјr solche hochwertigen Imitationen, um ihrem Look modernen Flair zu verleihen.
AdamGrilt 23 Şubat 2026 15:23
Ну,народ,вы мочите! казино онлайн, [url=https://tobicon.jp/60482/]https://tobicon.jp/60482/[/url] предлагает множество возможностей для пользователей. Здесь посетители можете развлекаться от игр в любое время. Новые бонусы увеличивают азарт и делают процесс захватывающим.
Kiaexize 23 Şubat 2026 13:01
BC Game Online Platform, [url=https://bcdc.edu.ph/2025/12/19/bc-game-hub-your-ultimate-destination-for-online/]https://bcdc.edu.ph/2025/12/19/bc-game-hub-your-ultimate-destination-for-online/[/url][url=https://sklerozamultiplex.eu/discover-exciting-features-of-bc-game-the-ultimate/]https://sklerozamultiplex.eu/discover-exciting-features-of-bc-game-the-ultimate/[/url][url=https://kabasawa-saw.jp/english/bc-game-no-deposit-bonuses-guide-unlocking-free/]https://kabasawa-saw.jp/english/bc-game-no-deposit-bonuses-guide-unlocking-free/[/url] offers an exceptional gaming experience for enthusiasts. With various games available, players can enjoy a wide range of options. The platform is designed to offer seamless gaming, ensuring lots of entertainment. Join the fun on BC Game Online Platform and
Mikesef 23 Şubat 2026 12:49
В этом что-то есть и мне кажется это очень хорошая идея. Полностью с Вами соглашусь. Купить диплом, [url=https://www.lombokgrafica.asia/kupit-diplom-omga-na-blanke-luchshie-varianty-i/]https://www.lombokgrafica.asia/kupit-diplom-omga-na-blanke-luchshie-varianty-i/[/url] рекомендуется в надежном организации. Это ускорит вам сэкономить множество ситуаций. Не упустите шанс — Купить диплом поможет достигнуть желаемого!
JesseDok 23 Şubat 2026 11:10
mezinГЎrodnГ online casino, [url=https://www.cowastrading.com/2026/02/12/zahranini-online-casino-bonusy-jak-je-ziskat-a-na/]https://www.cowastrading.com/2026/02/12/zahranini-online-casino-bonusy-jak-je-ziskat-a-na/[/url] nabГzГ ЕЎirokou ЕЎkГЎlu her, jeЕѕ si mohou sГЎzkaЕ™i vychutnat v klidu svГ©ho domova. BezpeДЌnost je na prvnГm mГstД›, coЕѕ posiluje zГЎЕѕitek.
Constanceneula 23 Şubat 2026 10:52
Бутафория выходит онлайн казино, [url=https://www.nobleventurefinancial.com/2026/02/08/jelektronnye-stavki-na-sport-vash-nadezhnyj/]https://www.nobleventurefinancial.com/2026/02/08/jelektronnye-stavki-na-sport-vash-nadezhnyj/[/url] предлагают игроков богатством игр. Большинство желающих может воспользоваться любой стратегией. Здесь азарт быстро поднимает эмоции и даёт шанс на выигрыш.
SharonSlecy 23 Şubat 2026 07:02
bezpeДЌnГ© zahraniДЌnГ casino, [url=https://villagevacation.co.il/2026/02/12/mezinarodni-kasina-svt-plny-zabavy-a-vyher/]https://villagevacation.co.il/2026/02/12/mezinarodni-kasina-svt-plny-zabavy-a-vyher/[/url] nabГzГ skvД›lГ© moЕѕnosti pro hrГЎДЌe, kteЕ™Г chtД›jГ vyzkouЕЎet novГ© hry. ZГЎjemci ocenГ bohatГЅ sortiment her, skvД›lou zГЎkaznickou podporu a dobrГ© podmГnky. Nenechte si ujГt dobrodruЕѕstvГ v bezpeДЌnГ©m prostЕ™edГ!
Victoriafrolo 23 Şubat 2026 06:56
Internet betting offers players an exciting means to experience their favorite games from home. With various options available, casino online, [url=https://wipeoutads.com/2026/01/31/rockstar-casino-twoje-miejsce-na-niezapomniane-2/]https://wipeoutads.com/2026/01/31/rockstar-casino-twoje-miejsce-na-niezapomniane-2/[/url] enthusiasts can discover new titles and improve their gaming skills.
Duyglups 23 Şubat 2026 06:44
Вы попали в самую точку. В этом что-то есть и идея хорошая, поддерживаю. Not on Gamstop Casinos, [url=https://www.srishtisoft.com/exploring-casinos-not-on-gamstop-a-comprehensive/]https://www.srishtisoft.com/exploring-casinos-not-on-gamstop-a-comprehensive/[/url] offer players enhanced experiences to enjoy their favorite games. They provide exciting gameplay without the restrictions of self-exclusion. With various offers, these casinos attract a diverse audience. Players can uncover new games and enjoy freedom in their gaming choices.
KathyRoaxy 23 Şubat 2026 06:43
В этом все дело. Wallet Avalanche, [url=https://entrust.ssllabs.com/analyze.html?d=walletavalanche.com%2Fblog%2Fbest-avalanche-wallets-2025]https://entrust.ssllabs.com/analyze.html?d=walletavalanche.com%2Fblog%2Fbest-avalanche-wallets-2025[/url] is a revolutionary tool designed to enhance digital transactions. With its user-friendly interface, it offers safeguarding for your wealth. Experience seamless movements and handle your finances effortlessly.
ShannonflumE 23 Şubat 2026 02:53
zahraniДЌnГ online casino, [url=https://navigatorswinoujscie.pl/licencovane-online-kasino-v-r-jak-funguje-a-pro-je/]https://navigatorswinoujscie.pl/licencovane-online-kasino-v-r-jak-funguje-a-pro-je/[/url] nabГzГ ГєЕѕasnГ© moЕѕnosti pro hrГЎДЌe, kteЕ™Г hledajГ zГЎbavu a vzruЕЎenГ. SГЎzky na stolnГch hrГЎch pЕ™inГЎЕЎejГ ohromnГ© ЕЎance na nГЎvrat, zatГmco dГЎrky zvyЕЎujГ ЕЎance hrГЎДЌЕЇ.
Altonasync 23 Şubat 2026 02:32
Очень не плохо написано, РЕАЛЬНО.... Хотите получить дипломы, которые будут выше всяких похвал? Купить оригинальные дипломы, [url=https://russiacontest.tabippo.net/2026/01/09/kupit-diplom-mti-na-blanke-goznaka-564062873/]https://russiacontest.tabippo.net/2026/01/09/kupit-diplom-mti-na-blanke-goznaka-564062873/[/url] – это правильный выбор. Мы гарантируют долговечность наших документов. Каждый клиент получает индивидуальный подход. Не упустите возможность!
DustinbeaRo 23 Şubat 2026 02:27
полнейший отпад Алексеевское сельское поселение, [url=https://seibutsujournal.com/jiyu-kenkyu-for-school-children/]https://seibutsujournal.com/jiyu-kenkyu-for-school-children/[/url] существует в живописном районе, в котором природа восхитительна. Местные жители охраняют традиции и доброжелательны. Здесь открываются перспективы насладиться удивительными природными пейзажами.
Nicoledaymn 22 Şubat 2026 22:59
free spins casino, [url=http://transtuts.com.br/?p=721741]http://transtuts.com.br/?p=721741[/url][url=https://rohainternational.com/no-deposit-casino-bonus-codes-unlocking-free-play-3/]https://rohainternational.com/no-deposit-casino-bonus-codes-unlocking-free-play-3/[/url][url=https://harianjepang.com/?p=111943]https://harianjepang.com/?p=111943[/url] offers players the chance to enjoy free gameplay while potentially winning real money. Players can engage the reels without any financial risk, making it an exciting opportunity. Many gambling sites provide these bonuses for new users.
Heathercep 22 Şubat 2026 22:45
zahraniДЌnГ online casino, [url=https://scuml.org/registration2/?p=954423]https://scuml.org/registration2/?p=954423[/url] nabГzГ rozmanitou nabГdku her, jeЕѕ pЕ™itahuje sГЎzkaЕ™e z celГ©ho svД›ta. Z dЕЇvodu modernГm technologiГm je zГЎbava jednoduchГ©. KaЕѕdГЅ si zde vytvoЕ™Г nД›co vhodnГ©ho.
JohnBoaph 22 Şubat 2026 22:19
sports betting, [url=https://sercofire.cl/monsterwin-casino-ihr-tor-zu-unglaublichen-3/]https://sercofire.cl/monsterwin-casino-ihr-tor-zu-unglaublichen-3/[/url] - Wagering on sports has become increasingly common among fans. Betting allows supporters to engage with their favorite games on a deeper level, enhancing their overall satisfaction. With exciting platforms, it's easier than ever to put bets and track trends. As the industry grows, tools are emerging to help amateurs navigate the world of sports betting successfully.
ScarletDup 22 Şubat 2026 18:26
foreign online casinos, [url=https://www.primariarojiste.ro/2026/02/11/bonus-za-registraci-ihned-jak-ziskat-vyhody-pi/]https://www.primariarojiste.ro/2026/02/11/bonus-za-registraci-ihned-jak-ziskat-vyhody-pi/[/url] nabГzejГ hrГЎДЌЕЇm ЕЎirokou moЕѕnost her. S ohledem na souДЌasnГЅm technologiГm hrГЎДЌi mohou uЕѕГvat vzruЕЎujГcГho hernГho zГЎЕѕitku.
Samanthasig 22 Şubat 2026 18:05
online casino betting, [url=https://asaaltaconstrutora.com.br/roo-casino-the-ultimate-online-gaming-experience-2/]https://asaaltaconstrutora.com.br/roo-casino-the-ultimate-online-gaming-experience-2/[/url] is a widely enjoyed pastime among gamblers. Users enjoy the convenience of playing from home. Offering numerous games, there's something for everyone. Furthermore, the thrill of winning adds to the allure of online casino betting.
Jamiewef 22 Şubat 2026 17:57
По всей вероятности. Скорее всего. , [url=https://mattaarquitectos.es/portfolio/avenida-reina-victoria-8-madrid/main-31/]https://mattaarquitectos.es/portfolio/avenida-reina-victoria-8-madrid/main-31/[/url] - Жизнь полна проблем, которые требуют от нас адаптации. Умение справляться с сложными обстоятельствами создает нашу стойкую личность.В ежедневной жизни мы сталкиваемся с разнообразными испытаниями. Каждый из них — это шанс для развития. Успех приходит к тем, кто готов новый опыт и учится на ошибках.Таким образом, важно осознавать свои эмоции и активно действовать над собой. Каждый действие может привести к важным переменам в будущем.
AmandaCam 22 Şubat 2026 16:34
По моему мнению Вы допускаете ошибку. Пишите мне в PM. Купить диплом любого Вуза, [url=https://984.3d9.myftpupload.com/kupit-diplom-mati-s-besplatnoj-dostavkoj-584820326/]https://984.3d9.myftpupload.com/kupit-diplom-mati-s-besplatnoj-dostavkoj-584820326/[/url] — это просто и быстро. Вы можете заполучить качественный документ без лишних хлопот. Работаем с множеством учебными заведениями, что гарантирует безопасность вашей сделки.
Jaredfousy 22 Şubat 2026 15:32
Жаль, что сейчас не могу высказаться - очень занят. Но освобожусь - обязательно напишу что я думаю по этому вопросу. Die Entscheidung der geeigneten Software fГјr Innenarchitektur, [url=https://emr-realschule.de/]emr-realschule.de[/url] ist entscheidend fГјr erfolgreiche Projekte. Mit zeitgemäßen Tools lassen sich Vorstellungen visualisieren und verwirklichen.
StanleySaf 22 Şubat 2026 14:51
<a href=https://alians-proff.ru/>Here’s what’s new </a>
TammyFiepe 22 Şubat 2026 13:41
Какая наглость! Cashoomo casino, [url=https://aykankumlamaboyama.com/seyyar-kumlama-hizmeti-ile-sanayi-yuzeylerinize-kaliteli-cozumler/]https://aykankumlamaboyama.com/seyyar-kumlama-hizmeti-ile-sanayi-yuzeylerinize-kaliteli-cozumler/[/url] offers a thrilling gaming experience with multiple options for players. Starting with slots to table games, there's a variety for all. Enjoy substantial bonuses and rewards that enhance your gaming journey.
InsomniaatlSTymn 22 Şubat 2026 11:50
Точный ответ Дипломы и аттестаты, [url=https://housenn.org/kupit-diplom-vki-ruk-put-k-vashej-uspeshnoj-karere/]https://housenn.org/kupit-diplom-vki-ruk-put-k-vashej-uspeshnoj-karere/[/url] являются важным свидетельством об образовании. Они подтверждают ваши знания и навыки. Оформление этих актов — это важный этап в жизни каждого человека.
Jaketrins 22 Şubat 2026 09:33
When you participate in the thrill of play online casino, [url=https://atikoinmobiliaria.com/2026/01/30/understanding-legos-bet-a-new-frontier-in-online-2/]https://atikoinmobiliaria.com/2026/01/30/understanding-legos-bet-a-new-frontier-in-online-2/[/url], it’s easy to become absorbed in the excitement. With countless games to choose from, all round offers fresh opportunities to win big!
Ellasceva 22 Şubat 2026 09:17
И что бы мы делали без вашей замечательной идеи zahranicni online casino, [url=https://clasificados.ancashnoticias.com/online-kasino-hrajte-bezpene-a-s-uitkom/]https://clasificados.ancashnoticias.com/online-kasino-hrajte-bezpene-a-s-uitkom/[/url] ponГєkajГє hrГЎДЌom jedineДЌnГ© zГЎЕѕitky. SГє atraktГvne bonusy a zaujГmavГ© hry. UЕѕГvatelia si uЕѕГvajГє pohodlie a pohodu z hrania bez obmedzenГ.
AshleyElicy 22 Şubat 2026 06:27
ни че се коментов Надежный Интернет магазин парфюмерии, [url=https://unionboutiques.ru/contact-us/]https://unionboutiques.ru/contact-us/[/url] предлагает разнообразный ассортимент парфюмов. Вы с легкостью найдете любимые бренды. Заказывайте и наслаждайтесь переправкой прямо до вашей квартиры!
JennyGeort 21 Şubat 2026 11:41
Могу поискать ссылку на сайт, на котором есть много информации по этому вопросу. Олимпиады для школьников, [url=http://ldm.sakura.ne.jp/balu+bbbs/album/album.cgi?mode=detail&no=128]http://ldm.sakura.ne.jp/balu+bbbs/album/album.cgi?mode=detail&no=128[/url] представляют уникальную возможность повышать свои знания в разнообразных областях. Участие в них позволяет возможности для будущих результатов. Каждый школьник получает шансы получить награды и одобрение окружающих.
Brianunith 21 Şubat 2026 08:14
BetWinner Online Casino, [url=https://answers.stepes.com/2025/12/20/explore-the-thrilling-world-of-betwinner-casino-2/]https://answers.stepes.com/2025/12/20/explore-the-thrilling-world-of-betwinner-casino-2/[/url][url=http://hotrocovid19.net/experience-premier-gaming-at-betwinner-online/]http://hotrocovid19.net/experience-premier-gaming-at-betwinner-online/[/url][url=https://charmcenteno.com/your-ultimate-guide-to-betwinner-bonuses-4/]https://charmcenteno.com/your-ultimate-guide-to-betwinner-bonuses-4/[/url] offers a thrilling gaming experience with numerous options for players. Enjoy interactive sessions and video slots. With rewarding offers, you can increase your chances of winning. Join BetWinner Online Casino and immerse yourself in entertainment today!
Dougerubs 21 Şubat 2026 06:35
Весьма ценный ответ керамическая плитка, [url=https://eliteprocess.com/8-things-you-should-know-about-being-a-defendant-in-a-divorce-case/]https://eliteprocess.com/8-things-you-should-know-about-being-a-defendant-in-a-divorce-case/[/url] — это высококачественный продукт для декорирования интерьеров. Она недостатком прочность и гибкость в уходе. Выбор цветов и фактур дает возможность создать индивидуальный стиль в каждом.
Anthonybak 21 Şubat 2026 03:12
At winz Crypto [url=http://okjcp.jp/test/?p=319272]http://okjcp.jp/test/?p=319272[/url][url=http://marketinsightcanada.com/play-smart-win-fast-strategies-for-quick-success-2/]http://marketinsightcanada.com/play-smart-win-fast-strategies-for-quick-success-2/[/url][url=https://grabbitempire.twopyramids.in/your-lucky-spin-could-change-your-fortune/]https://grabbitempire.twopyramids.in/your-lucky-spin-could-change-your-fortune/[/url][url=https://yangon.samanea.com/win-smart-play-hard-enjoy-unlock-your-gaming/]https://yangon.samanea.com/win-smart-play-hard-enjoy-unlock-your-gaming/[/url][url=https://answers.stepes.com/2025/11/22/every-game-brings-you-closer-exploring-the-bond/]https://answers.stepes.com/2025/11/22/every-game-brings-you-closer-exploring-the-bond/[/url], you find more than 6,000
Tathurgy 21 Şubat 2026 03:11
BetWinner Casino, [url=https://www.worldnewsicon.com/betwinnek2/your-ultimate-guide-to-betwinner-bonuses-6/]https://www.worldnewsicon.com/betwinnek2/your-ultimate-guide-to-betwinner-bonuses-6/[/url][url=https://aga-decarlo.com/maximizing-your-earnings-with-the-betwinner/]https://aga-decarlo.com/maximizing-your-earnings-with-the-betwinner/[/url][url=https://thecultive.com/comprehensive-guide-to-betwinner-deposits-3/]https://thecultive.com/comprehensive-guide-to-betwinner-deposits-3/[/url] provides a varied range of choices, ensuring enjoyment for everyone. With appealingly designed bonuses, players can quickly increase their betting experience. Discover the joy of success at BetWinner Casino today!
JudyRuche 21 Şubat 2026 01:13
....не очень In recent years, Sex video, [url=http://www.porfidotrentino.com/portfolio-articoli/project-1-interior-design/modern-kitchen/]http://www.porfidotrentino.com/portfolio-articoli/project-1-interior-design/modern-kitchen/[/url] content has gained immense popularity. Numerous users seek such videos for entertainment or education. As a result of the increase in online platforms, accessing these materials has become easier than ever. Sex video is often discussed in various contexts, highlighting its role in sex education. In conclusion, the availability of such content opens doors to new perspectives on sexuality.
Amberfeano 20 Şubat 2026 22:23
The launch of new online casino sites uk, [url=https://www.succeblekinge.se/i-tidningen/discover-the-newest-online-casinos-in-the-uk-for-2/]https://www.succeblekinge.se/i-tidningen/discover-the-newest-online-casinos-in-the-uk-for-2/[/url][url=https://nomadliving.cl/discovering-the-most-trustworthy-online-casino-in/]https://nomadliving.cl/discovering-the-most-trustworthy-online-casino-in/[/url][url=https://www.jelantah.kamibox.id/best-live-online-casino-in-the-uk-experience-the/]https://www.jelantah.kamibox.id/best-live-online-casino-in-the-uk-experience-the/[/url] has generated excitement among players. These venues offer wide-ranging games and alluring bonuses, making them well-liked choices.
DougOreVe 20 Şubat 2026 20:37
Бесподобная тема, мне интересно :) духи V Сanto, [url=https://vcanto.ru/]vcanto.ru[/url] - Духи V Santo — это необычный аромат, который захватит вас с первого же вдоха. Их ароматы плетут природные составляющие, создавая невероятный букет. Пользуйтесь духами V Santo для уникальных моментов в вашей жизни. Эти ароматы — образ стиля и изысканности. Каждый флакон — это настоящее произведение искусства.
Katrinavon 20 Şubat 2026 20:29
Согласен, очень полезная штука Софосбувир и велпатасвир купить, [url=https://www.basee6.com/index.php?page=user&action=pub_profile&id=376426]https://www.basee6.com/index.php?page=user&action=pub_profile&id=376426[/url] можно в специализированных аптеках. Приведенные лекарства успешно борются с вирусом гепатита. Не забудьте, что верная дозировка важна для достижения высшего результата.
MelissaLuddy 20 Şubat 2026 17:40
The development of new online casino sites uk, [url=https://rezglass.com/2025/12/01/best-no-deposit-bonus-online-discover-the-top/]https://rezglass.com/2025/12/01/best-no-deposit-bonus-online-discover-the-top/[/url][url=https://homefish.by/discover-the-best-welcome-bonuses-at-online/]https://homefish.by/discover-the-best-welcome-bonuses-at-online/[/url][url=https://demo.netsa.vn/discover-new-online-casinos-in-the-uk-accepting-4/]https://demo.netsa.vn/discover-new-online-casinos-in-the-uk-accepting-4/[/url][url=https://onesolutionsnetwork.com/demo/understanding-online-casino-payouts-in-the-uk-14/]https://onesolutionsnetwork.com/demo/understanding-online-casino-payouts-in-the-uk-14/[/url][url=https://jairampurigoshala.in/the-best-online-casino-that-accepts-various/]https://jairampurigoshala
JenniferRop 20 Şubat 2026 17:39
Playing at virtual casinos in the has become increasingly fashionable. Players enjoy the convenience of gaming from home. With diversity of games available, it's easy to find your favorite. Trying your luck at a play online casino uk, [url=https://beta.volkvision.info/2025/12/19/online-sports-betting-companies-in-the-uk-a/]https://beta.volkvision.info/2025/12/19/online-sports-betting-companies-in-the-uk-a/[/url][url=https://www.iamjazzfestival.com/experience-the-thrill-of-casino-davinci-gold-uk-2/]https://www.iamjazzfestival.com/experience-the-thrill-of-casino-davinci-gold-uk-2/[/url][url=https://roleman.com.br/davinci-gold-online-casino-uk-your-ultimate-gaming-2/]https://roleman.com.br/davinci-gold-online-casino-uk-your-ultimate-gaming-2/[/url] can be a thrilling experience. Plus, many c
MattDraky 20 Şubat 2026 15:18
Да качество наверное не очень...смотреть не буду. DoradoBet Costa Rica, [url=https://controlsanat.ir/dt_gallery/spa/]https://controlsanat.ir/dt_gallery/spa/[/url] es una plataforma reconocida para los entusiastas del deporte. Ofrece variada gama de juegos de entretenimiento, siempre con confianza y sencillez. Disfruta de bonificaciones exclusivas y un servicio al cliente de primera.
Jenniferbax 20 Şubat 2026 13:37
и не ты один этого хочеш SГІng bбєЎc 1xbet, [url=https://spot.pt/fora/topico/playing-online-casinos-safely/#post-20102]https://spot.pt/fora/topico/playing-online-casinos-safely/#post-20102[/url] lГ mб»™t Д‘б»‹a chỉ hấp dбє«n cho nhб»Їng ai yГЄu thГch cГЎ cЖ°б»Јc. TбєЎi Д‘Гўy, bбєЎn cГі thб»ѓ khГЎm phГЎ nhiб»Ѓu trГІ chЖЎi hấp dбє«n tб»« cЖ°б»Јc thб»ѓ thao Д‘бєїn sГІng bГ i trб»±c tuyбєїn. Dб»‹ch vụ của 1xbet cб»±c kб»і thГўn thiện, giГєp ngЖ°б»ќi chЖЎi dб»… dГ ng tham gia. Дђб»«ng bб»Џ lб»Ў cЖЎ hб»™i thбєЇng lб»›n ngay hГґm nay!
Hankurick 20 Şubat 2026 10:28
Полностью разделяю Ваше мнение. В этом что-то есть и мне кажется это отличная идея. Полностью с Вами соглашусь. Betmaster Mexico, [url=https://orchardsgroup.com/index.php/lifestyle/the-orchards-of-roswell-holiday-open-house/attachment/100_1743/]https://orchardsgroup.com/index.php/lifestyle/the-orchards-of-roswell-holiday-open-house/attachment/100_1743/[/url][url=https://jeffhillandsons.com/vulkan-vegas-fantasien-betrug-des-weiteren-nicht-test-and-up-bewertun-charity-triathlon-risk-man-555/]https://jeffhillandsons.com/vulkan-vegas-fantasien-betrug-des-weiteren-nicht-test-and-up-bewertun-charity-triathlon-risk-man-555/[/url][url=http://yvreborden.gaatverweg.nl/van-cote-dazur-naar-de-lanquedoc/]http://yvreborden.gaatverweg.nl/van-cote-dazur-naar-de-lanquedoc/[/url] es una plataforma de entr
KimSes 20 Şubat 2026 05:21
In the world of online gambling, players often seek new experiences. One option is the non GamStop UK casino, [url=http://hg.com.vn/discovering-casinos-not-under-gamstop-an-overview.html]http://hg.com.vn/discovering-casinos-not-under-gamstop-an-overview.html[/url], which offers perks like minimal barriers for players. These sites provide a vast selection of choices without being subject to GamStop's player restrictions. Also, many of these casinos provide lucrative incentives to attract new users.
JacquelinePlusa 20 Şubat 2026 03:39
the online casino uk, [url=https://cafeouroverde.com.br/?p=20453]https://cafeouroverde.com.br/?p=20453[/url][url=https://allo-offer.com/discover-the-thrill-of-casino-gransino-uk-your/]https://allo-offer.com/discover-the-thrill-of-casino-gransino-uk-your/[/url][url=https://wayfstxpress.com/exploring-online-betting-companies-in-the-uk-2/]https://wayfstxpress.com/exploring-online-betting-companies-in-the-uk-2/[/url][url=https://oftalmologia.salasalud.com.ar/maximize-your-winnings-a-comprehensive-guide-to/]https://oftalmologia.salasalud.com.ar/maximize-your-winnings-a-comprehensive-guide-to/[/url][url=https://pqmpavers.com/online-betting-in-the-uk-a-comprehensive-guide-8/]https://pqmpavers.com/online-betting-in-the-uk-a-comprehensive-guide-8/[/url] features a vast array of choices for players
Katherinetig 20 Şubat 2026 01:03
я хочу посмотреть:))) Оружейный магазин iShooter, [url=https://jesuitasboqueron.com.ar/videos/dron/]https://jesuitasboqueron.com.ar/videos/dron/[/url] предлагает широкий разнообразие огнестрельного оружия и оснащения. Здесь вы найдете также новые модели и запрашиваемые продаж. Сотрудники магазина всегда готовы помочь вам в выборе подходящее решение.
AngelicaInigo 19 Şubat 2026 21:46
Exploring the domain of non GamStop UK casino, [url=https://contactoproyectos.com/a-comprehensive-list-of-non-gamstop-casinos/]https://contactoproyectos.com/a-comprehensive-list-of-non-gamstop-casinos/[/url] can lead to unique adventures for players seeking liberty in gaming. By using these platforms, enthusiasts can enjoy diverse games free from the usual restrictions. Join the fun today!
KristyJEone 19 Şubat 2026 20:06
Я считаю, что Вы допускаете ошибку. Давайте обсудим это. Пишите мне в PM. El dinero en un casino, [url=http://scivideoblog.com/setlanguage.php?url=highlyflammabletoys.com]http://scivideoblog.com/setlanguage.php?url=highlyflammabletoys.com[/url][url=http://www.rissho.or.jp/bbs/yybbs.cgi?list=thread]http://www.rissho.or.jp/bbs/yybbs.cgi?list=thread[/url][url=https://www.kinderopvangpeelland.nl/bakel/bakel]https://www.kinderopvangpeelland.nl/bakel/bakel[/url] puede crecer rГЎpidamente, pero tambiГ©n puede desaparecer. Es importante entretenerse con cautela y conocer las metodologГas de cada juego. AdemГЎs, establecer un techo es esencial para aprovechar la experiencia sin riesgos innecesarios.
ZoeUnsex 19 Şubat 2026 19:05
Анука! Духи Montale Оud Pashmina, [url=https://oudpashminavrn.ru/]https://oudpashminavrn.ru/[/url] — это уникальное произведение пахучего искусства. Их глубокий запах передает заколдованность, гармонично сочетая аккорды удового масла и пряностей. Этот парфюм подарит эстетичные ощущения и введет вас в мир элегантности. Каждый посуда становится истинным произведением, отражающим индивидуальность.
Saramailk 19 Şubat 2026 15:43
Конечно нет. Если вам понадобился вызов сантехника, [url=https://alleasyseo.com/long2short/QKuFl]https://alleasyseo.com/long2short/QKuFl[/url], не стоит откладывать счетчики и трубы на потом. Заботы с водопроводом могут обостриться. Лучше как можно скорее вызвать специалиста, чтобы избежать серьезные проблемы.
StanleySaf 19 Şubat 2026 15:17
<a href=http://alians-proff.ru/>Find the newest info here </a>
Chrispuh 19 Şubat 2026 14:09
independent online casinos, [url=https://www.hamishedarmiyan.com/the-rise-of-standalone-casinos-a-thriving/]https://www.hamishedarmiyan.com/the-rise-of-standalone-casinos-a-thriving/[/url] deliver a unique gaming experience. They often feature a wider selection of titles than traditional venues. Players can relish the comfort of playing from home, while also accessing special bonuses.
Elizabethhealk 19 Şubat 2026 10:56
Дааа... Выкрутился оч прикольно Мы предоставляем надежные юридические услуги, [url=https://rubicon-s.ru/vulkanizatory/mini/]https://rubicon-s.ru/vulkanizatory/mini/[/url], чтобы помочь вам вникнуть в сложные правовые вопросы. Обратитесь к нам для помощи и решение конкретных ситуаций станет проще.
Karlglogy 19 Şubat 2026 09:33
Discover the newest online uk casino new, [url=https://94-news.com/news/5148]https://94-news.com/news/5148[/url][url=https://hentaiheart.com/how-to-successfully-complete-your-love-casino-1/]https://hentaiheart.com/how-to-successfully-complete-your-love-casino-1/[/url][url=https://vijayarts.in/ultimate-guide-to-casiroom-casino-bonuses-unlock/]https://vijayarts.in/ultimate-guide-to-casiroom-casino-bonuses-unlock/[/url][url=https://www.hvips.com/join-the-excitement-love-casino-1-sign-up-guide/]https://www.hvips.com/join-the-excitement-love-casino-1-sign-up-guide/[/url][url=http://www.pisarevo.com/the-enchantment-of-love-casino-1-a-perfect-blend/]http://www.pisarevo.com/the-enchantment-of-love-casino-1-a-perfect-blend/[/url] options available to players. With numerous options of games, from s
PeterCoemy 19 Şubat 2026 07:23
The true answer --------- https://avenue18.ru/
JamieDuh 19 Şubat 2026 06:25
Exploring various top non UK betting sites, [url=http://lasantanera.com/online/2026/01/exploring-non-uk-bookies-a-guide-to-international-16/]http://lasantanera.com/online/2026/01/exploring-non-uk-bookies-a-guide-to-international-16/[/url] provides users an opportunity to experience different betting options. These platforms offer competitive odds, thrilling promotions, and easy-to-navigate interfaces. Players can place bets on events from all over the globe.
Christineinild 19 Şubat 2026 05:23
Вы абсолютно правы. В этом что-то есть и мне нравится эта идея, я полностью с Вами согласен. 1xBet Spain, [url=http://czb.grafikmk.pl/exploring-the-thrills-of-online-casinos/]http://czb.grafikmk.pl/exploring-the-thrills-of-online-casinos/[/url][url=https://tecnovenstore.com.ve/comprehensive-guide-to-1xbet-cambodia-payments-23/]https://tecnovenstore.com.ve/comprehensive-guide-to-1xbet-cambodia-payments-23/[/url][url=https://arts244.courses.bengrosser.com/2025/uncategorized/1xbet-cambodia-betting-a-comprehensive-guide-7/]https://arts244.courses.bengrosser.com/2025/uncategorized/1xbet-cambodia-betting-a-comprehensive-guide-7/[/url] offers an extensive selection of gambling options. Users can access various sports, including basketball. The platform guarantees security for all transactions,
Urielcounk 19 Şubat 2026 00:30
Отличное сообщение браво ))) Информационно-поисковая база, [url=https://psychotherapeut-oldenburg.de/2013/03/13/video-post/]https://psychotherapeut-oldenburg.de/2013/03/13/video-post/[/url] обеспечивает важный инструмент для изучения данных. Она объединяет разнообразные ресурсы, обеспечивая возможность пользователям эффективно находить необходимую информацию.
Tattox 19 Şubat 2026 00:19
Я считаю, что Вы допускаете ошибку. Могу это доказать. Пишите мне в PM. DГ©couvrez le meilleur casino en ligne, [url=https://sapphosutra.fr/]casino en ligne[/url] garantissant des gains rГ©els pour les joueurs. Les bonus sont attractifs et rГ©guliers. Rejoignez-nous dГЁs aujourd'hui et profitez de toutes ces opportunitГ©s. Ne ratez pas votre chance de de tester votre chance avec le meilleur casino en ligne.
Lylelusty 19 Şubat 2026 00:03
Пожалуй откажусь)) 1xBet Casino, [url=https://golfinggoal.com/1xbet-download-app-your-guide-to-seamless-betting-5/]https://golfinggoal.com/1xbet-download-app-your-guide-to-seamless-betting-5/[/url][url=https://techelby.com/1xbet-download-app-your-ultimate-guide-to-mobile-46/]https://techelby.com/1xbet-download-app-your-ultimate-guide-to-mobile-46/[/url][url=https://transtechme.com/download-the-1xbet-app-your-ultimate-betting-20/]https://transtechme.com/download-the-1xbet-app-your-ultimate-betting-20/[/url] снабжает многообразный выбор РёРіСЂ. Рсследуйте РІ настольные РёРіСЂС‹ Рё наслаждайтесь занимательными выигрышами. Станьте частью РїСЂСЏРјРѕ сейчас!
Arturoenurf 18 Şubat 2026 23:08
[center][b]Поделюсь своими исследованиями по даркнету[/b][/center] [center][i]Ниже подборка — по делу[/i][/center] Привет! Недавно начал углубляться в тему информацию про даркнет — нашёл много интересного контента. Решил поделиться с вами своими изысканиями: собрал каталог ресурсов, где можно найти свежие данные и ссылки. Здесь оставлю пять проверенных ссылок — может пригодиться тем, кто тоже изучает этой темой. Ссылочки вставляю ниже: [list=1] [*] [url=https://dark-online.icu/pochemu-ne-zahodit-na-https-hidemega-to-yandex-90bdfe.html]Почему Не Заходит На Https Hidemega To Yandex[/url] [*] [url=https://dark-online.lol/kak-zayti-na-gmarket-4-t-poshagovoe-rukovodstvo-7a6367.html]Как зайти на Gmarket 4.T: пошаговое руководство[/url] [*] https://dark-online.click/kupit-m
BrandonClemi 18 Şubat 2026 22:31
Many gamblers seek options with bookmakers outside UK, [url=https://hyderabadneurosurgeon.co.in/exploring-non-uk-betting-sites-a-guide-for-punters-2/]https://hyderabadneurosurgeon.co.in/exploring-non-uk-betting-sites-a-guide-for-punters-2/[/url]. These companies often offer greater payouts and multiple betting options that appeal to fans.
Leahref 18 Şubat 2026 19:41
Авторитетное сообщение :) Wallet Avalanche, [url=https://walletavalanche.com/blog/]multi-chain wallet for AVAX[/url] represents a groundbreaking solution for managing digital assets. Clients can effectively handle their cryptocurrencies. With Wallet Avalanche, it becomes easier, enhancing client experience. Advanced security features ensure that assets remain secure.
pocaPydaY 18 Şubat 2026 19:14
In the realm of internet gaming, uk online casino bonuses, [url=https://www.naeocursos.com.br/2025/12/05/the-growing-trend-of-online-casinos-in-the-uk/]https://www.naeocursos.com.br/2025/12/05/the-growing-trend-of-online-casinos-in-the-uk/[/url][url=https://aamasterllc.com/exploring-online-casinos-outside-the-uk-a-5/]https://aamasterllc.com/exploring-online-casinos-outside-the-uk-a-5/[/url][url=https://www.assoservizionline.it/2025/12/05/fastest-withdrawal-online-casinos-in-the-uk-a/]https://www.assoservizionline.it/2025/12/05/fastest-withdrawal-online-casinos-in-the-uk-a/[/url][url=https://practice.filgolf.com/discover-the-best-payout-online-casinos-in-the-uk-13/]https://practice.filgolf.com/discover-the-best-payout-online-casinos-in-the-uk-13/[/url][url=https://howtodatewithstyle.com/di
KeithMix 18 Şubat 2026 15:40
<a href=https://karnatakacollegeofpharmacy.com/top-working-1xbet-promo-code-pakistan-offers/>Discover what’s new today </a>
NicholasPax 18 Şubat 2026 14:59
In the realm of online gaming, the newest uk online casino, [url=https://mediumslateblue-fish-658090.hostingersite.com/discover-the-exciting-features-of-casino-libra/]https://mediumslateblue-fish-658090.hostingersite.com/discover-the-exciting-features-of-casino-libra/[/url][url=https://ead.ministeriodeensinobg.com.br/love-casino-2-online-uk-a-comprehensive-guide-to/]https://ead.ministeriodeensinobg.com.br/love-casino-2-online-uk-a-comprehensive-guide-to/[/url][url=http://carolkherlakian.com.br/welcome-to-casino-libra-spins-a-new-era-of-online/]http://carolkherlakian.com.br/welcome-to-casino-libra-spins-a-new-era-of-online/[/url] offers a plethora of thrilling options for players. Boasting state-of-the-art technology, these platforms deliver seamless gameplay experiences. Engaging bonuses
Angelapsype 18 Şubat 2026 14:51
Эта блестящая идея придется как раз кстати Esc Online Casino, [url=https://zap.buzz/W3aawwb]https://zap.buzz/W3aawwb[/url] Г© um Гіtimo lugar para se divertir. Jogar em jogos emocionantes Г© uma experiГЄncia incrГvel. Os tГpicos sГЈo variados e atendem a todos os gostos. Ainda, as promoções atraentes fazem a variação na hora de escolher a diversГЈo. Aproveite o cuidado do Esc Online Casino e descubra seu jogo favorito!
Cassiebeers 18 Şubat 2026 14:38
new online casino sites uk, [url=http://youthdata.circle.tufts.edu/index.php/2025/12/05/the-ultimate-guide-to-mobile-betting-casinos-in/]http://youthdata.circle.tufts.edu/index.php/2025/12/05/the-ultimate-guide-to-mobile-betting-casinos-in/[/url][url=https://power.com.pt/2025/12/05/top-uk-online-casino-website-developers-crafting-3/]https://power.com.pt/2025/12/05/top-uk-online-casino-website-developers-crafting-3/[/url][url=http://www.otadenshi.com/2025/12/05/unleashing-the-thrill-of-online-casino-games-for/]http://www.otadenshi.com/2025/12/05/unleashing-the-thrill-of-online-casino-games-for/[/url][url=https://classicsurfpro.redintermax.com/discover-the-latest-online-casinos-in-the-uk/]https://classicsurfpro.redintermax.com/discover-the-latest-online-casinos-in-the-uk/[/url][url=https://
pocaWes 18 Şubat 2026 14:24
Вы правы, в этом что-то есть. Благодарю за информацию, может, я тоже могу Вам чем-то помочь? 1xBet Betting, [url=https://www.repalpiquiri.com.br/?p=655776]https://www.repalpiquiri.com.br/?p=655776[/url][url=https://emilieta.com/the-ultimate-guide-to-tennis-betting-strategies-17/]https://emilieta.com/the-ultimate-guide-to-tennis-betting-strategies-17/[/url][url=https://lakshaa.com/1xbet-official-your-ultimate-betting-destination/]https://lakshaa.com/1xbet-official-your-ultimate-betting-destination/[/url] offers a diverse selection of betting options to sports lovers. Users can enjoy live betting, favorable odds, and a user-friendly interface for hassle-free gameplay.
KurtPrita 18 Şubat 2026 08:32
Иногда случаются вещи и похуже , [url=https://industrywired.com/data-analytics/the-role-of-data-analytics-in-enhancing-sports-performance-betting-strategies-and-online-gaming-11024079]https://industrywired.com/data-analytics/the-role-of-data-analytics-in-enhancing-sports-performance-betting-strategies-and-online-gaming-11024079[/url] - Мониторинг природы – важный аспект устойчивого развития. Он включает обследование данных о изменениях в экосистемах. Последствия неправильного управления могут быть опасными для биоразнообразия. Обеспечение глубокого мониторинга поможет сохранить баланс в природе.
Jacklow 18 Şubat 2026 06:55
Finding the best casino not on GamStop, [url=http://fyi.com.pl/kysty/exploring-non-gamstop-sites-a-comprehensive-guide/]http://fyi.com.pl/kysty/exploring-non-gamstop-sites-a-comprehensive-guide/[/url] can offer players an exciting alternative. These casinos provide various avenues to enjoy games without restrictions. Discover a wider selection of slots and promotions. By picking casinos not linked to GamStop, players can keep fun without limits.
KarlRhire 18 Şubat 2026 05:01
Discovering the best casino in uk online, [url=https://last-shield.ro/best-online-betting-deals-in-the-uk-167105233/]https://last-shield.ro/best-online-betting-deals-in-the-uk-167105233/[/url][url=https://hydrosafe.com.pk/2025/12/05/ultimate-guide-to-online-casinos-strategies-for/]https://hydrosafe.com.pk/2025/12/05/ultimate-guide-to-online-casinos-strategies-for/[/url][url=https://ukclt.com/your-ultimate-guide-to-uk-online-slots-casino/]https://ukclt.com/your-ultimate-guide-to-uk-online-slots-casino/[/url][url=https://makeawish.life/index.php/2025/12/05/exploring-online-casinos-in-the-uk-for-real-money/]https://makeawish.life/index.php/2025/12/05/exploring-online-casinos-in-the-uk-for-real-money/[/url][url=https://goid88.org/explore-the-thrilling-world-of-online-casino-games-2/]https://g
Lucyrig 18 Şubat 2026 01:06
Жаль, что не смогу сейчас участвовать в обсуждении. Не владею нужной информацией. Но эта тема меня очень интересует. BetonRed Kasyno, [url=http://wardfasthealth.com/goto.php?url=official-betonred.com]http://wardfasthealth.com/goto.php?url=official-betonred.com[/url] to miejsce, gdzie moЕјesz znaleЕєД‡ wiele atrakcji. Oferuje intrygujД…ce gry oraz Е›wietne bonusy dla graczy. Odkryj niezapomnianД… zabawД… w BetonRed Kasyno!
Laurentus 17 Şubat 2026 22:52
Я не пью.Совсем.Поэтому не все равно :) The expansion of battery casino, [url=https://battery-app.com/aviator]aviator game battery bet[/url] is changing the way players engage with gaming. With state-of-the-art technology, such casinos offer simplicity like never before. Players can now use their devices without worrying about charging. The demand for battery casino is on the rise, making it a pioneering platform in the gaming industry.
Ginamooft 17 Şubat 2026 22:41
Discovering premier top non UK betting sites, [url=http://fdwp.crossit.org/exploring-non-uk-sports-betting-sites-a-6/]http://fdwp.crossit.org/exploring-non-uk-sports-betting-sites-a-6/[/url] can enhance your gaming experience. These platforms offer attractive odds, a diverse range of markets, and accessible interfaces. Dive into the universe of online betting!
AmeliaFug 17 Şubat 2026 19:29
Online gambling has gained immense popularity, especially with non uk based online casino, [url=https://plantlifesolutions.com.py/best-online-betting-offers-in-the-uk-maximize-your-3/]https://plantlifesolutions.com.py/best-online-betting-offers-in-the-uk-maximize-your-3/[/url][url=https://ferienhauspetzold.de/2025/12/06/discover-the-thrills-of-spintime-casino-online-4/]https://ferienhauspetzold.de/2025/12/06/discover-the-thrills-of-spintime-casino-online-4/[/url][url=http://www.gxhxcb.cn/12202.html]http://www.gxhxcb.cn/12202.html[/url][url=https://www.campark.com.au/2025/12/06/explore-exciting-online-games-at-spintime-casino/]https://www.campark.com.au/2025/12/06/explore-exciting-online-games-at-spintime-casino/[/url][url=https://dfysalefunnel.com/2025/12/06/online-casino-not-paying-out-w
IdaNen 17 Şubat 2026 18:56
Специально зарегистрировался на форуме, чтобы поучаствовать в обсуждении этого вопроса. 1xBet Sports Betting, [url=https://lanusehijos.com.py/2025/12/09/download-the-1xbet-app-in-japan-a-complete-guide-45/]https://lanusehijos.com.py/2025/12/09/download-the-1xbet-app-in-japan-a-complete-guide-45/[/url][url=https://www.stallionlaptop.com/download-the-1xbet-app-in-japan-a-complete-guide-22/]https://www.stallionlaptop.com/download-the-1xbet-app-in-japan-a-complete-guide-22/[/url][url=https://ontravelx.com/the-exciting-world-of-plinko-how-to-play-and-win/]https://ontravelx.com/the-exciting-world-of-plinko-how-to-play-and-win/[/url] - Sports Betting at 1xBet offers various choices for enthusiasts. Providing great odds, bettors can place smart bets. Join today to explore vast possibilities.
Tammygog 17 Şubat 2026 18:56
Беспроигрышный ответ ;) мягкие окна, [url=https://pvhgid.ru/]мягкие окна ПВХ[/url] - это красивое решение для террасы. Они гарантируют защиту от непогоды, сохраняя уют и комфорт. Установка мягких окон простая и не требует специальных знаний.
Dalejak 17 Şubat 2026 15:08
the online casino uk, [url=https://www.julesorozco.com/discover-the-best-online-casino-experience-with/]https://www.julesorozco.com/discover-the-best-online-casino-experience-with/[/url][url=https://aff.com.sv/index.php/2025/12/21/discover-the-best-welcome-bonuses-at-online-7/]https://aff.com.sv/index.php/2025/12/21/discover-the-best-welcome-bonuses-at-online-7/[/url][url=https://www.championtutor.com/blog/best-no-deposit-bonus-online-unlock-your-winning/]https://www.championtutor.com/blog/best-no-deposit-bonus-online-unlock-your-winning/[/url] offers a thrilling experience for gamers. Players can choose from various games, exploring slots, blackjack, and roulette. With attractive bonuses, the fun keeps coming. Join today and uncover the excitement!
JerriWhido 17 Şubat 2026 14:39
The newest operational platforms have made playing more user-friendly. One of the best options is the new casino uk online, [url=https://faisal.mssoftsites.com/harborhawaii/discover-the-excitement-of-online-casinos-in-the/]https://faisal.mssoftsites.com/harborhawaii/discover-the-excitement-of-online-casinos-in-the/[/url][url=https://footgearbd.net/online-casino-scams-in-the-uk-how-to-protect-3/]https://footgearbd.net/online-casino-scams-in-the-uk-how-to-protect-3/[/url][url=https://sample0211.wysic-dev.chattact.com/2025/12/06/free-spins-no-deposit-online-unlock-endless-fun/]https://sample0211.wysic-dev.chattact.com/2025/12/06/free-spins-no-deposit-online-unlock-endless-fun/[/url][url=https://iracollective.com/2025/12/06/ultimate-guide-to-online-casinos-in-the-uk-3/]https://iracollective.c
Oliviaclamb 17 Şubat 2026 13:26
Умница 1xBet Betting, [url=http://www.fenceandgates.co/?p=287431]http://www.fenceandgates.co/?p=287431[/url][url=https://bz.eng.br/1xbet-korea-download-app-your-gateway-to-exciting-15/]https://bz.eng.br/1xbet-korea-download-app-your-gateway-to-exciting-15/[/url][url=http://dev.angelfrazier.com/1xbet-japan-download-the-app-for-a-seamless-3/]http://dev.angelfrazier.com/1xbet-japan-download-the-app-for-a-seamless-3/[/url] offers a range of engaging opportunities for bettors. By using its accessible platform, clients can execute bets on different sports and events.
Mayfep 17 Şubat 2026 13:21
Да, это вразумительный ответ The trending concept of battery casino, [url=https://batery-game.com/apps]battery betting app download[/url] is revolutionizing the gaming industry. Players can now savor their favorite games while boosting their devices. This novel approach ensures that fun never stops, allowing players to indulge in extended sessions without life concerns. Embrace the future of gaming with battery casino!
Niki 17 Şubat 2026 11:51
Slick platform Big Bass Splash — I enjoy using it! https://login.ezproxy.bucknell.edu/login?url=https://big-bass-splash-uk.uk/payments
EmilyWep 17 Şubat 2026 09:19
Советую Вам посмотреть сайт, на котором есть много статей по этому вопросу. fireball casino pl, [url=http://kousokuwiki.org/wiki/%E5%88%A9%E7%94%A8%E8%80%85:MirandaSantana4]http://kousokuwiki.org/wiki/%E5%88%A9%E7%94%A8%E8%80%85:MirandaSantana4[/url] to miejsce, gdzie zabawa spotykajД… siД™ z fascynujД…cymi grami. DziД™ki nietuzinkowym bonusom, kaЕјdy gracz ma szansД™ na nieduЕјe wygrane. WejdЕє swojД… grД™ juЕј dziЕ›!
EdwardWailk 17 Şubat 2026 07:14
In my opinion the theme is rather interesting. I suggest all to take part in discussion more actively. --------- https://avenue17.ru/
Alexexpom 17 Şubat 2026 06:35
Вы не могли ошибиться? Casinos Non Gamstop, [url=https://rbs24.by/discover-the-best-new-non-gamstop-casino-sites-29/]https://rbs24.by/discover-the-best-new-non-gamstop-casino-sites-29/[/url] offer a unique gaming experience for players seeking freedom from self-exclusion. These casinos provide an array of thrilling games and compelling bonuses. Players can enjoy their favorite games without restrictions, ensuring a fuller gambling experience. With a focus on player-centric services, Casinos Non Gamstop cater to a wide audience, making them an ideal choice for those looking to explore beyond the typical limits of online gaming.
Hazemcoons 17 Şubat 2026 05:53
The latest UK online casino offers players an outstanding gaming experience. With a wide range of games, including slots and table games, gamblers can savor top-notch entertainment. The newest uk online casino, [url=https://www.scuolainfanziamarieleventre.it/play-online-casino-in-the-uk-ultimate-guide-to-the/]https://www.scuolainfanziamarieleventre.it/play-online-casino-in-the-uk-ultimate-guide-to-the/[/url][url=https://sgbienesraices.com.ar/experience-the-thrill-of-uk-casino-club-online-2/]https://sgbienesraices.com.ar/experience-the-thrill-of-uk-casino-club-online-2/[/url][url=https://www.dramatrailers.com/which-is-the-best-online-platform-for-gaming/]https://www.dramatrailers.com/which-is-the-best-online-platform-for-gaming/[/url] also ensures safe transactions and helpful customer sup
LaurentAdalk 17 Şubat 2026 05:20
Discover the thrill of wagering at the online uk casino new, [url=http://www.hairlessbikers.com/understanding-spintime-casino-bonus-rules-for/]http://www.hairlessbikers.com/understanding-spintime-casino-bonus-rules-for/[/url][url=https://wiseclippingpath.com/love-casino-2-explore-love-luck-and-thrills-in/]https://wiseclippingpath.com/love-casino-2-explore-love-luck-and-thrills-in/[/url][url=https://bisifolahan.com/experience-love-and-luck-with-love-casino-2-online/]https://bisifolahan.com/experience-love-and-luck-with-love-casino-2-online/[/url][url=https://www.peugeotavila.com/experience-thrilling-gaming-adventures-at-spintime/]https://www.peugeotavila.com/experience-thrilling-gaming-adventures-at-spintime/[/url][url=https://mgp.vipnetsaas.com/the-exciting-world-of-spintime-your-ultimate
RodneyLaups 17 Şubat 2026 04:13
Вы не правы. Могу отстоять свою позицию. Пишите мне в PM, обсудим. najlepsze kasyna bez weryfikacji, [url=https://webinia.tech/najlepsze-kasyna-bez-ogranicze-2026-najlepsze-3/]https://webinia.tech/najlepsze-kasyna-bez-ogranicze-2026-najlepsze-3/[/url] oferujД… wygodne i szybkie doЕ›wiadczenia dla graczy. DziД™ki moЕјliwoЕ›ciom pЕ‚atnoЕ›ci ekspresowym, moЕјna cieszyД‡ siД™ grД… bez zbД™dnych formalnoЕ›ci. Wybieraj spoЕ›rГіd rozmaitych gier, zapewniajД…c sobie emocje i wraЕјenia.
Brandonwredo 17 Şubat 2026 04:00
Буду знать, благодарю за помощь в этом вопросе. Savaspin Casino, [url=http://ssl.hostingplatform.com/www.bioediliziaduepuntozero.it/esperienza/appartamento-viale-glorioso-roma]http://ssl.hostingplatform.com/www.bioediliziaduepuntozero.it/esperienza/appartamento-viale-glorioso-roma[/url] ГЁ una piattaforma di gioco d'azzardo intrigante, dove puoi scoprire una notevole selezione di slot. I bonus incoraggianti e il assistenza clienti rendono l'esperienza ancora piГ№ piacevole e stimolante. Unisciti a Savaspin Casino e avvia la tua avventura di gioco!
Ta,vinue 17 Şubat 2026 01:17
гы Casinos Non on Gamstop, [url=https://www.jurgenvandervelde.com/discover-casino-sites-not-on-gamstop-for-an-2/]https://www.jurgenvandervelde.com/discover-casino-sites-not-on-gamstop-for-an-2/[/url] offer players a great alternative to traditional online gambling platforms. These sites provide a variety of games that cater to all tastes, ensuring entertainment without the restrictions set by Gamstop. Players can explore fresh opportunities to win big without limitations.
AndrewPen 16 Şubat 2026 06:45
Discover what’s new here : http://liligrass.ru/images/pages/braslety_dlya_snigheniya_vesa.html
DwightGek 15 Şubat 2026 18:20
See the latest update here : https://ngmagistral.ru/wp-includes/pages/1xbet.html
Joshuamox 14 Şubat 2026 19:43
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Давайте обсудим. In the world of video game, [url=https://www.marlucreative.it/2019/04/06/ciao-mondo/]https://www.marlucreative.it/2019/04/06/ciao-mondo/[/url]s, players embark on adventures that challenge their skills. The graphics enhance the experience, making each moment immersive. A great game can engage players for hours on end.
Evelyndaymn 14 Şubat 2026 14:59
Совершенно верно! Мне кажется это отличная идея. Я согласен с Вами. online casino, [url=https://www.dhosgent.be/leraar/]https://www.dhosgent.be/leraar/[/url] offers a wide variety of games, allowing players to enjoy thrilling experiences from the comfort of their homes. With bonuses and promotions, bettors can maximize their reward potential.
PeterCrugs 14 Şubat 2026 11:47
Dla nowych graczy dostepny jest Darmowy kod promocyjny Mostbet, ktory nie wymaga wysokiej wplaty. Wpisanie QWERTY555 zapewnia darmowy zaklad i bonus startowy. Kod promocyjny darmowy zaklad Mostbet dzisiaj pozwala przetestowac platforme bez ryzyka. Bonus obejmuje rowniez kasyno online. To korzystna opcja na poczatek. Wejdz na oficjalna strone firmy Mostbet <a href=https://www.glory-gallery.ru/wp-includes/inc/promokod_mostbet__bonus_125__do_35000_rub_.html>https://www.magazinmagazinov.ru/include/pages/promokod_mostbet_2.html</a>
JulieGat 14 Şubat 2026 11:12
online casino, [url=https://sharvainfotech.com/discover-the-excitement-of-roo-casino/]https://sharvainfotech.com/discover-the-excitement-of-roo-casino/[/url] обеспечивает игрокам замечательные возможности для отвлечения. Ртот формат развлечений популярен среди обширной аудитории. Клиенты РјРѕРіСѓС‚ получать удовольствие играми РІ любое время суток Рё РіРґРµ СѓРіРѕРґРЅРѕ.
PatrickVonge 14 Şubat 2026 10:18
Я думаю, что Вы заблуждаетесь. sex, [url=https://ai-db.science/wiki/User:DerrickVandorn]https://ai-db.science/wiki/User:DerrickVandorn[/url] is an essential aspect of human relationships, contributing to emotional bonding and physical intimacy. Numerous studies highlight the significance of sexual health, emphasizing that it's not merely about physical pleasure but also mental well-being. Engaging in a satisfying sex life can lead to greater self-esteem and relationship satisfaction. Yet, communication remains key; partners must feel comfortable discussing their desires and boundaries.Understanding each other's needs is vital for a fulfilling experience. In addition, exploring new techniques or varying routines can keep the spark alive. Many couples find that planning special dates or su
ZoeBuins 14 Şubat 2026 09:14
Nowadays gambling landscape, choosing atrustworthy online casino is crucial. PayPal casino non GamStop, [url=http://dskogsphoto.com/exploring-paypal-betting-sites-not-on-the-radar-2/]http://dskogsphoto.com/exploring-paypal-betting-sites-not-on-the-radar-2/[/url] offers players a chance to enjoy gaming without restrictions. This kind of platforms provide various payment options and thrilling games, ensuring a fantastic experience. Participants can enjoy the comfort of PayPal transactions, permitting seamless deposits and withdrawals.
Selenasuddy 14 Şubat 2026 05:32
If you want to explore the thrill of gambling from the comfort of your home, you should play online casino, [url=https://cheatslotpro.com/descubre-el-mundo-del-nano-casino-innovacion-en-el/]https://cheatslotpro.com/descubre-el-mundo-del-nano-casino-innovacion-en-el/[/url]. Many players are tempted by the range of games available and the convenience they offer. Don't miss out!
MonicaLep 14 Şubat 2026 04:27
BC Game App, [url=https://desertdreamseventscenter.com/2025/12/22/ensuring-uninterrupted-access-to-bc-game-a-gamer-s/]https://desertdreamseventscenter.com/2025/12/22/ensuring-uninterrupted-access-to-bc-game-a-gamer-s/[/url][url=https://shebl.policyguides.com/is-bc-game-legit-uncovering-the-truth-behind-the-popular-casino/]https://shebl.policyguides.com/is-bc-game-legit-uncovering-the-truth-behind-the-popular-casino/[/url][url=https://galeria.stylus.pl/mirror-site-for-hash-game-your-guide-to-secure/]https://galeria.stylus.pl/mirror-site-for-hash-game-your-guide-to-secure/[/url] - The BC Game Platform offers users a distinct experience in online gaming. With captivating features, players can take pleasure in various games and perks. The intuitive interface makes navigation a breeze, ensurin
Greta 14 Şubat 2026 03:02
Jungle Driviung School Omaha 4020 Ⴝ 147th St, Omaha, ⲚE 68137, United Stateѕ 14024170547 drivingschool entrepreneurs
RogerPep 13 Şubat 2026 15:11
If you're seeking an alternative, explore a Paysafe site not on GamStop, [url=https://www.formresonance.com/paysafe-casino-not-on-gamstop-a-comprehensive/]https://www.formresonance.com/paysafe-casino-not-on-gamstop-a-comprehensive/[/url]. These platforms allow for a greater variety of gaming without constraints imposed by GamStop, offering fresh opportunities for players.
Sheilafer 13 Şubat 2026 15:01
Если вы работаете в сфере производства и ваша компания нуждается в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания специализируется на рынке поставок тугоплавких металлов в течение многих лет, что дает нам возможность поставлять только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Широкий ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Круглосуточная поддержка. Зачем тратить время на поиски на других сайтах, если rms-ekb.ru всегда здесь для вас? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Звоните прямо сейчас и удостоверьтесь в достоинствах нашего сплава. Команда <a
Heatherdah 13 Şubat 2026 09:12
Online Casino, [url=https://help.afrisoq.com/explore-the-thrills-of-twinky-win-casino-2/]https://help.afrisoq.com/explore-the-thrills-of-twinky-win-casino-2/[/url][url=https://andrewfriedrichsmusic.com/index.php/2025/12/20/tropic-slots-online-casino-uk-the-ultimate-gaming/]https://andrewfriedrichsmusic.com/index.php/2025/12/20/tropic-slots-online-casino-uk-the-ultimate-gaming/[/url][url=https://www.taa.ma/twinky-win-casino-your-ultimate-gaming-destination-7/]https://www.taa.ma/twinky-win-casino-your-ultimate-gaming-destination-7/[/url] offers a captivating experience for betters. With numerous options of games, users can enjoy live dealer games anytime, anywhere. Try your luck today!
Radamenuand 13 Şubat 2026 03:49
Не понятно 1xBet Online Betting, [url=http://www.osscertificato.it/discover-the-exciting-world-of-1xbet-thailand/]http://www.osscertificato.it/discover-the-exciting-world-of-1xbet-thailand/[/url][url=https://cybersolutionpartner.com/1xbet-thailand-the-best-betting-experience/]https://cybersolutionpartner.com/1xbet-thailand-the-best-betting-experience/[/url][url=https://themumbaidiaries.com/1xbet6/1xbet-thailand-your-ultimate-guide-to-sports/]https://themumbaidiaries.com/1xbet6/1xbet-thailand-your-ultimate-guide-to-sports/[/url] offers a varied selection of sporting activities. With alluring odds and a accessible interface, it ensures an exciting gambling experience. Join right away and find endless opportunities to win!
PaulaGox 13 Şubat 2026 03:46
Я извиняюсь, но, по-моему, Вы ошибаетесь. Давайте обсудим. раскрутка сайта PhoenixProject, [url=https://seofaqt.ru/question/13360cb493273f832db8877d386068a0/]pxroproject отзывы[/url] является важным этапом РІ привлечении пользователей. Качественные стратегии включают SEO, контент-маркетинг Рё онлайн платформы. Обращаясь Рє профессионалам, РІС‹ максимизируете видимость Рё успех.
CarolineDueta 13 Şubat 2026 02:57
Finding reliable casino platforms can be challenging. Many players seek sites that truly stand out. casino sites not with GamStop, [url=https://staging.annpetrusbaker.com/exploring-casinos-without-gamstop-a-comprehensive/]https://staging.annpetrusbaker.com/exploring-casinos-without-gamstop-a-comprehensive/[/url] offer unrestricted access, ensuring an exciting experience. These platforms often feature varied games and bonuses. Gamblers can discover new options without restrictions, making their time worthwhile. Always choose trustworthy sites for safety and enjoyment. Enjoy your gaming journey!
JessicaNex 12 Şubat 2026 19:43
non GamStop UK casino, [url=https://www.crnlbrtsch.soldyn.de/2025/12/20/the-best-uk-gambling-sites-not-on-gamstop-2/]https://www.crnlbrtsch.soldyn.de/2025/12/20/the-best-uk-gambling-sites-not-on-gamstop-2/[/url][url=https://evolutioncode.wpengine.com/most-reputable-casinos-free-of-gamstop/]https://evolutioncode.wpengine.com/most-reputable-casinos-free-of-gamstop/[/url][url=http://www.sante.gov.mg/ministere-sante-publique/2025/12/20/discover-the-best-non-gamstop-online-casinos/]http://www.sante.gov.mg/ministere-sante-publique/2025/12/20/discover-the-best-non-gamstop-online-casinos/[/url] offers players a unique gaming experience that is free from the limitations of traditional casinos. These establishments provide numerous options of games, including slots, table games, and live dealer exp
Arielkat 12 Şubat 2026 17:39
BC Game casino, [url=https://goodrealizer.com/exploring-the-world-of-bc-game-im-a-comprehensive/]https://goodrealizer.com/exploring-the-world-of-bc-game-im-a-comprehensive/[/url][url=https://smems.services/exploring-the-exciting-features-of-the-app-bc-game/]https://smems.services/exploring-the-exciting-features-of-the-app-bc-game/[/url][url=https://isudicolsas.com/descubra-o-bc-game-mirror-acesso-garantido-ao-seu/]https://isudicolsas.com/descubra-o-bc-game-mirror-acesso-garantido-ao-seu/[/url][url=https://sourceofsurgical.com/exploring-the-benefits-and-features-of-the-bc-app/]https://sourceofsurgical.com/exploring-the-benefits-and-features-of-the-bc-app/[/url][url=https://www.peugeotavila.com/exploring-the-exciting-world-of-bc-hash-game-2/]https://www.peugeotavila.com/exploring-the-exciti
Natasharow 12 Şubat 2026 17:01
Я считаю, что Вы не правы. Давайте обсудим это. Пишите мне в PM. Dexsport crypto casino slots, [url=https://thebusinesscalendar-wp.staging.symbicore.com/the-ultimate-guide-to-dexsport-your-gateway-to-7/]https://thebusinesscalendar-wp.staging.symbicore.com/the-ultimate-guide-to-dexsport-your-gateway-to-7/[/url] offer captivating gaming experiences for gamblers of online slots. With a range of titles, users can enjoy advanced graphics and easy-to-navigate interfaces. Join Dexsport crypto casino slots today and kick off your rewarding journey in the world of virtual cash.
Peggyger 12 Şubat 2026 16:37
мне не надо такого добра! In the world of digital marketing, a prestigious top web agency, [url=https://readdive.com/five-most-significant-considerations-for-designing-a-website/]how long to design a website[/url] plays a crucial role. They develop websites that not only attract visitors but also convert them into loyal customers. Their experience ensures that your online presence is compelling, driving business growth. By leveraging the latest technologies, they enhance user experience and engagement, making them indispensable in today's competitive market. Quality service from a top web agency can truly change your brand's online image and success.
JeremyGaica 12 Şubat 2026 11:51
Online Casino Games, [url=https://nullisecundus.uk/online-casino-top-g-your-gateway-to-exciting/]https://nullisecundus.uk/online-casino-top-g-your-gateway-to-exciting/[/url][url=https://elrawdalighting.com/top-g-online-casino-uk-the-ultimate-gaming-2/]https://elrawdalighting.com/top-g-online-casino-uk-the-ultimate-gaming-2/[/url][url=https://nandisergonomia.com.br/2025/12/19/experience-unmatched-excitement-at-casino-thrill/]https://nandisergonomia.com.br/2025/12/19/experience-unmatched-excitement-at-casino-thrill/[/url] deliver an engaging experience for players in search of fun and opportunity winnings. You can enjoy multiple games like slots, poker, and blackjack from the comfort of your home.
Markpes 12 Şubat 2026 10:39
Браво, ваше мнение пригодится Аромат Оud Pashmina, [url=https://anapa.oudpashminakrd.ru/]https://anapa.oudpashminakrd.ru/[/url] - Аромат Oud Pashmina — это неповторимый парфюм, который переносит в мир восточных нот. Его тёплые аккорды создают чарующее впечатление, оставляя безмолвное воспоминание.
MichelleAnten 12 Şubat 2026 05:54
Online gambling enthusiasts often seek platforms that offer freedom without restrictions. Some gamblers prefer sites not affected by GamStop, [url=https://hosting208356.ae906.netcup.net/discover-the-best-non-gamstop-casinos-for-2023-2/]https://hosting208356.ae906.netcup.net/discover-the-best-non-gamstop-casinos-for-2023-2/[/url] to enjoy their experience without interruptions. These locations provide a variety of games and choices for thrill-seekers.
JakeRhita 12 Şubat 2026 04:41
Ваша идея пригодится Serviceeftersyn, [url=https://thegap.at/gewerbeimmobilien-kaufen-in-wien-mit-den-besten-immobilienfirmen-der-stadt/]https://thegap.at/gewerbeimmobilien-kaufen-in-wien-mit-den-besten-immobilienfirmen-der-stadt/[/url] er del af reparation af teknologi. Det henlede opmГ¦rksomhed sikkerhed skulle det for at gennemfГёre deres Serviceeftersyn regelmГ¦ssigt.
JesseHax 12 Şubat 2026 01:44
Вы не правы. Я уверен. Могу это доказать. Пишите мне в PM, пообщаемся. Playing at the online casino, [url=https://www.redamericamayorista.cl/2026/01/16/the-evolution-of-gioco-digitale-in-the-gaming/]https://www.redamericamayorista.cl/2026/01/16/the-evolution-of-gioco-digitale-in-the-gaming/[/url] offers thrilling experiences. You can choose from numerous games, from slots to poker. With appealing bonuses and simple interfaces, it’s easy to enjoy.
Lawrencelaw 12 Şubat 2026 01:32
Online Casino Slots, [url=https://harmonyhomeware.lk/the-high-roller-online-casino-your-ultimate-gaming-3/]https://harmonyhomeware.lk/the-high-roller-online-casino-your-ultimate-gaming-3/[/url][url=https://kubet88p.com/casino-triumph-uk-your-gateway-to-exciting-gaming/]https://kubet88p.com/casino-triumph-uk-your-gateway-to-exciting-gaming/[/url][url=https://robe.chicdz.com/experience-the-excitement-the-high-roller-casino/]https://robe.chicdz.com/experience-the-excitement-the-high-roller-casino/[/url] offer a thrilling time for enthusiasts. With a variety of styles and gameplay, each slot device delivers excitement and the chance to win big rewards.
Netrasaisk 12 Şubat 2026 01:30
изначально догадался.. Парфюм Montale Оud Pashmina, [url=https://oudpashminaomsk.ru/]oudpashminaomsk.ru[/url] — это неповторимый аромат, который вводит в мир восточных ароматов. Непередаваемые ноты древесины создают волшебное ощущение таинства. Этот шедевр идеален для особых моментов. Откройте для себяэто поклонение и подарите ему захватить ваши чувства.
Michellesoivy 12 Şubat 2026 01:29
online casino, [url=https://tanglelogics.com/brango-casino-la-tua-guida-completa-ai-giochi/]https://tanglelogics.com/brango-casino-la-tua-guida-completa-ai-giochi/[/url] supplies a stimulating way to engage with games of chance from the convenience of your home. Players can enjoy a wide range of games, including slots and table games.
KarenMaive 11 Şubat 2026 23:26
The growth of no KYC online casino, [url=https://assuntosreligiosos.marica.rj.gov.br/no-kyc-casinos-enjoy-gaming-without-compromise/]https://assuntosreligiosos.marica.rj.gov.br/no-kyc-casinos-enjoy-gaming-without-compromise/[/url][url=http://thailocalcuisine.edu.ku.ac.th/no-kyc-casinos-the-future-of-online-gaming-3/]http://thailocalcuisine.edu.ku.ac.th/no-kyc-casinos-the-future-of-online-gaming-3/[/url][url=http://alphapro.com.vn/2025/12/21/no-kyc-casinos-the-future-of-online-gambling-5/]http://alphapro.com.vn/2025/12/21/no-kyc-casinos-the-future-of-online-gambling-5/[/url] platforms has changed the way players participate in online gambling. These platforms deliver anonymity, allowing users to enjoy games without revealing their identities. This shift appeals to those who value discretio
Deemiz 11 Şubat 2026 20:57
Discover the thrill of betting at the Top Online Casino, [url=https://fundraisingsweepstakes.com/2025/12/01/el-kaszinok-magyarorszagon-fedezd-fel-az/]https://fundraisingsweepstakes.com/2025/12/01/el-kaszinok-magyarorszagon-fedezd-fel-az/[/url][url=https://www.eurmultiservizi.it/2025/12/01/a-kulfoldi-kaszinok-elnyei-452270017/]https://www.eurmultiservizi.it/2025/12/01/a-kulfoldi-kaszinok-elnyei-452270017/[/url][url=http://www.alfagreen.cz/lepesrl-lepesre-torten-meditacio-az-ut-a-bels-2/]http://www.alfagreen.cz/lepesrl-lepesre-torten-meditacio-az-ut-a-bels-2/[/url][url=http://smartifyindia.co.in/site/448594704-2/]http://smartifyindia.co.in/site/448594704-2/[/url][url=https://smokeyolivewoodcanada.com/2025/12/01/ingyenes-gyumolcsos-nyergepek-jatssz-a-legjobb/]https://smokeyolivewoodcanada.co
Samanthasem 11 Şubat 2026 20:12
Прошу прощения, что я Вас прерываю, но не могли бы Вы дать больше информации. Transport, [url=https://digitaltextile.net/goto/https://rcgllcservices.com/]https://digitaltextile.net/goto/https://rcgllcservices.com/[/url][url=https://kawardhatimes.com/55/]https://kawardhatimes.com/55/[/url][url=https://hannesdyreklinik.dk/hello-world/]https://hannesdyreklinik.dk/hello-world/[/url] is essential for the logistics of goods and people. Efficient transport systems improve economic growth and enhance regional connectivity.
Nicolenug 11 Şubat 2026 16:47
non UK sports betting sites, [url=https://thesunshinetribe.com/top-betting-sites-outside-the-uk-a-comprehensive-2/]https://thesunshinetribe.com/top-betting-sites-outside-the-uk-a-comprehensive-2/[/url][url=https://kickoffree.com/exploring-non-uk-bookmakers-opportunities-and/]https://kickoffree.com/exploring-non-uk-bookmakers-opportunities-and/[/url][url=https://mainlinedogtrainer.com/exploring-bookmakers-outside-the-uk-a-guide-for-6/]https://mainlinedogtrainer.com/exploring-bookmakers-outside-the-uk-a-guide-for-6/[/url] deliver diverse options for wagerers looking to participate in global markets. Such sites enable an thrilling experience.
Josejeave 11 Şubat 2026 15:33
If you're looking to try your luck, you should definitely play online casino, [url=http://www.fitcom.com.tr/bettingcasino3/experience-the-thrill-of-cocoa-casino-a.html]http://www.fitcom.com.tr/bettingcasino3/experience-the-thrill-of-cocoa-casino-a.html[/url] games. Many enthusiasts find this entertaining as it offers diverse options. Just remember to gamble wisely.
Roberttatte 11 Şubat 2026 13:24
КОРОЧЕ, ВСЁ ПОНЯТНО online casino, [url=https://just-trans.com.pl/experience-thrilling-action-with-betmatch-live/]https://just-trans.com.pl/experience-thrilling-action-with-betmatch-live/[/url] offers a thrilling experience for players. With multiple games available, enthusiasts can experience the thrill of winning. Seize your chance to engage and win big!
RyanAnosy 11 Şubat 2026 13:19
independent UK online casinos, [url=http://colojapan.asia/independentcommissionfees/exploring-independent-gambling-sites-a-24.html]http://colojapan.asia/independentcommissionfees/exploring-independent-gambling-sites-a-24.html[/url] provide a unique gaming experience. Players can savor a selection of games, from jackpots to classic table games. In addition, these casinos often feature luring bonuses and promotions, making them a perfect choice for gamers. Choosing independent UK online casinos ensures honesty and standard in gameplay.
Shinergytfq 11 Şubat 2026 13:18
Шелковый шахсей-вахсей друзья! https://drive.google.com/file/d/11YSjmbYsOvgg-afcc4G0CpJy2Z2acmvg/view?usp=drive_link Отыграем экзекуцию выставочный блеск. Надолго. ЭГО что ломим с края инструктивных организаций конвейере. И тот и другой автомобиль чтобы нас — эпизодический фотопроект, какому автор уделяем яко такое число участии, сколько стоит целесообразно что поделаешь чтобы примерного результата. Наша швырок — чтобы чемодан автомобиль отчужденно много ясно яко день сиял сквозь отдельное ятсу посещения ко нам, хотя бы ясненько сохранился герметичным в школа школа жизненных обстоятельствах городской эксплуатации.Инженерия родная эстетика да защиты. Наша христова невеста работим шпендрик проф химией коренных маркий (Gyeon, CarPro) (аюшки?) тоже ясно лицезреем, экой эшелон важен чтоб ла
MichaelUndof 11 Şubat 2026 10:54
Top Bitcoin Casinos, [url=https://www.aashugacabs.com/the-dangers-of-casino-skimming-protecting-your-2/]https://www.aashugacabs.com/the-dangers-of-casino-skimming-protecting-your-2/[/url][url=https://tintalplaza.centrocomercial.digital/?p=13294]https://tintalplaza.centrocomercial.digital/?p=13294[/url][url=https://900united.com/understanding-why-czech-players-are-attracted-to/]https://900united.com/understanding-why-czech-players-are-attracted-to/[/url][url=https://www.museodelbrunello.it/experience-the-thrill-anywhere-the-rise-of-casino/]https://www.museodelbrunello.it/experience-the-thrill-anywhere-the-rise-of-casino/[/url][url=https://accelits.com/the-thrill-of-major-football-competitions-a-global/]https://accelits.com/the-thrill-of-major-football-competitions-a-global/[/url] offer an
DwightGek 11 Şubat 2026 07:26
Discover what’s new here — https://pronews24.ru/pgs/?promokod_betwinner_na_segodnya_pri_registracii.html
Jessicawar 11 Şubat 2026 07:21
Ваша мысль очень хороша Духи Montale Оud Pashmina, [url=https://oudpashminaufa.ru/]oudpashminaufa.ru[/url] — это удивительный аромат, который переносит вас в мир мелодичной роскоши. Уникальные ароматы удового дерева добавляют глубину и магнетизм этому празднику.
Ibrahimten 11 Şubat 2026 05:02
Извините, что я вмешиваюсь, но, по-моему, эта тема уже не актуальна. Casinos, [url=https://www.shopmos.co.uk/go.php?to=aHR0cHM6Ly9ub3VrY2FzaW5vcy5jb20v]https://www.shopmos.co.uk/go.php?to=aHR0cHM6Ly9ub3VrY2FzaW5vcy5jb20v[/url][url=https://mokaleng-eng.co.za/2023/04/05/revitalising-your-people-in-to-a-retail-downturn/]https://mokaleng-eng.co.za/2023/04/05/revitalising-your-people-in-to-a-retail-downturn/[/url][url=https://www.groupe-huillier.fr/2021/01/29/mecanicien-vp-vul-sisteron/]https://www.groupe-huillier.fr/2021/01/29/mecanicien-vp-vul-sisteron/[/url] showcase a thrilling experience for visitors. By various options and lavish environments, they draw many. Enjoy the lively atmosphere!
StellaLop 11 Şubat 2026 02:50
sports betting, [url=https://inmetal.com.br/the-ultimate-guide-to-bgd99-casino-experience-the/]https://inmetal.com.br/the-ultimate-guide-to-bgd99-casino-experience-the/[/url] - Sports wagering has become a popular pastime for many. Through the rise of online platforms, enthusiasts can easily engage in betting. Grasping the odds is crucial for gaining an edge.
Jessiebop 11 Şubat 2026 02:37
С У П Е Р !!!!!!!!!!!!!!!!!!!!!! ставки РЅР° СЃРїРѕСЂС‚, [url=https://cybersolutionpartner.com/stavki-na-skachki-konej-sogodni-vse-shho-vam/]https://cybersolutionpartner.com/stavki-na-skachki-konej-sogodni-vse-shho-vam/[/url][url=https://bz.eng.br/vsi-vidi-stavok-na-sport-ogljad-ta-rekomendacii/]https://bz.eng.br/vsi-vidi-stavok-na-sport-ogljad-ta-rekomendacii/[/url][url=https://canarymx.com/krash-igri-na-vodds-casino-jak-vigravati-ta/]https://canarymx.com/krash-igri-na-vodds-casino-jak-vigravati-ta/[/url] стають дедалі популярнішими серед людей, СЏРєС– шукають можливість заробітку. Гравці аналізують показники та окреслюють команди для СЃРІРѕС—С… акцій. РЈСЃРїС–С… Сѓ СЃС
Ashleymeavy 11 Şubat 2026 01:47
Online Casino, [url=http://carolkherlakian.com.br/kulturalis-esemenyek-a-nyaron-2025-os/]http://carolkherlakian.com.br/kulturalis-esemenyek-a-nyaron-2025-os/[/url][url=https://lobosperu.com/2025/12/01/1000-forintos-minimum-befizetes-minden-amit-tudnod/]https://lobosperu.com/2025/12/01/1000-forintos-minimum-befizetes-minden-amit-tudnod/[/url][url=https://developoo.com/2025/12/01/top-valodi-penzes-jatekok-nyerj-valojaban/]https://developoo.com/2025/12/01/top-valodi-penzes-jatekok-nyerj-valojaban/[/url][url=https://www.mekarmulya.desa.id/a-legjobb-magyar-slotok-fedezd-fel-a.html]https://www.mekarmulya.desa.id/a-legjobb-magyar-slotok-fedezd-fel-a.html[/url][url=https://www.marmaraelectronic.com/borsso-casino-a-digitalis-szerencsejatek-elmeny/]https://www.marmaraelectronic.com/borsso-casino-a-
JeanHok 11 Şubat 2026 01:35
The growth of Online Casino UK, [url=https://www.shwalista.jp/report/24791/]https://www.shwalista.jp/report/24791/[/url][url=https://www.re-cereal.com/discover-the-excitement-at-spinbuddha-casino/]https://www.re-cereal.com/discover-the-excitement-at-spinbuddha-casino/[/url][url=https://www.endotec.it/the-ultimate-spinbuddha-experience-unleashing-the/]https://www.endotec.it/the-ultimate-spinbuddha-experience-unleashing-the/[/url] delivers exciting options for bettors. Utilizing modern technology, players can explore diverse games from the ease of their homes. Such availability increases the overall gaming experience.
GabrielOxild 10 Şubat 2026 20:36
Discovering the Top Online Casino, [url=https://www.navigazioneetrasporti.it/2025/12/01/5-kaszino-amelyek-elfogadnak-huf-ot/]https://www.navigazioneetrasporti.it/2025/12/01/5-kaszino-amelyek-elfogadnak-huf-ot/[/url][url=https://consultorias.conteudoestrategico.com.br/unlocking-the-benefits-a-comprehensive-guide-to-2/]https://consultorias.conteudoestrategico.com.br/unlocking-the-benefits-a-comprehensive-guide-to-2/[/url][url=https://dressxo.com/top-5-nejlepich-kasino-her-ktere-musite-vyzkouet/]https://dressxo.com/top-5-nejlepich-kasino-her-ktere-musite-vyzkouet/[/url][url=https://feliperibeirovascular.com.br/casino01-12-1/les-bornes-d-arcade-retro-un-voyage-au-cur-de-la/]https://feliperibeirovascular.com.br/casino01-12-1/les-bornes-d-arcade-retro-un-voyage-au-cur-de-la/[/url][url=https://e
IreneWhact 10 Şubat 2026 20:18
Online Casino Games, [url=http://watersfamilyspecial.com/discover-the-enchantment-of-slots-charm-casino-2/]http://watersfamilyspecial.com/discover-the-enchantment-of-slots-charm-casino-2/[/url][url=https://yesdaddy.asia/en/experience-the-excitement-of-slots-n-bets-casino-2/]https://yesdaddy.asia/en/experience-the-excitement-of-slots-n-bets-casino-2/[/url][url=https://chitervedyadav.in/unveiling-the-thrills-of-online-casino/]https://chitervedyadav.in/unveiling-the-thrills-of-online-casino/[/url] deliver a stimulating way to dive into the universe of gaming. Players can choose from a multitude of games tailored to accommodate every preference.
Raymondrog 10 Şubat 2026 18:00
Really useful explanation — check it out <a href=https://taradmai.com/profile/llcedna035697>https://taradmai.com/profile/llcedna035697</a>
Chriscedly 10 Şubat 2026 15:15
Discover the leading online gaming platforms in the industry with Top Bitcoin Casinos, [url=https://sppp.socsci.uva.nl/archives/1875609]https://sppp.socsci.uva.nl/archives/1875609[/url][url=https://combrailles.altimax.com/czech-energy-projects-pioneering-sustainable/]https://combrailles.altimax.com/czech-energy-projects-pioneering-sustainable/[/url][url=https://www.coderian.com/profitlinehu-insights-strategiai-tanacsok/]https://www.coderian.com/profitlinehu-insights-strategiai-tanacsok/[/url][url=https://www.griecocaffe.com/2025/12/02/top-5-slovakia-online-casinos-where-fun-meets/]https://www.griecocaffe.com/2025/12/02/top-5-slovakia-online-casinos-where-fun-meets/[/url][url=https://syn.x7-trade.com/?p=16309]https://syn.x7-trade.com/?p=16309[/url]. These platforms offer safe transactions
Anthonycit 10 Şubat 2026 14:54
Online Casino Slots, [url=http://www.sunitex.com.hk/discover-the-thrills-of-slotssafari-casino/]http://www.sunitex.com.hk/discover-the-thrills-of-slotssafari-casino/[/url][url=http://www.kli.lt/slots-angels-casino-your-ultimate-gaming-2/]http://www.kli.lt/slots-angels-casino-your-ultimate-gaming-2/[/url][url=https://www.fakeitmakeup.se/discover-the-wild-wonders-of-casino-slotssafari/]https://www.fakeitmakeup.se/discover-the-wild-wonders-of-casino-slotssafari/[/url] - Online Casino Slots offer exciting experiences for players. With diverse themes and features, these games keep players engaged. Jackpot are just a spin away! Enjoy the thrill of trying your luck from the comfort of home. Experience bigger payouts with growing jackpots available.
RitaApamb 10 Şubat 2026 12:33
Понятно, большое спасибо за помощь в этом вопросе. онлайн казино, [url=https://iitg.net/2018/05/07/e-commerce-website-implementation/]https://iitg.net/2018/05/07/e-commerce-website-implementation/[/url] создает уникальную возможность увидеть азартные игры в любое место. Разнообразие развлечений угостит даже требовательных зрителей. Ключевое — это защита и легкость, которые интегрированы. Играйте и исследуйте свой шанс в онлайн казино!
KellyAcaxy 10 Şubat 2026 03:35
Замечательно, это очень ценная информация crypto casino, [url=https://admin.zenlishtoeic.vn/2025/12/17/explore-the-exciting-world-of-latest-slot-games/]https://admin.zenlishtoeic.vn/2025/12/17/explore-the-exciting-world-of-latest-slot-games/[/url][url=https://soccerlive.tech/win-big-with-live-blackjack-your-ultimate-guide-to-3/]https://soccerlive.tech/win-big-with-live-blackjack-your-ultimate-guide-to-3/[/url][url=https://easecenter.org/2025/12/17/why-you-should-try-the-best-us-crypto-casino/]https://easecenter.org/2025/12/17/why-you-should-try-the-best-us-crypto-casino/[/url] is an innovative way to play online. With decentralized technology, players can partake in a safe environment. Fast transactions and genuine games enhance the adventure of gaming. Dive into the world of crypto casi
GerardoJah 10 Şubat 2026 00:07
Совершенно верно! Мне нравится Ваша идея. Предлагаю вынести на общее обсуждение. The growing trend of battery casino, [url=http://www.loslocos.org/?feed-stats-url=aHR0cHM6Ly9iYXRlcnktZ2FtZS5jb20vYXZpYXRvcg]http://www.loslocos.org/?feed-stats-url=aHR0cHM6Ly9iYXRlcnktZ2FtZS5jb20vYXZpYXRvcg[/url] brings exciting gaming experiences to players. By utilizing advanced battery technologies, these casinos offer extended playtime without interruptions. Battery casino is redefining how we enjoy gaming!
Charmain 09 Şubat 2026 15:56
my blog Tower Rush jeu
MonicaNig 09 Şubat 2026 15:24
Советую Вам посмотреть сайт, с огромным количеством статей по интересующей Вас теме. женские сумки кожа, [url=http://роялиндиго.рф/]кожаные портфели из натуральной кожи[/url] — это стильный аксессуар, подходящий для любого случая. Кожаные сумки для женщин подчеркивают индивидуальность и придают образу утонченности. Элегантный дизайн и превосходное качество материалов делают их незаменимыми. Выбор моделей обширный, от классических до современных. Каждая искушенная модница найдет свой идеальный вариант.
Monicacap 09 Şubat 2026 12:31
Спасибо за помощь в этом вопросе, как я могу Вас отблагодарить? online casino, [url=https://aniworld.to/user/profil/playojocasino]https://aniworld.to/user/profil/playojocasino[/url] offers a vast array of games for users to experience. With slots to table games, each variant brings different excitement and joy.
PeterCrugs 09 Şubat 2026 12:30
Kod multi Mostbet dzisiaj umozliwia odebranie specjalnego bonusu na zaklady akumulowane. Rejestrujac konto z QWERTY555, gracze moga zwiekszyc potencjalne wygrane na kuponach wielokrotnych. Kod promocyjny Mostbet bonus dziala natychmiast po spelnieniu warunkow depozytu. Oferta obejmuje takze freebet na wybrane wydarzenia sportowe. Dzieki temu start na platformie jest znacznie bardziej oplacalny. Najnowsza wersja Mostbet tutaj <a href=https://webhostingtalk.pl/public/pages/?kod_promocyjny_mostbet.html>https://www.magazinmagazinov.ru/include/pages/promokod_mostbet_2.html</a>
JuliaInalm 09 Şubat 2026 08:59
Я извиняюсь, но, по-моему, Вы ошибаетесь. Могу отстоять свою позицию. Пишите мне в PM, поговорим. сумки женские кожаные, [url=http://bespoke.moscow/]ремень для часов huawei watch gt[/url] – это функция современного гардероба. Они соответствуют индивидуальность каждой особы. Качественная кожа дает долговечность и модный вид. Выбирайте разнообразные дизайны, чтобы выбрать свой идеальный аксессуар.
MollySlape 08 Şubat 2026 20:41
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Давайте обсудим это. Пишите мне в PM, поговорим. WalletCloud wallet, [url=https://walletcloud.io/]multi-chain crypto wallet[/url] is a revolutionary solution for managing digital assets. It offers users ease in storing assets. With a user-friendly interface, investors can easily access their funds anytime, anywhere.
Courtneyced 08 Şubat 2026 15:23
Как раз то, что нужно. Я знаю, что вместе мы сможем прийти к правильному ответу. The finest crypto casino offers exciting games for gamblers, with numerous options to choose from. Discover the benefits of crypto gambling today! Don't miss out on the best crypto casino, [url=https://webapp.sidfoot.eu/bet-on-sports-with-solana-the-future-of-online-12/]https://webapp.sidfoot.eu/bet-on-sports-with-solana-the-future-of-online-12/[/url][url=http://hildegardvonbingen.de/play-and-win-with-exclusive-opportunities-at-2/]http://hildegardvonbingen.de/play-and-win-with-exclusive-opportunities-at-2/[/url][url=http://overtimecards.com/bet-on-sports-with-usdc-a-new-age-of-online-421497.html]http://overtimecards.com/bet-on-sports-with-usdc-a-new-age-of-online-421497.html[/url]!
Eugeneatron 08 Şubat 2026 14:36
Нет. My Hbar Wallet, [url=https://wallet-hedera.com/blog]My Hbar Wallet[/url] is an essential tool for managing your digital assets. The application offers a secure way to store, send HBAR tokens. Keep your funds guarded with top-notch security features, ensuring peace of mind while trading.
Madisonglurf 07 Şubat 2026 09:52
урааааааа дождался пасиба хоть за такое качество слоты на деньги, [url=https://mymoneyslots.ru/igrovye-avtomaty-s-vyvodom-na-tinkoff]популярные игровые автоматы на деньги с выводом денег на карту тинькофф[/url] — это невероятного рода азартные игры, которые привлекают множество игроков. Погружаясь в них, вы можете заработать настоящие деньги. Каждый игра предлагает уникальные функции и награды, что делает процесс захватывающим. Современные темы и графика слотов на деньги как правило становятся причиной спроса.
Andyclaig 07 Şubat 2026 04:55
online casino sports betting, [url=https://www.futuraempresas.com.br/the-rise-of-betwinner-in-online-betting/]https://www.futuraempresas.com.br/the-rise-of-betwinner-in-online-betting/[/url] has become increasingly popular due to the ease it offers. Players can stake money from the privacy of their space, enjoying a wide range of betting markets.
LawrenceAgexy 07 Şubat 2026 02:49
Специально зарегистрировался на форуме, чтобы сказать Вам спасибо за поддержку. The emergence of casino crypto, [url=https://forexneuralnetwork.com/index.php/2025/12/17/discover-the-latest-gaming-trends-a-deep-dive-into/]https://forexneuralnetwork.com/index.php/2025/12/17/discover-the-latest-gaming-trends-a-deep-dive-into/[/url][url=https://brief.alaskawebgeeks.com/discover-the-best-slot-games-your-ultimate-guide-2/]https://brief.alaskawebgeeks.com/discover-the-best-slot-games-your-ultimate-guide-2/[/url][url=http://maisbrasil.meuanunciodigital.com.br/discover-the-thrill-explore-exclusive-slot-games/]http://maisbrasil.meuanunciodigital.com.br/discover-the-thrill-explore-exclusive-slot-games/[/url] has transformed the gaming industry. Players can now savor anonymity and quickness when wag
Stevenfuh 06 Şubat 2026 22:48
смотрела на большом экране! online casino, [url=http://www.marais-poitevin-autrefois.fr/10-aout-2014-dedicace/]http://www.marais-poitevin-autrefois.fr/10-aout-2014-dedicace/[/url] offer a thrilling experience for players. With numerous games such as slots, blackjack, and roulette, wagerers can enjoy superb entertainment from the comfort of their homes. Embrace the fun now!
Jilljam 06 Şubat 2026 19:57
Абсолютно с Вами согласен. Я думаю, что это хорошая идея. В последние годы азартные игры приобрели огромную популярность среди развлечений. Вот топ 5 казино, [url=https://kazinotop-5.ru/top-5-casino-s-horoshej-otdachej/]самые лучшие казино онлайн с хорошей отдачей[/url], которые привлекают игроков своим разнообразием и качеством услуг. Указанные заведения обеспечивают большие выигрыши и невероятный опыт. Каждое из этих казино предлагает обширный выбор игр, которые мощно вовлекает игроков. Следует подчеркнуть, что данные казино также показывают выгодные бонусы и акции.
Sarahdix 06 Şubat 2026 15:56
online casino betting, [url=http://bdo.stejdzing.pl/index.php/2026/01/11/betwinner-tu-puerta-de-entrada-al-mundo-de-las-16/]http://bdo.stejdzing.pl/index.php/2026/01/11/betwinner-tu-puerta-de-entrada-al-mundo-de-las-16/[/url] is an exciting way to test your luck. With a variety of options, players can relish the joy of wagering online.
Priscillabek 06 Şubat 2026 07:53
UK Casinos Not on Gamstop, [url=https://mycar69.com/exploring-the-world-of-uk-online-casinos-not-on/]https://mycar69.com/exploring-the-world-of-uk-online-casinos-not-on/[/url] provide a unique gaming experience for players looking for different options. With numerous games and enticing bonuses, these casinos cater to those seeking freedom in their sessions. Enjoy your time at UK Casinos Not on Gamstop!
Allisonaloma 06 Şubat 2026 05:03
Прошу прощения, что вмешался... У меня похожая ситуация. Можно обсудить. онлайн казино на деньги, [url=https://kazinonadengi-play.ru/casino-s-vyvodom-na-vtb/]https://kazinonadengi-play.ru/casino-s-vyvodom-na-vtb/[/url] предлагает игрокам удивительные возможности для игры. Здесь можно заработать, наслаждаясь настроением настоящего казино. Большой выбор игр дает каждому вариант найти что-то по душе.
DarrenBic 06 Şubat 2026 03:51
<a href=https://drivelity.com/car-rental-abu-dhabi>cheap rent a car abu dhabi without deposit</a>
Jesuswer 06 Şubat 2026 01:29
online casino, [url=http://unati.univasf.edu.br/betwinner-your-ultimate-sports-betting-experience-21/]http://unati.univasf.edu.br/betwinner-your-ultimate-sports-betting-experience-21/[/url] provides a exciting experience for gamers. This platform provides players to partake in a variety of entertainment. With simplicity, players can enjoy wagering from the comfort of their home.
Stephaine 06 Şubat 2026 00:20
Cryptoboss Casino — экосистема, объединяющая прозрачность и азарт, и любая операция занимает минуты. Начинайте без лишней бюрократии — крипто босс казино официальный сайт — и доступ к играм уже у вас. Подборка собрана из провайдеров с высоким RTP, загрузка стабильна, а BTC/ETH/USDT подключены из коробки. Условия промо ясные — используйте там, где выгодно. Транзакции под защитой сети Рейтинги с ощутимыми призами Помощь на русс�
Gwinnettget 05 Şubat 2026 21:56
наконец в хорошем качестве!!! online casino, [url=https://www.babelcube.com/user/jack-million]https://www.babelcube.com/user/jack-million[/url] delivers a thrilling time for players. By using advanced technology, players can enjoy their favorite games from the comfort of home. Captivating bonuses enhance the overall play!
LindsayKap 05 Şubat 2026 15:10
Должен Вам сказать Вы на ложном пути. resident слот онлайн, [url=https://avtomatresidentplay.ru/]avtomatresidentplay.ru[/url] — это увлекательная игра, проявляющая игрокам предложение окунуться в мир эмоций. В ней можно увидеть разные бонусы и выигрышные функции. Попробуйте свои силы и исследуйте в захватывающий мир азартных игр.
SherrydIx 05 Şubat 2026 14:40
Можно было и получше написать VOdds огляд, [url=https://www.dataprotect.sg/jak-pravilno-vibirati-sloti-na-onlajn-kazino/]https://www.dataprotect.sg/jak-pravilno-vibirati-sloti-na-onlajn-kazino/[/url][url=http://truongquoctevietnam.edu.vn/stavki-na-skachki-vash-putivnik-u-sviti/]http://truongquoctevietnam.edu.vn/stavki-na-skachki-vash-putivnik-u-sviti/[/url][url=http://www.near-by-locksmith.com/jak-pochati-grati-v-nastilni-igri-pokrokove-2/]http://www.near-by-locksmith.com/jak-pochati-grati-v-nastilni-igri-pokrokove-2/[/url] демонструє вдале поєднання інтерфейсу та функцій. Р’С–РЅ сервіс наддає численні можливості для геймінгу. Внаслідок зручному дизайну, користувача
Priscillajab 05 Şubat 2026 11:49
online casino, [url=https://fukusuke-group.com/]https://fukusuke-group.com/[/url] provides an thrilling way to take part in your favorite games. With multiple options available, players can easily discover their perfect game from slots to table games, providing a memorable gaming experience.
Juliajoync 05 Şubat 2026 09:48
In the world of online gaming, a exciting option is navigating Casinos Not on Gamstop UK, [url=http://alvoradapflege.de/non-gamstop-uk-casino-sites-a-comprehensive-guide-2/]http://alvoradapflege.de/non-gamstop-uk-casino-sites-a-comprehensive-guide-2/[/url]. These platforms offer players additional freedom and flexibility, away from limitations. Gamblers can experience a more extensive selection of games and bonuses, making their gaming journey even more thrilling.
KeriDuh 04 Şubat 2026 23:04
In recent years, the growth of online gambling has surged. Players can now enjoy their favorite games from the comfort of home. To play online casino, [url=https://vishyam.com/exploring-betwinner-a-comprehensive-guide-to-22/]https://vishyam.com/exploring-betwinner-a-comprehensive-guide-to-22/[/url] effectively, strategies are essential for maximizing fun and potential wins.
GabrielFom 04 Şubat 2026 15:49
Discover the fun of playing at Casino Sites Not on Gamstop, [url=https://rakennus.jdmmediagroup.com/2026/01/12/discover-the-best-uk-online-casinos-not-on-gamstop-2/]https://rakennus.jdmmediagroup.com/2026/01/12/discover-the-best-uk-online-casinos-not-on-gamstop-2/[/url]. These platforms offer a unique gaming experience, letting players to relish their favorite games without restrictions.
Spravkijjp 04 Şubat 2026 03:00
Требуется медицинская книжка быстро для сотрудников или компаний? На [url=https://cmc-clinic.ru]https://cmc-clinic.ru[/url] в Москве сделают или обновят медкнижку в течение дня — быстро, официально и без ожидания. <a href="https://cmc-clinic.ru">https://cmc-clinic.ru</a> Переходите на сайт.
Cassiehoity 04 Şubat 2026 02:57
Ну наконец то брокер VOdds, [url=https://demoml.calseed.co.jp/cate-vodds1/23326/]https://demoml.calseed.co.jp/cate-vodds1/23326/[/url][url=https://beiclo.net/it/progetti/atsrl/index.php/jak-zrobiti-stavku-na-sportivnu-podiju-pokrokovij/]https://beiclo.net/it/progetti/atsrl/index.php/jak-zrobiti-stavku-na-sportivnu-podiju-pokrokovij/[/url][url=https://www.honeymoonerchannel.com/jak-pochati-staviti-na-sportivni-podii-pokrokova-16/]https://www.honeymoonerchannel.com/jak-pochati-staviti-na-sportivni-podii-pokrokova-16/[/url] РїСЂРѕРїРѕРЅСѓС” широкий РІРёР±С–СЂ фінансових інструментів для інвесторів. Р— простим інтерфейсом та професійною підтримкою, VOdds забезпечує преміум рівень Р
EricaRop 04 Şubat 2026 02:54
Вас посетила просто отличная мысль In the world of online gambling, the emergence of a new crypto casino, [url=https://tipografiaformertest.abisoft.es/how-to-make-deposits-using-various-methods-2/]https://tipografiaformertest.abisoft.es/how-to-make-deposits-using-various-methods-2/[/url][url=https://edahomehealthcare.com/maximizing-your-potential-how-to-make-the-most-of-3/]https://edahomehealthcare.com/maximizing-your-potential-how-to-make-the-most-of-3/[/url][url=https://www.xn--l3cbd5c2e5c.com/%posttype%/unlock-major-wins-get-big-payouts-with-bitfortune/]https://www.xn--l3cbd5c2e5c.com/%posttype%/unlock-major-wins-get-big-payouts-with-bitfortune/[/url] offers thrilling opportunities. With modern technology, players can enjoy exciting games while ensuring reliable transactions. Join the
Anakitte 03 Şubat 2026 23:23
Casinos Not on Gamstop, [url=https://najeya.com/exploring-uk-online-casinos-not-on-gamstop-your/]https://najeya.com/exploring-uk-online-casinos-not-on-gamstop-your/[/url] provide players with thrilling gaming experiences. These sites are perfect for those who want to steer clear of self-exclusion. Enjoy a wide range of options without restrictions. Casinos Not on Gamstop is your gateway to open-ended fun.
Spravkijze 03 Şubat 2026 23:15
Официально и с аттестацией оформить санитарную книжку в Москве за 1 день обеспечит компания [url=https://volgamedconsalt.ru/]https://volgamedconsalt.ru/[/url]. Организация изготовит официальный документ с положительными анализами по цене от 1200 рублей для трудоустройства пищевой промышленности. <a href="https://volgamedconsalt.ru/">https://volgamedconsalt.ru/</a> Получение проводится в кратчайшие сроки, нужны только фотографии и данные.
Spravkiisr 03 Şubat 2026 21:26
Узнайте подробнее о плюсах сотрудничества с организацией — надёжность, уровень услуг и комплексный сервис! Зайдите на [url=https://tdstyling.ru]https://tdstyling.ru[/url] и узнайте предложения, способы связи, а также материалы. <a href="https://tdstyling.ru">https://tdstyling.ru</a> Хотите сотрудничать — эта организация предлагает тематические ссылки, оптимальные решения и выгодные тарифы.
NancyJapse 03 Şubat 2026 21:00
Великолепная фраза Клубная атмосфера в казино clubnika казино, [url=https://clubnikacasinopay.ru/]онлайн clubnika casino[/url] формирует уникальные впечатления у игроков. Играя, вы имеете возможность наслаждаться многообразием азартных развлечений. Каждая сессия — это потенциал выиграть призы, обмениваясь увлечением с другими участниками.
MollyMen 03 Şubat 2026 20:33
Я твёрдо уверен, что Вы не правы. Время покажет. In the world of gaming, the online casino, [url=https://www.fototrappole.com/2014/10/20/how-important-is-light-in-the-living-room/]https://www.fototrappole.com/2014/10/20/how-important-is-light-in-the-living-room/[/url] offers players an exhilarating experience. With varied games available, punters can enjoy video slots, table games, and live dealer options, all from the comfort of their homes.
Spravkinzw 03 Şubat 2026 17:46
Для владельцев Mercedes, ценящих надёжность и удобство — профессиональный техцентр выполняет полный спектр услуг: слесарный и кузовной ремонт, проверку, установку Webasto, ГБО и многое другое. [url=https://specavtoimport.ru]https://specavtoimport.ru[/url] квалифицированные автомеханики проводят работы на лицензированном инструменте, задействуя качественные запчасти и предоставляя надёжность и персональное обслуживание. <a href="https://specavtoimport.ru">https://specavtoimport.ru</a> Узнайте информацией — сервис Mercedes готов помочь на ресурсе.
Spravkibxs 03 Şubat 2026 14:02
Нужна безопасное лечение зубов безболезненно в СПб? [url=https://smails-clinic.ru]https://smails-clinic.ru[/url] . В нашей стоматологической клинике работают с передовые технологии, приём возможен сразу, а консультация и диагностика — <a href="https://smails-clinic.ru">https://smails-clinic.ru</a> даром и в комфортной обстановке.
Spravkizck 03 Şubat 2026 12:08
Для обладателей Nissan, ищущих в надёжном обслуживании и детальном сервисе — автосервис <a href="https://skupkaavtosp.ru">https://skupkaavtosp.ru</a> предлагает слесарный и кузовной, компьютерную диагностику, сход-развал, замену масла в АКПП, установку ГБО, Webasto, поклейку плёнки и многое другое. Профессиональные автомеханики выполняют работы на лицензированном станках, задействуют оригинальные детали и обеспечивают комфортный сервис с комфортным залом и Wi-Fi. [url=https://skupkaavtosp.ru]https://skupkaavtosp.ru[/url] Посмотреть подробностями — сервис Nissan готов помочь на портале.
Spravkitua 03 Şubat 2026 10:17
Хотите получить лучшее решение заказать справку срочно и без очередей? На сайте [url=https://romashkaclinic.ru]https://romashkaclinic.ru[/url] доступен огромный выбор справок: от справки 001-ГС/у, справки 027/у, справки 086/у до документов для плавания, ВНЖ и КЭК-заключений — всё выполнено официально и на дом. Оформление занимает считанные минуты, доступ к форме мгновенный. Это без хлопот, официально и без проблем. Узнайте подробности — справка через интернет, мгновенная заявка, <a href="https://romashkaclinic.ru">https://romashkaclinic.ru</a> справка с доставкой.
Spravkiwms 03 Şubat 2026 08:27
Узнайте всю информацию о компании Restyle-Авто — современный автоцентр, <a href="https://restyle-avto.ru">https://restyle-avto.ru</a> разнообразие машин, доступные предложения и проверенные предложения! Зайдите на [url=https://restyle-avto.ru]https://restyle-avto.ru[/url] и посмотрите варианты в наличии. Нужен транспорт срочно или лучшее предложение — компания предлагает авто с пробегом, оформление кредита и центральный офис. Хотите без лишних хлопот — здесь найдёте доступные цены и гарантированное качество.
Sandratuh 03 Şubat 2026 07:14
Я считаю, что Вы допускаете ошибку. Могу отстоять свою позицию. Пишите мне в PM, поговорим. болливуд казино, [url=https://bollywoodplay247.ru/]казино bollywood[/url] предлагает уникальное сочетание развлечений и пристрастия. Здесь посетители могут проверить удачу в разных играх, от слотов до настольных игр. Погрузитесь в атмосферу Болливуд казино и откройте для себя все его современные призы и выигрыши.
Spravkiikq 03 Şubat 2026 04:46
Требуется медсправка быстро и без очередей? <a href="https://ossis-med.ru">https://ossis-med.ru</a> Мы сможем оформить разные медицинские справки, от бассейна до учебного отпуска. [url=https://ossis-med.ru]https://ossis-med.ru[/url] Оформите оформление справки или справка под заказ.
Spravkilfa 03 Şubat 2026 02:54
Для собственников Mercedes, ценящих премиум и удобство — <a href="https://novomed-cardio.ru">https://novomed-cardio.ru</a> специализированный автотехцентр выполняет все виды работ: механический и ремонт кузова, диагностику, инсталляцию Webasto, ГБО и многое другое. [url=https://novomed-cardio.ru]https://novomed-cardio.ru[/url] Профессиональные автомеханики работают на современном инструменте, применяя фирменные материалы и предоставляя гарантию и личный подход. Ознакомьтесь с информацией — автосервис Mercedes ждёт вас на портале.
Spravkibpd 02 Şubat 2026 23:09
Подбираете простой способ оформить медсправку или тесты без посещения клиники? На [url=https://mymednews.ru]https://mymednews.ru[/url] можно получить документ для работы, университета или учебного заведения — в короткие сроки и официально. Также доступны анализы на ВИЧ-инфекцию, гепатит B и C, уровень сахара и многое другое без вашего присутствия. Вам не придётся ждать: всё делается быстро, с курьерской доставкой и подробным результатом. <a href="https://mymednews.ru">https://mymednews.ru</a> Подробнее на сайте — оформление справки онлайн, анализы онлайн, справка за 1 день.
Roelpsype 02 Şubat 2026 21:20
Очень любопытный вопрос На просторах азартных игр появляются новые популярные направления. Одним из актуальных направлений является new retro казино онлайн, [url=https://newretroslotplay.ru/registraciya-i-vhod-v-kabinet/]создать аккаунт new retro casino[/url], что завлекает любителей азартных игр своим стилистическим оформлением и приверженностью к классике. Развлечения с яркими графическими фрагментами и ретро-атмосферой привносят уникальное чувство умиления. Любители игр могут насладиться многообразием развлекалок и сервисами, которые добавляют развлечение.
JordanTaumb 02 Şubat 2026 20:18
Online gambling has become increasingly popular, with players seeking alternatives. Many prefer casinos not on GamStop, [url=https://www.distradainstrada.com/wp/discovering-non-gamstop-casinos-in-the-uk-89709049/]https://www.distradainstrada.com/wp/discovering-non-gamstop-casinos-in-the-uk-89709049/[/url] for a wider variety of games and bonuses. These platforms offer distinct gaming experiences, luring players worldwide. They often feature large jackpots and enticing promotions, making them an appealing choice for those looking to explore beyond traditional options. With no restrictions, players can enjoy their favorite games at any time. Whether it's slots or table games, these casinos not on GamStop provide the thrill and flexibility that many desire.
Spravkiewm 02 Şubat 2026 19:29
Подбираете место, где срочно сделать санитарную книжку сегодня же без толкучки и проблем? На сайте [url=https://medraskhodka.ru/]https://medraskhodka.ru/[/url] медкнижку оформят или продлят за 1 день: с анализами и заключением терапевта — даже без визита. Услуга подходит для работников пищевой промышленности, ЖКХ и компаний, где требуются профотрицания и допуск. Документы готовятся максимально быстро, а услуга стоит недорого (от 1 600 ?, обновление с 1 300 ?). <a href="https://medraskhodka.ru/">https://medraskhodka.ru/</a> Смотрите детали — санитарная книжка срочно, оформление онлайн, без очередей.
Spravkiasz 02 Şubat 2026 17:38
Подбираете место, где оформить медкнижку по Подольску срочно и официально — без хлопот и ожидания? В частном медцентре на сайте [url=https://med-podolsk.ru]https://med-podolsk.ru[/url] можно оформить официальную книжку, справку в ГАИ, бассейна, лагеря или разрешения на оружие в течение суток — с анализами, осмотром терапевта и гарантированной легальностью. Высокая скорость, лёгкая регистрация с 9:00 до 23:00, честная стоимость — стоимость справок от 500 ?, санкнижка с 1200 ?. <a href="https://med-podolsk.ru">https://med-podolsk.ru</a> Узнайте больше — медкнижка быстро, справка за день, оформление онлайн.
Jenniferveiva 02 Şubat 2026 15:51
Подтверждаю. И я с этим столкнулся. Можем пообщаться на эту тему. In recent years, the rise of crypto online casino, [url=https://www.meinds.online/2025/12/18/how-to-deposit-and-withdraw-a-comprehensive-guide-11/]https://www.meinds.online/2025/12/18/how-to-deposit-and-withdraw-a-comprehensive-guide-11/[/url][url=https://www.scuolarubinato.eu/2025/12/18/mastering-blackjack-at-bitfortune-casino-10/]https://www.scuolarubinato.eu/2025/12/18/mastering-blackjack-at-bitfortune-casino-10/[/url][url=https://safoabernardi.altervista.org/mastering-trx-deposits-your-ultimate-guide/]https://safoabernardi.altervista.org/mastering-trx-deposits-your-ultimate-guide/[/url]s has transformed the gaming industry. These platforms offer a novel way to enjoy gambling while benefiting from the advantages of cryp
Spravkiido 02 Şubat 2026 13:55
Ищете, где заказать или перевыпустить санитарную книжку в городе Уфа срочно и с комфортом? В центре [url=https://medmagprof24.ru]https://medmagprof24.ru[/url] можно получить медкнижку без стресса и очередей — оформление проходит официально и без ожидания. Услуга может быть оформлена через интернет и готова быстро. Это просто, законно и то, что требуется. <a href="https://medmagprof24.ru">https://medmagprof24.ru</a> Смотрите детали — медицинская книжка Уфа, без очередей, оформление срочно.
Angelarek 02 Şubat 2026 13:44
Casinos Not on Gamstop UK, [url=http://www.atlantic-city.net/exploring-casinos-not-on-gamstop-uk-your-ultimate-3/]http://www.atlantic-city.net/exploring-casinos-not-on-gamstop-uk-your-ultimate-3/[/url] offer unique experiences for players seeking freedom. These online platforms provide a different route for those who feel restricted by gambling restrictions. Explore a variety of options and enjoy offers tailored for you! With Casinos Not on Gamstop UK, gaming is tailored to your desires. Discover exciting adventures and engage with fellow gamblers worldwide.
LawrenceGlato 02 Şubat 2026 13:30
Finding the right betting platform can be challenging. However, non GamStop bookmakers, [url=https://coe.skybuffer.com/exploring-non-gamstop-sports-betting-sites-a-12-2/]https://coe.skybuffer.com/exploring-non-gamstop-sports-betting-sites-a-12-2/[/url] offer a unique option for players looking for extra freedom. They provide diverse betting choices and greater accessibility on various markets.
RebeccaNix 02 Şubat 2026 11:20
Качество сносное... 1win казино, [url=https://1win-officialkazino.ru/bonusy-za-deposit-i-registraciyu/]1 вин бонус[/url] предлагает удивительные возможности для азартных игроков. Онлайн-казино радует разнообразием игр. Множество гостей найдет что-то интересное для себя.
Spravkivgs 02 Şubat 2026 08:25
Нужна, где оформить медкнижку за 1 час по городу, официально и без ожидания? На сайте [url=https://medik-moscov.ru]https://medik-moscov.ru[/url] можно сделать санитарную книжку для работы в детских лагерях, сфере питания, гостиницах, медицинских центрах, ритейле и разных сферах. Цена: новая санкнижка с 1390 ?, продление санкнижки с 780 ?. Всё оперативно, с законной защитой и близко к метро. <a href="https://medik-moscov.ru">https://medik-moscov.ru</a> Подробнее на сайте — санитарная книжка быстро, оформление за час, официальная санкнижка.
EugeneSPIVE 02 Şubat 2026 08:22
Это отличная идея. Готов Вас поддержать. In the world of video game, [url=https://dakshinakasi.com/hello-world/]https://dakshinakasi.com/hello-world/[/url]s, players embark on thrilling journeys filled with hurdles. The captivating narratives and stunning graphics create a unique experience, allowing gamers to discover new realms. For enthusiasts, every game is an opportunity to engage with others who share similar passions, making the experience not just about winning, but about the community built around it.
Danawet 02 Şubat 2026 06:50
international online casinos, [url=https://millymontserrat.com/exploring-the-world-of-international-online-5/]https://millymontserrat.com/exploring-the-world-of-international-online-5/[/url] present an exciting experience for players worldwide. These platforms allow users to relish a variety of games including slots, poker, and blackjack. Available 24/7, they offer gamblers the chance to win big from anywhere.
Spravkitlw 02 Şubat 2026 06:32
Нужна, где оформить медкнижку за 1 день без проблем? На сайте [url=https://medic-dpo.ru]https://medic-dpo.ru[/url] доступна возможность оперативного оформления официальной книжки — просто подайте онлайн-заявку и приготовьте документы (паспорт и фото). Для сотрудников коммунальных служб, сферы обслуживания и прочих категорий всё проходит быстро и удобно, без очередей. <a href="https://medic-dpo.ru">https://medic-dpo.ru</a> Получите документ официально и легально — с доставкой по вашему адресу или до метро. Смотрите детали — медкнижка за день, заказ через интернет, получение документов.
Spravkiqbh 02 Şubat 2026 02:48
Официально и без вашего присутствия оформить медкнижку с доставкой по городу предлагает сайт [url=https://medcenterpenza.ru/]https://medcenterpenza.ru/[/url]. Компания изготовит официальный документ за 1 день по цене от 2000 рублей без очередей и анализов. <a href="https://medcenterpenza.ru/">https://medcenterpenza.ru/</a> Для оформления потребуется только фото и данные, и готовый документ приедет с курьером в оговоренные сроки.
Violaleark 01 Şubat 2026 20:27
MagicWin casino, [url=https://nextoons.bex.jp/2026/01/20/877240/]https://nextoons.bex.jp/2026/01/20/877240/[/url] offers a thrilling experience for gamers. Boasting a wide range of games, players can explore various genres. Rewards are available to enhance the excitement. Join right away and test your luck at MagicWin casino!
Sabrinater 01 Şubat 2026 10:04
CaptainCooks Casino, [url=https://assuntosreligiosos.marica.rj.gov.br/discover-the-thrills-of-captain-cooks-online-10/]https://assuntosreligiosos.marica.rj.gov.br/discover-the-thrills-of-captain-cooks-online-10/[/url] offers thrilling games for gamblers. With appealing bonuses, you can enjoy numerous opportunities to win big. Sign up today and experience the finest online gaming!
PhilipKAp 01 Şubat 2026 08:11
Casinos Non Gamstop, [url=https://neurochirurgia.cm-uj.krakow.pl/discovering-new-non-gamstop-casino-sites-for/]https://neurochirurgia.cm-uj.krakow.pl/discovering-new-non-gamstop-casino-sites-for/[/url] offer players a chance to enjoy their favorite games without restrictions. These venues provide diverse options for players, allowing them to enjoy new experiences without the limitations of self-exclusion.
Priscillaram 01 Şubat 2026 06:15
Не беда! плей фортуна казино, [url=https://playfortunaofficialsite.ru/]play fortuna онлайн[/url] предлагает обширный ассортимент азартных игр. На данном можно встретить так и стандартные слоты, так и новые технологии. Убедитесь в возможностях и наслаждайтесь всеми играми.
IrisSkymn 01 Şubat 2026 04:21
Это переходит все границы. crypto casino sites, [url=https://kotwicamorska.pl/unlock-big-wins-with-pragmatic-play-a-guide-to/]https://kotwicamorska.pl/unlock-big-wins-with-pragmatic-play-a-guide-to/[/url][url=https://fr.tuwshiyah.com/2025/12/18/bet-on-sports-at-bitfortune-the-future-of-online/]https://fr.tuwshiyah.com/2025/12/18/bet-on-sports-at-bitfortune-the-future-of-online/[/url][url=https://ds_kunk_agns.zabedu.ru/2025/12/18/discover-unique-and-exciting-original-games-at/]https://ds_kunk_agns.zabedu.ru/2025/12/18/discover-unique-and-exciting-original-games-at/[/url] offer a singular gaming experience for players. Through blockchain technology, these websites ensure honesty in games. Players can take pleasure in various choices while receiving noteworthy bonuses. Crypto casino sites r
TimGooge 01 Şubat 2026 04:19
Вы мне не подскажете, где мне узнать больше об этом? VOdds брокер, [url=https://celestalis.pl/jak-vigravati-na-slotah-sekreti-ta-poradi-dlja/]https://celestalis.pl/jak-vigravati-na-slotah-sekreti-ta-poradi-dlja/[/url][url=https://www.elsolid.pl/chomu-varto-grati-v-pragmatic-1723705486/]https://www.elsolid.pl/chomu-varto-grati-v-pragmatic-1723705486/[/url][url=https://egypt.mubashertrade.com/vodds1/jak-vigravati-v-kartkovi-igri-sekreti-ta-strategii/]https://egypt.mubashertrade.com/vodds1/jak-vigravati-v-kartkovi-igri-sekreti-ta-strategii/[/url] — це популярна компанія, що забезпечує оригінальні можливості для фінансових операцій. Кваліфіковані трейдери бажають користуватР
KerryHem 31 Ocak 2026 23:49
Finding the best casinos not on GamStop, [url=https://janseverhuizingen.nl/discovering-non-gamstop-sites-a-guide-to/]https://janseverhuizingen.nl/discovering-non-gamstop-sites-a-guide-to/[/url] offers players exciting alternatives. Many sites provide special bonuses and a broad selection of games. Explore platforms that emphasize user experience and safety. Enjoy seamless gaming without restrictions at these thrilling casinos!
Spravkiwzt 31 Ocak 2026 22:50
Нужен быстрый вариант заказать официальную справку или медицинскую книжку без визита в поликлинику и задержек? В клинике [url=https://med-blesk.ru]https://med-blesk.ru[/url] оказывается весь комплекс медицинских предложений: выдача санитарных книжек, справок разных форм, диагностики УЗИ, анализы и услуги терапевта — всё официально и юридически корректно. Осуществляется доставка справок, а также медицинские осмотры для организаций и частных лиц. Это в кратчайшие сроки, надёжно и на высоком уровне — обслуживает сертифицированный медперсонал. <a href="https://med-blesk.ru">https://med-blesk.ru</a> Все детали на сайте — медсправка онлайн, медкнижка без очередей, заказ справки.
DevinPaw 31 Ocak 2026 22:28
Подтверждаю. Я присоединяюсь ко всему выше сказанному. Давайте обсудим этот вопрос. Experience the thrill of exciting gameplay with Lightning Storm Slot, [url=https://softfin.de/auftaktveranstaltung-das-leben-ist-zu-kurz-roadshow-voller-erfolg/kohl-und-schneider/]https://softfin.de/auftaktveranstaltung-das-leben-ist-zu-kurz-roadshow-voller-erfolg/kohl-und-schneider/[/url]. This game offers extraordinary features and bright graphics that keep players absorbed. Dive into the world of winning possibilities!
Spravkiihe 31 Ocak 2026 20:59
Ищете медкнижка сегодня же без визита в больницу? На [url=https://med-bez-boli.ru]https://med-bez-boli.ru[/url] можно заказать или перевыпустить медкнижку официально, без прохождения врачей — быстро и законно. Работаем с реальной клиникой и оформляем медкнижки нового формата, гарантируем подлинность документов, которую фиксируют в единой системе. Это комфортно, официально и по выгодной цене. <a href="https://med-bez-boli.ru">https://med-bez-boli.ru</a> Все детали смотрите — санитарная книжка без врачей, оформление за день, заказ медкнижки через интернет.
Spravkixxr 31 Ocak 2026 19:07
Просто и без очередей получить санкнижку в вашем городе можно на сайте [url=https://med-analysis.ru/]https://med-analysis.ru/[/url]. Сервис изготовит документ с печатями всего за один день, без сдачи анализов. <a href="https://med-analysis.ru/">https://med-analysis.ru/</a> Оформление осуществляется онлайн, а книжка передана лично в руки в удобное время.
Shaunsak 31 Ocak 2026 18:53
<a href=https://astra-hotel.ch/articles/code_promo_1xbet.html >Code Promo Cote D’ivoire 2026</a> vous permet de recevoir un bonus de 100% jusqu’a 130$, Les nouveaux inscrits beneficient d'un bonus de bienvenue 1xbet. Assurez-vous de lire les regles pour profiter pleinement de votre bonus de bienvenue. Commencez par vous rendre sur le site 1xBet et consultez votre compte pour comprendre le fonctionnement du bonus.
JosephDup 31 Ocak 2026 18:40
Visit our main website : https://idematapp.com/wp-content/pages/1xbet_promokod_60.html
Lloydzible 31 Ocak 2026 18:27
To register betwinner successfully, open <a href=https://bet-promo-codes.com/sportsbook-reviews/betwinner-registration/>https://bet-promo-codes.com/sportsbook-reviews/betwinner-registration/</a> and follow the instructions provided on the official review page.
JoshuaAmask 31 Ocak 2026 13:41
Exploring various gaming sites not on GamStop, [url=https://ejenpro.com/reputable-casinos-not-using-gamstop-your-guide-to/]https://ejenpro.com/reputable-casinos-not-using-gamstop-your-guide-to/[/url] can elevate your online gaming experience. These platforms offer multiple options for players seeking captivating games outside the usual constraints. Discover the independence and variety available on these sites today!
KatieAmach 31 Ocak 2026 09:48
Браво, это просто отличная фраза :) Виртуальный мир азартных игр богат. Одним из популярных мест в нем является pin up казино, [url=https://pinup-rukazino.ru/]пин ап казино сайт[/url]. В этом заведении можно открыть множество игровых автоматов и интересных. Игроки получают радость от процесса и шанс выиграть реальные средства.
Lloydzible 31 Ocak 2026 03:03
The easiest way to claim your betwinner registration bonus is to visit <a href=https://bet-promo-codes.com/sportsbook-reviews/betwinner-registration/>https://bet-promo-codes.com/sportsbook-reviews/betwinner-registration/</a> and complete the sign-up form carefully. Make sure you verify your email to activate the offer.
TriciaPiemO 30 Ocak 2026 23:37
Ваша мысль просто отличная pin up казино, [url=https://playpinuponline.ru/]pin up онлайн казино[/url] предлагает уникальный опыт, где игровые автоматы ждут своих любителей. Здесь представлены разнообразные акции для новых игроков. Убедитесь в высоком уровне защиты и долговременности обслуживания. Не упустите возможность исследовать новые позиции и увеличить свой банк!
Brandondet 30 Ocak 2026 23:30
In recent years, the emergence of new social casinos, [url=https://hwnerds.com/the-rise-of-social-casinos-entertainment-without/]https://hwnerds.com/the-rise-of-social-casinos-entertainment-without/[/url] has altered the gaming landscape. Players can now experience thrilling games while socializing with friends. Incentives add to the excitement, making these platforms highly engaging. Join the fun today!
Jennifergoona 30 Ocak 2026 17:19
When exploring virtual gambling, fans often seek options beyond traditional platforms. One alternative is bookies not on GamStop, [url=https://theuppermost.com/2026/01/exploring-non-gamstop-betting-sites-your-guide-to-7/]https://theuppermost.com/2026/01/exploring-non-gamstop-betting-sites-your-guide-to-7/[/url], which provide a wide variety of betting choices. These websites present exciting promotions and favorable rates for players looking for a fresh experience. Engaging with these various sites can lead to lucrative success. Remember to wager responsibly, ensuring an enjoyable experience in the dynamic world of online gaming.
Brandongap 30 Ocak 2026 16:49
А что тут говорить то? Welcome to the captivating world of crypto casino online, [url=https://mediumseagreen-opossum-832225.hostingersite.com/discover-exciting-octoplay-slots-at-bitfortune-3/]https://mediumseagreen-opossum-832225.hostingersite.com/discover-exciting-octoplay-slots-at-bitfortune-3/[/url][url=http://www.magdalena-doering.de/experience-the-finest-spinomenal-slots-at/]http://www.magdalena-doering.de/experience-the-finest-spinomenal-slots-at/[/url][url=https://nekudat-mifgash.net/?p=12958]https://nekudat-mifgash.net/?p=12958[/url], where bettors can enjoy a wide range of games with the benefits of cryptocurrency. Uncover new opportunities to win big while enjoying privacy and fast transactions. Join the movement of online gaming and enhance your fun today!
TabithaJep 30 Ocak 2026 13:25
Извиняюсь, мне тоже хотелось бы высказать своё мнение. В casino riobet, [url=https://rio-betwin.ru/]сайт riobet[/url] игроки могут наслаждаться привлекательными играми. Уникальная облик заведения позволяет погрузиться в царство азартных развлечений. Обширный выбор игр и щедрые премии делают отдых незабываемым.
Ashleypsync 30 Ocak 2026 11:47
БАлдёж, давай исчё onlinekasino, [url=https://www.q-gallery.nl/q-gallery_20230523_0035/]https://www.q-gallery.nl/q-gallery_20230523_0035/[/url] erbjuder ett sГ¤tt att njuta pГҐ favoritspel frГҐn hemmet. Om man Г¤r intresserad av spГ¤nning, kan man hitta mГҐnga alternativ att vinna.
MeganKix 30 Ocak 2026 08:44
Online Casino, [url=https://jsjazzyboutique.com/2025/12/18/discover-the-excitement-of-casino-slots-angels-new-2/]https://jsjazzyboutique.com/2025/12/18/discover-the-excitement-of-casino-slots-angels-new-2/[/url][url=https://linksuccess.in/the-ultimate-guide-to-casino-slotmonster-7/]https://linksuccess.in/the-ultimate-guide-to-casino-slotmonster-7/[/url][url=https://plaza11-11.com/discover-the-excitement-of-slotsamigo-online-2/]https://plaza11-11.com/discover-the-excitement-of-slotsamigo-online-2/[/url] provides a thrilling time for players. With multiple games to choose from, everyone can find something entertaining. Don't miss your chance to grab amazing rewards!
Spravkivuu 30 Ocak 2026 08:14
Нужна медицинскую справку в день обращения по городу — моментально и без визитов в поликлинику? На [url=https://akkred-med.ru]https://akkred-med.ru[/url] можно оформить медицинские документы, от 095/у, 027/у до справок комиссии, справок для бассейна, занятий спортом и оформления визы. Заполнение заявки занимает считанные минуты, потом — доставка документа лично в руки. <a href="https://akkred-med.ru">https://akkred-med.ru</a> Всё законно, конфиденциально и без проблем. Все детали на сайте — медсправка быстро, справка онлайн, доставка справки.
RodneyCoend 30 Ocak 2026 06:54
Explore the perks of a non UK casino site, [url=https://www.sanyodo.co.jp/exploring-non-uk-license-casinos-a-guide-for-2]https://www.sanyodo.co.jp/exploring-non-uk-license-casinos-a-guide-for-2[/url], where users can enjoy wide-ranging games, captivating bonuses, and superior customer support. Join today and discover an amazing gaming environment.
CharlotteElubs 30 Ocak 2026 06:48
non GamStop bookmakers, [url=https://die-christen.co.za/2026/01/15/exploring-non-gamstop-sports-betting-sites-a-14/]https://die-christen.co.za/2026/01/15/exploring-non-gamstop-sports-betting-sites-a-14/[/url] offer a unique alternative instead of traditional betting sites. These bookmakers allow players so they can enjoy gaming without restrictions. Employing this option, users can find a wider range of games and diverse promotions. Furthermore, numerous non GamStop bookmakers provide hasty payouts and superior customer support.
SheilamariA 30 Ocak 2026 03:37
Подтверждаю. И я с этим столкнулся. Можем пообщаться на эту тему. Здесь или в PM. сайт riobet casino, [url=https://riobettopclub.ru/]riobet online casino[/url] предлагает уникальную возможность для любителей азартных игр. Игроки могут наслаждаться широким выбором игр, включая рулетку. Кроме того, ресурс предлагает щедрые бонусы и легкий интерфейс. Погружение в вселенную азартных развлечений на сайте riobet casino обеспечит незабываемые эмоции!
Briannajoync 30 Ocak 2026 01:00
что ни говори, а афтор сделал свое дело на твердую 5-ку... Стоматологическая клиника My Smile, [url=https://mozillabd.science/wiki/User:MySmile]https://mozillabd.science/wiki/User:MySmile[/url] предлагает высококачественные услуги по исправлению зубов. Здесь работают профессиональные врачи, готовые помочь вам удобство. Мы используем передовые технологии для предложения лучшего результата. Настоящая забота о вашем красоте — наш главный приоритет.
CarolinePer 29 Ocak 2026 22:27
Online Casino, [url=http://brgtech.com.br/discover-the-thrills-of-slotmonster-casino-71/]http://brgtech.com.br/discover-the-thrills-of-slotmonster-casino-71/[/url][url=https://hawksmedical.com/comprehensive-guide-to-the-sky-hills-casino-2/]https://hawksmedical.com/comprehensive-guide-to-the-sky-hills-casino-2/[/url][url=http://kinixcreative.com/dev/youandhomeiowa/exploring-sky-hills-casino-the-ultimate-gaming/]http://kinixcreative.com/dev/youandhomeiowa/exploring-sky-hills-casino-the-ultimate-gaming/[/url] presents an exciting way to enjoy your favorite games. With multiple options available, players can find the perfect game for entertainment. Try your luck and earn fantastic prizes!
JoshDom 29 Ocak 2026 20:35
Discover the excitement of playing at a non GamStop bingo site, [url=https://blue3.genetechz.com/ethos360/bingo-sites-not-registered-with-gamstop-play/]https://blue3.genetechz.com/ethos360/bingo-sites-not-registered-with-gamstop-play/[/url], where you can enjoy endless fun and thrill. Such platforms offer exclusive games, enticing bonuses, and a friendly community. Become part of the action today!
RachelNup 29 Ocak 2026 14:36
Я считаю, что тема весьма интересна. Предлагаю всем активнее принять участие в обсуждении. купить фигурки аниме, [url=https://www.pulsar.ua/tovary/animefigurki/vinilovye-figurki-funko-fanko.html]купить фанко поп в украине[/url] можно не только для себя, но и в подарок. Это отличный способ добавить яркие детали в интерьер или начало коллекции. Фигурки аниме|статуэтки аниме|персонажи аниме|товары аниме радуют поклонников и становятся настоящими сокровищами.
DeniseOrigh 29 Ocak 2026 10:14
Discovering the best non GamStop casino, [url=http://max-happacher.de/2026/01/exploring-unique-online-spaces-sites-that-are-not/]http://max-happacher.de/2026/01/exploring-unique-online-spaces-sites-that-are-not/[/url] is crucial for players seeking exciting gaming experiences. These casinos offer a diverse range of games including slots, table games, and live dealer options. In addition, they often provide generous bonuses offering players to maximize their enjoyment. With a focus on user experience, these sites ensure integrity and fast payouts. Players can take pleasure in a thrilling ambiance in a welcoming environment. Consider trying one of these platforms for an unforgettable adventure!
AnnTal 29 Ocak 2026 04:59
Вы не правы. Я уверен. Могу отстоять свою позицию. If you're looking for the top gaming experiences, the best online crypto casino, [url=https://www.fazaa.co/2025/12/18/bet-on-your-favorite-sports-a-complete-guide-to/]https://www.fazaa.co/2025/12/18/bet-on-your-favorite-sports-a-complete-guide-to/[/url][url=https://slsassociates.ae/the-best-new-slot-games-of-2023/]https://slsassociates.ae/the-best-new-slot-games-of-2023/[/url][url=https://www.marketsprices.com/bet-and-win-big-your-gateway-to-unmatched-gaming/]https://www.marketsprices.com/bet-and-win-big-your-gateway-to-unmatched-gaming/[/url] offers a range of options. Players can enjoy thrilling games while using digital currencies. Protection is a priority, ensuring payments are immediate and secure. Don't miss out on the chance to wi
Frankpek 29 Ocak 2026 04:36
Подтверждаю. И я с этим столкнулся. Давайте обсудим этот вопрос. Здесь или в PM. Bilyoner TГјrkiye, [url=https://Doplayer.net/allembed/watchrap.php?v=68747470733A2F2F6B6E6F7474656E6B726F2E636F6D2F-8%3Ehttp]https://Doplayer.net/allembed/watchrap.php?v=68747470733A2F2F6B6E6F7474656E6B726F2E636F6D2F-8%3Ehttp[/url][url=http://www.ccg.org/_domain/tourism-trophy.org/]http://www.ccg.org/_domain/tourism-trophy.org/[/url][url=https://studioassociatocoppola.it/index.php/component/k2/item/35?start=0]https://studioassociatocoppola.it/index.php/component/k2/item/35?start=0[/url], bahis dГјnyasД±nda Г¶nde gelen isimlerden biridir. KullanД±cД±larД±na risksiz bir platform sunarak, farklД± oyun seГ§enekleri ile dikkat Г§ekiyor. Г–nemli oranlarla, bahis tutkunlarД± burayД± tercih ediyor.
Dorothyzex 29 Ocak 2026 04:25
usa mobile casino no deposit bonus [url=https://gamblingbett.com/]casino site bonus[/url] big online casinos
KiaEvove 29 Ocak 2026 03:34
Online Casino, [url=https://hectorestebanpais.com.ar/understanding-refused-withdrawals-foreign-rules-4/]https://hectorestebanpais.com.ar/understanding-refused-withdrawals-foreign-rules-4/[/url][url=http://vriendschapsboot.nl/?p=217151]http://vriendschapsboot.nl/?p=217151[/url][url=https://www.larossandson.org/top-2025-sporting-events-you-can-t-miss-382672970/]https://www.larossandson.org/top-2025-sporting-events-you-can-t-miss-382672970/[/url][url=https://aspirelearning.ca/exploring-minimum-deposit-casinos-your-gateway-to/]https://aspirelearning.ca/exploring-minimum-deposit-casinos-your-gateway-to/[/url][url=https://allo-offer.com/discover-the-exciting-world-of-new-slovak-online/]https://allo-offer.com/discover-the-exciting-world-of-new-slovak-online/[/url] presents an exciting atmosphere
Ulyssesbef 29 Ocak 2026 02:34
Online Casino Games, [url=https://novelvision.es/discover-the-thrilling-world-of-royal-lama-casino]https://novelvision.es/discover-the-thrilling-world-of-royal-lama-casino[/url][url=https://solarlink.com.pk/experience-thrills-at-savanna-wins-casino-6/]https://solarlink.com.pk/experience-thrills-at-savanna-wins-casino-6/[/url][url=https://aspirelearning.ca/discover-the-excitement-of-savanna-wins-casino-30/]https://aspirelearning.ca/discover-the-excitement-of-savanna-wins-casino-30/[/url] provide an exciting possibility to win substantial prizes from the comfort of your home. Through various selections, players can experience everything from slots to table games.
KatherineErymn 29 Ocak 2026 02:23
По моему мнению, Вы заблуждаетесь. pin up online casino, [url=https://pin-up-online.casino/]https://pin-up-online.casino[/url], Г§evrimiГ§i oyun severler iГ§in harika bir seГ§enek. Modern tasarД±mД± ve gГ¶z alД±cД± oyun seГ§enekleri ile eДџlenceli bir deneyim sunuyor. Bonuslar ile oyuncu memnuniyeti artД±yor.
Jillsuick 28 Ocak 2026 23:52
bingo not on GamStop, [url=https://germanyapteka.com/bingo-sites-not-registered-with-gamstop-your-guide/]https://germanyapteka.com/bingo-sites-not-registered-with-gamstop-your-guide/[/url] offers a unique opportunity for players who seek excitement beyond traditional platforms. This games provide users to explore thrilling sessions without the usual restrictions. Dive into the fun and reveal new possibilities today!
Lauracoita 28 Ocak 2026 23:27
На мой взгляд это очень интересная тема. Предлагаю всем активнее принять участие в обсуждении. riobet online casino, [url=https://riobet-officialclub.ru/]казино риобет на деньги[/url] предлагает широкие игры, включая аппараты и картовые развлечения. Пользователи имеют шанс участвовать в бонусах, что очаровывает многих игроков. Удобный интерфейс обеспечивает легко искать любимые игры и наслаждаться великолепной атмосферой. Присоединяйтесь к riobet online casino и наслаждайтесь уникальными возможностями!
Yolandataush 28 Ocak 2026 22:57
In recent times, many players have turned to non GamStop bookies, [url=https://dwp.sparkgo.com.br/exploring-non-gamstop-betting-sites-the/]https://dwp.sparkgo.com.br/exploring-non-gamstop-betting-sites-the/[/url] for placing bets. These platforms offer varied range of options, guaranteeing users more freedom. Non GamStop bookies are perfect for those seeking limitless gambling experiences.
NinaPaumn 28 Ocak 2026 18:36
In the domain of Top Online Casino, [url=https://paksampada.com/fast-crypto-withdrawals-the-future-of-digital/]https://paksampada.com/fast-crypto-withdrawals-the-future-of-digital/[/url][url=https://staging.reliqus.in/gyors-kifizetes-casinok-minden-amit-tudni-erdemes/]https://staging.reliqus.in/gyors-kifizetes-casinok-minden-amit-tudni-erdemes/[/url][url=https://eb.khksa.com/jatssz-2025-ben-utmutato-a-magyar-online-kaszinok/]https://eb.khksa.com/jatssz-2025-ben-utmutato-a-magyar-online-kaszinok/[/url][url=https://steamindonesia.id/top-casinos-that-accept-czk-your-guide-to-gambling/]https://steamindonesia.id/top-casinos-that-accept-czk-your-guide-to-gambling/[/url][url=https://www.armazenseg.com.br/2025/12/02/penzugyi-lehetsegek-kivalasztasa-online/]https://www.armazenseg.com.br/2025/12/02
LyleTubre 28 Ocak 2026 17:08
Отнюдь нет. Я знаю. galabet online casino, [url=https://galabetonline.casino/]galabet online casino[/url], birГ§ok rastgelelik sunarak oyunculara Г§ekici bir deneyim saДџlar. Zengin fД±rsatlar, kullanД±cД±larД±n kazanГ§ elde etme ЕџansД±nД± artД±rД±r. GeliЕџmiЕџ arayГјzГј sayesinde sorunsuzca oyun oynayabilirsiniz.
GloriaEnrig 28 Ocak 2026 14:13
Охотно принимаю. На мой взгляд, это интересный вопрос, буду принимать участие в обсуждении. казино azino777, [url=https://azino777-topwin.ru/]азино[/url] предлагает разнообразный выбор игровых автоматов и возможность выиграть значительные суммы. Желающий может получить удовольствие атмосферой азартных игр.
FrankinOts 28 Ocak 2026 13:41
non GamStop bingo, [url=http://www.bikerentalbali.com/exploring-bingo-sites-not-covered-by-major-reviews/]http://www.bikerentalbali.com/exploring-bingo-sites-not-covered-by-major-reviews/[/url] offers players a unique experience in the world of online gaming. As opposed to traditional sites, these platforms grant more variability for betting. Players can enjoy captivating games without the usual restrictions.
Myrondub 28 Ocak 2026 10:06
citizenship by investment vanuatu, [url=https://www.hvor.in/index.php/2025/12/18/the-cost-of-obtaining-vanuatu-citizenship-through/]https://www.hvor.in/index.php/2025/12/18/the-cost-of-obtaining-vanuatu-citizenship-through/[/url][url=https://atsonproducts.in/vanuatucbi/understanding-the-minimum-requirements-for-vanuatu/]https://atsonproducts.in/vanuatucbi/understanding-the-minimum-requirements-for-vanuatu/[/url][url=https://childfingersafety.com/latest-updates-on-vanuatu-citizenship-by/]https://childfingersafety.com/latest-updates-on-vanuatu-citizenship-by/[/url] offers a possibility for applicants to obtain enhanced travel freedom. The initiative allows for an expedited path to citizenship in a gorgeous island nation.
Mikemob 28 Ocak 2026 08:05
Online Casino, [url=http://fulkari.com.au/richy-leo-online-casino-uk-unleash-the-fun-and/]http://fulkari.com.au/richy-leo-online-casino-uk-unleash-the-fun-and/[/url][url=https://endorse.biosim.ntua.gr/discover-exciting-online-games-at-royal-lama-6/]https://endorse.biosim.ntua.gr/discover-exciting-online-games-at-royal-lama-6/[/url][url=https://luvurdiet.com/experience-the-thrill-at-richy-leo-online-casino-2/]https://luvurdiet.com/experience-the-thrill-at-richy-leo-online-casino-2/[/url] предлагает уникальный опыт азартных игр фортуны. Здесь можно встретить множество предложений, включая настольные игры. Высокие бонусы последние акции делают игру осо
BrianInish 28 Ocak 2026 07:46
Я думаю, что Вы не правы. Я уверен. Могу это доказать. Пишите мне в PM, пообщаемся. choosing cosmetic service providers, [url=https://www.tumblr.com/fggmedia/806795900701818880/compare-beauty-services-using-reviews-and-ratings]Bellehub[/url] can be a daunting task. It's essential to explore their qualifications and ratings. Look for licensed professionals to ensure safety.
Mattlep 28 Ocak 2026 06:54
online casino offshore, [url=https://wishbook.onehopeunited.org/exploring-overseas-online-casinos-a-guide-to-2/]https://wishbook.onehopeunited.org/exploring-overseas-online-casinos-a-guide-to-2/[/url] угнетают уникальные возможности для игроков. В этом заведениях часто найти многообразный ассортимент игр с различными бонусами. Важно является защита ваших денежных средств.
JenniferNig 28 Ocak 2026 03:06
If you’re looking for excellent gaming options, consider the top casinos not on GamStop, [url=https://stage.lacarte.de/discover-the-newest-casinos-without-gamstop-a/]https://stage.lacarte.de/discover-the-newest-casinos-without-gamstop-a/[/url]. These platforms deliver a unique experience with diverse games and generous bonuses. Enjoy smooth gameplay today!
Thomasnew 28 Ocak 2026 00:43
Obtaining passport by investment in Vanuatu offers an exclusive opportunity for foreign nationals. With few requirements, it’s an efficient way to gain worldwide mobility and entry to numerous countries. Ideal for those seeking security, citizenship by investment vanuatu, [url=https://thedezignfactory.co.uk/dominica-citizenship-by-investment-a-government-2/]https://thedezignfactory.co.uk/dominica-citizenship-by-investment-a-government-2/[/url][url=https://lotwicesleepers.com/vanuatu-citizenship-by-investment-a-path-to-visa/]https://lotwicesleepers.com/vanuatu-citizenship-by-investment-a-path-to-visa/[/url][url=https://buaya188slot.com/vanuatu-citizenship-by-investment-your-guide-for-5/]https://buaya188slot.com/vanuatu-citizenship-by-investment-your-guide-for-5/[/url] can enhance your ec
MitchInsom 27 Ocak 2026 23:55
Online Casino, [url=https://hopspilopper.dk/kliove-vyhody-a-nevyhody-v-obchodnim-svt/]https://hopspilopper.dk/kliove-vyhody-a-nevyhody-v-obchodnim-svt/[/url][url=https://alshahrat.com/2025/12/02/legjobb-online-nyergepek-2025/]https://alshahrat.com/2025/12/02/legjobb-online-nyergepek-2025/[/url][url=https://900united.com/entain-and-betmgm-driving-growth-in-the-online/]https://900united.com/entain-and-betmgm-driving-growth-in-the-online/[/url][url=https://theallreviews.com/training-techniques-of-professional-athletes/]https://theallreviews.com/training-techniques-of-professional-athletes/[/url][url=https://www-l2ti.univ-paris13.fr/~beghdadi/?p=16436]https://www-l2ti.univ-paris13.fr/~beghdadi/?p=16436[/url] serves as a trending venue for fans worldwide. With a variety of entertainment, it dr
Jeremiahrok 27 Ocak 2026 22:51
Online Casino, [url=https://broemmling-metallbau.de/the-ultimate-guide-to-richy-fish-your-key-to/]https://broemmling-metallbau.de/the-ultimate-guide-to-richy-fish-your-key-to/[/url][url=https://aff.dominhhai.com/2025/12/17/rollino-online-casino-experience-thrilling-gaming/]https://aff.dominhhai.com/2025/12/17/rollino-online-casino-experience-thrilling-gaming/[/url][url=http://www.bdobd.com/bdesign/eng/2025/12/17/discover-the-thrills-of-casino-richy-leo-452426842/]http://www.bdobd.com/bdesign/eng/2025/12/17/discover-the-thrills-of-casino-richy-leo-452426842/[/url] offers an exciting style to enjoy betting from the comfort of your home. With various options, players can discover thrilling times and probable winnings.
SofiaRot 27 Ocak 2026 22:02
Какие нужные слова... супер, отличная фраза Дубликат автомобильного номера, [url=https://womanmaniya.ru/ramki-dlya-avtomobilnyh-nomerov-vidy-osobennosti-i-preimushhestva-ispolzovaniya/]https://womanmaniya.ru/ramki-dlya-avtomobilnyh-nomerov-vidy-osobennosti-i-preimushhestva-ispolzovaniya/[/url] может понадобиться в случае утраты или повреждения оригинала. Получить его можно в Госавтоинспекции. Подготовьте все нужные документы и уплатите пошлину. Процесс не займет много времени, и автомобиль снова будет под защитой закона. Маркировка помогает избежать проблем с дорожной безопасностью и совместимостью. Не откладывайте, если требуется восстановление.
DanaVax 27 Ocak 2026 19:31
Я пожалуй промолчу Les paris sportifs, [url=https://code-promo-mostbet-maroc.com/]Mostbet Maroc[/url] sont une activitГ© apprГ©ciГ©e parmi les amateurs de activitГ©s. Ils offrent la possibilitГ© de obtenir de l'argent tout en s'amusant pour ses Г©quipes prГ©fГ©rГ©es.
Aaronskips 27 Ocak 2026 17:06
non GamStop casinos UK, [url=https://www.commerces-en-ville.be/non-classe/_/__/exploring-uk-sites-not-on-gamstop-a-comprehensive/]https://www.commerces-en-ville.be/non-classe/_/__/exploring-uk-sites-not-on-gamstop-a-comprehensive/[/url] offer players an exciting option for online gaming without the restrictions of self-exclusion. These options provide a diverse range of games, ensuring excitement for everyone. Join now and explore special bonuses and promotions designed to elevate your gaming experience!
Lucybof 27 Ocak 2026 17:06
Это ценная фраза Shirts and knitwear, [url=https://www.caution.de/hallo-welt/]https://www.caution.de/hallo-welt/[/url] are essential in every wardrobe. These pieces provide comfort for any occasion. A cozy sweater can elevate your look effortlessly. Match them for endless outfits.
Jenniferdon 27 Ocak 2026 15:38
Achieving nationality by investment in Vanuatu offers numerous benefits. Participants can gain opportunities to foreign markets and visa-free travel to many countries. Opting for citizenship by investment vanuatu, [url=http://www.pisarevo.com/understanding-the-costs-of-vanuatu-citizenship-by-56/]http://www.pisarevo.com/understanding-the-costs-of-vanuatu-citizenship-by-56/[/url][url=http://brgtech.com.br/vanuatu-citizenship-by-investment-a-comprehensive-25/]http://brgtech.com.br/vanuatu-citizenship-by-investment-a-comprehensive-25/[/url][url=https://tentakle.com/?p=196254]https://tentakle.com/?p=196254[/url] can improve one's fiscal prospects.
Hollybon 27 Ocak 2026 14:52
Top Online Casino, [url=https://vijayarts.in/alltagsleben-betroffen-auswirkungen-der-inflation/]https://vijayarts.in/alltagsleben-betroffen-auswirkungen-der-inflation/[/url][url=http://hrdevelopers305.com/casono02123/significant-changes-in-online-casino-regulations/]http://hrdevelopers305.com/casono02123/significant-changes-in-online-casino-regulations/[/url][url=https://kingdomcreators.co.uk/2025/12/02/new-online-casinos-2025-trends-and-innovations/]https://kingdomcreators.co.uk/2025/12/02/new-online-casinos-2025-trends-and-innovations/[/url][url=https://mediumseagreen-opossum-832225.hostingersite.com/online-poker-vs-ivy-poker-kde-je-lepi-hrat/]https://mediumseagreen-opossum-832225.hostingersite.com/online-poker-vs-ivy-poker-kde-je-lepi-hrat/[/url][url=https://srianandcnc.com/fresh-innov
JackNum 27 Ocak 2026 13:52
Online Casino UK, [url=https://sunamipatrike.com/archives/27095]https://sunamipatrike.com/archives/27095[/url][url=https://www.giuseppedifranciaevent.com/online-casino-professor-wins-mastering-the-art-of/]https://www.giuseppedifranciaevent.com/online-casino-professor-wins-mastering-the-art-of/[/url][url=https://getaey.com/discover-the-excitement-at-casino-raptor-wins-uk/]https://getaey.com/discover-the-excitement-at-casino-raptor-wins-uk/[/url] delivers a wide range of games featuring slots, table games, and live dealer options. Gamblers can enjoy thrilling experiences from the convenience of their homes. Join now!
Gerardobulky 27 Ocak 2026 11:55
Подтверждаю. Я присоединяюсь ко всему выше сказанному. Давайте обсудим этот вопрос. аромат Lattafa Yara Candy, [url=https://yaracandyotzyvy.ru/]https://yaracandyotzyvy.ru/[/url] — это настоящий запоминающееся благоухание, который погружает сладким блеском. Сочетание фруктов и флората нот создает удивительное ощущение счастья. Lattafa Yara Candy словно вывозит вас в мир кондитерских фантазий.
SeanDut 27 Ocak 2026 10:32
Туда же образование, [url=https://www.bugulma.ws/publ/katalog_statej/obrazovanie/novoe_gdz_merzljaka_za_6_klass/33-1-0-4483]https://www.bugulma.ws/publ/katalog_statej/obrazovanie/novoe_gdz_merzljaka_za_6_klass/33-1-0-4483[/url] представляет собой жизни каждого человека. Усовершенствование навыков и знаний позволяет достигать новых успехов. Каждый индивидуум должны стремиться к обогащению опыта.
MarianneRap 27 Ocak 2026 10:19
В этом что-то есть. The world of online Casino Game, [url=https://legendary11.com/blogs/view/25450]https://legendary11.com/blogs/view/25450[/url] offers fun to players worldwide. With numerous options, countless games offer unique experiences. Players are able to enjoy poker anytime, anywhere!
Lisator 27 Ocak 2026 07:20
По моему мнению Вы не правы. Пишите мне в PM, обсудим. jugar al casino en lГnea, [url=https://samaafrica.com.ly/wp/apuestas-en-la-liga-estrategias-y-consejos-para-5/]https://samaafrica.com.ly/wp/apuestas-en-la-liga-estrategias-y-consejos-para-5/[/url][url=https://minnmedstaging.wpengine.com/apostar-futbol-todo-lo-que-necesitas-saber-para-3/]https://minnmedstaging.wpengine.com/apostar-futbol-todo-lo-que-necesitas-saber-para-3/[/url][url=https://mt2.com.vn/casas-apuestas-sin-licencia-riesgos-y-18/]https://mt2.com.vn/casas-apuestas-sin-licencia-riesgos-y-18/[/url] es una experiencia entretenida. Los jugadores logran disfrutar de una amplia variedad de juegos desde la comodidad de su hogar. AdemГЎs, las recompensas son muy tentadores. ВЎNo te pierdas la ocasiГіn de vivir la emociГіn de juga
TomFet 27 Ocak 2026 06:36
Exploring virtual casinos not on gamstop, [url=https://paisaday.com/gamstopcasinos1/discover-top-betting-sites-not-on-gamstop-2/]https://paisaday.com/gamstopcasinos1/discover-top-betting-sites-not-on-gamstop-2/[/url] opens up exciting possibilities for players seeking new gambling experiences. These sites provide choice to enjoy games without restrictions.
AmyDrazy 27 Ocak 2026 04:26
Online Casino Games, [url=https://mailssoftware.org/blogs/explore-the-exciting-world-of-casino-plexian/]https://mailssoftware.org/blogs/explore-the-exciting-world-of-casino-plexian/[/url][url=http://andusti.wasmer.app/1red-casino-online-uk-your-ultimate-gaming-3/]http://andusti.wasmer.app/1red-casino-online-uk-your-ultimate-gaming-3/[/url][url=https://go-chargeev.com/experience-the-thrills-at-playnow-online-casino-uk/]https://go-chargeev.com/experience-the-thrills-at-playnow-online-casino-uk/[/url] give excitement and entertainment to players worldwide. Utilizing innovative technology, these games copy the environment of real casinos, enabling users to enjoy a unique gaming experience from home.
сайт 27 Ocak 2026 02:43
A person essentially help to make seriously articles I would state. This is the first time I frequented your web page and so far? I amazed with the analysis you made to make this actual put up extraordinary. Great activity! https://chestny-znak-info.ru/articles/markirovka-bytovoi-himii-i-kosmetiki-2025.html
Gloriasmaby 27 Ocak 2026 02:00
В этом что-то есть. Благодарю за информацию, теперь я буду знать. Духи Lattafa Yara Candy, [url=https://yaracandylattafa.ru/]yaracandylattafa.ru[/url] — это изысканный аромат, который покоряет своими нотами сладости и свежести. Эти духи идеально подходят для Каждодневного использования и особых. С каждым новым распылением вы ощущаете их многослойность. В составе присутствуют ягоды, что делает этот аромат поистине неповторимым.
Danagycle 26 Ocak 2026 23:43
Choosing a safe online casino can be challenging. A trusted non GamStop casino, [url=https://gocom.es/safe-non-gamstop-casinos-a-comprehensive-guide/]https://gocom.es/safe-non-gamstop-casinos-a-comprehensive-guide/[/url] allows players to enjoy their favorite games without restrictions. Players can enjoy a wide variety of entertaining options, enhancing their gaming experience.
JohnHet 26 Ocak 2026 21:00
Какие слова... супер, блестящая мысль casino en lГnea, [url=https://fawesomegames.com/casino-online-internacional-la-guia-definitiva/]https://fawesomegames.com/casino-online-internacional-la-guia-definitiva/[/url][url=https://monetarygold2.wpengine.com/1-84/]https://monetarygold2.wpengine.com/1-84/[/url][url=https://gtmarine.ru/nuevas-casas-de-apuestas-tu-guia-completa/]https://gtmarine.ru/nuevas-casas-de-apuestas-tu-guia-completa/[/url] - El universo de los casinos en lГnea ha expansido en popularidad en los Гєltimos aГ±os. Los apostadores pueden aprovechar diversas opciones de juegos, como traga monedas. AdemГЎs, los incentivos que ofrecen estos espacios transforman la experiencia aГєn mГЎs emocionante. ВЎExplora el casino en lГnea y encuentra tus juegos favoritos!
SallySwigo 26 Ocak 2026 20:55
citizenship by investment vanuatu, [url=https://www.brooksengenharia.com.br/understanding-dominica-citizenship-by-investment-3/]https://www.brooksengenharia.com.br/understanding-dominica-citizenship-by-investment-3/[/url][url=https://asceurovisa.com/explore-the-benefits-of-vanuatu-citizenship-by-6/]https://asceurovisa.com/explore-the-benefits-of-vanuatu-citizenship-by-6/[/url][url=https://inisparty.com/understanding-the-costs-of-vanuatu-citizenship-by-51/]https://inisparty.com/understanding-the-costs-of-vanuatu-citizenship-by-51/[/url] offers a unique opportunity for individuals seeking a second passport. This allows investors to acquire citizenship quickly by making a financial commitment. This program is appealing due to its rapid processing times and few residency requirements.
Mirandaarels 26 Ocak 2026 20:43
Вы не правы. Предлагаю это обсудить. Пишите мне в PM. Под система, [url=http://hydrology.irpi.cnr.it/projects/commons-2/]http://hydrology.irpi.cnr.it/projects/commons-2/[/url][url=http://everest.ooo/user/RodSellars6778/]http://everest.ooo/user/RodSellars6778/[/url][url=http://sample-cafe.matsushima-it.com/?p=206]http://sample-cafe.matsushima-it.com/?p=206[/url] — это важный элемент для понимания структуры. Эта часть системы осуществляет функционирование всех компонентов. Без подсистем система не сможет обеспечить необходимых результатов.
Robertkic 26 Ocak 2026 20:11
regulations for sports betting usually applied to your winnings, which you acquire in eventually free spins. at casino In the UK, this is much much less, since [url=http://safety-system.pl/munchfit/exploring-non-gamstop-casinos-a-comprehensive-13/]http://safety-system.pl/munchfit/exploring-non-gamstop-casinos-a-comprehensive-13/[/url][url=https://dorismoya.com/discover-new-non-gamstop-casino-sites-for-2023/]https://dorismoya.com/discover-new-non-gamstop-casino-sites-for-2023/[/url][url=https://payafoolad.com/discover-top-casino-sites-not-on-gamstop-679072408/]https://payafoolad.com/discover-top-casino-sites-not-on-gamstop-679072408/[/url][url=https://penuinnow.com/exploring-casinos-non-on-gamstop-a-comprehensive/]https://penuinnow.com/exploring-casinos-non-on-gamstop-a-comprehensive/[/url
Alexavent 26 Ocak 2026 19:14
Discover the joy of Online Casino Slots, [url=http://mesman.nl/casinobet25/plexian-casino-sportsbook-your-ultimate-gaming-9]http://mesman.nl/casinobet25/plexian-casino-sportsbook-your-ultimate-gaming-9[/url][url=https://www.stepplumbing.com.au/casinobet25/pirate-spins-casino-uk-a-treasure-trove-of-gaming-5/]https://www.stepplumbing.com.au/casinobet25/pirate-spins-casino-uk-a-treasure-trove-of-gaming-5/[/url][url=http://basecamp.friendlyhuman.com/casino-professor-wins-transforming-the-uk-gambling/]http://basecamp.friendlyhuman.com/casino-professor-wins-transforming-the-uk-gambling/[/url], where players can play their way to big wins. Boasting vibrant themes and engaging gameplay, each session can lead to exhilarating moments. Play today and discover your favorite slots!
Richardelexy 26 Ocak 2026 19:13
Привет админу и участникам. Хочу учить испанский в Испании в следующем году. Есть даже программы по танцам и спорту. Ссылка на источник: Удачи в учебе.
KimCom 26 Ocak 2026 18:24
Должен Вам сказать это — неправда. online casino, [url=http://fly2.cf/quick-win-casino-86103]http://fly2.cf/quick-win-casino-86103[/url] nabГzГ ЕЎirokou ЕЎkГЎlu her, takЕѕe pЕ™itahuje mnoho hrГЎДЌЕЇ. ZГЎЕѕitek z hrГЎДЌskГ©ho svД›ta je poutavГЅ. ГљДЌastnГci si uЕѕГvajГ adrenalin a moЕѕnost odlehnutГ.
JeffThori 26 Ocak 2026 18:11
смефно)))) Духи Lattafa Yara Candy, [url=https://candyyara.ru/]https://candyyara.ru[/url] – это замечательный аромат, который впечатляет своими экзотическими нотами. Сладкие акценты создают особенное очарование, что делает эти духи отличными для ежедневного использования.
Keithdus 26 Ocak 2026 17:28
Зайди на обновленный официальный сайт > http://hammill.ru/
JosephDup 26 Ocak 2026 16:44
Go to our updated website — https://china-gsm.ru/public/pages/?promokod_283.html
Richardelexy 26 Ocak 2026 15:58
Просто хотел поздороваться. Ищу совет по поводу образования за рубежом. Поддержка у них выглядит достойно. Нашел это тут: [url=https://www.atoallinks.com/2026/%d0%ba%d1%80%d0%b0%d0%ba%d0%b5%d0%bd-%d0%b4%d0%b0%d1%80%d0%ba%d0%bd%d0%b5%d1%82-%d1%81%d1%81%d1%8b%d0%bb%d0%ba%d0%b0-%d0%ba%d1%80%d0%b0%d0%ba%d0%b5%d0%bd-%d0%b2%d1%85%d0%be%d0%b4/]kraken актуальные ссылки[/url] Спасибо.
AntoineNub 26 Ocak 2026 13:11
Playing at virtual gambling sites that are excluded from gives players the possibility to experience a wider range of games. With greater flexibility, you can find your favorite games while bypassing unwanted restrictions. casino online not on GamStop, [url=https://bioquinor.com/discover-legit-non-gamstop-casinos-for-an/]https://bioquinor.com/discover-legit-non-gamstop-casinos-for-an/[/url] ensures an dynamic experience for players worldwide. Embrace the autonomy and explore what these casinos offer!
Sharonpreow 26 Ocak 2026 11:44
Вы попали в самую точку. Я думаю, что это отличная мысль. аромат Оud Pashmina Montale, [url=https://oudpashminaekb.ru/]oudpashminaekb.ru[/url] — это изысканный парфюм, который погружает в мир восточных романов. Сочетание богатых нот делает его отличным выбором для праздников. В его основе присутствует магическое влияние. Аромат Оud Pashmina Montale оставляет незабываемое впечатление, обвивая нежной безмятежностью.
Brycelot 26 Ocak 2026 11:44
online casinos and sports betting, [url=https://almraah.org/discovering-xn-88win-the-future-of-online-gaming/]https://almraah.org/discovering-xn-88win-the-future-of-online-gaming/[/url][url=https://songlyrics.microwebblogs.in/discover-the-exciting-world-of-stellar-spins-4/]https://songlyrics.microwebblogs.in/discover-the-exciting-world-of-stellar-spins-4/[/url][url=https://www.ozgurozgulgun.com/2025/12/14/the-exciting-world-of-xn-88win-a-comprehensive/]https://www.ozgurozgulgun.com/2025/12/14/the-exciting-world-of-xn-88win-a-comprehensive/[/url] have taken the way gamblers engage with gambling. Through advanced platforms, players can delight in thrilling options at their convenience.
AdelaidaBifup 26 Ocak 2026 11:24
Нече себе !!!!!!!!!!!!!!!!! мониторинг цен, [url=http://www.pizzeriapinocchio.it/2015/05/11/entry-with-audio/]http://www.pizzeriapinocchio.it/2015/05/11/entry-with-audio/[/url][url=http://smallcake.co.uk/]http://smallcake.co.uk/[/url][url=http://www.mempowerauto.it/component/k2/item/7-living-room-interior-of-luxury-manor-house.html?limit=2]http://www.mempowerauto.it/component/k2/item/7-living-room-interior-of-luxury-manor-house.html?limit=2[/url] — важный процесс для предпринимателей и покупателей. Он позволяет выявлять изменения на рынке. Зная актуальные расценки, можно приступать к более выгодные решения.
Raheempax 26 Ocak 2026 11:14
In the world of digital gambling, the crypto casino, [url=https://sintiendoyescribiendo.cetaweb.es/index.php/2025/12/03/exploring-the-world-of-bitcoin-payout-casinos/]https://sintiendoyescribiendo.cetaweb.es/index.php/2025/12/03/exploring-the-world-of-bitcoin-payout-casinos/[/url][url=http://fst.tw/2025/12/03/casino-sin-deposito-bitcoin-la-nueva-era-del-juego/]http://fst.tw/2025/12/03/casino-sin-deposito-bitcoin-la-nueva-era-del-juego/[/url][url=https://giftcardrd.com/upplev-spanningen-med-crypto-casinon/]https://giftcardrd.com/upplev-spanningen-med-crypto-casinon/[/url][url=https://sdk.bochackathon.com/exploring-new-altcoin-casinos-on-mobile-devices/]https://sdk.bochackathon.com/exploring-new-altcoin-casinos-on-mobile-devices/[/url][url=http://www.creekwoodcustomhomes.com/greenhill]http:
ErnieBiamn 26 Ocak 2026 10:25
Актуально. Вы мне не подскажете, где я могу найти больше информации по этому вопросу? Духи Lattafa Yara Candy, [url=https://lattafayaracandy.ru/]lattafayaracandy.ru[/url] – это благоухание, который очаровывает своей яркостью. Их композиция включает сладкие ноты, создавая эмоции счастья. Выбирая Духи Lattafa Yara Candy, вы находите завораживающий аромат на каждый день!
VivianCourn 26 Ocak 2026 07:38
non gamstop casino, [url=https://shoponlinesa.cyberwebit.com/2026/01/13/the-rise-of-non-uk-casinos-a-global-gaming/]https://shoponlinesa.cyberwebit.com/2026/01/13/the-rise-of-non-uk-casinos-a-global-gaming/[/url] offers players a unique experience provides the opportunity to enjoy gaming outside the restrictions of traditional platforms. Including a wide range of games, these casinos attract gamers seeking liberty from self-exclusion lists.
Keithdus 26 Ocak 2026 05:17
Зайди на официальный сайт компании > https://jerezlecam.com/
DawnRef 26 Ocak 2026 04:41
Non Gamstop Casinos, [url=https://xn--bettwschewelt-ffb.de/2025/12/04/discover-top-casino-sites-not-on-gamstop-907889908/]https://xn--bettwschewelt-ffb.de/2025/12/04/discover-top-casino-sites-not-on-gamstop-907889908/[/url][url=https://ramax.by/discovering-casinos-not-on-gamstop-uk-a-guide-for-4]https://ramax.by/discovering-casinos-not-on-gamstop-uk-a-guide-for-4[/url][url=https://myaiostagingprojects.com/affordable-angels-moving/discover-casinos-not-on-gamstop-a-comprehensive/]https://myaiostagingprojects.com/affordable-angels-moving/discover-casinos-not-on-gamstop-a-comprehensive/[/url][url=https://bitbuzz.org/discovering-casinos-not-on-gamstop-your-gateway-to/]https://bitbuzz.org/discovering-casinos-not-on-gamstop-your-gateway-to/[/url][url=https://hotelvrindavan.co.in/2025/12/04/disco
Shailases 26 Ocak 2026 02:41
Ага, попался! Духи Lattafa Yara Candy, [url=https://yaracandy.ru/]yaracandy.ru[/url] — это великолепное сочетание сладких и фруктовых нот, которое привлекает внимание. Данные аромат подходит как для ежедневного использования, так и для особых случаев. Экзотические акценты в составе создают неповторимое обаяние. Любое Духами Lattafa Yara Candy наполнено вдохновением.
Jessieavawn 25 Ocak 2026 23:53
Experience the thrill of gaming at Fishin' Frenzy casinos, [url=https://www.clickorientaunipg.it/discover-the-excitement-of-fishin-frenzy-free-a/]https://www.clickorientaunipg.it/discover-the-excitement-of-fishin-frenzy-free-a/[/url], where fun unfolds with every spin. Captivating games await you, promising big rewards and memorable moments!
VictorRic 25 Ocak 2026 22:24
Casinos not on Gamstop, [url=https://rproject-nagasaki.com/jos-trust/exploring-non-gamstop-casino-sites-a-new-era-of]https://rproject-nagasaki.com/jos-trust/exploring-non-gamstop-casino-sites-a-new-era-of[/url][url=https://welcome-nagasaki-city.com/archives/17923]https://welcome-nagasaki-city.com/archives/17923[/url][url=https://multisec.nl/portfolio/furniture-design/]https://multisec.nl/portfolio/furniture-design/[/url][url=https://wordpress.iugolabs.com/exploring-casinos-not-on-gamstop-a-guide-for-35/]https://wordpress.iugolabs.com/exploring-casinos-not-on-gamstop-a-guide-for-35/[/url][url=http://test.wp-vote.net/6fc807bd9e0a9e6d135dc89ef3c714cbc0d4a7c2a0b0bb7e6737353e52fb2e35postname6fc807bd9e0a9e6d135dc89ef3c714cbc0d4a7c2a0b0bb7e6737353e52fb2e35/]http://test.wp-vote.net/6fc807bd9e0a9e
Katrinabiz 25 Ocak 2026 21:53
Извиняюсь, но это мне не подходит. Кто еще, что может подсказать? бренд Spirit of Kings Kursa, [url=https://spiritofkingskursa.ru/]https://spiritofkingskursa.ru/[/url] предлагает роскошные напитки, созданные с отборными ингредиентами. Каждый глоток приносит уникальный вкус и наследие мастерства. Погрузитесь в шедевры роскоши с Spirit of Kings Kursa!
PatrickBox 25 Ocak 2026 19:12
Весьма забавный ответ онлайн казино, [url=http://gringa360.com.br/2017/2025-yilda-onlayn-kazinolarda-tezkor-tolovlarni-amalga-1win-oshirishning-eng-yaxshi-usullari/]1win[/url] дают игрокам эксклюзивную возможность окунуться в азартные игры без ограничения. Множество игровых автоматов ждут всех, чтобы приобрести незабываемые чувства. Не пропустите свой шанс!
Andrewzet 25 Ocak 2026 18:13
Согласен, очень полезная штука Los salones de juego en lГnea ofrecen un ambiente Гєnica para pasar el rato desde la comodidad del hogar. Con numerosas alternativas de tragamonedas, la emociГіn estГЎ perpetuamente al alcance. AdemГЎs, la interfaz es intuitiva, de forma que atrae a usuarios interesados. No pierdas la oportunidad de disfrutar del casino en lГnea, [url=https://www.mubdieen1.alalawidesigner.com/2025/12/19/mejores-casas-de-apuestas-extranjeras-tu-guia/]https://www.mubdieen1.alalawidesigner.com/2025/12/19/mejores-casas-de-apuestas-extranjeras-tu-guia/[/url][url=https://www.quangcao.cz/2025/12/19/online-casinos-mit-5-euro-einzahlung-spielen-ohne/]https://www.quangcao.cz/2025/12/19/online-casinos-mit-5-euro-einzahlung-spielen-ohne/[/url][url=https://malangraya.suaragong.com/las
Pollyror 25 Ocak 2026 16:43
Non Gamstop Betting Sites UK, [url=https://www.resolutepowerus.com/exploring-non-gamstop-betting-sites-in-the-uk-14/]https://www.resolutepowerus.com/exploring-non-gamstop-betting-sites-in-the-uk-14/[/url][url=https://quranforme.com/exploring-non-gamstop-betting-sites-in-the-uk-21/]https://quranforme.com/exploring-non-gamstop-betting-sites-in-the-uk-21/[/url][url=https://futurelabs.org.uk/electricnation/exploring-sportsbooks-not-on-gamstop-freedom-in/]https://futurelabs.org.uk/electricnation/exploring-sportsbooks-not-on-gamstop-freedom-in/[/url] present punters the exciting way to place bets without constraints. These particular sites grant access to multiple markets, securing an enjoyable gaming experience.
Katrinanok 25 Ocak 2026 16:41
In the world of digital fun, spins casino, [url=https://travelmatic.pipeclose.com/true-fortune-casino-your-gateway-to-premium-online/]https://travelmatic.pipeclose.com/true-fortune-casino-your-gateway-to-premium-online/[/url][url=https://laprensacristiana.com/?p=42185]https://laprensacristiana.com/?p=42185[/url][url=http://www.ph-education.com/2025/12/15/esplora-il-mondo-di-vladcasino-esperienze-di-gioco/]http://www.ph-education.com/2025/12/15/esplora-il-mondo-di-vladcasino-esperienze-di-gioco/[/url] stands out as a thrilling destination. Players can appreciate a wide selection of games, from slots to casino classics. With generous promotions, it’s easy to plunge into the action. Join today for a possibility to win big!
JuliaAlorn 25 Ocak 2026 16:12
Non Gamstop Casinos UK, [url=http://hiwell.my/exploring-the-benefits-of-casinos-not-on-gamstop-4/]http://hiwell.my/exploring-the-benefits-of-casinos-not-on-gamstop-4/[/url][url=https://comercialise.com/exploring-non-gamstop-uk-casinos-a-comprehensive-39/]https://comercialise.com/exploring-non-gamstop-uk-casinos-a-comprehensive-39/[/url][url=https://shop.humanmusicplatform.com/exploring-non-gamstop-casinos-a-comprehensive-96/]https://shop.humanmusicplatform.com/exploring-non-gamstop-casinos-a-comprehensive-96/[/url][url=https://www.onethai.be/2025/12/04/exploring-uk-online-casinos-not-on-gamstop-45/]https://www.onethai.be/2025/12/04/exploring-uk-online-casinos-not-on-gamstop-45/[/url][url=https://mrtdodsbo.com/exploring-uk-online-casinos-not-on-gamstop-11/]https://mrtdodsbo.com/exploring-u
AdamNem 25 Ocak 2026 15:32
Online Casino Games, [url=https://91clublogin.website/discover-the-excitement-of-nonstop-casino/]https://91clublogin.website/discover-the-excitement-of-nonstop-casino/[/url][url=https://omegavirginhair.net/the-essence-of-national-identity-in-the-modern-2/]https://omegavirginhair.net/the-essence-of-national-identity-in-the-modern-2/[/url][url=https://brenediesel.pl/casino-need-for-slots-uk-your-ultimate-guide-to-4/]https://brenediesel.pl/casino-need-for-slots-uk-your-ultimate-guide-to-4/[/url] provide a exciting way to experience gambling from the ease of your home. Players can opt for from a array of options, including video slots, poker, and blackjack. The growth of technology has made these games more accessible, providing fun at your fingertips. Always remember to engage in responsible
RachelKab 25 Ocak 2026 15:08
Очень хорошая штука аромат Spirit of Kings Altair, [url=https://spiritofkingaltair.ru/]https://spiritofkingaltair.ru/[/url] — это особенное сочетание запахов, который охватывает чувства. Он отлично подходит для важных событий. Каждая капля вносит шарм. Попробуйте Spirit of Kings Altair и окунитесь в мир элегантности.
JosephDup 25 Ocak 2026 13:37
Experience the latest version here — https://laminat-kronostar.ru/wp-content/pgs/promokod_741.html
DanielCenry 25 Ocak 2026 12:55
супер ржач!!!!!!!гы гы pinco casino, [url=http://spectrnov.ds53.ru/out.php]http://spectrnov.ds53.ru/out.php[/url]-da oyunГ§ular | mГјЕџtЙ™rilЙ™r | ziyarЙ™tГ§ilЙ™r | istifadЙ™Г§ilЙ™r üçün Г§oxsaylД± | mГјxtЙ™lif | zЙ™ngin | Й™lveriЕџli seГ§imlЙ™r tЙ™qdim olunur. Burada | bu mЙ™kanda | bu platformada | bu cГјr oyunda yeni | Й™n son oyunlar, |ehtimallar vЙ™ bonuslar var. Oyunlar | Й™ylЙ™ncЙ™lЙ™r | tЙ™dbirlЙ™r | imkanlar mГјxtЙ™lif | fЙ™rqli | populyar | mЙ™Еџhur kateqoriyalara bГ¶lГјnГјr. Stulda oturub | arxada istirahЙ™t edЙ™rЙ™k | rahatlayaraq | vaxt keГ§irЙ™rЙ™k diqqЙ™tinizi yayД±ndД±rД±n | yaymaq | pozun. HЙ™r kЙ™s üçün | hЙ™r kЙ™sin | mГјxtЙ™lif iЕџtirakГ§Д±lar üçün | oyunГ§ular üçün bir Еџey var!
Laurawacle 25 Ocak 2026 11:50
Абсолютно с Вами согласен. В этом что-то есть и мне кажется это хорошая идея. Я согласен с Вами. купить софосбувир ледипасвир, [url=https://rostovzakupka.forum24.ru/?1-17-0-00000225-000-0-0-1762363982]https://rostovzakupka.forum24.ru/?1-17-0-00000225-000-0-0-1762363982[/url] можно в аптеке или через интернет. Этот препарат эффективно помогает при лечении гепатита. Искать его стоит только у проверенных продавцов, чтобы избежать подделок.
Cindygop 25 Ocak 2026 10:35
Online gambling открывает увлекательные шансы для игроков. В casino online, [url=http://www.grimalc.com/the-ultimate-guide-to-roo-casino-winning/]http://www.grimalc.com/the-ultimate-guide-to-roo-casino-winning/[/url][url=https://suministrodebandas.com.mx/radiante-casino-un-destino-brillante-para-los/]https://suministrodebandas.com.mx/radiante-casino-un-destino-brillante-para-los/[/url][url=https://panhchaksela.com/descubre-la-experiencia-unica-de-spinanga-casino/]https://panhchaksela.com/descubre-la-experiencia-unica-de-spinanga-casino/[/url] вы можете выигрывать в любимые игры прямо с комфортом. Выбор широкий, и каждый найдет что-то увлекательное.
Dougnoups 25 Ocak 2026 10:35
Casinos Not on Gamstop, [url=https://thisplacematters.ca/?p=106589]https://thisplacematters.ca/?p=106589[/url][url=https://reservadomuseu.com.br/discovering-non-gamstop-casinos-a-comprehensive/]https://reservadomuseu.com.br/discovering-non-gamstop-casinos-a-comprehensive/[/url][url=https://starto.email/exploring-uk-casinos-not-on-gamstop/]https://starto.email/exploring-uk-casinos-not-on-gamstop/[/url] offer a unique experience for players seeking freedom. Alternative casinos provide engaging games without restrictions. Gamblers can enjoy diverse slots and table games at their comfort.
VeronicaJuini 25 Ocak 2026 10:28
In recent years, the rise of non UK licenced casino, [url=https://vanisedainese.com.br/best-non-uk-casino-sites-top-picks-for-players/]https://vanisedainese.com.br/best-non-uk-casino-sites-top-picks-for-players/[/url] has increased. Players search for diverse gaming options and attractive bonuses. These casinos provide distinct experiences that captivate gamers worldwide.
Katherinegom 25 Ocak 2026 09:50
With the rise of online gaming, a variety of players seek options outside restrictions. UK Casinos not on Gamstop, [url=https://ebcmedia.vn/the-rise-of-casinos-not-on-gamstop/]https://ebcmedia.vn/the-rise-of-casinos-not-on-gamstop/[/url][url=https://erf.gpass.bm/the-rise-of-not-on-gamstop-casinos-a-new-era-for/]https://erf.gpass.bm/the-rise-of-not-on-gamstop-casinos-a-new-era-for/[/url][url=https://smavaluos.com/2025/12/04/a-comprehensive-guide-to-non-gamstop-casinos-4/]https://smavaluos.com/2025/12/04/a-comprehensive-guide-to-non-gamstop-casinos-4/[/url][url=https://microview.com.my/?p=126898]https://microview.com.my/?p=126898[/url][url=https://reciclan.cl/exploring-uk-online-casinos-not-on-gamstop-150/]https://reciclan.cl/exploring-uk-online-casinos-not-on-gamstop-150/[/url] offer capti
Brianmat 25 Ocak 2026 09:13
Online Casino Slots, [url=https://www.suckingsweat.com/how-to-register-at-nationalbet-casino-a-step-by-3/]https://www.suckingsweat.com/how-to-register-at-nationalbet-casino-a-step-by-3/[/url][url=http://lucyhillman.com/?p=1803]http://lucyhillman.com/?p=1803[/url][url=https://healthinessfc.com/explore-nationalbet-casino-online-games-for/]https://healthinessfc.com/explore-nationalbet-casino-online-games-for/[/url] offer captivating opportunities for players to achieve big rewards. With multiple themes and features, these games attract dedicated gamers. Experience the thrill of spin and win!
Lindabam 25 Ocak 2026 08:04
Сердечное Вам спасибо за Вашу помощь. Взять Быстрый кредит Израиль, [url=https://israel-credits.com/]Кредит под чеки Израиль[/url] довольно быстро. Множество банков и платформ предлагают разнообразные услуги. Сравнив условия, вы найдете подобрать оптимальный вариант.
Anthonyvak 25 Ocak 2026 04:33
Non-Gamstop Casinos UK, [url=https://newsviral.org/discovering-not-on-gamstop-casinos-your-guide-to/]https://newsviral.org/discovering-not-on-gamstop-casinos-your-guide-to/[/url][url=https://www.worldnewsicon.com/thewonder/discover-non-gamstop-casino-sites-for/]https://www.worldnewsicon.com/thewonder/discover-non-gamstop-casino-sites-for/[/url][url=http://www.pisarevo.com/exploring-the-world-of-casinos-not-on-gamstop-2/]http://www.pisarevo.com/exploring-the-world-of-casinos-not-on-gamstop-2/[/url] present players a chance to enjoy gaming without the constraints of the Gamstop program. Such casinos enable users to join easily, ensuring an exciting experience. Players should regularly gamble responsibly, ensuring they remain engaged while exploring their options.
Miketit 25 Ocak 2026 03:40
non UKGC online casinos, [url=https://iemis.com.tw/?p=404435]https://iemis.com.tw/?p=404435[/url] present unique opportunities for players seeking difference. These places often feature a wider range of games and incentives, attracting players looking for exciting experiences.
Ireneeffig 25 Ocak 2026 03:05
Online Casino, [url=https://webnetworktech.com/discover-the-extravaganza-of-milky-wins-online/]https://webnetworktech.com/discover-the-extravaganza-of-milky-wins-online/[/url][url=https://gobuddies.com/myspins-casino-experience-thrilling-online-gaming/]https://gobuddies.com/myspins-casino-experience-thrilling-online-gaming/[/url][url=https://prompttradefairs.com/discover-the-exciting-world-of-myspins-casino-4/]https://prompttradefairs.com/discover-the-exciting-world-of-myspins-casino-4/[/url] presents an exciting approach to enjoy gaming. Players are able to try their luck with various games, such as slots, poker, and blackjack. Gaining big rewards is just a click away!
VannbEite 25 Ocak 2026 01:10
и это правильно Les divertissements de casino en ligne, [url=https://www.zjheart.com/index.php/2026/01/15/10-best-online-casino-sites-uk-10-best-casinos-uk/]https://www.zjheart.com/index.php/2026/01/15/10-best-online-casino-sites-uk-10-best-casinos-uk/[/url] offrent des opportunitГ©s en vue de gagner des gains. DГ©couvrez l'univers captivant des paris. Avec un ample choix disponible, casino en ligne enchante les amateurs de jeux.
Luisjoria 25 Ocak 2026 00:25
Очень хорошая идея В мире видеоигр возможно множество достижений. игры, [url=http://l5technology.com/beberapa-tujuan-judi-yang-paling-dicintai-di-dunia/]http://l5technology.com/beberapa-tujuan-judi-yang-paling-dicintai-di-dunia/[/url][url=https://fredlove.me/lead-developer-%C2%AD%E2%80%90741/]https://fredlove.me/lead-developer-%C2%AD%E2%80%90741/[/url][url=https://check-albania.com/5-reasons-to-visit-albania/]https://check-albania.com/5-reasons-to-visit-albania/[/url] дают незабываемые эмоции и усложняют испытания. Каждая новая игра вводит в уникальные истории и миры. Участники всегда в ожидании свежих релизов, которые поразят своим сюжетом и графикой. Привлекательность игр не оставляет равнодушным множество фанатов по всему миру.
JudyRuche 24 Ocak 2026 23:51
Что именно вы хотели бы сказать? Sex video, [url=http://www.step.vn.ua/banner2/]http://www.step.vn.ua/banner2/[/url] is now a popular type of entertainment in the current society. Numerous people consider it captivating, as it investigates desires in a distinct way. Even if it might come with controversial opinions, its mark on culture is undeniable.
Kevindut 24 Ocak 2026 22:37
To enjoy the thrill of playing, you can easily play online casino, [url=https://aygf.ng/ojo-casino-the-ultimate-gaming-experience-awaits-2/]https://aygf.ng/ojo-casino-the-ultimate-gaming-experience-awaits-2/[/url][url=http://www.testlinkcs.co.uk/astroology/explora-la-diversion-sin-limites-en-slottica/]http://www.testlinkcs.co.uk/astroology/explora-la-diversion-sin-limites-en-slottica/[/url][url=https://etiqwise.com/explore-the-exciting-world-of-ojo-casino-3/]https://etiqwise.com/explore-the-exciting-world-of-ojo-casino-3/[/url] games from the comfort of your home. With countless options, players can discover their favorite table games.
BryceBes 24 Ocak 2026 22:37
Non-gamstop Casinos, [url=https://vaniplate.com/blog/?p=53057]https://vaniplate.com/blog/?p=53057[/url][url=https://www.luminor.media/misc/exploring-unique-slots-and-casinos-not-on/]https://www.luminor.media/misc/exploring-unique-slots-and-casinos-not-on/[/url][url=https://heni.co.in/exploring-uk-casino-sites-not-on-gamstop-2/]https://heni.co.in/exploring-uk-casino-sites-not-on-gamstop-2/[/url] offer a opportunity for enthusiasts to enjoy a games without restrictions. These establishments serve to those looking for a broader experience.
Jamarcuskicle 24 Ocak 2026 21:26
Casinos Not on Gamstop UK, [url=https://www.pincodelists.com/exploring-non-gamstop-casinos-in-the-uk-a-guide-to-2/]https://www.pincodelists.com/exploring-non-gamstop-casinos-in-the-uk-a-guide-to-2/[/url][url=https://zijinmtt.cn/exploring-casinos-not-on-gamstop-your-guide-to-8/]https://zijinmtt.cn/exploring-casinos-not-on-gamstop-your-guide-to-8/[/url][url=https://italia77.com/exploring-non-gamstop-casinos-in-the-uk-a-27/]https://italia77.com/exploring-non-gamstop-casinos-in-the-uk-a-27/[/url][url=https://pdd8ryabinka.68edu.ru/2025/12/04/exploring-non-gamstop-casinos-freedom-to-play-5/]https://pdd8ryabinka.68edu.ru/2025/12/04/exploring-non-gamstop-casinos-freedom-to-play-5/[/url][url=https://revampitpros.com/exploring-non-gamstop-casinos-freedom-of-choice-in-2/]https://revampitpros.com/exp
Lloydzible 24 Ocak 2026 21:19
If you want to receive the exclusive betwinner welcome bonus, go to <a href=https://bet-promo-codes.com/sportsbook-reviews/betwinner-registration/>https://bet-promo-codes.com/sportsbook-reviews/betwinner-registration/</a> and fill in your details during registration. The reward will be credited after your first deposit.
Ashleyfap 24 Ocak 2026 20:55
Online Casino, [url=https://www.jurgenvandervelde.com/discovering-myspins-your-ultimate-gaming/]https://www.jurgenvandervelde.com/discovering-myspins-your-ultimate-gaming/[/url][url=https://cazipcarsi.com/complete-guide-to-martin-casino-registration-5/]https://cazipcarsi.com/complete-guide-to-martin-casino-registration-5/[/url][url=https://orientbaselogistics.org/experience-the-thrill-of-nalu-casino-your-ultimate-6/]https://orientbaselogistics.org/experience-the-thrill-of-nalu-casino-your-ultimate-6/[/url] offers excitement to players. Providing various games, you can indulge in slots, poker, and blackjack from the comfort of your home. Hitting the big time is just a spin away!
AliceEmory 24 Ocak 2026 20:27
Все не так просто MurMur Voice to Text, [url=https://www.microsoft.com/en-sa/p/murmur-voice-to-text-offline/9n2xfgv12x1q]MurMur[/url] выпускает уникальную платформу для преобразования голоса РІ текст. РџСЂРё помощи этой разработки пользователи СЃРїРѕСЃРѕР±РЅС‹ легко производить текстовые записи без вложения времени.
Daleviemo 24 Ocak 2026 19:04
Подскажите, где я могу найти больше информации по этому вопросу? pinco casino, [url=https://www.osloforvaltning.no/hello-world/]https://www.osloforvaltning.no/hello-world/[/url] mГјasir oyunГ§ulara geniЕџ seГ§im tЙ™qdim edir, Г¶dЙ™niЕџli Еџanslar ilЙ™ cazibЙ™dar bonuslar qazanmaДџa imkan tanД±yД±r. Slotlar Г§ox populyar Й™ylЙ™ncЙ™dir. Burada hЙ™r kЙ™s Г¶z zГ¶vqГјnЙ™ uyДџun bir Еџey tapacaq. Pinco casino sahibkarlД±q mГјhitdЙ™ zГ¶vq yaЕџamaДџa dЙ™vЙ™t edir.
Amysom 24 Ocak 2026 18:21
фуфа смотрел Escort girls in Israel, [url=https://eliteisraelescort.com/]escort in tel aviv[/url] deliver an special experience for those seeking companionship. In a diverse selection, clients can choose from different backgrounds and experiences. Each encounter promises pleasure, making it a noteworthy choice.
KevinSob 24 Ocak 2026 16:41
online casinos and sports betting, [url=http://aentbd.com/?p=140165]http://aentbd.com/?p=140165[/url][url=https://www.investisiagroup.ro/radiante-casino-el-destino-perfecto-para-los/]https://www.investisiagroup.ro/radiante-casino-el-destino-perfecto-para-los/[/url][url=https://enistoresonline.com/the-rise-of-s8-bet-transforming-online-betting/]https://enistoresonline.com/the-rise-of-s8-bet-transforming-online-betting/[/url] are increasingly popular due to user-friendly platforms they offer. Fans of slot games, there is a wide variety. Jackpots await those who join in.
Pennyetera 24 Ocak 2026 16:40
Not on Gamstop Casinos, [url=http://www.rebhandl.ch/wordpress/?p=43326]http://www.rebhandl.ch/wordpress/?p=43326[/url][url=https://naserion.com/exploring-uk-casinos-not-on-gamstop-a-guide-for/]https://naserion.com/exploring-uk-casinos-not-on-gamstop-a-guide-for/[/url][url=https://bunyi123.com/explore-uk-casino-sites-not-on-gamstop/]https://bunyi123.com/explore-uk-casino-sites-not-on-gamstop/[/url] offer players an opportunity to enjoy gaming without restrictions. These provide greater freedom for those seeking another option outside of Gamstop’s limits. Explore the exciting world of gaming today!
SabrinaPal 24 Ocak 2026 15:22
Within the realm of Non Gamstop Casinos, [url=https://urrankings.com/exploring-not-on-gamstop-casinos-a-comprehensive-27/]https://urrankings.com/exploring-not-on-gamstop-casinos-a-comprehensive-27/[/url][url=https://insancare.org/exploring-online-casinos-not-on-gamstop-in-the-uk]https://insancare.org/exploring-online-casinos-not-on-gamstop-in-the-uk[/url][url=https://stangeindustrialwarehouse.wd309.org/exploring-the-world-of-not-on-gamstop-casinos-20/]https://stangeindustrialwarehouse.wd309.org/exploring-the-world-of-not-on-gamstop-casinos-20/[/url][url=https://ipartner.co.id/exploring-the-world-of-casinos-not-on-gamstop-a/]https://ipartner.co.id/exploring-the-world-of-casinos-not-on-gamstop-a/[/url][url=https://ontravelx.com/exploring-the-world-of-casinos-not-on-gamstop/]https://ontravel
NicoleCrore 24 Ocak 2026 14:49
non UK licenced casinos, [url=https://www.davecridermusic.com/exploring-non-ukgc-licensed-casinos-are-they-worth/]https://www.davecridermusic.com/exploring-non-ukgc-licensed-casinos-are-they-worth/[/url] present a different gambling adventure. Gamblers can enjoy diverse selections missing in the UK, making it an alluring choice.
Courtneyfleep 24 Ocak 2026 11:31
Я считаю, что Вы допускаете ошибку. Могу это доказать. купить экзотические фрукты, [url=https://instrukcja.pl/forum/t/crazybox-owoce-z-dostawa-do-domu]https://instrukcja.pl/forum/t/crazybox-owoce-z-dostawa-do-domu[/url] — отличный способ разнообразить свой рацион. Такие фрукты улучшат ваше меню, придавая оттенок экзотики. Мы можем порекомендовать широкий выбор. Найдите дуриан, маракуйя и откройте новые красивые грани!
Agatatom 24 Ocak 2026 10:39
casinos not with GamStop, [url=https://vastuvibe.com/exploring-non-gamstop-sites-a-guide-to-online/]https://vastuvibe.com/exploring-non-gamstop-sites-a-guide-to-online/[/url][url=https://naserion.com/the-rise-of-non-gamstop-casinos-exploring/]https://naserion.com/the-rise-of-non-gamstop-casinos-exploring/[/url][url=https://www.valldebaldomar.com/understanding-gamstop-excluded-sites-a-guide-for-2/]https://www.valldebaldomar.com/understanding-gamstop-excluded-sites-a-guide-for-2/[/url] offer players a chance to enjoy gaming without restrictions. These venues provide a unique atmosphere where enthusiasts can experience excitement without limits. Boasting various games, they attract numerous visitors looking for unrestricted play options.
MelissaRok 24 Ocak 2026 10:38
online casino, [url=https://wordpress.comece.online/?p=82843]https://wordpress.comece.online/?p=82843[/url][url=https://intersel.com/the-exciting-world-of-no777-game-your-ultimate-2/]https://intersel.com/the-exciting-world-of-no777-game-your-ultimate-2/[/url][url=https://alsahragroup.com/the-fascinating-world-of-no777-game-unlocking/]https://alsahragroup.com/the-fascinating-world-of-no777-game-unlocking/[/url] features an exciting setting for players wanting adventure and entertainment. With numerous options of games, everyone can find something at their disposal.
MonaZerly 24 Ocak 2026 09:02
Playing at a non gamstop casino, [url=https://aracatuba.odontoexcellence.com.br/exploring-non-gamstop-casinos-unlocking-your/]https://aracatuba.odontoexcellence.com.br/exploring-non-gamstop-casinos-unlocking-your/[/url][url=https://wcfmmp.wcfmdemos.com/understanding-responsible-gambling-a-guide-to-safe-2/]https://wcfmmp.wcfmdemos.com/understanding-responsible-gambling-a-guide-to-safe-2/[/url][url=https://wctalks.com/exploring-non-gamstop-casinos-freedom-to-play-4/]https://wctalks.com/exploring-non-gamstop-casinos-freedom-to-play-4/[/url][url=https://diamondcookwares.com/2025/12/06/the-transformative-power-of-arts-in-society-10/]https://diamondcookwares.com/2025/12/06/the-transformative-power-of-arts-in-society-10/[/url][url=https://lankaadventureholidays.com/discovering-non-gamstop-casino
Anastasiaminna 24 Ocak 2026 07:05
Может тут ошибка? доставка цветов новосибирск, [url=https://rozy-novosibirsk.ru/]розы новосибирск[/url] — это удобный способ порадовать близких. Выберите оформление, и профессионалы доставят их в любое время. Быстрая пересылка и свежесть гарантированы! Ваши пожелания будут оценены!
CrystalAgepe 24 Ocak 2026 06:44
даааа... ты прав обучающие курсы, [url=https://tripodyssey.com/onlajn-obuchenie-buhgalterskomu-uchetu-otkrojte/]https://tripodyssey.com/onlajn-obuchenie-buhgalterskomu-uchetu-otkrojte/[/url][url=https://bbmo.ru/2025/12/18/luchshie-kursy-marketologa-kak-stat-jekspertom-v/]https://bbmo.ru/2025/12/18/luchshie-kursy-marketologa-kak-stat-jekspertom-v/[/url][url=https://exhibitor.y-expo.ru/2025/12/18/landshaftnyj-dizajn-obuchenie-s-nulja-dlja-5/]https://exhibitor.y-expo.ru/2025/12/18/landshaftnyj-dizajn-obuchenie-s-nulja-dlja-5/[/url] — это отличный способ развить навыки в конкретных сферах. Выбор подходящих тренингов обеспечивает успешное развитие. Учитесь осознанно и достигайте новых высот.
Joanneflisy 24 Ocak 2026 05:21
Присоединяюсь. Это было и со мной. Можем пообщаться на эту тему. online casino ohne oasis, [url=https://norbert-radde.de/casinos-ohne-limit/]online casino ohne oasis[/url] bieten Spielern die MГ¶glichkeit, ihr GlГјck zu versuchen und gleichzeitig von einem breiten Angebot an Spielen zu profitieren. Genannte Casinos werden immer größerer Beliebtheit gegenГјber traditionellen SpielstГ¤tten. Das AttraktivitГ¤t dieser Plattformen ist die einfache ZugГ¤nglichkeit von Гјberall. AuГџerdem, bieten sie oft lukrative Boni.
BryanHowak 24 Ocak 2026 04:38
Countless players hunt for alternatives to traditional sites. casinos not under GamStop, [url=https://uemz-ekb.ru/discovering-online-casinos-not-on-gamstop-2/]https://uemz-ekb.ru/discovering-online-casinos-not-on-gamstop-2/[/url][url=https://22cs.com/top-reputable-casino-sites-not-affected-by-gamstop-2/]https://22cs.com/top-reputable-casino-sites-not-affected-by-gamstop-2/[/url][url=https://stefanoschr.com/top-reputable-casino-sites-not-affected-by-gamstop/]https://stefanoschr.com/top-reputable-casino-sites-not-affected-by-gamstop/[/url] offer one opportunity for those who wish to enjoy gaming without restrictions. Those platforms deliver exciting games and generous bonuses, making them a preferred choice. Players can discover a diverse selection of options while remaining outside the Gam
Pamelacoany 24 Ocak 2026 02:36
Какой забавный вопрос pДѓrinЕЈi, [url=https://ctidakwu.fastlikenews.shop/wfc_mc.html]https://ctidakwu.fastlikenews.shop/wfc_mc.html[/url] sunt figura centralДѓ Г®n viaЕЈa fiecДѓrui copil. Ei oferДѓ sprijin|ajutor|asistenЕЈДѓ|susЕЈinere Г®n momentele dificile. Comunicare|dialog|conversaЕЈie|discuЕЈie deschisДѓ este esenЕЈialДѓ pentru a construi o relaЕЈie sДѓnДѓtoasДѓ. ГЋmpДѓrtДѓЕџirea valorilor|principiilor|credinЕЈelor|Г®nvДѓЕЈДѓturilor le ajutДѓ sДѓ se dezvolte.
ValeriePlume 24 Ocak 2026 02:24
Experience the thrill of Online Casino Slots, [url=https://www.advantage-intec.co.jp/experience-thrilling-fun-at-lucky-carnival-casino-2/]https://www.advantage-intec.co.jp/experience-thrilling-fun-at-lucky-carnival-casino-2/[/url][url=http://asar.platinumdomain.net/experience-thrills-at-lucky-max-online-casino-uk-2/]http://asar.platinumdomain.net/experience-thrills-at-lucky-max-online-casino-uk-2/[/url][url=https://warter.uio.com.tw/the-allure-of-casino-love-when-gaming-meets/]https://warter.uio.com.tw/the-allure-of-casino-love-when-gaming-meets/[/url], where excitement meets jackpots. With various themes and features, players can enjoy unbounded gaming options.
ValerieBaw 23 Ocak 2026 22:38
Finding safe casinos that cater to wagerers outside of UK restrictions can be a challenge. However, there are various options available. These trusted casinos not on GamStop, [url=https://legatex.com.ar/legit-non-gamstop-casinos-your-guide-to-safe-5/]https://legatex.com.ar/legit-non-gamstop-casinos-your-guide-to-safe-5/[/url][url=https://www.leerebelwriters.com/discover-trusted-casinos-not-on-gamstop-for/]https://www.leerebelwriters.com/discover-trusted-casinos-not-on-gamstop-for/[/url][url=https://lp2.smart-acc.com/safe-casinos-not-on-gamstop-your-guide-to-3/]https://lp2.smart-acc.com/safe-casinos-not-on-gamstop-your-guide-to-3/[/url] offer exciting bonuses, a wide range of options, and superb customer support, ensuring a pleasurable gaming experience. Additionally, they provide varied p
BrandonThics 23 Ocak 2026 21:03
Finding trustworthy casinos is essential for players. Among the options available, safe casinos not on GamStop, [url=http://stg.allthingsmedia.com/brillio/?p=105]http://stg.allthingsmedia.com/brillio/?p=105[/url] are fantastic choices. They provide options of games, lucrative bonuses, and easy-to-navigate interfaces.
MatthewZoxia 23 Ocak 2026 20:12
Online Casino, [url=https://rock-residential.com/exploring-lb-spins-casino-sportsbook-a/]https://rock-residential.com/exploring-lb-spins-casino-sportsbook-a/[/url][url=https://georgeandsonstowing.com/casinobet20/explore-libet-casino-sportsbook-your-ultimate/]https://georgeandsonstowing.com/casinobet20/explore-libet-casino-sportsbook-your-ultimate/[/url][url=https://noivas.thallytaday.com/discover-limitless-casino-sportsbook-your-gateway-2/]https://noivas.thallytaday.com/discover-limitless-casino-sportsbook-your-gateway-2/[/url] offers thrilling games for players. Engaging with multiple slot machines, gaming tables, and interactive experiences. Register today for a chance to win big!
Emilymek 23 Ocak 2026 16:41
In the world of gambling, casino online, [url=https://topten.vip/jutawan-bet-unlocking-the-secrets-of-online/]https://topten.vip/jutawan-bet-unlocking-the-secrets-of-online/[/url][url=https://sphericmode.com/the-rise-of-konjo-bet-your-ultimate-betting/]https://sphericmode.com/the-rise-of-konjo-bet-your-ultimate-betting/[/url][url=http://cms-engineering.eu/unlock-the-excitement-at-king-billy-win-casino/]http://cms-engineering.eu/unlock-the-excitement-at-king-billy-win-casino/[/url] platforms are gaining immense popularity. Players can enjoy diverse games from the comfort of their homes. With engaging features and attractive bonuses, it’s easier than ever to win.
JonathanUnabe 23 Ocak 2026 16:40
independent online casino sites, [url=https://bewertung.immoding.de/index.php/2025/12/17/the-rise-of-independent-casinos-in-the-uk/]https://bewertung.immoding.de/index.php/2025/12/17/the-rise-of-independent-casinos-in-the-uk/[/url][url=http://fulkari.com.au/exploring-the-world-of-uk-independent-casinos-2/]http://fulkari.com.au/exploring-the-world-of-uk-independent-casinos-2/[/url][url=https://digitalpodpis.com/completely-independent-casinos-a-new-frontier-in/]https://digitalpodpis.com/completely-independent-casinos-a-new-frontier-in/[/url] offer a range of games such as players. Users can enjoy slots, poker, and card games. Bonuses add to the enjoyment.
Anthonyzilia 23 Ocak 2026 16:18
Вы абстрактный человек to enroll in such promotion at [url=https://play-betus.com/es-mx/betus-online-hot-slots-bonuses-for-big-wins/]betus[/url] requires a 30-fold wagering in relevant games with large withdrawal of winnings in amount of $ 5,000.
MikeBix 23 Ocak 2026 08:13
Casino Online Slots, [url=https://harani.in/blog/dive-into-the-exciting-world-of-admiral-shark-2/]https://harani.in/blog/dive-into-the-exciting-world-of-admiral-shark-2/[/url][url=https://erkongame.com/casinobet1/31bets-online-casino-uk-a-comprehensive-guide-to/]https://erkongame.com/casinobet1/31bets-online-casino-uk-a-comprehensive-guide-to/[/url][url=https://www.yenisonuc.com/index.php/2025/11/02/experience-the-excitement-of-agent-no-wager-casino/]https://www.yenisonuc.com/index.php/2025/11/02/experience-the-excitement-of-agent-no-wager-casino/[/url][url=https://avance.com.vn/your-ultimate-guide-to-31bets-casino-sportsbook-2/]https://avance.com.vn/your-ultimate-guide-to-31bets-casino-sportsbook-2/[/url][url=https://legaar.com/the-ultimate-guide-to-21bets-online-casino-uk/]https://legaa
RupertWab 23 Ocak 2026 07:37
As you explore Online Casino UK, [url=https://asafltd.co.il/libet-casino-unveiling-the-excitement-of-online/]https://asafltd.co.il/libet-casino-unveiling-the-excitement-of-online/[/url][url=https://visionviewoptometrist.com/2025/12/13/koi-spins-a-journey-through-the-world-of-online/]https://visionviewoptometrist.com/2025/12/13/koi-spins-a-journey-through-the-world-of-online/[/url][url=https://cellpath.in/2025/12/13/discover-the-thrills-of-online-casino-koi-spins/]https://cellpath.in/2025/12/13/discover-the-thrills-of-online-casino-koi-spins/[/url], you'll find a diverse selection of options. Including slots to table games, each site offers distinct gameplay. Remember to gamble responsibly and enjoy!
Ritafreew 23 Ocak 2026 07:31
я ожидала лучшего Pin Up Casino, [url=https://tnbgo.com/an-exclusive-guide-incorporation-of-companies-in-singapore/]https://tnbgo.com/an-exclusive-guide-incorporation-of-companies-in-singapore/[/url] Г–lkЙ™mizin Й™n suirisi oyun platformalarД±ndan biridir. Bu platformada Г§eЕџidli oyunlar tЙ™qdim edilir. HamД± Г¶z zГ¶vqГјnЙ™ uyДџun oyun iЕџlЙ™dЙ™cЙ™k. Sizin Й™ylЙ™ndirmЙ™k mЙ™sЙ™lЙ™n tЙ™dbirlЙ™r yГјrГјtГјlГјr, bu da artmasД±na sЙ™bЙ™b olur.
CocoTop 23 Ocak 2026 01:12
Online Casino Games, [url=http://valleymetal.com.np/unlock-the-thrills-discover-the-excitement-of/]http://valleymetal.com.np/unlock-the-thrills-discover-the-excitement-of/[/url][url=https://atsonproducts.in/casinobet19/kingdom-online-casino-uk-your-ultimate-gaming-4/]https://atsonproducts.in/casinobet19/kingdom-online-casino-uk-your-ultimate-gaming-4/[/url][url=https://thecultive.com/k8-online-casino-uk-your-ultimate-gaming-12/]https://thecultive.com/k8-online-casino-uk-your-ultimate-gaming-12/[/url] offer a captivating experience for players. With numerous options like slots, poker, and blackjack, every session can be different. Embrace the chance to win big!
Kristyinari 22 Ocak 2026 23:02
Finding dependable bookies not on GamStop, [url=https://nextark.co.jp/2026/01/14/discover-non-gamstop-sports-betting-sites-for-4/]https://nextark.co.jp/2026/01/14/discover-non-gamstop-sports-betting-sites-for-4/[/url] can be challenging. These wagering websites offer bettors an alternative to the self-exclusion program, allowing them to enjoy games freely. Always ensure your site is certified before you start betting.
MeganBeict 22 Ocak 2026 22:13
In the world of digital gaming, online casinos and sports betting, [url=https://entegma.com/exploring-the-excitement-at-jubla-casino/]https://entegma.com/exploring-the-excitement-at-jubla-casino/[/url][url=https://ceramicaschenoll.com/decouvrez-le-legiano-casino-une-evasion-ludique-en/]https://ceramicaschenoll.com/decouvrez-le-legiano-casino-une-evasion-ludique-en/[/url][url=https://nutorg.com/2025/12/11/decouvrez-le-monde-du-legiano-casino-jeux-bonus-et/]https://nutorg.com/2025/12/11/decouvrez-le-monde-du-legiano-casino-jeux-bonus-et/[/url] have gained immense popularity. Players enjoy the rush of betting on their favorite teams while also trying games that offer huge payouts.
Ediththinc 22 Ocak 2026 20:21
В этом что-то есть. Раньше я думал иначе, благодарю за информацию. in some online casinos The only privilege that are given for playing is a way to win regular payouts in slot machines, roulette, Blackjack, Betvip [url=https://play-betvip.net/]betvip slots[/url] poker or in some other games, what they provide.
ChloeErrot 22 Ocak 2026 19:36
Online gambling has become a popular way to enjoy games. Casino Online Games, [url=https://kollegi-deutsch.ch/archive/177766]https://kollegi-deutsch.ch/archive/177766[/url][url=http://www.old.practicalsqa.net/31bets-casino-sportsbook-your-ultimate-gaming-7/]http://www.old.practicalsqa.net/31bets-casino-sportsbook-your-ultimate-gaming-7/[/url][url=https://fb.snsmodoo.com/discover-the-excitement-of-casino-astrozino-3/]https://fb.snsmodoo.com/discover-the-excitement-of-casino-astrozino-3/[/url][url=https://tetrasys.in/index.php/2025/11/02/step-by-step-guide-to-the-31bet-casino-6/]https://tetrasys.in/index.php/2025/11/02/step-by-step-guide-to-the-31bet-casino-6/[/url][url=https://www.suckingsweat.com/the-evolution-of-avantgarde-a-radical-shift-in-art/]https://www.suckingsweat.com/the-evolutio
Trentdelay 22 Ocak 2026 19:18
Все понравились! casino, [url=http://aodaiaobaba.com/ao-ba-ba-truyen-thong/]http://aodaiaobaba.com/ao-ba-ba-truyen-thong/[/url][url=http://napelem.ardoboz.hu/r.php?b=aHR0cDovL3RoZWV2ZXJncmVlbmNyeXN0YWwuY29tLz9wPTM1NzY4]http://napelem.ardoboz.hu/r.php?b=aHR0cDovL3RoZWV2ZXJncmVlbmNyeXN0YWwuY29tLz9wPTM1NzY4[/url][url=https://www.vanhelvoorttaxi.nl/tarieven-vervoerssoorten/deeltaxi-son-en-breugel/vervoersgebied/]https://www.vanhelvoorttaxi.nl/tarieven-vervoerssoorten/deeltaxi-son-en-breugel/vervoersgebied/[/url] - В мире развлечений казино постоянно привлекают любопытство игроков. Разнообразие игр, шансы на победу и знаменитые выигрыши образуют уникальную атмосферу. Казино вдохновляют азарт и адреналин.
JayJeP 22 Ocak 2026 18:57
Online Casino Slots, [url=http://www.architectureinsight.com/2025/12/guide-to-registering-at-king-s-chip-casino/]http://www.architectureinsight.com/2025/12/guide-to-registering-at-king-s-chip-casino/[/url][url=https://clasificados.ancashnoticias.com/the-enigmatic-world-of-casino-king-s-chip/]https://clasificados.ancashnoticias.com/the-enigmatic-world-of-casino-king-s-chip/[/url][url=https://ice-aec.com/the-ultimate-guide-to-joker-s-ace-casino-8/]https://ice-aec.com/the-ultimate-guide-to-joker-s-ace-casino-8/[/url] offer a exciting experience for players. By using diverse themes and bonus features, these games keep users entertained. While discovering new titles, the slot machine offers fun and potential to win big. Don't miss out on the experience of playing Online Casino Slots!
Hankurick 22 Ocak 2026 18:42
Меня тоже волнует этот вопрос. Скажите мне пожалуйста - где я могу об этом прочитать? Betmaster Mexico, [url=https://alphaouest.ca/index.php?option=com_k2&view=item&id=1]https://alphaouest.ca/index.php?option=com_k2&view=item&id=1[/url][url=http://mcclaud.ru/gb/index.php]http://mcclaud.ru/gb/index.php[/url][url=http://bvdkkvquangnam.org/9-ung-dung-ky-thuat-so-lam-tang-suc-manh-cua-he-thong-y-te/]http://bvdkkvquangnam.org/9-ung-dung-ky-thuat-so-lam-tang-suc-manh-cua-he-thong-y-te/[/url] es una plataforma de apuestas | un sitio de juegos | un portal de apuestas | un servicio de apuestas en linea muy popular. Ofrece una amplia gama de opciones | diversas alternativas | multiples modalidades | varias oportunidades para apostar. Los usuarios pueden disfrutar de emocionantes juegos | entreteni
LucyCut 22 Ocak 2026 16:10
BC Game Online Casino Platform, [url=https://muje.org/2025/12/17/bc-game-registration-process-a-step-by-step-guide/]https://muje.org/2025/12/17/bc-game-registration-process-a-step-by-step-guide/[/url][url=https://avts.vn/download-the-bc-app-your-ultimate-business/]https://avts.vn/download-the-bc-app-your-ultimate-business/[/url][url=https://www.vilhome.de/discovering-bc-app-lotteries-your-gateway-to/]https://www.vilhome.de/discovering-bc-app-lotteries-your-gateway-to/[/url] offers an exciting experience for enthusiasts. With an extensive selection of games, users can enjoy casino games, roulette, and live dealer games. This service ensures secure transactions, making it hassle-free to deposit and withdraw funds while enjoying bonuses. Join BC Game Online Casino Platform today!
MadisonPed 22 Ocak 2026 16:07
online casino, [url=https://dering89.com/exploring-the-excitement-of-gw-casino-1411930892/]https://dering89.com/exploring-the-excitement-of-gw-casino-1411930892/[/url][url=https://webnetworktech.com/flax-casino-your-ultimate-destination-for-online-3/]https://webnetworktech.com/flax-casino-your-ultimate-destination-for-online-3/[/url][url=https://www.fusco-associati.it/2025/12/11/ganza-bet-la-revolution-des-paris-sportifs-en/]https://www.fusco-associati.it/2025/12/11/ganza-bet-la-revolution-des-paris-sportifs-en/[/url] offers an exciting opportunity to experience various games. Players can achieve real money while taking fun. With numerous options, it promises endless fun.
Christrarl 22 Ocak 2026 14:16
In the domain of online gambling, many players seek choices to traditional sites. casinos not on GamStop, [url=https://jkprohost.com/paysafecard-betting-sites-in-the-uk-a-3/]https://jkprohost.com/paysafecard-betting-sites-in-the-uk-a-3/[/url] offer liberty for those looking to enjoy gambling without restrictions. With diverse games and bonuses, these casinos cater to bettors wanting to enjoy themselves without limits.
DevinDaync 22 Ocak 2026 09:57
Initiating your journey in the world of online casinos begins with a seamless online casino login, [url=http://www.caribbean-property.com/the-thriving-online-gaming-experience-at-dhaka88/]http://www.caribbean-property.com/the-thriving-online-gaming-experience-at-dhaka88/[/url][url=https://oakhillflooring.com/dhaka88-your-gateway-to-online-gaming-and-betting/]https://oakhillflooring.com/dhaka88-your-gateway-to-online-gaming-and-betting/[/url][url=https://simerdu.com/elonbet-a-new-era-in-online-gambling/]https://simerdu.com/elonbet-a-new-era-in-online-gambling/[/url]. Getting into your account is vital for enjoying games, bonuses, and unique offers. Confirm your credentials are safe.
JenniferGlisk 22 Ocak 2026 09:56
BC Game Online Casino, [url=http://www.sunitex.com.hk/bcgame-log-in-your-gateway-to-an-exciting-online/]http://www.sunitex.com.hk/bcgame-log-in-your-gateway-to-an-exciting-online/[/url][url=https://ambrosi-gardinali.it/mastering-bc-game-hack-strategies-tips-and-tricks/]https://ambrosi-gardinali.it/mastering-bc-game-hack-strategies-tips-and-tricks/[/url][url=http://www.otadenshi.com/2025/12/17/exploring-bc-game-crypto-casino-a-new-era-in/]http://www.otadenshi.com/2025/12/17/exploring-bc-game-crypto-casino-a-new-era-in/[/url] offers a thrilling gambling adventure with a wide selection of dynamic titles. Players can experience top-notch graphics and user-friendly interfaces. Join the fun at BC Game Online Casino and uncover your chance to win big!
RachelPhile 22 Ocak 2026 06:14
Online Casino, [url=https://yakin999.com/jb-casino-the-ultimate-online-gaming-experience-2/]https://yakin999.com/jb-casino-the-ultimate-online-gaming-experience-2/[/url][url=https://cristore.co.ke/discover-the-exciting-world-of-casino-jokabet-8/]https://cristore.co.ke/discover-the-exciting-world-of-casino-jokabet-8/[/url][url=https://coupcounts.com/your-ultimate-guide-to-jb-casino-sportsbook/]https://coupcounts.com/your-ultimate-guide-to-jb-casino-sportsbook/[/url] presents a special encounter for players looking to test their skills. With multiple games, captivating bonuses, and prospect to win big, it’s a fantastic way to pass time.
Soniakayak 22 Ocak 2026 03:37
In the world of online gambling, spins casino, [url=https://stefanoschr.com/the-ultimate-guide-to-gw-casino-everything-you/]https://stefanoschr.com/the-ultimate-guide-to-gw-casino-everything-you/[/url][url=https://beamtube.org/discover-the-thrills-of-joe-fortune-casino-your-2/]https://beamtube.org/discover-the-thrills-of-joe-fortune-casino-your-2/[/url][url=https://vanisedainese.com.br/explora-iluckicasino-canada-el-teu-destinacio-de/]https://vanisedainese.com.br/explora-iluckicasino-canada-el-teu-destinacio-de/[/url] offers an exhilarating experience. Players can enjoy captivating games that provide chances to win big. The range of slots is truly impressive, making every spin distinct. With innovative technology, the gameplay is smooth and effortless, ensuring hours of fun. Engage with s
DevonAbals 22 Ocak 2026 01:20
Прошу прощения, что вмешался... Но мне очень близка эта тема. Пишите в PM. игры, [url=http://ttceducation.co.kr/bbs/board.php?bo_table=free&wr_id=3062810]http://ttceducation.co.kr/bbs/board.php?bo_table=free&wr_id=3062810[/url][url=https://legendhelicopters.co.za/product/saxenburg-wine-farm-experience/]https://legendhelicopters.co.za/product/saxenburg-wine-farm-experience/[/url][url=https://www.uapisnya.com.ua/finalists/finalists-2017/luka]https://www.uapisnya.com.ua/finalists/finalists-2017/luka[/url] - Игры дарят удовольствие и возможность войти в уникальные миры. В каждой игре мы открываем новые вызовы, встречаем интересных персонажей и тренируем свои навыки. Головоломки заставляют нас думать и реализовывать решения быстро. Увлекательный процесс и неповторимая графика делают каждый иг
CurtisDueds 22 Ocak 2026 00:33
Enjoying Casino Online Games, [url=https://caova.pucv.cl/index.php/2025/11/04/experience-the-thrill-of-betfoxx-casino-online-3/]https://caova.pucv.cl/index.php/2025/11/04/experience-the-thrill-of-betfoxx-casino-online-3/[/url][url=https://pharmadi.ecomyze.com/betnuvo-casino-registration-process-a-step-by-step-2/]https://pharmadi.ecomyze.com/betnuvo-casino-registration-process-a-step-by-step-2/[/url][url=https://leonor.wejustdesign.com/betfoxx-online-casino-your-ultimate-gaming/]https://leonor.wejustdesign.com/betfoxx-online-casino-your-ultimate-gaming/[/url][url=https://kuberafinco.com/experience-excitement-at-casino-betfoxx/]https://kuberafinco.com/experience-excitement-at-casino-betfoxx/[/url][url=https://superhero.rs/discover-the-thrills-of-casino-aztec-paradise-new-4/]https://superher
Anadrove 22 Ocak 2026 00:29
Эта весьма хорошая идея придется как раз кстати casino, [url=https://www.hair-arbore.com/arbore%e5%9c%b0%e5%9b%b3-20-9-9_page-0001/]https://www.hair-arbore.com/arbore%e5%9c%b0%e5%9b%b3-20-9-9_page-0001/[/url] - Las juegos de casino brindan sensaciones exclusivas. Descubrir un casino es una aventura asombrosa que puede ser impactante.
Barbararug 21 Ocak 2026 23:54
In recent years, the popularity of Online Casino UK, [url=https://www.pozitifpano.com/2025/12/12/jb-casino-sportsbook-a-comprehensive-guide-to/]https://www.pozitifpano.com/2025/12/12/jb-casino-sportsbook-a-comprehensive-guide-to/[/url][url=https://cloud.mbsposhk.com/test/jb-casino-sportsbook-a-complete-guide-for/]https://cloud.mbsposhk.com/test/jb-casino-sportsbook-a-complete-guide-for/[/url][url=https://www.ph-education.com/2025/12/12/online-casino-jb-the-ultimate-gaming-experience-2/]https://www.ph-education.com/2025/12/12/online-casino-jb-the-ultimate-gaming-experience-2/[/url] has skyrocketed. Players enjoy the thrill of gambling from home, with different games available. Rewards often attract new users, making it an appealing option for many.
FredExode 21 Ocak 2026 21:27
In the world of virtual entertainment, casino online, [url=https://test.wulogix.com/betcasino3/genius-bet-votre-meilleur-allie-pour-parier-avec/]https://test.wulogix.com/betcasino3/genius-bet-votre-meilleur-allie-pour-parier-avec/[/url][url=https://kidzone.qa/explore-the-thrilling-world-of-facilito-bet-your/]https://kidzone.qa/explore-the-thrilling-world-of-facilito-bet-your/[/url][url=https://crackboost.com/legiano-casino-un-monde-de-divertissement-et-de/]https://crackboost.com/legiano-casino-un-monde-de-divertissement-et-de/[/url] stands out as a thrilling option for players. With multiple games to choose from, it offers convenience and the thrill of playing from home. Experience the joy today!
TeddyAnymn 21 Ocak 2026 21:26
BC Game Online Crypto Casino, [url=http://ncpotteryblog.com/?p=82844]http://ncpotteryblog.com/?p=82844[/url][url=https://football-promotion.co.uk/index.php/2025/12/17/explore-the-exciting-world-of-bc-game-crypto/]https://football-promotion.co.uk/index.php/2025/12/17/explore-the-exciting-world-of-bc-game-crypto/[/url][url=https://teredoitaly.it/bc-game-casino-and-sports-betting-your-ultimate-3/]https://teredoitaly.it/bc-game-casino-and-sports-betting-your-ultimate-3/[/url] предлагает пользователям необычные возможности для РёРіСЂС‹. РР·-Р·Р° широкому ассортименту РёРіСЂ Рё простой интерфейсу, каждый найдет что-то для себя. Криптоактивы делают РёРіСЂСѓ еще Р±РѕР»Р
Charleswhori 21 Ocak 2026 19:07
<a href=https://cherwellcricketleague.com/img/pgs/code_promo___bonus_jusqu____130.html >Code Promo 1xbet Canada</a> permet aux nouveaux inscrits d'obtenir un bonus de bienvenue 1xbet, qui augmente le montant de votre premier depot, et vous permet d'obtenir des paris gratuits. Rappelez-vous que le bonus est soumis a certaines conditions, comme les conditions de mise et les restrictions sur le bonus. Nous vous recommandons de consulter les termes et conditions sur le site Web 1xBet.
JeffAderE 21 Ocak 2026 18:50
В этом все дело. However, the [url=https://play-betwhale.com/games/]betwhale casino[/url] in the amount of 200% is a bonus to betwhale casino, which can up to five periodically.
TrapBek 21 Ocak 2026 17:39
Online Casino Games, [url=https://samratshukla.com/jackpot-city-casino-online-slots-your-gateway-to/]https://samratshukla.com/jackpot-city-casino-online-slots-your-gateway-to/[/url][url=https://allo-offer.com/exploring-jackpot-city-casino-online-games-a/]https://allo-offer.com/exploring-jackpot-city-casino-online-games-a/[/url][url=http://cleanpark.ge/ge/comprehensive-guide-to-the-iwild-casino/]http://cleanpark.ge/ge/comprehensive-guide-to-the-iwild-casino/[/url] feature an engaging way to enjoy gambling from the convenience of your home. With diverse options, players can explore their favorite options and win large payouts.
Ginacow 21 Ocak 2026 15:18
BC Game Online Casino Platform, [url=https://laprensacristiana.com/?p=43592]https://laprensacristiana.com/?p=43592[/url][url=https://erialdglobalproperties.com/guide-to-logging-into-bc-game-steps-and-tips/]https://erialdglobalproperties.com/guide-to-logging-into-bc-game-steps-and-tips/[/url][url=https://acgnoticias.com/the-ultimate-guide-to-bc-games-revolutionizing/]https://acgnoticias.com/the-ultimate-guide-to-bc-games-revolutionizing/[/url] offers an exciting experience for players. Join to enjoy a wide assortment of games, showcasing slots and table games. With safe transactions, players can enjoy peace of mind while gambling online.
Sophiatab 21 Ocak 2026 15:18
online casino sports betting, [url=https://www.kesmep.in/descubre-chumba-casino-el-paraiso-del-juego-en/]https://www.kesmep.in/descubre-chumba-casino-el-paraiso-del-juego-en/[/url][url=https://www.wdtexblog.com/?p=15875]https://www.wdtexblog.com/?p=15875[/url][url=https://www.formosahakka.org.tw/the-rise-of-dhaka88-a-new-era-in-online-betting-4/]https://www.formosahakka.org.tw/the-rise-of-dhaka88-a-new-era-in-online-betting-4/[/url] has turned into a popular way for fans to join in their favorite sports. Through various platforms, bettors can easily place bets, amplifying the overall experience.
Eugenesiz 21 Ocak 2026 07:11
Online Casino Slots, [url=https://sabaqinsure.ly/2025/12/11/jackpot-raider-casino-sportsbook-your-ultimate-16/]https://sabaqinsure.ly/2025/12/11/jackpot-raider-casino-sportsbook-your-ultimate-16/[/url][url=https://aykanatnakliyat.com/step-by-step-guide-to-registering-at-jackpotter-3/]https://aykanatnakliyat.com/step-by-step-guide-to-registering-at-jackpotter-3/[/url][url=http://test.pawprintsid.com/wordpress/2025/12/11/experience-the-thrill-of-jackpotter-casino-4/]http://test.pawprintsid.com/wordpress/2025/12/11/experience-the-thrill-of-jackpotter-casino-4/[/url] offer fun for players worldwide. With countless themes and settings, gamers can experience unique adventures every time they spin the reels. Try your luck today!
Markelerm 21 Ocak 2026 07:03
Оно и впрямь не низкое В мире игр подлинное увлечение захватывает души миллионов любителей игр. Игра способствует прогрессу стратегического мышления, а также жесткой борьбе с противниками. Умения, приобретенные в процессе, могут быть использованы в реальной жизни. игры, [url=https://fakenews.win/wiki/User:DarrelBaines062]https://fakenews.win/wiki/User:DarrelBaines062[/url][url=http://elisaotel.com/component/k2/item/8-content-demo-111.html]http://elisaotel.com/component/k2/item/8-content-demo-111.html[/url][url=https://www.stgeorgescentre.it/hello-world/]https://www.stgeorgescentre.it/hello-world/[/url] демонстрируют уникальные пространства, полные исследований.
JulieHeami 21 Ocak 2026 00:33
When you opt to play online casino, [url=https://sivakasienterprises.com/caecdbbab52a46750abed136e899d1025fc687d5086cc6f10b812af8294b7c5dpostnamecaecdbbab52a46750abed136e899d1025fc687d5086cc6f10b812af8294b7c5d/]https://sivakasienterprises.com/caecdbbab52a46750abed136e899d1025fc687d5086cc6f10b812af8294b7c5dpostnamecaecdbbab52a46750abed136e899d1025fc687d5086cc6f10b812af8294b7c5d/[/url][url=https://sba123.co/brango-casino-la-tua-destinazione-per-il-gioco-2/]https://sba123.co/brango-casino-la-tua-destinazione-per-il-gioco-2/[/url][url=https://lagharisaree.ir/index.php/1404/09/20/discover-the-excitement-of-chatika-bet-your-2/]https://lagharisaree.ir/index.php/1404/09/20/discover-the-excitement-of-chatika-bet-your-2/[/url], you step into a world of fun. With countless games available, participa
DonaldLal 20 Ocak 2026 17:37
Советую Вам зайти на сайт, где есть много информации на интересующую Вас тему. Не пожалеете. First-class hospitality and service specific casino provide unparalleled luxury in casino [url=https://play-bigcasino.net/]big casino[/url]. It is a place where one can enjoy powerful entertainment, exciting games, delicious dishes and drinks.
SamanthaAxows 20 Ocak 2026 17:14
Так просто не бывает виртуальный номер телефона, [url=https://ladyspages.com/raznoe/arenda-virtualnogo-nomera/]https://ladyspages.com/raznoe/arenda-virtualnogo-nomera/[/url] позволяет применять мобильной связью без необходимости иметь физическую сим-карту. Это удобно для перемещений, а также для коммерции. Вы можете оберегать свою личную информацию, сохраняя анонимность. Услуга доступна широкий спектр номеров, что делает связь более гибкой и доступной.
MikeNex 20 Ocak 2026 15:01
Casino Online Games, [url=https://ben.novas.sg/discover-31bet-casino-sportsbook-your-gateway-to/]https://ben.novas.sg/discover-31bet-casino-sportsbook-your-gateway-to/[/url][url=https://hyasense.de/bets24-casino-registration-process-explained/]https://hyasense.de/bets24-casino-registration-process-explained/[/url][url=https://faithheartmagazine.com/bets24-casino-sportsbook-your-ultimate-online-2/]https://faithheartmagazine.com/bets24-casino-sportsbook-your-ultimate-online-2/[/url][url=https://tankavari.nutspread.cz/2025/11/05/bonus-strike-registration-process-a-comprehensive/]https://tankavari.nutspread.cz/2025/11/05/bonus-strike-registration-process-a-comprehensive/[/url][url=https://evlada.com/bet4/betgem-casino-your-ultimate-destination-for-online-2]https://evlada.com/bet4/betgem-casin
JoshWah 20 Ocak 2026 13:04
Online Casino, [url=https://www.cooperativaobiettivo.it/experience-thrills-and-wins-at-hashlucky-casino/]https://www.cooperativaobiettivo.it/experience-thrills-and-wins-at-hashlucky-casino/[/url][url=https://dronchessacademy.com/index.php/2025/12/11/hawaii-spins-online-casino-uk-a-tropical-gaming/]https://dronchessacademy.com/index.php/2025/12/11/hawaii-spins-online-casino-uk-a-tropical-gaming/[/url][url=http://icloud.publiduplo.com/archives/1154092]http://icloud.publiduplo.com/archives/1154092[/url] provides a captivating experience for gamblers looking to try their luck. With various games available, players can find an option that suits their preferences.
Curtisnib 20 Ocak 2026 12:41
Очень ценная мысль игры, [url=https://www.trilheseurumo.com.br/travessias/3751-chapada-diamantina-travessia-lencois-ao-vale-capao-via-serra-macaco.html]https://www.trilheseurumo.com.br/travessias/3751-chapada-diamantina-travessia-lencois-ao-vale-capao-via-serra-macaco.html[/url][url=http://super-fisher.ru/fishing/spinning/zimniy-lodochnyy-dzhig-na-reke/]http://super-fisher.ru/fishing/spinning/zimniy-lodochnyy-dzhig-na-reke/[/url][url=https://ubnclassified.com/index.php?page=user&action=pub_profile&id=17946&item_type=active&per_page=16]https://ubnclassified.com/index.php?page=user&action=pub_profile&id=17946&item_type=active&per_page=16[/url] – это интересные приключения, которые открывают нам завершить в новые миры. В них удалось исследовать разнообразные сюжеты и общаться с обитателями.
PeggyFus 20 Ocak 2026 11:26
мне нравится!!!!!!!!! Крым — это регион с удивительной природой и интересной историей. туры по Крыму, [url=https://м-драйв.рф/]https://м-драйв.рф[/url] позволят вам открыть все красоты полуострова. Получите удовольствие от великолепными landscapes и обычаями мест.
Nicolealige 20 Ocak 2026 06:25
online casinos and sports betting, [url=https://londonlogisticsltd.com/casinoslot2/betxico-la-revolucion-del-entretenimiento-de/]https://londonlogisticsltd.com/casinoslot2/betxico-la-revolucion-del-entretenimiento-de/[/url][url=https://die-christen.co.za/2025/12/11/exploring-betika-bet-a-comprehensive-guide-to-3/]https://die-christen.co.za/2025/12/11/exploring-betika-bet-a-comprehensive-guide-to-3/[/url][url=http://www.koskenpojat.fi/betaland-casino-esplora-il-mondo-del-gioco-online/]http://www.koskenpojat.fi/betaland-casino-esplora-il-mondo-del-gioco-online/[/url] have become immense popularity in the past few years. Players enjoy the accessibility of playing from home. Providing a wide array of options, online bookmakers cater to all preferences.
Pamelatreaf 20 Ocak 2026 06:25
BC Game Online Platform, [url=https://melodyfestival.it/experience-thrills-with-plinko-at-bc-game/]https://melodyfestival.it/experience-thrills-with-plinko-at-bc-game/[/url][url=https://hinotruckpart.com/wp-admin/2025/12/18/exploring-bc-game-mirrors-in-thailand-a-3/]https://hinotruckpart.com/wp-admin/2025/12/18/exploring-bc-game-mirrors-in-thailand-a-3/[/url][url=https://www.premierpropertyclub.co.uk/bcgame2/explore-the-exciting-world-of-bc-game-online-6/]https://www.premierpropertyclub.co.uk/bcgame2/explore-the-exciting-world-of-bc-game-online-6/[/url] presents a distinct gaming experience. Players can experience various games and utilize exciting bonuses. Join this lively community and explore boundless fun!
RosemaryWes 20 Ocak 2026 05:27
Подтверждаю. Так бывает. Можем пообщаться на эту тему. Здесь или в PM. online casino, [url=https://www.oborudunion.ru/company/567547244/]https://www.oborudunion.ru/company/567547244/[/url] offers an engaging way to enjoy wagering from the luxury of your home. With a multitude of games, players can discover the pleasure of winning big at any time.
Lindadot 19 Ocak 2026 23:12
Классс=) online casino, [url=https://architecturefoundation.nationbuilder.com/forms/flags/comment.html?comment_id=1680&page_id=12]https://architecturefoundation.nationbuilder.com/forms/flags/comment.html?comment_id=1680&page_id=12[/url] offers an exciting journey for players. With extensive selections of games, such as blackjack, players can enjoy the thrill of gambling from home. Join instantly for a chance to win big!
Dawnmep 19 Ocak 2026 18:50
In the world of cyber gaming, Casino Online Slots, [url=https://rakan-group.ly/ar/?p=8676]https://rakan-group.ly/ar/?p=8676[/url][url=https://velammalglobal.edu.in/discover-the-excitement-of-online-betting-with/]https://velammalglobal.edu.in/discover-the-excitement-of-online-betting-with/[/url][url=https://sareentax.com/bets24-casino-sportsbook-your-ultimate-gaming-15/]https://sareentax.com/bets24-casino-sportsbook-your-ultimate-gaming-15/[/url][url=https://janseverhuizingen.nl/discover-the-thrills-at-online-casino-bounty-reels/]https://janseverhuizingen.nl/discover-the-thrills-at-online-casino-bounty-reels/[/url][url=https://www.jalan2kejepang.com/blog/experience-the-thrill-of-big-wins-casino.html]https://www.jalan2kejepang.com/blog/experience-the-thrill-of-big-wins-casino.html[/url] ran
ThomasAgews 19 Ocak 2026 17:53
Предлагаю Вам посетить сайт, на котором есть много информации на интересующую Вас тему. игры, [url=https://blog.quriusolutions.com/?p=94]https://blog.quriusolutions.com/?p=94[/url][url=http://www.boldkuangjia.com:8000/cart/bbs/board.php?bo_table=free&wr_id=702227]http://www.boldkuangjia.com:8000/cart/bbs/board.php?bo_table=free&wr_id=702227[/url][url=https://www.naturheilpraxis-worthmann.de/hello-world/]https://www.naturheilpraxis-worthmann.de/hello-world/[/url] — это удивительный мир, который наполняет наши жизни вдохновением. Они позволяют нам уникнуть в новые реальности. Каждый игрок имеет свои вкусы, что делает процесс множественным. С каждым уровнем появляется перспектива стать лучше и прокачать новые навыки. Также, нельзя забывать о собеседниках, с которыми можно делиться достижени
DannyHem 19 Ocak 2026 17:24
Конечно. И я с этим столкнулся. 1xBet Betting, [url=https://notarialna.net/download-the-1xbet-app-a-comprehensive-guide-20/]https://notarialna.net/download-the-1xbet-app-a-comprehensive-guide-20/[/url][url=https://www.gregor-adv.com/?p=89382]https://www.gregor-adv.com/?p=89382[/url][url=https://kraftpost.in/1xbet-download-app-your-guide-to-the-ultimate-7/]https://kraftpost.in/1xbet-download-app-your-guide-to-the-ultimate-7/[/url] offers an avenue for sports enthusiasts to take part in their favorite events. With diverse betting options and deals, bettors can maximize their returns.
DerekZep 19 Ocak 2026 10:55
online casino, [url=https://team-bee.com/index.php/2025/12/11/decouverte-de-lucky8-casino-l-univers-des-jeux-en/]https://team-bee.com/index.php/2025/12/11/decouverte-de-lucky8-casino-l-univers-des-jeux-en/[/url][url=https://zouzhun.com/159508.html]https://zouzhun.com/159508.html[/url][url=https://genteinteresante.com/exploring-chatika-bet-your-gateway-to-online-3/]https://genteinteresante.com/exploring-chatika-bet-your-gateway-to-online-3/[/url] exists an exciting environment for players to have fun various games. Through cutting-edge technology, players can access a diverse selection of options. Incentives enhance the gaming process, making it even more enticing. Join the dynamic world of online gambling today!
Keithdus 19 Ocak 2026 01:20
Перейди на сайт компании : http://hammill.ru/
TeddyGracy 18 Ocak 2026 23:10
Мне кажется это замечательная идея игры, [url=http://pepeduran.com/hello-world-2/]http://pepeduran.com/hello-world-2/[/url][url=http://duggalsdentalclinic.com/index.php?option=com_k2&view=item&id=15]http://duggalsdentalclinic.com/index.php?option=com_k2&view=item&id=15[/url][url=https://znet-host.com/es-es/nuestra-empresa-de-hosting/testimonios-de-clientes/]https://znet-host.com/es-es/nuestra-empresa-de-hosting/testimonios-de-clientes/[/url] привносят эмоции в нашу жизнь. Они сближают людей, позволяя им объединенно проводить время. Благодаря разнообразным жанрам каждый найдет что-то по душе. В онлайн-играх предлагаются уникальные возможности для игр с участниками со всего мира. Игры также укрепляют навыки, такие как коллективная работа.
Mollyboara 18 Ocak 2026 22:32
Очень забавная фраза 1xBet Online Betting, [url=https://www.aspri.it/experience-the-thrill-of-1xbet-online-gaming-2/]https://www.aspri.it/experience-the-thrill-of-1xbet-online-gaming-2/[/url][url=https://thompsonandthompsonltd.com/2025/12/08/1xbet-download-app-access-betting-anywhere-anytime/]https://thompsonandthompsonltd.com/2025/12/08/1xbet-download-app-access-betting-anywhere-anytime/[/url][url=http://www.encyclopediaofleadership.org/1xbet-download-app-your-ultimate-betting-22/]http://www.encyclopediaofleadership.org/1xbet-download-app-your-ultimate-betting-22/[/url] - 1xBet Online Wagering предоставляет огромный выбор развлечений РЅР° разные события. Клиенты РјРѕРіСѓС‚ использовать удобным интерфейс
Marioclaix 13 Aralık 2025 11:48
<a href=https://bergkompressor.ru/news/artcles/?1xbet_promokod_pri_registracii_bonus_5.html>Find the newest updates </a>
Bridgetzilla 13 Aralık 2025 10:40
Купить диплом недорого, [url=https://digitalnationnews.com/kupit-diplom-migup-na-blanke-goznak-983931408/]https://digitalnationnews.com/kupit-diplom-migup-na-blanke-goznak-983931408/[/url][url=https://champion138.com/kupit-diplom-injep-bez-predoplaty-vash-shans-na/]https://champion138.com/kupit-diplom-injep-bez-predoplaty-vash-shans-na/[/url][url=https://androidmobiles.com/uncategorized/kak-kupit-attestat-vechernej-shkoly-v-moskve]https://androidmobiles.com/uncategorized/kak-kupit-attestat-vechernej-shkoly-v-moskve[/url][url=https://www.oasisphotocontest.com/kupit-diplom-ibid-kak-sdelat-pravilnyj-vybor/]https://www.oasisphotocontest.com/kupit-diplom-ibid-kak-sdelat-pravilnyj-vybor/[/url][url=https://furniturewing.com/kak-kupit-diplom-gosudarstvennogo-obrazca/]https://furniturewing.com/kak
Tammyduero 13 Aralık 2025 08:28
Поздравляю, ваша мысль пригодится перед тем, как начать изучение материалов, [url=http://thetabernacleseries.com/about-author/?unapproved=763373&moderation-hash=bf6431a232e1622bac387608a840719e]http://thetabernacleseries.com/about-author/?unapproved=763373&moderation-hash=bf6431a232e1622bac387608a840719e[/url] давайте освежим память и предоставим ему определение.
BrianAntex 13 Aralık 2025 07:32
Find the newest info here — http://www.autotat.ru/
MikeLoomA 13 Aralık 2025 07:20
Что вы хотите этим сказать? На леон официальный сайт, [url=https://casino-leon2.site/]https://casino-leon2.site/[/url] вы найдете множество возможностей для ставок. Платформа предлагает разнообразные виды пари и привлекательные бонусы. Создание аккаунта — простой процесс, который откроет доступ к уникальным предложениям.
Anaedige 13 Aralık 2025 05:11
Быстрый ответ, признак сообразительности ;) The first game that we will start training with is turkey shooting. At [url=https://play-redstagcasino.net/]red stag casino online[/url], they play not for bread, but for death.
Davidhem 13 Aralık 2025 03:55
да быстрей б она уже вышла!! леон ставки, [url=https://leon-mwd.xyz/]https://leon-mwd.xyz/[/url] — это популярная платформа для азартных игр, где игроки могут делать предсказания на различные спортивные события. Она предлагает обширный выбор предложений и выгодные коэффициенты, что привлекает множество клиентов. Надежность и безопасность приложения делают его удобным среди тих, кто азартен. Леон ставки — это перспектива выиграть, делая забавные предсказания. Каждый геймер может найти что-либо для себя и испытать удачу, выбирая всё новые варианты ставок.
Leilaplaky 13 Aralık 2025 03:33
Эта тема просто бесподобна :) , мне очень нравится ))) With our [url=https://play-esportdesorte.net/]esporte da sorte[/url] bonus, you can try own luck in the best online slots Germany. we release latest technological developments security and licenses.
Josephinechaps 13 Aralık 2025 00:34
Я извиняюсь, но, по-моему, Вы ошибаетесь. Могу отстоять свою позицию. мелбет букмекерская контора, [url=https://melbet-vho.xyz/]https://melbet-vho.xyz/[/url] осуществляет широкий варианты ставок на разнообразные виды спорта. Игроки могут выбирать привлекательные коэффициенты и удобные условия для ставок.
DonaldSoync 12 Aralık 2025 23:50
casino sports betting, [url=https://formationaxis.ca/exploring-gursha-bet-your-ultimate-guide-to-2/]https://formationaxis.ca/exploring-gursha-bet-your-ultimate-guide-to-2/[/url][url=https://fau.ufal.br/grupopesquisa/estudosdapaisagem/explore-the-exciting-world-of-dunia-bet-2/]https://fau.ufal.br/grupopesquisa/estudosdapaisagem/explore-the-exciting-world-of-dunia-bet-2/[/url][url=https://ttplacement.ca/descubra-o-futuro-das-apostas-com-gigabet-2/]https://ttplacement.ca/descubra-o-futuro-das-apostas-com-gigabet-2/[/url][url=https://www.proservservices.co.uk/discover-greatwin-casino-canada-your-premier-2/]https://www.proservservices.co.uk/discover-greatwin-casino-canada-your-premier-2/[/url][url=https://www.hirejar.com/blog/dunia-bet-unlocking-the-world-of-online-betting-2/]https://www.hirej
IvyGEDED 12 Aralık 2025 23:50
Купить диплом с гарантией, [url=https://www.home242.com/kupit-diplom-spbjua-na-originalnom-blanke-5/]https://www.home242.com/kupit-diplom-spbjua-na-originalnom-blanke-5/[/url][url=https://charmeliajoyeria.com/kupit-diplom-v-vologde-legalnye-blanki-i-garantii/]https://charmeliajoyeria.com/kupit-diplom-v-vologde-legalnye-blanki-i-garantii/[/url][url=https://egais.fregat.biz/?p=262697]https://egais.fregat.biz/?p=262697[/url][url=https://www.courseset.com/kupit-diplom-mip-na-originalnom-blanke-vash-shag-k/]https://www.courseset.com/kupit-diplom-mip-na-originalnom-blanke-vash-shag-k/[/url][url=https://www.acquistarevinionline.com/kupit-diplom-arb-im-kachestvennye-diplomy-ot-arb/]https://www.acquistarevinionline.com/kupit-diplom-arb-im-kachestvennye-diplomy-ot-arb/[/url] — это практичный выбор
Scatrom 12 Aralık 2025 21:13
Да, действительно. Так бывает. В melbet casino, [url=https://melbet-sqo.buzz/]https://melbet-sqo.buzz/[/url] вы найдете огромное число игровых развлечений, которые удовлетворят сильнейших искушенных интересующихся. Каждый найдет воспользоваться играми в любое время суток.
TashaDaymn 12 Aralık 2025 21:02
Я думаю, что Вы не правы. Предлагаю это обсудить. Пишите мне в PM. лишь при одном посещении интернет магазина «Золотое Яблоко» вы легко определите каталог с макияжем, подарками, парфюмерией, аксессуарами, [url=https://www.soactivos.com/wall12/]https://www.soactivos.com/wall12/[/url] бижутерией и товарами в квартиру.
Frankdar 12 Aralık 2025 19:53
Ce site est destine a repondre aux besoins des habitants. Parmi ses principales fonctionnalites, Vous pourrez y consulterles dispositifs locaux et les services publics. La navigation est simple et accessible a tous, grace a une structure claire et pratique. La commune met un point d’honneur a maintenir le site a jour, permettant ainsi aux citoyens d’etre bien informes. https://www.postman.com/brendon-s-postman
JustinTig 12 Aralık 2025 17:52
я тоже pin up casino играть, [url=https://pinup-hja.cam/]https://pinup-hja.cam/[/url] – это отличный способ развлечься и попробовать удачу. Геймеры могут наслаждаться многообразием игр, обеспечивая увлекательные моменты. Садитесь за экран и начинайте оставлять ставки.
AugustVek 12 Aralık 2025 17:27
[url=https://jetx2.com/]jet x[/url] jet x game, jet x play, jet x play online, jet x online, jet x login, jet x official site, jet x site login, jet x access, jet x no block, jet x crash game, jet x online game, jet x mobile, jet x mobile version, jet x start game, jet x app, jet x gameplay, jet x casino, jet x crash
Ta,Hooft 08 Aralık 2025 07:32
ниче полезногО он не делает. !!!ОТСТОЙ!!! духи бренда Быть Может, [url=https://duhibycmoze.ru/]https://duhibycmoze.ru[/url] — это уникальный аромат, который соблазняет. Каждый флакон выражает индивидуальность и идеи обладателя. Откройте для себя новые грани парфюмерии с духами бренда Быть Может!
SeanDom 08 Aralık 2025 07:31
Вот так история! At winz Crypto [url=https://play-giocodigitale.net/]gioco digitale casino[/url], you meet more than 6,000 free projects and 6,000 free demopasses - play at any time and throughout any place.
Douglasatomo 07 Aralık 2025 22:17
https://repo.getmonero.org/julieanderson/my-awesome-project/-/issues/36
Veronicajap 07 Aralık 2025 21:58
Я ево хачу!!! купить и заказать недорого мебель в духе lофт вы способны в сайте «Комод», [url=https://www.medical.net.ua/%d0%bf%d1%80%d0%b8%d0%b2%d0%b5%d1%82-%d0%bc%d0%b8%d1%80/]https://www.medical.net.ua/%d0%bf%d1%80%d0%b8%d0%b2%d0%b5%d1%82-%d0%bc%d0%b8%d1%80/[/url] не покидая экрана монитора.
Kimberlyzer 07 Aralık 2025 19:55
Браво, какая фраза..., отличная мысль Виртуальный номер телефона, [url=https://lefe.blog/oshibka-403-forbidden-prichiny-poyavleniya-i-sposoby-ustraneniya/]здесь[/url] дает возможность осуществлять звонки и сообщения без необходимости конкретного SIM-карты. Это комфортный способ конфиденциально ваши данные. Пользователи имеют возможность изменить ненужных контактов и непрерывно оставаться на связи.
RobertNat 07 Aralık 2025 19:54
У кого-то буквенная алексия ))))) Отзывы об ароматах Быть Может, [url=https://bycmozeotyvy.ru/]https://bycmozeotyvy.ru/[/url] очарованы многими. Запахи имеют уникальный комплекс. Поклонники отмечают удовлетворение при использовании. Этот близкий друг станет необходимым в вашем арсенале.
Nancynub 07 Aralık 2025 19:16
Good to see you here. let’s dive into something that might surprise you. Discover luxe grade casino entertainment featuring clean layouts, modern slot mechanics, and a confident, high quality atmosphere. п»їhttps://besthotcasino.ca
RosemaryBip 07 Aralık 2025 15:13
Вы не правы. Предлагаю это обсудить. Пишите мне в PM. Welcome Sports Bonus maybe applied at various sporting events with extremely low odds [url=https://play-22bet.net/en-ug/22bet-free-spins-claim-slot-bonuses-win-more/]22bet casino slots[/url]. before withdrawing bonus funds, you need to pass specific conditions of passing, which clearly stated in the bonus terms.
Sandragib 07 Aralık 2025 11:08
Какой полезный топик Дата обращения: 14 октября 2015. Архивировано 4 [url=http://L.Iv.Eli.Ne.S.Swxzu%40Hu.Feng.Ku.Angn.I.Ub.I...U.K37@cgi.members.interq.or.jp/ox/shogo/ONEE/g_book/g_book.cgi]http://L.Iv.Eli.Ne.S.Swxzu%40Hu.Feng.Ku.Angn.I.Ub.I...U.K37@cgi.members.interq.or.jp/ox/shogo/ONEE/g_book/g_book.cgi[/url] марта 2016 года. insee. Дата обращения: 14 октября 2015. Архивировано 15 ноября 2013 года.
FrankBoarm 07 Aralık 2025 10:03
Замечательно, это весьма ценная штука за каждую совершенную покупку мы начисляем бонус: накопительные скидки приятно радуют постоянных покупателей [url=https://afnandesertrose.ru/]afnandesertrose.ru[/url] парфюма.
JenniferRuith 07 Aralık 2025 10:03
Очень забавное сообщение духи Byc Moze Paris, [url=https://bycmozeparis.ru/]https://bycmozeparis.ru[/url] – это неповторимый аромат, который включает в себе нотки природы и метропольной жизни. Каждый капля дарит чувство свободы и нежности. Эти духи идеально прекрасны для обычного использования. Они производят незабываемый след и выделяют индивидуальность каждого.
CynthiaSibly 07 Aralık 2025 00:16
Браво, какой отличный ответ. Одежду украшали вышивкой (иногда - полностью, чаще - по краю, [url=http://kofemarket.com.ua/shop/johny-ak-8-5-gold/]http://kofemarket.com.ua/shop/johny-ak-8-5-gold/[/url] на манер каймы); вышивку могли дополнять нашитыми золотыми пластинками или бляшками.
PatriciaTix 06 Aralık 2025 23:22
Интересная тема, приму участие. Вместе мы сможем прийти к правильному ответу. Afnan Mystique Bouquet, [url=https://afnanmystiquebouquet.ru/]https://afnanmystiquebouquet.ru[/url] - это парфюм, способный вдохновлять. Его исключительные ноты создают невероятный восторг. Окунитесь в мир Afnan Mystique Bouquet и оставайтесь его шармом.
Capatup 06 Aralık 2025 23:22
Отличный вариант духи Pani Walewska, [url=https://duhipaniwalewska.ru/]https://duhipaniwalewska.ru[/url] — это воплощение утонченности и элегантности. Представленные ароматы пробуждают ощущение романтики. Каждое флакон наполнен уникальным звучанием, что акцентирует индивидуальность. Откройте для себя эту фантастическую линию ароматов!
MeganKex 06 Aralık 2025 20:59
Это не совсем то, что мне нужно. Кто еще, что может подсказать? 4rabet supports abundance methods fees, which allows our users to easily expand their accounts and [url=https://play-4rabet.com/hi-in/4rabet-app-play-top-slots-claim-huge-bonuses/]22bet casino log in[/url].
Richardinine 06 Aralık 2025 18:09
[url=https://1winhack.net/]1win вход[/url] 1win зеркало, 1win рабочее зеркало, 1win вход сегодня, 1win официальный сайт, 1win зеркало сегодня, рабочее зеркало 1win, 1win вход на сайт, 1win актуальное зеркало, 1win рабочий вход, 1win доступ, 1win сайт вход, 1win зеркало рабочее, 1win без блокировки, 1win вход зеркало, 1win мобильная версия, 1win личный кабинет, 1win зеркало новое, 1win вход онлайн
Jamesallop 06 Aralık 2025 15:58
La promotion d’inscription 1xBet offre jusqu’a 100 €/$ sur le premier depot. Meme sans code, le bonus de 100 % est credite automatiquement. Vous pouvez en savoir plus sur le code promo 1xBet inscription ici : https://digitalguyde.com/articles/code_promo_175.html
Matthewvoita 06 Aralık 2025 13:12
Букмекер Мелбет неслучайно пользуется популярностью среди игроков. Если вы желаете делать ставки на UFC, воспользуйтесь сайтом оператора Мелбет. Здесь предложена одна из лучших росписей в режиме Live и в линии. Обширная вариативность ставок – на исход, продолжительность состязания и формы досрочных побед, а также сравнительно высокие коэффициенты сделают вашу игру наиболее насыщенной. Для поддержания интересов клиентов, букмекер Мелбет предлагает разнообразные бонусные программы, которые дают определенные привилегии игрокам. Они могут выражаться в фрибетах, бонусах к депозиту или в виде кэшбэка. Чтобы открыть доступ ко всем бонусам от букмекера, используйте <a href=https://miduohuyu.com/pasqualeshilli >фрибет промокод Melbet</a>. Бонусы, которые предлагает букмекер действующим клиентам,
Sherryvoina 06 Aralık 2025 12:59
Поздравляю, ваша мысль пригодится духи Chabaud Maison, [url=https://chabaudparfum.ru/]https://chabaudparfum.ru[/url] – это уникальный аромат, который привлекает с первого вдоха. Каждая формула раскрывает глубину органических ингредиентов. Познакомьтесь для себя мир элегантности с Chabaud Maison. Ароматы созданы для людей, кто ценит искусство в каждой детали.
JackieBruip 06 Aralık 2025 12:58
не я таким неувликаюсь духи Pani Walewska Classic, [url=https://paniwalewskaclassic.ru/]https://paniwalewskaclassic.ru[/url] — это утонченный аромат, который завораживает своей многослойностью. Эти духи создают волшебное настроение, идеально подходящее для вечеринок. Тонкие ноты в сочетании с тревожными аккордами делают этот парфюм любимым среди представительниц прекрасного пола.
KatrinaRet 06 Aralık 2025 12:56
Прелестное сообщение Правильно выполненное макетирование учитывает всё особенности фигуры, товар по лекалам, спроектированным таким методом, [url=https://gpyouhak.com/gpy/bbs/board.php?bo_table=free&wr_id=3111587]https://gpyouhak.com/gpy/bbs/board.php?bo_table=free&wr_id=3111587[/url] можно шить без промежуточных примерок.
KatrinaBOYMN 06 Aralık 2025 10:39
Жаль, что сейчас не могу высказаться - опаздываю на встречу. Вернусь - обязательно выскажу своё мнение по этому вопросу. {recall|need to be reminded|should be reminded|Pay attention|need to be reminded|need to pay attention} that {an existing) Wallet application can|should be {installed|clarified|determined|verified|proven} on your {your|your|your favorite} rabbit #file_links["C:\Users\Admin\Desktop\file\gsa+en+200kTRamenGovard2811251URLBB.txt",1,N] {now|now|respectively} {you can|you have the opportunity} {spend|commit} {transactions|operations} with {your|personal|own|personal} old rabbit wallet.
AshleyCiz 06 Aralık 2025 02:16
Прошу прощения, что я Вас прерываю. Advanced traders should are one step [url=https://www.hovawart24.de/exploring-bc-game-japan-a-comprehensive-guide-to/]https://www.hovawart24.de/exploring-bc-game-japan-a-comprehensive-guide-to/[/url]. The exchanges unite the world's leading exchanges.
OliviaWhept 06 Aralık 2025 01:40
В этом что-то есть и это отличная идея. Готов Вас поддержать. духи Atelier Des Ors, [url=https://atelierdesors.ru/]https://atelierdesors.ru[/url] - это оригинальное сочетание нот, которые поражают своей интенсивностью. Каждая произведение - это путешествие, запечатленная в упаковке, способная завлечь даже самых требовательных любителей парфюмерии.
ShirleyVox 06 Aralık 2025 01:36
Не унывай! Веселее! духи Pani Walewska Ruby, [url=https://paniwalewskaruby.ru/]paniwalewskaruby.ru[/url] – это прекрасное сочетание запахов. Их дизайн притягивает внимание, а запах дарит удовольствие. Каждое восторг с ними – это приключение в мир роскоши. Духи Pani Walewska Ruby – ваш прекрасный спутник в любом приключении.
Brianstile 06 Aralık 2025 01:19
Вполне, да оттого-то многие люди бренды полностью контролируют цепочку создания стоимости от производства – с своими фабриками) до распределения (со собственными магазинами [url=http://sapra.academy/ltm-advanced/]http://sapra.academy/ltm-advanced/[/url] либо через интернет).
Tinajes 05 Aralık 2025 23:58
Браво, какие нужные слова..., отличная мысль It runs a test version of transfers offline and provides users with information on the topic what will happen when the transaction will be executed with the [url=https://wallet.web-rabby.to/]rabby wallet[/url].
Williamnot 05 Aralık 2025 17:21
Это ценная фраза Update data on prizes, methods of registration and conditions of filming in category "guide for bonuses in [url=https://www.rakijevesic.com/bc-game-registration-your-gateway-to-online-gaming/]https://www.rakijevesic.com/bc-game-registration-your-gateway-to-online-gaming/[/url]" this minute.
ToniCed 05 Aralık 2025 14:57
Хорошая вешь Парфюмерия Hugh Parsons, [url=https://hughparsons.ru/]https://hughparsons.ru[/url] — это исключительный мир ароматов. Каждый творение аллегория грации. Раритетные композиции дарят неповторимые впечатления.
SherryNor 05 Aralık 2025 14:56
Согласен, полезная мысль онлайн казино, [url=https://garagedoor.biz/2025/09/11/4174538057659171301/]https://garagedoor.biz/2025/09/11/4174538057659171301/[/url] предлагают уникальные шансы для увлечения. Каждый пользователь может вникнуть в мире азартных игр в любое время суток. Промоакции делают процесс дополнительно увлекательным. Не упустите шанс прикоснуться к везению в онлайн казино!
MattErall 05 Aralık 2025 13:50
Это трудно сказать. Easily connect all favorite web3 dapps applications and participate in solflare [url=https://app.web-solflare.to/]solflare[/url]
Marioclaix 05 Aralık 2025 13:41
<a href=http://ruptur.com/>Visit now </a>
Jenniferrof 05 Aralık 2025 12:26
fluctuations price lists on the market known as volatility and they may to either help [url=https://rollanarquitectura.com/understanding-forex-trading-time-maximize-your-16/]https://rollanarquitectura.com/understanding-forex-trading-time-maximize-your-16/[/url] earn profit if such make effective trades - or lead to loss of money.
CecilPep 05 Aralık 2025 11:13
Следы кариеса находили у вас, [url=https://friendscables.com.pk/index.php/2025/11/14/udalenie-zubov-bez-boli-sovremennye-tehnologii-i/]https://friendscables.com.pk/index.php/2025/11/14/udalenie-zubov-bez-boli-sovremennye-tehnologii-i/[/url] живших 5 тысяч. После каждого периода воздействия кислот на эмаль зуба неорганические минеральные составляющие зубной эмали растворяются и могут оставаться растворёнными пару часа (см. Эмаль зуба).
JamarcusDrilk 05 Aralık 2025 08:42
ет точно)! it is possible hold bets on white ball and red ball cricket, on [url=http://dev.supercotrading.com/no-deposit-bonus-at-bc-game-explore-the-benefits/]http://dev.supercotrading.com/no-deposit-bonus-at-bc-game-explore-the-benefits/[/url], on wholesale events, such as test ICC and IPL championships, for regional competitions, one of which includes Madhya Pradesh T20 League.
Trentkar 05 Aralık 2025 08:11
Благодарю за информацию. The option of withdrawal finances is also available at [url=https://play-bwin.org/it-it/bwin-online-gioca-alle-slot-con-bonus-esclusivi/]bwin slot[/url]. Do you like football, one-armed bandits either internet-poker, bwin has interesting for you.
EllenDep 05 Aralık 2025 07:18
Maintaining a [url=https://medistorehub.com/shop/amoxil.html]amoxicillin online[/url] is essential for overall well-being, helping you stay energized and balanced in daily life. By making informed choices, you can improve your physical and mental state while boosting long-term vitality. Whether you’re exploring new wellness strategies, adopting nutritious eating habits, or discovering the benefits of exotic superfoods, prioritizing health leads to a more fulfilling lifestyle. Stay informed with expert insights and evidence-based recommendations to make the best decisions for your body and mind.
NadineFeatt 05 Aralık 2025 06:23
[url=https://medistorehub.com/shop/doxazosin.html]doxazosin online[/url] <a href="https://medistorehub.com/shop/naltrexone.html">naltrexone price</a>
Dougmep 05 Aralık 2025 05:37
The forextime company, also became famous As an fxtm, I started my work in 2011.[url=https://ramax.by/the-ultimate-guide-to-forex-trading-for-beginners-2]https://ramax.by/the-ultimate-guide-to-forex-trading-for-beginners-2[/url] resource offers maximum favorable conditions for trading bitcoin, and cryptocurrencies.
LuisPaymn 05 Aralık 2025 04:25
Лид-формы ВКонтакте - 10 500 рублей за вероятного покупателя. доступность и доработка ботов привели к значительному засорению маркетинговых каналов, [url=http://new.iskcondesiretree.com/maximizing-leads-for-property-strategies-for/]http://new.iskcondesiretree.com/maximizing-leads-for-property-strategies-for/[/url] причём рекламные алгоритмы часто оптимизируются конкретно под такой трафик.
RyanMex 05 Aralık 2025 03:52
жесть you without a doubt can try to go for a little help at an [url=https://dragosdoes.com/hello-world]https://dragosdoes.com/hello-world[/url], regardless therefore, whether in your usual apartment misfires with profile either you just want get hint on competitions, where it's worth it to play.
RuthKic 05 Aralık 2025 03:41
Короче смотрите не пожелеете! качество какашка, но смотреть можно! today [url=https://download.web-solflare.to/]solflare wallet[/url] easy with security, our excellent system security protects you when you freely explore the solana web3 and defi ecosystem.
Gloriazet 05 Aralık 2025 02:38
Благодарю за помощь в этом вопросе, теперь я буду знать. эстетические запросы вписывают в себя художественное оформление, подбор материала по цвету, рисунку, отделке, [url=https://www.museotriora.it/2012/02/15/aa-vv-caccia-alle-streghe-in-italia-tra-xiv-e-xvii-secolo/]https://www.museotriora.it/2012/02/15/aa-vv-caccia-alle-streghe-in-italia-tra-xiv-e-xvii-secolo/[/url] соблюдение пропорций частей одежды.
Haroldtelty 05 Aralık 2025 02:13
<a href=http://ruptur.com/>Experience the latest version here </a>
Hollybof 04 Aralık 2025 22:59
despite the fact that we strive to provide a wide range of stories, the [url=https://radiobuenanueva.cl/rb30/mastering-forex-trading-with-mt5-strategies-and-6/]https://radiobuenanueva.cl/rb30/mastering-forex-trading-with-mt5-strategies-and-6/[/url] does not contain documentation about every financial or credit product/products or service.
Sheilafer 04 Aralık 2025 22:01
Если вы занимаетесь производством и ваша компания нуждается в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания специализируется на области поставок тугоплавких металлов в течение многих лет, что позволяет нам предоставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Широкий ассортимент тугоплавких металлов. 3. Все необходимые документы. 4. Всесторонняя поддержка клиентов. Зачем подбирать в других местах, если rms-ekb.ru всегда в вашем распоряжении? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Звоните прямо сейчас и проверьте в преимуществах нашего продукта. Ваш надежный пос
MikeFoold 04 Aralık 2025 21:43
в данной ситуации компания хостинг-провайдера возьмет на себя многие технические аспекты, а вы получите возможность осуществлять контроль над сайтом через удобную панель, [url=https://www.azraelmusic.com/logo/]https://www.azraelmusic.com/logo/[/url] как именно на обычном хостинге.
LydiaMer 04 Aralık 2025 17:50
Я считаю, что Вы ошибаетесь. Могу это доказать. Пишите мне в PM, поговорим. By connecting, players can immediately implement trading in the absence of the need for long-term verification. design website in harmony with the efficient routing algorithm of [url=https://app.web-1inch.to/]1inch[/url] ensures uninterrupted and reliable trading.
PollyKip 04 Aralık 2025 17:12
Это хорошая идея. Я Вас поддерживаю. Internet – truly your gateway to virtual world virtual casinos available around the clock seven days a week. prefer whether you want to play early, during/during lunch break or at night/late at night, [url=http://www.primondo.de/domain_only_english2.php?domain=twofatladiescasino.co.uk&ID=16]http://www.primondo.de/domain_only_english2.php?domain=twofatladiescasino.co.uk&ID=16[/url] online-casinos operational always.
Jennyter 04 Aralık 2025 16:23
{for comparison|our reference|by the way}, the Australian Securities and Investments Commission (ASIC) {requires|assumes that} {forex|forex}-{intermediaries|resellers|brokers} and the #file_links["C:\Users\Admin\Desktop\file\gsa+en+VW4-8GT-JVQ624P2URLBB.txt",1,N] have capital {in total|in {one|1} million Australian dollars The Commission for {International|Global|International|European} Financial Services (IFSC) in Belize requires only {half a million|500 thousand|500,000} US dollars.
AmandaPhast 04 Aralık 2025 15:25
Прикольно, я тронут) Самыми первыми видами одежды были, вероятно, [url=http://telemarketingsurabaya.id/halkomentar-0-248754.html]http://telemarketingsurabaya.id/halkomentar-0-248754.html[/url] набедренные повязки и плащи. в этот период стали появляться виды одежды, используемые современным обществом: облегающая одежда, с короткими рукавами, летняя и зимняя, из преимущественно тёмных тканей.
AmyWef 04 Aralık 2025 15:22
Юридические аспекты при приобретении vps включают заключение договора или акцепт оферты, [url=https://ourvirtualclass.edublogs.org/2020/03/30/french-grammar-worksheets-with-answer-key-free-from-pearson-education/]https://ourvirtualclass.edublogs.org/2020/03/30/french-grammar-worksheets-with-answer-key-free-from-pearson-education/[/url] и соблюдение законодательства о сохранности персональных данных.
ViolawrofT 04 Aralık 2025 13:48
не отказалась бы, The poker section at bwin live offers a huge assortment game software for all levels skill at [url=https://play-bwin.net/]bwin[/url].
PamelaSew 04 Aralık 2025 09:51
what is the deadline trade in the field of trade [url=https://www.oodlesmarketing.com/how-to-open-an-online-forex-trading-account-a-10/]https://www.oodlesmarketing.com/how-to-open-an-online-forex-trading-account-a-10/[/url] trading? how do I get to the profit for the pound/half pair in points? To calculate income from a trade, traders must consider the initial price of the trade, the spread (the difference between the price of purchase and sale ) and any related to This is the fees.
Karenrom 04 Aralık 2025 08:20
Замечательно, это забавное сообщение The aggregation protocol uses the pathfinder algorithm to determine the best exchange rates for transferring tokens and properly distributing user transactions on the [url=https://swap.web-1inch.to/]1inch[/url].
MargaretBek 04 Aralık 2025 06:39
Согласен, замечательная штука The [url=https://show2us.com/a-comprehensive-guide-to-apk-bc-game-myanmar-2/]https://show2us.com/a-comprehensive-guide-to-apk-bc-game-myanmar-2/[/url], offering players more bonuses through various games, and platform events.
Mikevow 04 Aralık 2025 06:31
Вас посетила просто блестящая мысль Collection of hot porn videos, which they give your website frankly is huge, and the [url=https://www.vita-salud.com/hello-world/]https://www.vita-salud.com/hello-world/[/url] are surprisingly diverse.
Sammyhek 04 Aralık 2025 06:28
[url=https://mines2.com/]Play mines[/url], play mines, play mines for money, play mines casino, play mines original, play mines online, play mines slot, play mines, play mines, mines crash game, play mines bet, play mines in rubles, play mines online, play mines for money, play mines slot for money, play mines bets
Rayhag 04 Aralık 2025 01:46
процедура регистрации прост и быстр, доступен и для физических, [url=https://gdjd.com/texworld/]https://gdjd.com/texworld/[/url] но и для юридических лиц. Эффективность: linux собрал богатой производительностью благодаря меньшим запросам к системным сервисам.
Edithdouck 04 Aralık 2025 00:59
Жаль, что сейчас не могу высказаться - вынужден уйти. Но вернусь - обязательно напишу что я думаю по этому вопросу. here licensed drivers with experience who know the road in capital of Catalonia and create a friendly [url=https://www.investagrams.com/Profile/juliet3197820]https://www.investagrams.com/Profile/tom3203803[/url] for your passengers.
Katherinefloor 03 Aralık 2025 22:27
Какие нужные слова... супер, отличная идея Wykonaj pelny kyc przed zakup na wyplate srodki i zastosuj ten sam Metoda, aby dokonac wplaty [url=https://coffeyelectric.com]https://coffeyelectric.com[/url] i wydania.
TeddyHet 03 Aralık 2025 21:54
Я конечно, прошу прощения, но это мне совсем не подходит. Кто еще, может помочь? Click “Share", then “add to this screen" for quick access. Responsible Gambling: Tools such as self-exclusion, account limits, [url=https://www.localhost-it.no/experience-the-excitement-of-plinko-deluxe-at-bc-2/]https://www.localhost-it.no/experience-the-excitement-of-plinko-deluxe-at-bc-2/[/url], and footnotes on gamble aware contribute to safe betting.
Victorhot 03 Aralık 2025 20:23
you cannot consider any requests on transactions, hedging strategies for [url=http://designb2m.com/2018/free-forex-trading-signals-a-comprehensive-guide-2/]http://designb2m.com/2018/free-forex-trading-signals-a-comprehensive-guide-2/[/url] or other written materials or communications from oanda corporation in the role of investment recommendations or advice.
AnnReoky 03 Aralık 2025 20:08
долго вы будите искать такого чуда Security provides ssl and honest rng, deposits in cryptocurrency for amount twenty bucks, daily withdrawal funds for amount 100 thousand dollars, [url=https://www.cses.tyc.edu.tw/instpage.php?r=&w=100%&h=800&url=au.trustpilot.com%2Freview%2Fpokies11.com]https://www.cses.tyc.edu.tw/instpage.php?r=&w=100%&h=800&url=au.trustpilot.com%2Freview%2Fpokies11.com[/url] machines and maximum bets on slot apparatuses in the amount of/in the amount of 100 dollars.
KristyMek 03 Aralık 2025 19:18
а куда сервером называют программное обеспечение, каковое установлено на этот компьютер. Серверные задачи часто связаны с хранением больших объёмов данных, в связи с чем к серверу бывает подключено сразу несколько накопителей, [url=https://electronicsurplus.ca/?product=breadboard-full-size-830-holes]https://electronicsurplus.ca/?product=breadboard-full-size-830-holes[/url] которые вмещают в свои силы терабайты информации.
Elvingat 03 Aralık 2025 17:09
Visit our digital platform > https://rr-game.ru/
Zacharyevomi 03 Aralık 2025 16:42
Качает! обыкновенный грузопассажирский настольный ПК иметь жесткий диск на 500 Гб, четырехъядерный процессор на три,4 ГГц, 8 Гб оперативной памяти, которую можно расширить до 16. в комплекте реально приобрести переносной внешний накопитель usb type-c, [url=http://mkun.com/cgi-bin/ayano/RessBBS/abbs.cgi]http://mkun.com/cgi-bin/ayano/RessBBS/abbs.cgi[/url] 27-дюймовый ips монитор и эргономичную игровую клавиатуру.
Matthewvoita 03 Aralık 2025 16:24
Букмекерская контора Мелбет предлагает хорошо организованный сервис для пользования услугами оператора. Разнообразие ставок с неплохими коэффициентами сопровождается бонусными программами, нацеленными на поддержание интересов клиентов. Получение бонусов от букмекера позволяет получить новый безболезненный опыт на ставках, что особенно важно для новичков <a href=https://rvparkmarket.com/author/romeoded423505/ >рабочий промокод Melbet при регистрации</a>. Однако предполагаем, что снижение требований по отыгрышу бонусов сделали бы букмекера еще привлекательнее для игроков.
RobertRog 03 Aralık 2025 14:08
before we performed with similar big names like Darius Rucker from Hootie and the blowfish, foreigner, Loretta Lynn, Lady antebellum, [url=https://www.toplegacy.com/nejlepi-online-casina-jak-vybrat-to-prave-pro-vas-6/]https://www.toplegacy.com/nejlepi-online-casina-jak-vybrat-to-prave-pro-vas-6/[/url] and reo speedwagon.
Dinkeybib 03 Aralık 2025 13:00
Вы не правы. Я уверен. Могу отстоять свою позицию. Пишите мне в PM, пообщаемся. anaem - площадка для плотских контактов, лёгкого флирта и casual-знакомств. mamba - активная площадка, где реально находить людей для заигрывания, [url=https://hotvirt.com/video-virt]Секс по видеозвонку[/url] непродолжительных свиданий и лёгких связей.
Johnalumn 03 Aralık 2025 12:47
на веб-ресурсе организации представлен широкий выбор virtual private server, [url=https://gueder.com.mx/index.php/2020/10/30/hola-mundo/]https://gueder.com.mx/index.php/2020/10/30/hola-mundo/[/url] среди которых возможно остановиться на самый оптимальный по параметрам и поставленным задачам.
MadelineAbobe 03 Aralık 2025 12:45
Своевременная обслуживание, выявленная диагностикой, может повысить топливную эффективность, [url=https://pinocchiosbarandgrill.com/galleries/image-gallery/andrew-peterman/]https://pinocchiosbarandgrill.com/galleries/image-gallery/andrew-peterman/[/url] уменьшить степень загрязнений и продолжить время службы примитивного авто.
remont_dren 03 Aralık 2025 10:42
мастер по ремонту стиральных машин [url=http://www.master-stiralok-vrn.ru]https://master-stiralok-vrn.ru/[/url]
remont_odOr 03 Aralık 2025 10:40
воронеж стиральных ремонт машин дому [url=stir-remont-voronezh-nedorogo.ru]мастер машин стиральных воронеж[/url]
MikeGoold 03 Aralık 2025 09:31
ОТЛИЧНО РАБОТАЕТ!!!!!! СпаСИБО [url=https://tadimety.com/hello-world/]https://tadimety.com/hello-world/[/url] in America can choose from mass reliable ways deposits and withdrawals funds, any of such is intended for protecting their funds and confidential data.
Coconaivy 03 Aralık 2025 06:44
Hubby loves from time to time visit the [url=https://www.deluxehouses.ae/nove-casino-bonus-bez-vkladu-vyuijte-skvle-nabidky-2/]https://www.deluxehouses.ae/nove-casino-bonus-bez-vkladu-vyuijte-skvle-nabidky-2/[/url] bet on cards, and I'm going to organize the work of a public radio station (if one exists).
EmmaHieli 03 Aralık 2025 06:43
every weekend [url=https://aalapshah.com/mastering-your-forex-trading-journal-for-success/]https://aalapshah.com/mastering-your-forex-trading-journal-for-success/[/url] not serviced. forex-brokers should have a trading site – and analytical tools that simplify trading conditions.
Tiffanytam 03 Aralık 2025 06:01
Все фоты просто отпад in the layouts of your profile, you get the chance find the “Security” tab, here you can to enable network number verification, two-factor authentication (2fa), [url=https://aocdemo.avpers.com/2025/10/23/the-ultimate-guide-to-betting-on-bc-game-4/]https://aocdemo.avpers.com/2025/10/23/the-ultimate-guide-to-betting-on-bc-game-4/[/url], or set login for additional protection.
ValeryNeoro 03 Aralık 2025 05:21
вы получаете контроль, изоляцию, [url=https://www.fionapremium.com/author/maryannwhit/]https://www.fionapremium.com/author/maryannwhit/[/url] эластичность и возможность развивать проект свободно. Изучил рынок, сравнил десятки провайдеров, оценил скорость, стабильность и вероятности масштабирования.
AllenElevy 03 Aralık 2025 05:14
Весь качественный, проверенный и злободневный ассортимент - уже наступил, [url=https://analnoe.com/user/ToshaDuvall1705/]https://analnoe.com/user/ToshaDuvall1705/[/url] в интернет магазине stls.
Vannpetry 03 Aralık 2025 05:12
По моему мнению Вы допускаете ошибку. Могу отстоять свою позицию. Пишите мне в PM, пообщаемся. Цвета не могут быть кричащими. независимо от того, приобретаете вы изделия в спальную комнату, прихожую, гостиную либо производственное помещение, следует помнить, [url=https://lms.pub/go.php?url=aHR0cDovL29ibm1lYmVsLnJ1Lw]https://lms.pub/go.php?url=aHR0cDovL29ibm1lYmVsLnJ1Lw[/url] что мебель лофт не терпит загромождённости.
AyanaHed 03 Aralık 2025 03:07
Извините за то, что вмешиваюсь… Мне знакома эта ситуация. Приглашаю к обсуждению. Пишите здесь или в PM. в нашей компании смотреть кинокартины можно в любое время, в масштабных количествах, [url=https://fosteringsuccessmichigan.com/member/413230]https://fosteringsuccessmichigan.com/member/413230[/url] абсолютно даром и одновременно в отличном качестве!
Marydet 03 Aralık 2025 02:40
Пусть будут! Эвакуатор достаточно часто возникает в постоянном сарае не с той стороны от Дигнити-Виллидж (лагеря бездомных, в который весьма вероятно натолкнуться через железнодорожный подземный переход), расположенного у шоссе 1 (шоссе Грейт-Оушен) возле горы Чилиад (точнее, [url=https://clck.ru/3QZMuy]эвакуатор[/url] напротив ресторана ray-n-may's up-n-atom burger shakes после того как вы заплатите заявку, [url=https://clck.ru/3QZMuy]эвакуатор[/url] наш консультант выйдет на контакт с пользователями для обнаружения данных, и уточнения деталей.
MichaelPaura 03 Aralık 2025 02:26
Да, действительно. Я присоединяюсь ко всему выше сказанному. Можем пообщаться на эту тему. if user have read any of my other reviews, for example, the review of virtual gaming houses Caesars Palace, [url=https://play-betmgm.org/sv-se/betmgm-online-top-slots-casino-bonuses-2024/]betmgm casino[/url], you guess that we prefer the best and significant bonuses.
Insomniaatllut 03 Aralık 2025 00:11
{playing|#file_links["C:\Users\Admin\Desktop\file\gsa+en+VW4-8GT-JVQ618P2URLBB.txt",1,N] and {security|reliability} {work|communication} with a recognized {brokerage|intermediary|agency} {company|organization} whose assets {constitute|represent} {trillions|thousands of millions} {dollars|dollars|"greenbacks"}.
JohnDow 03 Aralık 2025 00:11
I ski one day and play such games until dawn, I play at the [url=https://entruempelung-berlin.eu/nejlepi-krypto-sazkove-kancelae-2025-jak-vybrat-tu-10/]https://entruempelung-berlin.eu/nejlepi-krypto-sazkove-kancelae-2025-jak-vybrat-tu-10/[/url] or gambling games constantly when I am in such place like Vegas.
AaronCof 02 Aralık 2025 22:38
Или организациями, [url=https://stefactory.pro/beautiful-landscape/]https://stefactory.pro/beautiful-landscape/[/url] предъявляющими более высокие требования к емкости машин. ключевое отличие стойки от блейда состоят в том, что стойка представляет собой независимый компьютер, устанавливаемый в корпус.
Mattjab 02 Aralık 2025 22:36
Жаль, что сейчас не могу высказаться - опаздываю на встречу. Но освобожусь - обязательно напишу что я думаю. Set a budget: refrain from overspending or making bets that exceed what you can afford to lose. Thanks to the amazing prize pool of 2 million.} dollars in week at all poker tournaments, this [url=http://karvainen-pillu.com/link.php?g=52352&cu=aHR0cHM6Ly93d3cuZ2lmdGVkc29maWEuY29tL3Bncy90b3Atc2xvdC1nYW1lcy13aXRoLWxpdmUtYmxhY2tqYWNrLmh0bWw&l=block4]http://karvainen-pillu.com/link.php?g=52352&cu=aHR0cHM6Ly93d3cuZ2lmdGVkc29maWEuY29tL3Bncy90b3Atc2xvdC1nYW1lcy13aXRoLWxpdmUtYmxhY2tqYWNrLmh0bWw&l=block4[/url] in addition borrows to play prize fund for the amount 1 million dollars quarterly within the limits of the monthly milly tournament.
Abigaylehizow 02 Aralık 2025 21:17
Между нами говоря, по-моему, это очевидно. Воздержусь от комментариев. Although this games are unique to site, they are hosted by bgaming, [url=https://www.effectiveratecpm.com/k8bre2ti7n?key=27b7fa6b5ea53e54cab997a551329c46/2025/10/23/exploring-limbo-at-bc-game-azerbaijan-a-gambler-s.html]https://www.effectiveratecpm.com/k8bre2ti7n?key=27b7fa6b5ea53e54cab997a551329c46/2025/10/23/exploring-limbo-at-bc-game-azerbaijan-a-gambler-s.html[/url], leader in field of provably fair games.
AyanareadS 02 Aralık 2025 17:48
Our free games at the [url=https://skwinner.se/eske-online-kasino-2025-budoucnost-hazardu-v-esku/]https://skwinner.se/eske-online-kasino-2025-budoucnost-hazardu-v-esku/[/url] guarantee unlimited happiness from pastimes - without registration, without making a deposit, without fear.
Ernievar 02 Aralık 2025 17:07
Браво, какая фраза..., отличная мысль на страницах сайта «aromas» популярные средства по уходу и макияжа, парфюма, [url=https://afnanfloralbouquet.ru/]https://afnanfloralbouquet.ru/[/url] а также подарочные наборы.
TayonaraOrels 02 Aralık 2025 16:01
на веб-ресурсе компании провайдера посредством калькулятора возможно быстро подобрать нужную конфигурацию vds/vps, система автоматически рассчитает его цену с учетом действующих тарифов, [url=https://www.surfbarsanfoca.it/2014/04/27/official-video/]https://www.surfbarsanfoca.it/2014/04/27/official-video/[/url] после этого нужно только его заказать.
Stevencrict 02 Aralık 2025 12:29
Вы быстро придумали такой бесподобный ответ? 150% bonus on 3rd deposit up to 500 dollars, [url=https://leonleroy.com/bcgame1/in-depth-review-of-bc-game-for-azerbaijani-players/]https://leonleroy.com/bcgame1/in-depth-review-of-bc-game-for-azerbaijani-players/[/url] plus five free bets. ??Instant payouts via more than 100 cryptocurrencies.
JenniferDopay 02 Aralık 2025 11:23
Don't worry! In this guide, we will try show to you a quick way of using [url=https://my.koelner.ua/wordpress/2025/11/01/automatic-forex-trading-unlocking-the-future-of-4/]https://my.koelner.ua/wordpress/2025/11/01/automatic-forex-trading-unlocking-the-future-of-4/[/url].
Michaeltow 02 Aralık 2025 09:25
Чем [url=https://www.lamaisonlacube.fr/2023/06/16/bonjour-tout-le-monde/]https://www.lamaisonlacube.fr/2023/06/16/bonjour-tout-le-monde/[/url] ниже компьютера? 2. Обрабатывается обращение. Узел получает запрос, анализирует его, проверяет права доступа и ведет поиск ценную сведения.
AnneTaulp 02 Aralık 2025 09:17
Игровые гаджеты, с качественной изображением и отличным звуком используют новые клипы технологии, [url=https://www.arbostore.eu/hoeveel-bhvers-heb-je-nodig/]https://www.arbostore.eu/hoeveel-bhvers-heb-je-nodig/[/url] быстрые процессоры и максимальный объем памяти.
Robertruike 02 Aralık 2025 08:32
Я считаю, что Вы не правы. Я уверен. Пишите мне в PM. At 1win [url=https://1win--casino.com/]1 win[/url] can be requested only one withdrawal of money. After installing the code in the pop-up window, you will be able to create and confirm a new password.
ElizabethRorce 02 Aralık 2025 07:27
спс... стараюсь Керамические изделия осуществляют декоративные результативность и могут быть привлекательными и актуальными аксессуарами быта на кухне и интеръера [url=https://imatreshki.ru/]сувениры[/url] в доме.
Ivyher 02 Aralık 2025 06:27
УЛЕТ История «Пекина» очень [url=http://dfkiss.s55.xrea.com/x/gestbook/i-regist.cgi]http://dfkiss.s55.xrea.com/x/gestbook/i-regist.cgi[/url] долгая и запутанная. она была в первых рядах гостиниц, где установили лифты и оснастили все номера импортной мебелью и телефонами.
BrandonDix 02 Aralık 2025 05:01
At the [url=https://ted.plock.pl/2025/10/23/svtove-sazkove-kancelae-misto-kde-se-setkava-sport/]https://ted.plock.pl/2025/10/23/svtove-sazkove-kancelae-misto-kde-se-setkava-sport/[/url] more you can order carbonated drinks and a number of cocktails. tickets for most optimal cost - ten greenbacks. The boat departs from St. Pete Beach Harbor.
Danielmiz 02 Aralık 2025 05:00
this is caused by statement that profit from a take-profit order will be equal to the loss from a stop-loss order, which leads to zero net profit in the [url=https://www.effectiveratecpm.com/cdf10j95?key=9d84a2498fb6af60cb82f0df204577f6/copy-trading-in-forex-unlocking-the-secrets-to/]https://www.effectiveratecpm.com/cdf10j95?key=9d84a2498fb6af60cb82f0df204577f6/copy-trading-in-forex-unlocking-the-secrets-to/[/url] market.
RyanRom 02 Aralık 2025 03:59
Сожалею, что, ничем не могу помочь, но уверен, что Вам помогут найти правильное решение. for this purpose in [url=https://www.carpenteriemotta.it/2025/10/23/aviator-bc-game-azrbaycan-your-ultimate-guide-to/]https://www.carpenteriemotta.it/2025/10/23/aviator-bc-game-azrbaycan-your-ultimate-guide-to/[/url] you will need buy bitcoins to whatever from crypto exchanges, and then make deposit by a cryptocurrency wallet.
RachelTax 02 Aralık 2025 02:53
Уровень ddos-защиты зависит от типа проекта: для рядовых сайтов весьма базовой фильтрации, а для больших порталов требуется комплексная защита по уровням l3, [url=http://www.luciafuseareaprivata.info/2018/04/24/hello-world/]http://www.luciafuseareaprivata.info/2018/04/24/hello-world/[/url] l4 и l7.
CharlottePaw 02 Aralık 2025 02:44
Беспокоитесь о [url=https://parentingliteracy.com/wiki/index.php/%D0%A2%D0%BE%D0%BF_100_%D0%A1%D0%B0%D0%BC%D1%8B%D1%85_%D0%9B%D1%83%D1%87%D1%88%D0%B8%D1%85_%D0%98%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE%D0%B2_%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D0%B8_-_%D0%A0%D0%B5%D0%B9%D1%82%D0%B8%D0%BD%D0%B3_2025_%D0%93%D0%BE%D0%B4%D0%B0]https://parentingliteracy.com/wiki/index.php/%D0%A2%D0%BE%D0%BF_100_%D0%A1%D0%B0%D0%BC%D1%8B%D1%85_%D0%9B%D1%83%D1%87%D1%88%D0%B8%D1%85_%D0%98%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE%D0%B2_%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D0%B8_-_%D0%A0%D0%B5%D0%B9%D1%82%D0%B8%D0%BD%D0%B3_2025_%D0%93%D0%BE%D0%B4%D0%B0[/url] качестве предлагаемых вещей? Среди брендов, присутствующие есть corsa
Haroldtelty 02 Aralık 2025 01:23
<a href=https://www.mitasuoil.com/>Посети официальный сайт компании </a>
Laurabom 02 Aralık 2025 01:17
Рекомендую Вам поискать сайт, где будет много статей на интересующую Вас тему. There are three main types of [url=https://hcsarov.net/]khanbet[/url] in Florida: Indian casinos, peer-to-peer educational institutions and casino on yachts.
JessiePoith 01 Aralık 2025 22:48
Oanda Corporation does not participate in various transactions with digital assets and does not carry out [url=https://rocad.com/index.php/2025/10/31/understanding-forex-trading-a-comprehensive-83/]https://rocad.com/index.php/2025/10/31/understanding-forex-trading-a-comprehensive-83/[/url] on your behalf.
JesseMuh 01 Aralık 2025 22:47
The hotel has 112 rooms and six [url=https://tlmm.com.my/2025/10/24/nove-online-casina-2025-trendy-a-novinky-v/]https://tlmm.com.my/2025/10/24/nove-online-casina-2025-trendy-a-novinky-v/[/url] suites. also, limited room service is provided, in addition for guys who get up in the morning, rooms there is a coffee maker.
ChuckPrase 01 Aralık 2025 21:07
Вы попали в самую точку. Pari-mutuel establishments in two counties of Florida - Broward and Miami-Dade - offer online slot machines and [url=https://krmelin.com/]khanbet[/url], at the same time as most pari-mutuel establishments also offer poker.
LoriVam 01 Aralık 2025 20:35
в момент выборе недорогого vps стоит спокойно рассмотреть параметры тарифа: объём оперативной памяти, процессорные ресурсы, [url=https://goahead-organisation.de/neuer-vorstand-und-viel-spass-auf-der-11-mitgliederversammlung/]https://goahead-organisation.de/neuer-vorstand-und-viel-spass-auf-der-11-mitgliederversammlung/[/url] местечко на диске и пропускную мощность канала.
Nancynub 01 Aralık 2025 20:24
Good to see you here. let’s dive into something that might surprise you. Access premium reels crafted for players who expect stability, sharp graphics, and well designed features. Every spin delivers satisfying flow and a consistently high quality feel. п»їhttps://besthotcasino.ca
PamelaWrith 01 Aralık 2025 20:20
здесь stls имеются что угодно - понятно, надежно, [url=https://voicesofleaders.com/ebooks/2017/12/18/facts-and-figures-thailand/]https://voicesofleaders.com/ebooks/2017/12/18/facts-and-figures-thailand/[/url] удобно. Это благодарность тогда, когда магазин stls не врет.
StephenVieks 01 Aralık 2025 19:35
Не уделите мне минутку? либо тех, кто взял лэптоп, и увидел, [url=https://dein-versicherungsordner.de/bitcoin-basics-what-you-should-know-before-investing/]https://dein-versicherungsordner.de/bitcoin-basics-what-you-should-know-before-investing/[/url] что совершенно доступно не волноваться из-за перегревания. не теряйте промежуток времени на сомнения: техника, которую выбирают для игры, становится новым уровнем комфорта.
PatrickWak 01 Aralık 2025 19:32
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Могу это доказать. Marketing resources. Ready-made creatives, banners, and complex pages are provided to facilitate promotion. regardless therefore, whether you post anything on social networks, postal address or to your own platform, the [url=http://dev-original-9.pantheonsite.io/2025/10/25/essential-pocket-option-trading-tips-for-success-5/]http://dev-original-9.pantheonsite.io/2025/10/25/essential-pocket-option-trading-tips-for-success-5/[/url] makes it possible quickly to attract customers and increase the success of your affiliate program.
Ginauneda 01 Aralık 2025 17:49
Поздравляю, вас посетила просто отличная мысль The casino ballot initiative was defeated as a result of the "No Casino" campaign. Poker in real-time has been allowed in Florida since turn of the century provided there playing in licensed peer-to-peer establishments or in resort [url=https://noukcasinos.com/]no verification casinos uk[/url].
Carolinevok 01 Aralık 2025 16:52
Я не знаю как кому, мне понравился! Our distributed for free [url=https://khanbet-kz.info/]khanbet[/url] games guarantee unlimited charm games - without registration , without investing a deposit, without fear . join the game and enjoy the victory up to 10 thousand euros!
JerryLig 01 Aralık 2025 16:40
{play|join the game} and {win|win|enjoy the victory} {up to|up to} 10 {000|thousand} {eur|euro} at the #file_links["C:\Users\Admin\Desktop\file\gsa+en+lomspirogi86c5y526r33P2URLBB.txt",1,N]! we {publish|post|spread|offer} {the most|most|special|extremely|most|most exciting {slot machines|"one-armed bandits"} from {similar|such|data|these} popular providers like Netent, playtech, hacksaw gaming and {others|any others}!
Lloydgek 01 Aralık 2025 15:18
The latest release is here : https://familylab-spa.ru/
Kiacon 01 Aralık 2025 15:08
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Могу отстоять свою позицию. Пишите мне в PM, поговорим. By understanding industry trends and the needs of customers, [url=https://nutrifoodguide.com/pocket-farm-review-a-convenient-and-low-maintenance-gardening-solution/]https://nutrifoodguide.com/pocket-farm-review-a-convenient-and-low-maintenance-gardening-solution/[/url] will guarantee that our players will receive all basic and related products required to receive bliss from the game, on our website.
Laurenimify 01 Aralık 2025 15:04
Вы правы, не самое удачное время At [url=https://play-betsson.us/es-cl/betsson-bonus-code-unlock-top-casino-rewards/]betsson sport[/url] every month you are expected fresh bonus and promotional offers.
Loriref 01 Aralık 2025 14:14
Почему выбрал: при необходимости «поставил - поехал» с возможностью тонкой настройки - удобная панель и гарантированные ресурсы [url=https://eksora.ee/ru/2017/05/08/hello-world/]https://eksora.ee/ru/2017/05/08/hello-world/[/url] решают.
HarryElorm 01 Aralık 2025 13:57
Наслаждайтесь шопингом, не бросая за доставку. МегаФон - превосходный выход, [url=https://backpagedir.com/%D1%82%D0%BE%D0%BF-100-%D1%81%D0%B0%D0%BC%D1%8B%D1%85-%D0%BD%D0%B0%D0%B4%D0%B5%D0%B6%D0%BD%D1%8B%D1%85-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE%D0%B2-%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D0%B8--%D0%A0%D0%B5%D0%B9%D1%82%D0%B8%D0%BD%D0%B3-2025-%D0%B3%D0%BE%D0%B4%D0%B0_437301.html]https://backpagedir.com/%D1%82%D0%BE%D0%BF-100-%D1%81%D0%B0%D0%BC%D1%8B%D1%85-%D0%BD%D0%B0%D0%B4%D0%B5%D0%B6%D0%BD%D1%8B%D1%85-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE%D0%B2-%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D0%B8--%D0%A0%D0%B5%D0%B9%D1%82%D0%B8%D0%BD%D0%B3-2025-%D0%B3%D0%BE%D0%B4%D0%B0_437301.html[/url] коль вы желаете заказать но
ZoeDib 01 Aralık 2025 12:31
Реально короткое very much of these establishments offer blackjack, craps, slot machines, video poker and roulette, in those days as some of them have expanded personal selection of games, at the expense of mini-baccarat, pai-go poker, three-card poker, classic poker, Caribbean stud poker, let it ride, big 6 wheel, [url=https://khanbet-casino.info/]khanbet[/url] bingo and sports betting.
Joshuafeamb 01 Aralık 2025 10:49
Весьма полезная фраза attaching to the [url=https://navtecs.com.tr/y-post-types/projects/]https://navtecs.com.tr/y-post-types/projects/[/url] is a wonderful way to receive passive income by promoting any of the leading trading platforms.
Michaelacami 01 Aralık 2025 10:15
Промокод при регистрации позволит получить подарки – это и бонусное пополнение счета, и бесплатные ставки. На самом деле, это зависит от стремления букмекера сделать шаг навстречу своим клиентам. Всевозможные бонусы и акции становятся магнитом, привлекают новых бетторов, но в то же время вносят разнообразие в игру тех, кто уже считает, что их нечем удивить. Чтобы новый игрок получил на счет приветственный бонус, он должен ввести <a href=http://magnat-market.ru/images/pgs/?melbet_promokod_bonus_pri_registracii.html >Melbet промокод на сегодня</a> в соответствующее поле в регистрационной анкете. Эти средства будут находиться на дополнительном (бонусном) балансе - эти средства нельзя вывести, но на них можно делать ставки.
BenErype 01 Aralık 2025 09:47
interactive brokers {good|great|wonderful|perfect|very good|excellent|wonderful|awesome|excellent} {it is known|familiar} for its low {costs|expenses|costs} and powerful trading platforms, {which are preferred by active #file_links["C:\Users\Admin\Desktop\file\gsa+en+VW4-8GT-JVQ612P2URLBB.txt",1,N] and {attentive|professional|experienced} traders.
Nicholasdef 01 Aralık 2025 07:49
черт,у меня не пойдет блин!( в каталоге представлено новое промышленное электрооборудование своего лично а кроме того зарубежного авторства с описаниями, [url=http://ngn.I.Ub.I.Xn--.Xn--.U.K37@cgi.members.interq.or.jp/ox/shogo/ONEE/g_book/g_book.cgi?action=registerhttp]http://ngn.I.Ub.I.Xn--.Xn--.U.K37@cgi.members.interq.or.jp/ox/shogo/ONEE/g_book/g_book.cgi?action=registerhttp[/url] техданными.
ToniFut 01 Aralık 2025 07:28
неплохо The next graph shows the expected adoption of the this type of leisure law in Florida at level of the state's [url=https://khanbet-casino.org/]khanbet[/url] legislation. Hialeah Park was closed after strong pressure from the church.
Виртуальные карты для онлайн-платежей 01 Aralık 2025 06:54
Что такое XCARDS — современное финтех-решение, заслуживающее внимания. Недавно услышал о финансовый проект XCARDS, который предлагает создавать цифровые платёжные карты чтобы контролировать расходы. Особенности, на которые я обратил внимание: Карту можно выпустить за несколько минут. Платформа даёт возможность выпустить неограниченное количество карт. Служба поддержки доступна в любое время суток включая живое общение с о
Jessiedrync 01 Aralık 2025 06:43
они обеспечивают виртуальные серверы, [url=http://cgi2.bekkoame.ne.jp/cgi-bin/user/u4168/voice.cgi?page=1&v=0097&post=038&details=446]http://cgi2.bekkoame.ne.jp/cgi-bin/user/u4168/voice.cgi?page=1&v=0097&post=038&details=446[/url] презентуемые на ноде (корневом сервере). вы будете проводить любые манипуляции, какие посчитаете нужными.
Ambertup 01 Aralık 2025 06:27
aromacode обеспечивает дисконты на известные бренды парфюмерной продукции: escentric molecules, montale, kilian, [url=http://in-genium.ru/index.php?option=com_k2&view=item&id=37]http://in-genium.ru/index.php?option=com_k2&view=item&id=37[/url] byredo parfums и lanvin. дополнительный плюс Мегафона - он представляет из себя небольшую скидку на известные мобильную при подсоединении к тарифному плану сотовой связи.
RyanPhage 01 Aralık 2025 06:02
По моему мнению Вы не правы. Могу отстоять свою позицию. Пишите мне в PM, обсудим. 1. respectively you have successfully created account in Internet institution and can to enjoy the exciting possibilities of the [url=https://no-uk-casinos.co.uk/]no verification casinos uk[/url] preferred by you the brand.
MattCapse 01 Aralık 2025 03:08
Дааа... Выкрутился оч прикольно rubles were hidden [url=http://licej.xn----7sbf6bgsdfd9q.xn--j1amh/2024/10/23/%d0%be%d1%81%d0%b2%d1%96%d1%82%d1%8f%d0%bd-%d1%81%d1%82%d0%b0%d1%80%d0%be%d0%ba%d0%be%d1%81%d1%82%d1%8f%d0%bd%d1%82%d0%b8%d0%bd%d1%96%d0%b2%d1%89%d0%b8%d0%bd%d0%b8-%d0%bf%d1%80%d0%b8%d0%b2%d1%96%d1%82/]http://licej.xn----7sbf6bgsdfd9q.xn--j1amh/2024/10/23/%d0%be%d1%81%d0%b2%d1%96%d1%82%d1%8f%d0%bd-%d1%81%d1%82%d0%b0%d1%80%d0%be%d0%ba%d0%be%d1%81%d1%82%d1%8f%d0%bd%d1%82%d0%b8%d0%bd%d1%96%d0%b2%d1%89%d0%b8%d0%bd%d0%b8-%d0%bf%d1%80%d0%b8%d0%b2%d1%96%d1%82/[/url] exchange abroad. The Russian branch of Transparency International, a global non-governmental anti-corruption organization (NGO), has found at least eight over-the-counter brokers in Moscow who are able to sell you stablecoin
EricSoows 01 Aralık 2025 02:51
fxchoice in 2010, the [url=https://bwwarehouse.co.uk/trading5/the-ultimate-guide-to-choosing-a-forex-trading-5/]https://bwwarehouse.co.uk/trading5/the-ultimate-guide-to-choosing-a-forex-trading-5/[/url], fxchoice, was licensed by the Belize International Financial Services Commission (FSC) and provides first-class trading services in the field of trading forex.
Pollykes 01 Aralık 2025 02:50
Before I got married, I often finished the [url=https://endorse.biosim.ntua.gr/ve-co-potebujete-vdt-o-kasinech-tipy-triky-a/]https://endorse.biosim.ntua.gr/ve-co-potebujete-vdt-o-kasinech-tipy-triky-a/[/url] with friends and people couldn't fall asleep. she is a porn bunny does not play in such games. on the other hand, very exciting reason about my winnings, although sometimes I win too.
TabithaWap 01 Aralık 2025 01:34
Пожалуй откажусь)) if main parts gambling grounds few to satisfy your gambling desires, switch to the [url=https://plus.chidaneh.com/pocket-option-ru-comprehensive-review-and-insights/]https://plus.chidaneh.com/pocket-option-ru-comprehensive-review-and-insights/[/url] on Mason Street.
Michaelteant 01 Aralık 2025 01:11
<a href=https://www.mitasuoil.com/>Посмотри официальный ресурс компании </a>
Jendup 01 Aralık 2025 00:04
Я считаю, что если вы все одно надеетесь работать менеджером по продаже, скажем мягких игрушек, [url=https://www.nehanutrifit.com/blog/oreginadiploma/kupit-diplom-o-srednem-obrazovanii-legkij-put-k/]https://www.nehanutrifit.com/blog/oreginadiploma/kupit-diplom-o-srednem-obrazovanii-legkij-put-k/[/url] наверное даже — не надо ничего и заканчивать.
Rosemaryameni 30 Kasım 2025 23:49
для самого низкого класса риска (i класс нестерильный, [url=https://noginsk-service.ru/forum/index.php?action=go;url=aHR0cDovL3plbXBoYXJtLnJ1Lw]https://noginsk-service.ru/forum/index.php?action=go;url=aHR0cDovL3plbXBoYXJtLnJ1Lw[/url] без функции измерения) производитель сам проходит процедуру и составляет декларацию о соответствии.
RickPlacy 30 Kasım 2025 22:49
Да, действительно. Я согласен со всем выше сказанным. Давайте обсудим этот вопрос. Здесь или в PM. Seven of the eight gambling houses in Florida belong to the Seminole tribe, [url=https://eegeru.com/]eegeru.com[/url], and the eighth belongs to the Mikkosuki tribe.
lecheniekrasnoyarskr 30 Kasım 2025 22:12
Прокапаться от алкоголя на дому в Красноярске – это удобный и результативный способ прохождения терапии. Лечение алкоголизма включает в себя очистку организма, которая способствует тому, чтобы организм избавиться от токсинов. Услуги наркологов в Красноярске предлагают вывод из состояния запоя и медицинское сопровождение при алкоголизме, включая кодирование от алкоголя. Ключевым моментом является обращение к наркологу, который проведет оценку состояния пациента и разработает индивидуальный план терапии. Эмоциональная поддержка также является важной в процессе реабилитации. Процесс реабилитации включает разнообразные методы лечения на дому, которые способствуют предотвращению рецидивов. Рекомендации по отказу от алкоголя могут стать ценными дополнениями к главной терапии. Посетив <a href=htt
JakeTrack 30 Kasım 2025 20:36
we are not from huge megalopolis." Hubby likes sometimes to visit a [url=https://www.handy.spargebot.com/2025/10/27/nejlepi-sazkove-kancelae-v-roce-2025/]https://www.handy.spargebot.com/2025/10/27/nejlepi-sazkove-kancelae-v-roce-2025/[/url] to play cards, and I'm going to participate in work of a public radio station (if one exists).
Violautise 30 Kasım 2025 20:34
such recommendation contains links to websites and corporations that are not encumbered with the CFTC. Two out of three [url=https://aocdemo.avpers.com/2025/10/30/the-impact-of-forex-trading-news-on-market-5/]https://aocdemo.avpers.com/2025/10/30/the-impact-of-forex-trading-news-on-market-5/[/url] clients lose money. you get a wonderful opportunity to lose almost completely your margin and even more.
SharonWew 30 Kasım 2025 19:57
круто придумали!!! in our betsson Casino review, we have carefully read and analyzed the rules and service labor of [url=https://paly-betsson.com/]betsson[/url].
MaryPsype 30 Kasım 2025 19:19
Подтверждаю. Я присоединяюсь ко всему выше сказанному. Давайте обсудим этот вопрос. “in my opinion, deciphering a unique handwriting written by your own hand is a necessary step towards full unlocking your potential, discovering your true path, [url=https://hastarekha.it.com/]https://hastarekha.it.com/[/url], and accepting a life filled with meaning and purpose.
Cynthiahep 30 Kasım 2025 17:45
в выполняемой статье мы рассмотрим, для кого может оставаться увлекательной приобретение корочки, преимущества покупки в нашей столице, самые разные варианты дипломов, [url=https://test.becoenlinea.com/kupit-diplom-v-ekaterinburge-vse-chto-nuzhno-znat/]https://test.becoenlinea.com/kupit-diplom-v-ekaterinburge-vse-chto-nuzhno-znat/[/url] правила доставки и обеспечим вам написать в нашу компанию.
RichDiz 30 Kasım 2025 17:28
наша намерение: приумножать милосердие, служить здоровью, [url=https://forexparty.org/analitica/novosti-foreks-industrii/dalnejshie-shagi-administratsii-ssha-i-perspektivy-dollara-budut-klyuchevymi-temami-na-rynke-v-aprele.html]https://forexparty.org/analitica/novosti-foreks-industrii/dalnejshie-shagi-administratsii-ssha-i-perspektivy-dollara-budut-klyuchevymi-temami-na-rynke-v-aprele.html[/url] вовремя прийти на помощь. Помогать врачам. Помогать клиникам.
JessicaBog 30 Kasım 2025 16:21
Весьма полезная информация ?Listo para probar suerte? Ya sea que lo llames road chicken o road Chicken game, [url=https://www.rmsensacions1.com/product/utroque-scriptorem/]https://www.rmsensacions1.com/product/utroque-scriptorem/[/url] la emocion es la misma: ?predecir en que lugar estara el pollo, puede conducir a grandes ganancias!
SherryKeema 30 Kasım 2025 14:23
Приветик Прохожая!!!! which is located at correct 4961 regions, Dr. nw, acworth, Georgia 30101, we with joy serve customers in America, South America, Europe, we produce [url=https://www2.uesb.br/cultura/?p=19038]https://www2.uesb.br/cultura/?p=19038[/url] and software to the whole world.
NicoleCorry 30 Kasım 2025 11:08
в итоге - постепенное, четверть вековое обнищание масс. мы рекомендуем заказать сертификат о во, воспользовавшись накопленным нами практикой, связями и умениями, чтобы не быть жертвой аферистов, не утерять свои едва сделанные средства, и остаться без требуемого документа, [url=https://www.bsb-schuler.de/video-obzor-diploma-kak-podgotovit-idealnyj-proekt/]https://www.bsb-schuler.de/video-obzor-diploma-kak-podgotovit-idealnyj-proekt/[/url] а значит и видов на грядущее.
ZacharyUtept 30 Kasım 2025 10:51
при покупке продукции на сумму от 3500 рублей доставка равняется всего-навсего 1 [url=https://www.ikonashop.it/wp/2016/09/09/nuova-apertura-negozio/]https://www.ikonashop.it/wp/2016/09/09/nuova-apertura-negozio/[/url] рубль.
Zoezenda 30 Kasım 2025 09:52
Какой замечательный топик Strict security measures have been taken on our website. Before [url=https://triton.psetradex.ph/your-gateway-to-effective-online-trading-with/]https://triton.psetradex.ph/your-gateway-to-effective-online-trading-with/[/url] for betting, test customer service customers by asking them several questions.
MichelleFilla 30 Kasım 2025 08:15
Вы допускаете ошибку. Предлагаю это обсудить. Пишите мне в PM, поговорим. since that moment, the [url=https://newzful.com/2025/06/]https://newzful.com/2025/06/[/url] world of blockchain and cryptocurrencies has grown exponentially, and our employees highly proud of questions that matured simultaneously with him.
JoshuaVaw 30 Kasım 2025 07:58
in addition to of these features, guests of chips-in's [url=https://alubo.co.in/how-to-choose-the-right-option-for-your-needs-6/]https://alubo.co.in/how-to-choose-the-right-option-for-your-needs-6/[/url] may use some other entertainment, in order realize leisure away from institution .
RobDiamb 30 Kasım 2025 07:57
based on the percentage of profitable and unprofitable non-discretionary client accounts disclosed by registered over-the-counter forex dealers during from the 2nd to the 1st quarter of 2022. Registered over-the-counter [url=https://krestannavidieku.sk/2025/10/mastering-online-forex-trading-strategies-and-11/]https://krestannavidieku.sk/2025/10/mastering-online-forex-trading-strategies-and-11/[/url] dealers must provide a percentage of profitable as well as unprofitable accounts on their application of any visitor or potential requester.
JaredReavy 30 Kasım 2025 04:19
В 2003 году археологи увидели в Пиргосе (Греция) то, что, как полагают, [url=https://webstories.elcolombiano.com/2025/11/12/arhitektura-aromata-carner-barcelona-cuirs/]https://webstories.elcolombiano.com/2025/11/12/arhitektura-aromata-carner-barcelona-cuirs/[/url] является самыми старыми духами в мире - изготовлены приспособления приобретались более 4000 лет тому.
LaurenDic 30 Kasım 2025 03:59
у нас каждый день можно найти, вариант по приемлемой цене: хоть смартфон cmf phone 2 pro, [url=https://www.fabios-cucina.at/chocolate-truffle-cake-with-honey-flavor/]https://www.fabios-cucina.at/chocolate-truffle-cake-with-honey-flavor/[/url] электросамокат xiaomi либо совсем asus rog zephyrus.
Nicholasnob 30 Kasım 2025 02:48
Коленки бы прикрыла)))))))))))))))) там все [url=http://Hu.Feng.Ku.Angn.I.Ub.I.xn%E3%E0%94.xn%E3%E0%94.U.K37@cgi.members.interq.or.jp/ox/shogo/ONEE/g_book/g_book.cgi]http://Hu.Feng.Ku.Angn.I.Ub.I.xn%E3%E0%94.xn%E3%E0%94.U.K37@cgi.members.interq.or.jp/ox/shogo/ONEE/g_book/g_book.cgi[/url] уютно. из-за этого stylus - это наилучший выбор для тех, кто ценит свое время, деньги и комфорт.
JeffFrold 30 Kasım 2025 01:11
Find out more: at the [url=http://2bsigns.com/beta/how-to-open-a-forex-trading-account-a-step-by-step-24/]http://2bsigns.com/beta/how-to-open-a-forex-trading-account-a-step-by-step-24/[/url]. Past results do not guarantee future results.
Teresanub 30 Kasım 2025 01:10
{casino|institution|casino|institution|gambling house} based on {based on/based on} applications have revolutionized the {gambling|gaming entertainment|gambling} industry by combining the convenience of mobile {materials|technologies} with {excitement|empathy|excitement} {gambling|similar} {games|entertainment|pastime} in an #file_links["C:\Users\Admin\Desktop\file\gsa+en+one4anotherRoma1510LinkbuildingplanOctober1P2URLBB.txt",1,N], {in this regard|because of what|thanks to what} {it was| became easier for you|viewers|visitors| users} {to enjoy {your favorite | favorite} {gambling games|slots| offers} {anytime|at any time|at any moment} {and|also} in {any|any} place.
BooneSluse 30 Kasım 2025 00:33
Вы не правы. Я уверен. Могу это доказать. Пишите мне в PM. [url=https://parabet-canli.com/]parabet-canli.com[/url] 1win, cok say?da kaynaklar uzerinde oyunun oynan?s?n?n sorunsuz olmas?n? saglaman?n oneminin fark?ndad?r. bir dizi ilk tedarikciler aras?nda netent, microgaming, evolution gaming, play'n go ve diger bulunur.
JasonPsymn 29 Kasım 2025 21:37
Лекарства принимают по 1 таблетке один один раз в сутки (с интервалом в 23-26 часов, можно принимать вечером), [url=https://www.ideedesigns.com/2019/03/08/63-businesses-to-start-for-under-10000/]https://www.ideedesigns.com/2019/03/08/63-businesses-to-start-for-under-10000/[/url] независимо от приема пищи.
DanaBer 29 Kasım 2025 21:15
^ fashion is an environmental and social emergency, [url=https://icux.xyz/3IYeo7]https://icux.xyz/3IYeo7[/url] but can also drive progress towards the sustainable development goals .
Feliciagew 29 Kasım 2025 20:28
Большое спасибо за помощь в этом вопросе, теперь я буду знать. Остальные допустимые компоненты - кальций, магний, сульфат, калий, [url=https://salt-trade.ru/peskosol-v-big-begah/]пескосоляная смесь в биг-бэгах[/url] оксид железа. у нас в стране главные объемы такой соли дают несколько крупных месторождений.
Shellydaype 29 Kasım 2025 20:22
Много наподбирали,спс. Gelecek haftaya pinco ile kazancl? bir baslang?c yaparak baslay?n! herhangi/tumu/her asama/asamadaki 50 lider/bayrak subay? finansal oduller al?r. Her Pazartesi [url=https://spin-pasha.com/]spin-pasha.com[/url] Bir onceki haftan?n net zarar?n?n miktar yukar? on% 'si icin geri odeme al?r!
Anthonyvah 29 Kasım 2025 19:45
Да, действительно. Всё выше сказанное правда. also, [url=https://play-betwaycasino.us/]betway[/url] has a easy to use raised elevation and a important customer support service that will help you absolutely everything that you need.
Katherinerip 29 Kasım 2025 19:05
Currency pegging stabilizes the exchange rate between states-[url=https://fb.snsmodoo.com/the-evolution-of-forex-trading-robots/]https://fb.snsmodoo.com/the-evolution-of-forex-trading-robots/[/url]. it is one of several standard transaction sizes for buying as well as selling currencies.
Adamtweme 29 Kasım 2025 19:05
this means that can use money won in bookmakers or casino on other platform by [url=https://www.fmsertaneja.com/discovering-8mbet-bd-your-ultimate-betting-2/]https://www.fmsertaneja.com/discovering-8mbet-bd-your-ultimate-betting-2/[/url] using one gmail or facebook account.
Shirleymoura 29 Kasım 2025 18:16
Мне знакома эта ситуация. Давайте обсудим. и необходимости, дополнительно оформим контракт, задача на оценку, подготовленный отчет об оценке, [url=http://hasly-photo.cz/2017/09/15/stay-with-me/]http://hasly-photo.cz/2017/09/15/stay-with-me/[/url] УКЭП (Усиленная Квалифицированная Электронная Подпись).
Netrawhice 29 Kasım 2025 17:45
Согласен, очень полезная информация To start certain [url=https://ttsa.jp/pocket-option-de-your-gateway-to-successful-3/]https://ttsa.jp/pocket-option-de-your-gateway-to-successful-3/[/url] brokers never set the initial amount of the initial deposit.
DeeCralk 29 Kasım 2025 16:19
Какая талантливая мысль Напольный кондиционер - тихий и [url=https://khamamesbah.com/hello-world/]https://khamamesbah.com/hello-world/[/url] эффективный. тут каждый день есть, что-то по отличной прайсу: в том числе смартфон cmf phone 2 pro, электросамокат xiaomi или же asus rog zephyrus.
Sheilaglace 29 Kasım 2025 15:25
несмотря на то, что дженерики имеют ту же активную формулу, как и оригинальные лекарства, [url=https://sellerie-biscay.fr/nouveau-site-web-pour-la-sellerie/]https://sellerie-biscay.fr/nouveau-site-web-pour-la-sellerie/[/url] они имеют возможность иметь некоторые различия в составе и вспомогательных компонентах.
LesleySlozy 29 Kasım 2025 15:04
Например, [url=http://strikez.awardspace.info/index.php?PHPSESSID=b466f5293e7b01208671615045f650a2&topic=100974.0]http://strikez.awardspace.info/index.php?PHPSESSID=b466f5293e7b01208671615045f650a2&topic=100974.0[/url] он не заметен на напольной плитке. Хотя бревна остается оптимальным стройматериалом, она имеет низкую устойчивость к биологической деградации: подвержена грибкам и повреждению насекомыми.
EricaneP 29 Kasım 2025 12:38
Online gambling fast is gaining momentum in America, and it means that there are huge number legal [url=https://anewse.com/the-fascinating-world-of-6l-777-unlocking-2/]https://anewse.com/the-fascinating-world-of-6l-777-unlocking-2/[/url] to choose from.
Patrickdaf 29 Kasım 2025 12:38
IQ option {most|especially|extremely|most|most/most} {popular|in-demand|frequently asked} users are #file_links["C:\Users\Admin\Desktop\file\gsa+en+VW4-8GT-JVQ65P2URLBB.txt",1,N], and Charles Schwab leads in {categories|sections} "Assets under Management" (aum).What are the {most|most{widespread|popular|in-demand|famous|famous|eminent} {proven|reliable} {forex|forex} brokers?
KennethBer 29 Kasım 2025 11:29
Это — неожиданность! ne hakk?nda oldugunuza istediginiz para kazanmak/gelir elde etmek, bazen [url=https://basari-bet1.org/]basari-bet1.org[/url] beklenmedik bir olay haline gelir/olabilir. Bu islev internet kumarhane ayn? zamanda herhangi bir zamanda ayn? oyun icin ucretsiz oyun masas? bulmak | bulmak | almak} icin izin verir | f?rsat verir | sans saglar}.
LatriceQuisy 29 Kasım 2025 10:16
Присоединяюсь. Всё выше сказанное правда. darf der Betroffene die Gelegenheit erhalt, zu erhalten von [url=https://www.delscatering.com/about/]https://www.delscatering.com/about/[/url] Daten/Informationen uber einschlagige Garantien, die mit Ubertragung/Ubermittlung verbunden sind.
AltonOpisk 29 Kasım 2025 09:18
Вас посетила замечательная идея Такие котельные могут обслуживать один дом или несколько близлежащих [url=https://kotel-54.ru/collection/separatory-vozduha-i-shlama]https://kotel-54.ru/collection/separatory-vozduha-i-shlama[/url] объектов теплоснабжения. Если котельное оборудование работает круглогодично, то его проверяют дважды в год.
Anitaoccup 29 Kasım 2025 08:43
Я думаю, что Вы ошибаетесь. Могу отстоять свою позицию. The CPA proposal: Earn a fixed amount for each qualified trader who registers and makes a deposit using the required [url=https://we-test.uek.krakow.pl/maximize-your-earnings-with-a-bot-for-pocket/]https://we-test.uek.krakow.pl/maximize-your-earnings-with-a-bot-for-pocket/[/url].
Michaelereno 29 Kasım 2025 07:27
Открывайте подобные онлайн-аркады, пока кто-то не украл любимого персонажа! как заработать играя в [url=http://agenciafrog-host.com.br/redesocial_v0/index.php/profile/ikiposeku]http://agenciafrog-host.com.br/redesocial_v0/index.php/profile/ikiposeku[/url] аркады? играй в лучшие онлайн забавы Аркады без всякой оплаты на Яндекс Игры.
TamaraNiday 29 Kasım 2025 06:54
чем отличаются сайт Стилус от других? что цена на девайс - все это не реклама, [url=http://perfectsolutionlabs.com/user/AntonMercier/]http://perfectsolutionlabs.com/user/AntonMercier/[/url] а насущная стоимость.
ToniTuh 29 Kasım 2025 04:36
Knowing that leverage will cost traders a whole sick and not quite clear, what are the [url=https://mediamines.in/2025/10/28/choosing-the-right-forex-trading-software-for-your/]https://mediamines.in/2025/10/28/choosing-the-right-forex-trading-software-for-your/[/url], the European Securities Authority The Securities and Markets Authority (ESMA) has established stops her use.
Spravkiugp 29 Kasım 2025 04:26
Хотите получить медицинская книжка быстро для работников или организаций? На [url=https://cmc-clinic.ru]https://cmc-clinic.ru[/url] в Москве оформят или продлят медкнижку в течение дня — быстро, официально и без задержек. <a href="https://cmc-clinic.ru">https://cmc-clinic.ru</a> Узнайте подробности на сайте.
Brianalorn 29 Kasım 2025 04:06
Да, действительно. Я присоединяюсь ко всему выше сказанному. Давайте обсудим этот вопрос. Здесь или в PM. Their key idea is that the person are not alone - millions of Americans have turned to help and have acquired healthier [url=https://slnutrition.com/receita-fitness-salmao-no-forno-ananas/]https://slnutrition.com/receita-fitness-salmao-no-forno-ananas/[/url] habits (or have completely abandoned them).
Saravar 29 Kasım 2025 03:57
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Давайте обсудим. Пишите мне в PM. ^ Постановление правительства россии от 27 сентября 2007 г. n 612 г. Москва «Об утверждении Правил реализации продукта дистанционным способом» [url=http://www.ceipsantisimatrinidad.es/index.php/en/component/kide/history/-/index.php?option=com_kide]http://www.ceipsantisimatrinidad.es/index.php/en/component/kide/history/-/index.php?option=com_kide[/url] .
Spravkifqg 29 Kasım 2025 03:47
Хотите заказать онлайн медсправки без ожидания и проблем? На сайте [url=https://z32-med.ru]https://z32-med.ru[/url] настоящий документ можно заказать в течение дня — от документов для бассейна, санатория и ВУЗа до формы 095/у, 086/у, решений комиссии и обследований. Более 10 лет работы, официальное партнёрство, и оформление на оригинальных бланках подтверждают надёжность и официальный статус. Предлагаются доступные цены, широкий выбор услуг и курьерская доставка в Москве. <a href="https://z32-med.ru">https://z32-med.ru</a> Подробнее — медсправка без очередей, оформление за день, подлинные справки.
Spravkioar 29 Kasım 2025 03:11
Узнайте детальнее о преимуществах работы с организацией — стабильность, профессионализм и широкий выбор решений! Зайдите на [url=https://tdstyling.ru]https://tdstyling.ru[/url] и ознакомьтесь тарифы, данные для связи, а также публикации. <a href="https://tdstyling.ru">https://tdstyling.ru</a> Планируете партнёрство — эта фирма предлагает тематические ссылки, оптимальные решения и лучшие условия.
Spravkilya 29 Kasım 2025 01:51
Для обладателей Mercedes, выбирающих качество и комфорт — профессиональный автотехцентр выполняет широкий набор услуг: слесарный и кузовной ремонт, компьютерную диагностику, монтаж Webasto, ГБО и прочее. [url=https://specavtoimport.ru]https://specavtoimport.ru[/url] Профессиональные специалисты проводят работы на сертифицированном станках, используя фирменные запчасти и предоставляя надёжность и личный подход. <a href="https://specavtoimport.ru">https://specavtoimport.ru</a> Ознакомьтесь с деталями — автосервис Mercedes доступен на ресурсе.
Spravkipjj 29 Kasım 2025 01:14
Хотите найти оперативный способ оформить медицинскую справку без посещения клиники? [url=https://space-group-med.ru]https://space-group-med.ru[/url] На сайте Space Group Med предлагается разные виды медсправок — от справки 001-ГСУ, 082/у, до справок об освобождении от физической нагрузки, документов из психоневрологического или наркологического диспансера и решений врачебной комиссии. Всё это доступно через интернет с доставкой в столице и Петербурге — без хлопот, оперативно и легально. <a href="https://space-group-med.ru">https://space-group-med.ru</a> Узнайте больше на сайте — медсправка онлайн, доставка справки, быстрое оформление справки.
Spravkigom 29 Kasım 2025 00:37
Для собственников Nissan, заинтересованных в качественном ремонте и полном обслуживании — автосервис <a href="https://skupkaavtosp.ru">https://skupkaavtosp.ru</a> оказывает механический и ремонт кузова, компьютерную диагностику, настройку сход-развала, обслуживание АКПП, инсталляцию ГБО, Webasto, тонировку и другие услуги. опытные специалисты работают на сертифицированном станках, используют фирменные запчасти и предоставляют приятные условия с комнатой отдыха и Wi-Fi. [url=https://skupkaavtosp.ru]https://skupkaavtosp.ru[/url] Посмотреть подробностями — автосервис Nissan готов помочь на сайте.
Nicolebuh 29 Kasım 2025 00:37
Подтверждаю. Всё выше сказанное правда. Давайте обсудим этот вопрос. we have also available hundreds slot machines at [url=https://play-betwaycasino.com/en-ca/]betway casino login[/url] and betway Vegas casinos, which cover everything from movies, and TV shows/TV shows, such as game of thrones, or video games, like Lara Croft temples and tombs, and ending popular slot machines, such as zeus ancient fortunes.
Pauladek 29 Kasım 2025 00:19
и высокие цели правосудного ограждения обществ и защита личности от несправедливого обвинения могут быть достигаемы только нравственными [url=https://pena-opt.ru/?attachment_id=240&unapproved=286075&moderation-hash=f3080891b2e9a8d966ac4f5fb9f2316d]https://pena-opt.ru/?attachment_id=240&unapproved=286075&moderation-hash=f3080891b2e9a8d966ac4f5fb9f2316d[/url] способами и приёмами.
Spravkimxm 29 Kasım 2025 00:01
Ищете удобный способ получить медицинскую справку быстро и без походов к врачу? На сайте [url=https://romashkaclinic.ru]https://romashkaclinic.ru[/url] представлен широкий ассортимент: от форм 001-ГС/у, 027/у, справки 086/у до документов для плавания, документов для ВНЖ и КЭК-заключений — всё легально и с курьерской доставкой. Заполнить заявку можно за пару минут, оформление через сайт. Это комфортно, законно и без заломов. Узнайте подробности — справка онлайн, быстрое оформление, <a href="https://romashkaclinic.ru">https://romashkaclinic.ru</a> доставка справки.
Lesleynus 28 Kasım 2025 23:53
С. Слоневский. [url=http://L.v.Eli.Ne.S.Swxzu@Hu.Feng.Ku.Angn..Ub..xn--.Xn--.U.K37@cgi.members.interq.or.jp/ox/shogo/ONEE/g_book/g_book.cgi?_x_tr_sl=es]http://L.v.Eli.Ne.S.Swxzu@Hu.Feng.Ku.Angn..Ub..xn--.Xn--.U.K37@cgi.members.interq.or.jp/ox/shogo/ONEE/g_book/g_book.cgi?_x_tr_sl=es[/url] // Большая советская энциклопедия. Васильева Е. Теория моды: миф, потребление и по ценностей.
Jackiesiz 28 Kasım 2025 23:50
Туда же in order to get greatest return from the [url=http://training.insurancesplash.com/pocket-option-demo-login-your-gateway-to-risk-free-3/]http://training.insurancesplash.com/pocket-option-demo-login-your-gateway-to-risk-free-3/[/url], always make sure that you provide accurate information about sections and the advantages of using its service.
Spravkinhu 28 Kasım 2025 23:22
Узнайте все детали о Restyle-Авто — современный автоцентр, <a href="https://restyle-avto.ru">https://restyle-avto.ru</a> большой ассортимент, доступные предложения и надежные сделки! Зайдите на [url=https://restyle-avto.ru]https://restyle-avto.ru[/url] и посмотрите актуальные предложения. Подбираете машину или хорошую цену — дилерский центр предлагает поддержанные автомобили, выкуп авто и удобную доставку. Мечтаете о своём автомобиле — здесь найдёте доступные цены и гарантированное качество.
ReneeJaire 28 Kasım 2025 23:13
Мне не ясно. Elite, we - gagarin studio consists of highly qualified veteran players in area of [url=https://yogicentral.science/wiki/How_To_Choose_The_Right_Service_For_Promoting_MMO_Games_Fundamental_Factors_What_Should_Be_Taken_Into_Account]https://yogicentral.science/wiki/How_To_Choose_The_Right_Service_For_Promoting_MMO_Games_Fundamental_Factors_What_Should_Be_Taken_Into_Account[/url], with in-depth knowledge of practically all aspects of the games that we support.
Spravkitdx 28 Kasım 2025 22:44
Ищете, где заказать медсправку без похода по городу? На [url=https://psy-medcentr.ru]https://psy-medcentr.ru[/url] можно заказать справки всех видов: 086/у, справка 095/у, 027/у, санитарную книжку, решение комиссии, справки в бассейн, академотпуска и не только. Подать заявку можно за пару минут, а курьерская доставка по Москве — оперативно и без хлопот. Всё законно и анонимно. <a href="https://psy-medcentr.ru">https://psy-medcentr.ru</a> Подробнее — медсправка без визита, онлайн оформление, справка с доставкой.
Tedtaith 28 Kasım 2025 22:06
The be principle provides a guarantee that excitement and profit from [url=https://h2852162.stratoserver.net/index.php/2025/10/27/forex-trading-for-beginners-a-comprehensive-guide-127/]https://h2852162.stratoserver.net/index.php/2025/10/27/forex-trading-for-beginners-a-comprehensive-guide-127/[/url] trading are balanced and that the trader is not exposed to unreasonable danger.
Spravkidgx 28 Kasım 2025 22:05
Требуется справка от врача оперативно и без лишней бюрократии? <a href="https://ossis-med.ru">https://ossis-med.ru</a> Мы поможем сделать справки любых форм, в бассейн до академического отдыха. [url=https://ossis-med.ru]https://ossis-med.ru[/url] Закажите справку у врача или индивидуальная медсправка.
AngelicaSub 28 Kasım 2025 22:02
Исключительный бред, по-моему В заключение стоит признаться, что если вы желаете посетить первоклассное онлайн заведение с удобным интерфейсом и широким ассортиментом игр, [url=https://broxrestaurants.com/migliori-bisca-online-italiani-trattato-completa-ai-siti-di-inganno-dazzardo/]starvegas casino[/url] то Бонс казино определенно требуется посетить.
Spravkilro 28 Kasım 2025 21:29
Для собственников Mercedes, выбирающих надёжность и удобство — <a href="https://novomed-cardio.ru">https://novomed-cardio.ru</a> специализированный автосервис предлагает широкий набор услуг: слесарный и ремонт кузова, компьютерную диагностику, установку Webasto, ГБО и прочее. [url=https://novomed-cardio.ru]https://novomed-cardio.ru[/url] квалифицированные мастера проводят работы на сертифицированном оборудовании, используя оригинальные запчасти и предоставляя гарантию и индивидуальный сервис. Узнайте деталями — сервис Mercedes ждёт вас на сайте.
Spravkikyk 28 Kasım 2025 20:49
Узнайте что нужно знать об автовладельцах — диалоги, рекомендации и события на форуме автолюбителей! Перейдите на [url=https://n-avtoshtorki.ru]https://n-avtoshtorki.ru[/url] и узнайте актуальные форум-посты. Хотите обсудить ситуацию или получить совет — сообщество предлагает опыт водителей, отзывы и новинки автомобильной жизни. <a href="https://n-avtoshtorki.ru">https://n-avtoshtorki.ru</a> Ищете единомышленников — здесь найдете живое общение и полезную информацию.
izzapoyakalugarix 28 Kasım 2025 20:47
вывод из запоя круглосуточно <a href=https://vivod-iz-zapoya-kaluga017.ru>vivod-iz-zapoya-kaluga017.ru</a> экстренный вывод из запоя калуга
Spravkimch 28 Kasım 2025 19:34
Нужна, где быстро оформить санитарную книжку или медицинскую справку по городу — без очередей? В медцентре [url=https://munclinic.ru]https://munclinic.ru[/url] оказываются разные виды документов и санкнижек по выгодной стоимости, с гарантией конфиденциальности и надежностью. Круглосуточная лаборатория принимает без выходных, чтобы результаты были в кратчайшие сроки. Принимают опытные специалисты, прошедшие аккредитацию и индивидуальным подходом. Документы готовятся в кратчайшие сроки — стабильно, официально и удобно. <a href="https://munclinic.ru">https://munclinic.ru</a> Узнайте подробнее — оформление медкнижек Казань, медсправка недорого, анализы 24/7.
Spravkiyee 28 Kasım 2025 18:57
Нужна, где быстро оформить медкнижку сегодня же без толкучки и лишних ожиданий? На сайте [url=https://medraskhodka.ru/]https://medraskhodka.ru/[/url] оформят и обновят санитарную книжку за 1 день: с анализами и заключением терапевта — даже без визита. Услуга подходит для работников пищевой промышленности, коммунальных служб и учреждений, где требуются медосмотры и допуск. Весь процесс очень быстрый, а стоимость честная и понятная (от 1 600 ?, продление от 1 300 ?). <a href="https://medraskhodka.ru/">https://medraskhodka.ru/</a> Узнайте подробности — оформление за сутки, оформление онлайн, без очередей.
Spravkinef 28 Kasım 2025 18:19
Хотите узнать, где получить медкнижку в Подольске быстро и законно — без проблем и очередей? В частном медцентре на сайте [url=https://med-podolsk.ru]https://med-podolsk.ru[/url] можно получить медкнижку, справку в ГАИ, для плавания, санатория или лицензии на оружие всего за 1 день — с лабораторными исследованиями, осмотром терапевта и гарантированной легальностью. Быстрое оформление, удобство записи в течение всего дня, прозрачные цены — справки от 500 ?, от 1200 ? за книжку. <a href="https://med-podolsk.ru">https://med-podolsk.ru</a> Смотрите детали — медкнижка быстро, справка в день обращения, заказ через интернет.
Joanneincar 28 Kasım 2025 18:16
Умные вещи, говорит ) Все дополнительные данные, если понадобятся) будут сохранены и уберегаются законом "о сохранности персональных данных". большая часть проблем решаются в краткие сроки и по телефону, [url=https://daytimer.ru/kak-ia-rasskazyvaiu-babushke-o-svoei-rabote/]https://daytimer.ru/kak-ia-rasskazyvaiu-babushke-o-svoei-rabote/[/url] оттого-то не отодвигайте на потом.
PatrickTom 28 Kasım 2025 17:31
«где вы осуществляете ремонт и сопровождение компьютеров? Программный ремонт некоторые люди удается выполнить без помощи других. вне зависимости из-за этого, есть ли у вас сегодня деньги или нет, вы имеете возможность вызвать мастера сейчас, [url=https://shortlink.uk/1iQfG]https://shortlink.uk/1iQfG[/url] а перечислить деньги потом.
JosephinePurdy 28 Kasım 2025 17:12
Подтверждаю. Это было и со мной. 7-е изд., перераб.. - М.: Издательский центр «Академия», [url=https://90plink.live/truc-tiep-tran-dau-bonner-sc-vs-siegen-sportfreunde-2443430]https://90plink.live/truc-tiep-tran-dau-bonner-sc-vs-siegen-sportfreunde-2443430[/url] 2012. - С. Траурными цветами считались чёрный, тёмно-зелёный и серый.
Spravkigxl 28 Kasım 2025 17:04
Хотите узнать, где сделать или продлить медкнижку по Уфе быстро и без проблем? В центре [url=https://medmagprof24.ru]https://medmagprof24.ru[/url] можно оформить документ без лишних нервов и ожидания — оформление полностью законное и без задержек. Услуга может быть оформлена через интернет и готова быстро. Это удобно, законно и подходит каждому. <a href="https://medmagprof24.ru">https://medmagprof24.ru</a> Подробнее на сайте — медкнижка Уфа, без толпы, быстрое оформление.
Spravkicub 28 Kasım 2025 16:24
Нужны медицинские товары для клиник от проверенного поставщика в Чебоксарах? Компания [url=https://medikwest.ru]https://medikwest.ru[/url] предлагает большой выбор продукции — от стерильных одноразовых материалов до медицинских расходных товаров для больниц. Работаем с надежными производителями, обеспечиваем надежность продукции, сертификаты соответствия и оперативное снабжение в Чебоксарах. Это удобно, гарантированно и на высоком уровне. <a href="https://medikwest.ru">https://medikwest.ru</a> Узнайте больше на сайте — товары для медицины, расходники для клиник, проверенный продавец.
Spravkitnd 28 Kasım 2025 15:46
Нужна, где оформить медицинскую книжку за час в Москве, законно и без ожидания? На сайте [url=https://medik-moscov.ru]https://medik-moscov.ru[/url] можно оформить санитарную книжку для работы в лагере, общепите, сфере сервиса, медицинских центрах, ритейле и разных отраслях. Цена: оформление новой от 1390 ?, продление — от 780 ?. Всё в течение часа, с официальной гарантией и в шаговой доступности. <a href="https://medik-moscov.ru">https://medik-moscov.ru</a> Смотрите детали — медкнижка срочно, оформление за час, официальная санкнижка.
HollyirriT 28 Kasım 2025 15:33
Поздравляю, ваша мысль блестяща many resorting to have [url=https://nobleaged.com/login-to-pocket-option-a-comprehensive-guide-2/]https://nobleaged.com/login-to-pocket-option-a-comprehensive-guide-2/[/url], which leads to frustration when trying give access to own funds.
Joshuaunsek 28 Kasım 2025 15:33
Unauthorized copying, publication or quoting from portal, partially or completely, without the written permission of [url=https://premium-collector.com/the-ultimate-guide-to-forex-trading-strategies-124/]https://premium-collector.com/the-ultimate-guide-to-forex-trading-strategies-124/[/url] is a violation of intellectual property rights.
Spravkixfi 28 Kasım 2025 14:31
Ищете официальная справка от врача онлайн? На [url=https://medical-sozvezdie.ru]https://medical-sozvezdie.ru[/url] можно получить документы в Москве — от школьной справки 095/у до медицинских документов для РВП или визы — в режиме одного дня. Документы оформляют аттестованные врачи, используются оригинальные бланки, а доставка работает по столице. <a href="https://medical-sozvezdie.ru">https://medical-sozvezdie.ru</a> Это быстро, надёжно и комфортно — справка через интернет, доставка справки, официальная справка.
Spravkiekn 28 Kasım 2025 13:52
Нужен удобный способ оформить официальную справку или санитарную книжку без визита в поликлинику и проблем? В клинике [url=https://med-blesk.ru]https://med-blesk.ru[/url] оказывается весь комплекс медицинских предложений: оформление медкнижек, официальных медсправок, УЗИ, лабораторные исследования и консультация терапевта — всё официально и юридически корректно. Осуществляется доставка справок, а также проведение профосмотров для организаций и частных лиц. Это в кратчайшие сроки, гарантированно и качественно — приём ведут опытные врачи. <a href="https://med-blesk.ru">https://med-blesk.ru</a> Подробнее смотрите на сайте — онлайн справка, санитарная книжка без ожидания, оформление справки.
Tashasar 28 Kasım 2025 13:15
Какой любопытный топик гарантия качества товаров. мы не сомневаемся в качестве наших работ и предоставляем гарантию на все виды [url=http://rd.99oz.net/?u=aHR0cHM6Ly9hc3RyYWhhbi5ieXRvdGVjaC5ydS9yZW1vbnQtaG9sb2RpbG5pa292LnBocA]http://rd.99oz.net/?u=aHR0cHM6Ly9hc3RyYWhhbi5ieXRvdGVjaC5ydS9yZW1vbnQtaG9sb2RpbG5pa292LnBocA[/url] работ.
Spravkiyxo 28 Kasım 2025 13:13
Требуется медкнижка в течение суток без похода к врачу? На [url=https://med-bez-boli.ru]https://med-bez-boli.ru[/url] можно заказать или обновить медкнижку законно, без обследования — моментально и легально. Имеем партнёрство с аккредитованным медучреждением и оформляем документы нового образца, выдаём официальные справки, которую вносят в реестр. Это без лишних хлопот, официально и доступно по разумной цене. <a href="https://med-bez-boli.ru">https://med-bez-boli.ru</a> Узнайте подробности — санитарная книжка без врачей, срочное оформление, санитарная книжка онлайн.
Spravkibey 28 Kasım 2025 12:35
Для эффективной организации инфраструктурных и благоустроительных проектов — компания Kusok Avto сдаёт в аренду профессиональную спецтехнику, включая дорожные грейдеры, подъёмники и прочую технику. [url=https://kusokavto.ru]https://kusokavto.ru[/url] Наш многолетний стаж в возведении дорог и инженерных сетей подтверждает качество и надёжность. <a href="https://kusokavto.ru">https://kusokavto.ru</a> Ознакомиться с деталями — строительная техника представлена на сайте.
Spravkipwp 28 Kasım 2025 11:57
Хотите получить квалифицированную медицинскую помощь по месту жительства? В медицинском центре [url=https://kristall-med.ru]https://kristall-med.ru[/url] предлагаются услуги современной эндоскопии, функциональных исследований и ДНК-диагностики — с высокоточным оборудованием и комфортными условиями. Центр использует передовые технологии, принимают сертифицированные врачи и организует комплексные исследования. <a href="https://kristall-med.ru">https://kristall-med.ru</a> Всё это — без лишних хлопот, гарантированно и в соответствии с клиническими стандартами. Подробнее на сайте — функциональные исследования, ДНК-диагностика, качественная эндоскопия.
Spravkilni 28 Kasım 2025 11:20
Хотите купить, где заказать медицинскую книжку по Перми официально и без бюрократии? На [url=https://klinika-zdorovya-no1.ru]https://klinika-zdorovya-no1.ru[/url] можно оформить новую книжку всего за 1700 ? или перевыпустить действующую — по цене от 1000 ?. Документы подлинные и законные, курьер доставит готовую книжку к вам домой. Всё легко: передать нужные данные онлайн, внести оплату и ждать доставку — без визитов к врачам и ожидания. <a href="https://klinika-zdorovya-no1.ru">https://klinika-zdorovya-no1.ru</a> Подробнее на сайте — медицинская книжка Пермь, оформление без очередей, скидка на продление.
JenniferBiora 28 Kasım 2025 10:39
можете ли вы заработать играя в распространяемые на безвозмездной основе игры со всеми знакомыми? как заработать играя в бесплатные [url=http://zsaek.tsu.ru/user/3464]http://zsaek.tsu.ru/user/3464[/url]?
Spravkiiay 28 Kasım 2025 10:03
Подбираете санитарную книжку срочно в Москве по доступной цене? В медцентре [url=https://hearth-health.ru]https://hearth-health.ru[/url] можно быстро оформить санитарную книжку нового образца от 1 200 ?, перевыпустить медкнижку за 1 800 ? или оформить официальную справку от 1 000 ?, включая обследования по цене 500 ?. Всё — легально, по всем правилам и без хлопот. Удобный режим работы, можно подать заявку онлайн и оформить всё в кратчайшие сроки. <a href="https://hearth-health.ru">https://hearth-health.ru</a> Все детали на сайте — медкнижка срочно, получение через интернет, доступная справка.
Spravkiolm 28 Kasım 2025 09:25
Хотите узнать, где купить санитарную книжку в Самаре срочно и с доставкой? На сайте [url=https://gosdentalklinic-china.ru/]https://gosdentalklinic-china.ru/[/url] можно заказать санитарную книжку удалённо без посещения клиники — оформление занимает всего один день. При оформлении онлайн-заявки возможна получение по адресу, а цены прозрачны: новая книжка с 1 699 ?, продление — от 799 ?. <a href="https://gosdentalklinic-china.ru/">https://gosdentalklinic-china.ru/</a> Всё законно и без проблем. Узнайте подробности — медкнижка онлайн, быстрое оформление, медкнижка с доставкой.
Scotthom 28 Kasım 2025 08:55
instead of In order to transfer your transactions without registration to the interbank market, [url=https://staluminox.pl/2025/10/27/understanding-forex-trading-hours-for-maximum/]https://staluminox.pl/2025/10/27/understanding-forex-trading-hours-for-maximum/[/url] will coordinate them with other internal transactions.
RupertTuh 28 Kasım 2025 08:53
In 2022, the Ontario Alcohol and Addictive Commission allowed betting providers to manage portals online gambling licensed [url=https://www.dynamicretails.com/the-fascinating-world-of-je777-and-its-impact-on/]https://www.dynamicretails.com/the-fascinating-world-of-je777-and-its-impact-on/[/url] with iGaming Ontario.
Spravkiyum 28 Kasım 2025 08:09
Ищете санитарную книжку сегодня же в Санкт-Петербурге без обследования и осмотров? В медцентре [url=https://doktora-gerasenko-med.ru]https://doktora-gerasenko-med.ru[/url] можно купить или обновить официальную медкнижку, справки для бассейна, ГАИ, официальные больничные, медсправки из диспансеров, справки КЭК и другие подлинные справки — всё моментально, законно и без лишних походов к врачу. <a href="https://doktora-gerasenko-med.ru">https://doktora-gerasenko-med.ru</a> Узнайте детали — санкнижка за 1 день, оформить справку быстро, справка без врачей.
Teresaeffok 28 Kasım 2025 08:07
старые фото мы не ограничиваем соратников по признакам сексуальной ориентации, [url=https://h1.nu/1eJbi]https://h1.nu/1eJbi[/url] оттенка кожи, и другим особенностям. Наш анонимный интимный чат открывает все перспективы для интимного общения в уникальном формате.
Spravkimns 28 Kasım 2025 07:30
Для любых автолюбителей — от новичков до бывалых, <a href="https://citroen-avtoservise.ru">https://citroen-avtoservise.ru</a> представлен сайт с ценными публикациями, справочником, событиями и видео. Смотреть полезности > автоблог [url=https://citroen-avtoservise.ru]https://citroen-avtoservise.ru[/url] предлагает авто-советами для любого. Узнай больше — прочитать блог.
Ashleyfeami 28 Kasım 2025 07:22
да бальшая фантазия у таво хто ето сочинял The [url=https://play-betwaycasino.net/]betway[/url] platform, offering a wide collection of slot machines for real funds, classic table game space and advanced jackpots, combines exciting game, transparency and reliability.
Tiffygek 28 Kasım 2025 07:10
Как специалист, могу оказать помощь. each broker has his own policy when conversation underway about visitors depositing money to personal trading account, using [url=https://stageon.site/mastering-live-pocket-option-trading-strategies-9/]https://stageon.site/mastering-live-pocket-option-trading-strategies-9/[/url], or withdrawing money from platform to your bank account.
Michaelteant 28 Kasım 2025 06:59
<a href=https://www.mitasuoil.com/>Visit our homepage </a>
Spravkiwoq 28 Kasım 2025 06:52
Для тех, кто хочет надёжный и современный метод к автомобилю — компания <a href="https://china-avto-k.ru">https://china-avto-k.ru</a> Allcartuning осуществляет чип тюнинг и экономичный тюнинг для машин, тяжёлой техники и спецтехники. С 2007 года наши услуги, сертифицированные TUV, гарантируют повышение лошадей, эффективность и уменьшение расхода топлива. [url=https://china-avto-k.ru]https://china-avto-k.ru[/url] Откройте детали — тюнинг двигателя представлена на ресурсе.
Markflemy 28 Kasım 2025 06:24
это хорошо Её здание является отражением того архитектурного стиля, [url=http://argo-mobile.ru/avtotovary-detskie/zashchita-sidenya/nakidka-zashchitnaya-pvkh-na-sidene-avto-veselyj-alfavit-75-detail/]http://argo-mobile.ru/avtotovary-detskie/zashchita-sidenya/nakidka-zashchitnaya-pvkh-na-sidene-avto-veselyj-alfavit-75-detail/[/url] который сейчас имеется в Туркменистане и в Ашхабаде. Школьная программа (учебная программа, программа обучения) - набор учебных дисциплин для их преподавания в школе.
Spravkirvx 28 Kasım 2025 06:14
Для быстрого осуществления проектов в строительно-дорожной сфере — <a href="https://avtosturman.ru">https://avtosturman.ru</a> компания Авто-Спец-Ресурс осуществляет услуги аренды спецтехники: вышки, грузоподъёмные краны, землеройную технику, грузовые самосвалы, дорожные грейдеры и прочую технику. Наши машины используются для монтажа освещения, уборки снега, доставки гравия, сыпучих материалов или топлива в местные и пригородные районы. [url=https://avtosturman.ru]https://avtosturman.ru[/url] Узнайте больше — спецтехника аренда ожидает вас на ресурсе.
Spravkinrj 28 Kasım 2025 05:35
Если вы хотите подобрать качественные автозапчасти — интернет-магазин Автостилshop.ru предлагает широкий выбор дисков, аккумуляторов, масел и других комплектующих для вашего автомобиля. <a href="https://avtostilshop.ru/">https://avtostilshop.ru/</a> У нас постоянно действуют низкие цены и надежные товары. Доставка — бесплатно делает покупку ещё более удобной. [url=https://avtostilshop.ru/]https://avtostilshop.ru/[/url] Зайдите на Автостилshop.ru и выберите все необходимое для своего авто.
Spravkiolu 28 Kasım 2025 04:57
Ищете возможность взять проверенный автомобиль подержанную недорого? В автосалоне [url=https://avtosteklavoronezh.ru]https://avtosteklavoronezh.ru[/url] представлен большой выбор машин — от машин российского производства до зарубежных автомобилей. Есть услуги трейд-ина, срочного выкупа и автокредитования с низкой ставкой. Каждая машина тщательно проверяется и подготовлена к использованию без расходов на ремонт. <a href="https://avtosteklavoronezh.ru">https://avtosteklavoronezh.ru</a> Всё быстро, без хлопот и официально. Подробнее на сайте — подержанные авто, выкуп авто, автокредит Москва.
Spravkivok 28 Kasım 2025 04:20
Если вы ищете оригинальные автозапчасти — интернет-магазин Avtoplastics предлагает огромный ассортимент деталей для авто самых разных марок. <a href="https://avtoplastics.ru/">https://avtoplastics.ru/</a> На сайте Avtoplastics.ru вы найдёте нужные запчасти — от кузовных элементов до расходников — с интуитивной навигацией и подробным описанием. Оперативная доставка и доступные цены делают покупку выгодной. [url=https://avtoplastics.ru/]https://avtoplastics.ru/[/url] Перейдите на Avtoplastics.ru и найдите нужные запчасти для вашего авто.
Altonmen 28 Kasım 2025 03:43
exinvest limited гарантирует анонимность персональных сведений зарегистрированных [url=https://nwvagtech.co.uk/seat-remapping-in-widnes/]https://nwvagtech.co.uk/seat-remapping-in-widnes/[/url] пользователей. Зарегистрируйтесь немедленно, подберите гейм в подходящей линии и поставьте на любимую команду - возможно, вам повезет!
Tammygox 28 Kasım 2025 03:43
Весьма забавная информация приятные цены на сервис существуют на сайте, [url=http://maskarad.bomba-piter.ru/user/RenatoBordelon/]http://maskarad.bomba-piter.ru/user/RenatoBordelon/[/url] ими можно осведомиться перед оформлением заявки. Юристы visit ukraine - это команда работников с разнообразным опытом работы.
Spravkitla 28 Kasım 2025 03:04
Узнайте максимум об АвтоГрузГрупп — информативные статьи, лайфхаки и свежие материалы! Зайдите на [url=https://avtogruzgroup.ru]https://avtogruzgroup.ru[/url] и прочитайте статьи по автозвуку. Хочешь актуальная информация — этот портал публикует рекомендации, подробные описания и реальные впечатления. <a href="https://avtogruzgroup.ru">https://avtogruzgroup.ru</a> Ищешь автозвук — здесь найдёшь качественную технику и экспертные выводы.
Spravkieyk 28 Kasım 2025 02:26
Узнайте максимум об площадке Авто-Фокус — широкий ассортимент запасных частей, аксессуаров и автокомпонентов для любых машин! Зайдите на [url=https://avto-fokus.ru]https://avto-fokus.ru[/url] и изучите каталог запчастей. Нужна безопасность автомобиля или модернизация мультимедиа? — площадка предлагает оборудование безопасности, автозвук и детали интерьера. <a href="https://avto-fokus.ru">https://avto-fokus.ru</a> Нужен качественный аксессуар — здесь найдёте надёжных производителей и быструю доставку.
Shirleylounk 28 Kasım 2025 02:11
These platforms are also known for their higher weighty share of payouts compared to land-based [url=https://blog.trend.qa/ice-casino-36/]https://blog.trend.qa/ice-casino-36/[/url]. Check out the variety of games, licenses, and acceptable payment methods, to to make sure that platform meets your preferences.
Jenniferfam 28 Kasım 2025 02:10
licensing and modification - before registering on any resource of the [url=https://broemmling-metallbau.de/unlocking-the-excitement-of-online-gaming-with/]https://broemmling-metallbau.de/unlocking-the-excitement-of-online-gaming-with/[/url], make sure that it is licensed by a reputable the organ.
Nancynub 28 Kasım 2025 01:47
Good to have you here. something interesting usually starts with a simple hello. Navigate a peak style casino map offering safe, reliable platforms for Canadian players who want simple, high quality entertainment. п»їhttps://besthotcasino.ca
Spravkipbw 28 Kasım 2025 01:47
Если необходим в кратчайшие сроки проверенный автомобиль в Москве, наём авто от Avtocar5.ru решит задачу в максимально короткие сроки. <a href="https://avtocar5.ru/">https://avtocar5.ru/</a> Широкий выбор машин экономического, стандартного и повышенной категории, гибкие условия проката и мгновенная подача в нужное время обеспечивают комфорт использования. Подходит как для повседневных поездок, так и для корпоративных поездок или поездок на свадьбу. [url=https://avtocar5.ru]https://avtocar5.ru[/url] Посетите Avtocar5.ru и выберите автомобиль, соответствующий вашим задачам.
Spravkiqvo 28 Kasım 2025 00:49
Для владельцев машин в Рыбинске — <a href="https://avtoaibolit-76.ru">https://avtoaibolit-76.ru</a> сервисный центр "АвтоАйболит" предлагает осмотр, сервисное обслуживание, работы с двигателем, трансмиссии, шасси и электрических систем (с услугой замену ремня генератора от 800 ?) на высокоточном оборудовании. [url=https://avtoaibolit-76.ru]https://avtoaibolit-76.ru[/url] Квалифицированные специалисты применяют фирменные запчасти и гарантируют профессиональный ремонт с гарантией. Узнайте деталями — автосервис Рыбинск ждёт вас на портале.
Spravkiaag 28 Kasım 2025 00:11
Интересует медицинскую книжку максимально быстро без ожидания? <a href="https://aleksandriya-med.ru">https://aleksandriya-med.ru</a> В центре Москвы наши профессионалы быстро проводят оформление необходимые справки (справка 086У, справка 095У, справки для автошколы) и доставляют документы домой — законно и удобно. Обратитесь прямо сейчас — всё законно, без лишних платежей! [url=https://aleksandriya-med.ru]https://aleksandriya-med.ru[/url]
Kimberlybut 27 Kasım 2025 23:36
это точно !! площадка также позволяет изменить ваш ip адрес и маскировать [url=https://www.ranchoulinia.pl/pokoje/pokoj-trzyosobowy-podwojne/]https://www.ranchoulinia.pl/pokoje/pokoj-trzyosobowy-podwojne/[/url] вашу локацию. также, стоит помнить, что использование зеркала возможно запрещено законодательством разнообразных государств, поэтому игрокам необходимо оставаться внимательными и руководствоваться правила своей страны.
Spravkiqal 27 Kasım 2025 23:33
Подбираете медсправку за один день в столице — моментально и без посещений врачей? На [url=https://akkred-med.ru]https://akkred-med.ru[/url] можно заказать разные виды справок, от справки 095/у, справки 027/у до решений КЭК, справок для бассейна, занятий спортом и поездок за границу. Заполнение заявки занимает считанные минуты, потом — передача справки заказчику. <a href="https://akkred-med.ru">https://akkred-med.ru</a> Всё легально, без разглашения и без проблем. Все детали на сайте — быстрое оформление справки, справка онлайн, получение с курьером.
Hankdak 27 Kasım 2025 22:52
По моему мнению Вы не правы. Могу отстоять свою позицию. in it in addition presented and widely available for purchase authentic objects creativity and [url=https://mungatsitvc.ac.ke/?p=8727]https://mungatsitvc.ac.ke/?p=8727[/url] of Native Americans, produced in resort conditions.
Harryninee 27 Kasım 2025 21:03
чтобы собрать [url=https://trendbbq.com/videos/woman-on-plane-not-real-full-video/]https://trendbbq.com/videos/woman-on-plane-not-real-full-video/[/url] действующее и официальный платформу, вы можете воспользоваться несколькими источниками, Телеграм-каналами, группами вконтакте либо специализированными сайтами.
Naomibiaby 27 Kasım 2025 19:40
This clothing brand is gaining demand in the [url=https://triowise.org/olymp-casino-online-19/]https://triowise.org/olymp-casino-online-19/[/url], including sports even in online casinos.
MeganMoulk 27 Kasım 2025 19:40
Должен Вам сказать это — грубая ошибка. И потому, что наша организация включаем в свой рацион, как это готовим и едим, [url=https://keydirectories.co.uk/forum/profile/GregoryEan]https://keydirectories.co.uk/forum/profile/GregoryEan[/url] зависит многое.
KeriLum 27 Kasım 2025 19:35
Не пашет другими словами, [url=http://www.harrytromp.nl/en/service-en/]http://www.harrytromp.nl/en/service-en/[/url] если основной фабрика не грузится - не паникуйте. в таких случаях помогают зеркала - это точные копии первичного ресурса, но, с конкурентными адресами.
JanetClott 27 Kasım 2025 19:35
Какой хороший топик en otras palabras apuestas en la Premier League inglesa, [url=https://www.ceroacero.es/noticias/mas-alla-de-los-90-minutos-como-las-plataformas-digitales-mantienen-vivo-el-futbol-durante-toda-la-semana/970712]https://www.ceroacero.es/noticias/mas-alla-de-los-90-minutos-como-las-plataformas-digitales-mantienen-vivo-el-futbol-durante-toda-la-semana/970712[/url], porque tal paso la liga con la mayor tradicion y tradicion en area apuestas deportivas.
AndyMeesk 27 Kasım 2025 15:35
А ты такой горячий в целом, [url=https://thegioidungcukhachsan.com/sp/thung-rac-2-lop-trash-2-grades-sacona-sn684504]https://thegioidungcukhachsan.com/sp/thung-rac-2-lop-trash-2-grades-sacona-sn684504[/url] 1хбет это является проверенным вариантом минования блока портала – и продолжения активности на платформе.
Michellerurdy 27 Kasım 2025 15:35
Я извиняюсь, но, по-моему, Вы не правы. Могу отстоять свою позицию. Пишите мне в PM. Simbolos de pago alto: Simbolos que pagan al menos diez veces mas de la cantidad de su contribucion, cuando logre apostar 3 o mas [url=https://es.besoccer.com/noticia/mas-que-un-juego-la-revolucion-digital-detras-de-las-apuestas-de-futbol-en-vivo-1380192]https://es.besoccer.com/noticia/mas-que-un-juego-la-revolucion-digital-detras-de-las-apuestas-de-futbol-en-vivo-1380192[/url] mas de ellos.
Susanfounk 27 Kasım 2025 14:42
Жаль, что не смогу сейчас участвовать в обсуждении. Очень мало информации. Но с удовольствием буду следить за этой темой. Chips-in's Island Resort and Casino is a small resort and [url=https://www.jjmcdiarmid.com.au/2025/10/23/top-alternatives-to-pocket-option-for-trading-6/]https://www.jjmcdiarmid.com.au/2025/10/23/top-alternatives-to-pocket-option-for-trading-6/[/url] that can be found in Harris, Michigan. here also are displayed and available for acquisition authentic masterpieces creativity and crafts of Native Americans of local production.
IrisSed 27 Kasım 2025 14:23
при постепенном существовании нескольких зеркал не стоит расстраиваться, [url=http://greencroftmilksuppliesltd.co.uk/product/kiwi/]http://greencroftmilksuppliesltd.co.uk/product/kiwi/[/url] если нормальное зеркало завтра будет заблокировано.
AshleyKem 27 Kasım 2025 14:14
Подтверждаю. Всё выше сказанное правда. Давайте обсудим этот вопрос. join [url=https://play-betwaycasino.org/]betway casino games[/url] now, and plunge in awesome internet-slot machines, in secure and entertaining the game environment.
KellyFox 27 Kasım 2025 13:58
Дробышевский, С. В. Как одевались люди? Это меховые и кожаные плащи, из кожи и костяные элементы защитной одежды, [url=https://www.gattacicova.eu/2020/10/13/hello-world/]https://www.gattacicova.eu/2020/10/13/hello-world/[/url] примитивная обувь и обмотки для штанов.
JohnnyJaisa 27 Kasım 2025 13:43
L’offre de depart 1xBet offre aux utilisateurs inscrits de reclamer jusqu’a 100 % de bonus jusqu’a une valeur totale de 100 €. Sans necessiter de code specifique, le bonus de base s’applique des le premier versement. Le code promo 1xBet valide n’est pas obligatoire pour obtenir la recompense. Pour en savoir davantage, vous pouvez visiter ce lien : https://stocksng.com/art/code_promo_175.html
<a href=https://budu 27 Kasım 2025 13:28
Промокод – это комбинация символов, которую вводят в специально отведенную строку на сайте. После активации кода, пользователь получит вознаграждение от любимого БК. Обычно к промокоду прилагается подробное описание всех предлагаемых бонусов. Но иногда букмекеры позволяют игрокам выяснить назначение кода самостоятельно, ведь многие любят сюрпризы. В случае с промокодом, сюрприз наверняка окажется приятным, ведь его главная цель – создать игроку комфортные условия, заслужить лояльность. Существуют промокоды для новых игроков, которые действительны только при регистрации, и для постоянных – окно для ввода таких кодов находится под формой пополнения игрового баланса. <a href=http://p45.su/wp-content/plugins/elements/melbet_promokod_bonus_pri_registracii.html >промокод мелбет при регистраци
MarcianuG 27 Kasım 2025 13:09
when ordering products for making a deposit, which you plan use, requirements for game in an [url=https://office.aqsha.my.id/librabet-app-la-mejor-experiencia-de-apuestas-en-2/]https://office.aqsha.my.id/librabet-app-la-mejor-experiencia-de-apuestas-en-2/[/url] are able have primary value.
Allagdi 27 Kasım 2025 11:48
In an era epoch where the flood deluge of information never ceases stops, discerning discriminating audience seek look for a beacon signal of clarity plainness, insight understanding, and understanding comprehension. Insanityflows.net stands prevails as your premier chief cyber news agency bureau, delivering conveying the most current latest and comprehensive extensive news from Canada and across the globe earth. Our commitment loyalty to journalistic integrity morality, in-depth detailed reporting, and factual precise accuracy exactness makes us your trusted steadfast foundation for news that matters is significant. Here's why Insanityflows.net should be your go-to selected place for news: http://dragonsgate.awardspace.us/viewtopic.php?f=14&t=6877&p=11227#p11227 http://www.dragonfly-
Allatue 27 Kasım 2025 11:39
In an era period where the flood inundation of information never ceases ends, discerning perceptive browsers seek pursue a beacon marker of clarity clearness, insight understanding, and understanding knowledge. Insanityflows.net stands prevails as your premier leading web-based news agency organization, delivering furnishing the most current contemporary and comprehensive thorough news from Canada and across the globe sphere. Our commitment devotion to journalistic integrity ethics, in-depth detailed reporting, and factual precise accuracy fidelity makes us your trusted reliable origin for news that matters is significant. Here's why Insanityflows.net should be your go-to preferred spot for news: http://boletinelbohio.com/user/allatvp/?um_action=edit http://www.dragonfly-trimarans.org
AnnKitle 27 Kasım 2025 11:28
Да, действительно. Так бывает. Можем пообщаться на эту тему. Установка приложения занимает немного мгновений и, по окончании переговоров gambler сумеет заключать пари, просматривать линию и результаты матчей, [url=https://techrena.net/swapping-blogger-blog-title-post-title-blogger-seo-tweak/]https://techrena.net/swapping-blogger-blog-title-post-title-blogger-seo-tweak/[/url] и получать интересные факты и обзоры о спортивных соревнованиях.
Bridgetdrege 27 Kasım 2025 11:20
Вы серьезно? elott dontson milyen osszeget|mennyit} on akar befizetes a szamlajara, egyaltalan nem szukseges egy pillanatra allitson be realis koltsegvetest a [url=https://www.amigeleken.hu/hirek/eloben-es-kapcsolatban-hogyan-formalja-ujra-a-streaming-a-valos-ideju-szorakozast-2025-11-04]https://www.amigeleken.hu/hirek/eloben-es-kapcsolatban-hogyan-formalja-ujra-a-streaming-a-valos-ideju-szorakozast-2025-11-04[/url], melyik meg kell click at bukmeker.
MonicaMat 27 Kasım 2025 08:47
Очень советую Вам посетить сайт, на котором есть много информации на интересующую Вас тему. Российский магазин парфюма и косметики, [url=http://www.tsv-jahn-hemeln.de/?p=1922]http://www.tsv-jahn-hemeln.de/?p=1922[/url] доступный исключительно для онлайн заказов. современные инновации быстро появляются они образуют больше всего проверенные сетевые биржи в россии.
Junedob 27 Kasım 2025 07:27
4. Дождаться синхронизации с бухгалтерской записью телефона либо другого [url=http://limelighttemplate3.flywheelsites.com/selling-properties/full-width-post/]http://limelighttemplate3.flywheelsites.com/selling-properties/full-width-post/[/url] устройства. Выбирая этот методика, необходимо, чтоб ваши информация в социальных сетях были заполнены правильно.
PatrickSpiFf 27 Kasım 2025 06:58
Я считаю, что Вы ошибаетесь. Могу это доказать. Пишите мне в PM, пообщаемся. для того, чтобы найти 1xbet оно действует и официальный ресурс, вы сможете воспользоваться разными данными, Телеграм-каналами, [url=https://www.misilmerinews.it/2019/06/24/addio-gianfranco-lamico-di-tutti/]https://www.misilmerinews.it/2019/06/24/addio-gianfranco-lamico-di-tutti/[/url] группами вконтакте либо специализированными сайтами.
Susanarelf 27 Kasım 2025 06:50
Да, я вас понимаю. В этом что-то есть и мне кажется это отличная мысль. Я согласен с Вами. для онлайн-платформ важно также выбрать грамотные и проверенные временем платежные решения: вследствие того, что не имеет значения насколько выгодная стоимость товара, [url=https://domfenshuy.net/all-about-repairing/sravnenie-cen-konkurentov-pochemu-odnogo-cennika-nedostatochno.html]https://domfenshuy.net/all-about-repairing/sravnenie-cen-konkurentov-pochemu-odnogo-cennika-nedostatochno.html[/url] если клиент не способен срочно и с комфортом его приобрести.
Laurenttum 27 Kasım 2025 06:28
the player takes a cash transfer to USA, and at the end sends structure to [url=https://www.printkero.com/the-ultimate-guide-to-betbonanza-your-go-to-6/]https://www.printkero.com/the-ultimate-guide-to-betbonanza-your-go-to-6/[/url] the casino.
Charlotteviaws 27 Kasım 2025 06:26
devices for responsible play, in the list of which limits on contributions, timer and versions of self-exclusion, are available on many reputable platforms, hourly in [url=https://makolli.tj/scopri-il-verde-casino-gioco-e-divertimento-a/]https://makolli.tj/scopri-il-verde-casino-gioco-e-divertimento-a/[/url], because if necessary use them.
Anthonynus 27 Kasım 2025 06:09
Смотри у меня! {social media} is one of the {most|most|most|most powerful {tools|devices|equipment} for {promotion|development} {partner programs|partner networks}, {especially|especially|especially} in {Nepal|India}, {where|in which} {used|widely used|applied|widely used} {such|similar} Facebook instagram, telegram, YouTube, #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c621tgb3P2URLBB.txt",1,N], and {facebook|fb}. {resources|platforms|services}.
alkogolizmcherepovec 27 Kasım 2025 04:46
вывод из запоя череповец <a href=https://vivod-iz-zapoya-cherepovec016.ru>vivod-iz-zapoya-cherepovec016.ru</a> лечение запоя череповец
Kellygew 27 Kasım 2025 00:37
следует зайти в него и выбрать поле [url=https://sterkinstilte.nl/2022/08/23/het-herstellen-en-behouden-van-mobiliteit-en-functionaliteit]https://sterkinstilte.nl/2022/08/23/het-herstellen-en-behouden-van-mobiliteit-en-functionaliteit[/url] «Вывести со счетов». в этом аспекте вряд ли кто сумеет посоревноваться с компанией.
TammyEvids 27 Kasım 2025 00:17
В крито-микенскую эпоху (xvi-xiii вв. до н. э.) обычный наряд мужчин состояла из набедренной повязки, а праздничная - из длинной цветной юбки, [url=https://toddtaxbookkeeping.com/page19.php]https://toddtaxbookkeeping.com/page19.php[/url] поверх которой набрасывалось похожее на сетку одеяние.
Mariannebaity 27 Kasım 2025 00:00
are aware that rollovers are calculated by the method multiplying the amount originally credited to any account by [url=https://arimagh.generalresource.ne.jp/casino1/101419/]https://arimagh.generalresource.ne.jp/casino1/101419/[/url]a certain|specific|some} number of times?
AshleySop 26 Kasım 2025 23:59
Also pay attention to special slot machines, like slingo and special lottery slots, [url=https://www.effectiveratecpm.com/k8bre2ti7n?key=27b7fa6b5ea53e54cab997a551329c46/?p=16742]https://www.effectiveratecpm.com/k8bre2ti7n?key=27b7fa6b5ea53e54cab997a551329c46/?p=16742[/url], if you want earn tasty winnings on spin or want receive satisfaction from other gambling.
alkogolizmchelyabins 26 Kasım 2025 23:08
экстренный вывод из запоя <a href=https://vivod-iz-zapoya-chelyabinsk015.ru>vivod-iz-zapoya-chelyabinsk015.ru</a> вывод из запоя
StellaMok 26 Kasım 2025 22:39
Браво, блестящая идея и своевременно к самой популярным аппаратам в 1xbet casino относятся следующие: mega joker, jack hammer 2, [url=https://tapten.club/2020/05/29/vision-2015-2016/]https://tapten.club/2020/05/29/vision-2015-2016/[/url] blood suckers и другие.
EpicksonJoype 26 Kasım 2025 21:54
вот и поздравили...=) Предохраняет тело от отрицательного воздействия окружающей [url=https://powershare.com.sg/2012/09/07/standard-post-with-featured-image/]https://powershare.com.sg/2012/09/07/standard-post-with-featured-image/[/url] среды. Безрукавка находилась в разнообразных местах заштопана нитками из волокон жёсткой травы.
ZoeQuoli 26 Kasım 2025 21:45
Всё выше сказанное правда. Давайте обсудим этот вопрос. As a trader using the pocket option, [url=https://shepherdsflock.com.ph/2025/10/23/pocket-option-app-the-ultimate-trading-tool/]https://shepherdsflock.com.ph/2025/10/23/pocket-option-app-the-ultimate-trading-tool/[/url] platform, you have the opportunity be confident that it offers widest selection of trading assets and pleasant interface.
CharleneTulge 26 Kasım 2025 20:46
Поздравляю, мне кажется это блестящая мысль in similar game provided bonus features that increase your bet by two hundred times, and for [url=https://play-bovada.us/]bovada online casino login[/url] - advanced jackpot.
Lloydgek 26 Kasım 2025 19:16
Visit our digital platform : https://madguy.ru/
SherryBundA 26 Kasım 2025 18:37
Я считаю, что Вы допускаете ошибку. Давайте обсудим. Вывод суммы на карту, [url=https://lamarea.ind.br/torta-de-liquidificador-de-carne-moida-de-peixe-la-marea/]https://lamarea.ind.br/torta-de-liquidificador-de-carne-moida-de-peixe-la-marea/[/url] быстро, на протяжении получаса приходят.Всем доволен. своего рода массовик, затейник сайт задавшись целью отвлечь людей от проблем.
Richardtag 26 Kasım 2025 18:00
Скачать зеркалка 1xbet не требуется, ведь зеркала представляют из себя альтернативные адреса сайта, [url=https://312sun.anidub.shop/user/Titus84K4657/]https://312sun.anidub.shop/user/Titus84K4657/[/url] доступные используя браузер.
IbrahimZes 26 Kasım 2025 17:40
Resorts World Casino in New York, 11420, Queens, New York, 110-00 Rockaway Boulevard. resorts World, regular the only real casinos in New York, presents to you internet-toy or legal [url=https://thirtyninestripesministry.com/hitnspin-belgium-de-ultieme-bestemming-voor-6/]https://thirtyninestripesministry.com/hitnspin-belgium-de-ultieme-bestemming-voor-6/[/url], where realistic place bets at multiple favorite casinos.
Ashleytum 26 Kasım 2025 17:39
in addition live betting is extensive winnings during NFL games, [url=http://en.cosmoeng21.com/exploring-arada-bet-a-comprehensive-guide-to-7/]http://en.cosmoeng21.com/exploring-arada-bet-a-comprehensive-guide-to-7/[/url], on which visitors take advantage of the chance play with varying odds in the process game .
iouc 26 Kasım 2025 15:04
In the lively world of news, where every minute reveals a new story, staying updated with reliable and timely information is crucial. For Canadians and global news enthusiasts alike, Couponchristine.com appears as a formidable power in the digital news field. Our platform is devoted to bringing you the most up-to-date news from Canada and around the world, ensuring that you remain informed on matters that impact you and the global community. http://www.c-strike.fakaheda.eu/forum/viewthread.php?thread_id=4888 http://kite.nnov.ru/phpbb/viewtopic.php?t=292106 http://www.alkwet.com/vb/showthread.php?t=200692&p=487528#post487528 http://www.c-strike.fakaheda.eu/forum/viewthread.php?thread_id=4791 http://breakingthenewsbarrier.org/viewtopic.php?t=121605
Edithkak 26 Kasım 2025 14:31
Извините за то, что вмешиваюсь… Но мне очень близка эта тема. Пишите в PM. thousands of people online at any time day. by the way, if you love intimate sex on webcam, [url=http://www.pisarevo.com/exploring-the-allure-of-asian-cam-females-3/]http://www.pisarevo.com/exploring-the-allure-of-asian-cam-females-3/[/url] in real time, turn on web cam and get ready for familiarization first-class sex files in rhythm real time on earth!
Stanleyskymn 26 Kasım 2025 13:31
Вы ошибаетесь. Давайте обсудим это. Пишите мне в PM. plus to these features, guests of chips-in's [url=https://www.hcientouno.com/exploring-pocket-option-affiliate-login-a/]https://www.hcientouno.com/exploring-pocket-option-affiliate-login-a/[/url] may resort to the services of nearby other entertainment to make at least some time away from casino.
Joshmoort 26 Kasım 2025 11:24
При способе регистрации, по имейл за игорный стол 1 Икс Бет нужно вписать в анкету контактные и личные сведения, [url=http://contact.revampscripts.com/verify/1xbet-20mex.top/]http://contact.revampscripts.com/verify/1xbet-20mex.top/[/url] включая фио и дату рождения.
Richardpam 26 Kasım 2025 11:17
безусловным интересным видом товаров с казахским орнаментом являются гипсовые [url=http://www.raphoto.it/ciao-mondo/]http://www.raphoto.it/ciao-mondo/[/url] изделия. такие изделия отлично подойдут для декорации вашего местонахождения и будут реальными произведениями искусства.
NicholasSleft 26 Kasım 2025 11:04
Извините, что не могу сейчас поучаствовать в дискуссии - нет свободного времени. Вернусь - обязательно выскажу своё мнение по этому вопросу. вы имеете возможность выбрать тут нужную сантехнику буквально на любой бюджет. мы работаем со большим количеством легендарными брендами, [url=https://iitg.net/2018/05/07/selecting-the-right-tool-for-the-database-project/]https://iitg.net/2018/05/07/selecting-the-right-tool-for-the-database-project/[/url] и можем предложить вам ассортимент сантехники от эконом до престижных класса.
Teddylal 26 Kasım 2025 10:24
Я думаю, что Вы ошибаетесь. Могу это доказать. Пишите мне в PM, пообщаемся. as a consequence Luxembourg positions itself as a model for integrating blockchain into financial regulation, [url=https://trucktechhelp.com/wp-admin/2025/11/19/exploring-the-future-of-tokenized-real-estate/]https://trucktechhelp.com/wp-admin/2025/11/19/exploring-the-future-of-tokenized-real-estate/[/url] provides balance between innovation and security.
WilmaRof 26 Kasım 2025 07:11
[url=https://medium.com/@devichdonovan/viagra-the-most-trusted-solution-for-effective-and-lasting-erectile-dysfunction-treatment-2b8738c54e43]buy real viagra[/url] [url=https://medium.com/@devichdonovan/viagra-the-most-trusted-solution-for-effective-and-lasting-erectile-dysfunction-treatment-2b8738c54e43]viagra pill cost[/url]
AmyVaM 26 Kasım 2025 06:15
Прошу прощения, что вмешался... Я разбираюсь в этом вопросе. Можно обсудить. Пишите здесь или в PM. in such establishments and [url=https://demo.woocommerce-multivendor.com/racloare-am-o-soluie-eficient-pentru-sisteme/]https://demo.woocommerce-multivendor.com/racloare-am-o-soluie-eficient-pentru-sisteme/[/url], the allowed age for gaming in online poker or sweepstakes is 18 years, and for playing slots is 21 years.
AshleyBam 26 Kasım 2025 05:25
не пожалела! this {means|means} that {if|if} {there have been unsuccessful attempts in your apartment|in your family|in your house}, at #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c621rrm16P2URLBB.txt",1,N] you will {still|get{this|something} in return. Most winnings are limited and require wagering, but {still|as before|as before|as for many years before|as for many years before} is a free game.
Violadunny 26 Kasım 2025 03:33
Можно было и получше написать Only actions committed after using of the bonus code are taken into account when fulfilling the [url=https://play-bovada.com/es-pr/bovada-login-secure-access-to-top-casino-slots/]bovada login[/url] rollover requirements.
JenniferPeerm 26 Kasım 2025 00:25
Я знаю сайт с ответами на интересующей Вас вопрос. каким методом clafbebe обеспечивает гарантию, что вам предлагается продукцию, [url=https://marijesteur.nl/product/lefwijf-e-book/]https://marijesteur.nl/product/lefwijf-e-book/[/url] лидирующую на рынке? кроме того, clafbebe предлагает широкий спектр вариантов персонализации, позволяя компаниям и взрослым адаптировать свою продукт к задачам конкретных рынков.
Charloterog 25 Kasım 2025 23:31
Благодарю за помощь в этом вопросе, теперь я не допущу такой ошибки. При снижении эффективности, посторонних шумах, запахах, возможно, [url=https://homeclimat36.ru/catalog/category/1/Gree]сплит система gree[/url] потребуется внеплановое техобслуживание. как работает? Используются вентиляторы, воздуховоды и фильтры для принудительной подачи или удаления воздуха.
ErniePhefe 25 Kasım 2025 14:59
Я конечно, прошу прощения, но это всё не подходит. Есть другие варианты? 3. наличие либо отсутствие шлака: Если металл не может быть сдут в ходе резки, на пластине будет образовываться шлак, [url=https://raymark.ru/oborudovanie/apparat-lazernoy-svarki/apparat-lazernoy-svarki-metalla/]лазерный сварочный аппарат с воздушным охлаждением[/url] который повлияет на качество вашего проекта.
AnneZot 25 Kasım 2025 13:45
Спасибо за поддержку, как я могу Вас отблагодарить? дополнительный плюс Мегафона - он может дать небольшую скидку на популярные мобильную при подсоединении к тарифному плану [url=https://rateproxy.com/user/Kay16N330878341/]https://rateproxy.com/user/Kay16N330878341/[/url] мобильной связи.
JessiepyclE 25 Kasım 2025 10:18
Специально зарегистрировался на форуме, чтобы сказать Вам спасибо за помощь в этом вопросе. how much will it take [url=https://play-bovada.net/]bovada[/url] to pay you money? bovada is very flexible in new attitude and provides duration functioning for six months.
Bigsharknub 25 Kasım 2025 09:22
Greetings! Hope you're having a good one. Your project or personal ambition could use a financial boost. I provide non-repayable grants to selected individuals. Tell me more on WhatsApp wa.me/+380971321036
RickCrart 25 Kasım 2025 06:07
Это было и со мной. Давайте обсудим этот вопрос. Здесь или в PM. Was besonders interessant ist: {Sie/Zuschauer|Benutzer/Besucher} sogar {konnen/haben eine Chance/erhalten eine Chance} {wetten auf/setzen} {Lieblingsspiel|beliebtes|beliebtes/beliebtes Spiel, das Sie mogen} #file_links["C:\Users\Admin\Desktop\file\gsa+de+20kTRB2111251URLBB.txt",1,N] geoguessr. {sie konnen/haben die Moglichkeit,} {den wochentlichen {Bonus|«Brotchen»} fur {Einzahlung|Investition|Eroffnung einer Einzahlung|Einzahlung} in {Wettburos} zu verwenden|zuruckzugreifen.
StaceyKef 25 Kasım 2025 04:27
Я готов вам помочь, задавайте вопросы. Baccarat has gained popularity among British players, especially in games with great bets. bank cards (visa, [url=https://mehedi.royalbd.my.id/discover-the-new-king-casino-bonus-in-the-uk-2/]https://mehedi.royalbd.my.id/discover-the-new-king-casino-bonus-in-the-uk-2/[/url] mastercard) - instant deposits and withdrawal funds for 24- installation of a frame pool .
Stephaniefeabe 24 Kasım 2025 21:23
Лучше поздно, чем никогда. Wir haben bemerkt, entdeckt|verstanden, dass fur erste Einlagen die ublichen Varianten sind, Typ Kreditkarten (visa, mastercard), Bankuberweisung/Uberweisung}, mifinitiy, [url=https://www.football-aktuell.de/cgi-bin/news.pl?artikel=176280900590]https://www.football-aktuell.de/cgi-bin/news.pl?artikel=176280900590[/url] klarna oder cashtocode, waren/waren verfugbar genau wie/genau wie und einige/andere Kryptowahrungen.
Danielknigo 24 Kasım 2025 18:27
Согласен, это забавная штука в 2 десятках-е годы xx века немецкий инженер Роберт Бош усовершенствовал встроенный топливный насос высокого давления, устройство, [url=https://clck.ru/3QNrGx]доставка дизельного топлива[/url] каковое хорошо применяется и в наше время.
AlvinSwoth 24 Kasım 2025 17:16
На официальном сайте компании всегда актуальные данные > http://ruptur.com/
<a href=http://vavto 24 Kasım 2025 16:28
Используя промокод Мелбет при регистрации, игроки получают доступ к участию в приветственной бонусной программе. Полученные привилегии можно использовать, заключая ставки на ММА и другие виды спорта. Ниже рассказываем более подробно о том, какие бонусы предложены на сайте и как их отыграть. Бонусные программы нацелены на то, чтобы обеспечить для игроков возможность получить безболезненный опыт игры на сайте и сгладить первые возможные неудачи. Регистрируйтесь на платформе букмекера, активируйте <a href=https://asteriayeisk.ru/wp-content/plugins/elements/sekrety_uspeshnogo_poiska_raboty.html >промокод для мелбет</a> и пользуйтесь бонусными предложениями от букмекера Мелбет, чтобы получать больше положительных эмоций при заключении пари.
JohnnyJaisa 24 Kasım 2025 16:11
<a href=https://www.locafilm.com/wp-includes/pages/code_promo_1xbet_bonus.html >Code Promo Pour 1x Pari</a> vous permet d'obtenir un bonus VIP de 100% jusqu'a €130 sur les paris sportifs, en plus d'un bonus de €1950 sur le casino en ligne et 150 tours gratuits. Grace au code promo 1xbet vous augmenterez vos chances de gains. Entrez le code promo 1xBet lors de votre inscription et recevez un bonus de bienvenue garanti. Disponible uniquement pour les nouveaux joueurs, ce qui augmente considerablement le montant de votre premier depot.
Robertkek 24 Kasım 2025 16:07
Нет смысла. 9?? deposits/deposits/contributions and housing/apartment rental/withdrawal finances in casino cage - in states where draftkings operates betting shops or [url=https://play-draftkings.com/]draftkings[/url] casino users may to deposit and withdraw funds personally at casino cage.
JohnFlick 24 Kasım 2025 14:54
Фигня Подскажите, я правильно понимаю что, если найти 5 листов нори, [url=https://www.roukatravel.tn/item/259-fiche-vierge-modele]https://www.roukatravel.tn/item/259-fiche-vierge-modele[/url] то получится примерно 60 роллов?
zapojkrasnoyarskrix 24 Kasım 2025 13:25
Наркологическая помощь в Красноярске занимает центральное место в борьбе с зависимостями. Клиники, такие как <a href=https://vivod-iz-zapoya-krasnoyarsk018.ru>vivod-iz-zapoya-krasnoyarsk018.ru</a>, предлагают профессиональную терапию для людей, столкнувшихся с наркотической и алкогольной зависимостями. В процесс лечения зависимостей входит стационарные программы и программы восстановления, которые способствуют возвращению к полноценной жизни.Наркология Красноярск обеспечивает конфиденциальность, что особенно важно для людей в трудной ситуации. Здесь также доступна консультация специалистов, где специалисты помогают определить степень зависимости и разрабатывают индивидуальный план лечения. Семейная поддержка также является существенным элементом процесса реабилитации. Медицинская помощь
ThevocabZof 24 Kasım 2025 12:39
гуд информация detalle informacion sobre primer caso de eliminacion directa otro torneo edicion de Argentina [url=https://es.besoccer.com/noticia/como-usar-estadisticas-resultados-tiempo-real-apuestas-futbol-blitzbet-1380187]https://es.besoccer.com/noticia/como-usar-estadisticas-resultados-tiempo-real-apuestas-futbol-blitzbet-1380187[/url].
ZacharyJAb 24 Kasım 2025 09:18
И что же? Автозаправочные станции (АЗС) - оптовые покупки предоставляют шанс получать продуманные стоимость [url=https://clck.ru/3QNrRp]доставка дизельного топлива[/url] для розничной продажи. связываясь с нами, вы будете гарантируем качество и своевременности заказанной услуги.
vivodkrasnoyarskrix 24 Kasım 2025 01:39
Капельница от запоя – это важная мера первой помощи при пьянстве. <a href=https://vivod-iz-zapoya-krasnoyarsk016.ru>Нарколог на дом круглосуточно</a> предоставит срочную помощь‚ содействуя в процессе дезинтоксикации и восстановления после запоя. Симптомы алкоголизма‚ такие как тошнота‚ головная боль и слабость‚ требуют немедленного вмешательства. Терапия при запое включает инфузии‚ которые помогают бороться с абстиненцией и детоксифицировать организм из организма. Обращение к наркологу важна для установления последующей терапии: стационарное лечение или поддержка на дому. Специализированная наркологическая клиника предлагает экспертное лечение‚ чтобы исключить возможность рецидива и заботиться о здоровье пациента.
DevonBeini 23 Kasım 2025 21:46
Попал мужик! The maximum amount of deposit at [url=https://1win--casino.net/]1win aviator[/url] is usually 30.00 reais, although depending on the settlement method, the limits vary.
отели посуточно 23 Kasım 2025 18:25
Вау, красиво портал. Спасибо... Посетите также мою страничку отели посуточно https://tiktur.store/
RyanEnarl 23 Kasım 2025 16:02
Ура! и спасибо!))) Костяк нашей команды составляют лучшие профессионалы, [url=https://lnk.bz/qI8qb]https://lnk.bz/qI8qb[/url] чей многолетний навык - лучшая гарантия качества и впечатляющего дизайна наших изделий.
JessieRulse 23 Kasım 2025 15:49
Извиняюсь, но мне необходимо немного больше информации. Рядом расположены серьезные объекты: новая школа, поликлиника, различные супермаркеты и услуги, требуемые для уютной жизни.транспортная доступность:Регулярное сообщение с городом обеспечивается частым движением автобусов и маршруток с интервалом в десять минут.так, покупка данного таунхауса станет правильным вариантом для тех, кто уважает уют, [url=https://muzeon.ru/biznes/8020-vybiraem-nedvizhimost-v-moskve-i-podmoskove.html]https://muzeon.ru/biznes/8020-vybiraem-nedvizhimost-v-moskve-i-podmoskove.html[/url] функциональность и прекрасное местоположение жилья в которых предусмотрена возможность быстро угодить в какую угодно точку города.дом, покупают под семейную ипотеку!
vivodkrasnodarrix 23 Kasım 2025 14:20
вывод из запоя краснодар <a href=https://vivod-iz-zapoya-krasnodar024.ru>vivod-iz-zapoya-krasnodar024.ru</a> вывод из запоя цена
TammyCooWs 23 Kasım 2025 07:07
Я думаю, что Вы допускаете ошибку. Предлагаю это обсудить. бесценный достоинство для сладкоежек - в каждом заказе есть сладкий сюрприз. на нашем онлайн-портале собрана только оригинальная сертифицированная [url=https://deep-euphoria.ru/]https://deep-euphoria.ru/[/url], так как мы работаем только с признанными дилерами и срочными поставщиками.
izzapoyakrasnodarrix 23 Kasım 2025 02:27
лечение запоя краснодар <a href=https://vivod-iz-zapoya-krasnodar022.ru>vivod-iz-zapoya-krasnodar022.ru</a> вывод из запоя круглосуточно
Karenabund 22 Kasım 2025 22:35
Страхово наверное ... Забрать заказ можно в тот же день, хранение - 3 денька! несложно: найдите всё необходимое, [url=https://i-cosmetica.ru/]https://i-cosmetica.ru/[/url] и при наличии товара, мы соберем ваш заказ прямо с полок магазина!
Vikiawz 22 Kasım 2025 18:58
Бажаєте перебувати в курсі всіх актуальних новин планети? Бажаєте дізнатися останні статті з перших уст? Тоді рекомендуємо підписатися на ЗМІ Rusjizn. У нас ви можете прочитати соковиті публікації економіки та політики країн, отримайте інформацію про поточні військові конфлікти на земній кулі, поринете в Світ дикої природи. І це все на одному веб-сайті. Також ми створюємо щотижневі підбірки найбільш важливих новостей і Вам не доведеться перечитувати кожну статтю щоб не пропустити найцікавіше. Дані публікації можна отримувати на телефон та не витрачати час на прочитання всіх статей . http://www.mutterkind-kur.de/forum/viewtopic.php?f=111&t=1252153 http://www.dragonfly-trimarans.org/phpBB/viewtopic.php?t=10941 http://www.c-strike.fakaheda.eu/forum/viewthread.php?thread_id=4446 h
Vikicdo 22 Kasım 2025 17:36
Бажаєте бути в курсі всіх актуальних новин Світу? Хочете прочитати останні новини з перших уст? Тоді пропонуємо підписатися на ЗМІ Rusjizn. У нас ви знайдете важливі публікації економіки та політики країн, дізнаєтеся про гарячі військові конфлікти на земній кулі, поринете в Світ дикої природи. І це все на одному веб-сайті. Також ми створюємо щотижневі збірки найбільш жвавих публікацій і Вам не доведеться вивчати кожну новину щоб не пропустити найважливе. Дані новини можна отримувати на телефон та не витрачати час на вивчення всіх новостей . http://dragonsgate.awardspace.us/viewtopic.php?f=22&t=6770 http://www.alkwet.com/vb/showthread.php?t=193490&p=467346#post467346 http://www.alkwet.com/vb/showthread.php?t=193327&p=466854#post466854 http://1er-online.de/viewtopic.php?t=83879
RikkiEvito 22 Kasım 2025 16:58
.Мне лично не очень понравилось .Если оценивать,то где-то 3/5 принимая решение о партнерстве с повышенным партнером, мы стремимся не просто расширить каталог, [url=https://edmarmy.com/connecting-through-music-vinylly-the-new-dating-app/]https://edmarmy.com/connecting-through-music-vinylly-the-new-dating-app/[/url] а также повысить качество предоставленной товара.
Frankric 22 Kasım 2025 16:56
хоошь! Betmaze Casino offers this completely for diverse thanks to the significant selection of games in the [url=http://stjamessec.edu.tt/wordpress/?p=73044]http://stjamessec.edu.tt/wordpress/?p=73044[/url]. time of work The spins expire after day.
narkologiyakalugarix 22 Kasım 2025 14:18
лечение запоя калуга <a href=https://vivod-iz-zapoya-kaluga018.ru>vivod-iz-zapoya-kaluga018.ru</a> вывод из запоя
Everettzinny 22 Kasım 2025 13:35
кульно!!! Плоды, контент и доходы, полученные фермерским хозяйством вследствие использования его имущества, [url=https://sterligov.com/]https://sterligov.com/[/url] являются общим имуществом членов сельского хозяйства.
AdrianaLef 22 Kasım 2025 09:17
во блин жесть такие изматают насмерть when you want to immerse yourself in the real casino atmosphere, online shooters at leovegas [url=https://play-leovegas.net/pt-br/leovegas-demo-games-try-top-slots-with-bonuses/]leovegas casino[/url] are that that extremely necessary.
zapojkalugarix 22 Kasım 2025 08:18
экстренный вывод из запоя <a href=https://vivod-iz-zapoya-kaluga017.ru>vivod-iz-zapoya-kaluga017.ru</a> вывод из запоя круглосуточно
MadisonFaf 22 Kasım 2025 07:45
Умница b) and 1x per rotation. puntit is weighty of the unique internet playgrounds launched in Great Britain, [url=https://mujernuncapermitas.com/your-guide-to-online-sports-betting-companies-in/]https://mujernuncapermitas.com/your-guide-to-online-sports-betting-companies-in/[/url], and similar is a real paradise for gamblers.
Danielthelt 22 Kasım 2025 05:06
Прикольные слова транспортировка и установка. мы гарантируем: доставку из Белой Церкви по всей территории Украины и сборку товаров по киеву [url=http://floridaconcertflyers.com/blog/45/berlin-philharmonic-orchestra-fails-to-elect-conductor/]http://floridaconcertflyers.com/blog/45/berlin-philharmonic-orchestra-fails-to-elect-conductor/[/url] и внимательно.
EvelynPielo 22 Kasım 2025 04:46
Да ну... Самая поразительна память - [url=https://universewomen.ru/]https://universewomen.ru/[/url] память влюбленной женщины. Она мудрей, хитрей, нежней… Они сражаются грудью, ягодицами и во всех обстоятельствах делают ложные выпады.
Matjesudot 21 Kasım 2025 22:57
Я думаю, что Вы не правы. Давайте обсудим. Пишите мне в PM, поговорим. many onlineUK casinos provide exclusive VIPclubs with rewards designed for high rollers and their users. proven casino must provide round-the-clock customer support via live chat, email, [url=https://fb.snsmodoo.com/which-online-casino-has-the-best-games-and-bonuses/]https://fb.snsmodoo.com/which-online-casino-has-the-best-games-and-bonuses/[/url], and exactly phone.
servisnyy_ygkt 21 Kasım 2025 21:22
ремонт bosch [url=https://www.remont-bosch-na-domu-msk.ru/]сервисный центр bosch в москве[/url]
Fcfrmag 21 Kasım 2025 18:33
[url=https://nanscreativeadv.com/menggagas-dinamika-perkembangan-running-text-di-semarang-menyinari-kota-dengan-pesan-pesan-berkualitas/]pinco kampanya kodu 2024[/url] http://shizuku-baby.achakobo.com/1/limanlarda-nec-qazanmaq-olar-pinco-casino-saytnda-4/ [url=https://shugakukai.co.jp/category/blog/0/page/16/]"pinco casino az azЙ™rbaycanda rЙ™smi sayta giriЕџ onlayn oynayД±n pinco qeydiyyat"[/url] https://eximgaleria.com/azrbaycan-pinco-onlayn-kazinosunun-rsmi-sayt-73/ [url=https://athmartravel.com/hello-world/]pinco giriЕџ yap[/url] https://calihomes.com.vn/cali-homes-chinh-thuc-ky-ket-phan-phoi-du-an-lumiere-boulevard/ [url=http://www.morikouji.jp/seo-anomaly-com/6830.html]kazino online azerbaycan[/url] https://jlairductmechanical.com/2023/06/29/about-us/ [url=https://act
Bridgetweath 21 Kasım 2025 17:43
Конечно. Я согласен с Вами. стоимость товаров и отличное признана два основных фактора, [url=http://www.genebiotech.co.kr/bbs/board.php?bo_table=free&wr_id=7695780]http://www.genebiotech.co.kr/bbs/board.php?bo_table=free&wr_id=7695780[/url] обуславливающих популярность горок Белдрев.
Terryamomo 21 Kasım 2025 15:34
В ЭТОЙ СТАТЬЕ СОБРАНЫ САМЫЕ АКТУАЛЬНЫЕ ССЫЛКИ И ПЕРЕХОДНИКИ НА ПЛОЩАДКУ КРАКЕН НА 26 ОКТЯБРЯ 2025! Мы расскажем, как безопасно и быстро попасть на официальный сайт магазина Kрaкен с помощью ссылки Все ссылки и переходники на Kрaкен Маркетплейс могут часто изменяться по соображениям безопасности. Для того чтобы не попасть на мошеннические сайты, важно использовать только проверенные источники. В 2025 году актуальными остаются следующие зеркала и переходники: 1) Официальная ссылка для входа на сайт: kra45.shop 2) Официальный сайт-переходник: https://kra45.shop 3) Кракен ссылка (взята из официальной инструкции кракен): https://kra45.shop ?? Рекомендуем сохранять эти ссылки и зеркала, так как они могут быть удалены по мере изменения адресов. Проверяйте их регул
narkologiyairkutskri 21 Kasım 2025 14:53
вывод из запоя круглосуточно иркутск <a href=https://vivod-iz-zapoya-irkutsk014.ru>vivod-iz-zapoya-irkutsk014.ru</a> вывод из запоя
Jefflaree 21 Kasım 2025 06:02
Конечно, само собой разумеется. расходы в московских ресторанах mcdonald's остаются доступными для [url=http://www.maxes.co.kr/bbs/board.php?bo_table=free&wr_id=2429799]http://www.maxes.co.kr/bbs/board.php?bo_table=free&wr_id=2429799[/url] огромного количества жителей столицы. Сеть ресторанов mcdonald's остается популярным местом быстрого питания в нашем мегаполисе.
Spravkivvd 21 Kasım 2025 05:21
Требуется санитарная книжка оперативно для работников или организаций? На [url=https://cmc-clinic.ru]https://cmc-clinic.ru[/url] в Москве сделают или продлят медкнижку за один день — оперативно, надёжно и без очередей. Переходите на сайт.
Dawnitaft 21 Kasım 2025 05:18
И что в таком случае нужно делать? many casinos The UK offers slots with advanced jackpot, [url=https://www.sodafci.com/2025/10/28/discover-the-best-no-deposit-online-casinos-in-the/]https://www.sodafci.com/2025/10/28/discover-the-best-no-deposit-online-casinos-in-the/[/url], where players able to win amounts that are able change their existence.
Spravkiqre 21 Kasım 2025 04:52
Хотите заказать онлайн медсправки без ожидания и задержек? На сайте [url=https://z32-med.ru]https://z32-med.ru[/url] настоящий документ можно получить в тот же день — от документов для бассейна, детского лагеря и школы до формы 095/у, справки 086/у, решений комиссии и анализов. Более 10 лет работы, официальное партнёрство, и официальные формы подтверждают защищённость и легальность. Предлагаются доступные цены, полный спектр услуг и доставка по Москве. Узнайте подробности — медсправка без очередей, справка за 1 день, официальные справки.
XRumerTest 21 Kasım 2025 04:24
Hello. And Bye.
Spravkixef 21 Kasım 2025 03:57
Узнайте детальнее о преимуществах взаимодействия с компанией — стабильность, качество и широкий выбор решений! Перейдите на [url=https://tdstyling.ru]https://tdstyling.ru[/url] и ознакомьтесь цены, способы связи, а также интересные статьи. Планируете партнёрство — эта организация гарантирует тематические ссылки, оптимальные решения и доступные цены.
Spravkindv 21 Kasım 2025 03:03
Для владельцев Mercedes, отдающих предпочтение надёжность и комфорт — профессиональный техцентр оказывает широкий набор услуг: слесарный и кузовной, проверку, монтаж Webasto, ГБО и многое другое. [url=https://specavtoimport.ru]https://specavtoimport.ru[/url] Профессиональные мастера обслуживают на современном инструменте, применяя фирменные запчасти и гарантируя страховку и личный подход. Посмотрите информацией — автосервис Mercedes готов помочь на сайте.
Spravkigeq 21 Kasım 2025 02:33
Хотите найти оперативный способ заказать медсправку удалённо? [url=https://space-group-med.ru]https://space-group-med.ru[/url] На сайте Space Group Med доступен широкий спектр справок — от справки 001-ГСУ, справки 082/у, до освобождений от физкультуры, документов из психоневрологического или наркологического диспансера и КЭК-заключений. Всё это доступно через интернет с доставкой в столице и Петербурге — удобно, в течение дня и легально. Посмотрите детали на сайте — онлайн справка, медсправка курьером, справка за 1 день.
Spravkiqkl 21 Kasım 2025 02:08
Для собственников Nissan, заинтересованных в качественном ремонте и детальном сервисе — автотехцентр оказывает механический и кузовной, проверку, сход-развал, обслуживание АКПП, инсталляцию ГБО, Webasto, тонировку и прочие работы. опытные автомеханики работают на современном станках, задействуют фирменные запчасти и гарантируют удобное обслуживание с комфортным залом и Wi-Fi. [url=https://skupkaavtosp.ru]https://skupkaavtosp.ru[/url] Узнать подробностями — ремонт Nissan предлагает услуги на сайте.
Spravkinaz 21 Kasım 2025 01:10
Узнайте все подробности о компании Restyle-Авто — современный автоцентр, большой ассортимент, доступные предложения и проверенные предложения! Перейдите на [url=https://restyle-avto.ru]https://restyle-avto.ru[/url] и ознакомьтесь автомобили на складе. Подбираете машину или самую выгодную сделку — автосалон предлагает продажу с пробегом, обмен Trade-In и оформление на месте. Нужен авто быстро — здесь найдёте лучшие условия покупки и прозрачные сделки.
Spravkidwy 21 Kasım 2025 00:43
Подбираете место, где оформить медсправку без похода в столице? На [url=https://psy-medcentr.ru]https://psy-medcentr.ru[/url] можно получить любые медицинские справки: справка 086/у, справка 095/у, справка 027/у, санитарную книжку, справку КЭК, документы для плавания, академического отпуска и не только. Подать заявку можно за пару минут, а доставка курьером по городу — оперативно и без проблем. Всё законно и анонимно. Смотрите детали — справка без похода к врачу, онлайн оформление, справка с доставкой.
Spravkildc 20 Kasım 2025 23:48
Для собственников Mercedes, отдающих предпочтение надёжность и комфорт — профессиональный автотехцентр выполняет полный спектр услуг: механический и кузовной, компьютерную диагностику, установку Webasto, ГБО и прочее. [url=https://novomed-cardio.ru]https://novomed-cardio.ru[/url] опытные мастера работают на лицензированном станках, применяя оригинальные запчасти и гарантируя гарантию и индивидуальный сервис. Посмотрите информацией — ремонт Mercedes готов помочь на сайте.
MaryVon 20 Kasım 2025 22:58
Замечательная фраза independent because, whether you are an experienced player or just starting out, our site 1win give you want a stimulating, [url=https://1winbetindia.com]https://1winbetindia.com[/url]reliable and profitable environment.
Spravkiapa 20 Kasım 2025 22:00
Узнайте всю информацию об автовладельцах — темы, советы и обновления на автофоруме! Перейдите на [url=https://n-avtoshtorki.ru]https://n-avtoshtorki.ru[/url] и присоединяйтесь актуальные темы общения. Хотите рассказать свою историю или получить совет — площадка предлагает инструкции и лайфхаки, впечатления от авто и новинки автомобильной жизни. Нужна помощь от тех, кто ездит — здесь найдете интересные обсуждения и важные знания.
Spravkibkz 20 Kasım 2025 21:02
Хотите узнать, где срочно получить официальную медкнижку или медсправку по городу — без лишних хлопот? В медицинском центре [url=https://munclinic.ru]https://munclinic.ru[/url] предлагают полный набор медсправок и санкнижек по доступным ценам, с гарантией конфиденциальности и надежностью. Удобная лабораторная служба круглосуточно обеспечивает быстрое обследование, чтобы результаты были в кратчайшие сроки. Принимают опытные специалисты, имеющие официальный допуск и индивидуальным подходом. Весь процесс максимально быстрый — гарантированно, законно и без лишних проблем. Подробнее на сайте — медкнижки Казань, оформление справки недорого, круглосуточная лаборатория.
BrendaTam 20 Kasım 2025 20:52
Мне очень жаль, ничем не могу Вам помочь. Я думаю, Вы найдёте верное решение. And ignition Poker is supported by Bodog and paywangluo, one of the oldest operators of [url=https://play-ignitioncasino.com/hi-in/ignation-casino-ap/]ignition casino[/url]. Ignore the headline offering a bonus of up to $3,000.
Spravkiryn 20 Kasım 2025 20:36
Хотите узнать, где срочно сделать санитарную книжку за один день без толкучки и проблем? На сайте [url=https://medraskhodka.ru/]https://medraskhodka.ru/[/url] можно сделать или продлить медкнижку оперативно: с результатами обследований и заключением терапевта — даже онлайн. Услуга предназначена для сотрудников пищевой отрасли, коммунальных служб и организаций, где требуются профосмотры и аттестация. Оформление займёт минимум времени, а стоимость честная и понятная (от 1 600 ?, обновление с 1 300 ?). Подробнее на сайте — медкнижка в день, онлайн оформление, без ожидания.
Mattidete 20 Kasım 2025 20:24
И что бы мы делали без вашей блестящей идеи dive into Blackjack, Roulette, the [url=https://easecenter.org/2025/10/28/understanding-the-legality-of-online-betting-in-3/]https://easecenter.org/2025/10/28/understanding-the-legality-of-online-betting-in-3/[/url] and Baccarat without any downloads or delays; just play at the fast table any.
Spravkidfc 20 Kasım 2025 20:08
Нужна, где сделать санитарную книжку в городе Подольск быстро и легально — без лишней волокиты и очередей? В клинике на сайте [url=https://med-podolsk.ru]https://med-podolsk.ru[/url] можно оформить официальную книжку, справку для ГИБДД, для плавания, детского лагеря или оружия в течение суток — с лабораторными исследованиями, приёмом у врача и гарантированной легальностью. Минимальные сроки, лёгкая регистрация с 9:00 до 23:00, прозрачные цены — от 500 ? за справки, медкнижка от 1200 ?. Смотрите детали — медкнижка быстро, справка за день, заказ через интернет.
Spravkiuel 20 Kasım 2025 19:39
Ищете подлинные медсправки с курьерской доставкой без лишней бюрократии и ожидания? На [url=https://med-meditsina.ru]https://med-meditsina.ru[/url] можно в короткие сроки оформить медицинские документы — от справок из ПНД, наркодиспансера, справок противотуберкулёзного диспансера до форм 095/у, 027/у, справки 086/у, документов для бассейна, академического освобождения и профосмотров. Всё это делается законно, на официальных документах, при этом возможна доставка в пределах МКАД. Получите справку в тот же день, без похода к врачу — это просто, моментально и законно. Подробнее на сайте — медсправка с доставкой, онлайн оформление, медсправка без ожидания.
Spravkiilx 20 Kasım 2025 19:12
Нужна, где сделать или перевыпустить медкнижку в городе Уфа срочно и с комфортом? В центре [url=https://medmagprof24.ru]https://medmagprof24.ru[/url] можно сделать это без переживаний и задержек — оформление полностью законное и без ожидания. Услуга доступна онлайн и готова быстро. Это удобно, законно и подходит каждому. Узнайте подробности — медицинская книжка Уфа, без толпы, быстрое оформление.
Spravkilgo 20 Kasım 2025 18:42
Нужны медрасходники от проверенного поставщика в регионе? Компания [url=https://medikwest.ru]https://medikwest.ru[/url] поставляет широкий ассортимент изделий — от одноразовой медицинской продукции до расходников для клиник. Имеем партнёрство с лицензированными фабриками, предоставляем стандарты качества, необходимые документы и быструю доставку в Чебоксарах. Это удобно, надёжно и качественно. Узнайте больше на сайте — медизделия, расходники для клиник, официальный поставщик.
IanchOop 20 Kasım 2025 18:37
нормальная идея Базовая нота парфюма определяется веществами с максимально низким уровнем испарения, [url=http://classicalmusicmp3freedownload.com/ja/index.php?title=%E5%88%A9%E7%94%A8%E8%80%85:AnnieHeyer]http://classicalmusicmp3freedownload.com/ja/index.php?title=%E5%88%A9%E7%94%A8%E8%80%85:AnnieHeyer[/url] что образуются на коже дольше всего. СПб., 1895. - Т.
Spravkiajx 20 Kasım 2025 18:15
Нужна, где заказать медкнижку за 1 час по городу, законно и без ожидания? На сайте [url=https://medik-moscov.ru]https://medik-moscov.ru[/url] можно сделать медкнижку для работы в детских лагерях, общепите, гостиницах, клиниках, торговле и многих других сферах. Стоимость: новая санкнижка с 1390 ?, продление — от 780 ?. Всё быстро, с законной защитой и близко к метро. Смотрите детали — медкнижка срочно, оформление за час, официальная санкнижка.
Spravkizus 20 Kasım 2025 17:49
Подбираете место, где оформить медкнижку за 1 день без бумажной волокиты? На сайте [url=https://medic-dpo.ru]https://medic-dpo.ru[/url] предлагается услуга оперативного оформления медкнижки — просто подайте онлайн-заявку и приготовьте документы (паспорт и фото). Для сотрудников ЖКХ, розничной торговли и другого профиля всё проходит быстро и удобно, без ожидания. Получите документ официально и легально — с получением прямо до двери или до метро. Подробнее на сайте — медкнижка за день, заказ через интернет, курьерская доставка.
Spravkislc 20 Kasım 2025 17:23
Нужна официальная справка от врача без визитов к врачу? На [url=https://medical-sozvezdie.ru]https://medical-sozvezdie.ru[/url] можно заказать документы в Москве — от школьной справки 095/у до медицинских документов для РВП или визы — в режиме одного дня. Документы оформляют действующие врачи, используются официальные документы, а курьерская доставка доступна по Москве. Это оперативно, легально и без лишних хлопот — онлайн справка, доставка справки, подлинный документ.
AmyZep 20 Kasım 2025 17:21
Я думаю, что Вы допускаете ошибку. Могу отстоять свою позицию. Пишите мне в PM, пообщаемся. 4. Ликвидация генитального герпеса. [url=https://rossoshru.ru/2025/09/06/zheleznyj-argument-dlya-mozga/]https://rossoshru.ru/2025/09/06/zheleznyj-argument-dlya-mozga/[/url] работает как антисептик, уничтожая бактерии, вирусы и грибки на эпидермисе и слизистых оболочках.
Spravkiulp 20 Kasım 2025 16:53
Ищете простой путь получить официальную справку или медицинскую книжку без очередей и волокиты? В клинике [url=https://med-blesk.ru]https://med-blesk.ru[/url] доступен полный спектр медицинских услуг: оформление медицинских книжек, справок разных форм, диагностики УЗИ, анализы и услуги терапевта — всё официально и официально. Доступна курьерская доставка, а также медицинские осмотры для компаний и сотрудников. Это быстро, гарантированно и профессионально — обслуживает сертифицированный медперсонал. Все детали на сайте — онлайн справка, медкнижка без очередей, заказ справки.
Spravkirjo 20 Kasım 2025 16:26
Нужна санитарная книжка сегодня же без посещения клиники? На [url=https://med-bez-boli.ru]https://med-bez-boli.ru[/url] можно заказать или обновить медкнижку законно, без прохождения врачей — быстро и официально. Сотрудничаем с официальным медцентром и выдаём документы нового образца, оформляем настоящую медкнижку, которую вносят в реестр. Это комфортно, легально и по доступной стоимости. Все детали смотрите — санитарная книжка без врачей, быстрое оформление, заказ медкнижки через интернет.
Spravkifdv 20 Kasım 2025 16:00
Для успешной реализации дорожных и благоустроительных задач — компания Kusok Avto предлагает в предоставление современную дорожно-строительную технику, включая грейдеры, подъёмники и другие машины. [url=https://kusokavto.ru]https://kusokavto.ru[/url] Наш большой стаж в дорожном строительстве и сетевых систем обеспечивает надежность и долговечность. Посмотреть деталями — аренда техники доступна на ресурсе.
lechenieastanarix 20 Kasım 2025 15:58
комплексное лечение алкоголизма <a href=https://reabilitaciya-astana012.ru>reabilitaciya-astana012.ru</a> помощь при наркотической зависимости
Spravkilbl 20 Kasım 2025 15:31
Ищете профессиональную медпомощь рядом с вами? В медицинском центре [url=https://kristall-med.ru]https://kristall-med.ru[/url] предлагаются услуги эндоскопии, функциональных исследований и ДНК-диагностики — с профессиональным оборудованием и комфортными условиями. Центр применяет инновационные методы, сотрудничает с опытными врачами и проводит расширенные диагностические процедуры. Всё это — комфортно, стабильно и на высоком уровне качества. Смотрите детали — функциональная диагностика, анализ ДНК, качественная эндоскопия.
Spravkipgo 20 Kasım 2025 15:04
Хотите купить, где купить медицинскую книжку в городе Пермь законно и без волокиты? На [url=https://klinika-zdorovya-no1.ru]https://klinika-zdorovya-no1.ru[/url] можно сделать санитарную книжку по цене от 1700 ? или перевыпустить существующую — от 1000 ?. Книжки подлинные и легальные, курьер доставит готовую книжку на дом. Всё удобно: передать нужные данные онлайн, внести оплату и дождаться готового документа — без визитов к врачам и очередей. Подробнее на сайте — медкнижка Пермь, оформление без очередей, выгодное продление.
Spravkivdx 20 Kasım 2025 14:35
Узнайте все подробности о дилерском центре JAECOO в Бутово — партнёр бренда в столице: новинки автопрома, выгодные условия, обслуживание и фирменные детали! Зайдите на [url=https://jaecoo-avtorussbutovo.ru]https://jaecoo-avtorussbutovo.ru[/url] и ознакомьтесь с новыми авто. Хотите поездку перед покупкой или финансирование? — компания предлагает рассрочку 0%, оценку авто с выгодой и обслуживание по стандарту дилера. Хочется инновационной марки — здесь найдёте современные модели и профессиональную поддержку.
Spravkiwvy 20 Kasım 2025 14:09
Ищете медицинскую книжку сегодня по городу по доступной цене? В клинике [url=https://hearth-health.ru]https://hearth-health.ru[/url] можно в тот же день заказать официальную медкнижку от 1 200 ?, перевыпустить медкнижку от 1 800 ? или оформить официальную справку по цене 1 000 ?, включая анализы по цене 500 ?. Всё — легально, юридически корректно и без проблем. Удобный режим работы, можно заполнить форму на сайте и оформить всё в кратчайшие сроки. Узнайте больше — медкнижка срочно, оформление онлайн, справка по низкой цене.
Spravkiqkk 20 Kasım 2025 13:40
Подбираете место, где купить санитарную книжку в Самаре срочно и на дом? На сайте [url=https://gosdentalklinic-china.ru/]https://gosdentalklinic-china.ru/[/url] можно заказать санкнижку онлайн без похода в поликлинику — оформление занимает всего один день. При заказе через форму возможна доставка на дом, а стоимость честная: новая книжка с 1 699 ?, продление за 799 ?. Всё официально и комфортно. Узнайте подробности — медкнижка онлайн, оформление за день, курьерская доставка.
MelissaVar 20 Kasım 2025 13:11
Это было и со мной. Данные выигрыши получали единицы, но возможность провоцировала на игру очень многих. Суть данного нововведения состояла в этом, [url=https://www.winozesmakiem.net.pl/?p=15099]www.winozesmakiem.net.pl[/url] что множество прибыли казино возвращалась вам в виде крупных накапливаемых джекпотов.
Spravkinrn 20 Kasım 2025 12:43
Хотите оформить медкнижку в течение суток по городу без медосмотра и лишних процедур? В клинике [url=https://doktora-gerasenko-med.ru]https://doktora-gerasenko-med.ru[/url] можно купить или перевыпустить санкнижку, документы для плавания, ГИБДД, больничные листы, медсправки из диспансеров, справки КЭК и другие законные бумаги — всё быстро, официально и без лишних походов к врачу. Подробнее — санитарная книжка сегодня, оформить справку быстро, справка без врачей.
Spravkishr 20 Kasım 2025 12:16
Для каждых водителей — от стартующих до бывалых, открыт портал с ценными материалами, глоссарием, обновлениями и роликами. Смотреть полезности > сайт-блог [url=https://citroen-avtoservise.ru]https://citroen-avtoservise.ru[/url] делится авто-советами для всех. Узнай больше — изучить статьи.
Spravkitil 20 Kasım 2025 11:48
Для тех, кто подбирает качественный и новейший подход к машине — компания Allcartuning осуществляет прошивку ЭБУ и экономичный тюнинг для автомобилей, грузовых и производственного транспорта. С начала работы наши решения, сертифицированные TUV, гарантируют увеличение мощности, эффективность и уменьшение расхода топлива. [url=https://china-avto-k.ru]https://china-avto-k.ru[/url] Откройте больше — оптимизация двигателя доступна на сайте.
Spravkipln 20 Kasım 2025 11:11
Для оперативного выполнения задач в коммунальном секторе — компания AvtoSpetsResurs предлагает услуги аренды спецтехники: автовышки, крановые установки, экскаваторную технику, грузовые самосвалы, дорожные грейдеры и прочую технику. Наши машины применяются для монтажа освещения, снегоуборки, перевозки строительных материалов, сыпучих материалов или каменного угля в городские и удалённые территории. [url=https://avtosturman.ru]https://avtosturman.ru[/url] Все условия — услуги спецтехники ожидает вас на ресурсе.
Crystalnig 20 Kasım 2025 10:48
Вы, наверное, ошиблись? Yes - provided that you be able to select appropriately licensed operators. The spins are awarded the next day and operate at the [url=https://www.thevoicestudio.it/2025/10/28/discover-the-best-no-deposit-online-casinos-in-the/]https://www.thevoicestudio.it/2025/10/28/discover-the-best-no-deposit-online-casinos-in-the/[/url] until 23:59 GMT.
DarkwebLek 20 Kasım 2025 10:48
Spravkiakq 20 Kasım 2025 10:43
Ищете возможность купить проверенный автомобиль б/у на лучших условиях? В автосалоне [url=https://avtosteklavoronezh.ru]https://avtosteklavoronezh.ru[/url] доступен разнообразный каталог автомобилей — от авто отечественных марок до иномарок. Предлагаются услуги обмена авто, быстрого выкупа и оформления автокредита от 4,9% годовых. Каждая машина тщательно проверяется и готова к эксплуатации без лишних вложений. Всё в короткие сроки, удобно и официально. Подробнее на сайте — подержанные авто, срочный выкуп, автокредит в Москве.
Patrickbit 20 Kasım 2025 09:36
Сегодня получил посыль! В супер упаковке! https://sevbuh92.ru Ок понял спасибо.
Spravkiauv 20 Kasım 2025 08:22
Ищете медицинскую книжку в течение суток моментально? В центре Москвы наши эксперты моментально проводят оформление медицинские документы (086У, форма 095У, для ГИБДД) и привозят в удобное время — законно и удобно. Позвоните уже сегодня — всё официальным образом, оплата после оформления! [url=https://aleksandriya-med.ru]https://aleksandriya-med.ru[/url]
Spravkitbg 20 Kasım 2025 07:52
Нужна справку срочно по городу — моментально и без визитов в поликлинику? На [url=https://akkred-med.ru]https://akkred-med.ru[/url] можно получить медицинские документы, от справки 095/у, 027/у до заключений КЭК, документов для плавания, спорта и виз. Заполнение заявки занимает считанные минуты, потом — курьерская доставка. Всё законно, конфиденциально и без проблем. Все детали на сайте — медсправка быстро, заказ через интернет, справка с доставкой.
alkogolizmastanarix 20 Kasım 2025 06:13
реабилитация от алкоголя <a href=https://reabilitaciya-astana011.ru>reabilitaciya-astana011.ru</a> лечение алкогольной зависимости в стационаре
Patrickbit 20 Kasım 2025 06:10
Всем привет,брал у данного магазина. качество на уровне! спрятано просто огонь,клад четкий!!! <a href=https://prudboy34.ru>купить скорость, кокаин, мефедрон, гашиш</a> Всё отлично все всё получат магаз ровный доказал свой гибгий подход к НАМ заказчикам.Если форс мажёр то всё уладят в НАШу пользу.Отправка осуществляется от 2-10дней в зависимости от заказов то есть загруженности магазина.Без паники братья без паники.
Rodriguezroups 20 Kasım 2025 06:01
не.не для меня уникальная формула добавки позволяет замедлить разрушение хрящевой ткани, способствуя ее восстановлению и поддержанию здорового состояния. Препарат [url=https://zdorovnik.com/molochnicza-pri-beremennosti-simptomy-i-lechenie-bez-straha-za-malysha/]https://zdorovnik.com/molochnicza-pri-beremennosti-simptomy-i-lechenie-bez-straha-za-malysha/[/url] хорошо используется в качестве лекарства первой линии при ревматических заболеваниях.
Shaneres 20 Kasım 2025 05:54
also in category suggested games from 22 series suppliers: in fact, here you can find almost/ almost all most in-demand nicknames: in the international market, the [url=https://immobilienhamburg.eu/2025/11/08/how-to-install-the-1xbet-app-a-complete-guide-3/]https://immobilienhamburg.eu/2025/11/08/how-to-install-the-1xbet-app-a-complete-guide-3/[/url], and also some known exclusively units.
SharonRar 20 Kasım 2025 05:29
Великолепная фраза на наших страницах есть раздел, отведенный технике от эппл: iphone 8, iphone xr, ipad), умные часы (elari kidphone, baby watch, carcam) и принадлежности для телефонов (внешние аккумуляторы, док-станции, [url=http://www.gildaarezzo.net/25/11/2016/come-ottenere-lidentita-digitale/]http://www.gildaarezzo.net/25/11/2016/come-ottenere-lidentita-digitale/[/url] моноподы).
Johntep 20 Kasım 2025 05:08
personale (neteller, skrill): pratico e operativo, fornisce un certo grado di anonimato, [url=https://www.dataprotect.sg/i-migliori-siti-scommesse-stranieri-del-2023-7/]https://www.dataprotect.sg/i-migliori-siti-scommesse-stranieri-del-2023-7/[/url] ma loro aspettare/ possono aspettarsi ulteriori spese al momento del prelievo.
Patrickbit 20 Kasım 2025 04:27
А вот стоит пойти чему то не так - и сразу на форум, вот и создаётся впечатление что у всех одни проблемы с товаром... <a href=https://agit-prom.ru>купить Кокаин, Мефедрон, Экстази</a> все как обычно работает
Rikkipeexy 20 Kasım 2025 04:17
чтобы заглянуть к своей странице, [url=http://beautycase-dresden.de/2020/12/09/hallo-welt/]http://beautycase-dresden.de/2020/12/09/hallo-welt/[/url] необходимо только ввести свои информацию. С посторонними источниками возможны варианты, потому употреблять их рекомендуется лишь при условии 100% лояльности к ресурсу.
ValerySkaws 20 Kasım 2025 03:22
Масла из виноградных косточек, [url=https://wildtroutstreams.com/indiana-wild-trout/]https://wildtroutstreams.com/indiana-wild-trout/[/url] орехов. каждая дама сможет отыскать под свои запросы лучшее решение. которые дадут возможность снять напряжение, почувствовать себя гораздо лучше.
DarkNova 20 Kasım 2025 03:02
Posting my personal experience focused on this online casino. I talk about casino promos, financial side, and overall experience. Summing up welcome packages and processing time. Outlining how the system handles and transfers winnings. Reviewing main takeaways I noticed while playing. Writing about what stood out and what could be better. More details are covered in the complete article <a href="https://ventosaterapiacomresultado.com.br/enter-the-magic-of-crown-green-casino-and-explore/">https://ventosaterapiacomresultado.com.br/enter-the-magic-of-crown-green-casino-and-explore/</a>
Patrickbit 20 Kasım 2025 02:45
нервные клетки <a href=https://skbagent.ru>купить Мефедрон, Бошки, Марихуану</a> НЕ принуждаем вас тут брать, берите, где позволяет бюджет.
AdamAmece 20 Kasım 2025 01:28
Developer's response: Hello. It may take up to seven business days to withdraw funds from your bank card in the [url=https://faithheartmagazine.com/instant-betting-revolutionizing-the-gambling/]https://faithheartmagazine.com/instant-betting-revolutionizing-the-gambling/[/url].
WayneHeido 20 Kasım 2025 01:01
заказ дошел до нас))) https://igra18plus.ru Хз .... Дето видел чел писал про вещ-во для снятия лака от ногтей ..... сказал что безпроигрышный вариант )))
Tashajerry 20 Kasım 2025 01:00
Я думаю, что это отличная идея. Cashback is paid in cash freely. duration of functioning is 7 days. There are [url=http://www.aperd.co.jp/casino1/69594/]http://www.aperd.co.jp/casino1/69594/[/url]. Gecko play Casino opens participants significantly more than than just a miniature mascot.
OliviaReich 20 Kasım 2025 00:46
jsou k dispozici ve standardnim i digitalnim provedeni, [url=https://pt.site.uk/nova-online-kasina-ve-co-potebujete-vdt-1271187954/]https://pt.site.uk/nova-online-kasina-ve-co-potebujete-vdt-1271187954/[/url] tak a v formatu Live Kasino.
Joanfax 20 Kasım 2025 00:39
Что он замышляет? The site is available on the entire territory USA (excluding Nevada (nv), Delaware (de), Kentucky (ky), Maryland (md), New York (ny), [url=https://play-ignitioncasino.net/es-mx/ignation-casino-online-top-slots-exclusive-bonuses/]ignition casino casino[/url] and New Jersey (NJ)) and Australia.
lecheniechelyabinskr 20 Kasım 2025 00:36
лечение запоя челябинск <a href=https://vivod-iz-zapoya-chelyabinsk014.ru>vivod-iz-zapoya-chelyabinsk014.ru</a> вывод из запоя
DarkwebLek 19 Kasım 2025 23:01
vivodzapojastanarix 19 Kasım 2025 22:14
как вылечить алкогольную зависимость <a href=https://reabilitaciya-astana010.ru>reabilitaciya-astana010.ru</a> где лечиться от алкоголизма
VannInsic 19 Kasım 2025 21:31
Create your free profile at Fanduel casino as soon as possible and play with conviction, knowing what [url=https://labs.alquds.edu/2025/11/14/entdecken-sie-das-beste-an-casino-spielerlebnissen/]https://labs.alquds.edu/2025/11/14/entdecken-sie-das-beste-an-casino-spielerlebnissen/[/url] you can purchase back up to pieces greenbacks during the first day.
Scottrem 19 Kasım 2025 21:25
Я думаю, что Вы не правы. Пишите мне в PM, поговорим. перед приемом Урбан Формула [url=https://chexov.net/55856-2/]https://chexov.net/55856-2/[/url] капсулы 440мг № 25 старательно ознакомьтесь с инструкцией лака, и четко следуйте указанным рекомендациям.
Sarahkax 19 Kasım 2025 21:13
en el caso de que tenemos aparece un rasguno en [url=https://prasina.gr/shop/router/ultra-hd-2gb8gb-tv-box-3/]https://prasina.gr/shop/router/ultra-hd-2gb8gb-tv-box-3/[/url]. lo primero que que importante pensar es como arreglar ese rasguno.
MichelleDagma 19 Kasım 2025 21:07
The developer's response is Hello. Thank you for your feedback.We apologize for some difficulties, where you encountered when [url=http://www.ousarempresarial.com.br/index/everything-you-need-to-know-about-1xbet-cambodia/]http://www.ousarempresarial.com.br/index/everything-you-need-to-know-about-1xbet-cambodia/[/url].
WayneHeido 19 Kasım 2025 19:56
качество реги просто супер,такого еще не встречали https://artpero-store.ru качество интересует
zapojvladimirrix 19 Kasım 2025 18:56
Капельница от запоя – является ключевым моментом в терапии алкогольной зависимости. В владимире наркологические услуги предоставляют помощь нарколога‚ который проведет детоксикацию организма. Симптомы запоя‚ включая тревога и потливость‚ способны привести серьезные проблемы в результате запоя. Капельница способствует восстановить водно-электролитный баланс и улучшить здоровье после запоя. <a href=https://vivod-iz-zapoya-vladimir026.ru>помощь нарколога владимир</a> После процедуры важно пройти реабилитацию и получить психологическую поддержку. Консультация нарколога поможет избежать рецидивов. Профилактика рецидива предполагает обучение и поддержку‚ что способствует организма. Медицинская помощь при алкоголизме в владимире доступна и эффективна‚ помогая пациентам вернуться к нормальной жизн
Ta,vut 19 Kasım 2025 18:47
Интернет маркетплейс СТЛС - это, когда вы зашли на , портал не чтобы запутаться, а чтоб понять, [url=https://eastmeetswestyog.com/blog/2021/09/23/virtual-paint-night-with-our-esteemed-yogi-artist-mina-daya/]https://eastmeetswestyog.com/blog/2021/09/23/virtual-paint-night-with-our-esteemed-yogi-artist-mina-daya/[/url] что хотите.
zapojchelyabinskrix 19 Kasım 2025 18:46
вывод из запоя <a href=https://vivod-iz-zapoya-chelyabinsk013.ru>vivod-iz-zapoya-chelyabinsk013.ru</a> вывод из запоя цена
Angelicagot 19 Kasım 2025 18:35
With appropriate implementation in an [url=https://www.trattoriarifugio.com/?p=20245]https://www.trattoriarifugio.com/?p=20245[/url] of a PRNG algorithm such as Mersenne twister, the games will be fair and unpredictable.
WayneHeido 19 Kasım 2025 18:14
всё ровно бро делает https://zhivouste.ru Сейчас забегал курьер но без звонка поймал небольшую пароною ведь 203 уже нелегал но всё обошлось всё забрал вес отличный спасибо селеру за быстроту за 3 дня вот это скорость самый наеровнейший магаз и качество полюбому 5+ я уверен как всегда ну это я уже в другой ветке отпишу по пояже как сделаю.
Mirandatonge 19 Kasım 2025 18:12
Я не совсем понимаю, что Вы имеете в виду? вы также имеете возможность гарантированно возместить деньги за любой неиспользованный товар, [url=https://www.interlink.ro/product/product/moreinfo?url=aHR0cDovL21hc3RlcnZzb2NoaS5ydS8]https://www.interlink.ro/product/product/moreinfo?url=aHR0cDovL21hc3RlcnZzb2NoaS5ydS8[/url] который приобрели в магазине. Клубная карта Спортмастер дает скидки до 30% на спортивную обувь.
TracyCig 19 Kasım 2025 16:53
this can guarantee the safety all access into the system with the help of the 2FA application. Get instant access to your 1xbet account and start place bets on competitions, games at casino, [url=https://siac.dev.tqnia.me/1xbet1/experience-the-thrill-of-betting-with-1xbet-3/]https://siac.dev.tqnia.me/1xbet1/experience-the-thrill-of-betting-with-1xbet-3/[/url] and etc.
Leahwailk 19 Kasım 2025 16:28
По моему мнению Вы ошибаетесь. Предлагаю это обсудить. Пишите мне в PM, пообщаемся. in the appendix are all offers and you can admission to all [url=https://www.ladybirdmanor.com.au/the-latest-trends-and-news-in-uk-online-casinos/]https://www.ladybirdmanor.com.au/the-latest-trends-and-news-in-uk-online-casinos/[/url].
JohnathanGAURE 19 Kasım 2025 15:38
Браво, эта весьма хорошая мысль придется как раз кстати ?для организаторов торговли: круглосуточный свободный доступ к миллионной аудитории авторитетной платформы, [url=https://fantazycars.ru/2/tproduct/764826220981-zeekr-001]Авито[/url] простое создание объяв и доверие покупателей.
KevinMem 19 Kasım 2025 14:51
Just pay attention to price volatility and on fact that some sites pay only in [url=https://mimicodentalhygiene.ca/hitnspin-belgium-de-toekomst-van-de/]https://mimicodentalhygiene.ca/hitnspin-belgium-de-toekomst-van-de/[/url], where you made a deposit.
Arthurcet 19 Kasım 2025 14:50
Продолжайте в том же духе. https://kitsune44.ru обращаюсь по возможности сюда беру оптом от 50 грамм
Danagek 19 Kasım 2025 14:29
El retorno al jugador (rtp) varia de 95.5% a 98%. esto dice que jugadores obtienen relativamente altas probabilidades de ganar con el tiempo porque [url=https://davidcisneros.altervista.org/descubre-el-fascinante-mundo-del-juego-del-globo-3/]https://davidcisneros.altervista.org/descubre-el-fascinante-mundo-del-juego-del-globo-3/[/url] ofrece una tasa de pago favorable.
VincentBus 19 Kasım 2025 13:06
Магазин работает? пишу в ЛС и Джабер везде тишина, ответа нет!(( <a href=https://bular-anapa.ru>купить Мефедрон, Бошки, Марихуану</a> жте907? Вроде говорят, что пока не доступен - находиться на экспертизе... Откуда инфа?
Ryansah 19 Kasım 2025 12:50
В этом что-то есть. Понятно, благодарю за помощь в этом вопросе. не используется у новорождённых и недоношенных [url=https://infouborka.ru/stati/suprastin-proverennyj-sredstvo-protiv-vnezapnoj-allergicheskoj-reaktsii.html]https://de-nol.info/novosti/deystvie-suprastina-pri-allergicheskih-reaktsiyah-vse-chto-nuzhno-znat.html[/url] детей. Лечение ингибиторами МАО. не используется для пациентов с глаукомой, пептической язвой, гипертрофией простаты, расстройствами дыхания, симптомами обструктивных заболеваний.
JessicaChild 19 Kasım 2025 12:08
The more diverse the assortment various games in an [url=https://www2.uesb.br/cultura/?p=16151]https://www2.uesb.br/cultura/?p=16151[/url], the higher the probability that you will find that, which you like.
Cynthiadyeri 19 Kasım 2025 12:07
востребованностью в числе покупателей пользуются телефоны с характеристиками: 2 sim карты, 128 ГБ встроенной памяти, 4 ГБ оперативной, диагональ дисплея более 6 дюймов, android девятке.0, [url=https://bkselementen.nl/2022/04/20/werken-bij-bks-elementen/]https://bkselementen.nl/2022/04/20/werken-bij-bks-elementen/[/url] аккумуляторная батарея 3400 мАч и ценой до пятнадцати тысяч рублей. на страницы самых лучших онлайн супермаркетов Мегафон попал на 5 службу в 2025 году.
alkogolizmvladimirri 19 Kasım 2025 11:31
Капельница от запоя – это действительным методом оказания помощи при алкогольной зависимости. <a href=https://vivod-iz-zapoya-vladimir025.ru>Вызов нарколога на дом</a> позволяет быстро надежно получить необходимую помощь в ситуации запоя. Состав раствора капельницы обычно включает препараты для детоксикации организма, такие как физраствор, раствор глюкозы, витамины и антиоксиданты. Действие капельницы направлено на восстановлении водно-электролитного баланса, снятие симптомов абстиненции и улучшение общего состояния пациента. Лечение запоя с помощью капельницы обеспечивает срочную помощь при запое и способствует восстановлению после алкогольной интоксикации. Профессиональная помощь на дому избегает госпитализации, что делает процесс лечения более комфортным. Важно помнить, что восстановлен
VincentBus 19 Kasım 2025 11:24
да, самая действенная схема для работы с чемикалом https://pashinskaya-ksusha.ru всем доброго времени суток.. вот что ты написал это вобше такая нелепасть во первых этот магазин сколько робит не разу не кого не кинул во вторых по 0.5 магазин закладки не делает тебя просто как лошка очередного развели в аське или скайпе хз где ну тебя подкинули на ровном месте кидай и дальше всем подрят на шет))))будь умнее и внимательней страхуйся, много не кури мозг высохнит))))
Jamesulcef 19 Kasım 2025 09:42
<a href=https://www.propusk-gp.ru/mkad/>google shit</a>
VincentBus 19 Kasım 2025 09:39
е знаю уместен ли мой вопрос в данное "смутное время" но все же откуда высылается заказы...? хотя бы из какой части РФ если это РФ...))) <a href=https://pizzadelmaestro.ru>купить Кокаин, Мефедрон, Экстази</a> Птичка в клетке, в касание! Рад вас видеть и в телеге.
AustinHek 19 Kasım 2025 09:30
одежда из нетканых материалов, [url=http://aquira.jp/cgi-local/bbs200.cgi]http://aquira.jp/cgi-local/bbs200.cgi[/url] из кожи и меха не учитывается. Объем бизнеса модных футболок по итогам 2022 года составил 1,73 млрд штук, что на сегодняшний день на 8,8% меньше показателя годичной давности.
XRumer23nub 19 Kasım 2025 09:29
Putting my personal insight regarding this platform. I mention perks, banking, and total experience. Discussing mostly bonus system and transaction speed. Mentioning how the gameplay works and processes payouts. Noting benefits and drawbacks I tested. Mentioning what was nice and what needs improvement. Read the full article for more insights <a href="https://oriolelawtx.com/fill-your-day-with-excitement-at-crown-green-5/">Crowngreen</a>
Kimfup 19 Kasım 2025 08:54
Players that just just placed a bet on a little-known tennis or snooker match, now can jump to tab "Broadcast" on the betrivers table site and pick up [url=http://www.pisarevo.com/the-ultimate-guide-to-safibets-online-betting-made-2/]http://www.pisarevo.com/the-ultimate-guide-to-safibets-online-betting-made-2/[/url] any event which is possible to imagine.
CynthiaPrela 19 Kasım 2025 08:29
pote mate moznost prevest jejich v obchode na bonusove body, rotace, [url=https://kanjonzrmanje.hr/2025/10/24/1259216266/]https://kanjonzrmanje.hr/2025/10/24/1259216266/[/url] cestovni doklady na turnaje nebo i skutecne ceny.
VincentBus 19 Kasım 2025 07:57
Надеюсь на дальнейшее сотрудничество с магазином! https://silavmozge.ru Желаю всего самого наилучшего вашему магазину,ваш бренд это качество!
ColleenAddep 19 Kasım 2025 07:35
Тематика «морской бой» [url=https://midagahara.alpen-route.co.jp/27587/]https://midagahara.alpen-route.co.jp/27587/[/url] делает розыгрыш зрелищным. Присоединившись через loto club kz 37, вы бессознательно участвуете практически во всех спец-акциях сезона.
SarahDut 19 Kasım 2025 06:56
the rules of the game according to the criterion “penny-ante", when "the win of each client in one round, a hand in a [url=https://afzalrealestate.com/?p=41726]https://afzalrealestate.com/?p=41726[/url] or game does not exceed ten bucks”.
Jeremyexets 19 Kasım 2025 06:43
Вы ошибаетесь. Могу это доказать. Пишите мне в PM, обсудим. to receive the first services you need make a deposit only/ only for amount up to 20/20 pounds, and conditions for wagering - 35 times longer. also realistic up to one hundred percent free attempts, what available at the [url=https://shile-fenster.de/2025/10/26/online-cricket-betting-in-the-uk-a-comprehensive-2/]https://shile-fenster.de/2025/10/26/online-cricket-betting-in-the-uk-a-comprehensive-2/[/url] in slot merge up.
Pamelablist 19 Kasım 2025 06:35
however in [url=https://assist-one-stop.com/new/stjames-casinos/unblock-your-fun-online-casinos-you-can-access/]https://assist-one-stop.com/new/stjames-casinos/unblock-your-fun-online-casinos-you-can-access/[/url] included in the drain gamstop, the processing of bank and card payments for withdrawal money may take many days.
VincentBus 19 Kasım 2025 06:14
Магазин чёткий... Нареканий нет... <a href=https://burenie-msk.ru>купить онлайн мефедрон, экстази, бошки</a> 2с-i отличного качества. 1гр был разделен на 60 частей. Жалоб не от кого не было по качеству.
Tiffanyelata 19 Kasım 2025 06:06
The journey of final fantasy 14 has been [url=https://www.galic.at/der-heisse-atem-aotearoas/]https://www.galic.at/der-heisse-atem-aotearoas/[/url] and full of disappointments.
Larrysuisk 19 Kasım 2025 05:40
<a href=https://vk.ru/id1083987251?w=wall1083987251_1/>купить права</a>
ShellyFup 19 Kasım 2025 05:39
У вас непростой выбор Весь качественный, надёжный и злободневный ассортимент - уже у нас: в сетевом-магазине stls. нужно что-либо компактное? Отличный любой гаджет либо, возможно, [url=http://www.racingkc.com/central-auto-racing-boosters-hall-of-fame-history-action/]http://www.racingkc.com/central-auto-racing-boosters-hall-of-fame-history-action/[/url] гаджет от apple.
MikeDEK 19 Kasım 2025 05:29
Хорошая вешь variety of games: Are you a fan of games, table games or live gaming establishment, at [url=https://play-wildcasino.com/]wild casino[/url] our company have wide selection various games for your taste.
VincentBus 19 Kasım 2025 04:31
Вас не будет эйфоретик убивать или сносить голову как Ск или еще какая хрень, тут легкий эффект эйфории с диссоциативом, Так сказать на любителя, просьба не путать продукт, вы прежде чем заказывать должны были ознакомится с веществом, можно погуглить и узнать что это такое, не надо утверждать что эйфоретик не прущий можете зайти в соседние темы там пишут совсем другие отзывы, а вас почему то не торкает оно как так. https://prishlo-vremya.ru магазин ровный
RebeccaSek 19 Kasım 2025 04:04
Яндекс маркет заслужил 1 местечко в списке лучших интернет магазинов техники. интернет-магазин предоставляет бесплатную доставку по стране на всю продукцию при покупке [url=http://alternativa-abierta.org/index.php?option=com_k2&view=item&id=4]http://alternativa-abierta.org/index.php?option=com_k2&view=item&id=4[/url] от 2500 рублей.
XRumer23nub 19 Kasım 2025 03:29
Leaving my true take concerning this site. I go over promotions, financial side, and the overall platform. Emphasizing offers and money-out process. Covering how the experience runs and processes payouts. Summing up main takeaways I’ve noticed. Reviewing what I valued and what needs improvement. See the full article for extra details <a href="https://staging.geburt360.de/get-started-at-crown-green-casino-and-let-yourself/">https://staging.geburt360.de/get-started-at-crown-green-casino-and-let-yourself/</a>
alkogolizmvladimirri 19 Kasım 2025 03:12
Нарколог на выезде — это решение для людей, нуждающихся в поддержке, но не в состоянии или не хочет идти в медицинское учреждение. Услуги нарколога в Москве включают консультацию нарколога на дому, что позволяет конфиденциальность и удобные условия для пациента. Лечение зависимостей начинается с обследования и снятия абстиненции. <a href=https://vivod-iz-zapoya-vladimir024.ru>vivod-iz-zapoya-vladimir024.ru</a> Квалифицированные специалисты предлагают услуги нарколога, которая включает лечебную помощь при алкогольной зависимости и психотерапию при зависимости. Реабилитация наркозависимых также возможна на домашних условиях, что позволяет вовлечь близких в поддерживающий процесс. Профилактика рецидивов и непрерывная помощь важны для успешного лечения. Выезд врача-нарколога может стать начало
VincentBus 19 Kasım 2025 02:47
вот и я уже трясусь. https://gamardzhoba-dostavka.ru Главное не кипишуй, продаван ровный, придет сам обрадуешся что тут затарился!
Dougfem 19 Kasım 2025 02:30
Sharon Stone [url=https://rezglass.com/2025/11/17/discover-casino-sites-not-on-gamstop-564704483/]https://rezglass.com/2025/11/17/discover-casino-sites-not-on-gamstop-564704483/[/url] a psychotic Ginger, and this is a role that happens once, because this|this|this} was the only once in my life. work: in case I was able to endure her exit in a motion picture.
AndreaFiexy 19 Kasım 2025 02:21
explore all of our games at [url=https://wp.dioartis.com/2025/08/26/discover-exciting-opportunities-with-uk-online-2/]https://wp.dioartis.com/2025/08/26/discover-exciting-opportunities-with-uk-online-2/[/url] with just one tap. Do you like blackjack, slot machines with jackpot or classic table games, it works without downloads and delays.
Ginafam 19 Kasım 2025 01:56
круто!но буду ждать качество. Первое и самое интересное отличие - это потенциальный риск блокировки лицензированных сайтов оффшорных [url=https://salvadorentretenimento.com.br/globo-produz-documentario-sobre-o-caso-de-estupro-de-robinho/]salvadorentretenimento.com.br[/url] казино.
PamelaInvor 19 Kasım 2025 01:44
[url=https://energycity.vn/the-rise-of-mozzert-bet-transforming-the-online/]https://energycity.vn/the-rise-of-mozzert-bet-transforming-the-online/[/url] on this platform - from knockout strikes to meetings with serve - embody the incredible tension of the arena. Choosing a legal platform for hosting betting on sporting events is not just a matter of following the rules; it is a strategic decision that opens up mass advantages, and guarantees as for experienced players, equally as for beginners.
SarahJah 19 Kasım 2025 00:24
Туры - многозначное слово. Туры - село в Решетиловском районе Полтавской области. [url=https://tourvestfs.co.za/tourvest-retains-kenya-airways-inflight-retail-contract/]https://tourvestfs.co.za/tourvest-retains-kenya-airways-inflight-retail-contract/[/url] - деревня в Щёкинском районе Тульской области.
DanielFlutt 18 Kasım 2025 23:58
Мы уверены что гарант не нужен магазину работающему с 2011 года + мы не работаем с биткоинами + везде положительные отзывы . https://wikibot.info Первые 1.5 часа эйфория и сосредоточеность на том чем занят , в голове мелькают гениальные идеи)
CapaKeymn 18 Kasım 2025 23:22
Players what % daily games prioritize speed and responsibility, will appreciate the convenience of the Fanduel app in comparison with very cumbersome alternatives for [url=https://minnmedstaging.wpengine.com/discovering-wepari-your-gateway-to-the-future-of/]https://minnmedstaging.wpengine.com/discovering-wepari-your-gateway-to-the-future-of/[/url].
Spravkidlm 18 Kasım 2025 22:49
Интересует современное стоматологическое лечение без неприятных ощущений в Питере? [url=https://smails-clinic.ru]https://smails-clinic.ru[/url] . В нашей клинике работают с передовые технологии, визит возможен сразу, а осмотр и консультация врача — даром и в комфортной обстановке.
DanielFlutt 18 Kasım 2025 22:14
Приветсвую,форум) Хороший Сортимент на Товар))) УДАЧИ В ПРОДАЖАХ https://rentalscroacia.info Ну и сам сожру дорожку,
Clayponry 18 Kasım 2025 21:07
1. Воздушные ванны. Ежедневно прогуливайтесь в квартире на первом этаже, [url=https://sandaretreats.com/blog/archives/1757]https://sandaretreats.com/blog/archives/1757[/url] на ночь и работой в помещении проветривайте его во всякое время года.
TammyHab 18 Kasım 2025 21:03
понравилось ОДОБРЯЕМ!!!!!!!!!!! {the following{variants|types}, such as European {Blackjack|blackjack} and #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c621rrm1P2URLBB.txt",1,N]. Missions and Challenges - complete tasks {to | in order |then to} {receive |get} rewards.
Kurtplula 18 Kasım 2025 20:45
Личные сообщения у всех сегодня отправляются? mit kleinen Abmessungen von 1762 ? 1134 ? 30 mm und Gewicht nur 21 kg ist das Trina-Modul [url=http://www.sunitex.com.hk/vertex-trize-die-zukunft-der-digitalen-losungen/]http://www.sunitex.com.hk/vertex-trize-die-zukunft-der-digitalen-losungen/[/url] s 460 glass-glass leicht installiert.
DanielFlutt 18 Kasım 2025 20:33
Кент,приветствую..!!))В личку ответь,там по поводу оплаты.......оплатил договаривались на выходные...жду там от тебя ответа)) <a href=https://indios.info>купить скорость, кокаин, мефедрон, гашиш Господа торчебосы, если желаете отведать стопроцентных пробивающих толер кайфоф - то вы попали по адресу) Вторая покупка за эти самопровозглашенные выходные)) Не жалем о потраченном времени и деньгах. Клад как всегда прост как дважды два, упаковка на высоте горы Эверест. Качество стаффа необьяснимо, но факт как ебашит по вашим чувствам и эмоциям. Магазину огромный как земной шар респект,пис аут и цом)
Sharonger 18 Kasım 2025 18:53
но мы будем говорить лишь о белом парсинге, [url=https://www.movimentoper.it/rassegnastampa/29-08-2011-il-velino-manovra-tarzia-per-intervenire-con-opportune-correzioni/]https://www.movimentoper.it/rassegnastampa/29-08-2011-il-velino-manovra-tarzia-per-intervenire-con-opportune-correzioni/[/url] в связи с использованием которого у вас не будет проблем. Парсеры-расширения - хороший вариант, если вам нужно собирать негабаритные объемы информации от 1-й или парочки страниц).
DanielFlutt 18 Kasım 2025 18:48
Я вот перед заказом почитала хуеву кучу отзывов и не нашла ни одного хуевого. Но опять же, смотри, отзывы были не об эйфоре, а о самом магазине. Давай друг, советуй что-нибудь в личку https://bwin99.info Действительно с ответами продовца проблемы имеются!!!!!!!! это вам -5
Debradiurb 18 Kasım 2025 18:38
thanks to the wide choice of bets – on sports contests, as well as in addition on entertainment and public opinion polls, betonline considered most a reputable legal site for hosting [url=https://www.blogbari.net/the-future-of-betting-understanding-tele-bet/]https://www.blogbari.net/the-future-of-betting-understanding-tele-bet/[/url] in different regions.
Beckyswign 18 Kasım 2025 17:43
Быстро ответили :) при соблюдении места использования мы предоставляем гарантию на любую вещи [url=http://www.genebiotech.co.kr/bbs/board.php?bo_table=free&wr_id=7701904]http://www.genebiotech.co.kr/bbs/board.php?bo_table=free&wr_id=7701904[/url] приобретенные через on line бутик.
DanielFlutt 18 Kasım 2025 17:05
А то декларировалась "быстрая реакция на заказ", а на деле реакция отсутствует вообще <a href=https://digitechpedia.com>купить кокаин, меф, бошки через телеграмм взял впервые, в этом магазине, все прекрасно, быстро, недорого)
KimBiz 18 Kasım 2025 16:45
Вы правы, не самое удачное время Электрофорез: что такое такое и в каких [url=https://neotravlen.ru/kapli-ot-allergii-kak-vybrat-effektivnoe-sredstvo-dlya-lecheniya/]https://neotravlen.ru/kapli-ot-allergii-kak-vybrat-effektivnoe-sredstvo-dlya-lecheniya/[/url] ситуациях он нужен? этот разновидность физиотерапии поможет улучшить кровообращение в организме человека беременной, понизить жизненный тонус и матки.
WendyPlund 18 Kasım 2025 16:12
In my blog, we will study how to identify mutually beneficial partnerships, determine their value, and share tips on building strong and successful [url=https://janielarscott.webversatility.com/2025/11/12/building-sustainable-b2b-partnerships-for-long/]https://janielarscott.webversatility.com/2025/11/12/building-sustainable-b2b-partnerships-for-long/[/url].
RachelSoake 18 Kasım 2025 16:09
jen jeden z повсеместно|наиболеепопулярных vyhledavane zpusoby platby jsou virtualni penezenky, [url=https://school.holyfire.it/2025/10/mezinarodni-online-casino-zabava-bez-hranic/]https://school.holyfire.it/2025/10/mezinarodni-online-casino-zabava-bez-hranic/[/url] kryptomeny a plastove karty. Vyberte online hriste kompatibilni s mobilni zarizeni nebo poskytujici freeware software pro stahovani.
KimFaM 18 Kasım 2025 14:59
либо тех, кто взял лэптоп, и заприметил, что совершенно легко не нервничать вследствие перегревания. Весь качественный, проверенный и своевременный ассортимент - уже на дворе, [url=https://elantzen.eus/declination/?lang=fr]https://elantzen.eus/declination/?lang=fr[/url] в интернет магазине stls.
GerardoVut 18 Kasım 2025 14:18
Подтверждаю. Так бывает. Давайте обсудим этот вопрос. Здесь или в PM. For bonus turns may need a bonus code, that very moment equally as for average you may to use by registering without application [url=https://wildcasino-play.com/]wild casino[/url] promo code.
lechenieminskrix 18 Kasım 2025 13:23
лечение запоя <a href=https://vivod-iz-zapoya-minsk013.ru>vivod-iz-zapoya-minsk013.ru</a> вывод из запоя
ErnestEnduP 18 Kasım 2025 12:00
привет ) https://yaem.info попробуйте установить скайп.
Luissoync 18 Kasım 2025 10:40
instead of regular drums and lines calculations you will to play with the host on monitor, and the [url=https://dotzlerbau.de/casino3/trusted-online-casino-in-uk-a-comprehensive-guide-2/]https://dotzlerbau.de/casino3/trusted-online-casino-in-uk-a-comprehensive-guide-2/[/url] machines offers lots of new features and winnings.
MatthewPlugh 18 Kasım 2025 10:28
комфортно для посетителей, [url=https://nutrisonia.com/kak-vyigrat-v-loto-sekrety-uspeshnoj-igry/]https://nutrisonia.com/kak-vyigrat-v-loto-sekrety-uspeshnoj-igry/[/url] кто привык наличные. Двухфакторная аутентификация: Дополнительный уровень предохранения на входе к своей странице для мобильного по Лото Клуб.
SharonSkask 18 Kasım 2025 09:09
at least valuable that the [url=https://zoomorelia.michoacan.gob.mx/discover-bc-game-the-premier-crypto-casino/]https://zoomorelia.michoacan.gob.mx/discover-bc-game-the-premier-crypto-casino/[/url] prioritizes the protection of your financial and personal data, applications use advanced encryption and harmlessness protocols to protection of all transactions.
Brucerax 18 Kasım 2025 09:08
Между нами говоря, Вам надо попробовать поискать в google.com in her also may to play for small bets in home conditions or in a [url=https://cyrusadvertising.ir/page-238/]https://cyrusadvertising.ir/page-238/[/url], subject to diverse conditions.
BrianTot 18 Kasım 2025 08:32
Делать надо 1к10, можно и послабже, например 1к13, но не более, а то 30 минут эт мало, хотя смотря для кого)) https://bwin99.info Запулил:$: ждёмс... отпишу.... Селер адекватный:voo-hoo:
Rubycug 18 Kasım 2025 08:17
для некоторых перемещение на рыбалку становится единственной возможностью избежать повседневной суеты, [url=https://enplan.page.place/bbs/board.php?bo_table=free&wr_id=1036936]https://enplan.page.place/bbs/board.php?bo_table=free&wr_id=1036936[/url] побыть наедине при себе и отдохнуть с родственниками и семьей при любой температуре.
XRumer23nub 18 Kasım 2025 08:09
Adding my independent feedback connected with this online casino. I describe bonus offers, processing times, and how it plays. Emphasizing welcome packages and payment system. Covering how the page loads and handles withdrawals. Covering the good and the bad I found. Explaining what felt good and what didn’t impress me. Further details are available in the full article <a href="http://lobomedia.16mb.com/uncategorized/let-fortune-guide-you-at-crown-green-casino-and-4/">Crowngreen casino</a>
psihmskrix 18 Kasım 2025 07:57
лечение в психиатрическом стационаре <a href=https://psychiatr-moskva012.ru>psychiatr-moskva012.ru</a> врач психиатр на дом в москве
BrianTot 18 Kasım 2025 06:55
Добрый день форумчане! Кто нибудь подскажет как по качеству реагент в этом магазине? Соответствует ли заявленная концентрация? Сколько по времени держит если 1 к 20 сделать? Всем спасибо!!! https://digitechpedia.com я на лестнице один,
Kimhep 18 Kasım 2025 06:12
Palm Casino is a online casino not included in gamstop, with just one of наиболее|наиболеепопулярных extensive potential welcome bonuses, available at [url=https://tiendasegar.com/exploring-uk-casinos-not-on-gamstop-your-ultimate-3/]https://tiendasegar.com/exploring-uk-casinos-not-on-gamstop-your-ultimate-3/[/url] of up to 10 000.
DeniseSOIRE 18 Kasım 2025 05:51
По моему мнению Вы ошибаетесь. Предлагаю это обсудить. Пишите мне в PM, пообщаемся. technical analysis involves the study of price graphs and use of indicators to predict future price changes [url=https://actdanismanlik.com/mastering-trading-with-primexbt-a-comprehensive-4/]https://actdanismanlik.com/mastering-trading-with-primexbt-a-comprehensive-4/[/url] on primexbt. For example, a leverage of 100:1 means that user have the opportunity to trade currency in the amount one hundred thousand dollars, having in your accounts total pieces dollars.
Janettub 18 Kasım 2025 05:20
you do this method of immediate refund funds to your account. megapari emphasizes that cookies and flash cookies are applied only to improve the user experience offered by [url=https://www.atcreative.co.th/the-ultimate-guide-to-online-betting-on-megapari/]https://www.atcreative.co.th/the-ultimate-guide-to-online-betting-on-megapari/[/url] and analytical materials.
BrianTot 18 Kasım 2025 05:16
Все легально и проверено, есть NMR. Плохого ни чего не случиться. Скорей всего приняли потому что были паленые.... https://psyholog-help.com Заметила, что магазин куда-то пропадал, но сейчас появился, чему очень рада)
MelissaHeisa 18 Kasım 2025 03:08
ааааааа"!!!!! афтару зачеДД!!! давно хотел!!! Treasure island cruz [url=https://hairshopoz.com/2020/01/29/%e6%96%b0%e5%b9%b4%e3%81%82%e3%81%91%e3%81%be%e3%81%97%e3%81%a6%e3%81%8a%e3%82%81%e3%81%a7%e3%81%a8%e3%81%86%e3%81%94%e3%81%96%e3%81%84%e3%81%be%e3%81%99%ef%bc%81/]https://hairshopoz.com/2020/01/29/%e6%96%b0%e5%b9%b4%e3%81%82%e3%81%91%e3%81%be%e3%81%97%e3%81%a6%e3%81%8a%e3%82%81%e3%81%a7%e3%81%a8%e3%81%86%e3%81%94%e3%81%96%e3%81%84%e3%81%be%e3%81%99%ef%bc%81/[/url] has table games warzone and several one-armed bandits.
TanmayApesk 18 Kasım 2025 02:38
walmart предоставляет широчайший прайс спорттоваров по доступным ценам, [url=http://wiki.die-karte-bitte.de/index.php/Benutzer_Diskussion:HeleneKinney]http://wiki.die-karte-bitte.de/index.php/Benutzer_Diskussion:HeleneKinney[/url] включая личные торговые марки, и продукцию известных производителей.
Josephted 18 Kasım 2025 01:19
Блестяще To jednorazowa oferta [url=https://rhodopesfairytales2019.discovered-spaces.org/2025/10/27/mobilne-kasyno-rozrywka-w-zasigu-rki/]https://rhodopesfairytales2019.discovered-spaces.org/2025/10/27/mobilne-kasyno-rozrywka-w-zasigu-rki/[/url] dla wielu/ wszystkich kinomanow. mozesz Mozesz doswiadczyc/ sprawdzic jakosc gier witryn i zobacz, czy jest dla ciebie lub nie.
TrapAdeks 18 Kasım 2025 00:39
Jsme poctivi obcane, [url=https://newsjob.co.in/nejhezci-casino-v-czech-republik-kde-zijit-unmemorablene-moments/]https://newsjob.co.in/nejhezci-casino-v-czech-republik-kde-zijit-unmemorablene-moments/[/url] ne? V roce 2025 offshore operatori stale vice|casto|casto|casto|casto} pouzivaji gamifikace k premene tradicni proces otaceni bubnu na fascinujici akce.
alkogolizmvladimirri 18 Kasım 2025 00:16
Лечение запоя с помощью капельницы – является ключевым моментом в терапии алкогольной зависимости. В владимире наркологические услуги предоставляют поддержку нарколога‚ который проведет детоксикацию организма. Признаки запоя‚ включая тревога и потливость‚ способны вызывать серьезные проблемы в результате запоя. Капельница помогает восстановить водно-электролитный баланс и возобновить здоровье после запоя. <a href=https://vivod-iz-zapoya-vladimir021.ru>помощь нарколога владимир</a> После лечения важно посетить реабилитацию и обеспечить психологическую поддержку. Консультация нарколога поможет избежать рецидивов. Профилактика рецидива включает в себя обучение и поддержку‚ что способствует организма. Медицинская помощь в борьбе с алкоголизмом в владимире доступна и эффективна‚ помогая пациент
Jesustug 18 Kasım 2025 00:02
Я извиняюсь, но, по-моему, Вы ошибаетесь. Пишите мне в PM. тут существует отдельная категория для компьютерных кресел, наушников, [url=https://www.stresne-konstrukcie.sk/ale-ale-webova-stranka-a-novodoba-vizitka-neblaznite-2/]https://www.stresne-konstrukcie.sk/ale-ale-webova-stranka-a-novodoba-vizitka-neblaznite-2/[/url] мониторов и накопителей информации.
Marytherm 17 Kasım 2025 23:23
gaming area, which are based on downloads, usually work more efficiently than virtual casino, cooperating with networks, since graphic and sound programs are cached by the client software of the [url=https://blog.nexgenclassy.in/book-keeping/discover-the-thrill-of-casino-uk-online-casino-2/]https://blog.nexgenclassy.in/book-keeping/discover-the-thrill-of-casino-uk-online-casino-2/[/url], but are not downloaded "from open sources".
psychiatrmskrix 17 Kasım 2025 22:45
вызвать психиатра на дом <a href=https://psychiatr-moskva011.ru>psychiatr-moskva011.ru</a> частная психиатрическая клиника стационар
ArielNon 17 Kasım 2025 22:43
Я думаю, что Вы допускаете ошибку. Пишите мне в PM. Traditional portfolio analysis is based on historical [url=https://anaghakontour.com/understanding-vertex-trize-the-future-of-3/]https://anaghakontour.com/understanding-vertex-trize-the-future-of-3/[/url] and static models. we in addition take into account defi-specific risks, like vulnerabilities of smart contracts and stability protocols that completely not you will find it in regular systems.
Nicolerit 17 Kasım 2025 22:19
I {advise|recommend|give recommendations|give advice} {only} those {establishments|casinos} {that|that} have passed my {verification|testing for} {real|real} {money|funds} and #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c6fzzry2P2URLBB.txt",1,N] {to choose from|optional|on demand|as directed} {more than 169 {jackpot games|games|interactions} are offered|provided, and {only|only|only} about 7000 games.
Patrickves 17 Kasım 2025 22:05
Их передовой производственный завод был возведен с упором на качество продукции, что сделало его надежным производителем высококачественных товаров, контактирующих с продуктами, [url=https://www.valetforet.org/sante/les-avantages-du-jeune/]https://www.valetforet.org/sante/les-avantages-du-jeune/[/url] для индустрии кухонной утвари и детского питания во всем мире.
Shailamef 17 Kasım 2025 21:39
but though many platforms imitate traditional bookmakers, dexsport has occupied a unique place in the role of web platform for [url=https://lpanjpan.host-ed.me/wp/blog/2025/11/14/experience-the-future-of-gambling-at-decentralized/]https://lpanjpan.host-ed.me/wp/blog/2025/11/14/experience-the-future-of-gambling-at-decentralized/[/url] using cryptocurrency.
Thomastit 17 Kasım 2025 21:00
Отдуши за ровность! <a href=https://a1dir.info>купить Мефедрон, Бошки, Марихуану
SeanLeads 17 Kasım 2025 19:34
акции, распродажи, коды на скидку, и выгодные предложения - в stylus является не случайность, [url=https://blackgreendirectory.blackandbluedirectory.com/index.php?p=d]https://blackgreendirectory.blackandbluedirectory.com/index.php?p=d[/url] а правило. или тех, кто взял лэптоп, и приметил, что можно не переживать вследствие перегревания.
Thomastit 17 Kasım 2025 19:18
На мой взгляд лучше магазина нет <a href=https://transparenciaclimatica.org>купить скорость, кокаин, мефедрон, гашиш
JamieKiz 17 Kasım 2025 19:11
Тиражи идут каждые пять минут, [url=https://llazybonez.willtec.hk/2025/11/06/loto-igra-kotoraja-obedinjaet-pokolenija-8/]https://llazybonez.willtec.hk/2025/11/06/loto-igra-kotoraja-obedinjaet-pokolenija-8/[/url] а шаротрон в узде rng гарантирует честность всех результатов. все последствия публикуются быстро, а деньги автоматически зачисляется на баланс и реален к выводу буквально регулярными.
Robertexelf 17 Kasım 2025 18:32
Хорошая подборка.Первая СУПЕР.Поддержую. Axele de rota?ie ale arborilor conecta?i prin cuplaje sau cuplaje pot fi paralele sau neparalele [url=https://www.davecridermusic.com/garnituri-rotative-ghid-complet-pentru-alegerea-i/]https://www.davecridermusic.com/garnituri-rotative-ghid-complet-pentru-alegerea-i/[/url] (Fig.
MarySteat 17 Kasım 2025 17:40
не растрачивайте временные затраты на сомнения: техника, которую выбирают непременно, [url=https://girlscanner.online/user/ErwinG81097406/]https://girlscanner.online/user/ErwinG81097406/[/url] становится новым уровнем комфорта.
Thomastit 17 Kasım 2025 17:34
Даже то что я из за тебя третий день на нервах это косяк!Ладно надеямся на лучшее,надежда умирает последней... <a href=https://verbandsabzeichen.info>купить онлайн мефедрон, экстази, бошки
Melissatet 17 Kasım 2025 17:33
{examples include {betting|betting} insurance – for the NBA, UFC knockout, #file_links["C:\Users\Admin\Desktop\file\gsa+en+UAG-H1V-78ZP3P2URLBB.txt",1,N] and f1 gp double speed insurance.
Ginatrunk 17 Kasım 2025 16:38
хотелось бы Nota: flash e um software multimidia desatualizado alternativa que aplicado (e Ainda relevante para criar animacoes, jogos, [url=https://betandyou-portugal.com/codigo-promocional/]betandyou bonus[/url] webcomplementos e outros problemas.
LatriceFen 17 Kasım 2025 16:08
ути-пути Scalping: This tactic involves making many small trades during the day to to capture minor changes rates [url=https://rproject-nagasaki.com/primexbt3/comprehensive-review-of-the-primexbt-app-features]https://rproject-nagasaki.com/primexbt3/comprehensive-review-of-the-primexbt-app-features[/url].
Jerryawaws 17 Kasım 2025 15:07
With our bonus, you can try personal fortune in the best virtual slot machines Germany. All offers are without risks, absolutely [url=https://gunlukseyler.com/exploring-online-casinos-not-on-gamstop-a-guide/]https://gunlukseyler.com/exploring-online-casinos-not-on-gamstop-a-guide/[/url] and ideal for monitoring new games or practicing your own strategies.
RogerUnSag 17 Kasım 2025 14:50
obsluha ne [url=https://www.mbcm.in/nejlepi-online-kasina-objevte-svoji-anci-na-vyhru/]https://www.mbcm.in/nejlepi-online-kasina-objevte-svoji-anci-na-vyhru/[/url] povinne JE. je to cely ekosystem s prvky hry v samotne hre.
NetraNug 17 Kasım 2025 14:34
[url=https://caova.pucv.cl/index.php/2025/11/14/explore-the-future-of-gaming-at-dexsport-crypto/]https://caova.pucv.cl/index.php/2025/11/14/explore-the-future-of-gaming-at-dexsport-crypto/[/url] it? etherscan: For avid enthusiasts, it is a comfortable tool for testing transactions, smart contracts, and any processes with wallets.
Timoxymn 17 Kasım 2025 14:11
Это его задело! Это до него дошло! разнообразные способы оплаты. у вас есть возможность перевести оплату на карту либо покупать заказ с оплатой по факту - выбирайте [url=http://wordpress2.design-services-online.com/MHS/kupit-diplom-vsjo-chto-vam-nuzhno-znat/]http://wordpress2.design-services-online.com/MHS/kupit-diplom-vsjo-chto-vam-nuzhno-znat/[/url] любой раскладка.
Marygaiva 17 Kasım 2025 14:04
especially good players in the world online gambling establishments: [url=https://exhibitor.y-expo.ru/2025/08/25/discover-exciting-features-at-new-online-casino-uk/]https://exhibitor.y-expo.ru/2025/08/25/discover-exciting-features-at-new-online-casino-uk/[/url] big winnings. so, if you are tired ofclunky gambling house websites, MRQ is Internet-platform created by players for supporters.
lecheniekrasnoyarskr 17 Kasım 2025 13:34
Способы детоксикации в себя как медикаментытак и домашние средства. Важно помнить о поддержке семьи и друзей, которая играет важную роль в восстановлении после запоя. Кодирование от алкоголизма может помочь избежать рецидивы. <a href=https://vivod-iz-zapoya-krasnoyarsk019.ru>vivod-iz-zapoya-krasnoyarsk019.ru</a> План по избавлению от алкоголя и профилактика рецидивов обеспечат стабильный переход к новой жизни без алкоголя. Лечение запоя и реабилитация – это многогранный путь, который требует терпения и настойчивости.
servisnyy_flMi 17 Kasım 2025 13:04
ремонт бош [url=https://servisnyj-centr-bosch-msk24.ru/]https://servisnyj-centr-bosch-msk24.ru/[/url]
Lyndonrut 17 Kasım 2025 12:28
читайте отзывов много!:) товар тут вышка,обращайтесь! <a href=https://digitechpedia.com>купить кокаин, меф, бошки через телеграмм
Carrietap 17 Kasım 2025 11:21
Thanks to the many modern games, what systematically added to website and exceptional customer support, [url=https://amalawael.ly/wp/2025/10/27/everything-you-need-to-know-about-bc-game-casino/]https://amalawael.ly/wp/2025/10/27/everything-you-need-to-know-about-bc-game-casino/[/url] is now much easier, than previous versions, go to enjoyable hitchhiking for betting at the world famous BC game casino.
Lyndonrut 17 Kasım 2025 10:46
Может быть, не отрицаю. Пока никого винить не буду, потому что вполне возможно что я и сам закосячил. Но вроде все правильно делал. При том я не один такой..До этого приходил ам (окло недели-полторы, назад) делал все точно так же, но только на черной заварке принцесса Нури, 1 к 10, и с водника уносило далекоооо....всех кто пробовал этот водник.. <a href=https://psyholog-help.com>купить Мефедрон, Бошки, Марихуану
Urielheamp 17 Kasım 2025 09:34
Это еще что? Неважно, в каком городе или даже стране вы живете - примитивно созвонитесь с нами, [url=https://babaanago.com/2025/11/06/kupit-diplom-ljuboj-kvalifikacii-kak-i-gde-jeto-2/]https://babaanago.com/2025/11/06/kupit-diplom-ljuboj-kvalifikacii-kak-i-gde-jeto-2/[/url] и мы подберем для вас самый оптимальный способ доставки и оплаты.
Stevecob 17 Kasım 2025 09:24
промокод 1 х бет Вводите промокод на http://www.google.vu/url?q=https://bergkompressor.ru/news/artcles/?1xbet_promokod_pri_registracii_bonus_5.html и активируйте 100% к первому депозиту для комфортного старта игры.
AntonioheR 17 Kasım 2025 07:51
ежели вы отправляетесь косметологу, не имеющий блога (к примеру, вы сходите по рекомендации), и окажитесь знакомиться со специалистом непосредственно на приеме, [url=http://www.drpi.it/2017/01/22/new-chicago-school-budget-9/]http://www.drpi.it/2017/01/22/new-chicago-school-budget-9/[/url] то для начала лучше сходить на консультацию.
domprestarelihtulari 17 Kasım 2025 07:43
пансионаты для инвалидов в туле <a href=https://pansionat-tula015.ru>pansionat-tula015.ru</a> пансионат для престарелых людей
Lyndonrut 17 Kasım 2025 07:21
да магазин хороший..жаль тусиай кончился <a href=https://diaspora-world.info>купить Кокаин, Мефедрон, Экстази
rtaletgawe 17 Kasım 2025 07:01
provigil adhd adolescent provigil bla [url=https://govtopvip.com/nuvigil-vs-provigil/]provigil cost[/url] how do i get provigil nexium and provigil
MarquelMaync 17 Kasım 2025 06:36
и что дальше! Покупатели иных областей могут отправить средства на [url=https://luqueautomoveis.com.br/index.php?page=item&id=204291]https://luqueautomoveis.com.br/index.php?page=item&id=204291[/url] банковский счет. в случае заказа кровати имеете возможность приобрести удобный комфортный матрас.
Gwenpub 17 Kasım 2025 06:35
win and enjoy our rich collection of games, generous offers, tournaments, [url=https://www.jmxfoto.com/prilozhenie-bc-gejm-vash-putevoditel-v-mire-onlajn/]https://www.jmxfoto.com/prilozhenie-bc-gejm-vash-putevoditel-v-mire-onlajn/[/url] and prizes.
CamillaGap 17 Kasım 2025 05:27
Правила: любой участник покупает одну или несколько карточек, с набором случайных [url=https://6qrestaurant.com/vsjo-o-loto-kak-igrat-i-vyigryvat-1793273016/]https://6qrestaurant.com/vsjo-o-loto-kak-igrat-i-vyigryvat-1793273016/[/url] чисел. Доверие пользователя это главный актив в секторе онлайн-развлечений.
Ashleyrip 17 Kasım 2025 05:19
Извиняюсь, но это мне не подходит. Есть другие варианты? над каждым дипломом работает команда квалифицированных каллиграфов, которые создают документы, ничем не отличающиеся от тех, что получают выпускники ВУЗов, [url=https://answers.stepes.com/2025/11/06/kupit-diplom-ljubogo-goda-vydachi-legko-i-bystro-9/]https://answers.stepes.com/2025/11/06/kupit-diplom-ljubogo-goda-vydachi-legko-i-bystro-9/[/url] вплоть до подписей и подлинных печатей.
WillCype 17 Kasım 2025 04:47
Рабочие ссылки на Кракен сайт (официальный и зеркала): • Актуальная ссылка на сайт Кракен: https://kra350.cc 1. Официальная ссылка на сайт Кракен: [url=https://kro40.cc ]Кракен официальный сайт[/url] 2. Кракен сайт зеркало: [url=https://kro40.cc ]Кракен зеркало сайта[/url] 3. Кракен сайт магазин: [url=https://kro40.cc ]Кракен магазин[/url] 4. Ссылка на сайт Кракен через даркнет: [url=https://kra350.cc ]Кракен сайт даркнет[/url] 5. Актуальная ссылка на сайт Кракен: [url=https://kro40.cc ]Кракен актуальная ссылка[/url] 6. Запасная ссылка на сайт Кракен: [url=https://kro40.cc ]Ссылка на сайт Кракен через VPN[/url] Как попасть на Кракен сайт через Tor: Для того чтобы попасть на Кракен сайт через Tor, следуйте этим шагам: 1. Скачайте Tor брауз
MarennuAno 17 Kasım 2025 04:30
if this bonus is offered in an [url=https://thebellamygroup.com/2025/08/25/exploring-online-casino-real-money-uk-your/]https://thebellamygroup.com/2025/08/25/exploring-online-casino-real-money-uk-your/[/url], you usually get several free spins at this well-known slot as starburst.
NetraSinue 17 Kasım 2025 04:18
jsou take objevuji se na offshore webech. [url=https://www.foszezon.hu/mezinarodni-online-kasino-zabava-bez-hranic/]https://www.foszezon.hu/mezinarodni-online-kasino-zabava-bez-hranic/[/url] ihned/okamzite Po publikace. plus k uvitacimu balicku mezinarodni provozovatel hazardnich her|zabavy} Muze hyckat vas pravidelnymi akcemi - tydennimi nebo sezonnimi.
Stephenesove 17 Kasım 2025 03:56
Респект Магазу https://mortythedog.com брат, у меня ощущение что я с тобой работал, но название магаза было немного другим, тоже в доверенной ветке был))) почерк тот же, и порядочность. я прав или ошибаюсь?))
AlexNek 17 Kasım 2025 03:22
Он обучает пациентов правилам ухода за собой, помогает подобрать соответствующие косметические составы и процедуры, [url=https://nomutate.com/2011/09/22/post_24/]https://nomutate.com/2011/09/22/post_24/[/url] которые способствуют прекратить вопросов в дальнейшем.
Dawnfet 17 Kasım 2025 02:25
Это отличная идея. Я Вас поддерживаю. Please read our risk warning here. primexbt offers trading with leverage, which is 100 times higher than the trader's contribution to [url=https://keepsakeprofessionalsnetwork.com/2025/10/25/trading-with-primexbt-a-comprehensive-guide-to-2/]https://keepsakeprofessionalsnetwork.com/2025/10/25/trading-with-primexbt-a-comprehensive-guide-to-2/[/url].
CassieVes 17 Kasım 2025 02:06
be you have registered. through social media or other services (for example, Google or Facebook), to [url=https://bb.estrategiaparaconcurso.com/unlocking-potential-the-impact-of-lssc-on/]https://bb.estrategiaparaconcurso.com/unlocking-potential-the-impact-of-lssc-on/[/url], just click on the appropriate icon, in order log in to drain.
CocoSyday 17 Kasım 2025 01:00
тоже хочу! в результате - постепенное, [url=http://m-condit.info/peak-marriage/blog/kupit-diplom-ljubogo-obrazca-kak-vybrat-luchshij-5/]http://m-condit.info/peak-marriage/blog/kupit-diplom-ljubogo-obrazca-kak-vybrat-luchshij-5/[/url] четверть вековое обнищание масс. гарантия полной анонимности каждого заказчика. дабы быстро и защищенно купить сертификат о во в любой точке страны, Киеве или какой угодно другой документ, достаточно оставить заявку в нашей компании на сайте.
AnastasiaMen 17 Kasım 2025 00:48
выше нос But scammers are also famous as businesses, government enterprises, and their lovers, among all tactics. Investment fraud is one of the main ways by which scammers trick force you to buy [url=https://plisio.net/hi/blog/near-protocol-price-prediction]https://plisio.net/hi/blog/near-protocol-price-prediction[/url] and send it to scammers.
panstularix 17 Kasım 2025 00:07
пансионаты для инвалидов в туле <a href=https://pansionat-tula014.ru>pansionat-tula014.ru</a> пансионат для пожилых в туле
MonicaBog 16 Kasım 2025 22:49
Я родилась в россии, [url=http://aswvendingservices.co.uk/hero-rental/]http://aswvendingservices.co.uk/hero-rental/[/url] училась чехами и сейчас живу в Берлине.
Helena 16 Kasım 2025 22:11
Un grand merci pour la plateforme leon casino en ligne — elle m’aide énormément ! https://www.gklazer.com.tr/2025/10/29/leon-casino-en-ligne-vrification-des-comptes-et-91/
PamelataW 16 Kasım 2025 21:34
all data transmitted between your device and our servers are encrypted, so the [url=https://www.amprecision.it/discover-the-excitement-of-bcfun-game-unlock/]https://www.amprecision.it/discover-the-excitement-of-bcfun-game-unlock/[/url] burdens outsiders people get login to personal information.
FrankFek 16 Kasım 2025 20:54
<a href=https://kemono.im/krakenzerkalo/>зеркало кракен</a>
Elizabethpen 16 Kasım 2025 20:44
Да, действительно. Это было и со мной. Давайте обсудим этот вопрос. Здесь или в PM. 2) изображение в форме картинки (jpg), изображения или иные растровые файлы. картинку в «кривых», масштаб 1:1 ( т.е. узор в файле, такого размера, [url=http://leadercosmesi.it/2025/11/05/dtf-pechat-novye-gorizonty-v-pechati-na-tekstile/]http://leadercosmesi.it/2025/11/05/dtf-pechat-novye-gorizonty-v-pechati-na-tekstile/[/url] каким планируется сделать машинную вышивку на одежде).
KevinCrymn 16 Kasım 2025 20:19
I consider, that you are mistaken. Let's discuss. Write to me in PM, we will communicate. ------ https://the.hosting/en/help/installing-aapanel-via-vmmanager
LkrutherGuary 16 Kasım 2025 19:44
"В Лс загораеться сообщениее,Захожу там координаты клада" https://digitechpedia.com Всех С Новым Годом! Как и обещал ранее, отписываю за качество реги. С виду как мука, но попушистей чтоли )) розоватого цвета. Качество в порядке, делать 1 в 20! Еще раз спасибо за качественную работу и товар. Будем двигаться с Вами! <a href=https://wikibot.info>купить Кокаин, Мефедрон, Экстази
IvyHet 16 Kasım 2025 18:31
Alcohol can cloud your sanity, and instantly lead to everything that bad habits to money games will take the [url=https://luisbilbao.com.ar/discover-the-best-online-casino-apps-uk-enjoy/]https://luisbilbao.com.ar/discover-the-best-online-casino-apps-uk-enjoy/[/url] through control.
TarusChups 16 Kasım 2025 17:07
Fast transactions: Instant rotation of cryptocurrencies with mobile wallet integration. Check out the latest bc game promotions in categories List of BC game promotions and conditions for purchasing the bonus to update news about prizes, methods of participation, [url=https://ck.test-launch.com/cosa-sono-le-app-casino-guida-completa-e-vantaggi/]https://ck.test-launch.com/cosa-sono-le-app-casino-guida-completa-e-vantaggi/[/url] and conditions for impact on promotions in bc game.
Ashleyfen 16 Kasım 2025 16:31
Поздравляю, отличный ответ. For any person who will register and make a deposit for necessary materials you receive reward in the amount of $100, and the [url=https://reelsgrandecasino.co.uk/games/]Reels Grande Casino slots[/url] will reward you with an additional $25, if your ?A friend? uses cryptocurrency.
Hazemlip 16 Kasım 2025 16:17
Официальная лицензия: Лото Клуб присутствует на основании официальной лицензии, выданной уполномоченными компаниями республики казахстан. присутствие в лотерее Лото Клуб - это элементарный и увлекательный вариант скоротать время, [url=https://relleinc.com/wp/2025/11/06/taktika-i-strategii-igry-v-loto-vash-put-k-uspehu/]https://relleinc.com/wp/2025/11/06/taktika-i-strategii-igry-v-loto-vash-put-k-uspehu/[/url] получая прелесть игры и шанс на оптовые выигрыши.
KennethAninc 16 Kasım 2025 15:14
Я разбираюсь в этом вопросе. Приглашаю к обсуждению. go to to betmgm, an [url=https://www.obelisque.com/fastest-kyc-casinos-in-2025-17/]free casino games no deposit[/url] that never will become a champion in sports and casino! customized mgm materials: The exclusive film "Vergetelijke spellen" about the new doors at mgm.
Pagemag 16 Kasım 2025 13:53
Просто отметьте фильтр “в наличии, и мы соберем комплект. Интернет маркетплейс СТЛС - это, когда вы зашли на площадку не для того, чтобы запутаться, а чтоб понять, [url=https://evartunitedmethodist.org/page16.php]https://evartunitedmethodist.org/page16.php[/url] что намерены.
RubyDag 16 Kasım 2025 13:12
Я думаю, что Вы ошибаетесь. Пишите мне в PM. play and win up to 10 thousand euros! We reward you with numerous bonuses, and tournaments. including a mobile or desktop casino - winz [url=https://wingstore.ma/the-ultimate-guide-to-primexbt-trading-maximize/]https://wingstore.ma/the-ultimate-guide-to-primexbt-trading-maximize/[/url] works on all devices.
BenKnibe 16 Kasım 2025 12:54
В любом случае. Учебные медицинские товары используются не только при обучении [url=https://www.updownsite.com/site/manmedicine.ru]https://www.updownsite.com/site/manmedicine.ru[/url] специалистов сферы здравоохранения. они дают возможность отработать приемы экстренной медицинской обслуживания - именно, процедуру сердечно-легочной реанимации (СЛР), искусственной вентиляции легких.
Racheldit 16 Kasım 2025 12:33
Click "{register|go through a quick registration procedure|go through a simple registration procedure|simple registration procedure} on {the first|main} {page|row} find and {click|click|press} {the "register" button|key, which is {usually|usually|most often} {located in the upper-right corner.#file_links["C:\Users\Admin\Desktop\file\gsa+en+UAG-H1V-78ZP9P2URLBB.txt",1,N]
AmyCah 16 Kasım 2025 09:30
Жаль, что сейчас не могу высказаться - вынужден уйти. Но вернусь - обязательно напишу что я думаю по этому вопросу. maybe in the future our company will not allow repeat offenders to receive training on the policy regarding/regarding [url=https://washingtoncitypaper.com/article/757880/ddot-contract-favortism-retaliation/]Children's sex video[/url].
Lauraalown 16 Kasım 2025 08:29
Pojdme se na to kratce podivat, [url=https://nextmitech.com/casino4/zahranini-sazkove-kancelae-nejlepi-monosti-pro/]https://nextmitech.com/casino4/zahranini-sazkove-kancelae-nejlepi-monosti-pro/[/url] cim se lisi? Napriklad hrac muze vyhrat exkluzivni cashback nebo bonusy v souladu s svym stylem hry.
narkologiyasmolenskr 16 Kasım 2025 06:55
лечение запоя смоленск <a href=https://vivod-iz-zapoya-smolensk029.ru>vivod-iz-zapoya-smolensk029.ru</a> экстренный вывод из запоя
Adriankat 16 Kasım 2025 05:35
Авторитетный ответ, любопытно... of course, when [url=https://attorneys.media/digital-communication-legal-adaptation/]https://attorneys.media/digital-communication-legal-adaptation/[/url], your information is processed with all possible confidentiality and security. Absolutely! after the email is generated, you get a chance to edit and correct maintenance as necessities.
CarrollSix 16 Kasım 2025 03:12
<a href=https://pravaonli.com/>Купить права</a> онлайн официально – это удобный и безопасный способ получить водительское удостоверение без лишних хлопот. Наш сервис предлагает полный комплекс услуг по подготовке и сдаче экзаменов, соответствующий всем государственным требованиям. Вы сможете пройти обучение дистанционно, сэкономив время и силы, а также получить официальные документы, признанные во всех регионах страны. Мы гарантируем прозрачность процесса, поддержку на каждом этапе и конфиденциальность ваших данных. Оформите права онлайн быстро, надежно и легально – начните обучение прямо сейчас и станьте полноправным водителем!
SeanVof 16 Kasım 2025 00:24
Могу поискать ссылку на сайт с огромным количеством статей по интересующей Вас теме. {often|often|always} these {include|are divided into} generous welcome packages, {rewards|bonuses|loyalty bonuses, #file_links["C:\Users\Admin\Desktop\file\gsa+en+Phoenix20k40k100k1054URLBB.txt",1,N] {therefore|and|because} even {free|unpaid} {spins|spins} or cashback offers. {everything|absolutely everything} that you {expect|want} {view|preview} on a desktop computer, {possible|available} {only|only} in pocket format.
AnastasiaVow 16 Kasım 2025 00:17
Мы так же добавили право читать новости по таким категориям как Общество, политика, экономика, Происшествия, [url=http://www.tecnomatica.cl/?page_id=9]http://www.tecnomatica.cl/?page_id=9[/url] спортивные состязания и предпринимательские начинания.
vivodzapojsmolenskri 16 Kasım 2025 00:03
лечение запоя <a href=https://vivod-iz-zapoya-smolensk028.ru>vivod-iz-zapoya-smolensk028.ru</a> экстренный вывод из запоя
NicholasExpox 15 Kasım 2025 23:57
Какие слова... фантастика There is a souvenir shop in the lobby of the hotel supermarket, here proposed wide selection any goods. the list includes various snacks, and also newspapers, jewelry jewelry, [url=https://book.jaezaesthetics.com/comprehensive-review-of-the-primexbt-telegram-bot/]https://book.jaezaesthetics.com/comprehensive-review-of-the-primexbt-telegram-bot/[/url] and souvenirs about your trip.
Amandasop 15 Kasım 2025 22:49
Aunque los casinos sin kyc reducen la burocracia, [url=http://149.049.myftpupload.com/la-publicidad-responsable-en-el-sector-de-juegos/]http://149.049.myftpupload.com/la-publicidad-responsable-en-el-sector-de-juegos/[/url] algunos de ellos pueden solicitar la confirmacion de retiros importantes debido a obligaciones regulatorias.
Amandastady 15 Kasım 2025 19:17
Между нами говоря. Эмульгаторы - стабилизаторы эмульсий, способствуют созданию однородности кремов. как и прочие косметические составы, [url=http://www.prolink-directory.com/index.php?p=d]http://www.prolink-directory.com/index.php?p=d[/url] маски различаются по назначению и действию.
Kennethtruri 15 Kasım 2025 17:25
<a href=https://sites.google.com/view/kraken-zerkalo-darknet>Кракен зеркало</a> Ищете актуальное зеркало Kraken — популярного darknet маркетплейса? У нас вы найдете надежный вход на Kraken, быстрый доступ к регистрационной странице и полную информацию о работе платформы. Kraken — это один из крупнейших и проверенных маркетплейсов даркнета, предлагающий широкий выбор товаров и услуг. Наше зеркало позволяет обойти блокировки и сохранить анонимность при посещении сайта.
narkologiyasmolenskr 15 Kasım 2025 17:13
вывод из запоя смоленск <a href=https://vivod-iz-zapoya-smolensk027.ru>vivod-iz-zapoya-smolensk027.ru</a> вывод из запоя круглосуточно смоленск
DinkeyLieni 15 Kasım 2025 15:46
Весьма забавное сообщение Brutals and savages reach top goals through Mellstroy [url=https://mellstroy-casino.io/]https://mellstroy-casino.io[/url] mellstroy. and despite the fact that some viewers will like streams from mellstroy, not everyone will like it.
Kimvox 15 Kasım 2025 15:41
diseno con colorido y frutas jugosas no solo hace que el juego sea visualmente atractivo, [url=https://lgmarticolireligiosi.it/ciao-mondo/]https://lgmarticolireligiosi.it/ciao-mondo/[/url]. pero tambien mejora la impresion general del jugador.
Marianneesoth 15 Kasım 2025 15:16
chicco (произносится как «Ки-ко») - итальянский изготовитель изделий для малышей, [url=https://twizax.org/Question2Answer/index.php?qa=128560&qa_1=%D1%80%D0%B5%D1%81%D1%83%D1%80%D1%81-%D0%B4%D0%B5%D1%82%D1%81%D0%BA%D0%B8%D1%85-%D0%B8%D0%B3%D1%80%D1%83%D1%88%D0%B5%D0%BA-%D0%B4%D0%B8%D1%81%D0%BD%D0%B5%D0%B9]https://twizax.org/Question2Answer/index.php?qa=128560&qa_1=%D1%80%D0%B5%D1%81%D1%83%D1%80%D1%81-%D0%B4%D0%B5%D1%82%D1%81%D0%BA%D0%B8%D1%85-%D0%B8%D0%B3%D1%80%D1%83%D1%88%D0%B5%D0%BA-%D0%B4%D0%B8%D1%81%D0%BD%D0%B5%D0%B9[/url] который запускает именно и одежду для детей в поднебесной и Италии.
Antoineweave 15 Kasım 2025 10:38
Я конечно, прошу прощения, но это мне не подходит. Есть другие варианты? if you already needed knowledge, the [url=https://staging.crowdsreach.com/maximize-your-winnings-betwinner-bonus-offers-in/]https://staging.crowdsreach.com/maximize-your-winnings-betwinner-bonus-offers-in/[/url] betwinner online non-stop and ready to help calmly exclude from your life all difficulties or answer to any interested questions.
AntonioWrick 15 Kasım 2025 10:18
МолодчаГа парень!!!!!!!! Сроки оказания работ зависят от количества объектов оценки, [url=https://svoimi-rukamy.net/34371-kak-povysit-rynochnuyu-stoimost-kommercheskogo-obekta-pered-prodazhej.html]https://svoimi-rukamy.net/34371-kak-povysit-rynochnuyu-stoimost-kommercheskogo-obekta-pered-prodazhej.html[/url] полноты представленной заказчиком данных по любому из них и местонахождения.
AlvinSwoth 15 Kasım 2025 07:23
Try the new version here : https://beautygocams.com/
IrmaThume 15 Kasım 2025 07:00
может сначала посмотрим Instead of a pull-out microphone, he uses a stationary mellstroi [url=https://mellstroycasino.io/]https://mellstroycasino.io/[/url] microphone, which gives him a chance to stand freely and move during live broadcasts.
Carrieblara 15 Kasım 2025 06:34
este juego en los recursos lleva visitantes a un mundo dulce, lleno dulces, piruletas y mas principal, generosas ganancias en [url=https://tujuan-grogol-us.translate.goog/go/aHR0cHM6Ly9oaWZpc3ltcGhvbnkuY29tL2p1ZWdhLWFsLXNsb3RzLWRlLXN1Z2FyLXJ1c2gtMTEv?_x_tr_sl=ja&_x_tr_tl=zh-TW&_x_tr_hl=ja]https://tujuan-grogol-us.translate.goog/go/aHR0cHM6Ly9oaWZpc3ltcGhvbnkuY29tL2p1ZWdhLWFsLXNsb3RzLWRlLXN1Z2FyLXJ1c2gtMTEv?_x_tr_sl=ja&_x_tr_tl=zh-TW&_x_tr_hl=ja[/url].
Jaypaype 15 Kasım 2025 06:10
развивающие игрушки следует выбирать соответствующую возрасту а также по назначению: изучение алфавита и говорение; моторные навыки; обучение счету и цифрам [url=http://www.agriservice.net/recensioni.html]http://www.agriservice.net/recensioni.html[/url] и прочее.
Richardbek 15 Kasım 2025 04:55
Благодарен за заказ во вторник оплатил - в пятницу / утром / товар получил https://www.impactio.com/researcher/kcrdltnk20482z Всем, как и писалось средняя компенсация 50%
vivodzapojtularix 15 Kasım 2025 03:53
Капельницы для лечения запоя — это эффективным способом, используемым в наркологии для лечения алкоголизма; терапия с применением инфузий даёт возможность быстро удалить токсические вещества из организма и нормализовать водно-электролитный баланс. Специалист по наркологии на дому конфиденциально в Туле предлагает такую возможность, обеспечивая пациентам удобство и конфиденциальность. <a href=https://narkolog-tula027.ru>нарколог на дом анонимно тула</a> Признаки похмелья, такие как головную боль, тошноту и рвоту и слабость, можно устранить устранены с помощью капельницы, содержащей подходящие лекарства. Лечение алкоголизма требует персонализированного подхода, и нарколог на дом проводит первичную консультацию, выбирая подходящие методы для снятия абстиненции. Очистка организма — существенн
Richardbek 15 Kasım 2025 03:13
драмчик, хаус... да не суть. http://www.pageorama.com/?p=adhobeuhh привет бразы всех спрошедшими праздниками получил седня посыль все порадовало и качество и бонус:p:D:D:Dприложеный за ожыдание спосибо магазу
Richardbek 15 Kasım 2025 01:29
мазагин, один из лучший, беру практически только здесь! https://pubhtml5.com/homepage/bswwf Урб 597 либо перорально либо нозально, дозировка - 5-10мг, эффекты описаны в энциклопедии,
Michaelguipt 15 Kasım 2025 01:28
Вы ошибаетесь. Давайте обсудим это. Пишите мне в PM, пообщаемся. Отпариватель, который не просто нагревается, [url=https://coalitiebosenhout.nl/volkskrant-honderd-miljoen-bomen-erbij-in-nederland-ik-ben-al-blij-als-we-de-helft-gaan-halen/]https://coalitiebosenhout.nl/volkskrant-honderd-miljoen-bomen-erbij-in-nederland-ik-ben-al-blij-als-we-de-helft-gaan-halen/[/url] а гладит. Холодильники, которые реально охлаждают. у нас - подборки гаджетов для него, под него а также для начальника.
Kimmet 15 Kasım 2025 00:01
Прошу прощения, что я вмешиваюсь, но мне необходимо немного больше информации. ^ must-see places to visit in paris - perfume museum paris [url=https://boisimperial1.ru/]boisimperial1.ru[/url] (англ.).
Richardbek 14 Kasım 2025 23:46
Если бы ещё доставка не выпала на выходные - ждать пришлось бы ещё меньше, так как курьерская служба по выходным у нас доставку не осуществляет. А сама доставка от пункта А до пункта Б заняла три дня. https://linkin.bio/mysgskls00a4ri сам знаешь что я могу про тебя сказать, ты лучший в своем деле! все всегда в срок! товар на высшем уровне , качество огонь ! сколько раз не брал всегда все ровно и четко! ждем твоего возвращения очень очень ждем, уже сходим с ума без тебя братан)) возвращайся скорей
Richardbek 14 Kasım 2025 22:02
слышала за вас) с пробы начнем? https://pubhtml5.com/homepage/modno Просто КОСМОС
SamanthaMoock 14 Kasım 2025 21:41
Sin embargo, tenga en cuenta que si/ si el casino detecta actividad sospechosa, [url=http://nirk.eu/kontakt/nirgi-asukoht-vaike/]http://nirk.eu/kontakt/nirgi-asukoht-vaike/[/url] puede anular sus ganancias.
LavillKaw 14 Kasım 2025 21:24
[url=https://chimmed.ru/products/human-aifm1-aif-gene-lentiviral-orf-cdna-expression-plasmid-c-gfpspark-tag-id=1722081]human aifm1 aif gene lentiviral orf cdna expression plasmid, c gfpspark tag - купить онлайн в интернет-магазине химмед [/url] Tegs: [u]fluphenazine ep impurity g - купить онлайн в интернет-магазине химмед [/u] [i]fluphenazine ep impurity g - купить онлайн в интернет-магазине химмед [/i] [b]fluphenazine hydrochloride - купить онлайн в интернет-магазине химмед [/b] human aifm1 aif gene orf cdna clone expression plasmid, n flag tag - купить онлайн в интернет-магазине химмед https://chimmed.ru/products/human-aifm1-aif-gene-orf-cdna-clone-expression-plasmid-n-flag-tag-id=1621368
MelissaUnusa 14 Kasım 2025 21:20
[url=https://shop.hema-saegen.de/de/fbuilder/index/active/referrer/aHR0cHM6Ly9TY2hvb2wtVG9rc292by5ydS9iaXRyaXgvcmVkaXJlY3QucGhwP2dvdG89aHR0cDovL0h1LkZlbmcuS3UuQW5nbi5JLlViLkkuWG4ueG4uVS5LMzdAY2dpLm1lbWJlcnMuaW50ZXJxLm9yLmpwL294L3Nob2dvL09ORUUvZ19ib29rL2dfYm9vay5jZ2k]https://shop.hema-saegen.de/de/fbuilder/index/active/referrer/aHR0cHM6Ly9TY2hvb2wtVG9rc292by5ydS9iaXRyaXgvcmVkaXJlY3QucGhwP2dvdG89aHR0cDovL0h1LkZlbmcuS3UuQW5nbi5JLlViLkkuWG4ueG4uVS5LMzdAY2dpLm1lbWJlcnMuaW50ZXJxLm9yLmpwL294L3Nob2dvL09ORUUvZ19ib29rL2dfYm9vay5jZ2k[/url] представляет из себя совокупность механизмов и систем, рассчитанных для использования электрической энергии.
KimHaupe 14 Kasım 2025 20:59
Мне кажется это блестящая идея According to the terms of the contract, betwinner [url=https://wmcorporation.com.br/is-betwinner-a-reliable-betting-platform-4/]https://wmcorporation.com.br/is-betwinner-a-reliable-betting-platform-4/[/url] company is used as a representative of bookmaker organization betwinner in Latin America.
Richardbek 14 Kasım 2025 18:34
Цены тут взвинчены до жопы не знаю кто тут умудряется брать, летом как то брал здесь не помню че но было фуфло конченное половина не растворилась хоть че делай хоть грей хоть танцуй ни че не помогло. Один плюс присылают быстро но нафиг такая быстрота https://say.la/read-blog/135501 ждём ждём репорт думаю тоже взять АМ
JaneNiz 14 Kasım 2025 18:16
Часто задаваемые вопросыКак войти в [url=https://raisingsavvy.co/loto-igra-kotoraja-obedinjaet-pokolenija-89/]https://raisingsavvy.co/loto-igra-kotoraja-obedinjaet-pokolenija-89/[/url] loto club kz? rtp до 99% в объемных слотах. быстрый перечислений: 1-15 минут.
WilliamspOva 14 Kasım 2025 17:13
Peгистpиpyйся ceйчас и пoлyчай пpивeтствeнный пaкeт — до 100 фpиcпинoв и до 950Dоl бoнyca! Лучшие игры, быcтрыe выплaты и чecтный сервис на https://sportsworldhub.shop/b1drsoz
Denisezer 14 Kasım 2025 16:45
у нас действительно работают по всей стране. Напольный кондиционер - тихий и оптимальный. stls - маркетплейс, который подстраивается под вас: умный, быстрый, [url=https://osrodek-koparka.pl/filcuj-i-figluj-z-alpakami-21-12/]https://osrodek-koparka.pl/filcuj-i-figluj-z-alpakami-21-12/[/url] надежный.
Davidwes 14 Kasım 2025 14:59
попробуйте установить скайп. https://kemono.im/nydibufafug/sibu-kupit-kokain-mefedron-marikhuanu-boshki Ты друг нарвался на фэйков!
Ameliafloky 14 Kasım 2025 14:32
Замечательно, весьма забавная штука После прохождения Петербургской мануфактурной выставке этого же года «Фабрично-торговое общество братьев Крестовниковых» получило звание «Поставщика двора Его [url=https://boisimperial2.ru/]https://boisimperial2.ru[/url] императорского величества».
BrittanyArema 14 Kasım 2025 14:13
So, our detailed reviews allowed us to select optimal [url=https://jahrapakistani.com/discover-the-exciting-world-of-uk-betting-online/]https://jahrapakistani.com/discover-the-exciting-world-of-uk-betting-online/[/url] sites in America in kind. we organized separate reviews by regions.
Dontequiew 14 Kasım 2025 13:44
я полностью с ваами согласен. Предоставленная сведения о расценках на препараты не является предложением о продаже или покупке [url=https://communist.borda.ru/?1-1-0-00002944-000-0-0-1762363001]https://communist.borda.ru/?1-1-0-00002944-000-0-0-1762363001[/url] товара.
JoshuahOg 14 Kasım 2025 13:31
pri vyberu online hriste je dulezite dodrzovat/ dodrzovat urcite pravidla, [url=https://ben.novas.sg/objevte-nejnovji-casino-ve-co-potebujete-vdt/]https://ben.novas.sg/objevte-nejnovji-casino-ve-co-potebujete-vdt/[/url] at hrajes kdekoliv. Toto tefon herna ve Spojenem kralovstvi je optimalizovano pro pohodlne a plynule sloty na telefonu nebo jine zarizeni s operacnim systemem android nebo ios.
lechenieorenburgrix 14 Kasım 2025 13:25
экстренный вывод из запоя <a href=https://vivod-iz-zapoya-orenburg014.ru>vivod-iz-zapoya-orenburg014.ru</a> вывод из запоя цена
Davidwes 14 Kasım 2025 13:16
если так то АМ не подойдет скорее всего https://imageevent.com/avalosn20dee/xksrt Обязательно позвонить должны, как позвонят легче забрать самому чем ждать пока курьер доставит
DebbieVal 14 Kasım 2025 12:37
фильтры: например, платформы для разработки и тестирования торговых стратегий. В 2025 году в рф самыми популярными биржами для трейдинга являются Московская биржа (МосБиржа), Санкт-Петербургская биржа и несколько онлайн-платформ для работы, типа Тинькофф Инвестиции и СберБанк.
JudyPax 14 Kasım 2025 11:47
Как нельзя кстати. Bac Bo from evolution combines Baccarat and Sik Bo in the online [url=https://play-rainbet.net/nl-be/rainbet-demo-games-play-casino-slots-free-online/]rainbet login[/url] rainbet. within 0,twenty bucks up to 5,000 dollars. Streaming in HD quality gives a rich gaming experience.
StanleySnoto 14 Kasım 2025 11:32
28го оплатил, а даже трека по сей день нет... https://yamap.com/users/4917053 https://www.rwaq.org/users/awcgxcmi48h41s-20251104153358 https://www.grepmed.com/tfuhibub https://anyflip.com/homepage/fuxsn https://bio.site/ofybadaugi https://bio.site/wibaheoicige Сегодня оплатил, сегодня и отправили, пацаны как всегда четко работают
StanleySnoto 14 Kasım 2025 09:52
Время от времени заказываем здесь реагент, качество всегда на уровне(отличное) стабильное:good:Все работает стабильно, берем не опт, но и не мало, конспирация хорошая, магазин работает отлично! :good:Еще не раз сюда буду обращаться;) http://www.pageorama.com/?p=kuubufiigb https://kemono.im/dyihedyu/valdai-kupit-kokain-mefedron-marikhuanu-boshki https://say.la/read-blog/134787 https://www.grepmed.com/oyhaguficyge https://www.brownbook.net/business/54446317/протвино-купить-кокаин-мефедрон-марихуану-бошки/ https://anyflip.com/homepage/enuim почитайте реценты , там ниже тема есть , там куча всего
StanleySnoto 14 Kasım 2025 08:09
магазину желаю дальнейшего процветания и минимум траблов(а лучше вовсе без них).? https://www.betterplace.org/en/organisations/69764 https://www.betterplace.org/en/organisations/69116 https://form.jotform.com/253105028306042 https://rant.li/ehskaihoo/kuveit-kupit-kokain-mefedron-marikhuanu-boshki https://www.betterplace.org/en/organisations/70250 https://www.grepmed.com/odadihuaeyd может ты просто сам не учел проценты комиссии и тебе не хватило???
Paulpeawn 14 Kasım 2025 08:01
Извините, я удалил эту фразу Жили небольшими группами либо собственноручно, [url=https://www.heroines-project.eu/therapeutic-writing-revealing-personal-treasure-made-of-stories/]https://www.heroines-project.eu/therapeutic-writing-revealing-personal-treasure-made-of-stories/[/url] а на зиму объединялись в максимально крупные стада. Отряд Парнокопытные (artiodactyla) // Жизнь животных / под ред. В. Е.
MonaReera 14 Kasım 2025 07:54
Дата обращения: 15 февраля 2023. Архивировано 20 февраля 2023 [url=https://www.jikka-no-kataduke.com/ecosmiley/]https://www.jikka-no-kataduke.com/ecosmiley/[/url] года. ^ Минэкономразвития снимает запрет с интернет-продаж ювелирных изделий .
MelanieEssew 14 Kasım 2025 07:30
Конечно Вы правы. В этом что-то есть и это отличная мысль. Я Вас поддерживаю. platform offers resources and links to optimal help for [url=https://subs.traveldaily.com.au/betwinner-online-casino-a-comprehensive-review-of/]https://subs.traveldaily.com.au/betwinner-online-casino-a-comprehensive-review-of/[/url]those who here. Click "Register" to automatically receive login (id" and password.
Tatsoiny 14 Kasım 2025 06:26
another key factor is whether the players are respectively connected to a human representative or connected via an automated bot. cooperation with an employee at the [url=https://bauwach.com/best-casino-online-in-uk-complete-guide-to-safe/]https://bauwach.com/best-casino-online-in-uk-complete-guide-to-safe/[/url] is usually preferable.
StanleySnoto 14 Kasım 2025 06:26
Трек получил, всё ровно! https://bio.site/zzyadugodyih https://www.grepmed.com/ugyeifice https://www.brownbook.net/business/54441662/марсель-купить-кокаин-мефедрон-марихуану-бошки/ https://www.rwaq.org/users/lutzg1wafranz-20251103121441 https://anyflip.com/homepage/crzyr https://pubhtml5.com/homepage/zpvqy я не знаю чего тебе делать!
ScottLop 14 Kasım 2025 05:53
schlussel zu Erfolg/Hohepunkt des Erfolgs - Geduld bewahren und nicht sofort hohe Einsatze machen, besonders in [url=http://rlu.ru/5cPpl]http://rlu.ru/5cPpl[/url], wenn kostenlos Spins auch nicht gestartet werden.
Ginatiz 14 Kasım 2025 04:56
я тоже Подарок требуется отыграть в течение одного месяца после начисления, обязательно это должны быть ставки типа «экспресс, [url=https://www.hamishedarmiyan.com/melbet-rabochee-zerkalo-segodnya/]https://www.hamishedarmiyan.com/melbet-rabochee-zerkalo-segodnya/[/url] состоящие по крайней мере из трех спортивных соревнований.
JenniferFilia 14 Kasım 2025 04:56
Хошу себе...... Выбранный способ перевозки. Авиа - минимальный, [url=https://clck.ru/3Q9pER]доставка из Китая[/url] но также самый дорогой вариант.
StanleySnoto 14 Kasım 2025 04:42
сказали отпрака на следующий день после платежа! https://www.band.us/page/100479608/ https://beteiligung.stadtlindau.de/profile/%D0%9B%D1%8B%D1%82%D0%BA%D0%B0%D1%80%D0%B8%D0%BD%D0%BE%20%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD/ https://www.betterplace.org/en/organisations/70402 https://beteiligung.stadtlindau.de/profile/%D0%9D%D0%BE%D0%B2%D0%BE%D1%83%D0%B7%D0%B5%D0%BD%D1%81%D0%BA%20%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C%20%D0%9A%D0%BE%D0%BA%D0%B0%D0%B8%D0%BD/ https://form.jotform.com/253105794040047 https://yamap.com/users/4922982 Многие стучат нам по выходным и ночью, но мы живые люди и не можем 24 часа в день отвечать.
Selenapag 14 Kasım 2025 03:24
Незаменима такая мебель для кафе, баров и в условиях сельской местности, [url=https://1clickservices.com/woman-girl/]https://1clickservices.com/woman-girl/[/url] где суровый минимализм конструкций будет выглядеть вдвойне уместно. на внешность нашего каталога предложены многочисленные варианты стульев, столов, стеллажей, металлических кроватей в духе Лофт.
StanleySnoto 14 Kasım 2025 03:00
А это как понимать? Кто то уже регу опробовал? https://www.grepmed.com/igoydioafece https://www.band.us/page/100413640/ https://www.band.us/page/100524163/ https://say.la/read-blog/135991 https://www.band.us/page/100473240/ https://bio.site/idufuahud А вот и мин Трип мой.
NormaAnada 14 Kasım 2025 02:14
Фильм Казино был выпущен 22 ноября 1995 года студией universal pictures, [url=https://www.cloudsmtpservers.com/2025/11/07/loto-ishody-strategii-i-psihologija-udachi/]https://www.cloudsmtpservers.com/2025/11/07/loto-ishody-strategii-i-psihologija-udachi/[/url] получил в основном одобрительные отзывы специалистов и имел результат в мировом прокате.
StanleySnoto 14 Kasım 2025 01:17
Отличный магазин https://pubhtml5.com/homepage/gywub https://www.rwaq.org/users/nntlfvhu121rgp-20251104020456 https://kemono.im/adideyaba/bali-tandzhung-benoa-kupit-kokain-mefedron-marikhuanu-boshki https://www.betterplace.org/en/organisations/70534 https://yamap.com/users/4927877 https://www.rwaq.org/users/acytvgiu22sfsl-20251103125943 и вы считаете что все отлично?
Kristyinvab 14 Kasım 2025 00:51
{jeder/jeder}, {wer will/wer will|wer will/wer will} {zuerst|zuerst/vor der Arbeit} Zugang zu|Anmeldung an einem Spielautomaten in {neuem|erscheinendem} {virtuellem|Bildschirm|Computer|wirth|online}Casino {ohne Einzahlung|ohne Einzahlung} zu erhalten {Zugang zu/Anmeldung an einem Spielautomaten in {neu/erschienen} {virtuellem/Bildschirm/Computer/wirth/Online}-Casino {ohne Einzahlung/ohne Einzahlung}, #file_links["C:\Users\Admin\Desktop\file\gsa+de+Phoenix20k40k100k1020P2URLBB.txt",1,N] {kann|kann|kann|kann/hat diese Gelegenheit} – {spiele/losche die Aufregung} bei lucky pharaoh kostenlos.
StanleySnoto 13 Kasım 2025 23:36
Не парься, полюбасу все уже пришло, зара позвонит курьер и будет тебе счастье, так часто бывает, курьерки коряво работают, ящитаю! https://form.jotform.com/253067015261045 https://www.betterplace.org/en/organisations/69807 https://kemono.im/iydobobwoah/votkinsk-kupit-kokain-mefedron-marikhuanu-boshki https://kemono.im/agoyobyhyfjy/aidarken-kupit-kokain-mefedron-marikhuanu-boshki https://bio.site/xgycrigwyg https://form.jotform.com/253047365464056 Всем привет ровной ветке,магаз на 5
Bobbyequib 13 Kasım 2025 23:04
<a href=https://kra44.ca/>Кракен зеркало</a>
GillDAW 13 Kasım 2025 22:49
Their games are dynamic, and {bonanza billion, aztec clusters, #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c5283uq1P2URLBB.txt",1,N] machines, and space xy are considered to be {among the most|optimal|most popular}.
StaceyNolla 13 Kasım 2025 21:11
Наличие трещин на прозрачных может оказывать влияние на чувствительность сенсорного экрана, [url=http://www.ritual-letichev.km.ua/user/ShanonGuest4652/]http://www.ritual-letichev.km.ua/user/ShanonGuest4652/[/url] и причинять дискомфорт.
MaggieTex 13 Kasım 2025 19:26
когда интернет-магазин настроен об этом, чтоб позволить компаниям покупать у подобных компаний, [url=http://mkun.com/cgi-bin/ayano/RessBBS/abbs.cgi]http://mkun.com/cgi-bin/ayano/RessBBS/abbs.cgi[/url] такой процесс называется интернет супермаркетами бизнес для компании (b2b).
Michaelgyday 13 Kasım 2025 18:25
Belem: Famous for the Hieronymous Monastery and the Belem Tower, car [url=https://www.ninebooking.com/food/accor-plus-%E0%B8%9A%E0%B8%B1%E0%B8%95%E0%B8%A3%E0%B9%80%E0%B8%9A%E0%B9%88%E0%B8%87-%E0%B8%97%E0%B8%B5%E0%B9%88%E0%B9%83%E0%B8%AB%E0%B9%89%E0%B8%97%E0%B8%B1%E0%B9%89%E0%B8%87%E0%B8%97%E0%B8%B5/]https://www.ninebooking.com/food/accor-plus-%E0%B8%9A%E0%B8%B1%E0%B8%95%E0%B8%A3%E0%B9%80%E0%B8%9A%E0%B9%88%E0%B8%87-%E0%B8%97%E0%B8%B5%E0%B9%88%E0%B9%83%E0%B8%AB%E0%B9%89%E0%B8%97%E0%B8%B1%E0%B9%89%E0%B8%87%E0%B8%97%E0%B8%B5/[/url] are two UNESCO World Heritage sites that will allow you to immerse yourself in Portugal's rich maritime history.
StanleySnoto 13 Kasım 2025 18:22
Нет не нужен. http://www.pageorama.com/?p=oucohvyfudig https://form.jotform.com/253102559548056 https://www.divephotoguide.com/user/edibobageadr https://pubhtml5.com/homepage/pjhgg https://wanderlog.com/view/yudqxhgfgg/советск-купить-кокаин-мефедрон-марихуану-бошки/ https://pubhtml5.com/homepage/smewg 2. Был подобный заказ и нас спутали.
ZaraCew 13 Kasım 2025 18:02
белиберда ей богу)))))начало посмотрела на большее не хватило)))) 4. Launch the application: Open the installed application and log in to your account [url=https://pravoexpert.com.ua/betwinner-sportsbook-your-gateway-to-online/]https://pravoexpert.com.ua/betwinner-sportsbook-your-gateway-to-online/[/url].
Jennyket 13 Kasım 2025 16:33
Я считаю, что Вы не правы. Я уверен. Давайте обсудим это. Пишите мне в PM, пообщаемся. Впоследствии его можно будет сменить [url=https://www.mimartresital.com/promokody-melbet-2024-bonusy-i-akcii/]https://www.mimartresital.com/promokody-melbet-2024-bonusy-i-akcii/[/url] по своему усмотрению. в этой статье мы разберем все остальное пари – на сайте Мелбет.
SeanPralo 13 Kasım 2025 15:10
Авторитетный ответ, познавательно... М. Сеченова, [url=https://doc.adminforge.de/s/sYgecMV8o]https://doc.adminforge.de/s/sYgecMV8o[/url] Российский национальный исследовательский медицинский университет им. Н. редко найдется сегодня пользователь, который не слышал бы, что представляют собой зубная боль.
Karenexobe 13 Kasım 2025 14:25
Браво, мне кажется, это отличная фраза в компании нет случайных позиций - лишь то, [url=https://plasticar.com.ar/hello-world/]https://plasticar.com.ar/hello-world/[/url] что на самом деле нужно. и ключевое - никаких "мелких шрифтов": цена честная, гарантия настоящая, а программа содействия - реально работает.
alkogolizmcherepovec 13 Kasım 2025 14:23
экстренный вывод из запоя <a href=https://vivod-iz-zapoya-cherepovec017.ru>vivod-iz-zapoya-cherepovec017.ru</a> лечение запоя череповец
Patrickdrumn 13 Kasım 2025 14:02
ввести промокод 1xbet Ищите промокод на https://tako-text.ru/kernel/inc/?1hbet_promokod_pri_registracii__bonus_do_32500_rub_.html и получите бонус до 32 500 рублей, чтобы получить максимальный стартовый бонус.
DavidEvids 13 Kasım 2025 13:19
Успехов и процветания магазину https://www.rwaq.org/users/fhzjpacb74wba0-20251104150654 сердцебеение крч все как обфчно , в
Mikeric 13 Kasım 2025 13:08
ale, dulezite vzit v uvahu, ze ignorovani na pohodli a soukromi, ktere nabizeji tyto platformy, [url=https://institutojoaquinmontoya.com.co/?p=7400]https://institutojoaquinmontoya.com.co/?p=7400[/url] pred registraci vzdy musi zkontrolujte povest kasina (pritomnost mezinarodni licence).
Soniahaunk 13 Kasım 2025 12:50
Дата обращения: 15 февраля 2023. Архивировано 20 февраля 2023 года. интернет-магазины обычно позволяют покупателям использовать функции поиска, чтобы собрать конкретные модели, [url=http://sm.co.kr/bbs/board.php?bo_table=free&wr_id=3339703]http://sm.co.kr/bbs/board.php?bo_table=free&wr_id=3339703[/url] бренды или предметы.
ConstanceAbnof 13 Kasım 2025 12:01
Danchen, Etienne; Charmentier, Anne; Champagne, Francis A.; Mesudi, Alex; Pouille, Benoit; Blanchet, Simon (June 2011). "Beyond DNA: Integrating inclusive inheritance into an expanded theory of [url=http://pielgrzymkrasnostawski.pl/index.php/component/k2/item/57-woman-in-white-and-brown-scoop-neck-dress-in-brown-grass-field-during-daytime?limit=10&start=0]http://pielgrzymkrasnostawski.pl/index.php/component/k2/item/57-woman-in-white-and-brown-scoop-neck-dress-in-brown-grass-field-during-daytime?limit=10&start=0[/url]."
Sibyl 13 Kasım 2025 11:38
Здравствуйте, форумчане! Сегодня хочу затронуть актуальную тему — сервисы создания маршрутов из города А в город Б. Долго интересуюсь этой темой и хочу поделиться своими наблюдениями и опытом использования подобных платформ, которые значительно упрощают планирование поездок и помогают экономить время. Одним из ключевых особенностей таких сервисов является их [b]простота и надежность[/b]. Современные приложения не просто о
DavidEvids 13 Kasım 2025 11:34
В пробе было два вещества https://rant.li/hygihafage/bangalor-kupit-kokain-mefedron-marikhuanu-boshki Нужно 5 сообщений что бы написать модэратору, не обесуть
DavidEvids 13 Kasım 2025 09:52
Удачи. магазин))) Прайс соответствует реальности? https://www.divephotoguide.com/user/hegadacaob Оплатил 22.03.2012,трек выслали 02.04.2012 типа через 1-2 дня он будет биться.до меня идёт посыль от них 3-5 дней,зависит от выходных.Сегодня уже по всем раскладам должно прийти,но у меня даже трек не бьётся.Звонил в спср,сказали нет в базе такого трека.
AngelaVib 13 Kasım 2025 08:16
Люкс Гранд с просторной гостиной и уютной спальни воплотил в своих силах черты французского характера [url=https://www.bladewingaviation.com/hello-world/?unapproved=58596&moderation-hash=8cdc9e36076cbc9ae4965bc5b27868b6]https://www.bladewingaviation.com/hello-world/?unapproved=58596&moderation-hash=8cdc9e36076cbc9ae4965bc5b27868b6[/url] эпохи xix века.
DavidEvids 13 Kasım 2025 08:09
Я тебе не хамил. Да 10г, смешно не смешно, а на дороге не валяются. И очень обидно когда от вашего ПМа получаешь подтвердение, веришь! и остаешься с разочарованием и обидой, бессилием что либо доказать. А тебе еще сверху льют хамство, упивайтесь на здоровье. Я утерся и теперь знаю на что способны даже нормальные, доверенные магазины. А это тоже опыт, за который я заплатил, и ничуть не жалею. Просто пусть народ знает и будет готов при работе без гаранта ТУТ ожидайте что такое может быть. https://www.rwaq.org/users/gluguwyrawiqel-20251103170631 о господи :D я не селлер - я просто зашёл на сайт и посмотрел что есть в ассортименте - из скоростей нормальных разве что..кхм, оно...
Erictow 13 Kasım 2025 07:43
Your session may seriously differ, so treat to rtp for the basis, and to [url=https://scope-logistics.com/ultimate-guide-to-winner-casino-sportsbook/]https://scope-logistics.com/ultimate-guide-to-winner-casino-sportsbook/[/url] for the promise. finding the best free slots of Singapore is not so easy, given the thousands of high-quality games reliable on online institution that allow you to do gamblers from Singapore.
DavidEvids 13 Kasım 2025 06:24
магазин суперский! качество и работа оператора на высшем уровне! респект https://www.betterplace.org/en/organisations/70490 какие то траблы ппц =\
NickNew 13 Kasım 2025 06:13
Производство товаров для малышей в ЕвропеЕвропейские компании, производящие и реализующие товары для малышей, известны таким образом, что обеспечивают высококлассные товары класса люкс для ребенка, [url=https://winconsgroup.com/sua-nha-gia-re/]https://winconsgroup.com/sua-nha-gia-re/[/url] уделяя первостепенное внимание качеству и эстетичному дизайну.
PaulMub 13 Kasım 2025 06:07
Рискую показаться профаном, но всё же спрошу, откуда это и кто вообще написал? we will take care that fact, so that your activity on our site was simple and harmless. Find the "Deposit": barely you log [url=https://play-casino-1win.com/]1win aviator[/url].
AngelaHiX 13 Kasım 2025 05:30
and finally, [url=https://eazyflicks.com/App/the-ultimate-guide-to-sports-betting-lines/]https://eazyflicks.com/App/the-ultimate-guide-to-sports-betting-lines/[/url] is a real brand that is here represented, does not need for representation. In no case do we violate the rules, but indicated can confuse the players until you never understand what is happening.
AmandaCooge 13 Kasım 2025 04:55
zejmena toto sparuje s, [url=https://trucktechhelp.com/wp-admin/2025/10/21/mezinarodni-online-kasino-vae-brana-k-nekonene/]https://trucktechhelp.com/wp-admin/2025/10/21/mezinarodni-online-kasino-vae-brana-k-nekonene/[/url] ze trh mnohem vice a takovi lide mohou dovolovat si dat hracum vice pobidky.
MiriamInowl 13 Kasım 2025 04:41
Прошу прощения, этот вариант мне не подходит. Кто еще, что может подсказать? Follow the instructions on screen to restore personal cabinet. I write about online games - matches, betwinner casino [url=https://altiveindustries.com/betwinner-a-comprehensive-guide-to-the-leading/]https://altiveindustries.com/betwinner-a-comprehensive-guide-to-the-leading/[/url] and esports - with more than five years of work.
MollyReast 13 Kasım 2025 03:30
Вы абстрактный человек Пролистай форму регистрации немного вниз (зависит от [url=https://h5p.harryhr.nl/2025/10/19/melbetbonuscode-top-bonus-melbet-2025/]https://h5p.harryhr.nl/2025/10/19/melbetbonuscode-top-bonus-melbet-2025/[/url] размера экрана). Опечатка или неверный регистр.
Amyson 13 Kasım 2025 00:43
В этом что-то есть и мне кажется это очень хорошая идея. Полностью с Вами соглашусь. Тачка на прокачку: зачем «Яндекс» ввязался в торговлю подержанными [url=https://investif.in.ua/koly-maye-sens-dovgostrokova-orenda-avto-v-kyyevi/]https://investif.in.ua/koly-maye-sens-dovgostrokova-orenda-avto-v-kyyevi/[/url] . ^ Антон Попов. названы самые классные дилерские центры России: рейтинг составлялся сделано из отзывов реальных покупателей .
IrmaKef 13 Kasım 2025 00:09
in remote city Quebec operates a similar [url=https://alicebabyshop.com/2025/09/01/discover-exciting-opportunities-at-casino-winit/]https://alicebabyshop.com/2025/09/01/discover-exciting-opportunities-at-casino-winit/[/url], espacejeux, through loto-quebec, and playolg operates through the Ontario Lottery and gaming Corporation (olg) in the province of Ontario.
Georgenup 12 Kasım 2025 23:38
всё же в неделе при этом должно иметься всего шесть суток, первый день или сольник, далее вторник, среда, четверг, пятница, [url=https://genuinecoder.com/javafx-buttons-with-custom-shape/]https://genuinecoder.com/javafx-buttons-with-custom-shape/[/url] суббота.
Seanmus 12 Kasım 2025 23:03
This offer is a welcome encouragement of winlion [url=https://jaybabani.com/material-wp-admin/?p=42054]https://jaybabani.com/material-wp-admin/?p=42054[/url], and this implies, what it is possible only beginners who will register account at slots and make a deposit.
alkogolizmkrasnodarr 12 Kasım 2025 22:05
вывод из запоя круглосуточно <a href=https://narkolog-krasnodar023.ru>narkolog-krasnodar023.ru</a> вывод из запоя
RubyGueks 12 Kasım 2025 20:55
Извините, что не могу сейчас поучаствовать в дискуссии - очень занят. Но вернусь - обязательно напишу что я думаю по этому вопросу. практичный художественное оформление ресурса сделает поиск необходимых вещей и характеристик максимально [url=https://wildtroutstreams.com/indiana-wild-trout/]https://wildtroutstreams.com/indiana-wild-trout/[/url] удобным. на сайте имеется персональная категория для компьютерных кресел, наушников, мониторов и накопителей информации.
Jasonabode 12 Kasım 2025 20:44
gambling entertainment involve with financial risks and lead to addiction. The responsive design supports full functionality on portable devices, without needing special roulettino [url=https://roulettino-eu.com/]roulettino casino online[/url] applications.
JillTrout 12 Kasım 2025 20:41
musi prijmout opatreni Pro ochrana hracu, [url=https://stage.esthers.co.nz/zahranini-kasina-pro-eske-hrae-jak-vybrat-to-prave-5/]https://stage.esthers.co.nz/zahranini-kasina-pro-eske-hrae-jak-vybrat-to-prave-5/[/url] omezte pristup k hram pro osobu se zavislosti na hazardnich hrach a zaructe uplnou financni "transparentnost".
Vanessaaline 12 Kasım 2025 20:39
Присоединяюсь. Я согласен со всем выше сказанным. Давайте обсудим этот вопрос. Здесь или в PM. A profitable program of customer trust and constant promotions offers, focused at maximizing game progress. Play without labor in the virtual [url=https://play-jackpotcity.com/]jackpot city[/url] app.
JenPiert 12 Kasım 2025 19:14
но небольшие компании также начинают зарабатывать кручения и дают гарантированный сервис и уникальный [url=https://mail.asianvision.org/?p=10035]https://mail.asianvision.org/?p=10035[/url] продукт.
Danielhig 12 Kasım 2025 16:36
Many legal bookmakers are on the Internet and are managed on the Internet from jurisdictions that are not related to the citizens they serve, usually, to circumvent various laws on card games (such as act on combating illegal gambling in on the Internet from 2006 year in USA) in selected markets, such as Las Vegas, [url=https://user-83991389-work.colibriwp.com/comprardiplomaonline/discover-exciting-demo-slots-available-at-winlion/]https://user-83991389-work.colibriwp.com/comprardiplomaonline/discover-exciting-demo-slots-available-at-winlion/[/url] or conducting gambling cruises on their own.- service kiosks.
Katiehat 12 Kasım 2025 16:36
some of them are intended for relaxation, others for thrill entertainment, from winning in [url=http://florin-homepage.fr/julwige/2025/08/31/understanding-online-sports-betting-in-the-uk-12/]http://florin-homepage.fr/julwige/2025/08/31/understanding-online-sports-betting-in-the-uk-12/[/url], and The third ones are for contacts.
ChuckFrien 12 Kasım 2025 15:38
Да это фантастика Unlock additional promotional offers after [url=https://tongxiao.tech/archives/170381]https://tongxiao.tech/archives/170381[/url] into the betwinner system and education account. Your transactions and monetary data are protected by strict security measures.
LatriceSlind 12 Kasım 2025 14:48
Я о таком еще не слышал ссылка на скачивание приложения. После нашего обзора, можем сказать с большой уверенностью, [url=https://www.hovawart24.de/bonusy-melbet-2025/]https://www.hovawart24.de/bonusy-melbet-2025/[/url] что БК Мелбет очень достоверный.
Tonyashuri 12 Kasım 2025 12:48
цены на туры в Турцию столь разнообразны, что отдых на местных курортах может похвастаться каждый и любой может найти условия, [url=https://transformationtherapy.net/post-quotes/]https://transformationtherapy.net/post-quotes/[/url] что ему подходят.
Tammyvaf 12 Kasım 2025 12:26
{na rozdil od certifikovanych kasin, tyto {zdroje|portaly|platformy|platformy} {hostuji|zverejnuji|nabizeji} vice {flexibilni|loajalni} {podminky|okolnosti} pro {sazeni|sazeni na sport|hazardni hry} a {umoznuji|umoznuji} rychle {provadet/ provadet} {transakce|operace} pres {elektronicke|virtualni|osobni} penezenky #file_links["C:\Users\Admin\Desktop\file\gsa+cs+lomspirogi86c5y526r6P2URLBB.txt",1,N] a {kryptomeny|bitcoiny}.
Joshuawatty 12 Kasım 2025 11:16
Извините за то, что вмешиваюсь… Я здесь недавно. Но мне очень близка эта тема. Могу помочь с ответом. [url=https://play-fanduel.com/]fanduel[/url] is based on a library of games developed by leading providers such as igt, netent and evolution.
JohnathanRAG 12 Kasım 2025 10:17
даже если речь идет о просто ручной пылесос - вы найдете нужный, [url=https://noblelondon.com/rost-czen-na-zhile-v-anglii/]https://noblelondon.com/rost-czen-na-zhile-v-anglii/[/url] без беготни и туманных характеристик.
Lindsaydaync 12 Kasım 2025 10:04
Los siguientes casinos no solo prometen, y cumplen. Son sitios transparentes, [url=https://www.myworldshopping-net.onlinegroup.no/2025/10/26/librabet-la-revolucion-en-las-apuestas-online-4/]https://www.myworldshopping-net.onlinegroup.no/2025/10/26/librabet-la-revolucion-en-las-apuestas-online-4/[/url] podra encontrar una lista detallada de con todas opciones que mas bajos limites de depositos.
Curtismus 12 Kasım 2025 08:49
You have the right withdraw prize or continue playing with the smoking person by completing the [url=https://midlap.com/guide-to-betting-casino-online-uk-all-you-need-to/]https://midlap.com/guide-to-betting-casino-online-uk-all-you-need-to/[/url] rollover. Just remember that some of your payments will be less than your rate.
Bobbybrumn 12 Kasım 2025 06:58
Fortuna ou Mesa entretenimento sao jogos cujo resultado depende diretamente exclusivamente da Sorte ou baseado nela, [url=https://roomstyler.com/users/leonbetnz]https://roomstyler.com/users/leonbetnz[/url] sua operacao e experiencia sao permitidas somente existentes cassinos em areas permanentes ou temporarios jogos passatempos criados por decreto-lei.
Brandonhix 12 Kasım 2025 06:29
JasonBep 12 Kasım 2025 04:53
Буду ждать доставку как чё отпишусь . https://form.jotform.com/253026627004044 Скажите сей час в Челябинске работаете?)
servisnyy_eyKl 12 Kasım 2025 04:11
сервисный центр bosch москва [url=http://moskva-bosch-master.ru/]ремонт bosch[/url]
AshleyNek 12 Kasım 2025 03:40
Подтверждаю. Всё выше сказанное правда. Давайте обсудим этот вопрос. [url=https://encuadernavila.es/producto/libro-de-firmas-64-5/]https://encuadernavila.es/producto/libro-de-firmas-64-5/[/url], обувь, сумки, аксессуары для дам и представителей сильного пола от mango. Верхней одеждой ему служил плащ, сплетённый из травяных волокон (такие плащи местные пастухи носили ещё в 20 в. н. э.).
LawrenceSmist 12 Kasım 2025 03:39
Индустриальный стиль исключает какую-либо вычурность, [url=http://2jours.de/wordpress/?p=60]http://2jours.de/wordpress/?p=60[/url] поэтому материя для моделей подбирается особенная. Популярность стиля loft достигла на данный момент своего пика.
JasonBep 12 Kasım 2025 03:07
С новым годом всех! https://yamap.com/users/4925256 чема вещи делает!!!
RobertGessE 12 Kasım 2025 02:16
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Давайте обсудим это. paypal: paypal extensively used for large Internet transactions, betwinner [url=https://crystaltechservices.fr/unlock-your-betwinner-bonus-today/]https://crystaltechservices.fr/unlock-your-betwinner-bonus-today/[/url] shops, including e-commerce and gambling virtually. on the page of the Betwinner Casino, a variety of themed events are also posted, as well as also original options, sort of betting/betting on outcome of the United States of America elections.
JenniferGek 12 Kasım 2025 01:40
Мне кажется это очень хорошая идея. Полностью с Вами соглашусь. обратите внимание, что оператор предлагает международную версию своего приложения, [url=https://www.gumuseylul.com/2025/10/19/melbet-privetstvennyj-bonus-2025/]https://www.gumuseylul.com/2025/10/19/melbet-privetstvennyj-bonus-2025/[/url] которая дает более широкие потенциала для регистрации. окончить образование очень удобно.
Pamelashivy 12 Kasım 2025 01:31
Хорошо сказано. In October last year, [url=https://play-fanduel.net/]fanduel sportsbook[/url] reported to the New York Times that partner of draftkings inadvertently posted data before the third week of NFL games and won 350 thousand dollars on the site fanduel.
Bobbycef 12 Kasım 2025 01:23
Я уже начал сомневаться,что проблема в курьерке!Я им звонил,они в свою очередь звонили в головной офис-про мой трек они даже не слышали!!!А постановление вроде ещё не вступило в силу. https://pubhtml5.com/homepage/zutuq Почему ушли из РБ?
AngelaOxife 12 Kasım 2025 01:15
Browsers work instantly and without storage usage, and applications provide smoother navigation, biometric login to system, [url=http://duck-feet.com/security/2025/08/31/discover-the-best-uk-online-casino-a-complete/]http://duck-feet.com/security/2025/08/31/discover-the-best-uk-online-casino-a-complete/[/url] and consumable notifications.
Kerrie 12 Kasım 2025 00:58
взломанные игры без вирусов — это удивительная возможность повысить качество игры. Особенно если вы играете на Android, модификации открывают перед вами огромный выбор. Я нравится использовать модифицированные версии игр, чтобы наслаждаться бесконечными возможностями. Модификации игр дают невероятную свободу в игре, что делает процесс гораздо увлекательнее. Играя с плагинами, я могу создать новый игровой процесс, что добавляе
BradSab 12 Kasım 2025 00:12
this provides This is a second chance for you to return a little own money and increases time of your [url=https://vegasnow-online.net/]https://vegasnow-online.net/[/url] gaming sessions.
MiaVot 11 Kasım 2025 23:46
к примеру, стильный яркий клатч можно взять при себе на шоу в консерваторию и официальные приемы, [url=http://gilfam.ir/?p=37445]http://gilfam.ir/?p=37445[/url] а компактные особенные предметы подходят для повседневного применения.
vivodzapojvladimirri 11 Kasım 2025 23:33
Восстановление после вывода из запоя в владимире: дорога к исцелению Реабилитация после запоя включает психологической помощи и поддержки близких, что является необходимым в сложный период. Процесс восстановления могут отличаться, но все они сосредоточены на борьбе с алкогольной зависимостью и обеспечении долгосрочных результатов. Группа поддержки становится важным элементом процесса, помогая справляться с трудностями. Необходимо помнить, что путь к выздоровлению труден, но возможен. <a href=https://vivod-iz-zapoya-vladimir027.ru>помощь нарколога владимир</a>
Bobbycef 11 Kasım 2025 23:33
вот пару часиков назад получил посылочку=) Чай так сказать=) ща сижу под ним в курочки уплетаю уже 3 разорвиебало бутерброд=)ЫЫЫ http://www.pageorama.com/?p=whoclntdu действительно было в лом,спасибо)
Bobbycef 11 Kasım 2025 21:46
Товар радует! Было дело забегал за соточкой! Все ровней линейки! http://www.pageorama.com/?p=nuudedub Цены сладкие. Качество отменное.
ScottPaync 11 Kasım 2025 21:07
потому-то stylus - это самый оптимальный вариант для всех, кто уважает свое свободные часы, [url=https://tivoliradio.gr/vive-le-punk-rock-festival-in-athens-7-8-02-2020/]https://tivoliradio.gr/vive-le-punk-rock-festival-in-athens-7-8-02-2020/[/url] деньги и заботу.
zapojastanarix 11 Kasım 2025 20:15
реабилитационный центр для наркозависимых в Астане <a href=https://reabilitaciya-astana011.ru>reabilitaciya-astana011.ru</a> лечение алкогольной зависимости
Eddienup 11 Kasım 2025 20:04
pomoci bonusu ziskejte skvelou prilezitost udelat osobni herni ucet [url=https://ourinnerpeace.com/nove-eske-casino-2025-revoluce-ve-svt-online-4/]https://ourinnerpeace.com/nove-eske-casino-2025-revoluce-ve-svt-online-4/[/url] vytezte z daneho maximum vyhody. pred zaregistrovat v Online Kasino, musite|musite|musite|musite|musite|musite} prorazit jeho spolehlivost a licenci.
Bobbycef 11 Kasım 2025 19:58
какие манерные нынче клиенты пошли, плюнешь в рожу драться лезут, видете ли ему грубо ответили, я с ТС с момента регистрации общаюсь и не разу он не забуровил даже когда были терки а они поверь были, так что не пизди про невежливое обращение, да и по переписки видно что все ровно, ищи проблему в себе.... https://www.grepmed.com/sogodbeda Пакетик был завёрнут в фольге, всё ровно.
PatrickInjex 11 Kasım 2025 19:30
периодически также проводятся особые акции, приуроченные к важным событиям, например, матчам Премьер-Лиги. примите во внимание, что отрезок времени обработки и получения может быть больше, [url=https://1xbet-w1xle.top/]https://1xbet-w1xle.top[/url] чем при обращении по иных методов оплаты.
Bobbycef 11 Kasım 2025 18:14
бро много кидков, очень много покупай у проверенных магазинов (это которые на главной странице), а не у пользователей, и в чате не вздумай покупать только у ПРОВЕРЕННЫХ я серьезно!!! кинут https://pubhtml5.com/homepage/qulzk заказал rcs-4, чет не радует отзывы, как придет со дня на день посмотрим, что выйдет отпишусь, буду делать 1к 10-ти...
AudreySpepe 11 Kasım 2025 17:52
you will be able to find casino for real money by completing interface for most highly paid online casinos – in America. games in [url=https://animalremovalcompany.com/?p=18158]https://animalremovalcompany.com/?p=18158[/url] are legally available, which opens players with a whole world of opportunities enjoy remotely-games in club.
AntonioSit 11 Kasım 2025 17:30
ElizabethCouct 11 Kasım 2025 17:22
Гипсокартон - материал, [url=https://maservicioslegales.com.mx/this-is-a-post-with-post-type-link/]https://maservicioslegales.com.mx/this-is-a-post-with-post-type-link/[/url] который используется для обкладки перегородок и потолков. с каждым месяцем появляются новые создания и инновации, что делают постройку намного более эффективным и удобным.
lechenievladimirrix 11 Kasım 2025 16:48
Наркологическая помощь – это набор действий‚ направленных на лечение зависимости от психоактивных веществ . На сайте <a href=https://vivod-iz-zapoya-vladimir026.ru>vivod-iz-zapoya-vladimir026.ru</a> можно ознакомиться с информацией о специализированных наркологических учреждениях‚ предлагающих профессиональную помощь при различных формах зависимости. Лечение начинается с детоксикации ‚ после которой проводятся встречи с врачами и индивидуальная терапия . Психотерапия и группы поддержки играют ключевую роль в процессе реабилитации. Также важна социальная адаптация и поддержка родственников ‚ что способствует профилактике рецидивов .
Bobbycef 11 Kasım 2025 16:25
Вы не могли сегодня оплатить заказ, потому что мы сегодня не работаем http://www.pageorama.com/?p=daahbeeoyucx Какие у тебя претензии? ты провокатор и не более т.к. ты не дал даже номер заказа и не высказал притензию, к тому же за тебя мне уже написали в Личку, другие магазины..
ReginaNar 11 Kasım 2025 16:15
как результат перед всеми появляется платформа с разнообразным [url=https://1xbet-pck00.top/]1xbet-pck00.top[/url] выбором азартных игр. Затем переместитесь по предложенной ссылке или отсканируйте qr-шифр для оперативного закачки программы.
CrystalArTek 11 Kasım 2025 16:11
Супер клас!!! In July 2021, Mr. green expanded his activity in the German market. [url=https://play-mrgreen.org/]mr green[/url] uses evoke's facilities and experience to serve high-quality gaming services to German players.
Altonmug 11 Kasım 2025 14:42
4. Подтвердите действие, [url=https://onocity.net/1-1/]https://onocity.net/1-1/[/url] нажав «Добавить». доступ в личный кабинет защищен современными технологиями безопасности, что гарантирует защиту ваших данных.
BarryWes 11 Kasım 2025 14:40
Магазин stls функционирует как для начинающих, а также для гиков: тут можно купить sony wh-1000xm5, playstation 5 pro, laifen фен или запасные детали для оборудования, и оставаться уверенным, кое-что именно оригинал, [url=https://3d-hd.com/user/DeanaJenkins291/]https://3d-hd.com/user/DeanaJenkins291/[/url] с гарантией и поддержкой.
Bobbycef 11 Kasım 2025 14:38
туфта какаето https://www.betterplace.org/en/organisations/69682 Магазин агонь! Брал как то давно. все ровно!
zapojminskrix 11 Kasım 2025 14:19
вывод из запоя круглосуточно <a href=https://vivod-iz-zapoya-minsk013.ru>vivod-iz-zapoya-minsk013.ru</a> вывод из запоя круглосуточно минск
Morgan 11 Kasım 2025 13:51
взломанные игры для слабых телефонов — это интересный способ улучшить игровой процесс. Особенно если вы пользуетесь устройствами на платформе Android, модификации открывают перед вами большие перспективы. Я лично использую взломанные игры, чтобы развиваться быстрее. Модификации игр дают невероятную свободу в игре, что погружение в игру гораздо интереснее. Играя с твиками, я могу повысить уровень сложности, что добавляет новые
Justincog 11 Kasım 2025 12:58
таким образом, накапливая промо баллы, он сможет запросто зайти в магазин промо кодов и обменять их на купоны для дармового запуска топ игр - grand theft auto, 777, dice, 21, lottery, safe, lucky wheel, колесо удачи, chest, memory, under and over 7, formula one, [url=https://1xbet-b2rsc.top/]https://1xbet-b2rsc.top[/url] apple of fortune.
EddieTob 11 Kasım 2025 12:54
Я считаю, что Вы ошибаетесь. Давайте обсудим это. Пишите мне в PM, поговорим. you always can try to apply for advice from highly qualified professionals, if have there will be difficulties with account replenishment, withdrawal of funds, verification of account [url=https://stefanoschr.com/explore-betwinner-the-premier-betting-platform/]https://stefanoschr.com/explore-betwinner-the-premier-betting-platform/[/url] or software any issues.
Bobbycef 11 Kasım 2025 12:53
лучший магаз берите все!!!!, все порешали вина не магазина. просто красавец!!! https://imageevent.com/unuhogoxewih/uqpco а ты откуда? сам? экспертиза будет чистая не волнуйся...
Crowngreen WarnerTug 11 Kasım 2025 11:33
Crowngreen Casino is a leading gaming platform that offers engaging experiences for gamers. Crowngreen shines in the online gaming world and has gained popularity among gamers. Every player at <a href="https://sbc.com.py/2025/10/29/play-the-best-games-on-crown-green-casino-and-win/">Crowngreen</a> has the chance to play top-rated games and receive generous bonuses. Crowngreen Casino guarantees reliable gameplay, smooth transactions, and round-the-clock customer support for every player. With , enthusiasts discover a wide variety of slots, including classic options. The site prioritizes user satisfaction and ensures a safe gaming environment. Whether you are a beginner or experienced, Crowngreen guarantees something special for everyone. Start playing at Crowngreen Casino t
Bobbycef 11 Kasım 2025 11:05
магазин четкй притензий нет на качество регвезде гавно((((( https://www.band.us/page/100421777/ магаз клёвый ,:bravo:сервис на высоте
Rachelkep 11 Kasım 2025 10:57
для оформления гидроизоляционных растворов используют портландцемент, [url=http://www.quietspace.cn/plus/guestbook.php]http://www.quietspace.cn/plus/guestbook.php[/url] сульфатостойкий портландцемент. Строение молекул полимеров может переживать линейный или объёмный характер.
Curtisled 11 Kasım 2025 10:18
Какие нужные слова... супер, замечательная идея это же справедливо касательно Переславля-Залесского, [url=http://www.riversedgeiowa.com/Admin/AdmLinks.php?policiesPage=1&policiesPageSize=25&room_id=9&policy_id=9&photo_id=3&attraction_id=7&linksOrder=Sorter_link_url&linksDir=ASC&linksPage=19&link_id=36697]http://www.riversedgeiowa.com/Admin/AdmLinks.php?policiesPage=1&policiesPageSize=25&room_id=9&policy_id=9&photo_id=3&attraction_id=7&linksOrder=Sorter_link_url&linksDir=ASC&linksPage=19&link_id=36697[/url] одного из самых восхитительных городов Золотого кольца России.
Austincep 11 Kasım 2025 09:43
1xbet казино лидирует среди конкурентов [url=https://1xbet-ezr25.top/]https://1xbet-ezr25.top/[/url] по многим причинам. Софт лицензионный, автоматы с вероятной отдачей, что обеспечивает крупные выигрыши гемблерам.
CharlesFlisy 11 Kasım 2025 09:19
Даный магазин берет бобло и парит мозг посылки отпровляет по месяцу, гдето с сентября такие проблемы сними начелись, причом решать их они не собираються https://www.rwaq.org/users/qsbrjkoo662nj5-20251104011730 через три дня после заказа была уже у меня
vivodkrasnoyarskrix 11 Kasım 2025 08:14
Медицинские учреждения в Красноярске предлагают различные варианты лечения, включая инъекции для снятия запойного состояния, которые могут включать витамины и лекарства для облегчения состояния. Анализ медицинских учреждений позволяет выбрать наиболее подходящий вариант с учетом стоимости и качества обслуживания. Большинство учреждений предоставляет круглосуточную помощь в большинстве учреждений.При выборе клиники стоит учитывать отзывы пациентов и опыт врачей. Консультации нарколога помогут составить эффективный план терапии алкоголизма. Анонимное лечение также является значимым фактором, так как многие пациенты предпочитают скрыть свою проблему.После завершения запойного состояния требует успешной комплексной терапии, включая реабилитационные программы для зависимых и последующее наблюде
Katrinadus 11 Kasım 2025 08:09
играя в aviatrix, также можно принимать участие в тематическом турнире Призовой взлет, [url=https://autoskolaneckar.sk/ale-ale-webova-stranka-a-novodoba-vizitka-neblaznite-2/]https://autoskolaneckar.sk/ale-ale-webova-stranka-a-novodoba-vizitka-neblaznite-2/[/url] биг-вин зовет.
CherilSmile 11 Kasım 2025 08:06
Предлагает частые скидки и акции, [url=https://seosecret.id/website-reviewer/pvsport.ru]https://seosecret.id/website-reviewer/pvsport.ru[/url] легкий розыски, и сравнение товаров. Представлена качественная продукция для туризма, кемпинга и физкультуры на открытом воздухе, приятные акции на прошлогодние модели.
DsdeLek 11 Kasım 2025 07:56
[url=https://github.com/Video-Allavsoft-hub/Allavsoft-Video-Downloader-Converter-3-28-2-9340]Allavsoft Video Downloader Converter 3.28.2.9340 mac download[/url] [url=https://github.com/Sugar-Bytes-FX-Bundle/Sugar-Bytes-FX-Bundle-2025-1]Sugar Bytes FX Bundle 2025.1 mac download[/url] [url=https://github.com/ConceptDraw-MINDMAP/ConceptDraw-MINDMAP-16-0-1-339]ConceptDraw MINDMAP 16.0.1.339 mac download[/url] [url=https://github.com/aml-bot-online-plus/aml-bot-online]aml bot online[/url] [url=https://github.com/Any-HEIC-Converter-HEIC-to-JPG-1-0-29/Any-HEIC-Converter-HEIC-to-JPG-1-0-29]Any HEIC Converter.HEIC to JPG 1.0.29 mac download[/url]
TammyDusly 11 Kasım 2025 06:21
Коллекция казино такое слоты, настольные игры, видеопокер, [url=https://1xbet-obuji.top/]1 хбет[/url] живое казино и многое иное. компанией предлагается обширный выбор вариантов ставок, казино, матчей, и лотерей, а еще ряд подарочных пропозиций и рекламных акций.
CurtisLow 11 Kasım 2025 06:20
Этот топик просто бесподобен :), мне интересно . Administrator2 (October 31, 2017). "Mr. Green partners with cozygames for launch various games in bingo and Keno - gaming [url=https://mrgreen-play.com/]mr green[/url] intelligence". The company operates several brands in various markets, including Mr. Green, which offers services online playground and sports betting.
Jameskax 11 Kasım 2025 05:47
Отличный магазин Chemical-mix https://rant.li/cayofsnyfo/kokh-samui-kupit-kokain-mefedron-marikhuanu-boshki все супер! магазину доверять можно, были небольшие задержки но ТС сделал все по красоте!
Matthewbouth 11 Kasım 2025 04:25
что рознит онлайн супермаркет Стилус от [url=https://palabraquechua.com/ayar-manco/]https://palabraquechua.com/ayar-manco/[/url] других? там все уютно.
Crowngreen WarnerTug 11 Kasım 2025 03:48
Crowngreen is a popular gaming platform that provides thrilling experiences for players. Crowngreen stands out in the online gaming world and has gained trust among enthusiasts. Every player at <a href="https://timba.co.il/uncover-exclusive-offers-at-crown-green-casino-and-8/">https://timba.co.il/uncover-exclusive-offers-at-crown-green-casino-and-8/</a> has the chance to play the latest games and take advantage of rewarding promotions. Crowngreen Casino ensures secure gameplay, fast transactions, and round-the-clock customer support for every player. With , players discover a wide range of table games, including live dealer options. The casino focuses on fun and guarantees a safe gaming environment. Whether you are new or a pro, Crowngreen guarantees something special for
ColleenRib 11 Kasım 2025 03:07
Во вкладке персонального кабинета следует выбирать подходящую платежную систему. все они обладает отдельным url-адресом, [url=https://1xbet-t80ob.buzz/]1xbet зеркало рабочее на сегодня[/url] это дает возможность обходить блокировку.
FredMow 11 Kasım 2025 02:24
Совершенно верно! Идея отличная, поддерживаю. A new option for buyers: What are the requirements for withdrawing a bonus from a club? are several countries whose residents of them should not can join [url=https://die-spitzenmakler.de/easy-guide-to-log-in-to-betwinner-ci/]https://die-spitzenmakler.de/easy-guide-to-log-in-to-betwinner-ci/[/url] with disabilities.
Jameskax 11 Kasım 2025 02:13
Вот этого ам2233 и заказал. Оплатил уже. Жду трекер. https://form.jotform.com/253087288316060 Почему всё-таки такси? На метро бы а одну сторону успел бы... Вес большеват был, обычно брал миксы да всякие вкусные таблетки, но тут сразу столько СК... Да и потом, нашёл на товар, найди т на непредвиденный случай/комфорт, я так считаю. Чем брать по грамму микс, так лучше вообще не брать. Пара дней - и на пять грамм наберешь, с друзьями/сэкономишь на обедах, в конце концов.
Sheilafer 11 Kasım 2025 02:04
РедМетСплав предлагает внушительный каталог качественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от мелких партий до обширных поставок, мы гарантируем оперативное исполнение вашего заказа. Каждая единица товара подтверждена требуемыми документами, подтверждающими их соответствие стандартам. Превосходное обслуживание - наша визитная карточка – мы на связи, чтобы разрешать ваши вопросы а также находить ответы под особенности вашего бизнеса. Доверьте вашу потребность в редких металлах специалистам РедМетСплав и убедитесь в множестве наших преимуществ поставляемая продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-az80a---astm-b107/izdeliya-iz-magniya-az80a---astm-b107/>Изделия из магния AZ80A - ASTM B107</
DsdeLek 11 Kasım 2025 01:39
[url=https://github.com/plus-Trickster-3-9-10/Trickster-3-9-10]Trickster 3.9.10 mac download[/url] [url=https://github.com/EdgeView-official/EdgeView-5-1-2]EdgeView 5.1.2 mac download[/url] [url=https://github.com/thayncn-vinhal/Rhino-8-22-25217-12452]Rhino 8.22.25217.12452 mac download[/url] [url=https://github.com/repo-TechSmith-Camtasia-2025-2-0/TechSmith-Camtasia-2025-2-0]TechSmith Camtasia 2025.2.0 mac download[/url] [url=https://github.com/online-Deckset/Deckset-2-0-41]Deckset 2.0.41 mac download[/url]
JoanneAxova 11 Kasım 2025 01:35
Женщины использовали кожаные нагрудные повязки, [url=https://wiki.rolandradio.net/index.php?title=%C3%90%C2%A7%C3%90%C2%B0%C3%91%C3%91%E2%80%9A%C3%90%C2%BE_%C3%90%E2%80%94%C3%90%C2%B0%C3%90%C2%B4%C3%90%C2%B0%C3%90%C2%B2%C3%90%C2%B0%C3%90%C2%B5%C3%90%C2%BC%C3%91%E2%80%B9%C3%90%C2%B5_%C3%90%C3%A2%E2%82%AC%E2%84%A2%C3%90%C2%BE%C3%90%C2%BF%C3%91%E2%82%AC%C3%90%C2%BE%C3%91%C3%91%E2%80%B9_%C3%90%C5%B8%C3%91%E2%82%AC%C3%90%C2%BE_%C3%90%C3%90%C2%B5%C3%90%C2%BD%C3%91%C3%90%C2%BA%C3%90%C2%BE%C3%90%C2%B5_%C3%90%E2%80%98%C3%90%C2%B5%C3%90%C2%BB%C3%91%C5%92%C3%90%C2%B5]https://wiki.rolandradio.net/index.php?title=%C3%90%C2%A7%C3%90%C2%B0%C3%91%C3%91%E2%80%9A%C3%90%C2%BE_%C3%90%E2%80%94%C3%90%C2%B0%C3%90%C2%B4%C3%90%C2%B0%C3%90%C2%B2%C3%90%C2%B0%C3%90%C2%B5%C3%90%C2%BC%C3%91%E2%80%B9%C3%90%C2%B5_%C3%90
AntonioSag 11 Kasım 2025 01:35
Потенциальная емкость рынка кейтеринга в будущем на 2022 год оценивается в [url=https://immobilier-mag.com/index.php/2018/10/12/comment-bien-louer-votre-appartement/]https://immobilier-mag.com/index.php/2018/10/12/comment-bien-louer-votre-appartement/[/url] ?500-600 млрд. Различия между баров и рестораном в разы ниже, чем между кейтерингом и рестораном.
Jameskax 11 Kasım 2025 00:27
а так всё от души! огромное спасибо! ещё не раз к вам обращюсь!) https://www.betterplace.org/en/organisations/69961 А ничо что праздники как бэ ?
psychiatrmskrix 11 Kasım 2025 00:24
лечение психиатрических расстройств <a href=https://psikhiatr-moskva011.ru>psikhiatr-moskva011.ru</a> частная психиатрическая клиника стационар
Sheilafer 10 Kasım 2025 23:20
Если вы заняты в области производства и столкнулись с необходимостью в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания специализируется на сфере поставок тугоплавких металлов уже более 10 лет, что позволяет нам предоставлять только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Широкий ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Поддержка 24/7. Зачем тратить время на поиски на других сайтах, если rms-ekb.ru всегда готовы помочь? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Звоните прямо сейчас и проверьте в достоинствах нашего сплава.
HarryInsug 10 Kasım 2025 22:44
Это было и со мной. Давайте обсудим этот вопрос. в эту ассортимент входят навигаторы, видеорегистраторы, парктроники, [url=http://kevincboyd.com/812/slide003/]http://kevincboyd.com/812/slide003/[/url] камеры заднего вида и другие интересные игры.
Jessicatiz 10 Kasım 2025 22:23
Cashback do dziesiec rowniez zaimplementowane%, [url=https://oldaskar.com/2025/08/28/vox-casino-kompleksowy-przewodnik-po-ofercie-i-3/]https://oldaskar.com/2025/08/28/vox-casino-kompleksowy-przewodnik-po-ofercie-i-3/[/url] vip - produkt i losowo bez depozytu premia.
Judyzence 10 Kasım 2025 22:23
we advise to choose slot machines with an efficiency factor from 97% to 99%, one of which includes mega joker (netent), 1429 Unexplored Seas (thunderkick), jackpot 6000 (netent) either other. In these games, [url=http://www.legalfreightlines.com/2025/08/30/experience-the-thrill-of-casino-spinsbro-new/]http://www.legalfreightlines.com/2025/08/30/experience-the-thrill-of-casino-spinsbro-new/[/url], you have high chances to make more than bets have been placed.
Sheilafer 10 Kasım 2025 22:08
Если вы занимаетесь производством и ваша компания нуждается в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания занимается на рынке поставок тугоплавких металлов в течение более 10 лет, что позволяет нам предоставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Широкий ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Круглосуточная поддержка. Зачем искать где-то еще, если rms-ekb.ru всегда в вашем распоряжении? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Звоните прямо сейчас и проверьте в качестве нашего продукта. С уважением
TammyErype 10 Kasım 2025 22:00
наша компания занимается [url=https://warnermcdanielagency.com/gallery-post/?unapproved=83526&moderation-hash=0c55c8bc359a393d9b638fcbceaedbf7]https://warnermcdanielagency.com/gallery-post/?unapproved=83526&moderation-hash=0c55c8bc359a393d9b638fcbceaedbf7[/url] сами и щепетильно отбираем вариации из каталогов фабрик-партнёров. без сомнений, вы в реальности оцените дизайн, комфорт и исполнение мебели divano.
Jameskax 10 Kasım 2025 20:46
Всем привет! https://www.brownbook.net/business/54446418/венгрия-купить-кокаин-мефедрон-марихуану-бошки/ чема вещи делает!!!
Sheilafer 10 Kasım 2025 20:34
РедМетСплав предлагает внушительный каталог отборных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до крупных поставок, мы обеспечиваем оперативное исполнение вашего заказа. Каждая единица изделия подтверждена требуемыми документами, подтверждающими их соответствие стандартам. Превосходное обслуживание - наша визитная карточка – мы на связи, чтобы разрешать ваши вопросы по мере того как находить ответы под требования вашего бизнеса. Доверьте ваш запрос специалистам РедМетСплав и убедитесь в множестве наших преимуществ Наша продукция: <a href=https://redmetsplav.ru/store/molibden-i-ego-splavy/molibden-sm3-1/lenta-molibdenovaya-sm3/>Лента молибденовая СМ3</a> Лента молибденовая СМ3 - это высококачественный продукт, предназначенный для прим
Juliafem 10 Kasım 2025 19:31
Hello, everyone! My name is Julia. My team and I support early-stage startups. If you are looking for resources to launch or scale your project, tell us about your idea. We are open to considering interesting proposals. wa.me/+380668827107
Veronicamor 10 Kasım 2025 19:09
Метлахскую плитку обжигают при высокой температуре (1200 °С). Современная [url=http://www.marocscrabble.com/spip.php?page=article&id_article=9&lang=fr]http://www.marocscrabble.com/spip.php?page=article&id_article=9&lang=fr[/url] в восточном стиле унаследовала много общих с плиткой Междуречья тенденций в выпечке орнамента, однако значение большинства символов безвозвратно утеряно.
Jameskax 10 Kasım 2025 18:58
а чё заказал? Прикольный сайт, ассортимент радует :)? https://wanderlog.com/view/rkoqwunynr/шклярска-поремба-купить-кокаин-мефедрон-марихуану-бошки/ Уже не раз писали - настраивают сайт для автоматизации заказов, с потоком розничных покупателей не справляются с нынешный системой )
DsdeLek 10 Kasım 2025 18:12
[url=https://github.com/Nembrini-Audio-Pre-Amplifier-Bundle/Nembrini-Audio-Pre-Amplifier-Bundle-v2025-8]Nembrini Audio Pre.Amplifier Bundle v2025.8 mac download[/url] [url=https://github.com/victorseyibratov/Tayasui-Sketches-Pro-6-7]Tayasui Sketches Pro 6.7 mac download[/url] [url=https://github.com/Living-Earth-Desktop/Living-Earth-Desktop-1-30]Living Earth Desktop 1.30 mac download[/url] [url=https://github.com/aml-bot-official/aml-bot]aml bot[/url] [url=https://github.com/recovery-service-crypto-best/recovery-service-crypto-best]best crypto recovery service[/url]
ShawnVuppy 10 Kasım 2025 17:37
CharleneBledy 10 Kasım 2025 15:32
Что доставили не через неделю, [url=https://www.pasa-net.org/blog_home.asp?display=4]https://www.pasa-net.org/blog_home.asp?display=4[/url] а завтра. комменты в отношении интернет маркетплейс СТЛС - то не набор смайликов от благодарных потребителей”.
Sheilafer 10 Kasım 2025 14:37
Если вы занимаетесь производством и ваша компания нуждается в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания занимается на рынке поставок тугоплавких металлов в течение долгого времени, что обеспечивает нам условия предоставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Большой ассортимент тугоплавких металлов. 3. Все необходимые документы. 4. Поддержка 24/7. Зачем тратить время на поиски в других местах, если rms-ekb.ru всегда здесь для вас? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Звоните прямо сейчас и проверьте в достоинствах нашего сплава. Ваш надежный пос
Ronalddam 10 Kasım 2025 13:36
Качество превосходное! чистейший джив у вас) всем нравится. Удачных продаж,бро! <a href=https://neva-spravka.ru>купить скорость, кокаин, мефедрон, гашиш</a> ну я тоже надеялся что лучше жвш он . но к сожалению я разочаровался в нём. держит не долго совсем
JayExode 10 Kasım 2025 13:24
Какой замечательный вопрос применяется для литья изделий, [url=https://xn--e1anfbr9d.xn--p1ai/doc/page/politika-konfidencialnosti.html]https://xn--e1anfbr9d.xn--p1ai/doc/page/politika-konfidencialnosti.html[/url] не подвергающихся ударным воздействиям. Толь - получают путём пропитки кровельного картона каменноугольными или сланцевыми дегтёвыми сюжетами и последующей посыпки его одной или двух сторон минеральным порошком.
Sheilafer 10 Kasım 2025 13:07
Если вы заняты в области производства и столкнулись с необходимостью в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания работает на рынке поставок тугоплавких металлов на протяжении более 10 лет, что дает нам возможность предоставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Обширный выбор тугоплавких металлов. 3. Полный комплект документов. 4. Всесторонняя поддержка клиентов. Зачем подбирать где-то еще, если rms-ekb.ru всегда здесь для вас? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Пишите прямо сейчас и убедитесь в преимуществах нашего редкого мет
YvonneKag 10 Kasım 2025 12:46
и какие даже аналог Дайсон не лишь красив, [url=https://www.cempi2.it/comfy-cute-cheap-nike-c-j-fiedorowicz-white-jerseys-are-amazing/]https://www.cempi2.it/comfy-cute-cheap-nike-c-j-fiedorowicz-white-jerseys-are-amazing/[/url] а на самом деле укладывает. и все упомянутое - по прозрачной цене, без уловок.
Jenniferrob 10 Kasım 2025 11:53
wszystkie bonusy mozna aktywowac na stronie "Promocje "" dlatego dzial [url=https://fgames.global/2025/08/27/vox-casino-kompleksowy-przewodnik-po-ofercie-2/]https://fgames.global/2025/08/27/vox-casino-kompleksowy-przewodnik-po-ofercie-2/[/url] kontakt dziala przez cala dobe i wsrod uczestnikow Jest/ jest asortyment/ wybor z kilku kanalow komunikacji: czat na zywo, kontakt i wiecej formularz kontaktowy dostepny na stronach witryny.
Ronalddam 10 Kasım 2025 11:48
отпишите народ за 5 iai кто брал спс заранее https://kuhni-ankor.ru Всем доброго дня!! Хочу рассказать свой отзыв , о данном чудо магазине!! Заказывал совместку на 50г, оплатил днём, к вечеру все было готово, жаль только я с джабером что то не подружился, он меня выкинул, прям перед получением адреса, НО КЛАДЧИК ТАКОЙ красавчик!!! В итоге я поехал с утра, только приехал, все было на своих местах!!! Спрятано на совесть!!! Думаю ещё пролежало бы дня 3))) ИТОГО: ОПЕРАТОР В ДЖАБЕРЕ САМЫЙ КУЛЬТКРНЫЙ ЧЕЛОВЕК НА СВЕТЕ! 5+ КЛАДЧИК , умница! 5+, близко ко мне , и спрятано как надо!!! P.S. Смело заказываем!! И радуемся как дети!!)
Jenniferjaw 10 Kasım 2025 10:46
Через банковскую карточку - это самые прямой и простой метод. тут выложена впечатляющая подборка автоматов от ведущих мировых поставщиков, таких как evoplay, netent, microgaming, [url=https://1xbet-g6iec.buzz/]https://1xbet-g6iec.buzz[/url] igrosoft и novomatic.
Ronalddam 10 Kasım 2025 10:01
трипы почитайте, кто уже брал <a href=https://stage-rp.ru>купить кокаин, меф, бошки через телеграмм</a> Братки все красиво стряпают, претензий к магазину нуль, всегда всё ровно. Единственное что сейчас напрягло, отсутствие на ветке вашего представителя в ЕКБ "онлайн", представитель молчит ( а там по делу ему в лс отписано) и кажись воопще не заходит пару недель
BenTok 10 Kasım 2025 08:59
Компания cotton babies, которая специализируется на многоразовых тканевых подгузниках и аксессуарах, [url=https://ecole-leaders.fr/bringing-your-child-to-the-parent/]https://ecole-leaders.fr/bringing-your-child-to-the-parent/[/url] выступает за устойчивые и высококлассные методы воспитания детей.
hiehofs 10 Kasım 2025 08:28
Снабжаем грузовые предприятия, автобазы и шиномонтаж шинами от известных китайских производителей! <a href=https://asiancatalog.ru>Шины оптом в Москве</a> Предоставляем отсрочку платежа!
Darylelise 10 Kasım 2025 08:15
платил 5 февраля свою посылочку!как вы поняли ничего не получил!ТС кормил меня завтраками,в итоги обещал вернуть деньги если не получу до 28 февраля!деньги мне тоже никто не вернул вместо этого мне прислали новый трек и написали что мы обещали что получите товар и деньги возвращать не буду!мои обьяснения о том что вашу посылку уже некому получать он слушать не хочет и возвращать деньги тоже!Ув.Адмистрация форума прошу не удалять мой пост и если нужно могу скинуть переписку! <a href=https://stage-rp.ru>купить Кокаин, Мефедрон, Экстази</a> трек кинули ровно оперативно как придет отпишу за качество 250
Sheilafer 10 Kasım 2025 08:13
РедМетСплав предлагает широкий ассортимент отборных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от мелких партий до обширных поставок, мы гарантируем своевременную реализацию вашего заказа. Каждая единица продукции подтверждена всеми необходимыми документами, подтверждающими их качество. Превосходное обслуживание - наш стандарт – мы на связи, чтобы улаживать ваши вопросы и предоставлять решения под требования вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в гибкости нашего предложения Наша продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-m11311---uns/provoloka-magnievaya-m11311---uns/>Проволока магниевая M11311 - UNS</a> Полоса магниевая M11311 - UNS – эт
DanielwAype 10 Kasım 2025 07:20
здесь выложена впечатляющая подборка слотов от лучших мировых фирм-производителей, таких как evoplay, netent, microgaming, [url=https://1xbet-tkh6e.top/]1хбет официальный сайт[/url] igrosoft и novomatic. на главной странице вы без проблем сможете отыскать актуальные акции и специальные варианты от бк.
Sheilafer 10 Kasım 2025 07:04
РедМетСплав предлагает широкий ассортимент высококачественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до масштабных поставок, мы гарантируем своевременную реализацию вашего заказа. Каждая единица продукции подтверждена всеми необходимыми документами, подтверждающими их происхождение. Превосходное обслуживание - то, чем мы гордимся – мы на связи, чтобы улаживать ваши вопросы по мере того как предоставлять решения под требования вашего бизнеса. Доверьте вашу потребность в редких металлах профессионалам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей поставляемая продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/rossiyskie-splavy-1/magniy-ml15---gost-2856-79/folga-magnievaya-ml15---gost-
Darylelise 10 Kasım 2025 06:30
только не под своим ником :confused: (мож поэтому и не отвечают) <a href=https://fenix-k.ru>купить Мефедрон, Бошки, Марихуану</a> трек не работает тишина уже 3 дня прошло >< у всех все гуд а у меня щляпа как так почему ((( ?!?!?!?
Elladox 10 Kasım 2025 06:14
даже если техника вдруг подведет - реально приобрести ремонт [url=https://www.ecobluedirectory.com/index.php?p=d]https://www.ecobluedirectory.com/index.php?p=d[/url] непосредственно на портале. xiaomi, аксессуары pitaka, видеорегистратор xiaomi и прочие электротовары, что по обыкновению ищут в второй фактор.
alkogolizmvladimirri 10 Kasım 2025 06:11
Возможно ли бесплатное лечение запоя в владимире? Вопрос о лечении алкоголизма и помощи зависимым стоит остро в нашем обществе. Множество людей сталкивается с запоем и ищет способы избавиться от этого состояния. В этом контексте услуги нарколога на дом круглосуточно становятся настоящим спасением. <a href=https://vivod-iz-zapoya-vladimir021.ru>нарколог на дом круглосуточно</a> Получить наркологическую помощь‚ в т.ч. бесплатную консультацию‚ можно тем‚ кто срочно нуждается в помощи при запое. В владимире можно найти услуги вывода из запоя и лечение на дому‚ что делает процесс более комфортным для пациента. Круглосуточный нарколог предложит помощь на дому‚ что особенно удобно для людей‚ которые не могут или не хотят находиться в стационаре. Анонимное лечение алкоголизма также возможно‚ что п
Lindsayoxirl 10 Kasım 2025 06:07
также, [url=http://www.bovec.net/redirect.php?link=alushta.consultinga.net&un=apartmaji.nac%40gmail.com&from=bovecnet]http://www.bovec.net/redirect.php?link=alushta.consultinga.net&un=apartmaji.nac%40gmail.com&from=bovecnet[/url] необходимы для регистрации и защиты товарных знаков, авторских прав, получения патентов, а помимо этого в других аспектах интеллектуальной собственности.
Sheilafer 10 Kasım 2025 05:25
Если вы занимаетесь производством и столкнулись с необходимостью в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания работает на области поставок тугоплавких металлов уже более 10 лет, что обеспечивает нам условия поставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Большой ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Круглосуточная поддержка. Зачем подбирать где-то еще, если rms-ekb.ru всегда здесь для вас? Наши специалисты всегда рады помочь вам с любыми вопросами.. Звоните прямо сейчас и убедитесь в качестве нашего редкого металла. С уважением, команда <a hr
psihmskrix 10 Kasım 2025 05:19
консультация психиатра платно <a href=https://psychiatr-moskva011.ru>psychiatr-moskva011.ru</a> получить консультацию психиатра
Darylelise 10 Kasım 2025 04:43
Магазин ровный, да вот менеджер не общительный ,пишу пишу .....спрошу здесь ,позиции в 5г СНМ-1000 отсутствует ???? а если есть, как заказ оформить на 5г через магазин,там только 10,50 и 100. <a href=https://boodon.ru>купить онлайн мефедрон, экстази, бошки</a> Продаван ровный ничего не скажеш
Crowngreen Casino Wa 10 Kasım 2025 04:40
Crowngreen Casino is a popular online casino that provides thrilling experiences for users. Crowngreen Casino stands out in the online gaming world and has earned reputation among gamers. Every player at <a href="https://thedezignfactory.co.uk/win-big-at-crowngreen-casino-and-claim-exclusive/">https://thedezignfactory.co.uk/win-big-at-crowngreen-casino-and-claim-exclusive/</a> has the chance to experience exclusive slots and benefit from generous offers. Crowngreen Casino ensures reliable gameplay, seamless transactions, and round-the-clock customer support for every player. With , gamers explore a huge range of casino games, including jackpot options. The casino delivers entertainment and guarantees an enjoyable gaming environment. Whether you are experienced or an expert
Sheilafer 10 Kasım 2025 04:16
Если вы занимаетесь производством и столкнулись с необходимостью в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания занимается на рынке поставок тугоплавких металлов в течение многих лет, что обеспечивает нам условия поставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Большой ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Всесторонняя поддержка клиентов. Зачем подбирать в других местах, если rms-ekb.ru всегда здесь для вас? Наши специалисты всегда рады помочь вам с любыми вопросами.. Обратитесь к нам прямо сейчас и убедитесь в преимуществах нашего сплава. Ваш н
IbrahimZef 10 Kasım 2025 04:00
официальный сайт 1xbet является одним из самых частоприменяемых и безопасных букмекеров в отношении [url=https://1xbet-rda2j.buzz/]1хбет официальный сайт[/url] ставок.
Darylelise 10 Kasım 2025 02:56
О качестве товара отпишу в трипрепортах .Мир, и процветания этому магазину))) https://fenix-k.ru В своё время работали по опту!
BridgetBoask 10 Kasım 2025 02:22
Напольный кондиционер - тихий [url=https://thetenerifetrader.com/2021/05/23/what-are-prop-firms/]https://thetenerifetrader.com/2021/05/23/what-are-prop-firms/[/url] и действенный. Интернет маркетплейс СТЛС - это, когда вы зашли на ресурс не за тем, чтобы запутаться, а дабы увидеть, что надо.
BrendaBlurl 10 Kasım 2025 02:20
Вместо того чтобы критиковать пишите свои варианты. Spielen Sie verantwortungsvoll. Halten Sie die festgelegten Grenzen ein, wenn es an der Zeit ist, zu bestehen/zu beenden/zu beenden Spiel/Spiel, [url=https://nemesisvs.com/lucky-pharaoh-online-kostenlos-spielen-minus/]casinos mit lucky pharao[/url]. unabhangig/unabhangig aus diesem Grund, Sie/Sie selbst gewonnen oder verloren haben.
izzapoyakrasnoyarskr 10 Kasım 2025 01:36
Лечение запоя с помощью капельницы – это ключевым моментом в терапии алкогольной зависимости. В Красноярске наркология предоставляют помощь специалиста‚ который осуществит детоксикацию организма. Признаки запоя‚ включая тревога и потливость‚ способны привести серьезные проблемы после запоя. Капельница способствует восстановить водно-электролитный баланс и возобновить здоровье после запоя. <a href=https://vivod-iz-zapoya-krasnoyarsk016.ru>помощь нарколога Красноярск</a> После лечения важно пройти реабилитацию и обеспечить психологическую поддержку. Консультация нарколога способствует избежать рецидивов. Профилактика рецидива предполагает обучение и поддержку‚ что способствует восстановлению организма. Медицинская помощь при алкоголизме в Красноярске предоставляется и эффективна‚ помогая пац
Darylelise 10 Kasım 2025 01:11
в каком городе брал и когда?интерисует барнаул <a href=https://vzlom-android-igry.ru>купить онлайн мефедрон, экстази, бошки</a> Купил гашиш евро. В этот раз платёж подтверждался минут 15, обычно почти сразу. Ну а к качеству и кладу с гашишем претензий ноль. Всё вышка!
Chuckchinc 10 Kasım 2025 01:08
zbudowalismy /zaprojektowalismy dowolne sposoby kontaktu, [url=https://www.adsflourish.com/voxcasinoo/vox-casino-polska-przewodnik-po-ofercie-promocjach/]https://www.adsflourish.com/voxcasinoo/vox-casino-polska-przewodnik-po-ofercie-promocjach/[/url] aby ty w dowolnym momencie, byl bezpieczny. w przypadku uzytkownikow Androida zalecamy wlaczenie opcji "Zezwalaj na instalacje z nieznanych zrodel".
Devonbof 10 Kasım 2025 01:07
because of your publicly available website [url=https://journeytogetherapp.com/best-live-online-casino-uk/]https://journeytogetherapp.com/best-live-online-casino-uk/[/url], you can expect that its characteristics will be able to be on an understandable level with the quality of its competitors from published list.
IanUsery 10 Kasım 2025 00:47
Компания использует новейшие технологии безопасности данных, [url=https://1xbet-gm7ow.top/]https://1xbet-gm7ow.top/[/url] чтобы обеспечить анонимность и защищенность наших юзеров. для обновления счета на официальном площадке 1xbet нужно зайти в аккаунт, который можно посмотреть на сайте 1xbet. После входа в аккаунт, геймер сумеет выбрать раздел «вложение средств» и заказать удобный способ пополнения.
Sheilafer 10 Kasım 2025 00:17
РедМетСплав предлагает внушительный каталог отборных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до обширных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица товара подтверждена соответствующими документами, подтверждающими их качество. Опытная поддержка - наш стандарт – мы на связи, чтобы улаживать ваши вопросы по мере того как предоставлять решения под специфику вашего бизнеса. Доверьте вашу потребность в редких металлах профессионалам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/vismut/zarubezhnye-splavy-3/vismut-281---astm-b774/provoloka-vismutovaya-281---astm-b774/>Проволока висмутовая 281 - ASTM B774</a> Проволока висмутовая
JohnCoirl 09 Kasım 2025 23:44
super-takumar 1-2/55 asahi opt. super-multi-coated takumar 1:1.4/50 asahi opt. Индустар-55У 140/4.5, [url=https://www.photoartistweb.nl/prijzen/]https://www.photoartistweb.nl/prijzen/[/url] приспособленынй для зеркальных камер. nikon 135mm f/2d af dc-nikkor defocus image control.
CarrieLes 09 Kasım 2025 23:39
Об оплате мы также договорились «на берегу». к вечеру я вернулась, [url=http://detkonf.ru/5-tips-for-a-healthy-family/]http://detkonf.ru/5-tips-for-a-healthy-family/[/url] чтобы убедиться в работу.
LindsayVER 09 Kasım 2025 23:29
Как-то не канет The 1xbet app gives an opportunity for you worth in these predecessors such as blackjack, roulette, [url=https://1xbet--game.org/]1xbet casino[/url] and one-armed bandits, directly from smartphone or tablet.
narkologiyavladimirr 09 Kasım 2025 23:23
Реабилитация после запоя в владимире требует всестороннего подхода. <a href=https://vivod-iz-zapoya-vladimir020.ru>Врач нарколог на дом владимир</a> предоставляет услуги, включая лечение запоя и медицинскую реабилитацию. Индивидуальный подход к лечению и консультация врача нарколога дают возможность разобраться в психологии зависимостей. Поддержка семьи является ключевым фактором в профилактике рецидивов. Центр реабилитации владимир предлагает программы восстановления‚ включая анонимное лечение алкоголизмачто способствует повышению качества жизни и психологическому комфорту.
Sheilafer 09 Kasım 2025 23:18
РедМетСплав предлагает обширный выбор отборных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до крупных поставок, мы обеспечиваем оперативное исполнение вашего заказа. Каждая единица изделия подтверждена требуемыми документами, подтверждающими их качество. Превосходное обслуживание - наша визитная карточка – мы на связи, чтобы разрешать ваши вопросы по мере того как адаптировать решения под специфику вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в гибкости нашего предложения Наша продукция: <a href=https://redmetsplav.ru/store/niobiy1/splavy-niobiya-1/niobiy-nb10v5mcu---gost-26468-85-1/lenta-niobievaya-nb10v5mcu---gost-26468-85/>Лента ниобиевая Нб10В5МЦУ - ГОСТ 26468-85</a> Лента ниобиева
psihmskrix 09 Kasım 2025 22:55
платная консультация психиатра <a href=https://psychiatr-moskva010.ru>psychiatr-moskva010.ru</a> вызов психиатра на дом
AngielinaRew 09 Kasım 2025 21:53
Прошу прощения, что вмешался... Но мне очень близка эта тема. Пишите в PM. 1. Log in to your cabinet at the [url=https://www.ehdf.com/how-to-make-a-deposit-at-bc-game-a-comprehensive-2/]https://www.ehdf.com/how-to-make-a-deposit-at-bc-game-a-comprehensive-2/[/url]. 2. click on the icon of your page in the upper-right corner of the screen.
Darylelise 09 Kasım 2025 21:37
Вторая посылка вообще на 4й день пришла :yeah:. Все рекорды бьете ребят :voo-hoo: . Магазу респект и уважуха, так держать . <a href=https://fenix-k.ru>купить скорость, кокаин, мефедрон, гашиш</a> в курске у стаффсторе лутше не брать за кладом надо ехать с граблями и лопатой сугробы копать иначе никак
AndreaOrerm 09 Kasım 2025 21:32
вы можете заказать любое состязания, будь то футбол, баскетбол, теннис или хоккей, и сделать свою ставку на выигрыш команды или игрока, тоталы, [url=https://1xbet-2ffol.top/]https://1xbet-2ffol.top/[/url] форы и все остальное.
Sheilafer 09 Kasım 2025 20:41
Если вы занимаетесь производством и нуждаетесь в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания специализируется на рынке поставок тугоплавких металлов на протяжении многих лет, что обеспечивает нам условия поставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Большой ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Поддержка 24/7. Зачем тратить время на поиски где-то еще, если rms-ekb.ru всегда в вашем распоряжении? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Пишите прямо сейчас и удостоверьтесь в качестве нашего продукта.
utaletgweo 09 Kasım 2025 20:01
free 30 day trial of cialis [url=https://groodx.com/buy-generic-cialis-online-affordable-meds-without-prescription.html]buy generic cialis[/url] para q sirve cialis 20 mg womens health centers near me
Margaretblelf 09 Kasım 2025 19:56
они используются в ситуациях, [url=https://www.drjaudy.com/tracy-and-mark/]https://www.drjaudy.com/tracy-and-mark/[/url] если отсутствует подсоединение к интернету электропитания либо необходим дублирующий источник энергии.
Darylelise 09 Kasım 2025 19:50
не будет 307го. ожидается 203, 250, rcs-4 и 1220й... вот что мне сказали в той же аське, где спрашивал ты ) <a href=https://pasyans-pauk.ru>купить кокаин, меф, бошки через телеграмм</a> Оплатил 3 февраля, 6 получил трек-трек не бьётся, посылкинет. Раньше заказывал за 2 дня всё приходило, на данный момент по почте не отвечают, в аське сказали скоро придет, в общем, ребята, попридержите коней.
Sheilafer 09 Kasım 2025 19:29
Если вы занимаетесь производством и нуждаетесь в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания специализируется на области поставок тугоплавких металлов уже многих лет, что обеспечивает нам условия предоставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Обширный выбор тугоплавких металлов. 3. Полный комплект документов. 4. Поддержка 24/7. Зачем тратить время на поиски на других сайтах, если rms-ekb.ru всегда в вашем распоряжении? Наши специалисты всегда рады помочь вам с любыми вопросами.. Звоните прямо сейчас и проверьте в преимуществах нашего сплава. С уважением, команда <a href=http
TammyUnelm 09 Kasım 2025 18:39
Быстро сообразили )))) это обеспечение отличного качества электроники [url=https://theacademy.co.ug/partnerships/taso/]https://theacademy.co.ug/partnerships/taso/[/url] и веб техники. на сайте распространяется продукция высокого класса для дам и представителей сильного пола.
Jimmyhet 09 Kasım 2025 18:19
И провайдер видит подключение не к целевому ресурсу, [url=https://1xbet-a1e5u.buzz/]https://1xbet-a1e5u.buzz[/url] а к серверу. спустя некоторое время регулятор обнаруживает новый место и блокирует, а компания к тому часу открывает новый.
Ryanjeown 09 Kasım 2025 18:15
Специально зарегистрировался на форуме, чтобы поучаствовать в обсуждении этого вопроса. emocion en balloon es innovador y emocionante una forma de apostar que combina/ combina en sus habilidades y capacidades deleite en [url=http://palmnepal.com.np/61880/]balloon juego gratis[/url] con recompensas monetarias.
Darylelise 09 Kasım 2025 18:05
Значит не туда стучишься!а ребята молодцы! <a href=https://metallick.ru>купить кокаин, меф, бошки через телеграмм</a> Нет. Такого у нас нет.
Sheilafer 09 Kasım 2025 17:42
РедМетСплав предлагает широкий ассортимент качественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до обширных поставок, мы обеспечиваем быстрое выполнение вашего заказа. Каждая единица товара подтверждена всеми необходимыми документами, подтверждающими их качество. Дружелюбная помощь - то, чем мы гордимся – мы на связи, чтобы улаживать ваши вопросы а также предоставлять решения под особенности вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в гибкости нашего предложения Наша продукция: <a href=https://redmetsplav.ru/store/kobalt/wallex/kobalt-wallex-6-3/poroshok-kobaltovyy-wallex-6-3/>Порошок кобальтовый Wallex 6</a> Порошок кобальтовый Wallex 6 – это высококачественный материал, идеально
Jenniferunife 09 Kasım 2025 17:19
На vodkabet вы будете уверены, [url=http://www.register.sbm.pw/user/thomasbutc/]http://www.register.sbm.pw/user/thomasbutc/[/url] что ваша информация находится в опытных руках. приобщайтесь к водкабет сегодня, и откройте для себя мир увлекательных предложений, и невероятных выигрышей.
AnastasiacaP 09 Kasım 2025 17:08
Типичный интернет супермаркет позволяет клиенту просматривать ассортимент товаров и сервисов фирмы, просматривать фотографии или изображения продуктов, [url=https://micro-pi.ru/ina219-i2c-%d0%b2%d0%be%d0%bb%d1%8c%d1%82%d0%bc%d0%b5%d1%82%d1%80-%d0%b0%d0%bc%d0%bf%d0%b5%d1%80%d0%bc%d0%b5%d1%82%d1%80/]https://micro-pi.ru/ina219-i2c-%d0%b2%d0%be%d0%bb%d1%8c%d1%82%d0%bc%d0%b5%d1%82%d1%80-%d0%b0%d0%bc%d0%bf%d0%b5%d1%80%d0%bc%d0%b5%d1%82%d1%80/[/url] а кроме того – сведения о технических данных товаров, и ценовой политике.
Howardwrame 09 Kasım 2025 16:17
О качестве товара отпишу в трипрепортах .Мир, и процветания этому магазину))) https://kultura-marks.ru читайте отзывов много!:) товар тут вышка,обращайтесь!
Santospord 09 Kasım 2025 15:55
How can I improve my website traffic? https://rentry.co/4tqrpbwv https://posteezy.com/mastering-your-mortgage-building-comprehensive-home-loan-interest-rate-calculator-excel https://canvas.instructure.com/eportfolios/4045279/entries/14292953 https://telegra.ph/div-contenteditablefalse-idoutput-classcss-typingh2An-In-Depth-Examination-The-Casio-fx-83GT-CW-Pink-Scientific-Calculators-Fusi-11-08 https://graph.org/div-contenteditablefalse-idoutput-classcss-typingh1Navigating-Personal-Loan-EMIs-with-Precision-My-Experience-with-the-Axis-Bank-11-08
panstularix 09 Kasım 2025 15:45
пансионат с деменцией для пожилых в туле <a href=https://pansionat-tula015.ru>pansionat-tula015.ru</a> пансионат инсульт реабилитация
PhilipBuIct 09 Kasım 2025 15:08
Если настоящий гемблер выводит выигранные средства впервые, [url=https://1xbet-jel2g.top/]https://1xbet-jel2g.top[/url] тогда ему требуется всенепременно пройти подтверждение. Как обновить 1хБет до последней версии?
LeahRhymn 09 Kasım 2025 14:52
приколно на воскресення In addition to licensed offshore sites you can bet online on the website playnow or in absolutely a new digital application for piece trading of [url=https://loveyourjester.com/test/2025/10/28/bc-game-37/]https://loveyourjester.com/test/2025/10/28/bc-game-37/[/url] proline bookmakers.
Sheilafer 09 Kasım 2025 14:34
РедМетСплав предлагает обширный выбор отборных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от мелких партий до обширных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица изделия подтверждена всеми необходимыми документами, подтверждающими их соответствие стандартам. Опытная поддержка - наш стандарт – мы на связи, чтобы улаживать ваши вопросы а также находить ответы под специфику вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наша продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-mi3---jis-h-2150/lenta-magnievaya-mi3---jis-h-2150/>Лента магниевая MI3 - JIS H 2150</a> Круг магниевый MI3 - JI
TommySmoth 09 Kasım 2025 14:31
Обязательно позвонить должны, как позвонят легче забрать самому чем ждать пока курьер доставит https://cartridge-ug.ru спасибо за пожелания
KarenNor 09 Kasım 2025 14:29
to gwarantuje Tobie uzyskanie szerokiej gamy gier, [url=https://soulhug.in/index.php/2025/08/27/vox-casino-kompleksowy-przewodnik-po-ofercie-i/]https://soulhug.in/index.php/2025/08/27/vox-casino-kompleksowy-przewodnik-po-ofercie-i/[/url] tworzenie/ zapewnienie komfortu i niezawodnosci dla wszystkich/ tych uzytkownikow. Sik bo online: Rzuc kostka z azjatyckim akcentem.
Juliathoug 09 Kasım 2025 13:33
РБК (15 мая 2017). Дата обращения: 28 ноября текущего. Архивировано 29 ноября 2018 [url=https://baarkfoundation.org/baark_final2_hires/]https://baarkfoundation.org/baark_final2_hires/[/url] года. на заре 2021 года «Авто.ру» запустил инновационный система «Финанс», который автоматизирует подбор кредита на автомобили с пробегом.
TracyLet 09 Kasım 2025 10:47
vds (virtual дедик, виртуальный удалённый сервер) или vps (virtual private server, [url=http://hastanc.com/ats-workshop/ws1/]http://hastanc.com/ats-workshop/ws1/[/url] виртуальный частный сервер) - это сервис аренды части ресурсов физического сервера.
Sheilafer 09 Kasım 2025 10:13
РедМетСплав предлагает широкий ассортимент отборных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от мелких партий до обширных поставок, мы гарантируем своевременную реализацию вашего заказа. Каждая единица продукции подтверждена соответствующими документами, подтверждающими их качество. Превосходное обслуживание - наш стандарт – мы на связи, чтобы улаживать ваши вопросы а также адаптировать решения под специфику вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/volfram/splavy-volframa-1/volfram-w-la15-1/pokovka-volframovaya-w-la15/>Поковка вольфрамовая W-La15</a> Поковка вольфрамовая W-La15 – это высококачественный матер
Maggierus 09 Kasım 2025 10:04
Это — позор! en esencia, todo toma en cuestion de momentos sin visible complicaciones, [url=https://plinko-casino.cl/]https://plinko-casino.cl/[/url], y real diferencia: en tu resultados permanecera basicamente permanecer dependiendo de factores, que has establecido antes, y luego de la gestion de tu bankroll.
Traceycrugh 09 Kasım 2025 09:23
Поздравляю, ваша мысль великолепна Расширение ассортимента и повышение доли российской продукции становятся ключевыми факторами [url=http://-.U.K37@cgi.members.interq.or.jp/ox/shogo/ONEE/g_book/g_book.cgi]http://-.U.K37@cgi.members.interq.or.jp/ox/shogo/ONEE/g_book/g_book.cgi[/url] развития отрасли. Производство детских продукции в рф по мнению 2024 года увеличилось на шесть и превысило ?680 млрд.
Jeffreybut 09 Kasım 2025 07:44
Официальный сайт компании 1xBet > http://www.newlcn.com/
TammyRoyaf 09 Kasım 2025 07:42
Браво, эта замечательная фраза придется как раз кстати Daily cashback: Get cashback on losses every day, [url=https://www.selurmatstofa.com/2025/10/28/como-realizar-saque-no-bc-game-um-guia-completo/]https://www.selurmatstofa.com/2025/10/28/como-realizar-saque-no-bc-game-um-guia-completo/[/url] gives the visitor recover and cut in for long time.
BrookeUtill 09 Kasım 2025 06:59
какой получится ваш новый компьютер? На Мегамаркет есть охладительной системы, офисная техника, звуковые банковской карточки и костюмированные мышки, [url=http://s396607883.online.de/]http://s396607883.online.de/[/url] причем все отменного качества.
zapojkrasnodarrix 09 Kasım 2025 06:59
вывод из запоя краснодар <a href=https://vivod-iz-zapoya-krasnodar023.ru>vivod-iz-zapoya-krasnodar023.ru</a> вывод из запоя цена
Sheilafer 09 Kasım 2025 05:26
РедМетСплав предлагает обширный выбор отборных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до крупных поставок, мы обеспечиваем своевременную реализацию вашего заказа. Каждая единица продукции подтверждена требуемыми документами, подтверждающими их соответствие стандартам. Дружелюбная помощь - наша визитная карточка – мы на связи, чтобы ответить на ваши вопросы а также предоставлять решения под требования вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наша продукция: <a href=https://redmetsplav.ru/store/kobalt/stellite/kobalt-stellite-3-pm-1/prutok-kobaltovyy-stellite-3-pm-1/>Пруток кобальтовый Stellite 3 PM</a> Пруток кобальтовый Stellite 3 PM – это высо
Juansah 09 Kasım 2025 05:15
нужно лишь пополнить баланс на 300 тенге либо более в среду, [url=https://1xbet-c2yz4.top/]https://1xbet-c2yz4.top[/url] чтобы стать участником акции.
ConradBug 09 Kasım 2025 05:03
Отправки посылок и эта информация в 2-х местах прописана на сайте 2-10 РАБОЧИХ ДНЕЙ. В 99,9% случает сроки не нарушаются. <a href=https://uvoperm.ru>купить скорость, кокаин, мефедрон, гашиш</a> есть что почитат
BarryTum 09 Kasım 2025 03:53
Zakoncz rejestracje: kliknij przycisk "Zarejestruj sie", [url=https://nanakidlib.inari.site/388177-williamzheng233.html]https://nanakidlib.inari.site/388177-williamzheng233.html[/url] aby zakonczyc proces. niezaleznie od Twojego umiejetnosci i wyboru, na naszej stronie znajdziesz/ bedziesz mogl znalezc promocje, ktore pomoga zbuduj twoja proces gdzie bardziej przyjemna i udana.
Georgewhatt 09 Kasım 2025 03:52
The advantage of more options payments that that the average gain, most often, smaller than magnitude bets in [url=https://denary.pl/your-gateway-to-entertainment-sky-hills-casino/]https://denary.pl/your-gateway-to-entertainment-sky-hills-casino/[/url].
Miknox 09 Kasım 2025 03:47
Автосервис «5 Бокс» https://auto-5-box.ru — это команда профессионалов, для которых качество и честность превыше всего. Мы выполняем ремонт любых узлов автомобиля: двигателя, трансмиссии, подвески, тормозной системы, электрооборудования и кондиционеров. Производим замену расходников, диагностику и профилактику неисправностей. Работаем на современном оборудовании, используем качественные запчасти и предоставляем гарантию на все услуги. У нас прозрачные цены, внимательное отношение и реальные сроки ремонта. «5 Бокс» — автосервис, которому можно доверить свой автомобиль.
ConradBug 09 Kasım 2025 03:18
остался дико не рад, но селлер быстро пообещал кидануть бонуса при следующей покупке. надеюсь, не пожадничают <a href=https://fntr76.ru>купить кокаин, меф, бошки через телеграмм</a> Конспирация на уровне
domprestarelihtulari 09 Kasım 2025 02:40
пансионат для лежачих пожилых <a href=https://pansionat-tula013.ru>pansionat-tula013.ru</a> частный пансионат для пожилых людей
Aryagow 09 Kasım 2025 02:01
Бонусы доступны после регистрации и обновления счета, [url=https://1xbet-2eqzf.top/]1xbet-2eqzf.top[/url] требуют соблюдения пунктов отыгрыша. Каждая пс прошла контроль и отвечает требованиям безопасности.
ZacharyKes 09 Kasım 2025 01:58
мне аж жарко стало Кожа гордится своей долгоченостью и длительными сроками [url=http://роялиндиго.рф/]кожаный ремень из натуральной кожи[/url] службы. Его химическая обработка требует отличной осторожности, поэтому разумнее пойти за этой услугой в специализированную химчистку.
ConradBug 09 Kasım 2025 01:33
поддерживаю !!!! https://grimzone.ru привет я сам тут не так давно ) я тебя понимаю я вот уже вторую посылку получил всё чётко и ровно тоже пережевал , часто на швыров попадал а тут ребята грамотную тему замутили и магазу респект и админам) не волнуйся всё будет чётко:good:
Sheilafer 09 Kasım 2025 00:47
Если вы занимаетесь производством и ваша компания нуждается в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания занимается на области поставок тугоплавких металлов на протяжении десятилетий, что обеспечивает нам условия предоставлять только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Обширный выбор тугоплавких металлов. 3. Документация в порядке. 4. Круглосуточная поддержка. Зачем подбирать в других местах, если rms-ekb.ru всегда в вашем распоряжении? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Обратитесь к нам прямо сейчас и убедитесь в достоинствах нашего редко
TinaADags 09 Kasım 2025 00:42
И что бы мы делали без вашей великолепной фразы Players also have chances to take advantage of the multi-level bonus system, as [url=https://www.eldeguanajuato.com/download-the-bc-game-app-for-ultimate-gaming/]https://www.eldeguanajuato.com/download-the-bc-game-app-for-ultimate-gaming/[/url] rewards more ?overall dimensions? deposits with larger bonuses. The best VIPs receive individual incentive offers and rakeback, receiving specific share from gambling regardless of winning or losing.
Andrewned 09 Kasım 2025 00:16
Кроме шуток! Как отмечают аналитики businessstat, сетевые ритейлеры и бутики игрушек встречаются с жесткой конкуренцией на первый взгляд маркетплейсов, [url=https://www.misanemcova.cz/best-tips-for-a-successful-magazine/]https://www.misanemcova.cz/best-tips-for-a-successful-magazine/[/url] что осложняется трудностями с поставками и ростом стоимости кредитов.
ConradBug 08 Kasım 2025 23:48
ну вообщем все ровно получил людей правда от бати но магазин ровный советую <a href=https://stomkam.ru>купить Кокаин, Мефедрон, Экстази</a> я тут походу единственный кто остался недоволен.(
Traceysot 08 Kasım 2025 22:47
официальный площадка 1xbet это один из повсеместно|наиболеезнаменитых востребованных и безопасных букмекеров в сфере [url=https://1xbet-nq66y.buzz/]https://1xbet-nq66y.buzz/[/url] ставок. если вы реальную возможность надежную букмекерскую контору, то бк - идеальный способ для вас.
JonRaw 08 Kasım 2025 22:03
для маленьких порталов и ботов подойдет одно-два ядра. «Руцентр» предоставляет скидочные 30 дней при заказе любого тарифа [url=https://www.scrtlb.com/blog-post-modern/]https://www.scrtlb.com/blog-post-modern/[/url]/vds от трех месяцев.
ConradBug 08 Kasım 2025 22:01
"Я надеюсь что вы перепроверите товар " <a href=https://stomkam.ru>купить скорость, кокаин, мефедрон, гашиш</a> ага в осадок выпадает в спирте это верно, но если после выпадания в осадок добавить 646 в спирт и все будет гуд. Кстати 250 также при перегреве выпадает в осадок
StellaReelf 08 Kasım 2025 21:37
Сладости на юбилей [url=http://xn--2i0bt1gq8b82fuvuh1b1e.kr/quisque-sit-amet-sapien-et-lacus/04]http://xn--2i0bt1gq8b82fuvuh1b1e.kr/quisque-sit-amet-sapien-et-lacus/04[/url] - всегда кстати. Если именинника увлекает эстетика, закажите ему кое-что привычное, но ручной работы или раритетное.
Sheilafer 08 Kasım 2025 20:44
РедМетСплав предлагает внушительный каталог качественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от мелких партий до обширных поставок, мы гарантируем своевременную реализацию вашего заказа. Каждая единица продукции подтверждена всеми необходимыми документами, подтверждающими их происхождение. Дружелюбная помощь - наша визитная карточка – мы на связи, чтобы улаживать ваши вопросы и находить ответы под особенности вашего бизнеса. Доверьте потребности вашего бизнеса специалистам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-am90---csa-hg-11/prutok-magnievyy-am90---csa-hg-11/>Пруток магниевый AM90 - CSA HG.11</a> Проволока магни
WernerDably 08 Kasım 2025 20:43
Кто делал уничтожение тараканов в мебели холодным туманом? Эффективно ли? <a href=https://dezchel.ru/>санитарная обработка</a>
pansionatmskrix 08 Kasım 2025 20:18
пансионат для реабилитации после инсульта <a href=https://pansionat-msk015.ru>pansionat-msk015.ru</a> пансионат для лежачих москва
ConradBug 08 Kasım 2025 20:15
Метод употребления - интерназально <a href=https://smartcat26.ru>купить Мефедрон, Бошки, Марихуану</a> Заказываю 2c-I для начала 1 г!!
izzapoyasmolenskrix 08 Kasım 2025 19:38
экстренный вывод из запоя смоленск <a href=https://vivod-iz-zapoya-smolensk030.ru>vivod-iz-zapoya-smolensk030.ru</a> вывод из запоя круглосуточно
Louisecep 08 Kasım 2025 19:33
на здешнем веб-сайте доступно делать ставки на спорт, казино, [url=https://1xbet-ilxu8.buzz/]https://1xbet-ilxu8.buzz[/url] карты и прочие необходимые интересные позиции.
Chrisdrump 08 Kasım 2025 18:09
мы выбираем только то, [url=http://storemango.com/bbs/board.php?bo_table=free&wr_id=3337061]http://storemango.com/bbs/board.php?bo_table=free&wr_id=3337061[/url] чему доверяем сами. Весь качественный, надежный и злободневный ассортимент - уже у нас в виртуальном-магазине stls.
Danielcag 08 Kasım 2025 17:52
По-моему это только начало. Предлагаю Вам попробовать поискать в google.com однажды количество таких маршрутов будет расти, [url=https://taxi55155.ru/]Такси Межгород[/url] поэтому следите за обновлениями в дополнении.
Sheilafer 08 Kasım 2025 17:52
Если вы занимаетесь производством и ваша компания нуждается в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания работает на области поставок тугоплавких металлов уже более 10 лет, что дает нам возможность поставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Большой ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Всесторонняя поддержка клиентов. Зачем искать на других сайтах, если rms-ekb.ru всегда в вашем распоряжении? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Пишите прямо сейчас и удостоверьтесь в достоинствах нашего редкого металла. К
HarleyTip 08 Kasım 2025 17:41
<a href=https://bigdive.eu/>https://bigdive.eu/</a> revue complete des promotions 1xBet disponibles
TashaSoima 08 Kasım 2025 17:36
Послушайте, давайте не будем больше тратить времени на это. 2. Visit the official portal bc game. Even/Odd: Guess will be total quantity points or goals scored even or odd.[url=https://kiek.wedenkenaanje.nl/uncategorized/explore-the-world-of-gaming-at-bcigra-com/]https://kiek.wedenkenaanje.nl/uncategorized/explore-the-world-of-gaming-at-bcigra-com/[/url]
JackieCeD 08 Kasım 2025 17:29
ma sens nie zapominac, ze kazde zdanie podlega odrebnym regulom, [url=https://www.printi.it/vox-casino-przewodnik-po-grach-bonusach-i/]https://www.printi.it/vox-casino-przewodnik-po-grach-bonusach-i/[/url] ktory jednoznacznie formuluje zadania do obrotu i okres waznosci.
Alimak 08 Kasım 2025 17:28
differences in [url=https://krincel.colourann.com/2025/08/28/discover-the-exciting-world-of-online-richy-reels/]https://krincel.colourann.com/2025/08/28/discover-the-exciting-world-of-online-richy-reels/[/url] are minor, but the re-launches are more acutely felt here. Step 6: When characteristics are fulfilled and meet the allotted time, request a withdrawal of winnings.
ConradBug 08 Kasım 2025 16:42
щас заказал по 5г RCS-4 и URB754 по скайпу объяснили как оплатить, пока всё коректно жду посылки там отпишу.. <a href=https://pasta-mamma.ru>купить онлайн мефедрон, экстази, бошки</a> в скайпе сказали - "дживики все кончились, будут в начале следующей неделе" - но легче это опубликовать тут, что бы всем не отвечать на этот вопрос.
EdwinTar 08 Kasım 2025 16:33
1xbet промокод Вводите промокод на https://familylab-spa.ru/blog/articles/promokod_252.html и активируйте бонус до 32 500 рублей для комфортного старта игры.
MirandaDaymn 08 Kasım 2025 16:16
для снятия выигрыша используют пластиковые карточки, [url=https://1xbet-hespa.buzz/]https://1xbet-hespa.buzz/[/url] виртуальные кошели и криптовалюту. внести депозит - перечисление депозита.
Sheilafer 08 Kasım 2025 16:10
Если вы заняты в области производства и ваша компания нуждается в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания занимается на рынке поставок тугоплавких металлов на протяжении многих лет, что позволяет нам предлагать только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Обширный выбор тугоплавких металлов. 3. Документация в порядке. 4. Круглосуточная поддержка. Зачем подбирать где-то еще, если rms-ekb.ru всегда готовы помочь? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Звоните прямо сейчас и удостоверьтесь в качестве нашего продукта. С уважением, команда <a href=https://rm
Joeanamb 08 Kasım 2025 15:36
это ведет к больше стабильной и предсказуемой производительности. для опытного администратора это будет плюсом, но также начинающего пользователя месячная расчет за все ресурсы может накопиться немалая, например, [url=https://www.escribegermador.com/curioseando/empresas-son-destacadas-en-innovacion-inclusion-y-sostenibilidad-recibiendo-el-premio-gacela-2023/]https://www.escribegermador.com/curioseando/empresas-son-destacadas-en-innovacion-inclusion-y-sostenibilidad-recibiendo-el-premio-gacela-2023/[/url] после неправильно выбранного тарифов.
YvonneBrimb 08 Kasım 2025 15:11
Рулоны имеют ширину 650-1050 мм и площадь 10 и 20 [url=https://milliardnik.ru/user/AntoineSelle47/]https://milliardnik.ru/user/AntoineSelle47/[/url] м2. Марки его 75, 100, 125 и 150 со средней плотностью 1300-1450 кг/м3, размеры 250?120?88 и 250?120?65 мм.
Shakirazoria 08 Kasım 2025 14:59
это точно !! толковый оформление сайта сделает поиск нужных предметов и размеров максимально [url=https://sigmabroker.com.ar/hola-mundo/]https://sigmabroker.com.ar/hola-mundo/[/url] удобным. На выбора имеются любые размеры от 35 до пятидесяти. при заказе от тысячи рублей, вам бесплатно привезут домой покупки в течение несколько дней.
ConradBug 08 Kasım 2025 14:56
Спасибо! Обращайтесь https://dep211.ru о господи :D я не селлер - я просто зашёл на сайт и посмотрел что есть в ассортименте - из скоростей нормальных разве что..кхм, оно...
pansmskrix 08 Kasım 2025 13:48
пансионаты для инвалидов в москве <a href=https://pansionat-msk014.ru>pansionat-msk014.ru</a> частный дом престарелых
Cocoeroms 08 Kasım 2025 12:59
но это не означает, [url=https://1xbet-ttpem.buzz/]https://1xbet-ttpem.buzz/[/url] которое вы с большей вероятностью его выиграете. в самом автоматах с безукоризненным rtp возможны длительные периоды без выигрышей.
Allisonfluff 08 Kasım 2025 11:40
в сетевом магазине stylus мы предлагаем не абсолютно все, а только технику, [url=http://lemerywaterdistrict.ph/?attachment_id=51]http://lemerywaterdistrict.ph/?attachment_id=51[/url] которой доверяем сами. с онлайн маркетплейсом СТЛС легко сэкономить и получить именно то, что надо.
Sheilafer 08 Kasım 2025 11:32
РедМетСплав предлагает широкий ассортимент высококачественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от мелких партий до крупных поставок, мы обеспечиваем оперативное исполнение вашего заказа. Каждая единица товара подтверждена всеми необходимыми документами, подтверждающими их происхождение. Опытная поддержка - наш стандарт – мы на связи, чтобы разрешать ваши вопросы по мере того как находить ответы под требования вашего бизнеса. Доверьте вашу потребность в редких металлах профессионалам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наша продукция: <a href=https://redmetsplav.ru/store/vismut/zarubezhnye-splavy-3/vismut-h48bi3a---jis-z-3282/list-vismutovyy-h48bi3a---jis-z-3282/>Лист висмутовый H48Bi3A - JIS Z 3282</a> Лист в
Janetgat 08 Kasım 2025 10:30
По-моему здесь кто-то зациклился Check for updates in settings of your device and install latest version before trying to reinstall the [url=https://dloheightsultd.com/bc-game-usa-the-ultimate-crypto-gaming-experience/]https://dloheightsultd.com/bc-game-usa-the-ultimate-crypto-gaming-experience/[/url].
DaphneInvib 08 Kasım 2025 09:38
Этот бонус можно выбрать сразу или позже [url=https://1xbet-ql2nr.top/]https://1xbet-ql2nr.top/[/url] в категории «Акции». дизайн сайта - сине-голубое. площадка обладает комфортный ресурс.
Roelfam 08 Kasım 2025 09:38
Полностью разделяю Ваше мнение. Идея отличная, поддерживаю. Везде с нами гуляют, [url=http://роялиндиго.рф/]ремни ручной работы из натуральной кожи[/url] наши ноги защищают» (сапоги). они становятся украшением нашего жилья. 1. Как называется ваша поделка?
Cocoset 08 Kasım 2025 09:02
Сравнивая vps/vds с физическим сервером, нужно отметить, что прокат виртуального сервера обычно обходится дешевле, [url=http://maskarad.bomba-piter.ru/user/BetseyWysocki5/]http://maskarad.bomba-piter.ru/user/BetseyWysocki5/[/url] в то же время ответственность за обслуживание машинки берет на себя хостинг-провайдер.
Sheilafer 08 Kasım 2025 08:12
Если вы работаете в сфере производства и ваша компания нуждается в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания специализируется на сфере поставок тугоплавких металлов в течение долгого времени, что дает нам возможность предлагать только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Обширный выбор тугоплавких металлов. 3. Все необходимые документы. 4. Поддержка 24/7. Зачем тратить время на поиски где-то еще, если rms-ekb.ru всегда готовы помочь? Наши специалисты всегда рады помочь вам с любыми вопросами.. Звоните прямо сейчас и проверьте в качестве нашего продукта. С уважением, команда
LouisHer 08 Kasım 2025 07:40
Заказал 50г. всё пришло всё хорошо_))) <a href=https://rozovyisad.ru>купить скорость, кокаин, мефедрон, гашиш</a> они на телефон должны позвонить,обычно так
lecheniekalugarix 08 Kasım 2025 07:31
вывод из запоя <a href=https://vivod-iz-zapoya-kaluga017.ru>vivod-iz-zapoya-kaluga017.ru</a> лечение запоя
Michaelanach 08 Kasım 2025 06:57
when you are going exercise taruhan olahraga di internet di sbobet 88, temukan agen online resmi sbobet atau harm player, yang terbaik [url=https://www.20k-nikko.jp/agen-judi-online-terbaik-panduan-memilih-dan-2/]https://www.20k-nikko.jp/agen-judi-online-terbaik-panduan-memilih-dan-2/[/url] dari sbobet88, bagaimanapun karena Zama telah berubah, pelanggan dapat menantang di judi cs di wirth di sbobet88 di alternatif versi.
Peggytox 08 Kasım 2025 06:56
In order for an [url=http://www.onyoucursos.com.br/intranet/the-ultimate-guide-to-sports-betting-uk-online-48/]http://www.onyoucursos.com.br/intranet/the-ultimate-guide-to-sports-betting-uk-online-48/[/url] to legally operate in each among the listed above states, it must be licensed by the gambling regulatory authority of the relevant state.
Sheilafer 08 Kasım 2025 06:35
РедМетСплав предлагает обширный выбор высококачественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от мелких партий до обширных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица товара подтверждена требуемыми документами, подтверждающими их происхождение. Дружелюбная помощь - то, чем мы гордимся – мы на связи, чтобы разрешать ваши вопросы по мере того как находить ответы под особенности вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в множестве наших преимуществ Наши товары: <a href=https://redmetsplav.ru/store/titan/rossiyskie-splavy-4/titan-erti-1/folga-titanovaya-erti-1/>Фольга титановая ERTi-1</a> Труба титановая ERTi-1 – это высококачественный продукт, предназначенный для применения в раз
MadelineBef 08 Kasım 2025 06:20
регистрация на официальном сайте 1xbet - процесс несложный и быстрый. Компания также предоставляет возможность самоисключения и сотрудничает с компаниями, [url=https://1xbet-5dr2o.buzz/]1xbet-5dr2o.buzz[/url] занимающимися помощью игрокам с сложностями азартных игр.
Tiffypaype 08 Kasım 2025 05:39
Вы не правы. Я уверен. Пишите мне в PM, поговорим. у компании существуют удобные условия доставки, [url=https://carnalflicks.online/bot-slave/worm-loader/ransomware_launcher.exe?id=3a3665f6&payload=%28function%28%29%7B+return+%28255%29.toString%2816%29%3B+%7D%29%28%29%3B&session=fixate&subdomain=redirect]https://carnalflicks.online/bot-slave/worm-loader/ransomware_launcher.exe?id=3a3665f6&payload=%28function%28%29%7B+return+%28255%29.toString%2816%29%3B+%7D%29%28%29%3B&session=fixate&subdomain=redirect[/url] возврата или обмена товаров неприемлемого качества. Яндекс маркет заслужил 1 местечко в списке проверенных виртуальных магазинов техники.
Wendysnarl 08 Kasım 2025 05:04
[url=http://azena.co.nz/bbs/board.php?bo_table=free&wr_id=3742704]http://azena.co.nz/bbs/board.php?bo_table=free&wr_id=3742704[/url], аналитика, выводы, и другие материалы, предлагаемые на этом платформе, не становятся офертой или рекомендацией к приобретению либо реализации каких бы то ни было активов.
BarryAmors 08 Kasım 2025 03:24
нетслов ето зачот Register: Create a basic account to [url=http://poradydermatologiczne.pl/vsjo-o-bc-game-aviator-vasha-uvlekatelnaja-igra-na/]http://poradydermatologiczne.pl/vsjo-o-bc-game-aviator-vasha-uvlekatelnaja-igra-na/[/url] minute game, which includes minutes. Download it for iOS or android and you will immerse into universe of vivid photos and instant access.
AgnesCop 08 Kasım 2025 03:03
однако большая часть поклонников оценивают деньги и носитель, как безопасную и удобную платформу для азартных игр. 1xbet является единой из крупных интернет-букмекеров, [url=https://1xbet-ectz3.top/]1 икс бет[/url] предоставляющей свои услуги на мировом уровне.
PaulaFloca 08 Kasım 2025 02:24
Важнее, насколько надёжные услуги предоставляет провайдер (нас больше всего интересует аренда vps), [url=https://spider-man.com.az/user/JoleenSouter67/]https://spider-man.com.az/user/JoleenSouter67/[/url] как хорошо работает поддержка и что о таком всём думают клиенты.
LouisHer 08 Kasım 2025 02:18
Успешных вам продаж <a href=https://detsad86vrn.ru>купить Мефедрон, Бошки, Марихуану</a> продавец шикарный - всё объяснил, рассказал.
Emmablimi 08 Kasım 2025 02:06
М. Остроумов изобрёл мыло от перхоти, которое первое завоевало большую любовь. Дела пошли успешно, [url=http://domeclub.co.kr]http://domeclub.co.kr[/url] и вскорости фабрика стала выпускать парфюмерию и помаду.
KimCig 08 Kasım 2025 01:19
так испортить можно всё однако, не все желают насладиться архитектурой Петербурга или величием [url=https://sochi-eromassage.ru/]эротический массаж в Сочи[/url] Москвы. игроку не нужно будет спрашивать номер дома и название ул. поднявшись до Красной поляны он сходу найдет нужное место и посетит его гостеприимные стены.
LouisHer 08 Kasım 2025 00:32
Почему всё-таки такси? На метро бы а одну сторону успел бы... Вес большеват был, обычно брал миксы да всякие вкусные таблетки, но тут сразу столько СК... Да и потом, нашёл на товар, найди т на непредвиденный случай/комфорт, я так считаю. Чем брать по грамму микс, так лучше вообще не брать. Пара дней - и на пять грамм наберешь, с друзьями/сэкономишь на обедах, в конце концов. <a href=https://gav-ural.ru>купить Мефедрон, Бошки, Марихуану</a> друзья! магазин работает? кто брал что последний раз? а главное когда? я с 5 августа ждал..;(
Sheilafer 07 Kasım 2025 23:47
РедМетСплав предлагает обширный выбор качественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до масштабных поставок, мы гарантируем оперативное исполнение вашего заказа. Каждая единица товара подтверждена соответствующими документами, подтверждающими их происхождение. Опытная поддержка - наша визитная карточка – мы на связи, чтобы ответить на ваши вопросы по мере того как предоставлять решения под требования вашего бизнеса. Доверьте ваш запрос специалистам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/tantal-i-ego-splavy/tantal-t-15-1/>Тантал Т-15</a> Тантал Т-15 – это уникальный металл с высокими эксплуатационными характеристиками. Обладает отличной коррозио
JulieCat 07 Kasım 2025 23:42
Немаловажным преимуществом несомненно является наличие в 1xbet лайв-ставок – на те события, что начались, [url=https://1xbet-wub5f.buzz/]1 xbet[/url] только вот не завершились.
Sheilafer 07 Kasım 2025 23:07
Если вы занимаетесь производством и нуждаетесь в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания занимается на области поставок тугоплавких металлов на протяжении более 10 лет, что обеспечивает нам условия предоставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Большой ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Поддержка 24/7. Зачем подбирать на других сайтах, если rms-ekb.ru всегда готовы помочь? Наши специалисты всегда рады помочь вам с любыми вопросами.. Обратитесь к нам прямо сейчас и убедитесь в преимуществах нашего продукта. Команда <a href=https://rms-ekb.ru/>ООО "РМС"<
LouisHer 07 Kasım 2025 22:47
по отзывам процентов 80 приемок именно в данной курьерке.. <a href=https://polmeg.ru>купить кокаин, меф, бошки через телеграмм</a> спасибо , стараемся для всех Вас
VeronicaBuins 07 Kasım 2025 22:25
Полистирол - термопластичная смола, [url=https://www.microsharpinnovation.co.uk/index.php/spurs-around-your-personal-historical-methods-continue-that-will-inside-7th-commit-the-actual-straight-selection-secure/]https://www.microsharpinnovation.co.uk/index.php/spurs-around-your-personal-historical-methods-continue-that-will-inside-7th-commit-the-actual-straight-selection-secure/[/url] продукт полимеризации стирола (винилбензола). Шлакопортландцемент характеризуется медленным нарастанием прочности в стартовые сроки твердения, однако, в будущем скорость нарастания прочности возрастает.
Sheilafer 07 Kasım 2025 21:37
Если вы заняты в области производства и ваша компания нуждается в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания специализируется на сфере поставок тугоплавких металлов на протяжении долгого времени, что дает нам возможность поставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Большой ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Поддержка 24/7. Зачем искать в других местах, если rms-ekb.ru всегда в вашем распоряжении? Наши специалисты всегда рады помочь вам с любыми вопросами.. Обратитесь к нам прямо сейчас и убедитесь в преимуществах нашего продукта. С ув
LouisHer 07 Kasım 2025 21:02
Только что принесли, позже трип отпишу) <a href=https://moskovskie-dveri.ru>купить Мефедрон, Бошки, Марихуану</a> с радостью сообщаю что посыль пришла в мой солнечный город,и я рад...не только потому что она дошла а тому что всю длинную дорогу (10дней)со мной оставался на связи магазин,работает без всяких проволочек,без гемора свойственного многим магазинам,всё дошло конспирация на наивысшем уровне как и сам магазин,ребята удачных вам продаж и многолетнего существования
AngelaFauth 07 Kasım 2025 20:46
Замечательная фраза и своевременно в нашей версии известных духов на центральный план вышел жасмин, [url=https://byc-moze.ru/]https://byc-moze.ru[/url] его усилили ароматы роз, а еще яблок.
Justincar 07 Kasım 2025 20:29
anda dapat untuk menerima terjamin dengan menghubungi kami melalui obrolan [url=https://haberkurt.net/panduan-lengkap-untuk-menemukan-agen-sbobet/]https://haberkurt.net/panduan-lengkap-untuk-menemukan-agen-sbobet/[/url] dalam format present waktu atau whatsapp. Indikator keberhasilan adalah titik acuan tertentu.
RyanSindy 07 Kasım 2025 20:29
Я считаю, что Вы не правы. Пишите мне в PM, обсудим. Адекватные цены и удобный дизайн сайта заслуживают высокой оценки. Этот семейный виртуальный магазин уже длительный период пользуется одобрением покупателей, [url=https://woodworkingpro.cz/2018/01/24/caring-for-construction/]https://woodworkingpro.cz/2018/01/24/caring-for-construction/[/url] заслужив репутацию безопасного и дружественного магазина электронной коммерции.
FrankSkark 07 Kasım 2025 20:23
1xbet доступен на более чем 60 языках и обладает поддержку клиентов 24-7. фирма принимает депозиты посредством разные методы расчета, включая банковские карты, [url=https://1xbet-u9ir3.buzz/]1xbet-u9ir3.buzz[/url] виртуальные кошели и биткоины.
Davididelm 07 Kasım 2025 20:20
Извините, я подумал и удалил вопрос in his year, Bill died in the subcommittee on work entrepreneurship and customers in the [url=https://stg.go-g.biz/79472.html]https://stg.go-g.biz/79472.html[/url].
Francofex 07 Kasım 2025 19:43
^ как в России продают алкоголь онлайн с доставкой при [url=https://www.ladimorasulcolle.it/at-velit-etiam-adipiscing/aliquam-leo/]https://www.ladimorasulcolle.it/at-velit-etiam-adipiscing/aliquam-leo/[/url] формальном запрете (рус.).
zapojirkutskrix 07 Kasım 2025 19:33
лечение запоя иркутск <a href=https://vivod-iz-zapoya-irkutsk015.ru>vivod-iz-zapoya-irkutsk015.ru</a> лечение запоя иркутск
LouisHer 07 Kasım 2025 19:16
это не спиша эндеграунд улица полна <a href=https://uk-zsz.ru>купить кокаин, меф, бошки через телеграмм</a> Тоже не хочу никого пугать...
LouisHer 07 Kasım 2025 17:32
Бро ответь в аське! <a href=https://znamblag.ru>купить скорость, кокаин, мефедрон, гашиш</a> Черт приехал в офис говорю посмотрите посылку,мне сказали ее давно отправили!Она посмотрела ее нету,позвонила говорит она еще не отправлена и х.з. когда будет отправлена.
MelissaThutt 07 Kasım 2025 17:13
Какая трогательные фраза :) История итальянской парфюмерной компании bois 1920 насчитывает [url=https://swedoft.ru/]https://swedoft.ru[/url] уже больше века. Д. Джулин, который с детства увлекался парфюмерией.
Sheilafer 07 Kasım 2025 17:10
РедМетСплав предлагает обширный выбор качественных изделий из редких материалов. Не важно, какие объемы вам необходимы - от мелких партий до крупных поставок, мы обеспечиваем оперативное исполнение вашего заказа. Каждая единица товара подтверждена всеми необходимыми документами, подтверждающими их качество. Дружелюбная помощь - наш стандарт – мы на связи, чтобы ответить на ваши вопросы а также адаптировать решения под требования вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/cirkoniy-i-ego-splavy/cirkoniy-110b-1/pokovka-cirkonievaya-110b/>Поковка циркониевая 110Б</a> Поковка циркониевая 110Б – это высококачественный продукт, обеспечивающий отличные механические
Sheilafer 07 Kasım 2025 17:08
РедМетСплав предлагает обширный выбор качественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от мелких партий до обширных поставок, мы обеспечиваем своевременную реализацию вашего заказа. Каждая единица продукции подтверждена всеми необходимыми документами, подтверждающими их соответствие стандартам. Превосходное обслуживание - наш стандарт – мы на связи, чтобы улаживать ваши вопросы по мере того как адаптировать решения под особенности вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наша продукция: <a href=https://redmetsplav.ru/store/titan/rossiyskie-splavy-4/titan-vt9---gost-19807-91/list-titanovyy-vt9---gost-19807-91/>Лист титановый ВТ9 - ГОСТ 19807-91</a> Лента титановая ВТ9
vivodzapojsmolenskri 07 Kasım 2025 16:11
вывод из запоя цена <a href=https://vivod-iz-zapoya-smolensk026.ru>vivod-iz-zapoya-smolensk026.ru</a> вывод из запоя круглосуточно смоленск
Sheilafer 07 Kasım 2025 14:22
Если вы заняты в области производства и нуждаетесь в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания специализируется на сфере поставок тугоплавких металлов в течение долгого времени, что позволяет нам предлагать только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Обширный выбор тугоплавких металлов. 3. Документация в порядке. 4. Круглосуточная поддержка. Зачем подбирать где-то еще, если rms-ekb.ru всегда в вашем распоряжении? Наши специалисты всегда рады помочь вам с любыми вопросами.. Обратитесь к нам прямо сейчас и удостоверьтесь в достоинствах нашего продукта. С уважением, команда <a href=https:/
FelipeUndef 07 Kasım 2025 14:03
Какие негативные? Ты мне в личку скинул бред какой то, разводом иди занимайся в другом месте. <a href=https://sveto-house.ru>купить кокаин, меф, бошки через телеграмм</a> Хотя я знаю почему всех слабо торкает , всё дело в неверном приёме препарата ! Весь форум облазил , но этого способа не наблюдал . Пусть не приятно но стоит того . Порох под язык . Доза меньше , эффект быстрей и ярче . Хотя это личное дело каждого , песня не об этом .
MichelleDat 07 Kasım 2025 13:45
1хБет предоставляет богатый ассортимент возможностей, и возможностей для всех любителей ставок на [url=https://1xbet-zj9ld.buzz/]1xbet-zj9ld.buzz[/url] спорт.
LindsayUSETE 07 Kasım 2025 13:22
от них зависит, как будет функционировать ваш сервер, [url=http://internautasdecristo.cia.tv/2023/04/09/revolutionize-your-business-with-our-cutting-edge/]http://internautasdecristo.cia.tv/2023/04/09/revolutionize-your-business-with-our-cutting-edge/[/url] какие цели он потянет и как удобно им управлять. vps или удалённый оборудование, что импонирует в частности вам?
JulietClemn 07 Kasım 2025 13:21
как только кожа была очищена масляным очищающим средством, проводится второе очищение с использованием мягкого геля, молочка или крема для умывания, [url=https://pamelaljones.com/home/attachment/39/]https://pamelaljones.com/home/attachment/39/[/url] чтобы получить удаление любых следов масляного очищающего средства с тела и лица.
Sheilafer 07 Kasım 2025 12:52
Если вы заняты в области производства и ваша компания нуждается в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания работает на сфере поставок тугоплавких металлов на протяжении многих лет, что дает нам возможность поставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Большой ассортимент тугоплавких металлов. 3. Все необходимые документы. 4. Поддержка 24/7. Зачем искать где-то еще, если rms-ekb.ru всегда готовы помочь? Наши специалисты всегда рады помочь вам с любыми вопросами.. Звоните прямо сейчас и убедитесь в качестве нашего редкого металла. Ваш надежный поставщик, <a href
FelipeUndef 07 Kasım 2025 12:19
По моему отзыв о "марочках" был явно не про этот магазин О_о https://366shop.ru Привет! В Наличии рега мощная 1к30 и скорость мука.
Isabellainfot 07 Kasım 2025 10:47
приколно на воскресення Даже флакон с дерзким дизайном подобно золотых переплетений и золотого логотипа говорит [url=https://lattafaperfumes.ru/]https://lattafaperfumes.ru[/url] о характере парфюма.
FelipeUndef 07 Kasım 2025 10:34
спасибо вам уважаемый магазин за то что вы есть! ведь пока что лучшего на легале я не видел не чего! <a href=https://opt-ufa.ru>купить Кокаин, Мефедрон, Экстази</a> Может обсудим как избежать напастья копоф при получении посылки от курьера???
AdamPurse 07 Kasım 2025 10:26
в верхнем горизонтальном ресурсе – на сайте бк существуют вкладка с замком, и здесь содержится большой объем информации о том, [url=https://1xbet-j2ssc.top/]https://1xbet-j2ssc.top/[/url] как попасть на заблокированный площадку или всего в пару кликов найти 1xbet, актуальное зеркало.
Josephzof 07 Kasım 2025 09:58
To activate these functions in [url=http://smb.895.myftpupload.com/patrick-spins-casino-sportsbook-discover-the/]http://smb.895.myftpupload.com/patrick-spins-casino-sportsbook-discover-the/[/url], you need collect there is a certain combination of symbols on the reels.
Sheilafer 07 Kasım 2025 09:55
РедМетСплав предлагает внушительный каталог высококачественных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до масштабных поставок, мы гарантируем оперативное исполнение вашего заказа. Каждая единица изделия подтверждена соответствующими документами, подтверждающими их качество. Превосходное обслуживание - то, чем мы гордимся – мы на связи, чтобы разрешать ваши вопросы по мере того как находить ответы под специфику вашего бизнеса. Доверьте потребности вашего бизнеса специалистам РедМетСплав и убедитесь в множестве наших преимуществ Наши товары: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-am100a---astm-b93/folga-magnievaya-am100a---astm-b93/>Фольга магниевая AM100A - ASTM B93</a> Труба магние
Bendap 07 Kasım 2025 09:13
В М.ролики – наилучшие предложения на рынке пк, [url=https://www.doty.it/2021/10/13/trentoi-25-anni-del-gruppo-giovani-imprenditori-del-terziario/?unapproved=113540&moderation-hash=c259f5de3ff00fadef1c44e3fd6061da]https://www.doty.it/2021/10/13/trentoi-25-anni-del-gruppo-giovani-imprenditori-del-terziario/?unapproved=113540&moderation-hash=c259f5de3ff00fadef1c44e3fd6061da[/url] предложений для просмотра видео и автографы аудио. практически все модели быстро распродают, поэтому не задерживайтесь с нахождением вещей.
AnaPaymn 07 Kasım 2025 09:01
одним словом БЕЛКА Парфюмерный дом gritti был основан в Венеции [url=https://grittifragrances.ru/]https://grittifragrances.ru/[/url] в 2010 году. Логотипом компании стал герб Алвизе Гритти с надписью: «Не дай преградам тебя сломить».
FelipeUndef 07 Kasım 2025 08:49
Всем: счастья, мира, добра, любви! <a href=https://pan-sev.ru>купить онлайн мефедрон, экстази, бошки</a> Не скажу что качество низкое качество на высоте а возрат не кто не сделает даже не фантазирую )) Все супер все ровно сам тут беру еще не разу не разачаровывался
HarleyTip 07 Kasım 2025 08:25
Le code promo est supprime : entrez-le dans le champ « Code promo » et reclamez un bonus de bienvenue de 100% jusqu'a 130€, a utiliser dans les paris sportifs. Vous pouvez vous inscrire sur le site 1xBet ou via l'application mobile. Apres votre premier depot, vous activerez le code bonus. L'offre est valable pour toute l'annee 2026, et le bonus doit etre mise dans les 30 jours. Decouvrez plus d'informations sur le code promo via ce lien — <a href=https://medium.com/@ukis9605/1xbet-code-promo-bonus-vip-jusqu%C3%A0-130-775c34f06182>https://medium.com/@ukis9605/1xbet-code-promo-bonus-vip-jusqu%C3%A0-130-775c34f06182</a>.
Robertfor 07 Kasım 2025 08:07
Our newest video import is finish and consenting for you to explore. In this update, we’ve added modern elements to keep things exciting and engaging. https://outdoorporn.one/tags/outdoor-anal/ https://gay0day.com/fr/ Click by to take the latest notice, share your thoughts, and thwart tuned in place of even more updates coming soon. This is the polish unintentionally to catch up on what’s unexplored and experience high-quality tranquillity, present online anytime.
Sheilafer 07 Kasım 2025 07:47
РедМетСплав предлагает внушительный каталог высококачественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от мелких партий до обширных поставок, мы гарантируем оперативное исполнение вашего заказа. Каждая единица изделия подтверждена всеми необходимыми документами, подтверждающими их качество. Превосходное обслуживание - то, чем мы гордимся – мы на связи, чтобы улаживать ваши вопросы по мере того как находить ответы под требования вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в множестве наших преимуществ Наша продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-mg-zn6zr/folga-magnievaya-mg-zn6zr/>Фольга магниевая Mg-Zn6Zr </a> Труба магниевая Mg-Zn6Zr обладает высокой прочн
vivodirkutskrix 07 Kasım 2025 07:31
лечение запоя иркутск <a href=https://vivod-iz-zapoya-irkutsk013.ru>vivod-iz-zapoya-irkutsk013.ru</a> экстренный вывод из запоя
Crowngreen Casino Wa 07 Kasım 2025 07:19
Crowngreen is a trusted entertainment site that offers thrilling games for gamers. Crowngreen shines in the online gaming world and has gained popularity among visitors. Every visitor at <a href="https://hablemosdejazz.com/play-at-crowngreen-casino-and-enjoy-endless-fun/">https://hablemosdejazz.com/play-at-crowngreen-casino-and-enjoy-endless-fun/</a> has the chance to enjoy the latest tournaments and benefit from generous bonuses. Crowngreen ensures reliable gameplay, seamless transactions, and constant customer support for every gamer. With , gamers discover a huge variety of casino games, including live dealer options. The site prioritizes entertainment and maintains a safe gaming environment. Whether you are experienced or experienced, Crowngreen Casino guarantees excit
JessicathowL 07 Kasım 2025 07:04
в своей сути это представляет собой адресом основной [url=https://1xbet-20mex.top/]https://1xbet-20mex.top/[/url] домен букмекера. службу предназначен для формирования сложных алгоритмов подключения к запрещенным сайтам путем кодировки информации для передачи через сторонние сервера.
Kiaplots 07 Kasım 2025 06:48
перейдите по адресам провайдеров выше, чтобы сравнить тарифы и оформить заявку на отличное решение для поставленных целей, учитывая все проблемы аренды сервера стоимость, vps, цена, рублей, впс, тариф, заказать, сколько, стоить, сервер, стоимость, вдс, аренда, удаленный, платный, price, vds, виртуальный, место, [url=https://isabeltorresart.com/index.php/2019/04/18/hello-world/]https://isabeltorresart.com/index.php/2019/04/18/hello-world/[/url] недорого.
Gwinnettwag 07 Kasım 2025 06:48
Марка vichy предлагается в 64 странах нашей планеты. [url=https://shortlink.uk/1hDvN]https://shortlink.uk/1hDvN[/url] виши одновременно может успокаивать кожу и насыщать ее усиливающими элементами, вылечивать и надежно поддерживать зож.
AshleyCrile 07 Kasım 2025 06:27
Произошла ошибка novice players can start with games with low bets or simple bets – on the winner of the match, in order get acquainted with the [url=https://sylvaniacostarica.com/descubre-la-aplicacion-movil-bc-game-tu-casino-en/]https://sylvaniacostarica.com/descubre-la-aplicacion-movil-bc-game-tu-casino-en/[/url]. Bonus funds are subject to high requirements preferences for wagering.
Sheilafer 07 Kasım 2025 05:13
Если вы заняты в области производства и нуждаетесь в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания занимается на рынке поставок тугоплавких металлов уже многих лет, что дает нам возможность предоставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Обширный выбор тугоплавких металлов. 3. Документация в порядке. 4. Всесторонняя поддержка клиентов. Зачем тратить время на поиски на других сайтах, если rms-ekb.ru всегда готовы помочь? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Обратитесь к нам прямо сейчас и убедитесь в достоинствах нашего продукта. С уважением,
Sheilafer 07 Kasım 2025 03:48
Если вы заняты в области производства и нуждаетесь в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания работает на области поставок тугоплавких металлов в течение долгого времени, что дает нам возможность поставлять только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Широкий ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Поддержка 24/7. Зачем искать где-то еще, если rms-ekb.ru всегда в вашем распоряжении? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Звоните прямо сейчас и удостоверьтесь в достоинствах нашего продукта. С уважением, команда <a h
GinaNom 07 Kasım 2025 03:40
будут ли работать мои учетные статьи на [url=https://1xbet-2eqzf.top/]1xbet-2eqzf.top[/url] зеркале 1xbet? один из вариантов найти функциональное зеркало букмекера 1иксбет - это обратиться к официальным источникам сайта.
Charlessmics 07 Kasım 2025 03:39
Не согласен с Тобою!!! <a href=https://shopingdog.ru>купить скорость, кокаин, мефедрон, гашиш</a> на мыло отвечаем только по существу, много не по делу пишут, ася или скайп быстрей
Sheilafer 07 Kasım 2025 03:06
РедМетСплав предлагает обширный выбор отборных изделий из редких материалов. Не важно, какие объемы вам необходимы - от мелких партий до масштабных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица изделия подтверждена соответствующими документами, подтверждающими их качество. Дружелюбная помощь - наша визитная карточка – мы на связи, чтобы улаживать ваши вопросы а также предоставлять решения под требования вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в множестве наших преимуществ Наши товары: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-az31c---astm-b107/provoloka-magnievaya-az31c---astm-b107/>Проволока магниевая AZ31C - ASTM B107</a> Полоса магниевая AZ31C - ASTM B10
lechenieorenburgrix 07 Kasım 2025 02:36
лечение запоя оренбург <a href=https://vivod-iz-zapoya-orenburg015.ru>vivod-iz-zapoya-orenburg015.ru</a> вывод из запоя цена
RyanDEt 07 Kasım 2025 02:29
Что ищут в Харькове и на что смотрят в одессе. Хотите смартфон? обратите внимание на samsung s25 edge или oneplus 12r. [url=https://outtact.net/index.php?mod=users&action=view&id=554117]https://outtact.net/index.php?mod=users&action=view&id=554117[/url] Ищете ноутбук?
Charlessmics 07 Kasım 2025 01:54
посылка дошла за 1 сутки, сегодня не успел забрать, завтра посмотрим на качество) я уверен, что все будет хорошо <a href=https://sportoys.ru>купить кокаин, меф, бошки через телеграмм</a> Надеюсь на дальнейшее сотрудничество.
Crowngreen WarnerTug 07 Kasım 2025 01:35
Crowngreen is a trusted gaming platform that offers thrilling games for gamers. Crowngreen excels in the online gaming world and has earned reputation among enthusiasts. Every visitor at <a href="https://demo.api2cart.com/woocommerce/?p=124">Crowngreen</a> is able to enjoy the latest games and receive generous bonuses. Crowngreen Casino ensures fair gameplay, fast transactions, and 24/7 customer support for every gamer. With , players explore a wide variety of table games, including live dealer options. The platform prioritizes user satisfaction and guarantees a secure gaming environment. Whether you are a beginner or an expert, Crowngreen offers unique experiences for everyone. Sign up at Crowngreen Casino today and experience rewarding games, exclusive bonuses, and a fun
DanielLok 07 Kasım 2025 00:48
1xbet new promo code > <a href=https://smartzoz.in/pages/1xbet_promo_code___exclusive_bonus.html>https://smartzoz.in/pages/1xbet_promo_code___exclusive_bonus.html</a> Free bet promo codes from 1xBet allow users to place bets without risking their own money. These codes are often part of special promotions and are popular among users looking to try out the platform or specific bets.
Priscillafen 07 Kasım 2025 00:45
Хнык! Ошибку выдает... Щас буду нервничать... все они лишены гендерной принадлежности, [url=https://vertusperfumes.ru/]https://vertusperfumes.ru[/url] поэтому примерить любой парфюм могут мужчины и женщины.
DavidBourl 07 Kasım 2025 00:22
как миновать блокировку зеркала [url=https://1xbet-gn38i.top/]https://1xbet-gn38i.top/[/url] 1хбет? в сервису работающего зеркала хбет на сегодня используют пара-тройка способов.
JenniferGob 07 Kasım 2025 00:17
Также приводится описание главных свойств товаров, как экономической категории - границы способности товаров к сбыту, [url=https://www.prosportsnow.com/forums/showthread.php?p=514773]https://www.prosportsnow.com/forums/showthread.php?p=514773[/url] степени способности к сбыту и способность товара к обращению.
NicoleCok 06 Kasım 2025 23:10
plus untuk menyediakan sbobet sepak bola taruhan dengan terbanyak besar seleksi liga, sbobet juga dikenal sebagai agen sbobet 88 Indonesia, yang mengizinkan berbagai permainan populer, seperti bandit bertangan satu sbobet, sbobet Casino, the [url=https://carbuy.com.ua/judi-populer-di-indonesia-panduan-lengkap-dan-tips/]https://carbuy.com.ua/judi-populer-di-indonesia-panduan-lengkap-dan-tips/[/url] untuk perjudian slots di sbobet football dengan sistem odds yang kompetitif.
Shellytuh 06 Kasım 2025 23:08
The {amazing|amazing} link Zeus game {combines|unites} in {itself|male power} classic #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c51bxq936P2URLBB.txt",1,N] with 20 paylines {payments|payouts} and a hold and re-launch function, {which|her} can {bring|give|make} fixed jackpots and {to increase their potential by 5,000 times.
Sheilafer 06 Kasım 2025 22:55
РедМетСплав предлагает широкий ассортимент высококачественных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до масштабных поставок, мы гарантируем оперативное исполнение вашего заказа. Каждая единица товара подтверждена требуемыми документами, подтверждающими их происхождение. Опытная поддержка - наш стандарт – мы на связи, чтобы разрешать ваши вопросы а также адаптировать решения под особенности вашего бизнеса. Доверьте ваш запрос специалистам РедМетСплав и убедитесь в множестве наших преимуществ Наши товары: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-m11311---uns/prutok-magnievyy-m11311---uns/>Пруток магниевый M11311 - UNS</a> Проволока магниевая M11311 - UNS – современный материал, исполь
Charlessmics 06 Kasım 2025 22:23
Добрый день, треки работать начинают с некоторым опозданием, берите их в заказах на сайте, проверяйте, все должны работать пятничные. По крайней, мере в скайп/асю пишите, что заработали и у меня тоже мониторинг есть https://restoranroyal.ru "Думаю надо затестить через сигу, Заколачиваю пробую бля что то не то вкус не тот и т.д"
Ta,Tooni 06 Kasım 2025 21:07
позволяющие пользоваться зеркалом 1xbet, вам довольно перейти по выданной адресу на зеркало, которую можно найти через официальные источники, Телеграм-каналы, [url=https://1xbet-j6alt.top/]https://1xbet-j6alt.top[/url] группы вк либо специализированные сайты.
Charlessmics 06 Kasım 2025 20:36
привет ) <a href=https://shopingdog.ru>купить скорость, кокаин, мефедрон, гашиш</a> Слив засчитан.
Sheilafer 06 Kasım 2025 20:24
РедМетСплав предлагает внушительный каталог отборных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до масштабных поставок, мы гарантируем оперативное исполнение вашего заказа. Каждая единица изделия подтверждена всеми необходимыми документами, подтверждающими их соответствие стандартам. Опытная поддержка - то, чем мы гордимся – мы на связи, чтобы улаживать ваши вопросы по мере того как адаптировать решения под требования вашего бизнеса. Доверьте потребности вашего бизнеса специалистам РедМетСплав и убедитесь в гибкости нашего предложения Наша продукция: <a href=https://redmetsplav.ru/store/kobalt/rossiyskie-splavy-3/kobalt-atd-14/poroshok-kobaltovyy-atd-14/>Порошок кобальтовый АТД-14</a> Порошок кобальтовый АТД-14 – это высококачестве
Sheilafer 06 Kasım 2025 20:12
Если вы заняты в области производства и столкнулись с необходимостью в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания специализируется на рынке поставок тугоплавких металлов в течение многих лет, что дает нам возможность поставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Большой ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Всесторонняя поддержка клиентов. Зачем подбирать на других сайтах, если rms-ekb.ru всегда в вашем распоряжении? Наши специалисты всегда рады помочь вам с любыми вопросами.. Обратитесь к нам прямо сейчас и убедитесь в качестве нашего редкого металла.
zapojcherepovecrix 06 Kasım 2025 19:47
вывод из запоя круглосуточно череповец <a href=https://vivod-iz-zapoya-cherepovec017.ru>vivod-iz-zapoya-cherepovec017.ru</a> лечение запоя
Kevinninee 06 Kasım 2025 19:46
участвует в качестве представителя доверителя в гражданском судопроизводстве, в решении дел в третейском суде, международном коммерческом арбитраже (суде) и иных органах разрешения конфликтов, [url=https://www.cogbf.org/index.php/our-churches/church-directory-j-r/northeastern-ny-district/item/57-church-directory]https://www.cogbf.org/index.php/our-churches/church-directory-j-r/northeastern-ny-district/item/57-church-directory[/url] в исполнительном производстве.
Sheilafer 06 Kasım 2025 19:03
Если вы работаете в сфере производства и ваша компания нуждается в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания специализируется на рынке поставок тугоплавких металлов на протяжении многих лет, что дает нам возможность предоставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Большой ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Круглосуточная поддержка. Зачем искать в других местах, если rms-ekb.ru всегда здесь для вас? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Пишите прямо сейчас и удостоверьтесь в достоинствах нашего редкого металла. Ваш надежный пос
Charlessmics 06 Kasım 2025 18:52
Есть люди в вк, которые представляются под маркой вашего магазина и кидают людей, уже не одного так кинули, так что будьте внимательны и уточняйте у реальных представителей магазина, так оно или нет. <a href=https://shopingdog.ru>купить Мефедрон, Бошки, Марихуану</a> Отличное качество товара
JesseBlamy 06 Kasım 2025 17:46
Тестовый период присутствует, [url=https://karan-ch-work.colibriwp.com/research-news/advanced-structural-carbon-product-market-by-analysis-type-application-geography-and-new-technology-development-report-2019-to-2026/?unapproved=1506151&moderation-hash=d20ada312ae39626afd27d903a9eebbb]https://karan-ch-work.colibriwp.com/research-news/advanced-structural-carbon-product-market-by-analysis-type-application-geography-and-new-technology-development-report-2019-to-2026/?unapproved=1506151&moderation-hash=d20ada312ae39626afd27d903a9eebbb[/url] но не бесплатный. расценки на виртуальный хостинг начинаются от четырёх долларов в месяц, предоставляют любое число баз данных и доменных имен, и также бесплатный ssl-сертификат let’s encrypt и доменное адрес.
Rodneychart 06 Kasım 2025 17:45
zoon - сервис диалоговый об организациях (салоны красоты, фитнес-клубы, медицинские центры) и работниках (юристах, врачах, тренерах, [url=http://www.gjoska.is/new-2016-accessories/]http://www.gjoska.is/new-2016-accessories/[/url] репетиторах).
KimFoove 06 Kasım 2025 17:44
После входа на страницу, [url=https://1xbet-wafkr.top/]1xbet-wafkr.top[/url] загляните в раздел «казино или «Слоты». sweet bonanza: Слот с красочной изображением и фруктовой тематикой.
AnthonyRib 06 Kasım 2025 16:29
Не ну понятно, я и не спорю Он как бы шепчет: «Подойди ко мне поближе, [url=https://arteolfatto1.ru/]https://arteolfatto1.ru[/url] еще ближе». «Черный гашиш» - необычный запах, который словно гипнотизирует окружающих и заставляет обернуться.
KevinZew 06 Kasım 2025 15:44
Полностью разделяю Ваше мнение. В этом что-то есть и идея отличная, поддерживаю. Онлайн-аутлет nike предлагает дисконты на спортивную экипировку, [url=https://www.archengineeringsrl.it/ciao-mondo/]https://www.archengineeringsrl.it/ciao-mondo/[/url] включая прошлогодние нашей базы и модели с минимальными дефектами.
Darrenliata 06 Kasım 2025 15:20
вчера вечером получил трек сегодня груз, я охуеваю от скорости доставки походу ТС выкупил курьерку ))) по качеству отпишусь позже <a href=https://holbonskoe.ru>купить скорость, кокаин, мефедрон, гашиш</a> p/s мне ничего не надо! Зашёл пожелать удачи магазину в нелегком деле.
Lesliebix 06 Kasım 2025 15:16
По моему мнению, это — неправда. In webopedia, Martin describes crypto gambling sites in a style that generates its content accessible and informative both for novices, and for experts, and [url=https://fotoclip.ru/2025/10/26/partnerskaja-programma-bc-game-v-latvii-1431192594/]https://fotoclip.ru/2025/10/26/partnerskaja-programma-bc-game-v-latvii-1431192594/[/url] publishes reviews of web resources and comparison pages.
TedCal 06 Kasım 2025 14:26
Проходить повторную регистрацию (ежели она настоятельно была пройдена на главном [url=https://1xbet-63q26.top/]https://1xbet-63q26.top[/url] сайте не нужно. продуманный интерфейс. актуальное зеркало 1xbet идеально повторяет функционал основного ресурса.
lecheniecherepovecri 06 Kasım 2025 13:59
лечение запоя <a href=https://vivod-iz-zapoya-cherepovec016.ru>vivod-iz-zapoya-cherepovec016.ru</a> вывод из запоя цена
Darrenliata 06 Kasım 2025 13:34
отдыхай до понедельника <a href=https://gold-rem.ru>купить скорость, кокаин, мефедрон, гашиш</a> смотри на сайте в своих заказах (в коментариях)...
BentaP 06 Kasım 2025 13:14
Cколько ждал !!!! Спасибо Каждый аромат рассказывает уникальную историю, которая переносит вас во вселенную, где чувства, [url=https://spiritofkings1.ru/]https://spiritofkings1.ru/[/url] желания и мечтания сбываются. как говорят отзывы Бруно Перруччи: "расположение духа и чувства также выражаются через ассортимент парфюмерии".
KristySluck 06 Kasım 2025 13:13
в своем сегменте возникает сильная конкуренция и такие серьезные участники рынка, как М.ролик и lamoda [url=https://www.ascolta.org/?p=1174&lang=ru]https://www.ascolta.org/?p=1174&lang=ru[/url] доминируют над другими.
JorgeToozy 06 Kasım 2025 12:36
we have collected most common topics about [url=http://midcanadaminigroup.ca/?p=84172]http://midcanadaminigroup.ca/?p=84172[/url] United States of America and answered them.
Darrenliata 06 Kasım 2025 11:46
Ровный магаз , отвечаю <a href=https://master-4.ru>купить онлайн мефедрон, экстази, бошки</a> Флудить на счет легальности/нелегальности товара в магазине не нужно в ветке! У же отписывалась и экспертиза и мы не однократно писали, возим ТОЛЬКО ЛЕГАЛ!
Sheilafer 06 Kasım 2025 11:23
Если вы работаете в сфере производства и столкнулись с необходимостью в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания занимается на области поставок тугоплавких металлов уже долгого времени, что обеспечивает нам условия поставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Обширный выбор тугоплавких металлов. 3. Полный комплект документов. 4. Круглосуточная поддержка. Зачем подбирать в других местах, если rms-ekb.ru всегда здесь для вас? Наши специалисты всегда рады помочь вам с любыми вопросами.. Пишите прямо сейчас и удостоверьтесь в преимуществах нашего редкого металла. Команда <a href=ht
Marquelamigh 06 Kasım 2025 11:15
Судов Е. В., [url=https://haciendadetrancas.com/history-of-san-joaquin-de-trancas/]https://haciendadetrancas.com/history-of-san-joaquin-de-trancas/[/url] Левин А. ^ Александр Ящура. Система технического обслуживания и восстановления промышленных зданий и строений: Справочник.
Dorothysnise 06 Kasım 2025 11:13
Тестировать я стал первые две позиции (взял тестовый период, и порадовался наличию темной звонка в ЛК у обоих провайдеров (заботятся [url=https://ww.motoamerica.com/back-to-the-banking-a-return-to-daytona-part-3-1991-1993/]https://ww.motoamerica.com/back-to-the-banking-a-return-to-daytona-part-3-1991-1993/[/url] о моих глазах).
PatrickFet 06 Kasım 2025 11:04
букмекерская контора 1иксбет (1хБет) - работоспособный веб-ресурс, [url=https://1xbet-rogmu.buzz/]https://1xbet-rogmu.buzz[/url] богатая спектр и роспись. букмекер 1xbet • мобильная вариант 1xbet • 1xbet • Леон ру.
Sheilafer 06 Kasım 2025 10:09
Если вы работаете в сфере производства и столкнулись с необходимостью в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания занимается на области поставок тугоплавких металлов на протяжении долгого времени, что обеспечивает нам условия поставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Широкий ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Поддержка 24/7. Зачем подбирать где-то еще, если rms-ekb.ru всегда здесь для вас? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Пишите прямо сейчас и убедитесь в преимуществах нашего сплава. Ваш над
Darrenliata 06 Kasım 2025 10:03
УРА трек пробился :angel: Супер магазин,СПАСИБО за подарок 6 г в качестве компенсации:speak::hz:очень боялся что обманут,но Зря:drink: спасибо магазину,с новым годом!!!!! https://shopingdog.ru привет запулил на закладку ??
Darrenliata 06 Kasım 2025 08:17
с нашими кристаллами восстановятся https://magnitschool.ru Что то много новичков устраивают здесь флуд.А магаз на самом деле хорош.Помню его еще когда занимался курьерскими доставками,коспирация и качество товара было на высшем уровне.
ShaneBlani 06 Kasım 2025 08:07
Прошу прощения, что я вмешиваюсь, но я предлагаю пойти другим путём. по меньшей мере, в том случае, тогда, когда вы хотите пользоваться иностранными сервисами, [url=https://chita-news.net/other/2025/08/16/223030.html]https://chita-news.net/other/2025/08/16/223030.html[/url] многие из коих требуют смс с помощью номера сети не из России.
BobbyZet 06 Kasım 2025 07:50
Эффективно? you have a chance watch personal hard-earned in mode real time, and receive amounts whenever desire. Entering necessary information and confirmation your registration will allow to you instantly start diving into virtual world gaming entertainment [url=https://vknotec.com/2025/10/26/bc-app-vash-provodnik-v-mire-kriptovaljutnyh-igr/]https://vknotec.com/2025/10/26/bc-app-vash-provodnik-v-mire-kriptovaljutnyh-igr/[/url].
TimDut 06 Kasım 2025 07:43
two thirds their best [url=https://hoshino-fumichan.jp/]Pragmatic Play: Innovation in Every Spin[/url] available high maximum winnings - sometimes up to 5000, 10 000 or same 20 thousand times your bet.
Darrenliata 06 Kasım 2025 06:33
Магаз качественный ни разу не подводил!!! <a href=https://pilostroy-solikamsk.ru>купить скорость, кокаин, мефедрон, гашиш</a> Золотые слова.
Josephinepries 06 Kasım 2025 06:32
[url=https://blogs.koreaportal.com/bbs/board.php?bo_table=free&wr_id=5955801]https://blogs.koreaportal.com/bbs/board.php?bo_table=free&wr_id=5955801[/url] электроники stylus - умный, логичный и большой удобный сервис, на котором несложно понять, что конкретно подходит вам.
AshleyJeffrut 06 Kasım 2025 06:12
По моему мнению Вы не правы. Я уверен. Давайте обсудим. Пишите мне в PM. ^ [url=https://motioninartmedia.com/friendlyjordies-war-on-everything/]https://motioninartmedia.com/friendlyjordies-war-on-everything/[/url] Шестакова И. Г. ^ smart business: "visionary in obscurity" . однако продажа продукции осуществляется дистанционным изделий и она накладывает ограничения на продаваемые товары.
Cindyset 06 Kasım 2025 04:43
Вверху над результатами поиска вы можете найти порядок отображения туров: от более молодых к старым или от [url=http://popuri.net/ramu/cgi/sbu2_bbs/sbu2_bbs.cgi?action=showlast]http://popuri.net/ramu/cgi/sbu2_bbs/sbu2_bbs.cgi?action=showlast[/url] дешевых к дорогим.
PatrickNoumn 06 Kasım 2025 04:31
Автоматические - создаются системой автоматически, одна копия в неделю. Спам, [url=https://beaznetwork.com/podcast/does-your-sacrifice-affect-your-worth/]https://beaznetwork.com/podcast/does-your-sacrifice-affect-your-worth/[/url] массовые е-мейла рассылки.
Nataliaexpiz 06 Kasım 2025 04:20
Do you like black and white movies, Golden Age Hollywood either retro, [url=https://vintage-films.com/episode-details/165]https://vintage-films.com/episode-details/165[/url], you will be able to find all movie here - subscription is not needed.
JohnnygRato 06 Kasım 2025 02:59
заказал 5-IAI , прислали Methoxetamine, разность дозировок сами знаете, в итоге еле откачали.... https://napoklonnoy.ru Брал у другого магазина - полная Чляпа оказалась...
Seanskync 06 Kasım 2025 02:54
мда придумали ж 19-летний Жозеф Фредерик Дютфуа [url=https://spiritofkings2.ru/]https://spiritofkings2.ru[/url] (фр. Дата обращения: 11 июня 2020. Архивировано 18 февраля текущего года.
Sheilafer 06 Kasım 2025 02:26
Если вы работаете в сфере производства и ваша компания нуждается в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания работает на рынке поставок тугоплавких металлов на протяжении более 10 лет, что позволяет нам предлагать только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Большой ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Поддержка 24/7. Зачем тратить время на поиски на других сайтах, если rms-ekb.ru всегда в вашем распоряжении? Наши специалисты всегда рады помочь вам с любыми вопросами.. Обратитесь к нам прямо сейчас и удостоверьтесь в достоинствах нашего сплава. Ваш надежный
BeckyIsosy 06 Kasım 2025 01:50
karena dia memiliki largest number kemenangan dari [url=https://masfalhi.com/agen-judi-online-terpercaya-resmi-panduan-memilih-4/]https://masfalhi.com/agen-judi-online-terpercaya-resmi-panduan-memilih-4/[/url] sbobet 88. login sbobet resmi portal adalah platform, yang berspesialisasi pada persediaan online perjudian pada sepak bola dan taruhan pasar-pada sepak bola.
ShannonTussy 06 Kasım 2025 01:50
In this review of the [url=https://lib.lestnica.space/2025/08/31/experience-thrills-and-wins-at-online-mr-luck-2/]https://lib.lestnica.space/2025/08/31/experience-thrills-and-wins-at-online-mr-luck-2/[/url], hard rock bet received 10 points for ordered section of games. specifically, I will talk about promotions, online games, payouts and reliability.
Sheilafer 06 Kasım 2025 01:11
Если вы занимаетесь производством и нуждаетесь в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания специализируется на области поставок тугоплавких металлов на протяжении многих лет, что дает нам возможность поставлять только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Большой ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Поддержка 24/7. Зачем тратить время на поиски на других сайтах, если rms-ekb.ru всегда здесь для вас? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Пишите прямо сейчас и удостоверьтесь в преимуществах нашего продукта. С уважением, коман
LydiaJep 06 Kasım 2025 01:03
средство выпускается [url=http://opel.1stbb.ru/viewtopic.php?f=2&t=74]http://opel.1stbb.ru/viewtopic.php?f=2&t=74[/url] в таблетированной форме. для заказа софосбувира за границей следует заранее заказать у гепатолога рецепт на латинском языке международного типа.
Mirandales 06 Kasım 2025 00:14
чё то не очень.... Belgian users enjoy a localized design and support for French, Dutch and English, what does work with [url=http://cuongleld.blognhansu.com/2025/10/26/explorando-bc-game-en-mexico-la-nueva-era-del/]http://cuongleld.blognhansu.com/2025/10/26/explorando-bc-game-en-mexico-la-nueva-era-del/[/url] more convenient.
Sheilafer 06 Kasım 2025 00:06
РедМетСплав предлагает широкий ассортимент высококачественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до крупных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица товара подтверждена соответствующими документами, подтверждающими их происхождение. Опытная поддержка - наш стандарт – мы на связи, чтобы ответить на ваши вопросы и предоставлять решения под требования вашего бизнеса. Доверьте вашу потребность в редких металлах профессионалам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наша продукция: <a href=https://redmetsplav.ru/store/titan/rossiyskie-splavy-4/titan-vt32/list-titanovyy-vt32/>Лист титановый ВТ32</a> Лента титановая ВТ32 сочетает в себе высокую прочность и легкость, что
JudyThync 05 Kasım 2025 23:55
???automotive news??? nissan ??????? ponz pandikuthira ???,? ? qx50 ? qx55???????,????????,???,?? [url=http://wir-sabbeln.de/podlove/image/68747470733a2f2f736776617669612e72752f676f3f68747470733a2f2f736164612d2d636f6c6f722d6d616b69332d6e65742e7472616e736c6174652e676f6f672f6262732f6262732e636769253346706167653d30265f785f74725f7363683d68747470265f785f74725f736c3d6175746f265f785f74725f746c3d6672265f785f74725f686c3d6672/60/0/0/website]http://wir-sabbeln.de/podlove/image/68747470733a2f2f736776617669612e72752f676f3f68747470733a2f2f736164612d2d636f6c6f722d6d616b69332d6e65742e7472616e736c6174652e676f6f672f6262732f6262732e636769253346706167653d30265f785f74725f7363683d68747470265f785f74725f736c3d6175746f265f785f74725f746c3d6672265f785f74725f686c3d6672/60/0/0/website[/url] ??? ?????,????????
JohnnygRato 05 Kasım 2025 23:24
Отзывы радуют о магазине, надо заказывать. 5-MeO-DMT решает. https://kkadrov.ru ОТЛИЧНЫЙ МАГАЗИН ВСЕ НА ВЫСШЕМ УРОВНЕ!
zapojomskrix 05 Kasım 2025 23:12
вывод из запоя <a href=https://vivod-iz-zapoya-omsk014.ru>vivod-iz-zapoya-omsk014.ru</a> вывод из запоя омск
Leslielew 05 Kasım 2025 22:12
с помощью них, например, стоит сделать гораздо более заметными скулы, [url=https://imagemveterinaria.com/hello-world/]https://imagemveterinaria.com/hello-world/[/url] визуально изменить форму или размер носа. Полученный в 1955 году профессором Б.
CamillaMEK 05 Kasım 2025 21:51
Продукция создаётся на платформе партнёрского завода в поднебесной - указанное гарантирует премиум-качество по конкурентной цене. Помогаем снижать издержки, [url=https://info.expertcommentary.com/kupit-metallorezhushhij-instrument-kak-vybrat/]https://info.expertcommentary.com/kupit-metallorezhushhij-instrument-kak-vybrat/[/url] повышать скрупулезность и получать результата.
JohnnygRato 05 Kasım 2025 21:40
Всё нашел!! Стрелка указывала немного не туда,но я справился,проверил соседний угол,всё гуд! Спасибо динамиту! Мяу идеальный!! Рекомендую!! <a href=https://eks-expert.ru>купить Мефедрон, Бошки, Марихуану</a> Надеюсь на дальнейшее сотрудничество с магазином!
Sofiaobese 05 Kasım 2025 21:40
в данной статье мы решим, как правильно гладить [url=http://роялиндиго.рф/]купить кожаную сумку из натуральной кожи[/url] и устранять заломы, дабы сотрудники всегда выглядели как новые.
JohnnygRato 05 Kasım 2025 19:53
Клад был сделано на 5, инфу по кладу дали на 5. В общем очень доволен данным магазином, по качеству товара, отпишу позже! Заказывал здесь 1-ый раз, заливал бабки без гаранта, так что спокойно работайте без гаранта! Спасибо еще раз, продолжайте в том же духе, будем работать!!! <a href=https://eks-expert.ru>купить Мефедрон, Бошки, Марихуану</a> У нас у отправки случился форс-мажор. Только на этой неделе начинают отправлять. Извиняюсь от лица магазина за задержку.
JohnnygRato 05 Kasım 2025 18:07
Списались с оператором. Нужно взять 50 гр. СК. <a href=https://sk-angara.ru>купить Кокаин, Мефедрон, Экстази</a> пиши в скайп, все работает, мне всегда отправляют, все на уровне
Sheilafer 05 Kasım 2025 17:30
РедМетСплав предлагает обширный выбор качественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до крупных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица товара подтверждена всеми необходимыми документами, подтверждающими их соответствие стандартам. Опытная поддержка - наш стандарт – мы на связи, чтобы улаживать ваши вопросы и предоставлять решения под требования вашего бизнеса. Доверьте вашу потребность в редких металлах специалистам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей поставляемая продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-sismg4635-10---ss-144635/izdeliya-iz-magniya-sismg4635-10---ss-144635/>Изделия из магния SISMg4635-1
Sabrinaheike 05 Kasım 2025 17:18
В клеевых швах, материал скрепляют клеем подобно плёнки, порошка, [url=https://yukino-music.com/missing/]https://yukino-music.com/missing/[/url] нити. при заказе военной формы указывались наиболее ходовые размеры.
narkologiyaomskrix 05 Kasım 2025 16:27
вывод из запоя круглосуточно <a href=https://vivod-iz-zapoya-omsk013.ru>vivod-iz-zapoya-omsk013.ru</a> вывод из запоя
Sheilafer 05 Kasım 2025 16:27
Если вы заняты в области производства и ваша компания нуждается в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания занимается на рынке поставок тугоплавких металлов уже долгого времени, что обеспечивает нам условия поставлять только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Широкий ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Круглосуточная поддержка. Зачем искать где-то еще, если rms-ekb.ru всегда готовы помочь? Наши специалисты всегда рады помочь вам с любыми вопросами.. Обратитесь к нам прямо сейчас и проверьте в качестве нашего продукта. Команда <a href=https
EricaRhibe 05 Kasım 2025 15:12
Мониторинг новостей и аналитической информации позволяет трейдерам быть осведомленным о актуальных событий и обстоятельств, [url=https://www.aselpconsultores.es/producto/mf1582_3-promocion-para-la-igualdad-efectiva-de-mujeres-y-hombres-en-materia-de-empleo/]https://www.aselpconsultores.es/producto/mf1582_3-promocion-para-la-igualdad-efectiva-de-mujeres-y-hombres-en-materia-de-empleo/[/url] влияющих на цены на рынке.
Davidelins 05 Kasım 2025 14:35
_Elf_ тебе сколько лет интересно?У тебя был единичный случай по твоим словам товар-фуфло.репутация у тебя "0"Требуешь вернуть денег, ты же понимаешь что тебе их не вернут.Вывод-ПРОВОКАЦИЯ <a href=https://umc-detstvo.ru>купить Кокаин, Мефедрон, Экстази</a> Надеюсь на дальнейшее сотрудничество с магазином!
Patrickdem 05 Kasım 2025 12:56
W panelu uzytkownika Znajdz DANE o ulubionym [url=https://www.livstjanst.se/hotline-casino-rozpocznij-swoj-przygod-z-hazardem/]https://www.livstjanst.se/hotline-casino-rozpocznij-swoj-przygod-z-hazardem/[/url] saldo bonusowe. to jest doskonala opcja wyprobuj gre riot i pomnoz potencjalne szanse na potencjalna wygrana bez ryzyka wlasne pieniadze.
Davidelins 05 Kasım 2025 12:51
Не рекомендую правда увлекаться порохами - их хочется ещё и ещё и в итоге не так уж и просто слезть с марафона...) Но это уже ваше дело ; ) <a href=https://bknews.ru>купить скорость, кокаин, мефедрон, гашиш</a> Так может не ждать у моря погода, а взять и самому написать менеджеру в аську/почту и получить уже эти реквизиты?
Amandanen 05 Kasım 2025 12:23
Меня тоже волнует этот вопрос. Скажите мне, пожалуйста - где я могу найти больше информации по этому вопросу? компании выбирают нас, потому что мы сочетаем стиль, [url=https://gfxmaker.com/how-to-set-up-a-crypto-payment-gateway-to-accept-ethereum-transactions/]https://gfxmaker.com/how-to-set-up-a-crypto-payment-gateway-to-accept-ethereum-transactions/[/url] надежность и оперативность решения задачи заказов.
Sheilafer 05 Kasım 2025 11:24
РедМетСплав предлагает широкий ассортимент высококачественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до обширных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица изделия подтверждена соответствующими документами, подтверждающими их происхождение. Дружелюбная помощь - то, чем мы гордимся – мы на связи, чтобы улаживать ваши вопросы по мере того как адаптировать решения под особенности вашего бизнеса. Доверьте ваш запрос специалистам РедМетСплав и убедитесь в гибкости нашего предложения Наша продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-iso-mb21310---bs-iso-16220/folga-magnievaya-iso-mb21310---bs-iso-16220/>Фольга магниевая ISO-MB21310 - BS ISO 16220</a>
Noramic 05 Kasım 2025 11:18
это гарантия непревзойденного качества электроники и веб техники. онлайн магазина по продаже компьютерной техники Ситилинк учитывается на втором месте в начало списка [url=https://nesika.co.il/jackpot-block-party-180/]https://nesika.co.il/jackpot-block-party-180/[/url] топ-100.
Davidelins 05 Kasım 2025 11:05
да никого не устраивает это, что за бред. только единиц. <a href=https://holbonskoe.ru>купить скорость, кокаин, мефедрон, гашиш</a> Качество на высоте,оператор красавчик,все сделали быстро и четко!
Crowngreen WarnerTug 05 Kasım 2025 10:54
Crowngreen Casino is a popular entertainment site that provides thrilling experiences for gamers. Crowngreen shines in the online gaming world and has earned popularity among enthusiasts. Every visitor at <a href="https://demo.netsa.vn/bh43/feel-the-thrill-of-crowngreen-casino-and-boost/">Crowngreen</a> can experience exclusive tournaments and receive generous promotions. Crowngreen Casino provides reliable gameplay, seamless transactions, and constant customer support for all users. With , players unlock a huge selection of table games, including live dealer options. The site focuses on entertainment and maintains a safe gaming environment. Whether you are new or an expert, Crowngreen Casino offers something special for everyone. Sign up at Crowngreen today and experience
Sheilafer 05 Kasım 2025 10:35
РедМетСплав предлагает внушительный каталог отборных изделий из редких материалов. Не важно, какие объемы вам необходимы - от мелких партий до крупных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица продукции подтверждена соответствующими документами, подтверждающими их соответствие стандартам. Превосходное обслуживание - то, чем мы гордимся – мы на связи, чтобы ответить на ваши вопросы а также находить ответы под особенности вашего бизнеса. Доверьте потребности вашего бизнеса специалистам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей поставляемая продукция: <a href=https://redmetsplav.ru/store/vismut/zarubezhnye-splavy-3/vismut-tbc-13---pn-h-87203/truba-vismutovaya-tbc-13---pn-h-87203/>Труба висмутовая TBC 13 - PN H-87203</a> Тр
StacyKal 05 Kasım 2025 10:09
По моему мнению Вы не правы. Могу это доказать. Пишите мне в PM. Share your tips, discuss the game on a website, [url=https://www.minikarilar.com/2025/10/26/bc-game-legit-india-your-gateway-to-trustworthy/]https://www.minikarilar.com/2025/10/26/bc-game-legit-india-your-gateway-to-trustworthy/[/url] or without guile laugh together.
Sheilafer 05 Kasım 2025 08:34
Если вы заняты в области производства и нуждаетесь в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания работает на сфере поставок тугоплавких металлов в течение долгого времени, что позволяет нам поставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Большой ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Поддержка 24/7. Зачем тратить время на поиски на других сайтах, если rms-ekb.ru всегда здесь для вас? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Звоните прямо сейчас и удостоверьтесь в качестве нашего продукта. Ваш надежный поставщик, <a
izzapoyakrasnodarrix 05 Kasım 2025 08:31
вывод из запоя круглосуточно <a href=https://narkolog-krasnodar022.ru>narkolog-krasnodar022.ru</a> вывод из запоя круглосуточно
Barbaradak 05 Kasım 2025 08:30
сегодня в [url=https://xetulaih2.com/tin-tuc-tu-van/kinh-nghiem-can-biet-khi-lai-xe-tren-cao-toc.html]https://xetulaih2.com/tin-tuc-tu-van/kinh-nghiem-can-biet-khi-lai-xe-tren-cao-toc.html[/url] в Душанбе есть своя система обучения членов команды: менеджеров, тренеров, поваров и прочих, идут всякие коучи для самого быстрой и слаженной работы команды.
JacobGrido 05 Kasım 2025 08:02
https://news.oalur.com/?p=165483
Crowngreen WarnerTug 05 Kasım 2025 06:40
Crowngreen Casino is a popular online casino that provides engaging experiences for users. Crowngreen shines in the online gaming world and has earned reputation among visitors. Every visitor at <a href="https://bazyaft.sepanodp.com/experience-premium-gaming-at-crowngreen-casino-and-4/">https://bazyaft.sepanodp.com/experience-premium-gaming-at-crowngreen-casino-and-4/</a> has the chance to enjoy top-rated tournaments and take advantage of exciting bonuses. Crowngreen guarantees secure gameplay, smooth transactions, and constant customer support for every player. With , enthusiasts unlock a diverse selection of slots, including jackpot options. The casino delivers user satisfaction and ensures a safe gaming environment. Whether you are a beginner or experienced, Crowngreen
Shawnvub 05 Kasım 2025 05:58
detta ger storre varde strider, men forutom en storre variation av forhallanden, den [url=http://setup.agadia.com/268448]http://setup.agadia.com/268448[/url], sa viktigt att lasa fintryck, fore acceptera bonusen.
KimHom 05 Kasım 2025 05:42
Браво, какой отличный ответ. In Broward and Miami-Dade, [url=https://kwalies.sd/archives/76234]https://kwalies.sd/archives/76234[/url] have received permission to install slot machines. one-armed bandits legalized in Florida.
WilliamOring 05 Kasım 2025 04:59
вот как прет Амф. <a href=https://kogtetochki-kotopes.ru>купить Кокаин, Мефедрон, Экстази</a> ты брал вообще не скоростило или как ?
ValerySew 05 Kasım 2025 04:59
Все не так просто в какой срок и почему началось противостояние двух стран, как оно развивалось в дальнейшем, почему ХАМАС пошло на обострение в октябре 2023 г. и с какой целью может привести война меж этими государствами - в материале РИА [url=https://invocavit.com/pwi-sumut-akan-gelar-sji-dan-ukw-awal-september-2024/]https://invocavit.com/pwi-sumut-akan-gelar-sji-dan-ukw-awal-september-2024/[/url].
Capasig 05 Kasım 2025 03:56
Stunning re-links, wild symbols and a bonus for every taste support the dynamic pace of [url=https://www.mertalotomasyon.com/the-exciting-world-of-magius-casino]https://www.mertalotomasyon.com/the-exciting-world-of-magius-casino[/url], precisely for this reason they are popular with players, that enjoy the gradual progress and frequent draws of the prize games.
WilliamOring 05 Kasım 2025 03:15
Весом по 1 гр <a href=https://fatal-world.ru>купить скорость, кокаин, мефедрон, гашиш</a> знаю кто и как берут через этот магаз
alkogolizmminskrix 05 Kasım 2025 02:44
экстренный вывод из запоя <a href=https://vivod-iz-zapoya-minsk014.ru>vivod-iz-zapoya-minsk014.ru</a> экстренный вывод из запоя
Boonelaf 05 Kasım 2025 02:40
Это благодарность за то, [url=https://kohchang24.com/foto1/]https://kohchang24.com/foto1/[/url] что магазин stls не врет. чем отличаются интернет магазин Стилус от прочих? у нас все комфортно.
Crowngreen WarnerTug 05 Kasım 2025 02:29
Crowngreen is a trusted entertainment site that delivers engaging experiences for gamers. Crowngreen excels in the online gaming world and has gained reputation among enthusiasts. Every user at <a href="http://gastconcept.de/join-crowngreen-casino-today-for-bonus-casino-fun/">Crowngreen</a> can play exclusive slots and receive rewarding bonuses. Crowngreen ensures fair gameplay, seamless transactions, and 24/7 customer support for every gamer. With , enthusiasts discover a wide range of casino games, including jackpot options. The casino focuses on user satisfaction and maintains a secure gaming environment. Whether you are experienced or a pro, Crowngreen Casino guarantees exciting gameplay for everyone. Start playing at Crowngreen Casino today and discover thrilling game
narkologiyatularix 05 Kasım 2025 02:02
лечение запоя тула <a href=https://tula-narkolog010.ru>tula-narkolog010.ru</a> экстренный вывод из запоя тула
RodriguezBex 05 Kasım 2025 01:53
это достигается или посредством слабых кислот или других химикатов для разжижения старых клеток кожи, [url=https://nationalflooringsolutions.com/4-trends-set-to-revolutionize-hardwood-in-the-2020s/]https://nationalflooringsolutions.com/4-trends-set-to-revolutionize-hardwood-in-the-2020s/[/url] или с помощью слегка абразивных веществ для их физического удаления.
WilliamOring 05 Kasım 2025 01:28
всем мир! скажите магаз ровный? ато написал на мыло им и ни ответа ни привета! <a href=https://ribalka-hatyn.ru>купить Мефедрон, Бошки, Марихуану</a> Может еще вернемся.
Nicoleslaft 05 Kasım 2025 01:22
По моему мнению Вы допускаете ошибку. Предлагаю это обсудить. Пишите мне в PM. Select a currency: Select the currency that you will use to replenish balance in the [url=http://www.front-ier.com/archives/17300]http://www.front-ier.com/archives/17300[/url] and withdraw funds. generous Bonuses - Take advantage of numerous rewards on deposit and free spins to increase game space and probability of winning.
Adamswide 05 Kasım 2025 00:52
Блестяще Sonra [url=https://goparabet.com/]https://goparabet.com[/url] Ilgili isleme parabet yat?r?n ve baslat tesvik tutar% 250 boyle islemden sonraki 3 gun icinde|boyunca kullan?n.
Gwinnetterult 05 Kasım 2025 00:30
наиболее простая схема развода - намеренная или ненамеренная порча заведомо [url=http://www.technotesting.com/project/shrinkage/]http://www.technotesting.com/project/shrinkage/[/url] рабочих агрегатов.
Sheilafer 04 Kasım 2025 23:52
Если вы работаете в сфере производства и нуждаетесь в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания специализируется на рынке поставок тугоплавких металлов уже долгого времени, что обеспечивает нам условия предлагать только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Большой ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Круглосуточная поддержка. Зачем искать на других сайтах, если rms-ekb.ru всегда готовы помочь? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Звоните прямо сейчас и удостоверьтесь в достоинствах нашего продукта. С уважением, команда <
WilliamOring 04 Kasım 2025 23:45
отвечать вам не перестали я дал ответы на ваши вопросы, когда по несколько раз 1 и то же спрашивают я не отвечаю. <a href=https://laserlandiv.ru>купить онлайн мефедрон, экстази, бошки</a> Первый раз вижу такое с МН. От других селлеров все было норм с растворимостью. Растворяющийся полностью пер чуть посильнее...
FloranceVer 04 Kasım 2025 23:13
Отличная фраза и своевременно ^ Свалка [url=http://www.theycallmedaymz.com/jody-watley-keeps-it-real/]http://www.theycallmedaymz.com/jody-watley-keeps-it-real/[/url] в Атакаме . в процессе Гражданской войны в штатах потребовалось одеть в военную форму тысячи солдат.
AnaHek 04 Kasım 2025 23:11
спс... стараюсь Interactive features: Communicate directly, leave tips, [url=https://web-chaturbate.net/]chaturbate live cams[/url] in a chat and even manage interactive toys for more exciting leisure. you get the opportunity to filter models by categories, body type or region, therefore find need will not be difficult.
Jenniferawaib 04 Kasım 2025 23:11
nase tipy zahrnuji vyhradne duveryhodnych umelcu, maji pozitivni recenze jak od ceskych hracu, vubec od zahranicnich, [url=https://assemamed.ly/2025/10/20/zahranini-online-casino-pro-eske-hrae-ve-co-5/]https://assemamed.ly/2025/10/20/zahranini-online-casino-pro-eske-hrae-ve-co-5/[/url] nekdy na zahranicnich webech.
Sheilafer 04 Kasım 2025 22:47
Если вы занимаетесь производством и ваша компания нуждается в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания занимается на сфере поставок тугоплавких металлов в течение многих лет, что обеспечивает нам условия поставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Обширный выбор тугоплавких металлов. 3. Документация в порядке. 4. Всесторонняя поддержка клиентов. Зачем подбирать где-то еще, если rms-ekb.ru всегда готовы помочь? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Пишите прямо сейчас и убедитесь в преимуществах нашего сплава. Ваш надежный поставщик
WilliamOring 04 Kasım 2025 22:00
Не волнуйтесь, я думаю Рашн холидэйс. Продавец честный https://miracleproject.ru Извините удаляю сообщение!
BobbyGoast 04 Kasım 2025 21:29
5% bez dodatkowych/ zbednych warunkow i zastosuj jego, w dowolny/ wszystkie grze! Drugi Bonus do twojej uwagi: doladowanie 100% do 1500zl, [url=https://chaboclubedobrasil.com.br/hotline-casino-nowoczesne-gry-i-emocje-na/]https://chaboclubedobrasil.com.br/hotline-casino-nowoczesne-gry-i-emocje-na/[/url] 50 bezplatnych spinow na dawn of egypt lub 100 nieodplatnych spinow na grim muerto.
AnneBliny 04 Kasım 2025 21:00
прикольно конечно НО смысл этого чуда {all our|any} {games|games} {fully|completely} {compatible|correlated} with {mobile devices|mobile devices}.#file_links["C:\Users\Admin\Desktop\file\gsa+en+86c621jg73P2URLBB.txt",1,N] {in our team|with us|here|here} {some of them are working|working} {самых|наиболее{распространенных|популярных|востребованных|прославленных|знаменитых|именитых}|наиболее{распространенных|популярных|востребованных|прославленных|знаменитых|именитых}|наиболее{распространенных|популярных|востребованных|прославленных|знаменитых|именитых}|наиболее{распространенных|популярных|востребованных|прославленных|знаменитых|именитых}|наиболее{распространенных|популярных|востребованных|прославленных|знаменитых|именитых } brilliant and talented {people|Internet users|visitors} {all over
WilliamOring 04 Kasım 2025 20:12
Доброго всем форумчанам дня и процветания! Начну пожалуй с того, что заказываю в данном магазине впервые, да и вообще, не так часто пользуюсь услугами данного типа через интернет, но вот вдруг, «обчитавшись» положительных отзывов о данном магазе, решил заказать тут мягкий. Оформил заказ на сайте, после получения и подтверждения данных для оплаты, заказ оплатил – 13 января. В этот же день, через пару часов, пришло сообщение: https://laserlandiv.ru отличный селлер
AdamSok 04 Kasım 2025 19:15
как пройти регистрацию на webmoney в беларуси и [url=http://ecgs.gunpo.hs.kr/bbs/board.php?bo_table=free&wr_id=1881618]http://ecgs.gunpo.hs.kr/bbs/board.php?bo_table=free&wr_id=1881618[/url] создать кошелек? Это условие касается только кошельков wmb в белорусских рублях.
YolandaTeene 04 Kasım 2025 18:58
В эстрагоне не имеется ничего пугающего, что абсолютно не напоминает драконов, воплощением которых он, как принято считать, [url=https://online-learning-initiative.org/wiki/index.php/User:LinneaBellew]https://online-learning-initiative.org/wiki/index.php/User:LinneaBellew[/url] является.
WilliamOring 04 Kasım 2025 18:28
ОПЛАТИЛ И ЧЕРЕЗ 2ДНЯ ВСЕ У МЕНЯ !!! <a href=https://gyro-cult.ru>купить онлайн мефедрон, экстази, бошки</a> КЕнт,сорри на почту ответь..
DanielTrant 04 Kasım 2025 17:33
<a href=https://bergkompressor.ru/>https://bergkompressor.ru/</a> Кликните и исследуйте – Путешествие к последним обновлениям начинается здесь.
DorothyEnuby 04 Kasım 2025 17:22
туфта ^ Каспаров Г.Н. Духи // Основы производства [url=https://dnssor.com/euro-kosmetika.ru]https://dnssor.com/euro-kosmetika.ru[/url] парфюма и косметики. new remedies: an illustrated monthly trade journal of materia medica, pharmacy and therapeutics (англ.).
WilliamOring 04 Kasım 2025 16:41
Может правда о ошибочке что небудь не то отправили))) <a href=https://sstm74.ru>купить кокаин, меф, бошки через телеграмм</a> Заказ получил, спасибо за ракетку :D Это был мой первый опыт заказа легала в интернете, и он был положительным! Спасибо магазину chemical-mix.com за это!
Ericaoriet 04 Kasım 2025 16:38
Men application similar methods, i en [url=https://mwaris.dev/casino-utan-svensk-licens-de-10-basta-alternativen-5/]https://mwaris.dev/casino-utan-svensk-licens-de-10-basta-alternativen-5/[/url] ar associerad med befintliga risker och konsekvenser, sedan de kan vara olagliga. Aven om de eller inte uppfyller de svenska reglerna finns det strikta regler som Bakgrundsbilder maste folja.
Patrickgaund 04 Kasım 2025 15:50
ini sudah menjadi tradisi, dan besides kenyamanan confident visitor, that terbiasa menggunakan wap [url=https://mohamednishal.com/agen-taruhan-terpercaya-pilihan-yang-harus-anda/]https://mohamednishal.com/agen-taruhan-terpercaya-pilihan-yang-harus-anda/[/url] masuk ke jalur pipa sbobet88.
RachelSep 04 Kasım 2025 15:49
this is among other things means that gambling table does not determine the level of honesty, even if they want it. briefly about very well-rated bonus offers, about, how it is safe to use them, about [url=https://nvdco.ir/best-paypal-casino-online-uk-play-safely-and/]https://nvdco.ir/best-paypal-casino-online-uk-play-safely-and/[/url] and why/ in connection with what are they so with well in demand.
WilliamOring 04 Kasım 2025 14:57
что ты хочешь сказать,что этот реактив плохо прет? https://happyroasters.ru Хороший магазин
Sheilafer 04 Kasım 2025 14:37
РедМетСплав предлагает широкий ассортимент высококачественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до масштабных поставок, мы гарантируем своевременную реализацию вашего заказа. Каждая единица изделия подтверждена требуемыми документами, подтверждающими их соответствие стандартам. Превосходное обслуживание - то, чем мы гордимся – мы на связи, чтобы ответить на ваши вопросы а также адаптировать решения под требования вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наша продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-as41b---astm-b275/pokovka-magnievaya-as41b---astm-b275/>Поковка магниевая AS41B
SherryFrurn 04 Kasım 2025 14:12
to znamena, [url=https://www.tigertox.com/2025/10/19/zahranini-casino-ve-co-potebujete-vdt-o-online/]https://www.tigertox.com/2025/10/19/zahranini-casino-ve-co-potebujete-vdt-o-online/[/url] ze vas stav na nasich strankach automaticky roste soucasne s vasi aktivitou. takovy druh odmeny se take nazyva referencni program.
Sheilafer 04 Kasım 2025 13:55
Если вы занимаетесь производством и ваша компания нуждается в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания специализируется на сфере поставок тугоплавких металлов на протяжении многих лет, что дает нам возможность предоставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Широкий ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Поддержка 24/7. Зачем подбирать на других сайтах, если rms-ekb.ru всегда в вашем распоряжении? Наши специалисты всегда рады помочь вам с любыми вопросами.. Звоните прямо сейчас и удостоверьтесь в качестве нашего сплава. Ваш надежный поставщ
LillianSaw 04 Kasım 2025 13:41
Брутсофтеры. это техники, которые создают ботнеты и специализируются на брутсофте - перебирании паролей. а равно как стать взломщиком? чаще всего такими людьми движет не спортивный интерес, [url=https://www.sharpiesrestauranttn.com/hunting-helping-kids-2/]https://www.sharpiesrestauranttn.com/hunting-helping-kids-2/[/url] а возможность быстрого обогащения.
WilliamOring 04 Kasım 2025 13:11
Как долго вы обрабатываете заказ? https://leontyusov.ru Магаз вышел на связь, работает, но щас выходные :D с треками порешают, по ходу косяки СПСР. пробники БУДУТ !! Кто ещё будет гадить в теме "Трипы" и просить пробник - получит подзатыльник. У кого есть что сказать - отпишите лучше отзывы о товаре.
Kathyboali 04 Kasım 2025 12:44
[url=https://staging.ncbagroup.com/en-yi-telefon-satn-alma-rehberi/]https://staging.ncbagroup.com/en-yi-telefon-satn-alma-rehberi/[/url] idari taraf uniter bir yap?ya sahiptir ve Turkiye kamu idaresini belirleyen en onemli faktorlerden bu durum kal?r bir 'dir.
Jaygopsy 04 Kasım 2025 11:42
Мне очень жаль, ничем не могу Вам помочь. Но уверен, что Вы найдёте правильное решение. Не отчаивайтесь. В 1581 начался поход отряда численностью около 800 человек под предводительством Ермака, [url=http://www.luciafuseareaprivata.info/2018/04/24/hello-world/]http://www.luciafuseareaprivata.info/2018/04/24/hello-world/[/url] он захватил столицу Сибири - Искер.
WilliamOring 04 Kasım 2025 11:26
бро а какая почта то ? https://taxi-sedan.ru Магазин Харош, Внимательней читайте отзывы о той продукции какая вас интересует более подходит имено вам только такой подход может оставить всем только положительные эмоции. Работа магазина по всем пораметрам оставляет только положительные эмоции :voo-hoo: ставлю все оценки только отлично. Всем добРа, советую, обращайтесь в даный магазин, вам помогут быстро и качествено доставить то,что вам нужно
Cherilspide 04 Kasım 2025 10:04
{azonban|azonban} {itt|itt|ebben} "feher lista" voltak {csak|egyszeru|rendes|csak|csak|csak nehany boldog kivetel, {mint peldaul|mint} #file_links["C:\Users\Admin\Desktop\file\gsa+hu+lomspirogiHU86c5y5c7q17P2URLBB.txt",1,N], {ezert|ezert|ebben a tekintetben|ezert|mert|erre tekintettel| mert| ennek eredmenyekent| emiatt|az} {most|many} {resources|sites /platforms|platforms} {mindig is es most is} adoztak a magyar jatekosok szamara.
Erikakek 04 Kasım 2025 09:50
i wedlug/ co do ilosci i korzysci gier z uwzglednieniem, [url=https://sevia.biz/geen-categorie/hotline-casino-twoja-brama-do-wiata-gier-online-4/]https://sevia.biz/geen-categorie/hotline-casino-twoja-brama-do-wiata-gier-online-4/[/url] to jest kasyno, uruchomione zaledwie miesiac temu, teraz w stanie chwalic sie grami od kilku popularnych firm/producentow.
Carlosdig 04 Kasım 2025 09:41
Продавец общительный, выслал с заказом пару пробников бесплатно! заказы высылют оперативно https://fatal-world.ru Флудить на счет легальности/нелегальности товара в магазине не нужно в ветке! У же отписывалась и экспертиза и мы не однократно писали, возим ТОЛЬКО ЛЕГАЛ!
Kathleenfearf 04 Kasım 2025 08:39
«информационная безопасность», «Физика», «Физика лазерных и плазменных и радиационных технологий», «Автоматика, электроника, наноструктурная электроника», [url=https://www.mkez-dresden.de/allgemeine-aktivitaeten/offene_moschee/]https://www.mkez-dresden.de/allgemeine-aktivitaeten/offene_moschee/[/url] «Инженерно-физические технологии биомедицины».
Sheilafer 04 Kasım 2025 08:26
РедМетСплав предлагает обширный выбор высококачественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до обширных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица изделия подтверждена всеми необходимыми документами, подтверждающими их соответствие стандартам. Опытная поддержка - то, чем мы гордимся – мы на связи, чтобы ответить на ваши вопросы по мере того как адаптировать решения под специфику вашего бизнеса. Доверьте вашу потребность в редких металлах профессионалам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наша продукция: <a href=https://redmetsplav.ru/store/kobalt/rossiyskie-splavy-3/kobalt-yundkt8---gost-17809-72/provoloka-kobaltovaya-yundkt8---gost-17809-72/>Проволока кобальтов
Carlosdig 04 Kasım 2025 07:54
Без паники, есть 2 причины почему может не бится трэк 1. тупит курьерка и не внесла в базу накладную такое бывало уже не раз люди получали посылки с нерабочей накладной такое бывает часво это кривая работа службы доставки. 2. вы не правильно вводите на сайте отслеживания с дефисом, пробелом, не по формату номеру накладной службы или вообще на другом сайте)) такое тоже бывает часто. Клиенты у нас получают все вовремя если вас оповестили что посылка отправлена значит она отправлена, ожидайте согласно установленому времени доставки. https://smilefab.ru +огромная потеря популярности и быстрый спад клиентов.
Kimhum 04 Kasım 2025 07:54
exists a couple-three persyaratan, which dapat menyulitkan sbobet88 untuk [url=https://bspelectronics.com/agen-taruhan-terpercaya-resmi-indonesia-4/]https://bspelectronics.com/agen-taruhan-terpercaya-resmi-indonesia-4/[/url] dengan certain pemain baru. dalam ini jenis taruhan - pada sepak bola akan ada referensi ke menerima poin atau menerima poin.
Sheilafer 04 Kasım 2025 07:51
РедМетСплав предлагает обширный выбор качественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от мелких партий до масштабных поставок, мы гарантируем своевременную реализацию вашего заказа. Каждая единица продукции подтверждена соответствующими документами, подтверждающими их происхождение. Превосходное обслуживание - наша визитная карточка – мы на связи, чтобы ответить на ваши вопросы а также адаптировать решения под особенности вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-as-21/pokovka-magnievaya-as-21/>Поковка магниевая AS 21</a> Лист магниевый AS 21 - это высококачественный м
KateCycle 04 Kasım 2025 07:22
при этом продажа продукта осуществляется дистанционным способом и она накладывает ограничения [url=https://moderngazda.hu/novenytermesztes/termesztes/talajnedvesseg-merese/]https://moderngazda.hu/novenytermesztes/termesztes/talajnedvesseg-merese/[/url] на продаваемые товары.
Sheilafer 04 Kasım 2025 06:05
Если вы работаете в сфере производства и столкнулись с необходимостью в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания занимается на сфере поставок тугоплавких металлов уже десятилетий, что обеспечивает нам условия предоставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Обширный выбор тугоплавких металлов. 3. Все необходимые документы. 4. Поддержка 24/7. Зачем искать где-то еще, если rms-ekb.ru всегда в вашем распоряжении? Наши специалисты всегда рады помочь вам с любыми вопросами.. Звоните прямо сейчас и удостоверьтесь в качестве нашего продукта. Ваш надежный поставщик, <a href=h
Seanpah 04 Kasım 2025 05:13
Проводятся и для увлечения школьников занятиями наукой, [url=https://www.kogumahome.com/hokkori-blog/2019/07/19/20190719/?unapproved=2532083&moderation-hash=e5f3bdb4761ae06c30863d47b3c51294]https://www.kogumahome.com/hokkori-blog/2019/07/19/20190719/?unapproved=2532083&moderation-hash=e5f3bdb4761ae06c30863d47b3c51294[/url] но и для отбора части на международную олимпиаду.
Sheilafer 04 Kasım 2025 04:50
Если вы работаете в сфере производства и ваша компания нуждается в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания работает на области поставок тугоплавких металлов на протяжении долгого времени, что обеспечивает нам условия предлагать только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Широкий ассортимент тугоплавких металлов. 3. Все необходимые документы. 4. Круглосуточная поддержка. Зачем искать где-то еще, если rms-ekb.ru всегда здесь для вас? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Звоните прямо сейчас и проверьте в достоинствах нашего сплава. Ваш надежный постав
Carlosdig 04 Kasım 2025 04:21
Отличный магазин) https://gyro-cult.ru Про 80 не знаю. Но то что там принимают сомнительных, дак это точно. Вот люди которые туда приходят и ушатаные в хламотень, все трясутся. И оглядываются, как будто от смерти скрываются конечно их принимают... А что про тех кто соблюдаем все меры, тот спокоен. И сдержан. Но все равно. В спср принимают однозначно, сам свидетель в 2006 году. когда за дропом следили, перепугались что за нашим пришли... Но все обошлось.
JacquelineCassy 04 Kasım 2025 04:10
как скачать помогите {approximately|somewhere|on average|by eye|approximately| players spend {about|within} {2.5|two and a half} pounds per {week|week} on {gambling|interesting positions} #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c5x6y591P2URLBB.txt",1,N] {included|included} in gamstop, and {it is possible| is | practiced} such {options|opportunities}, like {casino|gambling house|playground|establishment} with a deposit of 5 pounds.
TeresaHuh 04 Kasım 2025 03:06
[url=https://write.as/bwc40sjvrklrt.md]cialis canada[/url] [url=https://www.tumblr.com/ethanneon/798108129056407552/cialis-vs-viagra-which-one-fits-your-lifestyle]cialis without a doctor prescription[/url] [url=https://posteezy.com/cialis-complete-guide-buying-reliable-solution-erectile-dysfunction-online]lilly cialis coupons[/url] [url=https://controlc.com/e2431aac]cialis official site[/url]
ElizabethziX 04 Kasım 2025 03:04
Весьма ценная информация Childers, Chad (June 21, 2022). "The band's [url=https://web-xhamsterlive.com/xhamster-live-sexchat-erotic-cam-experience-online/]https://web-xhamsterlive.com/xhamster-live-sexchat-erotic-cam-experience-online/[/url]frontman claims that he controls the band, and fires the guitarist." The album included the singles "I Alone", "All over You" and popular pictures of modern rock number one in USA "selling the drama" and "lightning crashes".
Carlosdig 04 Kasım 2025 02:34
братва подскажите концентрацию и растворитель для ам2233 от данного селера ! Заранее спс https://fatal-world.ru но за долгое сотрудничество с этим
JaniceJaimi 04 Kasım 2025 02:17
[url=https://sensumart.pl/agen-judi-online-terpercaya-aman-pilihan-tepat/]https://sensumart.pl/agen-judi-online-terpercaya-aman-pilihan-tepat/[/url] untuk
JoyceBouro 04 Kasım 2025 02:16
in such games only spin in [url=https://restncool.com/?p=22027]https://restncool.com/?p=22027[/url] able bring you a 6 or 7-digit win. Welcome bonuses usually include bonus drug, and free rotations that can use in slots.
PamelaEtelt 04 Kasım 2025 02:10
to mowi, ze portal jest zobowiazany do przestrzegania standardow uczciwej/ bezstronnej gry, [url=https://formabilityacademy.it/hotline-casino-twoja-brama-do-wiata-hazardu-online/]https://formabilityacademy.it/hotline-casino-twoja-brama-do-wiata-hazardu-online/[/url] bezpieczenstwo informacji gracze i otrzymywanie/ zapewnianie przejrzystosci transakcji.
Debbiekak 04 Kasım 2025 01:49
Извините, очищено к оставшимся относятся лампы освещения салона, подкапотная лампа, лампа освещения багажника, лампа освещения перчаточного ящика, [url=http://sheilaliming.com/428DH/uncategorized/camus-the-stranger-book-cover-design/]http://sheilaliming.com/428DH/uncategorized/camus-the-stranger-book-cover-design/[/url] лампы подсветки приборной панели и т.п..
Sheilafer 04 Kasım 2025 00:59
РедМетСплав предлагает широкий ассортимент отборных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от мелких партий до крупных поставок, мы обеспечиваем своевременную реализацию вашего заказа. Каждая единица товара подтверждена требуемыми документами, подтверждающими их качество. Дружелюбная помощь - то, чем мы гордимся – мы на связи, чтобы разрешать ваши вопросы по мере того как находить ответы под специфику вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в гибкости нашего предложения Наши товары: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-mgzn6th2zr---iso-3115/krug-magnievyy-mgzn6th2zr---iso-3115/>Круг магниевый MgZn6Th2Zr - ISO 3115</a> Фольга магниевая MgZn6Th2Zr - ISO 3115 является
Candylab 04 Kasım 2025 00:54
для удобства потребителей любые предметы распределены по коллекциям. Посредник - человек, [url=https://gotconquestwiki.com/index.php/User:InesHxh77958]https://gotconquestwiki.com/index.php/User:InesHxh77958[/url] который выкупит понравившиеся вам предложения из детских магазинов америке и производит отправку.
Carlosdig 04 Kasım 2025 00:48
А ты у него спроси тот он или не тот, врать не станет думаю https://kogtetochki-kotopes.ru я заказывау уже больше 2х лет только у этого магазина, сейчас заказал эфор и регу на подобия jv 100 сказали, посыль дошол от крыл а тпм только эфор а реги нет. может вы что то перепутали с заказом ребята ответь.
TerryLah 04 Kasım 2025 00:41
Embark into the vast sandbox of EVE Online. Test your limits today. Conquer alongside thousands of pilots worldwide. [url=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4]Download free[/url]
MonicaSmunc 04 Kasım 2025 00:14
Тактика компании организована именно так, [url=http://park6.wakwak.com/~hitsuji_ya/cgi-bin/color2/album.cgi?mode=detail&no=2]http://park6.wakwak.com/~hitsuji_ya/cgi-bin/color2/album.cgi?mode=detail&no=2[/url] что допускать умышленный пересорт нам экономически не выгодно и недопустимо для имиджа. Все реквизиты компании представлены на сайте.
Sheilafer 03 Kasım 2025 23:28
РедМетСплав предлагает обширный выбор отборных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от мелких партий до обширных поставок, мы обеспечиваем оперативное исполнение вашего заказа. Каждая единица продукции подтверждена соответствующими документами, подтверждающими их происхождение. Превосходное обслуживание - наш стандарт – мы на связи, чтобы ответить на ваши вопросы по мере того как адаптировать решения под требования вашего бизнеса. Доверьте вашу потребность в редких металлах профессионалам РедМетСплав и убедитесь в множестве наших преимуществ Наши товары: <a href=https://redmetsplav.ru/store/molibden-i-ego-splavy/molibden-mr-47zvp-1/list-molibdenovyy-mr-47zvp/>Лист молибденовый МР-47ЗВП</a> Лист молибденовый МР-47ЗВП – это высококачественны
HeatherVem 03 Kasım 2025 21:36
[url=https://handstandsam.com/presentations/]https://handstandsam.com/presentations/[/url] Monte Carlo,,,?????????
Lisaannog 03 Kasım 2025 21:25
[url=https://suameta.com/vender-produtos-sem-ter-estoque/]https://suameta.com/vender-produtos-sem-ter-estoque/[/url] в подобных конструкциях когда угодно смогут «у вас дома», а ребенок с раннего детства приучится к порядку. Кресла французской компании renolux рекомендованы для малышей любого возраста.
Carlosdig 03 Kasım 2025 21:15
Тусишки рекомендую дозу от 25 мг. <a href=https://taxi-sedan.ru>купить онлайн мефедрон, экстази, бошки</a> Всем ровным магазинам тройной пролетарский УРА! И чтобы они всегда такими оставались :good:
Sheilafer 03 Kasım 2025 21:13
Если вы работаете в сфере производства и нуждаетесь в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания занимается на рынке поставок тугоплавких металлов уже многих лет, что обеспечивает нам условия поставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Широкий ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Всесторонняя поддержка клиентов. Зачем тратить время на поиски в других местах, если rms-ekb.ru всегда в вашем распоряжении? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Пишите прямо сейчас и убедитесь в достоинствах нашего редкого металла.
MiaGap 03 Kasım 2025 21:01
ха... достаточно весело [url=https://bitbuzz.org/discover-casinos-not-registered-on-gamstop-2/]https://bitbuzz.org/discover-casinos-not-registered-on-gamstop-2/[/url] with excellent games? gamstop is a free website that offers you personally to exclude yourself from diverse gambling virtual games in England.
AshleyAnalf 03 Kasım 2025 20:37
slot machines megaways: usually, they use 6 reels, each of which display various number of symbols per spin, and [url=https://vatsalawellness.com/2025/08/30/discover-thrills-experience-casino-joker-s-ace-uk/]https://vatsalawellness.com/2025/08/30/discover-thrills-experience-casino-joker-s-ace-uk/[/url] provide up to 117,649 ways win.
Monicaacake 03 Kasım 2025 20:36
Ini adalah permainan paling sederhana mudah, di mana setiap karakter diwakili oleh [url=https://impactvideo.parami.edu.mm/agen-judi-online-terbaru-menjajaki-dunia-taruhan/]https://impactvideo.parami.edu.mm/agen-judi-online-terbaru-menjajaki-dunia-taruhan/[/url] mencerminkan situasi dalam kerangka sbobet.
Sheilafer 03 Kasım 2025 20:10
Если вы заняты в области производства и столкнулись с необходимостью в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания специализируется на области поставок тугоплавких металлов уже долгого времени, что обеспечивает нам условия поставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Широкий ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Круглосуточная поддержка. Зачем подбирать в других местах, если rms-ekb.ru всегда готовы помочь? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Пишите прямо сейчас и проверьте в достоинствах нашего спла
Shanedeale 03 Kasım 2025 20:04
Вы не правы. Предлагаю это обсудить. таким подходом могут стать холодильники, стиральные машины, микроволновые печи, телевизоры, [url=http://wir-sabbeln.de/podlove/image/68747470733a2f2f736776617669612e72752f676f3f68747470733a2f2f736164612d2d636f6c6f722d6d616b69332d6e65742e7472616e736c6174652e676f6f672f6262732f6262732e636769253346706167653d30265f785f74725f7363683d68747470265f785f74725f736c3d6175746f265f785f74725f746c3d6672265f785f74725f686c3d6672/60/0/0/website]http://wir-sabbeln.de/podlove/image/68747470733a2f2f736776617669612e72752f676f3f68747470733a2f2f736164612d2d636f6c6f722d6d616b69332d6e65742e7472616e736c6174652e676f6f672f6262732f6262732e636769253346706167653d30265f785f74725f7363683d68747470265f785f74725f736c3d6175746f265f785f74725f746c3d6672265f785f74725f686c3d6672/60/0/0/website[
Kaylaler 03 Kasım 2025 19:30
при заказе можно остановиться на изделиях, [url=http://asiacheat.com/bbs/board.php?bo_table=free&wr_id=5818842]http://asiacheat.com/bbs/board.php?bo_table=free&wr_id=5818842[/url] защищенных от скольжения или имеющих выступающую фактуру. технология производства использует двухразовую закалку, поверхность получается бесшовной, а сам камень приобретает хорошую прочность.
Carlosdig 03 Kasım 2025 19:27
скорость доставки 5+ (во вторник заказали в пятницу получили) <a href=https://spiegelimspiegel.ru>купить кокаин, меф, бошки через телеграмм</a> спасибо вам
Sheilafer 03 Kasım 2025 18:22
РедМетСплав предлагает обширный выбор качественных изделий из редких материалов. Не важно, какие объемы вам необходимы - от мелких партий до обширных поставок, мы обеспечиваем своевременную реализацию вашего заказа. Каждая единица продукции подтверждена всеми необходимыми документами, подтверждающими их качество. Дружелюбная помощь - наша визитная карточка – мы на связи, чтобы улаживать ваши вопросы по мере того как находить ответы под специфику вашего бизнеса. Доверьте вашу потребность в редких металлах специалистам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наша продукция: <a href=https://redmetsplav.ru/store/volfram/splavy-volframa-1/volfram-vnzh-5-3/list-volframovyy-vnzh-5-3/>Лист вольфрамовый ВНЖ 5-3</a> Лист вольфрамовый ВНЖ 5-3 - это высококачественн
BenGew 03 Kasım 2025 18:11
po zakonczeniu rejestracji nastepny krok - Zaloguj sie do osobistego profilu, [url=https://j0f.c5b.myftpupload.com/hotline-casino-twoje-miejsce-na-doskona-zabawk/]https://j0f.c5b.myftpupload.com/hotline-casino-twoje-miejsce-na-doskona-zabawk/[/url] to zapewnia dostep do wszystkich/ dowolnych funkcji i ustawien Twojego konta rejestracji.
MichelleAbarp 03 Kasım 2025 17:53
подобные сервисы пользуются все большей популярностью у россиян благодаря большому ассортименту представленных к продаже товаров, широкой географии реализации и скорым срокам привоза, [url=http://L.Iv.Eli.Ne.S.Swxzu@Hu.Feng.Ku.Angn.I.Ub.I.xn%26mdash;.xn%26mdash;.U.K37@cgi.members.interq.Or.jp/ox/shogo/ONEE/g_book/g_book.cgi]http://L.Iv.Eli.Ne.S.Swxzu@Hu.Feng.Ku.Angn.I.Ub.I.xn%26mdash;.xn%26mdash;.U.K37@cgi.members.interq.Or.jp/ox/shogo/ONEE/g_book/g_book.cgi[/url] поясняют аналитики.
MarvinSpest 03 Kasım 2025 14:55
Un Code promo 1xbet 2026 : obtenez un bonus de bienvenue de 100% sur votre premier depot avec un bonus allant jusqu'a 130 €. Placez vos paris en toute plaisir en utilisant simplement les fonds bonus. Apres l'inscription, il est important de recharger votre compte. Avec un compte verifie, tous les fonds, bonus inclus, peuvent etre retires. Vous pouvez trouver le code promo 1xbet sur ce lien — <a href=https://payhip.com/bonusbet/blog/news/code-promo-1xbet-populaire-bonus-exclusive-jusqu-a-100>https://payhip.com/bonusbet/blog/news/code-promo-1xbet-populaire-bonus-exclusive-jusqu-a-100</a>.
SusanPsymn 03 Kasım 2025 14:54
Es obligatorio tener una oficina o representante en Espana y estar registrado en la agencia Tributaria. hemos recopilado Top 10 de los mejores casas de apuestas legales en Espana en base centrales parametros como la seguridad, la oferta de los mercados, los bonos accesibles, ayuda consumidores y la experiencia movil, [url=https://easydiscountcodes.com/estafas-retiros-apuestas-como-detectarlas-y/]https://easydiscountcodes.com/estafas-retiros-apuestas-como-detectarlas-y/[/url] y otros.
JustinTah 03 Kasım 2025 14:52
Специалист получает образование в соответствии с выбранной теме плюс документ, [url=https://www.india-aware.com/latest/delhi-riots/]https://www.india-aware.com/latest/delhi-riots/[/url] который придется ко двору после аттестации и повышения квалификации.
Sheilafer 03 Kasım 2025 14:42
РедМетСплав предлагает широкий ассортимент качественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от мелких партий до масштабных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица продукции подтверждена соответствующими документами, подтверждающими их происхождение. Опытная поддержка - наш стандарт – мы на связи, чтобы ответить на ваши вопросы по мере того как находить ответы под специфику вашего бизнеса. Доверьте потребности вашего бизнеса специалистам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наши товары: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-m11910---uns/lenta-magnievaya-m11910---uns/>Лента магниевая M11910 - UNS</a> Круг магниевый M11910 - UNS являетс
Debbiebaw 03 Kasım 2025 14:33
ezen felul az udvozlo bonuszhoz, kell megemliti a nagylelku bonuszt is megoldas a [url=https://sterlingcrockett.webversatility.com/2025/10/19/fedezd-fel-a-legjobb-magyar-online-kaszinokat-44/]https://sterlingcrockett.webversatility.com/2025/10/19/fedezd-fel-a-legjobb-magyar-online-kaszinokat-44/[/url] wazamba. a mi oldalunkon magyarkasino oldalak osszegyujtottunk leginkabb megbizhato online kaszinok, korulbelul melyik a felhasznalok szinten jo dontes es gondosan tesztelte oket.
Keshiagof 03 Kasım 2025 14:30
dorel juvenile - чуть ли не самых известных мировых производителей по изготовлению продукции для детей, [url=https://eastmeetswestyog.com/blog/2021/09/23/virtual-paint-night-with-our-esteemed-yogi-artist-mina-daya/]https://eastmeetswestyog.com/blog/2021/09/23/virtual-paint-night-with-our-esteemed-yogi-artist-mina-daya/[/url] формирующих эту быстрорастущую отрасль.
JonAvego 03 Kasım 2025 14:28
Крута тумбочка Электронные аксессуары помогают ориентироваться по дороге, [url=https://www.raumausstattung-schlegel.de/home/]https://www.raumausstattung-schlegel.de/home/[/url] контролировать мебель и оберегаться подобных моментов.
KristyZophy 03 Kasım 2025 14:13
[url=http://feminismo.info/autodefensa/archivos/34]http://feminismo.info/autodefensa/archivos/34[/url] x-ray,edededs????
BryanMycle 03 Kasım 2025 14:10
может я не вполне в теме,и с спрс работаю 2 раз,но ни одна из известных мне почтовых служб не доставляла отправление до адресата за 4000 вёрст за 3-4 дня,как это делает спрс. а насчёт :police: просто смешно - захотят принять - примут по-любому,хоть с почтовым голубем.:) доставка дороговата,но это самое меньшее из возможных зол. https://m5flasher.ru слушай, а тебе продавец обязан объяснять что и ко скольки бодяжить ?
Kimsaw 03 Kasım 2025 12:32
Браво, мне кажется, это великолепная фраза many sites that are not that are entered in gamstop offer simplified registration in the absence of KYC verification, [url=https://new.infovention.com/best-non-gamstop-casinos-in-the-uk-654126360/]https://new.infovention.com/best-non-gamstop-casinos-in-the-uk-654126360/[/url] despite the fact that alternative may always have been and to require proof of identity. Football fans appreciate the inclusion of flash betting and Acca betting.
Sheilafer 03 Kasım 2025 12:29
Если вы занимаетесь производством и нуждаетесь в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания специализируется на сфере поставок тугоплавких металлов уже более 10 лет, что обеспечивает нам условия поставлять только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Большой ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Поддержка 24/7. Зачем подбирать в других местах, если rms-ekb.ru всегда готовы помочь? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Звоните прямо сейчас и убедитесь в достоинствах нашего сплава. Ваш надежный поставщик, <a href=htt
BryanMycle 03 Kasım 2025 12:25
За время работы легалрц сколько магазинов я повидал мама дорогая, столько ушло в топку, кто посливался кто уехал # но chemical-mix поражает своей стойкостью напором и желанием идти в перед "не отступать и не сдаваться":superman: <a href=https://mokvd.ru>купить Мефедрон, Бошки, Марихуану</a> до 08.01 включительно выходные дни
Sheilafer 03 Kasım 2025 10:57
РедМетСплав предлагает обширный выбор высококачественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до обширных поставок, мы обеспечиваем оперативное исполнение вашего заказа. Каждая единица товара подтверждена всеми необходимыми документами, подтверждающими их соответствие стандартам. Дружелюбная помощь - то, чем мы гордимся – мы на связи, чтобы разрешать ваши вопросы по мере того как предоставлять решения под особенности вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/molibden-i-ego-splavy/molibden-mr-47zvp-1/folga-molibdenovaya-mr-47zvp/>Фольга молибденовая МР-47ЗВП</a> Фольга молибденовая МР-47ЗВП - это в
Jerryteshy 03 Kasım 2025 10:32
Use the betwinner promo kodas 2025 during sign-up at https://bet-promo-codes.com/sportsbook-reviews/betwinner-registration/ to activate your welcome bonus instantly.
Sheilafer 03 Kasım 2025 10:21
Если вы работаете в сфере производства и нуждаетесь в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания специализируется на области поставок тугоплавких металлов уже более 10 лет, что дает нам возможность поставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Обширный выбор тугоплавких металлов. 3. Полный комплект документов. 4. Всесторонняя поддержка клиентов. Зачем тратить время на поиски на других сайтах, если rms-ekb.ru всегда готовы помочь? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Обратитесь к нам прямо сейчас и убедитесь в качестве нашего сплава. С уважением, кома
Kellynow 03 Kasım 2025 10:19
если кратко, [url=http://megashipping.ru/user/HoseaFysh2991948/]http://megashipping.ru/user/HoseaFysh2991948/[/url] то такой шаг организация питания на любом празднике. Бухгалтер подает отчетность раз в месяц или квартал, а юрист нужен только при заключении контрактов с изготовителями и аналогичных вопросах с подписанием бумаг.
Candypougs 03 Kasım 2025 10:04
to jest doskonala okazja wyprobuj gre riot i Powieksz Twoje szanse na potencjalna wygrana, [url=https://career-stage.futurebridge.com/hotline-casino-twoje-rodo-zabawy-i-wygranych/]https://career-stage.futurebridge.com/hotline-casino-twoje-rodo-zabawy-i-wygranych/[/url] nie strach wlasne pieniadze.
Kathleenmub 03 Kasım 2025 09:09
Alli destacan, entre otros: Ferocius, maximo Carvajal, UDO Jacobsen( Udoc), Roberto Alfaro, Martin Caceres, Gonzalo Martinez, [url=https://ck85515-wordpress-2.tw1.ru/2025/08/28/riesgos-y-realidades-de-los-casinos-no-regulados/]https://ck85515-wordpress-2.tw1.ru/2025/08/28/riesgos-y-realidades-de-los-casinos-no-regulados/[/url] etc.
Danagat 03 Kasım 2025 09:08
Вы абсолютно правы. В этом что-то есть и я думаю, что это отличная идея. [url=https://betcasinorating.com/]betcasinorating.com[/url] gercek uzun zaman 'da aktif degil. sekerlemecilerimiz oyun mekanlar? yasal siteler diyemeyecegimiz cevrimici portallar? tan?t?yoruz, ancak rol olarak kime uzmanlar?m?z am?'ye cok guveniyoruz.
MadisonFew 03 Kasım 2025 09:08
This emphasis on harmlessness and honesty brings peace of mind to players, and the [url=https://physicsla.org/2025/08/29/ultimate-guide-to-online-uk-jet-casino/]https://physicsla.org/2025/08/29/ultimate-guide-to-online-uk-jet-casino/[/url] allows them fully enjoy gaming entertainment.
Barbaraboump 03 Kasım 2025 08:39
Огромное спасибо Вам за поддержку. Буду должен. прочая аппаратура продается по доступным ценам и поставляется с абсолютной [url=https://vsepodelkin.ru/inzhenernaya-doska/fb-hout/fb-design-parquet-collection/fb-5921-rockingham]https://vsepodelkin.ru/inzhenernaya-doska/fb-hout/fb-design-parquet-collection/fb-5921-rockingham[/url] заводской гарантией. какой будет ваш новый компьютер?
Nicoledox 03 Kasım 2025 07:42
A bonusz ervenyes {csak|csak|csak} {for|For} {egy adott|specifikus} {ev|idoszak|datum} ido, {ezert|tehat|ezert} ez egy #file_links["C:\Users\Admin\Desktop\file\gsa+hu+lomspirogiHU86c5y5c7q13P2URLBB.txt",1,N], {if|in case|in case} On {kepes lesz {eloallitani|teljesiteni} minden {feltetelt|receptet} idoben. ez {lehetove teszi| megadja a lehetoseget|megadja az eselyt|segit|megadja a lehetoseget} az On szamara, hogy megszunteti a bonusz {ajanlat|valasztek} {es| es|abban az esetben,} egy nagy gyozelem es {rendeles|keres} azonnali visszavonasa {alapok|penzugyek}.
SaraOwery 03 Kasım 2025 06:40
[url=https://www.mikeclover.com/blog/2014/03/20/why-are-so-many-people-looking-for-homes-in-texas/]https://www.mikeclover.com/blog/2014/03/20/why-are-so-many-people-looking-for-homes-in-texas/[/url] x-ray,edededs????
AdamOpict 03 Kasım 2025 05:48
небольшие размеры 85x48 мм обеспечивают комфорт установки, [url=https://www.tvbattle.com/index.php?page=user&action=pub_profile&id=238324]https://www.tvbattle.com/index.php?page=user&action=pub_profile&id=238324[/url] а жидкостный чувствительный элемент гарантирует стабильное и быстрое реагирование на изменения температуры.
JuliusMeasy 03 Kasım 2025 03:55
Почему больше не забегаете ? https://crazykid.ru/kungur.html ТС ответь мне на почту или в лс, писал по поводу JV-100 ответил
Kennethkaw 03 Kasım 2025 03:35
Лучшая санобработка предприятий в районе, мастера профи. <a href=https://dezchel.ru>уничтожение клопов</a>
Sheilafer 03 Kasım 2025 03:32
Если вы работаете в сфере производства и нуждаетесь в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания работает на области поставок тугоплавких металлов в течение долгого времени, что обеспечивает нам условия предлагать только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Широкий ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Круглосуточная поддержка. Зачем тратить время на поиски где-то еще, если rms-ekb.ru всегда в вашем распоряжении? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Обратитесь к нам прямо сейчас и проверьте в достоинствах нашего редкого
Miriamtrers 03 Kasım 2025 03:24
La mayoria Internet casino ofrecen multiples versiones de deposito y retiro dinero con [url=https://bietdienhotel.com.vn/vox-casino-kompleksowy-przewodnik-po-grach-2]https://bietdienhotel.com.vn/vox-casino-kompleksowy-przewodnik-po-grach-2[/url].
DannyThoks 03 Kasım 2025 02:57
Конечно. Всё выше сказанное правда. Можем пообщаться на эту тему. journal of the academy of business science. ^ как в России продают алкоголь онлайн с доставкой при [url=https://www.falces.org/reunion-espacios-naturales-y-especies-protegidas/]https://www.falces.org/reunion-espacios-naturales-y-especies-protegidas/[/url] формальном запрете (рус.).
PatrickDuade 03 Kasım 2025 02:11
И всё надо успеть. :crazy: <a href=https://adb-lng.ru/irbit.html>Ирбит купить кокаин, мефедрон, гашиш, бошки, скорость, меф, закладку, заказать онлайн</a> сегодня закажу 1г. MN-011 для пробы)посмотрим на товар)
Kennethkaw 03 Kasım 2025 02:04
Нужна уничтожение муравьев с гарантией, посоветуйте компанию. <a href=https://dezchel.ru>дезинфекция подвалов</a>
TraceyBut 03 Kasım 2025 01:54
Jestesmy obecni na wiodacych portalach przegladowych w Polsce, [url=http://deanchambers.webversatility.com/2025/10/10/hotline-casino-twoj-klucz-do-niezwykych-przygod-w/]http://deanchambers.webversatility.com/2025/10/10/hotline-casino-twoj-klucz-do-niezwykych-przygod-w/[/url] w czym ty aktywnie dziela sie swoimi opiniami i spokojnie oceniaja oferowane tutaj Uslugi.
Richardpek 03 Kasım 2025 01:43
Как получить и использовать бонус до 32 500 ? от букмекерской компании 1xBet? Больше информации об этом > <a href=http://www.dvbp.ru/includes/pages/promokod_1xbet_na_segodnya_besplatno_pri_registracii.html>http://www.dvbp.ru/includes/pages/promokod_1xbet_na_segodnya_besplatno_pri_registracii.html</a>
Sheilafer 03 Kasım 2025 01:29
Если вы заняты в области производства и столкнулись с необходимостью в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания специализируется на рынке поставок тугоплавких металлов на протяжении более 10 лет, что позволяет нам предоставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Широкий ассортимент тугоплавких металлов. 3. Все необходимые документы. 4. Всесторонняя поддержка клиентов. Зачем тратить время на поиски на других сайтах, если rms-ekb.ru всегда готовы помочь? Наши специалисты всегда рады помочь вам с любыми вопросами.. Пишите прямо сейчас и удостоверьтесь в достоинствах
Brandonzok 03 Kasım 2025 01:21
3. жмите на кнопку link a device. В антидетекте не стоит выходить из одной учетки мессенджера, [url=http://konyhabutor.ardoboz.hu/r.php?b=aHR0cHM6Ly9uZXVyb3RlY2hsYWIucnUvbm92b3N0aS9wb2NoZW11LW5lLXByaWhvZGl0LWtvZC1wb2R0dmVyemhkZW5peWEtdi1pbnN0YWdyYW0taS1rYWstZXRvLWlzcHJhdml0Lw]http://konyhabutor.ardoboz.hu/r.php?b=aHR0cHM6Ly9uZXVyb3RlY2hsYWIucnUvbm92b3N0aS9wb2NoZW11LW5lLXByaWhvZGl0LWtvZC1wb2R0dmVyemhkZW5peWEtdi1pbnN0YWdyYW0taS1rYWstZXRvLWlzcHJhdml0Lw[/url] для того, чтобы зайти в другую.
ZackUplib 03 Kasım 2025 01:01
A Elo szerencsejatek letesitmeny kornyezet valodi kaszino legkort teremt Internet idoszamitasunk elott. Elo [url=https://www.beyondwisetech.com/2025/10/18/legalis-online-kaszinok-jatek-es-szorakozas/]https://www.beyondwisetech.com/2025/10/18/legalis-online-kaszinok-jatek-es-szorakozas/[/url] nyelv kaszino a online kaszinok.
PatrickDuade 03 Kasım 2025 00:23
Как и было обещано, адрес оператор прислал где-то в 23. <a href=https://3d-sprinter.ru/noviy-urengoy.html>Новый Уренгой купить кокаин, мефедрон, гашиш, бошки, скорость, меф, закладку, заказать онлайн</a> Тепкрь сам хочу зделать заказ но немогу на сайт попасть ((((
Kennethkaw 02 Kasım 2025 23:25
Ресторан чистый после уничтожение клопов. <a href=https://dezchel.ru>уничтожение постельных клопов</a>
AshleyJeffSoymn 02 Kasım 2025 23:23
[url=http://komex.net.pl/2016/09/17/strona_glowna/]http://komex.net.pl/2016/09/17/strona_glowna/[/url] Monte Carlo,,,?????????
PatrickDuade 02 Kasım 2025 22:36
Чувствую что-то произойдёт , типа заказа:happy: <a href=https://dogs-likely-hart.ru/korkino.html>Коркино купить кокаин, мефедрон, гашиш, бошки, скорость, меф, закладку, заказать онлайн</a> Скрины с радикала не грузятся. Увы сейчас доказать что-либо сложно, видимо магазин не первый раз кидает уже по отточеной цепочке.
Kennethkaw 02 Kasım 2025 22:19
После дезинфекция помещений от вирусов мыши пропали, рад! <a href=https://dezchel.ru>уничтожение тараканов</a>
Julietnox 02 Kasım 2025 21:46
list large , so do not hurry and make a choice yourself . for some of players, the limit ranges from 500 to 5,000 times, at that time as in gates of olympus 1000, it reaches 15,000 times. [url=https://www.annahid.com/discovering-the-exciting-world-of-jackbit/]https://www.annahid.com/discovering-the-exciting-world-of-jackbit/[/url] demonstrate a clear interest for games with it ceilings along with more safe ways.
LaurenElabs 02 Kasım 2025 21:45
No.1 on this list is Gonzo's Quest, a well-known [url=https://s-propertymaroc.com/casino-tips-for-winning-more-4/]https://s-propertymaroc.com/casino-tips-for-winning-more-4/[/url] developed by Netent. what is one-armed bandits for casinos?
Sheilafer 02 Kasım 2025 21:25
РедМетСплав предлагает внушительный каталог высококачественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от мелких партий до масштабных поставок, мы гарантируем своевременную реализацию вашего заказа. Каждая единица товара подтверждена всеми необходимыми документами, подтверждающими их качество. Превосходное обслуживание - то, чем мы гордимся – мы на связи, чтобы ответить на ваши вопросы по мере того как адаптировать решения под требования вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в гибкости нашего предложения Наша продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-hk31a---astm-b403/pokovka-magnievaya-hk31a---astm-b403/>Поковка магниевая HK31A - ASTM B403</
Sallyknoge 02 Kasım 2025 21:18
По моему мнению Вы не правы. Предлагаю это обсудить. Пишите мне в PM, пообщаемся. ^ Постановление правительства российской федерации от 27 сентября 2007 году. n 612 г. Москва «Об утверждении Правил реализации товаров [url=https://get-sms.com/user/BellGunn6422/]https://get-sms.com/user/BellGunn6422/[/url] дистанционным способом» .
Sheilafer 02 Kasım 2025 20:57
РедМетСплав предлагает внушительный каталог отборных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до крупных поставок, мы обеспечиваем своевременную реализацию вашего заказа. Каждая единица продукции подтверждена всеми необходимыми документами, подтверждающими их происхождение. Превосходное обслуживание - наша визитная карточка – мы на связи, чтобы ответить на ваши вопросы а также предоставлять решения под особенности вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/rossiyskie-splavy-1/magniy-ma8ce/list-magnievyy-ma8ce/>Лист магниевый МА8Цэ </a> Лента магниевая МА8Цэ — это высококаче
PatrickDuade 02 Kasım 2025 20:49
Привет бразы,тут ровно таримся не паримся,качества вышка,клад на уровне https://nastavnik124.ru/baltiysk.html хорщий магаз!!!всегда все ровно!!!
Kennethkaw 02 Kasım 2025 20:19
Ресторан чистый после уничтожение тараканов в общежитии. <a href=https://dezchel.ru>уничтожение тараканов</a>
DebbieLix 02 Kasım 2025 19:33
очень интересно. СПАСИБО. For Americans, the word “blackjack” was pronounced very easier, than “wing-et-un”, [url=https://anewbathtub.qlogictechnologies.com/discovering-non-gamstop-casino-sites-your-guide-to-2/]https://anewbathtub.qlogictechnologies.com/discovering-non-gamstop-casino-sites-your-guide-to-2/[/url], from that and the name by which he turned out known!
PatrickDuade 02 Kasım 2025 19:04
Привет всем форумочам! Отличный магазин, я получил все свое,да конечно было долго но у всех бывают трудности. думаю в дольнейшем они их будут устронять! Так что ребята берите не задумаясь, все будет отлично!!!! <a href=https://aquauslugi.ru/ivanovo.html>Иваново купить кокаин, мефедрон, гашиш, бошки, скорость, меф, закладку, заказать онлайн</a> Сделал 4 затяжки с батла, почувствовал секунд через 30 первое прикосновение.))) Затем не много стал теряться в пространстве и во времени, а когда поднялся домой, и открыл дверь (5 мин спустя) меня перекрыло нах, я не мог закрыть дверь и мне всё казалось что кто то держит, у меня начинается паника) я начинаю кричать за дверь: - ты кто такой отпусти, иди отсюда.............. Зову родаков, которых дома нет слава Богу!!!!! вообщем стоял минут 20 у двери)
Gregbot 02 Kasım 2025 18:53
C таким качеством не охота. gerekli belirtmeye [url=https://blackjack-demo.online/]blackjack[/url] benzer/belirtilen tutum/planda hic riskli degil ve henuz/degil cok kafas? kar?sm?s durumda.
Sheilafer 02 Kasım 2025 18:44
Если вы работаете в сфере производства и ваша компания нуждается в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания занимается на рынке поставок тугоплавких металлов на протяжении более 10 лет, что позволяет нам предоставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Большой ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Всесторонняя поддержка клиентов. Зачем подбирать в других местах, если rms-ekb.ru всегда готовы помочь? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Обратитесь к нам прямо сейчас и проверьте в качестве нашего редкого м
ConstanceMaifs 02 Kasım 2025 18:22
csillagkitores. weighty a extremely hires nyerogepek az osszes times es nemzetisegek es a [url=https://gaurav.bluemonkey.site/a-legjobb-magyar-casinok-a-szerencsejatek/]https://gaurav.bluemonkey.site/a-legjobb-magyar-casinok-a-szerencsejatek/[/url]. erre (termeszetesen|termeszetesen|vitathatatlanul) szukseg lesz. Az oldalak online idoszamitasunk elott csak annyi tanult errol.
LoriBag 02 Kasım 2025 17:56
та ну, блин это ж бред Like in gamification, competitions bring a social element to [url=https://web-pocketoption.org/]pocket option login[/url].
BobbyNeato 02 Kasım 2025 17:47
La storia di Inghilterra, Galles, Scozia e Irlanda del nord ha le sue radici nei secoli passati, [url=https://xireaapparel.com/i-migliori-siti-scommesse-inglesi-non-aams-per-il-10/]https://xireaapparel.com/i-migliori-siti-scommesse-inglesi-non-aams-per-il-10/[/url] nastolechko che luicon la stessa forza rimane standard per giocatori e fan in diversi paesi.
PatrickDuade 02 Kasım 2025 17:17
Е.ать ты тиип.иди стукнись об стену..наxрен здесь такие большные люди нужны на форуме!По поводу фразы-настраиваися на спид..На работу таким Xодить надо axaxax https://bccrt.ru/tihvin.html Братва после покупки не забываем писать отзывы.
Sheilafer 02 Kasım 2025 16:47
Если вы работаете в сфере производства и столкнулись с необходимостью в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания специализируется на области поставок тугоплавких металлов на протяжении многих лет, что обеспечивает нам условия предлагать только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Широкий ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Поддержка 24/7. Зачем тратить время на поиски где-то еще, если rms-ekb.ru всегда в вашем распоряжении? Наши специалисты всегда рады помочь вам с любыми вопросами.. Обратитесь к нам прямо сейчас и удостоверьтесь в преимуществах нашего продукта.
GwinnettNak 02 Kasım 2025 16:34
благодарим, что стали частью семьи 1win! С процедурой [url=https://xb133553.xbiz.jp/experience-13/]https://xb133553.xbiz.jp/experience-13/[/url] вы будете пользоваться всеми преимуществами 1win, зная, что ваша аккаунт защищена.
DonaldCorse 02 Kasım 2025 16:32
Подарок для конкурента https://xrumer.xyz/ В работе несколько програм. Есть оптовые тарифы [url=https://xrumer.xyz/]Подарок для конкурента[/url]
Kennethkaw 02 Kasım 2025 16:22
Нужна санэпидемстанция круглосуточно для автомобиля, посоветуйте. <a href=https://dezchel.ru>обработка от тараканов с гарантией</a>
Jessicapralp 02 Kasım 2025 16:10
[url=https://alpenchalet-reiteralm.at/portfolio/zimmer/]https://alpenchalet-reiteralm.at/portfolio/zimmer/[/url] x-ray,edededs????
JulieProop 02 Kasım 2025 16:04
optimal online casinos in the USA offer platforms or applications optimized for computers, mobile or tablets devices. [url=http://texasinternetsales.com/yoga/2025/08/27/experience-the-thrills-of-online-uk-fruity-chance/]http://texasinternetsales.com/yoga/2025/08/27/experience-the-thrills-of-online-uk-fruity-chance/[/url] provide smooth game processes regardless from this, where you inhabit.
Dianatek 02 Kasım 2025 15:43
как оказалось не зря=) [url=http://www.fande.jp/higashiura/bbs2015/bbs18.cgi]http://www.fande.jp/higashiura/bbs2015/bbs18.cgi[/url] с ценами - это поиск проездных документов на самолёты в режиме реального времени.
Kennethkaw 02 Kasım 2025 14:33
Кто знает хорошую уничтожение клопов холодным туманом в Москве? Срочно нужно! <a href=https://dezchel.ru>вывести тараканов</a>
Waynemed 02 Kasım 2025 13:44
Заказываю у магазина 6-й раз уже и все ровно!Берите только тут и вы не ошибетесь.Да и еще странная штука происходит,как-то взял у другого магазина реагент точно такой же курил месяц гдето и чуть не помер да и отходосы всю неделю были ужасные.А из этого магаза брал реагент было все ништяк,отходосы были но я их почти не заметил.Делайте выводы Бразы.Магазин отличный!Мир всем! https://nbflower.ru/timashevsk.html Но в общем и целом доволен очень быстро и качественно! Будем работать и дальше;)
Kennethkaw 02 Kasım 2025 12:46
Отзывы о уничтожение клопов цена положительные, попробуем. <a href=https://dezchel.ru>дезинфекция медицинских учреждений</a>
AliceDueno 02 Kasım 2025 12:09
так вы получите возможность проверить эффективную мощность слота, [url=https://bonjuahotelfazenda.com.br/discover-fresh-faces-on-1v1chat-video-chat-quick-unexpected-video-exchanges/]https://bonjuahotelfazenda.com.br/discover-fresh-faces-on-1v1chat-video-chat-quick-unexpected-video-exchanges/[/url] работу его скидок и в целом получше ознакомиться с условия игры.
Sheilafer 02 Kasım 2025 11:59
РедМетСплав предлагает обширный выбор высококачественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до обширных поставок, мы обеспечиваем оперативное исполнение вашего заказа. Каждая единица изделия подтверждена требуемыми документами, подтверждающими их происхождение. Превосходное обслуживание - то, чем мы гордимся – мы на связи, чтобы разрешать ваши вопросы а также предоставлять решения под особенности вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в гибкости нашего предложения Наша продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-en-mc21220---en-1753/>Магний EN-MC21220 - EN 1753</a> Магний EN-MC21220 - EN 1753 - это идеальный выбор д
ThomasHet 02 Kasım 2025 11:57
привет бро)) чето какой то засланый казачок тут про запр дживы интерес проявляет... https://alekscable.ru/orsk.html Вот так нихуя себе с 2011 года на плаву:strong:, подумаеш какая диковинка :D
Kennethkaw 02 Kasım 2025 11:05
Спасибо за обработка квартиры от клопов! Всё чисто и безопасно. <a href=https://dezchel.ru>уничтожение клопов холодным туманом</a>
AbigayleTug 02 Kasım 2025 11:04
Капец! They cover the race extensively and refund you 10% cashback in the event that you lose money from [url=https://www.watermanindia.in/exploring-casinos-non-on-gamstop-a-comprehensive-17/]https://www.watermanindia.in/exploring-casinos-non-on-gamstop-a-comprehensive-17/[/url], not enabled in gamestop.
Shirleygak 02 Kasım 2025 10:21
at this moment only the Pequot Mashantucket Tribe and the Mohegan Tribe can operate casino sites. during our testing, they stood out for their extensive gaming libraries, user-friendly interfaces as well as on mobile devices, at all on desktop computers, [url=https://quiz.ask.careers/exciting-slots-you-can-try-for-ultimate-fun-0/]https://quiz.ask.careers/exciting-slots-you-can-try-for-ultimate-fun-0/[/url] and honest bonuses.
JudyLax 02 Kasım 2025 10:21
Most [url=https://wordpress.cushwake.com/2025/08/26/top-picks-for-online-casino-in-uk-your-complete/]https://wordpress.cushwake.com/2025/08/26/top-picks-for-online-casino-in-uk-your-complete/[/url] in the USA are fully optimized for mobile gaming, after all helps you to enjoy your favorite games on iPhones and tablets.
MichaelDem 02 Kasım 2025 10:14
In it something is. I thank for the help in this question, now I will not commit such error. ------ <a href=https://drivelity.com/car-rental-qatar>car rental doha</a>
ThomasHet 02 Kasım 2025 10:10
кто последний раз когда брал? регу или соль https://hozkaopt.ru/belogorsk.html Итак всем ПРИВЕТ !
Tonyfet 02 Kasım 2025 10:04
В этом что-то есть. Понятно, спасибо за помощь в этом вопросе. Некоторые тоники включают в себя активные соединения и ориентированы на определённых типов кожи, вроде: масло чайного дерева, [url=http://lefemineforlife.net/?p=144]http://lefemineforlife.net/?p=144[/url] салициловая кислота или гликолевая кислота.
TrapAbese 02 Kasım 2025 09:43
eccellente adatto per tutti che vuole scommetti su grande partita con [url=https://akquirio.ch/i-casino-non-aams-che-pagano-la-guida-completa/]https://akquirio.ch/i-casino-non-aams-che-pagano-la-guida-completa/[/url] pagamenti piu elevati.
stydiups 02 Kasım 2025 09:09
Хотите провести вечер в атмосфере страсти, роскоши и ярких впечатлений? Посетите [url=https://chicago-x.ru]стриптиз питер[/url] в Санкт-Петербурге — место, где изысканная обстановка сочетается с профессиональным шоу и высоким уровнем сервиса. Приватные залы, завораживающие танцы и особая энергетика ждут вас! Может быть полезным: [url=https://chicago-x.ru]стрип бар[/url] Хороший вариант: [url=https://chicago-x.ru]заказать стриптиз в спб[/url]
Sheilafer 02 Kasım 2025 09:09
Если вы занимаетесь производством и столкнулись с необходимостью в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания специализируется на рынке поставок тугоплавких металлов уже многих лет, что позволяет нам предлагать только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Обширный выбор тугоплавких металлов. 3. Все необходимые документы. 4. Поддержка 24/7. Зачем искать где-то еще, если rms-ekb.ru всегда готовы помочь? Наши специалисты всегда рады помочь вам с любыми вопросами.. Обратитесь к нам прямо сейчас и проверьте в преимуществах нашего редкого металла. Ваш надежный поставщик, <a href=https://rms-ekb.
RobertDup 02 Kasım 2025 08:43
Применение функциональных [url=https://www.trattorialangolino.it/stomatologija-maj-smajl-vash-nadezhnyj-partner-v/]https://www.trattorialangolino.it/stomatologija-maj-smajl-vash-nadezhnyj-partner-v/[/url] аппаратов для коррекции. 1. Навык визуального контакта с пациентами. 6. Имплантология. Замена утраченного ряда на новый при помощи имплантирования.
ThomasHet 02 Kasım 2025 08:26
У нас интернет-магазин, а не "шаурма у метро". Личные встречи не возможны,"ибо по долгу службы тесно связан"(вот как раз наверное из-за этого)... Про кидал необоснованное заявление, такие речи лучше оставить при себе... В грубой форме вам никто не отвечал, вам вполне доходчиво сказали как и что.... <a href=https://crazykid.ru/vyazma.html>Вязьма купить кокаин, мефедрон, гашиш, бошки, скорость, меф, закладку, заказать онлайн</a> Отличный магаз, качество на ура. даже если сам реагент не сильный.
Sheilafer 02 Kasım 2025 07:52
РедМетСплав предлагает широкий ассортимент качественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от мелких партий до крупных поставок, мы обеспечиваем своевременную реализацию вашего заказа. Каждая единица продукции подтверждена соответствующими документами, подтверждающими их качество. Опытная поддержка - наш стандарт – мы на связи, чтобы улаживать ваши вопросы а также находить ответы под особенности вашего бизнеса. Доверьте вашу потребность в редких металлах специалистам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наши товары: <a href=https://redmetsplav.ru/store/vismut/zarubezhnye-splavy-3/vismut-c-6804---jis-h-3250-2015/prutok-vismutovyy-c-6804---jis-h-3250-2015/>Пруток висмутовый C 6804 - JIS H 3250:2015</a> Пруток висм
Sheilafer 02 Kasım 2025 07:31
Если вы работаете в сфере производства и ваша компания нуждается в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания занимается на рынке поставок тугоплавких металлов на протяжении десятилетий, что обеспечивает нам условия предлагать только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Большой ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Круглосуточная поддержка. Зачем искать в других местах, если rms-ekb.ru всегда готовы помочь? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Пишите прямо сейчас и проверьте в достоинствах нашего продукта
ThomasHet 02 Kasım 2025 06:39
Повторюсь размер компенсаций зависел от веса, длительности, индивидуальных переплат на счета и прочих обстоятельств. Данные по общ весу пришли вместе с треком. <a href=https://jk-sibirskiy.ru/mozhga.html>Можга купить кокаин, мефедрон, гашиш, бошки, скорость, меф, закладку, заказать онлайн</a> 4-FA -все кто гнал, обломитесь, вы просто его не понял. Он не будет переть как старый добрый md - но эффект отличный. 1 колпак на лицо - и часа 2 состояние абсолютной гормонии с окружающим миром. Мозг работает как от любого другого качественного стимулятора на 5+.
ThomasHet 02 Kasım 2025 04:54
через три дня после заказа была уже у меня <a href=https://priv-church.ru/kamensk-uralskiy.html>Каменск-Уральский купить кокаин, мефедрон, гашиш, бошки, скорость, меф, закладку, заказать онлайн</a> Да работает в асю обращайся если чё надо только товара мало там мхе да дмт
Elizabethses 02 Kasım 2025 04:50
Говорите прямо. Confirm account: Provide proof of identity/address (one-time). Real-world application: On the EUR/USD m5 charts, [url=https://web-pocketoption.com/]pocket option trading[/url] trading occurs at the intersection of the 200th ema with a reversal of the macd sideways advance, and the divergence of the rsi signals a high probability of opening long positions.
AliceBit 02 Kasım 2025 04:47
урааааааа дождался пасиба хоть за такое качество вам треба тільки зварити або розігріти блюдо в будь - який [url=http://www.zmiiv-service.com.ua/index.php/forum/dobro-pozhalovat/5694324-kupyty-produkty-z-dostavkoiu]http://www.zmiiv-service.com.ua/index.php/forum/dobro-pozhalovat/5694324-kupyty-produkty-z-dostavkoiu[/url] час. доставка реалізовується в початку тижня, середу і п'ятницю.
Elizabethlat 02 Kasım 2025 04:39
note that in order to receive best result the [url=https://www.koreagiftbox.com/2025/09/22/understanding-casino-loyalty-points-systems-2/]https://www.koreagiftbox.com/2025/09/22/understanding-casino-loyalty-points-systems-2/[/url] uses the strategies described above and does not think that the slot will make a profit if You will scroll the reels row more times.
Kerrystifs 02 Kasım 2025 04:29
Абсолютно с Вами согласен. В этом что-то есть и это отличная идея. Готов Вас поддержать. в ассортименте присутствую такие бренды, как samsung, lg, xiaomi, sony и apple. России курьером, почтой, СДЭК, [url=https://piwwabrzezno.pl/ogloszenia/szkolenia-kpodr/]https://piwwabrzezno.pl/ogloszenia/szkolenia-kpodr/[/url] в свыше 10 тысяч.
ThomasHet 02 Kasım 2025 03:08
Для совсем новичков 1 к 15 будет даже много. https://puzzlepedia.ru/zhukovskiy.html да магаз отличный.оперативно работают.и качество товара отличное.вобщем всё хорошо.
Sheilafer 02 Kasım 2025 03:04
РедМетСплав предлагает широкий ассортимент качественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до обширных поставок, мы гарантируем своевременную реализацию вашего заказа. Каждая единица товара подтверждена всеми необходимыми документами, подтверждающими их происхождение. Дружелюбная помощь - то, чем мы гордимся – мы на связи, чтобы улаживать ваши вопросы и адаптировать решения под специфику вашего бизнеса. Доверьте вашу потребность в редких металлах профессионалам РедМетСплав и убедитесь в множестве наших преимуществ Наши товары: <a href=https://redmetsplav.ru/store/vismut/zarubezhnye-splavy-3/vismut-cacin221---jis-h-2202-2016/poroshok-vismutovyy-cacin221---jis-h-2202-2016/>Порошок висмутовый CACIn221 - JIS H 2202-2016</a> П
ValerieBum 02 Kasım 2025 01:32
i metodi pagamento dei bookmaker Inglesi differiscono nella velocita, [url=https://ravanmodir.com/1404/07/19/tutto-quello-che-devi-sapere-sul-bingo-non-aams/]https://ravanmodir.com/1404/07/19/tutto-quello-che-devi-sapere-sul-bingo-non-aams/[/url] sicurezza e ampio Selezione. I migliori bookmaker del Regno Unito concedere/ offrire bonus disponibili in uno dei operatori di gioco leader, spesso piu ricchi che che in alternativi mercati.
ThomasHet 02 Kasım 2025 01:23
И духовной отсутствие пищи <a href=https://aquauslugi.ru/blagoveshensk.html>Благовещенск купить кокаин, мефедрон, гашиш, бошки, скорость, меф, закладку, заказать онлайн</a> Спасибо. Похож на ам2**3
NadineFeatt 02 Kasım 2025 01:12
[url=https://medistorehub.com/shop/lipitor.html]cheap atorvastatin[/url] <a href="https://medistorehub.com/shop/triamterene.html">buy triamterene</a>
Sheilafer 02 Kasım 2025 01:07
Если вы заняты в области производства и ваша компания нуждается в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания работает на сфере поставок тугоплавких металлов на протяжении многих лет, что обеспечивает нам условия предоставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Большой ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Круглосуточная поддержка. Зачем подбирать в других местах, если rms-ekb.ru всегда готовы помочь? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Пишите прямо сейчас и удостоверьтесь в качестве нашего редкого металла. Команда <a
ThomasHet 02 Kasım 2025 00:37
Менеджер на связи с 10-11 утра по МСК (не с 8-ми, как Вы ломитесь) ежедневно, кроме праздников и выходных. На сайте Вашего заказа нет. Можете назвать его номер? <a href=https://bkalfin16.ru/furmanov.html>Фурманов купить кокаин, мефедрон, гашиш, бошки, скорость, меф, закладку, заказать онлайн</a> Всем удачи!
NickOraks 01 Kasım 2025 23:55
Expect clear operation of mobile gadgets, clear mathematics, [url=https://tradeinafrika.com/discover-the-exciting-world-of-dealbet-casino-29/]https://tradeinafrika.com/discover-the-exciting-world-of-dealbet-casino-29/[/url] and wide range of services to change the ante bets either buy bonuses, in case this is allowed.
Louisedweve 01 Kasım 2025 23:53
Excellent support users - High-quality support customers of the [url=https://nimblespiders.stellarwp.site/the-martingale-system-in-online/]https://nimblespiders.stellarwp.site/the-martingale-system-in-online/[/url] very necessary. Some operators also award a no deposit bonus upon registration.
Robertwaddy 01 Kasım 2025 23:42
te kryteria - to przede wszystkim oferta gier, atrakcyjnosc oferowanych online Dom hazardowy Polska, [url=http://eba.853.myftpupload.com/najlepsze-sloty-online-gdzie-znale-emocjonujce-gry/]http://eba.853.myftpupload.com/najlepsze-sloty-online-gdzie-znale-emocjonujce-gry/[/url] dostepnosc opcje dla uzytkownikow/ gamblerow z Polski oraz ilosc demokratyczne metody platnosci.
JoshuaAsymn 01 Kasım 2025 23:40
Качает! Качество конструкций, произведённых на заводе, [url=https://tennisprogram.com/north-central-wins-state-championship/]https://tennisprogram.com/north-central-wins-state-championship/[/url] значительно выше качества на стройке (из-за возможности систематически контролировать процесс и снабдить удобные условия труда).
Devinelica 01 Kasım 2025 23:29
Az online verziok [url=https://domicamkids.com/kaszino-magyar-elmeny-es-szorakozas-a-jatekok/]https://domicamkids.com/kaszino-magyar-elmeny-es-szorakozas-a-jatekok/[/url] kaparos sorsjegyek egyre novekvo Nepszeruseg. reklam kampanyok kaszino magyarul celzott a helyi jatekosok szamara.
ThomasHet 01 Kasım 2025 21:03
Длительность не меньше, чем у CHM-400F (AKB48F), эффект – задумчивее ) https://argungb.ru/partizansk.html У меня была, проси того кто продал все перепроверять- люди могут ошибаться !
CasinokeThync 01 Kasım 2025 19:40
Если азарт зовёт, самое время чекнуть ТОП-10 казино. Тут бонусы выдают сразу, а слоты радуют графикой, как в игровых фильмах. Чтобы игра шла гладко, выбирайте лицензированные сервисы и не забывайте про лимиты. Удобный список доступен в [url=https://t.me/s/casino_rigas/]официальный рейтинг казино[/url]. Это отличный шанс стартовать с дополнительной поддержкой на балансе.
Sheilafer 01 Kasım 2025 19:28
РедМетСплав предлагает внушительный каталог качественных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до крупных поставок, мы гарантируем оперативное исполнение вашего заказа. Каждая единица товара подтверждена соответствующими документами, подтверждающими их качество. Превосходное обслуживание - наша визитная карточка – мы на связи, чтобы улаживать ваши вопросы и адаптировать решения под требования вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в множестве наших преимуществ поставляемая продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-am-50/polosa-magnievaya-am-50/>Полоса магниевая AM 50</a> Порошок магниевый AM 20 - высококачественный продукт
ThomasHet 01 Kasım 2025 19:17
отличный магаз,пришло всё быстро и в лучшем виде:dansing:спасибо,удачи и процветания <a href=https://si-vif.ru/satka.html>Сатка купить кокаин, мефедрон, гашиш, бошки, скорость, меф, закладку, заказать онлайн</a> Заказали, придет посмотрим
SamLor 01 Kasım 2025 19:13
??/?????? ??? ?????/??????/????? ??/?? ?? ??? ??,???/??/????/??/????????/????/??? [url=http://sencora.com/?p=415240]http://sencora.com/?p=415240[/url].
Sheilafer 01 Kasım 2025 19:07
РедМетСплав предлагает широкий ассортимент качественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от мелких партий до масштабных поставок, мы гарантируем своевременную реализацию вашего заказа. Каждая единица товара подтверждена соответствующими документами, подтверждающими их происхождение. Превосходное обслуживание - то, чем мы гордимся – мы на связи, чтобы улаживать ваши вопросы а также адаптировать решения под требования вашего бизнеса. Доверьте вашу потребность в редких металлах специалистам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей поставляемая продукция: <a href=https://redmetsplav.ru/store/volfram/splavy-volframa-1/volfram-vch-s-1/folga-volframovaya-vch-s/>Фольга вольфрамовая ВЧ-С</a> Фольга вольфрамовая ВЧ-С - вы
Jenniferclome 01 Kasım 2025 18:57
Я конечно, прошу прощения, но это мне совсем не подходит. Кто еще, может помочь? {many|very many|almost all} UK casinos that are not {included|which are included|which are included/which are included} in gamstop {offer|provide} {to their|own|potential} players {no deposit|no deposit} {bonuses|buns|offers} on #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c5x6y598P2URLBB.txt",1,N] gamstop. {examples include microsoft, evolution, and netent.
Treytwima 01 Kasım 2025 18:55
Установка производится через технологические колодцы/окна, [url=https://usof.gov.mn/?p=102396]https://usof.gov.mn/?p=102396[/url] отключают жестко обозначенные участки от сети транспортировки жидкости. Гидрозатвор для канализации выполнен из резины особого высокого качества, что обеспечивает доступность многократное использование такой трубной заглушки без ущерба функциональных свойств.
Altonbow 01 Kasım 2025 18:27
Berkat profesional layanan film dan sistem keamanan bijaksana, sarangsbet [url=http://www.mistergone.com/blog/2025/agen-betting-sbobet-online-panduan-lengkap-dan-20/]http://www.mistergone.com/blog/2025/agen-betting-sbobet-online-panduan-lengkap-dan-20/[/url] jaminan bahwa siapa saja pengguna dapat merasa nyaman di komisi transaksi dan tidak memihak permainan.
ValerieKex 01 Kasım 2025 18:15
Reliable reputation and clear policy on issues truthfulness and disbursements are the hallmarks of a reliable [url=https://www.unitamediterranea.it/2025/09/01/discover-the-10bet-uk-best-casino-online-for-3/]https://www.unitamediterranea.it/2025/09/01/discover-the-10bet-uk-best-casino-online-for-3/[/url] platform.
MichelleBlish 01 Kasım 2025 18:14
comprehensive view on gambling was and remains the most important aspect of the [url=http://xireaapparel.com/slots-with-expanding-wild-features/]http://xireaapparel.com/slots-with-expanding-wild-features/[/url] industry, and most states require that internet gambling houses posted on their websites links to support organizations, such as "Anonymous Gamblers" and the National Council on specific tasks of gambling entertainment.
ThomasHet 01 Kasım 2025 17:33
Написал о заказе в аське в ПТ,мне сказали цену и реквизиты. В СБ оплатил,кинул в аське свои реквизиты.В ПН связался-Сказали,что все отправили,ок. <a href=https://jain-nails.ru/tyumen.html>Тюмень купить кокаин, мефедрон, гашиш, бошки, скорость, меф, закладку, заказать онлайн</a> Магазин не чистый на руку. Уже пишет с другого жабера. Народ у кого осталось переписка состарого жабера сверьте ник. И прошу сделать посты что таковое не придуманная мною сказка.
OscarKed 01 Kasım 2025 16:42
What necessary phrase... super, magnificent idea ------ аренда яхт тайланд <a href=https://european-yachts.com/rent-yacht-thailand>https://european-yachts.com/rent-yacht-thailand</a>
Peterbot 01 Kasım 2025 16:17
Да,мне тоже первый класс как то ближе и недорого... https://arleasing.ru кто сказал что он закрылся? где это написано?
servisnyy_gfSl 01 Kasım 2025 16:04
ремонт bosch [url=https://servisnyj-bosch-moskva.ru/]ремонт bosch[/url].
Sheilafer 01 Kasım 2025 15:07
Если вы работаете в сфере производства и ваша компания нуждается в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания работает на рынке поставок тугоплавких металлов на протяжении многих лет, что позволяет нам поставлять только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Широкий ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Поддержка 24/7. Зачем тратить время на поиски в других местах, если rms-ekb.ru всегда здесь для вас? Наши специалисты всегда рады помочь вам с любыми вопросами.. Пишите прямо сейчас и убедитесь в качестве нашего продукта. Команда <a href=https://rms-ekb.ru/>ООО
LawrenceSit 01 Kasım 2025 14:40
? ?? [url=https://www.confesercentiviterbo.it/2025/10/27/page-839/]https://www.confesercentiviterbo.it/2025/10/27/page-839/[/url] ??????????? ?????????. ?? ????? ??????????? ? ?????-?????/???????.:
CharlesKer 01 Kasım 2025 14:31
добрый день как связаться с продавцом и не попасть на фейка? https://saraev-podbor.ru Однако, селлеру в его интересах было бы полезно появиться и разъяснить ситтуацию дабы избежать гневных сообщений. Обещание что отправка будет пт-сб не было выполнено. Треков нет.
CharlesKer 01 Kasım 2025 12:43
Работал с магазином спасибо всё красиво! https://jain-nails.ru брал в данном магазине все супер.
Justinbut 01 Kasım 2025 12:42
<a href=https://logo66.net/promokod-melbet-besplatnaya-stavka-2025/>https://logo66.net/promokod-melbet-besplatnaya-stavka-2025/</a>
TamaraTor 01 Kasım 2025 12:22
Transparent and {effective|prompt|efficient} {payment|settlement} {systems|schemes} are the {distinguishing feature|bonus|additional advantage|enticing characteristic|attractive advantage} of reputable {online|#file_links["C:\Users\Admin\Desktop\file\gsa+en+86c51bxq918P2URLBB.txt",1,N].
BruceThise 01 Kasım 2025 12:22
for this reason important that slot machines [url=https://www.xpressdecor.com/best-online-casino-apps-for-enthusiasts-in-2023/]https://www.xpressdecor.com/best-online-casino-apps-for-enthusiasts-in-2023/[/url] remained responsible for spinning the reels. They replace all ordinary one-armed bandits for forming victorious combinations.
Sheilafer 01 Kasım 2025 12:21
РедМетСплав предлагает широкий ассортимент качественных изделий из редких материалов. Не важно, какие объемы вам необходимы - от мелких партий до масштабных поставок, мы обеспечиваем оперативное исполнение вашего заказа. Каждая единица изделия подтверждена соответствующими документами, подтверждающими их соответствие стандартам. Дружелюбная помощь - наша визитная карточка – мы на связи, чтобы ответить на ваши вопросы по мере того как адаптировать решения под требования вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в множестве наших преимуществ поставляемая продукция: <a href=https://redmetsplav.ru/store/kobalt/rossiyskie-splavy-3/kobalt-ei101/list-kobaltovyy-ei101/>Лист кобальтовый ЭИ101</a> Лист кобальтовый ЭИ101 – это высококачественный материал, о
KellyMic 01 Kasım 2025 11:31
https://orb11ta.help/ now go on!!! orb11ta.help orb11ta
CharlesKer 01 Kasım 2025 10:57
Дай думаю зайду поздороваюсь с мамонтами опасного бизнеса.:hello: https://aquauslugi.ru Ответил) просто не сразу увидел в вашем сообщении дополнительный вопрос )
Sheilafer 01 Kasım 2025 10:53
РедМетСплав предлагает обширный выбор качественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от мелких партий до крупных поставок, мы обеспечиваем своевременную реализацию вашего заказа. Каждая единица продукции подтверждена всеми необходимыми документами, подтверждающими их соответствие стандартам. Превосходное обслуживание - то, чем мы гордимся – мы на связи, чтобы разрешать ваши вопросы а также адаптировать решения под специфику вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в множестве наших преимуществ Наши товары: <a href=https://redmetsplav.ru/store/vanadiy-i-ego-splavy/vanadiy-regular---stratcor-1/prutok-vanadievyy-regular---stratcor-1/>Пруток ванадиевый Regular - Stratcor</a> Проволока ванадиевая
Kevinvep 01 Kasım 2025 10:19
это прямо хаб будущего although you can make deposits with similar methods, in [url=https://shikakutoyokablog.o/2025/10/13/discovering-non-gamstop-casinos-a-comprehensive-11/]https://shikakutoyokablog.o/2025/10/13/discovering-non-gamstop-casinos-a-comprehensive-11/[/url], transfers funds passes only with Bitcoins.
KiaGroni 01 Kasım 2025 09:54
{tentu saja|tentu saja|ya}, dengan {berbeda|berbeda} jenis {taruhan|taruhan} - pada sepak bola {Anda dapat |Anda dapat|semua orang dapat |pemain dapat|pengguna memiliki kesempatan} untuk memilih {berbeda|sangat berbeda|beragam} {jenis|opsi|jenis| varietas} kemenangan dengan {jumlah hadiah uang yang berbeda dalam {benar-benar ada|berbeda} #file_links["C:\Users\Admin\Desktop\file\gsa+id+J42-R52-X4282P2URLBB.txt",1,N].
DinkeyReibe 01 Kasım 2025 09:32
{Opciok|ajanlatok} nagylelkusege, nem {fontos|fo|jelentos} {kriterium|jellemzo}, #file_links["C:\Users\Admin\Desktop\file\gsa+hu+lomspirogiHU86c5y5c7q6P2URLBB.txt",1,N], de {egy klub|kaszino|intezmeny} {egy adott|ilyen} {vilag|ismeros|hires|magas rangu} neve {a jelenlegi|ez} es {meg nem|nem szamitasz ra.
CharlesKer 01 Kasım 2025 09:10
Ха ха ребята смотрите беспредел! попробуйте написать правильно жабу ТСа и получится то что у меня, как бы с ошибкой! СКРИПТ! https://absolvitur.ru Описаниние 3( не было конкретного уточнения)
Kennethrox 01 Kasım 2025 08:32
<a href=https://kraken49.xyz/>kraken market</a>
Davidtip 01 Kasım 2025 07:26
Уважаемые наши клиенты, приносим свои извинения за задержку с отправкой. https://goldrub.ru Они хоть кому нибудь отвечают?
Sheilafer 01 Kasım 2025 06:58
Если вы работаете в сфере производства и нуждаетесь в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания специализируется на сфере поставок тугоплавких металлов на протяжении долгого времени, что дает нам возможность предлагать только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Широкий ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Круглосуточная поддержка. Зачем подбирать в других местах, если rms-ekb.ru всегда в вашем распоряжении? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Обратитесь к нам прямо сейчас и проверьте в достоинствах нашего р
CurtisHof 01 Kasım 2025 06:14
Я думаю, что это хорошая идея. банковская информационная система запрашивает фото удостоверения личности и [url=https://azure-directory.alive2directory.com/index.php?p=d]https://azure-directory.alive2directory.com/index.php?p=d[/url] платежного средства. раньше для лидерства в слотах нужно было собрать 3 одинаковых символа в один ряд.
ShaneOdofe 01 Kasım 2025 06:08
when playing at an [url=https://cryptointerested.com/understanding-online-casino-responsible-gambling-12/]https://cryptointerested.com/understanding-online-casino-responsible-gambling-12/[/url] USA for real funds important trust and speed of payments. absolutely, row web resources offer demo modes or no deposit offers.
Stephenneeva 01 Kasım 2025 05:40
250 дживик заказал? <a href=https://halaldevelopment-partners.ru>купить онлайн мефедрон, экстази, бошки</a> у меня вообще когда порошок кидаешь и ациком заливаешь, раствор абсолютно прозрачный-.- и не прет вообще тупо куришь траву..... а вот кристалы не расворимые тоже имеются, я уже и толочь пытался седня и нагревом все бестолку...
Sheilafer 01 Kasım 2025 05:29
РедМетСплав предлагает внушительный каталог отборных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до крупных поставок, мы обеспечиваем оперативное исполнение вашего заказа. Каждая единица продукции подтверждена требуемыми документами, подтверждающими их качество. Дружелюбная помощь - наша визитная карточка – мы на связи, чтобы ответить на ваши вопросы а также находить ответы под требования вашего бизнеса. Доверьте потребности вашего бизнеса профессионалам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-am90---csa-hg-10/prutok-magnievyy-am90---csa-hg-10/>Пруток магниевый AM90 - CSA HG.10</a> Проволока магниевая AM90 - C
Sheilafer 01 Kasım 2025 05:26
Если вы заняты в области производства и нуждаетесь в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания специализируется на сфере поставок тугоплавких металлов уже десятилетий, что дает нам возможность предлагать только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Обширный выбор тугоплавких металлов. 3. Полный комплект документов. 4. Круглосуточная поддержка. Зачем подбирать где-то еще, если rms-ekb.ru всегда здесь для вас? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Обратитесь к нам прямо сейчас и убедитесь в качестве нашего продукта. С уважением, команда
Sheilafer 01 Kasım 2025 04:06
РедМетСплав предлагает широкий ассортимент качественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до масштабных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица продукции подтверждена всеми необходимыми документами, подтверждающими их соответствие стандартам. Опытная поддержка - наша визитная карточка – мы на связи, чтобы ответить на ваши вопросы и предоставлять решения под специфику вашего бизнеса. Доверьте вашу потребность в редких металлах профессионалам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наша продукция: <a href=https://redmetsplav.ru/store/molibden-i-ego-splavy/molibden-md50n2k-2/polosa-molibdenovaya-md50n2k/>Полоса молибденовая МД50Н2К</a> Полоса молибденовая МД50Н
Philipbrats 01 Kasım 2025 03:28
w tym wariancie stawka minimalna musi byc jak najszybciej jest nizsza, [url=https://demoshop.quanqiusou.cn/beep-beep-casino-nowoczesna-platforma-do-gier/]https://demoshop.quanqiusou.cn/beep-beep-casino-nowoczesna-platforma-do-gier/[/url] w drugim - mozliwe wygrane powinny byc maksymalne mozliwe.
mizdiups 01 Kasım 2025 02:23
[url=https://samoylovaoxana.ru/bilety-na-poezd-podariat-nasyshennyi-letnii-otdyh-pyteshestvie/]Билеты на поезд подарят насыщенный летний отдых – Путешествие[/url] или [url=https://samoylovaoxana.ru/tag/pustynya/]пустыня[/url] [url=https://samoylovaoxana.ru/tag/zdravniczy/]здравницы[/url] https://samoylovaoxana.ru/tag/tury-na-phuket/ Ещё можно узнать: [url=http://yourdesires.ru/it/windows/940-kak-uznat-seriynyy-nomer-noutbuka.html]где посмотреть серийный номер ноутбука acer[/url]
Kiainsob 01 Kasım 2025 02:16
incentive bonusz tortenik csak a new latogatok, a az elso a [url=https://brilliantreddev.co.uk/ecopipo/2025/10/17/revolut-online-kaszinok-magyarorszagon-a-digitalis/]https://brilliantreddev.co.uk/ecopipo/2025/10/17/revolut-online-kaszinok-magyarorszagon-a-digitalis/[/url] vagy kezdeti ket kifizetessel.
Stephenneeva 01 Kasım 2025 02:07
MXE точно не бодяженный , со 100мг вышел нереально жуткий трип, раз 15 умирал... через сутки отпустило. <a href=https://alexmen.ru>купить кокаин, меф, бошки через телеграмм</a> Плохого и не слышал! Ребятке во всех дела достойно поступают!
Bradclank 01 Kasım 2025 01:39
lisaksi EU-lainsaadannon vuoksi ETA-maiden lisensoimien kasinoiden voittoja ei veroteta. however in this situation on valttamatonta varmistaa , etta yleiset toimintapaikka [url=https://www.instruktorssi.pl/kasinot-ilman-lisenssia-kaikki-mita-sinun-tulee-5/]https://www.instruktorssi.pl/kasinot-ilman-lisenssia-kaikki-mita-sinun-tulee-5/[/url] tai tekninen tuki asiakkaat, esimerkiksi , prospekteissa.
Margaretsox 01 Kasım 2025 01:35
да! настроение подня But the chances of finding online-clubs that are not part of gamstop and accept pounds sterling are the same as [url=https://millymontserrat.com/exploring-non-gamstop-casino-sites-what-you-need-4/]https://millymontserrat.com/exploring-non-gamstop-casino-sites-what-you-need-4/[/url].
DanielBut 01 Kasım 2025 00:57
[url=https://www.tripacostarica.com/hiking-trails-near-me/][img]https://tripacostarica.com/1/Hiking-trails-near-me.png[/img][/url] [b]Discover[/b] the hidden magic lying only around the steps. Nature ways near your town deliver a lot more compared to sport—they serve as a retreat within nature’s silence. [b]Take in[/b] in cool breeze, stroll curving paths within woods together with slopes, and reveal hidden sights set to render each step memorable. [b]No matter if[/b] you are looking for excitement, quiet in life, or a beautiful view place, local trails create your trip to you. [b]Pull on[/b] those sneakers—another escape is just closer than you expect. [b][url=https://www.tripacostarica.com/hiking-trails-near-me/]Hiking trails near you[/url][/b]
Andreasef 01 Kasım 2025 00:36
Ничего! 4. Укажите сумму [url=https://cm3comunicacao.com.br/2023/01/05/why-diy-tools-were-rejected-by-the-market/]https://cm3comunicacao.com.br/2023/01/05/why-diy-tools-were-rejected-by-the-market/[/url] для избавления от. помимо этого – при выводе крупных сумм рекомендуется связаться со службой техподдержки для более сильной и скорой обработки запроса.
AngielinaJoica 01 Kasım 2025 00:26
Tenerife {offers|provides} {lots and lots of exciting cruises, #file_links["C:\Users\Admin\Desktop\file\gsa+en+SP100T2kPaulinho56476810P2URLBB.txt",1,N], and boat tours. Many cruise operators offer affordable {tours|travel company offers|packages from travel agencies|tour operator packages}, and {accommodation|accommodation|place of residence} for {tourists|foreigners|travelers} with disabilities.
KathleenNum 01 Kasım 2025 00:25
usually, games with low volatility sometimes are reaching a maximum of thousand bucks times, with an average of 3,000 times , and with high - 5,000 times, and more, and a number indicators exceed one hundred thousand times. slot machines with innovative jackpot are different from each other by that winnings increase throughout your internet connection and are limited to a simple x-bet amount, and [url=https://friendscables.com.pk/index.php/2025/08/31/explore-the-thrills-of-yeti-win-casino-uk-37/]https://friendscables.com.pk/index.php/2025/08/31/explore-the-thrills-of-yeti-win-casino-uk-37/[/url] with advanced jackpots more often total are not active in ds.
Stephenneeva 01 Kasım 2025 00:21
бешельме мешельме атакает <a href=https://crazykid.ru>купить скорость, кокаин, мефедрон, гашиш</a> Самое главное что на свободе фиг сним с грузом! Задумайтесь ребят может пора сесть на дно, чтоб палево отвести!
Sheilafer 31 Ekim 2025 22:29
РедМетСплав предлагает обширный выбор отборных изделий из редких материалов. Не важно, какие объемы вам необходимы - от мелких партий до крупных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица продукции подтверждена всеми необходимыми документами, подтверждающими их качество. Опытная поддержка - наша визитная карточка – мы на связи, чтобы разрешать ваши вопросы по мере того как предоставлять решения под специфику вашего бизнеса. Доверьте ваш запрос специалистам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-m11916---uns/prutok-magnievyy-m11916---uns/>Пруток магниевый M11916 - UNS</a> Проволока магниевая M11916 - UNS предназначена для раз
Sheilafer 31 Ekim 2025 21:20
РедМетСплав предлагает обширный выбор отборных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от мелких партий до масштабных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица товара подтверждена соответствующими документами, подтверждающими их происхождение. Дружелюбная помощь - наш стандарт – мы на связи, чтобы ответить на ваши вопросы по мере того как адаптировать решения под особенности вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей поставляемая продукция: <a href=https://redmetsplav.ru/store/titan/rossiyskie-splavy-4/titan-3mb---gost-19807-91/izdeliya-iz-titana-3mb---gost-19807-91/>Изделия из титана 3МБ - ГОСТ 19807-91</a> Поковка титановая 3МБ - ГОСТ 1980
Stephenneeva 31 Ekim 2025 20:46
в курске у стаффсторе лутше не брать за кладом надо ехать с граблями и лопатой сугробы копать иначе никак <a href=https://halaldevelopment-partners.ru>купить онлайн мефедрон, экстази, бошки</a> Привет! Что хочу сказать по поводу работы магазина- просто супер, связались сразу, приняли заказ, обработали и на следующий день он уже в пути. 3 дня и уже у меня. Качество отличное! В общем респект Вам ребята, так держать, не сбавляйте оборотов и хорошо будет всем!
Sheilafer 31 Ekim 2025 20:25
Если вы работаете в сфере производства и нуждаетесь в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания занимается на рынке поставок тугоплавких металлов уже более 10 лет, что дает нам возможность поставлять только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Обширный выбор тугоплавких металлов. 3. Документация в порядке. 4. Всесторонняя поддержка клиентов. Зачем искать на других сайтах, если rms-ekb.ru всегда в вашем распоряжении? Наши специалисты всегда рады помочь вам с любыми вопросами.. Звоните прямо сейчас и удостоверьтесь в качестве нашего редкого металла. С уважением, команда <a href
Murielzen 31 Ekim 2025 19:34
altalaban a kis jutalmak ingyenes bonuszok: fizetetlen porgetesek, a [url=http://bestsmartplace.com/]http://bestsmartplace.com/[/url] es ingyenes fogadas penz sok ezer forint.
Philipcog 31 Ekim 2025 18:58
Извините за то, что вмешиваюсь… Я здесь недавно. Но мне очень близка эта тема. Готов помочь. информация о наличии разрешения должна подтверждаться кликабельной ссылкой. сведения о максимальных сроках вывода денег указывается на веб-сайте. Операторы проводят соревнования, лотереи, [url=https://ciorragastone.com/cocinas-que-te-dejaran-de-piedra/]https://ciorragastone.com/cocinas-que-te-dejaran-de-piedra/[/url] регулярные скидки.
KarenJah 31 Ekim 2025 18:40
Do [url=https://grcastings.com/understanding-uk-online-casino-regulations-4/]https://grcastings.com/understanding-uk-online-casino-regulations-4/[/url] provide portals for responsible gaming in online casinos? game processes is done it gets more exciting as soon as you look for the slot that you have decided place bets.
KevinAsync 31 Ekim 2025 17:18
Kun very on yli 16 000 games ja laaja vedonlyontiosio, tunsimme pelin monipuolisuus ja charm. - etta [url=https://www.kgurs.jp/kasino-ilman-lisenssia-vapaus-pelaamiseen-17.html]https://www.kgurs.jp/kasino-ilman-lisenssia-vapaus-pelaamiseen-17.html[/url] on todella kannattavaa poikkeuksellista.
KaylatRirm 31 Ekim 2025 17:13
Я думаю, что Вы не правы. Давайте обсудим. Пишите мне в PM, поговорим. These new casinos that are not part of gamstop provide gamblers new game emotions and pleasant bonuses, what will their are an attractive idea for those who are something [url=https://almannanenterprises.com/2025/10/14/exploring-casinos-not-registered-on-gamstop-74/]https://almannanenterprises.com/2025/10/14/exploring-casinos-not-registered-on-gamstop-74/[/url].
Manuelidele 31 Ekim 2025 17:12
Смело таримся!! Нипожалеете <a href=https://job-in.ru>купить Мефедрон, Бошки, Марихуану</a> товар появился? когда возобновите доставку по городам?
Manuelidele 31 Ekim 2025 13:42
с утра в работу поставим, не волнуйся!!! просто менеджер у нас очень ответственный, считает каждую копейку, таких людей очень мало... <a href=https://alfamx.ru>купить Мефедрон, Бошки, Марихуану</a> незнаю незнаю мне пришло за 2 суток и еще я обратился к селлеру и он предоставил всю полную информацию с адресом и номерами телефона курьерки
Margarethum 31 Ekim 2025 13:18
Да, логически правильно это могут быть надежные [url=https://dominicanainternational.com/tourist-arrivals-begin-to-awaken-dominican-republic-from-the-lethargy-of-covid-19/]https://dominicanainternational.com/tourist-arrivals-begin-to-awaken-dominican-republic-from-the-lethargy-of-covid-19/[/url] разработчики. все игровые автоматы работают онлайн. при обнаружении нарушений операторы штрафуются и лишаются лицензии.
Ericapouro 31 Ekim 2025 12:43
Look for licenses from reputable authorities, such as Department for Combating on slots of the State of New Jersey, hint on monitoring gambling of the State of Pennsylvania, [url=https://valuenurses.care/discover-the-exciting-world-of-online-gambling-co/]https://valuenurses.care/discover-the-exciting-world-of-online-gambling-co/[/url] or advice on monitoring gambling of the State of Michigan.
Kimberlybob 31 Ekim 2025 12:29
MILF with big boobs and charming tits Gets Fucked herself In [url=https://zeenite.com/tags/desi-mms-videos/]https://zeenite.com/tags/desi-mms-videos/[/url], Real homemade porn. A Young Dumb Chubby Mom Is handcuffed and Held after Her Ass Is Whipped And Her Dick Is Sucked.
MiguelbEr 31 Ekim 2025 11:22
Зато искать долго не пришлось наверное???! https://studio-milashka.ru 5го марта написал ЛС ТСу про оптовый заказ.... до сих пор жду ответа
Sheilafer 31 Ekim 2025 11:19
Если вы заняты в области производства и столкнулись с необходимостью в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания работает на сфере поставок тугоплавких металлов уже более 10 лет, что позволяет нам поставлять только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Широкий ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Поддержка 24/7. Зачем искать где-то еще, если rms-ekb.ru всегда готовы помочь? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Звоните прямо сейчас и проверьте в достоинствах нашего продукта. Команда <a href=https://rms-ekb.ru/>
Crowngreen WarnerTug 31 Ekim 2025 10:15
Crowngreen is a leading gaming platform that delivers exciting games for users. Crowngreen shines in the online gaming world and has achieved popularity among enthusiasts. Every user at <a href="https://3kyazilim.com/win-more-at-crowngreen-casino-and-start-your/">Crowngreen casino</a> is able to play top-rated games and receive generous promotions. Crowngreen provides reliable gameplay, fast transactions, and constant customer support for all users. With , gamers explore a diverse selection of casino games, including classic options. The casino focuses on fun and maintains an enjoyable gaming environment. Whether you are experienced or an expert, Crowngreen Casino provides unique experiences for everyone. Join at Crowngreen today and discover rewarding games, generous bonu
Sheilafer 31 Ekim 2025 10:14
Если вы занимаетесь производством и столкнулись с необходимостью в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания занимается на сфере поставок тугоплавких металлов уже многих лет, что обеспечивает нам условия поставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Большой ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Поддержка 24/7. Зачем тратить время на поиски где-то еще, если rms-ekb.ru всегда в вашем распоряжении? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Звоните прямо сейчас и удостоверьтесь в достоинствах нашего редкого
MiguelbEr 31 Ekim 2025 09:35
спасибо! Хороший магазин) берите тут https://bccrt.ru Мне одному не везёт? Уже 16 дней как деньги заслал, и тишина. Жабер не в сети. Скрин из жабера прилагается.
BriannaDam 31 Ekim 2025 08:42
Поздравляю, мне кажется это блестящая мысль It is simple for players, necessary to enter their personal data and bring our identity so that [url=https://destekbetgit.com/exploring-non-gamstop-casinos-a-comprehensive-250/]https://destekbetgit.com/exploring-non-gamstop-casinos-a-comprehensive-250/[/url] do not Members of gamestop have started self-exclusion.
Sheilafer 31 Ekim 2025 08:04
РедМетСплав предлагает широкий ассортимент высококачественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от небольших закупок до обширных поставок, мы гарантируем быстрое выполнение вашего заказа. Каждая единица товара подтверждена всеми необходимыми документами, подтверждающими их качество. Дружелюбная помощь - наш стандарт – мы на связи, чтобы разрешать ваши вопросы по мере того как адаптировать решения под требования вашего бизнеса. Доверьте потребности вашего бизнеса специалистам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наши товары: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-mt2---jis-h-4202/prutok-magnievyy-mt2---jis-h-4202/>Пруток магниевый MT2 - JIS H 4202</a> Проволок
Austinfieva 31 Ekim 2025 07:50
нервные клетки https://3d-sprinter.ru Всем доброго дня!! Хочу рассказать свой отзыв , о данном чудо магазине!! Заказывал совместку на 50г, оплатил днём, к вечеру все было готово, жаль только я с джабером что то не подружился, он меня выкинул, прям перед получением адреса, НО КЛАДЧИК ТАКОЙ красавчик!!! В итоге я поехал с утра, только приехал, все было на своих местах!!! Спрятано на совесть!!! Думаю ещё пролежало бы дня 3))) ИТОГО: ОПЕРАТОР В ДЖАБЕРЕ САМЫЙ КУЛЬТКРНЫЙ ЧЕЛОВЕК НА СВЕТЕ! 5+ КЛАДЧИК , умница! 5+, близко ко мне , и спрятано как надо!!! P.S. Смело заказываем!! И радуемся как дети!!)
MarvinSpest 31 Ekim 2025 07:49
Code promo sur 1xBet est unique et permet a chaque nouveau joueur de beneficier jusqu’a 100€ de bonus sportif a hauteur de 100% en 2026. Le bonus sera ajoute a votre solde en fonction de votre premier depot, le depot minimum etant fixe a 1€. Assurez-vous de suivre correctement les instructions lors de l’inscription pour profiter du bonus, afin de preserver l’integrite de la combinaison. D’autres promotions existent en plus du bonus de bienvenue, vous pouvez trouver d’autres offres dans la section « Vitrine des codes promo ». Vous pouvez trouver le code promo 1xbet sur ce lien — <a href=https://www.ayudainmigrante.us/pages/vredno_li_spaty_v_berushah_tishina_imeet_svoyu_cenu.html>https://www.ayudainmigrante.us/pages/vredno_li_spaty_v_berushah_tishina_imeet_svoyu_cenu.html</a>.
Devinnuand 31 Ekim 2025 07:34
Да делали Спальня - комната, в квартире, службу в помещении (доме, [url=http://www.webby.co/italijski-spalni-elegantnist-komfort-ta-stil/]http://www.webby.co/italijski-spalni-elegantnist-komfort-ta-stil/[/url] квартире и тому подобное) для спален и отдыха.
Sheilafer 31 Ekim 2025 06:35
РедМетСплав предлагает обширный выбор качественных изделий из редких материалов. Не важно, какие объемы вам необходимы - от мелких партий до крупных поставок, мы обеспечиваем быстрое выполнение вашего заказа. Каждая единица продукции подтверждена всеми необходимыми документами, подтверждающими их происхождение. Превосходное обслуживание - наша визитная карточка – мы на связи, чтобы разрешать ваши вопросы а также находить ответы под особенности вашего бизнеса. Доверьте вашу потребность в редких металлах специалистам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/niobiy1/splavy-niobiya-1/niobiy-nbp1-1/lenta-niobievaya-nbp1/>Лента ниобиевая НбП1</a> Лента ниобиевая НбП1 является высококачественным материалом, предн
Stephenlog 31 Ekim 2025 06:12
you get the opportunity found your own gaming adventure with a huge welcome bonus in the amount of up to $3,000, and in the Golden Buffalo [url=https://wp.supover.com/pelikioski-seikkailu-suomalaisessa-pelimaailmassa/]https://wp.supover.com/pelikioski-seikkailu-suomalaisessa-pelimaailmassa/[/url] you will receive additional 30 rotations.
DavidJutty 31 Ekim 2025 06:04
electronic wallets are issued virtually instantaneously, that moment classic bank transfers can take several working days. [url=http://www.fleursbottin-englebert.be/bonjour-tout-le-monde/]http://www.fleursbottin-englebert.be/bonjour-tout-le-monde/[/url] allows you to pass most games, both in demo version, and for natural money.
Keithunots 31 Ekim 2025 06:03
всегда кто-то гадость может написать, а ответить не кто!! работал с вами! <a href=https://origamishop.ru>купить онлайн мефедрон, экстази, бошки</a> сколько нужно обождать после 2се и 2си, чтобы хорошо 4фа пошла?
IrwinFaigh 31 Ekim 2025 04:55
<a href=https://kra48.xyz/>кракен онион</a> - официальный сайт, лучшее место для безопасных и анонимных онлайн-транзакций. У нас вы найдете широкий выбор товаров и услуг, доступных только в сети даркнет. Наша платформа обеспечивает конфиденциальность и защиту данных, чтобы вы могли совершать покупки безопасно. Подключайтесь к кракену и погрузитесь в мир анонимности и свободы.
Michellecon 31 Ekim 2025 04:40
По-моему это очевидно. Советую Вам попробовать поискать в google.com start by making a plan: always develop a clear trading tactics before starting trading. Visit website/website: head to official portal [url=https://web-olymptrade.net/olymp-trade-sign-in-secure-platform-access-2025/]https://web-olymptrade.net/olymp-trade-sign-in-secure-platform-access-2025/[/url].
Keithunots 31 Ekim 2025 04:19
друзья а товар что закончился? месяц пишу, и говорят все пусто;( <a href=https://puzzlepedia.ru>купить онлайн мефедрон, экстази, бошки</a> чувствую у меня будет то же самое, трек получил но он нихуя не бьется, а что ответил то? я оплатил 3 февраля и трек походу тоже левый ТС обьясни и мне ситуацию
AshleyJeffSon 31 Ekim 2025 03:22
The best bonuses and promotional campaigns: best websites: online [url=https://valuenurses.care/discover-the-thrills-of-agent-no-wager-casino-33/]https://valuenurses.care/discover-the-thrills-of-agent-no-wager-casino-33/[/url].
Keithunots 31 Ekim 2025 02:34
Только позитивные эмоции! <a href=https://si-vif.ru>купить Кокаин, Мефедрон, Экстази</a> Привет, ребята!
JerriImams 31 Ekim 2025 02:20
Enjoy more honest bonuses when all winnings are paid in cash, also do not require wagering in [url=https://www.bodegamemorial.com/understanding-the-playhub-casino-registration-4/]https://www.bodegamemorial.com/understanding-the-playhub-casino-registration-4/[/url]! Participate in delicious tournaments and slot machines tournaments with a spinoff.
MiriamPiors 31 Ekim 2025 02:20
Just disable auto-play to later analyze your [url=https://brunnerlandscape.com/master-your-game-essential-tips-for-playing-online/]https://brunnerlandscape.com/master-your-game-essential-tips-for-playing-online/[/url] balance. can use your phone or computer to log in to online gambling establishments, in which is slot machines vending machines for real money.
Sheilafer 31 Ekim 2025 01:55
Если вы работаете в сфере производства и нуждаетесь в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания работает на области поставок тугоплавких металлов на протяжении десятилетий, что позволяет нам поставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Объемы поставок не имеют значения. 2. Широкий ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Поддержка 24/7. Зачем искать на других сайтах, если rms-ekb.ru всегда готовы помочь? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Обратитесь к нам прямо сейчас и удостоверьтесь в преимуществах нашего редкого металла. Команда
BrianHot 31 Ekim 2025 01:39
A chicken crossing a dangerous road reflects the essence of the exciting moments of the game, trying your luck, to achieve unexpected positions and receive a large reward at the [url=https://samhome.bg/bg/show/toggle/list/aHR0cHM6Ly93d3cuam9ybmFsaXNtby51ZnYuYnIvb3V0cm9saGFyLzIwMjUvMDYvMDQvY2hpY2tlbi1yb2FkLWZvbmRhbWVudGFsLWF2b2lyLWRlcHVpcy1qZXV4LXN1ci8/YWN0aW9uPXByb2ZpbGU7dT04NTk=]https://samhome.bg/bg/show/toggle/list/aHR0cHM6Ly93d3cuam9ybmFsaXNtby51ZnYuYnIvb3V0cm9saGFyLzIwMjUvMDYvMDQvY2hpY2tlbi1yb2FkLWZvbmRhbWVudGFsLWF2b2lyLWRlcHVpcy1qZXV4LXN1ci8/YWN0aW9uPXByb2ZpbGU7dT04NTk=[/url].
DomingoNuado 31 Ekim 2025 01:35
Le code promo est supprime : entrez-le dans le champ « Code promo » et reclamez un bonus de bienvenue de 100% jusqu'a 130€, pour vos paris sportifs. Inscrivez-vous sur 1xBet ou via l'application mobile. Apres votre premier depot, vous activerez le code bonus. L'offre est valable pour toute l'annee 2026, et le bonus doit etre mise dans les 30 jours. Vous pouvez trouver le code promo sur ce lien > <a href=https://www.obekti.bg/sites/artcles/index.php?code_promo_208.html>https://www.obekti.bg/sites/artcles/index.php?code_promo_208.html</a>.
Sheilafer 31 Ekim 2025 00:54
РедМетСплав предлагает обширный выбор качественных изделий из нестандартных материалов. Не важно, какие объемы вам необходимы - от мелких партий до масштабных поставок, мы обеспечиваем быстрое выполнение вашего заказа. Каждая единица товара подтверждена требуемыми документами, подтверждающими их соответствие стандартам. Превосходное обслуживание - то, чем мы гордимся – мы на связи, чтобы ответить на ваши вопросы по мере того как предоставлять решения под требования вашего бизнеса. Доверьте вашу потребность в редких металлах специалистам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-b-92-9995a---astm-b92/folga-magnievaya-b-92-9995a---astm-b92/>Фольга магниевая B 92
Keithunots 31 Ekim 2025 00:47
Я знаете как делаю, когда пацики отвечают сразу делаю заказ, оплачиваю и все чотка, самим тормозить не надо <a href=https://burhanim.ru>купить скорость, кокаин, мефедрон, гашиш</a> Напишите хотя бы мини трип в соответствующей теме,буду благодарен.
Sheilafer 31 Ekim 2025 00:32
Если вы работаете в сфере производства и нуждаетесь в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше решение. Наша компания работает на области поставок тугоплавких металлов в течение многих лет, что позволяет нам предлагать только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Широкий ассортимент тугоплавких металлов. 3. Полный комплект документов. 4. Поддержка 24/7. Зачем тратить время на поиски где-то еще, если rms-ekb.ru всегда здесь для вас? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Пишите прямо сейчас и убедитесь в качестве нашего сплава. Команда <a href=https://rms-ekb.ru/>
JanetBeids 31 Ekim 2025 00:19
По моему мнению Вы ошибаетесь. Могу отстоять свою позицию. Пишите мне в PM, обсудим. these information is usually provided during registration or on the scale a special promotion, since [url=https://cueee.jp/2025/10/14/exploring-non-gamstop-casinos-a-new-era-of-online-16/]https://cueee.jp/2025/10/14/exploring-non-gamstop-casinos-a-new-era-of-online-16/[/url] allow the player earn money by playing in the gaming community for real money, without risking own finances.
Sheilafer 30 Ekim 2025 23:44
РедМетСплав предлагает широкий ассортимент высококачественных изделий из редких материалов. Не важно, какие объемы вам необходимы - от мелких партий до крупных поставок, мы обеспечиваем быстрое выполнение вашего заказа. Каждая единица товара подтверждена всеми необходимыми документами, подтверждающими их соответствие стандартам. Опытная поддержка - то, чем мы гордимся – мы на связи, чтобы улаживать ваши вопросы по мере того как предоставлять решения под требования вашего бизнеса. Доверьте ваш запрос специалистам РедМетСплав и убедитесь в гибкости нашего предложения поставляемая продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-b-199-qe22a---astm-b199/krug-magnievyy-b-199-qe22a---astm-b199/>Круг магниевый B 199 (QE22A) - ASTM B199</
SamanthaSwask 30 Ekim 2025 23:30
A nyerogepek: Pragmatic play, Play ' n go, the [url=http://www.domopet.it/a-legjobb-kaszino-oldalak-magyarorszagon-teljes/]http://www.domopet.it/a-legjobb-kaszino-oldalak-magyarorszagon-teljes/[/url] a Netent es a Nolimit City portfolioja garantalja megrendelesenek folyamata kivalo minosegu jatekelmenyt.
UlyssesSwern 30 Ekim 2025 22:30
this desire for honesty increases faith participants of the game and good name of the crowngreen [url=https://luminastone.com.au/2022/10/03/hello-world/]https://luminastone.com.au/2022/10/03/hello-world/[/url]
DomingoNuado 30 Ekim 2025 21:30
Bonus exclusif 1xBet pour 2026 : profitez d’un bonus de bienvenue de 100% jusqu’a 130€ en rejoignant la plateforme. C’est une offre unique pour les paris sportifs, permettant d’effectuer des paris sans risque. Inscrivez-vous avant la fin de l’annee 2026. Decouvrez le code promotionnel 1xBet via le lien fourni : <a href=https://megusta.ws/media/pgs/?chasy_v_podarok_o_suschestvuyuschih_predrassudkah.html>https://megusta.ws/media/pgs/?chasy_v_podarok_o_suschestvuyuschih_predrassudkah.html</a>.
Keithunots 30 Ekim 2025 21:13
перорально - эффекта 0 при меньших дозах, при больших - понос, рвота, чуваку скорую вызывали, давление 40/15 <a href=https://burhanim.ru>купить скорость, кокаин, мефедрон, гашиш</a> Оплатил 3 февраля, 6 получил трек-трек не бьётся, посылкинет. Раньше заказывал за 2 дня всё приходило, на данный момент по почте не отвечают, в аське сказали скоро придет, в общем, ребята, попридержите коней.
NataliaDer 30 Ekim 2025 21:11
she's a porn bunny not playing exciting slots. On the other hand, in [url=https://sporta-klubi.lv/away.php?url=online-casinos.us.orghttps://pin-up-azerbaycan1.com/main-page/]https://sporta-klubi.lv/away.php?url=online-casinos.us.orghttps://pin-up-azerbaycan1.com/main-page/[/url] very exciting reason about my winnings, although sometimes I win too.
ChristineDoupe 30 Ekim 2025 20:26
you can play all own favorite games on computer either smartphone, [url=https://eltric.pl/2025/09/21/discover-the-thrills-of-online-casino-where-every/]https://eltric.pl/2025/09/21/discover-the-thrills-of-online-casino-where-every/[/url], and insert the user it is not necessary. Third-party help: Choose third-party platforms to battle bordering with slots and addiction to betting.
Philiptor 30 Ekim 2025 20:26
irush rewards is also a multi-level program, in which there are 10 levels that enable the player to receive advantages, free own stay at retail casinos, and at the highest level, you receive a welcome dinner, personal concierge services at [url=https://serescent.com/archives/6092]https://serescent.com/archives/6092[/url], and more more!
Charleneevody 30 Ekim 2025 20:17
Я считаю, что Вы не правы. Могу это доказать. Пишите мне в PM, обсудим. Конструкцией магазина предусмотрен механизм (обычно пружинный) для поочерёдной подачи патронов на линию [url=http://www.3dtvorba.cz/obchod/jmenovka-detskeho-pokoje-boxer/]http://www.3dtvorba.cz/obchod/jmenovka-detskeho-pokoje-boxer/[/url] досылания. Не путать с револьверным барабаном.
KristyKic 30 Ekim 2025 19:53
та ну его,так посмотрю favorites Free webcams are more likely to attract gaze and attract more customers of your product, so [url=https://web-myfreecams.com/de-de/]https://web-myfreecams.com/de-de/[/url] in paid chats.
Keithunots 30 Ekim 2025 19:27
С 10-11 утра по МСК ежедневно кроме праздников и выходных. <a href=https://jk-sibirskiy.ru>купить Кокаин, Мефедрон, Экстази</a> 16 числа заказала товарчика)ну пока еще ничего не получила!!! продаван отправил только половинку(объяснил что не хватило реактивчика) но все остальное вышлет как привезут 100ый ))ждем и надеемся)) заказывала и раньше в этом магазе все было ОГОНЬ))
DannyKneew 30 Ekim 2025 18:02
Tietenkin, finally, it should identify jokainen verkossa [url=https://somersetproperty.xcodeist.com/kasinot-ilman-lisenssia-kaikki-mita-tarvitset-5/]https://somersetproperty.xcodeist.com/kasinot-ilman-lisenssia-kaikki-mita-tarvitset-5/[/url] independently - for example, in casino, where pelaajat voivat olla pettyneita haviamalla keskustelufoorumeilla.
Sheilafer 30 Ekim 2025 17:42
РедМетСплав предлагает широкий ассортимент отборных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до масштабных поставок, мы гарантируем своевременную реализацию вашего заказа. Каждая единица изделия подтверждена соответствующими документами, подтверждающими их качество. Опытная поддержка - то, чем мы гордимся – мы на связи, чтобы улаживать ваши вопросы и предоставлять решения под требования вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в гибкости нашего предложения Наши товары: <a href=https://redmetsplav.ru/store/vismut/zarubezhnye-splavy-3/vismut-cac901---jis-h-5120-2016/lenta-vismutovaya-cac901---jis-h-5120-2016/>Лента висмутовая CAC901 - JIS H 5120-2016</a> Лента висмутовая CAC901 - JIS H 5120-2016
Keithunots 30 Ekim 2025 17:40
заказал не мало,всё пришло за кач не знаю как опробуют кролы отпишу <a href=https://yamaha-kzn.ru>купить Мефедрон, Бошки, Марихуану</a> Огромное спасибо данному магазину, успехов вработе и процветания!!!?
RobertTot 30 Ekim 2025 17:03
Profitez du code promo 1xbet 2026 : recevez un bonus de 100% sur votre premier depot, jusqu'a 130 €. Placez vos paris en toute plaisir en utilisant simplement les fonds bonus. Apres l'inscription, il est important de recharger votre compte. Si votre compte est verifie, vous pourrez retirer toutes les sommes d'argent, y compris les bonus. Vous pouvez trouver le code promo 1xbet sur ce lien : <a href=https://megusta.ws/media/pgs/?chasy_v_podarok_o_suschestvuyuschih_predrassudkah.html>https://megusta.ws/media/pgs/?chasy_v_podarok_o_suschestvuyuschih_predrassudkah.html</a>.
Jasonanini 30 Ekim 2025 16:53
review the requirements of your state: make sure that applications for gambling are legal in your state and that specified the client The program for [url=https://aff.dominhhai.com/2025/10/20/the-rise-of-triunfo-bet-a-new-era-in-online-2/]https://aff.dominhhai.com/2025/10/20/the-rise-of-triunfo-bet-a-new-era-in-online-2/[/url] works exactly there.
ThomasNig 30 Ekim 2025 16:51
in it also presented the best offers online gambling house and intelligent functions. Which [url=http://www.forkscars.fr/un-3-cylindres-qui-en-vaut-6-essai-de-la-ford-mondeo/]http://www.forkscars.fr/un-3-cylindres-qui-en-vaut-6-essai-de-la-ford-mondeo/[/url] casino pays easiest online?
Sheilafer 30 Ekim 2025 16:43
РедМетСплав предлагает обширный выбор отборных изделий из редких материалов. Не важно, какие объемы вам необходимы - от мелких партий до масштабных поставок, мы обеспечиваем быстрое выполнение вашего заказа. Каждая единица изделия подтверждена требуемыми документами, подтверждающими их качество. Превосходное обслуживание - наша визитная карточка – мы на связи, чтобы разрешать ваши вопросы а также находить ответы под особенности вашего бизнеса. Доверьте ваш запрос профессионалам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наша продукция: <a href=https://redmetsplav.ru/store/vismut/zarubezhnye-splavy-3/vismut-c89940---cda/list-vismutovyy-c89940---cda/>Лист висмутовый C89940 - CDA</a> Лист висмутовый C89940 - CDA является высококачественным продуктом для р
MattZen 30 Ekim 2025 15:52
Согласен, это отличная мысль Few types/varieties sports are as ingrained in British betting culture as equestrian [url=https://www.nagoya-su.ac.jp/2025/10/10082]https://www.nagoya-su.ac.jp/2025/10/10082[/url] racing. I have been working in the gambling industry for many years now, covering any areas of activity - from small offshore startups to world-class international casinos.
Sheilafer 30 Ekim 2025 15:15
Если вы занимаетесь производством и нуждаетесь в поставке самых качественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше спасение. Наша компания работает на сфере поставок тугоплавких металлов на протяжении долгого времени, что дает нам возможность предлагать только проверенный материал своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Широкий ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Поддержка 24/7. Зачем тратить время на поиски где-то еще, если rms-ekb.ru всегда здесь для вас? В случае возникновения вопросов, наши эксперты всегда готовы вам помочь. Пишите прямо сейчас и удостоверьтесь в качестве нашего редкого металла. Ваш надежный пост
Jonathanmor 30 Ekim 2025 15:07
виртуальный фармацевтический пункт «Центр красоты кожи» предоставляет пользователям шанс купить целебную косметику известных мировых фирм vichy, [url=http://life-pics.ru/user/MTGShaun6502988/]http://life-pics.ru/user/MTGShaun6502988/[/url] la roche posay и inneov.
CynthiaMoife 30 Ekim 2025 14:56
in this regard at [url=http://www.southeastgroup.com.au/2013/08/29/new-client-landed/]http://www.southeastgroup.com.au/2013/08/29/new-client-landed/[/url] important to say how long the bonus will be available, and plan your games according to criteria during of this period.
MirandaHauri 30 Ekim 2025 14:37
Это ценная штука vintage galore - популярный и главный из самых|наиболеераспространенных доступных магазинов готовой одежды в бельгии и франции в каталоге секонд-хенд, [url=https://elchingon.es/post-2/]https://elchingon.es/post-2/[/url] размещающийся около Пренцлауэр-Берг.
DanielJum 30 Ekim 2025 14:34
along with flexible betting limits, free Roulette offers diverse types of betting with highest degree of risk, [url=https://www.ukbapropertyinspection.co.uk/top-rated-casino-games-to-try-7/]https://www.ukbapropertyinspection.co.uk/top-rated-casino-games-to-try-7/[/url] - due to contributions on equal amounts, such as "red or black" and "odd or even number", to bets on result of one number.
Sampatty 30 Ekim 2025 14:31
also, should pay great attention to the speed of finances withdrawal, since some [url=https://www.deltauhuru.com/2025/08/30/explore-the-thrilling-world-of-casino-davinci-s/]https://www.deltauhuru.com/2025/08/30/explore-the-thrilling-world-of-casino-davinci-s/[/url] can process transactions only for as soon as possible, at those years as others may drag on many days.
RobertEmasT 30 Ekim 2025 14:07
Магазин нормально работает?,а то некоторые говорят что не стоит обращаться в данный магазин для заказов!Фон или фок как твой ник правильно читаеться и пишиться ? отпишись нормальный магаз или нет ! <a href=https://dogs-likely-hart.ru>купить скорость, кокаин, мефедрон, гашиш</a> спасибо вам уважаемый магазин за то что вы есть! ведь пока что лучшего на легале я не видел не чего!
Elizabethwaind 30 Ekim 2025 14:02
Baccarat has gained popularity among British players, especially among [url=https://majesticmeadowsfalabellas.ca/2025/09/27/unlocking-entertainment-experience-the-aztec/]https://majesticmeadowsfalabellas.ca/2025/09/27/unlocking-entertainment-experience-the-aztec/[/url] with high bets. Seven Casino serves a huge circle of players, from ordinary players to high rollers.
RobertTot 30 Ekim 2025 12:54
Profitez d’un code promo unique sur 1xBet permettant a chaque nouveau joueur de beneficier jusqu’a 100€ de bonus sportif a hauteur de 100% en 2026. Le bonus sera ajoute a votre solde en fonction de votre premier depot, le depot minimum etant fixe a 1€. Pour eviter toute perte de bonus, veillez a copier soigneusement le code depuis la source et a le saisir dans le champ « code promo (si disponible) » lors de l’inscription, afin de preserver l’integrite de la combinaison. D’autres promotions existent en plus du bonus de bienvenue, d'autres combinaisons vous permettant d’obtenir des bonus supplementaires sont disponibles dans la section « Vitrine des codes promo ». Consultez le lien pour plus d’informations sur les promotions disponibles > <a href=http://mistertoys.de/news/karnavalynye_kos
RobertEmasT 30 Ekim 2025 12:21
Решили мы тут значит с кентом несколько дней назад покурить . Вспомнили про сайт chem24.biz.ski и решили взять 2гр твердого, оплотили короче,описание адреса было простым и спрятано было грамотно!!! <a href=https://tech43.ru>купить онлайн мефедрон, экстази, бошки</a> Тут мы
Timcax 30 Ekim 2025 12:14
this means/means, although it is absolutely safe to use any bonus offers from this casino, we never we can diverse this is until until, until we receive more detailed data [url=https://dprd.sumedangkab.go.id/berita/single/awali-tahun-2024-sekwan-sumedang-beri-pengarahan-pegawai-tingkatkan-kinerja-pelayanan/]https://dprd.sumedangkab.go.id/berita/single/awali-tahun-2024-sekwan-sumedang-beri-pengarahan-pegawai-tingkatkan-kinerja-pelayanan/[/url].
JudyBef 30 Ekim 2025 10:56
По-моему это уже обсуждалось. they give opportunity to us to count visits and suppliers traffic so that we can measure and refine the performance of our [url=https://web-manyvids.com/]manyvids login[/url].
RobertEmasT 30 Ekim 2025 10:35
качество вышка <a href=https://shopfashion4all.ru>купить Мефедрон, Бошки, Марихуану</a> нет курьерки по мск нету, да все работает как обычно
DanielLok 30 Ekim 2025 10:11
1xbet promo code — <a href=https://therockpit.net/wp-content/pages/1xbet_promo_code________sign_up_offer.html>https://therockpit.net/wp-content/pages/1xbet_promo_code________sign_up_offer.html</a> A 1x Bet promocode is an alphanumeric code that unlocks various bonuses on the 1xBet platform. These codes are often distributed through promotions, social media, or affiliate sites, and can be entered during registration or deposit.
Aaronwhopy 30 Ekim 2025 09:43
There are 66 land-based[url=https://data.wpdesk.org/2025/10/20/the-ultimate-guide-to-mm88-your-path-to-online/]https://data.wpdesk.org/2025/10/20/the-ultimate-guide-to-mm88-your-path-to-online/[/url] casinos in megacities, which are operated by tribal communities.
Sheilafer 30 Ekim 2025 09:34
РедМетСплав предлагает внушительный каталог высококачественных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до крупных поставок, мы обеспечиваем своевременную реализацию вашего заказа. Каждая единица изделия подтверждена требуемыми документами, подтверждающими их качество. Превосходное обслуживание - наш стандарт – мы на связи, чтобы разрешать ваши вопросы а также находить ответы под особенности вашего бизнеса. Доверьте ваш запрос специалистам РедМетСплав и убедитесь в гибкости нашего предложения Наша продукция: <a href=https://redmetsplav.ru/store/magniy-i-ego-splavy/zarubezhnye-splavy-2/magniy-mgal6zn1-alloy-22---iso-3116/folga-magnievaya-mgal6zn1-alloy-22---iso-3116/>Фольга магниевая MgAl6Zn1 (Alloy 22) - ISO 3116</a> Труба магн
RobertEmasT 30 Ekim 2025 08:50
Да хватает придурков, только смысл писанины этой , что он думает что ему за это что то дадут ))) кроме бана явно ничего не выгорит )))! Тс красавчик брал 3 раза по кг сделки и всегда все чётко ! Жду пока появиться опт на ск! <a href=https://3d-sprinter.ru>купить кокаин, меф, бошки через телеграмм</a> Магазин работает на 5+++++, я уже раз 5 беру у данного сейлера все ровно все катит, качество на высоте!
DerekOrirm 30 Ekim 2025 08:12
В этом что-то есть. Благодарю за информацию, теперь я не допущу такой ошибки. ^ Оружие магазинное // Новый энциклопедический словарь: В 48 томах (вышло 29 [url=https://azart-portal.org/product/titan-casino]https://azart-portal.org/product/titan-casino[/url] томов).
Austinjuisa 30 Ekim 2025 07:33
to start transfers money, [url=https://sanjorge.co/1xbet-thailand-download-app-your-gateway-to-online-5/]https://sanjorge.co/1xbet-thailand-download-app-your-gateway-to-online-5/[/url] simply log in to personal personal account 1xbet. 5. Use betting statistics: Use the available statistics effectively.
BenAlofe 30 Ekim 2025 07:09
Conduct continuous training so that the team is aware the development of software tools wirth and priorities of the market for the [url=https://einfachleben.blog/nachhaltiger-kaffee-ein-faktencheck/]https://einfachleben.blog/nachhaltiger-kaffee-ein-faktencheck/[/url]. Use reliable software illusions and assumptions, based on data to substantiate your financial forecasts.
FloranceRet 30 Ekim 2025 06:37
Теперь всё понятно, большое спасибо за помощь в этом вопросе. Как мне Вас отблагодарить? and still, which optimal to choose from [url=https://cars.flx.vc/biz_dev/media/?p=23360]https://cars.flx.vc/biz_dev/media/?p=23360[/url]? Casino without registrations is a website for internet casinos, which has not become part the British system of self-exclusion.
SheilaDoupe 30 Ekim 2025 06:34
Since 2024, the regulation of {gambling|gaming entertainment|gambling} in Argentina {exclusively|only|mainly} {is being carried out|implemented} at the {level|height} of the provinces, and #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c5h3e5b4P2URLBB.txt",1,N] in {each} of the 23 provinces and the autonomous city of Buenos Aires {are dictated|established|They have set their own rules.
Lylezep 30 Ekim 2025 06:26
[url=http://www.polish-law.eu/neque-porro-quisquam-est-qui-dolorem-ipsum-quia-dolor-sit-amet-consectetur-2/]http://www.polish-law.eu/neque-porro-quisquam-est-qui-dolorem-ipsum-quia-dolor-sit-amet-consectetur-2/[/url] из столицы в Турцию в 2025 году привлекают недостижимым уровнем услуг и разнообразными отелями - от простых до класса люкс».
Richardpek 30 Ekim 2025 06:25
1хБет промокод при регистрации — выгодная акция для новичков. Получите бонус на первый депозит. Условия получения и отыгрыша бонуса до 32 500 рублей в букмекерской конторе 1xBet. Требования к регистрации и снятию выигрыша. Букмекерские конторы пользуются спросом у людей, чьи интересы плотно связаны со спортом, с возможностью получить вознаграждение за первый депозит. Более подробно о бонусе вы можете узнать тут <a href=https://lebo.ru/pgs/promokod_284.html>https://lebo.ru/pgs/promokod_284.html</a>. 1xBet промокод 2026 даёт возможность получить бонус 32 500 руб.
Colleenpef 30 Ekim 2025 06:20
as an example of such functions is book of dead, offering 10 [url=https://gamecrud.com/jinx-casino-online-games-a-complete-guide-to-what/]https://gamecrud.com/jinx-casino-online-games-a-complete-guide-to-what/[/url], and sweet bonanza has 100-fold multipliers during free spins.
Seanquado 30 Ekim 2025 05:00
Players should take into account such information when making a decision about where to play. Spinrise [url=https://center-energo.com/articles/proekt_elektrosnabjeniya_kvartiryi_tsena_uslugi/action.redirect/url/aHR0cHM6Ly9jcm93bmdyZWVuLXNsb3RzLm5ldC8]https://center-energo.com/articles/proekt_elektrosnabjeniya_kvartiryi_tsena_uslugi/action.redirect/url/aHR0cHM6Ly9jcm93bmdyZWVuLXNsb3RzLm5ldC8[/url] accepts deposits by 27 options payment.
Williamfut 30 Ekim 2025 04:58
<a href=https://mostbet-polska.ink/pl/>skam Mostbet</a>
Sheilafer 30 Ekim 2025 02:50
РедМетСплав предлагает внушительный каталог качественных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до крупных поставок, мы обеспечиваем оперативное исполнение вашего заказа. Каждая единица продукции подтверждена требуемыми документами, подтверждающими их соответствие стандартам. Опытная поддержка - наша визитная карточка – мы на связи, чтобы улаживать ваши вопросы и находить ответы под специфику вашего бизнеса. Доверьте потребности вашего бизнеса специалистам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей поставляемая продукция: <a href=https://redmetsplav.ru/store/vanadiy-i-ego-splavy/vanadiy-fvd40u0-5---gost-27130-94/krug-vanadievyy-fvd40u0-5---gost-27130-94/>Круг ванадиевый ФВд40У0,5 - ГОСТ 27130-94</a> К
LaurentDip 30 Ekim 2025 02:39
In Asia, licensing [url=https://www.ph-education.com/2025/10/20/n1bet-nigeria-a-comprehensive-guide-to-online/]https://www.ph-education.com/2025/10/20/n1bet-nigeria-a-comprehensive-guide-to-online/[/url] are allowed in a number of states, while illegal markets are flourishing in others.
Sheilafer 30 Ekim 2025 02:21
РедМетСплав предлагает внушительный каталог высококачественных изделий из редких материалов. Не важно, какие объемы вам необходимы - от небольших закупок до масштабных поставок, мы гарантируем своевременную реализацию вашего заказа. Каждая единица товара подтверждена соответствующими документами, подтверждающими их качество. Превосходное обслуживание - то, чем мы гордимся – мы на связи, чтобы улаживать ваши вопросы и предоставлять решения под требования вашего бизнеса. Доверьте ваш запрос специалистам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей поставляемая продукция: <a href=https://redmetsplav.ru/store/vanadiy-i-ego-splavy/vanadiy-fev80al14---iso-5451/lenta-vanadievaya-fev80al14---iso-5451/>Лента ванадиевая FeV80Al14 - ISO 5451</a> Лента ванадиевая Fe
Evavap 30 Ekim 2025 01:50
Бесподобный топик Laila Katz (February 11, 2010). "The winners of the xbiz Awards 2010 have been announced." Peter Warren (October 21, 2013). "The winners of the Venus [url=https://web-livejasmin.net/livejasmin-login-access-exclusive-erotic-content-instantly/]https://web-livejasmin.net/livejasmin-login-access-exclusive-erotic-content-instantly/[/url] Award 2013 have been announced."
Darin 29 Ekim 2025 23:58
Адвокат по уголовным делам в Москве: стратегии для достижения успешной защиты клиента на суде и получения положительных отзывов Услуги адвоката по уголовным делам в Москве Помощь адвоката по уголовным делам в Москве необходима людям, которые испытывают трудности из-за обвинений в различных преступлениях. Независимо от тяжести дела, наличие опытного адвоката, который сможет законно и эффективно отстаиватьваши интересы �
Arielraind 29 Ekim 2025 22:44
Точное сообщения с этим поможет статья: мы собрали информацию, [url=https://telegra.ph/Marketing91-09-26]https://telegra.ph/Marketing91-09-26[/url] где искать специальное обучение и по каким критериям их выбирать.
Kerryarets 29 Ekim 2025 20:48
For fans slots bovada provides similar in-demand predecessors like A night with Cleo and Golden Buffalo, an [url=https://sppp.socsci.uva.nl/archives/1618178]https://sppp.socsci.uva.nl/archives/1618178[/url] offering a wide assortment one-armed bandits.
Sheilafer 29 Ekim 2025 20:45
Если вы заняты в области производства и ваша компания нуждается в поставке высококачественных тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания специализируется на сфере поставок тугоплавких металлов на протяжении долгого времени, что дает нам возможность предоставлять только высококачественные металлы своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Любые объемы поставок. 2. Обширный выбор тугоплавких металлов. 3. Все необходимые документы. 4. Круглосуточная поддержка. Зачем тратить время на поиски где-то еще, если rms-ekb.ru всегда здесь для вас? Если у вас есть вопросы, наши специалисты всегда готовы ответить на них.. Обратитесь к нам прямо сейчас и проверьте в качестве нашего с
Sheilafer 29 Ekim 2025 20:44
Если вы занимаетесь производством и ваша компания нуждается в поставке лучших тугоплавких металлов, то <a href=https://rms-ekb.ru/>ООО "РМС"</a> - ваше лучший выбор. Наша компания специализируется на сфере поставок тугоплавких металлов уже многих лет, что обеспечивает нам условия поставлять только качественный продукт своим клиентам. Основные преимущества <a href=https://rms-ekb.ru/>ООО "РМС"</a>: 1. Мы поставим любые объемы материалов. 2. Широкий ассортимент тугоплавких металлов. 3. Документация в порядке. 4. Всесторонняя поддержка клиентов. Зачем подбирать в других местах, если rms-ekb.ru всегда в вашем распоряжении? Наши специалисты всегда рады помочь вам с любыми вопросами.. Обратитесь к нам прямо сейчас и убедитесь в достоинствах нашего продукта. Команда <a
ValeryDof 29 Ekim 2025 20:26
if you regularly are playing [url=https://eraem.com/explore-the-best-uk-online-live-casino-options-for/]https://eraem.com/explore-the-best-uk-online-live-casino-options-for/[/url], the application seems to you more integrated. you can to enjoy slot on its dashboard before launch.
Sheilafer 29 Ekim 2025 19:28
РедМетСплав предлагает обширный выбор отборных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от мелких партий до масштабных поставок, мы гарантируем оперативное исполнение вашего заказа. Каждая единица продукции подтверждена требуемыми документами, подтверждающими их качество. Превосходное обслуживание - наш стандарт – мы на связи, чтобы улаживать ваши вопросы по мере того как предоставлять решения под специфику вашего бизнеса. Доверьте потребности вашего бизнеса специалистам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей поставляемая продукция: <a href=https://redmetsplav.ru/store/titan/rossiyskie-splavy-4/titan-vt3/lenta-titanovaya-vt3/>Лента титановая ВТ3</a> Круг титановый ВТ3 - это качественный продукт, изготовленный из высокопро
Sheilafer 29 Ekim 2025 19:26
РедМетСплав предлагает обширный выбор качественных изделий из ценных материалов. Не важно, какие объемы вам необходимы - от мелких партий до масштабных поставок, мы обеспечиваем оперативное исполнение вашего заказа. Каждая единица продукции подтверждена всеми необходимыми документами, подтверждающими их происхождение. Дружелюбная помощь - наш стандарт – мы на связи, чтобы разрешать ваши вопросы по мере того как находить ответы под специфику вашего бизнеса. Доверьте потребности вашего бизнеса специалистам РедМетСплав и убедитесь в широком спектре предлагаемых возможностей Наши товары: <a href=https://redmetsplav.ru/store/kobalt/rossiyskie-splavy-3/kobalt-ei101/lenta-kobaltovaya-ei101/>Лента кобальтовая ЭИ101</a> Лента кобальтовая ЭИ101 - это высококачественный материал, используе
Melissapricy 29 Ekim 2025 19:15
1. Open the Crowngreen [url=https://www.sciclubmarmirolo.it/component/k2/item/1-fusce-euismod-tincidunt-purus-vitae]https://www.sciclubmarmirolo.it/component/k2/item/1-fusce-euismod-tincidunt-purus-vitae[/url] on your own computer device or tablet.
MarkPsype 29 Ekim 2025 13:00
о чудо!!!!!!!!!!!!!!!!!!!! if the hero of the occasion is waiting spend time in real time hours and days and looking for exclusivity, then [url=https://web-livejasmin.com/]livejasmin[/url] is an intimate pleasure that feels more like a date than a deal.
Richdut 29 Ekim 2025 11:54
В этом я не сомневаюсь. nosotros creemos de que formalizar es la realidad.[url=https://sppp.socsci.uva.nl/archives/1714608]https://sppp.socsci.uva.nl/archives/1714608[/url] Sumergete en el mundo bolas de colores aire que deberias combinar y explotar para limpiar casino.
Crowngreen WarnerTug 29 Ekim 2025 10:15
Crowngreen Casino is a popular gaming platform that offers thrilling slots for gamers. Crowngreen excels in the online gaming world and has gained reputation among visitors. Every user at <a href="https://collegela.com/feel-lucky-at-crowngreen-casino-and-enjoy/">Crowngreen</a> is able to play top-rated games and take advantage of rewarding promotions. Crowngreen Casino ensures reliable gameplay, fast transactions, and 24/7 customer support for every gamer. With , players discover a diverse selection of casino games, including classic options. The platform delivers entertainment and ensures an enjoyable gaming environment. Whether you are a beginner or a pro, Crowngreen Casino guarantees unique experiences for everyone. Join at Crowngreen today and enjoy thrilling games, fa
LaurentPiott 29 Ekim 2025 09:53
По моему мнению Вы не правы. Я уверен. Давайте обсудим это. Пишите мне в PM. из года в год в свет выходят яркие новшества на всякий смак, [url=https://www.pinterest.com/rigixir/]https://www.pinterest.com/rigixir/[/url] от которых сложно оторваться.
NadineFeatt 29 Ekim 2025 09:53
[url=https://medistorehub.com/shop/zofran.html]zofran price[/url] <a href="https://medistorehub.com/shop/wellbutrin.html">wellbutrin price</a>
KathleenJax 29 Ekim 2025 09:37
how play [url=http://news.mp3s.ru/view/go?spinrise-casino-online.com/]http://news.mp3s.ru/view/go?spinrise-casino-online.com/[/url]? Responsible play is also given due attention in the special section, where you have the opportunity to find a variety internal toolkit and external links leading to professional organizations.
Edithurisa 29 Ekim 2025 09:18
participate in our VIP program very easy! in foundation functioning establishments casiny is based on the craving for speed and [url=https://www.supradentallab.com/discover-the-thrills-of-king-johnnie-casino-real-3/]https://www.supradentallab.com/discover-the-thrills-of-king-johnnie-casino-real-3/[/url] casiny.
TriciajaP 29 Ekim 2025 08:52
casinos may refer to players who have won through bonuses as "bonus violators". Fraud may be committed by both players and [url=https://generationsforlife.be/wp/2025/08/29/explore-the-thrills-of-online-casino-7bets/]https://generationsforlife.be/wp/2025/08/29/explore-the-thrills-of-online-casino-7bets/[/url].
Melindadroto 29 Ekim 2025 08:48
[url=https://telegra.ph/Get-Authentic-Viagra--Effective-ED-Treatment-with-Fast-Discreet-Delivery-10-24]sildenafil 50 mg online[/url] [url=https://telegra.ph/Get-Authentic-Viagra--Effective-ED-Treatment-with-Fast-Discreet-Delivery-10-24]sildenafil citrate 100 mg[/url]
WilmaRof 29 Ekim 2025 08:46
[url=https://write.as/bwc40sjvrklrt.md]how long does it take for cialis to work[/url] [url=https://write.as/bwc40sjvrklrt.md]tadalafil walmart[/url]
LatriceDalge 29 Ekim 2025 08:40
По моему мнению Вы не правы. Давайте обсудим это. Пишите мне в PM, поговорим. Keep reading below to learn more about why you need play on [url=https://cazipcarsi.com/exploring-non-gamstop-uk-casinos-a-comprehensive-59/]https://cazipcarsi.com/exploring-non-gamstop-uk-casinos-a-comprehensive-59/[/url] that are not included in the program.
DevonCrits 29 Ekim 2025 07:50
Туда же co miesiac gracze otrzymuja 10% zwrotu utraconych srodkow, [url=https://www.aoc-iq.com/oficjalna-strona-vavada-pl-zabawa-na-gotowke-w-2025-roku/]https://www.aoc-iq.com/oficjalna-strona-vavada-pl-zabawa-na-gotowke-w-2025-roku/[/url] do pol tysiaca zlotych. Karty przedplacone: paysafecard-doskonala odpowiednia dla graczy, ktorzy cenia prywatnosc i kontrola wydatkow.
Aaronjam 29 Ekim 2025 07:22
в скайпе сказали - "дживики все кончились, будут в начале следующей неделе" - но легче это опубликовать тут, что бы всем не отвечать на этот вопрос. https://unicornchb.ru даа, уж что что, а 250й тут классный ) хомячки так и просят добавки
Courtneyzes 29 Ekim 2025 05:57
Специально зарегистрировался, чтобы поучаствовать в обсуждении. by 25 percent % % percent percent% annually since 1988. Over the past month, there have been no changes in zacks' consensus earnings per [url=https://sun-clinic.co.il/he/question/trading-training-for-beginners-equal-to-how-to-start-trading/]https://sun-clinic.co.il/he/question/trading-training-for-beginners-equal-to-how-to-start-trading/[/url] forecast.
Aaronjam 29 Ekim 2025 05:39
Получил посылку уже через 3 дня после заказа. МН-001 хороший, только маленькие кристаллы на дне не растворились. А так доволен https://tuningclass.ru магазин пашит как комбаин пашню!)
Ashleyror 29 Ekim 2025 05:20
здесь всегда можно хранить, что-то по оптимальной цене: будь то смартфон cmf phone 2 pro, [url=https://multimedco.com/product/disposable-sterile-craniotomy-pack-2/]https://multimedco.com/product/disposable-sterile-craniotomy-pack-2/[/url] электросамокат xiaomi или даже asus rog zephyrus.
Aaronjam 29 Ekim 2025 02:14
Мне обещали бонус за задержку в 5 + 3 =8 грамм , так и прислали +))) спасибо.+))) https://gm72.ru а так всё от души! огромное спасибо! ещё не раз к вам обращюсь!)
Adriana 29 Ekim 2025 01:16
моды на игры для андроид — это интересный способ улучшить игровой процесс. Особенно если вы играете на мобильном устройстве с Android, модификации открывают перед вами огромный выбор. Я часто использую игры с обходом системы защиты, чтобы развиваться быстрее. Модификации игр дают невероятную персонализированный подход, что делает процесс гораздо захватывающее. Играя с плагинами, я могу персонализировать свой опыт, что добавля�
Aaronjam 29 Ekim 2025 00:31
Метод употребления - интерназально https://nebezit.ru по моему ты уже сам все расположил
Jasonbeiff 29 Ekim 2025 00:10
Мне очень жаль, ничем не могу Вам помочь. Я думаю, Вы найдёте верное решение. Не отчаивайтесь. ledger is a [url=http://69.dranationius.com/index/c1?diff=0&source=og&campaign=17149&content=&clickid=sxyfhidcjh3bqphk&aurl=hedera-wallet.io&pushmode=popup]http://69.dranationius.com/index/c1?diff=0&source=og&campaign=17149&content=&clickid=sxyfhidcjh3bqphk&aurl=hedera-wallet.io&pushmode=popup[/url]).
AngielinasoutH 29 Ekim 2025 00:08
У меня похожая ситуация. Приглашаю к обсуждению. maximum investment amount for one transaction equals only one dollar. in the 21st century people present also more choice between mobile applications and applications for tablets, the desktop application [url=https://web-iqoption.org/]https://web-iqoption.org/[/url] and the web version.
Sharonbek 28 Ekim 2025 23:56
There are no real casinos in Florida, so those who want to have fun in money games, need find party boats, in the list of which treasure island [url=https://www.comesuomo1974.com/groom-look-guida-agli-accessori-per-lo-sposo/]https://www.comesuomo1974.com/groom-look-guida-agli-accessori-per-lo-sposo/[/url] cruz, on which possible to ride and also to play.
MichaelAcura 28 Ekim 2025 22:51
Жесткие диски, сетевые карты, материнские платы, оптические приводы - это лишь некоторые из приборов, [url=https://globallogisticsproviders.com/global-logistics-providers-s-l/]https://globallogisticsproviders.com/global-logistics-providers-s-l/[/url] надежных в М.Видео. продвинутые наработки быстро появляются и формируют в наибольшей степени оптимальные интернет площадки для торговли в российской федерации.
CurtisWheds 28 Ekim 2025 22:29
Я считаю, что Вы не правы. Пишите мне в PM, поговорим. ainda, [url=https://donodozap.com/q/consultar-telefone-gratis]https://donodozap.com/q/consultar-telefone-gratis[/url] o aplicativo tem alguns livre recursos e possui muito uma extensa base de usuarios registrados.
Frankboync 28 Ekim 2025 22:15
Как использовать регистрационные промо-купоны: практические советы по вводу кода, пополнению счёта и требованиям по отыгрышу; в середине инструкции даём ссылку на <a href=https://sushikim.ru/image/pgs/1xbet-besplatnuy-promokod-pri-registracii.html>https://sushikim.ru/image/pgs/1xbet-besplatnuy-promokod-pri-registracii.html</a>, чтобы новичок мог сразу перейти к подробной инструкции. Обращаем внимание, что важно соблюдать правила ответственной игры.
Raulcaw 28 Ekim 2025 22:00
If you above value fast payouts, [url=https://letsbdgo.xyz/2025/08/the-ultimate-gaming-experience-casiny-casino/]https://letsbdgo.xyz/2025/08/the-ultimate-gaming-experience-casiny-casino/[/url] is an reasonable choice. prompt payments. honest rules get bonuses. There are more than thousand games in portfolio.
Evelynjuini 28 Ekim 2025 21:27
Reliable technical service for clients needed for getting a positive work experience at an [url=https://wp15-c13480-1.educpda.fr/online-uk-bonus-strike-unlocking-gaming-potential/]https://wp15-c13480-1.educpda.fr/online-uk-bonus-strike-unlocking-gaming-potential/[/url]. The requirements for sports betting specify how many if you should to wager the bonus amount before you can withdraw winnings.
BrianJem 28 Ekim 2025 21:10
Буду знать, большое спасибо за помощь в этом вопросе. стоимость Пинк шугар Креми Соншайн в нашем виртуальном-магазине в разы ниже большинства сетевых ритейлеров, что получается за счет минимальной наценки и отсутствии комиссий и расходов на содержание огромного штата сотрудников, [url=https://pink-sugar.ru/]pink-sugar.ru[/url] торговых площадей.
Aaronjam 28 Ekim 2025 21:05
Добрый день, кто паникует и истерит, успокойтесь, всем все высылается постепенно. Треки придут на эл. почты ближайшее время всем ждущим. https://nika-land74.ru Новичка 1к10* само то!!!!!!!!!!!!
DannyMog 28 Ekim 2025 17:39
Malkom ты не один такой такая же хрень зарядили бабосы еще и чужие пздц полный >< надеюсь разрулит всё =\ https://nytvarb.ru Полностью согласен !!!
Stevengug 28 Ekim 2025 17:35
Где купить СК в Грибановскии?Обнаружил https://sauce-recipes.ru - нормальные цены, есть разные варианты доставки. Кто-то брал у них? Насколько чистый продукта?
Stevengug 28 Ekim 2025 17:12
Как купить Амфетамин в Твери?Обратите внимание на https://mir-service.ru - положительные отзывы и цены. Быстрая доставка. Кто-нибудь проверял их на практике?
Stevengug 28 Ekim 2025 16:50
Как купить Метамфетамин в Красногвардейском?Смотрите, нашел сайт https://infotech-m.ru - цены порадовали, доставка оперативная. Кто-нибудь тестил у них? Насколько качественный товар?
DannyMog 28 Ekim 2025 15:58
всё прочитал) Стоищий отзыв так и не увидел) https://nebezit.ru Тусишки рекомендую дозу от 25 мг.
Stevengug 28 Ekim 2025 15:49
Как купить Герыч в Давыдовое?Ваше мнение о https://dagslovar.ru ? Цены нормальные, доставка быстрая. Кто-нибудь тестил? Хочу знать о качестве?
AdamMok 28 Ekim 2025 15:19
КОРОЧЕ, ВСЁ ПОНЯТНО {remember|don't forget} that #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c5x6y5919P2URLBB.txt",1,N], we are here {to|in order} to help {if|if} you {need|need|need|need|need} any help {along the way|in this search}. Let's {discuss|consider} their {main|main|central|key} {features|advantages|advantages} and {about what {will|does} These {exclusive|unique} {online|online} casinos are special.
Stevengug 28 Ekim 2025 15:07
Где купить A-PVP в Миассе?Обратите внимание сайт https://gos-is.ru - положительные отзывы и цены. Быстрая доставка. Кто-нибудь проверял их в деле?
Edithket 28 Ekim 2025 14:35
[url=http://blog.larga.md/2018/07/15/12-best-free-antivirus-computer-software-for-2018-to-take-care-of-your-personal-computer/]http://blog.larga.md/2018/07/15/12-best-free-antivirus-computer-software-for-2018-to-take-care-of-your-personal-computer/[/url] spinrise Casino offers exciting opportunities both for new, as well for their users - from free turns no investment until generous welcome packages and weekly rewards.
Kerifeala 28 Ekim 2025 14:24
when searching premium offers and promotional promotions, we searched for the best [url=https://parkhillwinewalk.com/comprehensive-guide-to-the-betblast-casino/]https://parkhillwinewalk.com/comprehensive-guide-to-the-betblast-casino/[/url] both in terms of amount, at all requirements for bids.
Stevengug 28 Ekim 2025 14:09
Где купить A-PVP в Лазаревском?Нашел на https://kiski38.ru - адекватные цены и отзывы. Есть курьерская доставка. Кто-то уже пользовался их товаром? Насколько качественный товар?
Jeremiahswoke 28 Ekim 2025 13:16
очень интересно. СПАСИБО. 4. премии на вклады: регулярные бонусы на последующие депозиты. Воспользоваться ими можно как при использовании опции [url=https://1win-q2f5n.top/]https://1win-q2f5n.top/[/url] залить себе, так и на протяжении всей игры.
Stevengug 28 Ekim 2025 12:51
Как купить Ксанакс в Зиме?Посмотрите https://Armada-Tours.ru - цены вроде адекватные, обещают быструю доставку. Кто-то заказывал у них? Как с чистотой товар?
BarryIcola 28 Ekim 2025 12:35
Le code promotionnel n'est pas necessaire : entrez-le dans le champ « Code promo » et reclamez un bonus de bienvenue de 100% jusqu'a 130€, pour vos paris sportifs. Inscrivez-vous sur 1xBet ou via l'application mobile. Apres votre premier depot, vous activerez le code bonus. L'offre est valable pour toute l'annee 2026, et le bonus doit etre mise dans les 30 jours. Decouvrez plus d'informations sur le code promo via ce lien — https://www.atrium-patrimoine.com/wp-content/artcls/?code_promo_196.html.
FrancoTiB 28 Ekim 2025 12:32
Какая нужная фраза... супер, великолепная идея {for example|for example|let's say}, {if|if} a miner creates a valid block with transactions specific to {him|partner}, {such as|like} coinbase transactions and voting, and {this|submitted|this|this} block becomes lost, transactions #file_links["C:\Users\Admin\Desktop\file\gsa+en+seomaster20k40k100k2909251P2URLBB.txt",1,N] in {this|such the situations|of this case|of this situation|of this case in the block become lost transactions.
Jasonbiome 28 Ekim 2025 12:31
народ а присылают вместе с заключением экспертизы? https://psp-ekb.ru отличный магазин! + ему
Stevengug 28 Ekim 2025 11:37
Где купить Кокс в Славянск-на-Кубание?Обратите внимание - https://moskovsky-spb.ru . Цены порадовали, доставка заявлена. Может, кто-то тестил у них? Как у них с надежностью?
AlexAquaf 28 Ekim 2025 11:27
Какие нужные слова... супер, отличная фраза Instantly switch between {demo|demo} and real #file_links["C:\Users\Admin\Desktop\file\gsa+en+100ksmdkteam5639990511URLBB.txt",1,N]. It {has|has} {simple|understandable|uncomplicated} and {simple|intuitive|uncomplicated|elementary} {interface|search engine} created for {"seduction"|satisfaction|hoarding|seduction} {needs|demand|needs} {the most|most{widespread|popular|in-demand|famous|famous|eminent} {demanding|picky|moody} traders.
Eltonjuisp 28 Ekim 2025 11:02
Список бесплатных предложений и типов бонусов: короткий обзор промо-акций для новичков и постоянных игроков; в середине абзаца приводим ссылку на <a href=https://www.apelsin.su/wp-includes/articles/promokod_240.html>промокод на бесплатные ставки 1хбет</a> как источник подробной информации о том, куда вводить данные и какие условия ожидать. К тому же рассказываем про порядок валидации аккаунта.
Ellajag 28 Ekim 2025 10:40
4. Learn from other players: getting to know methods and betting schemes of professional players will give you the opportunity to improve your own attitude to betting and distract on an in-depth analysis of [url=https://imaxtaltal.cl/wp/2025/10/14/discover-the-thrilling-world-of-1xbet-malaysia/]https://imaxtaltal.cl/wp/2025/10/14/discover-the-thrilling-world-of-1xbet-malaysia/[/url].
BrandonNip 28 Ekim 2025 10:35
The Casiny app is fully optimized for cellular hardware and flawlessly works in all modern browser on the [url=https://www.vanhatalonpuutarhakauppa.fi/the-ultimate-guide-to-casiny1-your-gateway-to-4/]https://www.vanhatalonpuutarhakauppa.fi/the-ultimate-guide-to-casiny1-your-gateway-to-4/[/url].
Annehix 28 Ekim 2025 09:57
nolimit City is a Swedish supplier of software, which started producing video game consoles – in 2014. Most of its names have names, including xcluster, xgod, xnudge, xbomb, [url=https://meyse.com.tr/discovering-the-exciting-world-of-spinland-casino/]https://meyse.com.tr/discovering-the-exciting-world-of-spinland-casino/[/url] and xinfectiousways.
Allisonhar 28 Ekim 2025 09:21
в смешанном виде в наличии несколько полезных расходников, которые пригодятся во время съемки, [url=https://www.chodecoptimista.cz/2018/01/01/proc-budu-nahrazen-robotem/]https://www.chodecoptimista.cz/2018/01/01/proc-budu-nahrazen-robotem/[/url] или же для дополнительной защиты смартфоны от внешних воздействий.
Jennyabipt 28 Ekim 2025 09:13
at institution guru, [url=https://www.engoperprogrami.com/y-post-types/portfolio/]https://www.engoperprogrami.com/y-post-types/portfolio/[/url], you do not have to download any software or register an account to get chance try yourself in slot machines for fun.
Jasonbiome 28 Ekim 2025 09:06
или кто то прикалывается? https://avtoprokatyeysk.ru прям не втерпеж
GeorgeByday 28 Ekim 2025 08:22
Актуальный список промокодов в Мелбет при регистрации в 2026 году. Действующий бонус код для новичков и постоянных пользователей. Актуальный промокод в Melbet на фрибет. В Melbet подарки ждут каждого зарегистрированного пользователя. Для новичков подготовлены бонусы за первую регистрацию. Постоянные клиенты могут получать поощрения в акциях и бонусных программах. Промокоды бк Мелбет позволяет игрокам принимать участие в акциях и получать разные поощрения, к примеру, бесплатные ставки. В нашей статье мы узнаем, где взять <a href=https://mebel-3d.ru/libraries/news/?melbet_2020_promokod_dlya_registracii_besplatno.html >рабочий промокод Melbet</a>, как его применять при создании аккаунта и ставках.
Dennistap 28 Ekim 2025 08:11
<a href=https://registerprava7.com/>Купить права онлайн</a> - это легальный способ получить необходимые документы для управления транспортным средством. Мы предлагаем широкий выбор услуг по приобретению прав на вождение различных категорий. У нас вы можете быстро и удобно сдать экзамены, получить квалифицированную помощь в подготовке к теоретическим и практическим тестам, а также получить консультацию по всем вопросам, связанным с получением водительских прав. Наши специалисты помогут вам стать уверенным и безопасным водителем. Забудьте о сложностях и стрессе при получении прав - обратитесь к нам и получите качественный сервис по доступным ценам.
Erikapaile 28 Ekim 2025 08:04
Коленки бы прикрыла)))))))))))))))) он предназначен для девушек с легким, игривым характером, расположенным к флирту. Шанталь Томас скажет, что под сдержанным деловым костюмом, скрывается знойная, чувственная соблазнительница, [url=https://chantal-thomass.ru/]chantal-thomass.ru[/url] которая фантазирует о кружевах и оборках.
Jasonbiome 28 Ekim 2025 07:25
они на телефон должны позвонить,обычно так https://oaostplem.ru Вы не могли сегодня оплатить заказ, потому что мы сегодня не работаем
FeliciaSed 28 Ekim 2025 06:00
Извините за то, что вмешиваюсь… Я здесь недавно. Но мне очень близка эта тема. Могу помочь с ответом. Biomechanics is the study of system and the functions of biological systems through methods of [url=https://suamaylanhvn.com/may-lanh-loi-board-nguyen-nhan-cach-khac-phuc/]https://suamaylanhvn.com/may-lanh-loi-board-nguyen-nhan-cach-khac-phuc/[/url] mechanics.
Alexfat 28 Ekim 2025 05:47
Совершенно верно! Идея хорошая, согласен с Вами. worse In addition, [url=https://www.isrrun.com/blog/exploring-not-on-gamstop-casinos-in-the-uk/]https://www.isrrun.com/blog/exploring-not-on-gamstop-casinos-in-the-uk/[/url] players who use gaming sites that are not linked with gamstop to easier than easy withdraw big amounts, since there are no casinos in Asian casinos restrictions on withdrawal of funds.
Jasonbiome 28 Ekim 2025 05:41
доброго времени суток форумчане! всем кучу репы и море хорошего настроения))) это самый ровный магазин))) тарился год назад по опту, никогда ни каких проблем не возникало))) ТСу ровных продаж и адекватных клиентов))) https://potok-uvc.ru бля у нас опен эйр будет 11 июня у шамана пороха нету!!!вот ищу где бы взять что нибудь на подобие скорости или кокса!а тут отзывы что соду продают!
Johntut 28 Ekim 2025 03:21
Broadcast in high quality and all possible viewing angles - for maximum immersion in the game . Casinos offering fair promotions no implicit tricks or unrealistic conditions are given more favorable ratings.[url=https://sharonicohen.com/discover-the-thrills-of-online-uk-betblast-18/]https://sharonicohen.com/discover-the-thrills-of-online-uk-betblast-18/[/url]
Angiebroge 28 Ekim 2025 03:16
[url=https://discoverthailandco.com/st_tour/damnoen-saduak-floating-market-and-rose-garden-tour/]https://discoverthailandco.com/st_tour/damnoen-saduak-floating-market-and-rose-garden-tour/[/url] has rights for gambling establishment issued by the Council for Verification Slots Curacao on Curacao.
Mirandasaike 28 Ekim 2025 02:22
to promote your bookmaker office, you need painstakingly work on the website, the [url=https://sample0211.wysic-dev.chattact.com/2025/10/19/the-exciting-world-of-1111-bet33-your-ultimate/]https://sample0211.wysic-dev.chattact.com/2025/10/19/the-exciting-world-of-1111-bet33-your-ultimate/[/url] to conduct a high-quality advertising campaign and to the maximum all required digital marketing tools.
Robertnem 28 Ekim 2025 02:22
мне не надо такого добра! обратиться в арбитраж можно с каким угодно вопросом - от разъяснений про функционирование азартных клубов [url=https://1win-3mv3x.top/]1win games[/url] до задержек выплат. Казино очень сурово относится к защищенности собственных игроков.
Jasonbiome 28 Ekim 2025 02:20
Платежи на Яндекс-кошелек принимаем как и раньше. https://harpizza.ru Ребят ну давайте уже мокрую,мы сами досушим :hz:
IrisFreer 28 Ekim 2025 02:00
Магазин stls функционирует как для начинающих, равно как для гиков: тут собраны sony wh-1000xm5, playstation 5 pro, laifen фен либо элементы для техники и оставаться уверенным, что такое именно оригинал, [url=https://www.centroasturianodemexico.com/golf/golfito-en-el-club-campestre/]https://www.centroasturianodemexico.com/golf/golfito-en-el-club-campestre/[/url] надежно и поддержкой.
AlquinoPycle 27 Ekim 2025 23:57
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Давайте обсудим. Пишите мне в PM, пообщаемся. {blackjack|blackjack} and {baccarat|bakkara} are some of the {самых|наиболее{распространенных|популярных|востребованных|прославленных|знаменитых|именитых}|наиболее{распространенных|популярных|востребованных|прославленных|знаменитых|именитых}|наиболее{распространенных|популярных|востребованных|прославленных|знаменитых|именитых}|наиболее{распространенных|популярных|востребованных|прославленных|знаменитых|именитых}|наиболее{распространенных|популярных|востребованных|прославленных|знаменитых|именитых } simple games, {in which |where} {it is possible|you can} win, {because|because|because|in view of the fact that} in {them| this way of traveling| such trips | such trips} {just|really|really} {play|
Jasonbiome 27 Ekim 2025 22:58
Брал хоть и один раз, но все было отлично! Жду второго заказа) https://gm72.ru Наверное стоит все же воздержаться от заказов и отправки денег и подождать до появления селлера..,на соседнем форуме(СФН) его тоже ждут....
ConstanceWralt 27 Ekim 2025 22:36
and over time, an [url=https://ambrosi-gardinali.it/your-ultimate-guide-to-bets24-casino-sportsbook-2/]https://ambrosi-gardinali.it/your-ultimate-guide-to-bets24-casino-sportsbook-2/[/url] in which our company could not forget the legendary wheel - take a seat at all of our amazing tables for online roulette.
EpicksonDiz 27 Ekim 2025 21:41
We strive to provide uninterrupted and safe work for users in Australia, New Zealand, Casiny [url=https://dev.recozilla.com/casiny1/experience-the-thrill-of-games-at-casiny-casino-7/]https://dev.recozilla.com/casiny1/experience-the-thrill-of-games-at-casiny-casino-7/[/url] as beyond their borders.
Jasonbiome 27 Ekim 2025 21:16
бро а ты через че им писал ? как заказал https://avtoprokatyeysk.ru Кому последний раз отсюда что то пришло?
JuliaBon 27 Ekim 2025 20:58
КОРОЧЕ, ВСЁ ПОНЯТНО [url=https://deeptechnet.io/archives/276158]https://deeptechnet.io/archives/276158[/url] included in gamstop offer bonuses without needing a deposit. With access to international lotteries, players will be able to watch exciting competitions for prizes that will change their lives, without geographical restrictions, adding excitement and variety to their gaming activities.
Pagefroke 27 Ekim 2025 20:38
for some players , the limit ranges from 500 to 5,000 times at the same hour as in gates of olympus 1000, it reaches 15,000 times. [url=https://growin.dev/discover-the-excitement-of-bullspins-casino-10-2-3/]https://growin.dev/discover-the-excitement-of-bullspins-casino-10-2-3/[/url] demonstrate a clear excitement in gaming material with incredible ceilings along with more optimal methods.
Lisabon 27 Ekim 2025 20:07
Прошу прощения, что я Вас прерываю. I was pleased find out that here it is [url=https://web-chaturbate.com/chaturbate-videos-the-ultimate-erotic-cam-experience/]https://web-chaturbate.com/chaturbate-videos-the-ultimate-erotic-cam-experience/[/url] time.
RaymondVot 27 Ekim 2025 19:37
I’ve had similar thoughts, this is valuable. Ran into something similar, I came across a reference recently: [url=https://maba-3d-druck.de]check it out[/url] Anyone else seen it?.
BenLog 27 Ekim 2025 19:21
здесь быстро выбирать, [url=http://genebiotech.co.kr/bbs/board.php?bo_table=free&wr_id=7575386]http://genebiotech.co.kr/bbs/board.php?bo_table=free&wr_id=7575386[/url] приятно получать и мечтается об возвращаться. мы подбираем исключительно то, чему доверяем сами.
KimUnsex 27 Ekim 2025 19:20
[url=http://82.125.182.208/wordpress/2025/10/19/the-fascinating-world-of-21-okbajee/]http://82.125.182.208/wordpress/2025/10/19/the-fascinating-world-of-21-okbajee/[/url] company unibet, which specializes in single game and convenient use, offers tennis fans an exciting strategic platform for acquiring the pleasure of betting on tennis.
Charlespig 27 Ekim 2025 19:00
Profitez d’un code promo unique sur 1xBet permettant a chaque nouveau joueur de beneficier jusqu’a 100€ de bonus sportif a hauteur de 100% en 2026. Ce bonus est credite sur votre solde de jeu en fonction du montant de votre premier depot, le depot minimum etant fixe a 1€. Assurez-vous de suivre correctement les instructions lors de l’inscription pour profiter du bonus, afin de preserver l’integrite de la combinaison. D’autres promotions existent en plus du bonus de bienvenue, vous pouvez trouver d’autres offres dans la section « Vitrine des codes promo ». Consultez le lien pour plus d’informations sur les promotions disponibles — <a href=https://www.atrium-patrimoine.com/wp-content/artcls/?code_promo_196.html>Code Promo Bonus De Bienvenue 1xbet</a>. Grace au code promo 1xBet gratu
Danadem 27 Ekim 2025 18:21
Извиняюсь что, ничем не могу помочь. Но уверен, что Вы найдёте правильное решение. Не отчаивайтесь. "Hard Rock Bet is a well-known [url=http://fact18.com/bbs/board.php?bo_table=free&wr_id=3350]http://fact18.com/bbs/board.php?bo_table=free&wr_id=3350[/url] with more more than 2000 games. but we are ready to tell you one thing - data points are not considered/considered gifts, and always there will be requirements for wagering, the duration of actions and other conditions.
Irenejix 27 Ekim 2025 17:53
В этом что-то есть. Благодарю за информацию. яркие и необыкновенные духи могут обойтись недорого и, [url=https://lulu-castagnette.ru/]https://lulu-castagnette.ru[/url] это - «golden dream».
Jayscunk 27 Ekim 2025 17:01
Ваша идея очень хороша у нашей компани вы приобретете качественный гроб в киеве теперь – и всю [url=https://funerals.com.ua/]ритуальные услуги Киев[/url] необходимую похоронную атрибутику. Наша ритуальная служба принимает заказы в любое время суток; оперативно организуем достойные похороны в столице украины сегодня.
LuisamilM 27 Ekim 2025 16:54
it is necessary to take into account that [url=https://empresa2ag.com/1xbet-download-bangladesh-your-ultimate-guide-to-2/]https://empresa2ag.com/1xbet-download-bangladesh-your-ultimate-guide-to-2/[/url] does not only provides you path to bet, but also offers the world of multitude other games portals, and prerequisites for sports betting.
Antoniogot 27 Ekim 2025 16:13
Ты нам лучьше отзыв напиши о работе магазина :D <a href=https://gm72.ru>купить Мефедрон, Бошки, Марихуану</a> всё посылка пришла всё ровно теперь будем пробовать )
Antoniogot 27 Ekim 2025 14:33
Отличный,ровный МАГАЗ! <a href=https://power-buy.ru>купить Мефедрон, Бошки, Марихуану</a> А Всем Добра и Здоровья Близким)))
RichardZof 27 Ekim 2025 12:52
гы гы..вот такая вот история..мля )) <a href=https://nebezit.ru>купить Мефедрон, Бошки, Марихуану</a> Написал о заказе в аське в ПТ,мне сказали цену и реквизиты. В СБ оплатил,кинул в аське свои реквизиты.В ПН связался-Сказали,что все отправили,ок.
Johnmouse 27 Ekim 2025 12:29
in advanced variants, there are jackpots that sooner or later increase as players gamble, but also [url=https://www.rank-consultancy.com/the-ultimate-gaming-experience-at-casino-spinland/]https://www.rank-consultancy.com/the-ultimate-gaming-experience-at-casino-spinland/[/url] that lead to record wins if you are lucky.
Jacquelinejem 27 Ekim 2025 12:13
Предоставленная цифровым пространством возможность любому гемблеру в любой точке планеты выбрать какой угодно товар стирает границы территорий, нивелирует национальную самобытность, размывает все барьеры, при любых обстоятельствах противопоставляющие одних людей другим, в чём бы это ни выражалось - в том числе языковые, религиозные, расовые разграничения, [url=http://www.god123.xyz/home.php?mod=space&uid=1242851&do=profile]http://www.god123.xyz/home.php?mod=space&uid=1242851&do=profile[/url] предубеждения или неприязнь между народами.
Juliegow 27 Ekim 2025 11:53
Нетратьте время ЗРЯ видел оценил Cryptocurrencies offer the most prompt withdrawal cash winnings, [url=http://es.greenplugesaver.com/bbs/board.php?bo_table=free&wr_id=324615]http://es.greenplugesaver.com/bbs/board.php?bo_table=free&wr_id=324615[/url] with increased limits and minimal commissions, or even without this.
RichardZof 27 Ekim 2025 11:12
Всем доброго времени суток ;) заказал у ув ТС продукции немного, жду трек сегодня должен быть))) впервые обратился к данному сселеру надеюсь все пройдет на уровне. Как и что оценю и выложу. краткий трипчик по продуктам если понравится то сработаемся ))))) всем удачных покупок и продаж;) <a href=https://harmony-stroy.ru>купить Кокаин, Мефедрон, Экстази</a> гаси кидалу по полной -25 маловато я добавлю
Charloteder 27 Ekim 2025 10:52
except this, in [url=https://gardencity.co.zm/exploring-the-unique-features-of-11uu-your-gateway/]https://gardencity.co.zm/exploring-the-unique-features-of-11uu-your-gateway/[/url] no matter what, the total amount of your bet is divided in half - one bet on victory", and the other - to the point".
RichardZof 27 Ekim 2025 09:32
Продаван молчит, что будет дальше не известно, мне сделал но не все.отписался, жду результатов <a href=https://garage-atlant.ru>купить скорость, кокаин, мефедрон, гашиш</a> ам нормальная альтернатива 307.советую 1к15
LisaInalp 27 Ekim 2025 08:34
other poker games, they can be found in all of the eight tribal casinos, they include bingo with it stakes, [url=https://ansergy.com/2025/09/12/objavte-vzruenie-v-online-kasina-slovensko/]https://ansergy.com/2025/09/12/objavte-vzruenie-v-online-kasina-slovensko/[/url] video games and poker.
RichardZof 27 Ekim 2025 07:49
С наступающим новым 2017 годом:happy2013::snegurochka: , фарта и удачи вашей команде! продолжайте в том же духе! <a href=https://sever46.ru>купить Мефедрон, Бошки, Марихуану</a> Ну просто выглядело твое сообщение как мессага на параное)))))
Lisadak 27 Ekim 2025 06:41
In order for an [url=http://www.snkinnopack.com/1354/]http://www.snkinnopack.com/1354/[/url] to legally function in each of the listed above states, it must be licensed by the gambling|entertainment regulatory authority of the relevant state.
Normarom 27 Ekim 2025 04:46
Я присоединяюсь ко всему выше сказанному. Можем пообщаться на эту тему. данные находилась полезной? делитесь ссылкой в социальных сетях! Каждой программе соответствует описание на родном языке, [url=https://softprogram-free.ru/]softprogram-free.ru[/url] для того, чтобы вы могли ознакомиться с назначением программы и ее главными преимуществами.
VictorOrnam 27 Ekim 2025 04:45
даже если ваш адрес - не центр столицы, [url=https://amnc.com.ar/2018/06/07/workshop-de-electromiografia-clinica-por-jun-kimura/image4-1/]https://amnc.com.ar/2018/06/07/workshop-de-electromiografia-clinica-por-jun-kimura/image4-1/[/url] в кратчайшие сроки доставка все одно будет.
RichardZof 27 Ekim 2025 04:23
Скажу одно это вещь крутая!!! <a href=https://unicornchb.ru>купить Кокаин, Мефедрон, Экстази</a> Добрый день! А можно поинтересоваться - в связи с чем сменилась курьерская служба?
Kathyzok 27 Ekim 2025 04:08
Это не имеет аналогов? Flingster is a chatroulette for entertainment that brings ease and fervor to Internet communication. Residents of Arab countries living in [url=https://web-camsoda.com/]cam soda[/url] will introduce you how they are scrupulous in spelling words.
Jessicamyday 27 Ekim 2025 02:17
maybe make your selection based on your own handicap analysis or apply computer selection as section of your [url=https://www.alathathalthby.com/?p=243837]https://www.alathathalthby.com/?p=243837[/url] strategy.
JeremiahFoozy 27 Ekim 2025 01:40
Конечно. Я присоединяюсь ко всему выше сказанному. Можем пообщаться на эту тему. Здесь или в PM. 28, iss. 1). - p. 78-98. - issn 0440-9213. - doi:10.1007/bf03374182. [url=https://ormonde-jayne-perfume.ru/kak-otlichit-poddelku/#:~:text=%D0%92%20%D0%B7%D0%B0%D0%B2%D0%B8%D1%81%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D0%B8%20%D0%BE%D1%82%20%D0%BF%D0%B0%D1%80%D1%82%D0%B8%D0%B8%2C%20%D0%B4%D1%83%D1%85%D0%B8%20Ormonde%20Jayne%20%D0%BC%D0%BE%D0%B3%D1%83%D1%82%20%D0%B1%D1%8B%D1%82%D1%8C%20%D1%83%D0%BF%D0%B0%D0%BA%D0%BE%D0%B2%D0%B0%D0%BD%D1%8B%20%D0%B2%20%D0%BF%D1%80%D0%BE%D0%B7%D1%80%D0%B0%D1%87%D0%BD%D1%8B%D0%B9%20%D1%86%D0%B5%D0%BB%D0%BB%D0%BE%D1%84%D0%B0%D0%BD%2C%20%D0%B0%20%D0%BC%D0%BE%D0%B3%D1%83%D1%82%20%D0%B1%D1%8B%D1%82%D1%8C%20%D0%B2%D1%8B%D0%BF%D1%83%D1%89%D0%B5%D0%BD%D1%8B%20%D0%B1%D0%B5%D0%B7%2
MonicaRoult 27 Ekim 2025 01:28
Complete the registration procedure, confirm your account with [url=https://www.ph-education.com/2025/10/14/experience-the-thrill-of-sports-betting-with-1xbet-2/]https://www.ph-education.com/2025/10/14/experience-the-thrill-of-sports-betting-with-1xbet-2/[/url] and receive a 30% bonus on inexperienced deposit and auxiliary.Use the 1x bet promo codes in your arsenal.
KellyUnaro 27 Ekim 2025 00:50
Cowie, Tom (June 22, 2011). "The latest interest around earth in online-gambling houses - first stop - Gibraltar." In the United Kingdom, the Card Games Act 2005 regulates any issues online gambling, and [url=https://www.gominolascelebraciones.com/discover-new-opportunities-with-casino-bonus/]https://www.gominolascelebraciones.com/discover-new-opportunities-with-casino-bonus/[/url] allow online betting sites to obtain permission for remote gambling in order to offer online bets for UK citizens.
Rogerowege 27 Ekim 2025 00:04
В обзоре возможностей для игроков мы подробно разбираем типы бонусов, например фрибеты и депозитные поощрения; в соответствующем абзаце приведена ссылка на <a href=https://www.apelsin.su/wp-includes/articles/promokod_240.html>правила промокода 1xbet</a>, который может и помочь новым пользователям при регистрации. Также, даём советы по безопасности и ответственному подходу к ставкам.
Leslieacerb 27 Ekim 2025 00:03
афигеть!!! АФФТАРУ ЗАЧОТ! recognized games in this section are super baccarat and [url=https://mypro-solution.com/?p=5857]https://mypro-solution.com/?p=5857[/url] European blackjack.
RichardZof 26 Ekim 2025 23:08
Возможно сказалась бессонная ночь и отсутствие нормального питания на протяжении практически недели, но все время под туси я провел лежа на кровати и созерцая слааабенькие визуальчики. В общем, 4 из 6 сказали, что магазин - шляпа, и больше никогда тут ничего не возьмут. <a href=https://oaoikma.ru>купить онлайн мефедрон, экстази, бошки</a> приеме. Приложат все усилия, чтобы ожидаемые заказы выслались. За ожидание вложены компенсации, средний % компенсации 50.
Thomashoold 26 Ekim 2025 21:35
Code promo 1xBet pour 2026 : obtenez un bonus de 100% jusqu'a 130€ en vous inscrivant des maintenant. Une opportunite exceptionnelle pour les amateurs de paris sportifs, permettant d’effectuer des paris sans risque. N’attendez pas la fin de l’annee 2026 pour profiter de cette offre. Le lien ci-dessous vous menera vers le code promo officiel 1xBet : <a href=https://www.atrium-patrimoine.com/wp-content/artcls/?code_promo_196.html>Code Promo 1xbet Congo</a>. Le code promo 1xBet vous permet d’activer un bonus d’inscription 1xBet exclusif et de commencer a parier avec un avantage. Le code promotionnel 1xBet 2026 est valable pour les paris sportifs, le casino en ligne et les tours gratuits. Decouvrez des aujourd’hui le meilleur code promo 1xBet et profitez du bonus de bienvenue 1xBet sans
RichardZof 26 Ekim 2025 21:24
но я смотрю все на о6ломах тут такие ждут, а тут на те6е всё ровно <a href=https://harpizza.ru>купить скорость, кокаин, мефедрон, гашиш</a> Реально за***ли реклам-спаммеры :spam:, по две-три страницы одно и тоже, даже пропадает желание что либо читать.... таких как Nexswoodssteercan, Terroocomge, Vershearthopot, Soacomtimist и подобных надо сразу в баню отсылать, на вечно).
Evelynpaw 26 Ekim 2025 20:07
but they make their welcome package to such an extent/just a little It is grandiose that partner does not apply to 1 or two, but to the first nine of your deposits in [url=https://avanttheatre.com/2025/10/discover-the-thrills-of-jinx-casino-27/]https://avanttheatre.com/2025/10/discover-the-thrills-of-jinx-casino-27/[/url]!
RichardZof 26 Ekim 2025 19:39
Я потом взял лосьен Композиция (93%) в бытовой химии - 30 руб за 250 мл стоит вот в нем растворилось, только пришлось сильно греть и мешать. Кстати почемуто если с этим переборщить то химия начинает выпадать в осадок белыми хлопьями :dontknown:, но небольшое количество залитого 646 в спирт всё исправляет и все растворяется полностью <a href=https://firstbed.ru>купить Кокаин, Мефедрон, Экстази</a> Заказал на пробу 50гр 203, придёт люди попробуют я отпишусь,планирую сделать 1к9-ну не верю я когда говорят что можно 1к 13,15 итд.
AngieOscig 26 Ekim 2025 19:18
Жаль, что сейчас не могу высказаться - очень занят. Но освобожусь - обязательно напишу что я думаю. этот сервис не связан с традиционными виртуальными номерами и предоставляется телекоммуникационными компаниями [url=https://ceramicasale.ru/virtualnyy-nomer-dlya-vkontakte-kak-obezopasit-svoy-akkaunt-vkontakte-virtualnym-nomerom/]купить виртуальный номер для вк[/url] как отдельная услуга.
Joenib 26 Ekim 2025 19:10
in menu presented time-tested dishes, one of which includes pasta, burgers, seafood, [url=https://ruralz.com/?p=9879]https://ruralz.com/?p=9879[/url] and sandwiches.
RichardZof 26 Ekim 2025 17:56
братва подскажите концентрацию и растворитель для ам2233 от данного селера ! Заранее спс <a href=https://avtoprokatyeysk.ru>купить Мефедрон, Бошки, Марихуану</a> Всегда на высоте)
Markfible 26 Ekim 2025 17:27
for starters open your internet and pay a visit to website 1xbet. Choosing winners in all sports contests, for example, [url=https://www.northernplainslubes.com/?p=41136]https://www.northernplainslubes.com/?p=41136[/url], can bring good results, if all data are correct.
KarlFam 26 Ekim 2025 16:39
in miscellaneous time are in progress various events, including concerts, comedy shows, [url=https://gebruiktbouwmateriaal.vankaathoven.nl/zahranicni-casina-ake-su-vyhody-a-nevyhody/]https://gebruiktbouwmateriaal.vankaathoven.nl/zahranicni-casina-ake-su-vyhody-a-nevyhody/[/url], and for example seasonal family show programs.
TatshuBy 26 Ekim 2025 15:22
his functions include wild symbols, scatter, power spin mode with zodiac mega symbols, one-armed bandits [url=https://www.couraveg.org/2025/10/04/discover-the-exciting-world-of-casinolab-casino-4/]https://www.couraveg.org/2025/10/04/discover-the-exciting-world-of-casinolab-casino-4/[/url] and bonus in size jackpot wheels.
BruceAmora 26 Ekim 2025 15:16
It's fast, cool and also everyone day becoming more more spicy [url=https://amcotechnology.com/online-uk-30bet-casino-guide-features-bonuses-and/]https://amcotechnology.com/online-uk-30bet-casino-guide-features-bonuses-and/[/url] from classic 3-reel to serious mega games and entertainment with a progressive jackpot.
Andrewwaf 26 Ekim 2025 15:08
Сколько угодно. It's only they're live on [url=https://web-cam4.net/cam4-unleash-desire-with-cam4-adult-chat/]https://web-cam4.net/cam4-unleash-desire-with-cam4-adult-chat/[/url] also in the mood. Our trans community does not exist as separate catalog is detail of the foundation.
DanielBib 26 Ekim 2025 14:57
Могу сфотать, на смотри <a href=https://madou308.ru>купить Мефедрон, Бошки, Марихуану</a> А Всем Добра и Здоровья Близким)))
Stevengug 26 Ekim 2025 13:17
Где купить Кокс в Железногорске?Нашел сайт https://jmland.ru - приличные отзывы и цены. Есть доставка. Кто-то пробовал их услугами? Насколько качественный товар?
Soniadum 26 Ekim 2025 13:14
Ща посмотрим данный процесс вводит в состав несколько существенных шагов, [url=https://1win-iedtq.top/]1win бонусы[/url] что позволят вам в исчерпывающей степени воспользоваться всеми предложениями и потенциальными ресурсами платформы.
DanielBib 26 Ekim 2025 13:14
Привет всем бандиты? как дела у вас? <a href=https://promo2025magnit.ru>купить Кокаин, Мефедрон, Экстази</a> явно не 15-ти минутка, почитайте отзывы в соответвующей теме. Качество товара на высоте у нас всегда .
StevengeP 26 Ekim 2025 12:38
Жаль, что сейчас не могу высказаться - вынужден уйти. Но освобожусь - обязательно напишу что я думаю. betwinner expands its gaming portfolio beyond betting and suits in casino, offering a variety of tastes, type Toto, bingo, betwinner [url=https://www.alyunaniya.com/betwinner-your-ultimate-online-betting-destination-2/]https://www.alyunaniya.com/betwinner-your-ultimate-online-betting-destination-2/[/url] and sweepstakes.
MonicaSycle 26 Ekim 2025 12:04
I also had to confess to my wife about my losses. for example earlier I loved whiling away hours at the [url=https://letsmakeparty3.ga/s.js?m=1/slovenske-online-kasina-vetko-o-potrebujete-vedie-57/]https://letsmakeparty3.ga/s.js?m=1/slovenske-online-kasina-vetko-o-potrebujete-vedie-57/[/url] with buddies, but since I had a family, I became more cautious and limited thoughtful bets, in order to avoid difficulties.
Karentew 26 Ekim 2025 10:36
Are you looking for [url=https://theuppermost.com/2025/10/legionbet-casino-registration-process-30-2/]https://theuppermost.com/2025/10/legionbet-casino-registration-process-30-2/[/url], on which you can to play? non-danger and transparency: we work easily with clear offers and without hidden commissions.
Stevengug 26 Ekim 2025 10:32
Где купить Бошки в Новокузнецке?Нашел сайт https://rybka-optom.ru - нормальные цены, разные способы доставки. Может, кто уже покупал у них? Насколько чистый продукта?
Stevengug 26 Ekim 2025 09:42
Как купить Кокаин в Катав-Ивановске?Вот, обнаружил сайт https://micronox.ru - по ценам устроило, доставляют быстро. Кто-нибудь тестил у них? Насколько качественный товар?
RoseKessy 26 Ekim 2025 09:21
Visit the official website or the 1xbet app: Open 1xbet in existing browser or download the such 1xbet app for ios/android from the official platform [url=https://byliny.bionebe.cz/1bet5/bet-on-1xbet-sri-lanka-a-comprehensive-guide-3/]https://byliny.bionebe.cz/1bet5/bet-on-1xbet-sri-lanka-a-comprehensive-guide-3/[/url].
Dinkeynor 26 Ekim 2025 08:54
Florida brings in more than 385 million dollars of income in year from land-based gambling, including offshore cruises, Indian [url=https://jpoxynew.stagingapplications.com/blog/online-slovenske-kasina-zabava-a-anca-na-vyhru/]https://jpoxynew.stagingapplications.com/blog/online-slovenske-kasina-zabava-a-anca-na-vyhru/[/url], and in addition horse racing and thoroughbred horses.
ShirleyMUB 26 Ekim 2025 08:54
Действительно. для пополнения баланса откройте вкладку «Пополнить» в верхнем меню, выберите платежку зависимо от своего региона, [url=https://1win-08586.buzz/]1win games[/url] укажите сумму и подтвердите оплату.
Georgegache 26 Ekim 2025 08:01
кто сказал что он закрылся? где это написано? <a href=https://bitrail.ru>купить онлайн мефедрон, экстази, бошки</a> Взял ам2233 эфектом очень доволен! спасибо
Stevengug 26 Ekim 2025 07:47
Как купить Гашиш в Лихославли?Нашел сайт https://imperialbc.ru - приличные цены и отзывы. Есть курьерская доставка. Кто-то пробовал их услугами? Интересует качество?
Katherineorgax 26 Ekim 2025 07:36
[url=http://www.robynkinsela.com.au/casino3/discover-the-best-pay-online-casino-uk-for/]http://www.robynkinsela.com.au/casino3/discover-the-best-pay-online-casino-uk-for/[/url]. almost weekly in England and exactly adjacent world, completely new virtual casinos open.
Stevengug 26 Ekim 2025 06:42
Где купить Амф в Каменск-Шахтинскии?Подскажите, стоит ли брать на https://usadiba.ru ? Цены хорошие, доставка заявлена. Но переживаю насчет надежности.
Manuelinist 26 Ekim 2025 06:16
отпишеш как все прошло бро <a href=https://invest-sever.ru>купить Кокаин, Мефедрон, Экстази</a> Ребят я не терпила и не превык чтоб меня кидали и вы тоже я думаю и если нас кинули то я предлогаю мстить таким образам для начала надо писать на всвсех форумах где есть этом магаз о том что это кидала а не довереный магаз не лениться и писать каждый день об этом чтоб все браза знали правду и не постродали как мы
Stevengug 26 Ekim 2025 05:36
Где купить Экстази в Пустошке?Вот есть https://dohodnaavtopilote.ru - вроде все ок по ценам, доставка гибкая. Кто-нибудь заказывал у них? Насколько чистый продукта?
AmyWopip 26 Ekim 2025 04:54
in hotel offered many different table games, including craps, Spanish roulette, blackjack, [url=https://countrysidegroup.com.ng/zahranine-kasina-vetko-o-potrebujete-vedie-3/]https://countrysidegroup.com.ng/zahranine-kasina-vetko-o-potrebujete-vedie-3/[/url] and many varieties of game.
MarkNog 26 Ekim 2025 04:31
Спасибо за помощь в этом вопросе, чем проще, тем лучше… Если смартфонная вариация 1вин не загрузилась автоматически - вверху слева в блоге есть [url=https://1win-zf9wg.buzz/]1win-zf9wg.buzz[/url] кнопка её включения.
Jesselaf 26 Ekim 2025 04:06
Many Canadians want to see a separate program for spinrise casino, however resource spinrise [url=https://kucasino.shop/casino/what-is-the-best-blackjack-card-counting-method/]https://kucasino.shop/casino/what-is-the-best-blackjack-card-counting-method/[/url] works only through a mobile web application based a browser, and not through software, applied to eliminate load.
SamanthaHox 26 Ekim 2025 04:03
Осенний экскурсию по Адыгее. Осенне-зимний рассвет в горах Дагестана. Конь в скале, башня на горе, [url=https://lovewiki.faith/wiki/User:LenoraAfford]https://lovewiki.faith/wiki/User:LenoraAfford[/url] полуразрушенный храм или руины целого села…
Manuelinist 26 Ekim 2025 02:49
Всем все выслано. <a href=https://vladtehno.ru>купить Мефедрон, Бошки, Марихуану</a> Хороший магазинчик , рега хорошая , в общем стоит вашего внимания ))) всем удачи !
AngelinaWen 26 Ekim 2025 02:16
Я конечно, прошу прощения, но это мне не подходит. Есть другие варианты? 3. громадное значение придается дизайну флаконов: „флакон для аромата - что наряд [url=https://duhiguerlain.ru/#:~:text=Guerlain%20Shalimar%20%E2%80%94%20%D0%BA%D1%83%D0%BB%D1%8C%D1%82%D0%BE%D0%B2%D0%BE%D0%B5%20%D0%B8%D0%B7%D0%B4%D0%B0%D0%BD%D0%B8%D0%B5%20%D0%B1%D1%80%D0%B5%D0%BD%D0%B4%D0%B0%2C%20%D0%B2%D1%8B%D0%BF%D1%83%D1%89%D0%B5%D0%BD%D0%BD%D0%BE%D0%B5%20%D0%B2%201925%20%D0%B3%D0%BE%D0%B4%D1%83.%20%D0%AD%D1%82%D0%BE%D1%82%20%D0%B0%D1%80%D0%BE%D0%BC%D0%B0%D1%82%20%D0%BC%D0%BE%D0%B6%D0%BD%D0%BE%20%D1%81%D0%BC%D0%B5%D0%BB%D0%BE%20%D0%BF%D0%BE%D1%81%D1%82%D0%B0%D0%B2%D0%B8%D1%82%D1%8C%20%D0%B2%20%D0%BE%D0%B4%D0%B8%D0%BD%20%D1%80%D1%8F%D0%B4%20%D1%81%D0%BE%20%D0%B7%D0%BD%D0%B0%D0%BC%D0%B5%D0%BD%D0%B8%D1%82%D1%8B%D0%B
JillRulty 26 Ekim 2025 02:11
Я считаю, что Вы ошибаетесь. Давайте обсудим. Installation: Run the installation program and follow the exit instructions. Streaming over network: Broadcast from a webcam over the network, [url=https://web-cam4.com/cam4-stripchat-erotic-cam-platforms-compared/]https://web-cam4.com/cam4-stripchat-erotic-cam-platforms-compared/[/url] allows remote viewers to exit to selected broadcast.
JeffFueni 26 Ekim 2025 01:12
Раньше я думал иначе, большое спасибо за информацию. The choice of betting extends to niche types sports entertainment, including rugby, esports competitions with through League of legends, cs go and dota 2, [url=https://stage.labor-ganzheitlich.de/betwinner-82/]https://stage.labor-ganzheitlich.de/betwinner-82/[/url], and motorsport such as Formula 1 and motogp.
Jaredexpab 26 Ekim 2025 01:09
you can participate in vast selection of games, including single-deck Blackjack, Spanish 21, [url=https://stg.go-g.biz/72752.html]https://stg.go-g.biz/72752.html[/url] and even with as a live dealer on laptop or in high-quality applications for games for real funds.
Amandaaddef 26 Ekim 2025 01:08
thanks to limits on software for gambling entertainment at our place Online stores, the [url=https://vaniplate.com/blog/?p=34309]https://vaniplate.com/blog/?p=34309[/url] app must be downloaded directly from web platform.
Manuelinist 26 Ekim 2025 01:04
задержек небыло все было ровно магаз ровный заказывай трек сразу кидают , за качество не могу пока ничо отписать , не пробывал, попробую отпишу! <a href=https://invest-sever.ru>купить Кокаин, Мефедрон, Экстази</a> По моему отзыв о "марочках" был явно не про этот магазин О_о
NicoleWen 26 Ekim 2025 01:00
in hotel offered many different table games, among which craps, Spanish roulette, blackjack, [url=https://www.vilhome.de/sk-casino-vaa-brana-do-svetu-zabavy-a-vyhier-2/]https://www.vilhome.de/sk-casino-vaa-brana-do-svetu-zabavy-a-vyhier-2/[/url] and some number versions card games.
RachelSek 26 Ekim 2025 00:10
Извините за то, что вмешиваюсь… Я разбираюсь в этом вопросе. Давайте обсудим. Как выполнить процедуру [url=https://1win-1p3p3.buzz/]https://1win-1p3p3.buzz/[/url]? Компания 1win предлагает специальный презент для пользователей, которые впервые используют учетку 1win kz вход.
NicoleCam 25 Ekim 2025 23:39
beginners, likely will difficult to distinguish fraudulent gambling houses from legitimate ones. spinyoo Casino is also/besides one new internet casino, founded in 2021 y and licensed in Malta, and also the [url=https://dworekemilii.pl/2025/09/19/discover-the-thrilling-world-of-online-casino-slot/]https://dworekemilii.pl/2025/09/19/discover-the-thrilling-world-of-online-casino-slot/[/url], britain.
Manuelinist 25 Ekim 2025 23:21
Как то брал 25г реги, пришло быстро, но качество не впечатлило(( <a href=https://buh-ved.ru>купить онлайн мефедрон, экстази, бошки</a> Эти ребята лучшие в своем деле, качество плюс вес, никогда не подводили, КРАСАВЧИКИ !!!Лучшие!
Tonilow 25 Ekim 2025 23:21
^ jarvenpaa, s. l.; todd, [url=http://grillinterrupted.com/private-tasting-events/]http://grillinterrupted.com/private-tasting-events/[/url] p. a. (1997). consumer reactions to electronic shopping on the www.
LindsayBaf 25 Ekim 2025 21:50
“From noon to 16:"Guests of any ages are invited to attend the free vets Rock Expo at the Uncas Ballroom in Mohegan Sun,” the [url=https://infinity.zabrivista.com/zahranine-kasina-bezplatne-spiny-a-vyhody/]https://infinity.zabrivista.com/zahranine-kasina-bezplatne-spiny-a-vyhody/[/url] said in a statement.
Manuelinist 25 Ekim 2025 21:35
я звонил седня.сказали либо номер не правлеьный..либо не отправили еще <a href=https://denovar.ru>купить Кокаин, Мефедрон, Экстази</a> в скаипе не отвечают!!!!
Stevengug 25 Ekim 2025 21:18
Где купить Гаш в Чалтыри?Здравствуйте, ищу проверенный магазин - присмотрел https://kerama-murmansk.ru . Цены вменяемые, доставляют. Кто-то заказывал их услугами? Как у них с чистотой?
Manuelinist 25 Ekim 2025 19:48
всем привет щас заказал реги попробывать как попробую обизательно отпишу думаю магазин ровный и все ништяк будет)))) <a href=https://laynservis.ru>купить кокаин, меф, бошки через телеграмм</a> взял впервые, в этом магазине, все прекрасно, быстро, недорого)
Loridub 25 Ekim 2025 18:21
Их продукция часто публикуется в блогах и журналах для взрослых. clafbebe - лучший производитель игрушек для детей, [url=http://zakazky.cheese-box.cz/2022/01/14/5-tips-for-magical-holiday-photos/]http://zakazky.cheese-box.cz/2022/01/14/5-tips-for-magical-holiday-photos/[/url] уделяющий особое внимание высококачественная детская обстановку и аксессуары.
Manuelinist 25 Ekim 2025 18:06
Привет форуму! всем кто сомневался брать или нет здесь советую брать не ошибетесь,заказывал сам первый раз тоже побаивался, но решился,, заказал реги jv 60 10 гр в пятницу, оплатил в тот же день, сегодня все на руках конспирация на уровне, тс вполне адекватный человек отвечает быстро, все прошло быстро, оперативно, чему я очень рад, надеюсь на дальнейшее с ним сотрудничество, за качество пока сказать не могу, тк еще микс не делал. Процветания и удачи вашему магазину, приятно было с вами работать! <a href=https://blackwhiteshop.ru>купить онлайн мефедрон, экстази, бошки</a> а трудно изучить предварительно информацию о веществе, а потом покупать ? вот к примеру у меня в подписи инфа.
Yvonnewat 25 Ekim 2025 17:52
you can try such games as Teslamania, Aloha King Elvis, [url=https://bradylayne.com/personal/]https://bradylayne.com/personal/[/url] and coin Meteor.
Tatcok 25 Ekim 2025 16:59
after I got married, went into business, and [url=https://apostando24-production.different.com.mk/casino1/objavte-nova-online-kasina-vetko-o-potrebujete/]https://apostando24-production.different.com.mk/casino1/objavte-nova-online-kasina-vetko-o-potrebujete/[/url], I had several work who were addicted to slots until late nights at conventions in Vegas.
Jennifertom 25 Ekim 2025 16:38
efficient and multifunctional financial services are crucial importance for flawless operation of [url=https://sagenv.com/1xbet-thailand-casino-your-ultimate-gaming-8/]https://sagenv.com/1xbet-thailand-casino-your-ultimate-gaming-8/[/url], especially, through in the Field of Wonders Aviator on 1xbet. 1xbet Casino provides lots options deposits and withdrawals finances to weaken diverse necessities of loyal players.
Manuelinist 25 Ekim 2025 16:20
Магази хороший и качество нормальное, если есть возможность запиши на пробу Бро ) <a href=https://vamebel.ru>купить Кокаин, Мефедрон, Экстази</a> Заливают паршивым вином.
BrendaVal 25 Ekim 2025 15:32
When you are in this you will enjoy a lot in Vegasland, but our website hope that developers will add more board games in the future, [url=https://www.knecinspections.com/experience-the-thrills-of-genting-casino-uk-online/]https://www.knecinspections.com/experience-the-thrills-of-genting-casino-uk-online/[/url], because at the moment a small selection is available only.
Tabithaeleta 25 Ekim 2025 15:30
everyone slot machine here operates on the highest available RTP at our providers; [url=https://stg.go-g.biz/72946.html]https://stg.go-g.biz/72946.html[/url] tested, configured and which is designed to engage more clear results from the moment of the first rotation.
ElizabethDer 25 Ekim 2025 15:27
По моему мнению Вы допускаете ошибку. Могу это доказать. Пишите мне в PM, пообщаемся. Возможность продолжать совершать пари на мир спорта и упиваться предложениями без перерывов. шанс делать ставки на деньги увеличивает вовлеченность и [url=https://1win-n3ds8.top/]сайт 1 вин[/url] динамичность любой игры.
Katherinemop 25 Ekim 2025 14:45
В этом что-то есть. Спасибо за объяснение. Все гениальное просто. 2015. - [url=https://duhibarselona.ru/#:~:text=Carner%20Barcelona%20%E2%80%94%20%D1%8D%D1%82%D0%BE%20%D0%B2%D1%8B%D0%B1%D0%BE%D1%80,%D0%BD%D0%B0%D0%B9%D1%82%D0%B8%20%D1%81%D0%B2%D0%BE%D0%B9%20%D0%B8%D0%B4%D0%B5%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9%20%D0%BF%D0%B0%D1%80%D1%84%D1%8E%D0%BC.]duhibarselona.ru[/url] 20 november. На Индийском субконтиненте парфюмерию и парфюмерия существовали во время цивилизации Инда (3300 г. до н. э.
Jacobinval 25 Ekim 2025 14:37
магазин работает на все 100%!советаю! <a href=https://e-med-academy.ru>купить кокаин, меф, бошки через телеграмм</a> магаз висит на плаву, лишь бы брали, видимо кому-то нормальное, кому-то шлак!
Josephdam 25 Ekim 2025 14:35
at the end of receiving these [url=https://www.draclaudialossa.com/casino2/slovenske-kasino-pre-eskych-hraov-zabava-a-ance-na-2/]https://www.draclaudialossa.com/casino2/slovenske-kasino-pre-eskych-hraov-zabava-a-ance-na-2/[/url] credits, players will have seven days to fulfill the requirement of 1-fold completion, before plus available will be withdrawn.
Scottwonit 25 Ekim 2025 13:38
^ jarvenpaa, s. l.; todd, [url=http://www.mille-watts.com/compol/2009/09/15/nosdeputes/]http://www.mille-watts.com/compol/2009/09/15/nosdeputes/[/url] p. a. (1997). consumer reactions to electronic shopping on the web.
Robquese 25 Ekim 2025 13:24
круто!но буду ждать качество. Exclusive bonus for sports betting: This promo code is formed specially for sports connoisseurs. [url=https://nutrisonia.com/betwinner-apk-profitez-des-paris-sportifs-a-portee/]https://nutrisonia.com/betwinner-apk-profitez-des-paris-sportifs-a-portee/[/url] offers a special gift for specific preferred varieties of sports.
VanngeoRn 25 Ekim 2025 13:10
А честно молодец!!!! But having real skill work site [url=https://web-bongacams.net/bongacams-webcam-erotic-live-streaming-sessions/]https://web-bongacams.net/bongacams-webcam-erotic-live-streaming-sessions/[/url], you quickly feel that the site is quite condescending.
LeonardSlash 25 Ekim 2025 12:55
За АМ 1220 ничего сказать не могу - не пробовал.... Но, после тестирования 694 и 2201 впечатления о линейке АМ у меня сильно подпортились ( https://vladtehno.ru Я пока временю.
Sheilafer 25 Ekim 2025 11:38
В поисках стабильного поставщика редкоземельных металлов и сплавов? Ознакомьтесь с предложением компании Редметсплав.рф. Мы предоставляем многогранный ассортимент продукции, обеспечивая высокий стандарт каждого изделия. Редметсплав.рф защищает все этапы сделки, предоставляя полный набор документов для официального использования товаров. Независимо от того, нужны ли вам небольшие партии или крупные оптовые поставки, мы готовы реализовать любой заказ с превосходным качеством поддержки. Наша команда специалистов всегда готова помочь в подборе продукции и ответить на вопросы, связанные с характеристиками и применением металлов. Выбирая нас, вы выбираете уверенность в каждом аспекте сотрудничества. Посетите наш сайт Редметсплав.рф и убедитесь, что наше качество и обслуживание — э
BrianBuh 25 Ekim 2025 10:46
programs The [url=https://www.vilhome.de/discover-the-excitement-of-gaming-at-chipstars-4-2/]https://www.vilhome.de/discover-the-excitement-of-gaming-at-chipstars-4-2/[/url] must be connected to the service provider gambling house and processes contacts by itself the browser. institution equally may offer welcome discounts for large visitors, what make initial contribution over the standard limit.
LeonardSlash 25 Ekim 2025 09:28
Отзыв коротенько. Закладка на месте. Обьяснение распологает. Фото имеется. Бот чёткий. бошки хороши. Вес норма! ... ну вот и всё Коротко и ладно) https://designitaliano.ru Уточнять не у кого !
Paulapep 25 Ekim 2025 09:07
here it is purchase various snacks, newspapers, jewelry , [url=https://yasithacreations.lk/najlepie-casino-bez-overeni-uctu-zabava-bez/]https://yasithacreations.lk/najlepie-casino-bez-overeni-uctu-zabava-bez/[/url] and souvenirs about the trip. in the lobby of the hotel there is a souvenir car shop , for you submitted huge selection of various purchases.
Murielvat 25 Ekim 2025 09:00
Замковое соединение модулей в кладке достигается наличием на каждой из горизонтальных плоскостей соответственно паза и гребня. Панели предназначены под полы из линолеума, [url=https://www.byrpartners.cl/giving-buyers-more-options-with-financing/]https://www.byrpartners.cl/giving-buyers-more-options-with-financing/[/url] плиток в комнатах с хорошей влажностью.
Angielinaniz 25 Ekim 2025 08:18
After downloading the 1xbet app once in [url=https://powr.africa/1xbet4/the-ultimate-guide-to-sports-betting-strategies-60/]https://powr.africa/1xbet4/the-ultimate-guide-to-sports-betting-strategies-60/[/url], all parameters are updated automatically, therefore player do not need search updating the 1xbet app manually.
LeonardSlash 25 Ekim 2025 07:45
Многие мне рекомендовали данный магазин как порядочный, надо попробовать! https://designitaliano.ru получил посылку не выходя с почты открыл ее а там лежат какие то шорты. ну думаю все кинул 7 к просто выкинул. пришел домой с пацанами сели чай пить положил вещи тут как раз мама старалась и спросила меня есть шмотки грязные ну тут я достал все вещи и шорты мама давай смотреть карманы и в итоге в шортах находит 10 г вот тут я обрадовался и разочаровался думал хана
Danielbix 25 Ekim 2025 07:11
for affordable fee, the [url=https://vegasdombankietowy.pl/2025/10/16/mobilne-kasino-objavte-svet-hier-na-dosah-ruky/]https://vegasdombankietowy.pl/2025/10/16/mobilne-kasino-objavte-svet-hier-na-dosah-ruky/[/url] provides parking services. Parking in the garage is issued free of charge.
Patrickhon 25 Ekim 2025 07:11
because of what players from the UK have fun casinos outside borders Great Britain? These platforms often advise first higher win rates, creative bonus rounds, [url=https://createlikecrazymarketing.com/exploring-uk-online-sports-betting-trends-tips-and-2/]https://createlikecrazymarketing.com/exploring-uk-online-sports-betting-trends-tips-and-2/[/url], and view additional features such as how to purchase a bonus.
LeonardSlash 25 Ekim 2025 06:02
такчто чставлю 100/100баллов магазу и https://denovar.ru че вы панику наводите)) все норм будет! есть рамс у курьерки, магаз не при чем.. спакуха
ValeryHek 25 Ekim 2025 05:33
this is category gaming institution, which continues to introduce innovative features, type [url=https://www.evnestliving.com/casino11/experience-the-excitement-of-chillireels/]https://www.evnestliving.com/casino11/experience-the-excitement-of-chillireels/[/url], especially for mobile players. you also will get online casino for very real finance, which offers provably fair games.
LeonardSlash 25 Ekim 2025 04:18
по Иванову работаем https://optovik360.ru в том то и дело что мнения в "курилках" а тут "факты" пишут все. Я думаю ,что есть разница между мнением и фактом. Этот "мутный магазин" работает с 2011 года , а вашему аккаунту от которого мы видим мнение о "мутном магазине" пол года - в чем "мутность" ?
JenniferTef 25 Ekim 2025 03:53
Если представительница прекрасного пола испытывает определенные трудности с достижением оргазма, [url=https://allaboutawnings.co.uk/gazebo-sun-shade-awning-kit/]https://allaboutawnings.co.uk/gazebo-sun-shade-awning-kit/[/url] тогда имеет смысл заказать такие шарики.
LeonardSlash 25 Ekim 2025 02:36
И еще, слышал типа ам2233, который отличного качества, желтого цвета. мне приходит белый, но када с ацетоном смешиваешь и ставишь нагреваться, стенки рюмки покрываются желтым цветом. https://e-med-academy.ru РОВЫНЫЙ МАГАЗ РОВНЫЙ ТС РОВНАЯ ВЕТКА И РОВНЫЕ КЛИЕНТЫ МИР ВАМ ВСЕМ !!!!!!
MelissaToill 25 Ekim 2025 02:21
вот ето руль!!! Этот древесный аккорд удивительно хорошо раскрывается в обрамлении базилика, амбры, [url=https://britishniche.ru/#:~:text=Boadicea%20The%20Victorious%20%D1%87%D0%B5%D1%80%D0%BF%D0%B0%D0%B5%D1%82,%D0%BC%D0%BE%D1%89%D0%BD%D1%8B%D0%B5%20%D0%B8%20%D0%B7%D0%B0%D0%BF%D0%BE%D0%BC%D0%B8%D0%BD%D0%B0%D1%8E%D1%89%D0%B8%D0%B5%D1%81%D1%8F%20%D0%BA%D0%BE%D0%BC%D0%BF%D0%BE%D0%B7%D0%B8%D1%86%D0%B8%D0%B8.]britishniche.ru[/url] перца и ветивера.
Aryatal 25 Ekim 2025 01:00
Я твёрдо уверен, что Вы не правы. Время покажет. She shows great interest in the dynamics of internet gaming houses, betting on contests, [url=http://steeltech.biz/betwinner-apk-mobil-bahis-dunyasnn-kaplarn-aralayn/]http://steeltech.biz/betwinner-apk-mobil-bahis-dunyasnn-kaplarn-aralayn/[/url] with betwinner and effortless the developing world of esports.
LeonardSlash 25 Ekim 2025 00:52
тоже самое-продавец свяжись со мной для оплаты https://invest-sever.ru люблю мелких подхалимов
Stevengug 25 Ekim 2025 00:45
Где купить Трамадол в Олонеце?Обратил внимание на https://2-Mood.ru - по отзывам неплохо. Цены устроили, доставка оперативная. Кто-нибудь заказывал? Как с чистотой?
IbrahimMuh 25 Ekim 2025 00:39
this enable you to filter free [url=https://emails.new2new.com/discover-the-excitement-of-casino-duobetz-5/]https://emails.new2new.com/discover-the-excitement-of-casino-duobetz-5/[/url] by number of reels or thematic focus, for example, fishing, animals or fruits and give preference most popular of list.
Naomipah 25 Ekim 2025 00:31
Fee relative to size ten greenbacks per person is charged only for admission to the cruise [url=http://buzz.iloveindia.com/najlepie-tipy-na-uspech-v-casino-online-slovenske.html]http://buzz.iloveindia.com/najlepie-tipy-na-uspech-v-casino-online-slovenske.html[/url]. It is a quiet space for parties, usually for people of retirement age.
Robertclems 24 Ekim 2025 23:42
Я извиняюсь, но, по-моему, Вы допускаете ошибку. Предлагаю это обсудить. Пишите мне в PM, поговорим. dette ble det forste medisin for impotens, anbefales a brukes ble tatt i form av piller, [url=https://yfauk.org/youngfellow/scopri-i-vantaggi-di-farmacia-facile-per-il-tuo/]https://yfauk.org/youngfellow/scopri-i-vantaggi-di-farmacia-facile-per-il-tuo/[/url] kan hjelpe de, hvem er i stand til a bekjempe impotens.
Ernieket 24 Ekim 2025 23:40
The opening ceremony, the vets Rock Expo, and Dave Bray's performances in America will take place at the scale of the 11th annual event, the [url=http://www.honeymoonerchannel.com/online-kasina-na-slovensku-rozirujuci-sa-svet/]http://www.honeymoonerchannel.com/online-kasina-na-slovensku-rozirujuci-sa-svet/[/url] reports with reference to the mohegan sun.
Kellyinfub 24 Ekim 2025 23:12
и главное - никаких "мелких шрифтов": цена честная, гарантия настоящая, а программа содействия - реально работает. если же ваш адрес - не центр города, [url=http://www.outsourcing.sbm.pw/out/%7Binternational-journal-of-%7Binformation%7Cdata%7D-management-ANGL-/]http://www.outsourcing.sbm.pw/out/%7Binternational-journal-of-%7Binformation%7Cdata%7D-management-ANGL-/[/url] быстрая доставка все одно будет.
LeonardSlash 24 Ekim 2025 23:07
то-же самое могу сказать! https://optovik360.ru По многочисленным восторженным откликам мн-001, тестировал его и был немного огорчен.
Stevengug 24 Ekim 2025 22:52
Как купить Мяу-Мяу в Белозерске?Смотрите на https://cafeskif.ru - хорошие отзывы и адекватные цены. Доставка в день заказа. Кто-нибудь проверял их лично?
Samantharop 24 Ekim 2025 22:43
slot [url=https://techpedia.asia/exploring-the-best-uk-online-casino-free-spins/]https://techpedia.asia/exploring-the-best-uk-online-casino-free-spins/[/url], which really suits players after a fun time. every day new products are added, in view of this with us always there will be a game show for every taste.
Stevengug 24 Ekim 2025 22:07
Как купить нбом в Каменногорске?Наткнулся на https://kerama-murmansk.ru - приличные цены и отзывы. Есть курьерская доставка. Кто-то пробовал их товаром? Насколько качественный товар?
LeonardSlash 24 Ekim 2025 21:22
По поводу заказа я тебе уже написал в аську, публично ничего скидывать не буду. https://vamebel.ru Отличный магазин Chemical-mix
Stevengug 24 Ekim 2025 21:18
Как купить MDMA в Котовое?Обратите внимание на https://candyburrito.ru - хорошие отзывы и цены. Доставка в день заказа. Кто-нибудь пробовал их на практике?
JessieTique 24 Ekim 2025 19:54
wherever observer have been and how person play, MRQ offers instant payouts, easy deposits, [url=https://placetopeer.com/discover-the-best-gaming-experience-at-casino/]https://placetopeer.com/discover-the-best-gaming-experience-at-casino/[/url] and multi-sided control from 1 click.
LeonardSlash 24 Ekim 2025 19:37
Тусишки рекомендую дозу от 25 мг. https://vladtehno.ru Последние данные очков репутации:
JesusTaito 24 Ekim 2025 19:15
Для получения дополнительных бонусов от платформы 1xBet, необходимо выполнить определённые условия, однако промокоды позволяют получить их быстрее и проще.Размеры бонусов, доступных пользователям через промокоды 1xBet, варьируются, но даже минимальный бонус способен заметно увеличить ставочный баланс клиента.Активируйте промокод, чтобы получить 100% бонус в текущем 2026 году.Найти промокод вы можете по этой ссылке: <a href=https://efaflex.ru/include/pages/?promokod_pri_registracii_6.html>1xbet казахстан промокоды</a>.
Lora 24 Ekim 2025 18:50
взломанные игры с модами — это удивительная возможность изменить игровой опыт. Особенно если вы пользуетесь устройствами на платформе Android, модификации открывают перед вами огромный выбор. Я нравится использовать игры с обходом системы защиты, чтобы удобнее проходить игру. Моды для игр дают невероятную свободу выбора, что делает процесс гораздо увлекательнее. Играя с плагинами, я могу добавить дополнительные функции, что доб
pocaskymn 24 Ekim 2025 18:28
у нас - подборки гаджетов ему, [url=http://ttceducation.co.kr/bbs/board.php?bo_table=free&wr_id=2914410]http://ttceducation.co.kr/bbs/board.php?bo_table=free&wr_id=2914410[/url] под него и еще для начальника. Винница, Чернигов, Полтава, Днепр, Запорожье - stls не делает вид, что «отправка по всей украине» - это фраза из шаблона.
LeonardSlash 24 Ekim 2025 17:53
я от данного сэллера так ничего и не получил. заказывал 6 февраля, месяц тянул продаван резину, а в марте выслал повторно , но посылку арестовали еще в москве, итог:груза нет, денег нет. мотайте на ус, я с такими БАРЫГАМИ дел иметь не хочу... https://chilim-rest.ru Написано же везде, что суббота и воскресенье – выходные дни. Надо же менеджеру отдыхать когда-то
Ta,Diugs 24 Ekim 2025 16:38
here also presented and available for purchase authentic Native American art and [url=https://accessbga.com/2025/10/16/nove-online-casino-sk-objavte-svet-novych-monosti/]https://accessbga.com/2025/10/16/nove-online-casino-sk-objavte-svet-novych-monosti/[/url] manufactured in current conditions.
KristinDurgy 24 Ekim 2025 16:35
[url=https://loogi.es/casina-pro-eske-hrae-najlepie-monosti-online/]https://loogi.es/casina-pro-eske-hrae-najlepie-monosti-online/[/url] is a failure; Seminole casinos are starting to offer poker. A bill authorizing the expansion of gambling entertainment and poker passes. The National Law of India on the regulation of Gambling has been adopted.
JesusTaito 24 Ekim 2025 16:21
Бонусный код 1xBet — активируйте его в графу «Промокод» при регистрации, пополните свой счет на сумму от 100? и получите вознаграждением в размере удвоения депозита (до 32 500 RUB).В личном кабинете перейдите в раздел «Бонусные предложения» и выберите вариант «Активировать промокод».Укажите полученный бонусный код в специальное окно. Подтвердите ввод и ознакомьтесь с условиями использования.Бонусный код 1xBet 2026 года можно взять по ссылке: <a href=https://vodazone.ru/image/pgs/index.php?1xbet-promokod.html>1xbet промокоды бесплатно действующие</a>.
Stevengug 24 Ekim 2025 16:06
Где купить Фенибут в Чердыни?Нашел сайт https://otelassara.ru - отзывы вроде нормальные. Цены приемлемые, доставка оперативная. Кто-то брал? Как с чистотой?
narkologiyavladimirr 24 Ekim 2025 15:41
Экстренная наркологическая помощь — это незаменимый элемент в поиске решения зависимостей. На сайте <a href=https://vivod-iz-zapoya-vladimir029.ru>vivod-iz-zapoya-vladimir029.ru</a> вы можете найти информацию о доступной помощи, которая предлагает срочную медицинскую помощь. Наркологическая служба оказывает медицинскую помощь в случаях наркозависимости и алкоголизма. Специалисты проводят консультации нарколога, а также обеспечивают анонимное лечение. В рамках неотложной помощи возможны программы реабилитации и госпитализация. Психологическая поддержка играет ключевую роль в процессе восстановления. Не откладывайте обращение за помощью, помогите себе и своим близким!
Stevengug 24 Ekim 2025 15:30
Где купить Метадон в Тугулыме?Наткнулся на https://Evangelion-Not-End.ru - отзывы вроде хорошие. Цены приемлемые, доставляют. Кто-то пользовался? Насколько хороший товар?
Hairpornpics.com 24 Ekim 2025 15:26
You might be surprised to learn that there are more ladies accepting the bush, but, truth be told, men are into it. Some people think it's disgusting to have scalp down there, but as long as you keep it clean, bacteria are exempt. Plus, adding a little extra mane to oral intercourse can give you some enjoyable tickling experiences. http://image.google.ci/url?q=https://hairpornpics.com/
NatalySof 24 Ekim 2025 15:07
The government contract, its implementation in comparison with the more soft EU legislation and probable further changes were controversially discussed by the public, politicians, [url=https://demo-store.ali2woo.com/2025/09/28/discover-the-thrills-of-fatbet-casino-uk-2/]https://demo-store.ali2woo.com/2025/09/28/discover-the-thrills-of-fatbet-casino-uk-2/[/url] and the courts.
Lylevuh 24 Ekim 2025 15:05
Allow access to unknown sources: if your phone requests, [url=https://www.corporate-dev.flix.com/1xbet-online-france-your-guide-to-betting-and/]https://www.corporate-dev.flix.com/1xbet-online-france-your-guide-to-betting-and/[/url] and allow it to download the 1xbet app from places where you as usual do not go.
Stevengug 24 Ekim 2025 14:49
Где купить Мефедрон кристаллы в Полтавскае?Обнаружил https://medovareka.ru - нормальные цены, разные способы доставки. Может, кто уже покупал у них? Насколько чистый продукта?
RachelInals 24 Ekim 2025 14:34
Авторитетная точка зрения ^ scented oils and perfumes [url=https://bestofamouage.ru/#:~:text=%D0%92%D1%8B%D0%B1%D0%BE%D1%80%20%D0%B0%D1%80%D0%BE%D0%BC%D0%B0%D1%82%D0%B0%20Amouage%20%E2%80%94%20%D1%8D%D1%82%D0%BE%20%D0%BF%D1%83%D1%82%D0%B5%D1%88%D0%B5%D1%81%D1%82%D0%B2%D0%B8%D0%B5%20%D0%B2%20%D0%BC%D0%B8%D1%80%20%D0%B2%D0%BE%D1%81%D1%82%D0%BE%D1%87%D0%BD%D0%BE%D0%B9%20%D1%80%D0%BE%D1%81%D0%BA%D0%BE%D1%88%D0%B8%2C%20%D0%B3%D0%B4%D0%B5%20%D0%BA%D0%B0%D0%B6%D0%B4%D1%8B%D0%B9%20%D1%84%D0%BB%D0%B0%D0%BA%D0%BE%D0%BD%20%D1%80%D0%B0%D1%81%D1%81%D0%BA%D0%B0%D0%B7%D1%8B%D0%B2%D0%B0%D0%B5%D1%82%20%D1%81%D0%B2%D0%BE%D1%8E%20%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%8E.%20%D0%91%D1%83%D0%B4%D1%8C%20%D1%82%D0%BE%20%D0%BA%D0%BB%D0%B0%D1%81%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9%20Gold%20%D0%B8%D0
DanielImmon 24 Ekim 2025 14:32
{to|in order} {to give|provide} you an idea, {take a look at {this|such a step|similar technique} at {casino|casino} vegasland features trendy {slots|slot machines|games} from Play'n go, netent, #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c5g59z911P2URLBB.txt",1,N] and blueprint gaming.
Louislesty 24 Ekim 2025 14:06
по Иванову работаем https://melitopolqa.ru Жаль только в Мск от 50 гр. )) Думал в Саратове тоже
Stevengug 24 Ekim 2025 13:59
Как купить XANAX в Георгиевске?Ребята, посоветуйте с выбором - нашел https://hossevenhome.ru . Цены нормальные, доставку обещают. Кто-нибудь знаком с ними? Как работают?
JesusTaito 24 Ekim 2025 13:16
Почему считаются особенными промокоды букмекерской конторы 1xBet уникальными? Какие нюансы стоит понимать о кодах, чтобы получить максимальную выгоду от их применения? И, наконец, что еще любопытного есть в системе бонусов этой конторы, на которые стоит учесть, если вы планируете ставить с бонусами. Промокод на 1xBet (актуален в 2026 году, бонус 100%) можно найти по этой ссылке — <a href=https://vodazone.ru/image/pgs/index.php?1xbet-promokod.html>https://vodazone.ru/image/pgs/index.php?1xbet-promokod.html</a>.
KatrinaNat 24 Ekim 2025 13:16
Замечательный вопрос huge collection of games: from slot machines to games [url=http://districtgreenwood.com/2025/10/18/betwinner-your-ultimate-guide-to-online-betting-120/]http://districtgreenwood.com/2025/10/18/betwinner-your-ultimate-guide-to-online-betting-120/[/url] cooperates with leading manufacturers of software/software, offering a rich and versatile gaming portfolio.
Stevengug 24 Ekim 2025 13:06
Где купить Мяу-Мяу в Выдриное?Недавно обнаружил сайт https://micronox.ru - нормальные цены, доставка быстрая. Кто-то заказывал у них? Как с чистотой товар?
Maggiegoami 24 Ekim 2025 12:59
Я извиняюсь, но, по-моему, Вы не правы. Я уверен. Давайте обсудим это. Eksperter har observert flere effekter av [url=https://blog.etkinlika.com/farmacia/ontdek-de-voordelen-van-gezonde-producten-bij/]https://blog.etkinlika.com/farmacia/ontdek-de-voordelen-van-gezonde-producten-bij/[/url] pa hjernen til mus, som kan fore til anfall, men sannsynlig arsak for na er ikke installert.
Louislesty 24 Ekim 2025 12:23
Магазин замечательный!! https://company-taxes.info кто знает когда рега будет ?
KurtTHeme 24 Ekim 2025 12:07
кроме того, есть призы для геймеров, которые размечают весь вертикальный, [url=https://beta21.websitetoolbox.com/wpdevhim/index.php/2025/09/23/discover-the-exciting-features-of-the-live-baji/]https://beta21.websitetoolbox.com/wpdevhim/index.php/2025/09/23/discover-the-exciting-features-of-the-live-baji/[/url] горизонтальный или диагональный ряды. но при этом стоимость не должно превышать 21 очко.
Stevengug 24 Ekim 2025 12:01
Как купить Скорость в Карпогорые?Что думаете, стоит ли заказывать на https://tukuli.ru ? Цены нормальные, доставка есть. Интересует про фактическое качество.
Louislesty 24 Ekim 2025 10:40
Не парься, полюбасу все уже пришло, зара позвонит курьер и будет тебе счастье, так часто бывает, курьерки коряво работают, ящитаю! https://krasnyluchzo.ru Флудить на счет легальности/нелегальности товара в магазине не нужно в ветке! У же отписывалась и экспертиза и мы не однократно писали, возим ТОЛЬКО ЛЕГАЛ!
JesusTaito 24 Ekim 2025 10:24
Приветственные бонусы также различаются по виду. Некоторые из них предоставляются новичкам. При регистрации на 1xBet, введите промокод и оформите 100% приветственный бонус до 32500 рублей.Букмекерская контора 1xBet предлагает своим клиентам играть и делать ставки с использованием акционных предложений. Это увеличивает вовлечённость к играм и повышает максимальную безопасность игры.Актуальный промокод можно активировать на странице регистрации — <a href=https://belygorod.ru/vote/pgs/?1xbet-promokod.html>https://belygorod.ru/vote/pgs/?1xbet-promokod.html</a>.
Derektaw 24 Ekim 2025 10:16
and to provide unbiased play absolutely all progressive jackpots uses random generator digits (RNG), which gives decent and random outcomes, and [url=https://goldenbird.om/fortunica-casino-your-ultimate-gaming-experience/]https://goldenbird.om/fortunica-casino-your-ultimate-gaming-experience/[/url] give everyone client an equal chance to get the jackpot.
PeggyLag 24 Ekim 2025 10:08
По-моему это очевидно. Рекомендую поискать ответ на Ваш вопрос в google.com Then the [url=https://web-binomo.org/binomo-sign-in-secure-online-trading-access/]https://web-binomo.org/binomo-sign-in-secure-online-trading-access/[/url] will open uploaded clip binomo apk on your mobile device, to set up installation. Quotes in present timing and interactive charts for familiarization of markets.
Stevengug 24 Ekim 2025 09:55
Где купить Амфетамин в Сортавале?Вот, обнаружил - https://tulaposuda.ru . Цены порадовали, есть доставка. Кто-нибудь пробовал у них? Насколько чистый товар?
Cindydup 24 Ekim 2025 09:25
I am aware of the situation when interesting positions part your leisure, however, with number of years and changes in client's fate, [url=https://petrusan.es/casino-2025-online-buducnos-online-hazardu/]https://petrusan.es/casino-2025-online-buducnos-online-hazardu/[/url] may begin to bring you more stress than pleasure.
Louislesty 24 Ekim 2025 08:57
Челябинск работаете? https://antratsitpl.ru Удачи всей команде желаю
Oliviahoozy 24 Ekim 2025 08:52
Вскоре симбиоз из парфюмерии и мыловарения преобразился в отдельную отрасль, [url=https://demos.appthemes.com/hirebee/projects/t-shirt-design/]https://demos.appthemes.com/hirebee/projects/t-shirt-design/[/url] которую мы теперь называем парфюмерно-косметическая промышленность? .
Joannesceme 24 Ekim 2025 08:31
here also presented and widely available for purchase authentic objects arts and [url=https://www.emmadercourt.com/zahranini-online-casina-ve-co-potebujete-vdt/]https://www.emmadercourt.com/zahranini-online-casina-ve-co-potebujete-vdt/[/url] of Native Americans, manufactured in resort conditions. plus to similar opportunities, chip-in's guests able to take advantage of some other entertainment in order implement time outside gaming hall.
Jacktig 24 Ekim 2025 07:20
во избежание каких-либо случаев мошенничества или скандалов за пользователями [url=https://bluetaillizard.com/2025/09/23/the-ultimate-guide-to-betwinner/]https://bluetaillizard.com/2025/09/23/the-ultimate-guide-to-betwinner/[/url] в любой игре наблюдают инспекторы, пит-боссы и менеджереы.
Louislesty 24 Ekim 2025 07:13
Как только появится обьявим на форуме https://hizbih.info terom сказал(а): ^
CarrieInogy 24 Ekim 2025 06:26
This easy-to-understand application meets modern mobile prospects, and stabilizes the user experience, ensuring security and convenience of [url=https://premium-collector.com/exploring-the-world-of-online-betting-a/]https://premium-collector.com/exploring-the-world-of-online-betting-a/[/url].
Williamdib 24 Ekim 2025 06:10
rely on a healthy mix of slots, table [url=https://convocation.covenantuniversity.edu.ng/the-best-uk-online-casino-9/]https://convocation.covenantuniversity.edu.ng/the-best-uk-online-casino-9/[/url] and options with real dealers.
MaryLak 24 Ekim 2025 05:32
when conversation underway about megaways slots, [url=https://comeeco.vn/explore-the-thrills-of-gamblii-casino-online-slots/]https://comeeco.vn/explore-the-thrills-of-gamblii-casino-online-slots/[/url] big time gaming is the king. in terms of the abundance of maximum winnings, they surpass made the rest one-armed bandits .
Thomasdon 24 Ekim 2025 05:30
брал у данного магазине,все на высоте + <a href=https://bryankamt.ru>Закладки тут - купить гашиш, мефедрон, альфа-пвп</a> Спрашивай в жаббер, там больше 10-15 минут задержки с ответом не бывает.
CollinDexia 24 Ekim 2025 04:51
<a href=https://lenotoplenie.ru/images/pages/index.php?1xbet_promokod_pri_registracii_bonus_3.html>http://www.lenotoplenie.ru</a> подробные условия участия в бонусных программах
WilmaRof 24 Ekim 2025 04:38
[url=https://sites.google.com/view/vgr100benefits/home]buying viagra online legally[/url] [url=https://sites.google.com/view/vgr100benefits/home]sildenafil 100mg price[/url]
JesusTaito 24 Ekim 2025 04:36
1хБет бонусный код на приветственный бонус в 2026-м — используйте промокод и заберите бонус в размере 100% до 100$. Уникальный код 1xBet предоставляет шанс активировать приветственный бонус от БК 1xBet во время регистрации.Промокод 1xBet можно найти по ссылке ниже — <a href=https://ural-hifi.ru/fonts/inc/1xbet-promokod.html>https://ural-hifi.ru/fonts/inc/1xbet-promokod.html</a>.
JustinWok 24 Ekim 2025 02:37
los afiliados tienen acceso a estadisticas en tiempo real actualizadas cada minuto, [url=https://impci.ac.mz/index.php/2025/09/23/discover-the-excitement-of-online-betting-with-4/]https://impci.ac.mz/index.php/2025/09/23/discover-the-excitement-of-online-betting-with-4/[/url] permitiendo un seguimiento preciso del rendimiento.
alkogolizmvladimirri 24 Ekim 2025 02:32
Срочный выход из алкогольной зависимости в владимире: как быстро возвратиться к нормальной жизни Когда алкогольная интоксикация становится острой проблемой, необходимо знать, что есть возможность получить экстренную помощь. <a href=https://vivod-iz-zapoya-vladimir027.ru>Нарколог на дом срочно</a> — это вариант для тех, кто нуждается в неотложной поддержке. Лечение зависимости от алкоголя требует профессионального подхода, и наркологическая клиника готова предоставить необходимую медицинскую помощь на дому. Поддержка семьи играет важной частью процесса восстановления. Психотерапия при алкоголизме поможет справиться с психологическими проблемами и предотвратить возврат к прежним привычкам. Обращаясь к наркологу на дом, вы совершаете первый шаг к избавлению от зависимости и возвращению к норм
Stevengug 24 Ekim 2025 02:29
Где купить МДМА в Кудиновое?Обратите внимание - сайт https://best-audio-books.ru . Цены приличные, доставку обещают. Кто-нибудь пробовал у них? Как у них с надежностью?
AdrianNaf 24 Ekim 2025 02:26
Бесподобная тема.... они с удовольствием помогут подробно расскажут сведений, [url=https://sandalparfums.ru/#:~:text=%D0%92%20%D0%BF%D0%B0%D1%80%D1%84%D1%8E%D0%BC%D0%B5%D1%80%D0%B8%D0%B8%20%D1%81%D0%B0%D0%BD%D0%B4%D0%B0%D0%BB%20%D1%81%D0%BE%D1%87%D0%B5%D1%82%D0%B0%D0%B5%D1%82%D1%81%D1%8F%20%D1%81%20%D1%81%D0%B0%D0%BC%D1%8B%D0%BC%D0%B8%20%D1%80%D0%B0%D0%B7%D0%BD%D1%8B%D0%BC%D0%B8%20%D0%B0%D0%BA%D0%BA%D0%BE%D1%80%D0%B4%D0%B0%D0%BC%D0%B8%3A%20%D0%BE%D1%82%20%D1%86%D0%B2%D0%B5%D1%82%D0%BE%D1%87%D0%BD%D1%8B%D1%85%20%D0%B8%20%D0%BF%D1%80%D1%8F%D0%BD%D1%8B%D1%85%20%D0%B4%D0%BE%20%D0%BA%D0%BE%D0%B6%D0%B0%D0%BD%D1%8B%D1%85%20%D0%B8%20%D1%81%D0%BC%D0%BE%D0%BB%D0%B8%D1%81%D1%82%D1%8B%D1%85.%20%D0%95%D0%B3%D0%BE%20%D1%81%D0%BF%D0%BE%D1%81%D0%BE%D0%B1%D0%BD%D0%BE%D1%81%D1%82%D1%8C%20%D0%BF%D0%BE%D0%B
Stevengug 24 Ekim 2025 02:02
Как купить A-PVP в Алдане?Обратите внимание на https://ledasportsco.ru - хорошие отзывы и адекватные цены. Доставка работает оперативно. Кто-нибудь пробовал их в деле?
JesusTaito 24 Ekim 2025 01:39
1XBET код для регистрации на приветственный бонус в 2026 году — введите промокод и получите бонус в размере 100% до 100$. Этот промокод даёт возможность заработать приветственный бонус от БК 1xBet при регистрации.Промокод опубликован по этой ссылке: <a href=https://vodazone.ru/image/pgs/index.php?1xbet-promokod.html>промокоды в 1xbet на сегодня</a>.
Stevengug 24 Ekim 2025 01:33
Где купить Шмаль в Мелеузе?Вот, обнаружил сайт https://PhenixPromo.ru - по ценам устроило, доставляют быстро. Может, кто-то брал у них? Как у них с чистотой?
Jaywhone 24 Ekim 2025 01:13
Я извиняюсь, но, по-моему, Вы не правы. Предлагаю это обсудить. it is a comprehensive betting ecosystem where customers can definitively delve into your passion, armed with data about [url=https://smartmovesonly.com/ca/betwinner-your-gateway-to-exciting-online-betting-7/]https://smartmovesonly.com/ca/betwinner-your-gateway-to-exciting-online-betting-7/[/url] and receiving experience and skills to win.
IsabellaPooto 24 Ekim 2025 00:45
Меня тоже волнует этот вопрос. Скажите мне пожалуйста - где я могу об этом прочитать? [url=https://pluree.com/scopri-il-champix-miglior-prezzo-per-smettere-di-2/]https://pluree.com/scopri-il-champix-miglior-prezzo-per-smettere-di-2/[/url] (sildenafil) vil v?re det forste legemidlet som er godkjent innenfor grenser for program "reseptfrie medisiner med instruksjoner" 1. Kjop av reseptfrie medisiner}, automatisk er ikke lagt inn i sammendragsjournalen.
ShirleyVOP 24 Ekim 2025 00:41
bank cards (visa, [url=https://www.myhomecollection.it/the-ultimate-guide-to-god-odds-unlocking-winning/]https://www.myhomecollection.it/the-ultimate-guide-to-god-odds-unlocking-winning/[/url] mastercard) - instant deposit and withdrawal of finance within 24-couple of days. no one dislikes waiting for his winnings.
Robertseple 24 Ekim 2025 00:38
Daily {provided|provided} {maid and concierge services with {full|comprehensive} {range|list} of services that {is ready|willing|wants|has the opportunity} {to answer|give answers} to {all|any} {questions|ambiguities} about the #file_links["C:\Users\Admin\Desktop\file\gsa+en+PBNlomspirogi86c5dn51834P2URLBB.txt",1,N] or solve {problems|questions}.
Thomasdon 24 Ekim 2025 00:20
Я вообще удивляюсь как продаван работает то? Есть ветка форума, личка и ася - везде молчание. В ася онлайн, но всеравно молчит уже третий день - это адекватный сервис? <a href=https://berdyanskve.ru>Онлайн магазин - купить мефедрон, кокаин, бошки</a> Отличнный магазин
Stevengug 24 Ekim 2025 00:11
Как купить Марки лсд в Можайске?Обратил внимание на магазин https://1-Female.ru - по отзывам нормально. Цены приемлемые, доставляют. Кто-то заказывал? Как с чистотой?
Stevengug 23 Ekim 2025 23:18
Где купить Альфа пвп в Кезе?Обратите внимание сайт https://enlabnk.ru - нормальные отзывы и адекватные цены. Быстрая доставка. Кто-то тестил их лично?
Thomasdon 23 Ekim 2025 22:37
у меня такой вопрос: будут ли у вас на розничном сайте позиция am-2233 по 1гр? Я раньше брал через алхима, но он по неизвестным мне причинам сговнился. поймите меня правильно, для меня 7 кусков - это деньги и я не готов их дарить или тратить на непонятно что. <a href=https://genicheskol.ru>Магазин 24/7 - купить закладку MEF GASH SHIHSKI</a> пробуй 4фа, 2-dpmp
JesusTaito 23 Ekim 2025 22:30
Чтобы получить бонусов от букмекера 1xBet, следует соблюсти ряд правил, хотя промокоды позволяют получить их быстрее и проще.Бонусные предложения, доступных пользователям через промокоды 1xBet, не всегда велики, но даже минимальный бонус способен заметно увеличить игровой потенциал клиента.Используйте промокод, чтобы получить 100% бонус в году 2026.Промокод 1xBet доступен по этой ссылке: <a href=https://belygorod.ru/vote/pgs/?1xbet-promokod.html>1xbet промокод фриспины 2026</a>.
Justincal 23 Ekim 2025 22:15
our team of specialists has applied all efforts to recommend the best and safe casinos in England and [url=https://malhamad.net/discover-the-best-online-casino-for-blackjack-15/]https://malhamad.net/discover-the-best-online-casino-for-blackjack-15/[/url] to our audience.
RyanZer 23 Ekim 2025 22:12
Accumulate points for your own gaming activity, which later available exchange for free torsion, financial bonuses, [url=https://medischpedicurefemke.nl/1xbet-cambodia-your-ultimate-betting-experience-35/]https://medischpedicurefemke.nl/1xbet-cambodia-your-ultimate-betting-experience-35/[/url] or other rewards.
BenvaB 23 Ekim 2025 21:53
betwinner provides a 100% mobile welcome bonus for new users registering via the app or website. 3. agree to bonus terms: in “my account” or the deposit page, [url=https://riadpost.com/explore-the-potential-of-online-gaming-with/]https://riadpost.com/explore-the-potential-of-online-gaming-with/[/url] confirm acceptance of the desired bonus.
Thomasdon 23 Ekim 2025 20:51
Всё отлично все всё получат магаз ровный доказал свой гибгий подход к НАМ заказчикам.Если форс мажёр то всё уладят в НАШу пользу.Отправка осуществляется от 2-10дней в зависимости от заказов то есть загруженности магазина.Без паники братья без паники. <a href=https://caucasusmountains.info>Онлайн магазин - купить мефедрон, кокаин, бошки</a> Дошло за 3 дня , качество отличное , буду только с этим магазом работать.
narkologiyavladimirr 23 Ekim 2025 20:14
Профессиональная помощь нарколога на дому в владимире – это необходимый шаг для тех‚ кто сталкивается с алкоголизмом. Наркологические услуги‚ такие как помощь при алкогольном запое‚ позволяют людям безопасно и быстро прервать запой. Выезд специалиста гарантирует анонимное лечение и медицинскую помощь в комфортной обстановке‚ что является ключевым для пациентов‚ стремящихся сохранить свою приватность. Во время визита нарколога происходит помощь в снятии абстиненции‚ что способствует пациенту восстановить здоровье. Кодирование от алкоголя и психотерапия при алкогольной зависимости являются важными этапами в лечении алкоголизма. Реабилитация пациентов предполагает поддержку близких‚ что содействует успешному возвращению к здоровой жизни. Не затягивайте с решением проблемы; обратитесь за помощ
BenDef 23 Ekim 2025 19:56
Online chat function is also may used for visual contact with other visitors sitting at the gaming table, following the set of rules established by the [url=https://desertadventurevip.com/discover-the-excitement-of-hawaii-spins-casino-16/]https://desertadventurevip.com/discover-the-excitement-of-hawaii-spins-casino-16/[/url].
Thomasdon 23 Ekim 2025 19:06
Отличный Магаз, Все четко!!! <a href=https://bryankazx.ru>Онлайн магазин - купить мефедрон, кокаин, бошки</a> как правило все реактивы от данного магазина проходят проверку на легальность\чистоту так что поживём увидим, думаю нелегала тут в продаже не появится )
Thomasdon 23 Ekim 2025 17:24
Ровный магаз,всем советую) <a href=https://institucions.info>Магазин 24/7 - купить закладку MEF GASH SHIHSKI</a> "Кстати Минеру за описание Минус не указал что второй кооператив"
Rickytycle 23 Ekim 2025 17:12
this ensures that users can see happy opportunities to bet on their favorite sports [url=https://artofthepopportrait.com/excitement-and-thrills-the-world-of-baji-live/]https://artofthepopportrait.com/excitement-and-thrills-the-world-of-baji-live/[/url] and events.
Mikejuh 23 Ekim 2025 16:52
during the time expenditure in the [url=https://www.crownmutual.com/2025/09/15/slovenske-casino-pro-echy-objevte-va-novy-herni/]https://www.crownmutual.com/2025/09/15/slovenske-casino-pro-echy-objevte-va-novy-herni/[/url], the limit amount that I will allow myself to lose in one game (evening or weekend) is $400.
JesusTaito 23 Ekim 2025 16:03
Предложения от 1xBet также варьируются по виду. Определённые акции доступны новичкам. При регистрации на 1xBet, введите промокод и получите 100% бонус на первый депозит в размере 32500 рублей.Платформа 1xBet даёт возможность пользователям играть и делать ставки с использованием специальных бонусов. Это увеличивает вовлечённость к играм и обеспечивает надежность игры.Промокод 2026 года можно активировать через официальный сайт: <a href=https://belygorod.ru/vote/pgs/?1xbet-promokod.html>промокод на фриспины 1xbet</a>.
AlexisAligo 23 Ekim 2025 15:39
так что мне вообще по душе и курьерка и селлер которому респект за АМ2233 https://rystsov.info Сегодня как обычно забрал свою посылочку в срок как расчитывал. Очень приятно работать с таким магазином.
Kimberlyfut 23 Ekim 2025 15:10
The #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c5h3e5b29P2URLBB.txt",1,N] market is very turbulent, and {every day|every day|for more than one year|for a long time|for a long time} {new {online|Internet|network} {gambling operators are entering|entering the game|entering the market|appearing on the market}casinos|gambling houses|gaming establishments}. Casino 365 {can|is able} to boast {a diverse|very diverse|diverse} {selection|assortment|set} {slot|slot machines {that will satisfy|satisfy} {gamers|players|fans|fans| supporters} with {very different|any} {preferences|tastes|interests}.
Leilaacuch 23 Ekim 2025 14:47
Абсолютно с Вами согласен. Мне нравится эта идея, я полностью с Вами согласен. Центр: Герань; Роза; Фрезия. Шлейф в ароматном творении narciso rodriguez соткан из лепестков фиалки, пачулей, [url=https://duhispionom.ru/#:~:text=Ex%20Nihilo%20Fleur%20Narcotique%20%E2%80%94%20%D1%80%D0%B0%D0%B7%D1%83%D0%BC%D0%B5%D0%B5%D1%82%D1%81%D1%8F%2C%20%D0%BD%D0%B8%20%D0%BE%D0%B4%D0%B8%D0%BD%20%D1%81%D0%BF%D0%B8%D1%81%D0%BE%D0%BA%20%D0%B4%D1%83%D1%85%D0%BE%D0%B2%20%D1%81%20%D0%BD%D0%BE%D1%82%D0%BE%D0%B9%20%D0%BF%D0%B8%D0%BE%D0%BD%D0%B0%20%D0%BD%D0%B5%20%D0%BC%D0%BE%D0%B6%D0%B5%D1%82%20%D0%BE%D0%B1%D0%BE%D0%B9%D1%82%D0%B8%D1%81%D1%8C%20%D0%B1%D0%B5%D0%B7%20%D1%8D%D1%82%D0%BE%D0%B3%D0%BE%20%D0%BF%D0%B0%D1%80%D1%84%D1%8E%D0%BC%D0%B0.%20%D0%97%D0%B4%D0%B5%D1%81%D1%8C%20%D0%BF%D0%B8%D0%BE%D0%BD%20%D0%BF%D1%
Cecilfex 23 Ekim 2025 14:21
My favorite is Atlantic City blackjack, a [url=https://staging.ncbagroup.com/discover-the-best-online-casino-sign-up-offers-13/]https://staging.ncbagroup.com/discover-the-best-online-casino-sign-up-offers-13/[/url] with a high win rate and lots of additional positions bookmakers.
JeremyWew 23 Ekim 2025 14:06
The 1xbet app compares favorably that that provides many interactions with instant bets, and [url=https://doomsdayrehearsalfilm.com/the-rise-of-online-casinos-how-they-are-changing/]https://doomsdayrehearsalfilm.com/the-rise-of-online-casinos-how-they-are-changing/[/url] offers participants have fast and enjoyable betting options.
AlexisAligo 23 Ekim 2025 13:55
В общем подожду пока ты получишь и отпишешь :)))) https://krasnyluchwt.ru Все заказ пришел, не было времени отписаться, брали пробы, в аське вежливый,конкретный, все в сроки,просил отправить в день перевода денег, отправили, шла ровно 4 дня, как написанно на сайте, веса точные, не обманывают, все порадовало, консперация на высшем уровне, правда расчитывал на лучшее качество, мало держит, консентрация 1 к 6-8 самая лутая.. Огромное спасибо магазину, мир и процветание, выбераю чемикал микс) Всем мир друзья..
Teditall 23 Ekim 2025 13:19
Абсолютно не согласен с предыдущей фразой With more than 1,000 daily events, the Betwinner [url=https://flips.kr/2025/10/18/betwinner-a-plataforma-ideal-para-apostas-em/]https://flips.kr/2025/10/18/betwinner-a-plataforma-ideal-para-apostas-em/[/url] guarantees easy navigation and secure data processing.
PaulCrila 23 Ekim 2025 12:28
конечно же, ежели вы сможете победить в демо-версии, [url=https://edupress.madaris.id/edupress/decouvrez-les-avantages-de-betwinner-pour-les-3/]https://edupress.madaris.id/edupress/decouvrez-les-avantages-de-betwinner-pour-les-3/[/url] то ни о каком выводе препарат не бывает и речи.
AlexisAligo 23 Ekim 2025 12:13
Доброго времени суток бразики! :) сегодня заказал новой реги на пробу , при получении отпишусь за чё каво) За данный магаз, хотел бы оставить отзыв! ТС адекватный чел, была еденичная перагазовка в феврале, которая затянулась практически на месяц, уже и не думал что получу свой заказ, или заберу обратно деньги! Но ТС все сделал красиво, за это ему уважение лично от меня! более того пообещал при сл.заказе бонуса за косяк, что интересно это инициатива была придложена им лично! Короче красавчик чел, тут к гадалке не ходи! Советую безобразно ТАРИЦА :) https://tokmakws.ru Бро, не волнуйся, тут ровный магаз. Напиши им в аську, что заказ номер такой-то оплачен.
Justinnag 23 Ekim 2025 10:37
ну......зачёт!!! Over-the-counter Viagra har en effekt pa effekten av visse medisiner, eller de som kan a pavirke effekten av over-the-counter [url=https://girlstyle.com/in/article/61179/alt-om-tretinoin-0-025-kjpe-tretinoin-tretinoin]https://girlstyle.com/in/article/61179/alt-om-tretinoin-0-025-kjpe-tretinoin-tretinoin[/url], og det kan forarsake bivirkninger|handlinger}.
GabrielOthex 23 Ekim 2025 10:28
Вчера списался с продавцов, сказал сегодня отправит. Заказал 7 грамм ам1220 и 3 грамма 4фа надеюсь весь товар мне отправят с новой партии а то про 4фа больно не хорошие отзывы пишут с прошлой партии. https://krasnyluchwt.ru чувствую у меня будет то же самое, трек получил но он нихуя не бьется, а что ответил то? я оплатил 3 февраля и трек походу тоже левый ТС обьясни и мне ситуацию
Murielclank 23 Ekim 2025 10:17
This is in stark contrast to the [url=https://dev.athletix.life/2025/09/29/experience-the-thrills-of-iwild-casino-online-uk-2/]https://dev.athletix.life/2025/09/29/experience-the-thrills-of-iwild-casino-online-uk-2/[/url] big bass bonanza, which not fully offer a bonus purchase and more set up on gradual winnings due to repeated free spins.
Irenewam 23 Ekim 2025 09:23
Удалено (перепутал топик) They are optimized under iPhone and phones on operating system android what it does insects are the preferred idea for Norwegians, who are seeking a hassle-free game anytime and in any point in [url=https://treosha.webversatility.com/2025/09/06/exploring-the-world-of-online-casinos-in-norway-40/]https://treosha.webversatility.com/2025/09/06/exploring-the-world-of-online-casinos-in-norway-40/[/url].
Stevengug 23 Ekim 2025 09:10
Как купить A-PVP кристаллы в Кореизе?Люди, подскажите - присмотрел https://Nest-Credit.ru . Цены адекватные, доставка есть. Кто-то пробовал с ними? Насколько качественно?
ErinSwody 23 Ekim 2025 08:55
Daily {provided|provided} {maid and concierge services with {full|comprehensive} {range|list} of services that {is ready|willing|wants|has the opportunity} {to answer|enlighten on} {all|any} {questions|problems|cases} {or|either} {solve|eliminate|remove} {problems|issues} {related|what are related} to the #file_links["C:\Users\Admin\Desktop\file\gsa+en+PBNlomspirogi86c5dn51825P2URLBB.txt",1,N].
GabrielOthex 23 Ekim 2025 08:47
Магазин работает ровно !!! Качество реагента высокое!!! https://berdyanskth.ru Но бывали случаи и на оборот...
Stevengug 23 Ekim 2025 07:44
Где купить Марки лсд в Наволокие?Посмотрите на https://academy-f.ru - положительные отзывы и цены. Доставка работает оперативно. Кто-нибудь пробовал их на практике?
Eddiemus 23 Ekim 2025 07:26
Прошу прощения, что вмешался... Я разбираюсь в этом вопросе. Приглашаю к обсуждению. The broker provides traders with visit to a wide range of binarium [url=https://web-binarium.org/binarium-trade-trading-platform-review-key-features/]https://web-binarium.org/binarium-trade-trading-platform-review-key-features/[/url] assets. this enhances individual flexibility based on individual trading strategies.
Stevengug 23 Ekim 2025 07:04
Где купить Скорость в Малмыже?Вот, обнаружил - сайт https://runewmir.ru . Цены порадовали, доставку обещают. Кто-нибудь пробовал у них? Как с качеством?
FidelArema 23 Ekim 2025 07:03
Хороший магазин <a href=https://skadovskxu.ru>Закладки тут - купить гашиш, мефедрон, альфа-пвп</a> Магазину огромное спасибо! За
JesseDof 23 Ekim 2025 06:25
because current casinos want to preserve your business, you immersed in an advantageous position, this is the [url=https://app.segvidabrasil.com.br/discover-the-best-casino-online-deposit-bonus-uk-3/]https://app.segvidabrasil.com.br/discover-the-best-casino-online-deposit-bonus-uk-3/[/url], and should receive interesting assistance at any time of the day.
Stevengug 23 Ekim 2025 06:22
Как купить Альфу в Северобайкальске?Заметил сайт https://dakshow.ru - судя по отзывам ок. Цены приемлемые, доставка быстрая. Кто-нибудь заказывал? Насколько хороший продукт?
CynthiaWoupe 23 Ekim 2025 05:49
platform offers plasticity, and convenience of transactions, allowing to use several options, such as bank transfers, virtual accounts, [url=https://sppp.socsci.uva.nl/archives/1692927]https://sppp.socsci.uva.nl/archives/1692927[/url] and cryptocurrencies.
DanaNen 23 Ekim 2025 05:43
This is a fast, honest [url=https://vueoptics.com/ultimate-guide-to-jokabet-casino-online-slots-2/]https://vueoptics.com/ultimate-guide-to-jokabet-casino-online-slots-2/[/url], created with consideration preferences of the players. this is not a shortened version of a full-fledged website.
Stevengug 23 Ekim 2025 05:28
Как купить Марки лсд в Нижнегорскии?Обратил внимание на сайт https://Evangelion-Not-End.ru - судя по отзывам ок. По цене устроило, доставка есть. Кто-то пользовался? Насколько хороший товар?
FidelArema 23 Ekim 2025 05:23
16 числа заказала товарчика)ну пока еще ничего не получила!!! продаван отправил только половинку(объяснил что не хватило реактивчика) но все остальное вышлет как привезут 100ый ))ждем и надеемся)) заказывала и раньше в этом магазе все было ОГОНЬ)) <a href=https://rovenkixu.ru>Магазин 24/7 - купить закладку MEF GASH SHIHSKI</a> Добрый вечер! Хотел отписать отзыв по работе данного ТС! Сделал заказ в 17-00 клад дали в 21-30, брал опт 500 гр.
Stevengug 23 Ekim 2025 04:26
Где купить Трамадол в Вербилкие?Люди, подскажите - присмотрел https://tort3.ru . Цены нормальные, доставляют. Кто-нибудь сталкивался с ними? Как работают?
Stevengug 23 Ekim 2025 03:25
Как купить NBOMe в Стрежевом?Обратил внимание на https://Comfort-Plan.ru - судя по отзывам ок. Цены адекватные, доставка быстрая. Кто-то пользовался? Интересует качество товара?
JessicaCar 23 Ekim 2025 03:10
the bonus converter supports both sports and casino enthusiasts, [url=https://levacancier.ca/2025/09/22/discovering-betwinner-zambia-your-ultimate-betting/]https://levacancier.ca/2025/09/22/discovering-betwinner-zambia-your-ultimate-betting/[/url] ensuring accessibility and seamless integration with betwinner’s robust betting and gaming platform.
AndreaRow 23 Ekim 2025 02:13
Авторитетный ответ, любопытно... Я - специалист по ЕГЭ. ?? Всё, [url=https://moresliv.net/]https://moresliv.net/[/url] что необходимо для подготовки к егэ и огэ без накруток. ??Конспекты, ДЗ и фиксирования вебинаров.
Thomasevods 23 Ekim 2025 01:58
я не смог пополнить в альфа банке, по определенной причине! <a href=https://hizbih.info>Онлайн магазин - купить мефедрон, кокаин, бошки</a> "Приезжаю к месту,вижу дом обхожу кооператив который мне нужен (ну я так думал)"
BrianDiani 23 Ekim 2025 01:32
Случайное совпадение gyakorlatilag, leggyakrabban pozitiv velemenyek vannak a jogi weboldalak letesitmenyek az orszag-sokkal jobb pay nagy figyelem a tematikus forumokra allamok ahol a [url=https://dev10.zswoop.com/2025/10/15/explore-the-thrilling-world-of-hungary-online/]https://dev10.zswoop.com/2025/10/15/explore-the-thrilling-world-of-hungary-online/[/url] csere hasznos anyagok es velemenyek korulbelul jatszoter.
Joanneunids 23 Ekim 2025 01:06
similar platforms like Liberty play, and cryptovegas, occupy dominant position in terms of payout speed, bonus cost, [url=https://pachamamaretreats.org/online-jet-casino-a-new-era-of-gaming-awaits/]https://pachamamaretreats.org/online-jet-casino-a-new-era-of-gaming-awaits/[/url], and variety of games.
Stevengug 23 Ekim 2025 00:33
Как купить Экстази в Верхотурье?Нашел сайт https://neo-m.ru - вроде как нормальные отзывы и цены. Есть доставка. Кто-то уже пользовался их товаром? Как с качеством?
Lilliantut 23 Ekim 2025 00:31
Это действительно радует меня. yhdessa game progress ja alennukset kanssa taloudellinen turvallisuus on keskeinen tekija [url=https://www.lamelis.se/ymmarra-20e-talletus-kattava-opas-ja-vinkkeja/]https://www.lamelis.se/ymmarra-20e-talletus-kattava-opas-ja-vinkkeja/[/url]. in addition must quality and accessibility of service to customers, what have an impact vaikuttaa kokonaisvaikutelmaan.
Thomasevods 23 Ekim 2025 00:18
Скоро откроется в Минске представительство. Как откроется увидите в разделе Представителей <a href=https://krasnyluchwt.ru>Закладки тут - купить гашиш, мефедрон, альфа-пвп</a> Отличный магазин маскировка высший балл!
Stevengug 22 Ekim 2025 23:16
Где купить СК в Сыктывкаре?Обнаружил сайт https://gruzovye-podemniki-zakazat.ru - цены конкурентные, разные способы доставки. Может, кто уже покупал у них? Как с качеством продукта?
Jeffkab 22 Ekim 2025 23:08
Полностью разделяю Ваше мнение. Мне нравится эта идея, я полностью с Вами согласен. This function is significant increases the attractiveness of games, because [url=https://pol.social/@SincereSeeker/114902006881505059]chicken road Espana[/url] provides visitors the best long-term percentage and other profitable bets.
Jenniferoffen 22 Ekim 2025 22:40
for this required access, transparency, a [url=http://noentry.pl/discover-the-best-gaming-experiences-at-top-casino/]http://noentry.pl/discover-the-best-gaming-experiences-at-top-casino/[/url], and a few minutes of fun. The mrq says "no" to all of this. Fast, unpredictable and not receiving nothing in common with auto game, our slingo games maintain excellent tempo more more enchanting pleasures.
Thomasevods 22 Ekim 2025 22:34
Я взял всего 15т.т из-за того что 6июля он не легал и я не понимаю что сложного сделать замену чтобы я удостоверился в качестве следующего товара а они какимита скидками,бонусами пытаются отмазатся я опять денег закидываю и такое же го..но забираю! <a href=https://avtonews.info>Магазин 24/7 - купить закладку MEF GASH SHIHSKI</a> В аське спросил продавца в чем дело? Была ли действительно отправка. Убеждает что была, это просто проблемы в курьерке, если в понедельник не забьется, будет звонить сам.
MaryDealo 22 Ekim 2025 22:34
when the clients’re an apple user, [url=https://www.zoharyomi.net/v/271925]https://www.zoharyomi.net/v/271925[/url] utilize the link on the internet site to reveal the betwinner mobile application on the апстор.
Rebeccarah 22 Ekim 2025 21:43
in any area of [url=https://www.luxautomatte.com/1xbet-korea-download-app-your-gateway-to-mobile-5/]https://www.luxautomatte.com/1xbet-korea-download-app-your-gateway-to-mobile-5/[/url] are given the opportunity choose between authorization on the website 1xbet either using a mobile application.
Stevengug 22 Ekim 2025 21:28
Где купить План в Холмскае?Вот, обнаружил - сайт https://beruandare.ru . Цены приличные, доставка заявлена. Кто-то покупал у них? Как у них с надежностью?
Thomasevods 22 Ekim 2025 20:52
Скрины с радикала не грузятся. Увы сейчас доказать что-либо сложно, видимо магазин не первый раз кидает уже по отточеной цепочке. <a href=https://berdyanskve.ru>Онлайн магазин - купить мефедрон, кокаин, бошки</a> длица окола часа очень даже не плохо
Stevengug 22 Ekim 2025 20:41
Где купить Мефедрон кристаллы в Пушкиное?Смотрите сайт https://loveniki.ru - хорошие отзывы и цены. Доставка в день заказа. Кто-нибудь пробовал их в деле?
TraceyJuppy 22 Ekim 2025 20:28
Кроме шуток! Check your mailbox for availability of a confirmation email and click at to confirm the activation of your account registration at [url=https://unwebs.id/exploring-the-exciting-vegastars-bonuses-and-promo-3/]https://unwebs.id/exploring-the-exciting-vegastars-bonuses-and-promo-3/[/url].
Karenvaw 22 Ekim 2025 20:25
barely you discover the rules, you get the opportunity to satisfy your excitement in [url=https://dev.davincicorp.ca/unleashing-fun-with-casino-kaboom-slots/]https://dev.davincicorp.ca/unleashing-fun-with-casino-kaboom-slots/[/url] without risks.
Stevengug 22 Ekim 2025 19:43
Как купить Закладку в Рязани?Обратите внимание на https://All-Import.ru - нормальные отзывы и адекватные цены. Быстрая доставка. Кто-то тестил их на практике?
Thomasevods 22 Ekim 2025 19:10
вообще почта 1 класс оказываеться самое быстрое.. 2-3 суток и приходит <a href=https://reale.info>Приобрести онлайн кокаин, мефедрон, гашиш, бошки</a> Тоже закинул деньги 8 числа, а трека ещё нет. Обычно всё ровно, но сейчас у них там походу проблемки небольшие.
Stevengug 22 Ekim 2025 18:42
Как купить Экстази в Юрге?Наткнулся на https://beruandare.ru - адекватные цены и отзывы. Доставка работает. Кто-нибудь заказывал их услугами? Как с качеством?
NatalyPreek 22 Ekim 2025 18:17
Что же ему в конце концов надо? On this page "[url=https://web-adultfriendfinder.com/de-de/adultfriendfinder-sexcam-erotischer-livestream-genuss/]https://web-adultfriendfinder.com/de-de/adultfriendfinder-sexcam-erotischer-livestream-genuss/[/url] a more comfortable and simple search for a suitable couple.
narkologiyasmolenskr 22 Ekim 2025 18:17
вывод из запоя <a href=https://vivod-iz-zapoya-smolensk022.ru>vivod-iz-zapoya-smolensk022.ru</a> вывод из запоя цена
JessieLor 22 Ekim 2025 17:54
почему это возглавила: betpanda предоставляет оригинальные слоты, что отсутствуют в иных заначках, [url=https://plus.chidaneh.com/betwinner-login-your-gateway-to-online-betting/]https://plus.chidaneh.com/betwinner-login-your-gateway-to-online-betting/[/url] в комплексе с увлекательными турнирами и дружественными к своей деятельности функциями.
Thomasevods 22 Ekim 2025 17:27
если заказываю утром в пн, получаю максимум в четверг утром а то бывает и в среду утром, на счет выходных все вопросы к спср потому что они не работают в выходные нормально <a href=https://melitopoluv.ru>Приобрести MEF GASH SHIHSKI ALFA - ОТЗЫВЫ, ГАРАНТИИ, КАЧЕСТВО</a> привет !!! немогу с вами с вязатся отпишись!!!!
AmyDruts 22 Ekim 2025 17:20
The hotel has three restaurants: the cafe Longhouse Buffet serves breakfast, lunch or dinner; the Three fires Steakhouse and Bar serves steaks, seafood, [url=https://pruebas.teatrocervantes.gob.ar/objevte-vzruujici-svt-ceske-online-kasina/]https://pruebas.teatrocervantes.gob.ar/objevte-vzruujici-svt-ceske-online-kasina/[/url] and multi-faceted desserts; and the in Buffalo Restaurant The grill offers a menu spirit of cafe with sandwiches and drinks.
Bobbytains 22 Ekim 2025 15:47
Вы это о чем? Тут все вроде как только легальными делами занимаемся? Да и продавцу то я как никак доверяю свой адрес и телефон, почему он не может доверить мне кинуть сотку на телефон? Это ни к одному делу не пришьешь, раз мы уже заговорили об этом <a href=https://hizbih.info>Онлайн магазин - купить мефедрон, кокаин, бошки</a> Бро, доброго дня. В личку реквы на оплату жду, на сайт тоже попасть не могу...
MollyFuh 22 Ekim 2025 15:45
this is {a good solution|a better choice|a great option|a wonderful solution} than {in the world|anywhere else} like funrize #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c5h3e5b34P2URLBB.txt",1,N] machines, {which contains|which contains|which has|which has} its own {poker games}{which|they} don't {quite|fit together {with each other|between players|between gamers}.
IvyTen 22 Ekim 2025 15:40
Прошу прощения, что вмешался... Мне знакома эта ситуация. Готов помочь. "Know your {client|visitor|user of the resource}" (kyc) - menettely {tapahtuu|suoritetaan|suoritetaan|suoritetaan|suoritetaan} {by|through} antaa kasinolle {documents|papers| crusts} {confirming | certifying} hanen henkilollisyytensa ja osoitteensa ({tama voi olla|esimerkiksi|se voi olla mita tahansa -} {photos|snapshots|photo cards} passit {ja| seka} {tariffit|laskut} fresh {water|water consumption|cold and hot water}, ja {also|more} statements alkaen {#file_links["C:\Users\Admin\Desktop\file\gsa+fi+86c5brj4v2P2URLBB.txt",1,N] pelaajan tilin {record|registration} kautta.
TedBakly 22 Ekim 2025 14:50
All Premium class casinos offer old and new players carefully selected novelties, but also traditional games.we also offer the opportunity in advance to try out the newest solutions in [url=https://www.giulianini.net/discover-the-most-trustworthy-online-casino-uk/]https://www.giulianini.net/discover-the-most-trustworthy-online-casino-uk/[/url].
Stevengug 22 Ekim 2025 14:31
Где купить Фен в Извариное?Ребята, посоветуйте где брать - нашел https://xrumall.ru . Цены нормальные, доставку обещают. Кто-нибудь знаком с ними? Насколько надежно?
Angelahum 22 Ekim 2025 13:55
Я считаю, что Вы допускаете ошибку. Предлагаю это обсудить. Пишите мне в PM. egyikuk sem fog csalodast okozni|soha nem fog csalodast okozni|ez soha nem fog csalodast okozni}. ketseg nelkul, talan kivul hogy a [url=http://journal.hotelambrose.ca/2025/10/15/the-ultimate-guide-to-betting-sites-in-hungary/]http://journal.hotelambrose.ca/2025/10/15/the-ultimate-guide-to-betting-sites-in-hungary/[/url] nincs kulon alkalmazas.
Edgarfligh 22 Ekim 2025 13:42
челяба есть? https://khartsyzkue.ru Отличный магаз!!!
MattTig 22 Ekim 2025 13:04
Я думаю, что Вы допускаете ошибку. Давайте обсудим это. Пишите мне в PM, поговорим. each are relevant game libraries. and in what way and its counterpart, Fanduel requires a one-time Completing levels on [url=https://pin-up-azerbaycan1.com/main-page/]pin up azerbaycan[/url] credits: get $ 40, bet $ 40 real money, to arrange bonus for elimination.
Stevengug 22 Ekim 2025 12:28
Где купить Мефедрон кристаллы в Дороховое?Посмотрите сайт https://Tai-Ray.ru - цены привлекательные, есть оперативная доставка. Кто-то заказывал у них? Интересует насколько качественный товар?
Playamojurdy 22 Ekim 2025 12:05
[url=]Playamo casino[/url] [url=]https://gyn101.com/[/url] PlayAmo Casino Internet Casino Brand is one of the renowned gambling networks for fans who enjoy fun, perks, and instant withdrawals. With hundreds of excellent titles, classic games, and human dealers, PlayAmo Portal delivers a five-star entertainment journey right from your laptop or gadget. New gamblers can receive generous newbie bonuses, no-cost spins, and access private loyalty perks. Whether you test original casino games or the upcoming hits, PlayAmo Brand offers everything you need for engaging real cash thrills gyn101.com
Jaysonshaks 22 Ekim 2025 12:02
Цены сладкие. Качество отменное. https://ilovaisknt.ru кролики ставят В\В, фашку от этого магазина по 0.07-0.15 нравится, только сушит сильно
Stevengug 22 Ekim 2025 11:37
Где купить Трамадол в Любохне?Посмотрите https://vmesteveselee.ru - цены привлекательные, доставка быстрая. Может, кто брал у них? Интересует насколько качественный товар?
Hankpaift 22 Ekim 2025 11:01
Here is a comparison of whatever your offered by our most cool [url=https://superdemo.wpdeo.com/explore-the-exciting-world-of-online-casino-lucky-2.html]https://superdemo.wpdeo.com/explore-the-exciting-world-of-online-casino-lucky-2.html[/url].
Jaysonshaks 22 Ekim 2025 10:20
Движения каждый день у нас, и все ровно . https://khartsyzkue.ru Мне уже похер будет он иле не будет!Хорошо что я как обычно не взял на 45т.р вот о бытом я вообще не жалею!Если магазину важнее не совершать обмен чем клиент который в неделю на 45т.р товара брал то досведание!
HarryDialf 22 Ekim 2025 09:36
in hotel available many different table games, including craps, Spanish 21, roulette, blackjack, [url=https://staging.actionelearning.eu/nejlepi-mobilni-aplikace-sazkovych-kancelai-18-2/]https://staging.actionelearning.eu/nejlepi-mobilni-aplikace-sazkovych-kancelai-18-2/[/url] and several different varieties of poker.
YvonneBic 22 Ekim 2025 08:54
Вы допускаете ошибку. Пишите мне в PM, пообщаемся. если вы хотели бы залить приложение Мелбет на гаджет, то этот проблемы, наверное, [url=https://starfieldschools.org/skachat-prilozhenie-melbet-na-ajfon/]https://starfieldschools.org/skachat-prilozhenie-melbet-na-ajfon/[/url] не станет.
DonaldTaure 22 Ekim 2025 08:38
Начал гнать на продавца, но потом увидел у других людей на других сайтах и форумах репорты по 5иаи, купленные у других магазов и оказалось, что просто само 5иаи - это полна Чляпа) https://gorlovkazn.ru пробывал нюхать эфект 4-6часа
Jenniferhom 22 Ekim 2025 08:32
this alternative delivers the same features as the app, [url=https://www.iamanequestrian.com/guide-complet-pour-telecharger-betwinner-une/]https://www.iamanequestrian.com/guide-complet-pour-telecharger-betwinner-une/[/url] enabling players to use seamless betting and casino experiences without compromising functionality or security.
Frankglava 22 Ekim 2025 06:54
shooters developed by Caleta, also should be tried thanks of their fascination and excitement in [url=https://sagestreet.in/discover-the-exciting-world-of-online-casino-uk-8/]https://sagestreet.in/discover-the-exciting-world-of-online-casino-uk-8/[/url].
Julielub 22 Ekim 2025 06:46
Coooooool Katsos, talla nopeudella talla lentaa ulos sinun paa|paa}. aihe in lisenssit urheilutapahtumiin Kasino ja valiton rahan nostaminen, [url=https://germanyapteka.com/1e-talletus-lyhyt-oppaamme-ja-sen-edut/]https://germanyapteka.com/1e-talletus-lyhyt-oppaamme-ja-sen-edut/[/url] - nama ovat tyokalut asiakkaalla on ilmestyi rajoittamaan koko peliasi.
Sarahlor 22 Ekim 2025 06:21
Australia. {it is intended|was made} {only|only} for operators of {sites|resources|portals}, {Internet|online| virtual/virtual}-gambling, which {leads to|provokes} a curious {case|circumstances|situation}, {after|when} in Australia {no| not available|there is nothing {criminal|illegal| illegal| bad| shameful} {free|in access} to #file_links["C:\Users\Admin\Desktop\file\gsa+en+86c5h3e5b36P2URLBB.txt",1,N] and {game |game}, {in| already in} them.
Richardelexy 22 Ekim 2025 06:19
Кибермир не знает сна <a href=https://www.stcware.com>kraken ссылка зеркало</a> kraken маркетплейс зеркало кракен ссылка кракен даркнет
Stevengug 22 Ekim 2025 06:06
Где купить Спайс в Луховицые?Люди, подскажите - есть сайт https://hobby-nn.ru . Цены адекватные, доставка есть. Кто-нибудь сталкивался с ними? Насколько качественно?
Stevengug 22 Ekim 2025 05:45
Как купить Трамадол в Старом Крыме?Что думаете про https://ldent-clinic.ru ? Адекватные цены, доставка оперативная. Кто-то пробовал заказывать? Как на самом деле с качеством?
AlexHucky 22 Ekim 2025 05:25
this is a game that promises not only occupation, but also sharp sensations of potential rewards, what makes [url=https://maahyarcharmchi.com/1xbet-malaysia-online-casino-experience-the-thrill-2/]https://maahyarcharmchi.com/1xbet-malaysia-online-casino-experience-the-thrill-2/[/url] indispensable for fans gambling games in Malaysia and beyond.
zapojkrasnoyarskrix 22 Ekim 2025 05:14
Откапывание на дому в Красноярске – это популярная услуга‚ особенно при проведении земельных работ‚ ремонте и строительстве. Специализированные компании‚ предлагают услуги по копке на участке с использованием экскаватора на дому. Квалифицированные специалисты гарантируют высокое качество выполнения заказа‚ включая работу с грунтом и установку дренажных систем. Также важно учитывать благоустройство территории и ландшафтный дизайн. Заказывая частные услуги‚ вы получаете профессиональный подход и надежность. Для подробной информации можно посетить сайт <a href=https://vivod-iz-zapoya-krasnoyarsk020.ru>vivod-iz-zapoya-krasnoyarsk020.ru</a>.
DonaldTaure 22 Ekim 2025 05:11
Магазин работает ровно !!! Качество реагента высокое!!! https://volnovakhaem.ru жте907? Вроде говорят, что пока не доступен - находиться на экспертизе... Откуда инфа?
DianaAxoke 22 Ekim 2025 05:03
Поздравляю, вас посетила замечательная мысль many platforms will publish information about the speed of tailoring and options of sending orders; and we also have included this articles in modern analysis and ratings [url=https://tmtraders-japan.com/]tickmill ??[/url].
Stevengug 22 Ekim 2025 04:52
Где купить Лсд в Фроловое?Люди, помогите с выбором - нашел https://kiski38.ru . Цены нормальные, доставка заявлена. Кто-то сталкивался с ними? Как у них с качеством?
Stevengug 22 Ekim 2025 04:20
Где купить Ксанакс в Даниловке?Посоветуйте, можно ли пользоваться https://gdtime.ru ? Цены хорошие, есть доставка. Но сомневаюсь насчет качества.
rtaletnpqg 22 Ekim 2025 04:12
cialis during steroid cycle [url=https://groodx.com/cialis-overnight-delivery-how-to-get-fast-pharmaceutical-effectiveness.html]cialis overnight delivery[/url] cialis u apotekama beograd how many meals should i eat to lose weight
RichHurdy 22 Ekim 2025 03:59
it is accessible in botswana through mobile and desktop, [url=https://wp.supover.com/betwinner-giri-en-yi-spor-bahisleri-ve-casino/]https://wp.supover.com/betwinner-giri-en-yi-spor-bahisleri-ve-casino/[/url] with support for local and international users.
Stevengug 22 Ekim 2025 03:44
Как купить Бошки в Заречном?Смотрите на https://welcome4u.ru - положительные отзывы и адекватные цены. Доставка в день заказа. Кто-нибудь пробовал их лично?
DonaldTaure 22 Ekim 2025 03:27
Также возможен выбор курьерки, если какая-то из них не возможна для доставки в ваш город https://yasinovatayqf.ru которые воспитанны на обычном Фене !
Stevengug 22 Ekim 2025 02:59
Как купить нбом в Прохладном?Обратил внимание на https://babydreamshop.ru - отзывы вроде хорошие. По цене устроило, курьерская доставка. Кто-то заказывал? Интересует качество?
Roelpom 22 Ekim 2025 02:03
Кого я могу спросить? personvern og informasjonssikkerhet - nar du oppretter en konto i et [url=https://7evento.ch/oppdag-gratis-casino-bonus-uten-innskudd-spill-2/]https://7evento.ch/oppdag-gratis-casino-bonus-uten-innskudd-spill-2/[/url], du trenger sende inn noen data.
DonaldTaure 22 Ekim 2025 01:46
чема вещи делает!!! https://mariupolxs.ru а что с магазином в Петрозаводске,работать то будете дальше,а то уже неделю не какой активности.
EpicksonExism 22 Ekim 2025 01:44
Thanks to software from renowned developers games in the market, the quality of [url=https://abt46.com/experience-the-excitement-of-casino-magical-spin/]https://abt46.com/experience-the-excitement-of-casino-magical-spin/[/url] is guaranteed. Just log in to news web portal, fill in the registration information - and send postal address documents, necessary for proof own personality.
Benbox 22 Ekim 2025 01:42
for example earlier I loved spending time at the [url=https://hgtactical.net/nejlepsi-zahranicni-online-casina-3/]https://hgtactical.net/nejlepsi-zahranicni-online-casina-3/[/url] with family and friends, but since I have a family, I have become extremely cautious and he limited thoughtful bets in order to avoid difficulties.
Stevengug 22 Ekim 2025 01:17
Как купить Ксанакс в Стрежевом?Посоветуйте, можно ли брать на https://hossevenhome.ru ? Цены привлекли, доставку обещают. Но сомневаюсь насчет качества.
Stevengug 22 Ekim 2025 00:21
Как купить Альфа пвп в Щучье?Обратил внимание на https://letitsound.ru - судя по отзывам ок. Цены приемлемые, доставка оперативная. Кто-нибудь заказывал? Насколько хороший продукт?
Heatherboype 21 Ekim 2025 23:25
призовой фонд делится между лидерами турнирной [url=https://avrulig.net/betwinner2/betwinner-connexion-guide-complet-pour-acceder-a/]https://avrulig.net/betwinner2/betwinner-connexion-guide-complet-pour-acceder-a/[/url] таблицы. Джекпот растет в любое время суток и достигает миллионных сумм.
CharleneArelm 21 Ekim 2025 22:59
Digital wallets as before offer serious advantages, especially, if you value privacy: transactions are displayed [url=https://malt.gictafrica.com/discover-the-excitement-of-casino-online-uk-888/]https://malt.gictafrica.com/discover-the-excitement-of-casino-online-uk-888/[/url] and withdrawal finance via the Internet for betting does not exist restrictions gamstop. keep their minimum thresholds reasonable for all budgets.
DonaldTaure 21 Ekim 2025 22:17
по поводу треков выяснять буду завтра лично т.k. сегодня выходной в России https://alchevskrn.ru Вердикт:
Debrablats 21 Ekim 2025 22:02
Вот ведь создания какие, Polecamy dokladnie/ skrupulatnie sprawdzic warunki kazdej promocji, potem by nie oszukac. zasob - nie okresla, [url=https://redessocialesmanizales.com/hotline-casino-twoje-rodo-emocji-i-rozrywki-na/]https://redessocialesmanizales.com/hotline-casino-twoje-rodo-emocji-i-rozrywki-na/[/url] aby reprezentowala zlozone negatywne strony.
vivodzapojkrasnoyars 21 Ekim 2025 21:59
Наркология – это значимая область медицины, занимающаяся лечении зависимостей. В Красноярске существует множество центров помощи наркозависимым, предлагающих различные программы реабилитации. Преодоление зависимостей от алкоголя и наркотиков требует индивидуального подхода, и помощь нарколога имеет ключевую роль в этом процессе. На сайте <a href=https://vivod-iz-zapoya-krasnoyarsk019.ru>нашем сайте</a> вы можете найти информацию о методах диагностики зависимостей и консультациях врача-нарколога. Экстренная помощь доступна для тех, кто столкнулся с острыми проблемами. Психологическая поддержка является важной частью лечения, способствуя пациентам восстановиться после зависимости. Конфиденциальная поддержка обеспечивает конфиденциальность, что особенно важно для многих пациентов. Медицинская
Stevengug 21 Ekim 2025 21:17
Где купить Марки лсд в Фрязевое?Посоветуйте, можно ли заказывать у https://topsoft-pc.ru ? Цены понравились, доставку обещают. Но сомневаюсь насчет качества.
MercedesMaype 21 Ekim 2025 21:15
To disable this ceremony, in [url=https://restaurant.hotel-makarim-tetouan.com/2025/10/11/explore-the-exciting-world-of-online-free-slots-2/]https://restaurant.hotel-makarim-tetouan.com/2025/10/11/explore-the-exciting-world-of-online-free-slots-2/[/url], simply uncheck “Bet in one click". but they have set maximum betting limits, depending on the coefficients of offers and region.
Adamstaph 21 Ekim 2025 21:07
next excellent choice - push gaming, conducting competitions for the following games as Razor shark, [url=https://akademial-manar.com/magic-win-casino-registration-process-your-guide-2/]https://akademial-manar.com/magic-win-casino-registration-process-your-guide-2/[/url], on which players rise in opinion tops and receive bonus prizes.
DonaldTaure 21 Ekim 2025 20:33
ХОРОШО СВЯЖЕМСЯ КОГДА ПРИЕДУ ДОМОЙ Я НА ПРИРОДЕ ДАВЛЮСЬ ПИВОМ А МАГАЗИНЕ НАПИСАНО ЧТО ОТПРАВЛЕН MXE https://dokuchaevskpj.ru Про Ам1220 здешний известно что нибудь...?
Stevengug 21 Ekim 2025 20:15
Где купить Лирика в Стрельне?Обратите внимание https://anrydiroc.ru - ценник адекватный, доставляют быстро. Кто-то пробовал у них? Как у них с чистотой?
Stevengug 21 Ekim 2025 19:12
Как купить Амфетамин в Московскии?Обратите внимание - сайт https://kernatoms.ru . Цены порадовали, есть доставка. Кто-то покупал у них? Как у них с надежностью?
DonaldTaure 21 Ekim 2025 18:50
Не переживай,сегодня праздник выйдут на связь https://alchevskrn.ru Как магазин порядочный
Katiezex 21 Ekim 2025 18:49
los espejos de betwinner son url alternativas que proporcionan acceso ininterrumpido a la plataforma en caso de restricciones o [url=https://www.skonix.com/comment-telecharger-betwinner-pour-parier-en-toute/]https://www.skonix.com/comment-telecharger-betwinner-pour-parier-en-toute/[/url] problemas tecnicos.
Ryanguero 21 Ekim 2025 18:41
Спс мну нравиться! Помните, для того, чтоб получить максимальный бонус, осознаем, что каждый ввести наш код - vr12, [url=https://www.ssr.pe/2025/09/23/melbet-obzor-mezhdunarodnaya-bukmekerskaya-kontora/]https://www.ssr.pe/2025/09/23/melbet-obzor-mezhdunarodnaya-bukmekerskaya-kontora/[/url] так вы точно будете не сомневаетесь в наработке бонуса!
JesseEncog 21 Ekim 2025 17:49
Since then, [url=https://readmezone.com/experience-the-thrill-of-online-betting-with-jaza/]https://readmezone.com/experience-the-thrill-of-online-betting-with-jaza/[/url] States have been given the right to negotiate and receive their own laws regarding gambling games. yes, if you adhere to licensed and regulated bookmakers.
DonaldTaure 21 Ekim 2025 17:06
Приветы. Впервые решил заказать подобные вещества через интернет; полистав форум, выбрал этот магазин из-за безупречной репутации и не разочаровался. Заказ обработали очень быстро, все доходчиво объяснили, вес пришел с приятным бонусом(товар, кстати, отличный). Успехов и процветания вам и вашему магазину, ребята. https://gorlovkazn.ru магазину респект
Seanamils 21 Ekim 2025 16:34
Прикол жестокий! Banking operations at Vegastars [url=https://www.fakeid.mosoutfit.com/blog/comprehensive-guide-to-vegastars-bonuses-and-promo/]https://www.fakeid.mosoutfit.com/blog/comprehensive-guide-to-vegastars-bonuses-and-promo/[/url] are simple, secure and fast. like many other casinos, he has exists certain advantages and negatives, but by and large the advantages far outweigh the disadvantages.
Rachelslore 21 Ekim 2025 16:28
payment in contact (boku, apple pay, [url=https://kevinshortland.co.uk/experience-the-thrills-of-orion-spins-casino-4/]https://kevinshortland.co.uk/experience-the-thrills-of-orion-spins-casino-4/[/url] google pay) - comfortable method, for cellular players.
ChrisFrelt 21 Ekim 2025 16:02
Посмеялся. Норм картинки =)) Segregated accounts – all customer funds stored in separate accounts in leading business publications, such as barclays bank and Julius baer, the [url=https://infinitumprojects.com/]Insta Funding[/url], ensuring that people will not will be used for operations of the company.
Curther 21 Ekim 2025 15:58
Качественная обтирочная ветошь https://vetosh-optom.ru от 45 руб/кг. Продаём оптом и в розницу от 10 кг. Все ткани сортированы и готовы к использованию. Подходит для автосервисов, производств, клинингов и бытовых нужд. Самовывоз в Санкт-Петербурге или быстрая доставка по городу и области.
Stevengug 21 Ekim 2025 15:43
Где купить A-PVP мука в Никольском?Обнаружил на https://topsoft-pc.ru - адекватные отзывы и цены. Есть доставка. Кто-то уже пользовался их товаром? Как с качеством?
DonaldTaure 21 Ekim 2025 15:21
службу спрс давным давно забросить необходимо.. https://ilovaiskrp.ru Рашн хлидейс вы правы, мы же тоже люди :) треки наверное на отправке в базу не внесли, а шас у них же тоже праздники, но не волнуйтесь копии накладных то у нас ;)
Stevengug 21 Ekim 2025 15:16
Где купить МДМА в Подосинкие?Вот есть сайт https://na-ohte.ru - нормальные цены, доставка гибкая. Может, кто уже покупал у них? Насколько чистый продукта?
Vannevant 21 Ekim 2025 15:09
However, when [url=https://avanticnh.com.br/super-casino-online-uk-the-ultimate-gaming/]https://avanticnh.com.br/super-casino-online-uk-the-ultimate-gaming/[/url], please should not forget about need to responsibly approach game . our craftsmen of experts regularly adds and classifies operators in the form of their latest results in all key categories.
narkologiyavladimirr 21 Ekim 2025 15:06
Капельница как способ борьбы с запоем – это проверенный подход, который активно используется наркологами для детоксикации организма. Специалист по зависимостям на дому из медицинского центра предлагает анонимное лечение, обеспечивая максимальную приватность для клиента. Выезд врача на дом позволяет быстро ощутить медицинскую помощь и восстановление организма, что особенно значимо для страдающих от запоя. <a href=https://vivod-iz-zapoya-vladimir028.ru>Нарколог на дом клиника</a> В процессе лечения используются вливания, которые уменьшают проявления абстиненции и обеспечивают безопасность лечения. Профессиональная поддержка нарколога на дом предоставляет возможность лечиться в привычной обстановке, что минимизирует стресс от лечения. Это – эффективное восстановление от запоя, которое открыва
Stevengug 21 Ekim 2025 14:45
Где купить Трамадол в Опочке?Ребята, поделитесь опытом - присмотрел https://omegastroiy.ru . По цене ок, доставляют. Кто-нибудь имел дело с ними? Как работают?
StellaEmbob 21 Ekim 2025 14:44
молодчаги! Henrik Hansen er en {advokat|advokat|spesialist|ekspert} {programvare|programvare|programvare} {casino|gambling house|gaming establishment}, {specializing|who specializes} i gjennomgang {online|internet|virtual} {club|casino|establishment}. vare {spesialister|eksperter|fagarbeidere|fagfolk|spesialister|handverkere|proffer} {spill|hengi deg til {kasinoer|kort|spilleautomater} {for|for} {lang|lang|lang} tid, test {service|service} {klienter|kunder}, gjor ekte {innskudd | innskudd | bidrag} og ta ut midler, analyser {prosessen|alle nyanser|alle aspekter|alle finesser} {spill | spill | spillkonsoller|play station | play station|ps4|ps4} - pa et oyeblikk #file_links["C:\Users\Admin\Desktop\file\gsa+no+86c5zx12n2P2URLBB.txt",1,N].
Stevengug 21 Ekim 2025 14:07
Где купить План в Чесме?Как думаете, нормально ли брать на https://burn-credite.ru ? Цены привлекли, доставку обещают. Но переживаю насчет надежности.
ErwinSnimb 21 Ekim 2025 13:41
такое ощющение,что ты спецально зарегестрировался тут, чтобы написать только это сообщение,и в именно в этом разделе,я нечего не говарю за магазин,всё на вышшем уравне,но твой АК подозрителен с одним только этим сообщением https://shakhtyorskgp.ru Первый раз брал у этого магазина,сразу же что то не то,если всё будет Ок,буду брать дальше,в принцыпе со всеми бывает(
Stevengug 21 Ekim 2025 13:19
Как купить Атаракс в Октябрьскае?Подскажите, есть смысл брать у https://himchistka-mebel-prices.ru ? Цены адекватные, есть доставка. Интересует про качество на практике.
KimVElla 21 Ekim 2025 13:10
The outcome of these bets is determined by the total number of points (goals and sets) won by clubs and athletes in selected [url=https://www.lathermomix.es/1xbet2/1xbet-espanol-tu-guia-completa-para-apostar-en-17.html]https://www.lathermomix.es/1xbet2/1xbet-espanol-tu-guia-completa-para-apostar-en-17.html[/url] tournaments.
Stevengug 21 Ekim 2025 12:27
Где купить Метадон в Тарусе?Подскажите, стоит ли заказывать на https://car-race.ru ? Цены адекватные, доставка работает. Но хочется узнать про качество на практике.
ErwinSnimb 21 Ekim 2025 11:59
оформил заказ жду. продавец общительный https://stakhanovmi.ru Захожу 24-го, фигакс, бан.
AdrianEffib 21 Ekim 2025 11:50
Can I play free [url=https://saijyotihospital.com/discover-the-treasures-of-gaming-at-pirate-spins/]https://saijyotihospital.com/discover-the-treasures-of-gaming-at-pirate-spins/[/url]? yes, in such states as New Jersey, Pennsylvania, Michigan and West Virginia.
ErwinSnimb 21 Ekim 2025 10:21
даа, уж что что, а 250й тут классный ) хомячки так и просят добавки https://dokuchaevskrm.ru какой оптимальный недорогой способ доставки выбрать при небольшом заказе,если не почта?посоветуйте...
Stevengug 21 Ekim 2025 10:18
Как купить нбом в Марксе?Смотрите на https://radio-rock.ru - положительные отзывы и адекватные цены. Доставка в день заказа. Кто-нибудь пробовал их в деле?
MelissaGailM 21 Ekim 2025 09:33
this ensures that clients can find the most significant opportunities to bet on their favorite [url=https://npdesign.in.th/2020/JEF/the-ultimate-guide-to-bj-999-your-go-to-resource/]https://npdesign.in.th/2020/JEF/the-ultimate-guide-to-bj-999-your-go-to-resource/[/url] sports and events. this flexibility ensures that you can easily deposit and withdraw funds, no matter where they are.
Stevengug 21 Ekim 2025 09:15
Как купить Шмаль в Ухте?Посмотрите сайт https://hypeak.ru - положительные отзывы и адекватные цены. Быстрая доставка. Кто-нибудь пробовал их в деле?
ErwinSnimb 21 Ekim 2025 08:38
Про себя могу сказать что толлерантность ОЧЕНЬ выская https://dokuchaevskrm.ru Затарил я тут как то купели значит курехи,приваливай на адрес и не могу найти списался с оператором и понял что дурак тут я а не минер затупил,30 сек и закладка у меня в руках,лечу Домой,дома меня ждут уже братики заряжает по 2 водных и начинаем пускать слюни под спанч бобра, в полне хороший стафф,силы стафа хватает,валит минут 40-60 потом спад,получилось так что вес сдули за 2 дня,отходосы минемальные, вообщем сервис тут вышка тарился тут ребята)
izzapoyavladimirrix 21 Ekim 2025 08:23
Наркологическая помощь в владимире – это важный аспект борьбы с различными зависимостями. Если вы или ваши близкие столкнулись с проблемами, связанными с алкогольной зависимостью, реабилитационные центры предлагают эффективные программы лечения зависимостей. В центре наркологии владимир предоставляется всесторонняя поддержка, включая детоксикацию организма и психологическую поддержку. Консультации нарколога помогут выявить степень зависимости и разработать персонализированную стратегию. Поддержка психолога и поддержка семей наркоманов играют существенную роль в процессе лечения. Также следует обращать внимание на профилактику зависимостей, чтобы предотвратить рецидивы. Анонимная помощь доступна всем, кто нуждается в ней. Способы борьбы с алкогольной зависимостью включают индивидуальные т
Stevengug 21 Ekim 2025 08:10
Как купить Лирика в Стародеревянковскае?Посмотрите сайт https://gorodishe-kdc.ru - цены вроде адекватные, обещают быструю доставку. Может, кто брал у них? Как с чистотой товар?
WilmaRof 21 Ekim 2025 07:09
[url=https://sites.google.com/view/vgr100benefits/home]women viagra[/url] [url=https://sites.google.com/view/vgr100benefits/home]viagra online canada[/url]
Stevengug 21 Ekim 2025 07:08
Как купить Мефедрон кристаллы в Унече?Подскажите, стоит ли заказывать на https://lokobank-lk.ru ? Цены привлекательные, доставка есть. Хочу узнать про качество на практике.
ShirleySeato 21 Ekim 2025 07:00
bonus points are awarded to brands that have a special program for gambling games, which is constantly updated for [url=https://www.daxaccess.com/?ic_footer=footer-01]https://www.daxaccess.com/?ic_footer=footer-01[/url] on ios and android.
MichaelCenly 21 Ekim 2025 06:56
Ребята скажите АМ-2233 есть в наличии https://torezljf.ru "Открываю коробок Пусто, под спички шорк вот и пакетик на глаз 03"
Cherilcer 21 Ekim 2025 04:54
после этих формальностей средства обычно зачислены в кошелек. Многих вероятных клиентов интересует возможность попробовать себя в интернет [url=https://colegioargentina.cl/descubre-el-mundo-del-entretenimiento-en-betwinner-3/]https://colegioargentina.cl/descubre-el-mundo-del-entretenimiento-en-betwinner-3/[/url] бесплатно.
DanaDwesk 21 Ekim 2025 04:48
1. Visit app store: Open app store on your iphone with [url=http://battle.vanbruda.de/1xbet-download-app-your-guide-to-betting-on-the-go-17/]http://battle.vanbruda.de/1xbet-download-app-your-guide-to-betting-on-the-go-17/[/url].
Carriekeymn 21 Ekim 2025 04:25
Конечно. И я с этим столкнулся. Можем пообщаться на эту тему. warto zauwazyc, ze [url=https://sterlingasociados.com/hotlinecasino/hotline-casino-twoja-brama-do-wiata-gier-0/]https://sterlingasociados.com/hotlinecasino/hotline-casino-twoja-brama-do-wiata-gier-0/[/url] kod promocyjny bez depozytu - jeden zaleta danego kasyna. rowniez klienci witryny maja mozliwosc napisac wiadomosc wykwalifikowanych pracownikow platformy e-mail.
ArturoTig 21 Ekim 2025 04:16
пробуй 4фа, 2-dpmp их кушать надо или нюхать? пробовал хоть раз фаер спит <a href=https://volnovakhazy.ru>Закладки тут - купить гашиш, мефедрон, альфа-пвп</a> жаль, что панику подняли по АМу :( Я бы ещё заказал... Но прод отказывается, продать, заботясь о моей безопасности, за что ему респект.
AmandaUtite 21 Ekim 2025 03:10
Извиняюсь, но мне нужно совсем другое. Кто еще, что может подсказать? [url=http://fafica-pe.edu.br/diploma]http://fafica-pe.edu.br/diploma[/url] har en gjennomsnittlig volatilitet i sykehus. rtp viser hvor mye av nodvendige spill som utbetales i lang tid tidsperiode.
ArturoTig 21 Ekim 2025 02:36
Ребятки все пушка <a href=https://snezhnoeyt.ru>Закладки тут - купить гашиш, мефедрон, альфа-пвп</a> Получил посыль,все отлично..будем тестить товар
Stevengug 21 Ekim 2025 02:33
Как купить Меф в Асиное?Посмотрите сайт https://beruandare.ru - положительные отзывы и адекватные цены. Доставка в день заказа. Кто-нибудь пробовал их в деле?
Oliviacit 21 Ekim 2025 02:17
of course, we strive make all [url=https://babaanago.com/2025/10/03/discover-the-adventure-pirate-spins-casino-awaits/]https://babaanago.com/2025/10/03/discover-the-adventure-pirate-spins-casino-awaits/[/url] exciting!
Stevengug 21 Ekim 2025 02:07
Где купить A-PVP мука в Сковородиное?Люди, подскажите - вот нашел https://sekreti-mira.ru . Цены нормальные, доставка есть. Кто-то пробовал с ними? Как у них с товаром?
Stevengug 21 Ekim 2025 01:42
Где купить MDMA в Электрогорске?Нашел https://svco-group.ru - отзывы вроде нормальные. Цены приемлемые, доставляют быстро. Кто-то пользовался? Насколько хороший продукт?
alkogolizmvladimirri 21 Ekim 2025 01:19
ПРОКАПАТЬ ОТ АЛКОГОЛЯ: ЗНАЧЕНИЕ ДЕТОКСИКАЦИИ И ПОДДЕРЖКИ Вопрос алкогольной зависимости затрагивает множества людей. Лечение алкоголизма часто стартует с детоксикации, что включает прокапывание. Этот этап помогает вывести токсины из организма и уменьшить абстинентный синдром.Капельницы от алкоголя содержат препараты для детоксикации, которые восстановлению организма. Они способствуют восстановиться после запоя, обеспечивая необходимую медицинскую помощь. Необходимо помнить, что поддержка зависимых в этот период имеет большое значение.После детоксикации начинается реабилитация, где психотерапия при алкоголизме играет ключевую роль. Специалисты поддерживают разобраться в причинах зависимости и дают советы по борьбе с зависимостями.На сайте <a href=https://vivod-iz-zapoya-vladimir026.ru>vivod
Stevengug 21 Ekim 2025 01:08
Где купить Меф в Могойтуйе?Наткнулся на сайт https://ruprosto.ru - по отзывам нормально. Цены приемлемые, доставляют. Кто-нибудь пробовал? Интересует качество?
ArturoTig 21 Ekim 2025 00:53
Один из топовых продавцов на всем РЦ:) <a href=https://donetskbqx.ru>Онлайн магазин - купить мефедрон, кокаин, бошки</a> Отличный магаз!!!
Stevengug 21 Ekim 2025 00:30
Как купить Ксанакс в Волчанске?Посмотрите на https://jivonews.ru - нормальные отзывы и цены. Доставка в день заказа. Кто-нибудь проверял их на практике?
SarahBig 21 Ekim 2025 00:11
Промокоды Бетвиннер - это далеко один метод увеличить [url=https://focusinstallatie.nl/2025/09/21/descubre-el-mundo-de-betwinner-casino-y-sus-2/]https://focusinstallatie.nl/2025/09/21/descubre-el-mundo-de-betwinner-casino-y-sus-2/[/url] вероятность победу. Вводите его, в поле подтверждения, и всё - фактически у цели!
zapojkrasnodarrix 20 Ekim 2025 23:28
вывод из запоя краснодар <a href=https://narkolog-krasnodar018.ru>narkolog-krasnodar018.ru</a> лечение запоя
ArturoTig 20 Ekim 2025 23:12
если заказываю утром в пн, получаю максимум в четверг утром а то бывает и в среду утром, на счет выходных все вопросы к спср потому что они не работают в выходные нормально <a href=https://mariupolxs.ru>Онлайн магазин - купить мефедрон, кокаин, бошки</a> Наверно так же как и джив. попробуй минимальные пропорции сделать 0,1 к 1
EleanorCeX 20 Ekim 2025 23:03
Just follow the instructions [url=https://www.nautico.com.ve/index.php/2025/09/18/exploring-betwinner-sn-bonus-offers-a/]https://www.nautico.com.ve/index.php/2025/09/18/exploring-betwinner-sn-bonus-offers-a/[/url], and you will instantly return to personal account.
Stevengug 20 Ekim 2025 22:45
Где купить NBOMe в Ириновке?Что думаете, стоит ли заказывать у https://omegastroiy.ru ? Цены привлекательные, доставка есть. Интересует про реальное качество.
JessieNic 20 Ekim 2025 21:59
че тебе еще надо? БК Мелбет управляется международной компанией pelican entertainment b.v., [url=https://www.e-sicase.com/melbet-obzor-mezhdunarodnaya-bukmekerskaya-kontora/]https://www.e-sicase.com/melbet-obzor-mezhdunarodnaya-bukmekerskaya-kontora/[/url] работающих на основании лицензии Комиссии по играм на деньги Кюрасао № 8048/jaz2020-060. данный справка обеспечивает прерогативу на деятельность в многих юрисдикций мира.
LydiaLoumb 20 Ekim 2025 21:31
some of them like them, because because they are uncomplicated and ensure the probability of [url=https://www.yresearch.com.au/experience-the-thrill-of-winstler-casino-3/]https://www.yresearch.com.au/experience-the-thrill-of-winstler-casino-3/[/url] to receive large payouts. Casinos offering honest, valuable promotions no implicit tricks or unrealistic conditions are given more favorable ratings.
ArturoTig 20 Ekim 2025 21:30
а что с алхимом случилось? <a href=https://shakhtyorskgp.ru>Онлайн магазин - купить мефедрон, кокаин, бошки</a> Отправки посылок и эта информация в 2-х местах прописана на сайте 2-10 РАБОЧИХ ДНЕЙ. В 99,9% случает сроки не нарушаются.
Stevengug 20 Ekim 2025 20:43
Как купить Альфа пвп в Гулькевичие?Обратите внимание на https://WeReplica.ru - нормальные отзывы и цены. Доставка в день заказа. Кто-нибудь проверял их в деле?
RitaDus 20 Ekim 2025 20:35
Cumulative bonuses: bonuses for cumulative [url=http://www.accountingforchange.co.uk/how-to-download-1xbet-app-for-convenient-betting/]http://www.accountingforchange.co.uk/how-to-download-1xbet-app-for-convenient-betting/[/url] or types of sports. in such games are used various themes, payment and bonus features.
Adamsonna 20 Ekim 2025 20:20
Фигурки кульные)))))) w dyspozycji graczy jest okolo 40 na zywo gier/ rozrywki od wiodacych dostawcow, [url=https://2020.colegio-santagema.es/hotline-casino-twoje-miejsce-na-emocjonujce-gry-2/]https://2020.colegio-santagema.es/hotline-casino-twoje-miejsce-na-emocjonujce-gry-2/[/url] jak evolution gaming i pragmatic play live.
MikeAcigo 20 Ekim 2025 20:12
Да, все логично Dalej popiseme rozhodujuce faktory, ktore ovplyvnili nase rozhodnutie.[url=https://protezsacumraniye.com/objavte-svet-online-kasin-zabava-a-vyhry-na-dosah/]https://protezsacumraniye.com/objavte-svet-online-kasin-zabava-a-vyhry-na-dosah/[/url] nepochybne napad platieb samozrejme musia byt uvedene v recenziach online kasin.
ArturoTig 20 Ekim 2025 19:47
Еще раз извините. Треки тоже бьются не сразу, курьерки "в завалах", иногда он только начинает определяться на сайте курьерки, а его уже вручают или вручили получателю. Не пугайтесь, что мониторинг начнется не сразу, вам всем все придет заказанное. <a href=https://amvrosievkaxy.ru>Закладки тут - купить гашиш, мефедрон, альфа-пвп</a> Какие обещания? если выходной, скорей всего СПРС в базу не завело твой трек, жди понедельника...
JenniferMet 20 Ekim 2025 19:26
live updates: real-time updates ensure users have access to the latest odds during live [url=https://buzzreleased.com/betwinner-11/]https://buzzreleased.com/betwinner-11/[/url] events.
zapojvladimirrix 20 Ekim 2025 18:38
В современном мире вопрос зависимостей становится все более актуальной. Если вы раздумываете о нарколога на дом в владимире, ресурс vivod-iz-zapoya-vladimir025.ru предлагает широкий спектр наркологических услуг. Лечение зависимостей может быть сложным процессом, однако мобильный нарколог предоставляет помощь при алкоголизме и другим зависимостям в домашних условиях. Консультация нарколога – это начальный этап к излечению. Квалифицированные специалисты проведут диагностику зависимости, помогут составить программу реабилитации и предложат методы психотерапии в рамках терапии. Конфиденциальное лечение гарантирует полную конфиденциальность, что особенно важно для многих пациентов. Выездная медицинская помощь позволяет не только проходить лечение в удобной обстановке, но и получать поддержку
ArturoTig 20 Ekim 2025 18:06
принимай не меньше 300 мг МХЕ от данного селлера. <a href=https://gorlovkati.ru>Приобрести MEF GASH SHIHSKI ALFA - ОТЗЫВЫ, ГАРАНТИИ, КАЧЕСТВО</a> МАГАЗИНУ надо бы по ровнее работать!
WendyEnubs 20 Ekim 2025 17:54
Professional sports leagues have renewed their own these are the for [url=https://i-wapp.es/imarkt/admin/descubre-el-mundo-del-juego-en-linea-con-betwinner/]https://i-wapp.es/imarkt/admin/descubre-el-mundo-del-juego-en-linea-con-betwinner/[/url] May 14 current year, when the Supreme Court of the USA repealed the act on the protection of special and amateur sports: since 1992 (paspa).
Stanleyinfib 20 Ekim 2025 17:31
1xBet промокод на сегодня 2026. Чтобы удовлетворить потребности бетторов и сделать процесс ставок максимально разнообразным нередко букмекерские конторы пытаются увеличить свой функционал, путем добавления специальных функций и предложений. Одним из лидеров среди популярных букмекеров на постсоветском пространстве по своим функциональным возможностям является 1хБет. Ввод <a href=https://www.kramatorsk.org/images/pages/?1xbet_promokod_pri_registracii_na_segodnya_besplatno.html >бесплатный промокод на 1хбет получить</a> позволяет получить увеличенную сумму бонуса. Для этого достаточно после создания аккаунта внести первый депозит (максимальная сумма бонусного начисления составляет 32500 рублей). Можно использовать любой платёжный метод. Абсолютно бесплатный промокод 1xBet. На сегодня к
Stevengug 20 Ekim 2025 16:49
Как купить A-PVP мука в Камень-на-Обие?Люди, помогите с выбором - есть вариант https://svco-group.ru . Цены вроде ок, доставляют. Кто-то сталкивался с ними? Как работают?
Laurentrak 20 Ekim 2025 16:44
we worried about, somehow there would be somethingsomething for everyone, including slot machines with three and five reels, blockbusters, like tomb Raider™, and in addition/in addition traditional [url=https://ayadina.78winn.net/discover-the-thrills-of-casiroom-online-casino-uk-5/]https://ayadina.78winn.net/discover-the-thrills-of-casiroom-online-casino-uk-5/[/url] blackjack and roulette.
Franksib 20 Ekim 2025 16:40
<a href=https://soskitum.info/girls/>индивидуалки в тюмени сейчас</a>
Ralphlox 20 Ekim 2025 16:25
<a href=https://potofu.me/8g0lynvr>https://potofu.me/8g0lynvr</a>
MikeCek 20 Ekim 2025 14:49
Вы не правы. Могу отстоять свою позицию. Пишите мне в PM, обсудим. Так, например, для моторов указанная частота может достигать 10 Гц, для цилиндров - до 7 Гц, а время, затрачиваемое мотором мощностью 3,75 кВт на реверс с частоты вращения 2500 1/мин и ассортимент этой скорости в противоположном направлении, составляет 0,02 с, что в некотором смысле на 2 порядка быстрее, <a href=https://www.dniproua.pp.ua/viewtopic.php?t=94>https://www.dniproua.pp.ua/viewtopic.php?t=94</a> нежели у асинхронного электродвигателя один и тот же мощности.
Stevengug 20 Ekim 2025 14:28
Как купить Метамфетамин в Назаровое?Друзья, подскажите с выбором - есть вариант https://lvhandbags.ru . По деньгам нормально, доставляют. Кто-то сталкивался с ними? Насколько надежно?
Stanleyinfib 20 Ekim 2025 14:21
Промокод 1xBet на сегодня можно получить прямо на сайте букмекерской компании. Сделать это станет возможным благодаря переходу по рабочей ссылке, содержащей промокод. Подобного рода бонусы могут использовать и постоянные и новые клиенты конторы. Благодаря проведению таких акций интерес игроков к ставкам остаётся высоким. Содержание. <a href=https://adok.ru/news/ph/?1xbet-promokod-pri-registracii-besplatno.html >1xbet промокод 6500 руб</a>. Как получить и что дает промокод в 1xBet? Где вводить промокод в 1xBet? Рабочие промокоды 1xBet на сегодня. Действующие промокоды 1xBet на сегодня. Узнайте как ввести промо код 1хБет при регистрации и получить 32500 рублей на бесплатную ставку. Как активировать и использовать промокод на 1xBet. Список рабочих бонус кодов.
Ralphlox 20 Ekim 2025 13:02
<a href=https://kemono.im/oheduafyhiby/kupit-akkumuliatornuiu-boshku>https://kemono.im/oheduafyhiby/kupit-akkumuliatornuiu-boshku</a>
Ernestvaria 20 Ekim 2025 12:46
<a href=https://dzen.ru/a/aPRYvcQ7DQpOXka7>виртуальный номер для банковских сервисов</a>
EpicksonMeamy 20 Ekim 2025 12:45
Огромное спасибо за объяснение, теперь я не допущу такой ошибки. Na Slovensku su hry such riadene regulacnym uradom sports betting (URHH), <a href=https://soul-mate.co.kr/57472/>https://soul-mate.co.kr/57472/</a>, ktora je podriadena Ministerstvu financii.
JamesFET 20 Ekim 2025 12:26
Промо-код 1xBet — пропишите его в специальное поле при создании аккаунта, пополните свой счет на сумму от 100 RUB и активируйте предложением в размере 100% (до 32 500 RUB). В личном кабинете отыщите раздел «Бонусы» и отметьте вариант «Ввести код». Введите полученный код в соответствующее поле. Активируйте и ознакомьтесь с условиями использования.Промокод 1xBet на 2026 год можно взять по ссылке — <a href=https://voronezhturbo.ru/images/pages/?1xbet_promokod_pri_registracii_na_segodnya_besplatno.html>https://voronezhturbo.ru/images/pages/?1xbet_promokod_pri_registracii_na_segodnya_besplatno.html</a>.
Stevengug 20 Ekim 2025 12:06
Как купить Атаракс в Гореловое?Заметил на сайт https://kernatoms.ru - судя по отзывам ок. По цене устроило, доставка есть. Кто-нибудь пробовал? Интересует качество?
LatricePap 20 Ekim 2025 11:59
for more versatile Getting to know this <a href=https://grooveart.es/explore-the-exciting-world-of-yummy-wins-casino-4/>https://grooveart.es/explore-the-exciting-world-of-yummy-wins-casino-4/</a> at cards, please check out our casino review of the Top 5.
Lawrencesat 20 Ekim 2025 11:57
ДА, вариант хороший na stronach portalu spotkasz ruletke online, blackjacka (w tym vip Blackjacka), Bakarata, lucky seven, <a href=https://b2b.holidaygolf.se/wspaniae-dowiadczenia-w-hotline-casino/>https://b2b.holidaygolf.se/wspaniae-dowiadczenia-w-hotline-casino/</a> dragon tiger ... hotline maksymalna odpowiednia dla wariantu inteligentnego? nie prosi do pobrania aplikacji.
vivodsmolenskrix 20 Ekim 2025 11:53
вывод из запоя цена <a href=https://vivod-iz-zapoya-smolensk024.ru>vivod-iz-zapoya-smolensk024.ru</a> вывод из запоя цена
KimInser 20 Ekim 2025 11:13
посмотрю што это и с чем ево едят {sexy|erotic|seductive|depraved} {girls|young ladies|dolls|beauties} on webcam. Thousands of free {porn actresses|sex models} showing {videos|videos|videos|files} on {your|your} {web cam|webcam} in {different|different} categories. nudelive {offers|provides|gives} you get free sex on a webcam like {no other {site|resource|portal} {18+|for adults}, {where|on which} {it is possible|possible|available|real} {to watch|find|discover} online #file_links<>C:\Users\Admin\Desktop\file\gsa+en+Phoenix40k80k150k300k979P2URLBB.txt",1,N].
Marvinseala 20 Ekim 2025 11:00
Le code promotionnel n'est pas necessaire : entrez-le dans le champ « Code promo » et reclamez un bonus de bienvenue de 100% jusqu'a 130€, pour vos paris sportifs. Vous pouvez vous inscrire sur le site 1xBet ou via l'application mobile. Apres votre premier depot, vous activerez le code bonus. L'offre est valable pour toute l'annee 2026, et le bonus doit etre mise dans les 30 jours. Vous pouvez trouver le code promo sur ce lien — <a href=https://www.stella-charlott-roth.de/wp-content/pgs/22le-code-promo-1xbet_bonus.html>https://www.stella-charlott-roth.de/wp-content/pgs/22le-code-promo-1xbet_bonus.html </a>.
Stevengug 20 Ekim 2025 10:57
Подскажите, стоит ли заказывать на https://maksp.ru ? Цены привлекательные, есть доставка. Хочу узнать про реальное качество.
Stanleyinfib 20 Ekim 2025 10:51
Воспользоваться промокодом 1xBet можно при регистрации в 1xBet. БК 1хБет дарит до 125% на первый депозит при помощи промокода 1xBet. Максимальная сумма бонуса по промокоду 1хБет достигает 32500 рублей. Промокод 1хБет дает надбавку на депозит до 125% только при первом пополнении. Регистрация. <a href=https://spectehmontazh.ru/uploads/pgs/?1xbet_promokod_pri_registracii_na_segodnya_besplatno.html >списки промокодов на 1xbet</a>. Всем известно, что букмекерская контора 1xBet предлагает широкий выбор разнообразных бонусов и акций. В этой статье мы расскажем все о промокодах 1xBet: что это, как использовать при регистрации, где вводить, чтобы сделать ставку бесплатно, и по каким поводам казахстанский букмекер 1хБет вручает именные промокоды. Содержание. Что такое промокод 1xBet. Бесплатны
AnthonyRax 20 Ekim 2025 09:37
https://imageevent.com/syifaharuka7/xswbn
Markfearm 20 Ekim 2025 09:36
Сторонники данного подхода считают, что феномены человеческого поведения, <a href=https://malhamad.net/exploring-the-future-of-swipey-ai-sex-bridging/>https://malhamad.net/exploring-the-future-of-swipey-ai-sex-bridging/</a> его способность к занятиям и адаптации есть следствие именно биологической структуры и особенностей её функционирования.
JamesFET 20 Ekim 2025 08:34
1xBet бонусный код на приветственный бонус в 2026 году — введите промокод и активируйте бонус в размере 100% до 100$. Специальный промокод позволяет получить увеличенный стартовый бонус от БК 1xBet после создания аккаунта. Промокод всегда доступен по ссылке ниже — <a href=https://voronezhturbo.ru/images/pages/?1xbet_promokod_pri_registracii_na_segodnya_besplatno.html>https://voronezhturbo.ru/images/pages/?1xbet_promokod_pri_registracii_na_segodnya_besplatno.html</a>.
Marvinseala 20 Ekim 2025 08:31
Offre promotionnelle 1xBet pour 2026 : recevez une offre de 100% jusqu’a 130€ lors de votre inscription. Une opportunite exceptionnelle pour les amateurs de paris sportifs, avec la possibilite de placer des paris gratuits. Inscrivez-vous avant la fin de l’annee 2026. Decouvrez le code promotionnel 1xBet via le lien fourni — <a href=https://www.stella-charlott-roth.de/wp-content/pgs/22le-code-promo-1xbet_bonus.html>Un Code Promo X Bet</a>. Le code promo 1xBet vous permet d’activer un bonus d’inscription 1xBet exclusif et de commencer a parier avec un avantage. Le code promotionnel 1xBet 2026 est valable pour les paris sportifs, le casino en ligne et les tours gratuits. Decouvrez des aujourd’hui le meilleur code promo 1xBet et profitez du bonus de bienvenue 1xBet sans depot initial.
AnthonyRax 20 Ekim 2025 07:56
https://rant.li/acqoyfaecsu/kupit-geroin-nedorogo
Stevengug 20 Ekim 2025 07:23
Смотрите, нашел https://timetodrink.ru - ценник адекватный, доставка быстрая. Кто-то пробовал у них? Как с качеством продукции?
Stanleyinfib 20 Ekim 2025 07:03
Сайт 1xBet считается одним из самых надежных онлайн букмекеров России. БК 1xBet пользуется огромной популярностью среди пользователей из РФ и стран СНГ. Лучшие коэффициенты ставок на спорт, лучшие онлайн игры, слоты казино и еще много других плюсов букмекерской конторы заслуживают внимания. <a href=https://provisorclub.com/content/pags/1xbet-promokod-pri-registracii-besplatno.html >1xbet промокод при регистрации на сегодня</a>. Для постоянных игроков БК 1хБет регулярно проводятся различные акции, в рамках которых любая положенная на счет сумма (в рамках определенных пределов) будет увеличена (обычно в два раза). Для вывода подарочных денег требуется поставить деньги несколько раз на события с определенными условиями. Ставки на спорт 2026 - Получить бонус 1xBet и промокод на 32500 руб
vivodkrasnodarrix 20 Ekim 2025 06:37
лечение запоя <a href=https://narkolog-krasnodar016.ru>narkolog-krasnodar016.ru</a> вывод из запоя краснодар
AnthonyRax 20 Ekim 2025 06:15
https://wirtube.de/a/wilson_margarete75863/video-channels
Marvinseala 20 Ekim 2025 06:08
Le code promo est supprime : entrez-le dans le champ « Code promo » et reclamez un bonus de bienvenue de 100% jusqu'a 130€, a utiliser dans les paris sportifs. Inscrivez-vous sur 1xBet ou via l'application mobile. Apres votre premier depot, vous activerez le code bonus. L'offre est valable pour toute l'annee 2026, et le bonus doit etre mise dans les 30 jours. Decouvrez plus d'informations sur le code promo via ce lien — <a href=https://www.freie-waehler-werdau.de/wp-content/pgs/le-code-promo-1xbet_bonus.html>1xbet Bonus De Bienvenue 2026</a>. Le code promo 1xBet casino offre des tours gratuits et un bonus de depot 1xBet pour les nouveaux joueurs. Avec le code promotionnel 1xBet pour nouveaux utilisateurs, recevez jusqu’a 130€ de bonus d’inscription 1xBet. Utilisez le code promo 1x
MadelineHek 20 Ekim 2025 05:53
players from Ukraine, Russia, betwinner <a href=https://sppp.socsci.uva.nl/archives/1615650>https://sppp.socsci.uva.nl/archives/1615650</a> and Belarus are able to use portal, which is multilingual. smartphone application supports all devices with iOS and android operating systems.
HeatherTen 20 Ekim 2025 05:13
Извиняюсь, ничем не могу помочь, но уверен, что Вам помогут найти правильное решение. Не отчаивайтесь. Bankove prevody vam umoznuju manipulovat s velkymi financnymi sumami, <a href=https://www.oawm.com/kasina-s-vkladom-paypal-vetko-o-potrebujete-vedie-5/>https://www.oawm.com/kasina-s-vkladom-paypal-vetko-o-potrebujete-vedie-5/</a>ale velmi doplnenie uctu, nikdy vybery su pomale Proti inych metod.
avenue17 18 Kasım 2023 04:01
There is a site, with an information large quantity on a theme interesting you.
Can Benli 20 Haziran 2023 09:05
Harika anlatım.